IS ARTICLE STILL A WORK IN PROGRESS
One of those great revolutionary technologies that have transformed how developers think of and Interact with cloud infrastructure is Kubernetes. Initially Developed at Google, Kubernetes, also known as K8s, is an open source system for automating deployment, scaling, and management of containerized applications. It is Designed on the same principles that allow Google to run billions of containers a week, Kubernetes can scale without increasing your operations team.
Despite its remarkable capabilities, Kubernetes is fundamentally a container orchestration technology. While it greatly simplifies deployment and scaling, it doesn't address all challenges that software engineers encounter in software development and DevOps. To Solve this Kubernetes provides ways it can be Extended and customized to meet your team's needs. It Provides Client Libraries in many languages. But even better are Kubernetes Operators.
A formal definition of a kubernetes operator can be:
A Kubernetes Operator is a method of automating the management of complex applications on Kubernetes. It extends Kubernetes' capabilities by using custom resources and controllers to manage the lifecycle of an application, automating tasks such as deployment, scaling, and updates. Operators encode the operational knowledge of an application into Kubernetes, making it easier to manage stateful or complex workloads with less manual intervention.
In this article. We shall go through a guide to get started building your own Custom kubernetes Operator. We shall cover different topics like Custom Resource Definitions, Controllers and look at the Kubernetes Controller Runtime.
There are a few thing we need to know and have before continuing with this tutorial
- A good understanding of Kubernetes and how to use it.
- Programming Knowledge in GoLang
- Access to a Kubernetes Cluster (You can try it locally using Minikube or Kind)
To set up your environment you will first need to have Go installed. The Kubernetes Golang Client usually requires a specific Go version so depending on your time of reading this article it might have changed but for now i will use go1.21.6. To know what version you are using, run
go version
# Example output: go version go1.21.6 linux/amd64Next you will need to have access to a Kubernetes cluster but for development purposes I would advise you use a local cluster from tools like Minikube or Kind. You can visit their websites for the installation steps.
Before we dive right into code. There are certain key concepts you will need to know so let's look at those first.
To understand CRDs you need to first know what a resource is. Pods, Deployments, Services etc are all resources. Formally
A resource is an endpoint in the Kubernetes API that stores a collection of API objects of a certain kind; for example, the built-in pods resource contains a collection of Pod objects.
Resources are in built within the Kubernetes API. But in our case, we said one of the main resons we build operators is to handle custom problems that Kubernetes does not solve out of the box. In some cases we might need to define our own resource objects. Forexample. Imagine we are building an operator that manages postgreSql databases, we would like to provide an API to define configurations of each database we initiate, we can do this by defining a Custom resource definition PGDatabase as an Object that stores the configuration of the database.
Example of a Custom Resource Definition for demostration
apiVersion: example.com/v1 # Every resource must have an API Version
kind: PGDatabase # CRD Name
metadata:
name: mydb
spec:
config:
port: 5432
user: root
dbname: mydb
volumes:
- pgvolume: /pgdata/
envFrom: wordpress-secretsNote: CRDs are just definitions of the actually objects or they just represent an actual object in the kubernetes cluster but are not the actual object. For example when you write a yaml file defining how a pod should be scheduled, that yaml just defines but its not the actual pod.
Therefore we can define a CRD as an extension of the Kubernetes API that is not necessarily available in a default Kubernetes installation. It represents a customization of a particular Kubernetes installation. Actually, many core Kubernetes functions are now built using custom resources, making Kubernetes more modular.
Next Lets look at Kubernetes Controllers. As we have seen above, CRDs represent objects or state of objects in the Kubernetes Cluster, but we need something to reconcile or transform that state into actual resources on the cluster, this is where Controllers come in.
A Kubernetes controller is a software component within Kubernetes that continuously monitors the state of cluster resources and takes action to reconcile the actual state of the cluster with the desired state specified in resource configurations (YAML files).
