Text to Speech of Electronic Documents Containing Ruby: User Requirements (OBSOLETE)
Maintenance of this document migrated to W3C.
We are concerned about issues around the text-to-speech of HTML documents and EPUB publications containing ruby. Although typographical characteristics of ruby are covered by JLreq (W3C Note) and Simple Ruby (W3C Note), text-to-speech issues have not been widely recognized. This document focuses on user requirements, while a companion document (now in Japanese only) focuses on implementation issues.
Section 2 enumerates the roles ruby plays in relation to base characters. Section 3 describes possible options for using base characters and/or ruby for the text-to-speech and discusses the pros and cons of each option. Section 4 shows ruby markup issues around the text-to-speech. Section 5 introduces alternative mechanisms (SSML and PLS), Section 6 describes the use of ruby in translating HTML or EPUB to braille, and Section 7 provides a brief summary of the text-to-speech of Word documents and PDF documents containing ruby.
The primary use of ruby is to indicate how to read CJK ideographic characters (furigana).
Nowadays, it is not common to attach ruby to all CJK ideographic characters (general ruby). Ruby is typically attached to difficult CJK ideographic characters only (para ruby).
Ruby is used in trade books, newspapers, textbooks, teaching materials, etc., but is rarely used in business documents.
Even for simple CJK ideographic characters, ruby may be added for some users who have particular difficulties with CJK ideographic characters (in electronic documents, it is easy to make ruby visible or invisible based on user preferences). Such ruby is called furigana-added-for-enhanced-accessibility.
Some simple CJK ideographic characters have more than one possible reading and thus require ruby for disambiguation. This is common for names of people and places. For example, "山崎" (a person's name) may be read as "Yamazaki" or "Yamasaki".
In the case of para ruby, ruby is often attached to the first occurrence of a CJK ideographic character, and not attached to the second and subsequent occurrences of the same character, probably because users should learn from the first occurrence.
Especially in Japan, ruby is also used for indicating something different from the reading of a CJK ideographic character. Such ruby is called Gikun. Gikun tends to be used in light novels and comics.
Here are some examples of Gikun:
- 生命 (the typical reading of 生命 is SEIMEI rather than いのち (INOCHI), where both 生命 and いのち mean "Life")
- 背景 (the typical reading of 背景 is HAIKEI rather than バック ("back"), which is an English translation)
- 牛乳 (the typical reading of 牛乳 is GYUUNYUU rather than ミルク ("milk"), which is an English translation)
Even when Gikun is used for a compound word, it is unlikely to be repeated for later occurrences of the same word. Moreover, different GIKUN may be added for subsequent occurrences of the same word. For example, the next occurrence of 生命 may well be 生命 where ライフ ("life") is an English translation.
Unusual names of people in Japan are written in CJK ideographic characters but read as something completely different from the typical reading of the CJK ideographic characters. For example, 男 is an unusual name, where 男 (usually read as OTOKO) means "man" and あだむ is "Adam" in Kana.
Character names in comics, animation and light novels are sometimes extremely difficult to read. Many of the character names in Demon Slayer (Kimetsu no Yaiba) fall into this category. For example, almost no one can read 不死川 玄弥 as "Shinazugawa Gennya" from the beginning.
Names of places are sometimes hard to read for historical reasons. For example, 神居古潭, 温根沼, 音威子府 are names of places in Hokkaido (the northern island of Japan). These names are hard to read since they came from the Ainu language, which is totally different from the Japanese language.
In many cases, the first occurrence of an unusual name is accompanied by ruby but the other occurrences are not.
Interlinear notes look similar to ruby. A note from JLreq (just before 4.2.2) introduces interlinear notes.
NOTE
Other than these styles of note, explanations of facts and persons in study aid books and history texts, and modern translations of Japanese classic texts are sometimes set between lines. These notes are called interlinear notes (see Figure 241).
In the example shown in Figure 241, 徳川家康 (Tokugawa Ieyasu) is accompanied by an interlinear note "1543-1616 江戸幕府最後の将軍" (1543-1616 the last shogun of the Edo shogunate). Other examples are: a modern kana phrase as an interlinear note for a historical kana phrase, a standard Japanese expression as an interlinear note for an expression in a dialect, a modern CJK ideographic character as an interlinear note for a traditional CJK ideographic character, an English text chunk as an interlinear note for a Japanese text chunk, and an official name as an interlinear note for an abbreviated name.
