Architecture and Pipeline
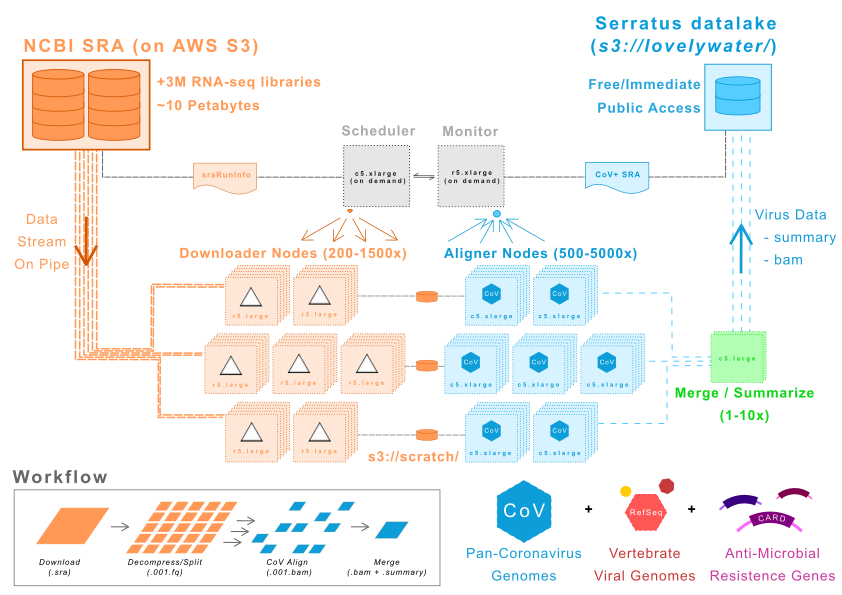
In February 2020, AWS mirrored the NCBI/NIH Sequence Read Archive (SRA) onto their S3 servers as an Open Data-set which allows for an unprecedented rate of access to the petabytes of raw data.
To perform the ultra-high throughput CoV search, AWS cloud computing was employed to create a 22,500 vCPU cluster (1460 x R5.xlarge, 4120 x C5.xlarge, and 90 x C5.large EC2 instances). Using this hyper-parallelized architecture we bypass conventional networking and disk IO limitations that would stall a conventional cluster to accelerate the rate of discovery.
The Serratus architecture is aggressively cost-optimized for big data analysis, achieving a maximum alignment throughput of +1,000,000 sequencing libraries per 24 hours, at a cost of $0.004 to $0.006 per library.
The workhorse for Serratus is currently the C5.large EC2 instance on AWS. Each instance has 2 vCPU and 4 GB of memory running the minimal amazon linux 2 with docker. All workflows are containerized to allows for rapid and cheap scaling of the cluster.
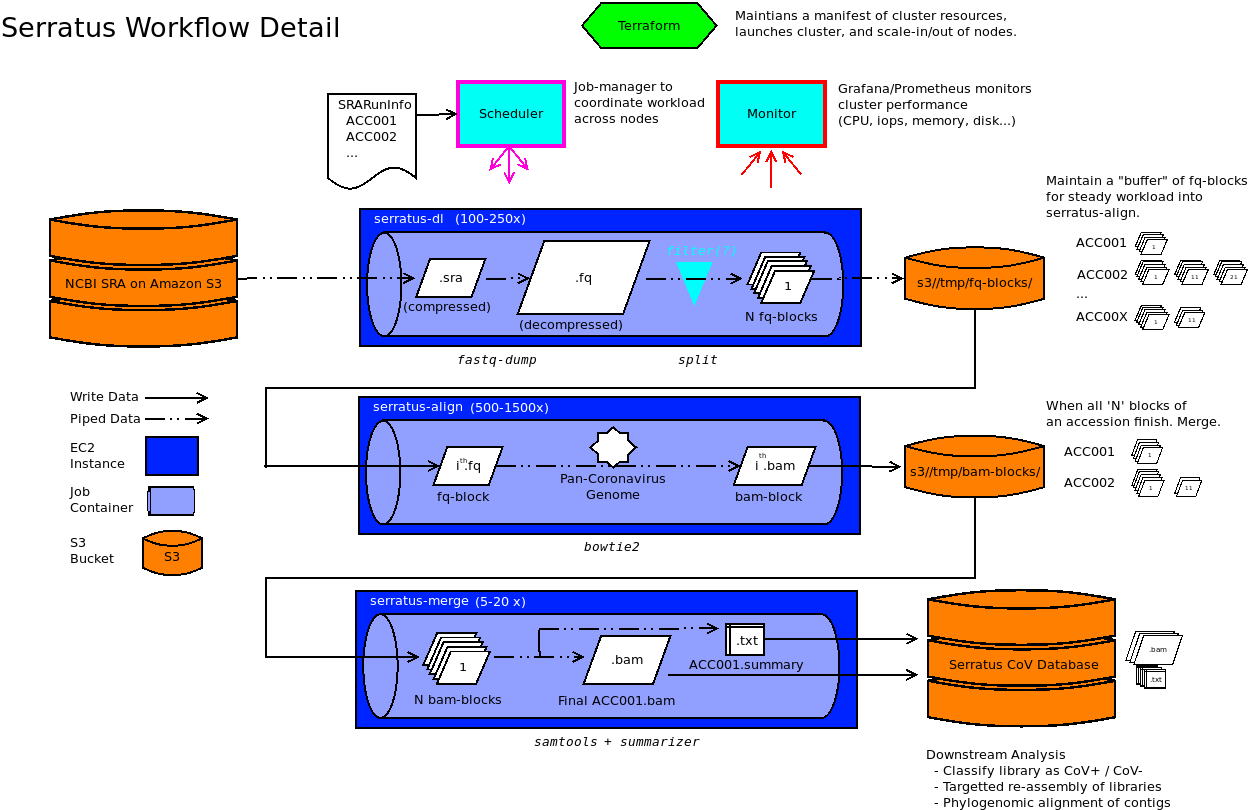
To detect known and diverged viruses, we selected bowtie2 for nucleotide alignment and diamond2 for translated-nucleotide alignment. Each SRA accession is downloaded (prefetch), decompressed (fastq-dump) and split into equal-sized "blocks" of 1 million reads. This allows for a highly uniform and predictable workload, and independent scaling of download instances and alignment instances` to provide optimal resource usage.
