ZhiJian (执简驭繁) 是一个基于PyTorch框架的模型复用工具包,为再次利用许多基座预训练模型以及已有任务上的已训练模型,充分提取它们蕴含的知识并激发目标任务上的学习,提供了全面且统一的复用方案。
近年来人工智能的蓬勃发展产出了许多开源预训练模型(Pre-Trained Models),例如PyTorch、TensorFlow和HuggingFace Transformers等平台上存储了大量模型资源。模型复用通过适配网络结构、定制学习方式以及优化推理策略来利用这些预训练模型,来进一步加速和强化目标任务上的学习,这将为机器学习社区源源不断地贡献价值。

为了全面而简洁地考虑各种模型复用策略,ZhiJian 将复用方法归类为三个主要模块:构建者,微调者,和融合者,它们分别与目标任务部署时模型准备阶段、学习阶段和推理阶段相对应。执简工具包提供的接口和方法包括:
构建者 模块 [点击以展开]构建者模块包含修改预训练模型以适应目标任务,引入具有任务特定结构的全新可学习参数,同时确定重用预训练模型的某些部分。
Linear Probing & Partial-k, How transferable are features in deep neural networks? In: NeurIPS'14. [Paper] [Code]





Scaling & Shifting, Scaling & Shifting Your Features: A New Baseline for Efficient Model Tuning. In: NeurIPS'22. [Paper] [Code]

AdaptFormer, AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition. In: NeurIPS'22. [Paper] [Code]

BitFit, BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models. In: ACL'22. [Paper] [Code]



微调者 模块 [点击以展开]微调者模块专注于在预训练模型知识的引导下训练目标模型,以加快优化过程,例如通过调整训练目标、优化器或正则化器等方式。
Knowledge Transfer, NeC4.5: neural ensemble based C4.5. In: IEEE Trans. Knowl. Data Eng. 2004. [Paper] [Code]

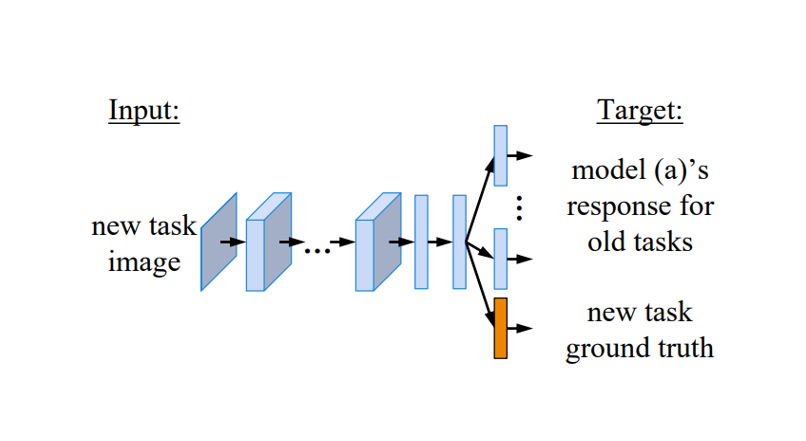
FSP, A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning. In: CVPR'17. [Paper] [Code]

NST, Like What You Like: Knowledge Distill via Neuron Selectivity Transfer. In: CVPR'17. [Paper] [Code]
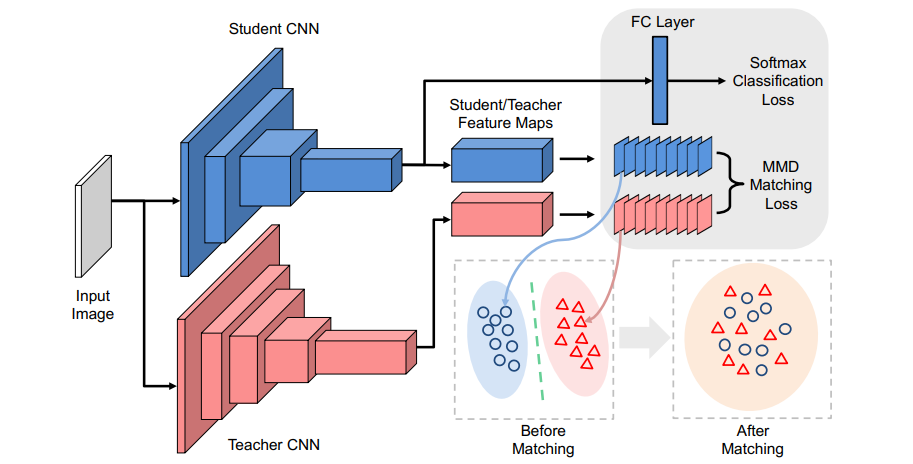





