Design Doc: Asynchronous Rewriting Framework
Joshua Marantz, April 2011
When mod_pagespeed was released in November 2010, resource rewriting, particularly image compression, occurred in the line of user-facing HTML requests. Since it had an asynchronous (threaded) HTTP fetching mechanism, this would typically mean that the first time an HTML page was viewed, it was rendered quickly but without any resource optimization, spawning parallel HTTP fetches for all resources. Once these resources were fetched and cached, the next HTML request would be extremely slow: all of the images would be recompressed or resized as the HTML was streamed through the system. The last byte of HTML would not be delivered until the images were all optimized.
Spec on how this worked originally: https://github.com/pagespeed/mod_pagespeed/wiki/Rewrite-Result-Metadata-Caching
This was a known problem at the time of launch, but it didn’t prevent the module from growing in popularity. However we knew we needed to solve this second-request slowdown. We were also wooing CDNs to try to adopt mod_pagespeed technology. Discussions with all these teams helped us understand better how we needed to improve mod_pagespeed’s architecture to scale to CDNs and to work well as a proxy. This process helped clarify two fundamental shortcomings of mod_pagespeed’s current architecture at the time:
-
Avoid punishing the second client to request an image-rich HTML page with high latency
-
Efficiently work with distributed caches with hard-to-predict latencies.
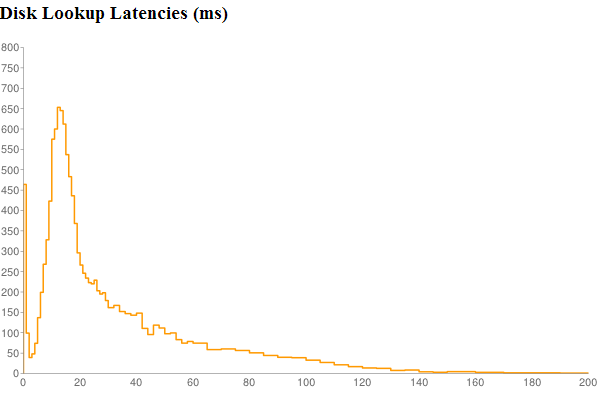
The implication of slow cache lookups is that a rich HTML page with (say) 200 resources will suffer unacceptable latency if a 20ms cache lookup must be done for each resource in series. A batching or asynchronous architecture must be employed to avoid multiplying these latencies.
To resolve these issues, new infrastructure was needed, as well as changes to every existing and in-progress filter (e.g. image optimization, combining CSS & JS, inlining, spriting). Thus the new system and old must co-exist while the new one is put in place and extensively tested for functionality, load, and performance.
-
April-June 2011: jmarantz started exploring an architecture for rewriting resources in the background with threads
-
July - November 2011: mod_pagespeed team migrates the resource-rewriting filters to the asynchronous framework
-
December 2011 - Spring 2012: the old mechanism of blocking cache lookups & resource optimization was ripped out to simplify the system
Maksim Orlovich ported the most complex filter: css_filter.cc to the async system and made the async rewriting system robust enough for successful nested rewrites (rewritten CSS files containing rewritten images). Along the way he drew an FSM Diagram showing the system behavior, and later added a great description in the header of rewrite_context.h explaining how to write a filter using the async framework.
Many others have extended and improved this system. Nikhil Madan implemented in-place resource optimization, which allows rewriting resources without changing URLs. Josh Karlin implemented blocking rewrites which, together with his preserve-URLs mode, formed the basis for V1 of the Chrome Data Compression Proxy.
The operational premise is that most resources are cacheable but only 6% of HTML is cacheable, so the initial design effort focused on uncacheable HTML. Additionally, HTML is streamed from server to client: well-designed sites with databases will flush out an initial rendering of the page very quickly before blocking on a back-end lookup. PSOL operates as a filter in this path but should not add any new buffering, delaying the initial page rendering.
When a resource (image, css, JavaScript) is referenced by an HTML tag, a PSOL filter (rewrite_filter.h) initiates a background rewrite state machine for it by instantiating a RewriteContext (rewrite_context.h) and attaching one more ResourceSlots (resource_slot.h). A filter that combines multiple resources together, such as combine_css (css_combine_filter.h) or sprite_images (image_combine_filter.h), will have multiple slots for a single context.
The strategy is to minimize added latency for a client talking to a PSOL engine with a warm server-side cache. Even though the HTML is not cached, PSOL remembers the optimizations of each resource in context. Two distinct logical caches are used: a metadata cache and an http cache. The metadata cache maps the original resource url(s) and any important contextual information into optimized URLs.
