| title | thumbnail | authors | translators | ||||||
|---|---|---|---|---|---|---|---|---|---|
越小越好:Q8-Chat,在英特尔至强 CPU 上体验高效的生成式 AI |
/blog/assets/143_q8chat/thumbnail.png |
|
|
大语言模型(LLM)正在席卷整个机器学习世界。得益于其 transformer 架构,LLM 拥有从大量非结构化数据(如文本、图像、视频或音频)中学习的不可思议的能力。它们在多种任务类型上表现非常出色,无论是文本分类之类的抽取任务(extractive task)还是文本摘要和文生图像之类的生成任务(generative task)。
顾名思义,LLM 是大模型,其通常拥有超过 100 亿个参数,有些甚至拥有超过 1000 亿个参数,如 BLOOM 模型。 LLM 需要大量的算力才能满足某些场景(如搜索、对话式应用等)的低延迟需求。而大算力通常只有高端 GPU 才能提供,不幸的是,对于很多组织而言,相关成本可能高得令人望而却步,因此它们很难在其应用场景中用上最先进的 LLM。
在本文中,我们将讨论有助于减少 LLM 尺寸和推理延迟的优化技术,以使得它们可以在英特尔 CPU 上高效运行。
LLM 通常使用 16 位浮点参数(即 FP16 或 BF16)进行训练。因此,存储一个权重值或激活值需要 2 个字节的内存。此外,浮点运算比整型运算更复杂、更慢,且需要额外的计算能力。
量化是一种模型压缩技术,旨在通过减少模型参数的值域来解决上述两个问题。举个例子,你可以将模型量化为较低的精度,如 8 位整型 (INT8),以缩小它们的位宽并用更简单、更快的整型运算代替复杂的浮点运算。
简而言之,量化将模型参数缩放到一个更小的值域。一旦成功,它会将你的模型缩小至少 2 倍,而不会对模型精度产生任何影响。
你可以进行训时量化,即量化感知训练 (QAT),这个方法通常精度更高。如果你需要对已经训成的模型进行量化,则可以使用训后量化(PTQ),它会更快一些,需要的算力也更小。
市面上有不少量化工具。例如,PyTorch 内置了对量化的支持。你还可以使用 Hugging Face Optimum-Intel 库,其中包含面向开发人员的 QAT 和 PTQ API。
最近,有研究 [1][2] 表明目前的量化技术不适用于 LLM。LLM 中有一个特别的现象,即在每层及每个词向量中都能观察到某些特定的激活通道的幅度异常,即某些通道的激活值的幅度比其他通道更大。举个例子,下图来自于 OPT-13B 模型,你可以看到在所有词向量中,其中一个通道的激活值比其他所有通道的大得多。这种现象在每个 transformer 层中都存在。
