Animal Shogi (Dōbutsu shōgi) is a variant of shogi primarily developed for children. It consists of a 3x4 board and four types of pieces (five including promoted pieces). One of the rule differences from regular shogi is the Try Rule, where entering the opponent's territory with the king leads to victory.
This is the list of all public APIs of Pgx.
+Two important components in Pgx are State and Env.
+
+
+
+
+
+
+
+ pgx.State
+
+
+
+
+
+
+
+ Bases: abc.ABC
+
+
+
Base state class of all Pgx game environments. Basically an immutable (frozen) dataclass.
+A basic usage is generating via Env.init:
+
state = env.init(jax.random.PRNGKey(0))
+
+
and Env.step receives and returns this state class:
+
state = env.step(state, action)
+
+
Serialization via flax.struct.serialization is supported.
+There are 6 common attributes over all games:
+
+
Attributes:
+
+
+
+
Name
+
Type
+
Description
+
+
+
+
+
current_player
+
+ jnp.ndarray
+
+
id of agent to play.
+Note that this does NOT represent the turn (e.g., black/white in Go).
+This ID is consistent over the parallel vmapped states.
+
+
+
observation
+
+ jnp.ndarray
+
+
observation for the current state.
+Env.observe is called to compute.
+
+
+
rewards
+
+ jnp.ndarray
+
+
the i-th element indicates the intermediate reward for
+the agent with player-id i. If Env.step is called for a terminal state,
+the following state.rewards is zero for all players.
+
+
+
terminated
+
+ jnp.ndarray
+
+
denotes that the state is terminal state. Note that
+some environments (e.g., Go) have an max_termination_steps parameter inside
+and will terminate within a limited number of states (following AlphaGo).
+
+
+
truncated
+
+ jnp.ndarray
+
+
indicates that the episode ends with the reason other than termination.
+Note that current Pgx environments do not invoke truncation but users can use TimeLimit wrapper
+to truncate the environment. In Pgx environments, some MinAtar games may not terminate within a finite timestep.
+However, the other environments are supposed to terminate within a finite timestep with probability one.
+
+
+
legal_action_mask
+
+ jnp.ndarray
+
+
Boolean array of legal actions. If illegal action is taken,
+the game will terminate immediately with the penalty to the palyer.
@dataclass
+classState(abc.ABC):
+"""Base state class of all Pgx game environments. Basically an immutable (frozen) dataclass.
+ A basic usage is generating via `Env.init`:
+
+ state = env.init(jax.random.PRNGKey(0))
+
+ and `Env.step` receives and returns this state class:
+
+ state = env.step(state, action)
+
+ Serialization via `flax.struct.serialization` is supported.
+ There are 6 common attributes over all games:
+
+ Attributes:
+ current_player (jnp.ndarray): id of agent to play.
+ Note that this does NOT represent the turn (e.g., black/white in Go).
+ This ID is consistent over the parallel vmapped states.
+ observation (jnp.ndarray): observation for the current state.
+ `Env.observe` is called to compute.
+ rewards (jnp.ndarray): the `i`-th element indicates the intermediate reward for
+ the agent with player-id `i`. If `Env.step` is called for a terminal state,
+ the following `state.rewards` is zero for all players.
+ terminated (jnp.ndarray): denotes that the state is terminal state. Note that
+ some environments (e.g., Go) have an `max_termination_steps` parameter inside
+ and will terminate within a limited number of states (following AlphaGo).
+ truncated (jnp.ndarray): indicates that the episode ends with the reason other than termination.
+ Note that current Pgx environments do not invoke truncation but users can use `TimeLimit` wrapper
+ to truncate the environment. In Pgx environments, some MinAtar games may not terminate within a finite timestep.
+ However, the other environments are supposed to terminate within a finite timestep with probability one.
+ legal_action_mask (jnp.ndarray): Boolean array of legal actions. If illegal action is taken,
+ the game will terminate immediately with the penalty to the palyer.
+ """
+
+current_player:jnp.ndarray
+observation:jnp.ndarray
+rewards:jnp.ndarray
+terminated:jnp.ndarray
+truncated:jnp.ndarray
+legal_action_mask:jnp.ndarray
+# NOTE: _rng_key is
+# - used for stochastic env and auto reset
+# - updated only when actually used
+# - supposed NOT to be used by agent
+_rng_key:jax.random.KeyArray
+_step_count:jnp.ndarray
+
+@property
+@abc.abstractmethod
+defenv_id(self)->EnvId:
+"""Environment id (e.g. "go_19x19")"""
+...
+
+def_repr_html_(self)->str:
+returnself.to_svg()
+
+defto_svg(
+self,
+*,
+color_theme:Optional[Literal["light","dark"]]=None,
+scale:Optional[float]=None,
+)->str:
+"""Return SVG string. Useful for visualization in notebook.
+
+ Args:
+ color_theme (Optional[Literal["light", "dark"]]): xxx see also global config.
+ scale (Optional[float]): change image size. Default(None) is 1.0
+
+ Returns:
+ str: SVG string
+ """
+frompgx._src.visualizerimportVisualizer
+
+v=Visualizer(color_theme=color_theme,scale=scale)
+returnv.get_dwg(states=self).tostring()
+
+defsave_svg(
+self,
+filename,
+*,
+color_theme:Optional[Literal["light","dark"]]=None,
+scale:Optional[float]=None,
+)->None:
+"""Save the entire state (not observation) to a file.
+ The filename must end with `.svg`
+
+ Args:
+ color_theme (Optional[Literal["light", "dark"]]): xxx see also global config.
+ scale (Optional[float]): change image size. Default(None) is 1.0
+
+ Returns:
+ None
+ """
+frompgx._src.visualizerimportsave_svg
+
+save_svg(self,filename,color_theme=color_theme,scale=scale)
+
defsave_svg(
+self,
+filename,
+*,
+color_theme:Optional[Literal["light","dark"]]=None,
+scale:Optional[float]=None,
+)->None:
+"""Save the entire state (not observation) to a file.
+ The filename must end with `.svg`
+
+ Args:
+ color_theme (Optional[Literal["light", "dark"]]): xxx see also global config.
+ scale (Optional[float]): change image size. Default(None) is 1.0
+
+ Returns:
+ None
+ """
+frompgx._src.visualizerimportsave_svg
+
+save_svg(self,filename,color_theme=color_theme,scale=scale)
+
+
+
+
+
+
+
+
+
+
+
+to_svg(*,color_theme=None,scale=None)
+
+
+
+
+
+
+
Return SVG string. Useful for visualization in notebook.
classEnv(abc.ABC):
+"""Environment class API.
+
+ !!! example "Example usage"
+
+ ```py
+ env: Env = pgx.make("tic_tac_toe")
+ state = env.init(jax.random.PRNGKey(0))
+ action = jax.random.int32(4)
+ state = env.step(state, action)
+ ```
+
+ """
+
+def__init__(self):
+...
+
+definit(self,key:jax.random.KeyArray)->State:
+"""Return the initial state. Note that no internal state of
+ environment changes.
+
+ Args:
+ key: pseudo-random generator key in JAX
+
+ Returns:
+ State: initial state of environment
+
+ """
+key,subkey=jax.random.split(key)
+state=self._init(subkey)
+state=state.replace(_rng_key=key)# type: ignore
+observation=self.observe(state,state.current_player)
+returnstate.replace(observation=observation)# type: ignore
+
+defstep(self,state:State,action:jnp.ndarray)->State:
+"""Step function."""
+is_illegal=~state.legal_action_mask[action]
+current_player=state.current_player
+
+# If the state is already terminated or truncated, environment does not take usual step,
+# but return the same state with zero-rewards for all players
+state=jax.lax.cond(
+(state.terminated|state.truncated),
+lambda:state.replace(rewards=jnp.zeros_like(state.rewards)),# type: ignore
+lambda:self._step(state.replace(_step_count=state._step_count+1),action),# type: ignore
+)
+
+# Taking illegal action leads to immediate game terminal with negative reward
+state=jax.lax.cond(
+is_illegal,
+lambda:self._step_with_illegal_action(state,current_player),
+lambda:state,
+)
+
+# All legal_action_mask elements are **TRUE** at terminal state
+# This is to avoid zero-division error when normalizing action probability
+# Taking any action at terminal state does not give any effect to the state
+state=jax.lax.cond(
+state.terminated,
+lambda:state.replace(# type: ignore
+legal_action_mask=jnp.ones_like(state.legal_action_mask)
+),
+lambda:state,
+)
+
+observation=self.observe(state,state.current_player)
+state=state.replace(observation=observation)# type: ignore
+
+returnstate
+
+defobserve(self,state:State,player_id:jnp.ndarray)->jnp.ndarray:
+"""Observation function."""
+obs=self._observe(state,player_id)
+returnjax.lax.stop_gradient(obs)
+
+@abc.abstractmethod
+def_init(self,key:jax.random.KeyArray)->State:
+"""Implement game-specific init function here."""
+...
+
+@abc.abstractmethod
+def_step(self,state,action)->State:
+"""Implement game-specific step function here."""
+...
+
+@abc.abstractmethod
+def_observe(self,state:State,player_id:jnp.ndarray)->jnp.ndarray:
+"""Implement game-specific observe function here."""
+...
+
+@property
+@abc.abstractmethod
+defid(self)->EnvId:
+"""Environment id."""
+...
+
+@property
+@abc.abstractmethod
+defversion(self)->str:
+"""Environment version. Updated when behavior, parameter, or API is changed.
+ Refactoring or speeding up without any expected behavior changes will NOT update the version number.
+ """
+...
+
+@property
+@abc.abstractmethod
+defnum_players(self)->int:
+"""Number of players (e.g., 2 in Tic-tac-toe)"""
+...
+
+@property
+defnum_actions(self)->int:
+"""Return the size of action space (e.g., 9 in Tic-tac-toe)"""
+state=self.init(jax.random.PRNGKey(0))
+returnint(state.legal_action_mask.shape[0])
+
+@property
+defobservation_shape(self)->Tuple[int,...]:
+"""Return the matrix shape of observation"""
+state=self.init(jax.random.PRNGKey(0))
+obs=self._observe(state,state.current_player)
+returnobs.shape
+
+@property
+def_illegal_action_penalty(self)->float:
+"""Negative reward given when illegal action is selected."""
+return-1.0
+
+def_step_with_illegal_action(
+self,state:State,loser:jnp.ndarray
+)->State:
+penalty=self._illegal_action_penalty
+reward=(
+jnp.ones_like(state.rewards)
+*(-1*penalty)
+*(self.num_players-1)
+)
+reward=reward.at[loser].set(penalty)
+returnstate.replace(rewards=reward,terminated=TRUE)# type: ignore
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+id:EnvId
+
+
+ property
+ abstractmethod
+
+
+
+
+
+
+
+
Environment id.
