Hypernetworks in Pytorch made easy


HyperLight is a Pytorch library designed to make implementing hypernetwork models easy and painless. What sets HyperLight apart from other hypernetwork implementations:
- Bring your own architecture – Reuse your existing model code.
- Principled Parametrizations and Initializations – Default networks can have unstable training dynamics, HyperLight has good defaults that lead to improved training [1].
- Work with pretrained models – Use pretrained weights as part of the hypernetwork initialization.
- Seamless Composability – It's hypernets all the way down! Hypernetize hypernet models without issue.
- Pytorch-nic API design – Parameters are treated as an attribute of the layer, preventing the need for rewriting PyTorch modules.
[1] Magnitude Invariant Parametrizations Improve Hypernetwork Learning
To install the stable version of HyperLight via pip:
pip install hyperlightOr for the latest version:
pip install git+https://github.com/JJGO/hyperlight.gitFor the manual install:
# clone it
git clone https://github.com/JJGO/hyperlight
# install dependencies
python -m pip install -r ./hyperlight/requirements.txt # only dependency is PyTorch
# add this to your .bashrc/.zshrc
export PYTHONPATH="$PYTHONPATH:/path/to/hyperlight)"The main advantage of HyperLight is that it allows to easily reuse existing networks without having to redo the model code.
For example, here's a Bayesian Neural Hypernetwork for a simple convnet architecture. We start bt declaring the main architecture without having to worry about hypernetworks
import torch
from torch import nn, Tensor
import torch.nn.functional as F
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 16, 5, 1)
self.conv2 = nn.Conv2d(16, 32, 3, 1)
self.conv3 = nn.Conv2d(32, 64, 3, 1)
self.conv4 = nn.Conv2d(64, 64, 3, 1)
self.fc = nn.Linear(64, 10)
def forward(self, x):
x = F.leaky_relu(self.conv1(x))
x = F.leaky_relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = F.leaky_relu(self.conv3(x))
x = F.max_pool2d(x, 2, 2)
x = F.leaky_relu(self.conv4(x))
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.reshape(-1, self.fc.in_features)
x = self.fc(x)
return xNow, we use HyperLight to hypernetize the convolutional layers. Hypernetizing a module involes 3 steps:
- Instantiating a regular version of the
nn.Module - Using
hl.hypernetizeto swapnn.Parameterwithhl.ExternalParameterobjects - Creating a
hl.HyperNetnetwork to predict the weights of the primary network.
import hyperlight as hl
# 1. First, instantiate the main network and
mainnet = ConvNet()
# 2. hypernetize: Replace nn.Parameter objects with ExternalParameters
module_to_hypernetize = [
mainnet.conv1,
mainnet.conv2,
mainnet.conv3,
mainnet.conv4
]
mainnet = hl.hypernetize(mainnet, modules=module_to_hypernetize)
# 3. Create a hypernet to preduct the weights
# Get the spec of the weights we need to predict
parameter_shapes = mainnet.external_shapes()
# We can predict these shapes any way we want,
# but hyperlight provides hypernetwork models
hyperparam_shape = {'h': (10,)} # 10-dim input
hypernet = hl.HyperNet(
input_shapes=hyperparam_shape,
output_shapes=parameter_shapes,
hidden_sizes=[16,64,128],
)We are now ready to use our model, let's define some simple inputs and make a prediction
h = torch.zeros((10,))
x = torch.zeros((1,1,28,28))
# Now, instead of model(input) we first predict the main network weights
parameters = hypernet(h=h)
# and then use the main network
with mainnet.using_externals(parameters):
# Within this with block, the weights are accessible
prediction = mainnet(x)
# After this point, weights are removed, and it will trigger an error
# >>> prediction = mainnet(x)
# AttributeError: Uninitialized External Parameter, please set the value firstWe can also wrap this into nn.Module to pair-up the hypernet with the main network and have a more selfcontained API
class HyperConvNet(nn.Module):
def __init__(self):
super().__init__()
