+
+[](https://paperswithcode.com/sota/2d-human-pose-estimation-on-coco-wholebody-1?p=rtmpose-real-time-multi-person-pose)
+
+
+
+
+

+
+- Discord Group:
+ - 🙌 https://discord.gg/raweFPmdzG 🙌
+
+## ⚡ Pipeline 性能 [🔝](#-table-of-contents)
+
+**说明**
+
+- Pipeline 速度测试时开启了隔帧检测策略,默认检测间隔为 5 帧。
+- 环境配置:
+ - torch >= 1.7.1
+ - onnxruntime 1.12.1
+ - TensorRT 8.4.3.1
+ - cuDNN 8.3.2
+ - CUDA 11.3
+
+| Detection Config | Pose Config | Input Size
(Det/Pose) | Model AP
(COCO) | Pipeline AP
(COCO) | Params (M)
(Det/Pose) | Flops (G)
(Det/Pose) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Download |
+| :------------------------------------------------------------------ | :---------------------------------------------------------------------------- | :---------------------------: | :---------------------: | :------------------------: | :---------------------------: | :--------------------------: | :--------------------------------: | :---------------------------------------: | :----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: |
+| [RTMDet-nano](./rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py) | [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 320x320
256x192 | 40.3
67.1 | 64.4 | 0.99
3.34 | 0.31
0.36 | 12.403 | 2.467 | [det](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth)
[pose](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) |
+| [RTMDet-nano](./rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py) | [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 320x320
256x192 | 40.3
71.1 | 68.5 | 0.99
5.47 | 0.31
0.68 | 16.658 | 2.730 | [det](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth)
[pose](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) |
+| [RTMDet-nano](./rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py) | [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 320x320
256x192 | 40.3
75.3 | 73.2 | 0.99
13.59 | 0.31
1.93 | 26.613 | 4.312 | [det](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth)
[pose](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) |
+| [RTMDet-nano](./rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py) | [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 320x320
256x192 | 40.3
76.3 | 74.2 | 0.99
27.66 | 0.31
4.16 | 36.311 | 4.644 | [det](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_nano_8xb32-100e_coco-obj365-person-05d8511e.pth)
[pose](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) |
+| [RTMDet-m](./rtmdet/person/rtmdet_m_640-8xb32_coco-person.py) | [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 640x640
256x192 | 62.5
75.3 | 75.7 | 24.66
13.59 | 38.95
1.93 | - | 6.923 | [det](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth)
[pose](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) |
+| [RTMDet-m](./rtmdet/person/rtmdet_m_640-8xb32_coco-person.py) | [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 640x640
256x192 | 62.5
76.3 | 76.6 | 24.66
27.66 | 38.95
4.16 | - | 7.204 | [det](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmdet_m_8xb32-100e_coco-obj365-person-235e8209.pth)
[pose](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) |
+
+## 📊 模型库 [🔝](#-table-of-contents)
+
+**说明**
+
+- 此处提供的模型采用了多数据集联合训练以提高性能,模型指标不适用于学术比较。
+- 表格中为开启了 Flip Test 的测试结果。
+- RTMPose 在更多公开数据集上的性能指标可以前往 [Model Zoo](https://mmpose.readthedocs.io/en/1.x/model_zoo_papers/algorithms.html) 查看。
+- RTMPose 在更多硬件平台上的推理速度可以前往 [Benchmark](./benchmark/README_CN.md) 查看。
+- 如果你有希望我们支持的数据集,欢迎[联系我们](https://uua478.fanqier.cn/f/xxmynrki)/[Google Questionnaire](https://docs.google.com/forms/d/e/1FAIpQLSfzwWr3eNlDzhU98qzk2Eph44Zio6hi5r0iSwfO9wSARkHdWg/viewform?usp=sf_link)!
+
+### 人体 2d 关键点 (17 Keypoints)
+
+| Config | Input Size | AP
(COCO) | Params(M) | FLOPS(G) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | ncnn-FP16-Latency(ms)
(Snapdragon 865) | Logs | Download |
+| :---------: | :--------: | :---------------: | :-------: | :------: | :--------------------------------: | :---------------------------------------: | :--------------------------------------------: | :--------: | :------------: |
+| [RTMPose-t](./rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 3.34 | 0.36 | 3.20 | 1.06 | 9.02 | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-tiny_simcc-aic-coco_pt-aic-coco_420e-256x192-cfc8f33d_20230126.pth) |
+| [RTMPose-s](./rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 5.47 | 0.68 | 4.48 | 1.39 | 13.89 | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth) |
+| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 13.59 | 1.93 | 11.06 | 2.29 | 26.44 | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-256x192-63eb25f7_20230126.pth) |
+| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 27.66 | 4.16 | 18.85 | 3.46 | 45.37 | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-256x192-f016ffe0_20230126.pth) |
+| [RTMPose-m](./rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 13.72 | 4.33 | 24.78 | 3.66 | - | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-aic-coco_pt-aic-coco_420e-384x288-a62a0b32_20230228.pth) |
+| [RTMPose-l](./rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 27.79 | 9.35 | - | 6.05 | - | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-aic-coco_pt-aic-coco_420e-384x288-97d6cb0f_20230228.pth) |
+
+#### 模型剪枝
+
+**说明**
+
+- 模型剪枝由 [MMRazor](https://github.com/open-mmlab/mmrazor) 提供
+
+| Config | Input Size | AP
(COCO) | Params(M) | FLOPS(G) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | ncnn-FP16-Latency(ms)
(Snapdragon 865) | Logs | Download |
+| :---------: | :--------: | :---------------: | :-------: | :------: | :--------------------------------: | :---------------------------------------: | :--------------------------------------------: | :--------: | :------------: |
+| RTMPose-s-aic-coco-pruned | 256x192 | 69.4 | 3.43 | 0.35 | - | - | - | [log](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.json) | [model](https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth) |
+
+更多信息,请参考 [GroupFisher Pruning for RTMPose](./rtmpose/pruning/README.md).
+
+### 人体全身 2d 关键点 (133 Keypoints)
+
+| Config | Input Size | Whole AP | Whole AR | FLOPS(G) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Logs | Download |
+| :----------------------------- | :--------: | :------: | :------: | :------: | :--------------------------------: | :---------------------------------------: | :--------------------------: | :-------------------------------: |
+| [RTMPose-m](./rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 60.4 | 66.7 | 2.22 | 13.50 | 4.00 | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-coco-wholebody_pt-aic-coco_270e-256x192-cd5e845c_20230123.pth) |
+| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 63.2 | 69.4 | 4.52 | 23.41 | 5.67 | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-256x192-6f206314_20230124.pth) |
+| [RTMPose-l](./rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 67.0 | 72.3 | 10.07 | 44.58 | 7.68 | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-l_simcc-coco-wholebody_pt-aic-coco_270e-384x288-eaeb96c8_20230125.pth) |
+
+### 动物 2d 关键点 (17 Keypoints)
+
+| Config | Input Size | AP
(AP10K) | FLOPS(G) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Logs | Download |
+| :---------------------------: | :--------: | :----------------: | :------: | :--------------------------------: | :---------------------------------------: | :--------------------------: | :------------------------------: |
+| [RTMPose-m](./rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py) | 256x256 | 72.2 | 2.57 | 14.157 | 2.404 | [Log](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.json) | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-m_simcc-ap10k_pt-aic-coco_210e-256x256-7a041aa1_20230206.pth) |
+
+### 脸部 2d 关键点
+
+| Config | Input Size | NME
(COCO-WholeBody-Face) | FLOPS(G) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Logs | Download |
+| :--------------------------------------------------: | :--------: | :-------------------------------: | :------: | :--------------------------------: | :---------------------------------------: | :---------: | :---------: |
+| [RTMPose-m](./rtmpose/face_2d_keypoint/wflw/rtmpose-m_8xb64-60e_coco-wholebody-face-256x256.py) | 256x256 | 4.57 | - | - | - | Coming soon | Coming soon |
+
+### 手部 2d 关键点
+
+| Config | Input Size | PCK
(COCO-WholeBody-Hand) | FLOPS(G) | ORT-Latency(ms)
(i7-11700) | TRT-FP16-Latency(ms)
(GTX 1660Ti) | Logs | Download |
+| :--------------------------------------------------: | :--------: | :-------------------------------: | :------: | :--------------------------------: | :---------------------------------------: | :---------: | :---------: |
+| [RTMPose-m](./rtmpose/hand_2d_keypoint/coco_wholebody_hand/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py) | 256x256 | 81.5 | - | - | - | Coming soon | Coming soon |
+
+### 预训练模型
+
+我们提供了 UDP 预训练的 CSPNeXt 模型参数,训练配置请参考 [pretrain_cspnext_udp folder](./rtmpose/pretrain_cspnext_udp/)。
+
+| Model | Input Size | Params(M) | Flops(G) | AP
(GT) | AR
(GT) | Download |
+| :-------: | :--------: | :-------: | :------: | :-------------: | :-------------: | :-----------------------------------------------------------------------------------------------------------------------------: |
+| CSPNeXt-t | 256x192 | 6.03 | 1.43 | 65.5 | 68.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth) |
+| CSPNeXt-s | 256x192 | 8.58 | 1.78 | 70.0 | 73.3 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth) |
+| CSPNeXt-m | 256x192 | 13.05 | 3.06 | 74.8 | 77.7 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth) |
+| CSPNeXt-l | 256x192 | 32.44 | 5.33 | 77.2 | 79.9 | [Model](https://download.openmmlab.com/mmpose/v1/projects/rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth) |
+
+我们提供了 ImageNet 分类训练的 CSPNeXt 模型参数,更多细节请参考 [RTMDet](https://github.com/open-mmlab/mmdetection/blob/dev-3.x/configs/rtmdet/README.md#classification)。
+
+| Model | Input Size | Params(M) | Flops(G) | Top-1 (%) | Top-5 (%) | Download |
+| :----------: | :--------: | :-------: | :------: | :-------: | :-------: | :---------------------------------------------------------------------------------------------------------------------------------: |
+| CSPNeXt-tiny | 224x224 | 2.73 | 0.34 | 69.44 | 89.45 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-tiny_imagenet_600e-3a2dd350.pth) |
+| CSPNeXt-s | 224x224 | 4.89 | 0.66 | 74.41 | 92.23 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-s_imagenet_600e-ea671761.pth) |
+| CSPNeXt-m | 224x224 | 13.05 | 1.93 | 79.27 | 94.79 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth) |
+| CSPNeXt-l | 224x224 | 27.16 | 4.19 | 81.30 | 95.62 | [Model](https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth) |
+
+## 👀 可视化 [🔝](#-table-of-contents)
+
+
+
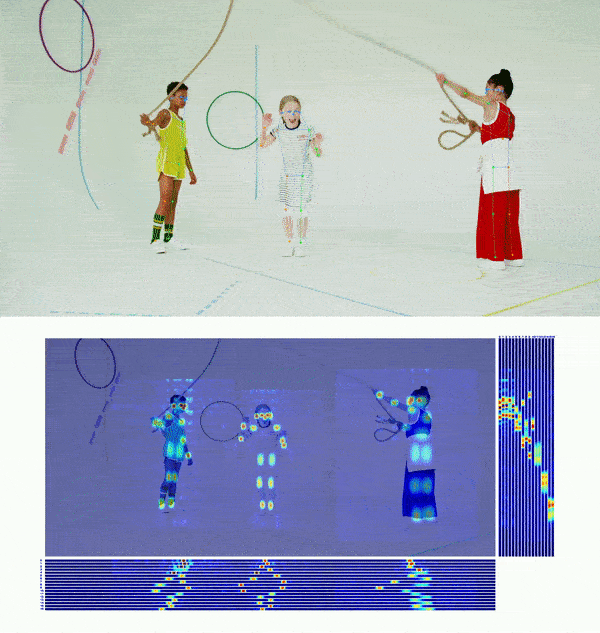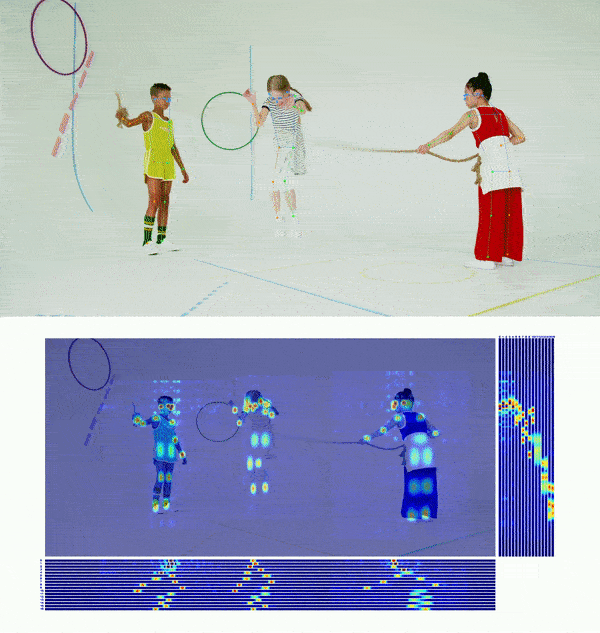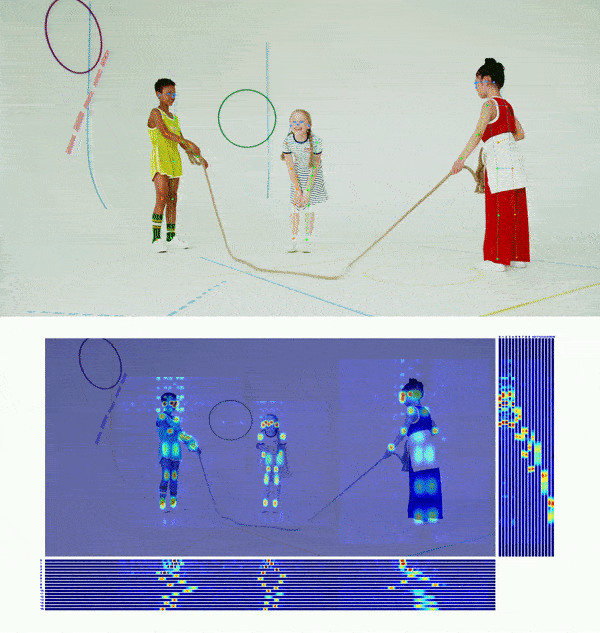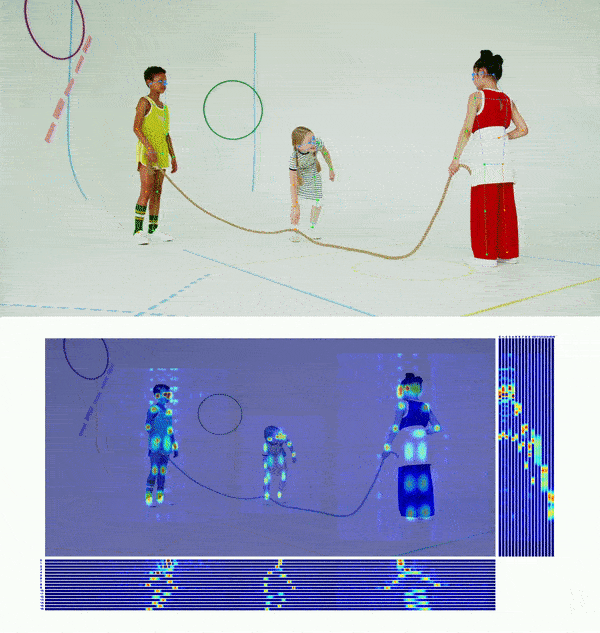
+
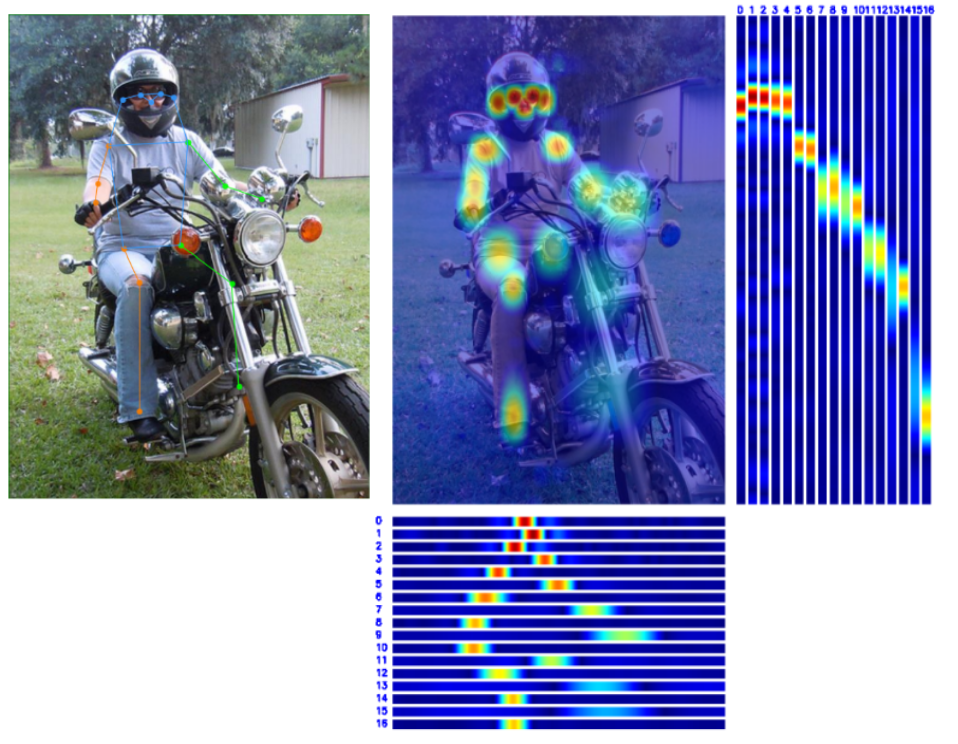
+
(COCO) | Params(M) | FLOPS(G) |
+| :-------------------------------------------------------------------------------: | :--------: | :---------------: | :-------: | :------: |
+| [RTMPose-t](../rtmpose/body_2d_keypoint/rtmpose-tiny_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 3.34 | 0.36 |
+| [RTMPose-s](../rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 5.47 | 0.68 |
+| [RTMPose-m](../rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 13.59 | 1.93 |
+| [RTMPose-l](../rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 27.66 | 4.16 |
+| [RTMPose-m](../rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 13.72 | 4.33 |
+| [RTMPose-l](../rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 27.79 | 9.35 |
+
+### Speed Benchmark
+
+- Numbers displayed in the table are inference latencies in millisecond(ms).
+
+| Config | Input Size | ORT
(i7-11700) | TRT-FP16
(GTX 1660Ti) | TRT-FP16
(RTX 3090) | ncnn-FP16
(Snapdragon 865) | TRT-FP16
(Jetson AGX Orin) | TRT-FP16
(Jetson Orin NX) |
+| :---------: | :--------: | :--------------------: | :---------------------------: | :-------------------------: | :--------------------------------: | :--------------------------------: | :-------------------------------: |
+| [RTMPose-t](../rtmpose/body_2d_keypoint/rtmpose-tiny_8xb256-420e_coco-256x192.py) | 256x192 | 3.20 | 1.06 | 0.98 | 9.02 | 1.63 | 1.97 |
+| [RTMPose-s](../rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 4.48 | 1.39 | 1.12 | 13.89 | 1.85 | 2.18 |
+| [RTMPose-m](../rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 11.06 | 2.29 | 1.18 | 26.44 | 2.72 | 3.35 |
+| [RTMPose-l](../rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 18.85 | 3.46 | 1.37 | 45.37 | 3.67 | 4.78 |
+| [RTMPose-m](../rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 24.78 | 3.66 | 1.20 | 26.44 | 3.45 | 5.08 |
+| [RTMPose-l](../rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | - | 6.05 | 1.74 | - | 4.93 | 7.23 |
+
+## WholeBody 2d (133 Keypoints)
+
+### Model Info
+
+| Config | Input Size | Whole AP | Whole AR | FLOPS(G) |
+| :------------------------------------------------------------------------------------------- | :--------: | :------: | :------: | :------: |
+| [RTMPose-m](../rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 60.4 | 66.7 | 2.22 |
+| [RTMPose-l](../rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 63.2 | 69.4 | 4.52 |
+| [RTMPose-l](../rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 67.0 | 72.3 | 10.07 |
+
+### Speed Benchmark
+
+- Numbers displayed in the table are inference latencies in millisecond(ms).
+- Data from different community users are separated by `|`.
+
+| Config | Input Size | ORT
(i7-11700) | TRT-FP16
(GTX 1660Ti) | TRT-FP16
(RTX 3090) | TRT-FP16
(Jetson AGX Orin) | TRT-FP16
(Jetson Orin NX) |
+| :-------------------------------------------- | :--------: | :--------------------: | :---------------------------: | :-------------------------: | :--------------------------------: | :-------------------------------: |
+| [RTMPose-m](../rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 13.50 | 4.00 | 1.17 \| 1.84 | 2.79 | 3.51 |
+| [RTMPose-l](../rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 23.41 | 5.67 | 1.44 \| 2.61 | 3.80 | 4.95 |
+| [RTMPose-l](../rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 44.58 | 7.68 | 1.75 \| 4.24 | 5.08 | 7.20 |
+
+## How To Test Speed
+
+If you need to test the inference speed of the model under the deployment framework, MMDeploy provides a convenient `tools/profiler.py` script.
+
+The user needs to prepare a folder for the test images `./test_images`, the profiler will randomly read images from this directory for the model speed test.
+
+```shell
+python tools/profiler.py \
+ configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \
+ {RTMPOSE_PROJECT}/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
+ ../test_images \
+ --model {WORK_DIR}/end2end.onnx \
+ --shape 256x192 \
+ --device cpu \
+ --warmup 50 \
+ --num-iter 200
+```
+
+The result is as follows:
+
+```shell
+01/30 15:06:35 - mmengine - INFO - [onnxruntime]-70 times per count: 8.73 ms, 114.50 FPS
+01/30 15:06:36 - mmengine - INFO - [onnxruntime]-90 times per count: 9.05 ms, 110.48 FPS
+01/30 15:06:37 - mmengine - INFO - [onnxruntime]-110 times per count: 9.87 ms, 101.32 FPS
+01/30 15:06:37 - mmengine - INFO - [onnxruntime]-130 times per count: 9.99 ms, 100.10 FPS
+01/30 15:06:38 - mmengine - INFO - [onnxruntime]-150 times per count: 10.39 ms, 96.29 FPS
+01/30 15:06:39 - mmengine - INFO - [onnxruntime]-170 times per count: 10.77 ms, 92.86 FPS
+01/30 15:06:40 - mmengine - INFO - [onnxruntime]-190 times per count: 10.98 ms, 91.05 FPS
+01/30 15:06:40 - mmengine - INFO - [onnxruntime]-210 times per count: 11.19 ms, 89.33 FPS
+01/30 15:06:41 - mmengine - INFO - [onnxruntime]-230 times per count: 11.16 ms, 89.58 FPS
+01/30 15:06:42 - mmengine - INFO - [onnxruntime]-250 times per count: 11.06 ms, 90.41 FPS
+----- Settings:
++------------+---------+
+| batch size | 1 |
+| shape | 256x192 |
+| iterations | 200 |
+| warmup | 50 |
++------------+---------+
+----- Results:
++--------+------------+---------+
+| Stats | Latency/ms | FPS |
++--------+------------+---------+
+| Mean | 11.060 | 90.412 |
+| Median | 11.852 | 84.375 |
+| Min | 7.812 | 128.007 |
+| Max | 13.690 | 73.044 |
++--------+------------+---------+
+```
+
+If you want to learn more details of profiler, you can refer to the [Profiler Docs](https://mmdeploy.readthedocs.io/en/1.x/02-how-to-run/useful_tools.html#profiler).
