NLP
Python Code (in Jupyter Notebook) :
from teanaps.nlp import MorphologicalAnalyzer ma = MorphologicalAnalyzer()
Notes :
- import시 최초 1회 경고메시지 (Warnning)가 출력될 수 있습니다. 무시하셔도 좋습니다.
-
teanaps.nlp.MorphologicalAnalyzer.parse(sentence)[Top]-
문장을 형태소 분석하고 그 결과를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
-
Returns
- result (list) : (형태소, 품사, 단어위치) 구조의 Tuple을 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 라이브러리 입니다." result = ma.parse(sentence) print(result)
Output (in Jupyter Notebook) :
[('TEANAPS', 'OL', (0, 7)), ('는', 'VV', (7, 8)), ('텍스트', 'NNG', (9, 12)), ('마', 'NNG', (13, 14)), ('이닝', 'NNG', (14, 16)), ('을', 'JC', (16, 17)), ('위', 'NNG', (18, 19)), ('한', 'JC', (19, 20)), ('Python', 'OL', (21, 27)), ('라이브러리', 'NNG', (28, 33)), ('입니다', 'VA', (34, 37)), ('.', 'SW', (37, 38))]
Notes :
-
TEANAPS형태소분석기의 품사태그는 세종말뭉치 품사태그를 기본으로 사용합니다. 품사태그표는 Appendix를 참고해주세요. -
TEANAPS형태소분석기 성능은 선택한 오픈소스 형태소분석기와 동일합니다. -
TEANAPS개체명인식기와 구문분석기를 활용하면 더 높은 정확도로 형태소분석을 수행할 수 있습니다. (성능평가 결과 살펴보기)
-
-
-
teanaps.nlp.MorphologicalAnalyzer.set_tagger(tagger)[Top]-
형태소 분석기를 선택합니다. 형태소 분석기는
MeCab,Okt (Twitter),Kkma,NLTK총 4가지를 지원합니다. 형태소 분석기를 선택하지 않으면 기본으로 한국어는OKt, 영어는NLTK형태소 분석기를 사용합니다. -
Parameters
- tagger (str) : 형태소 분석기 {"okt", "mecab", "kkma"} 중 하나 입력.
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
ma.set_tagger("okt") # or ma.set_tagger("mecab") # or ma.set_tagger("kkma") sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 라이브러리 입니다." result = ma.parse(sentence) print(result)
Output (in Jupyter Notebook) :
[('TEANAPS', 'OL', (0, 7)), ('는', 'VV', (7, 8)), ('텍스트', 'NNG', (9, 12)), ('마', 'NNG', (13, 14)), ('이닝', 'NNG', (14, 16)), ('을', 'JC', (16, 17)), ('위', 'NNG', (18, 19)), ('한', 'JC', (19, 20)), ('Python', 'OL', (21, 27)), ('라이브러리', 'NNG', (28, 33)), ('입니다', 'VA', (34, 37)), ('.', 'SW', (37, 38))]
-
Python Code (in Jupyter Notebook) :
from teanaps.nlp import NamedEntityRecognizer ner = NamedEntityRecognizer(model_path="/model")
Notes :
- 모델 파일을 별도로 다운로드하여 파일 경로를
model_path변수에 포함해야합니다.- import시 최초 1회 경고메시지 (Warnning)가 출력될 수 있습니다. 무시하셔도 좋습니다.
-
teanaps.nlp.NamedEntityRecognizer.parse(sentence)[Top]-
문장에서 개체명을 인식하고 그 결과를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
-
Returns
- result (list) : (개체명, 개체명 태그, 개체명위치) 구조의 Tuple을 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다." result = ner.parse(sentence) print(result)
Output (in Jupyter Notebook) :
[('TEANAPS', 'UN', (0, 7)), ('Python', 'UN', (21, 27))]
Notes :
-
TEANAPS개체명인식기의 개체명 태그는 총 16종으로 구분됩니다. 태그 종류 및 구분은 정보통신단체표준 (TTAS)을 따릅니다. - 개체명 태그표는 Appendix를 참고해주세요.
-
TEANAPS개체명인식기의 성능 및 특징은 성능평가 결과를 참고해주세요.
-
-
-
teanaps.nlp.NamedEntityRecognizer.parse_sentence(sentence)[Top]-
문장에서 개체명을 인식하고 그 결과를 문장 형태로 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
-
Returns
- result (str) : 표준 개체명 태그 형식으로 개체명 태깅된 문장.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다." result = ner.parse_sentence(sentence) print(result)
Output (in Jupyter Notebook) :
"<TEANAPS:UN>는 텍스트 마이닝을 위한 <Python:UN> 패키지 입니다."