One could argue that HTML ruby elements should not be used for representing interlinear notes (see Kobayashi Sensei's mail in Japanese). However, it is not difficult to imagine that ruby elements are actually used for representing interlinear notes.
In language textbooks, ruby is sometimes used to indicate the reading of a foreign phrase in hiragana or katakana. For example, a Chinese phrase 我去学校 may have ウオ チュー シュエシャオ as ruby.
A sequence of base characters may be accompanied by two ruby text chunks. Typically, one of them is Furigana and the other is either a GIKUN or interlinear note. In an example in JLreq, 東南 is accompanied by たつみ and とうなん. Here 東南 means "southeast", とうなん (TOUNAN) is a furigana, and たつみ (Tatsumi) is a GIKUN, since 辰巳 (read as たつみ) means the same direction as 東南.

Here とうよう is a furigana and オリエント is a Gikun.
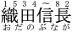
Here おだのぶなが is a furigana and "1534-82" is an interlinear note.
There are three possible options: (1) both base characters and ruby, (2) ruby only, and (3) base characters only.
In this option, base characters are read aloud first and ruby is then read aloud. Many implementations (screen readers, in particular) support this option only. For example, foo is read aloud as "foo bar".
The option of reading aloud both interferes with readers' understanding significantly. This is true for both group ruby and mono ruby.
Consider an example from "The Rich Man and the Chicken" by 小川未明 (OGAWA Mimei). Note that the mono ruby for 新鮮 is expressed by two rt elements: one for 新 and the other is for 鮮.
鶏でも飼って、新鮮な卵を産まして食べようと思いました。
If there is no ruby, this should be read aloud as:
にわとりでもかって、しんせんなたまごをうましてたべようとおもいました。
(Niwatori demo katte shinsenna tamagowo umashite tabeyouto omoimashita.)
Translation in English: I thought that I should raise a hen so that I can eat fresh eggs.
The option of reading aloud both provides:
にわとりにわとりでもかかって、しんしんせんせんなたまごたまごをううましてたたべようとおもおもいました。
(Niwatoriniwatori demo kakatte shinshinsensenna tamagotamagowo uumashite tatabeyouto omoomoimashita.)
This reading does not make any sense at all.
Moreover, in some cases, reading both completely changes the meaning (see examples).
The option of reading aloud both is sensible.
生命 is read aloud as "Seimei Inochi", where "Seimei" is a loan word from Chinese and "Inochi" is a native Japanese word. Both means life.
The option of reading aloud both interferes with readers' understanding significantly.
不死川玄弥 ("Fushikawa Genya") is read aloud as "Fushikawa Genya Shinazugawa Genya", which suggests two persons rather than one person.
The option of reading aloud both is sensible.
For example, 徳川家康 is read aloud as "Tokugawa Ieyasu 1543-1616 Edo Bakufu Saigono Shougun", which means "Tokugawa Ieyasu 1543-1616, the last shogun of the Edo shogunate".
The option of reading aloud both interferes with readers' understanding significantly.
In the example of 我去学校, even if ウオ チュー シュエシャオ is read aloud using the Japanese text-to-speech engine, the result will not be helpful to learners because of the incorrect pronunciation and four tones. Katakana pronunciation is also useless in languages such as English.
Since there are two ruby text chunks, double-sided ruby leads to reading aloud three times. One of the ruby text chunks is typically furigana, so the description in 1) applies. If the other ruby text chunk is a Gikun, the description in 2) applies; if it is an interlinear note, the description in 4) applies.
In this option, ruby is read aloud but base characters are not. For example, foo is read aloud as "bar".
The option of reading aloud ruby only provides not-incorrect-but-unnatural results usually. In some cases, it causes mistakes in deciding whether へ should be read aloud as え (/e/) or へ (/he/) and whether は should be read aloud as わ (/wa/) or は (/ha/). This is because the morphological analysis does not work properly and pronunciation dictionaries for compound words cannot be used, as kana characters are used instead of CJK ideographic characters. As an example, consider 今後は発展. T2S of 今後は発展 typically works fine but that of 今後ははってん does not. The first occurrence of は should be read aloud as わ (/wa/) but is mistakenly read aloud as は (/ha/).
