Kubernetes é um orquestrador de código aberto para implantação de aplicações conteinerizadas. Foi originalmente desenvolvido pela Goolge, inspirado em uma década de experiência com a implantação de sistemas escaláveis e confiáveis em contêineres por meio de APIs orientada a aplicações. (BURNS; BEDA; HIGHTOWER, 2019)
Kubernetes: Up and Running: Dive into the Future of Infrastructure
Livro Descomplicando Kubernetes
As certificações Kubernetes são valorizadas pelo mercado.
- CKA - Certified Kubernetes Administrator
- CKAD - Certified Kubernetes Application Developer
- CKS - Certified Kubernetes Security Specialist
Um cluster Kubernetes consiste em um conjunto de servidores de processamento, chamados nós, que executam aplicações containerizadas. Todo cluster possui ao menos um servidor de processamento (worker node).


1º Instalar o docker
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
Usar docker sem ser root
sudo usermod -aG docker ${USER}
bash
- Você pode precisar configurar o autopreenchimento
Autocomplete Kubectl:
echo 'source <(kubectl completion bash)' >>~/.bashrc
Instalar o MiniKube Documentação Oficial:
minikube start
minikube stop
minikube delete
minikube delete --all
kind é uma ferramenta para executar clusters locais do Kubernetes usando “nós” de contêiner do Docker. kind foi projetado principalmente para testar o próprio Kubernetes, mas pode ser usado para desenvolvimento local ou CI.
Requisitos:
- Docker Instalado
On Linux:
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.11.1/kind-linux-amd64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/
#Verificar se o
kind
#Ativar auto complete
source <(kind completion bash)
- Criando um cluster com Kind
kind create cluster --name o2bacademy
- Criando um cluster com vários nós kind create cluster --name o2bacademy --config arquivodeconfiguração.yaml
Para trabalhar com o Kubernetes, utilizamos o binário do kubectl
kubectlé uma sigla para Kubernetes Control, muitas das vezes podemos ouvir seu nome pronunciado como "Kube C T L", "Kube Control" e "Kube Cuttle/Cuddle", esse ultimo surgiu como um apelido, devido ao seu "Mascote" ser o cuttlefish (Em português Choco, sibas ou sépia) que é uma espécie de molusco parecido com o polvo
Alguns dos comandos do kubectl são similares aos comandos do Docker, como por exemplo o comando kubectl get nodes para listar os nós do cluster
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
minikube Ready control-plane,master 13m v1.22.1Os comandos do kubectl seguem a seguinte semântica:
kubectl + VERBO + recurso + OPÇÕESAlguns exemplos de verbos:
get, list, describe, create, update, patch, delete ...Alguns exemplos de recursos:
nodes, pods, namespaces, services, deployment, replicaset, pv(persistent volume), pvc(persistent volume claim) ...No Kubernetes podemos utilizar o termo
allcomo recurso para trabalhar com todos os recursos.
kubectl cluster-info
kubectl get nodes
kubectl get pods
kubectl get pods -n <namespaces>
kubectl get pods -A -o wide
kubectl get namespaces
kubectl describe pod etcd-minikube -n kube-system
Há duas maneiras básicas de interagir com o Kubernetes:
-
Imperativa: através de diversos parâmetros do kubectl
- Diz ao K8S o que fazer
- Boa para usar quando se está aprendendo, para fazer experimentos interativos ou debugar serviços em produção.
-
Declarativa: escrevendo manifestos e os usando com o comando kubectl apply.
- Diz ao K8s o que você quer
- Melhor para implantar serviços de maneira a facilitar a reprodutibilidade.
- Recomendada para gerenciar aplicações K8s em produção
Utilizando os arquivos de manifesto. Arquivos com a extensão yaml ou yml.
Os pods são as menores unidades de computação implantáveis que você pode criar e gerenciar no Kubernetes.
Em termos de conceitos do Docker, um Pod é semelhante a um grupo de contêineres do Docker com namespaces compartilhados e volumes de sistema de arquivos compartilhados.

- Abordagem Imperativa:
kubectl run meunginx --image=nginx:1.14.2
# ou
kubectl run meuapache --image=httpd:2.4
- Deletar Pod
?
