| title | thumbnail | authors | translators | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Open LLM 排行榜近况 |
/blog/assets/evaluating-mmlu-leaderboard/thumbnail.png |
|
|
Open LLM 排行榜是 Hugging Face 设立的一个用于评测开放大语言模型的公开榜单。最近,随着 Falcon 🦅 的发布并在 Open LLM 排行榜上疯狂屠榜,围绕这个榜单在推特上掀起了一轮热烈的讨论。
讨论主要围绕排行榜上的四个评测基准其中之一:大规模多任务语言理解(Massive Multitask Language Understanding,MMLU)基准。
社区发现头部模型 LLaMA 🦙 在Open LLM 榜单上的 MMLU 得分比 LLaMA 论文 中宣称的数字要低很多,大家都感觉很奇怪。
因此,我们决定深入分析一下这个现象🕳🐇,看看到底是什么原因,又应该如何解决。
在求索的过程中,我们与 @javier-m 大神进行了讨论,他之前参与了 LLaMA 模型的评估;我们还与来自 Falcon 团队的 @slippylolo 进行了讨论。虽然承教这两位甚多,但文章中所有可能的错误都应该归咎于我们而不是他们!
在这段旅程中,你将学到很多有关如何评测模型的知识,因此,如果后面你在网络上或论文中看到了相关的评测数字,相信你就会有一定的判断力了。
准备好了吗?系好安全带,我们要起飞了🚀。
首先,请注意 Open LLM 排行榜实际上只是对开源基准测试库 EleutherAI LM Evaluation Harness的一个封装,该库是由 EleutherAI 非营利性人工智能研究实验室创建的。EleutherAI 实验室是一支在人工智能领域资历深厚的团队,他们有很多耳熟能详的工作,如创建 The Pile 数据集,训练 GPT-J 、GPT-Neo-X 20B 以及 Pythia 模型。
Open LLM 排行榜会在 Hugging Face 计算集群空闲时运行 lm-evaluation-harness 以对众多模型进行评测,将结果保存在 Hub 上的一个数据集中,并最终显示在 排行榜 space 上。
