-
Notifications
You must be signed in to change notification settings - Fork 110
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
PullRequest: 5480 更新OceanBase AP概述,新增多个测试文件和其他文件
- Loading branch information
Showing
29 changed files
with
6,544 additions
and
4 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,73 @@ | ||
| # OceanBase AP 概述 | ||
|
|
||
| ## OceanBase AP 是什么 | ||
|
|
||
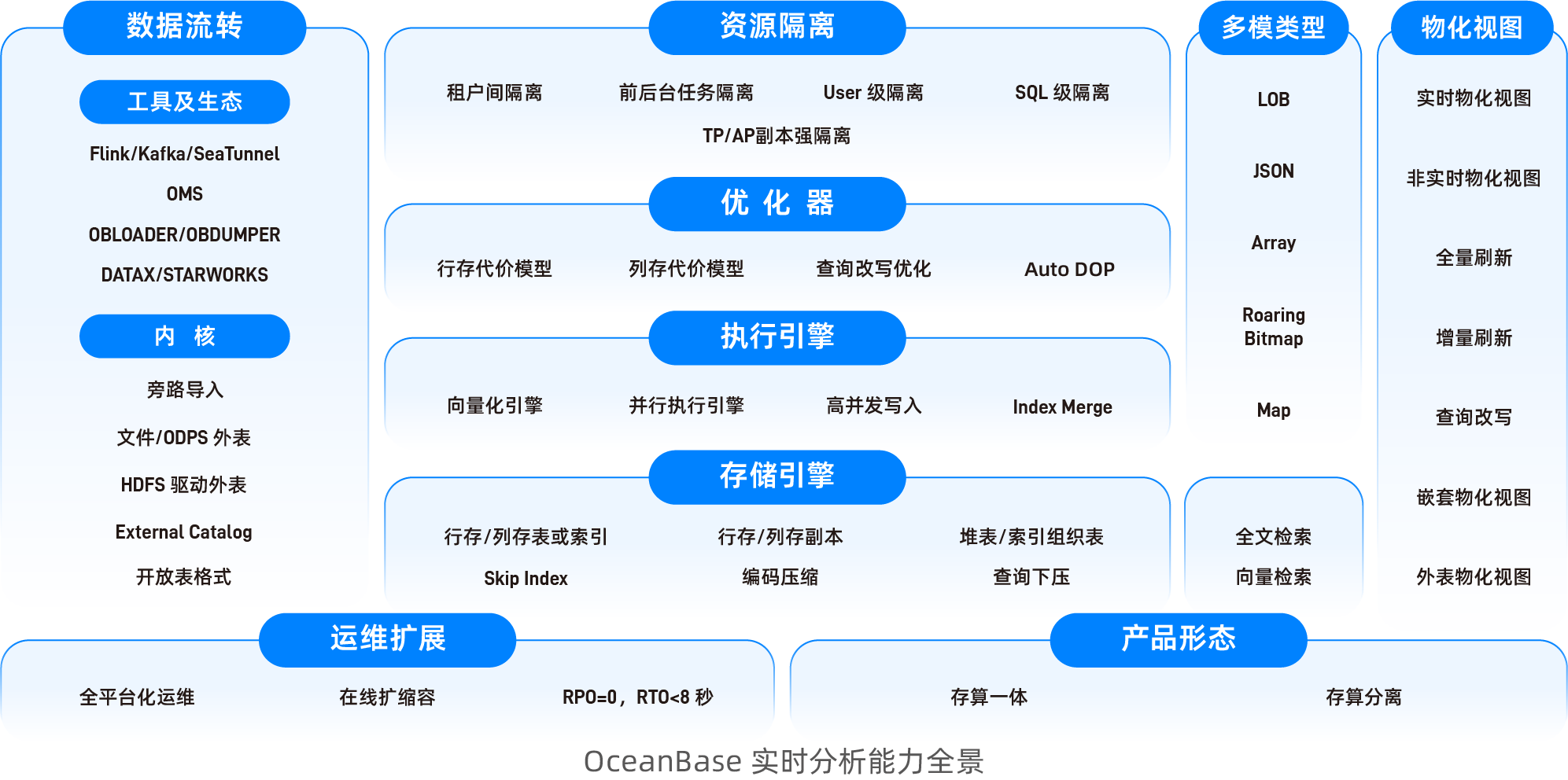
| OceanBase 是一款完全自研的企业级原生分布式数据库,在普通硬件上实现金融级高可用,首创“三地五中心”城市级故障自动无损容灾新标准,刷新过 TPC-C 标准测试世界纪录,单集群规模超过 1500 节点,具有云原生、强一致性、高度兼容 Oracle/MySQL 等特性。在 V4.3.x 版本中,OceanBase 数据库集中优化了分析处理(AP)场景,并实现了事务处理(TP)与分析处理(AP)的结合。此次更新依托 OceanBase 的 LSM-Tree 架构,实现行存列存存储一体化,同时推出了基于列存的全新向量化引擎以及代价评估模型。通过这些功能强化,大幅提升处理宽表的效率,显著增强了 AP 场景下的查询性能,同时也支持实时导入、二级索引、高并发主键查询等实时 OLAP 常见需求。 | ||
|
|
||
|  | ||
|
|
||
| ## 核心优势 | ||
|
|
||
| * **稳定可靠** | ||
|
|
||
| * TP、AP 一体化构建,金融核心交易系统证明的稳定性。 | ||
| * 业内首创的三地五中心可支撑城市级无损容灾,全球领先的 RPO = 0,RTO 小于 8 秒故障自动恢复能力,满足严苛条件下的业务连续性。 | ||
|
|
||
| * **高性能分析** | ||
|
|
||
| * OceanBase 数据库支持列存和行列混存,以及做种查询优化手段,保障良好的查询性能。此外,OceanBase 数据库 V4.3 版本中实现了向量化引擎 2.0,通过对数据格式,算子实现优化及存储向量化优化等大幅提升了向量化引擎执行性能。 | ||
| * Ad-hoc 查询性能与 ClickHouse 相当。 | ||
| * TPC-H 30000GB 第一。 | ||
|
|
||
| * **低成本&易管理** | ||
|
|
||
| * HTAP 混合负载,一套系统代替原来 TP+AP 两套系统,无需分库分表。 | ||
|
|
||
| * **HSAP** | ||
|
|
||
| * 分析结果直接提供在线数据服务。 | ||
|
|
||
| * **多模** | ||
|
|
||
| * 支持用 SQL 对 JSON、GIS、文本等非结构化数据进行分析。 | ||
|
|
||
| ## 应用场景 | ||
|
|
||
| #### 场景一:实时报表和实时风控 | ||
|
|
||
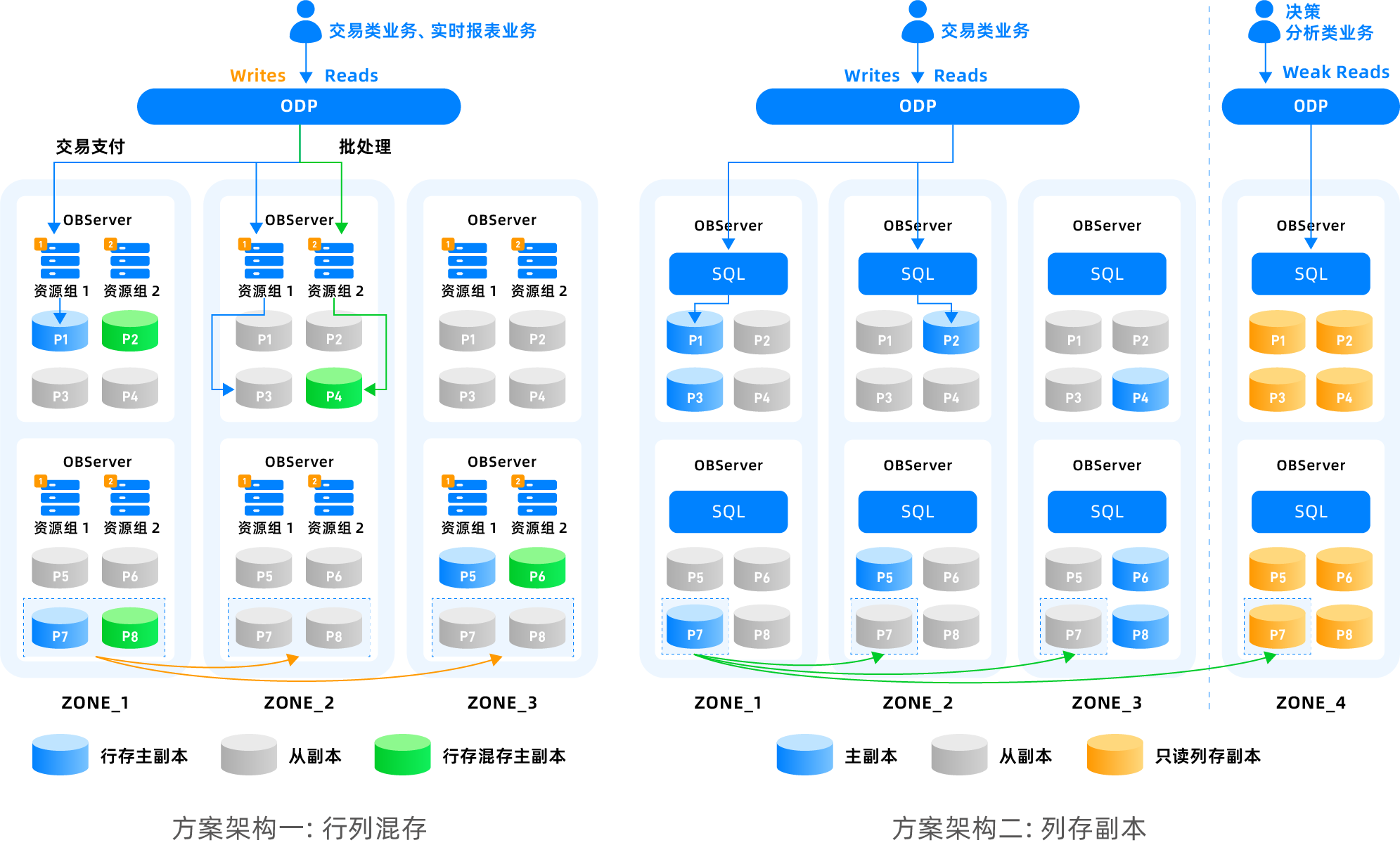
| 存在这样一种数据库用法:绝大部分场景下,数据库里都是 OLTP 负载,少数时候会有一些 OLAP 负载。这种场景下,专门购买一个 AP 集群来做分析是非常不经济的,此时,可以采用 OceanBase 数据库行列混合副本,或者在行存副本上建立列存索引。在行格式上做 TP、在列格式上做 AP,并通过资源组做软隔离。 | ||
|
|
||
| 在行存的基础上,通过创建列存索引的方式,在集群内即可获得列存的能力,实现查询加速。行存和列存在同一个集群内,共享同一套资源,有资源隔离的需求,同一个租户内部提供了 cgroup 隔离,CPU、IO 等的隔离,TP 和 AP 之间会不干扰。 | ||
|
|
||
| - TP 用行存 | ||
