Getting Started
This post will discuss how you can get started with the Streams Healthcare Analytics Platform.
A traditional SPL toolkit contains a set of operators, functions or types for clients to reuse. To use a toolkit, an application developer needs to write a new SPL application that invokes the operators or functions from the toolkit. This approach provides flexibility, but it requires SPL knowledge. Using the Graphical Editor in Streams Studio makes writing SPL application much easier, but it still requires some work. So, we started thinking about how we can simplify the process.
As discussed in our previous post, the Streams Healthcare Analytics Platform is designed using the Microservice architecture. A microservice is a small Streams application that fulfills a specific task in a bigger application. In this architecture, a microservice is the smallest building block of an application. An application is a composition of one or more microservices.
This diagram demonstrates the microservice concept:
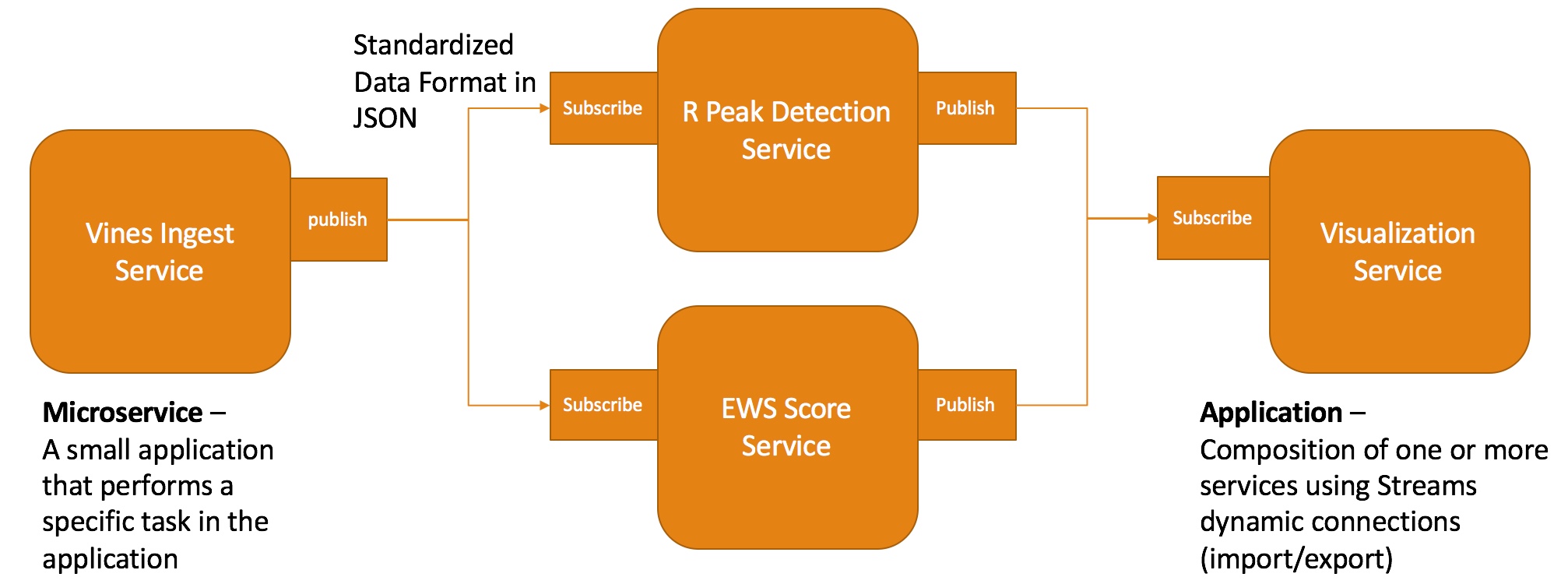
In this application we have an application that ingests data from the Vines microservice. The microservice publishes data in the standardized Observation format in JSON. Downstream services subscribe to the data from the Vines Ingest service and perform the required analysis. The analytics results are then published as new data streams. The Visualization service subscribes to these new data streams and displays the results.
Since the building blocks are already written as small applications, to reuse a microservice from from the platform, all one has to do is to configure and build the service and have it submitted to a Streams instance. There is no need to write a new Streams application. No need to code. It’s as simple as clone, build and run! In the following sections, I am going to go through the steps on how to get a copy of the platform, build the microservices and then show you how to construct an application using the microservices.
There are two ways to get the Streams Healthcare Analytics Platform. You can download a snapshot of the v0.1 release here:
The platform is being developed and therefore we are constantly adding new features to the platform. To get the latest features from the Streams Healthcare Analytics Platform, you can get the latest code from the develop branch of the project. To do that, clone the repository as follows:
git clone https://github.com/IBMStreams/streamsx.health.git
Once you have downloaded a copy of the platform to your workstation, you will find a repository with multiple directories. In this section, we will describe how this repository is organized.