+
+
+
+
+
+
+
+
+
+num_actions:int
+
+
+ property
+
+
+
+
+
+
+
+
Return the size of action space (e.g., 9 in Tic-tac-toe)
Environment version. Updated when behavior, parameter, or API is changed.
+Refactoring or speeding up without any expected behavior changes will NOT update the version number.
+
+
+
+
+
+
+
+
+
+
+
+init(key)
+
+
+
+
+
+
+
Return the initial state. Note that no internal state of
+environment changes.
defstep(self,state:State,action:jnp.ndarray)->State:
+"""Step function."""
+is_illegal=~state.legal_action_mask[action]
+current_player=state.current_player
+
+# If the state is already terminated or truncated, environment does not take usual step,
+# but return the same state with zero-rewards for all players
+state=jax.lax.cond(
+(state.terminated|state.truncated),
+lambda:state.replace(rewards=jnp.zeros_like(state.rewards)),# type: ignore
+lambda:self._step(state.replace(_step_count=state._step_count+1),action),# type: ignore
+)
+
+# Taking illegal action leads to immediate game terminal with negative reward
+state=jax.lax.cond(
+is_illegal,
+lambda:self._step_with_illegal_action(state,current_player),
+lambda:state,
+)
+
+# All legal_action_mask elements are **TRUE** at terminal state
+# This is to avoid zero-division error when normalizing action probability
+# Taking any action at terminal state does not give any effect to the state
+state=jax.lax.cond(
+state.terminated,
+lambda:state.replace(# type: ignore
+legal_action_mask=jnp.ones_like(state.legal_action_mask)
+),
+lambda:state,
+)
+
+observation=self.observe(state,state.current_player)
+state=state.replace(observation=observation)# type: ignore
+
+returnstate
+
Hyphen - is used to represent that there is a different original game source (e.g., MinAtar), and underscore - is used for the other cases.
+
+
+
+
+
+
+
+
+pgx.make(env_id)
+
+
+
+
+
+
+
Load the specified environment.
+
+
Example usage
+
env=pgx.make("tic_tac_toe")
+
+
+
+
BridgeBidding environment
+
BridgeBidding environment requires the domain knowledge of bridge game.
+So we forbid users to load the bridge environment by make("bridge_bidding").
+Use BridgeBidding class directly by from pgx.bridge_bidding import BridgeBidding.
defmake(env_id:EnvId):# noqa: C901
+"""Load the specified environment.
+
+ !!! example "Example usage"
+
+ ```py
+ env = pgx.make("tic_tac_toe")
+ ```
+
+ !!! note "`BridgeBidding` environment"
+
+ `BridgeBidding` environment requires the domain knowledge of bridge game.
+ So we forbid users to load the bridge environment by `make("bridge_bidding")`.
+ Use `BridgeBidding` class directly by `from pgx.bridge_bidding import BridgeBidding`.
+
+ """
+# NOTE: BridgeBidding environment requires the domain knowledge of bridge
+# So we forbid users to load the bridge environment by `make("bridge_bidding")`.
+ifenv_id=="2048":
+frompgx.play2048importPlay2048
+
+returnPlay2048()
+elifenv_id=="animal_shogi":
+frompgx.animal_shogiimportAnimalShogi
+
+returnAnimalShogi()
+elifenv_id=="backgammon":
+frompgx.backgammonimportBackgammon
+
+returnBackgammon()
+elifenv_id=="chess":
+frompgx.chessimportChess
+
+returnChess()
+elifenv_id=="connect_four":
+frompgx.connect_fourimportConnectFour
+
+returnConnectFour()
+elifenv_id=="gardner_chess":
+frompgx.gardner_chessimportGardnerChess
+
+returnGardnerChess()
+elifenv_id=="go_9x9":
+frompgx.goimportGo
+
+returnGo(size=9,komi=7.5)
+elifenv_id=="go_19x19":
+frompgx.goimportGo
+
+returnGo(size=19,komi=7.5)
+elifenv_id=="hex":
+frompgx.heximportHex
+
+returnHex()
+elifenv_id=="kuhn_poker":
+frompgx.kuhn_pokerimportKuhnPoker
+
+returnKuhnPoker()
+elifenv_id=="leduc_holdem":
+frompgx.leduc_holdemimportLeducHoldem
+
+returnLeducHoldem()
+elifenv_id=="minatar-asterix":
+try:
+frompgx_minatar.asteriximportMinAtarAsterix# type: ignore
+
+returnMinAtarAsterix()
+exceptModuleNotFoundError:
+print(
+'"minatar-asterix" environment is provided as a separate plugin of Pgx.\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',
+file=sys.stderr,
+)
+sys.exit(1)
+elifenv_id=="minatar-breakout":
+try:
+frompgx_minatar.breakoutimportMinAtarBreakout# type: ignore
+
+returnMinAtarBreakout()
+exceptModuleNotFoundError:
+print(
+'"minatar-breakout" environment is provided as a separate plugin of Pgx.\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',
+file=sys.stderr,
+)
+sys.exit(1)
+elifenv_id=="minatar-freeway":
+try:
+frompgx_minatar.freewayimportMinAtarFreeway# type: ignore
+
+returnMinAtarFreeway()
+exceptModuleNotFoundError:
+print(
+'"minatar-freeway" environment is provided as a separate plugin of Pgx.\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',
+file=sys.stderr,
+)
+sys.exit(1)
+elifenv_id=="minatar-seaquest":
+try:
+frompgx_minatar.seaquestimportMinAtarSeaquest# type: ignore
+
+returnMinAtarSeaquest()
+exceptModuleNotFoundError:
+print(
+'"minatar-seaquest" environment is provided as a separate plugin of Pgx.\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',
+file=sys.stderr,
+)
+sys.exit(1)
+elifenv_id=="minatar-space_invaders":
+try:
+frompgx_minatar.space_invadersimport(# type: ignore
+MinAtarSpaceInvaders,
+)
+
+returnMinAtarSpaceInvaders()
+exceptModuleNotFoundError:
+print(
+'"minatar-space_invaders" environment is provided as a separate plugin of Pgx.\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',
+file=sys.stderr,
+)
+sys.exit(1)
+elifenv_id=="othello":
+frompgx.othelloimportOthello
+
+returnOthello()
+elifenv_id=="shogi":
+frompgx.shogiimportShogi
+
+returnShogi()
+elifenv_id=="sparrow_mahjong":
+frompgx.sparrow_mahjongimportSparrowMahjong
+
+returnSparrowMahjong()
+elifenv_id=="tic_tac_toe":
+frompgx.tic_tac_toeimportTicTacToe
+
+returnTicTacToe()
+else:
+envs="\n".join(available_envs())
+raiseValueError(
+f"Wrong env_id '{env_id}' is passed. Available ids are: \n{envs}"
+)
+
+
+
+
+
+
+
+
+
+
+
+pgx.available_envs()
+
+
+
+
+
+
+
List up all environment id available in pgx.make function.
BridgeBidding environment requires the domain knowledge of bridge game.
+So we forbid users to load the bridge environment by make("bridge_bidding").
+Use BridgeBidding class directly by from pgx.bridge_bidding import BridgeBidding.
The first 28 observation dimensions follow [Antonoglou+22]:
+
+
An action in our implementation consists of 4 micro-actions, the same as the maximum number
+of dice a player can play at each turn. Each micro-action encodes the source position of a chip
+along with the value of the die used. We consider 26 possible source positions, with the 0-th position corresponding to a no-op, the 1st to retrieving a chip from the hit pile, and the remaining to selecting a chip in one of the 24 possible points. Each micro-action is encoded as a single integer with micro-action = src · 6 + die.
+
+
+
+
+
Index
+
Description
+
+
+
+
+
[:24]
+
represents
+
+
+
[24:28]
+
represents
+
+
+
[28:34]
+
is one-hot vector of playable dice
+
+
+
+
Action
+
...
+
Rewards
+
...
+
Termination
+
...
+
Version History
+
+
v0 : Initial release (v1.0.0)
+
+
Reference
+
+
[Antonoglou+22] "Planning in Stochastic Environments with a Learned Modell", ICLR
Connect Four is a two-player connection rack game, in which the players choose a color and then take turns dropping colored tokens into a seven-column, six-row vertically suspended grid. The pieces fall straight down, occupying the lowest available space within the column. The objective of the game is to be the first to form a horizontal, vertical, or diagonal line of four of one's own tokens.
importpgx
+
+env=pgx.make("go_19x19")# or "go_9x9"
+
+
or you can directly load Go class
+
frompgx.goimportGo
+
+env=Go(size=19,komi=6.5)
+
+
Description
+
+
Go is an abstract strategy board game for two players in which the aim is to surround more territory than the opponent. The game was invented in China more than 2,500 years ago and is believed to be the oldest board game continuously played to the present day.
By default, we use 6.5. Users can set different komi at Go class constructor.
+
+
+
Ko
+
On PSK implementations.
+
Tromp-Taylor rule employ PSK. However, implementing strict PSK is inefficient because
+
+
Simulator has to store all previous board (or hash) history, and
+
Agent also has to remember all previous board to avoid losing by PSK
+
+
As PSK rarely happens, as far as our best knowledge, it is usual to compromise in PSK implementations.
+For example,
+
+
OpenSpiel employs SSK (instead of PSK) for computing legal actions, and if PSK action happened, the game ends with tie.
+
Pros: Detect all PSK actions
+
Cons: Agent cannot know why the game ends with tie (if the same board is too old)
+
+
+
PettingZoo employs SSK for legal actions, and ignores even if PSK action happened.
+
Pros: Simple
+
Cons: PSK is totally ignored
+
+
+
+
Note that the strict rule is "PSK for legal actions, and PSK action leads to immediate lose."
+So, we also compromise at this point, our approach is
+
+
Pgx employs SSK for legal actions, PSK is approximated by up to 8-steps before board, and approximate PSK action leads to immediate lose
+
Pros: Agent may be able to avoid PSK (as it observes board history up to 8-steps in AlphaGo Zero feature)
+
Cons: Ignoring the old same boards
+
+
+
+
Anyway, we believe it's effect is very small as PSK rarely happens, especially in 19x19 board.
+
+
Specs
+
Let N be the board size (e.g., 19).
+
+
+
+
Name
+
Value
+
+
+
+
+
Version
+
v0
+
+
+
Number of players
+
2
+
+
+
Number of actions
+
N x N + 1
+
+
+
Observation shape
+
(N, N, 17)
+
+
+
Observation type
+
bool
+
+
+
Rewards
+
{-1, 1}
+
+
+
+
Observation
+
We follow the observation design of AlphaGo Zero [Silver+17].