diff --git a/projects/rtmpose/benchmark/README_CN.md b/projects/rtmpose/benchmark/README_CN.md
new file mode 100644
index 0000000000..08578f44f5
--- /dev/null
+++ b/projects/rtmpose/benchmark/README_CN.md
@@ -0,0 +1,116 @@
+# RTMPose Benchmarks
+
+简体中文 | [English](./README.md)
+
+欢迎社区用户在不同硬件设备上进行推理速度测试,贡献到本项目目录下。
+
+当前已测试:
+
+- CPU
+ - Intel i7-11700
+- GPU
+ - NVIDIA GeForce 1660 Ti
+ - NVIDIA GeForce RTX 3090
+- Nvidia Jetson
+ - AGX Orin
+ - Orin NX
+- ARM
+ - Snapdragon 865
+
+### 人体 2d 关键点 (17 Keypoints)
+
+### Model Info
+
+| Config | Input Size | AP
(COCO) | Params(M) | FLOPS(G) |
+| :-------------------------------------------------------------------------------: | :--------: | :---------------: | :-------: | :------: |
+| [RTMPose-t](../rtmpose/body_2d_keypoint/rtmpose-tiny_8xb256-420e_coco-256x192.py) | 256x192 | 68.5 | 3.34 | 0.36 |
+| [RTMPose-s](../rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 72.2 | 5.47 | 0.68 |
+| [RTMPose-m](../rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 75.8 | 13.59 | 1.93 |
+| [RTMPose-l](../rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 76.5 | 27.66 | 4.16 |
+| [RTMPose-m](../rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 77.0 | 13.72 | 4.33 |
+| [RTMPose-l](../rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | 77.3 | 27.79 | 9.35 |
+
+### Speed Benchmark
+
+图中所示为模型推理时间,单位毫秒。
+
+| Config | Input Size | ORT
(i7-11700) | TRT-FP16
(GTX 1660Ti) | TRT-FP16
(RTX 3090) | ncnn-FP16
(Snapdragon 865) | TRT-FP16
(Jetson AGX Orin) | TRT-FP16
(Jetson Orin NX) |
+| :---------: | :--------: | :--------------------: | :---------------------------: | :-------------------------: | :--------------------------------: | :--------------------------------: | :-------------------------------: |
+| [RTMPose-t](../rtmpose/body_2d_keypoint/rtmpose-tiny_8xb256-420e_coco-256x192.py) | 256x192 | 3.20 | 1.06 | 0.98 | 9.02 | 1.63 | 1.97 |
+| [RTMPose-s](../rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 4.48 | 1.39 | 1.12 | 13.89 | 1.85 | 2.18 |
+| [RTMPose-m](../rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py) | 256x192 | 11.06 | 2.29 | 1.18 | 26.44 | 2.72 | 3.35 |
+| [RTMPose-l](../rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py) | 256x192 | 18.85 | 3.46 | 1.37 | 45.37 | 3.67 | 4.78 |
+| [RTMPose-m](../rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py) | 384x288 | 24.78 | 3.66 | 1.20 | 26.44 | 3.45 | 5.08 |
+| [RTMPose-l](../rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py) | 384x288 | - | 6.05 | 1.74 | - | 4.93 | 7.23 |
+
+### 人体全身 2d 关键点 (133 Keypoints)
+
+### Model Info
+
+| Config | Input Size | Whole AP | Whole AR | FLOPS(G) |
+| :------------------------------------------------------------------------------------------- | :--------: | :------: | :------: | :------: |
+| [RTMPose-m](../rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 60.4 | 66.7 | 2.22 |
+| [RTMPose-l](../rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 63.2 | 69.4 | 4.52 |
+| [RTMPose-l](../rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 67.0 | 72.3 | 10.07 |
+
+### Speed Benchmark
+
+- 图中所示为模型推理时间,单位毫秒。
+- 来自不同社区用户的测试数据用 `|` 分隔开。
+
+| Config | Input Size | ORT
(i7-11700) | TRT-FP16
(GTX 1660Ti) | TRT-FP16
(RTX 3090) | TRT-FP16
(Jetson AGX Orin) | TRT-FP16
(Jetson Orin NX) |
+| :-------------------------------------------- | :--------: | :--------------------: | :---------------------------: | :-------------------------: | :--------------------------------: | :-------------------------------: |
+| [RTMPose-m](../rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 13.50 | 4.00 | 1.17 \| 1.84 | 2.79 | 3.51 |
+| [RTMPose-l](../rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py) | 256x192 | 23.41 | 5.67 | 1.44 \| 2.61 | 3.80 | 4.95 |
+| [RTMPose-l](../rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py) | 384x288 | 44.58 | 7.68 | 1.75 \| 4.24 | 5.08 | 7.20 |
+
+## 如何测试推理速度
+
+我们使用 MMDeploy 提供的 `tools/profiler.py` 脚本进行模型测速。
+
+用户需要准备一个存放测试图片的文件夹`./test_images`,profiler 将随机从该目录下抽取图片用于模型测速。
+
+```shell
+python tools/profiler.py \
+ configs/mmpose/pose-detection_simcc_onnxruntime_dynamic.py \
+ {RTMPOSE_PROJECT}/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py \
+ ../test_images \
+ --model {WORK_DIR}/end2end.onnx \
+ --shape 256x192 \
+ --device cpu \
+ --warmup 50 \
+ --num-iter 200
+```
+
+The result is as follows:
+
+```shell
+01/30 15:06:35 - mmengine - INFO - [onnxruntime]-70 times per count: 8.73 ms, 114.50 FPS
+01/30 15:06:36 - mmengine - INFO - [onnxruntime]-90 times per count: 9.05 ms, 110.48 FPS
+01/30 15:06:37 - mmengine - INFO - [onnxruntime]-110 times per count: 9.87 ms, 101.32 FPS
+01/30 15:06:37 - mmengine - INFO - [onnxruntime]-130 times per count: 9.99 ms, 100.10 FPS
+01/30 15:06:38 - mmengine - INFO - [onnxruntime]-150 times per count: 10.39 ms, 96.29 FPS
+01/30 15:06:39 - mmengine - INFO - [onnxruntime]-170 times per count: 10.77 ms, 92.86 FPS
+01/30 15:06:40 - mmengine - INFO - [onnxruntime]-190 times per count: 10.98 ms, 91.05 FPS
+01/30 15:06:40 - mmengine - INFO - [onnxruntime]-210 times per count: 11.19 ms, 89.33 FPS
+01/30 15:06:41 - mmengine - INFO - [onnxruntime]-230 times per count: 11.16 ms, 89.58 FPS
+01/30 15:06:42 - mmengine - INFO - [onnxruntime]-250 times per count: 11.06 ms, 90.41 FPS
+----- Settings:
++------------+---------+
+| batch size | 1 |
+| shape | 256x192 |
+| iterations | 200 |
+| warmup | 50 |
++------------+---------+
+----- Results:
++--------+------------+---------+
+| Stats | Latency/ms | FPS |
++--------+------------+---------+
+| Mean | 11.060 | 90.412 |
+| Median | 11.852 | 84.375 |
+| Min | 7.812 | 128.007 |
+| Max | 13.690 | 73.044 |
++--------+------------+---------+
+```
+
+If you want to learn more details of profiler, you can refer to the [Profiler Docs](https://mmdeploy.readthedocs.io/en/1.x/02-how-to-run/useful_tools.html#profiler).
diff --git a/projects/rtmpose/rtmdet/person/rtmdet_m_640-8xb32_coco-person.py b/projects/rtmpose/rtmdet/person/rtmdet_m_640-8xb32_coco-person.py
new file mode 100644
index 0000000000..620de8dc8f
--- /dev/null
+++ b/projects/rtmpose/rtmdet/person/rtmdet_m_640-8xb32_coco-person.py
@@ -0,0 +1,20 @@
+_base_ = 'mmdet::rtmdet/rtmdet_m_8xb32-300e_coco.py'
+
+checkpoint = 'https://download.openmmlab.com/mmdetection/v3.0/rtmdet/cspnext_rsb_pretrain/cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth' # noqa
+
+model = dict(
+ backbone=dict(
+ init_cfg=dict(
+ type='Pretrained', prefix='backbone.', checkpoint=checkpoint)),
+ bbox_head=dict(num_classes=1),
+ test_cfg=dict(
+ nms_pre=1000,
+ min_bbox_size=0,
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.6),
+ max_per_img=100))
+
+train_dataloader = dict(dataset=dict(metainfo=dict(classes=('person', ))))
+
+val_dataloader = dict(dataset=dict(metainfo=dict(classes=('person', ))))
+test_dataloader = val_dataloader
diff --git a/projects/rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py b/projects/rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py
new file mode 100644
index 0000000000..b93d651735
--- /dev/null
+++ b/projects/rtmpose/rtmdet/person/rtmdet_nano_320-8xb32_coco-person.py
@@ -0,0 +1,110 @@
+_base_ = 'mmdet::rtmdet/rtmdet_l_8xb32-300e_coco.py'
+
+input_shape = 320
+
+model = dict(
+ backbone=dict(
+ deepen_factor=0.33,
+ widen_factor=0.25,
+ use_depthwise=True,
+ ),
+ neck=dict(
+ in_channels=[64, 128, 256],
+ out_channels=64,
+ num_csp_blocks=1,
+ use_depthwise=True,
+ ),
+ bbox_head=dict(
+ in_channels=64,
+ feat_channels=64,
+ share_conv=False,
+ exp_on_reg=False,
+ use_depthwise=True,
+ num_classes=1),
+ test_cfg=dict(
+ nms_pre=1000,
+ min_bbox_size=0,
+ score_thr=0.05,
+ nms=dict(type='nms', iou_threshold=0.6),
+ max_per_img=100))
+
+train_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ file_client_args={{_base_.file_client_args}}),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='CachedMosaic',
+ img_scale=(input_shape, input_shape),
+ pad_val=114.0,
+ max_cached_images=20,
+ random_pop=False),
+ dict(
+ type='RandomResize',
+ scale=(input_shape * 2, input_shape * 2),
+ ratio_range=(0.5, 1.5),
+ keep_ratio=True),
+ dict(type='RandomCrop', crop_size=(input_shape, input_shape)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(
+ type='Pad',
+ size=(input_shape, input_shape),
+ pad_val=dict(img=(114, 114, 114))),
+ dict(type='PackDetInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(
+ type='LoadImageFromFile',
+ file_client_args={{_base_.file_client_args}}),
+ dict(type='LoadAnnotations', with_bbox=True),
+ dict(
+ type='RandomResize',
+ scale=(input_shape, input_shape),
+ ratio_range=(0.5, 1.5),
+ keep_ratio=True),
+ dict(type='RandomCrop', crop_size=(input_shape, input_shape)),
+ dict(type='YOLOXHSVRandomAug'),
+ dict(type='RandomFlip', prob=0.5),
+ dict(
+ type='Pad',
+ size=(input_shape, input_shape),
+ pad_val=dict(img=(114, 114, 114))),
+ dict(type='PackDetInputs')
+]
+
+test_pipeline = [
+ dict(
+ type='LoadImageFromFile',
+ file_client_args={{_base_.file_client_args}}),
+ dict(type='Resize', scale=(input_shape, input_shape), keep_ratio=True),
+ dict(
+ type='Pad',
+ size=(input_shape, input_shape),
+ pad_val=dict(img=(114, 114, 114))),
+ dict(
+ type='PackDetInputs',
+ meta_keys=('img_id', 'img_path', 'ori_shape', 'img_shape',
+ 'scale_factor'))
+]
+
+train_dataloader = dict(
+ dataset=dict(pipeline=train_pipeline, metainfo=dict(classes=('person', ))))
+
+val_dataloader = dict(
+ dataset=dict(pipeline=test_pipeline, metainfo=dict(classes=('person', ))))
+test_dataloader = val_dataloader
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='PipelineSwitchHook',
+ switch_epoch=280,
+ switch_pipeline=train_pipeline_stage2)
+]
diff --git a/projects/rtmpose/rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py b/projects/rtmpose/rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py
new file mode 100644
index 0000000000..0fa5c5d30c
--- /dev/null
+++ b/projects/rtmpose/rtmpose/animal_2d_keypoint/rtmpose-m_8xb64-210e_ap10k-256x256.py
@@ -0,0 +1,246 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 210
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(256, 256),
+ sigma=(5.66, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=768,
+ out_channels=17,
+ input_size=codec['input_size'],
+ in_featuremap_size=(8, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'AP10KDataset'
+data_mode = 'topdown'
+data_root = 'data/ap10k/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/pose/ap10k/',
+# f'{data_root}': 's3://openmmlab/datasets/pose/ap10k/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/ap10k-train-split1.json',
+ data_prefix=dict(img='data/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/ap10k-val-split1.json',
+ data_prefix=dict(img='data/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/ap10k-test-split1.json',
+ data_prefix=dict(img='data/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/ap10k-val-split1.json')
+test_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/ap10k-test-split1.json')
diff --git a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py
new file mode 100644
index 0000000000..b44df792a1
--- /dev/null
+++ b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-256x192.py
@@ -0,0 +1,232 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 420
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 210 to 420 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=1024,
+ out_channels=17,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file=f'{data_root}person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py
new file mode 100644
index 0000000000..2468c40d53
--- /dev/null
+++ b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-l_8xb256-420e_coco-384x288.py
@@ -0,0 +1,232 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 420
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 210 to 420 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(288, 384),
+ sigma=(6., 6.93),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=1024,
+ out_channels=17,
+ input_size=codec['input_size'],
+ in_featuremap_size=(9, 12),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file=f'{data_root}person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py
new file mode 100644
index 0000000000..c7e3061c53
--- /dev/null
+++ b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-256x192.py
@@ -0,0 +1,232 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 420
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 210 to 420 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=768,
+ out_channels=17,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file=f'{data_root}person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py
new file mode 100644
index 0000000000..16a7b0c493
--- /dev/null
+++ b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-m_8xb256-420e_coco-384x288.py
@@ -0,0 +1,232 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 420
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 210 to 420 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(288, 384),
+ sigma=(6., 6.93),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=768,
+ out_channels=17,
+ input_size=codec['input_size'],
+ in_featuremap_size=(9, 12),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file=f'{data_root}person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py
new file mode 100644
index 0000000000..dca589bef9
--- /dev/null
+++ b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-s_8xb256-420e_coco-256x192.py
@@ -0,0 +1,232 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 420
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 210 to 420 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.33,
+ widen_factor=0.5,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-s_udp-aic-coco_210e-256x192-92f5a029_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=512,
+ out_channels=17,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file=f'{data_root}person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py
new file mode 100644
index 0000000000..cd16e0a98a
--- /dev/null
+++ b/projects/rtmpose/rtmpose/body_2d_keypoint/rtmpose-t_8xb256-420e_coco-256x192.py
@@ -0,0 +1,233 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 420
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 210 to 420 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.167,
+ widen_factor=0.375,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-tiny_udp-aic-coco_210e-256x192-cbed682d_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=384,
+ out_channels=17,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file=f'{data_root}person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ # Turn off EMA while training the tiny model
+ # dict(
+ # type='EMAHook',
+ # ema_type='ExpMomentumEMA',
+ # momentum=0.0002,
+ # update_buffers=True,
+ # priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/face_2d_keypoint/rtmpose-m_8xb32-60e_coco-wholebody-face-256x256.py b/projects/rtmpose/rtmpose/face_2d_keypoint/rtmpose-m_8xb32-60e_coco-wholebody-face-256x256.py
new file mode 100644
index 0000000000..dba43a7d72
--- /dev/null
+++ b/projects/rtmpose/rtmpose/face_2d_keypoint/rtmpose-m_8xb32-60e_coco-wholebody-face-256x256.py
@@ -0,0 +1,232 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 60
+stage2_num_epochs = 10
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=1)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(256, 256),
+ sigma=(5.66, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=768,
+ out_channels=68,
+ input_size=codec['input_size'],
+ in_featuremap_size=(8, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyFaceDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ # dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ # dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='NME', rule='less', max_keep_ckpts=1, interval=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='NME',
+ norm_mode='keypoint_distance',
+)
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py b/projects/rtmpose/rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py
new file mode 100644
index 0000000000..63049aa4d1
--- /dev/null
+++ b/projects/rtmpose/rtmpose/hand_2d_keypoint/rtmpose-m_8xb32-210e_coco-wholebody-hand-256x256.py
@@ -0,0 +1,233 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 210
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=256)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(256, 256),
+ sigma=(5.66, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=768,
+ out_channels=21,
+ input_size=codec['input_size'],
+ in_featuremap_size=(8, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyHandDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ # dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.5, 1.5],
+ rotate_factor=180),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ # dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=180),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='AUC', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = [
+ dict(type='PCKAccuracy', thr=0.2),
+ dict(type='AUC'),
+ dict(type='EPE')
+]
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-l_udp_8xb256-210e_coco-256x192.py b/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-l_udp_8xb256-210e_coco-256x192.py
new file mode 100644
index 0000000000..148976f792
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-l_udp_8xb256-210e_coco-256x192.py
@@ -0,0 +1,214 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 210
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 105 to 210 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmdetection/v3.0/'
+ 'rtmdet/cspnext_rsb_pretrain/'
+ 'cspnext-l_8xb256-rsb-a1-600e_in1k-6a760974.pth')),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=1024,
+ out_channels=17,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=False,
+ flip_mode='heatmap',
+ shift_heatmap=False,
+ ))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file='data/coco/person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-m_udp_8xb256-210e_coco-256x192.py b/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-m_udp_8xb256-210e_coco-256x192.py
new file mode 100644
index 0000000000..b42699fd11
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-m_udp_8xb256-210e_coco-256x192.py
@@ -0,0 +1,214 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 210
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 105 to 210 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmdetection/v3.0/'
+ 'rtmdet/cspnext_rsb_pretrain/'
+ 'cspnext-m_8xb256-rsb-a1-600e_in1k-ecb3bbd9.pth')),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=768,
+ out_channels=17,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=False,
+ flip_mode='heatmap',
+ shift_heatmap=False,
+ ))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file='data/coco/person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-s_udp_8xb256-210e_coco-256x192.py b/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-s_udp_8xb256-210e_coco-256x192.py
new file mode 100644
index 0000000000..0a458406ff
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-s_udp_8xb256-210e_coco-256x192.py
@@ -0,0 +1,214 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 210
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 105 to 210 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.33,
+ widen_factor=0.5,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmdetection/v3.0/'
+ 'rtmdet/cspnext_rsb_pretrain/'
+ 'cspnext-s_imagenet_600e-ea671761.pth')),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=512,
+ out_channels=17,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=False,
+ flip_mode='heatmap',
+ shift_heatmap=False,
+ ))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file='data/coco/person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-tiny_udp_8xb256-210e_coco-256x192.py b/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-tiny_udp_8xb256-210e_coco-256x192.py
new file mode 100644
index 0000000000..adde3c0af3
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pretrain_cspnext_udp/cspnext-tiny_udp_8xb256-210e_coco-256x192.py
@@ -0,0 +1,214 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 210
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 105 to 210 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=1024)
+
+# codec settings
+codec = dict(
+ type='UDPHeatmap', input_size=(192, 256), heatmap_size=(48, 64), sigma=2)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.167,
+ widen_factor=0.375,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmdetection/v3.0/'
+ 'rtmdet/cspnext_rsb_pretrain/'
+ 'cspnext-tiny_imagenet_600e-3a2dd350.pth')),
+ head=dict(
+ type='HeatmapHead',
+ in_channels=384,
+ out_channels=17,
+ loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ decoder=codec),
+ test_cfg=dict(
+ flip_test=False,
+ flip_mode='heatmap',
+ shift_heatmap=False,
+ ))
+
+# base dataset settings
+dataset_type = 'CocoDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size'], use_udp=True),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=256,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_train2017.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/person_keypoints_val2017.json',
+ # bbox_file='data/coco/person_detection_results/'
+ # 'COCO_val2017_detections_AP_H_56_person.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(save_best='coco/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ # dict(
+ # type='EMAHook',
+ # ema_type='ExpMomentumEMA',
+ # momentum=0.0002,
+ # update_buffers=True,
+ # priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoMetric',
+ ann_file=data_root + 'annotations/person_keypoints_val2017.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/pruning/README.md b/projects/rtmpose/rtmpose/pruning/README.md
new file mode 100644
index 0000000000..28be530cc1
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pruning/README.md
@@ -0,0 +1,117 @@
+# GroupFisher Pruning for RTMPose
+
+# Description
+
+We try to apply a pruning algorithm to RTMPose models. In detail, we prune a RTMPose model to a smaller size as the same as a smaller RTMPose model, like pruning RTMPose-S to the size of RTMPose-T.
+The expriments show that the pruned model have better performance(AP) than the RTMPose model with the similar size and inference speed.
+
+Concretly, we select the RTMPose-S as the base model and prune it to the size of RTMPose-T, and use GroupFisher pruning algorithm which is able to determine the pruning structure automatically.
+Furthermore, we provide two version of the pruned models including only using coco and using both of coco and ai-challenge datasets.
+
+# Results and Models
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | Flops | Params | ckpt | log |
+| :-------------------------------------------------------------------- | :--------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :---: | :----: | :---------------------------------------: | :------------: |
+| [rtmpose-s-pruned](./group_fisher_finetune_rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 0.691 | 0.885 | 0.765 | 0.745 | 0.925 | 0.34 | 3.42 | [pruned][rp_sc_p] \| [finetuned][rp_sc_f] | [log][rp_sc_l] |
+| [rtmpose-s-aic-coco-pruned](./group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.py) | 256x192 | 0.694 | 0.884 | 0.771 | 0.747 | 0.922 | 0.35 | 3.43 | [pruned][rp_sa_p] \| [finetuned][rp_sa_f] | [log][rp_sa_l] |
+
+## Get Started
+
+We have three steps to apply GroupFisher to your model, including Prune, Finetune, Deploy.
+
+Note: please use torch>=1.12, as we need fxtracer to parse the models automatically.
+
+### Prune
+
+```bash
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 PORT=29500 ./tools/dist_train.sh \
+ {config_folder}/group_fisher_{normalization_type}_prune_{model_name}.py 8 \
+ --work-dir $WORK_DIR
+```
+
+In the pruning config file. You have to fill some args as below.
+
+```python
+"""
+_base_ (str): The path to your pretrained model checkpoint.
+pretrained_path (str): The path to your pretrained model checkpoint.
+
+interval (int): Interval between pruning two channels. You should ensure you
+ can reach your target pruning ratio when the training ends.
+normalization_type (str): GroupFisher uses two methods to normlized the channel
+ importance, including ['flops','act']. The former uses flops, while the
+ latter uses the memory occupation of activation feature maps.
+lr_ratio (float): Ratio to decrease lr rate. As pruning progress is unstable,
+ you need to decrease the original lr rate until the pruning training work
+ steadly without getting nan.
+
+target_flop_ratio (float): The target flop ratio to prune your model.
+input_shape (Tuple): input shape to measure the flops.
+"""
+```
+
+After the pruning process, you will get a checkpoint of the pruned model named flops\_{target_flop_ratio}.pth in your workdir.
+
+### Finetune
+
+```bash
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 PORT=29500 ./tools/dist_train.sh \
+ {config_folder}/group_fisher_{normalization_type}_finetune_{model_name}.py 8 \
+ --work-dir $WORK_DIR
+```
+
+There are also some args for you to fill in the config file as below.
+
+```python
+"""
+_base_(str): The path to your pruning config file.
+pruned_path (str): The path to the checkpoint of the pruned model.
+finetune_lr (float): The lr rate to finetune. Usually, we directly use the lr
+ rate of the pretrain.
+"""
+```
+
+After finetuning, except a checkpoint of the best model, there is also a fix_subnet.json, which records the pruned model structure. It will be used when deploying.
+
+### Test
+
+```bash
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 PORT=29500 ./tools/dist_test.sh \
+ {config_folder}/group_fisher_{normalization_type}_finetune_{model_name}.py {checkpoint_path} 8
+```
+
+### Deploy
+
+For a pruned model, you only need to use the pruning deploy config to instead the pretrain config to deploy the pruned version of your model. If you are not familiar with mmdeploy, it's recommended to refer to [MMDeploy document](https://mmdeploy.readthedocs.io/en/1.x/02-how-to-run/convert_model.html).
+
+```bash
+python {mmdeploy}/tools/deploy.py \
+ {mmdeploy}/{mmdeploy_config}.py \
+ {config_folder}/group_fisher_{normalization_type}_deploy_{model_name}.py \
+ {path_to_finetuned_checkpoint}.pth \
+ {mmdeploy}/tests/data/tiger.jpeg
+```
+
+The deploy config has some args as below:
+
+```python
+"""
+_base_ (str): The path to your pretrain config file.
+fix_subnet (Union[dict,str]): The dict store the pruning structure or the
+ json file including it.
+divisor (int): The divisor the make the channel number divisible.
+"""
+```
+
+The divisor is important for the actual inference speed, and we suggest you to test it in \[1,2,4,8,16,32\] to find the fastest divisor.
+
+## Reference
+
+[GroupFisher in MMRazor](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/pruning/base/group_fisher)
+
+[rp_sa_f]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth
+[rp_sa_l]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.json
+[rp_sa_p]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_prune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth
+[rp_sc_f]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_coco-256x192.pth
+[rp_sc_l]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_coco-256x192.json
+[rp_sc_p]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_prune_rtmpose-s_8xb256-420e_coco-256x192.pth
diff --git a/projects/rtmpose/rtmpose/pruning/README_CN.md b/projects/rtmpose/rtmpose/pruning/README_CN.md
new file mode 100644
index 0000000000..945160b246
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pruning/README_CN.md
@@ -0,0 +1,116 @@
+# 使用GroupFisher剪枝RTMPose
+
+# 概述
+
+我们尝试使用 GroupFisher 算法对 RTMPose 模型进行剪枝。具体来说,我们将一个 RTMPose 模型剪枝到与较小的 RTMPose 模型相同的大小,例如将 RTMPose-S 剪枝到 RTMPose-T 的大小。
+实验表明,剪枝后的模型比具有相似大小和推理速度的 RTMPose 模型具有更好的性能(AP)。
+
+我们使用能自动确定剪枝结构的 GroupFisher 剪枝算法,将 RTMPose-S 剪枝到 RTMPose-T 的大小。
+此外,我们提供了两个版本的剪枝模型,其中一个只使用 coco 数据集,另一个同时使用 coco 和 ai-challenge 数据集。
+
+# 实验结果
+
+| Arch | Input Size | AP | AP50 | AP75 | AR | AR50 | Flops | Params | ckpt | log |
+| :-------------------------------------------------------------------- | :--------: | :---: | :-------------: | :-------------: | :---: | :-------------: | :---: | :----: | :---------------------------------------: | :------------: |
+| [rtmpose-s-pruned](./group_fisher_finetune_rtmpose-s_8xb256-420e_coco-256x192.py) | 256x192 | 0.691 | 0.885 | 0.765 | 0.745 | 0.925 | 0.34 | 3.42 | [pruned][rp_sc_p] \| [finetuned][rp_sc_f] | [log][rp_sc_l] |
+| [rtmpose-s-aic-coco-pruned](./group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.py) | 256x192 | 0.694 | 0.884 | 0.771 | 0.747 | 0.922 | 0.35 | 3.43 | [pruned][rp_sa_p] \| [finetuned][rp_sa_f] | [log][rp_sa_l] |
+
+## Get Started
+
+我们需要三个步骤来将 GroupFisher 应用于你的模型,包括剪枝(Prune),微调(Finetune),部署(Deploy)。
+注意:请使用torch>=1.12,因为我们需要fxtracer来自动解析模型。
+
+### Prune
+
+```bash
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 PORT=29500 ./tools/dist_train.sh \
+ {config_folder}/group_fisher_{normalization_type}_prune_{model_name}.py 8 \
+ --work-dir $WORK_DIR
+```
+
+在剪枝配置文件中,你需要填写以下参数。
+
+```python
+"""
+_base_ (str): The path to your pretrained model checkpoint.