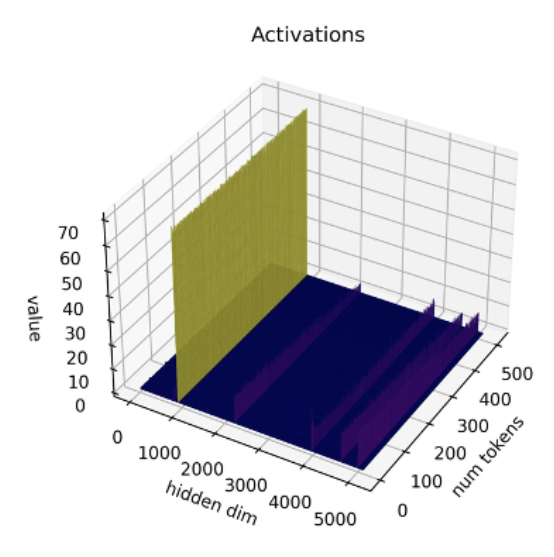
*图源: SmoothQuant 论文*
迄今为止,最好的激活量化技术是逐词量化,而逐词量化会导致要么离群值(outlier)被截断或要么幅度小的激活值出现下溢,它们都会显著降低模型质量。而量化感知训练又需要额外的训练,由于缺乏计算资源和数据,这在大多数情况下是不切实际的。
SmoothQuant [3][4] 作为一种新的量化技术可以解决这个问题。其通过对权重和激活进行联合数学变换,以增加权重中离群值和非离群值之间的比率为代价降低激活中离群值和非离群值之间的比率,从而行平滑之实。该变换使 transformer 模型的各层变得“量化友好”,并在不损害模型质量的情况下使得 8 位量化重新成为可能。因此,SmoothQuant 可以帮助生成更小、更快的模型,而这些模型能够在英特尔 CPU 平台上运行良好。
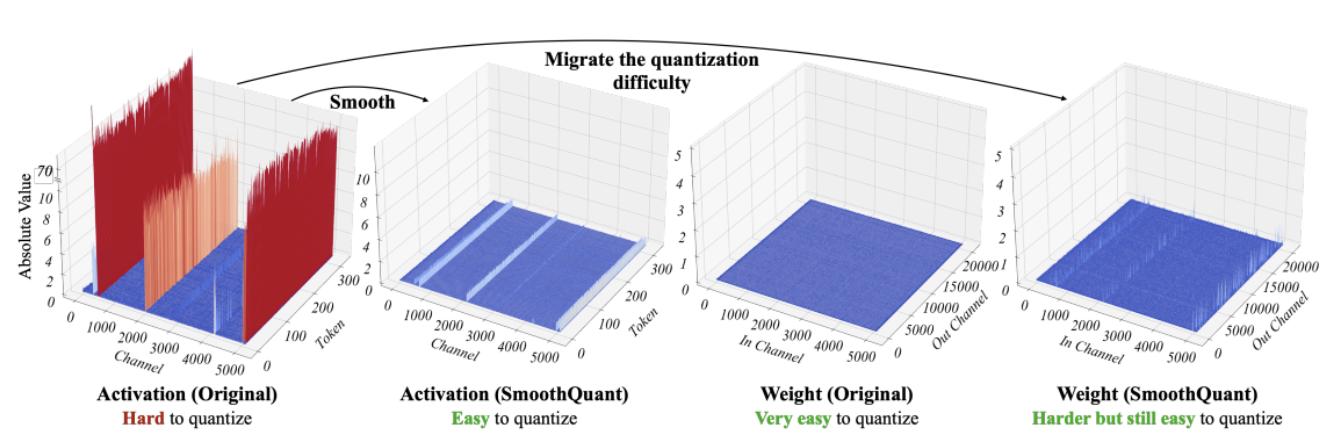
*图源: SmoothQuant 论文*
现在,我们看看 SmoothQuant 在流行的 LLM 上效果如何。
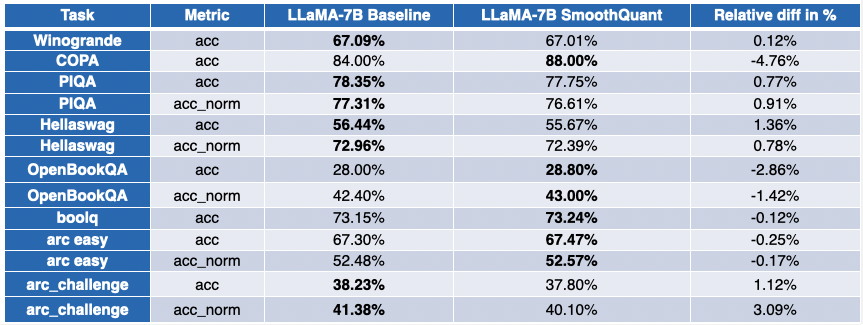
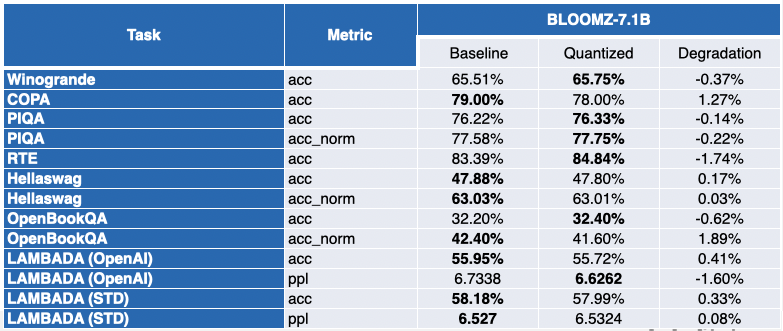
我们在英特尔的合作伙伴使用 SmoothQuant-O3 量化了几个 LLM,分别是:OPT 2.7B、6.7B [5],LLaMA 7B [6],Alpaca 7B [7],Vicuna 7B [8],BloomZ 7.1B [9] 以及 MPT-7B-chat [10]。他们还使用 EleutherAI 的语言模型评估工具 对量化模型的准确性进行了评估。
下表总结了他们的发现。第二列展示了量化后性能反而得到提升的任务数。第三列展示了量化后各个任务平均性能退化的均值(* 负值表示量化后模型的平均性能提高了)。你可以在文末找到详细结果。
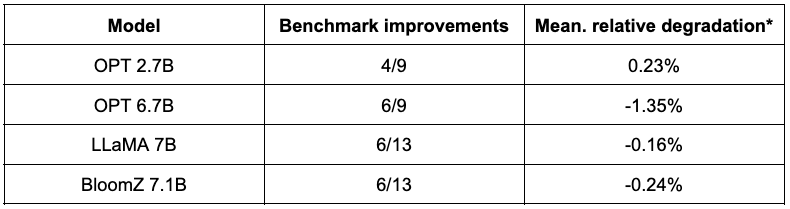
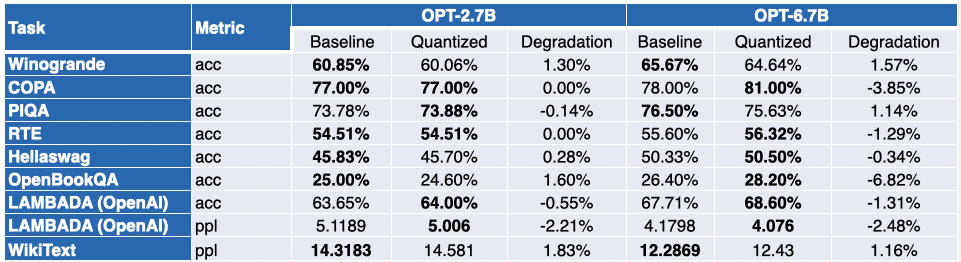
如你所见,OPT 模型非常适合 SmoothQuant 量化。模型比预训练的 16 位模型约小 2 倍。大多数指标都会有所改善,而那些没有改善的指标仅有轻微的降低。
对于 LLaMA 7B 和 BloomZ 7.1B,情况则好坏参半。模型被压缩了约 2 倍,大约一半的任务的指标有所改进。但同样,另一半的指标仅受到轻微影响,仅有一个任务的相对退化超过了 3%。
