![]()
一款基于机器学习的Web日志统计分析与异常检测命令行工具
Documents»
Demo
·
Installation
·
View Paper
analog 是一款命令行下的Web日志审计工具,旨在帮助使用者能够在终端上快速得进行Web日志审计和排查,包含了日志审计、统计的终端图形化和机器学习识别恶意请求的功能。
完整项目文档:Analog Document
特征提取、模型选取、参数优化等相关问题讨论: 《基于机器学习的Web日志异常检测实践》

目录
analog> show statistics requests current day
analog> show log of current month
analog> show statistics requests current day top 20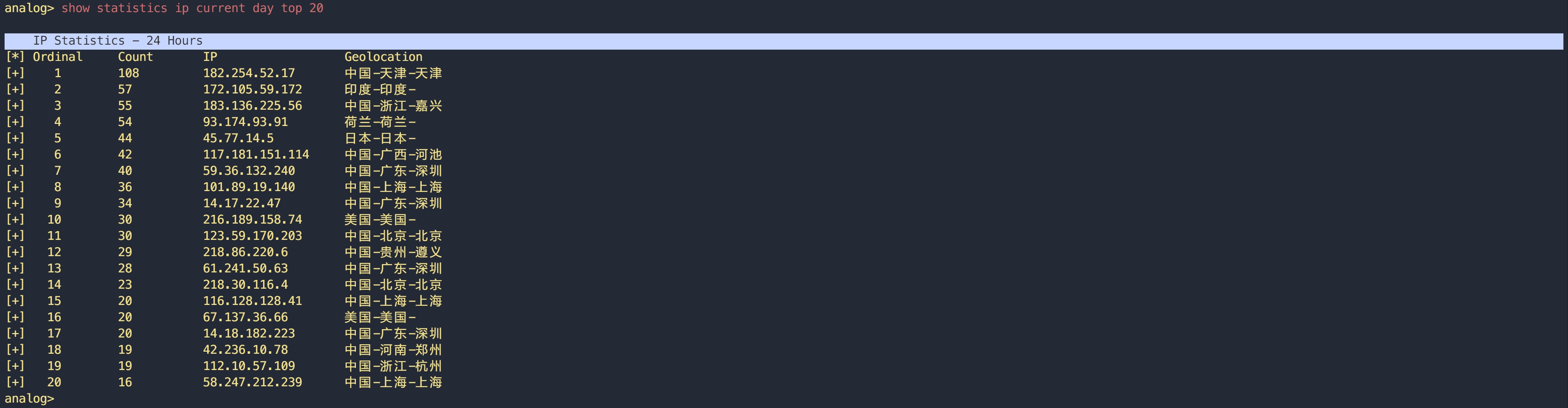
analog> show statistics url current day top 20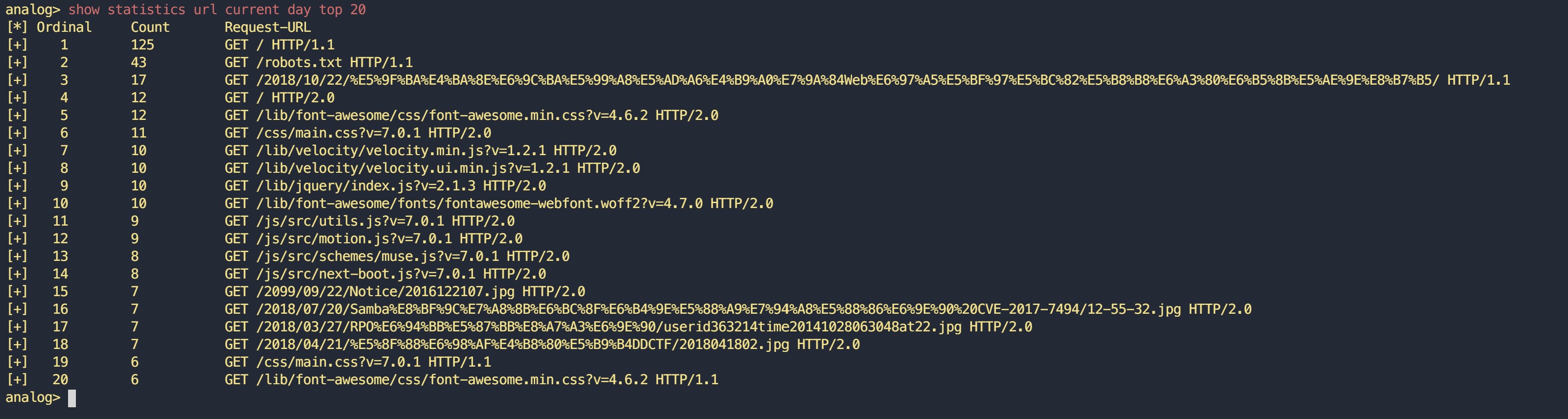
包括恶意IP定位、恶意请求统计,恶意IP地理分布统计,正、异常请求比
analog> show analysis of current month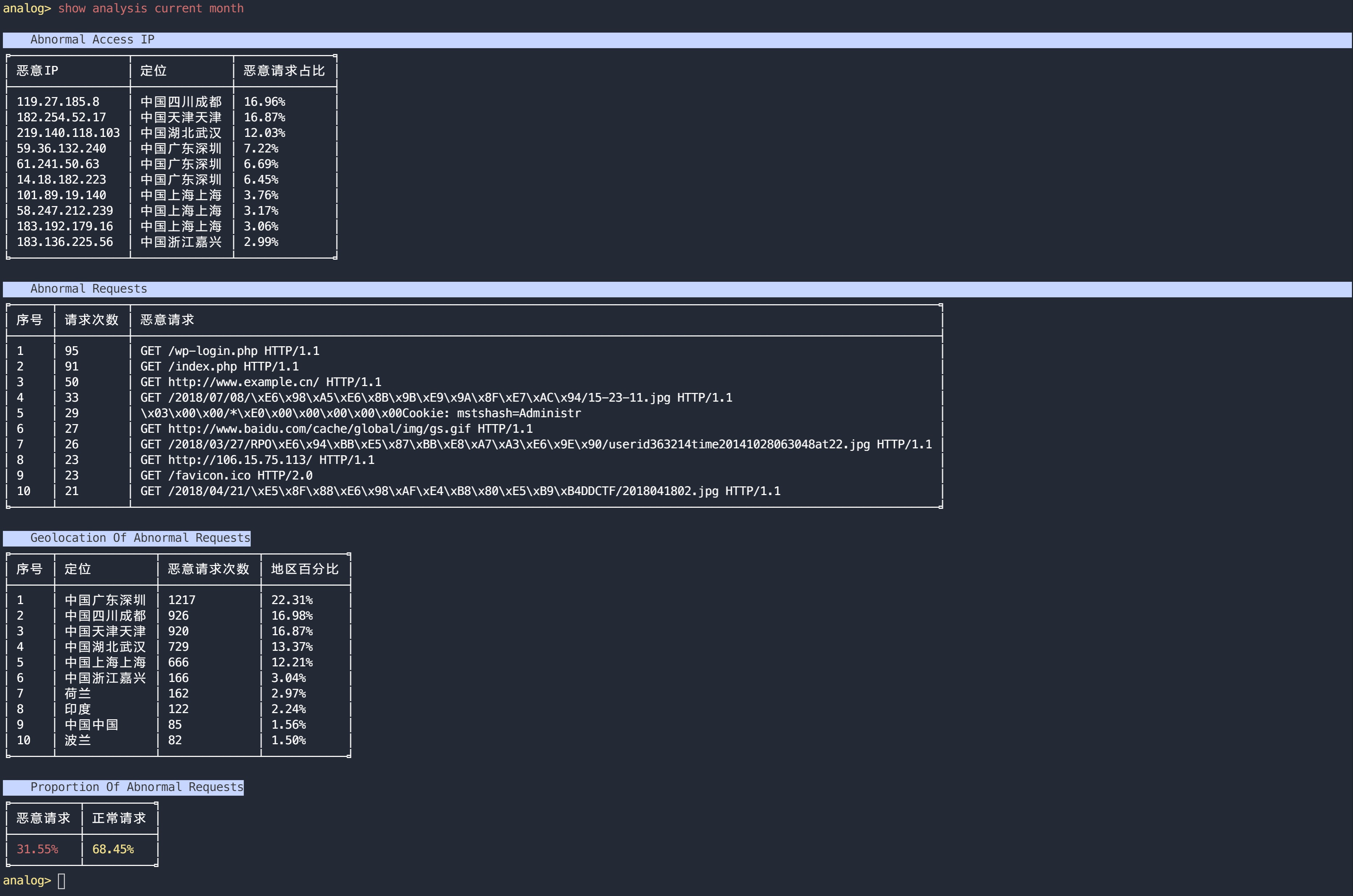
-
安装Python依赖(Python版本要求3.6+):
$ python -r requirements.txt
-
(可选)安装Mysql,默认使用标准库sqlite。
-
在analog的根目录下存在配置文件
config.ini,需要简单的配置一下一些用于连接数据库以及日志读取所需参数。# Database type: mysql or sqlite db_type = sqlite # mysql config host = 127.0.0.1 port = 3306 user = root password = # Database name database = WebLog_Analysis table_name = weblog # Database charset charset = utf8 [Log] # Log file root path path = /var/log/nginx/ # if you dont know what it means, leave it alone. logs_per_query = 5000 # All files name include word 'access' are log file log_file_pattern = .