{kind=link}
{kind=link}
This code will Add pages inside of a Notion Database as documents to marqo so that they can get vectorized and accessed by LLama 3.2
- Go through all steps in a ORIGINAL DOCS - Marqo x Llama 3.2 for RAG
- Before running backend code, go through Notion Steps
- Create Notion integration https://www.notion.so/profile/integrations
- Set Content Capabilities to only Read Content
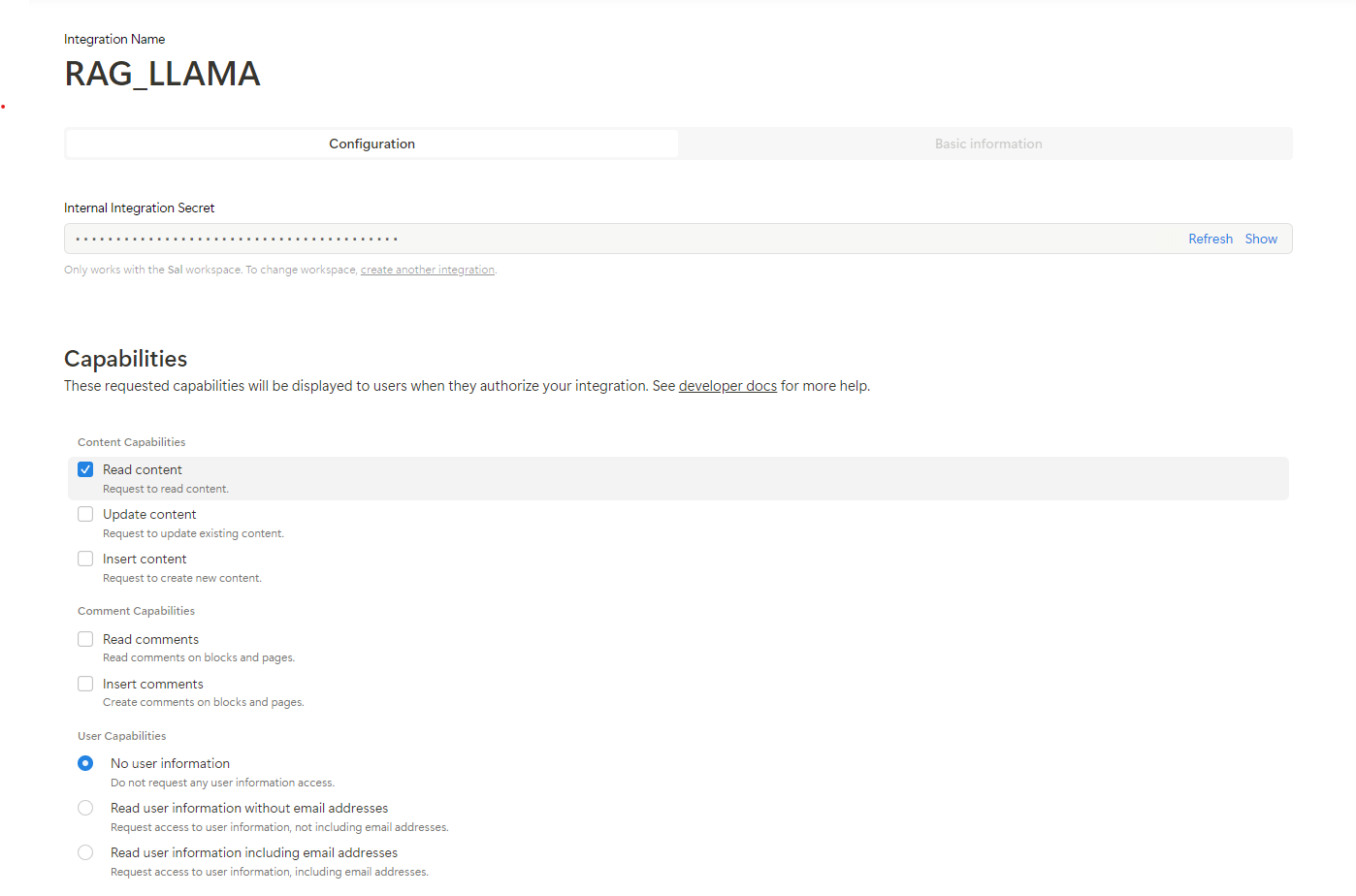
-
- Go to Notion page that you want to share with integration and allow the connection
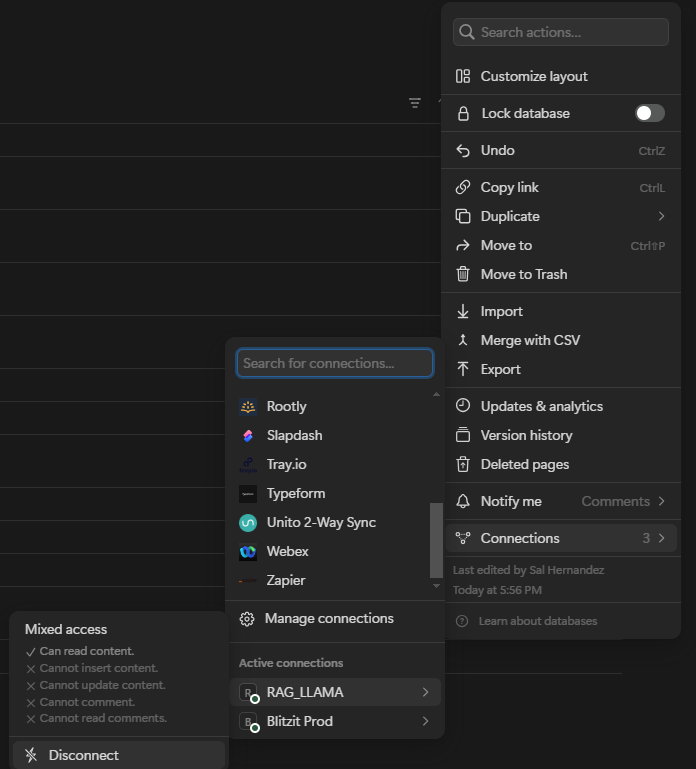
-
- Go to app.py and update
page_idwith your page ID- You can
copy linkof Notion page and get the first hash after your user- Example:
- if link is
https://www.notion.so/salhernandez/1234vvaaa1234then page id is1234vvaaa1234
- if link is
- Example:
- You can