For details on the caching structure, please see my blog: http://modpagespeed.jmarantz.com/.
The dynamic we are going for is that when parsing HTML, in each flush window (the html bytes passed through PSOL between each network FLUSH event), we may encounter dozens or hundreds of URLs. Once we know the optimized form of each URL, we can look them all up in parallel in the (potentially) distributed caches. We will need to block the flushing of rewritten HTML until these cache lookups return, so that we may discover the optimized URL form, as described in https://github.com/pagespeed/mod_pagespeed/wiki/DesignDoc:-Resource-Naming, and rewrite the HTML tags to reference them.
The simplest flow involves single-resource rewrites. For example, replacing an image URL with an optimized version of it, sized to context, potentially transcoded to a better encoding, such as webp, given the current user-agent, and signed with the content-hash to allow it to be cached for a year.
In this flow, when the rewrite_images filter (image_rewrite_filter.h) encounters an <img> tag, it forms a cache key based on the input URL(s), any width and height specified in the HTML or inline CSS, whether the user-agent supports webp, and a hash of the overall configuration of the rewriters. The metadata cache lookup returns (for a warm cache) a protobuf identifying the full URL of the optimized result, and expiration date information based on the origin image so we know when we must re-fetch and potentially re-optimize it. Given a cache miss, the image must be asynchronously fetched from the origin, and optimized by an image_rewrite_filter.cc method supplied by the rewrite_images filter. Given a stale cache, the async rewriting infrastructure will re-fetch the image, detect whether it has changed by comparing md5 sums against a value in the protobuf, and re-optimize the image only if necessary.
It should be noted that the rewriting state machines is heavily system-tested in a cc_test framework using mock time (rewrite_context_test.cc), in addition to system-testing using real servers via wget automatic/system_test.sh.
A more complex flow involves nested resources. CSS files contain references to images. The rewritten CSS URL is itself signed with the md5-sum of its content, which is dependent on the md5-sum of all the embedded images. Thus the completion of a CSS rewrite requires completion of the rewriting of each subresources. This introduces a new phase into the rewriting state machine: Harvest. This is a method supplied by filters that need to manage nested resources, such as rewrite_css (css_filter.cc).
Another layer of complexity is added for combiners -- filters that take multiple HTML tags referencing URLs and replace them with a single tag. Thus filters such as combine_css and combine_javascript have Partition methods (see css_combine_filter.cc for an example), which are called by the framework to determine which resources should be combined together. For example, CSS files with matching media tags can theoretically be combined together, even if they are not adjacent in order in the HTML. Partition is called by the framework on a cold metadata cache lookup, after all the resources have been fetched and stored in memory.
In this fashion, people writing filters do not need to be intimately familiar with the rewriting state machine or threading model. They just need to implement one or more methods, depending on whether they are managing nested resources or combining multiple resources together.
This is a simple protobuf containing various optional fields that describe the context in which a resource is optimized. Some of these fields may be serialized into rewritten URLs, such as the width and height. Others might result in cache-key
A ResourceSlot contains a reference to a some kind of optimizable resource. HtmlResourceSlots are used for resources specified as HTML attributes. CssResourceSlots are for images referenced in CSS files. FetchResourceSlots are used for reconstructing optimized resources when they are fetched by browsers. Usually such reconstruction is not necessary because when a resource is optimized from the HTML flow, its optimized form is written to the HTTP Cache so that it can be quickly served to clients. However if the cache is flushed, or the resource fetch is handled by a different data center from the HTML, it might be necessary to reconstruct it on demand, so in that situation a FetchResourceSlot is used.
This structure provides the context for advancing the asynchronous rewriting state machine. It is a base class with several pure virtual methods. Relatively simple rewriters can avoid implementing all the methods (e.g. Partition and Harvest) by deriving instead from a subclass, SingleRewriteContext (single_rewrite_context.h), which provides degenerate implementations of those.
The RewriteContext mostly operates out of a single thread, the Rewrite thread. Callbacks for asynchronous fetches and cache lookups must queue up closures to run in the rewrite thread in order to safely call back into the RewriteContext. Resource optimization, however, runs in a separate thread called the SlowRewriteThread or LowPriorityRewriteThread (two names for the same concept). This avoids having simple cache lookups (particularly cache-hits) blocked behind compute-intensive image optimizations.
As indicated above, the rewriting system works primarily on two threads: the RewriteThread and the SlowRewriteThread. However, we expect that much of the time these threads will be idle. Thus there is a shared pool of physical threads (QueuedWorkerPool) and each http request being serviced by PSOL will generally have access to one of each.