#Miles Deep - AI Porn Video Editor
Using a deep convolutional neural network with residual connections, Miles Deep quickly classifies each second of a pornographic video into 6 categories based on sexual act with 95% accuracy. Then it uses that classification to automatically edit the video. It can remove all the scenes not containing sexual contact, or edit out just a specific act.
Unlike Yahoo's recently released NSFW model, which uses a similar architecture, Miles Deep can tell the difference between nudity and various explicit sexual acts. As far as I know this is the first and only public pornography classification or editing tool.
This program can also be viewed as a general framework for classifying video with a Caffe model, using batching and threading in C++. By replacing the weights, model definition, and mean file it can immediately be used to edit videos with other classes without recompiling. See below for an example.
##Installation
###Ubuntu Installation (16.04)
####Dependencies
sudo apt install ffmpeg libopenblas-base libhdf5-serial-dev libgoogle-glog-dev libopencv-dev
#####Additional 14.04 Dependencies
sudo apt install libgflags-dev
#####CUDA (Recommended) For GPU usage you need an Nvidia GPU and CUDA 8.0 drivers. Highly recommended; increases speed 10x. This can be installed from a package or by downloading from NVIDIA directly.
#####CuDNN (Optional)
Additional drivers from NVIDIA that make the CUDA GPU support even faster. Download here. (Requires registration)
####Download Miles Deep
Download the model too. Put miles-deep in the same location as the model folder (not in it).
| Version | Runtime |
|---|---|
| GPU + CuDNN | 15s |
| GPU | 19s |
| CPU | 1m 59s |
| *on a 24.5 minute video with a GTX 960 4GB | |
| ###Windows and OSX | |
| I'm working on a version for Windows. Sorry, I don't have a Mac but it should run on OSX with few changes. Compilations instructions below. I'll accept pull requests related to OSX or other linux compatibility. Windows will likely require anothe repository to link with Caffe for windows. |
##Usage
Example:
miles-deep -t sex_back,sex_front movie.mp4This finds the scenes sex from the back or front and outputs the result
in movie.cut.avi
Example:
miles-deep -x movie.aviThis edits out all the non-sexual scenes from movie.avi
and outputs the result in movie.cut.avi.
Example:
miles-deep -b 16 -t cunnilingus -o /cut_movies movie.mkvThis reduces the batch size to 16 (default 32).
Finds only scenes with cunnilingus,
outputs result in /cut_movies/movie.cut.mkv.
NOTE: Reduce the batch size if you run out of memory
####GPU VRAM used and runtime for various batch sizes:
| VRAM(GB) | batch_size | run time |
|---|---|---|
| 3.5 | 32 | 14.9s |
| 1.9 | 16 | 15.7s |
| 1.2 | 8 | 16.9s |
| 0.8 | 4 | 19.5s |
| 0.6 | 2 | 24.3s |
| 0.1 | 1 | 36.2s |
Tested on an Nvidia GTX 960 with 4GB VRAM and a 24.5 minute video file. At batch_size 32 it took approximately 0.6 seconds to process 1 minute of input video or about 36 seconds per hour.
In addition to batching, Miles Deep also uses threading, which allows the screenshots to be captured and processed while they are classified.
###Auto-Tagging Without Cutting
Example:
miles-deep movie.mp4 -aBy popular demand I added this option, which outputs movie.tag:
movie_name, label_1, ..., label_n
total_time, label_1_time, ..., label_n_time
label, start, end, score, coverage
.
.
.
The file contains the cuts for each target, ordered as they occur in the movie. The first lines gives the movie name, the labels, the total movie time, and the total seconds for each label. Then for each cut it list the start time, end time, average score, and coverage. Because of the threshold and the gaps, these cuts may overlap and aren't guaranteed to cover every second.
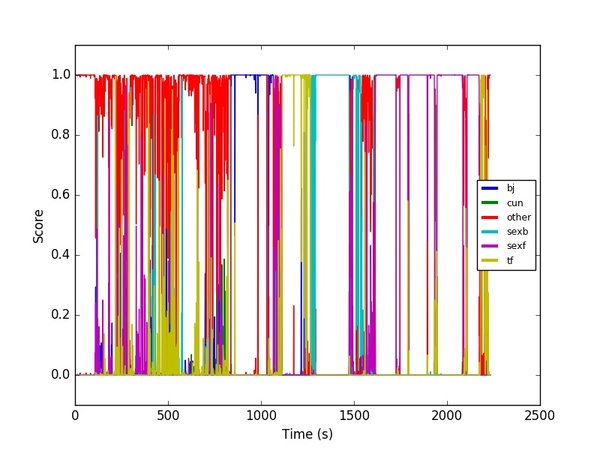
###Prediction Weights Here is an example of the predictions for each second of a video:
###Using Miles Deep with your own Caffe model ####Cat finding
Here's an example of how to use the program with your own model (or a pre-trained one):
MODEL_PATH=/models/bvlc_reference_caffenet/
miles-deep -t n02123045 \
-p caffe/${MODEL_PATH}/deploy.prototxt \
-m caffe/data/ilsvrc12/imagenet_mean.binaryproto \
-w caffe/${MODEL_PATH/bvlc_reference_caffenet.caffemodel \
-l caffe/data/ilsvrc12/synsets.txt \
movie.mp4This finds the scenes in movie.mp4 with a tabby cat and returns movie.cut.mp4 with only those parts. n02123045 is the category for tabby cats. You can find the category names in caffe/data/ilsvrc12/synset_words.txt. You can use a pre-trained model from the model zoo instead.