Even when this option is used, it might be wise to ignore furigana-added-for-enhanced-accessibility but rely on base characters.
If furigana is assigned only for the first occurrence of a word, there is a risk that the first occurrence and the others are read aloud differently.
Note: One way to avoid this problem is for the text-to-speech engine to maintain a correspondence table between base characters and ruby.
The option of reading aloud ruby only provides an understandable result but does not properly convey the author's intention.
生命 will be read aloud as いのち ("inochi").
The option of reading aloud ruby only works correctly. However, if the first occurrence of a name is accompanied by ruby and the other occurrences are not, the first occurrence is read aloud differently from the others thus suggesting different persons or places.
For example, 不死川玄弥 is read aloud as Shinazugawa Genya correctly. But later occurrences of 不死川玄弥 are read aloud as Fushikawa Genya if they do not have ruby.
Note: A workaround is available as described in the note in 1).
The option of reading aloud ruby provides incomprehensible results often.
If "1543-1616 江戸幕府最後の将軍" is attached to 徳川家康 as ruby, it will be read aloud as "1543-1616 エドバクフサイゴノショウグン" (1543-1616 the last shogun of the Edo shogunate), which is reasonable. But if only "1543-1616" is attached as ruby, the result is "1543-1616" which does not make any sense.
The option of reading aloud ruby only interferes with readers' understanding significantly.
In the example of 我去学校 (ウオ チュー シュエシャオ), even if ウオ チュー シュエシャオ is read out in the Japanese style, it will not be helpful to learners because of the inaccurate pronunciation and the four tones (tones). Katakana pronunciation is also useless in languages such as English.
The option of reading aloud ruby only makes two ruby text chunks be read aloud while ignoring base characters. Since one of the ruby text chunks is typically furigana, the description in 1) applies. If the other ruby text chunk is a Gikun, the description in 2) applies; if it is an interlinear note, the description in 4) applies.
In this option, base characters are read aloud but ruby is not. For example, foo is read aloud as "foo".
Note: This option does not necessarily ignore ruby. Although text-to-speech engines mainly use base characters, they may also use ruby as a hint.
The option of reading aloud base characters only may or may not provide good results, depending on text-to-speech engines.
The following is a quote from "Guidelines for creating accessible e-books for text-to-speech (2015)" from the Ministry of Internal Affairs and Communications.
The characters that can be read out aloud by TTS engines are currently limited to JIS X 0208:1997. Half of the JIS CJK ideographic characters cannot be read aloud.
Furthermore, compound words made up from CJK ideographic characters in JIS X 0208 are sometimes read aloud incorrectly.
As the importance of accessibility is well recognized and text-to-speech engines are improved, more and more words will be read aloud correctly. However, there are some words, such as the aforementioned "Yamazaki," that cannot be read aloud correctly by text-to-speech engines and even native Japanese speakers.
The option of reading aloud base characters only results in a perfectly understandable result. However, since gikun is ignored, the author's intent is not completely conveyed.
生命 is read out as "seimei".
The option of reading base characters only leads to incorrect results. However, since every occurrence of a name is read aloud in the same way, users will not be confused.
Every occurrence 不死川 玄弥 will always be incorrectly read aloud as ふしかわ げんや, regardless of the presence or absence of ruby.
The option of reading base characters only provides a perfectly understandable result. However, since interline notes are ignored, the author's intention is not conveyed well.
徳川家康 (Tokugawa Yeyasu 1543-1616, the last shogun of the Edo shogunate), will be read aloud as とくがわいえやす(Tokugawa Yeyasu).
The option of reading base characters only is most appropriate when natural languages are correctly identified and base characters are read aloud by a text-to-speech engine in that language. On the other hand, if the natural language cannot be identified or the text-to-speech engine for that language is not available, the result is not understandable.
The option of reading base characters only will ignore the two ruby text chunks and read the base characters. When one of the ruby text chunks is furigana, the description in 1) applies. If the other is a gikun, the description in 2) applies, and if it is an interlinear note, the description in 4) applies.