| - AP 用列存索引(降低存储开销) | ||
| - 隔离用资源组 | ||
|
|
||
|  | ||
|
|
||
| #### 场景二:轻量级实时数仓 | ||
|
|
||
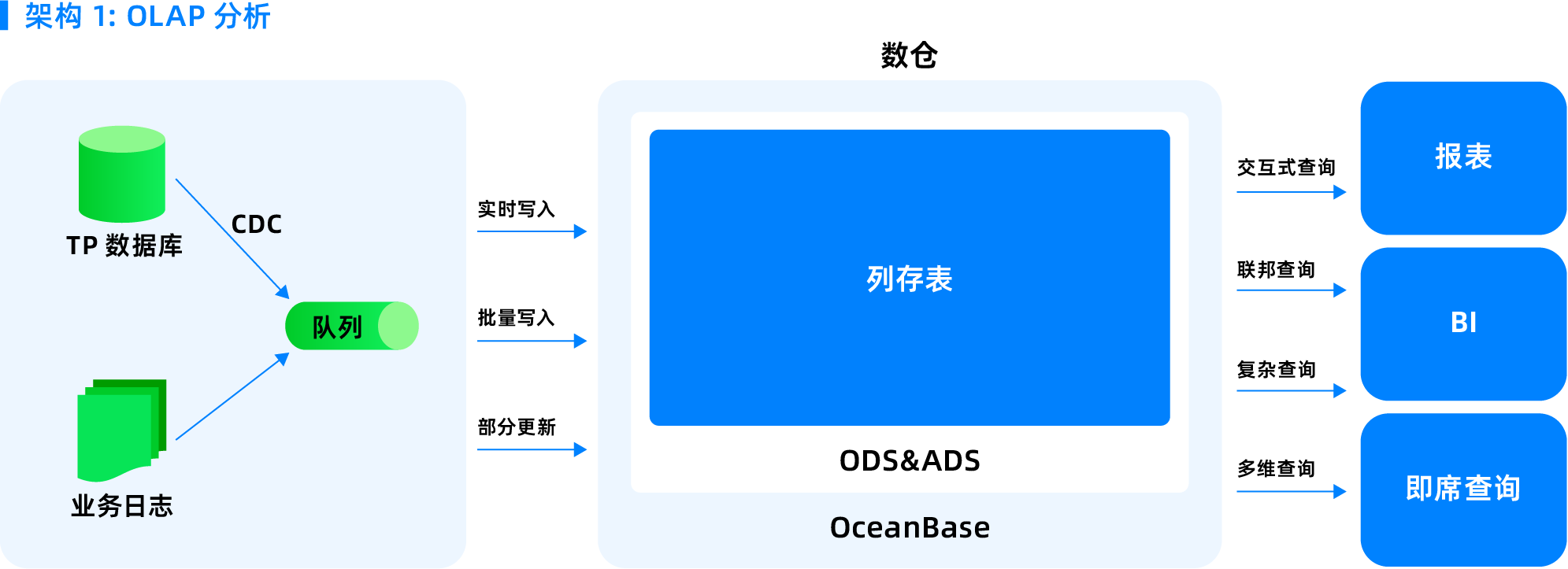
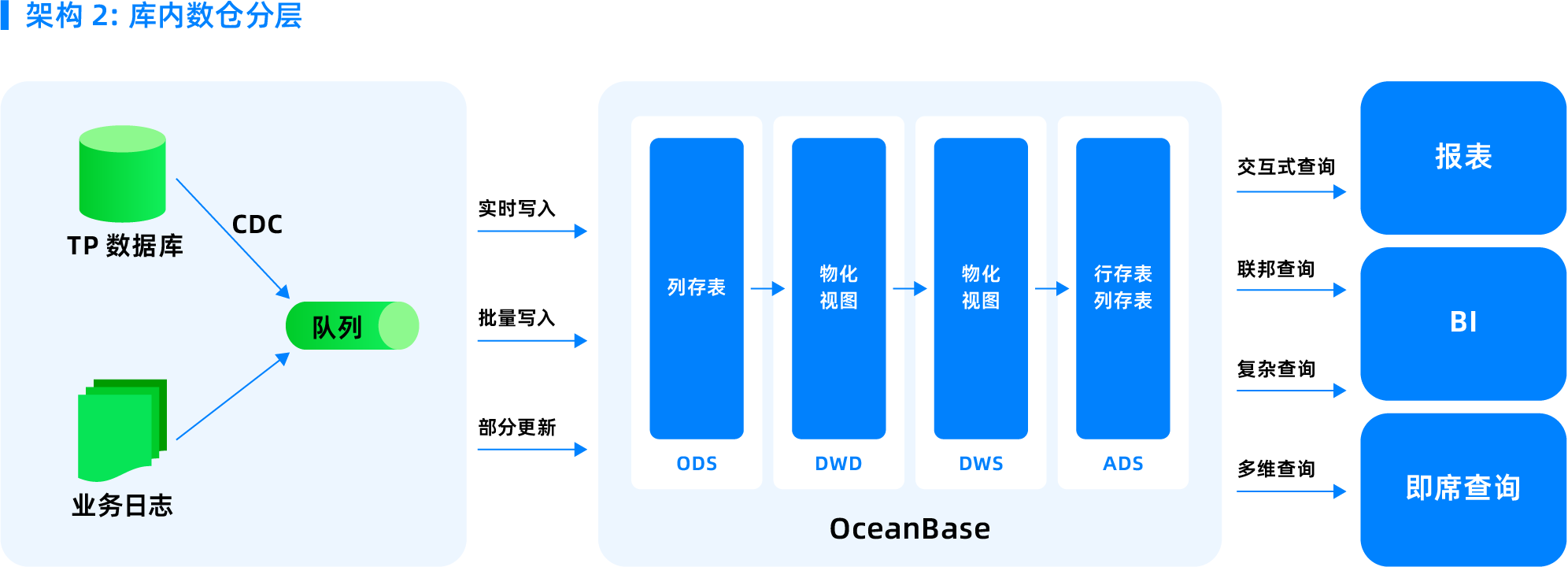
| OceanBase 数据库基于列存、并行执行引擎、向量化引擎、基于改写和代价的优化器,具备担任轻型数仓的能力。数仓场景可以全部使用 OceanBase 数据库来简化 ETL。通过物化视图来简化 ETL,同时也可以支持 Flink,Flink query 可以继续使用,不需要修改,把 OceanBase 数据库当做存储来用。OceanBase 数据库可以去订阅 ODS 的日志实时做流式计算,结果写到 ODS 里对外体统交互查询和联邦查询。 | ||
|
|
||
| - AP 用列存 | ||
| - TP 用行存索引(加速 AP 点查) | ||
| - 隔离用资源组 | ||
|
|
||
|  | ||
|
|
||
|  | ||
|
|
||
| #### 场景三:Serving 场景 | ||
|
|
||
| Serving 场景是指那些要求快速响应、低延迟地处理和分析数据,以支持即时决策和交互式数据探索的场景。通常采用列式存储来加速聚合操作,利用索引减少数据检索时间,并借助分布式计算框架横向扩展,处理大规模数据集。 | ||
|
|
||
| 为了提升 Serving 的性能,业务上通常将结果预连接好,形成大宽表存储数据库中,然后在这个大宽表上执行高并发的单表聚合操作。 | ||
|
|
||
| OceanBase 数据库可用于替换 ClickHouse 用于 Serving 场景。 | ||
|
|
||
| 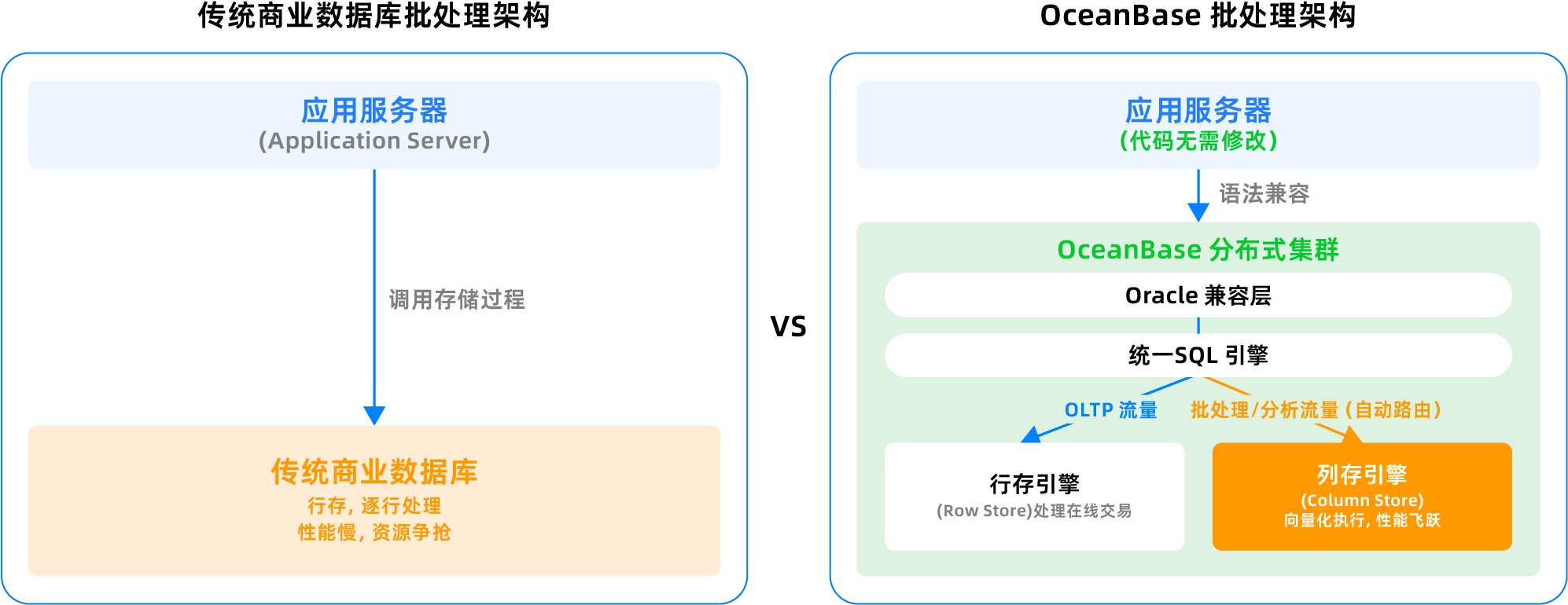 | ||
|
|
||
| ## 技术架构 | ||
|
|
||
| * 关于 OceanBase 数据库的技术架构介绍,参见 [OceanBase 系统架构](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000818349)。 | ||
| * 关于 OceanBase 数据库技术原理的详细介绍,参见 [OceanBase 系统原理](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000818607) 章节。 |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,35 @@ | ||
| # OceanBase AP 部署概述 | ||
|
|
||
| 可以根据需要选择合适的产品形态、部署方案和部署方式。 | ||
|
|
||
| ## 选择合适的产品形态 | ||
|
|
||
| OceanBase 数据库提供企业版和社区版两种形态: | ||
|
|
||
| * OceanBase 数据库企业版:OceanBase 企业版是一款完全自研的企业级原生分布式数据库,在普通硬件上实现金融级高可用,首创 “三地五中心” 城市级故障自动无损容灾新标准,刷新 TPC-C 标准测试,单集群规模超过 1500 节点,具有云原生、强一致性、高度兼容 Oracle/MySQL 等特性。 | ||
| * OceanBase 数据库社区版:兼容 MySQL 的单机分布式一体化数据库,具有原生分布式架构,支持金融级高可用、透明水平扩展、分布式事务、多租户和语法兼容等企业级特性。OceanBase 社区版数据库内核开源,同时社区版提供开放的接口和丰富的生态能力,支持企业或个人更好的实现定制化业务需求。 | ||
|
|
||
| 有关 OceanBase 企业版和社区版的功能差异,参见 [企业版和社区版的功能差异](../../100.learn-more-about-oceanbase/200.differences-between-enterprise-edition-and-community-edition.md)。 | ||
|
|
||
| ## 选择合适的部署方案 | ||