- Go to app.py and update
notion_secretwith your integration secret
When code starts it will
- Get Notion Page data
- Get content inside of database
- Add the following to a list:
- Title
- Title of page in database
- Description
- Content of page in database
- Title
- Add documents (list) to marqo
The documents will now be accessible through marqo and when you chat with it it will be able to use it when answering!
Example: Llama3.2 is answering based on a Notion Page that was added as a document to marqo
When I ask "How to remove empty folders", it will return the following:
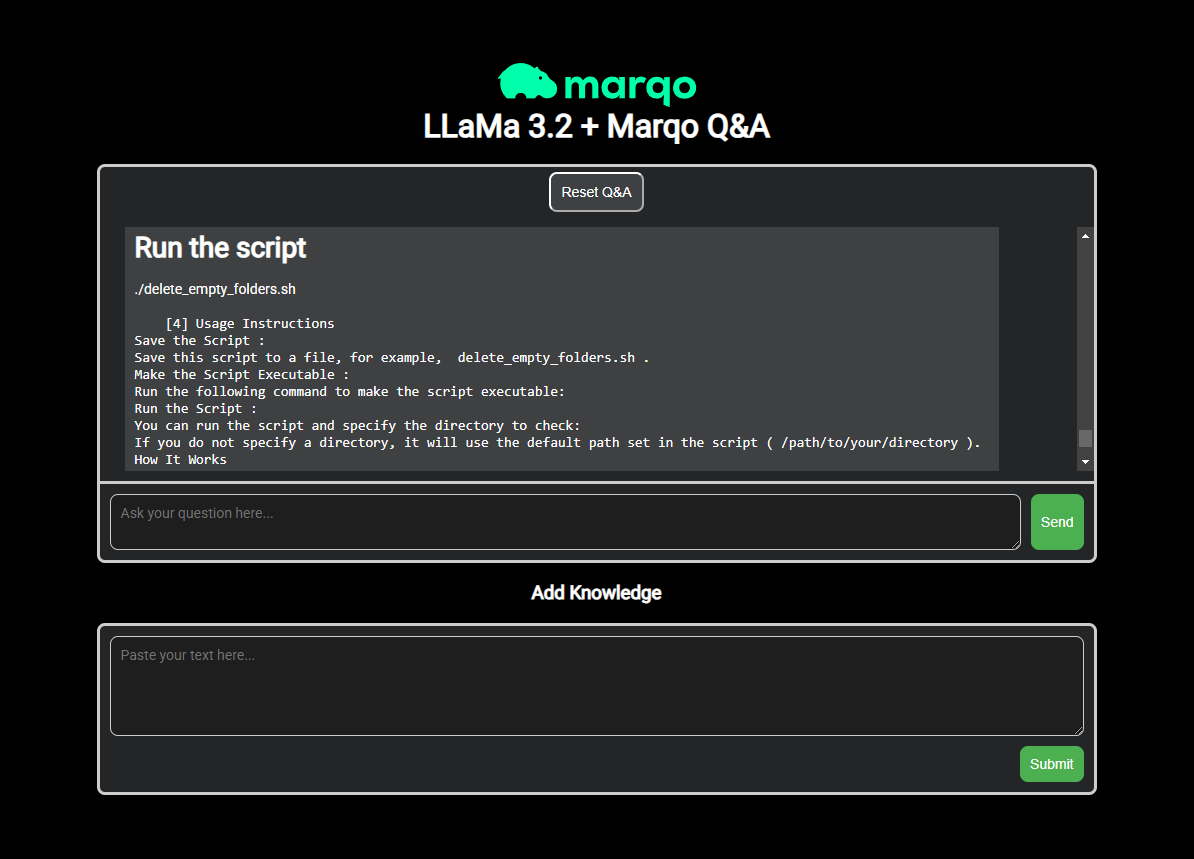
Original page referenced in Notion:
This is a small demo of a Local RAG Question and Answering System with Llama 3.2 1B and Marqo. This project has been built based off the original Marqo & Llama repo by Owen Elliot.