- Salva manifesto de um Pod
kubectl get pod my-pod -o yaml > my-pod.yaml
- Abordagem Declarativa, utilizando manifesto yaml
Criar um arquivo com a extensão .yaml, exemplo: meu-pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-pod
spec:
containers:
- name: nginx-container
image: nginx:1.14.2
ports:
- containerPort: 80
- Após criar um arquivo de manifesto, precisamos aplicá-lo;
kubectl apply -f <nomedoarquivo.yaml>
# expondo uma pod
kubectl port-forward pod/meupod 8080:80
Se estiver usando Kind
kubectl port-forward svc/frontend --address 0.0.0.0 8080:80
Cada Pod deve executar uma única instância de um determinado aplicativo. Se você quiser dimensionar seu aplicativo horizontalmente (para fornecer mais recursos gerais executando mais instâncias), use vários pods, um para cada instância. No Kubernetes, isso geralmente é chamado de replicação . Os pods replicados geralmente são criados e gerenciados como um grupo por um recurso de carga de trabalho e seucontrolador.
K8s usa namespaces para organizar objetos no cluster através de uma divisão lógica (como se fosse uma pasta).
Por padrão, kubectl interage com o namespace padrão (default). Para usar um namespace específico, diferente do padrão, pode-se usar a flag --namespace=nome, ou ainda -n nome.
Para interagir com todos os namespaces, pode-se passar a flag --all-namespaces ou -A para o comando.
 Fonte: https://stacksimplify.com/
Fonte: https://stacksimplify.com/
- Criar um novo namespaces
kubectl create namespace dev
kubectl create namespace teste
- Listar os namespaces?
?
- Remover os namespaces?
?
- Filtrar Pods por namespace
kubectl get pods --namespace=teste
kubectl get pods -n teste
- Listar pods de todos os namespaces?
?
 Fonte: https://www.wecloudpro.com/2020/04/06/kubernetes-nodes-auto-label.html
Fonte: https://www.wecloudpro.com/2020/04/06/kubernetes-nodes-auto-label.html
Um Label é um par chave-valor do tipo string. Todos os recursos/objetos K8s podem ser rotulados.
-
Equality-based requirement environment = production tier != frontend
-
Set-based requirement environment in (production, qa) tier notin (frontend, backend)
-
Mostrar labels dos recursos:
kubectl get pods --show-labels
- Deletar Pods que têm label run=myapp
kubectl delete pods -l environment=production,tier=frontend
kubectl get pods -l 'environment in (production),tier in (frontend)'
*Atribuir label
kubectl label deployment nginx-deployment tier=dev
Você pode usar recursos de carga de trabalho para criar e gerenciar vários pods para você. Um controlador para o recurso lida com a replicação, a distribuição e a correção automática em caso de falha do pod. Por exemplo, se um nó falhar, um controlador perceberá que os pods nesse nó pararam de funcionar e cria um pod substituto. O agendador coloca o Pod substituto em um Node.
Veja alguns exemplos de recursos de carga de trabalho que gerenciam um ou mais pods:
- Deployment
- StatefulSet
- DaemonSet
Você pode usar recursos de carga de trabalho que gerenciam um conjunto de pods em seu nome (Labels e Selectors). Esses recursos configuram controladores que garantem que o número certo do tipo certo de pod esteja em execução, para corresponder ao estado que você especificou.
O Kubernetes fornece vários recursos de carga de trabalho integrados:
A finalidade de um ReplicaSet é manter um conjunto estável de réplica de pods em execução a todo momento. Na teoria: É frequentemente usado para garantir a disponibilidade de um número especificado de Pods idênticos.
-
Na prática: É raramente utilizado diretamente. Motivo: versionamento.
-
Exemplo:
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: frontend
labels:
app: guestbook
tier: frontend
spec:
# modify replicas according to your case
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
labels:
tier: frontend
spec:
containers:
- name: php-redis
image: gcr.io/google_samples/gb-frontend:v3
*Criar ReplicaSet
kubectl create -f rs-frontend.yaml
*Listar ReplicaSets e Pods
kubectl get rs
kubectl get pods -o wide
*Mostrar detalhes do ReplicaSet
kubectl describe rs frontend
*Escalar um ReplicaSet
kubectl scale --replicas 3 rs frontend
kubectl scale --replicas 1 rs frontend
*Deletar um ReplicaSet
kubectl delete rs frontend
*Deletar todos os Pods e ReplicaSets
kubectl delete pod,rs --all
- Exercicio Versionamento:
Altere o nome ou a versão da image no seu manifesto, aplique as modificações e após isso verifique se os pods foram atualizados para a nova imagem.