L2 penalty / L2-SP, Explicit Inductive Bias for Transfer Learning with Convolutional Networks. In: ICML'18. [Paper] [Code]

Spectral Norm, Spectral Normalization for Generative Adversarial Networks. In: ICLR'18. [Paper] [Code]

BSS, Catastrophic Forgetting Meets Negative Transfer: Batch Spectral Shrinkage for Safe Transfer Learning. In: NeurIPS'19. [Paper] [Code]

DELTA, DELTA: DEep Learning Transfer using Feature Map with Attention for Convolutional Networks. In: ICLR'19. [Paper] [Code]



融合者 模块 [点击以展开]融合者模块在推理阶段通过复用预训练特征,或融合来自适配后的预训练输出来获得更强的泛化能力。

SimpleShot, SimpleShot: Revisiting Nearest-Neighbor Classification for Few-Shot Learning. In: CVPR'19. [Paper] [Code]

Head2Toe, Head2Toe: Utilizing Intermediate Representations for Better Transfer Learning. In: ICML'22. [Paper] [Code]

VQT, Visual Query Tuning: Towards Effective Usage of Intermediate Representations for Parameter and Memory Efficient Transfer Learning. In: CVPR'23. [Paper] [Code]
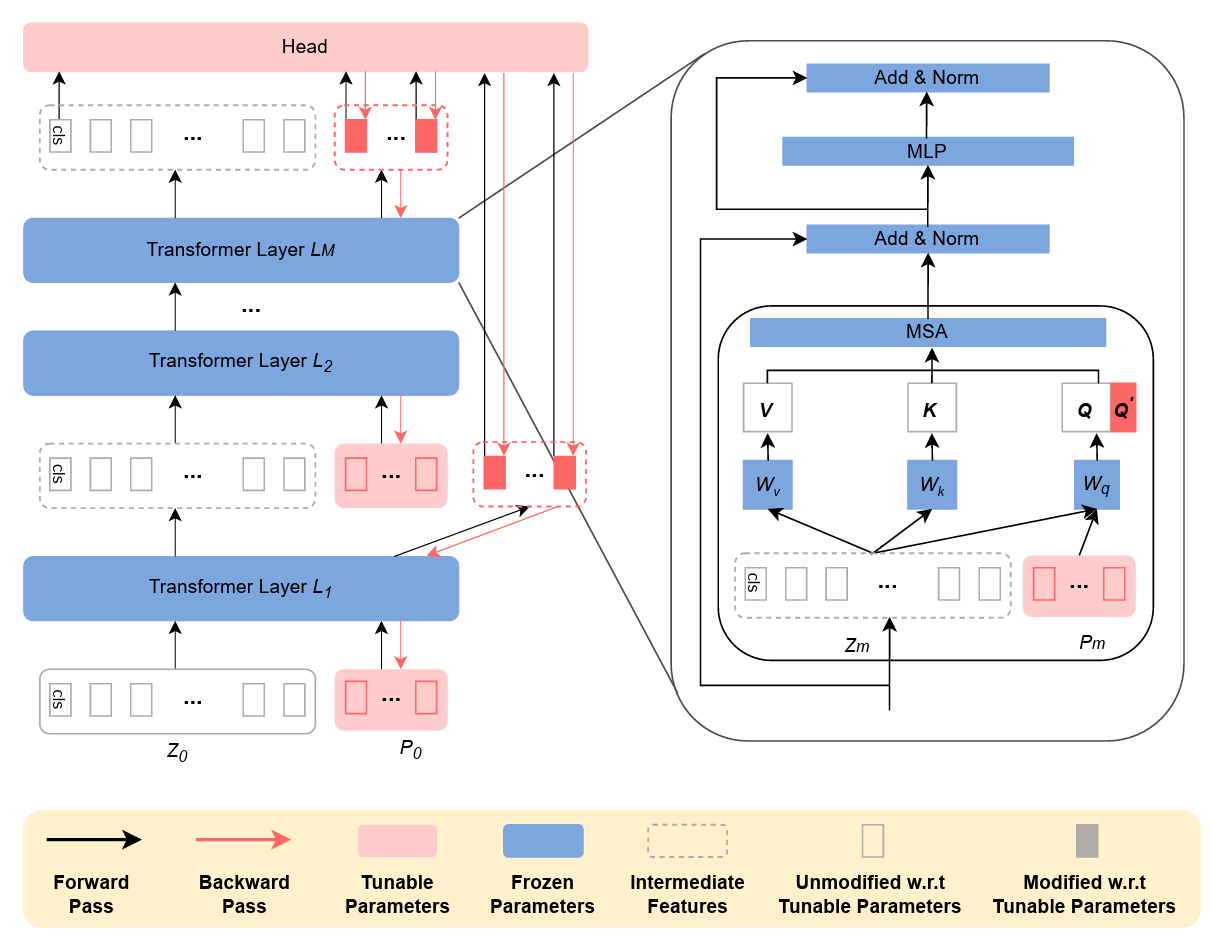