+
+
+
+
Index
+
Description
+
+
+
+
+
obs[:, :, 0]
+
stones of player_id (@ current board)
+
+
+
obs[:, :, 1]
+
stones of player_id's opponent (@ current board)
+
+
+
obs[:, :, 2]
+
stones of player_id (@ 1-step before)
+
+
+
obs[:, :, 3]
+
stones of player_id's opponent (@ 1-step before)
+
+
+
...
+
...
+
+
+
obs[:, :, -1]
+
color of player_id
+
+
+
+
+
Final observation dimension
+
For the final dimension, there are two possible options:
+
+
Use the color of current player to play
+
Use the color of player_id
+
+
This ambiguity happens because observe function is available even if player_id is different from state.current_player.
+In AlphaGo Zero paper [Silver+17], the final dimension C is explained as:
+
+
The final feature plane, C, represents the colour to play, and has a constant value of either 1 if black
+ is to play or 0 if white is to play.
+
+
however, it also describes as
+
+
the colour feature C is necessary because the komi is not observable.
+
+
So, we use player_id's color to let the agent know komi information.
+As long as it's called when player_id == state.current_player, this doesn't matter.
+
+
Action
+
Each action ({0, ..., N * N - 1}) represents the point to be colored.
+The final action represents pass action.
+
Rewards
+
Non-zero rewards are given only at the terminal states.
+The reward at terminal state is described in this table:
+
+
+
+
+
Reward
+
+
+
+
+
Win
+
+1
+
+
+
Lose
+
-1
+
+
+
+
Termination
+
Termination happens when
+
+
either one plays two consecutive passes, or
+
N * N * 2 steps are elapsed [Silver+17].
+
+
Version History
+
+
v0 : Initial release (v1.0.0)
+
+
Reference
+
+
[Silver+17] "Mastering the game of go without human knowledge" Nature
Hex is a two player abstract strategy board game in which players attempt to connect opposite sides of a rhombus-shaped board made of hexagonal cells. Hex was invented by mathematician and poet Piet Hein in 1942 and later rediscovered and popularized by John Nash.
As the first player to move has a distinct advantage, the swap rule is used to compensate for this.
+The detailed swap rule used in Pgx follows swap pieces:
+
+
"Swap pieces": The players perform the swap by switching pieces. This means the initial red piece is replaced by a blue piece in the mirror image position, where the mirroring takes place with respect to the board's long diagonal. For example, a red piece at a3 becomes a blue piece at c1. The players do not switch colours: Red stays Red and Blue stays Blue. After the swap, it is Red's turn.
Leduc hold’em is a simplified poker proposed in [Souhty+05].
+
Rules
+
We quote the description in [Souhty+05]:
+
+
Leduc Hold ’Em. We have also constructed a smaller
+version of hold ’em, which seeks to retain the strategic elements of the large game while keeping the size of the game
+tractable. In Leduc hold ’em, the deck consists of two suits
+with three cards in each suit. There are two rounds. In the
+first round a single private card is dealt to each player. In
+the second round a single board card is revealed. There is
+a two-bet maximum, with raise amounts of 2 and 4 in the
+first and second round, respectively. Both players start the
+first round with 1 already in the pot.
+
+
Figure 1: An example decision tree for a single betting
+round in poker with a two-bet maximum. Leaf nodes with
+open boxes continue to the next round, while closed boxes
+end the hand.
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
+
pip install pgx-minatar
+
+
Then, you can use the environment as follows:
+
importpgx
+
+env=pgx.make("minatar-asterix")
+
+
Description
+
MinAtar is originally proposed by [Young&Tian+19].
+The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Asterix environment is described as follows:
+
+
The player can move freely along the 4 cardinal directions. Enemies and treasure spawn from the sides. A reward of
++1 is given for picking up treasure. Termination occurs if the player makes contact with an enemy. Enemy and
+treasure direction are indicated by a trail channel. Difficulty is periodically increased by increasing the speed
+and spawn rate of enemies and treasure.
[Young&Tian+19] "Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments" arXiv:1903.03176
+
+
License
+
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
+
pip install pgx-minatar
+
+
Then, you can use the environment as follows:
+
importpgx
+
+env=pgx.make("minatar-breakout")
+
+
Description
+
MinAtar is originally proposed by [Young&Tian+19].
+The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Breakout environment is described as follows:
+
+
The player controls a paddle on the bottom of the screen and must bounce a ball tobreak 3 rows of bricks along the
+top of the screen. A reward of +1 is given for each brick broken by the ball. When all bricks are cleared another 3
+rows are added. The ball travels only along diagonals, when it hits the paddle it is bounced either to the left or
+right depending on the side of the paddle hit, when it hits a wall or brick it is reflected. Termination occurs when
+the ball hits the bottom of the screen. The balls direction is indicated by a trail channel.
[Young&Tian+19] "Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments" arXiv:1903.03176
+
+
License
+
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
+
pip install pgx-minatar
+
+
Then, you can use the environment as follows:
+
importpgx
+
+env=pgx.make("minatar-freeway")
+
+
Description
+
MinAtar is originally proposed by [Young&Tian+19].
+The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Freeway environment is described as follows:
+
+
The player begins at the bottom of the screen and motion is restricted to traveling up and down. Player speed is
+also restricted such that the player can only move every 3 frames. A reward of +1 is given when the player reaches
+the top of the screen, at which point the player is returned to the bottom. Cars travel horizontally on the screen
+and teleport to the other side when the edge is reached. When hit by a car, the player is returned to the bottom of
+the screen. Car direction and speed is indicated by 5 trail channels, the location of the trail gives direction
+while the specific channel indicates how frequently the car moves (from once every frame to once every 5 frames).
+Each time the player successfully reaches the top of the screen, the car speeds are randomized. Termination occurs
+after 2500 frames have elapsed.
[Young&Tian+19] "Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments" arXiv:1903.03176
+
+
LICENSE
+
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
+
pip install pgx-minatar
+
+
Then, you can use the environment as follows:
+
importpgx
+
+env=pgx.make("minatar-seaquest")
+
+
Description
+
MinAtar is originally proposed by [Young&Tian+19].
+The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Seaquest environment is described as follows:
+
+
The player controls a submarine consisting of two cells, front and back, to allow direction to be determined. The
+player can also fire bullets from the front of the submarine. Enemies consist of submarines and fish, distinguished
+by the fact that submarines shoot bullets and fish do not. A reward of +1 is given each time an enemy is struck by
+one of the player's bullets, at which point the enemy is also removed. There are also divers which the player can
+move onto to pick up, doing so increments a bar indicated by another channel along the bottom of the screen. The
+player also has a limited supply of oxygen indicated by another bar in another channel. Oxygen degrades over time,
+and is replenished whenever the player moves to the top of the screen as long as the player has at least one rescued
+diver on board. The player can carry a maximum of 6 divers. When surfacing with less than 6, one diver is removed.
+When surfacing with 6, all divers are removed and a reward is given for each active cell in the oxygen bar. Each
+time the player surfaces the difficulty is increased by increasing the spawn rate and movement speed of enemies.
+Termination occurs when the player is hit by an enemy fish, sub or bullet; or when oxygen reached 0; or when the
+player attempts to surface with no rescued divers. Enemy and diver directions are indicated by a trail channel
+active in their previous location to reduce partial observability.
[Young&Tian+19] "Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments" arXiv:1903.03176
+
+
LICENSE
+
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
MinAtar is originally proposed by [Young&Tian+19].
+The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Space Invaders environment is described as follows:
+
+
The player controls a cannon at the bottom of the screen and can shoot bullets upward at a cluster of aliens above.
+The aliens move across the screen until one of them hits the edge, at which point they all move down and switch
+directions. The current alien direction is indicated by 2 channels (one for left and one for right) one of which is
+active at the location of each alien. A reward of +1 is given each time an alien is shot, and that alien is also
+removed. The aliens will also shoot bullets back at the player. When few aliens are left, alien speed will begin to
+increase. When only one alien is left, it will move at one cell per frame. When a wave of aliens is fully cleared a
+new one will spawn which moves at a slightly faster speed than the last. Termination occurs when an alien or bullet
+hits the player.
[Young&Tian+19] "Minatar: An atari-inspired testbed for thorough and reproducible reinforcement learning experiments" arXiv:1903.03176
+
+
LICENSE
+
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
Othello, or differing in not having a defined starting position, Reversi, is a two-player zero-sum and perfect information abstract strategy board game, usually played on a board with 8 rows and 8 columns and a set of light and a dark turnable pieces for each side. The player's goal is to have a majority of their colored pieces showing at the end of the game, turning over as many of their opponent's pieces as possible. The dark player makes the first move from the starting position, alternating with the light player. Each player has to place a piece on the board such that there exists at least one straight (horizontal, vertical, or diagonal) occupied line of opponent pieces between the new piece and another own piece. After placing the piece, the side turns over (flips, captures) all opponent pieces lying on any straight lines between the new piece and any anchoring own pieces.
In our 2048 experiments we used a binary representation of the observation as an input to our model.
+Specifically, the 4 × 4 board was flattened into a single vector of size 16, and a binary representation
+of 31 bits for each number was obtained, for a total size of 496 numbers.
+
+
However, instaead of 496-d flat vector, we employ (4, 4, 31) vector.
+
+
+
+
Index
+
Description
+
+
+
+
+
[i, j, b]
+
represents that square (i, j) has a tile of 2 ^ b if b > 0
+
+
+
+
Action
+
Each action corresnponds to 0 (left), 1 (up), 2 (right), 3 (down).
+
Rewards
+
Sum of merged tiles.
+
Termination
+
If all squares are filled with tiles and no legal actions are available, the game terminates.