|
|
||
| OceanBase 数据库采用基于无共享(Shared-Nothing)的多副本架构,让整个系统没有任何单点故障,保证系统的持续可用。OceanBase 数据库支持单机(单机房部署 OceanBase 集群)、机房(同城多机房部署 OceanBase 集群,机房以下统称:IDC)、城市(多城市部署 OceanBase 集群)级别的高可用和容灾,可以进行单机房、双机房、两地三中心、三地五中心部署,且支持部署仲裁服务来降低成本。 | ||
|
|
||
| 关于每种部署方案的详细介绍,参见 [OceanBase 集群高可用部署方案简介](../../400.deploy/200.introduction-to-oceanbase-cluster-high-availability-deployment-scheme.md)。 | ||
|
|
||
| ## 选择合适的部署方式 | ||
|
|
||
| |**产品形态**|**使用场景**|**推荐的部署方式**|**部署工具**| | ||
| |---|---|---|---| | ||
| | **OceanBase 企业版** | 生产环境 | 建议使用 OCP 部署 OceanBase 集群。<br/>具体操作请参见 [使用 OCP 部署三副本 OceanBase 集群](../../400.deploy/300.deploy-oceanbase-enterprise-edition/300.deploy-through-a-graphical-interface/300.deploy-oceanbase-cluster-use-ocp/500.deploy-three-oceanbase-replica-clusters-use-ocp.md)。 | OAT + OCP | | ||
| |**OceanBase 企业版** | 非生产环境 | 可以使用命令行部署 OceanBase 集群。<br/>具体操作请参见 [使用命令行部署三副本 OceanBase 集群](../../400.deploy/300.deploy-oceanbase-enterprise-edition/400.deploy-through-the-command-line/200.deploy-the-oceanbase-cluster-command-line/400.deploy-three-oceanbase-replica-clusters.md)。 | oatcli 命令行工具 | | ||
| | **OceanBase 社区版** | 线上环境 | 建议使用 OBD 进行标准部署。<br/>具体操作参见 [通过 OBD 白屏部署 OceanBase 集群](../../400.deploy/500.deploy-oceanbase-database-community-edition/200.local-deployment/400.deploy-by-ui/100.deploy-by-obd.md)。 | OBD | | ||
| | **OceanBase 社区版** | kubernetes 环境 | 建议使用 ob-operator 的方式部署。<br/>具体操作参见 [在 Kubernetes 集群中部署 OceanBase 数据库](../../400.deploy/500.deploy-oceanbase-database-community-edition/300.deploy-in-the-k8s-cluster.md)。 | ob-operator | | ||
| | **OceanBase 社区版** | 非原生支持的操作系统(比如 MAC 和 Windows)的快速体验场景 | 建议使用 Docker 镜像的方式进行部署。<br/>具体操作参见 [快速体验 OceanBase 数据库](../../200.quickstart/100.quickly-experience-oceanbase-for-community.md) 中的 **方案三:部署 OceanBase 容器环境** 一节。 | | | ||