Model Soup Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In: ICML'22. [Paper] [Code]



REPAIR REPAIR: REnormalizing Permuted Activations for Interpolation Repair. In: ICLR'23. [Paper] [Code]



💡 ZhiJian 还包含如下特色:
- 支持复用许多开源预训练模型库, 包含:
- PyTorch Torchvision; OpenAI CLIP; 🤗Hugging Face PyTorch Image Models (timm), Transformers
- 其他流行的复用框架,例如,vit-pytorch (stars 14k).
- 大语言模型,包含 baichuan, LLaMA, and BLOOM.
- 极简上手与个性化定制:
- 在10分钟内极速开始
- 一步步地定制数据集和预训练模型
- 随心所欲地创造模型复用的新方法
- 在10分钟内极速开始
- 简洁的结构做得大事儿
“执简驭繁”的意思是用简洁高效的方法驾驭纷繁复杂的事物。“繁”表示现有预训练模型和复用方法种类多、差异大、部署难,所以取名"执简"的意思是通过该工具包,能轻松地驾驭模型复用方法,易上手、快复用、稳精度,最大限度地唤醒预训练模型的知识。
-
用 conda, venv, 或 virtualenv 部署 Python 3.7+ 的环境
-
使用 pip 来安装 ZhiJian:
$ pip install zhijian
- [Option] Install with the newest version through GitHub:
$ pip install git+https://github.com/ZhangYikaii/LAMDA-ZhiJian.git@main --upgrade
- [Option] Install with the newest version through GitHub:
-
打开 Python 控制台,输入
import zhijian print(zhijian.__version__)
如果没有错误出现,则成功安装了执简工具包
📚 相关教程和API文档请点击 ZhiJian.readthedocs.io

| Related Library | GitHub Stars | # of Alg.(1) | # of Model(1) | # of Dataset(1) | # of Fields(2) | LLM Supp. | Docs. | Last Update |
| PEFT |

|
6 | ~15 | ➖(3) | 1(a) | ✔️ | ✔️ |

|
| adapter-transformers |

|
10 | ~15 | ➖(3) | 1(a) | ❌ | ✔️ |

|
| LLaMA-Efficient-Tuning |

|
4 | 5 | ~20 | 1(a) | ✔️ | ❌ |

|
| Knowledge-Distillation-Zoo |

|
20 | 2 | 2 | 1(b) | ❌ | ❌ |

|
| Easy Few-Shot Learning |

|
10 | 3 | 2 | 1(b) | ❌ | ❌ |

|
| Model soups |

|
3 | 3 | 5 | 1(c) | ❌ | ❌ |

|
| Git Re-Basin |

|
3 | 5 | 4 | 1(c) | ❌ | ❌ |

|
| ZhiJian | 🙌 | 30+ | ~50 | 19 | 3(a,b,c) | ✔️ | ✔️ |

|
(1): 更新日期: 2023-08-05 (2): 涉及领域:(a) 构建者模块;(b) 微调者模块;(c) 融合者模块;
ZhiJian 固定了随机种子,以确保复现结果,仅在不同设备间存在微小不同
ZhiJian 目前正在积极地开发中,欢迎任何形式的贡献。无论您是否对预训练模型、目标数据或创新的重用方法有哪些见解,我们都热切地邀请您加入我们,共同使 ZhiJian 变得更加优秀。如果您希望提交宝贵的贡献,请点击 这里。
@misc{zhang2023zhijian,
title={ZhiJian: A Unifying and Rapidly Deployable Toolbox for Pre-trained Model Reuse},
author={Yi-Kai Zhang and Lu Ren and Chao Yi and Qi-Wei Wang and De-Chuan Zhan and Han-Jia Ye},
year={2023},
eprint={2308.09158},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{zhijian2023,
author = {ZhiJian Contributors},
title = {LAMDA-ZhiJian},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/zhangyikaii/LAMDA-ZhiJian}}
}