+pretrained_path (str): The path to your pretrained model checkpoint.
+
+interval (int): Interval between pruning two channels. You should ensure you
+ can reach your target pruning ratio when the training ends.
+normalization_type (str): GroupFisher uses two methods to normlized the channel
+ importance, including ['flops','act']. The former uses flops, while the
+ latter uses the memory occupation of activation feature maps.
+lr_ratio (float): Ratio to decrease lr rate. As pruning progress is unstable,
+ you need to decrease the original lr rate until the pruning training work
+ steadly without getting nan.
+
+target_flop_ratio (float): The target flop ratio to prune your model.
+input_shape (Tuple): input shape to measure the flops.
+"""
+```
+
+在剪枝结束后,你将获得一个剪枝模型的 checkpoint,该 checkpoint 的名称为 flops\_{target_flop_ratio}.pth,位于你的 workdir 中。
+
+### Finetune
+
+```bash
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 PORT=29500 ./tools/dist_train.sh \
+ {config_folder}/group_fisher_{normalization_type}_finetune_{model_name}.py 8 \
+ --work-dir $WORK_DIR
+```
+
+微调时也有一些参数需要你填写。
+
+```python
+"""
+_base_(str): The path to your pruning config file.
+pruned_path (str): The path to the checkpoint of the pruned model.
+finetune_lr (float): The lr rate to finetune. Usually, we directly use the lr
+ rate of the pretrain.
+"""
+```
+
+在微调结束后,除了最佳模型的 checkpoint 外,还有一个 fix_subnet.json,它记录了剪枝模型的结构。它将在部署时使用。
+
+### Test
+
+```bash
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 PORT=29500 ./tools/dist_test.sh \
+ {config_folder}/group_fisher_{normalization_type}_finetune_{model_name}.py {checkpoint_path} 8
+```
+
+### Deploy
+
+对于剪枝模型,你只需要使用剪枝部署 config 来代替预训练 config 来部署模型的剪枝版本。如果你不熟悉 MMDeploy,请参看[MMDeploy document](https://mmdeploy.readthedocs.io/en/1.x/02-how-to-run/convert_model.html)。
+
+```bash
+python {mmdeploy}/tools/deploy.py \
+ {mmdeploy}/{mmdeploy_config}.py \
+ {config_folder}/group_fisher_{normalization_type}_deploy_{model_name}.py \
+ {path_to_finetuned_checkpoint}.pth \
+ {mmdeploy}/tests/data/tiger.jpeg
+```
+
+部署配置文件有如下参数:
+
+```python
+"""
+_base_ (str): The path to your pretrain config file.
+fix_subnet (Union[dict,str]): The dict store the pruning structure or the
+ json file including it.
+divisor (int): The divisor the make the channel number divisible.
+"""
+```
+
+divisor 设置十分重要,我们建议你在尝试 \[1,2,4,8,16,32\],以找到最佳设置。
+
+## Reference
+
+[GroupFisher in MMRazor](https://github.com/open-mmlab/mmrazor/tree/dev-1.x/configs/pruning/base/group_fisher)
+
+[rp_sa_f]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth
+[rp_sa_l]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.json
+[rp_sa_p]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_prune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth
+[rp_sc_f]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_coco-256x192.pth
+[rp_sc_l]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_finetune_rtmpose-s_8xb256-420e_coco-256x192.json
+[rp_sc_p]: https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_prune_rtmpose-s_8xb256-420e_coco-256x192.pth
diff --git a/projects/rtmpose/rtmpose/pruning/group_fisher_deploy_rtmpose-s_8xb256-420e_aic-coco-256x192.py b/projects/rtmpose/rtmpose/pruning/group_fisher_deploy_rtmpose-s_8xb256-420e_aic-coco-256x192.py
new file mode 100644
index 0000000000..3c720566f0
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pruning/group_fisher_deploy_rtmpose-s_8xb256-420e_aic-coco-256x192.py
@@ -0,0 +1,53 @@
+#############################################################################
+"""You have to fill these args.
+
+_base_(str): The path to your pretrain config file.
+fix_subnet (Union[dict,str]): The dict store the pruning structure or the
+ json file including it.
+divisor (int): The divisor the make the channel number divisible.
+"""
+
+_base_ = 'mmpose::body_2d_keypoint/rtmpose/coco/rtmpose-s_8xb256-420e_aic-coco-256x192.py' # noqa
+fix_subnet = {
+ 'backbone.stem.0.conv_(0, 16)_16': 8,
+ 'backbone.stem.1.conv_(0, 16)_16': 9,
+ 'backbone.stem.2.conv_(0, 32)_32': 9,
+ 'backbone.stage1.0.conv_(0, 64)_64': 32,
+ 'backbone.stage1.1.short_conv.conv_(0, 32)_32': 30,
+ 'backbone.stage1.1.main_conv.conv_(0, 32)_32': 29,
+ 'backbone.stage1.1.blocks.0.conv1.conv_(0, 32)_32': 24,
+ 'backbone.stage1.1.final_conv.conv_(0, 64)_64': 27,
+ 'backbone.stage2.0.conv_(0, 128)_128': 62,
+ 'backbone.stage2.1.short_conv.conv_(0, 64)_64': 63,
+ 'backbone.stage2.1.main_conv.conv_(0, 64)_64': 64,
+ 'backbone.stage2.1.blocks.0.conv1.conv_(0, 64)_64': 56,
+ 'backbone.stage2.1.blocks.1.conv1.conv_(0, 64)_64': 62,
+ 'backbone.stage2.1.final_conv.conv_(0, 128)_128': 65,
+ 'backbone.stage3.0.conv_(0, 256)_256': 167,
+ 'backbone.stage3.1.short_conv.conv_(0, 128)_128': 127,
+ 'backbone.stage3.1.main_conv.conv_(0, 128)_128': 128,
+ 'backbone.stage3.1.blocks.0.conv1.conv_(0, 128)_128': 124,
+ 'backbone.stage3.1.blocks.1.conv1.conv_(0, 128)_128': 123,
+ 'backbone.stage3.1.final_conv.conv_(0, 256)_256': 172,
+ 'backbone.stage4.0.conv_(0, 512)_512': 337,
+ 'backbone.stage4.1.conv1.conv_(0, 256)_256': 256,
+ 'backbone.stage4.1.conv2.conv_(0, 512)_512': 379,
+ 'backbone.stage4.2.short_conv.conv_(0, 256)_256': 188,
+ 'backbone.stage4.2.main_conv.conv_(0, 256)_256': 227,
+ 'backbone.stage4.2.blocks.0.conv1.conv_(0, 256)_256': 238,
+ 'backbone.stage4.2.blocks.0.conv2.pointwise_conv.conv_(0, 256)_256': 195,
+ 'backbone.stage4.2.final_conv.conv_(0, 512)_512': 163
+}
+divisor = 8
+##############################################################################
+
+architecture = _base_.model
+
+model = dict(
+ _delete_=True,
+ _scope_='mmrazor',
+ type='GroupFisherDeploySubModel',
+ architecture=architecture,
+ fix_subnet=fix_subnet,
+ divisor=divisor,
+)
diff --git a/projects/rtmpose/rtmpose/pruning/group_fisher_deploy_rtmpose-s_8xb256-420e_coco-256x192.py b/projects/rtmpose/rtmpose/pruning/group_fisher_deploy_rtmpose-s_8xb256-420e_coco-256x192.py
new file mode 100644
index 0000000000..64fa6c2b6b
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pruning/group_fisher_deploy_rtmpose-s_8xb256-420e_coco-256x192.py
@@ -0,0 +1,53 @@
+#############################################################################
+"""You have to fill these args.
+
+_base_(str): The path to your pretrain config file.
+fix_subnet (Union[dict,str]): The dict store the pruning structure or the
+ json file including it.
+divisor (int): The divisor the make the channel number divisible.
+"""
+
+_base_ = 'mmpose::body_2d_keypoint/rtmpose/coco/rtmpose-s_8xb256-420e_coco-256x192.py' # noqa
+fix_subnet = {
+ 'backbone.stem.0.conv_(0, 16)_16': 8,
+ 'backbone.stem.1.conv_(0, 16)_16': 10,
+ 'backbone.stem.2.conv_(0, 32)_32': 11,
+ 'backbone.stage1.0.conv_(0, 64)_64': 32,
+ 'backbone.stage1.1.short_conv.conv_(0, 32)_32': 32,
+ 'backbone.stage1.1.main_conv.conv_(0, 32)_32': 23,
+ 'backbone.stage1.1.blocks.0.conv1.conv_(0, 32)_32': 25,
+ 'backbone.stage1.1.final_conv.conv_(0, 64)_64': 25,
+ 'backbone.stage2.0.conv_(0, 128)_128': 71,
+ 'backbone.stage2.1.short_conv.conv_(0, 64)_64': 61,
+ 'backbone.stage2.1.main_conv.conv_(0, 64)_64': 62,
+ 'backbone.stage2.1.blocks.0.conv1.conv_(0, 64)_64': 57,
+ 'backbone.stage2.1.blocks.1.conv1.conv_(0, 64)_64': 59,
+ 'backbone.stage2.1.final_conv.conv_(0, 128)_128': 69,
+ 'backbone.stage3.0.conv_(0, 256)_256': 177,
+ 'backbone.stage3.1.short_conv.conv_(0, 128)_128': 122,
+ 'backbone.stage3.1.main_conv.conv_(0, 128)_128': 123,
+ 'backbone.stage3.1.blocks.0.conv1.conv_(0, 128)_128': 125,
+ 'backbone.stage3.1.blocks.1.conv1.conv_(0, 128)_128': 123,
+ 'backbone.stage3.1.final_conv.conv_(0, 256)_256': 171,
+ 'backbone.stage4.0.conv_(0, 512)_512': 351,
+ 'backbone.stage4.1.conv1.conv_(0, 256)_256': 256,
+ 'backbone.stage4.1.conv2.conv_(0, 512)_512': 367,
+ 'backbone.stage4.2.short_conv.conv_(0, 256)_256': 183,
+ 'backbone.stage4.2.main_conv.conv_(0, 256)_256': 216,
+ 'backbone.stage4.2.blocks.0.conv1.conv_(0, 256)_256': 238,
+ 'backbone.stage4.2.blocks.0.conv2.pointwise_conv.conv_(0, 256)_256': 195,
+ 'backbone.stage4.2.final_conv.conv_(0, 512)_512': 187
+}
+divisor = 16
+##############################################################################
+
+architecture = _base_.model
+
+model = dict(
+ _delete_=True,
+ _scope_='mmrazor',
+ type='GroupFisherDeploySubModel',
+ architecture=architecture,
+ fix_subnet=fix_subnet,
+ divisor=divisor,
+)
diff --git a/projects/rtmpose/rtmpose/pruning/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.py b/projects/rtmpose/rtmpose/pruning/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.py
new file mode 100644
index 0000000000..b4fb4f827c
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pruning/group_fisher_finetune_rtmpose-s_8xb256-420e_aic-coco-256x192.py
@@ -0,0 +1,32 @@
+#############################################################################
+"""# You have to fill these args.
+
+_base_(str): The path to your pruning config file.
+pruned_path (str): The path to the checkpoint of the pruned model.
+finetune_lr (float): The lr rate to finetune. Usually, we directly use the lr
+ rate of the pretrain.
+"""
+
+_base_ = './group_fisher_prune_rtmpose-s_8xb256-420e_aic-coco-256x192.py' # noqa
+pruned_path = 'https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_prune_rtmpose-s_8xb256-420e_aic-coco-256x192.pth' # noqa
+finetune_lr = 4e-3
+##############################################################################
+
+algorithm = _base_.model
+algorithm.init_cfg = dict(type='Pretrained', checkpoint=pruned_path)
+
+model = dict(
+ _delete_=True,
+ _scope_='mmrazor',
+ type='GroupFisherSubModel',
+ algorithm=algorithm,
+)
+
+# restore lr
+optim_wrapper = dict(optimizer=dict(lr=finetune_lr))
+
+# remove pruning related hooks
+custom_hooks = _base_.custom_hooks[:-2]
+
+# delete ddp
+model_wrapper_cfg = None
diff --git a/projects/rtmpose/rtmpose/pruning/group_fisher_finetune_rtmpose-s_8xb256-420e_coco-256x192.py b/projects/rtmpose/rtmpose/pruning/group_fisher_finetune_rtmpose-s_8xb256-420e_coco-256x192.py
new file mode 100644
index 0000000000..5cc6db15e4
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pruning/group_fisher_finetune_rtmpose-s_8xb256-420e_coco-256x192.py
@@ -0,0 +1,33 @@
+#############################################################################
+"""# You have to fill these args.
+
+_base_(str): The path to your pruning config file.
+pruned_path (str): The path to the checkpoint of the pruned model.
+finetune_lr (float): The lr rate to finetune. Usually, we directly use the lr
+ rate of the pretrain.
+"""
+
+_base_ = './group_fisher_prune_rtmpose-s_8xb256-420e_coco-256x192.py'
+pruned_path = 'https://download.openmmlab.com/mmrazor/v1/pruning/group_fisher/rtmpose-s/group_fisher_prune_rtmpose-s_8xb256-420e_coco-256x192.pth' # noqa
+finetune_lr = 4e-3
+##############################################################################
+
+algorithm = _base_.model
+algorithm.init_cfg = dict(type='Pretrained', checkpoint=pruned_path)
+# algorithm.update(dict(architecture=dict(test_cfg=dict(flip_test=False), ))) # disable flip test # noqa
+
+model = dict(
+ _delete_=True,
+ _scope_='mmrazor',
+ type='GroupFisherSubModel',
+ algorithm=algorithm,
+)
+
+# restore lr
+optim_wrapper = dict(optimizer=dict(lr=finetune_lr))
+
+# remove pruning related hooks
+custom_hooks = _base_.custom_hooks[:-2]
+
+# delete ddp
+model_wrapper_cfg = None
diff --git a/projects/rtmpose/rtmpose/pruning/group_fisher_prune_rtmpose-s_8xb256-420e_aic-coco-256x192.py b/projects/rtmpose/rtmpose/pruning/group_fisher_prune_rtmpose-s_8xb256-420e_aic-coco-256x192.py
new file mode 100644
index 0000000000..14bdc96f5e
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pruning/group_fisher_prune_rtmpose-s_8xb256-420e_aic-coco-256x192.py
@@ -0,0 +1,75 @@
+#############################################################################
+"""You have to fill these args.
+
+_base_ (str): The path to your pretrained model checkpoint.
+pretrained_path (str): The path to your pretrained model checkpoint.
+
+interval (int): Interval between pruning two channels. You should ensure you
+ can reach your target pruning ratio when the training ends.
+normalization_type (str): GroupFisher uses two methods to normlized the channel
+ importance, including ['flops','act']. The former uses flops, while the
+ latter uses the memory occupation of activation feature maps.
+lr_ratio (float): Ratio to decrease lr rate. As pruning progress is unstable,
+ you need to decrease the original lr rate until the pruning training work
+ steadly without getting nan.
+
+target_flop_ratio (float): The target flop ratio to prune your model.
+input_shape (Tuple): input shape to measure the flops.
+"""
+
+_base_ = 'mmpose::body_2d_keypoint/rtmpose/coco/rtmpose-s_8xb256-420e_aic-coco-256x192.py' # noqa
+pretrained_path = 'https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-s_simcc-aic-coco_pt-aic-coco_420e-256x192-fcb2599b_20230126.pth' # noqa
+
+interval = 10
+normalization_type = 'act'
+lr_ratio = 0.1
+
+target_flop_ratio = 0.51
+input_shape = (1, 3, 256, 192)
+##############################################################################
+
+architecture = _base_.model
+
+if hasattr(_base_, 'data_preprocessor'):
+ architecture.update({'data_preprocessor': _base_.data_preprocessor})
+ data_preprocessor = None
+
+architecture.init_cfg = dict(type='Pretrained', checkpoint=pretrained_path)
+architecture['_scope_'] = _base_.default_scope
+
+model = dict(
+ _delete_=True,
+ _scope_='mmrazor',
+ type='GroupFisherAlgorithm',
+ architecture=architecture,
+ interval=interval,
+ mutator=dict(
+ type='GroupFisherChannelMutator',
+ parse_cfg=dict(type='ChannelAnalyzer', tracer_type='FxTracer'),
+ channel_unit_cfg=dict(
+ type='GroupFisherChannelUnit',
+ default_args=dict(normalization_type=normalization_type, ),
+ ),
+ ),
+)
+
+model_wrapper_cfg = dict(
+ type='mmrazor.GroupFisherDDP',
+ broadcast_buffers=False,
+)
+
+optim_wrapper = dict(
+ optimizer=dict(lr=_base_.optim_wrapper.optimizer.lr * lr_ratio))
+
+custom_hooks = getattr(_base_, 'custom_hooks', []) + [
+ dict(type='mmrazor.PruningStructureHook'),
+ dict(
+ type='mmrazor.ResourceInfoHook',
+ interval=interval,
+ demo_input=dict(
+ type='mmrazor.DefaultDemoInput',
+ input_shape=input_shape,
+ ),
+ save_ckpt_thr=[target_flop_ratio],
+ ),
+]
diff --git a/projects/rtmpose/rtmpose/pruning/group_fisher_prune_rtmpose-s_8xb256-420e_coco-256x192.py b/projects/rtmpose/rtmpose/pruning/group_fisher_prune_rtmpose-s_8xb256-420e_coco-256x192.py
new file mode 100644
index 0000000000..5a998e5934
--- /dev/null
+++ b/projects/rtmpose/rtmpose/pruning/group_fisher_prune_rtmpose-s_8xb256-420e_coco-256x192.py
@@ -0,0 +1,75 @@
+#############################################################################
+"""You have to fill these args.
+
+_base_ (str): The path to your pretrained model checkpoint.
+pretrained_path (str): The path to your pretrained model checkpoint.
+
+interval (int): Interval between pruning two channels. You should ensure you
+ can reach your target pruning ratio when the training ends.
+normalization_type (str): GroupFisher uses two methods to normlized the channel
+ importance, including ['flops','act']. The former uses flops, while the
+ latter uses the memory occupation of activation feature maps.
+lr_ratio (float): Ratio to decrease lr rate. As pruning progress is unstable,
+ you need to decrease the original lr rate until the pruning training work
+ steadly without getting nan.
+
+target_flop_ratio (float): The target flop ratio to prune your model.
+input_shape (Tuple): input shape to measure the flops.