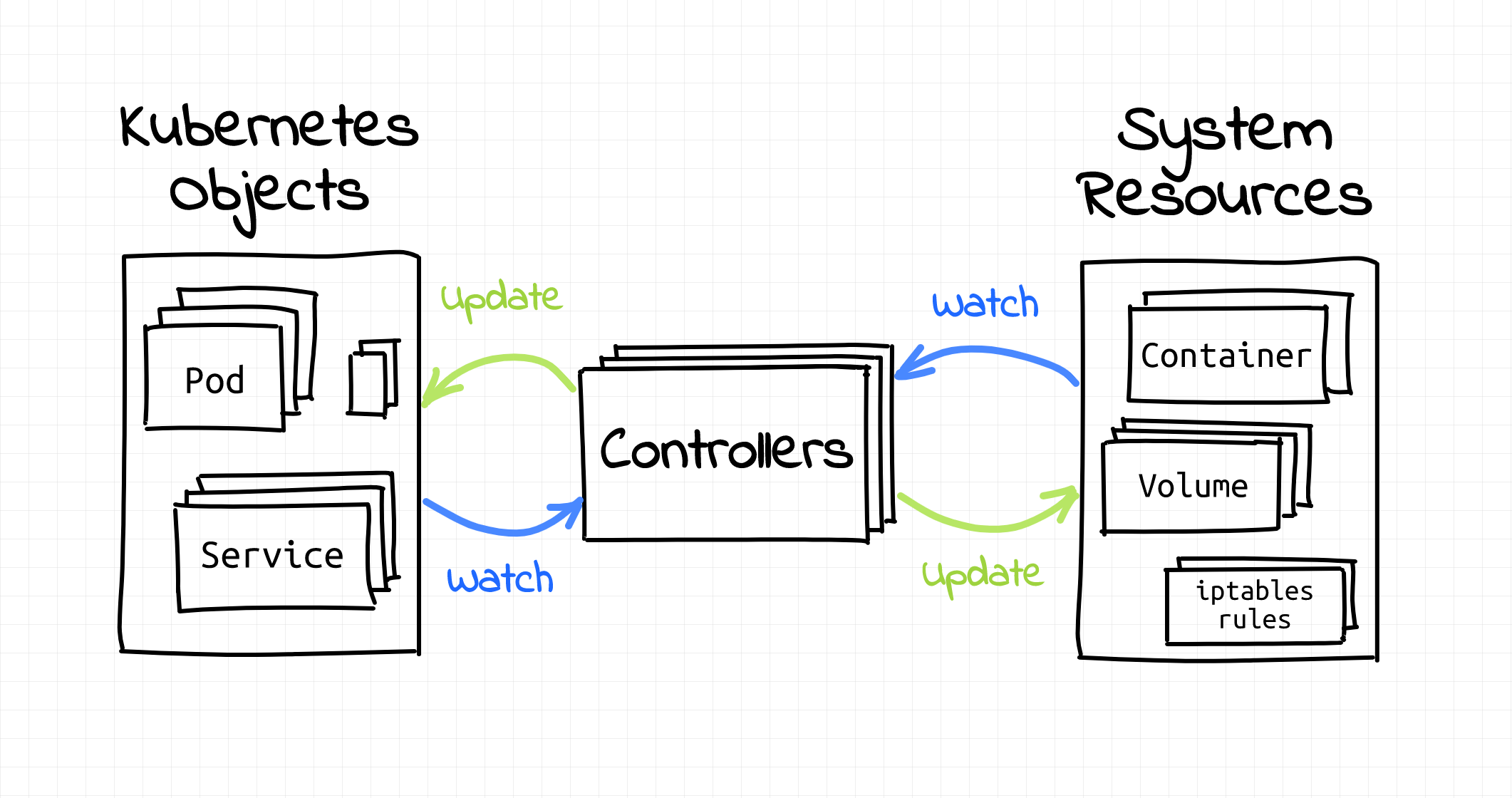
Controllers are responsible for managing the lifecycle of Kubernetes objects, such as Pods, Deployments, and Services. Each controller typically handles one or more resource types and performs tasks like creating, updating, or deleting resources based on a declared specification. Here's a breakdown of how a Kubernetes controller operates:
- Observe: The controller watches the API server for changes to resources it's responsible for. It monitors these resources by querying the Kubernetes API periodically or via an event stream.