+
Version History
+
+
v0 : Initial release (v1.0.0)
+
+
Reference
+
+
[Antonoglou+22] "Planning in Stochastic Environments with a Learned Modell", ICLR
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
\ No newline at end of file
diff --git a/requirements.in b/requirements.in
new file mode 100644
index 000000000..bec300ca6
--- /dev/null
+++ b/requirements.in
@@ -0,0 +1,3 @@
+mkdocs
+mkdocstrings[python]
+markdown-include
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 000000000..a12290afc
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,63 @@
+#
+# This file is autogenerated by pip-compile with Python 3.9
+# by the following command:
+#
+# pip-compile requirements.in
+#
+click==8.1.3
+ # via mkdocs
+colorama==0.4.6
+ # via griffe
+ghp-import==2.1.0
+ # via mkdocs
+griffe==0.27.1
+ # via mkdocstrings-python
+jinja2==3.1.2
+ # via
+ # mkdocs
+ # mkdocstrings
+markdown==3.3.7
+ # via
+ # markdown-include
+ # mkdocs
+ # mkdocs-autorefs
+ # mkdocstrings
+ # pymdown-extensions
+markdown-include==0.8.1
+ # via -r requirements.in
+markupsafe==2.1.2
+ # via
+ # jinja2
+ # mkdocstrings
+mergedeep==1.3.4
+ # via mkdocs
+mkdocs==1.4.2
+ # via
+ # -r requirements.in
+ # mkdocs-autorefs
+ # mkdocstrings
+mkdocs-autorefs==0.4.1
+ # via mkdocstrings
+mkdocstrings[python]==0.21.2
+ # via
+ # -r requirements.in
+ # mkdocstrings-python
+mkdocstrings-python==0.9.0
+ # via mkdocstrings
+packaging==23.1
+ # via mkdocs
+pymdown-extensions==10.0
+ # via mkdocstrings
+python-dateutil==2.8.2
+ # via ghp-import
+pyyaml==6.0
+ # via
+ # mkdocs
+ # pymdown-extensions
+ # pyyaml-env-tag
+pyyaml-env-tag==0.1
+ # via mkdocs
+six==1.16.0
+ # via python-dateutil
+watchdog==3.0.0
+ # via mkdocs
diff --git a/search/search_index.json b/search/search_index.json
new file mode 100644
index 000000000..b31b4ac8e
--- /dev/null
+++ b/search/search_index.json
@@ -0,0 +1 @@
+{"config":{"lang":["en"],"separator":"[\\s\\-]+","pipeline":["stopWordFilter"]},"docs":[{"location":"","title":"Home","text":""},{"location":"#pgx-documentation","title":"Pgx Documentation","text":"
Animal Shogi (D\u014dbutsu sh\u014dgi) is a variant of shogi primarily developed for children. It consists of a 3x4 board and four types of pieces (five including promoted pieces). One of the rule differences from regular shogi is the Try Rule, where entering the opponent's territory with the king leads to victory.
See also Wikipedia
"},{"location":"animal_shogi/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 132 Observation shape (4, 3, 194) Observation type float Rewards {-1, 0, 1}"},{"location":"animal_shogi/#observation","title":"Observation","text":"Index Description [:, :, 0:5] my pieces on board [:, :, 5:10] opponent's pieces on board [:, :, 10:16] my hands [:, :, 16:22] opponent's hands [:, :, 22:24] repetitions ... ... [:, :, 193]player_id's turn' [:, :, 194] Elapsed timesteps (normalized to 1)"},{"location":"animal_shogi/#action","title":"Action","text":"
Uses AlphaZero like action label:
132 labels
Move: 8 x 12 (direction) x (source square)
Drop: 3 x 12 (drop piece type) x (destination square)
Base state class of all Pgx game environments. Basically an immutable (frozen) dataclass. A basic usage is generating via Env.init:
state = env.init(jax.random.PRNGKey(0))\n
and Env.step receives and returns this state class:
state = env.step(state, action)\n
Serialization via flax.struct.serialization is supported. There are 6 common attributes over all games:
Attributes:
Name Type Description current_playerjnp.ndarray
id of agent to play. Note that this does NOT represent the turn (e.g., black/white in Go). This ID is consistent over the parallel vmapped states.
observationjnp.ndarray
observation for the current state. Env.observe is called to compute.
rewardsjnp.ndarray
the i-th element indicates the intermediate reward for the agent with player-id i. If Env.step is called for a terminal state, the following state.rewards is zero for all players.
terminatedjnp.ndarray
denotes that the state is terminal state. Note that some environments (e.g., Go) have an max_termination_steps parameter inside and will terminate within a limited number of states (following AlphaGo).
truncatedjnp.ndarray
indicates that the episode ends with the reason other than termination. Note that current Pgx environments do not invoke truncation but users can use TimeLimit wrapper to truncate the environment. In Pgx environments, some MinAtar games may not terminate within a finite timestep. However, the other environments are supposed to terminate within a finite timestep with probability one.
legal_action_maskjnp.ndarray
Boolean array of legal actions. If illegal action is taken, the game will terminate immediately with the penalty to the palyer.
Source code in pgx/v1.py
@dataclass\nclass State(abc.ABC):\n\"\"\"Base state class of all Pgx game environments. Basically an immutable (frozen) dataclass.\n A basic usage is generating via `Env.init`:\n state = env.init(jax.random.PRNGKey(0))\n and `Env.step` receives and returns this state class:\n state = env.step(state, action)\n Serialization via `flax.struct.serialization` is supported.\n There are 6 common attributes over all games:\n Attributes:\n current_player (jnp.ndarray): id of agent to play.\n Note that this does NOT represent the turn (e.g., black/white in Go).\n This ID is consistent over the parallel vmapped states.\n observation (jnp.ndarray): observation for the current state.\n `Env.observe` is called to compute.\n rewards (jnp.ndarray): the `i`-th element indicates the intermediate reward for\n the agent with player-id `i`. If `Env.step` is called for a terminal state,\n the following `state.rewards` is zero for all players.\n terminated (jnp.ndarray): denotes that the state is terminal state. Note that\n some environments (e.g., Go) have an `max_termination_steps` parameter inside\n and will terminate within a limited number of states (following AlphaGo).\n truncated (jnp.ndarray): indicates that the episode ends with the reason other than termination.\n Note that current Pgx environments do not invoke truncation but users can use `TimeLimit` wrapper\n to truncate the environment. In Pgx environments, some MinAtar games may not terminate within a finite timestep.\n However, the other environments are supposed to terminate within a finite timestep with probability one.\n legal_action_mask (jnp.ndarray): Boolean array of legal actions. If illegal action is taken,\n the game will terminate immediately with the penalty to the palyer.\n \"\"\"\ncurrent_player: jnp.ndarray\nobservation: jnp.ndarray\nrewards: jnp.ndarray\nterminated: jnp.ndarray\ntruncated: jnp.ndarray\nlegal_action_mask: jnp.ndarray\n# NOTE: _rng_key is\n# - used for stochastic env and auto reset\n# - updated only when actually used\n# - supposed NOT to be used by agent\n_rng_key: jax.random.KeyArray\n_step_count: jnp.ndarray\n@property\n@abc.abstractmethod\ndef env_id(self) -> EnvId:\n\"\"\"Environment id (e.g. \"go_19x19\")\"\"\"\n...\ndef _repr_html_(self) -> str:\nreturn self.to_svg()\ndef to_svg(\nself,\n*,\ncolor_theme: Optional[Literal[\"light\", \"dark\"]] = None,\nscale: Optional[float] = None,\n) -> str:\n\"\"\"Return SVG string. Useful for visualization in notebook.\n Args:\n color_theme (Optional[Literal[\"light\", \"dark\"]]): xxx see also global config.\n scale (Optional[float]): change image size. Default(None) is 1.0\n Returns:\n str: SVG string\n \"\"\"\nfrom pgx._src.visualizer import Visualizer\nv = Visualizer(color_theme=color_theme, scale=scale)\nreturn v.get_dwg(states=self).tostring()\ndef save_svg(\nself,\nfilename,\n*,\ncolor_theme: Optional[Literal[\"light\", \"dark\"]] = None,\nscale: Optional[float] = None,\n) -> None:\n\"\"\"Save the entire state (not observation) to a file.\n The filename must end with `.svg`\n Args:\n color_theme (Optional[Literal[\"light\", \"dark\"]]): xxx see also global config.\n scale (Optional[float]): change image size. Default(None) is 1.0\n Returns:\n None\n \"\"\"\nfrom pgx._src.visualizer import save_svg\nsave_svg(self, filename, color_theme=color_theme, scale=scale)\n
Save the entire state (not observation) to a file. The filename must end with .svg
Parameters:
Name Type Description Default color_themeOptional[Literal['light', 'dark']]
xxx see also global config.
NonescaleOptional[float]
change image size. Default(None) is 1.0
None
Returns:
Type Description None
None
Source code in pgx/v1.py
def save_svg(\nself,\nfilename,\n*,\ncolor_theme: Optional[Literal[\"light\", \"dark\"]] = None,\nscale: Optional[float] = None,\n) -> None:\n\"\"\"Save the entire state (not observation) to a file.\n The filename must end with `.svg`\n Args:\n color_theme (Optional[Literal[\"light\", \"dark\"]]): xxx see also global config.\n scale (Optional[float]): change image size. Default(None) is 1.0\n Returns:\n None\n \"\"\"\nfrom pgx._src.visualizer import save_svg\nsave_svg(self, filename, color_theme=color_theme, scale=scale)\n
class Env(abc.ABC):\n\"\"\"Environment class API.\n !!! example \"Example usage\"\n ```py\n env: Env = pgx.make(\"tic_tac_toe\")\n state = env.init(jax.random.PRNGKey(0))\n action = jax.random.int32(4)\n state = env.step(state, action)\n ```\n \"\"\"\ndef __init__(self):\n...\ndef init(self, key: jax.random.KeyArray) -> State:\n\"\"\"Return the initial state. Note that no internal state of\n environment changes.\n Args:\n key: pseudo-random generator key in JAX\n Returns:\n State: initial state of environment\n \"\"\"\nkey, subkey = jax.random.split(key)\nstate = self._init(subkey)\nstate = state.replace(_rng_key=key) # type: ignore\nobservation = self.observe(state, state.current_player)\nreturn state.replace(observation=observation) # type: ignore\ndef step(self, state: State, action: jnp.ndarray) -> State:\n\"\"\"Step function.\"\"\"\nis_illegal = ~state.legal_action_mask[action]\ncurrent_player = state.current_player\n# If the state is already terminated or truncated, environment does not take usual step,\n# but return the same state with zero-rewards for all players\nstate = jax.lax.cond(\n(state.terminated | state.truncated),\nlambda: state.replace(rewards=jnp.zeros_like(state.rewards)), # type: ignore\nlambda: self._step(state.replace(_step_count=state._step_count + 1), action), # type: ignore\n)\n# Taking illegal action leads to immediate game terminal with negative reward\nstate = jax.lax.cond(\nis_illegal,\nlambda: self._step_with_illegal_action(state, current_player),\nlambda: state,\n)\n# All legal_action_mask elements are **TRUE** at terminal state\n# This is to avoid zero-division error when normalizing action probability\n# Taking any action at terminal state does not give any effect to the state\nstate = jax.lax.cond(\nstate.terminated,\nlambda: state.replace( # type: ignore\nlegal_action_mask=jnp.ones_like(state.legal_action_mask)\n),\nlambda: state,\n)\nobservation = self.observe(state, state.current_player)\nstate = state.replace(observation=observation) # type: ignore\nreturn state\ndef observe(self, state: State, player_id: jnp.ndarray) -> jnp.ndarray:\n\"\"\"Observation function.\"\"\"\nobs = self._observe(state, player_id)\nreturn jax.lax.stop_gradient(obs)\n@abc.abstractmethod\ndef _init(self, key: jax.random.KeyArray) -> State:\n\"\"\"Implement game-specific init function here.\"\"\"\n...\n@abc.abstractmethod\ndef _step(self, state, action) -> State:\n\"\"\"Implement game-specific step function here.\"\"\"\n...\n@abc.abstractmethod\ndef _observe(self, state: State, player_id: jnp.ndarray) -> jnp.ndarray:\n\"\"\"Implement game-specific observe function here.\"\"\"\n...\n@property\n@abc.abstractmethod\ndef id(self) -> EnvId:\n\"\"\"Environment id.\"\"\"\n...\n@property\n@abc.abstractmethod\ndef version(self) -> str:\n\"\"\"Environment version. Updated when behavior, parameter, or API is changed.\n Refactoring or speeding up without any expected behavior changes will NOT update the version number.\n \"\"\"\n...\n@property\n@abc.abstractmethod\ndef num_players(self) -> int:\n\"\"\"Number of players (e.g., 2 in Tic-tac-toe)\"\"\"\n...\n@property\ndef num_actions(self) -> int:\n\"\"\"Return the size of action space (e.g., 9 in Tic-tac-toe)\"\"\"\nstate = self.init(jax.random.PRNGKey(0))\nreturn int(state.legal_action_mask.shape[0])\n@property\ndef observation_shape(self) -> Tuple[int, ...]:\n\"\"\"Return the matrix shape of observation\"\"\"\nstate = self.init(jax.random.PRNGKey(0))\nobs = self._observe(state, state.current_player)\nreturn obs.shape\n@property\ndef _illegal_action_penalty(self) -> float:\n\"\"\"Negative reward given when illegal action is selected.\"\"\"\nreturn -1.0\ndef _step_with_illegal_action(\nself, state: State, loser: jnp.ndarray\n) -> State:\npenalty = self._illegal_action_penalty\nreward = (\njnp.ones_like(state.rewards)\n* (-1 * penalty)\n* (self.num_players - 1)\n)\nreward = reward.at[loser].set(penalty)\nreturn state.replace(rewards=reward, terminated=TRUE) # type: ignore\n
Environment version. Updated when behavior, parameter, or API is changed. Refactoring or speeding up without any expected behavior changes will NOT update the version number.