+"""
+
+_base_ = 'mmpose::body_2d_keypoint/rtmpose/coco/rtmpose-s_8xb256-420e_coco-256x192.py' # noqa
+pretrained_path = 'https://download.openmmlab.com/mmpose/v1/projects/rtmpose/rtmpose-s_simcc-coco_pt-aic-coco_420e-256x192-8edcf0d7_20230127.pth' # noqa
+
+interval = 10
+normalization_type = 'act'
+lr_ratio = 0.1
+
+target_flop_ratio = 0.51
+input_shape = (1, 3, 256, 192)
+##############################################################################
+
+architecture = _base_.model
+
+if hasattr(_base_, 'data_preprocessor'):
+ architecture.update({'data_preprocessor': _base_.data_preprocessor})
+ data_preprocessor = None
+
+architecture.init_cfg = dict(type='Pretrained', checkpoint=pretrained_path)
+architecture['_scope_'] = _base_.default_scope
+
+model = dict(
+ _delete_=True,
+ _scope_='mmrazor',
+ type='GroupFisherAlgorithm',
+ architecture=architecture,
+ interval=interval,
+ mutator=dict(
+ type='GroupFisherChannelMutator',
+ parse_cfg=dict(type='ChannelAnalyzer', tracer_type='FxTracer'),
+ channel_unit_cfg=dict(
+ type='GroupFisherChannelUnit',
+ default_args=dict(normalization_type=normalization_type, ),
+ ),
+ ),
+)
+
+model_wrapper_cfg = dict(
+ type='mmrazor.GroupFisherDDP',
+ broadcast_buffers=False,
+)
+
+optim_wrapper = dict(
+ optimizer=dict(lr=_base_.optim_wrapper.optimizer.lr * lr_ratio))
+
+custom_hooks = getattr(_base_, 'custom_hooks', []) + [
+ dict(type='mmrazor.PruningStructureHook'),
+ dict(
+ type='mmrazor.ResourceInfoHook',
+ interval=interval,
+ demo_input=dict(
+ type='mmrazor.DefaultDemoInput',
+ input_shape=input_shape,
+ ),
+ save_ckpt_thr=[target_flop_ratio],
+ ),
+]
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py
new file mode 100644
index 0000000000..83f1bdce00
--- /dev/null
+++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb32-270e_coco-wholebody-384x288.py
@@ -0,0 +1,231 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(288, 384),
+ sigma=(6., 6.93),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=1024,
+ out_channels=133,
+ input_size=codec['input_size'],
+ in_featuremap_size=(9, 12),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file=data_root + 'annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py
new file mode 100644
index 0000000000..a060d59a40
--- /dev/null
+++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-l_8xb64-270e_coco-wholebody-256x192.py
@@ -0,0 +1,231 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=1.,
+ widen_factor=1.,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=1024,
+ out_channels=133,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file=data_root + 'annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py
new file mode 100644
index 0000000000..f1f86f24b7
--- /dev/null
+++ b/projects/rtmpose/rtmpose/wholebody_2d_keypoint/rtmpose-m_8xb64-270e_coco-wholebody-256x192.py
@@ -0,0 +1,231 @@
+_base_ = ['mmpose::_base_/default_runtime.py']
+
+# runtime
+max_epochs = 270
+stage2_num_epochs = 30
+base_lr = 4e-3
+
+train_cfg = dict(max_epochs=max_epochs, val_interval=10)
+randomness = dict(seed=21)
+
+# optimizer
+optim_wrapper = dict(
+ type='OptimWrapper',
+ optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
+ paramwise_cfg=dict(
+ norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
+
+# learning rate
+param_scheduler = [
+ dict(
+ type='LinearLR',
+ start_factor=1.0e-5,
+ by_epoch=False,
+ begin=0,
+ end=1000),
+ dict(
+ # use cosine lr from 150 to 300 epoch
+ type='CosineAnnealingLR',
+ eta_min=base_lr * 0.05,
+ begin=max_epochs // 2,
+ end=max_epochs,
+ T_max=max_epochs // 2,
+ by_epoch=True,
+ convert_to_iter_based=True),
+]
+
+# automatically scaling LR based on the actual training batch size
+auto_scale_lr = dict(base_batch_size=512)
+
+# codec settings
+codec = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False,
+ use_dark=False)
+
+# model settings
+model = dict(
+ type='TopdownPoseEstimator',
+ data_preprocessor=dict(
+ type='PoseDataPreprocessor',
+ mean=[123.675, 116.28, 103.53],
+ std=[58.395, 57.12, 57.375],
+ bgr_to_rgb=True),
+ backbone=dict(
+ _scope_='mmdet',
+ type='CSPNeXt',
+ arch='P5',
+ expand_ratio=0.5,
+ deepen_factor=0.67,
+ widen_factor=0.75,
+ out_indices=(4, ),
+ channel_attention=True,
+ norm_cfg=dict(type='SyncBN'),
+ act_cfg=dict(type='SiLU'),
+ init_cfg=dict(
+ type='Pretrained',
+ prefix='backbone.',
+ checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
+ 'rtmpose/cspnext-m_udp-aic-coco_210e-256x192-f2f7d6f6_20230130.pth' # noqa
+ )),
+ head=dict(
+ type='RTMCCHead',
+ in_channels=768,
+ out_channels=133,
+ input_size=codec['input_size'],
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=codec['simcc_split_ratio'],
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True),
+ decoder=codec),
+ test_cfg=dict(flip_test=True, ))
+
+# base dataset settings
+dataset_type = 'CocoWholeBodyDataset'
+data_mode = 'topdown'
+data_root = 'data/coco/'
+
+file_client_args = dict(backend='disk')
+# file_client_args = dict(
+# backend='petrel',
+# path_mapping=dict({
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/',
+# f'{data_root}': 's3://openmmlab/datasets/detection/coco/'
+# }))
+
+# pipelines
+train_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform', scale_factor=[0.6, 1.4], rotate_factor=80),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=1.0),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+val_pipeline = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='PackPoseInputs')
+]
+
+train_pipeline_stage2 = [
+ dict(type='LoadImage', file_client_args=file_client_args),
+ dict(type='GetBBoxCenterScale'),
+ dict(type='RandomFlip', direction='horizontal'),
+ dict(type='RandomHalfBody'),
+ dict(
+ type='RandomBBoxTransform',
+ shift_factor=0.,
+ scale_factor=[0.75, 1.25],
+ rotate_factor=60),
+ dict(type='TopdownAffine', input_size=codec['input_size']),
+ dict(type='mmdet.YOLOXHSVRandomAug'),
+ dict(
+ type='Albumentation',
+ transforms=[
+ dict(type='Blur', p=0.1),
+ dict(type='MedianBlur', p=0.1),
+ dict(
+ type='CoarseDropout',
+ max_holes=1,
+ max_height=0.4,
+ max_width=0.4,
+ min_holes=1,
+ min_height=0.2,
+ min_width=0.2,
+ p=0.5),
+ ]),
+ dict(type='GenerateTarget', encoder=codec),
+ dict(type='PackPoseInputs')
+]
+
+# data loaders
+train_dataloader = dict(
+ batch_size=64,
+ num_workers=10,
+ persistent_workers=True,
+ sampler=dict(type='DefaultSampler', shuffle=True),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_train_v1.0.json',
+ data_prefix=dict(img='train2017/'),
+ pipeline=train_pipeline,
+ ))
+val_dataloader = dict(
+ batch_size=32,
+ num_workers=10,
+ persistent_workers=True,
+ drop_last=False,
+ sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
+ dataset=dict(
+ type=dataset_type,
+ data_root=data_root,
+ data_mode=data_mode,
+ ann_file='annotations/coco_wholebody_val_v1.0.json',
+ data_prefix=dict(img='val2017/'),
+ test_mode=True,
+ pipeline=val_pipeline,
+ ))
+test_dataloader = val_dataloader
+
+# hooks
+default_hooks = dict(
+ checkpoint=dict(
+ save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
+
+custom_hooks = [
+ dict(
+ type='EMAHook',
+ ema_type='ExpMomentumEMA',
+ momentum=0.0002,
+ update_buffers=True,
+ priority=49),
+ dict(
+ type='mmdet.PipelineSwitchHook',
+ switch_epoch=max_epochs - stage2_num_epochs,
+ switch_pipeline=train_pipeline_stage2)
+]
+
+# evaluators
+val_evaluator = dict(
+ type='CocoWholeBodyMetric',
+ ann_file=data_root + 'annotations/coco_wholebody_val_v1.0.json')
+test_evaluator = val_evaluator
diff --git a/requirements/mminstall.txt b/requirements/mminstall.txt
index 580af80e5e..7b85a2f3f6 100644
--- a/requirements/mminstall.txt
+++ b/requirements/mminstall.txt
@@ -1,2 +1,2 @@
mmcv>=2.0.0rc1
-mmengine
+mmengine>=0.4.0,<1.0.0
diff --git a/requirements/readthedocs.txt b/requirements/readthedocs.txt
index ba5d0bfd79..6615950400 100644
--- a/requirements/readthedocs.txt
+++ b/requirements/readthedocs.txt
@@ -1,5 +1,5 @@
mmcv>=2.0.0rc1
-mmengine
+mmengine>=0.4.0,<1.0.0
munkres
regex
scipy
diff --git a/requirements/runtime.txt b/requirements/runtime.txt
index ed0648440c..ab5c0172e4 100644
--- a/requirements/runtime.txt
+++ b/requirements/runtime.txt
@@ -1,5 +1,4 @@
chumpy
-dataclasses; python_version == '3.6'
json_tricks
matplotlib
munkres
diff --git a/setup.py b/setup.py
index b436a7431d..7222188e2f 100644
--- a/setup.py
+++ b/setup.py
@@ -176,14 +176,13 @@ def add_mim_extension():
'License :: OSI Approved :: Apache Software License',
'Operating System :: OS Independent',
'Programming Language :: Python :: 3',
- 'Programming Language :: Python :: 3.5',
- 'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
'Programming Language :: Python :: 3.8',
'Programming Language :: Python :: 3.9',
],
url='https://github.com/open-mmlab/mmpose',
license='Apache License 2.0',
+ python_requires='>=3.7',
install_requires=parse_requirements('requirements/runtime.txt'),
extras_require={
'all': parse_requirements('requirements.txt'),
diff --git a/tests/data/coco/test_keypoint_partition_metric.json b/tests/data/coco/test_keypoint_partition_metric.json
new file mode 100644
index 0000000000..9d04f5e87b
--- /dev/null
+++ b/tests/data/coco/test_keypoint_partition_metric.json
@@ -0,0 +1,7647 @@
+{
+ "info": {
+ "description": "COCO-WholeBody sample",
+ "url": "https://github.com/jin-s13/COCO-WholeBody",
+ "version": "1.0",
+ "year": "2020",
+ "date_created": "2020/09/18"
+ },
+ "licenses": [
+ {
+ "url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
+ "id": 1,
+ "name": "Attribution-NonCommercial-ShareAlike License"
+ },
+ {
+ "url": "http://creativecommons.org/licenses/by-nc/2.0/",
+ "id": 2,
+ "name": "Attribution-NonCommercial License"
+ },
+ {
+ "url": "http://creativecommons.org/licenses/by-nc-nd/2.0/",
+ "id": 3,
+ "name": "Attribution-NonCommercial-NoDerivs License"
+ },
+ {
+ "url": "http://creativecommons.org/licenses/by/2.0/",
+ "id": 4,
+ "name": "Attribution License"
+ },
+ {
+ "url": "http://creativecommons.org/licenses/by-sa/2.0/",
+ "id": 5,
+ "name": "Attribution-ShareAlike License"
+ },
+ {
+ "url": "http://creativecommons.org/licenses/by-nd/2.0/",
+ "id": 6,
+ "name": "Attribution-NoDerivs License"
+ },
+ {
+ "url": "http://flickr.com/commons/usage/",
+ "id": 7,
+ "name": "No known copyright restrictions"
+ },
+ {
+ "url": "http://www.usa.gov/copyright.shtml",
+ "id": 8,
+ "name": "United States Government Work"
+ }
+ ],
+ "categories": [
+ {
+ "supercategory": "person",
+ "id": 1,
+ "name": "person",
+ "keypoints": [
+ "nose",
+ "left_eye",
+ "right_eye",
+ "left_ear",
+ "right_ear",
+ "left_shoulder",
+ "right_shoulder",
+ "left_elbow",
+ "right_elbow",
+ "left_wrist",
+ "right_wrist",
+ "left_hip",
+ "right_hip",
+ "left_knee",
+ "right_knee",
+ "left_ankle",
+ "right_ankle"
+ ],
+ "skeleton": [
+ [
+ 16,
+ 14
+ ],
+ [
+ 14,
+ 12
+ ],
+ [
+ 17,
+ 15
+ ],
+ [
+ 15,
+ 13
+ ],
+ [
+ 12,
+ 13
+ ],
+ [
+ 6,
+ 12
+ ],
+ [
+ 7,
+ 13
+ ],
+ [
+ 6,
+ 7
+ ],
+ [
+ 6,
+ 8
+ ],
+ [
+ 7,
+ 9
+ ],
+ [
+ 8,
+ 10
+ ],
+ [
+ 9,
+ 11
+ ],
+ [
+ 2,
+ 3
+ ],
+ [
+ 1,
+ 2
+ ],
+ [
+ 1,
+ 3
+ ],
+ [
+ 2,
+ 4
+ ],
+ [
+ 3,
+ 5
+ ],
+ [
+ 4,
+ 6
+ ],
+ [
+ 5,
+ 7
+ ]
+ ]
+ }
+ ],
+ "images": [
+ {
+ "license": 4,
+ "file_name": "000000000785.jpg",
+ "coco_url": "http://images.cocodataset.org/val2017/000000000785.jpg",
+ "height": 425,
+ "width": 640,
+ "date_captured": "2013-11-19 21:22:42",
+ "flickr_url": "http://farm8.staticflickr.com/7015/6795644157_f019453ae7_z.jpg",
+ "id": 785
+ },
+ {
+ "license": 3,
+ "file_name": "000000040083.jpg",
+ "coco_url": "http://images.cocodataset.org/val2017/000000040083.jpg",
+ "height": 333,
+ "width": 500,
+ "date_captured": "2013-11-18 03:30:24",
+ "flickr_url": "http://farm1.staticflickr.com/116/254881838_e21c6d17b8_z.jpg",
+ "id": 40083
+ },
+ {
+ "license": 1,
+ "file_name": "000000196141.jpg",
+ "coco_url": "http://images.cocodataset.org/val2017/000000196141.jpg",
+ "height": 429,
+ "width": 640,
+ "date_captured": "2013-11-22 22:37:15",
+ "flickr_url": "http://farm4.staticflickr.com/3310/3611902235_57d4ae496d_z.jpg",
+ "id": 196141
+ },
+ {
+ "license": 3,
+ "file_name": "000000197388.jpg",
+ "coco_url": "http://images.cocodataset.org/val2017/000000197388.jpg",
+ "height": 392,
+ "width": 640,
+ "date_captured": "2013-11-19 20:10:37",
+ "flickr_url": "http://farm9.staticflickr.com/8375/8507321836_5b8b13188f_z.jpg",
+ "id": 197388
+ }
+ ],
+ "annotations": [
+ {
+ "segmentation": [
+ [
+ 353.37,
+ 67.65,
+ 358.15,
+ 52.37,
+ 362.92,
+ 47.59,
+ 374.38,
+ 44.73,
+ 389.66,
+ 52.37,
+ 389.66,
+ 67.65,
+ 389.66,
+ 76.25,
+ 393.48,
+ 83.89,
+ 396.35,
+ 88.66,
+ 397.3,
+ 91.53,
+ 406.85,
+ 99.17,
+ 413.54,
+ 104.9,
+ 451.74,
+ 148.83,
+ 458.43,
+ 153.6,
+ 462.25,
+ 166.02,
+ 467.02,
+ 173.66,
+ 463.2,
+ 181.3,
+ 449.83,
+ 183.21,
+ 448.88,
+ 191.81,
+ 455.56,
+ 226.19,
+ 448.88,
+ 254.84,
+ 453.65,
+ 286.36,
+ 475.62,
+ 323.6,
+ 491.85,
+ 361.81,
+ 494.72,
+ 382.82,
+ 494.72,
+ 382.82,
+ 499.49,
+ 391.41,
+ 416.4,
+ 391.41,
+ 424.04,
+ 383.77,
+ 439.33,
+ 374.22,
+ 445.06,
+ 360.85,
+ 436.46,
+ 334.11,
+ 421.18,
+ 303.55,
+ 416.4,
+ 289.22,
+ 409.72,
+ 268.21,
+ 396.35,
+ 280.63,
+ 405.9,
+ 298.77,
+ 417.36,
+ 324.56,
+ 425,
+ 349.39,
+ 425,
+ 357.99,
+ 419.27,
+ 360.85,
+ 394.44,
+ 367.54,
+ 362.92,
+ 370.4,
+ 346.69,
+ 367.54,
+ 360.06,
+ 362.76,
+ 369.61,
+ 360.85,
+ 382.98,
+ 340.8,
+ 355.28,
+ 271.08,
+ 360.06,
+ 266.3,
+ 386.8,
+ 219.5,
+ 368.65,
+ 162.2,
+ 348.6,
+ 175.57,
+ 309.44,
+ 187.03,
+ 301.8,
+ 192.76,
+ 288.43,
+ 193.72,
+ 282.7,
+ 193.72,
+ 280.79,
+ 187.03,
+ 280.79,
+ 174.62,
+ 287.47,
+ 171.75,
+ 291.29,
+ 171.75,
+ 295.11,
+ 171.75,
+ 306.57,
+ 166.98,
+ 312.3,
+ 165.07,
+ 345.73,
+ 142.14,
+ 350.51,
+ 117.31,
+ 350.51,
+ 102.03,
+ 350.51,
+ 90.57,
+ 353.37,
+ 65.74
+ ]
+ ],
+ "num_keypoints": 112,
+ "area": 27789.11055,
+ "iscrowd": 0,
+ "keypoints": [
+ 367,
+ 81,
+ 2,
+ 374,
+ 73,
+ 2,
+ 360,
+ 75,
+ 2,
+ 386,
+ 78,
+ 2,
+ 356,
+ 81,
+ 2,
+ 399,
+ 108,
+ 2,
+ 358,
+ 129,
+ 2,
+ 433,
+ 142,
+ 2,
+ 341,
+ 159,
+ 2,
+ 449,
+ 165,
+ 2,
+ 309,
+ 178,
+ 2,
+ 424,
+ 203,
+ 2,
+ 393,
+ 214,
+ 2,
+ 429,
+ 294,
+ 2,
+ 367,
+ 273,
+ 2,
+ 466,
+ 362,
+ 2,
+ 396,
+ 341,
+ 2,
+ 439,
+ 378,
+ 2,
+ 446,
+ 380,
+ 2,
+ 479,
+ 370,
+ 2,
+ 377,
+ 359,
+ 2,
+ 376,
+ 358,
+ 2,
+ 413,
+ 353,
+ 2,
+ 355.823,
+ 75.36,
+ 1.0,
+ 356.354,
+ 79.0837,
+ 1.0,
+ 357.244,
+ 82.7374,
+ 1.0,
+ 358.518,
+ 86.2722,
+ 1.0,
+ 360.146,
+ 89.6578,
+ 1.0,
+ 362.266,
+ 92.7538,
+ 1.0,
+ 365.004,
+ 95.3223,
+ 1.0,
+ 368.487,
+ 96.6454,
+ 1.0,
+ 372.191,
+ 96.1419,
+ 1.0,
+ 375.644,
+ 94.6832,
+ 1.0,
+ 378.601,
+ 92.3665,
+ 1.0,
+ 381.101,
+ 89.5662,
+ 1.0,
+ 382.903,
+ 86.2741,
+ 1.0,
+ 383.896,
+ 82.6509,
+ 1.0,
+ 384.075,
+ 78.9011,
+ 1.0,
+ 384.1,
+ 75.1408,
+ 1.0,
+ 383.903,
+ 71.3861,
+ 1.0,
+ 357.084,
+ 72.9743,
+ 1.0,
+ 358.602,
+ 71.7848,
+ 1.0,
+ 360.42,
+ 71.3443,
+ 1.0,
+ 362.377,
+ 71.1566,
+ 1.0,
+ 364.36,
+ 71.1889,
+ 1.0,
+ 368.971,
+ 70.4992,
+ 1.0,
+ 370.945,
+ 69.8179,
+ 1.0,
+ 373.001,
+ 69.3543,
+ 1.0,
+ 375.14,
+ 69.2666,
+ 1.0,
+ 377.358,
+ 69.8865,
+ 1.0,
+ 366.57,
+ 73.9588,
+ 1.0,
+ 366.734,
+ 76.1499,
+ 1.0,
+ 366.88,
+ 78.3018,
+ 1.0,
+ 366.99,
+ 80.4957,
+ 1.0,
+ 365.104,
+ 82.5589,
+ 1.0,
+ 366.308,
+ 82.8331,
+ 1.0,
+ 367.645,
+ 82.8037,
+ 1.0,
+ 369.172,
+ 82.2061,
+ 1.0,
+ 370.693,
+ 81.6521,
+ 1.0,
+ 358.705,
+ 75.4542,
+ 1.0,
+ 360.294,
+ 74.0903,
+ 1.0,
+ 362.376,
+ 73.8423,
+ 1.0,
+ 364.302,
+ 74.6834,
+ 1.0,
+ 362.543,
+ 75.568,
+ 1.0,
+ 360.612,
+ 75.8883,
+ 1.0,
+ 369.771,
+ 73.7734,
+ 1.0,
+ 371.409,
+ 72.2638,
+ 1.0,
+ 373.615,
+ 71.9502,
+ 1.0,
+ 375.722,
+ 72.7144,
+ 1.0,
+ 373.888,
+ 73.699,
+ 1.0,
+ 371.835,
+ 74.0238,
+ 1.0,
+ 363.184,
+ 86.9317,
+ 1.0,
+ 364.788,
+ 85.4484,
+ 1.0,
+ 367.021,
+ 84.7474,
+ 1.0,
+ 368.048,
+ 84.5364,
+ 1.0,
+ 369.083,
+ 84.3709,
+ 1.0,
+ 372.183,
+ 84.0529,
+ 1.0,
+ 375.083,
+ 84.8901,
+ 1.0,
+ 373.687,
+ 87.0735,
+ 1.0,
+ 371.644,
+ 88.8121,
+ 1.0,
+ 369.024,
+ 89.6982,
+ 1.0,
+ 366.67,
+ 89.6039,
+ 1.0,
+ 364.721,
+ 88.606,
+ 1.0,
+ 363.588,
+ 86.903,
+ 1.0,
+ 365.723,
+ 85.8496,
+ 1.0,
+ 368.184,
+ 85.2863,
+ 1.0,
+ 371.444,
+ 84.8294,
+ 1.0,
+ 374.647,
+ 85.0454,
+ 1.0,
+ 372.166,
+ 87.2914,
+ 1.0,
+ 368.81,
+ 88.3791,
+ 1.0,
+ 365.965,
+ 88.3238,
+ 1.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 304.10366,
+ 181.75134,
+ 1,
+ 300.70183,
+ 182.77567,
+ 1,
+ 297.3,
+ 183.8,
+ 1,
+ 294.7,
+ 186.5,
+ 1,
+ 290.1,
+ 187.8,
+ 1,
+ 290.9,
+ 176.6,
+ 1,
+ 287.5,
+ 176.0,
+ 1,
+ 285.5,
+ 178.4,
+ 1,
+ 286.4,
+ 182.4,
+ 1,
+ 288.8,
+ 179.4,
+ 1,
+ 285.0,
+ 181.0,
+ 1,
+ 287.3,
+ 186.1,
+ 1,
+ 291.8,
+ 189.5,
+ 1,
+ 287.7,
+ 182.7,
+ 1,
+ 283.8,
+ 184.1,
+ 1,
+ 286.5,
+ 189.1,
+ 1,
+ 290.0,
+ 192.0,
+ 1,
+ 286.7,
+ 185.3,
+ 1,
+ 282.8,
+ 187.4,
+ 1,
+ 284.8,
+ 191.6,
+ 1,
+ 288.4,
+ 194.5,
+ 1
+ ],
+ "image_id": 785,
+ "bbox": [
+ 280.79,
+ 44.73,
+ 218.7,
+ 346.68
+ ],
+ "category_id": 1,
+ "id": 442619,
+ "face_box": [
+ 358.2,
+ 69.86,
+ 26.360000000000014,
+ 25.849999999999994
+ ],
+ "lefthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "righthand_box": [
+ 280.43,
+ 173.12,
+ 27.860000000000014,
+ 24.849999999999994
+ ],
+ "face_valid": true,
+ "lefthand_valid": false,
+ "righthand_valid": true,
+ "foot_valid": true
+ },
+ {
+ "segmentation": [
+ [
+ 98.56,
+ 273.72,
+ 132.9,
+ 267,
+ 140.37,
+ 281.93,
+ 165.75,
+ 285.66,
+ 156.79,
+ 264.01,
+ 170.23,
+ 261.02,
+ 177.7,
+ 272.97,
+ 182.18,
+ 279.69,
+ 200.85,
+ 268.49,
+ 212.79,
+ 255.05,
+ 188.9,
+ 256.54,
+ 164.26,
+ 240.12,
+ 139.62,
+ 212.49,
+ 109.01,
