Vermouth: Bridging Generative and Discriminative Models for Unified Visual Perception with Diffusion Priors | IJCAI2024
This is office PyTorch implementation for Vermouth that was accepted by IJCAI2024.
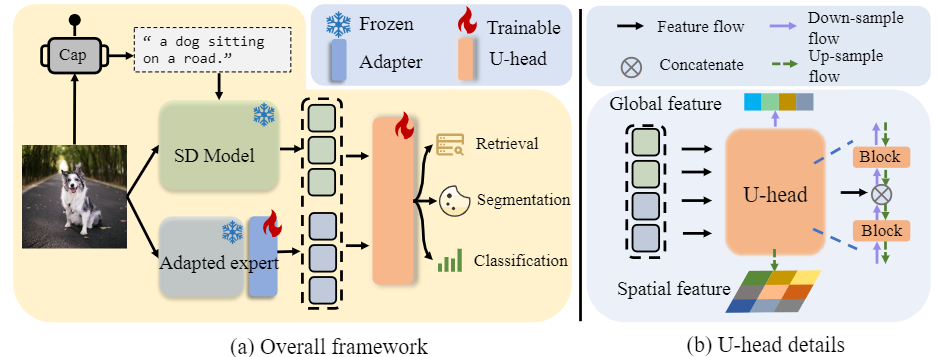
Vermouth is a simple yet effective framework to migrate the diffusion model to non-generated tasks, which comprising a pre-trained Stable Diffusion (SD) model containing rich generative priors, a pre-trained Stable Diffusion (SD) model containing rich generative priors, a unified head (U-head) capable of integrating hierarchical representations, and an adapted expert providing discriminative priors
| Model | Sketchy | TU_Berlin | QuickDraw |
|---|---|---|---|
| MAE-L | 39.23 | 41.99 | 11.71 |
| BeiTv3-G | 54.54 | 50.93 | 13.67 |
| Swinv2-L | 43.39 | 45.51 | 12.08 |
| DINO-B | 38.51 | 25.49 | |
| Vermouth | 56.8 | 52.83 | 15.11 |
| Model | ADE-150 | PC-59 | VOC20 | ADE-847 | PC-459 |
|---|---|---|---|---|---|
| MAE-L | 17.5 | 53.27 | 93.51 | 3.42 | 8.82 |
| ConvNeXt-L | 18.65 | 53.42 | 94.62 | 3.53 | 9.53 |
| Swinv2-L | 18.8 | 53.37 | 94.76 | 3.8 | 9.42 |
| DINO-B | 17.13 | 47.84 | 92.44 | 3.16 | 7.75 |
| Vermouth | 19.0 | 52.88 | 92.87 | 3.7 | 9.0 |
| Model | OxfordPets | Flowers102 | FGVCAircraft | DTD | EuroSAT | StanfordCars | Food101 | SUN397 | Caltech101 | UF101 | ImageNet |
|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE-L | 91.87 | 92.04 | 36.51 | 63.74 | 87.39 | 24.15 | 59.31 | 62.08 | 94.45 | 76.55 | 39.74 |
| BeiTv3-G | 93.79 | 97.84 | 38.34 | 72.41 | 86.11 | 62.58 | 74.42 | 71.57 | 96.9 | 84.38 | 86.95 |
| Swinv2-L | 89.65 | 99.61 | 29.13 | 73.1 | 86.9 | 37.75 | 77.41 | 72.63 | 97.01 | 81.06 | 78.84 |
| DINO-B | 89.32 | 97.82 | 48.3 | 69 | 91.15 | 57.17 | 58.5 | 62.44 | 95.57 | 76.97 | 67.66 |
| Vermouth | 66.13 | 92.35 | 42.52 | 66.62 | 88.93 | 51.05 | 45.78 | 58.09 | 95.83 | 70.49 | 55.89 |
You should clone thos repo and create a python env
git clone https://github.com/develop-productivity/Vermouth.git
cd Vermouth
conda create -n env_name python=3.10
pip install -r requirments.txt
You can follow these repo to download the datasets
- Few-shot classification: https://github.com/gaopengcuhk/Tip-Adapter.git
- Sketch-based image retrieval: https://github.com/qliu24/SAKE
- Open-vocabulary image segmentation: https://github.com/MendelXu/zsseg.baseline.git
You should originize you file as datasets dir
- release core code
- release the web page
- release model pre-train weight
If you find our work useful in your research, please consider citing:
@article{dong2024bridging,
title={Bridging Generative and Discriminative Models for Unified Visual Perception with Diffusion Priors},
author={Dong, Shiyin and Zhu, Mingrui and Cheng, Kun and Wang, Nannan and Gao, Xinbo},
journal={arXiv preprint arXiv:2401.16459},
year={2024}
}