- Analyze: It compares the actual state (current conditions of the resources) to the desired state (specified in configurations).
- Act: If there’s a discrepancy between the actual and desired state, the controller performs operations to align the actual state with the desired state. For example, a Deployment controller might create or terminate Pods to match the specified replica count.
- Loop: The controller operates in a loop, continuously monitoring and responding to changes to ensure the system’s resources are always in the desired state.
Kubernetes provides a set of tools to build native Controllers and these are Known as the Controller Runtime.
Lets take a deep look into the Controller runtime because its what we shall be using to build out Operators
Controller Runtime is a set of libraries and tools in the Kubernetes ecosystem, designed to simplify the process of building and managing Kubernetes controllers and operators. It’s part of the Kubernetes Operator SDK and is widely used to develop custom controllers that can manage Kubernetes resources, including custom resources (CRDs).
Controller Runtime provides a structured framework for controller logic, handling many of the lower-level details of working with the Kubernetes API, so developers can focus more on defining the behavior of the controller and less on boilerplate code. It is written in Go and builds on the Kubernetes client-go libraries.
To use it, you can add it to you golang project by importing it like this:
package controller
// Controller runtime packages
import (
"sigs.k8s.io/controller-runtime"
"sigs.k8s.io/controller-runtime/pkg/client"
)Note: The Controller runtime is not the only way one can build a Kubernetes Operator, there are multiple ways to do so such as using the Operator Framework SDK or Kubebuilder, which are both frameworks built on top of the Controller runtime and utilize it under the hood to assist you when building complex Operators. You could even build an application that utilizes the Kubernetes Rest API through client libraries in various languages such as Python, Java, JavaScript etc depending on your tech stack. Find the Full list of Client Libraries on the Kubernetes Documentation. In this article, we will use the Controller runtime because it offers flexibility and provides a hands-on understanding of how Controllers work internally. This approach is ideal for gaining deeper insight into the inner workings of Kubernetes Operators while maintaining the ability to extend or customize as needed.
The Controller Runtime has several key components that streamline the process of building and running Kubernetes controllers. Together, these components create a robust framework for building Kubernetes controllers.
The Manager initiates and manages other components; the Controller defines reconciliation logic; the Client simplifies API interactions; the Cache optimizes resource access; Event Sources and Watches enable event-driven behavior; and the Reconcile Loop ensures continuous alignment with the desired state. These components make it easier to build controllers and operators that efficiently manage Kubernetes resources, allowing for custom automation and orchestration at scale.
The Manager is the main entry point of a controller or operator, responsible for initializing and managing the lifecycle of other components, such as controllers, caches, and clients. Developers usually start by creating a Manager in the main function, which acts as the foundational setup for the entire operator or controller.
It provides shared dependencies (e.g., the Kubernetes client and cache) that can be reused across controllers, allowing multiple controllers to be bundled within a single process.
The Manager also coordinates starting and stopping all controllers it manages, ensuring that they shut down gracefully if the Manager itself is stopped.