*access.* # Time local pattern time_local_pattern = %d/%b/%Y:%H:%M:%S # Log pattern, default: nginx log format log_content_pattern = ^(?P<remote_addr>.*?) - (?P<remote_user>.*) \[(?P<time_local>.*?) \+(?P<nums>[0-9]+?)\] "(?P<request>.*?)" (?P<status>.*?) (?P<body_bytes_sent>.*?) "(?P<http_referer>.*?)" "(?P<http_user_agent>.*?)" "(?P<http_x_forwarded_for>.*?)"$
-
将上述字段配置好之后,可以运行检查程序
check_conf.py进行配置的正确性检测。$ python check_conf.py
若只想使用日志统计、可视化部分功能可跳过这一步开始使用。
若想使用异常请求识别功能,则需要 手动 地将一些训练数据筛选出来以供训练OneClassSVM单分类模型。
首先我们需要找到路径/analog/sample_set/下的三个文件,分别为:
-
test_black_log.txt :用于评估训练模型F1值的黑样本;
-
test_white_log.txt :用于评估训练模型F1值的白样本;
-
train.txt :用于训练OneClassSVM模型的样本。
其中test_black_log.txt和test_white_log.txt分别要求为全黑或者全白,因为这两个txt是用于评估模型的训练效果的。
而由于我们使用的模型是OneClassSVM,属于单分类模型,所以也要求 train.txt 中的样本 尽量 全为白样本:
a. 保证样本的数量(视网站情况适量加减,太少不准确,太多影响参数优化速度);
b. 尽可能地覆盖正常访问流量;
c. 保证异常率不超过5%,否则会影响模型预测效果;
d. 训练样本、测试样本和访问日志读取是使用同一套正则,请使用相同的格式放入各个样本集中。
白样本可能比较好取,毕竟我们访问日志中大多数都是白样本,花少量的时间就能达到大量的白样本。但是黑样本由于需要符合正则格式,则需要在日常访问日志中手动筛选一些黑样本(约1000条)进行模型预测结果测试。
BTW,这可能是最耗时间的活了。 筛选时间长短取决于你的网站大小以及是否能快速地收集较为完整的访问数据集。
