Considerations and Reflections
On the way to an architecture for a scalable IoT data pipeline we focus on two central components:
- a message queue to ingest data
- a stream processing framework
Both components need to work together in 3 major scenarios:
- Stream mode to process event data in near real time. The operations range from basic arithmetics to complex event processing and model inference, for example to detect anomalies in stream data
- Batch mode to train models
- Direct data access mode to render graphs based on historic event data
Because we focus on machine learning it would be desirable to have python binding, resp. a python SDK for the first two modes.
While there are numerous Open Source message queue frameworks to choose from Apache Kafka has become the de-facto standard. However, tiered storage support over the S3 API using Apache jCloud, is a major differentiator, see also pulsar tiered storage overview. After offloading data can be queried with Pulsar SQL so historic data for UI and model training can be access through Pulsar.
(Reference](https://digitalis.io/blog/technology/apache-kafka-vs-apache-pulsar/)
For a longer discussion, please see also the following master thesis A Comparison of Data Ingestion Platforms in Real-Time Stream Processing Pipelines
The author evaluates Redis, Kafka and Pulsar against the following five requirements, data persistence and retention, fault tolerance, language and container support, throughput and end-to-end latency. Redis doesn't allow for long-term storage of historic data, so is not a viable candidate. Kafka and Pulsar are shown to be suitable candidates with Kafka being the more mature product compared to Pulsar.
Conclusion: Neither message queue framework is available as out-of-the box solution in our case, so operational costs are on par. Hence tiered storage support tips the balance in favor of Pulsar.
See also the following preview book
Background: Pulsar fault tolerance
Compared to message queue frameworks there are even more options for stream processing from the veteran Apache Storm over Apache Flink to Apache Spark. Even in the Kafka eco-system there is a stream processor with Kafka Streams that unfortunately doesn't support batch mode. Pulsar Functions support both, stream and batch mode, and might constitute a very light-weight alternatives to a full-blown streaming analytics platform.
Let's start discussing them, i.e. Apache Spark and Flink first.
Both frameworks are suitable candidates, both support stream and batch mode. Also both come with python bindings (PySpark, resp. PyFlink). Also both interact in a similar way with kubernetes: A Spark or Flink application is bundled with the basic Spark or Flink image. The submit command interacts with the kubernetes API server to start a pod with this application. This pod then impersonates a Spark worker or Flink task manager.
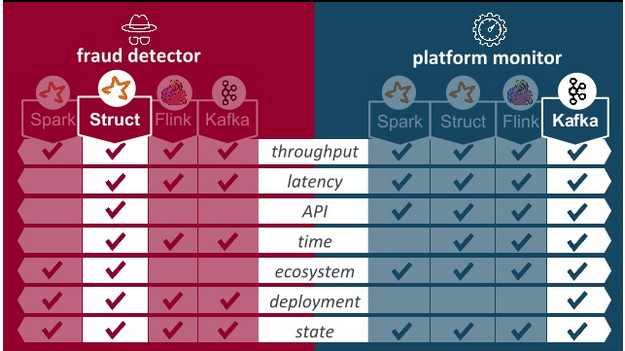
For a thorough comparison I'd recommend Giselle de Jongen's 2019 talk Choosing the right tool for the job. She focuses on two use cases, fraud detection and platform monitoring, and concludes that Spark Structured Streaming is the right tool for the fraud detection case - which is similar to our stream analytics scenario 1.
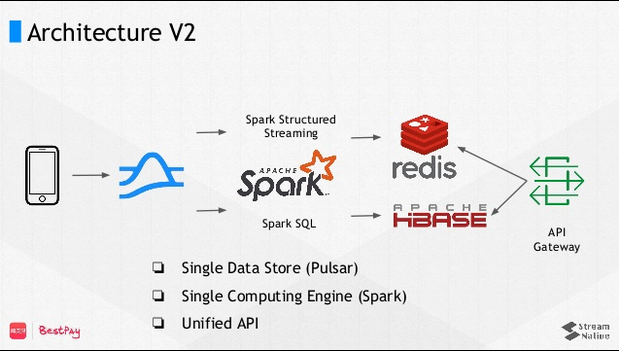
Discussing Pulsar as light-weight alternative
Although Pulsar functions are typically geared towards ETL with the likes of Spark for more complex tasks, see also here
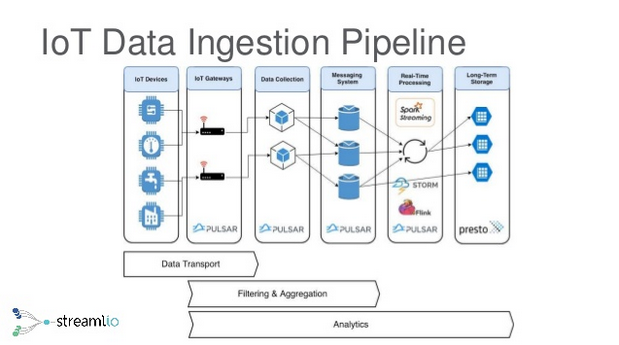
Reference: From the slide deck Apache Pulsar real-time analytics.
It supports event windowing and hence can be used for IoT anomaly detection.