Any input collection of nucleotide or protein sequences can be queried with Serratus. For more details about the searches we performed see Sequence-Resources.
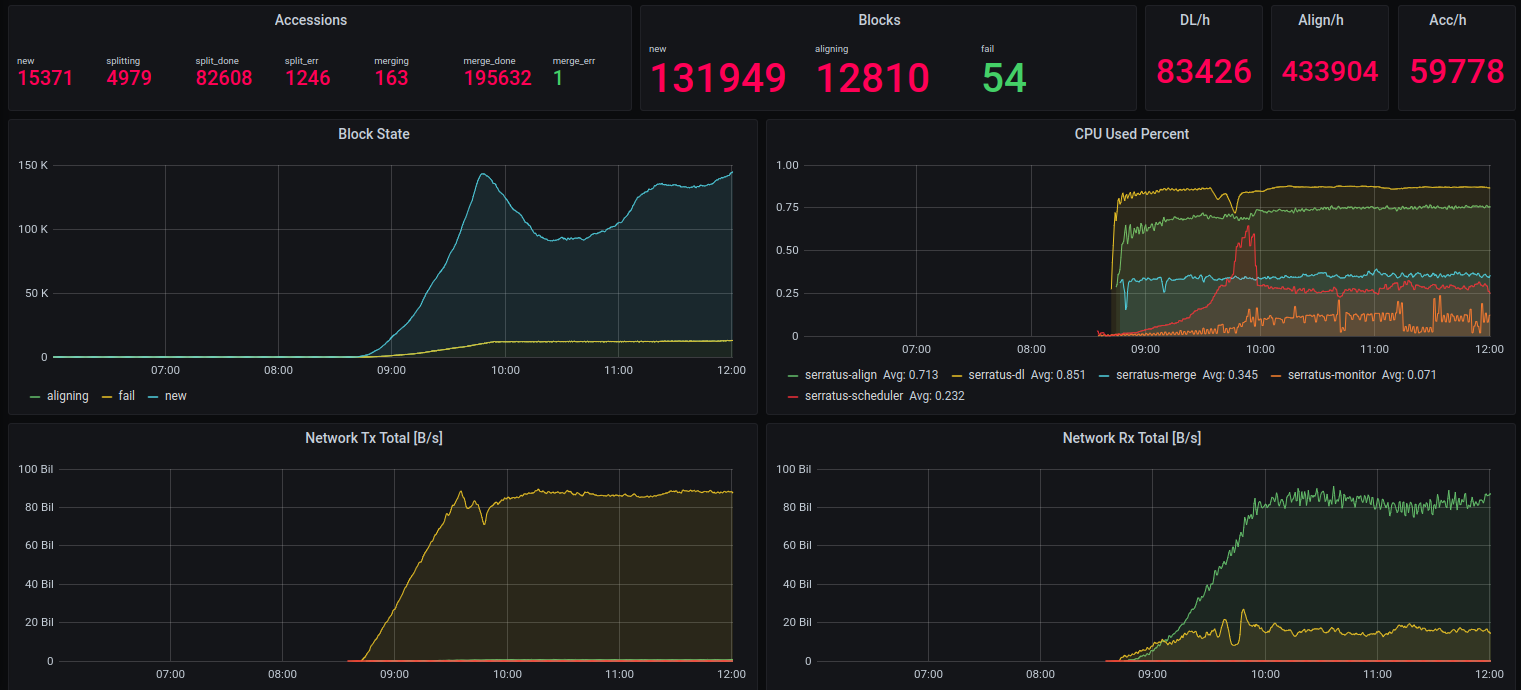
We implemented a Grafana/Prometheus cluster monitoring system. Performance of the cluster can be monitored at high granularity in real time to ensure smooth performance and to avoid cost over-runs.