使用较小模型的明显好处是推理延迟得到了显著的降低。该视频演示了在一个 32 核心的单路英特尔 Sapphire Rapids CPU 上使用 MPT-7B-chat 模型以 batch size 1 实时生成文本的效果。
在这个例子中,我们问模型:“What is the role of Hugging Face in democratizing NLP?”。程序会向模型发送以下提示: “A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: What is the role of Hugging Face in democratizing NLP? ASSISTANT:”
这个例子展示了 8 位量化可以在第 4 代至强处理器上获得额外的延迟增益,从而使每个词的生成时间非常短。这种性能水平无疑使得在 CPU 平台上运行 LLM 成为可能,从而为客户提供比以往任何时候都更大的 IT 灵活性和更好的性价比。
HuggingFace 的首席执行官 Clement 最近表示:“*专注于训练和运行成本更低的小尺寸、垂域模型,会使更多的公司会收益。” Alpaca、BloomZ 以及 Vicuna 等小模型的兴起,为企业在生产中降低微调和推理成本的创造了新机会。如上文我们展示的,高质量的量化为英特尔 CPU 平台带来了高质量的聊天体验,而无需庞大的 LLM 和复杂的 AI 加速器。
我们与英特尔一起在 Spaces 中创建了一个很有意思的新应用演示,名为 Q8-Chat(发音为 Cute chat)。Q8-Chat 提供了类似于 ChatGPT 的聊天体验,而仅需一个有 32 核心的单路英特尔 Sapphire Rapids CPU 即可(batch size 为 1)。
我们正致力于将 Intel Neural Compressor 集成入 Hugging Face Optimum Intel,从而使得 Optimum Intel 能够利用这一新量化技术。一旦完成,你只需几行代码就可以复现我们的结果。
敬请关注。
未来属于 8 比特!
本文保证纯纯不含 ChatGPT。
本文系与来自英特尔实验室的 Ofir Zafrir、Igor Margulis、Guy Boudoukh 和 Moshe Wasserblat 共同完成。特别感谢他们的宝贵意见及合作。
负值表示量化后性能有所提高。

英文原文: https://huggingface.co/blog/generative-ai-models-on-intel-cpu 原文作者:Julien Simon 译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。