- Outras considerações:
Embora você possa criar pods vazios sem problemas, é altamente recomendável garantir que os pods vazios não tenham rótulos que correspondam ao seletor de um de seus ReplicaSets. A razão para isso é porque um ReplicaSet não se limita a possuir Pods especificados por seu modelo - ele pode adquirir outros Pods da maneira especificada nas seções anteriores.
Um Deployment fornece atualizações declarativas para Pods e ReplicaSet.
Você descreve um estado desejado em um Deployment e a Deployment Controlador altera o estado real para o estado desejado a uma taxa controlada. Você pode definir implantações para criar novos ReplicaSets ou remover implantações existentes e adotar todos os seus recursos com novas implantações.
- Vantagens:
Escalabilidade: com um Deployment, pode-se especificar o número de réplicas desejado e o Deployment vai criar ou remover Pods até alcançar o número desejado.
Atualizações: é possível alterar a imagem de um container para uma nova versão e o Deployment vai gradualmente substituir os containers para a nova versão (evita downtime).
Self-healing: se um dos Pods for acidentalmente destruído, o Deployment vai imediatamente iniciar um novo Pod para substituí-lo.
 Fonte: https://www.bluematador.com/blog/kubernetes-deployments-rolling-update-configuration
Fonte: https://www.bluematador.com/blog/kubernetes-deployments-rolling-update-configuration
- Criar Deployment, abordagem imperativa
kubectl create deployment http-deployment --image=nginx
- Exemplo, abordagem declarativa:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
- Listar Pods, ReplicaSet e Deployments
kubectl get deployments ou kubectl get deploy
kubectl get rs
kubectl get pods
kubectl get pods --show-labels
- Verificar o Status da implatanção:
kubectl rollout status deployment/nginx-deployment
- Aumentar/diminuir a quantidade de réplicas
kubectl scale --replicas 3 deployment http-deployment
- Mostrar detalhes de um deployment
kubectl describe deployment http-deployment
- Nova versão da aplicação
Siga as etapas abaixo para atualizar sua implantação:
- Vamos atualizar os pods nginx para usar a imagem nginx:1.16 em vez da nginx:1.14.2.
Você pode fazer isso básicamente de três maneiras:
- Editando o arquivo de manifesto:
Altere o arquivo de manifesto e aplique as alterações.
- De maneira Imperativa:
kubectl set image deployment/nginx-deployment nginx=nginx:1.16
- Editar o Deployment diretamente:
kubectl edit deployment/nginx-deployment
A implantação garante que apenas um determinado número de pods fique inativo enquanto estão sendo atualizados. Por padrão, ele garante que pelo menos 75% do número desejado de pods esteja ativo (máximo de 25% indisponível).
A implantação também garante que apenas um determinado número de pods seja criado acima do número desejado de pods. Por padrão, ele garante que no máximo 125% do número desejado de Pods esteja ativo (25% de aumento máximo).
Às vezes, você pode querer reverter uma implantação; por exemplo, quando a implantação não é estável, como loop de falha. Por padrão, todo o histórico de distribuição da implantação é mantido no sistema para que você possa reverter a qualquer momento (você pode alterar isso modificando o limite do histórico de revisões).
- Suponha que você tenha cometido um erro de digitação ao atualizar a implantação, colocando o nome da imagem como nginx:1.161 em vez de nginx:1.16.1.
- O lançamento fica travado. Você pode verificá-lo verificando o status do lançamento:
kubectl rollout status deployment/nginx-deployment
kubectl get rs
-
Para corrigir isso, você precisa reverter para uma revisão anterior do Deployment que seja estável.
-
Verificar o histórico de lançamento de uma aplicação:
kubectl rollout history deployment/nginx-deployment
- Para ver os detalhes de cada revisão, execute:
kubectl rollout history deployment/nginx-deployment --revision=2
- Agora você decidiu desfazer a distribuição atual e reverter para a revisão anterior:
kubectl rollout undo deployment/nginx-deployment
Etapa01
Você está responsável por fazer a implantação de uma aplicação que vai utilizar a imagem gcr.io/google_samples/echo-go:1.0
- Criar Deployment da aplicação utilizando um arquivo de manifesto e com 3 réplicas.
