In this team project we have explored how prefix trees work, the derivatives of prefix trees, the algorithms used to build them and the applications of it all.
We will start at the basis of the prefix tree - the tree, specificall the rooted tree.
In graph theory, a tree is a connected acyclic undirected graph. More formally, a tree is a set of vertices (nodes) and edges that satisfies the following properties:
-
Connectedness: There is a path between any two vertices in the tree. In other words, for any pair of vertices in the tree, there exists a sequence of edges that connects them.
-
Acyclicity: There are no cycles in the tree. This means that it is not possible to start at a vertex and follow a sequence of edges that eventually returns to the same vertex.
Mathematically, a tree can be represented as a pair (V, E), where V is a set of vertices and E is a set of edges. The set of vertices represents the nodes of the tree, and the set of edges represents the connections between the nodes.

The concept of a rooted tree is similar to an ordinary tree, but with the additional notion of a root node. The root node serves as the starting point for traversing or navigating the tree structure. From the root, you can move downwards to its child nodes, and from there, continue exploring the tree by following paths to further child nodes.
The relationship between nodes in a rooted tree is hierarchical, with child nodes stemming from their parent nodes. Each node represents a distinct element or concept, and the connections between nodes depict the relationships or dependencies among them.
Rooted trees are widely used in computer science and other fields for representing hierarchical structures and organizing data. They are utilized in various algorithms and data structures, such as binary trees, B-trees, and decision trees, to efficiently store, search, and manipulate data.
Now that we've defined what a rooted tree is, let's move on to the prefix trie
A prefix tree, also known as a trie (pronounced "try"), is a tree-based data structure that is primarily used for efficient storage and retrieval of strings or sequences. The name "trie" is derived from the word "retrieval."
In a prefix tree, each node represents a character or a symbol from the input alphabet. The tree's structure allows for efficient searching and retrieval of strings by prefix. It is particularly useful when dealing with large sets of strings, such as dictionaries or word lists, where common prefixes are shared among multiple strings.
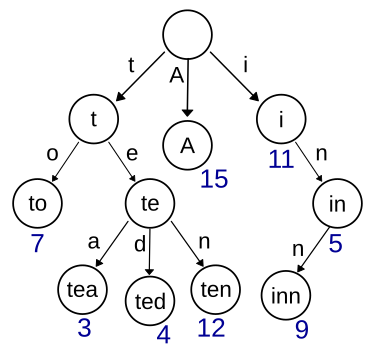
Here are some key characteristics of a prefix tree:
-
Node Structure: Each node in the tree represents a character or symbol. The nodes are connected by edges, where each edge represents a transition from one character to the next. The edges leaving a node represent all the possible characters that can follow the current node.
-
Root Node: The topmost node in the tree is called the root node. It does not represent any character but serves as the entry point to the tree.
-
Path from Root to Leaf: A path from the root node to a leaf node represents a complete string. Each node along the path corresponds to a character in the string.
-
Prefix Property: The primary advantage of a prefix tree is its ability to efficiently handle prefixes. All the strings represented by the tree can be obtained by traversing paths from the root node. The common prefixes among multiple strings are shared by their respective paths in the tree, minimizing redundancy and enabling efficient prefix-based searches. *The search for a string is thus linear in the length of the string searched, and not quadratic in
length of the string * length of the dictionary -
Leaf Nodes: The leaf nodes in the tree indicate the end of a string. They often carry additional information associated with the string, such as a frequency count or a value.
Prefix trees are commonly used in various applications, such as autocomplete functionality in search engines, spell-checking algorithms, IP routing tables, and many more scenarios where efficient string storage and retrieval are required.
Now, on to building the tree.
The algorithm in itself is trivial: each node represents a single letter, and thus we can simply traverse a tree node by node, while also incrementing the index inside the word. Then, we simply add the missing letters as the children of the last node we found.
here's the pseudocode for that
struct Node {
val: char,
children: [Node],
}
struct PrefixTree {
root: Node,
}
fn new_tree() -> PrefixTree {
return PrefixTree(Node{val = "", children = []});
}
fn add_word(tree: PrefixTree, string: word) {
Node current_node = tree.root;
int index = 0;
while exists child of current_node: child.val = word[index] and idx < word.length{
currend_node = child;
idx++;
}
while idx < word.length {
current_node.children.push_back(Node {val = word[idx], children = []});
current_node = current_node.children.last;
idx++;
}
}A compressed prefix trie, also known as a compressed trie or a Patricia trie (Practical Algorithm to Retrieve Information Coded in Alphanumeric), is a space-efficient variation of a trie data structure used for storing and retrieving strings or keys with associated values.
In a compressed prefix trie, the primary objective is to reduce the storage space required by eliminating redundant information and merging common prefixes among the keys. This compression technique significantly reduces the memory footprint compared to a standard trie.
A compressed prefix trie would look the same as a common prefix trie, but it's node would look like this:

