This repo takes the initial step towards leveraging text learning for online action detection without explicit human supervision.
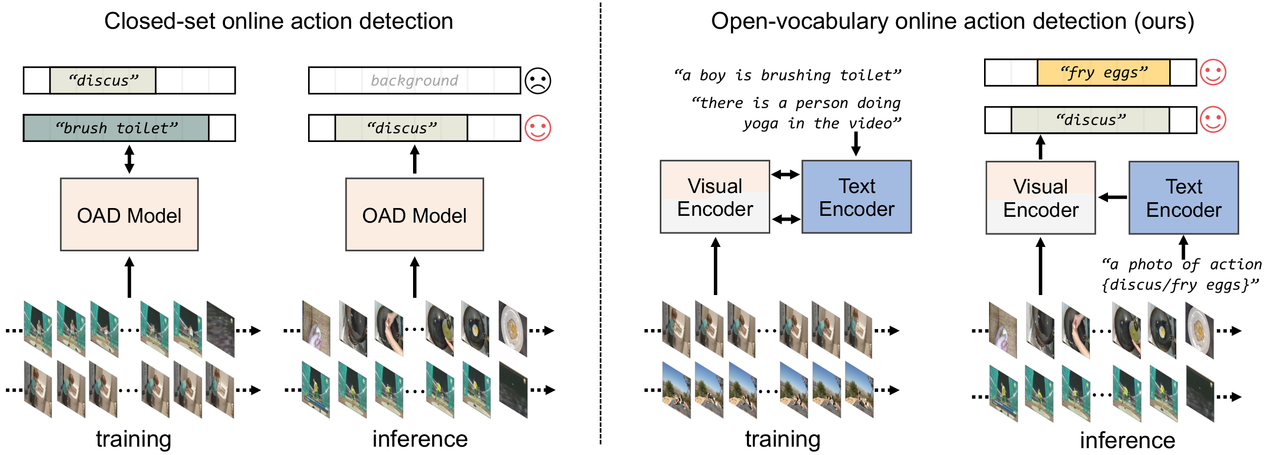
Video understanding relies on accurate action detection for temporal analysis. However, existing mainstream methods have limitations in real-world applications due to their offline and closed-set evaluation approaches, as well as their dependence on manual annotations. To address these challenges and enable real-time action understanding in open-world scenarios, we propose OV-OAD, a zero-shot online action detector that leverages vision-language models and learns solely from text supervision. By introducing an object-centered decoder unit into a Transformer-based model, we aggregate frames with similar semantics using video-text correspondence. Extensive experiments on four action detection benchmarks demonstrate that OV-OAD outperforms other advanced zero-shot methods. Specifically, it achieves 37.5% mean average precision on THUMOS’14 and 73.8% calibrated average precision on TVSeries. This research establishes a robust baseline for zero-shot transfer in online action detection, enabling scalable solutions for open-world temporal understanding. The code will be available for download at https://github.com/OpenGVLab/OV-OAD.
- [2024/10/04] OV-OAD Code release.
- [2024/12/11] OV-OAD Open source data processing.
- [2024/12/13] 🔥 OV-OAD Open source training and testing code.
git clone https://github.com/OV-OAD
cd OV-OADconda create -n ovoad python=3.7 -y
conda activate ovoadPlease checkout the following page for more inference & evaluation details.
bash extract_features/run_save_imgs.sh
bash extract_features/run_extc_feat.shpython -u -m main_pretrain \
--cfg configs/enc32_anet_3layers_lsxattn.yml \python -u -m main_pretrain \
--cfg configs/test_oad.yml \
--resume xxx/ovoador_bs256x1/best_map.pth \If you find it useful for your research and applications, please cite related papers/blogs using this BibTeX:
@article{zhao2024ovoad,
title={Does Video-Text Pretraining Help Open-Vocabulary Online Action Detection?},
author={Qingsong Zhao, Yi Wang, Jilan Xu, Yinan He, Zifan Song, Limin Wang, Yu Qiao, Cairong Zhao},
journal={Advances in neural information processing systems},
year={2024}
}