+ 221.45,
+ 103.04,
+ 220.71,
+ 122.45,
+ 202.04,
+ 113.49,
+ 196.07,
+ 96.32,
+ 168.44,
+ 97.06,
+ 162.47,
+ 110.5,
+ 136.34,
+ 112,
+ 124.39,
+ 91.09,
+ 110.95,
+ 80.64,
+ 114.68,
+ 71.68,
+ 131.86,
+ 62.72,
+ 147.54,
+ 57.49,
+ 156.5,
+ 48.53,
+ 168.44,
+ 41.07,
+ 180.39,
+ 38.08,
+ 193.08,
+ 40.32,
+ 205.03,
+ 47.04,
+ 213.24,
+ 54.5,
+ 216.23,
+ 82.13,
+ 252.06,
+ 91.09,
+ 271.48
+ ]
+ ],
+ "num_keypoints": 106,
+ "area": 11025.219,
+ "iscrowd": 0,
+ "keypoints": [
+ 99,
+ 144,
+ 2,
+ 104,
+ 141,
+ 2,
+ 96,
+ 137,
+ 2,
+ 0,
+ 0,
+ 0,
+ 78,
+ 133,
+ 2,
+ 56,
+ 161,
+ 2,
+ 81,
+ 162,
+ 2,
+ 0,
+ 0,
+ 0,
+ 103,
+ 208,
+ 2,
+ 116,
+ 204,
+ 2,
+ 0,
+ 0,
+ 0,
+ 57,
+ 246,
+ 1,
+ 82,
+ 259,
+ 1,
+ 137,
+ 219,
+ 2,
+ 138,
+ 247,
+ 2,
+ 177,
+ 256,
+ 2,
+ 158,
+ 296,
+ 1,
+ 208.16049,
+ 257.42419,
+ 2.0,
+ 205.8824,
+ 259.13276,
+ 2.0,
+ 183.38626,
+ 275.93367,
+ 2.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 82.9654,
+ 131.144,
+ 1.0,
+ 81.8046,
+ 134.328,
+ 1.0,
+ 80.7007,
+ 137.531,
+ 1.0,
+ 79.8836,
+ 140.818,
+ 1.0,
+ 79.734,
+ 144.196,
+ 1.0,
+ 80.4763,
+ 147.486,
+ 1.0,
+ 82.0188,
+ 150.498,
+ 1.0,
+ 84.2352,
+ 153.057,
+ 1.0,
+ 86.8081,
+ 155.258,
+ 1.0,
+ 89.652,
+ 157.095,
+ 1.0,
+ 92.9128,
+ 157.812,
+ 1.0,
+ 95.962,
+ 156.474,
+ 1.0,
+ 98.5377,
+ 154.281,
+ 1.0,
+ 100.557,
+ 151.568,
+ 1.0,
+ 102.508,
+ 148.799,
+ 1.0,
+ 103.987,
+ 145.756,
+ 1.0,
+ 105.345,
+ 142.655,
+ 1.0,
+ 93.6074,
+ 132.13,
+ 1.0,
+ 95.8108,
+ 132.112,
+ 1.0,
+ 97.7956,
+ 132.618,
+ 1.0,
+ 99.6897,
+ 133.398,
+ 1.0,
+ 101.364,
+ 134.432,
+ 1.0,
+ 105.0,
+ 136.896,
+ 1.0,
+ 105.708,
+ 137.334,
+ 1.0,
+ 106.267,
+ 137.852,
+ 1.0,
+ 106.759,
+ 138.404,
+ 1.0,
+ 107.013,
+ 139.401,
+ 1.0,
+ 100.904,
+ 139.994,
+ 1.0,
+ 100.551,
+ 142.0,
+ 1.0,
+ 100.202,
+ 143.956,
+ 1.0,
+ 99.8116,
+ 145.919,
+ 1.0,
+ 94.7941,
+ 146.187,
+ 1.0,
+ 95.9823,
+ 147.027,
+ 1.0,
+ 97.3054,
+ 147.849,
+ 1.0,
+ 98.2362,
+ 148.403,
+ 1.0,
+ 99.2812,
+ 148.491,
+ 1.0,
+ 93.151,
+ 135.98,
+ 1.0,
+ 94.9184,
+ 136.187,
+ 1.0,
+ 96.5441,
+ 136.903,
+ 1.0,
+ 97.6034,
+ 138.308,
+ 1.0,
+ 95.8998,
+ 138.017,
+ 1.0,
+ 94.3941,
+ 137.178,
+ 1.0,
+ 102.085,
+ 141.003,
+ 1.0,
+ 103.379,
+ 141.05,
+ 1.0,
+ 104.485,
+ 141.71,
+ 1.0,
+ 104.899,
+ 142.915,
+ 1.0,
+ 103.704,
+ 142.739,
+ 1.0,
+ 102.729,
+ 142.026,
+ 1.0,
+ 89.8433,
+ 148.685,
+ 1.0,
+ 92.6494,
+ 149.006,
+ 1.0,
+ 95.2801,
+ 149.78,
+ 1.0,
+ 96.1096,
+ 150.259,
+ 1.0,
+ 96.7411,
+ 150.719,
+ 1.0,
+ 97.3853,
+ 151.82,
+ 1.0,
+ 97.337,
+ 153.217,
+ 1.0,
+ 96.5124,
+ 153.108,
+ 1.0,
+ 95.6091,
+ 152.796,
+ 1.0,
+ 94.7518,
+ 152.399,
+ 1.0,
+ 93.0313,
+ 151.317,
+ 1.0,
+ 91.3461,
+ 150.149,
+ 1.0,
+ 90.24,
+ 148.802,
+ 1.0,
+ 92.9121,
+ 149.883,
+ 1.0,
+ 95.4213,
+ 151.204,
+ 1.0,
+ 96.3082,
+ 152.03,
+ 1.0,
+ 97.1377,
+ 152.997,
+ 1.0,
+ 96.3098,
+ 152.035,
+ 1.0,
+ 95.406,
+ 151.234,
+ 1.0,
+ 92.8725,
+ 149.984,
+ 1.0,
+ 109.88978,
+ 204.46047,
+ 1,
+ 113.101195,
+ 201.939065,
+ 1,
+ 116.31261,
+ 199.41766,
+ 1,
+ 113.19977,
+ 199.3139,
+ 1,
+ 109.8794,
+ 200.24775,
+ 1,
+ 117.86903,
+ 199.10638,
+ 2,
+ 113.9261,
+ 199.00262,
+ 2,
+ 109.56812,
+ 198.48381,
+ 2,
+ 106.6628,
+ 198.38004999999998,
+ 1,
+ 117.1427,
+ 202.32298,
+ 2,
+ 111.2283,
+ 201.80417,
+ 2,
+ 107.07784000000001,
+ 201.38913,
+ 2,
+ 103.65371999999999,
+ 201.18161,
+ 1,
+ 116.52013,
+ 205.95463,
+ 2,
+ 112.5772,
+ 205.53958,
+ 2,
+ 107.59665,
+ 204.39821,
+ 2,
+ 104.27629,
+ 203.77564,
+ 2,
+ 116.41637,
+ 209.69004,
+ 2,
+ 112.16215,
+ 209.48252,
+ 2,
+ 108.73803000000001,
+ 208.34114,
+ 2,
+ 105.72895,
+ 206.68096,
+ 2,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "image_id": 40083,
+ "bbox": [
+ 38.08,
+ 110.95,
+ 174.71,
+ 174.71
+ ],
+ "category_id": 1,
+ "id": 198196,
+ "face_box": [
+ 79.19,
+ 131.64,
+ 29.290000000000006,
+ 28.480000000000018
+ ],
+ "lefthand_box": [
+ 104.83,
+ 196.48,
+ 16.400000000000006,
+ 15.810000000000002
+ ],
+ "righthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "face_valid": true,
+ "lefthand_valid": true,
+ "righthand_valid": false,
+ "foot_valid": true
+ },
+ {
+ "segmentation": [
+ [
+ 257.76,
+ 288.05,
+ 273.4,
+ 258.26,
+ 325.55,
+ 253.79,
+ 335.23,
+ 232.93,
+ 326.3,
+ 186.74,
+ 333.74,
+ 177.05,
+ 327.79,
+ 153.21,
+ 333.74,
+ 142.04,
+ 344.17,
+ 139.06,
+ 353.11,
+ 139.06,
+ 359.07,
+ 145.02,
+ 360.56,
+ 148.74,
+ 362.05,
+ 168.86,
+ 388.87,
+ 197.17,
+ 397.81,
+ 276.88,
+ 372.48,
+ 293.27
+ ]
+ ],
+ "num_keypoints": 83,
+ "area": 10171.9544,
+ "iscrowd": 0,
+ "keypoints": [
+ 343,
+ 164,
+ 2,
+ 348,
+ 160,
+ 2,
+ 340,
+ 160,
+ 2,
+ 359,
+ 163,
+ 2,
+ 332,
+ 164,
+ 2,
+ 370,
+ 189,
+ 2,
+ 334,
+ 190,
+ 2,
+ 358,
+ 236,
+ 2,
+ 348,
+ 234,
+ 2,
+ 339,
+ 270,
+ 2,
+ 330,
+ 262,
+ 2,
+ 378,
+ 262,
+ 2,
+ 343,
+ 254,
+ 2,
+ 338,
+ 280,
+ 2,
+ 283,
+ 272,
+ 2,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 333.383,
+ 160.62,
+ 1.0,
+ 333.607,
+ 163.811,
+ 1.0,
+ 334.137,
+ 166.965,
+ 1.0,
+ 334.934,
+ 170.062,
+ 1.0,
+ 336.036,
+ 173.062,
+ 1.0,
+ 337.69,
+ 175.794,
+ 1.0,
+ 340.01,
+ 177.986,
+ 1.0,
+ 342.889,
+ 179.347,
+ 1.0,
+ 346.063,
+ 179.445,
+ 1.0,
+ 349.16,
+ 178.674,
+ 1.0,
+ 351.892,
+ 177.033,
+ 1.0,
+ 354.132,
+ 174.761,
+ 1.0,
+ 355.652,
+ 171.957,
+ 1.0,
+ 356.482,
+ 168.871,
+ 1.0,
+ 356.751,
+ 165.691,
+ 1.0,
+ 356.914,
+ 162.496,
+ 1.0,
+ 356.913,
+ 159.299,
+ 1.0,
+ 335.435,
+ 157.491,
+ 1.0,
+ 336.759,
+ 156.383,
+ 1.0,
+ 338.264,
+ 155.821,
+ 1.0,
+ 339.903,
+ 155.445,
+ 1.0,
+ 341.565,
+ 155.312,
+ 1.0,
+ 345.805,
+ 155.039,
+ 1.0,
+ 347.424,
+ 154.896,
+ 1.0,
+ 349.044,
+ 154.957,
+ 1.0,
+ 350.677,
+ 155.266,
+ 1.0,
+ 352.333,
+ 156.08,
+ 1.0,
+ 343.65,
+ 159.186,
+ 1.0,
+ 343.687,
+ 161.041,
+ 1.0,
+ 343.68,
+ 162.886,
+ 1.0,
+ 343.657,
+ 164.752,
+ 1.0,
+ 341.61,
+ 167.049,
+ 1.0,
+ 342.69,
+ 167.145,
+ 1.0,
+ 343.906,
+ 167.123,
+ 1.0,
+ 345.179,
+ 166.907,
+ 1.0,
+ 346.456,
+ 166.707,
+ 1.0,
+ 336.707,
+ 159.932,
+ 1.0,
+ 338.078,
+ 158.999,
+ 1.0,
+ 339.726,
+ 158.864,
+ 1.0,
+ 341.204,
+ 159.605,
+ 1.0,
+ 339.755,
+ 160.185,
+ 1.0,
+ 338.21,
+ 160.321,
+ 1.0,
+ 346.612,
+ 159.27,
+ 1.0,
+ 348.028,
+ 158.307,
+ 1.0,
+ 349.739,
+ 158.245,
+ 1.0,
+ 351.302,
+ 158.965,
+ 1.0,
+ 349.802,
+ 159.575,
+ 1.0,
+ 348.188,
+ 159.642,
+ 1.0,
+ 340.049,
+ 171.873,
+ 1.0,
+ 341.307,
+ 170.304,
+ 1.0,
+ 343.097,
+ 169.499,
+ 1.0,
+ 343.987,
+ 169.41,
+ 1.0,
+ 344.876,
+ 169.314,
+ 1.0,
+ 346.909,
+ 169.61,
+ 1.0,
+ 348.603,
+ 170.874,
+ 1.0,
+ 347.548,
+ 172.219,
+ 1.0,
+ 346.133,
+ 173.242,
+ 1.0,
+ 344.378,
+ 173.742,
+ 1.0,
+ 342.683,
+ 173.666,
+ 1.0,
+ 341.218,
+ 173.038,
+ 1.0,
+ 340.398,
+ 171.815,
+ 1.0,
+ 342.1,
+ 170.752,
+ 1.0,
+ 344.043,
+ 170.287,
+ 1.0,
+ 346.21,
+ 170.271,
+ 1.0,
+ 348.214,
+ 170.913,
+ 1.0,
+ 346.462,
+ 171.947,
+ 1.0,
+ 344.283,
+ 172.468,
+ 1.0,
+ 342.246,
+ 172.507,
+ 1.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "image_id": 40083,
+ "bbox": [
+ 257.76,
+ 139.06,
+ 140.05,
+ 154.21
+ ],
+ "category_id": 1,
+ "id": 230195,
+ "face_box": [
+ 333.96,
+ 154.32,
+ 23.28000000000003,
+ 26.79000000000002
+ ],
+ "lefthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "righthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "face_valid": true,
+ "lefthand_valid": false,
+ "righthand_valid": false,
+ "foot_valid": false
+ },
+ {
+ "segmentation": [
+ [
+ 285.37,
+ 126.5,
+ 281.97,
+ 127.72,
+ 280.76,
+ 132.33,
+ 280.76,
+ 136.46,
+ 275.17,
+ 143.26,
+ 275.9,
+ 158.08,
+ 277.6,
+ 164.4,
+ 278.33,
+ 173.87,
+ 278.33,
+ 183.83,
+ 279.79,
+ 191.11,
+ 281.97,
+ 194.76,
+ 284.89,
+ 192.09,
+ 284.89,
+ 186.99,
+ 284.89,
+ 181.16,
+ 284.64,
+ 177.51,
+ 285.86,
+ 173.87
+ ]
+ ],
+ "num_keypoints": 0,
+ "area": 491.2669,
+ "iscrowd": 0,
+ "keypoints": [
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "image_id": 40083,
+ "bbox": [
+ 275.17,
+ 126.5,
+ 10.69,
+ 68.26
+ ],
+ "category_id": 1,
+ "id": 1202706,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "righthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "face_valid": false,
+ "lefthand_valid": false,
+ "righthand_valid": false,
+ "foot_valid": false
+ },
+ {
+ "segmentation": [
+ [
+ 339.34,
+ 107.97,
+ 338.38,
+ 102.19,
+ 339.34,
+ 91.58,
+ 335.49,
+ 84.84,
+ 326.81,
+ 74.23,
+ 312.35,
+ 74.23,
+ 301.75,
+ 74.23,
+ 295,
+ 86.76,
+ 295,
+ 93.51,
+ 292.11,
+ 99.3,
+ 287.29,
+ 102.19,
+ 291.14,
+ 107.01,
+ 295,
+ 107.01,
+ 295.96,
+ 112.79,
+ 301.75,
+ 115.69,
+ 305.6,
+ 119.54,
+ 307.53,
+ 123.4,
+ 317.17,
+ 123.4,
+ 311.39,
+ 129.18,
+ 286.32,
+ 139.79,
+ 274.75,
+ 139.79,
+ 264.15,
+ 138.82,
+ 262.22,
+ 144.61,
+ 261.26,
+ 147.5,
+ 253.54,
+ 147.5,
+ 247.76,
+ 150.39,
+ 249.69,
+ 159.07,
+ 256.44,
+ 161,
+ 262.22,
+ 161,
+ 268,
+ 161,
+ 276.68,
+ 161.96,
+ 284.39,
+ 168.71,
+ 293.07,
+ 174.49,
+ 301.75,
+ 174.49,
+ 308.49,
+ 169.67,
+ 308.49,
+ 188.95,
+ 311.39,
+ 194.74,
+ 312.35,
+ 208.23,
+ 307.53,
+ 221.73,
+ 297.89,
+ 229.44,
+ 281.5,
+ 250.65,
+ 269.93,
+ 262.22,
+ 278.61,
+ 320.06,
+ 281.5,
+ 331.63,
+ 276.68,
+ 338.38,
+ 270.9,
+ 349.95,
+ 262.22,
+ 356.7,
+ 253.54,
+ 359.59,
+ 253.54,
+ 365.37,
+ 274.75,
+ 365.37,
+ 291.14,
+ 365.37,
+ 306.57,
+ 359.59,
+ 303.67,
+ 352.84,
+ 297.89,
+ 340.31,
+ 293.07,
+ 318.13,
+ 295,
+ 294.03,
+ 293.07,
+ 278.61,
+ 294.03,
+ 270.9,
+ 305.6,
+ 259.33,
+ 313.31,
+ 299.82,
+ 319.1,
+ 309.46,
+ 341.27,
+ 317.17,
+ 384.65,
+ 330.67,
+ 387.55,
+ 335.49,
+ 383.69,
+ 341.27,
+ 397.19,
+ 350.91,
+ 398.15,
+ 363.44,
+ 398.15,
+ 375.01,
+ 405.86,
+ 374.05,
+ 409.72,
+ 357.66,
+ 411.65,
+ 342.24,
+ 416.47,
+ 328.74,
+ 417.43,
+ 321.03,
+ 410.68,
+ 319.1,
+ 401.04,
+ 318.13,
+ 392.37,
+ 318.13,
+ 382.73,
+ 314.28,
+ 348.98,
+ 300.78,
+ 339.34,
+ 293.07,
+ 334.52,
+ 285.36,
+ 340.31,
+ 259.33,
+ 340.31,
+ 246.8,
+ 340.31,
+ 242.94,
+ 350.91,
+ 228.48,
+ 358.62,
+ 214.98,
+ 355.22,
+ 204.32,
+ 357.05,
+ 196.11,
+ 361.61,
+ 188.82,
+ 361.61,
+ 181.97,
+ 365.26,
+ 165.63,
+ 367.54,
+ 139.18,
+ 366.17,
+ 123.68,
+ 361.15,
+ 112.73,
+ 353.86,
+ 107.72,
+ 351.58,
+ 105.89,
+ 344.74,
+ 105.89,
+ 340.18,
+ 109.08
+ ]
+ ],
+ "num_keypoints": 63,
+ "area": 17123.92955,
+ "iscrowd": 0,
+ "keypoints": [
+ 297,
+ 111,
+ 2,
+ 299,
+ 106,
+ 2,
+ 0,
+ 0,
+ 0,
+ 314,
+ 108,
+ 2,
+ 0,
+ 0,
+ 0,
+ 329,
+ 141,
+ 2,
+ 346,
+ 125,
+ 2,
+ 295,
+ 164,
+ 2,
+ 323,
+ 130,
+ 2,
+ 266,
+ 155,
+ 2,
+ 279,
+ 143,
+ 2,
+ 329,
+ 225,
+ 2,
+ 331,
+ 221,
+ 2,
+ 327,
+ 298,
+ 2,
+ 283,
+ 269,
+ 2,
+ 398,
+ 327,
+ 2,
+ 288,
+ 349,
+ 2,
+ 401.79499,
+ 364.28207,
+ 2.0,
+ 407.21854,
+ 361.57029,
+ 2.0,
+ 407.21854,
+ 325.86523,
+ 2.0,
+ 257.16687,
+ 361.57029,
+ 2.0,
+ 258.52276,
+ 361.11833,
+ 2.0,
+ 297.84353,
+ 355.69477,
+ 2.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 265.1,
+ 155.9,
+ 1,
+ 260.05,
+ 152.25,
+ 1,
+ 255.0,
+ 148.6,
+ 1,
+ 250.6,
+ 148.6,
+ 1,
+ 249.1,
+ 151.0,
+ 1,
+ 253.4,
+ 158.9,
+ 1,
+ 251.9,
+ 155.1,
+ 1,
+ 252.0,
+ 151.9,
+ 1,
+ 252.9,
+ 150.0,
+ 1,
+ 257.4,
+ 157.9,
+ 1,
+ 256.7,
+ 154.2,
+ 1,
+ 256.3,
+ 151.6,
+ 1,
+ 256.9,
+ 149.3,
+ 1,
+ 260.2,
+ 156.5,
+ 1,
+ 260.1,
+ 153.0,
+ 1,
+ 259.9,
+ 150.7,
+ 1,
+ 260.2,
+ 148.7,
+ 1,
+ 262.8,
+ 154.8,
+ 1,
+ 262.7,
+ 152.5,
+ 1,
+ 262.7,
+ 150.9,
+ 1,
+ 262.6,
+ 148.8,
+ 1,
+ 280.8,
+ 146.5,
+ 1,
+ 275.4,
+ 149.15,
+ 1,
+ 270.0,
+ 151.8,
+ 1,
+ 266.2,
+ 152.2,
+ 1,
+ 263.5,
+ 151.9,
+ 1,
+ 266.6,
+ 142.5,
+ 1,
+ 263.6,
+ 147.0,
+ 1,
+ 264.9,
+ 151.0,
+ 1,
+ 268.5,
+ 152.9,
+ 1,
+ 270.6,
+ 142.0,
+ 1,
+ 267.9,
+ 146.0,
+ 1,
+ 269.4,
+ 149.6,
+ 1,
+ 272.5,
+ 151.5,
+ 1,
+ 273.8,
+ 142.1,
+ 1,
+ 272.2,
+ 146.0,
+ 1,
+ 274.2,
+ 149.1,
+ 1,
+ 276.5,
+ 149.6,
+ 1,
+ 277.4,
+ 142.3,
+ 1,
+ 276.6,
+ 145.2,
+ 1,
+ 277.6,
+ 148.3,
+ 1,
+ 279.4,
+ 148.6,
+ 1
+ ],
+ "image_id": 196141,
+ "bbox": [
+ 247.76,
+ 74.23,
+ 169.67,
+ 300.78
+ ],
+ "category_id": 1,
+ "id": 460541,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 249.12,
+ 146.31,
+ 19.920000000000016,
+ 15.819999999999993
+ ],
+ "righthand_box": [
+ 262.82,
+ 139.96,
+ 18.930000000000007,
+ 14.679999999999978
+ ],
+ "face_valid": false,
+ "lefthand_valid": true,
+ "righthand_valid": true,
+ "foot_valid": true
+ },
+ {
+ "segmentation": [
+ [
+ 578.76,
+ 112.4,
+ 589.39,
+ 100.81,
+ 589.39,
+ 99.84,
+ 596.16,
+ 116.27,
+ 603.89,
+ 122.07,
+ 603.89,
+ 138.49,
+ 598.09,
+ 159.75,
+ 597.12,
+ 181,
+ 594.22,
+ 191.63,
+ 589.39,
+ 212.89,
+ 583.59,
+ 208.06,
+ 583.59,
+ 206.13,
+ 582.63,
+ 200.33,
+ 582.63,
+ 193.57,
+ 582.63,
+ 182.94,
+ 575.86,
+ 181,
+ 567.17,
+ 197.43,
+ 571.03,
+ 203.23,
+ 567.17,
+ 207.09,
+ 555.57,
+ 208.06,
+ 562.34,
+ 200.33,
+ 565.24,
+ 190.67,
+ 565.24,
+ 173.27,
+ 566.2,
+ 163.61,
+ 568.14,
+ 156.85,
+ 570.07,
+ 148.15,
+ 566.2,
+ 143.32,
+ 565.24,
+ 133.66,
+ 575.86,
+ 118.2
+ ]
+ ],
+ "num_keypoints": 36,
+ "area": 2789.0208,
+ "iscrowd": 0,
+ "keypoints": [
+ 589,
+ 113,
+ 2,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 595,
+ 112,
+ 1,
+ 584,
+ 110,
+ 2,
+ 598,
+ 123,
+ 2,
+ 579,
+ 119,
+ 2,
+ 594,
+ 141,
+ 2,
+ 570,
+ 137,
+ 2,
+ 576,
+ 135,
+ 2,
+ 585,
+ 139,
+ 2,
+ 590,
+ 157,
+ 2,
+ 574,
+ 156,
+ 2,
+ 589,
+ 192,
+ 2,
+ 565,
+ 189,
+ 1,
+ 587,
+ 222,
+ 1,
+ 557,
+ 219,
+ 1,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 578.8,
+ 135.7,
+ 2,
+ 577.55,
+ 134.35,
+ 2,
+ 576.3,
+ 133.0,
+ 1,
+ 574.6,
+ 134.1,
+ 1,
+ 574.0,
+ 135.5,
+ 1,
+ 574.3,
+ 132.9,
+ 2,
+ 572.0,
+ 132.4,
+ 2,
+ 570.3,
+ 131.8,
+ 2,
+ 568.9,
+ 130.7,
+ 2,
+ 573.3,
+ 134.4,
+ 2,
+ 570.9,
+ 134.0,
+ 2,
+ 569.5,
+ 133.9,
+ 2,
+ 568.2,
+ 133.8,
+ 2,
+ 572.8,
+ 135.7,
+ 2,
+ 572.6,
+ 138.3,
+ 2,
+ 574.1,
+ 139.4,
+ 2,
+ 576.2,
+ 139.4,
+ 1,
+ 574.4,
+ 138.0,
+ 2,
+ 575.4,
+ 139.5,
+ 2,
+ 576.3,
+ 140.2,
+ 2,
+ 577.6,
+ 140.8,
+ 2,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "image_id": 196141,
+ "bbox": [
+ 555.57,
+ 99.84,
+ 48.32,
+ 113.05
+ ],
+ "category_id": 1,
+ "id": 488308,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 568.2,
+ 130.89,
+ 10.75,
+ 11.130000000000024
+ ],
+ "righthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "face_valid": false,
+ "lefthand_valid": true,
+ "righthand_valid": false,
+ "foot_valid": false
+ },
+ {
+ "segmentation": [
+ [
+ 446.96,
+ 73.13,
+ 445.81,
+ 77.71,
+ 443.33,
+ 78.29,
+ 441.61,
+ 81.72,
+ 441.23,
+ 84.58,
+ 440.85,
+ 90.5,
+ 442.19,
+ 94.32,
+ 443.52,
+ 97.18,
+ 443.52,
+ 102.33,
+ 442.57,
+ 105.58,
+ 446.58,
+ 105.19,
+ 447.15,
+ 99.85,
+ 447.53,
+ 94.89,
+ 446,
+ 93.55,
+ 446.38,
+ 92.03,
+ 453.64,
+ 92.41,
+ 454.02,
+ 94.51,
+ 457.64,
+ 94.51,
+ 455.74,
+ 88.4,
+ 455.35,
+ 82.29,
+ 453.64,
+ 78.48,
+ 451.92,
+ 77.71,
+ 452.87,
+ 74.47,
+ 450.58,
+ 73.13
+ ]
+ ],
+ "num_keypoints": 0,
+ "area": 285.7906,
+ "iscrowd": 0,
+ "keypoints": [
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "image_id": 196141,
+ "bbox": [
+ 440.85,
+ 73.13,
+ 16.79,
+ 32.45
+ ],
+ "category_id": 1,
+ "id": 508900,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "righthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "face_valid": false,
+ "lefthand_valid": false,
+ "righthand_valid": false,
+ "foot_valid": false
+ },
+ {
+ "segmentation": [
+ [
+ 497.15,
+ 413.95,
+ 531.55,
+ 417.68,
+ 548.74,
+ 411.7,
+ 551.74,
+ 403.48,
+ 546.5,
+ 394.5,
+ 543.51,
+ 386.28,
+ 571.93,
+ 390.76,
+ 574.92,
+ 391.51,
+ 579.4,
+ 409.46,
+ 605.58,
+ 409.46,
+ 615.3,
+ 408.71,
+ 607.07,
+ 389.27,
+ 598.1,
+ 381.79,
+ 607.82,
+ 366.83,
+ 607.82,
+ 352.63,
+ 610.06,
+ 338.42,
+ 619.04,
+ 345.15,
+ 631,
+ 344.4,
+ 630.25,
+ 336.92,
+ 626.51,
+ 318.98,
+ 616.05,
+ 286.07,
+ 598.85,
+ 263.64,
+ 585.39,
+ 257.66,
+ 593.61,
+ 244.2,
+ 601.09,
+ 235.97,
+ 596.6,
+ 219.52,
+ 587.63,
+ 211.29,
+ 577.91,
+ 208.3,
+ 563.7,
+ 206.81,
+ 556.22,
+ 214.29,
+ 548,
+ 217.28,
+ 539.77,
+ 229.99,
+ 539.77,
+ 241.95,
+ 539.02,
+ 247.19,
+ 523.32,
+ 247.19,
+ 503.88,
+ 254.67,
+ 485.93,
+ 254.67,
+ 479.95,
+ 248.68,
+ 473.22,
+ 241.21,
+ 485.93,
+ 227,
+ 477.7,
+ 215.78,
+ 457.51,
+ 215.78,
+ 453.77,
+ 235.22,
+ 463.5,
+ 246.44,
+ 465.74,
+ 261.4,
+ 490.42,
+ 274.11,
+ 501.63,
+ 275.6,
+ 504.62,
+ 286.07,
+ 519.58,
+ 286.07,
+ 522.57,
+ 292.06,
+ 512.85,
+ 310,
+ 515.09,
+ 330.94,
+ 530.05,
+ 343.65,
+ 505.37,
+ 341.41,
+ 479.95,
+ 339.91,
+ 465.74,
+ 346.64,
+ 463.5,
+ 358.61,
+ 473.97,
+ 381.04,
+ 485.18,
+ 390.02,
+ 501.63,
+ 398.99,
+ 504.62,
+ 404.22,
+ 491.16,
+ 412.45,
+ 495.65,
+ 417.68
+ ]
+ ],
+ "num_keypoints": 15,
+ "area": 21608.94075,
+ "iscrowd": 0,
+ "keypoints": [
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 0,
+ 552,
+ 234,
+ 2,
+ 0,
+ 0,
+ 0,
+ 531,
+ 262,
+ 2,
+ 600,
+ 283,
+ 2,
+ 480,
+ 260,
+ 2,
+ 622,
+ 336,
+ 2,
+ 466,
+ 242,
+ 2,
+ 0,
+ 0,
+ 0,
+ 546,
+ 365,
+ 2,
+ 592,
+ 371,
+ 2,
+ 470,
+ 351,
+ 2,
+ 551,
+ 330,
+ 2,
+ 519,
+ 394,
+ 2,
+ 589,
+ 391,
+ 2,
+ 0.0,
+ 0.0,
+ 0.0,
+ 498.08009,
+ 412.23863,
+ 2.0,
+ 541.66626,
+ 400.39384,
+ 2.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 602.22109,
+ 403.58794,
+ 2.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "image_id": 196141,
+ "bbox": [
+ 453.77,
+ 206.81,
+ 177.23,
+ 210.87
+ ],
+ "category_id": 1,
+ "id": 1717641,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "righthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "face_valid": false,
+ "lefthand_valid": false,
+ "righthand_valid": false,
+ "foot_valid": true
+ },
+ {
+ "segmentation": [
+ [
+ 58.93,
+ 163.67,
+ 47.18,
+ 161.59,
+ 36.12,
+ 93.86,
+ 41.65,
+ 82.8,
+ 40.27,
+ 69.66,
+ 50.64,
+ 67.59,
+ 55.48,
+ 73.81,
+ 63.08,
+ 92.47,
+ 66.53,
+ 99.38,
+ 65.15,
+ 109.06,
+ 61,
+ 127.03,
+ 59.62,
+ 162.97
+ ]
+ ],
+ "num_keypoints": 20,
+ "area": 1870.14015,
+ "iscrowd": 0,
+ "keypoints": [