-
-
teanaps.nlp.NamedEntityRecognizer.get_weight(sentence)[Top]-
문장에서 개체명을 인식하고 각 형태소별 가중치를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
-
Returns
- result (str) : token_list, weight_list가 포함된 튜플.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다." token_list, weight_list = ner.get_weight(sentence) print(token_list) print(weight_list)
Output (in Jupyter Notebook) :
[' T', 'E', 'A', 'NA', 'PS', '는', ' ', '텍', '스트', ' 마', '이닝', '을', ' 위한', ' P', 'y', 'th', 'on', ' 패키지', ' ', '입니다', '.'] [0.41024893522262573, 0.08311055600643158, 0.1084287092089653, 0.1453726887702942, 0.25153452157974243, 0.004453524947166443, 0.0038948641158640385, 0.0018726392881944776, 0.0029991772025823593, 0.0017985135782510042, 0.001928122597746551, 0.0021339845843613148, 0.0020090234465897083, 0.14324823021888733, 0.20584315061569214, 0.11403589695692062, 0.14470143616199493, 0.09357250481843948, 0.0024957722052931786, 0.0019250106997787952, 0.004643643740564585]
-
-
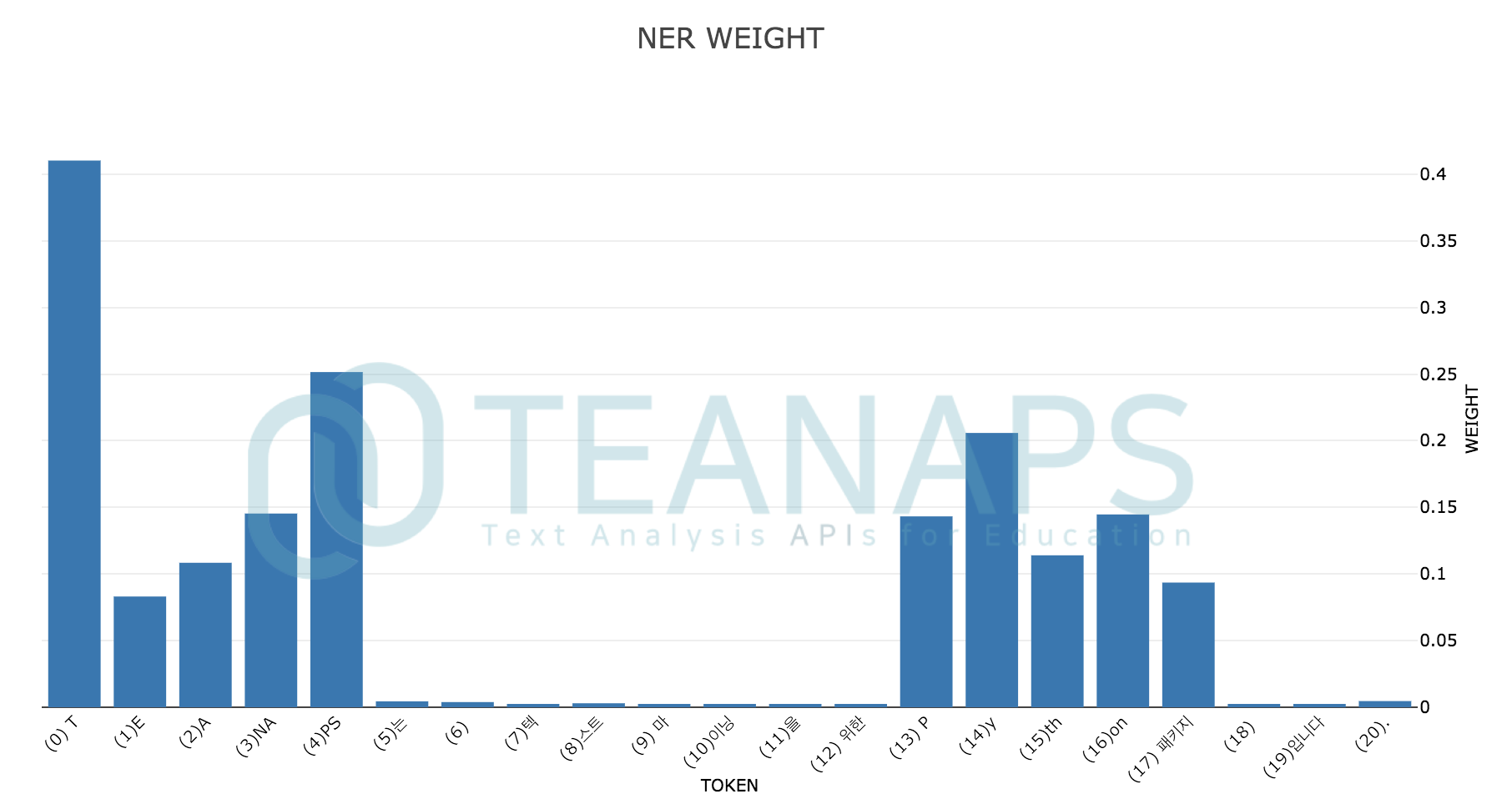
teanaps.nlp.NamedEntityRecognizer.draw_sentence_weight(sentence)[Top]-
문장에서 개체로 인식된 형태소에 대한 가중치를 text attention 그래프로 출력합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
-
Returns
- plotly graph (graph object) : 문장에서 개체로 인식된 부분에 대한 가중치 그래프.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다." ner.draw_sentence_weight(sentence)
Output (in Jupyter Notebook) :

-
-
teanaps.nlp.NamedEntityRecognizer.draw_weight(sentence)[Top]-
문장에서 개체로 인식된 형태소에 대한 가중치를 히스토그램으로 출력합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
-
Returns
- plotly graph (graph object) : 문장에서 개체로 인식된 부분에 대한 가중치 그래프.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다." ner.draw_weight(sentence)
Output (in Jupyter Notebook) :
-
Python Code (in Jupyter Notebook) :
from teanaps.nlp import SyntaxAnalyzer sa = SyntaxAnalyzer()
Notes :
- import시 최초 1회 경고메시지 (Warnning)가 출력될 수 있습니다. 무시하셔도 좋습니다.