Note: This example is just to show the syntax. It performs somewhat poorly in my experience, likely due to the 1000 classes. This program is ideally suited to models with a smaller number of categories with an 'other' category too.
##Model
The model is a CNN with residual connections created by pynetbuilder. These models are pre-trained on ImageNet. Then the final layer is changed to fit the new number of classes and fine-tuned.
As Karpathy et al suggest, I train the weights for the top-3 layers not just the top-layer, which improves the accuracy slightly:
| RetunedLayers | Accuracy |
|---|---|
| Top3 | 94.6 |
| Top1 | 93.9 |
Below are the results for fine-tuning the top3 layers with different models, tested on 2500 images, taken from different videos than the training set.
| Model | Accuracy(%) | Flops(millions) | Params(millions) |
|---|---|---|---|
| resnet50 | 80.0 | 3858 | 25.5 |
| resnet50_1by2 | 94.6 | 1070 | 6.9 |
| resnet77_1by2 | 95.7 | 1561 | 9.4 |
The training loss and test accuracy:


Of all the models tested, the resnet50_1by2 provides the best balance between runtime, memory, and accuracy. I believe the full resnet50's low accuracy is due to overfitting because it has more parameters, or perhaps the training could be done differently.
The results above were obtained with mirroring but not cropping. Using cropping slightly improves the results on the resnet50_1by2 to 95.2%, therefore it is used as the final model.
Fine-tuning the Inception V3 model with Tensorflow also only achieved 80% accuracy. However, that is with a 299x299 image size instead of 224x224 with no mirroring or cropping, so the result is not directly comparable. Overfitting may be a problem with this model too.
###Editing the Movie
Given the predictions for a frame each second, it takes the argmax of those predictions and creates cut blocks of the movie where argmax equals the target and the score is greater than some threshold. The gap size, the minimum fraction of frames matching the target in each block, and the score threshold are all adjustable.
FFmpeg supports a lot of codecs including: mp4, avi, flv, mkv, wmv, and many more.
###Single Frame vs Multiple Frames
This model doesn't make use of any temporal information since it treats each image separately. Karpathy et al showed that other models which use multiple frames don't perform much better. They have difficulty dealing with camera movement. It would still be interesting to compare their slow fusion model with the results here.
##Data
The training database consists of 36,000 (and 2500 test images) images divided into 6 categories:
- blowjob_handjob
- cunnilingus
- other
- sex_back
- sex_front
- titfuck
The images are resized to 256x256 with horizontal mirroring and random cropping to 224x224 for data augmentation. A lot of the experiments were done without cropping but it slightly improves the results for the resnet50_1by2.
For now the dataset is limited to two heterosexual performers. But given the success of this method, I plan to expand the number of categories. Due to the nature of the material, I will not be releasing the database itself; only the trained model.
####Sex back and front
Sex front and back are defined by the position of the camera, instead of the orientation of the performers. If the female's body is facing the camera so the front of the vagina is shown, it's sex front. If the female's rear is shown instead, it's sex back. This creates two visually distinct classes. No distinction is made between vaginal and anal intercourse; sex back or sex front could include either.
##Compiling
-
Clone the git repository which includes Caffe as an external dependency.
-
Follow the step-by-step instructions to install the Caffe dependencies for your plaform. Ubuntu instructions. The default is OpenBlas. Don't worry about editing the Makefile.config or making Caffe. On Ubuntu 16.04 try this in addition to the dependencies at the top:
sudo apt install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt install --no-install-recommends libboost-all-dev
sudo apt install libopenblas-dev python-numpy
#Add symbolic links for hdf5 library
#(not necessary on LinuxMint 18)
cd /usr/lib/x86_64-linux-gnu
sudo ln -s libhdf5_serial.so libhdf5.so
sudo ln -s libhdf5_serial_hl.so libhdf5_hl.so
-
The default is GPU without CuDNN. If you want something else edit
MakefileandMakefile.caffe. Comment out or uncomment the proper lines in both files. -
make
#####License Code licensed under GPLv3, including the trained model. Caffe is licensed under BSD 2.
####Contact
If you have problems, suggestions, or thoughts open an issue or send me email nipplerdeeplearning at gmail.