OBJECT DETECTION USING MOBILENET:
Single Shot Detectors for object detection:

When it comes to deep learning-based object detection there are three primary object detection methods that you’ll likely encounter:
-
Faster R-CNNs (Girshick et al., 2015)
-
You Only Look Once (YOLO) (Redmon and Farhadi, 2015)
-
Single Shot Detectors (SSDs) (Liu et al., 2015)
Faster R-CNNs are likely the most “heard of” method for object detection using deep learning; however, the technique can be difficult to understand (especially for beginners in deep learning), hard to implement, and challenging to train.
Furthermore, even with the “faster” implementation R-CNNs (where the “R” stands for “Region Proposal”) the algorithm can be quite slow, on the order of 7 FPS.
If we are looking for pure speed then we tend to use YOLO as this algorithm is much faster, capable of processing 40-90 FPS on a Titan X GPU. The super fast variant of YOLO can even get up to 155 FPS.
The problem with YOLO is that it leaves much accuracy to be desired.
SSDs, originally developed by Google, are a balance between the two. The algorithm is more straightforward (and I would argue better explained in the original seminal paper) than Faster R-CNNs.
We can also enjoy a much faster FPS throughput than Girshick et al. at 22-46 FPS depending on which variant of the network we use. SSDs also tend to be more accurate than YOLO. To learn more about SSDs, please refer to Liu et al.
When building object detection networks we normally use an existing network architecture, such as VGG or ResNet, and then use it inside the object detection pipeline. The problem is that these network architectures can be very large in the order of 200-500MB.
Network architectures such as these are unsuitable for resource constrained devices due to their sheer size and resulting number of computations.
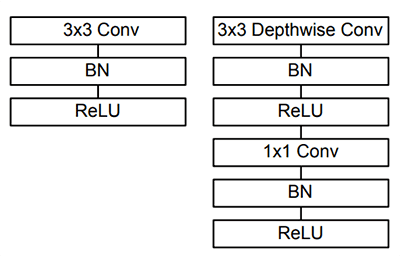
Instead, we can use MobileNets (Howard et al., 2017), another paper by Google researchers. We call these networks “MobileNets” because they are designed for resource constrained devices such as your smartphone. MobileNets differ from traditional CNNs through the usage of depthwise separable convolution (Figure 2 above).
The general idea behind depthwise separable convolution is to split convolution into two stages:
-
A 3×3 depthwise convolution.
-
Followed by a 1×1 pointwise convolution.
This allows us to actually reduce the number of parameters in our network.
The problem is that we sacrifice accuracy — MobileNets are normally not as accurate as their larger big brothers…
Combining MobileNets and Single Shot Detectors for fast, efficient deep-learning based object detection
If we combine both the MobileNet architecture and the Single Shot Detector (SSD) framework, we arrive at a fast, efficient deep learning-based method to object detection.
The model we’ll be using in this blog post is a Caffe version of the original TensorFlow implementation by Howard et al. and was trained by chuanqi305 (see GitHub).
The MobileNet SSD was first trained on the COCO dataset (Common Objects in Context) and was then fine-tuned on PASCAL VOC reaching 72.7% mAP (mean average precision).
We can therefore detect 20 objects in images (+1 for the background class), including airplanes, bicycles, birds, boats, bottles, buses, cars, cats, chairs, cows, dining tables, dogs, horses, motorbikes, people, potted plants, sheep, sofas, trains, and tv monitors.