Small kana characters ゃ、ゅ、ょ、and っare too small when they appear in ruby. For this reason, instead of these small characters, full-size kana characters や、ゆ、よ、and つ are used in ruby.
However, since full-size kana characters are pronounced differently from small kana, ruby containing full-size kana is read aloud differently.
CSS has a mechanism for overcoming this problem. Value 'full-size-kana' of the text-transform property as specified in CSS Text converts small kana characters to full-size kana. It is thus possible to use small kana in ruby markup while rendering ruby using full-size kana. Text-to-speech engines can provide correct results even when ruby is read aloud.
Okayama-san of Hitach has argued that, even in the case of mono ruby, creating a single ruby element per compound word is better than creating a ruby element for each base character in a compound word. For example, to attach mono ruby to 生命, he recommends a single ruby element and two rt elements: one for 生 and another for 命 rather than creating two ruby elements.
A single ruby element per compound word can be rendered as mono ruby or jukugo ruby by CSS. Moreover, it is also easy for the text-to-speech engine to maintain a correspondence table between base characters and ruby.
Although furigana-added-for-enhanced-accessibility is necessary for those readers who have particular difficulties with CJK ideographic characters, it is unnecessary or slightly disturbing for others. If furigana-added-for-enhanced-accessibility is distinguishable from normal furigana, it can be made visible or invisible depending on user preferences. It is thus necessary to standardize a markup mechanism for indicating furigana-added-for-enhanced-accessibility.
In Section 3, we have seen that ruby used as gikun or interline notes should be read aloud differently from the other cases. It is thus necessary to standardize a markup mechanism for clearly indicating ruby used as gikun or interlinear note.
In EPUB publications, SSML attributes can be attached to XHTML elements for specifying phonemic/phonetic pronunciations. SSML attributes are used by text-to-speech engines for speech synthesis but they are not used for visual rendering. SSML can control text-to-speech much better than ruby.
However, it has been reported that attaching SSML to CJK ideographic characters thoroughly significantly increases the authoring cost. Although SSML has been used by some textbook publishers in Japan, it is unlikely to be widely used for trade books.
While SSML attributes are embedded within XHTML content documents in EPUB publications, PLS dictionaries (see Pronunciation Lexicon Specification) in EPUB publications are stored externally to and referenced by XHTML content documents. A PLS dictionary contains a collection of words or phrases containing pronunciation information.
PLS is a powerful mechanism for the text-to-speech of unusual names of people and places. Every occurrence of a word or phrase is read aloud in the same way regardless of ruby.
Conversion of HTML documents and EPUB publications to braille is expected to become important in the near future.
Japanese braille does not have CJK ideographic characters and does not distinguish hiragana and katakana. (Note: Han braille has CJK ideographic characters, but it is not widely used.)
Braille has some syntactical differences from the Japanese writing system. First, the space character is inserted as delimiters between words. Second, two Japanese particles はand へ are written as they are pronounced; that is, は and へ are represented as if they were わ and え. Third, う pronounced as the elongated sound is represented by the long vowel character.
Natural language processing is required for handling these differences in the conversion to braille. But, unlike in the case of text-to-speech, intonation is not relevant.
To convert HTML or EPUB to braille, it is crucial to choose the correct reading of each CJK ideographic character. If an incorrect reading is chosen, the generated braille becomes incorrect. As in the case of text-to-speech, ruby provides useful hints while SSML and PLS are good alternatives.
For furigana and unusual names of people and places, natural language processing will work better when CJK ideographic characters are used as a basis, while correct reading will be chosen when ruby is used as a basis. It is even possible to use both parent characters and ruby.
Microsoft Word reads aloud neither base characters nor ruby. Therefore, text-to-speech does not work when ruby is used.
Ruby in PDF documents is represented as separate lines containing tiny characters. The relationship between base characters and ruby is not explicitly represented.
Some implementations read aloud the ruby line first and then read the original line, which contains base characters. Such implementations provide incomprehensible results. Other implementations simply ignore ruby lines. Subsection 3.3 applies to these implementations.
- Requirements for Japanese Text Layout (W3C Working Group Note), available at https://www.w3.org/TR/jlreq/.
- Rules for Simple Placement of Japanese Ruby (W3C First Public Working Draft), available at https://www.w3.org/TR/simple-ruby/.