The Streams Healthcare Analytics platform Github repository structure is designed to accommodate the microservice architecture. The top directories organize the microservices by function:
- ingest – contains services for ingesting data into a Streams application
- simulate – contains services that simulate patient data
- prepare – contains services that prepare the data for analysis
- analyze – contains services that analyze the incoming data
- debug – contains services that help debug your application
- samples – contains samples that is built using the microservices from the platform
In each of the top directories, each of the microservices is stored in its own directory. For example, if you look into the ingest directory, you will find the following:
- common – contains the foundational toolkit and common components healthcare ingest services
- hl7 – contains services for ingesting HL7 data
- physionet – contains services to ingest data from Physionet databases
- vines – contains services for ingesting data from ViNES medication device integration solution from True Process
Before you can run the microservices, you need to build them. The repository is organized such that you can build the entire repository from its root directory, or you can build each of the major component or services independently. To build the entire repository:
-
Make sure the following environment variables are set:
STREAMS_INSTALL= [Streams_Install_Path] e.g. /opt/ibm/InfoSphere_Streams/4.2.1.1 STREAMS_SPLPATH= [Streams_Install_Path]/toolkits
-
To build:
cd streamsx.health ./gradlew build
This will build all of the services and samples in the repository. It will take a few minutes to complete.
You may want to build just one of the services:
-
Navigate to the service directory. For example, if you would like to build the
simulateservice:cd streamsx.health/simulate/com.ibm.streamsx.health.simulate.beacon
In the service directory, you will find a README.md file that describes the service, how to build and execute it.
-
To build the simulate service, execute the build script from the service directory.
../../gradlew build
Before running a microservice, make sure the following environment variables are set:
STREAMS_DOMAIN_ID=[Stream Domain ID]
STREAMS_INSTANCE_ID=[Streams Instance ID]
To run a microservice:
-
Navigate to the service directory. For example, if you would like to run the
simulateservice:cd streamsx.health/simulate/com.ibm.streamsx.health.simulate.beacon -
Review the service’s README.md to see how it can be customized and launched.
-
Many of the services can be customized via a properties file. For example, in the
simulateservice, you can control the number of patients to simulate by specifying thenumPatientsproperty in the beacon.properties file. -
To execute the service, run the
executetarget from the gradle script:../../gradlew execute
The execute target of the gradle script will run the application and submit it to the streams instance as specified in the STREAMS_INSTANCE_ID environment variable.
Most of the services follow the pattern of building and launching described above. There are a few exceptions, and we are working on standardizing this in process. To build and run a service, please refer to its README.md for details.
Now that we have the microservices running, it’s important to understand how we can work with the data produced by a microservice, or how we can feed data to a microservice for analysis. This is crucial for composing a larger application using the microservices.
A microservice is defined by the following API contract:
- Output
- Topic – A service has one or more data publication topics. Downstream services should subscribe to data from these topics.
- Output Schema – For each topic, the JSON schema of the data being published
- Input:
- Topic – A service has one or more input topics. This describes the topic that this service should subscribe to data from. This is generally customizable at submission time.
- Input Schema – For each topic, its expected input JSON schema.
This is documented in the README.md file for each service.
To connect two microservices, you will need to match the output of a microservice to the input of the downstream microservice. For example, the output definition of the simulate microservice is as follows:
- Publish Topic – ingest-beacon
- JSON Schema – JSON Schema in Health Platform’s Observation Type
To connect to the simulate service, a downstream microservice needs to subscribe to data from the ingest-beacon topic. It also needs to be able to decode the Observation data type encoded in JSON format. All of the services in the healthcare platform downstream from the ingest services are capable of handling the Observation data type. More information on the Ingest Service Framework is available on the project’s page.
All of the microservices have a README.md that describes the expected input and output of the service. Please refer to their README.md for details about data topics and formats.