+ 48,
+ 79,
+ 2,
+ 50,
+ 77,
+ 2,
+ 46,
+ 77,
+ 2,
+ 54,
+ 78,
+ 2,
+ 45,
+ 78,
+ 2,
+ 57,
+ 90,
+ 2,
+ 42,
+ 90,
+ 2,
+ 63,
+ 103,
+ 2,
+ 42,
+ 105,
+ 2,
+ 56,
+ 113,
+ 2,
+ 49,
+ 112,
+ 2,
+ 55,
+ 117,
+ 2,
+ 44,
+ 117,
+ 2,
+ 55,
+ 140,
+ 2,
+ 47,
+ 140,
+ 2,
+ 56,
+ 160,
+ 2,
+ 49,
+ 159,
+ 2,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 44.4,
+ 162.6,
+ 2.0,
+ 43.4,
+ 161.5,
+ 2.0,
+ 51.7,
+ 160.7,
+ 2.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "image_id": 196141,
+ "bbox": [
+ 36.12,
+ 67.59,
+ 30.41,
+ 96.08
+ ],
+ "category_id": 1,
+ "id": 1724673,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "righthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "face_valid": false,
+ "lefthand_valid": false,
+ "righthand_valid": false,
+ "foot_valid": true
+ },
+ {
+ "segmentation": [
+ [
+ 139.41,
+ 321.58,
+ 144.78,
+ 326.56,
+ 196.92,
+ 314.68,
+ 196.16,
+ 309.31,
+ 207.28,
+ 292.05,
+ 213.03,
+ 284,
+ 228.75,
+ 270.2,
+ 233.35,
+ 261.38,
+ 244.47,
+ 252.56,
+ 254.44,
+ 237.61,
+ 267.86,
+ 215.37,
+ 272.08,
+ 212.68,
+ 285.5,
+ 232.62,
+ 294.7,
+ 250.64,
+ 295.08,
+ 264.06,
+ 290.87,
+ 277.87,
+ 290.87,
+ 286.3,
+ 289.71,
+ 298.19,
+ 281.66,
+ 318.89,
+ 282.05,
+ 334.23,
+ 295.08,
+ 340.37,
+ 315.02,
+ 343.82,
+ 314.25,
+ 336.53,
+ 310.42,
+ 330.4,
+ 301.98,
+ 322.34,
+ 304.29,
+ 310.84,
+ 304.67,
+ 302.79,
+ 306.2,
+ 292.05,
+ 311.19,
+ 275.56,
+ 313.87,
+ 251.79,
+ 311.19,
+ 234.54,
+ 312.72,
+ 224.57,
+ 310.42,
+ 212.3,
+ 307.74,
+ 201.56,
+ 306.2,
+ 193.51,
+ 306.59,
+ 183.16,
+ 310.04,
+ 177.41,
+ 314.64,
+ 173.19,
+ 316.94,
+ 171.65,
+ 328.06,
+ 163.99,
+ 337.64,
+ 157.85,
+ 343.4,
+ 159.77,
+ 346.46,
+ 166.67,
+ 346.85,
+ 170.5,
+ 346.46,
+ 179.71,
+ 346.85,
+ 188.53,
+ 346.85,
+ 191.98,
+ 344.55,
+ 198.11,
+ 342.25,
+ 203.48,
+ 338.41,
+ 208.46,
+ 335.34,
+ 212.68,
+ 335.34,
+ 217.67,
+ 343.01,
+ 222.65,
+ 354.9,
+ 210.76,
+ 359.12,
+ 196.19,
+ 361.8,
+ 173.19,
+ 361.42,
+ 161.69,
+ 356.43,
+ 150.18,
+ 344.93,
+ 135.61,
+ 343.01,
+ 132.93,
+ 345.31,
+ 126.41,
+ 345.7,
+ 124.88,
+ 343.4,
+ 115.29,
+ 340.33,
+ 104.17,
+ 337.26,
+ 102.25,
+ 330.36,
+ 103.4,
+ 326.14,
+ 106.09,
+ 320.01,
+ 111.07,
+ 314.64,
+ 119.89,
+ 310.42,
+ 121.04,
+ 292.02,
+ 121.81,
+ 279.75,
+ 127.94,
+ 244.09,
+ 138.68,
+ 240.25,
+ 142.51,
+ 238.72,
+ 154.4,
+ 239.1,
+ 163.6,
+ 239.87,
+ 173.96,
+ 241.79,
+ 181.24,
+ 248.3,
+ 192.36,
+ 240.25,
+ 206.55,
+ 236.42,
+ 219.2,
+ 229.9,
+ 236.45,
+ 225.3,
+ 247.57,
+ 218.4,
+ 254.48,
+ 208.81,
+ 265.6,
+ 202.29,
+ 278.25,
+ 195.39,
+ 285.92,
+ 188.49,
+ 292.05,
+ 183.5,
+ 295.89,
+ 176.6,
+ 302.41,
+ 172,
+ 308.54,
+ 167.78,
+ 313.14,
+ 146.31,
+ 318.89
+ ]
+ ],
+ "num_keypoints": 132,
+ "area": 14250.29385,
+ "iscrowd": 0,
+ "keypoints": [
+ 334,
+ 135,
+ 2,
+ 340,
+ 129,
+ 2,
+ 331,
+ 129,
+ 2,
+ 0,
+ 0,
+ 0,
+ 319,
+ 123,
+ 2,
+ 340,
+ 146,
+ 2,
+ 292,
+ 133,
+ 2,
+ 353,
+ 164,
+ 2,
+ 246,
+ 144,
+ 2,
+ 354,
+ 197,
+ 2,
+ 250,
+ 185,
+ 2,
+ 293,
+ 197,
+ 2,
+ 265,
+ 187,
+ 2,
+ 305,
+ 252,
+ 2,
+ 231,
+ 254,
+ 2,
+ 293,
+ 321,
+ 2,
+ 193,
+ 297,
+ 2,
+ 300.24175,
+ 336.83838,
+ 2.0,
+ 306.59015,
+ 335.34464,
+ 2.0,
+ 290.07408,
+ 326.47826,
+ 2.0,
+ 182.60972,
+ 314.05885,
+ 2.0,
+ 175.88789,
+ 305.84328,
+ 2.0,
+ 189.70499,
+ 302.48236,
+ 2.0,
+ 319.681,
+ 126.613,
+ 1.0,
+ 319.155,
+ 129.261,
+ 1.0,
+ 318.92,
+ 131.954,
+ 1.0,
+ 319.187,
+ 134.631,
+ 1.0,
+ 319.707,
+ 137.271,
+ 1.0,
+ 320.991,
+ 139.649,
+ 1.0,
+ 322.846,
+ 141.606,
+ 1.0,
+ 325.009,
+ 143.216,
+ 1.0,
+ 327.359,
+ 144.544,
+ 1.0,
+ 329.907,
+ 145.384,
+ 1.0,
+ 332.347,
+ 144.347,
+ 1.0,
+ 334.268,
+ 142.449,
+ 1.0,
+ 335.767,
+ 140.222,
+ 1.0,
+ 336.675,
+ 137.69,
+ 1.0,
+ 337.019,
+ 135.009,
+ 1.0,
+ 336.982,
+ 132.311,
+ 1.0,
+ 337.13,
+ 129.618,
+ 1.0,
+ 328.503,
+ 125.823,
+ 1.0,
+ 329.531,
+ 125.489,
+ 1.0,
+ 330.619,
+ 125.626,
+ 1.0,
+ 331.573,
+ 125.909,
+ 1.0,
+ 332.529,
+ 126.431,
+ 1.0,
+ 334.479,
+ 127.459,
+ 1.0,
+ 334.815,
+ 127.43,
+ 1.0,
+ 335.157,
+ 127.316,
+ 1.0,
+ 335.52,
+ 127.327,
+ 1.0,
+ 335.949,
+ 127.701,
+ 1.0,
+ 332.762,
+ 129.334,
+ 1.0,
+ 333.168,
+ 130.389,
+ 1.0,
+ 333.603,
+ 131.342,
+ 1.0,
+ 333.928,
+ 132.331,
+ 1.0,
+ 331.671,
+ 134.291,
+ 1.0,
+ 332.232,
+ 134.389,
+ 1.0,
+ 332.931,
+ 134.487,
+ 1.0,
+ 333.332,
+ 134.463,
+ 1.0,
+ 333.645,
+ 134.212,
+ 1.0,
+ 329.271,
+ 128.208,
+ 1.0,
+ 329.963,
+ 128.464,
+ 1.0,
+ 330.676,
+ 128.659,
+ 1.0,
+ 331.392,
+ 128.839,
+ 1.0,
+ 330.672,
+ 128.659,
+ 1.0,
+ 330.003,
+ 128.334,
+ 1.0,
+ 333.792,
+ 129.611,
+ 1.0,
+ 334.158,
+ 129.741,
+ 1.0,
+ 334.546,
+ 129.765,
+ 1.0,
+ 334.878,
+ 129.954,
+ 1.0,
+ 334.523,
+ 129.822,
+ 1.0,
+ 334.161,
+ 129.704,
+ 1.0,
+ 327.38,
+ 138.818,
+ 1.0,
+ 329.757,
+ 138.136,
+ 1.0,
+ 332.086,
+ 137.874,
+ 1.0,
+ 332.75,
+ 138.208,
+ 1.0,
+ 333.221,
+ 138.515,
+ 1.0,
+ 334.495,
+ 139.634,
+ 1.0,
+ 335.213,
+ 141.054,
+ 1.0,
+ 334.12,
+ 140.754,
+ 1.0,
+ 333.208,
+ 140.234,
+ 1.0,
+ 332.2,
+ 139.888,
+ 1.0,
+ 330.765,
+ 139.414,
+ 1.0,
+ 329.069,
+ 139.351,
+ 1.0,
+ 327.561,
+ 138.814,
+ 1.0,
+ 329.88,
+ 138.346,
+ 1.0,
+ 332.517,
+ 138.668,
+ 1.0,
+ 334.031,
+ 139.589,
+ 1.0,
+ 335.123,
+ 140.862,
+ 1.0,
+ 333.726,
+ 140.572,
+ 1.0,
+ 332.203,
+ 140.032,
+ 1.0,
+ 329.731,
+ 139.403,
+ 1.0,
+ 353.87482,
+ 196.49984999999998,
+ 1,
+ 349.01957500000003,
+ 201.76511,
+ 1,
+ 344.16433,
+ 207.03037,
+ 1,
+ 340.81534,
+ 210.64729,
+ 1,
+ 337.46165,
+ 216.59183000000002,
+ 1,
+ 346.65868,
+ 216.02586,
+ 1,
+ 342.27241,
+ 219.28019999999998,
+ 1,
+ 337.88613,
+ 219.70467,
+ 1,
+ 334.4903,
+ 218.57273,
+ 1,
+ 345.5,
+ 215.0,
+ 1,
+ 342.27241,
+ 217.72377,
+ 1,
+ 338.73509,
+ 218.00675999999999,
+ 1,
+ 334.77329,
+ 216.30885,
+ 1,
+ 343.7,
+ 213.8,
+ 1,
+ 341.42345,
+ 215.74288,
+ 1,
+ 338.73509,
+ 215.60138,
+ 1,
+ 335.62225,
+ 213.76198,
+ 1,
+ 342.4139,
+ 212.63003,
+ 1,
+ 340.85748,
+ 213.76198,
+ 1,
+ 338.87658,
+ 214.04496,
+ 1,
+ 337.17867,
+ 213.76198,
+ 1,
+ 249.4,
+ 180.4,
+ 1,
+ 254.3,
+ 184.9,
+ 1,
+ 259.2,
+ 189.4,
+ 1,
+ 259.3,
+ 192.1,
+ 1,
+ 258.2,
+ 194.9,
+ 1,
+ 254.9,
+ 193.2,
+ 1,
+ 255.9,
+ 192.3,
+ 1,
+ 255.9,
+ 190.5,
+ 1,
+ 255.4,
+ 188.5,
+ 1,
+ 252.2,
+ 194.0,
+ 1,
+ 253.2,
+ 193.6,
+ 1,
+ 253.2,
+ 191.1,
+ 1,
+ 252.9,
+ 188.8,
+ 1,
+ 249.4,
+ 193.6,
+ 1,
+ 250.4,
+ 193.6,
+ 1,
+ 250.4,
+ 191.3,
+ 1,
+ 249.9,
+ 188.7,
+ 1,
+ 247.1,
+ 192.2,
+ 1,
+ 248.0,
+ 192.2,
+ 1,
+ 247.9,
+ 190.3,
+ 1,
+ 247.5,
+ 188.3,
+ 1
+ ],
+ "image_id": 197388,
+ "bbox": [
+ 139.41,
+ 102.25,
+ 222.39,
+ 241.57
+ ],
+ "category_id": 1,
+ "id": 437295,
+ "face_box": [
+ 320.23,
+ 123.84,
+ 21.049999999999955,
+ 23.5
+ ],
+ "lefthand_box": [
+ 333.65,
+ 198.45,
+ 23.150000000000034,
+ 23.57000000000002
+ ],
+ "righthand_box": [
+ 247.5,
+ 184.92,
+ 23.30000000000001,
+ 22.360000000000014
+ ],
+ "face_valid": true,
+ "lefthand_valid": true,
+ "righthand_valid": true,
+ "foot_valid": true
+ },
+ {
+ "segmentation": [
+ [
+ 287.17,
+ 121.42,
+ 294.22,
+ 106.44,
+ 302.15,
+ 116.13,
+ 303.03,
+ 121.42
+ ],
+ [
+ 297.74,
+ 99.39,
+ 310.08,
+ 76.49,
+ 326.81,
+ 76.49,
+ 329.46,
+ 67.68,
+ 337.38,
+ 61.52,
+ 346.19,
+ 62.4,
+ 353.24,
+ 65.92,
+ 353.24,
+ 76.49,
+ 355.88,
+ 84.42,
+ 359.41,
+ 87.94,
+ 362.05,
+ 96.75,
+ 354.12,
+ 139.04,
+ 349.72,
+ 142.56,
+ 345.31,
+ 139.92,
+ 349.72,
+ 117.89,
+ 348.84,
+ 108.2,
+ 345.31,
+ 113.49,
+ 336.5,
+ 101.16,
+ 325.93,
+ 110.85,
+ 311.84,
+ 123.18
+ ],
+ [
+ 324.17,
+ 176.91,
+ 332.1,
+ 191.89,
+ 328.58,
+ 198.94,
+ 327.69,
+ 205.98,
+ 333.86,
+ 213.03,
+ 337.38,
+ 227.13,
+ 332.98,
+ 227.13,
+ 319.77,
+ 219.2,
+ 313.6,
+ 211.27
+ ],
+ [
+ 332.98,
+ 165.46,
+ 341.79,
+ 161.06,
+ 336.5,
+ 174.27,
+ 333.86,
+ 186.6,
+ 326.81,
+ 176.03
+ ]
+ ],
+ "num_keypoints": 19,
+ "area": 3404.869,
+ "iscrowd": 0,
+ "keypoints": [
+ 345,
+ 92,
+ 2,
+ 350,
+ 87,
+ 2,
+ 341,
+ 87,
+ 2,
+ 0,
+ 0,
+ 0,
+ 330,
+ 83,
+ 2,
+ 357,
+ 94,
+ 2,
+ 316,
+ 92,
+ 2,
+ 357,
+ 104,
+ 2,
+ 291,
+ 123,
+ 1,
+ 351,
+ 133,
+ 2,
+ 281,
+ 136,
+ 1,
+ 326,
+ 131,
+ 1,
+ 305,
+ 128,
+ 1,
+ 336,
+ 152,
+ 1,
+ 303,
+ 171,
+ 1,
+ 318,
+ 206,
+ 2,
+ 294,
+ 211,
+ 1,
+ 322.595,
+ 216.245,
+ 2.0,
+ 327.23077,
+ 215.42692,
+ 2.0,
+ 316.81553,
+ 207.67155,
+ 2.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "image_id": 197388,
+ "bbox": [
+ 287.17,
+ 61.52,
+ 74.88,
+ 165.61
+ ],
+ "category_id": 1,
+ "id": 467657,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "righthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "face_valid": false,
+ "lefthand_valid": false,
+ "righthand_valid": false,
+ "foot_valid": true
+ },
+ {
+ "segmentation": [
+ [
+ 547.95,
+ 201.57,
+ 546.73,
+ 190.62,
+ 547.95,
+ 181.49,
+ 547.95,
+ 169.31,
+ 547.95,
+ 156.53,
+ 546.73,
+ 144.36,
+ 544.3,
+ 139.49,
+ 540.04,
+ 132.19,
+ 540.04,
+ 121.84,
+ 542.47,
+ 107.24,
+ 544.3,
+ 99.33,
+ 548.56,
+ 88.98,
+ 561.95,
+ 78.03,
+ 572.29,
+ 71.33,
+ 572.29,
+ 71.33,
+ 572.29,
+ 65.25,
+ 574.12,
+ 51.86,
+ 583.86,
+ 48.81,
+ 592.99,
+ 48.81,
+ 597.86,
+ 57.33,
+ 599.07,
+ 64.64,
+ 608.2,
+ 76.81,
+ 614.9,
+ 82.89,
+ 620.98,
+ 89.59,
+ 628.89,
+ 93.24,
+ 636.81,
+ 101.76,
+ 640,
+ 109.67,
+ 640,
+ 115.76,
+ 640,
+ 127.93,
+ 620.37,
+ 111.5,
+ 619.16,
+ 111.5,
+ 618.55,
+ 112.11,
+ 608.2,
+ 105.41,
+ 600.9,
+ 119.41,
+ 592.99,
+ 131.58,
+ 596.03,
+ 148.01,
+ 605.16,
+ 162.01,
+ 612.46,
+ 190.01,
+ 614.9,
+ 204.61,
+ 606.98,
+ 216.78,
+ 603.94,
+ 226.52,
+ 606.38,
+ 239.91,
+ 605.16,
+ 256.95,
+ 604.55,
+ 264.26,
+ 602.12,
+ 271.56,
+ 586.29,
+ 272.17,
+ 584.47,
+ 255.13,
+ 588.73,
+ 237.48,
+ 592.99,
+ 221.65,
+ 596.64,
+ 207.05,
+ 596.64,
+ 197.31,
+ 594.2,
+ 186.96,
+ 584.47,
+ 172.36,
+ 577.77,
+ 166.27,
+ 570.47,
+ 170.53,
+ 558.91,
+ 179.66,
+ 555.86,
+ 192.44,
+ 548.56,
+ 198.53,
+ 547.95,
+ 198.53
+ ]
+ ],
+ "num_keypoints": 39,
+ "area": 8913.98475,
+ "iscrowd": 0,
+ "keypoints": [
+ 591,
+ 78,
+ 2,
+ 594,
+ 74,
+ 2,
+ 586,
+ 74,
+ 2,
+ 0,
+ 0,
+ 0,
+ 573,
+ 70,
+ 2,
+ 598,
+ 86,
+ 2,
+ 566,
+ 93,
+ 2,
+ 626,
+ 105,
+ 2,
+ 546,
+ 126,
+ 2,
+ 0,
+ 0,
+ 0,
+ 561,
+ 150,
+ 2,
+ 582,
+ 150,
+ 2,
+ 557,
+ 154,
+ 2,
+ 606,
+ 194,
+ 2,
+ 558,
+ 209,
+ 1,
+ 591,
+ 252,
+ 2,
+ 539,
+ 262,
+ 1,
+ 599.72032,
+ 264.75714,
+ 2.0,
+ 603.91172,
+ 265.80499,
+ 2.0,
+ 585.74897,
+ 265.10642,
+ 2.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 565.0,
+ 153.0,
+ 0.08773341029882431,
+ 568.0,
+ 156.0,
+ 0.04602484405040741,
+ 571.0,
+ 159.0,
+ 0.04602484405040741,
+ 573.0,
+ 161.0,
+ 0.06972061097621918,
+ 575.0,
+ 164.0,
+ 0.06297813355922699,
+ 569.0,
+ 158.0,
+ 0.294232040643692,
+ 570.0,
+ 162.0,
+ 0.26472434401512146,
+ 570.0,
+ 166.0,
+ 0.2826344072818756,
+ 571.0,
+ 171.0,
+ 0.374575674533844,
+ 565.0,
+ 159.0,
+ 0.2154899388551712,
+ 566.0,
+ 162.0,
+ 0.21613340079784393,
+ 566.0,
+ 164.0,
+ 0.2544613480567932,
+ 567.0,
+ 168.0,
+ 0.31771761178970337,
+ 562.0,
+ 160.0,
+ 0.23286579549312592,
+ 563.0,
+ 166.0,
+ 0.1579097956418991,
+ 564.0,
+ 166.0,
+ 0.17961391806602478,
+ 564.0,
+ 166.0,
+ 0.17504136264324188,
+ 559.0,
+ 160.0,
+ 0.3428754508495331,
+ 559.0,
+ 162.0,
+ 0.2897874116897583,
+ 561.0,
+ 165.0,
+ 0.24125981330871582,
+ 562.0,
+ 166.0,
+ 0.20118576288223267
+ ],
+ "image_id": 197388,
+ "bbox": [
+ 540.04,
+ 48.81,
+ 99.96,
+ 223.36
+ ],
+ "category_id": 1,
+ "id": 531914,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "righthand_box": [
+ 557.05,
+ 149.73,
+ 19.879999999999995,
+ 21.76000000000002
+ ],
+ "face_valid": false,
+ "lefthand_valid": false,
+ "righthand_valid": true,
+ "foot_valid": true
+ },
+ {
+ "segmentation": [
+ [
+ 561.51,
+ 385.38,
+ 572.11,
+ 352.71,
+ 570.34,
+ 317.4,
+ 559.75,
+ 282.08,
+ 552.68,
+ 267.07,
+ 565.93,
+ 236.17,
+ 583.59,
+ 236.17,
+ 602.13,
+ 260.01,
+ 614.49,
+ 286.5,
+ 628.61,
+ 302.39,
+ 639.21,
+ 281.2,
+ 614.49,
+ 251.18,
+ 588,
+ 218.51,
+ 595.95,
+ 202.62,
+ 594.18,
+ 185.85,
+ 580.05,
+ 170.84,
+ 562.4,
+ 179.67,
+ 557.98,
+ 198.21,
+ 554.45,
+ 202.62,
+ 532.38,
+ 199.97,
+ 525.32,
+ 202.62,
+ 511.19,
+ 229.11,
+ 493.53,
+ 256.48,
+ 484.7,
+ 276.78,
+ 451.15,
+ 323.58,
+ 423.78,
+ 338.59,
+ 388.47,
+ 373.9,
+ 372.58,
+ 387.14,
+ 396.41,
+ 388.03,
+ 418.49,
+ 367.72,
+ 450.27,
+ 345.65,
+ 501.48,
+ 306.8,
+ 520.02,
+ 301.5,
+ 552.68,
+ 340.35,
+ 543.86,
+ 369.49
+ ]
+ ],
+ "num_keypoints": 60,
+ "area": 14267.20475,
+ "iscrowd": 0,
+ "keypoints": [
+ 580,
+ 211,
+ 2,
+ 586,
+ 206,
+ 2,
+ 574,
+ 204,
+ 2,
+ 0,
+ 0,
+ 0,
+ 562,
+ 198,
+ 2,
+ 584,
+ 220,
+ 2,
+ 529,
+ 215,
+ 2,
+ 599,
+ 242,
+ 2,
+ 512,
+ 260,
+ 2,
+ 619,
+ 274,
+ 2,
+ 538,
+ 285,
+ 2,
+ 537,
+ 288,
+ 2,
+ 506,
+ 277,
+ 2,
+ 562,
+ 332,
+ 2,
+ 452,
+ 332,
+ 2,
+ 550,
+ 387,
+ 1,
+ 402,
+ 371,
+ 2,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 375.00826,
+ 386.35839,
+ 2.0,
+ 399.52454,
+ 375.91627,
+ 2.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 620.284,
+ 274.54006,
+ 1,
+ 621.65135,
+ 282.30908999999997,
+ 1,
+ 623.0187,
+ 290.07812,
+ 1,
+ 625.38048,
+ 294.55308,
+ 1,
+ 628.86101,
+ 298.90373999999997,
+ 1,
+ 630.22836,
+ 289.20799,
+ 1,
+ 634.57901,
+ 292.43991,
+ 1,
+ 633.08736,
+ 295.54752,
+ 1,
+ 628.6124,
+ 295.42321,
+ 1,
+ 632.46584,
+ 286.5976,
+ 1,
+ 631.3,
+ 291.9,
+ 1,
+ 627.7,
+ 291.6,
+ 1,
+ 625.6,
+ 288.9,
+ 1,
+ 633.7,
+ 284.2,
+ 1,
+ 632.3,
+ 288.0,
+ 1,
+ 629.1,
+ 288.0,
+ 1,
+ 627.0,
+ 285.9,
+ 1,
+ 633.2,
+ 280.4,
+ 1,
+ 632.8,
+ 283.6,
+ 1,
+ 630.8,
+ 284.4,
+ 1,
+ 629.1,
+ 283.2,
+ 1,
+ 544.0,
+ 291.0,
+ 0.09089653939008713,
+ 551.0,
+ 291.0,
+ 0.041192591190338135,
+ 558.0,
+ 291.0,
+ 0.041192591190338135,
+ 559.0,
+ 294.0,
+ 0.056781601160764694,
+ 563.0,
+ 298.0,
+ 0.2960541546344757,
+ 559.0,
+ 296.0,
+ 0.18105527758598328,
+ 562.0,
+ 301.0,
+ 0.12244582921266556,
+ 559.0,
+ 308.0,
+ 0.05529222637414932,
+ 564.0,
+ 306.0,
+ 0.05997529253363609,
+ 555.0,
+ 299.0,
+ 0.18805834650993347,
+ 556.0,
+ 302.0,
+ 0.1534559577703476,
+ 555.0,
+ 306.0,
+ 0.20564205944538116,
+ 556.0,
+ 309.0,
+ 0.06228385493159294,
+ 550.0,
+ 300.0,
+ 0.1409723311662674,
+ 550.0,
+ 301.0,
+ 0.2223101258277893,
+ 551.0,
+ 305.0,
+ 0.2001882642507553,
+ 553.0,
+ 308.0,
+ 0.1712668538093567,
+ 545.0,
+ 302.0,
+ 0.1908813714981079,
+ 546.0,
+ 304.0,
+ 0.13619276881217957,
+ 547.0,
+ 306.0,
+ 0.19773860275745392,
+ 549.0,
+ 308.0,
+ 0.1341865360736847
+ ],
+ "image_id": 197388,
+ "bbox": [
+ 372.58,
+ 170.84,
+ 266.63,
+ 217.19
+ ],
+ "category_id": 1,
+ "id": 533949,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 615.22,
+ 271.56,
+ 22.139999999999986,
+ 28.839999999999975
+ ],
+ "righthand_box": [
+ 538.83,
+ 283.74,
+ 25.639999999999986,
+ 30.659999999999968
+ ],
+ "face_valid": false,
+ "lefthand_valid": true,
+ "righthand_valid": true,
+ "foot_valid": true
+ },
+ {
+ "segmentation": [
+ [
+ 2.03,
+ 75.18,
+ 10.85,
+ 70.58,
+ 16.99,
+ 65.59,
+ 17.75,
+ 55.24,
+ 20.05,
+ 50.25,
+ 29.64,
+ 43.74,
+ 37.31,
+ 47.57,
+ 41.52,
+ 53.7,
+ 43.83,
+ 64.82,
+ 53.03,
+ 70.19,
+ 61.85,
+ 77.09,
+ 72.58,
+ 87.06,
+ 74.88,
+ 79.01,
+ 78.72,
+ 73.64,
+ 86.39,
+ 77.86,
+ 90.6,
+ 90.13,
+ 86,
+ 93.2,
+ 82.17,
+ 102.4,
+ 75.27,
+ 106.24,
+ 68.75,
+ 104.7,
+ 50.34,
+ 90.9,
+ 43.06,
+ 112.37,
+ 40.76,
+ 123.11,
+ 42.29,
+ 130.78,
+ 48.04,
+ 161.83,
+ 52.26,
+ 190.59,
+ 50.73,
+ 210.15,
+ 44.21,
+ 245.04,
+ 50.34,
+ 256.16,
+ 53.03,
+ 261.53,
+ 47.28,
+ 263.83,
+ 40.37,
+ 263.83,
+ 31.56,
+ 260.76,
+ 28.1,
+ 256.16,
+ 26.95,
+ 244.65,
+ 29.25,
+ 233.54,
+ 32.71,
+ 223.95,
+ 33.09,
+ 213.98,
+ 32.32,
+ 206.31,
+ 32.71,
+ 194.81,
+ 33.09,
+ 185.61,
+ 24.65,
+ 177.17,
+ 16.99,
+ 161.45,
+ 13.53,
+ 176.02,
+ 10.85,
+ 206.31,
+ 1.65,
+ 231.62,
+ 1.65,
+ 235.84,
+ 0.5,
+ 146.88,
+ 0.88,
+ 122.34,
+ 1.65,
+ 75.56
+ ]
+ ],
+ "num_keypoints": 16,
+ "area": 8260.75085,
+ "iscrowd": 0,
+ "keypoints": [
+ 36,
+ 79,
+ 2,
+ 40,
+ 74,
+ 2,
+ 31,
+ 75,
+ 2,
+ 0,
+ 0,
+ 0,
+ 19,
+ 69,
+ 2,
+ 45,
+ 77,
+ 2,
+ 2,
+ 89,
+ 2,
+ 74,
+ 99,
+ 2,
+ 0,
+ 0,
+ 0,
+ 78,
+ 92,
+ 2,
+ 0,
+ 0,
+ 0,
+ 33,
+ 149,
+ 2,
+ 7,
+ 153,
+ 2,
+ 44,
+ 196,
+ 2,
+ 2,
+ 205,
+ 2,
+ 35,
+ 245,
+ 2,
+ 0,
+ 0,
+ 0,
+ 43.80826,
+ 259.40011,
+ 2.0,
+ 48.63752,
+ 257.67537,
+ 2.0,
+ 32.08007,
+ 256.29558,
+ 2.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "image_id": 197388,
+ "bbox": [
+ 0.5,
+ 43.74,
+ 90.1,
+ 220.09
+ ],
+ "category_id": 1,
+ "id": 543117,
+ "face_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "lefthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "righthand_box": [
+ 0.0,
+ 0.0,
+ 0.0,
+ 0.0
+ ],
+ "face_valid": false,
+ "lefthand_valid": false,
+ "righthand_valid": false,
+ "foot_valid": true
+ }
+ ]
+}
\ No newline at end of file
diff --git a/tests/test_apis/test_inference.py b/tests/test_apis/test_inference.py
index fa08970f73..c38c619a9e 100644
--- a/tests/test_apis/test_inference.py
+++ b/tests/test_apis/test_inference.py
@@ -6,13 +6,13 @@
import numpy as np
import torch
-from mmcv.image import imwrite
+from mmcv.image import imread, imwrite
from mmengine.utils import is_list_of
from parameterized import parameterized
-from mmpose.apis import inference_topdown, init_model
+from mmpose.apis import inference_bottomup, inference_topdown, init_model
from mmpose.structures import PoseDataSample
-from mmpose.testing._utils import _rand_bboxes
+from mmpose.testing._utils import _rand_bboxes, get_config_file, get_repo_dir
from mmpose.utils import register_all_modules
@@ -25,9 +25,7 @@ def setUp(self) -> None:
'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py'),
('cpu', 'cuda'))])
def test_init_model(self, config, devices):
- project_dir = osp.abspath(osp.dirname(osp.dirname(__file__)))
- project_dir = osp.join(project_dir, '..')