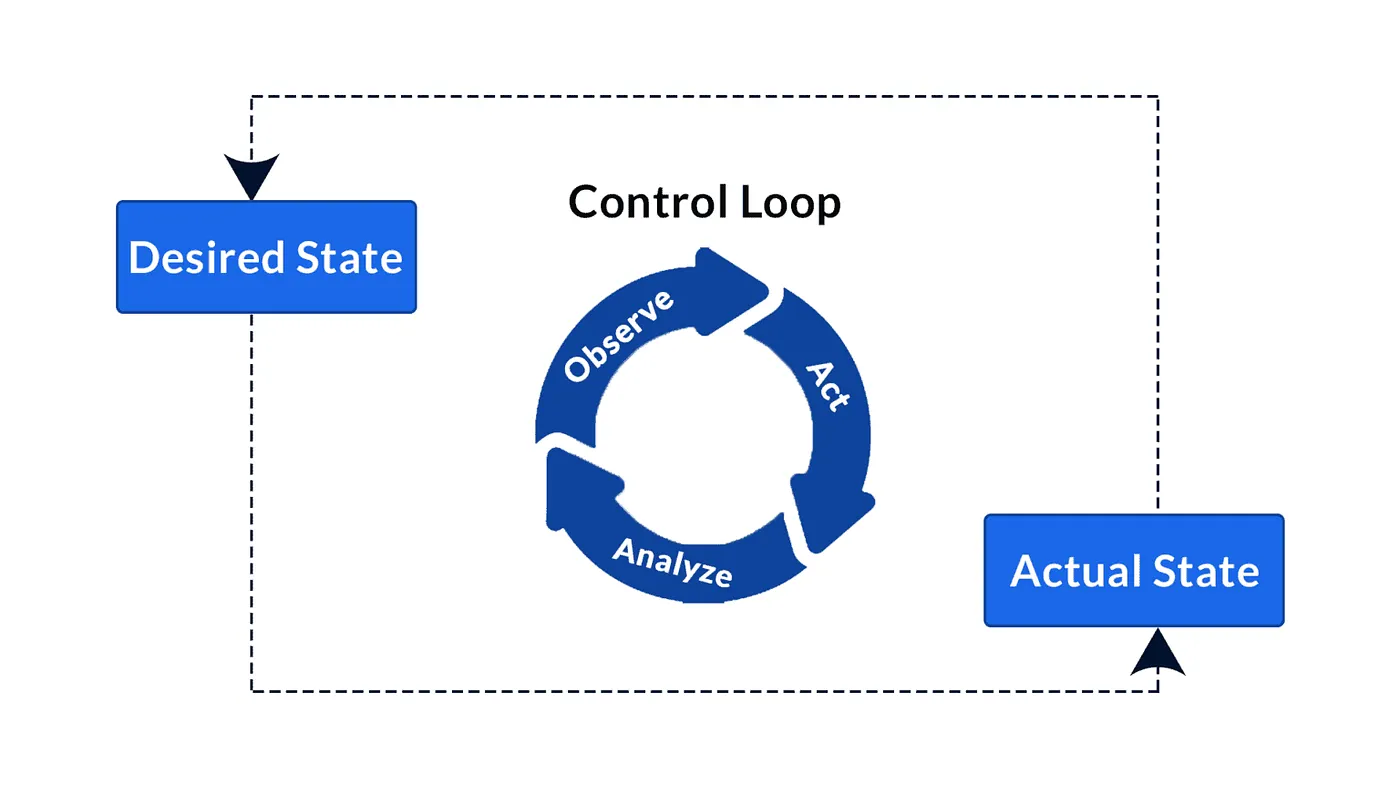
The Controller is the core component that defines the reconciliation logic responsible for adjusting the state of Kubernetes resources. It is a control loop that monitors a cluster's state and makes changes to move it closer to the desired state
Each controller watches specific resources, whether built-in (e.g., Pods, Deployments) or custom resources (CRDs). It includes a Reconcile function that’s triggered whenever a resource changes, allowing the controller to bring the current state in line with the desired state.
Developers specify which resources the controller should watch, and Controller Runtime will automatically track and respond to events (like create, update, delete) for those resources. In a controller for managing custom Foo resources, the Reconcile function might create or delete associated resources based on Foo specifications.
When building a Kubernetes operator, you need some interface to interact with the Kubernetes Cluster and carry out your operations. Just like kubectl the command line client we use, the Controller runtime provided a client in its SDK tools. This client is also used to interact with the Kubernetes API pragrammatically in your code.
The Client is an abstraction that simplifies interactions with the Kubernetes API, enabling CRUD operations on resources.