| | **OceanBase 社区版** | 原生支持的操作系统(Linux 系列,具体见支持的操作系统列表)的快速体验场景 | 建议使用 OBD 进行部署;具体操作参见 [快速体验 OceanBase 数据库](../../200.quickstart/100.quickly-experience-oceanbase-for-community.md) 中的 **方案一:部署 OceanBase 演示环境** 或 **方案二:部署 OceanBase 集群环境**。 | OBD | | ||
|
|
||
|
|
||
| ## 规划您的资源 | ||
|
|
||
| 选择了合适的部署方案开始部署之前,您需要规划和准备部署所需的资源。 | ||
| * 有关服务器的配置要求,参见 [准备服务器](../../400.deploy/300.deploy-oceanbase-enterprise-edition/200.preparations-before-deploy/100.prepare-servers.md)。 |
178 changes: 178 additions & 0 deletions
178
zh-CN/620.obap/110.obap-deploy/100.obap-parameter-config.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,178 @@ | ||
| # AP 场景下的参数配置推荐 | ||
|
|
||
| 为了确保用户在各种业务场景下,能够基于 OceanBase 数据库获得比较好的性能,OceanBase 基于过往大量真实场景的调优经验总结了各类业务场景下一些核心配置项和变量的推荐配置。本文介绍在 AP 场景下,为了确保查询性能,一些核心配置项和变量的推荐配置。 | ||
|
|
||
| 不同业务场景下的推荐参数配置可以在 OceanBase 源码的如下路径下查看。 | ||
|
|
||
| ```shell | ||
| # system variables | ||
| src/share/system_variable/default_system_variable.json | ||
| # parameters | ||
| src/share/parameter/default_parameter.json | ||
| ``` | ||
|
|
||
| ## 配置项推荐配置 | ||
|
|
||
| 在 AP 场景下,您可以参考如下配置项配置来确保比较好的查询性能。 | ||
|
|
||
| ```bash | ||
| [ | ||
| { | ||
| "scenario": "olap", | ||
| "comment": "for real-time data warehouse analytics scenarios.", | ||
| "parameters": { | ||
| "cluster": [ | ||
| { | ||
| "name": "enable_record_trace_log", | ||
| "value": false, | ||
| "comment": "disable trace log for better AP performance" | ||
| }, | ||
| { | ||
| "name":"trace_log_slow_query_watermark", | ||
| "value":"7d", | ||
| "comment":"7 days. no 'slow query' concept for AP query" | ||
| }, | ||
| { | ||
| "name":"large_query_threshold", | ||
| "value":"0ms", | ||
| "comment":"disable large query detection for AP query" | ||
| } | ||
| ], | ||
| "tenant": [ | ||
| { | ||
| "name":"default_table_store_format", | ||
| "value":"column", | ||