-
teanaps.nlp.SyntaxAnalyzer.parse(ma_result, ner_result)[Top]-
형태소 분석과 개체명 인식 결과를 바탕으로 문장 구조를 파악하고 그 결과를 반환합니다.
-
Parameters
- ma_result (list) : (형태소, 품사, 단어위치) 구조의 Tuple을 포함하는 리스트.
teanaps.nlp.ma.parse참고. - ner_result (list) : (개체명, 개체명 태그, 개체명위치) 구조의 Tuple을 포함하는 리스트.
teanaps.nlp.ner.parse참고.
- ma_result (list) : (형태소, 품사, 단어위치) 구조의 Tuple을 포함하는 리스트.
-
Returns
- result (list) : (형태소, 형태소 태그, 개체명 태그, 개체명위치) 구조의 Tuple을 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
#sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다." #ma_result = [('TEANAPS', 'OL', (0, 7)), ('는', 'JX', (7, 8)), ('텍스트', 'NNG', (9, 12)), ('마이닝', 'NNP', (13, 16)), ('을', 'JKO', (16, 17)), ('위한', 'VV+ETM', (18, 20)), ('Python', 'OL', (21, 27)), ('패키지', 'NNG', (28, 31)), ('입니다', 'VCP+EF', (32, 35)), ('.', 'SW', (35, 36))] #ner_result = [('TEANAPS', 'UN', (0, 7)), ('Python', 'UN', (21, 27))] result = sa.parse(ma_result, ner_result) print(result)
Output (in Jupyter Notebook) :
[('TEANAPS', 'NNP', 'UN', (0, 7)), ('는', 'JX', 'UN', (7, 8)), ('텍스트', 'NNG', 'UN', (9, 12)), ('마이닝', 'NNP', 'UN', (13, 16)), ('을', 'JKO', 'UN', (16, 17)), ('위한', 'VV+ETM', 'UN', (18, 20)), ('Python', 'NNP', 'UN', (21, 27)), ('패키지', 'NNG', 'UN', (28, 31)), ('입니다', 'VCP+EF', 'UN', (32, 35)), ('.', 'SW', 'UN', (35, 36))]
-
-
teanaps.nlp.SyntaxAnalyzer.get_phrase(sentence, sa_result)[Top]-
문장의 구조를 파악하고 어절단위로 나눈 결과를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
-
Returns
- phrase_sa_list (list) : (형태소, 형태소 태그, 개체명 태그, 개체명위치) 구조의 형태소를 어구, 어절 단위로 묶어 표현된 리스트.
- phrase_list (list) : 분리된 어절 단위를 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
#sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다." #sa_result = [('TEANAPS', 'NNP', 'UN', (0, 7)), ('는', 'JX', 'UN', (7, 8)), ('텍스트', 'NNG', 'UN', (9, 12)), ('마이닝', 'NNP', 'UN', (13, 16)), ('을', 'JKO', 'UN', (16, 17)), ('위한', 'VV+ETM', 'UN', (18, 20)), ('Python', 'NNP', 'UN', (21, 27)), ('패키지', 'NNG', 'UN', (28, 31)), ('입니다', 'VCP+EF', 'UN', (32, 35)), ('.', 'SW', 'UN', (35, 36))] phrase_sa_list, phrase_list = sa.get_phrase(sentence, sa_result) print(phrase_sa_list) print(phrase_list)
Output (in Jupyter Notebook) :
[[[('TEANAPS', 'NNP', 'UN', (0, 7))], [('는', 'JX', 'UN', (7, 8))]], [[('텍스트', 'NNG', 'UN', (9, 12)), ('마이닝', 'NNP', 'UN', (13, 16))], [('을', 'JKO', 'UN', (16, 17))]], [[('위한', 'VV+ETM', 'UN', (18, 20))], [('Python', 'NNP', 'UN', (21, 27)), ('패키지', 'NNG', 'UN', (28, 31))], [('입니다', 'VCP+EF', 'UN', (32, 35)), ('.', 'SW', 'UN', (35, 36))]]] ['TEANAPS는', '텍스트 마이닝을', '위한 Python 패키지 입니다.']
-
-
teanaps.nlp.SyntaxAnalyzer.get_sentence_tree(sentence, sa_result)[Top]-
형태소 분석과 개체명 인식 결과를 바탕으로 문장 구조를 트리 구조로 생성하고 그 결과를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
- sa_result (list) : (형태소, 개체명, 개체명 태그, 개체명위치) 구조의 Tuple을 포함하는 리스트.
teanaps.nlp.sa.parse참고.
-
Returns
- label_list (list) : 트리구조 문장의 각 인덱스에 해당하는 라벨을 포함하는 리스트.
