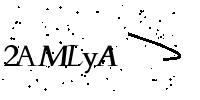Basic version of ddddocr (OCR only).
DdddOcr,其由 本作者 与 kerlomz 共同合作完成,通过大批量生成随机数据后进行深度网络训练,本身并非针对任何一家验证码厂商而制作,本库使用效果完全靠玄学,可能可以识别,可能不能识别。
DdddOcr、最简依赖的理念,尽量减少用户的配置和使用成本,希望给每一位测试者带来舒适的体验
项目地址: 点我传送
一个容易使用的通用验证码识别python库
探索本项目的文档 »
·
报告Bug
·
提出新特性
| 系统 | CPU | 备注 |
|---|---|---|
| Windows 64 位 | √ | 部分版本 windows 需要安装vc 运行库 |
| Windows 32 位 | × | |
| Linux 64 / ARM64 | √ | |
| Linux 32 | × | |
| Macos X64 | √ | M1/M2/M3...芯片参考#67 |
从 pypi 安装
pip install ddddocr-basic本项目基于dddd_trainer 训练所得,训练底层框架位 pytorch,ddddocr 推理底层抵赖于onnxruntime,故本项目的最大兼容性与 python 版本支持主要取决于onnxruntime。
主要用于识别单行文字,即文字部分占据图片的主体部分,例如常见的英数验证码等,本项目可以对中文、英文(随机大小写 or 通过设置结果范围圈定大小写)、数字以及部分特殊字符。
# example.py
import ddddocr
ocr = ddddocr.DdddOcr()
image = open("example.jpg", "rb").read()
result = ocr.classification(image)
print(result)注意
之前发现很多人喜欢在每次 ocr 识别的时候都重新初始化 ddddocr,即每次都执行ocr = ddddocr.DdddOcr(),这是错误的,通常来说只需要初始化一次即可,因为每次初始化和初始化后的第一次识别速度都非常慢
参考例图
包括且不限于以下图片