-
Utilize os comandos para verificar se sua implantação está correta. Liste os deployments, rs e pods.
-
Escalar o Deployment com ou comando abaixo ou através do arquivo de manifesto
kubectl scale --replicas 5 deployment <nome_do_deployment>
Etapa02
A equipe de desenvolvimento enviou para você uma nova imagem da aplicação chamada: gcr.io/google_samples/echo-go faça a atualização para a nova versão.
- Lembre-se de verificar se a atualização ocorreu normalmente.
Etapa03
Após um tempo, a equipe te enviou novamente uma nova versão que é: gcr.io/google_samples/echo-go:2.0 faça a atualização para a nova versão.
- Lembre-se de verificar se a atualização ocorreu normalmente.
Etapa04
A equipe de desenvolvimento constatou alguns problemas e solicitou que você faça um rollback para a versão 1.0, faça a reversão e verifique se está tudo correto.
Entrega: Enviar para [email protected], assunto: Atividade prática K8S 01, os print de conclusão de cada etapa, junto com o arquivo de manifesto.
Um serviço no Kubernetes é uma abstração que define um conjunto lógico de Pods e uma política pela qual acessá-los. O conjunto de Pods selecionados por um Serviço é geralmente determinado por um seletor de rótulos LabelSelector.
Embora cada Pod tenha um endereço IP único, estes IPs não são expostos externamente ao cluster sem um Serviço. Serviços permitem que suas aplicações recebam tráfego. Serviços podem ser expostos de formas diferentes especificando um tipo type na especificação do serviço ServiceSpec:
- ClusterIP (padrão) - Expõe o serviço sob um endereço IP interno no cluster. Este tipo faz do serviço somente alcançável de dentro do cluster.
- NodePort - Expõe o serviço sob a mesma porta em cada nó selecionado no cluster usando NAT. Faz o serviço acessível externamente ao cluster usando :. Superconjunto de ClusterIP.
- LoadBalancer - Cria um balanceador de carga externo no provedor de nuvem atual (se suportado) e assinala um endereço IP fixo e externo para o serviço. Superconjunto de NodePort.
- ExternalName - Expõe o serviço usando um nome arbitrário (especificado através de externalName na especificação spec) retornando um registro de CNAME com o nome. Nenhum proxy é utilizado. Este tipo requer v1.7 ou mais recente de kube-dns.
 Fonte: Medium
Fonte: Medium

Exemplo: Conectado aplicativos com serviços
Exemplo: Usando Service para acessar um aplicativo em um cluster
Exercício
- Como exportar o service para um arquivo .yaml?
Para realizar o exemplo abaixo é necessário que seu cluster esteja em um cloud provider.
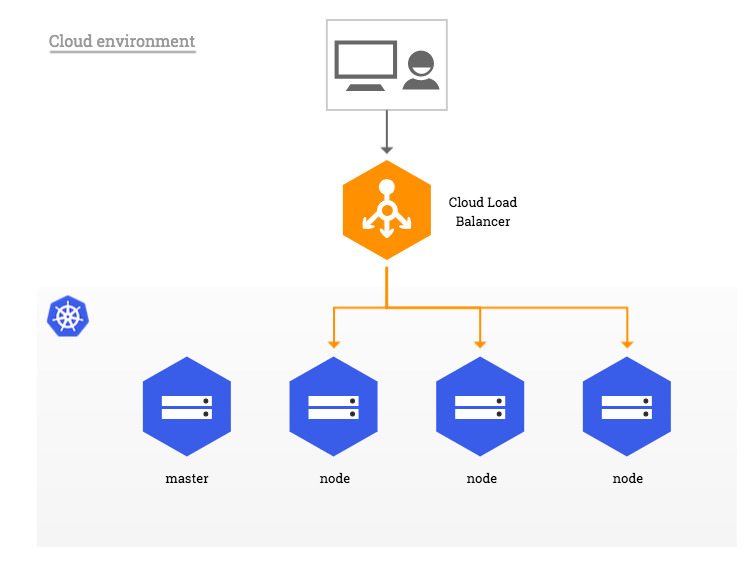
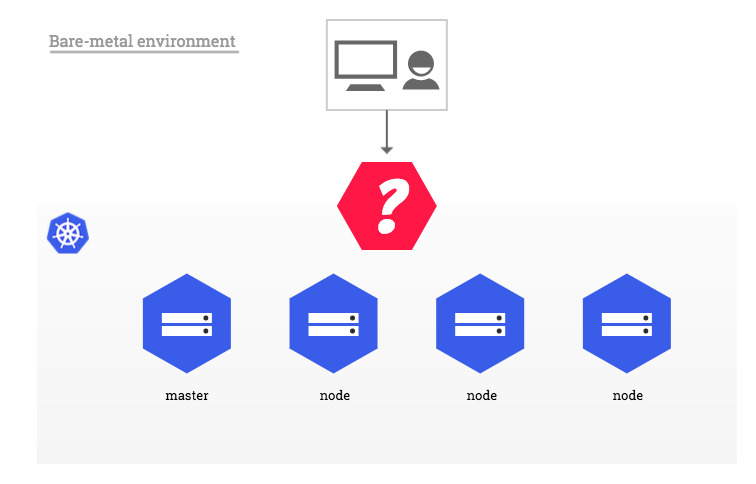
Documentação Kind Loadbalancer
Exemplo: Load Balancer
Todo o Service deve possuir endepoints saudáveis para que possa encaminhar o tráfego, sendo esse objetivo denominado EndPoint. Um Endpoint nada mais é que uma lista de todos os IPs dos PODs que tem Match no Selector utilizado no Service em questão. O Controllador interno do Kubernetes chega continuamente todos os PODs checando pelas LABELS definidas nos SELECTOR e atribui via POST ao EndPoint do Service.