当然也有偷懒一点的方法,使用我开源的一个轻量级Web扫描器——wscan ,仅需两步:
$ python3 -m pip install wscan -U
$ wscan -u "https://your_web_site.com" -m -s -t 20然后耐心等待wscan输出结束,扫描器将遍历你网站的所有页面以及链接,包括图片、js等静态资源。 随后我们可以在服务器上的访问日志中拿到覆盖绝大部分的网站访问记录,将wscan产生的访问日志添加到train.txt中即可,如果覆盖不全可以手动添加一下没有爬到的连接。
网站连通性不好可以将请求超时参数-t调大点,如30。另外大型的网站建议自己手动筛选,wscan可能支持不来大型网站的全站遍历。
当我们全部整理好训练数据之后,就可以进入到analog的控制台界面,输入下列命令进行模型的训练。
analog> train该操作会覆盖之前存在于路径 /analog/cache/中的模型缓存文件,若想保留,请提前备份。
训练过程是异步的,我们可以通过输入下列命令获取当前训练进度:
analog> get progress当我们得到训练结束的通知时,说明训练完成,模型缓存文件已更新。
使用的预测模型为Oneclass-SVM,内核为rbf,参数遍历取最优。
特征提取用的是TF-IDF计算2-grams截取未url解码的请求路径,特征向量空间为100*100,取的是string.printable可打印字符
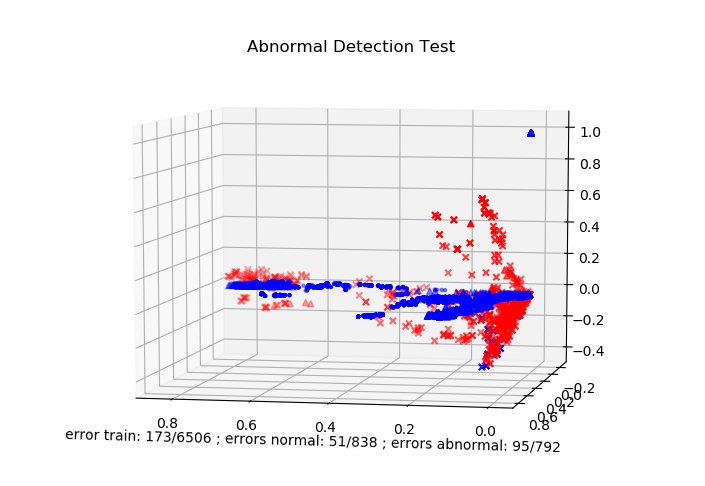
有好的idea也可以请求pull,欢迎在issue中提出问题!
如遇Bug,可以键入dedug,进入debug模式,获取错误信息并在issue中提出,以帮助我改善代码。
更多解释及用法详见文档:Analog Document
- 提高检测模型效率
- 提高检测模型F1值
- McPAD-A Multiple Classifier System for Accurate Payload-based Anomaly Detection
- Preprocessing Web Logs for Web Intrusion
- System Log Analysis for Anomaly Detection
- Cybersercurity-data-mining
- Anomaly-detection-via-server-log
- Anomaly Detection of Web-based Attacks
- 基于机器学习的web异常检测 - 阿里聚安全