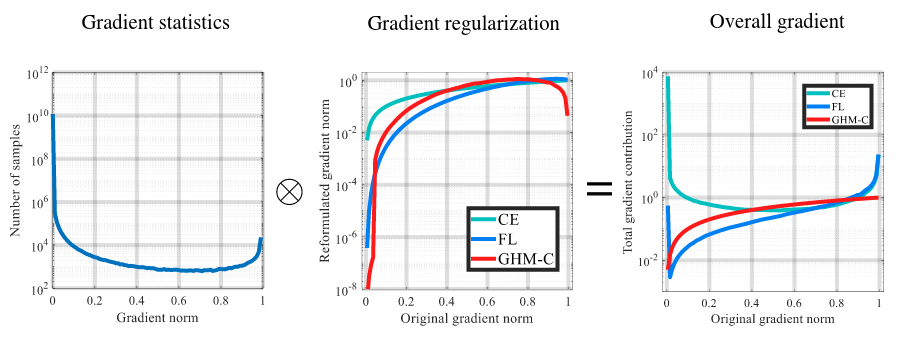
Despite the great success of two-stage detectors, single-stage detector is still a more elegant and efficient way, yet suffers from the two well-known disharmonies during training, i.e. the huge difference in quantity between positive and negative examples as well as between easy and hard examples. In this work, we first point out that the essential effect of the two disharmonies can be summarized in term of the gradient. Further, we propose a novel gradient harmonizing mechanism (GHM) to be a hedging for the disharmonies. The philosophy behind GHM can be easily embedded into both classification loss function like cross-entropy (CE) and regression loss function like smooth-L1 (SL1) loss. To this end, two novel loss functions called GHM-C and GHM-R are designed to balancing the gradient flow for anchor classification and bounding box refinement, respectively. Ablation study on MS COCO demonstrates that without laborious hyper-parameter tuning, both GHM-C and GHM-R can bring substantial improvement for single-stage detector. Without any whistles and bells, our model achieves 41.6 mAP on COCO test-dev set which surpasses the state-of-the-art method, Focal Loss (FL) + SL1, by 0.8.
@inproceedings{li2019gradient,
title={Gradient Harmonized Single-stage Detector},
author={Li, Buyu and Liu, Yu and Wang, Xiaogang},
booktitle={AAAI Conference on Artificial Intelligence},
year={2019}
}
| Backbone | Style | Lr schd | Mem (GB) | Inf time (fps) | box AP | Config | Download |
|---|---|---|---|---|---|---|---|
| R-50-FPN | pytorch | 1x | 4.0 | 3.3 | 37.0 | config | model | log |
| R-101-FPN | pytorch | 1x | 6.0 | 4.4 | 39.1 | config | model | log |
| X-101-32x4d-FPN | pytorch | 1x | 7.2 | 5.1 | 40.7 | config | model | log |
| X-101-64x4d-FPN | pytorch | 1x | 10.3 | 5.2 | 41.4 | config | model | log |