- Endpoints não necessariamente apontam para um POD, um Sevice sem um SELECTOR pode ter seu Endpoint criado manualmente para apontar para um IP ou DNS qualquer a sua escolha.
apiVersion: apps/v1
kind: Deployment
metadata:
name: alpaca-prod
labels:
ver: "1"
app: alpaca
env: prod
# namespace: dev
spec:
replicas: 3
selector:
matchLabels:
app: alpaca
template:
metadata:
labels:
app: alpaca
env: prod
spec:
containers:
- name: alpaca
image: gcr.io/kuar-demo/kuard-arm64:blue
ports:
- containerPort: 8080
Acessar o Exemplo e implementar de forma prática. Escolha qual é a melhor estratégia para implantar essa aplicação.
- Caso tenha dificuldade ou dívidas, solicite apoio no grupo do Whatsapp.
- Ao finalizar exercício, enviar um print da tela do aplicativo funcionando.
Entrega: Enviar para [email protected], assunto: Atividade prática K8S 02, os print de conclusão da implantação.
Um DaemonSet garante que todos (ou alguns) nós executem uma cópia de um pod. À medida que os nós são adicionados ao cluster, os pods são adicionados a eles. À medida que os nós são removidos do cluster, esses pods são coletados como lixo. A exclusão de um DaemonSet limpará os pods que ele criou.
Alguns usos típicos de um DaemonSet são:
executando um daemon de armazenamento de cluster em cada nó executando um daemon de coleta de logs em cada nó executando um daemon de monitoramento de nó em cada nó
Exemplo:
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: example-daemonset
namespace: default
labels:
app: example-daemonset
spec:
selector:
matchLabels:
name: example-daemonset
template:
metadata:
labels:
name: example-daemonset
spec:
tolerations:
# this toleration is to have the daemonset runnable on master nodes
# remove it if your masters can't run pods
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: example-daemonset
image: alpine:latest
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
command:
- "bin/sh"
- "-c"
- "echo 'Hello! I am running on '$NODE_NAME; while true; do sleep 300s ; done;"
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
terminationGracePeriodSeconds: 30
Um StatefulSet gerência pods que são baseados em uma especificação de contêiner idêntica. Ao contrário de uma implantação(Deployment), um StatefulSet mantém uma identidade fixa para cada um de seus pods.
Esses pods são criados a partir da mesma especificação, mas não são intercambiáveis: cada um tem um identificador persistente que mantém em qualquer reprogramação.
Se quiser usar volumes de armazenamento para fornecer persistência para sua carga de trabalho, você pode usar um StatefulSet como parte da solução. Embora os pods individuais em um StatefulSet sejam suscetíveis a falhas, os identificadores de pod persistentes facilitam a correspondência dos volumes existentes com os novos pods que substituem os que falharam.