在 EleutherAI lm-evaluation-harness 上运行 LLaMA 模型所得的 MMLU 分数与 LLaMA 论文宣称的分数有很大差距。
为什么会这样?
事实证明,LLaMA 团队使用的是另一个开源实现:由最初提出并开发 MMLU 基准的加州大学伯克利分校团队实现的版本,见这儿,我们称其为 “原始实现”。
随着调查的进一步深入,我们还发现了另一个有趣的实现:斯坦福大学基础模型研究中心(CRFM) 开发的一个全面的评估基准:语言模型整体评估(Holistic Evaluation of Language Models,HELM) 中也实现了 MMLU 基准,我们将其称为 HELM 实现。
EleutherAI Harness 和斯坦福 HELM 的设计理念殊途同归,两者都在单个代码库中集成了多个评测基准(包括 MMLU),以为模型提供一个全景式性能评估工具。Open LLM 排行榜也秉持相同的理念,因此我们在实现 Open LLM 排行榜时选择了封装 EleutherAI Harness 这样的“整体”基准,而不是集成多个单指标评测代码库。
为了弄清楚得分差异的问题,我们决定在同一组模型上运行 MMLU 评测的三种不同实现,并根据得分对这些模型进行排名:
- Harness 实现(commit e47e01b)
- HELM 实现(提交 cab5d89)
- 原始实现(由 @olmer 大神集成入 Hugging Face(代码))
(请注意,Harness 实现最近有更新,更多信息请参见文末。)
结果很神奇(下图只是排名,后文有完整的评分):
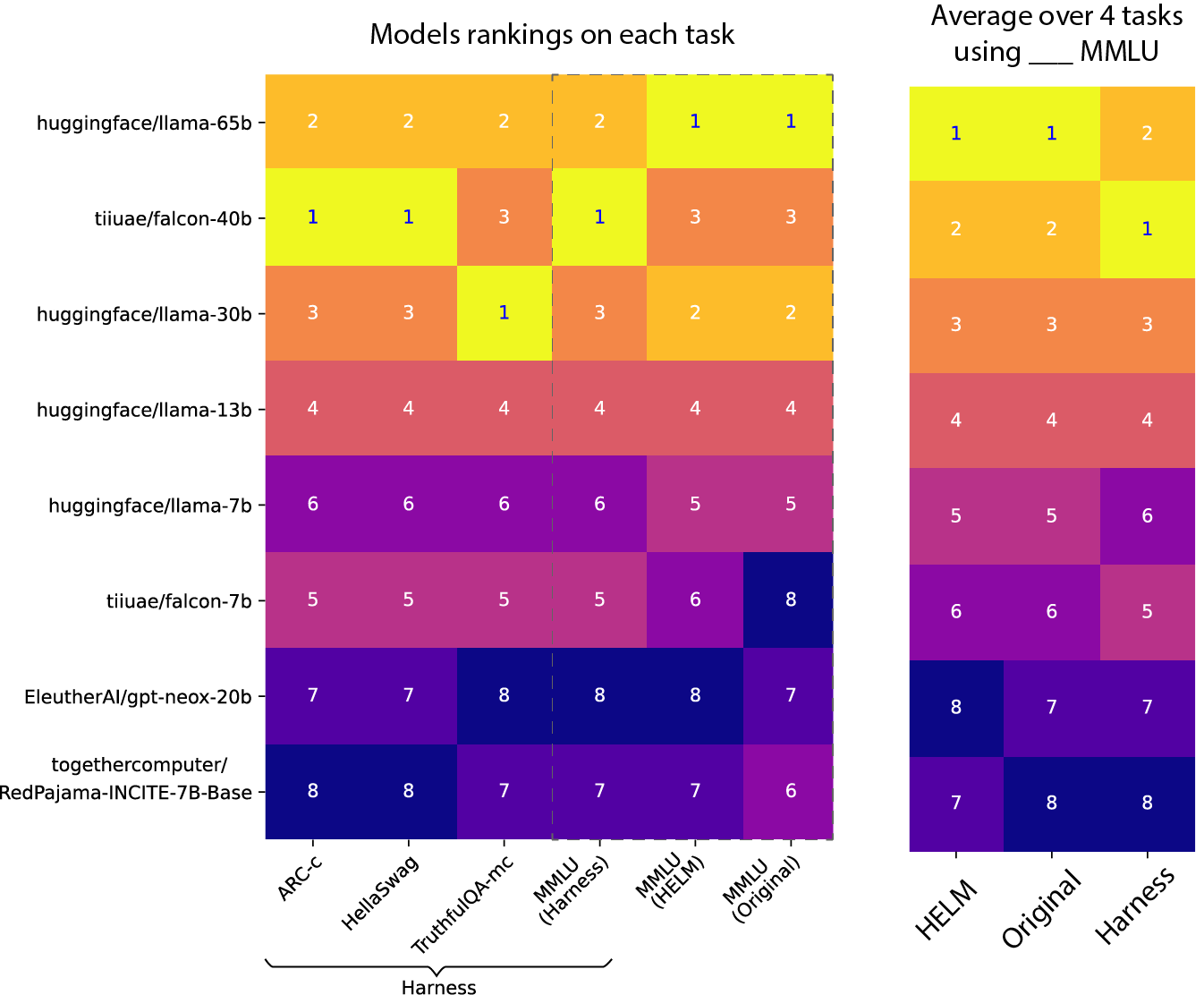
我们发现,MMLU 的不同实现给出的得分竟然截然不同,甚至于改变了模型的排名顺序!
下面我们试着了解下这种差异从何而来。🕵️在此之前,我们先简要了解一下大家都如何对现代 LLM 进行自动化评估。
MMLU 测试由一组多项选择题组成,因此相对于开放式问答题这样的题型而言,该基准算是比较简单了。但正如大家后面会看到的,即便这么简单,这里面依然存在一些空间使得实现细节上的差异足以影响评测结果。MMLU 基准涵盖“人文”、“社会科学”、“STEM” 等 57 个通用知识领域,里面的每个问题包含四个可能选项,且每个问题只有一个正确答案。