- edge_list (list) : 트리구조 문장의 각 라벨 인덱스 간의 연결된 엣지를 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
#sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다." #sa_result = [('TEANAPS', 'NNP', 'UN', (0, 7)), ('는', 'JX', 'UN', (7, 8)), ('텍스트', 'NNG', 'UN', (9, 12)), ('마이닝', 'NNP', 'UN', (13, 16)), ('을', 'JKO', 'UN', (16, 17)), ('위한', 'VV+ETM', 'UN', (18, 20)), ('Python', 'NNP', 'UN', (21, 27)), ('패키지', 'NNG', 'UN', (28, 31)), ('입니다', 'VCP+EF', 'UN', (32, 35)), ('.', 'SW', 'UN', (35, 36))] label_list, edge_list = sa.get_sentence_tree(sentence, sa_result) print(label_list) print(edge_list)
Output (in Jupyter Notebook) :
['TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다.<br>/SENTENCE', 'TEANAPS는<br>/SUBJECT', '텍스트 마이닝을<br>/OBJECT', '위한 Python 패키지 입니다.<br>/EF', 'TEANAPS<br>/N', '는<br>/J', '텍스트 마이닝<br>/N', '을<br>/J', '위한<br>/V', 'Python 패키지<br>/N', '입니다.<br>/S', 'TEANAPS<br>/NNP<br>/UN', '는<br>/JX<br>/UN', '텍스트<br>/NNG<br>/UN', '마이닝<br>/NNP<br>/UN', '을<br>/JKO<br>/UN', '위한<br>/VV+ETM<br>/UN', 'Python<br>/NNP<br>/UN', '패키지<br>/NNG<br>/UN', '입니다<br>/VCP+EF<br>/UN', '.<br>/SW<br>/UN'] [(0, 1), (1, 4), (4, 11), (1, 5), (5, 12), (0, 2), (2, 6), (6, 13), (6, 14), (2, 7), (7, 15), (0, 3), (3, 8), (8, 16), (3, 9), (9, 17), (9, 18), (3, 10), (10, 19), (10, 20)]
-
-
teanaps.nlp.SyntaxAnalyzer.draw_sentence_tree(sentence, label_list, edge_list)[Top]-
형태소 분석과 개체명 인식 결과를 바탕으로 생성된 트리 구조의 문장을 트리 그래프로 출력합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
- label_list (list) : 트리구조 문장의 각 인덱스에 해당하는 라벨을 포함하는 리스트.
teanaps.nlp.sa.get_sentence_tree참고. - edge_list (list) : 트리구조 문장의 각 라벨 인덱스 간의 연결된 엣지를 포함하는 리스트.
teanaps.nlp.sa.get_sentence_tree참고.
-
Returns
- plotly graph (graph object) : 트리구조 문장에 대한 트리 그래프.
-
Examples
Python Code (in Jupyter Notebook) :
#sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다." #label_list = ['TEANAPS는 텍스트 마이닝을 위한 Python 패키지 입니다.<br>/SENTENCE', 'TEANAPS는<br>/SUBJECT', '텍스트 마이닝을<br>/OBJECT', '위한 Python 패키지 입니다.<br>/EF', 'TEANAPS<br>/N', '는<br>/J', '텍스트 마이닝<br>/N', '을<br>/J', '위한<br>/V', 'Python 패키지<br>/N', '입니다.<br>/S', 'TEANAPS<br>/NNP<br>/UN', '는<br>/JX<br>/UN', '텍스트<br>/NNG<br>/UN', '마이닝<br>/NNP<br>/UN', '을<br>/JKO<br>/UN', '위한<br>/VV+ETM<br>/UN', 'Python<br>/NNP<br>/UN', '패키지<br>/NNG<br>/UN', '입니다<br>/VCP+EF<br>/UN', '.<br>/SW<br>/UN'] #edge_list = [(0, 1), (1, 4), (4, 11), (1, 5), (5, 12), (0, 2), (2, 6), (6, 13), (6, 14), (2, 7), (7, 15), (0, 3), (3, 8), (8, 16), (3, 9), (9, 17), (9, 18), (3, 10), (10, 19), (10, 20)] sa.draw_sentence_tree(sentence, label_list, edge_list)
Output (in Jupyter Notebook) :
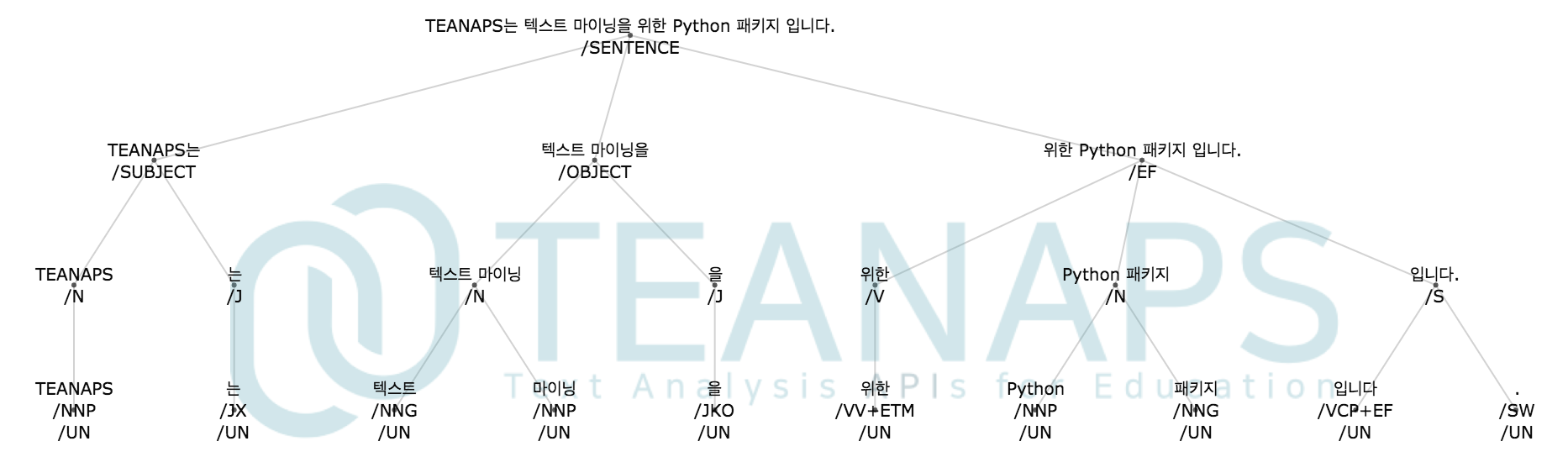
-
Python Code (in Jupyter Notebook) :
from teanaps.nlp import Processing pro = Processing()
Notes :
- import시 최초 1회 경고메시지 (Warnning)가 출력될 수 있습니다. 무시하셔도 좋습니다.