def step(self, state: State, action: jnp.ndarray) -> State:\n\"\"\"Step function.\"\"\"\nis_illegal = ~state.legal_action_mask[action]\ncurrent_player = state.current_player\n# If the state is already terminated or truncated, environment does not take usual step,\n# but return the same state with zero-rewards for all players\nstate = jax.lax.cond(\n(state.terminated | state.truncated),\nlambda: state.replace(rewards=jnp.zeros_like(state.rewards)), # type: ignore\nlambda: self._step(state.replace(_step_count=state._step_count + 1), action), # type: ignore\n)\n# Taking illegal action leads to immediate game terminal with negative reward\nstate = jax.lax.cond(\nis_illegal,\nlambda: self._step_with_illegal_action(state, current_player),\nlambda: state,\n)\n# All legal_action_mask elements are **TRUE** at terminal state\n# This is to avoid zero-division error when normalizing action probability\n# Taking any action at terminal state does not give any effect to the state\nstate = jax.lax.cond(\nstate.terminated,\nlambda: state.replace( # type: ignore\nlegal_action_mask=jnp.ones_like(state.legal_action_mask)\n),\nlambda: state,\n)\nobservation = self.observe(state, state.current_player)\nstate = state.replace(observation=observation) # type: ignore\nreturn state\n
BridgeBidding environment requires the domain knowledge of bridge game. So we forbid users to load the bridge environment by make(\"bridge_bidding\"). Use BridgeBidding class directly by from pgx.bridge_bidding import BridgeBidding.
Source code in pgx/v1.py
def make(env_id: EnvId): # noqa: C901\n\"\"\"Load the specified environment.\n !!! example \"Example usage\"\n ```py\n env = pgx.make(\"tic_tac_toe\")\n ```\n !!! note \"`BridgeBidding` environment\"\n `BridgeBidding` environment requires the domain knowledge of bridge game.\n So we forbid users to load the bridge environment by `make(\"bridge_bidding\")`.\n Use `BridgeBidding` class directly by `from pgx.bridge_bidding import BridgeBidding`.\n \"\"\"\n# NOTE: BridgeBidding environment requires the domain knowledge of bridge\n# So we forbid users to load the bridge environment by `make(\"bridge_bidding\")`.\nif env_id == \"2048\":\nfrom pgx.play2048 import Play2048\nreturn Play2048()\nelif env_id == \"animal_shogi\":\nfrom pgx.animal_shogi import AnimalShogi\nreturn AnimalShogi()\nelif env_id == \"backgammon\":\nfrom pgx.backgammon import Backgammon\nreturn Backgammon()\nelif env_id == \"chess\":\nfrom pgx.chess import Chess\nreturn Chess()\nelif env_id == \"connect_four\":\nfrom pgx.connect_four import ConnectFour\nreturn ConnectFour()\nelif env_id == \"gardner_chess\":\nfrom pgx.gardner_chess import GardnerChess\nreturn GardnerChess()\nelif env_id == \"go_9x9\":\nfrom pgx.go import Go\nreturn Go(size=9, komi=7.5)\nelif env_id == \"go_19x19\":\nfrom pgx.go import Go\nreturn Go(size=19, komi=7.5)\nelif env_id == \"hex\":\nfrom pgx.hex import Hex\nreturn Hex()\nelif env_id == \"kuhn_poker\":\nfrom pgx.kuhn_poker import KuhnPoker\nreturn KuhnPoker()\nelif env_id == \"leduc_holdem\":\nfrom pgx.leduc_holdem import LeducHoldem\nreturn LeducHoldem()\nelif env_id == \"minatar-asterix\":\ntry:\nfrom pgx_minatar.asterix import MinAtarAsterix # type: ignore\nreturn MinAtarAsterix()\nexcept ModuleNotFoundError:\nprint(\n'\"minatar-asterix\" environment is provided as a separate plugin of Pgx.\\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',\nfile=sys.stderr,\n)\nsys.exit(1)\nelif env_id == \"minatar-breakout\":\ntry:\nfrom pgx_minatar.breakout import MinAtarBreakout # type: ignore\nreturn MinAtarBreakout()\nexcept ModuleNotFoundError:\nprint(\n'\"minatar-breakout\" environment is provided as a separate plugin of Pgx.\\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',\nfile=sys.stderr,\n)\nsys.exit(1)\nelif env_id == \"minatar-freeway\":\ntry:\nfrom pgx_minatar.freeway import MinAtarFreeway # type: ignore\nreturn MinAtarFreeway()\nexcept ModuleNotFoundError:\nprint(\n'\"minatar-freeway\" environment is provided as a separate plugin of Pgx.\\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',\nfile=sys.stderr,\n)\nsys.exit(1)\nelif env_id == \"minatar-seaquest\":\ntry:\nfrom pgx_minatar.seaquest import MinAtarSeaquest # type: ignore\nreturn MinAtarSeaquest()\nexcept ModuleNotFoundError:\nprint(\n'\"minatar-seaquest\" environment is provided as a separate plugin of Pgx.\\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',\nfile=sys.stderr,\n)\nsys.exit(1)\nelif env_id == \"minatar-space_invaders\":\ntry:\nfrom pgx_minatar.space_invaders import ( # type: ignore\nMinAtarSpaceInvaders,\n)\nreturn MinAtarSpaceInvaders()\nexcept ModuleNotFoundError:\nprint(\n'\"minatar-space_invaders\" environment is provided as a separate plugin of Pgx.\\nPlease run `$ pip install pgx-minatar` to use this environment in Pgx.',\nfile=sys.stderr,\n)\nsys.exit(1)\nelif env_id == \"othello\":\nfrom pgx.othello import Othello\nreturn Othello()\nelif env_id == \"shogi\":\nfrom pgx.shogi import Shogi\nreturn Shogi()\nelif env_id == \"sparrow_mahjong\":\nfrom pgx.sparrow_mahjong import SparrowMahjong\nreturn SparrowMahjong()\nelif env_id == \"tic_tac_toe\":\nfrom pgx.tic_tac_toe import TicTacToe\nreturn TicTacToe()\nelse:\nenvs = \"\\n\".join(available_envs())\nraise ValueError(\nf\"Wrong env_id '{env_id}' is passed. Available ids are: \\n{envs}\"\n)\n
BridgeBidding environment requires the domain knowledge of bridge game. So we forbid users to load the bridge environment by make(\"bridge_bidding\"). Use BridgeBidding class directly by from pgx.bridge_bidding import BridgeBidding.
Source code in pgx/v1.py
def available_envs() -> Tuple[EnvId, ...]:\n\"\"\"List up all environment id available in `pgx.make` function.\n !!! example \"Example usage\"\n ```py\n pgx.available_envs()\n ('2048', 'animal_shogi', 'backgammon', 'chess', 'connect_four', 'go_9x9', 'go_19x19', 'hex', 'kuhn_poker', 'leduc_holdem', 'minatar-asterix', 'minatar-breakout', 'minatar-freeway', 'minatar-seaquest', 'minatar-space_invaders', 'othello', 'shogi', 'sparrow_mahjong', 'tic_tac_toe')\n ```\n !!! note \"`BridgeBidding` environment\"\n `BridgeBidding` environment requires the domain knowledge of bridge game.\n So we forbid users to load the bridge environment by `make(\"bridge_bidding\")`.\n Use `BridgeBidding` class directly by `from pgx.bridge_bidding import BridgeBidding`.\n \"\"\"\ngames = get_args(EnvId)\ngames = tuple(filter(lambda x: x != \"bridge_bidding\", games))\nreturn games\n
"},{"location":"api/#pgx.set_visualization_config","title":"pgx.set_visualization_config(*, color_theme='light', scale=1.0, frame_duration_seconds=0.2)","text":"Source code in pgx/_src/visualizer.py
"},{"location":"backgammon/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 162 (= 6 * 26 + 6) Observation shape (34,) Observation type int Rewards {-3, -2, -1, 0, 1, 2, 3}"},{"location":"backgammon/#observation","title":"Observation","text":"
The first 28 observation dimensions follow [Antonoglou+22]:
An action in our implementation consists of 4 micro-actions, the same as the maximum number of dice a player can play at each turn. Each micro-action encodes the source position of a chip along with the value of the die used. We consider 26 possible source positions, with the 0-th position corresponding to a no-op, the 1st to retrieving a chip from the hit pile, and the remaining to selecting a chip in one of the 24 possible points. Each micro-action is encoded as a single integer with micro-action = src \u00b7 6 + die.