下面给出一个例子:
Question: Glucose is transported into the muscle cell:
Choices:
A. via protein transporters called GLUT4.
B. only in the presence of insulin.
C. via hexokinase.
D. via monocarbylic acid transporters.
Correct answer: A
注意:你可以使用 Hub 的数据集查看器来轻松探索该数据集的更多细节。
大语言模型在所有 AI 模型中其实算比较简单的模型。其输入为“文本字符串”(或称为“提示”),该输入会被切分成词元(词元可以是单词、子词或字符,具体取决于模型的要求)并馈送至模型。根据这个输入,模型预测词汇表中每一个词元是下一输出词元的概率,至此,你就得到了词汇表中每一个词适合作为输入提示的下一个词的可能性。
然后,我们可以采取一些策略来从这个概率分布中选择一个词元作为输出词元,例如可以选择概率最大的词元(或者我们还可以通过采样引入些微噪声,以避免出现“过于机械”的答案)。接着,我们把选择的词元添加到提示中并将其馈送给模型以继续生成下一个词元,依此类推,直至句子结束:
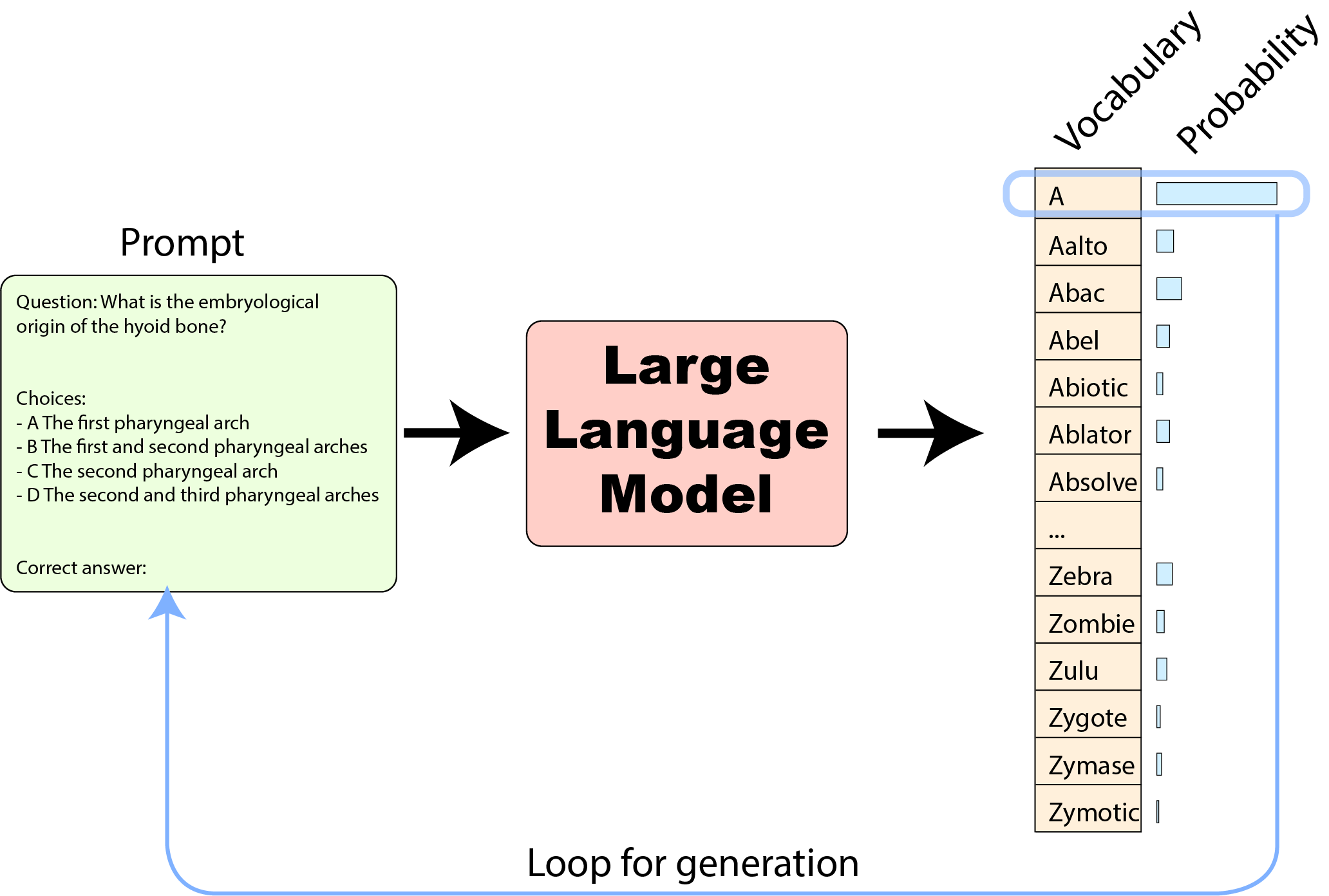
上图展示了 ChatGPT 或 Hugging Chat 生成答案的过程。
总结一下,从模型中获取信息以对其进行评测,主要有两种方法:
-
获取某一组特定词元的输出概率,并将其与样本中的备选项进行比较;
-
获取模型生成的文本(用上文所述的方法一个个迭代生成),并将这些文本与样本中的备选项进行比较。
有了这些知识,我们就可以开始深入研究 MMLU 的三种实现,以了解馈送到模型的输入是什么、预期的输出是什么以及如何比较这些输出。
我们先比较一下对同一个 MMLU 数据集样本,这三种实现都是如何构建模型输入的:
| 原始实现 Ollmer PR | HELM 实现commit cab5d89 | Harness 实现commit e47e01b |