This component allows for easy creation, reading, updating, and deletion of Kubernetes resources. The Client is integrated with the cache to provide efficient access to resources without overloading the API server.
Controller Runtime’s Client extends the basic Kubernetes client-go library, making API calls more straightforward by handling details like retries and caching behind the scenes.
Using the Client, developers can create a Pod directly from the controller logic with a single line of code, client.Create(ctx, pod), without having to worry about raw API requests.
Event Sources and Watches determine the resources that a controller will monitor for changes, providing a way to respond to specific events in the cluster.
Event Sources define what triggers the controller’s reconciliation loop, which can be based on changes in specific Kubernetes resources. Watches monitor these resources, allowing the controller to act on create, update, or delete events as needed.
Developers can define multiple Watches for a single controller, which is useful if the controller’s behavior depends on multiple resources.
A controller managing a custom App resource might watch Pods, Services, and ConfigMaps, reacting to changes in any of these resources by adjusting the App accordingly.
The Reconcile loop is the heart of the controller, implementing the main logic that determines the steps to bring resources into the desired state. Each controller’s Reconcile function checks the actual state of a resource and then applies necessary changes to make it conform to the desired state. This loop continues indefinitely, with each reconciliation acting as a self-healing mechanism to correct any divergence from the specification. The Reconcile loop is usually idempotent, meaning it can be repeated without causing unintended side effects, ensuring consistency even with frequent updates. In a Reconcile function, the controller might find that a Deployment lacks the specified number of replicas, so it updates the Deployment configuration to match the desired replica count.
Now that you have grasped a few required concepts, lets take a practical approach by building a simple kubernetes oparator and deploying it on our Kubernetes Cluster. This will help you to apply the concepts above and understand the process more.
In this section, we will build a simple Kubernetes operator that helps deploy applications using a custom resource definition (CRD). This operator will automate the creation of Deployments and Services based on the application configuration provided in the custom resource. By the end, you'll have a working operator deployed on a Kubernetes cluster and understand its key components.
- All code will be made available on Github at https://github.com/jim-junior/crane-operator
- I will ensure code is commented in detail to ensure you can easily read and understand it
Our goal is to minimize the complexity of defining Kubernetes resources for deploying an application. Instead of writing multiple YAML files for Deployments, Services, etc., we will define a single CRD Application that encapsulates all required configurations. The operator will then create the necessary Kubernetes resources automatically.
Requirements for the Example:
- The operator shall define a CRD Application that includes all the configuration of the application.
- From the CRD, it should create the associated Kubernetes resources such and Deployments, Services
- We shall Implement a controller to reconcile the state of Application resources.
- Use the controller to create and manage Deployments and Services.
Now that we have a high level understanding of what our Operator is supposed to do and accomplish, lets setup our project and get started building the operator.
As mentioned earlier, we will use the Go programming language for this tutorial. Why Go? Primarily because the Controller runtime, as well as Kubernetes itself, is built using Go. Additionally, Go is specifically designed with features that make it ideal for building cloud-native applications. Its architecture ensures that your Operator will be well-suited to scale efficiently in cloud environments. We are using go1.21.6
So lets begin by initialising out Go project:
mkdir app-operator && cd app-operator
go mod init github.com/jim-junior/crane-operatorWe shall then install the go dependencies that we shall use in our project. You can install then by running this in the command line.
go get sigs.k8s.io/controller-runtime
go get k8s.io/apimachinery
go get k8s.io/client-goNext lets setup our project file/directory structure. Depending on your development paradigm you can choose one that favours you but for now we shall use this simple that i have found to work in most Operator projects.
app-operator/
├── api/ # Contains CRD definitions
├── cmd/controller/
├──reconciler.go # Contains the reconciliation logic
├── main.go # Entry point for the operator
├── config/ # Configuration files for testing and deploymentAs metioned above, the CRD defines the specification of how our Object will look like. From familiarity with deploying multiple applications or web services, there are a few things an application needs:
- A port to expose your application
- A Volume, incase you want to Persist Data
- A Container Image for application distribution and deployment
- Enviroment Variables
Since this is just an example we shall keep the requirements as minimal as possible, its not like we are building some operator to be used in an actual Organisation. Plus I dont want the code to become huge.