| "comment":"default to column format for AP" | ||
| }, | ||
| { | ||
| "name":"_rowsets_max_rows", | ||
| "value": 256, | ||
| "comment":"for classic OLAP workloads, rowset 256 is adequate" | ||
| } | ||
| ] | ||
| } | ||
| } | ||
| ] | ||
| ``` | ||
|
|
||
| 以上配置项的详细介绍。 | ||
|
|
||
| |**配置项**|**描述**|**默认值**|**AP 场景下的推荐配置**| | ||
| |---|---|---|---| | ||
| | [enable_record_trace_log](../../700.reference/800.configuration-items-and-system-variables/100.system-configuration-items/300.cluster-level-configuration-items/7900.enable_record_trace_log.md) | 用于设置是否记录追踪日志。 | True | False </br>关闭追踪日志可以带来更好的 AP 性能。 | | ||
| | [trace_log_slow_query_watermark](../../700.reference/800.configuration-items-and-system-variables/100.system-configuration-items/300.cluster-level-configuration-items/23900.trace_log_slow_query_watermark.md) | 用于设置查询的执行时间阈值,如果查询的执行时间超过该阈值,则被认为是慢查询,慢查询的追踪日志会被打印到系统日志中。 | 1s,默认单位为毫秒 | 7d</br>AP 场景下无需定义慢查询。 | | ||
| | [large_query_threshold](../../700.reference/800.configuration-items-and-system-variables/100.system-configuration-items/300.cluster-level-configuration-items/11100.large_query_threshold.md) | 用于设置查询执行时间的阈值。超过时间的请求可能被暂停,暂停后自动被判断为大查询,执行大查询调度策略。 | 5s | 0ms</br>表示关闭大查询的检测。 | | ||
| | [default_table_store_format](../../700.reference/800.configuration-items-and-system-variables/100.system-configuration-items/400.tenant-level-configuration-items/2200.default_table_store_format.md) | 用于指定用户租户默认创建表的格式,包括行存、纯列存和冗余行存列存。 | row | column</br>指定默认的建表格式为纯列存表 | | ||
| | _rowsets_max_rows | 用于指定 SQL 引擎向量化执行一次执行最大行数。| 256 | 256</br>对于传统 OLAP 负载,256 rowset 足够了。 | | ||
|
|
||
| ## 系统变量推荐配置 | ||
|
|
||
| 在 AP 场景下,您可以参考如下变量配置来确保比较好的查询性能。 | ||
|
|
||
| ```bash | ||
| { | ||
| "scenario": "olap", | ||
| "comment": "for real-time data warehouse analytics scenarios.", | ||
| "variables": { | ||
| "tenant": [ | ||
| { | ||