| The following are multiple choice questions (with answers) about us foreign policy. How did the 2008 financial crisis affect America's international reputation? A. It damaged support for the US model of political economy and capitalism B. It created anger at the United States for exaggerating the crisis C. It increased support for American global leadership under President Obama D. It reduced global use of the US dollar Answer: |
The following are multiple choice questions (with answers) about us foreign policy. Question: How did the 2008 financial crisis affect America's international reputation? A. It damaged support for the US model of political economy and capitalism B. It created anger at the United States for exaggerating the crisis C. It increased support for American global leadership under President Obama D. It reduced global use of the US dollar Answer: |
Question: How did the 2008 financial crisis affect America's international reputation? Choices: A. It damaged support for the US model of political economy and capitalism B. It created anger at the United States for exaggerating the crisis C. It increased support for American global leadership under President Obama D. It reduced global use of the US dollar Answer: |
可以看到,三者之间差异虽小,但仍不可忽视:
- 首句(或指令):差异不大。HELM 实现额外多加了一个空格,但注意 Harness 实现是没有指令句的;
- 问题:HELM 实现和 Harness 实现都加了
Question:前缀; - 选项:Harness 实现在选项之前加了
Choice:前缀。
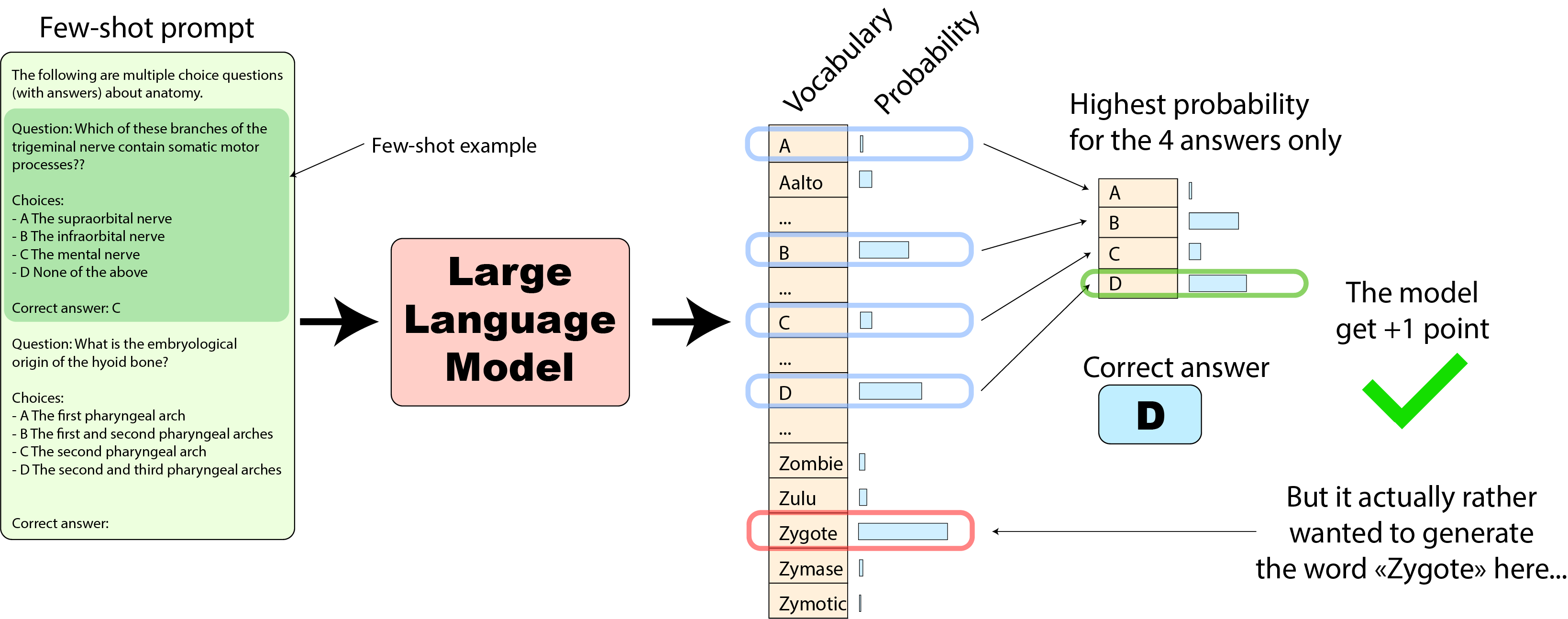
我们首先看看原始实现 是如何做的:其仅比较模型对四个选项字母的预测概率。
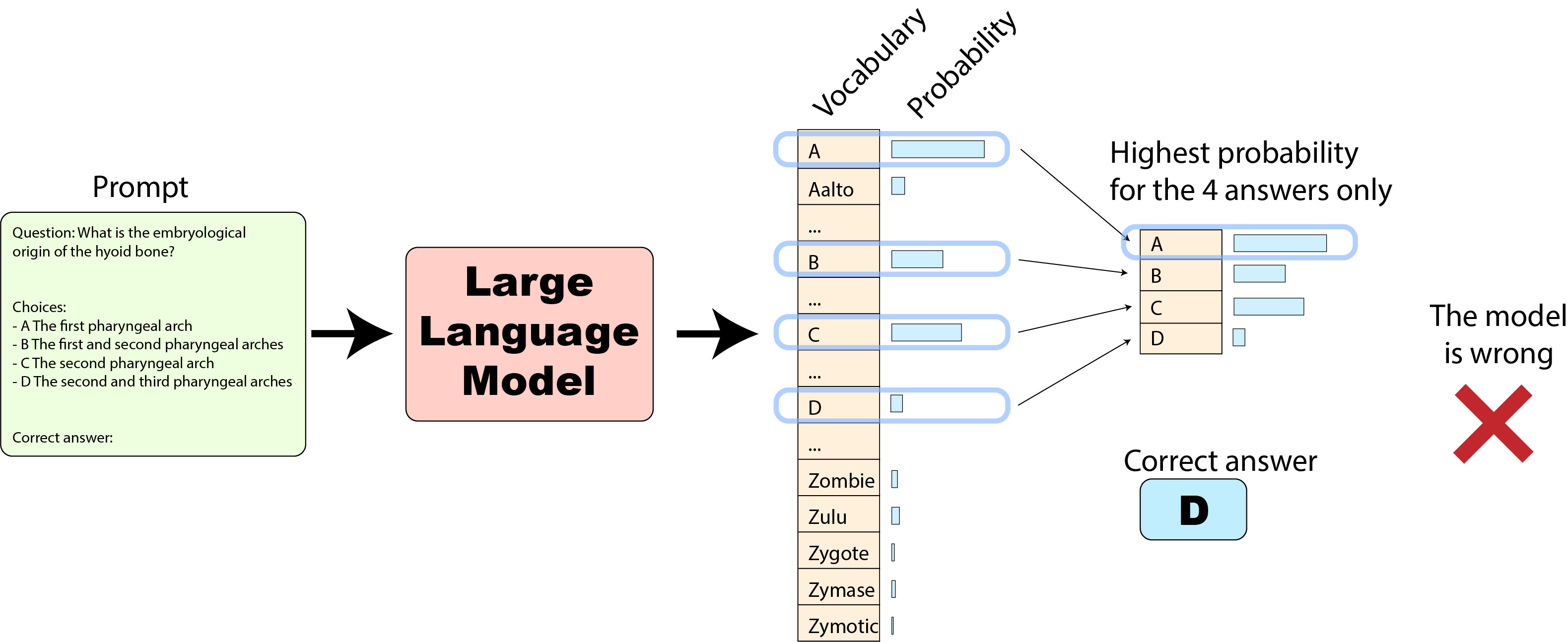
这种方法其实是有点放水的,举个例子:
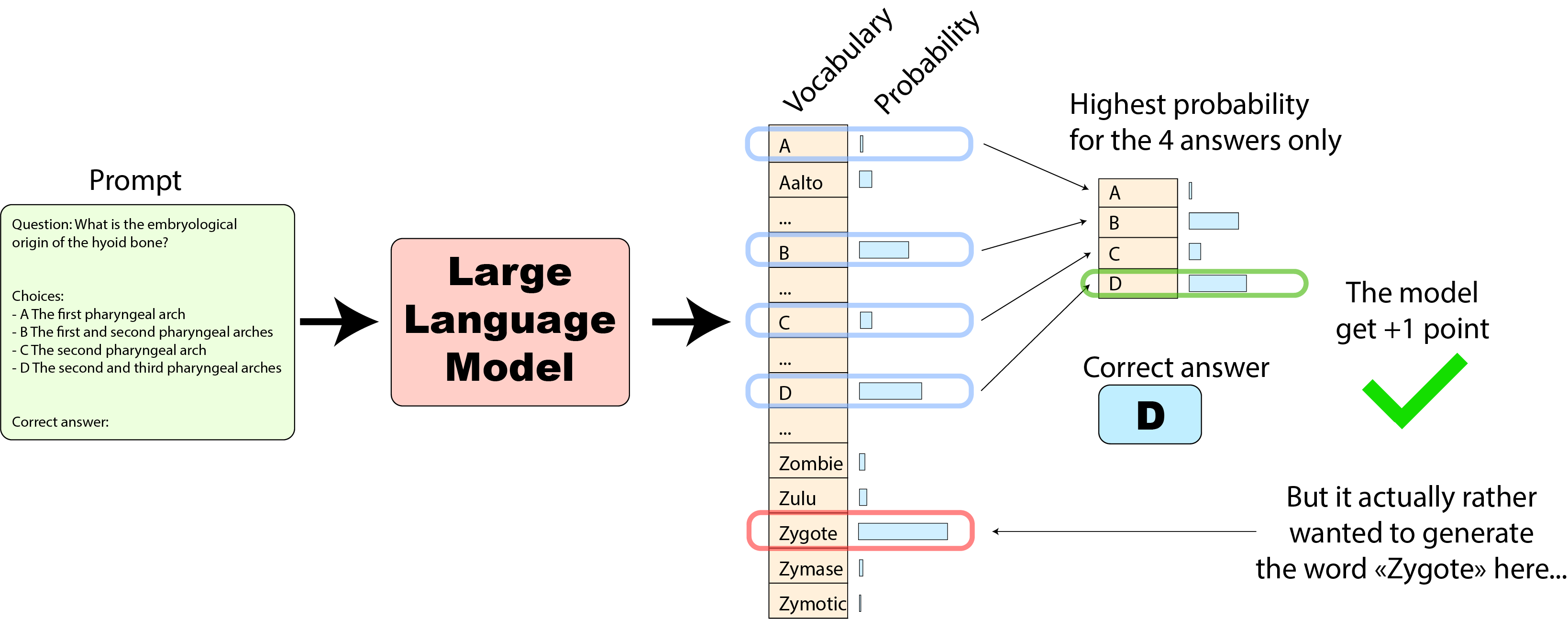
在上图这种情况下,因为在模型给 D 选项的概率在 4 个选项中是最高的,因此原始实现认为模型预测正确,给加了 1 分。但如果我们抬起头来看一下完整的概率输出,单词 “Zygote” 的概率其实是最高的,而它并不属于 4 个选项之一(这仅是一个示例,而不是一个真实的例子)。
那么,如何确保模型尽可能少犯这类错误呢?
我们可以使用“少样本”方法,在提示中为模型提供一个或多个范例(包括示例问题及其答案),如下:
上图,我们在提示中加了一个范例,用于告诉模型我们的预期,这样在预测时模型就不太可能给出超出选项范围的答案。
由于这种方法能够提高性能,因此在全部 3 种实现中,我们均选择了以 5 样本方式进行 MMLU 评估(即每个提示中都含有 5 个范例)。(注意:在每个基准测试中,虽然我们用了同样 5 个范例,但它们的排列顺序可能有所不同,这也有可能导致性能差异,但我们在此不深入。另外,我们还必须注意避免范例中的某些答案泄漏到预测样本中......)