When defining a Custom Resource Definition (CRD), it must be specified in two formats. The first is as a yaml or json OpenAPI specification (yaml is preffered is its more human readable), which can be applied using kubectl apply to install the CRD on a Kubernetes cluster. The second is as a Go language specification, used in your code to define and interact with the CRD programmatically.
While tools like Operator SDK and Kubebuilder can automatically generate one or both of these formats for you, it's important for a developer building a Kubernetes Operator to understand the configurations being generated. This knowledge is invaluable for debugging or handling custom scenarios that may arise.
Lets begin first with an example showing how we would like our CRD to look like. This will help use comeup with a Specification. Incase you dont understand some aspects of it, dont worry, we shall look into everything.
apiVersion: operator.com/v1
kind: Application
metadata:
name: mysql
spec:
image: mysql:9.0
ports:
- internal: 3306
external: 3306
volumes:
- volume-name: /data/
envFrom: mysql-secretsBefore we define the Open API Specification, lets look at what each component means in out CRD above.
apiVersion: operator.com/v1This defines the Version of your resource. Every resource on kubernetes MUST have an api version. Even inbuilt kubernetes resources have. I would recommend versioning your resources while following the Kubernetes API versioning convetions.
Kubernetes API versioning follows conventions that reflect the maturity and stability of an API. Here’s a list of the common versioning conventions and what each represents:
- Alpha (e.g., v1alpha1): Experimental and not stable.
- Beta (e.g., v1beta1): More stable than alpha but still under active development.
- Stable (e.g., v1): Fully stable and backward-compatible.
Kubernetes APIs use a convention of <group>/<version> (e.g., apps/v1), where:
- Group: The API group (e.g., apps, batch, core).
- Version: The maturity level of the API (v1alpha1, v1beta1, v1).
Custom Resource Definitions (CRDs) follow the same versioning principles as core Kubernetes APIs.
Lets move on to.
kind: ApplicationIn Kubernetes, the kind field in a resource manifest specifies the type of resource being defined or manipulated. It is a crucial identifier that tells Kubernetes which resource object the YAML or JSON file represents, enabling the API server to process it accordingly. Learn more here
Note: The value is case-sensitive and typically written in PascalCase (e.g.,
ConfigMap,Deployment).
Next is
spec:
.....This is where you define the properties of your CRD.
We can now define the Open API Specification for the CRD. You basically have to transform the above yaml into an Open API Specification. You can learn more about Open API Specification on its Documentation. But its pretty straight forward. For the above CRD this is what it would look like.
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: applications.operator.com
spec:
group: operator.com
names:
kind: Application
plural: applications
singular: application
scope: Namespaced
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
apiVersion:
type: string
kind:
description: 'You can provide a description'
type: string
metadata:
type: object
spec:
type: object
properties:
# image name
image:
type: string
# Volumes
volumes:
type: array
items:
type: object
properties:
volume-name:
type: string
path:
type: string
# Port Configuration
ports:
type: array
items:
type: object
properties:
name:
type: string
internal:
type: integer
format: int64
external:
type: integer
format: int64
# Environment variables
envFrom:
type: stringNote that even the Specification is also a resource in Kubernetes of kind
CustomResourceDefinition
You can now store that code in the file located in app-operator/config/crd.yml.