Let’s walk through an example of composing an application using the Streams Healthcare Analytics Platform. Our application will do the following:
[Simulate Patient Data] -> [Calculate the Early Warning Score of the Patient] -> [Print the results to the console]
To compose this application, you need to make use of the following services:
- Simulate – simulate/com.ibm.streamsx.health.simulate.beacon
- Analyze – analyze/vitals_ews/com.ibm.streamsx.health.analyze.rules.vitals.spl
- Print – debug/print/com.ibm.streamsx.health.debug.print
The simulate service publishes data as ingest-beacon in Observation data format. The Early Warning Score service subscribes to the ingest-beacon by default and is set up to handle the Observation data format. Therefore, if you just launch the two services, data from the simulate service will be sent to the early warning score service, by default, without any modification. Here’s a script to launch these services:
cd simulate/com.ibm.streamsx.health.simulate.beacon
../../gradlew execute
cd analyze/vitals_ews/com.ibm.streamsx.health.analyze.rules.vitals.spl
../../../gradlew execute
Running this script will result in the following in the Instance Graph:
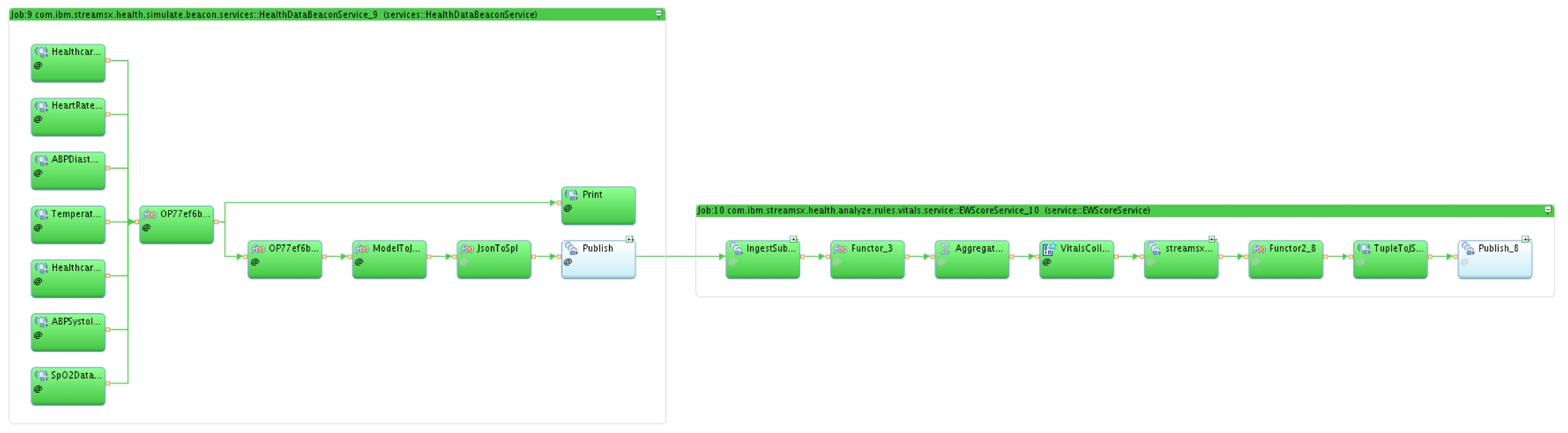
The application on the left is the simulate service. The application on the right is the Early Warning Score service.
To print the result of the early warning score service, we need to run the Print service. The Print service ingests data from the ingest-beacon topic by default, but the Early Warning Score service publishes its data using a topic name of analytics-ews. So, we need to modify Print service to subscribe to data from the Early Warning Score service.
cd debug/print/com.ibm.streamsx.health.debug.print
vi print.service.properties
Change the subscribeTopic property to analyltics-ews. Then, save the property file and launch the service by running the following command:
../../../gradlew execute
This will launch the print service and you should see the following in the Instance Graph. To see the output of the application, gather the PE Console Log from the Print service.
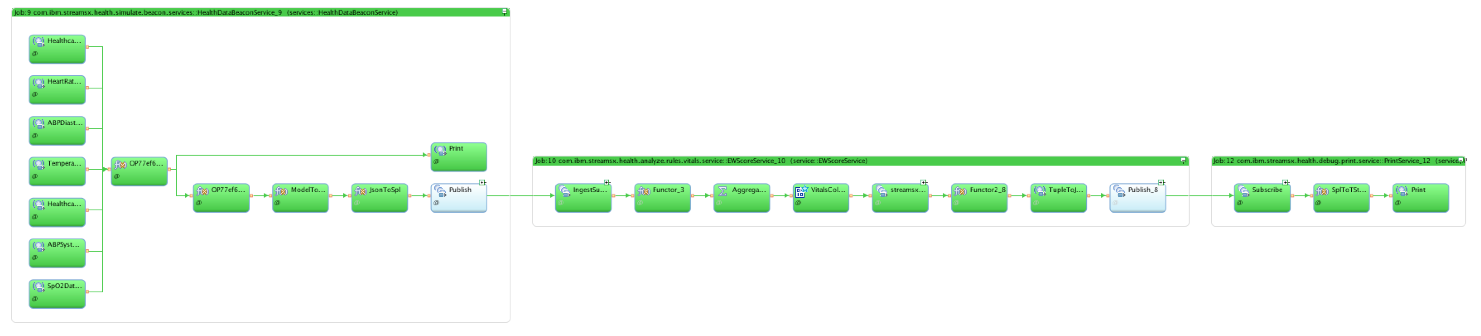
This example shows how you can easily compose an application by mixing and matching one or more microservices. You can see a more complex demonstration of this approach using the Patient Monitoring Demo.
In this post, I have described the steps to build and run the microservices of the Streams Healthcare Analytics Platform. I have also gone through the basic steps in composing an application using the services. In the next post, I will discuss the Ingest Service framework and how you can develop your own analytics using the Streams Healthcare Analytics platform.