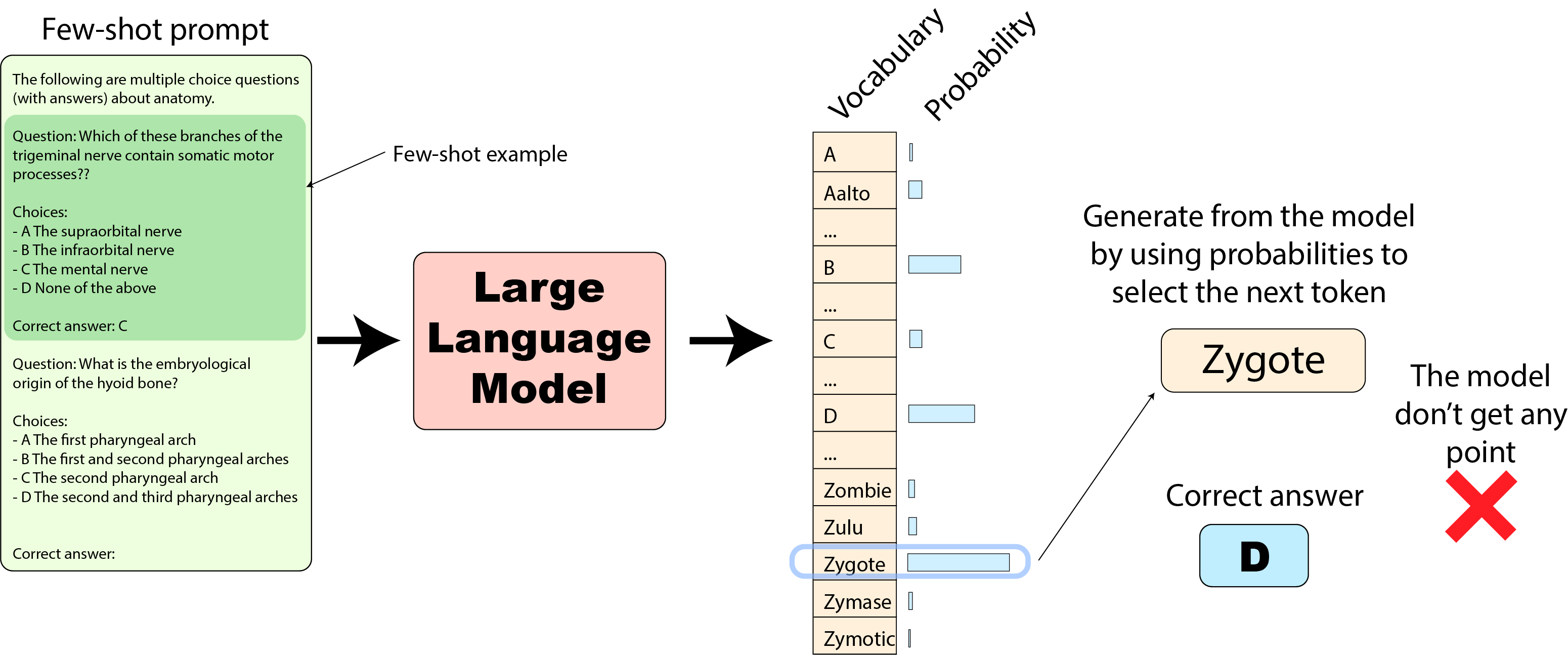
HELM 实现: 我们再看看 HELM 实现。其少样本提示的实现与原始实现类似,但其模型评估方式与我们刚刚看到的原始实现有很大不同:其根据模型预测的下一个输出词元的概率来选择输出文本,并将生成的文本与正确答案的文本进行对比,如下所示:
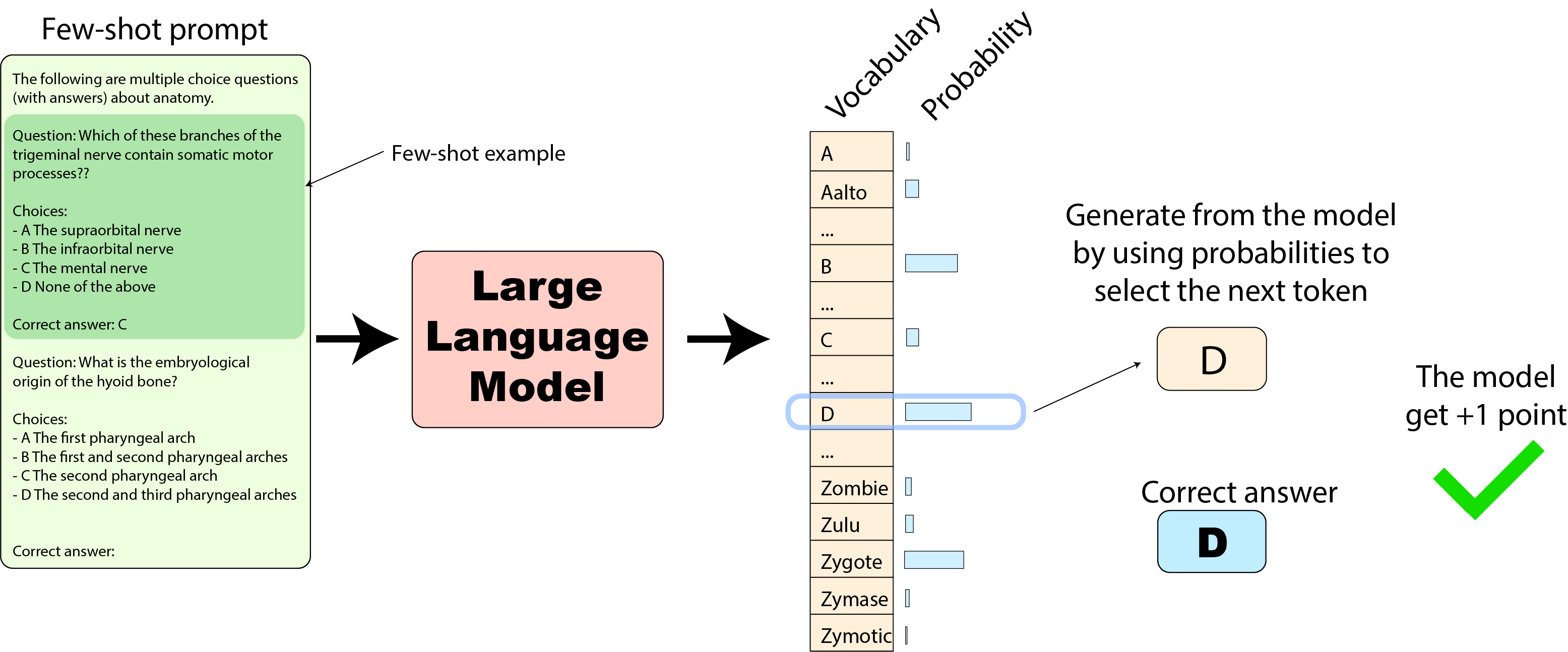
此时,如果输出词元中 “Zygote” 概率最高(如上图),则模型会输出 “Zygote”,然后 HELM 实现就将其判为错误,模型就无法得分:
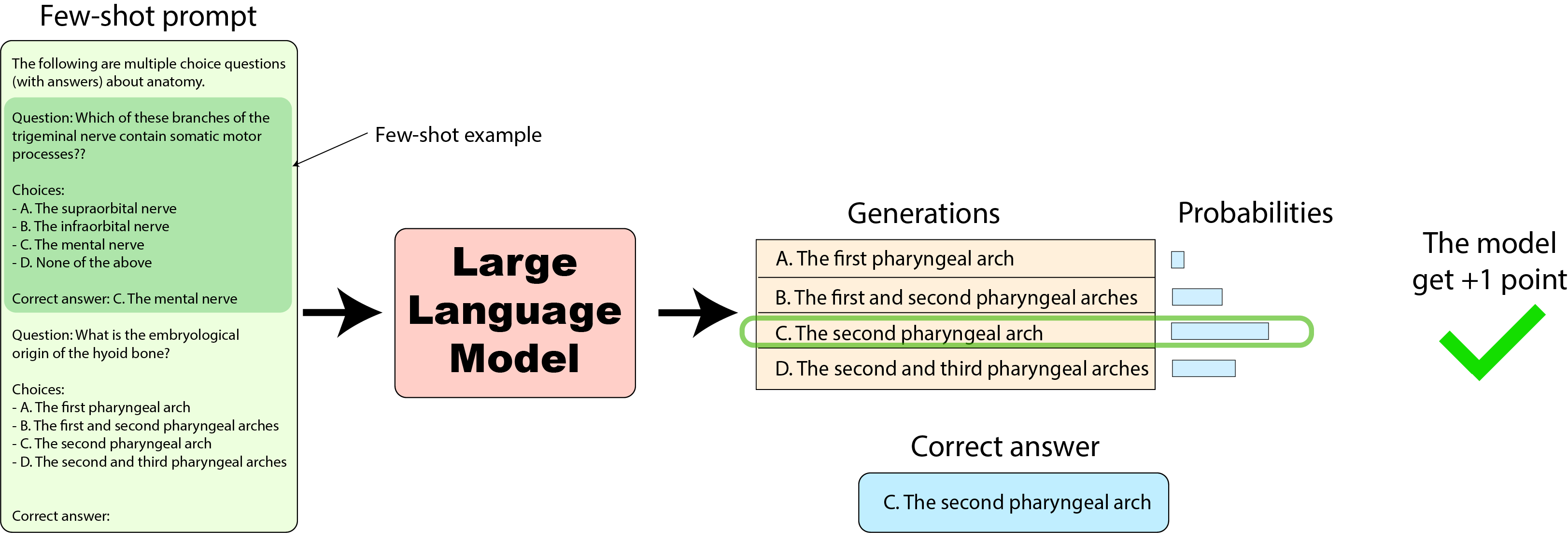
Harness 实现: 最后我们看下截至 2023 年 1 月 的 Harness 实现,Open LLM 排行榜使用了该实现。它对同一个数据集的得分计算方法又不一样(请注意,该实现最近有重大更新,文末有详细信息)。
这里,我们仍然使用概率,但这次用的是完整答案序列的概率,这个完整序列包括选项字母及其后面的答案文本,例如 “C. The second pharyngeal arch”。为了计算整序列的概率,我们获取每个词元的概率(与上面其他实现一样)并求它们的联合概率。为了数值稳定性,在计算联合概率时我们主要计算对数概率并对其进行求和,最后对其进行归一化(可选,也可以不做),归一化主要是将对数联合概率除以词元数,以避免长答案有不公平的得分优势(稍后会详细介绍)。工作原理如下图所示:
下表总结了每种实现对模型的输出形式的要求:
| 原始实现 | HELM 实现 | Harness 实现(截至 2023 年 1 月) |
| 比较选项字母的预测概率: | 期望模型输出正确选项的字母: | 比较所有答案文本的概率: |
| A B C D |
A | A. It damaged support for the US model of political economy and capitalism B. It created anger at the United States for exaggerating the crisis C. It increased support for American global leadership under President Obama D. It reduced global use of the US dollar |
搞清楚这些之后,我们比较一下多个模型在这三种实现上的得分:
| MMLU (HELM 实现) | MMLU (Harness 实现) | MMLU (原始实现) | |