- config_file = osp.join(project_dir, config)
+ config_file = get_config_file(config)
for device in devices:
if device == 'cuda' and not torch.cuda.is_available():
@@ -89,3 +87,31 @@ def test_inference_topdown(self, config, devices):
self.assertEqual(len(results), 1)
self.assertTrue(results[0].pred_instances.keypoints.shape,
(1, 17, 2))
+
+ @parameterized.expand([(('configs/body_2d_keypoint/'
+ 'associative_embedding/coco/'
+ 'ae_hrnet-w32_8xb24-300e_coco-512x512.py'),
+ ('cpu', 'cuda'))])
+ def test_inference_bottomup(self, config, devices):
+ config_file = get_config_file(config)
+ img = osp.join(get_repo_dir(), 'tests/data/coco/000000000785.jpg')
+
+ for device in devices:
+ if device == 'cuda' and not torch.cuda.is_available():
+ # Skip the test if cuda is required but unavailable
+ continue
+ model = init_model(config_file, device=device)
+
+ # test inference from image
+ results = inference_bottomup(model, img=imread(img))
+ self.assertTrue(is_list_of(results, PoseDataSample))
+ self.assertEqual(len(results), 1)
+ self.assertTrue(results[0].pred_instances.keypoints.shape,
+ (1, 17, 2))
+
+ # test inference from file
+ results = inference_bottomup(model, img=img)
+ self.assertTrue(is_list_of(results, PoseDataSample))
+ self.assertEqual(len(results), 1)
+ self.assertTrue(results[0].pred_instances.keypoints.shape,
+ (1, 17, 2))
diff --git a/tests/test_apis/test_inferencers/test_mmpose_inferencer.py b/tests/test_apis/test_inferencers/test_mmpose_inferencer.py
new file mode 100644
index 0000000000..3df85fc46e
--- /dev/null
+++ b/tests/test_apis/test_inferencers/test_mmpose_inferencer.py
@@ -0,0 +1,74 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+from collections import defaultdict
+from tempfile import TemporaryDirectory
+from unittest import TestCase
+
+import mmcv
+
+from mmpose.apis.inferencers import MMPoseInferencer
+from mmpose.structures import PoseDataSample
+
+
+class TestMMPoseInferencer(TestCase):
+
+ def test_call(self):
+
+ # top-down model
+ inferencer = MMPoseInferencer('human')
+
+ img_path = 'tests/data/coco/000000197388.jpg'
+ img = mmcv.imread(img_path)
+
+ # `inputs` is path to an image
+ inputs = img_path
+ results1 = next(inferencer(inputs, return_vis=True))
+ self.assertIn('visualization', results1)
+ self.assertSequenceEqual(results1['visualization'][0].shape, img.shape)
+ self.assertIn('predictions', results1)
+ self.assertIn('keypoints', results1['predictions'][0][0])
+ self.assertEqual(len(results1['predictions'][0][0]['keypoints']), 17)
+
+ # `inputs` is an image array
+ inputs = img
+ results2 = next(inferencer(inputs))
+ self.assertEqual(
+ len(results1['predictions'][0]), len(results2['predictions'][0]))
+ self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'],
+ results2['predictions'][0][0]['keypoints'])
+ results2 = next(inferencer(inputs, return_datasample=True))
+ self.assertIsInstance(results2['predictions'][0], PoseDataSample)
+
+ # `inputs` is path to a directory
+ inputs = osp.dirname(img_path)
+ with TemporaryDirectory() as tmp_dir:
+ # only save visualizations
+ for res in inferencer(inputs, vis_out_dir=tmp_dir):
+ pass
+ self.assertEqual(len(os.listdir(tmp_dir)), 4)
+ # save both visualizations and predictions
+ results3 = defaultdict(list)
+ for res in inferencer(inputs, out_dir=tmp_dir):
+ for key in res:
+ results3[key].extend(res[key])
+ self.assertEqual(len(os.listdir(f'{tmp_dir}/visualizations')), 4)
+ self.assertEqual(len(os.listdir(f'{tmp_dir}/predictions')), 4)
+ self.assertEqual(len(results3['predictions']), 4)
+ self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'],
+ results3['predictions'][3][0]['keypoints'])
+
+ # `inputs` is path to a video
+ inputs = 'tests/data/posetrack18/videos/000001_mpiinew_test/' \
+ '000001_mpiinew_test.mp4'
+ with TemporaryDirectory() as tmp_dir:
+ results = defaultdict(list)
+ for res in inferencer(inputs, out_dir=tmp_dir):
+ for key in res:
+ results[key].extend(res[key])
+ self.assertIn('000001_mpiinew_test.mp4',
+ os.listdir(f'{tmp_dir}/visualizations'))
+ self.assertIn('000001_mpiinew_test.json',
+ os.listdir(f'{tmp_dir}/predictions'))
+ self.assertTrue(inferencer._video_input)
+ self.assertIn(len(results['predictions']), (4, 5))
diff --git a/tests/test_apis/test_inferencers/test_pose2d_inferencer.py b/tests/test_apis/test_inferencers/test_pose2d_inferencer.py
new file mode 100644
index 0000000000..f402d05d19
--- /dev/null
+++ b/tests/test_apis/test_inferencers/test_pose2d_inferencer.py
@@ -0,0 +1,119 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import os
+import os.path as osp
+from collections import defaultdict
+from tempfile import TemporaryDirectory
+from unittest import TestCase
+
+import mmcv
+import torch
+from mmengine.infer.infer import BaseInferencer
+
+from mmpose.apis.inferencers import Pose2DInferencer
+from mmpose.structures import PoseDataSample
+
+
+class TestPose2DInferencer(TestCase):
+
+ def _test_init(self):
+
+ # 1. init with config path and checkpoint
+ inferencer = Pose2DInferencer(
+ model='configs/body_2d_keypoint/simcc/coco/'
+ 'simcc_res50_8xb64-210e_coco-256x192.py',
+ weights='https://download.openmmlab.com/mmpose/'
+ 'v1/body_2d_keypoint/simcc/coco/'
+ 'simcc_res50_8xb64-210e_coco-256x192-8e0f5b59_20220919.pth',
+ )
+ self.assertIsInstance(inferencer.model, torch.nn.Module)
+ self.assertIsInstance(inferencer.detector, BaseInferencer)
+ self.assertSequenceEqual(inferencer.det_cat_ids, (0, ))
+
+ # 2. init with config name
+ inferencer = Pose2DInferencer(
+ model='td-hm_res50_8xb32-210e_onehand10k-256x256')
+ self.assertIsInstance(inferencer.model, torch.nn.Module)
+ self.assertIsInstance(inferencer.detector, BaseInferencer)
+ self.assertSequenceEqual(inferencer.det_cat_ids, (0, ))
+
+ # 3. init with alias
+ with self.assertWarnsRegex(
+ Warning, 'dataset_meta are not saved in '
+ 'the checkpoint\'s meta data, load via config.'):
+ inferencer = Pose2DInferencer(model='animal')
+ self.assertIsInstance(inferencer.model, torch.nn.Module)
+ self.assertIsInstance(inferencer.detector, BaseInferencer)
+ self.assertSequenceEqual(inferencer.det_cat_ids,
+ (15, 16, 17, 18, 19, 20, 21, 22, 23))
+
+ # 4. init with bottom-up model
+ inferencer = Pose2DInferencer(
+ model='configs/body_2d_keypoint/dekr/coco/'
+ 'dekr_hrnet-w32_8xb10-140e_coco-512x512.py',
+ weights='https://download.openmmlab.com/mmpose/v1/'
+ 'body_2d_keypoint/dekr/coco/'
+ 'dekr_hrnet-w32_8xb10-140e_coco-512x512_ac7c17bf-20221228.pth',
+ )
+ self.assertIsInstance(inferencer.model, torch.nn.Module)
+ self.assertFalse(hasattr(inferencer, 'detector'))
+
+ def test_call(self):
+
+ # top-down model
+ inferencer = Pose2DInferencer('human')
+
+ img_path = 'tests/data/coco/000000197388.jpg'
+ img = mmcv.imread(img_path)
+
+ # `inputs` is path to an image
+ inputs = img_path
+ results1 = next(inferencer(inputs, return_vis=True))
+ self.assertIn('visualization', results1)
+ self.assertSequenceEqual(results1['visualization'][0].shape, img.shape)
+ self.assertIn('predictions', results1)
+ self.assertIn('keypoints', results1['predictions'][0][0])
+ self.assertEqual(len(results1['predictions'][0][0]['keypoints']), 17)
+
+ # `inputs` is an image array
+ inputs = img
+ results2 = next(inferencer(inputs))
+ self.assertEqual(
+ len(results1['predictions'][0]), len(results2['predictions'][0]))
+ self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'],
+ results2['predictions'][0][0]['keypoints'])
+ results2 = next(inferencer(inputs, return_datasample=True))
+ self.assertIsInstance(results2['predictions'][0], PoseDataSample)
+
+ # `inputs` is path to a directory
+ inputs = osp.dirname(img_path)
+
+ with TemporaryDirectory() as tmp_dir:
+ # only save visualizations
+ for res in inferencer(inputs, vis_out_dir=tmp_dir):
+ pass
+ self.assertEqual(len(os.listdir(tmp_dir)), 4)
+ # save both visualizations and predictions
+ results3 = defaultdict(list)
+ for res in inferencer(inputs, out_dir=tmp_dir):
+ for key in res:
+ results3[key].extend(res[key])
+ self.assertEqual(len(os.listdir(f'{tmp_dir}/visualizations')), 4)
+ self.assertEqual(len(os.listdir(f'{tmp_dir}/predictions')), 4)
+ self.assertEqual(len(results3['predictions']), 4)
+ self.assertSequenceEqual(results1['predictions'][0][0]['keypoints'],
+ results3['predictions'][3][0]['keypoints'])
+
+ # `inputs` is path to a video
+ inputs = 'tests/data/posetrack18/videos/000001_mpiinew_test/' \
+ '000001_mpiinew_test.mp4'
+ with TemporaryDirectory() as tmp_dir:
+ results = defaultdict(list)
+ for res in inferencer(inputs, out_dir=tmp_dir):
+ for key in res:
+ results[key].extend(res[key])
+ self.assertIn('000001_mpiinew_test.mp4',
+ os.listdir(f'{tmp_dir}/visualizations'))
+ self.assertIn('000001_mpiinew_test.json',
+ os.listdir(f'{tmp_dir}/predictions'))
+ self.assertTrue(inferencer._video_input)
+ self.assertIn(len(results['predictions']), (4, 5))
diff --git a/tests/test_apis/test_webcam/test_utils/test_misc.py b/tests/test_apis/test_webcam/test_utils/test_misc.py