Index Description [:24] represents [24:28] represents [28:34] is one-hot vector of playable dice"},{"location":"backgammon/#action","title":"Action","text":"
"},{"location":"chess/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 4672 Observation shape (8, 8, 119) Observation type float Rewards {-1, 0, 1}"},{"location":"chess/#observation","title":"Observation","text":"
We follow the observation design of AlphaZero [Silver+18].
Index Description TBA TBA"},{"location":"chess/#action","title":"Action","text":"
Connect Four is a two-player connection rack game, in which the players choose a color and then take turns dropping colored tokens into a seven-column, six-row vertically suspended grid. The pieces fall straight down, occupying the lowest available space within the column. The objective of the game is to be the first to form a horizontal, vertical, or diagonal line of four of one's own tokens.
Wikipedia
"},{"location":"connect_four/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 7 Observation shape (6, 7, 2) Observation type bool Rewards {-1, 0, 1}"},{"location":"connect_four/#observation","title":"Observation","text":"Index Description [:, :, 0] represents (6, 7) squares filled by the current player [:, :, 1] represents (6, 7) squares filled by the opponent player of current player"},{"location":"connect_four/#action","title":"Action","text":"
Each action represents the column index the player drops the token to.
"},{"location":"gardner_chess/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 1225 Observation shape (5, 5, 115) Observation type float Rewards {-1, 0, 1}"},{"location":"gardner_chess/#observation","title":"Observation","text":"
We follow the observation design of AlphaZero [Silver+18].
Index Description TBA TBA"},{"location":"gardner_chess/#action","title":"Action","text":"
Go is an abstract strategy board game for two players in which the aim is to surround more territory than the opponent. The game was invented in China more than 2,500 years ago and is believed to be the oldest board game continuously played to the present day.
Name Value Version v0 Number of players 2 Number of actions N x N + 1 Observation shape (N, N, 17) Observation type bool Rewards {-1, 1}"},{"location":"go/#observation","title":"Observation","text":"
We follow the observation design of AlphaGo Zero [Silver+17].
Index Description obs[:, :, 0] stones of player_id (@ current board) obs[:, :, 1] stones of player_id's opponent (@ current board) obs[:, :, 2] stones of player_id (@ 1-step before) obs[:, :, 3] stones of player_id's opponent (@ 1-step before) ... ... obs[:, :, -1] color of player_id
Final observation dimension
For the final dimension, there are two possible options:
Use the color of current player to play
Use the color of player_id
This ambiguity happens because observe function is available even if player_id is different from state.current_player. In AlphaGo Zero paper [Silver+17], the final dimension C is explained as:
The final feature plane, C, represents the colour to play, and has a constant value of either 1 if black is to play or 0 if white is to play.
however, it also describes as
the colour feature C is necessary because the komi is not observable.
So, we use player_id's color to let the agent know komi information. As long as it's called when player_id == state.current_player, this doesn't matter.
Hex is a two player abstract strategy board game in which players attempt to connect opposite sides of a rhombus-shaped board made of hexagonal cells. Hex was invented by mathematician and poet Piet Hein in 1942 and later rediscovered and popularized by John Nash.
As the first player to move has a distinct advantage, the swap rule is used to compensate for this. The detailed swap rule used in Pgx follows swap pieces:
\"Swap pieces\": The players perform the swap by switching pieces. This means the initial red piece is replaced by a blue piece in the mirror image position, where the mirroring takes place with respect to the board's long diagonal. For example, a red piece at a3 becomes a blue piece at c1. The players do not switch colours: Red stays Red and Blue stays Blue. After the swap, it is Red's turn.
Hex Wiki - Swap rule
"},{"location":"hex/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 122 (= 11 x 11) + 1 Observation shape (11, 11, 3) Observation type bool Rewards {-1, 1}"},{"location":"hex/#observation","title":"Observation","text":"Index Description [:, :, 0] represents (11, 11) cells filled by player_ix[:, :, 1] represents (11, 11) cells filled by the opponent player of player_id[:, :, 2] represents whether player_id is black or white"},{"location":"hex/#action","title":"Action","text":"
Each action ({0, ... 120}) represents the cell index to be filled. The final action 121 is the swap action available only at the second turn.
"},{"location":"kuhn_poker/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 4 Observation shape (7,) Observation type bool Rewards {-2, -1, +1, +2}"},{"location":"kuhn_poker/#observation","title":"Observation","text":"Index Description [0] One if J in my hand [1] One if Q in my hand [2] One if K in my hand [3] One if 0 chip is bet by me [4] One if 1 chip is bet by me [5] One if 0 chip of the opponent [6] One if 1 chip of the opponent"},{"location":"kuhn_poker/#action","title":"Action","text":"
There are four distinct actions.
Action Index Call 0 Bet 1 Fold 2 Check 3"},{"location":"kuhn_poker/#rewards","title":"Rewards","text":"
The winner takes +2 or +1 depending on the game payoff. As Kuhn poker is zero-sum game, the loser takes -2 or -1 respectively.
Leduc Hold \u2019Em. We have also constructed a smaller version of hold \u2019em, which seeks to retain the strategic elements of the large game while keeping the size of the game tractable. In Leduc hold \u2019em, the deck consists of two suits with three cards in each suit. There are two rounds. In the first round a single private card is dealt to each player. In the second round a single board card is revealed. There is a two-bet maximum, with raise amounts of 2 and 4 in the first and second round, respectively. Both players start the first round with 1 already in the pot.
Figure 1: An example decision tree for a single betting round in poker with a two-bet maximum. Leaf nodes with open boxes continue to the next round, while closed boxes end the hand.
"},{"location":"leduc_holdem/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 4 Observation shape (7,) Observation type bool Rewards {-13, -12, ... 0, ..., 12, 13}"},{"location":"leduc_holdem/#observation","title":"Observation","text":"Index Description [0] True if J in hand [1] True if Q in hand [2] True if K in hand [3] True if J is the public card [4] True if J is the public card [5] True if J is the public card [6:19] represent my chip count (0, ..., 13) [20:33] represent opponent's chip count (0, ..., 13)"},{"location":"leduc_holdem/#action","title":"Action","text":"
There are four distinct actions.
Index Action 0 Call 1 Raise 2 Fold"},{"location":"leduc_holdem/#rewards","title":"Rewards","text":"
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
MinAtar is originally proposed by [Young&Tian+19]. The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Asterix environment is described as follows:
The player can move freely along the 4 cardinal directions. Enemies and treasure spawn from the sides. A reward of +1 is given for picking up treasure. Termination occurs if the player makes contact with an enemy. Enemy and treasure direction are indicated by a trail channel. Difficulty is periodically increased by increasing the speed and spawn rate of enemies and treasure.
github.com/kenjyoung/MinAtar - asterix.py
"},{"location":"minatar_asterix/#specs","title":"Specs","text":"Name Value Version v0 Number of players 1 Number of actions 5 Observation shape (10, 10, 4) Observation type bool Rewards {0, 1}"},{"location":"minatar_asterix/#observation","title":"Observation","text":"Index Channel [:, :, 0] Player [:, :, 1] Enemy [:, :, 2] Trail [:, :, 3] Gold"},{"location":"minatar_asterix/#action","title":"Action","text":"
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
MinAtar is originally proposed by [Young&Tian+19]. The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Breakout environment is described as follows:
The player controls a paddle on the bottom of the screen and must bounce a ball tobreak 3 rows of bricks along the top of the screen. A reward of +1 is given for each brick broken by the ball. When all bricks are cleared another 3 rows are added. The ball travels only along diagonals, when it hits the paddle it is bounced either to the left or right depending on the side of the paddle hit, when it hits a wall or brick it is reflected. Termination occurs when the ball hits the bottom of the screen. The balls direction is indicated by a trail channel.
github.com/kenjyoung/MinAtar - breakout.py
"},{"location":"minatar_breakout/#specs","title":"Specs","text":"Name Value Version v0 Number of players 1 Number of actions 3 Observation shape (10, 10, 4) Observation type bool Rewards {0, 1}"},{"location":"minatar_breakout/#observation","title":"Observation","text":"Index Channel [:, :, 0] Paddle [:, :, 1] Ball [:, :, 2] Trail [:, :, 3] Brick"},{"location":"minatar_breakout/#action","title":"Action","text":"
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
MinAtar is originally proposed by [Young&Tian+19]. The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Freeway environment is described as follows:
The player begins at the bottom of the screen and motion is restricted to traveling up and down. Player speed is also restricted such that the player can only move every 3 frames. A reward of +1 is given when the player reaches the top of the screen, at which point the player is returned to the bottom. Cars travel horizontally on the screen and teleport to the other side when the edge is reached. When hit by a car, the player is returned to the bottom of the screen. Car direction and speed is indicated by 5 trail channels, the location of the trail gives direction while the specific channel indicates how frequently the car moves (from once every frame to once every 5 frames). Each time the player successfully reaches the top of the screen, the car speeds are randomized. Termination occurs after 2500 frames have elapsed.
github.com/kenjyoung/MinAtar - freeway.py
"},{"location":"minatar_freeway/#specs","title":"Specs","text":"Name Value Version v0 Number of players 1 Number of actions 3 Observation shape (10, 10, 7) Observation type bool Rewards {0, 1}"},{"location":"minatar_freeway/#observation","title":"Observation","text":"Index Channel [:, :, 0] Chicken [:, :, 1] Car [:, :, 2] Speed 1 [:, :, 3] Speed 2 [:, :, 4] Speed 3 [:, :, 5] Speed 4"},{"location":"minatar_freeway/#action","title":"Action","text":"
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
MinAtar is originally proposed by [Young&Tian+19]. The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Seaquest environment is described as follows:
The player controls a submarine consisting of two cells, front and back, to allow direction to be determined. The player can also fire bullets from the front of the submarine. Enemies consist of submarines and fish, distinguished by the fact that submarines shoot bullets and fish do not. A reward of +1 is given each time an enemy is struck by one of the player's bullets, at which point the enemy is also removed. There are also divers which the player can move onto to pick up, doing so increments a bar indicated by another channel along the bottom of the screen. The player also has a limited supply of oxygen indicated by another bar in another channel. Oxygen degrades over time, and is replenished whenever the player moves to the top of the screen as long as the player has at least one rescued diver on board. The player can carry a maximum of 6 divers. When surfacing with less than 6, one diver is removed. When surfacing with 6, all divers are removed and a reward is given for each active cell in the oxygen bar. Each time the player surfaces the difficulty is increased by increasing the spawn rate and movement speed of enemies. Termination occurs when the player is hit by an enemy fish, sub or bullet; or when oxygen reached 0; or when the player attempts to surface with no rescued divers. Enemy and diver directions are indicated by a trail channel active in their previous location to reduce partial observability.