|---|---|---|---|
| huggingface/llama-65b | 0.637 | 0.488 | 0.636 |
| tiiuae/falcon-40b | 0.571 | 0.527 | 0.558 |
| huggingface/llama-30b | 0.583 | 0.457 | 0.584 |
| EleutherAI/gpt-neox-20b | 0.256 | 0.333 | 0.262 |
| huggingface/llama-13b | 0.471 | 0.377 | 0.47 |
| huggingface/llama-7b | 0.339 | 0.342 | 0.351 |
| tiiuae/falcon-7b | 0.278 | 0.35 | 0.254 |
| togethercomputer/RedPajama-INCITE-7B-Base | 0.275 | 0.34 | 0.269 |
可以看到,即便对于相同的 MMLU 数据集,模型的绝对分数和相对排名(参见第一张图)对评测基准的实现方式仍非常敏感。
假设你已经完美复刻了一个 LLaMA 65B 模型,并使用 Harness 对其进行了评估(得分 0.488,见上表)。现在,你想要将其与其他人发表的公开结果进行比较(假设他是在原始 MMLU 实现上进行评估的,得分为 0.637),分数竟相差 30% 之巨。你可能会想:“天哪,我的训练完全毁了😱”。但事实并非如此,这些都只是毫无可比性的数字,即使它们都叫 “MMLU 分数”,且都是在同一个 MMLU 数据集上进行评测的。
那么,是否存在一个评估 LLM 模型性能的“最佳方法”呢?这个问题不好回答。正如我们在上文看到的,使用不同的评测方式对不同的模型进行评估时,其排名会变得混乱。为了尽可能保持公平,人们可能会倾向于选择那个平均打分最高的评测方法,因为看上去好像它更能“解锁”模型的实力。在本文中,这意味着我们应该使用原始实现。但正如我们在上面看到的,使用仅对四个选项的概率进行排序的方式有可能以某种方式给模型放水,而且它更偏心那些性能较弱的模型。此外,从开源模型中获取词元预测概率(或似然)可能很容易,但闭源 API 模型可能并不会提供这样的 API。
亲爱的读者,我们说了这么多,你有何高见?不妨到 Open LLM 排行榜的这个帖子中说上两句:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard/discussions/82。
