Textual Training Examples from Data
Tabular data is becoming increasingly important in Natural Language Processing (NLP) tasks, such as Tabular Natural Language Inference (TNLI). Given a table and a hypothesis expressed in NL text, the goal is to assess if the former structured data supports or refutes the latter. We introduce Tenet, for the automatic augmentation and generation of training examples for TNLI. Our approach is built around the intuition that SQL queries are the right tool to achieve variety in the generated examples, both in terms of data variety and reasoning complexity. The first is achieved by evidence-queries that identify cell values over tables according to different data patterns. Once the data for the example is identified, semantic-queries describe the different ways such data can be identified with standard SQL clauses. These rich descriptions are then verbalized as text to create the annotated examples for the TNLI task. The same approach is also extended to create counterfactual examples, i.e., examples where the hypothesis is false, with a method based on injecting errors in the original (clean) table. For all steps, we introduce generic generation algorithms that take as input only the tables. Tenet generates human-like examples, which lead to the effective training of several inference models with results comparable to those obtained by training the same models with manually-written examples.
- 2023-08 Research paper Generation of Training Examples for Tabular Natural Language Inference Accepted to SIGMOD 2024
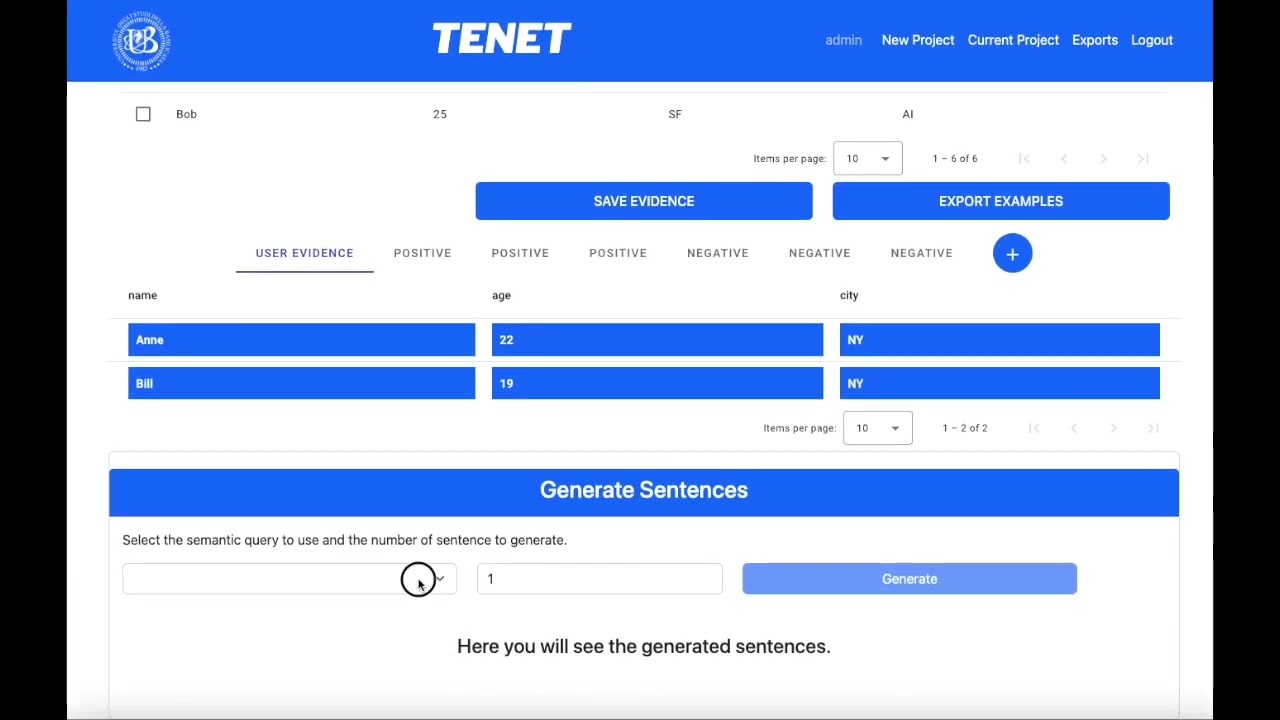
In order to execute the engine, a valid LLM provider need to be specify. The system supports three providers:
- OpenAI with a valid API key
- TogheterAI with a valid API key
- Ollama installed locally or via docker, with the Mistral model The configuration of one of these providers needs to be specified in the configuration section.