mainnet = ConvNet()
# HyperLight provides convenience funtions to select relevant modules
modules = hl.find_modules_of_type(mainnet, [nn.Conv2d])
self.mainnet = hl.hypernetize(mainnet, modules=modules)
self.hypernet = hl.HyperNet(
input_shapes={'h': (10,)},
output_shapes=parameter_shapes,
hidden_sizes=[16,64,128],
)
def forward(self, main_input, hyper_input):
parameters = self.hypernet(h=hyper_input)
with self.mainnet.using_externals(parameters):
prediction = self.mainnet(main_input)
return prediction
model = HyperConvNet()
model(x, h).shapeHyperLight introduces a few new concepts:
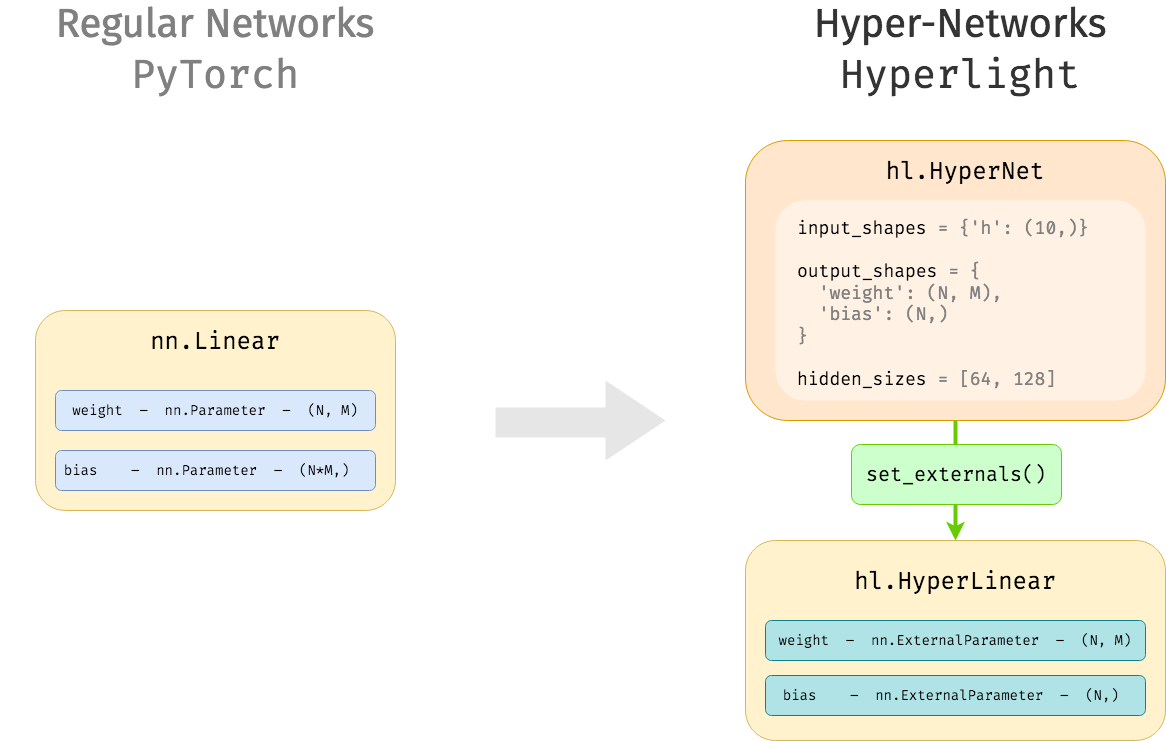
HyperModule– A specializednn.Moduleobject that can hold both regular parameters andExternalParametersto be predicted by an external hypernetwork.ExternalParameter–nn.Parameterreplacement that only stores the required shape of the externalized parameter. Parameter data can be set and reset with the hypernetwork predictions.HyperNetwork–nn.Modulethat predicts a main network parameters for a given input.
Here is an example of how we define a hypernetized Linear layer. We need to make sure to
define the ExternalParameter properties with their correct shapes.
import torch.nn.functional as F
import hyperlight as hl
class HyperLinear(hl.HyperModule):
"""Implementation of a nn.Linear layer but with external parameters
that will be predicted by an external hypernetwork"""
in_features: int
out_features: int
def __init__(self, in_features: int, out_features: int, bias: bool = True) -> None:
super().__init__()
assert isinstance(in_features, int) and isinstance(out_features, int)
self.in_features = in_features
self.out_features = out_features
self.weight = hl.ExternalParameter(shape=(out_features, in_features))
if bias:
self.bias = hl.ExternalParameter(shape=(out_features,))
else:
self.bias = None
def forward(self, input: Tensor) -> Tensor:
return F.linear(input, self.weight, self.bias)Once defined, we can make use of this module as follows:
layer = HyperLinear(in_features=8, out_features=16)
print(layer.external_shapes())
# >>> {'weight': (16, 8), 'bias': (16,)}
x = torch.zeros(1, 8)
# We need to set the weights before using the layer otherwise we will get an error
# Initialize the external weights
layer.set_externals(weight=torch.rand(size=(16,8)), bias=torch.zeros((16,)))
print(layer(x).shape)
# >>> torch.Size([1, 16])
# Once we are done, we reset the external parameter values
layer.reset_externals()Alternatively, we can use the using_externals contextmanager that will set and reset
the parameters accordingly:
params = {
'weight': torch.rand(size=(16,8)),
'bias': torch.zeros((16,))
}
with layer.using_externals(params):
y = layer(x)HyperLight provides implementations of most parametric layers such as hl.HyperLinear or hl.HyperConv2d. We can use this to directly define our primary architecture. Let's revise our earlier example with ConvNet
from torch import nn, Tensor
import torch.nn.functional as F
# We change nn.Module -> hl.HyperModule
class PrimaryConvNet(hl.HyperModule):
def __init__(self):
super().__init__()
# we hypernetize the first two conv layers
self.conv1 = hl.HyperConv2d(1, 16, 5, 1)
self.conv2 = hl.HyperConv2d(16, 32, 3, 1)
self.conv3 = nn.Conv2d(32, 64, 3, 1)
self.conv4 = nn.Conv2d(64, 64, 3, 1)
# we do not hypernetize the last layer
self.fc = nn.Linear(64, 10)
def forward(self, x):
x = F.leaky_relu(self.conv1(x))
x = F.leaky_relu(self.conv2(x))
x = F.max_pool2d(x, 2, 2)
x = F.leaky_relu(self.conv3(x))
x = F.max_pool2d(x, 2, 2)
x = F.leaky_relu(self.conv4(x))
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.reshape(-1, self.fc.in_features)
x = self.fc(x)
return xprimary = PrimaryConvNet()
print(primary.external_shapes())
# >>> {'conv1.bias': (16,),
# 'conv1.weight': (16, 1, 5, 5),
# 'conv2.bias': (32,),
# 'conv2.weight': (32, 16, 3, 3)}More practically, HyperLight supports dynamic HyperModule creation using the hypernetize helper.