We can now define our CRD in Go code. When defininga CRD in Go. We need to do the following
- Define the CRD Specification
- Define a deepCopy function that defines how kubernetes copies the CRD object into another object
- Setup code for Registering the CRD
We use Go Structs to define the CRD. Probably due to how it is easy to define JSON-like data structures usung structs. Create a file in app-operator/api/v1/application.go and save the following code in it.
package v1
import metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
// This defines an instance of multiple Application resources
type ApplicationList struct {
metav1.TypeMeta `json:",inline"`
metav1.ListMeta `json:"metadata,omitempty"`
Items []Application `json:"items"`
}
// This defines our CRD
type Application struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec ApplicationSpec `json:"spec"`
}
type ApplicationSpec struct {
Image string `json:"image"`
Volumes []ApplicationVolume `json:"volumes"`
Ports []ApplicationPortMap `json:"ports"`
EnvFrom string `json:"envFrom"`
}
type ApplicationVolume struct {
VolumeName string `json:"volume-name"`
Path string `json:"path"`
}
type ApplicationPortMap struct {
Name string `json:"name"`
Internal int `json:"internal"`
External int `json:"external"`
}Next lets write the code that defines the Deep Copy functions. In you project create a file in app-operator/api/v1/deepcopy.go. And add the following code
package v1
import "k8s.io/apimachinery/pkg/runtime"
// DeepCopyInto copies all properties of this object into another object of the
// same type that is provided as a pointer.
func (in *Application) DeepCopyInto(out *Application) {
out.TypeMeta = in.TypeMeta
out.ObjectMeta = in.ObjectMeta
out.Spec = ApplicationSpec{
Volumes: in.Spec.Volumes,
Ports: in.Spec.Ports,
EnvFrom: in.Spec.EnvFrom,
Image: in.Spec.Image,
}
}
// DeepCopyObject returns a generically typed copy of an object
func (in *Application) DeepCopyObject() runtime.Object {
out := Application{}
in.DeepCopyInto(&out)
return &out
}
// DeepCopyObject returns a generically typed copy of an object
func (in *ApplicationList) DeepCopyObject() runtime.Object {
out := ApplicationList{}
out.TypeMeta = in.TypeMeta
out.ListMeta = in.ListMeta
if in.Items != nil {
out.Items = make([]Application, len(in.Items))
for i := range in.Items {
in.Items[i].DeepCopyInto(&out.Items[i])
}
}
return &out
}Lastly lets write the code that defines how our CRD is registed. In you project create a file in app-operator/api/v1/register.go. And add the following code
package v1
import (
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/runtime/schema"
)
// Define the API group name for the custom resource
const GroupName = "operator.com"
// Define the API group version for the custom resource
const GroupVersion = "v1"
// Create a GroupVersion object that combines the group and version
var SchemeGroupVersion = schema.GroupVersion{Group: GroupName, Version: GroupVersion}
// SchemeBuilder is a runtime.SchemeBuilder used to add types to the scheme
var (
SchemeBuilder = runtime.NewSchemeBuilder(addKnownTypes) // Initializes the SchemeBuilder with the addKnownTypes function
AddToScheme = SchemeBuilder.AddToScheme // Provides a shorthand for adding types to the scheme
)
// addKnownTypes registers the custom resource types with the runtime.Scheme
func addKnownTypes(scheme *runtime.Scheme) error {
// Register the custom resources Application and ApplicationList with the scheme
scheme.AddKnownTypes(SchemeGroupVersion,
&Application{},
&ApplicationList{},
)
// Add the group version to the scheme for metav1 objects
metav1.AddToGroupVersion(scheme, SchemeGroupVersion)
return nil // Return nil to indicate success
}We can now move on to the next section of Implementing the Controller that will transform our CRD state into the desired objects on the kubernetes cluster.
Brandon Philips, (November 3, 2016). Introducing Operators: Putting Operational Knowledge into Software. Internet Archive Wayback Machine. https://web.archive.org/web/20170129131616/https://coreos.com/blog/introducing-operators.html
CNCF TAG App-Delivery Operator Working Group, CNCF Operator White Paper - Final Version. Github. https://github.com/cncf/tag-app-delivery/blob/163962c4b1cd70d085107fc579e3e04c2e14d59c/operator-wg/whitepaper/Operator-WhitePaper_v1-0.md
Kubernetes Documentation, Custom Resources. https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/
Kubernetes Documentation, Controllers. https://kubernetes.io/docs/concepts/extend-kubernetes/api-extension/custom-resources/