Home
Rikolti is a new project currently in development by the California Digital Library, to replace our existing harvesting infrastructure for Calisphere, which aggregates digital cultural heritage content from hundreds of organizations throughout California. A standard set of requirements informs this work, including: ingest from multiple different sources, mapping to a standard metadata model, pulling in content files, and producing a search index.
The existing Calisphere harvester uses deprecated, unsupported technologies from DPLA’s version 1 harvesting stack, developed in 2013. The harvesting system is too central to our operations to allow it to degrade in unsupported, undocumented, and outdated technologies. Further, an assessment that we conducted in 2016 signals the opportunity to shift technologies to streamline processes and support scalability of the service. Additional analysis was conducted on existing technologies, including Supplejack, Combine, and Ingestion3, but these were not readily adaptable to Calisphere’s identified use cases and requirements.
The Rikolti system is designed to be modular and fast, using current, well-supported systems:
- Modular components will allow us to re-run individual pieces as needed: for example, we can iterate on a metadata mapping independently from other steps. Modular components also make it easier to develop and test locally, and allow for better error handling at each step.
- Rapid processing will allow us to handle data much more quickly, and opens up new opportunities for reporting, understanding, and sharing that data.
Rikolti also investigates new features that speak to specific needs identified by Calisphere’s contributors, such as full-text indexing of the text appearing in object content files (e.g., PDFs).
Proposed Rikolti structure:
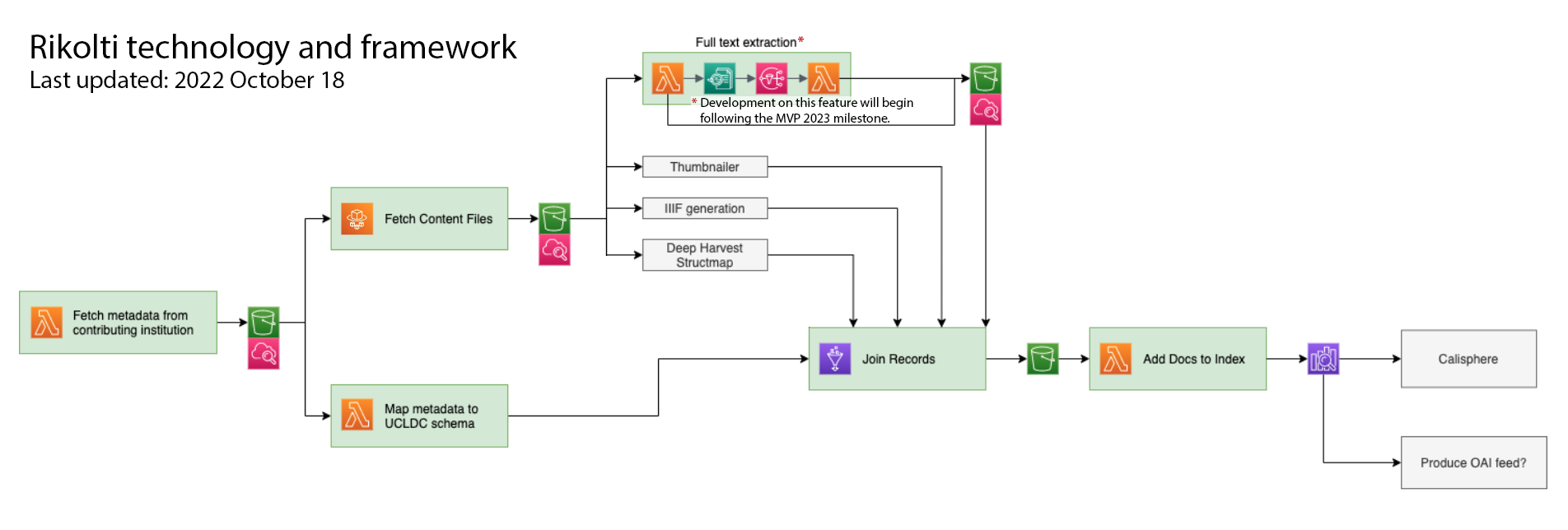
- Sever-less solutions: AWS Lambda runs quick small jobs (i.e., perfect for building small, modular components like thumbnail generation and metadata fetching).
- Data storage: AWS Simple Storage Service (s3) will store harvest data.
The green components in the diagram above have been prototyped:
- Metadata fetcher: Uses AWS Lambda to fetch the vernacular metadata & content files. The fetcher on our current harvesting stack is written in python2; will be updated to python3.
- Metadata transformation: Uses Python running in AWS Lambda to conduct ETL (extract, transform, load) processes to homogenize all of the different metadata that comes from our hundreds of sources; reads and writes output to s3.
- Content file fetcher: Uses Python running in a docker container deployed in AWS Fargate (ECR) to fetch content files from contributors.
- Full-text indexing: Uses AWS Textract to index the text within content files, such as PDFs. Note that this feature is not in scope for the MVP milestone.
- Search index: ElasticSearch (likely deployed through the AWS ElasticSearch service) to power the Calisphere search function.
Rikolti development is organized around quarterly milestones. We are currently developing a minimum viable product (MVP), with a goal to completely replace our current harvesting infrastructure with Rikolti by early 2024. We will provide updates on our timeline as our development work continues.
MVP (target release date: Early 2024)
- Completely replace the current harvesting infrastructure with Rikolti.
- Migrate and/or re-build existing metadata fetchers and mappers.
- Migrate and/or rebuild existing content file fetcher code.
- Migrate and/or re-harvest existing Calisphere records into the new AWS ElasticSearch index.
- Document updated harvest operation workflows.
Spring 2022 (release date: June 30, 2022)
- Create, test, and document a workflow for writing fetchers/mappers in Rikolti. This will include identifying and preparing one fetcher/mapper pair as a run-through to prepare and refine the documentation.
Winter 2022 (release date: March 31, 2022)
- Begin to build out mappers and associated fetchers for Rikolti. This includes creating a time table for building fetcher/mapper combos, and starting to build out other fetcher/mapper combos.
Year End 2021 (release date: December 22, 2021)
- Build the full pipeline for complex objects through to the frontend, including the complex object media mapper, complex object content file fetcher, and thumbnail fetcher; and create a timetable to implement all fetcher/mapper components.
Summer 2021 (release date: October 30, 2021)
- Have a new end-to-end demo (through to Calisphere frontend) to develop further Rikolti components, specifically around Nuxeo image harvesting and complex objects.
Spring 2021 (release date: June 30, 2021)
- Have a new end-to-end demo that we can get feedback from Shared DAMS (Nuxeo) campuses on their content, specifically re “full-text”.
Winter 2021 (release date: March 31, 2021)
- Scale up proof-of-concept to work with 3 top kinds of enrichment chain types. Look into workflow management systems and operator interface (Airflow, Steps).
Fall 2020 (release date: December 22, 2020)
- Determine a high-level approach and overall task list. This will include a plan for migration of a limited amount of code and data.
Rikolti [riˈkolti] is the Esperanto word meaning “to harvest.”
Esperanto is a constructed international auxiliary language, created in 1887 by Polish ophthalmologist L. L. Zamenhof. Zamenhof's goal was to create an easy and flexible language that would serve as a universal second language to foster world peace and international understanding. The word esperanto translates into English as "one who hopes." Summarized from https://en.wikipedia.org/wiki/Esperanto.
Rikolti is in development by staff at the California Digital Library.