We need to specify which parameters we want to remove from the module and convert to
ExternalParameter objects:
layer = nn.Linear(in_features=8, out_features=16)
layer = hl.hypernetize(layer, parameters=[layer.weight, layer.bias])
print(layer)
# HypernetizedLinear()
print(layer.external_shapes())
# {'weight': (16, 8), 'bias': (16,)}hypernetize is recursive, and supports entire modules being specified:
model = ConvNet()
# This is equivalent to our earlier static definition
model = hl.hypernetize(model, modules=[model.conv1, model.conv2])
print(model.external_shapes())
# {'conv1.bias': (16),
# 'conv1.weight': (16, 1, 5, 5),
# 'conv2.bias': (32),
# 'conv2.weight': (32, 16, 3, 3)}In addition, HyperLight provides several routines to recursively search for parameters and modules to feed into hypernetize:
find_modules_of_type(model, module_types)– Find modules of a certain type, e.g.nn.Linearornn.Conv2dfind_modules_from_patterns(model, globs=None, regex=None)– Find modules that match specific patterns using globs, e.g.*.conv; or regexes, e.g.layer[1-3].*convfind_parameters_from_patterns(model, globs=None, regex=None)– Find parameters that match specific patterns.
model = ConvNet()
# Find all convolutions
hl.find_modules_of_type(model, [nn.Conv2d])
# {'conv1': Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1)),
# 'conv2': Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1)),
# 'conv3': Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1)),
# 'conv4': Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1))}hl.find_modules_from_patterns(model, regex=['conv[1-3]'])
# {'conv3': Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1)),
# 'conv1': Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1)),
# 'conv2': Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1))}hl.find_parameters_from_patterns(model, globs=['conv*.weight']).keys()
# dict_keys(['conv3.weight', 'conv2.weight', 'conv1.weight', 'conv4.weight'])HyperLight goes beyond hypernetworks and helps implement other Deep Learning techniques related to hypernetworks.
As an example, the following code implements FiLM. Instead of having to modify
our entire forward pass to keep track of the
# FiLM module
class FiLM(hl.HyperModule):
def __init__(
self, n_features: int, dims: int = 2,
):
super().__init__()
self.n_features = n_features
self.dims = dims
extra_dims = [1 for _ in range(dims)]
self.gamma = hl.ExternalParameter((n_features, *extra_dims))
self.beta = hl.ExternalParameter((n_features, *extra_dims))
def forward(self, x):
return self.gamma * x + self.beta
# Primary Network
class FiLM_ConvNet(hl.HyperModule):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 16, 5, 1)
self.film1 = FiLM(16)
self.conv2 = nn.Conv2d(16, 32, 3, 1)
self.film2 = FiLM(32)
self.conv3 = nn.Conv2d(32, 64, 3, 1)
self.film3 = FiLM(64)
self.conv4 = nn.Conv2d(64, 64, 3, 1)
self.film4 = FiLM(64)
self.fc = nn.Linear(64, 10)
def forward(self, x):
x = F.leaky_relu(self.conv1(x))
x = self.film1(x)
x = F.leaky_relu(self.conv2(x))
x = self.film2(x)
x = F.max_pool2d(x, 2, 2)
x = F.leaky_relu(self.conv3(x))
x = self.film3(x)
x = F.max_pool2d(x, 2, 2)
x = F.leaky_relu(self.conv4(x))
x = self.film4(x)
x = F.adaptive_avg_pool2d(x, (1, 1))
x = x.reshape(-1, self.fc.in_features)
x = self.fc(x)
return x# Wrapper
class FiLM_Model(nn.Module):
def __init__(self, embedding_size):
super().__init__()
self.main = FiLM_ConvNet()
self.cond = hl.HyperNet(
input_shapes={'film_input': (embedding_size,)},
output_shapes=self.main.external_shapes(),
hidden_sizes=[],
)
def forward(self, x, conditioning):
params = self.cond(film_input=conditioning)
with self.main.using_externals(params):
return self.main(x)
model = FiLM_Model(7)
x = torch.randn((1,1,28,28))
cond = torch.rand(1,7)
print(model(x, cond).shape)