Article to accompany project: Fully Local RAG with Llama 3.2 & Marqo

I have also written an article that walks through this project that I encourage you to read when getting started.
First clone this repository:
git clone https://github.com/ellie-sleightholm/marqo-llama-3.2-1B-rag.git
Installs the necessary Node.js packages for the frontend project and then start the development server. This will be at http://localhost:3000.
cd frontend
npm i
npm run dev
The frontend will look the same as in the video at the top of this README.
To run this project locally, you will need to obtain the appropriate models. If you have 16GB of RAM, I would recommend starting with LlaMa 3.2 GGUF models. For this demo I used Llama-3.2-1B-Instruct-Q6_K_L.gguf.
There are several models you can download from the bartowski/Llama-3.2-1B-Instruct-GGUF Hugging Face hub. I recommend starting with Llama-3.2-1B-Instruct-Q6_K_L.gguf.
Download this model and place it into a new directory backend/models/1B/.
Important note: there is some adjustment needed for llama cpp (see this issue). Please be aware of this when working with this project.
Next, navigate to the backend directory, create a virtual environment, activate it, and install the required Python packages listed in the requirements.txt file.
cd backend
python3 -m venv venv
source venv/bin/activate
pip3 install -r requirements.txt
To run this project, you'll need download NLTK (Natural Language Toolkit) data because the document_processors.py script uses NLTK's sentence tokenization functionality. Specifically, the sentence_chunker and sentence_pair_chunker functions rely on NLTK's sent_tokenize method to split text into sentences.
Specify Python interpreter:
python3
Import NLTK:
import nltk
nltk.download("all")For the RAG aspect of this project, I will be using Marqo, the end-to-end vector search engine.
Marqo requires Docker. To install Docker go to the Docker Official website. Ensure that docker has at least 8GB memory and 50GB storage. In Docker desktop, you can do this by clicking the settings icon, then resources, and selecting 8GB memory.
Use docker to run Marqo:
docker rm -f marqo
docker pull marqoai/marqo:latest
docker run --name marqo -it -p 8882:8882 marqoai/marqo:latestWhen the project starts, the Marqo index will be empty until you add information in the 'Add Knowledge' section of the frontend.
Great, now all that's left to do is run the webserver!
Starts a Flask development server in debug mode on port 5001 using Python 3:
python3 -m flask run --debug -p 5001
Navigate to http://localhost:3000 and begin inputting your questions to Llama 3.2!
When running this project, feel free to experiment with different settings.
You can change the model in backend/ai_chat.py:
LLM = Llama(
model_path="models/1B/your_model",
)You can also change the score in the function query_for_content in backend/knowledge_store.py:
relevance_score = 0.6This queries the Marqo knowledge store and retrieves content based on the provided query. It filters the results to include only those with a relevance score above 0.6 and returns the specified content from these results, limited to a maximum number of results as specified by the limit parameter. Feel free to change this score depending on your relevance needs.
This can run locally on an M1 or M2 Mac or with a CUDA capable GPU on Linux or Windows. If you want to run this on an M1 or M2 Mac please be sure to have the ARM64 version of Python installed, this will make llama.cpp builds for ARM64 and utilises Metal for inference rather than building for an x86 CPU and being emulated with Rosetta.
This is a very simple demo. Future work on this project will include several enhancements:
- Enable Chatbot Memory: Store conversation history to make conversing with the chatbot more like a real-life experience
- Provide an Initial Set of Documents: at the moment, when the project starts, the Marqo index is empty. Results will be better if we preload the Marqo knowledge store with a set of initial documents relevant to the domain of interest.
- Improve User Interface
- Optimize Backend Performance
- Extend Support for Different Document Types
To accompany this project, I wrote an article covering how you can run this repository and what you can expect to see when doing so.