-
Utilize o arquivo exStatefulset.yaml
-
Crie um Stateful set
- Verifique o processo de criação dos pods
kubectl get pods -w -l app=nginx
- Verifique o Serviço:
kubectl get svc
- Verifique o Statefulset
kubectl get statefulsets
kubectl describe statefulset web
#Você pode editar se for necessário
kubectl edit statefulset web
- Aumente e depois diminua a escala de um statefulset
kubectl scale statefulset web --replicas=5
- Excluindo o Statefulset
kubectl delete statefulset web
kubectl delete svc nginx
kubectl delete persistentvolumeclaims myclaim
Implantando WordPress e MySQL com Volumes Persistentes
Baixe os arquivos:
- kustomization.yaml
- mysql-deployment.yaml
- wordpress-deployment.yaml
Aplicar as configurações:
kubectl create -k ./
Expor a aplicação no host
kubectl port-forward svc/wordpress 8080:80
- Testar
- Objetivo
Definir quanto de recurso computacional (CPU e Memória) um POD deveria/pode consumir em meu ambiente.
- Motivação
Evitar que um POD consuma todos os recursos computacionais de um Node;
Evitar que devido ao alto consumo de um POD outro seja degradado;
Garantir a correta distribuição de carga entres os Nodes;
- Exemplo:
O pod a seguir tem dois contêineres. Ambos os contêineres são definidos com uma solicitação de 0,25 CPU e 64MiB (2 26 bytes) de memória. Cada contêiner tem um limite de 0,5 CPU e 128MiB de memória. Você pode dizer que o Pod tem uma solicitação de 0,5 CPU e 128 MiB de memória e um limite de 1 CPU e 256MiB de memória.
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
- name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
Ao contrário de outros tipos de controladores que são executados como parte do kube-controller-managerbinário, os controladores do Ingress não são iniciados automaticamente com um cluster.
O Ingress expõe as rotas HTTP e HTTPS de fora do cluster para serviços dentro do cluster. O roteamento de tráfego é controlado por regras definidas no recurso Ingress.

Para que o Ingress controller tenha essas informações de Rotas, precisamos criar um novo tipo de Objeto chamado Ingress. Esse objeto irá ter as definições de DNS de Origem, Certificado, Destino...
- Criar o Deployment e o Service abaixo:
apiVersion: apps/v1
kind: Deployment
metadata:
name: simple-api
labels:
app: simple-api
spec:
replicas: 5
selector:
matchLabels:
app: simple-api
template:
metadata:
labels:
app: simple-api
spec:
containers:
- name: simple-api
image: gustavoleitao/simple-api:1.0.4
ports:
- containerPort: 3000
readinessProbe:
httpGet:
path: /
port: 3000
---
apiVersion: v1
kind: Service
metadata:
name: simple-api
labels:
app: simple-api
spec:
type: NodePort
ports:
- port: 3000
targetPort: 3000
nodePort: 30007
selector:
app: simple-api
Não vem por padrão instalado junto com o Kubernetes.
- Instalar o Nginx Ingress
https://kubernetes.github.io/ingress-nginx/deploy/#quick-start
Baixar o arquivo yaml e aplicar. tag 0.42.0
kubectl get pods -n ingress-nginx
kubectl get svc -n ingress-nginx
- Testando o Ingress.
curl <End_IP_no_Cluster>:<Porta_alta>
- Você receberá uma resposta de Not Found, Ingress Controler não sabe para quem encaminhar.
- Editar o arquivo /etc/hosts
#adicionar o ip e um domínio ficticio
10.0.0.71 simpleapi.com.br
-
Pingar o domínio
-
Fazer um curl no domínio com a porta alta.
- Editar o arquivo ingresscontroler.yaml e adicionar os compos abaixo:
- procurar pela linha NodePort
spec:
type: NodePort
ports:
- name: http
port: 80
protocol: TCP
targetPort: http
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/component: controller
#adicionar as linhas abaixo
externalIPs:
- 10.0.0.71
- Criar o Arquivo do Ingress
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: simple-api-ing
annotations:
kubernetes.io/ingress.class: "nginx"
spec:
rules:
- host: simpleapi.com.br
http:
paths:
- path: /
backend:
serviceName: simple-api
servicePort: 3000
Secrets e ConfigMaps possuem comportamentos similares, porém com Objetivos diferentes.