| "name": "ob_query_timeout", | ||
| "value": 604800000000, | ||
| "comment":"query timeout for AP is 7 days" | ||
| }, | ||
| { | ||
| "name": "ob_trx_timeout", | ||
| "value": 604800000000, | ||
| "comment":"transaction timeout for AP is 7 days" | ||
| }, | ||
| { | ||
| "name": "parallel_degree_policy", | ||
| "value" : "AUTO", | ||
| "comment" : "auto dop is enabled by default for OLAP" | ||
| }, | ||
| { | ||
| "name": "parallel_min_scan_time_threshold", | ||
| "value": 10, | ||
| "comment":"10ms. enable best parallel performance for query which require 100ms+ only" | ||
| }, | ||
| { | ||
| "name": "ob_sql_work_area_percentage", | ||
| "value": 30, | ||
| "comment":"larger sql work area can save spill cost" | ||
| }, | ||
| { | ||
| "name": "collation_server", | ||
| "value": "utf8mb4_bin", | ||
| "comment": "use binary collation can achieve 20% performance gain compared with other collations" | ||
| }, | ||
| { | ||
| "name": "collation_connection", | ||
| "value": "utf8mb4_bin", | ||
| "comment": "use binary collation can achieve 20% performance gain compared with other collations" | ||
| } | ||
| ] | ||
| } | ||
| }, | ||
| ``` | ||
|
|
||
| 以上变量的详细介绍。 | ||
|
|
||
| |**变量**|**描述**|**默认值**|**AP 场景下的推荐配置**| | ||
| |---|---|---|---| | ||
| | [ob_query_timeout](../../700.reference/800.configuration-items-and-system-variables/200.system-variable/300.global-system-variable/8600.ob_query_timeout-global.md) | 用于设置 SQL 最大执行时间。 | 10000000,单位为微秒。 | 604800000000</br>设置为 7 天。 | | ||
| | [ob_trx_timeout](../../700.reference/800.configuration-items-and-system-variables/200.system-variable/300.global-system-variable/9700.ob_trx_timeout-global.md) | 用于设置事务超时时间。 | 86400000000,单位为微秒。 | 604800000000</br>设置为 7 天。 | | ||