In addition, the following tools are required:
- Docker - to run the Engine
- Node (optional) - to run the Web Interface
- Java (at least 21) - to run the Web Interface
Is possible to install the requirements via Brew.
brew install docker
brew install node
brew install openjdk@21-
Make sure you have an LLM installed on your machine or an API_KEY to execute the workflow.
-
Edit the configuration:
- In compose/tenet_engine/data rename the config.json.TEMPLATE with config.json (see command below)
- Edit config.json according to the configuration properties presented in the Configuration Section
To simplify project setup, a docker-compose.yml file containing all the necessary tools is provided in the repository. To use this environment, simply rename the config.json.TEMPLATE file—no additional configuration is required.
mv compose/tenet_engine/data/config.json.TEMPLATE compose/tenet_engine/data/config.json- Execute the engine
cd compose/ docker-compose up --build
This command will start PostgreSQL, Ollama, MongoDB and the Engine in the background. Please note that the first time you start Ollama, it will download the mistral model, which may take some time.
Please be sure to run the next steps only when the download of the mistral model is concluded (you should see the message tenet-ollama | 🟢 Done!)
- Run the examples
- Using another terminal, navigate again to the compose folder execute the test:
cd compose/ docker-compose exec -it engine python -m unittest discover -s test -p 'TestTenet.py'
- Execute the engine on a custom class. An example of the code can be seen in TestTenet. We assume that the previous steps have been executed. For simplicity we simply duplicate TestTenet.
Using this approach, custom data (table and selected evidence) can be introduced in the NewTest class and the workflow can be executed. For example, the NewTest.py can be edited to change the input data, and the input evidence. Essentially, the input for the classes is as follows:
cp ../engine/test/TestTenet.py ./TestNew.py docker cp ./TestNew.py tenet-engine:/usr/src/app/test/TestNew.py docker-compose exec -it engine python -m unittest discover -s test -p 'TestNew.py'
- A relational table
- The evidence (a set of cells selected by the user)
To ease the execution we use Docker. We also assume that Java (at least 21) is available on the machine.
-
Execute the engine with the previous commands:
cd compose/ docker-compose up --build -d -
Execute the backend in a new terminal using Gradle Wrapper. Go to the backend folder:
cd backend/ ./gradlew quarkusDev -
Execute the frontend in a new terminal. Go to the frontend folder:
cd frontend/ npm install ng serve -
Open the application at http://localhost:4200/. The current username is admin and password tenet! you could change it by connecting to the Mongo DB instance deployed with docker.
The configuration can be done through the config.json file. It consists of three main sections:
NEGATIVE_TABLE_GENERATIONcontains the different strategies to use to generate negative evidence through an error injection process.
addRows(removeRows) ='True'or'False'if new rows should be added (rows to be removed) to generate the negative table.rowsToAdd(rowsToRemove) = the number of new rows to add (remove).strategy="ActiveDomain"or"LMGenerator". With "ActiveDomain" values for new rows are extracted from the Active Domain, instead by using "LMGenerator" it uses a PLM to generate the values.
SENTENCE_GENERATIONcontains the allowed semantic-queries to use and that could be discovered through the searching process, and also the comparison operator to use. Available values foroperationsare: "lookup", "comparison", "filter", "min", "max", "count", "sum", "avg", "grouping", "ranked", "percentage", "combined". While values forcomparisonsare "<", ">", "=".- Text generation Language Model configuration
TENET_CONFIG.
api_keyshould contains your ChatGPT API key or your TogetherAI API key-languageModelspecifies the LM to use to generate the sentences. Values are:"ChatGPT","MistralOllama"or"MistralTogetherAi". In the case of "MistralOllama" the api_key is not required but the model should be executed by using Ollama.addressallows to set up the address of the Ollama server, the default configuration contains the default address for Ollama through Docker.
To execute the experiments please refer to the following page: Running The Pipeline.
@article{TenetSigmod,
author = {Jean-Flavien, Bussotti and Enzo, Veltri and Donatello, Santoro and Paolo, Papotti},
title = {{Generation of Training Examples for Tabular Natural Language Inference}},
publisher = {Association for Computing Machinery},
journal = {Proc. ACM Manag. Data},
year = {2023},
doi = {10.1145/3626730},
}