-
ConfigMaps: Um objeto que contém dados não confidenciais, como arquivos de configuração da aplicação, esses dados podem ser montados em um ou mais Pods como Arquivo ou Variáveis de ambiente;
-
Secret: Um objeto que contém uma pequena quantidade de dados confidenciais, como uma senha, um token ou uma chave. Essas informações podem ser colocadas em um ou mais Pods como Arquivo ou Variáveis de ambiente; Isso evita que deixe dados confidenciais diretamente em sua aplicação;
Exemplo:
Fonte: https://github.com/xcad2k/boilerplates/tree/main/kubernetes/templates/cm-and-secrets
-
Criar os dois arquivos e aplicar: nginx-http-cm.yaml nginx-http-deploy.yml
-
Acessar o container
kubectl exec -it <nome_do_container> -- /bin/bash
cd /etc/nginx/
ls
cat
cat nginx.conf
- Criar o arquivo do Service tipo NodePort: nginx-http-svc.yml
Acessar a aplicação
Exemplo:
Fonte: https://github.com/xcad2k/boilerplates/tree/main/kubernetes/templates/cm-and-secrets
-
Criar os dois arquivos e aplicar: mysql-deploy.yaml e mysql-secret.yml
-
Acessar o container
kubectl get secrets
kubectl edit secrets mysql-secret
# Acessar o pod
kubectl exec -it <nome_do_container> -- /bin/bash
#Conectar ao mySQL
mysql -p
Você pode restringir um Pod que ele só possa ser executado em um conjunto específico de Nós. Existem várias maneiras de fazer isso e todas as abordagens recomendadas usam seletores de rótulos para facilitar a seleção. Geralmente, essas restrições são desnecessárias, pois o agendador fará automaticamente um posicionamento razoável (por exemplo, espalhar seus pods entre nós para não colocar o pod em um nó com recursos livres insuficientes etc.), mas há algumas circunstâncias em que você pode querer controlar em qual nó o pod é implantado - por exemplo, para garantir que um pod termine em uma máquina com um SSD conectado a ele ou para colocar pods de dois serviços diferentes que se comunicam muito na mesma zona de disponibilidade.
Este tutorial é uma apoio no deploy de um cluster kubernetes. Nesse laboratório vamos criar um nó master e dois worker node.
Você precisará de três instâncias com as configurações abaixo que podem ser criadas localmente utilizando o Virutalbox/Vmware ou instâncias em um cloud provider (aws, gcp, azure etc) de sua preferência.
| Função | IP | OS | RAM | CPU |
|---|---|---|---|---|
| Master | 192.168.1.100 | Ubuntu 18.04/20.04 | 4G | 4 |
| Worker1 | 192.168.1.101 | Ubuntu 18.04/20.04 | 2G | 2 |
| Worker2 | 192.168.1.102 | Ubuntu 18.04/20.04 | 2G | 2 |
Os endereços de Ips são somente uma sugestão.
- Docker instalados em todos os nós do cluster
- Os comandos abaixo devem ser executados em todos os nós do cluster. Faça login com o usuário
root
sudo su -
ufw disable
swapoff -a; sed -i '/swap/d' /etc/fstab
cat > /etc/docker/daemon.json <<EOF
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}
EOF
systemctl restart docker
systemctl enable docker
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
echo "deb https://apt.kubernetes.io/ kubernetes-xenial main" > /etc/apt/sources.list.d/kubernetes.list
apt update && apt install -y kubeadm=1.21.0-00 kubelet=1.21.0-00 kubectl=1.21.0-00
sudo apt-mark hold kubeadm kubelet kubectl
Antes de executar o comando abaixo você precisa alterar:
--apiserver-advertise-address=<ip_do_no_master>
kubeadm init --apiserver-advertise-address=192.168.1.100 --pod-network-cidr=172.16.0.0/16 --ignore-preflight-errors=all
Para poder executar comandos junto ao cluster Kubernetes
exit
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Escolha somente um tipo abaixo:
- Flannel
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
- Calico
kubectl --kubeconfig=/etc/kubernetes/admin.conf create -f https://docs.projectcalico.org/v3.14/manifests/calico.yaml
Execute o comando abaixo para verificar o status do nó master
kubectl get nodes
echo 'source <(kubectl completion bash)' >>~/.bashrc
Executar o comando para adicionar os worker ao cluster!
kubeadm token create --print-join-command