-
teanaps.nlp.Processing.get_synonym()[Top]-
TEANAPS에서 기본으로 제공하는 동의어 리스트를 호출하고 그 결과를 반환합니다. -
Parameters
- None
-
Returns
- result (list) : 동의어를 모두 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
result = pro.get_synonym() print(result)
Output (in Jupyter Notebook) :
{'맨체스터 유나이티드': ['맨체스터 유나이티드', '맨유'], '아이폰': ['아이폰', 'iphone', '사과폰', '아이폰3s', '아이폰3', '아이폰6', '아이폰x'] }
-
-
teanaps.nlp.Processing.add_synonym(word_dict)[Top]-
TEANAPS에서 기본으로 제공하는 동의어 리스트에 임의의 동의어를 추가합니다. -
Parameters
- word_dict (dict) : 동의어 관계가 정의된 딕셔너리
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.add_synonym({"아이폰": ["아이폰13", "아이폰13 프로"]}) result = pro.get_synonym() print(result)
Output (in Jupyter Notebook) :
#{'맨체스터 유나이티드': ['맨체스터 유나이티드', '맨유'], # '아이폰': ['아이폰', 'iphone', '사과폰', '아이폰3s', '아이폰3', '아이폰6', '아이폰x'] #} {'맨체스터 유나이티드': ['맨체스터 유나이티드', '맨유'], '아이폰': ['아이폰', 'iphone', '사과폰', '아이폰3s', '아이폰3', '아이폰6', '아이폰x', '아이폰13', '아이폰13 프로'] }
-
-
teanaps.nlp.Processing.remove_synonym(word/word_list)[Top]-
전체 동의어 리스트에서 동의어 또는 동의어 리스트에 포함된 모든 동의어를 삭제합니다.
-
Parameters
- word/word_list (str/list) : 동의어 또는 동의어를 포함하는 리스트
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.remove_synonym("아이폰3") result = pro.get_synonym() print(result)
Output (in Jupyter Notebook) :
#{'맨체스터 유나이티드': ['맨체스터 유나이티드', '맨유'], # '아이폰': ['아이폰', 'iphone', '사과폰', '아이폰3s', '아이폰3', '아이폰6', '아이폰x', '아이폰13', '아이폰13 프로'] #} {'맨체스터 유나이티드': ['맨체스터 유나이티드', '맨유'], '아이폰': ['아이폰', 'iphone', '사과폰', '아이폰3s', '아이폰6', '아이폰x', '아이폰13', '아이폰13 프로'] }
Python Code (in Jupyter Notebook) :
pro.remove_synonym(["iphone", "사과폰", "아이폰3s"]) result = pro.get_synonym() print(result)
Output (in Jupyter Notebook) :
#{'맨체스터 유나이티드': ['맨체스터 유나이티드', '맨유'], # '아이폰': ['아이폰', 'iphone', '사과폰', '아이폰3s', '아이폰6', '아이폰x', '아이폰13', '아이폰13 프로'] #} {'맨체스터 유나이티드': ['맨체스터 유나이티드', '맨유'], '아이폰': ['아이폰', '아이폰6', '아이폰x', '아이폰13', '아이폰13 프로'] }
-
-
teanaps.nlp.Processing.pro.clear_synonym()[Top]-
전체 동의어 리스트에서 동의어를 모두 삭제합니다.
-
Parameters
- None
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.clear_synonym() result = pro.get_synonym() print(result)
Output (in Jupyter Notebook) :
#{'맨체스터 유나이티드': ['맨체스터 유나이티드', '맨유'], # '아이폰': ['아이폰', '아이폰6', '아이폰x', '아이폰13', '아이폰13 프로'] #} {'': ['']}
-
-
teanaps.nlp.Processing.set_org_synonym()[Top]-
동의어 리스트를
TEANAPS에서 기본으로 제공하는 동의어 리스트로 초기화합니다. -
Parameters
- None
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.set_org_synonym() result = pro.get_synonym() print(result)
Output (in Jupyter Notebook) :
#{'': ['']} {'맨체스터 유나이티드': ['맨체스터 유나이티드', '맨유'], '아이폰': ['아이폰', 'iphone', '사과폰', '아이폰3s', '아이폰3', '아이폰6', '아이폰x'] }
-
-
teanaps.nlp.Processing.is_synonym(word)[Top]-
단어가 복합명사 리스트에 포함되어있는지 여부를 확인하고 그 결과를 반환합니다.