| | [parallel_degree_policy](../../700.reference/800.configuration-items-and-system-variables/200.system-variable/400.session-system-variable/1400.parallel_degree_policy-session.md) | 用于设置并行度选择策略。 | MANUAL | AUTO</br>表示启用 启用 Auto DOP 策略。</br>关于 Auto DOP 的详细介绍,参见 [Auto DOP](../../700.reference/1000.performance-tuning-guide/500.sql-optimization/300.distributed-execution-plan/600.auto-dop.md)。 | | ||
| | [parallel_min_scan_time_threshold](../../700.reference/800.configuration-items-and-system-variables/200.system-variable/400.session-system-variable/1500.parallel_min_scan_time_threshold-session.md) | 是在 Auto DOP 策略中用于计算并行度的参数,即设置对基表扫描进行并行处理的最小评估执行时间。当基表扫描评估的执行时间超过这个设定值时,会开启并行,并利用这个值计算一个合适的并行度。 | 1000,单位为 ms。 | 10</br>对于执行时间在 100ms+ 的查询,可以带来最佳的并行执行性能。 | | ||
| | [ob_sql_work_area_percentage](../../700.reference/800.configuration-items-and-system-variables/200.system-variable/300.global-system-variable/9100.ob_sql_work_area_percentage-global.md) | 用于设置 SQL 工作区内存占整个租户内存百分比。 | 5 | 30</br>设置比较大的工作区内存可以节省内存泄漏带来的成本。 | | ||
| | [collation_server](../../700.reference/800.configuration-items-and-system-variables/200.system-variable/300.global-system-variable/1600.collation_server-global.md) | 用于设置服务器默认字符集和字符序。 | utf8mb4_general_ci | utf8mb4_bin</br>相较其他 collation,使用二进制 collation 可以实现 20% 的性能提升。 | | ||
| | [collation_connection](../../700.reference/800.configuration-items-and-system-variables/200.system-variable/300.global-system-variable/1400.collation_connection-global.md) | 用于设置连接使用的字符集和字符序。 | utf8mb4_general_ci | utf8mb4_bin</br>相较其他 collation,使用二进制 collation 可以实现 20% 的性能提升。 | | ||
|
|
||
| ## MySQL 租户的配置示例 | ||
|
|
||
| ```sql | ||
|
|
||
| # 设置 collation 为 utf8mb4_bin,性能瞬间提升 15% | ||
| set global collation_connection = utf8mb4_bin; | ||
| set global collation_server = utf8mb4_bin; | ||
|
|
||
| set global ob_query_timeout= 10000000000; | ||
| set global ob_trx_timeout= 100000000000; | ||
| set global ob_sql_work_area_percentage=30; | ||