github.com/kenjyoung/MinAtar - seaquest.py
"},{"location":"minatar_seaquest/#specs","title":"Specs","text":"Name Value Version v0 Number of players 1 Number of actions 6 Observation shape (10, 10, 10) Observation type bool Rewards {0, 1, ..., 10}"},{"location":"minatar_seaquest/#observation","title":"Observation","text":"Index Channel [:, :, 0] Player submarine (front) [:, :, 1] Player submarine (back) [:, :, 2] Friendly bullet [:, :, 3] Trail [:, :, 4] Enemy bullet [:, :, 5] Enemy fish [:, :, 6] Enemy submarine [:, :, 7] Oxygen guage [:, :, 8] Diver guage [:, :, 9] Diver"},{"location":"minatar_seaquest/#action","title":"Action","text":"
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
"},{"location":"minatar_space_invaders/","title":"MinAtar Space Invaders","text":""},{"location":"minatar_space_invaders/#usage","title":"Usage","text":"
Note that the MinAtar suite is provided as a separate extension for Pgx (pgx-minatar). Therefore, please run the following command additionaly to use the MinAtar suite in Pgx:
MinAtar is originally proposed by [Young&Tian+19]. The Pgx implementation is intended to be the exact copy of the original MinAtar implementation in JAX. The Space Invaders environment is described as follows:
The player controls a cannon at the bottom of the screen and can shoot bullets upward at a cluster of aliens above. The aliens move across the screen until one of them hits the edge, at which point they all move down and switch directions. The current alien direction is indicated by 2 channels (one for left and one for right) one of which is active at the location of each alien. A reward of +1 is given each time an alien is shot, and that alien is also removed. The aliens will also shoot bullets back at the player. When few aliens are left, alien speed will begin to increase. When only one alien is left, it will move at one cell per frame. When a wave of aliens is fully cleared a new one will spawn which moves at a slightly faster speed than the last. Termination occurs when an alien or bullet hits the player.
github.com/kenjyoung/MinAtar - space_invaders.py
"},{"location":"minatar_space_invaders/#specs","title":"Specs","text":"Name Value Version v0 Number of players 1 Number of actions 4 Observation shape (10, 10, 6) Observation type bool Rewards {0, 1}"},{"location":"minatar_space_invaders/#observation","title":"Observation","text":"Index Channel [:, :, 0] Cannon [:, :, 1] Alien [:, :, 2] Alien left [:, :, 3] Alien right [:, :, 4] Friendly bullet [:, :, 5] Enemy bullet"},{"location":"minatar_space_invaders/#action","title":"Action","text":"
Pgx is provided under the Apache 2.0 License, but the original MinAtar suite follows the GPL 3.0 License. Therefore, please note that the separated MinAtar extension for Pgx also adheres to the GPL 3.0 License.
Othello, or differing in not having a defined starting position, Reversi, is a two-player zero-sum and perfect information abstract strategy board game, usually played on a board with 8 rows and 8 columns and a set of light and a dark turnable pieces for each side. The player's goal is to have a majority of their colored pieces showing at the end of the game, turning over as many of their opponent's pieces as possible. The dark player makes the first move from the starting position, alternating with the light player. Each player has to place a piece on the board such that there exists at least one straight (horizontal, vertical, or diagonal) occupied line of opponent pieces between the new piece and another own piece. After placing the piece, the side turns over (flips, captures) all opponent pieces lying on any straight lines between the new piece and any anchoring own pieces.
Chess Programming Wiki
"},{"location":"othello/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 65 (= 8 x 8 + 1) Observation shape (8, 8, 2) Observation type bool Rewards {-1, 0, 1}"},{"location":"othello/#observation","title":"Observation","text":"Index Description [:, :, 0] represents (8, 8) squares colored by the current player [:, :, 1] represents (8, 8) squares colored by the opponent player of current player"},{"location":"othello/#action","title":"Action","text":"
Each action ({0, ..., 63}) represents the square index to be filled. The last 64-th action represents pass action.
"},{"location":"play2048/#specs","title":"Specs","text":"Name Value Version v0 Number of players 1 Number of actions 4 Observation shape (4, 4, 31) Observation type bool Rewards {0, 2, 4, ...}"},{"location":"play2048/#observation","title":"Observation","text":"
In our 2048 experiments we used a binary representation of the observation as an input to our model. Specifically, the 4 \u00d7 4 board was flattened into a single vector of size 16, and a binary representation of 31 bits for each number was obtained, for a total size of 496 numbers.
However, instaead of 496-d flat vector, we employ (4, 4, 31) vector.
Index Description [i, j, b] represents that square (i, j) has a tile of 2 ^ b if b > 0"},{"location":"play2048/#action","title":"Action","text":"
Each action corresnponds to 0 (left), 1 (up), 2 (right), 3 (down).
"},{"location":"shogi/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 2187 Observation shape (9, 9, 119) Observation type bool Rewards {-1, 0, 1}"},{"location":"shogi/#observation","title":"Observation","text":"
We follow the observation design of dlshogi, an open-source shogi AI. Ther original dlshogi implementations are here. Pgx implementation has [9, 9, 119] shape and [:, :, x] denotes:
x Description 0:14 Where my piece x exists 14:28 Where my pieces x are attacking 28:31 Where the number of my attacking pieces are >= 1,2,3 respectively 31:45 Where opponent's piece x exists 45:59 Where opponent's pieces x are attacking 59:62 Where the number of opponent's attacking pieces are >= 1,2,3 respectively
The following planes are all ones ore zeros
x Description 62:70 My hand has >= 1, ..., 8 Pawn 70:74 My hand has >= 1, 2, 3, 4 Lance 74:78 My hand has >= 1, 2, 3, 4 Knight 78:82 My hand has >= 1, 2, 3, 4 Silver 82:86 My hand has >= 1, 2, 3, 4 Gold 86:88 My hand has >= 1, 2 Bishop 88:90 My hand has >= 1, 2 Rook 90:98 Oppnent's hand has >= 1, ..., 8 Pawn 98:102 Oppnent's hand has >= 1, 2, 3, 4 Lance 102:106 Oppnent's hand has >= 1, 2, 3, 4 Knight 106:110 Oppnent's hand has >= 1, 2, 3, 4 Silver 110:114 Oppnent's hand has >= 1, 2, 3, 4 Gold 114:116 Oppnent's hand has >= 1, 2 Bishop 116:118 Oppnent's hand has >= 1, 2 Rook 118 Ones if checked
The design of action also follows that of dlshogi. There are 2187 = 81 x 27 distinct actions. The action can be decomposed into
direction from which the piece moves and
destination to which the piece moves
by direction, destination = action // 81, action % 81. The direction is encoded by
id direction 0 Up 1 Up left 2 Up right 3 Left 4 Right 5 Down 6 Down left 7 Down right 8 Up2 left 9 Up2 right 10 Promote + Up 11 Promote + Up left 12 Promote + Up right 13 Promote + Left 14 Promote + Right 15 Promote + Down 16 Promote + Down left 17 Promote + Down right 18 Promote + Up2 left 19 Promote + Up2 right 20 Drop Pawn 21 Drop Lance 22 Drop Knight 23 Drop Silver 24 Drop Bishop 25 Drop Rook 26 Drop Gold"},{"location":"shogi/#rewards","title":"Rewards","text":"
Non-zero rewards are given only at the terminal states. The reward at terminal state is described in this table:
Tic-tac-toe is a paper-and-pencil game for two players who take turns marking the spaces in a three-by-three grid with X or O. The player who succeeds in placing three of their marks in a horizontal, vertical, or diagonal row is the winner.
Wikipedia
"},{"location":"tic_tac_toe/#specs","title":"Specs","text":"Name Value Version v0 Number of players 2 Number of actions 9 Observation shape (3, 3, 2) Observation type bool Rewards {-1, 0, 1}"},{"location":"tic_tac_toe/#observation","title":"Observation","text":"Index Description [:, :, 0] represents (3, 3) squares filled by the current player [:, :, 1] represents (3, 3) squares filled by the opponent player of current player"},{"location":"tic_tac_toe/#action","title":"Action","text":"
Each action represents the square index to be filled.
We follow the observation design of dlshogi, an open-source shogi AI.
+Ther original dlshogi implementations are here.
+Pgx implementation has [9, 9, 119] shape and [:, :, x] denotes:
+
+
+
+
x
+
Description
+
+
+
+
+
0:14
+
Where my piece x exists
+
+
+
14:28
+
Where my pieces x are attacking
+
+
+
28:31
+
Where the number of my attacking pieces are >= 1,2,3 respectively
+
+
+
31:45
+
Where opponent's piece x exists
+
+
+
45:59
+
Where opponent's pieces x are attacking
+
+
+
59:62
+
Where the number of opponent's attacking pieces are >= 1,2,3 respectively
+
+
+
+
The following planes are all ones ore zeros
+
+
+
+
x
+
Description
+
+
+
+
+
62:70
+
My hand has >= 1, ..., 8 Pawn
+
+
+
70:74
+
My hand has >= 1, 2, 3, 4 Lance
+
+
+
74:78
+
My hand has >= 1, 2, 3, 4 Knight
+
+
+
78:82
+
My hand has >= 1, 2, 3, 4 Silver
+
+
+
82:86
+
My hand has >= 1, 2, 3, 4 Gold
+
+
+
86:88
+
My hand has >= 1, 2 Bishop
+
+
+
88:90
+
My hand has >= 1, 2 Rook
+
+
+
90:98
+
Oppnent's hand has >= 1, ..., 8 Pawn
+
+
+
98:102
+
Oppnent's hand has >= 1, 2, 3, 4 Lance
+
+
+
102:106
+
Oppnent's hand has >= 1, 2, 3, 4 Knight
+
+
+
106:110
+
Oppnent's hand has >= 1, 2, 3, 4 Silver
+
+
+
110:114
+
Oppnent's hand has >= 1, 2, 3, 4 Gold
+
+
+
114:116
+
Oppnent's hand has >= 1, 2 Bishop
+
+
+
116:118
+
Oppnent's hand has >= 1, 2 Rook
+
+
+
118
+
Ones if checked
+
+
+
+
Note that piece ids are
+
+
+
+
Piece
+
Id
+
+
+
+
+
歩 PAWN
+
0
+
+
+
香 LANCE
+
1
+
+
+
桂 KNIGHT
+
2
+
+
+
銀 SILVER
+
3
+
+
+
角 BISHOP
+
4
+
+
+
飛 ROOK
+
5
+
+
+
金 GOLD
+
6
+
+
+
玉 KING
+
7
+
+
+
と PRO_PAWN
+
8
+
+
+
成香 PRO_LANCE
+
9
+
+
+
成桂 PRO_KNIGHT
+
10
+
+
+
成銀 PRO_SILVER
+
11
+
+
+
馬 HORSE
+
12
+
+
+
龍 DRAGON
+
13
+
+
+
+
Action
+
The design of action also follows that of dlshogi.