-
Parameters
- word (str) : 동의어
-
Returns
- result (bool) : 동의어 포함여부. True or False
-
Examples
Python Code (in Jupyter Notebook) :
result = pro.is_synonym("맨체스터 유나이티드") print(result)
Output (in Jupyter Notebook) :
TruePython Code (in Jupyter Notebook) :
result = pro.is_synonym("맨체스터 시티") print(result)
Output (in Jupyter Notebook) :
False
-
-
teanaps.nlp.Processing.get_cnoun()[Top]-
TEANAPS에서 기본으로 제공하는 복합명사 리스트를 호출하고 그 결과를 반환합니다. -
Parameters
- None
-
Returns
- result (list) : 복합명사를 모두 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
result = pro.get_cnoun() print(result[-10:])
Output (in Jupyter Notebook) :
['텍스트마이닝', '텍스트분석', '자연어처리', '지능정보학회', '비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자']
-
-
teanaps.nlp.Processing.add_cnoun(word/word_list)[Top]-
TEANAPS에서 기본으로 제공하는 복합명사 리스트에 임의의 복합명사 또는 복합명사 리스트를 추가합니다. -
Parameters
- word/word_list (str/list) : 복합명사 또는 복합명사를 포함하는 리스트
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.add_cnoun("전기자동차") result = pro.get_cnoun() print(result[-10:])
Output (in Jupyter Notebook) :
#['텍스트마이닝', '텍스트분석', '자연어처리', '지능정보학회', '비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자'] ['텍스트분석', '자연어처리', '지능정보학회', '비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자', '전기자동차']
Python Code (in Jupyter Notebook) :
pro.add_cnoun(["장난감자동차", "이차전지", "전동트렁크"]) result = pro.get_cnoun() print(result[-10:])
Output (in Jupyter Notebook) :
#['텍스트분석', '자연어처리', '지능정보학회', '비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자', '전기자동차'] ['비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자', '전기자동차', '장난감자동차', '이차전지', '전동트렁크']
-
-
teanaps.nlp.Processing.remove_cnoun(word/word_list)[Top]-
전체 복합명사 리스트에서 복합명사 또는 복합명사 리스트를 모두 삭제합니다.
-
Parameters
- word/word_list (str/list) : 복합명사 또는 복합명사를 포함하는 리스트
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.remove_cnoun("전동트렁크") result = pro.get_cnoun() print(result[-10:])
Output (in Jupyter Notebook) :
#['비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자', '전기자동차', '장난감자동차', '이차전지', '전동트렁크'] ['지능정보학회', '비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자', '전기자동차', '장난감자동차', '이차전지']
Python Code (in Jupyter Notebook) :
pro.remove_cnoun(["전기자동차", "장난감자동차", "이차전지"]) result = pro.get_cnoun() print(result[-10:])
Output (in Jupyter Notebook) :
#['지능정보학회', '비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자', '전기자동차', '이차전지'] ['텍스트마이닝', '텍스트분석', '자연어처리', '지능정보학회', '비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자']
-
-
teanaps.nlp.Processing.clear_cnoun()[Top]-
전체 복합명사 리스트에서 복합명사 또는 복합명사 리스트를 모두 삭제합니다.
-
Parameters
- None
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.clear_cnoun() result = pro.get_cnoun() print(result[-10:])
Output (in Jupyter Notebook) :
#['텍스트마이닝', '텍스트분석', '자연어처리', '지능정보학회', '비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자'] []
-
-
teanaps.nlp.Processing.set_org_cnoun()[Top]-
복합명사 리스트를
TEANAPS에서 기본으로 제공하는 복합명사 리스트로 초기화합니다. -
Parameters
- None
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.set_org_cnoun() result = pro.get_cnoun() print(result[-10:])
Output (in Jupyter Notebook) :
#[] ['텍스트마이닝', '텍스트분석', '자연어처리', '지능정보학회', '비정형데이터', '악성댓글', '걸그룹', '쇼케이스', '허위유포', '흔들의자']
-
-
teanaps.nlp.Processing.is_cnoun(word)[Top]-
단어가 복합명사 리스트에 포함되어있는지 여부를 확인하고 그 결과를 반환합니다.
-
Parameters
- word (str) : 복합명사
-
Returns
- result (bool) : 복합명사 포함여부. True or False
-
Examples
Python Code (in Jupyter Notebook) :
result = pro.is_cnoun("텍스트마이닝") print(result)
Output (in Jupyter Notebook) :
TruePython Code (in Jupyter Notebook) :
result = pro.is_cnoun("전기자동차") print(result)
Output (in Jupyter Notebook) :
False
-
-
teanaps.nlp.Processing.get_stopword()[Top]-
TEANAPS에서 기본으로 제공하는 불용어를 호출하고 그 결과를 반환합니다. -
Parameters
- None
-
Returns
- result (list) : 불용어를 모두 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
result = pro.get_stopword() print(result[-10:])
Output (in Jupyter Notebook) :
['ㅗ', 'ㅛ', 'ㅜ', 'ㅠ', 'ㅡ', 'ㅣ', '', '은', '는', '이']
-
-
teanaps.nlp.Processing.add_stopword(word/word_list)[Top]-
TEANAPS에서 기본으로 제공하는 불용어 리스트에 임의의 불용어 또는 불용어 리스트를 추가합니다. -
Parameters
- word/word_list (str/list) : 불용어 또는 불용어를 포함하는 리스트
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.add_stopword("가") result = pro.get_stopword() print(result[-10:])
Output (in Jupyter Notebook) :
#['ㅗ', 'ㅛ', 'ㅜ', 'ㅠ', 'ㅡ', 'ㅣ', '', '은', '는', '이'] ['ㅛ', 'ㅜ', 'ㅠ', 'ㅡ', 'ㅣ', '', '은', '는', '이', '가']
Python Code (in Jupyter Notebook) :
pro.add_stopword(["으로", "로서", "때문에"]) result = pro.get_stopword() print(result[-10:])
Output (in Jupyter Notebook) :
#['ㅛ', 'ㅜ', 'ㅠ', 'ㅡ', 'ㅣ', '', '은', '는', '이', '가'] ['ㅡ', 'ㅣ', '', '은', '는', '이', '가', '으로', '로서', '때문에']
-
-
teanaps.nlp.Processing.remove_stopword(word/word_list)[Top]-
전체 불용어 리스트에서 불용어 또는 불용어 리스트를 모두 삭제합니다.