整个过程走下来,我们学到了一个重要的教训:评测得分与实现紧密相关 —— 具体到提示、分词等微小细节的差异都有可能导致最终得分的差异。仅靠 “MMLU 得分” 这几个字不足以带来什么信息量,因为它们所使用的评测代码实现可能不同,所以根本没有可比性。
这就是为什么我们需要开放、标准化、可重复的基准测试。诸如 EleutherAI Eval Harness 或 Stanford HELM 这样的开放基准对社区来说是无价的,如果没有它们,我们就无法比较模型和论文之间的结果,更谈不上改进 LLM 了。
后记:就 Open LLM 排行榜而言,我们决定坚持使用社区维护的评估库。值得庆幸的是,本文撰写期间,优秀的 EleutherAI Harness 的社区,尤其是 ollmer ,完成了一项壮举:更新了 Harness 实现中的 MMLU 的评测代码,使其不管是实现还是得分都与原始实现更相似。
现在,我们正在用新版的 EleutherAI Eval Harness 重刷排行榜,在未来的几周内你将看到基于 Eleuther Harness v2 的跑分,敬请期待!(重新运行所有模型需要一些时间,请耐心等待,:抱抱:)
非常感谢 LLaMA 团队的 Xavier Martinet、Aurélien Rodriguez 和 Sharan Narang 对本文内容的宝贵建议,并拨冗回答了我们所有的问题。
以下是本文使用的各代码库的 commit 版本。
- EleutherAI LM harness 实现 commit e47e01b: https://github.com/EleutherAI/lm-evaluation-harness/tree/e47e01beea79cfe87421e2dac49e64d499c240b4
- HELM 实现 commit cab5d89: https://github.com/stanford-crfm/helm/tree/cab5d89fadbff86190f29ddfa497301958eaf2ec
- 原始 MMLU 实现 (由 @olmer 大神集成至 Hugging Face): hendrycks/test#13
英文原文: https://huggingface.co/blog/evaluating-mmlu-leaderboard 原文作者:Clémentine Fourrier,Nathan Habib,Julien Launay,Thomas Wolf 译者: Matrix Yao (姚伟峰),英特尔深度学习工程师,工作方向为 transformer-family 模型在各模态数据上的应用及大规模模型的训练推理。