| set global max_allowed_packet=67108864; | ||
| # 建议是cpu的10倍 | ||
| set global parallel_servers_target=1000; | ||
| set global parallel_degree_policy = auto; | ||
| set global parallel_min_scan_time_threshold = 10; | ||
| # 限制 parallel_degree_policy = auto 时的最大 dop | ||
| # 出现较大 dop 可能导致性能问题。下面的值建议设为 cpu_count * 2 | ||
| set global parallel_degree_limit = 0; | ||
|
|
||
|
|
||
| alter system set compaction_low_thread_score = cpu_count; | ||
| alter system set compaction_mid_thread_score = cpu_count; | ||
| alter system set default_table_store_format = "column"; | ||
| ``` | ||
| ## Oracle 租户的配置示例 | ||
| ```sql | ||
| set global ob_query_timeout= 10000000000; | ||
| set global ob_trx_timeout= 100000000000; | ||
| set global ob_sql_work_area_percentage=30; | ||
| set global max_allowed_packet=67108864; | ||
| # 建议是cpu的10倍 | ||
| set global parallel_servers_target=1000; | ||
| set global parallel_degree_policy = auto; | ||
| set global parallel_min_scan_time_threshold = 10; | ||
| # 限制 parallel_degree_policy = auto 时的最大 dop | ||
| # 出现较大 dop 可能导致性能问题。下面的值建议设为 cpu_count * 2 | ||
| set global parallel_degree_limit = 0; | ||
|
|
||
| alter system set compaction_low_thread_score = cpu_count; | ||
| alter system set compaction_mid_thread_score = cpu_count; | ||
| alter system set default_table_store_format = "column"; | ||
| ``` | ||
|
|
||
| ## 相关文档 | ||
|
|
||
| * 有关配置项和变量的详细介绍,参见 [配置项和系统变量概述](../../700.reference/800.configuration-items-and-system-variables/000.configuration-items-and-system-variables-overview.md)。 | ||
| * 有关配置项的设置方法,参见 [设置参数](../../700.reference/200.system-management/200.configuration-management/200.set-parameters.md)。 | ||
| * 有关变量的设置方法,参见 [设置变量](../../700.reference/200.system-management/200.configuration-management/300.set-variables.md)。 |
Oops, something went wrong.