-
Parameters
- word/word_list (str/list) : 불용어 또는 불용어를 포함하는 리스트
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.remove_stopword("때문에") result = pro.get_stopword() print(result[-10:])
Output (in Jupyter Notebook) :
#['ㅡ', 'ㅣ', '', '은', '는', '이', '가', '으로', '로서', '때문에'] ['ㅠ', 'ㅡ', 'ㅣ', '', '은', '는', '이', '가', '으로', '로서']
Python Code (in Jupyter Notebook) :
pro.remove_stopword(["은", "는", "이", "가"]) result = pro.get_stopword() print(result[-10:])
Output (in Jupyter Notebook) :
#['ㅠ', 'ㅡ', 'ㅣ', '', '은', '는', '이', '가', '으로', '로서'] ['ㅖ', 'ㅗ', 'ㅛ', 'ㅜ', 'ㅠ', 'ㅡ', 'ㅣ', '', '으로', '로서']
-
-
teanaps.nlp.Processing.clear_stopword()[Top]-
전체 불용어 리스트에서 불용어 또는 불용어 리스트를 모두 삭제합니다.
-
Parameters
- None
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.clear_stopword() result = pro.get_stopword() print(result[-10:])
Output (in Jupyter Notebook) :
#['ㅠ', 'ㅡ', 'ㅣ', '', '은', '는', '이', '가', '으로', '로서'] []
-
-
teanaps.nlp.Processing.set_org_stopword()[Top]-
불용어 리스트를
TEANAPS에서 기본으로 제공하는 불용어 리스트로 초기화합니다. -
Parameters
- None
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.set_org_stopword() result = pro.get_stopword() print(result[-10:])
Output (in Jupyter Notebook) :
#[] ['ㅗ', 'ㅛ', 'ㅜ', 'ㅠ', 'ㅡ', 'ㅣ', '', '은', '는', '이']
-
-
teanaps.nlp.Processing.is_stopword(word)[Top]-
단어가 불용어 리스트에 포함되어있는지 여부를 확인하고 그 결과를 반환합니다.
-
Parameters
- word (str) : 불용어
-
Returns
- result (bool) : 불용어 포함여부. True or False
-
Examples
Python Code (in Jupyter Notebook) :
result = pro.is_stopword("은") print(result)
Output (in Jupyter Notebook) :
TruePython Code (in Jupyter Notebook) :
result = pro.is_stopword("없는단어") print(result)
Output (in Jupyter Notebook) :
False
-
-
teanaps.nlp.Processing.start_timer()[Top]-
타이머를 초기화하고 다시 시작합니다.
-
Parameters
- None
-
Returns
- None
-
Examples
Python Code (in Jupyter Notebook) :
pro.start_timer()
-
-
teanaps.nlp.Processing.lab_timer()[Top]-
타이머 랩타임을 기록하고 그 결과를 반환합니다.
-
Parameters
- None
-
Returns
- result (list) : (랩, 랩타임) 구조의 Tuple을 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
import time #pro.start_timer() time.sleep(1) result = pro.lab_timer() print(result) time.sleep(2) result = pro.lab_timer() print(result)
Output (in Jupyter Notebook) :
[(1, 1.0033)] [(1, 1.0033), (2, 3.0068)]
-
-
teanaps.nlp.Processing.get_token_position(sentence, tag_list)[Top]-
문장의 띄어쓰기 오류를 보정하고 그 결과를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
- tag_list (str) : (단어, 태그) 구조의 Tuple을 포함하는 리스트.
-
Returns
- result (str) : (단어, 태그, 위치) 구조의 Tuple을 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지입니다." tag_list = [("TEANAPS", "UN"), ("Python", "UN")] result = pro.get_token_position(sentence, tag_list) print(result)
Output (in Jupyter Notebook) :
[('TEANAPS', 'UN', (0, 7)), ('Python', 'UN', (21, 27))]
-
-
teanaps.nlp.Processing.language_detector(sentence)[Top]-
문장의 언어를 식별하고 그 결과를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
-
Returns
- result (str) : 식별된 언어 유형. 한국어는 "ko", 영어는 "en".
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지입니다." result = pro.language_detector(sentence) print(result)
Output (in Jupyter Notebook) :
koPython Code (in Jupyter Notebook) :
sentence = "If it is to be, it's up to me." result = pro.language_detector(sentence) print(result)
Output (in Jupyter Notebook) :
en
-
-
teanaps.nlp.Processing.iteration_remover(sentence, replace_char=".")[Top]-
문장에서 무의미하게 반복되는 패턴을 찾아내 "."으로 치환한 문장을 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
- replace_char (str) : 반복되는 패턴을 대체할 문자열.