struct Node {
val: string,
children: [Node],
}The easiest way to build a compressed prefix trie would be to just compress a prefix trie. It would be done as such:
fn compress_prefix_tree(tree: PrefixTree) {
uncompressed_nodes = [
// All nodes that have only one child;
// could easily be found by BFS
];
for node in uncompressed_nodes {
node.val = // string made from concatenating values of the node's children
// until any child has multiple children; again, a slight modification of BFS
}
}A suffix tree is a data structure that is used for efficient storage and retrieval of strings or sequences based on their suffixes. It is the derivative of a prefix tree (trie), where suffixes of a string are used as words for the prefix tree.
A suffix tree represents all the suffixes of a given string in a compressed form. It allows for fast searching, pattern matching, and other operations on strings. Suffix trees are particularly useful in applications that involve string manipulation, such as string indexing, string searching, and substring matching.
Here are some key characteristics of a suffix tree:
-
Node Structure: Each node in the suffix tree represents a substring or a suffix of the original string. The nodes are connected by edges, where each edge represents a transition from one character to the next.
-
Path from Root to Leaf: A path from the root node to a leaf node represents a complete suffix of the original string. Each node along the path corresponds to a substring or suffix.
-
Suffix Property: The primary purpose of a suffix tree is to efficiently handle suffixes. All the suffixes of the original string can be obtained by traversing paths from the root node. This property allows for fast suffix-based operations and substring matching.
-
Leaf Nodes: The leaf nodes in the tree indicate the end of a suffix. They often carry additional information associated with the suffix, such as its starting position in the original string.

In python, there is no point in using any linear algorithm, as all of the linear algorithms use pointers to an int, which represents the end of text. The proper node would look like this:
A proper suffix tree uses indices, and does not contain the text itself, so as to take up less space!
struct Node {
Node *suffix_link,
Node *children,
int *suffx_end,
int suffix_start,
int remainder_split,
}The construction of a proper suffix trie would look as such:
string full_text;
int *end;
Node *active_split = root, *last_new = root;
fn add_suffix(Node *root, int pos) {
*end = pos;
int remaining_suffixes = 1;
while remaining_suffixes > 0 {
if active_split != root {
if full_text[pos] == active_split[active_split.remainder_split++] {
active_split.remainder_split++;
remaining_suffixes++;
} else {
perform the split at index remaindes.
active_split.end = new int(active_split.remainder_split);
for child in active_split.children {
child.start = active_split.remainder_split;
}
active_split.remainder_split = 0;
}
}
else if full_text[pos] == child[0] for any child in root.children {
new_child = Node {NULL, root, end, pos, 0};
if full_text[active_split.end] == text[pos] {
new_child.suffix_link = active_split;
}
}
}
else {
active_split.children.add(
Node {NULL, root, end, pos, 0}
)
}
remaining_suffixes--;
}
}In python, however, this does not work, since no pointers
We use a prefix tree to search the required words in the text, and a suffix tree, which rebuild preffix tree for certain word search.