+There are 2187 = 81 x 27 distinct actions.
+The action can be decomposed into
+
+
direction from which the piece moves and
+
destination to which the piece moves
+
+
by direction, destination = action // 81, action % 81.
+The direction is encoded by
+
+
+
+
id
+
direction
+
+
+
+
+
0
+
Up
+
+
+
1
+
Up left
+
+
+
2
+
Up right
+
+
+
3
+
Left
+
+
+
4
+
Right
+
+
+
5
+
Down
+
+
+
6
+
Down left
+
+
+
7
+
Down right
+
+
+
8
+
Up2 left
+
+
+
9
+
Up2 right
+
+
+
10
+
Promote + Up
+
+
+
11
+
Promote + Up left
+
+
+
12
+
Promote + Up right
+
+
+
13
+
Promote + Left
+
+
+
14
+
Promote + Right
+
+
+
15
+
Promote + Down
+
+
+
16
+
Promote + Down left
+
+
+
17
+
Promote + Down right
+
+
+
18
+
Promote + Up2 left
+
+
+
19
+
Promote + Up2 right
+
+
+
20
+
Drop Pawn
+
+
+
21
+
Drop Lance
+
+
+
22
+
Drop Knight
+
+
+
23
+
Drop Silver
+
+
+
24
+
Drop Bishop
+
+
+
25
+
Drop Rook
+
+
+
26
+
Drop Gold
+
+
+
+
Rewards
+
Non-zero rewards are given only at the terminal states.
+The reward at terminal state is described in this table:
Tic-tac-toe is a paper-and-pencil game for two players who take turns marking the spaces in a three-by-three grid with X or O. The player who succeeds in placing three of their marks in a horizontal, vertical, or diagonal row is the winner.
 +
+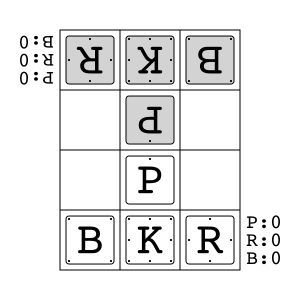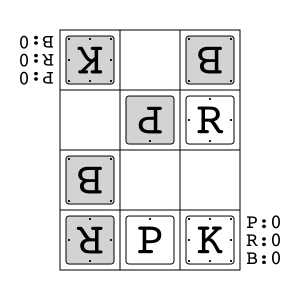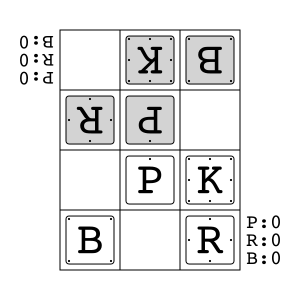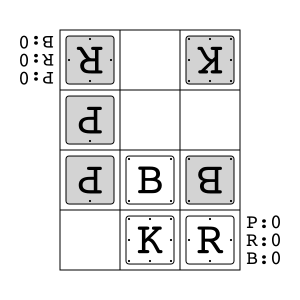 +
+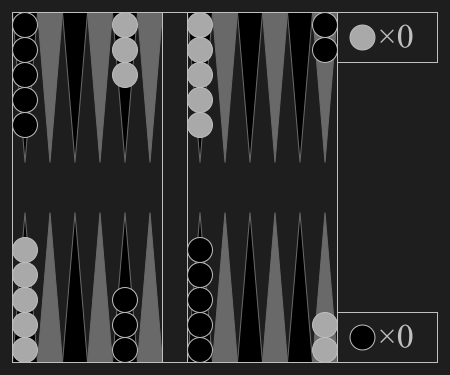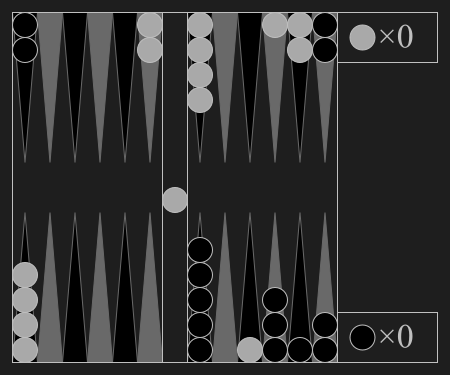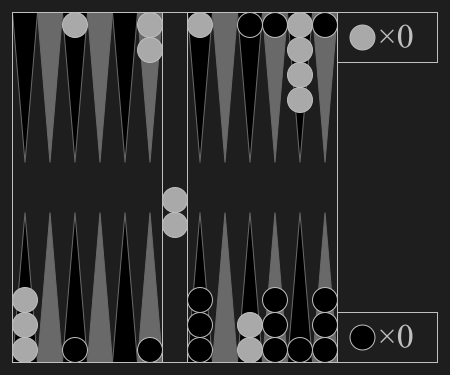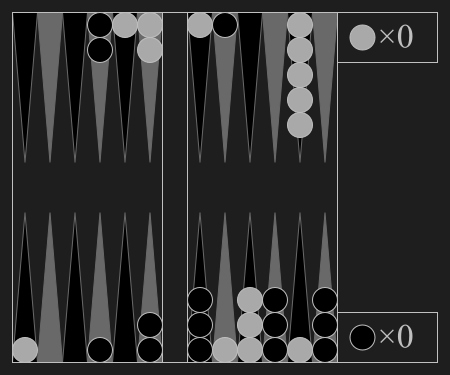 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+
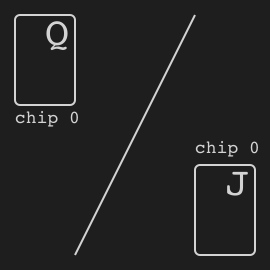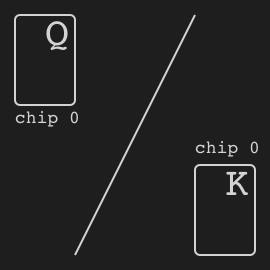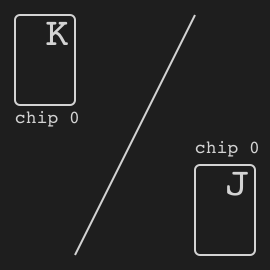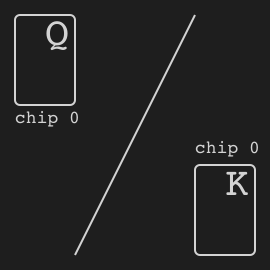 +
+ +
+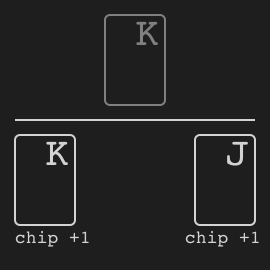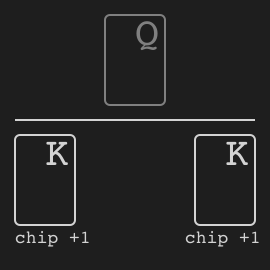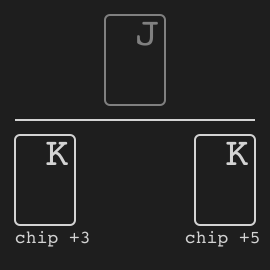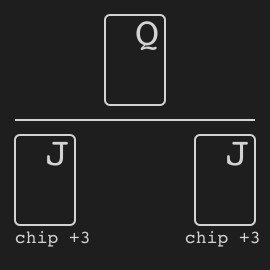 +
+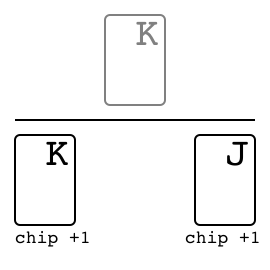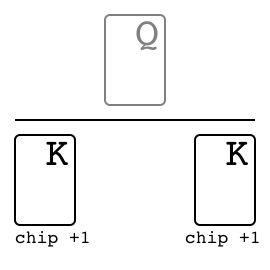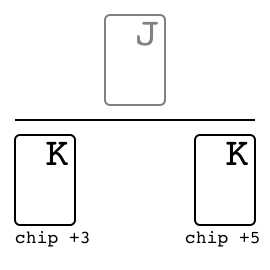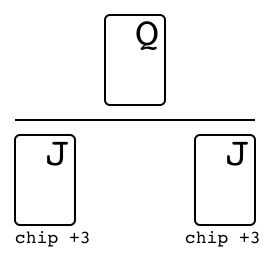 +
+
 +
+ +
+ +
+ +
+ +
+ +
+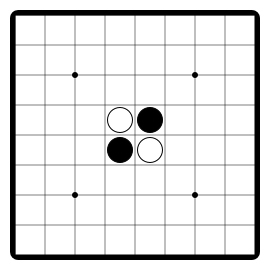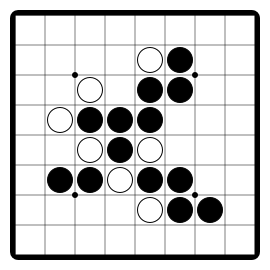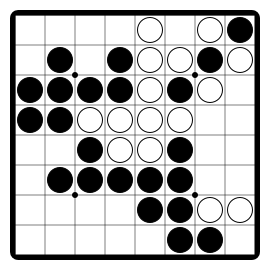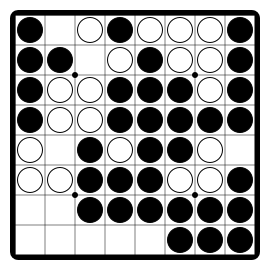 +
+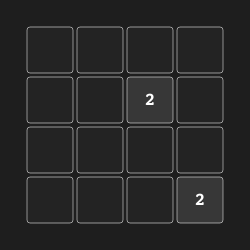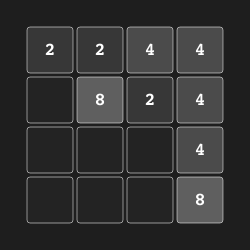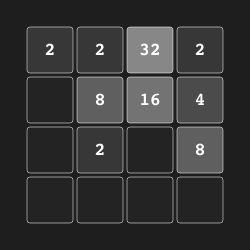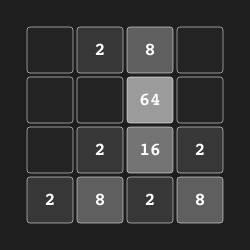 +
+ +
+ +
+ +
+ +
+ +
+ +
+ +
+