-
Returns
- result (str) : 반복된 패턴이 치환된 문장.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지입니다ㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋㅋ" result = pro.iteration_remover(sentence) print(result)
Output (in Jupyter Notebook) :
TEANAPS는 텍스트 마이닝을 위한 Python 패키지입니다ㅋ........
-
-
teanaps.nlp.Processing.get_plain_text(sentence, pos_list=[], word_index=0, pos_index=1, tag_index=1, tag=True)[Top]-
형태소 또는 개체명 태그를 "/"로 구분해 태깅하여 문장 형태로 생성하고 그 결과를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
- pos_list (list) : 필터링할 태그가 포함된 튜플의 인덱스.
- word_index (str) : 단어가 포함된 튜플의 인덱스.
- pos_index (int) : 필터링할 태그가 포함된 튜플의 인덱스.
- tag_index (int) : 태깅할 태그가 포함된 튜플의 인덱스.
- tag (bool) : 태그 포함여부.
-
Returns
- result (str) : 반복된 패턴이 치환된 문장.
-
Examples
Python Code (in Jupyter Notebook) :
#from teanaps.nlp import MorphologicalAnalyzer #ma = MorphologicalAnalyzer() #ma.set_tagger("mecab") #sentence = "TEANAPS는 텍스트 마이닝을 위한 Python 패키지입니다." #ma_result = ma.parse(sentence) ma_result = [('TEANAPS', 'OL', (0, 7)), ('는', 'JX', (7, 8)), ('텍스트', 'NNG', (9, 12)), ('마이닝', 'NNP', (13, 16)), ('을', 'JKO', (16, 17)), ('위한', 'VV+ETM', (18, 20)), ('Python', 'OL', (21, 27)), ('패키지', 'NNG', (28, 31)), ('입니다', 'VCP+EF', (31, 34)), ('.', 'SW', (34, 35))] result = pro.get_plain_text(ma_result) print(result)
Output (in Jupyter Notebook) :
TEANAPS/OL 는/JX 텍스트/NNG 마이닝/NNP 을/JKO 위한/VV+ETM Python/OL 패키지/NNG 입니다/VCP+EF ./SW
-
-
teanaps.nlp.Processing.replacer(sentence)[Top]-
문장에서 축약된 표현을 찾아 원래의 표현으로 수정하고 그 결과를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
-
Returns
- result (str) : 축약된 표현이 수정된 문장.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "If it is to be, it's up to me." result = pro.replacer(sentence) print(result)
Output (in Jupyter Notebook) :
If it is to be, it is up to me.
-
-
teanaps.nlp.Processing.masking(sentence, replace_char="*", replace_char_pattern = "", ner_tag_list=[], model_path="")[Top]-
문장에서 추출된 개체명을 다른 문자열로 치환하고 그 결과를 반환합니다.
-
Parameters
- sentence (str) : 한국어 또는 영어로 구성된 문장. 최대 128자.
- replace_char (str) : 개체명을 치환할 문자열.
- replace_char_pattern (str) : 개체명을 치환할 문자열 패턴.
- ner_tag_list (list) : 치환 대상 개체명 태그 리스트.
- model_path (str) : 개체명 인식 모델 파일 경로.
-
Returns
- result (str) : 개체명을 다른 문자열로 치환한 문장.
-
Examples
Python Code (in Jupyter Notebook) :
sentence = "제 이름은 제임스 포터이고 연락처는 010-1234-5678 입니다." result = pro.masking(sentence) print(result)
Output (in Jupyter Notebook) :
제 이름은 ******이고 연락처는 ************* 입니다.
Python Code (in Jupyter Notebook) :
sentence = "제 이름은 제임스 포터이고 연락처는 010-1234-5678 입니다." replace_char_pattern = "___-**__-**__" result = pro.masking(sentence) print(result)
Output (in Jupyter Notebook) :
제 이름은 제임스 **이고 연락처는 010-**34-**78 입니다.
-
-
teanaps.nlp.Processing.sentence_splitter(paragraph)[Top]-
여러개 문장이 포함된 문단을 문장 단위로 구분하고 그 결과를 반환합니다.
-
Parameters
- paragraph (str) : 한국어 또는 영어로 구성된 문단
-
Returns
- result (list) : 문단에 포함된 문장을 포함하는 리스트.
-
Examples
Python Code (in Jupyter Notebook) :
paragraph = "어머나...안녕하세요. TEANAPS를 다시 찾아주셨군요!" result = pro.sentence_splitter(paragraph) print(result)
Output (in Jupyter Notebook) :
['어머나...', '안녕하세요.', 'TEANAPS를 다시 찾아주셨군요!']
-
- TBU
- 본 자료는 텍스트 마이닝을 활용한 연구 및 강의를 위한 목적으로 제작되었습니다.
- 본 자료를 강의 또는 연구 목적으로 활용하고자 하시는 경우 꼭 아래 메일주소로 연락주세요.
- 본 자료에 대한 상업적 활용과 허가되지 않은 배포를 금지합니다.
- 강의, 저작권, 출판, 특허, 공동저자에 관련해서는 문의 바랍니다.