index 371aaf3f76..d60fdaa002 100644
--- a/tests/test_apis/test_webcam/test_utils/test_misc.py
+++ b/tests/test_apis/test_webcam/test_utils/test_misc.py
@@ -1,5 +1,6 @@
# Copyright (c) OpenMMLab. All rights reserved.
import os
+import tempfile
import unittest
import mmcv
@@ -16,11 +17,13 @@ class TestMISC(unittest.TestCase):
def test_get_cached_file_path(self):
url = 'https://user-images.githubusercontent.com/15977946/' \
'170850839-acc59e26-c6b3-48c9-a9ec-87556edb99ed.jpg'
- cached_file = get_cached_file_path(url, file_name='sunglasses.jpg')
- self.assertTrue(os.path.exists(cached_file))
- # check if image is successfully cached
- img = mmcv.imread(cached_file)
- self.assertIsNotNone(img)
+ with tempfile.TemporaryDirectory() as tmpdir:
+ cached_file = get_cached_file_path(
+ url, save_dir=tmpdir, file_name='sunglasses.jpg')
+ self.assertTrue(os.path.exists(cached_file))
+ # check if image is successfully cached
+ img = mmcv.imread(cached_file)
+ self.assertIsNotNone(img)
def test_get_config_path(self):
cfg_path = 'configs/_base_/datasets/coco.py'
diff --git a/tests/test_codecs/test_associative_embedding.py b/tests/test_codecs/test_associative_embedding.py
index 6f5266d6d6..983fc93fb1 100644
--- a/tests/test_codecs/test_associative_embedding.py
+++ b/tests/test_codecs/test_associative_embedding.py
@@ -39,8 +39,11 @@ def test_encode(self):
use_udp=False,
decode_keypoint_order=self.decode_keypoint_order)
- heatmaps, keypoint_indices, keypoint_weights = codec.encode(
- data['keypoints'], data['keypoints_visible'])
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
+
+ heatmaps = encoded['heatmaps']
+ keypoint_indices = encoded['keypoint_indices']
+ keypoint_weights = encoded['keypoint_weights']
self.assertEqual(heatmaps.shape, (17, 64, 64))
self.assertEqual(keypoint_indices.shape, (1, 17, 2))
@@ -58,8 +61,11 @@ def test_encode(self):
use_udp=True,
decode_keypoint_order=self.decode_keypoint_order)
- heatmaps, keypoint_indices, keypoint_weights = codec.encode(
- data['keypoints'], data['keypoints_visible'])
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
+
+ heatmaps = encoded['heatmaps']
+ keypoint_indices = encoded['keypoint_indices']
+ keypoint_weights = encoded['keypoint_weights']
self.assertEqual(heatmaps.shape, (17, 64, 64))
self.assertEqual(keypoint_indices.shape, (1, 17, 2))
@@ -70,22 +76,26 @@ def test_encode(self):
index_encoded = keypoint_indices[0, k, 0]
self.assertEqual(index_expected, index_encoded)
- def _get_tags(self, heatmaps, keypoint_indices, tag_per_keypoint: bool):
+ def _get_tags(self,
+ heatmaps,
+ keypoint_indices,
+ tag_per_keypoint: bool,
+ tag_dim: int = 1):
K, H, W = heatmaps.shape
N = keypoint_indices.shape[0]
if tag_per_keypoint:
- tags = np.zeros((K, H, W), dtype=np.float32)
+ tags = np.zeros((K * tag_dim, H, W), dtype=np.float32)
else:
- tags = np.zeros((1, H, W), dtype=np.float32)
+ tags = np.zeros((tag_dim, H, W), dtype=np.float32)
for n, k in product(range(N), range(K)):
y, x = np.unravel_index(keypoint_indices[n, k, 0], (H, W))
if tag_per_keypoint:
- tags[k, y, x] = n
+ tags[k::K, y, x] = n
else:
- tags[0, y, x] = n
+ tags[:, y, x] = n
return tags
@@ -117,16 +127,17 @@ def test_decode(self):
data = get_coco_sample(
img_shape=(256, 256), num_instances=2, non_occlusion=True)
- # w/o UDP, tag_per_keypoint==True
+ # w/o UDP
codec = AssociativeEmbedding(
input_size=(256, 256),
heatmap_size=(64, 64),
use_udp=False,
- decode_keypoint_order=self.decode_keypoint_order,
- tag_per_keypoint=True)
+ decode_keypoint_order=self.decode_keypoint_order)
- heatmaps, keypoint_indices, _ = codec.encode(data['keypoints'],
- data['keypoints_visible'])
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
+
+ heatmaps = encoded['heatmaps']
+ keypoint_indices = encoded['keypoint_indices']
tags = self._get_tags(
heatmaps, keypoint_indices, tag_per_keypoint=True)
@@ -154,56 +165,20 @@ def test_decode(self):
self.assertTrue(np.allclose(keypoints, data['keypoints'], atol=4.0))
- # w/o UDP, tag_per_keypoint==False
+ # w/o UDP, tag_imd=2
codec = AssociativeEmbedding(
input_size=(256, 256),
heatmap_size=(64, 64),
use_udp=False,
- decode_keypoint_order=self.decode_keypoint_order,
- tag_per_keypoint=False)
-
- heatmaps, keypoint_indices, _ = codec.encode(data['keypoints'],
- data['keypoints_visible'])
-
- tags = self._get_tags(
- heatmaps, keypoint_indices, tag_per_keypoint=False)
-
- # to Tensor
- batch_heatmaps = torch.from_numpy(heatmaps[None])
- batch_tags = torch.from_numpy(tags[None])
-
- batch_keypoints, batch_keypoint_scores = codec.batch_decode(
- batch_heatmaps, batch_tags)
-
- self.assertIsInstance(batch_keypoints, list)
- self.assertIsInstance(batch_keypoint_scores, list)
- self.assertEqual(len(batch_keypoints), 1)
- self.assertEqual(len(batch_keypoint_scores), 1)
-
- keypoints, scores = self._sort_preds(batch_keypoints[0],
- batch_keypoint_scores[0],
- data['keypoints'])
-
- self.assertIsInstance(keypoints, np.ndarray)
- self.assertIsInstance(scores, np.ndarray)
- self.assertEqual(keypoints.shape, (2, 17, 2))
- self.assertEqual(scores.shape, (2, 17))
+ decode_keypoint_order=self.decode_keypoint_order)
- self.assertTrue(np.allclose(keypoints, data['keypoints'], atol=4.0))
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
- # w/ UDP, tag_per_keypoint==True
- codec = AssociativeEmbedding(
- input_size=(256, 256),
- heatmap_size=(64, 64),
- use_udp=True,
- decode_keypoint_order=self.decode_keypoint_order,
- tag_per_keypoint=True)
-
- heatmaps, keypoint_indices, _ = codec.encode(data['keypoints'],
- data['keypoints_visible'])
+ heatmaps = encoded['heatmaps']
+ keypoint_indices = encoded['keypoint_indices']
tags = self._get_tags(
- heatmaps, keypoint_indices, tag_per_keypoint=True)
+ heatmaps, keypoint_indices, tag_per_keypoint=True, tag_dim=2)
# to Tensor
batch_heatmaps = torch.from_numpy(heatmaps[None])
@@ -228,53 +203,17 @@ def test_decode(self):
self.assertTrue(np.allclose(keypoints, data['keypoints'], atol=4.0))
- # w/ UDP, tag_per_keypoint==False
+ # w/ UDP
codec = AssociativeEmbedding(
input_size=(256, 256),
heatmap_size=(64, 64),
use_udp=True,
- decode_keypoint_order=self.decode_keypoint_order,
- tag_per_keypoint=False)
-
- heatmaps, keypoint_indices, _ = codec.encode(data['keypoints'],
- data['keypoints_visible'])
-
- tags = self._get_tags(
- heatmaps, keypoint_indices, tag_per_keypoint=False)
-
- # to Tensor
- batch_heatmaps = torch.from_numpy(heatmaps[None])
- batch_tags = torch.from_numpy(tags[None])
-
- batch_keypoints, batch_keypoint_scores = codec.batch_decode(
- batch_heatmaps, batch_tags)
-
- self.assertIsInstance(batch_keypoints, list)
- self.assertIsInstance(batch_keypoint_scores, list)
- self.assertEqual(len(batch_keypoints), 1)
- self.assertEqual(len(batch_keypoint_scores), 1)
-
- keypoints, scores = self._sort_preds(batch_keypoints[0],
- batch_keypoint_scores[0],
- data['keypoints'])
-
- self.assertIsInstance(keypoints, np.ndarray)
- self.assertIsInstance(scores, np.ndarray)
- self.assertEqual(keypoints.shape, (2, 17, 2))
- self.assertEqual(scores.shape, (2, 17))
+ decode_keypoint_order=self.decode_keypoint_order)
- self.assertTrue(np.allclose(keypoints, data['keypoints'], atol=4.0))
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
- # Dynamic input sizes in decoder
- codec = AssociativeEmbedding(
- input_size=(256, 256),
- heatmap_size=(64, 64),
- use_udp=False,
- decode_keypoint_order=self.decode_keypoint_order,
- tag_per_keypoint=True)
-
- heatmaps, keypoint_indices, _ = codec.encode(data['keypoints'],
- data['keypoints_visible'])
+ heatmaps = encoded['heatmaps']
+ keypoint_indices = encoded['keypoint_indices']
tags = self._get_tags(
heatmaps, keypoint_indices, tag_per_keypoint=True)
@@ -284,7 +223,7 @@ def test_decode(self):
batch_tags = torch.from_numpy(tags[None])
batch_keypoints, batch_keypoint_scores = codec.batch_decode(
- batch_heatmaps, batch_tags, input_sizes=[(256, 256)])
+ batch_heatmaps, batch_tags)
self.assertIsInstance(batch_keypoints, list)
self.assertIsInstance(batch_keypoint_scores, list)
diff --git a/tests/test_codecs/test_decoupled_heatmap.py b/tests/test_codecs/test_decoupled_heatmap.py
new file mode 100644
index 0000000000..747491c185
--- /dev/null
+++ b/tests/test_codecs/test_decoupled_heatmap.py
@@ -0,0 +1,168 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import numpy as np
+
+from mmpose.codecs import DecoupledHeatmap
+from mmpose.registry import KEYPOINT_CODECS
+from mmpose.testing import get_coco_sample
+
+
+class TestDecoupledHeatmap(TestCase):
+
+ def setUp(self) -> None:
+ pass
+
+ def _make_multi_instance_data(self, data):
+ bbox = data['bbox'].reshape(-1, 2, 2)
+ keypoints = data['keypoints']
+ keypoints_visible = data['keypoints_visible']
+
+ keypoints_visible[..., 0] = 0
+
+ offset = keypoints.max(axis=1, keepdims=True)
+ bbox_outside = bbox - offset
+ keypoints_outside = keypoints - offset
+ keypoints_outside_visible = np.zeros(keypoints_visible.shape)
+
+ bbox_overlap = bbox.mean(
+ axis=1, keepdims=True) + 0.8 * (
+ bbox - bbox.mean(axis=1, keepdims=True))
+ keypoint_overlap = keypoints.mean(
+ axis=1, keepdims=True) + 0.8 * (
+ keypoints - keypoints.mean(axis=1, keepdims=True))
+ keypoint_overlap_visible = keypoints_visible
+
+ data['bbox'] = np.concatenate((bbox, bbox_outside, bbox_overlap),
+ axis=0)
+ data['keypoints'] = np.concatenate(
+ (keypoints, keypoints_outside, keypoint_overlap), axis=0)
+ data['keypoints_visible'] = np.concatenate(
+ (keypoints_visible, keypoints_outside_visible,
+ keypoint_overlap_visible),
+ axis=0)
+
+ return data
+
+ def test_build(self):
+ cfg = dict(
+ type='DecoupledHeatmap',
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ )
+ codec = KEYPOINT_CODECS.build(cfg)
+ self.assertIsInstance(codec, DecoupledHeatmap)
+
+ def test_encode(self):
+ data = get_coco_sample(img_shape=(512, 512), num_instances=1)
+ data['bbox'] = np.tile(data['bbox'], 2).reshape(-1, 4, 2)
+ data['bbox'][:, 1:3, 0] = data['bbox'][:, 0:2, 0]
+ data = self._make_multi_instance_data(data)
+
+ codec = DecoupledHeatmap(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ )
+
+ print(data['bbox'].shape)
+ encoded = codec.encode(
+ data['keypoints'], data['keypoints_visible'], bbox=data['bbox'])
+
+ heatmaps = encoded['heatmaps']
+ instance_heatmaps = encoded['instance_heatmaps']
+ keypoint_weights = encoded['keypoint_weights']
+ instance_coords = encoded['instance_coords']
+
+ self.assertEqual(heatmaps.shape, (18, 128, 128))
+ self.assertEqual(keypoint_weights.shape, (2, 17))
+ self.assertEqual(instance_heatmaps.shape, (34, 128, 128))
+ self.assertEqual(instance_coords.shape, (2, 2))
+
+ # without bbox
+ encoded = codec.encode(
+ data['keypoints'], data['keypoints_visible'], bbox=None)
+
+ heatmaps = encoded['heatmaps']
+ instance_heatmaps = encoded['instance_heatmaps']
+ keypoint_weights = encoded['keypoint_weights']
+ instance_coords = encoded['instance_coords']
+
+ self.assertEqual(heatmaps.shape, (18, 128, 128))
+ self.assertEqual(keypoint_weights.shape, (2, 17))
+ self.assertEqual(instance_heatmaps.shape, (34, 128, 128))
+ self.assertEqual(instance_coords.shape, (2, 2))
+
+ # root_type
+ with self.assertRaises(ValueError):
+ codec = DecoupledHeatmap(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ root_type='box_center',
+ )
+ encoded = codec.encode(
+ data['keypoints'],
+ data['keypoints_visible'],
+ bbox=data['bbox'])
+
+ codec = DecoupledHeatmap(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ root_type='bbox_center',
+ )
+
+ encoded = codec.encode(
+ data['keypoints'], data['keypoints_visible'], bbox=data['bbox'])
+
+ heatmaps = encoded['heatmaps']
+ instance_heatmaps = encoded['instance_heatmaps']
+ keypoint_weights = encoded['keypoint_weights']
+ instance_coords = encoded['instance_coords']
+
+ self.assertEqual(heatmaps.shape, (18, 128, 128))
+ self.assertEqual(keypoint_weights.shape, (2, 17))
+ self.assertEqual(instance_heatmaps.shape, (34, 128, 128))
+ self.assertEqual(instance_coords.shape, (2, 2))
+
+ def test_decode(self):
+ data = get_coco_sample(img_shape=(512, 512), num_instances=2)
+ data['bbox'] = np.tile(data['bbox'], 2).reshape(-1, 4, 2)
+ data['bbox'][:, 1:3, 0] = data['bbox'][:, 0:2, 0]
+
+ codec = DecoupledHeatmap(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ )
+
+ encoded = codec.encode(
+ data['keypoints'], data['keypoints_visible'], bbox=data['bbox'])
+ instance_heatmaps = encoded['instance_heatmaps'].reshape(
+ encoded['instance_coords'].shape[0], -1,
+ *encoded['instance_heatmaps'].shape[-2:])
+ instance_scores = np.ones(encoded['instance_coords'].shape[0])
+ decoded = codec.decode(instance_heatmaps, instance_scores[:, None])
+ keypoints, keypoint_scores = decoded
+
+ self.assertEqual(keypoints.shape, (2, 17, 2))
+ self.assertEqual(keypoint_scores.shape, (2, 17))
+
+ def test_cicular_verification(self):
+ data = get_coco_sample(img_shape=(512, 512), num_instances=1)
+ data['bbox'] = np.tile(data['bbox'], 2).reshape(-1, 4, 2)
+ data['bbox'][:, 1:3, 0] = data['bbox'][:, 0:2, 0]
+
+ codec = DecoupledHeatmap(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ )
+
+ encoded = codec.encode(
+ data['keypoints'], data['keypoints_visible'], bbox=data['bbox'])
+ instance_heatmaps = encoded['instance_heatmaps'].reshape(
+ encoded['instance_coords'].shape[0], -1,
+ *encoded['instance_heatmaps'].shape[-2:])
+ instance_scores = np.ones(encoded['instance_coords'].shape[0])
+ decoded = codec.decode(instance_heatmaps, instance_scores[:, None])
+ keypoints, _ = decoded
+ keypoints += 1.5
+
+ self.assertTrue(np.allclose(keypoints, data['keypoints'], atol=5.))
diff --git a/tests/test_codecs/test_integral_regression_label.py b/tests/test_codecs/test_integral_regression_label.py
index b94e596189..8f53a0b21f 100644
--- a/tests/test_codecs/test_integral_regression_label.py
+++ b/tests/test_codecs/test_integral_regression_label.py
@@ -42,12 +42,14 @@ def test_encode(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- heatmaps, reg_label, keypoint_weights = codec.encode(
- keypoints, keypoints_visible)
+ encoded = codec.encode(keypoints, keypoints_visible)
+ heatmaps = encoded['heatmaps']
+ keypoint_labels = encoded['keypoint_labels']
+ keypoint_weights = encoded['keypoint_weights']
self.assertEqual(heatmaps.shape, (17, 64, 48),
f'Failed case: "{name}"')
- self.assertEqual(reg_label.shape, (1, 17, 2),
+ self.assertEqual(keypoint_labels.shape, (1, 17, 2),
f'Failed case: "{name}"')
self.assertEqual(keypoint_weights.shape, (1, 17),
f'Failed case: "{name}"')
@@ -71,9 +73,10 @@ def test_cicular_verification(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- _, reg_label, _ = codec.encode(keypoints, keypoints_visible)
+ encoded = codec.encode(keypoints, keypoints_visible)
+ keypoint_labels = encoded['keypoint_labels']
- _keypoints, _ = codec.decode(reg_label)
+ _keypoints, _ = codec.decode(keypoint_labels)
self.assertTrue(
np.allclose(keypoints, _keypoints, atol=5.),
diff --git a/tests/test_codecs/test_megvii_heatmap.py b/tests/test_codecs/test_megvii_heatmap.py
index b6277f9d1a..31a5a965c9 100644
--- a/tests/test_codecs/test_megvii_heatmap.py
+++ b/tests/test_codecs/test_megvii_heatmap.py
@@ -40,12 +40,11 @@ def test_encode(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- heatmaps, keypoint_weights = codec.encode(keypoints,
- keypoints_visible)
+ encoded = codec.encode(keypoints, keypoints_visible)
- self.assertEqual(heatmaps.shape, (17, 64, 48),
+ self.assertEqual(encoded['heatmaps'].shape, (17, 64, 48),
f'Failed case: "{name}"')
- self.assertEqual(keypoint_weights.shape,
+ self.assertEqual(encoded['keypoint_weights'].shape,
(1, 17)), f'Failed case: "{name}"'
def test_decode(self):
@@ -67,8 +66,8 @@ def test_cicular_verification(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- heatmaps, _ = codec.encode(keypoints, keypoints_visible)
- _keypoints, _ = codec.decode(heatmaps)
+ encoded = codec.encode(keypoints, keypoints_visible)
+ _keypoints, _ = codec.decode(encoded['heatmaps'])
self.assertTrue(
np.allclose(keypoints, _keypoints, atol=5.),
diff --git a/tests/test_codecs/test_msra_heatmap.py b/tests/test_codecs/test_msra_heatmap.py
index c6f4a876d9..5897d01461 100644
--- a/tests/test_codecs/test_msra_heatmap.py
+++ b/tests/test_codecs/test_msra_heatmap.py
@@ -49,12 +49,11 @@ def test_encode(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- heatmaps, keypoint_weights = codec.encode(keypoints,
- keypoints_visible)
+ encoded = codec.encode(keypoints, keypoints_visible)
- self.assertEqual(heatmaps.shape, (17, 64, 48),
+ self.assertEqual(encoded['heatmaps'].shape, (17, 64, 48),
f'Failed case: "{name}"')
- self.assertEqual(keypoint_weights.shape,
+ self.assertEqual(encoded['keypoint_weights'].shape,
(1, 17)), f'Failed case: "{name}"'
def test_decode(self):
@@ -76,8 +75,8 @@ def test_cicular_verification(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- heatmaps, _ = codec.encode(keypoints, keypoints_visible)
- _keypoints, _ = codec.decode(heatmaps)
+ encoded = codec.encode(keypoints, keypoints_visible)
+ _keypoints, _ = codec.decode(encoded['heatmaps'])
self.assertTrue(
np.allclose(keypoints, _keypoints, atol=5.),
diff --git a/tests/test_codecs/test_regression_label.py b/tests/test_codecs/test_regression_label.py
index 482bcf1ae9..e83a3aab18 100644
--- a/tests/test_codecs/test_regression_label.py
+++ b/tests/test_codecs/test_regression_label.py
@@ -41,12 +41,11 @@ def test_encode(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- reg_label, keypoint_weights = codec.encode(keypoints,
- keypoints_visible)
+ encoded = codec.encode(keypoints, keypoints_visible)
- self.assertEqual(reg_label.shape, (1, 17, 2),
+ self.assertEqual(encoded['keypoint_labels'].shape, (1, 17, 2),
f'Failed case: "{name}"')
- self.assertEqual(keypoint_weights.shape, (1, 17),
+ self.assertEqual(encoded['keypoint_weights'].shape, (1, 17),
f'Failed case: "{name}"')
def test_decode(self):
@@ -73,9 +72,9 @@ def test_cicular_verification(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- reg_label, _ = codec.encode(keypoints, keypoints_visible)
+ encoded = codec.encode(keypoints, keypoints_visible)
- _keypoints, _ = codec.decode(reg_label)
+ _keypoints, _ = codec.decode(encoded['keypoint_labels'])
self.assertTrue(
np.allclose(keypoints, _keypoints, atol=5.),
diff --git a/tests/test_codecs/test_simcc_label.py b/tests/test_codecs/test_simcc_label.py
index 98f02cc102..b4c242ef4e 100644
--- a/tests/test_codecs/test_simcc_label.py
+++ b/tests/test_codecs/test_simcc_label.py
@@ -40,6 +40,25 @@ def setUp(self) -> None:
sigma=5.0,
simcc_split_ratio=3.0),
),
+ (
+ 'simcc dark',
+ dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=6.0,
+ simcc_split_ratio=2.0,
+ use_dark=True),
+ ),
+ (
+ 'simcc separated sigmas',
+ dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0),
+ ),
]
# The bbox is usually padded so the keypoint will not be near the
@@ -57,16 +76,15 @@ def test_encode(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- target_x, target_y, keypoint_weights = codec.encode(
- keypoints, keypoints_visible)
+ encoded = codec.encode(keypoints, keypoints_visible)
- self.assertEqual(target_x.shape,
+ self.assertEqual(encoded['keypoint_x_labels'].shape,
(1, 17, int(192 * codec.simcc_split_ratio)),
f'Failed case: "{name}"')
- self.assertEqual(target_y.shape,
+ self.assertEqual(encoded['keypoint_y_labels'].shape,
(1, 17, int(256 * codec.simcc_split_ratio)),
f'Failed case: "{name}"')
- self.assertEqual(keypoint_weights.shape, (1, 17),
+ self.assertEqual(encoded['keypoint_weights'].shape, (1, 17),
f'Failed case: "{name}"')
def test_decode(self):
@@ -75,9 +93,8 @@ def test_decode(self):
simcc_x = np.random.rand(1, 17, int(192 * codec.simcc_split_ratio))
simcc_y = np.random.rand(1, 17, int(256 * codec.simcc_split_ratio))
- encoded = (simcc_x, simcc_y)
- keypoints, scores = codec.decode(encoded)
+ keypoints, scores = codec.decode(simcc_x, simcc_y)
self.assertEqual(keypoints.shape, (1, 17, 2),
f'Failed case: "{name}"')
@@ -90,11 +107,11 @@ def test_cicular_verification(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- target_x, target_y, _ = codec.encode(keypoints, keypoints_visible)
-
- encoded = (target_x, target_y)
+ encoded = codec.encode(keypoints, keypoints_visible)
+ keypoint_x_labels = encoded['keypoint_x_labels']
+ keypoint_y_labels = encoded['keypoint_y_labels']
- _keypoints, _ = codec.decode(encoded)
+ _keypoints, _ = codec.decode(keypoint_x_labels, keypoint_y_labels)
self.assertTrue(
np.allclose(keypoints, _keypoints, atol=5.),
diff --git a/tests/test_codecs/test_spr.py b/tests/test_codecs/test_spr.py
new file mode 100644
index 0000000000..58eeeb7d17
--- /dev/null
+++ b/tests/test_codecs/test_spr.py
@@ -0,0 +1,188 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import numpy as np
+
+from mmpose.codecs import SPR
+from mmpose.registry import KEYPOINT_CODECS
+from mmpose.testing import get_coco_sample
+from mmpose.utils.tensor_utils import to_numpy, to_tensor
+
+
+class TestSPR(TestCase):
+
+ def setUp(self) -> None:
+ pass
+
+ def _make_multi_instance_data(self, data):
+ keypoints = data['keypoints']
+ keypoints_visible = data['keypoints_visible']
+
+ keypoints_visible[..., 0] = 0
+
+ keypoints_outside = keypoints - keypoints.max(axis=-1, keepdims=True)
+ keypoints_outside_visible = np.zeros(keypoints_visible.shape)
+
+ keypoint_overlap = keypoints.mean(
+ axis=-1, keepdims=True) + 0.8 * (
+ keypoints - keypoints.mean(axis=-1, keepdims=True))
+ keypoint_overlap_visible = keypoints_visible
+
+ data['keypoints'] = np.concatenate(
+ (keypoints, keypoints_outside, keypoint_overlap), axis=0)
+ data['keypoints_visible'] = np.concatenate(
+ (keypoints_visible, keypoints_outside_visible,
+ keypoint_overlap_visible),
+ axis=0)
+
+ return data
+
+ def test_build(self):
+ cfg = dict(
+ type='SPR',
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=4,
+ )
+ codec = KEYPOINT_CODECS.build(cfg)
+ self.assertIsInstance(codec, SPR)
+
+ def test_encode(self):
+ data = get_coco_sample(img_shape=(512, 512), num_instances=1)
+ data = self._make_multi_instance_data(data)
+
+ # w/o keypoint heatmaps
+ codec = SPR(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=4,
+ )
+
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
+
+ heatmaps = encoded['heatmaps']
+ displacements = encoded['displacements']
+ heatmap_weights = encoded['heatmap_weights']
+ displacement_weights = encoded['displacement_weights']
+
+ self.assertEqual(heatmaps.shape, (1, 128, 128))
+ self.assertEqual(heatmap_weights.shape, (1, 128, 128))
+ self.assertEqual(displacements.shape, (34, 128, 128))
+ self.assertEqual(displacement_weights.shape, (34, 128, 128))
+
+ # w/ keypoint heatmaps
+ with self.assertRaises(AssertionError):
+ codec = SPR(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=4,
+ generate_keypoint_heatmaps=True,
+ )
+
+ codec = SPR(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, 2),
+ generate_keypoint_heatmaps=True,
+ )
+
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
+
+ heatmaps = encoded['heatmaps']
+ displacements = encoded['displacements']
+ heatmap_weights = encoded['heatmap_weights']
+ displacement_weights = encoded['displacement_weights']
+
+ self.assertEqual(heatmaps.shape, (18, 128, 128))
+ self.assertEqual(heatmap_weights.shape, (18, 128, 128))
+ self.assertEqual(displacements.shape, (34, 128, 128))
+ self.assertEqual(displacement_weights.shape, (34, 128, 128))
+
+ # root_type
+ with self.assertRaises(ValueError):
+ codec = SPR(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, ),
+ root_type='box_center',
+ )
+ encoded = codec.encode(data['keypoints'],
+ data['keypoints_visible'])
+
+ codec = SPR(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, ),
+ root_type='bbox_center',
+ )
+
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
+
+ heatmaps = encoded['heatmaps']
+ displacements = encoded['displacements']
+ heatmap_weights = encoded['heatmap_weights']
+ displacement_weights = encoded['displacement_weights']
+
+ self.assertEqual(heatmaps.shape, (1, 128, 128))
+ self.assertEqual(heatmap_weights.shape, (1, 128, 128))
+ self.assertEqual(displacements.shape, (34, 128, 128))
+ self.assertEqual(displacement_weights.shape, (34, 128, 128))
+
+ def test_decode(self):
+ data = get_coco_sample(img_shape=(512, 512), num_instances=1)
+
+ # decode w/o keypoint heatmaps
+ codec = SPR(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, ),
+ generate_keypoint_heatmaps=False,
+ )
+
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
+ decoded = codec.decode(
+ to_tensor(encoded['heatmaps']),
+ to_tensor(encoded['displacements']))
+
+ keypoints, (root_scores, keypoint_scores) = decoded
+ self.assertIsNone(keypoint_scores)
+ self.assertEqual(keypoints.shape, data['keypoints'].shape)
+ self.assertEqual(root_scores.shape, data['keypoints'].shape[:1])
+
+ # decode w/ keypoint heatmaps
+ codec = SPR(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, 2),
+ generate_keypoint_heatmaps=True,
+ )
+
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
+ decoded = codec.decode(
+ to_tensor(encoded['heatmaps']),
+ to_tensor(encoded['displacements']))
+
+ keypoints, (root_scores, keypoint_scores) = decoded
+ self.assertIsNotNone(keypoint_scores)
+ self.assertEqual(keypoints.shape, data['keypoints'].shape)
+ self.assertEqual(root_scores.shape, data['keypoints'].shape[:1])
+ self.assertEqual(keypoint_scores.shape, data['keypoints'].shape[:2])
+
+ def test_cicular_verification(self):
+ data = get_coco_sample(img_shape=(512, 512), num_instances=1)
+
+ codec = SPR(
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, ),
+ generate_keypoint_heatmaps=False,
+ )
+
+ encoded = codec.encode(data['keypoints'], data['keypoints_visible'])
+ decoded = codec.decode(
+ to_tensor(encoded['heatmaps']),
+ to_tensor(encoded['displacements']))
+
+ keypoints, _ = decoded
+ self.assertTrue(
+ np.allclose(to_numpy(keypoints), data['keypoints'], atol=5.))
diff --git a/tests/test_codecs/test_udp_heatmap.py b/tests/test_codecs/test_udp_heatmap.py
index 0e7d6990eb..81913ddee4 100644
--- a/tests/test_codecs/test_udp_heatmap.py
+++ b/tests/test_codecs/test_udp_heatmap.py
@@ -46,17 +46,17 @@ def test_encode(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- heatmaps, keypoint_weights = codec.encode(keypoints,
- keypoints_visible)
+ encoded = codec.encode(keypoints, keypoints_visible)
if codec.heatmap_type == 'combined':
channel_per_kpt = 3
else:
channel_per_kpt = 1
- self.assertEqual(heatmaps.shape, (channel_per_kpt * 17, 64, 48),
+ self.assertEqual(encoded['heatmaps'].shape,
+ (channel_per_kpt * 17, 64, 48),
f'Failed case: "{name}"')
- self.assertEqual(keypoint_weights.shape,
+ self.assertEqual(encoded['keypoint_weights'].shape,
(1, 17)), f'Failed case: "{name}"'
def test_decode(self):
@@ -84,8 +84,8 @@ def test_cicular_verification(self):
for name, cfg in self.configs:
codec = KEYPOINT_CODECS.build(cfg)
- heatmaps, k = codec.encode(keypoints, keypoints_visible)
- _keypoints, _ = codec.decode(heatmaps)
+ encoded = codec.encode(keypoints, keypoints_visible)
+ _keypoints, _ = codec.decode(encoded['heatmaps'])
self.assertTrue(
np.allclose(keypoints, _keypoints, atol=10.),
diff --git a/tests/test_datasets/test_datasets/test_animal_datasets/test_animalpose_dataset.py b/tests/test_datasets/test_datasets/test_animal_datasets/test_animalpose_dataset.py
index 18ae409cae..9bb9725252 100644
--- a/tests/test_datasets/test_datasets/test_animal_datasets/test_animalpose_dataset.py
+++ b/tests/test_datasets/test_datasets/test_animal_datasets/test_animalpose_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_animalpose_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -107,7 +107,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_animalpose_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_animal_datasets/test_ap10k_dataset.py b/tests/test_datasets/test_datasets/test_animal_datasets/test_ap10k_dataset.py
index 1e3496b0b8..74ae89e960 100644
--- a/tests/test_datasets/test_datasets/test_animal_datasets/test_ap10k_dataset.py
+++ b/tests/test_datasets/test_datasets/test_animal_datasets/test_ap10k_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_ap10k_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -107,7 +107,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_ap10k_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_animal_datasets/test_atrw_dataset.py b/tests/test_datasets/test_datasets/test_animal_datasets/test_atrw_dataset.py
index e93a76afdf..e1554b55c4 100644
--- a/tests/test_datasets/test_datasets/test_animal_datasets/test_atrw_dataset.py
+++ b/tests/test_datasets/test_datasets/test_animal_datasets/test_atrw_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_atrw_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -106,7 +106,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_atrw_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_animal_datasets/test_fly_dataset.py b/tests/test_datasets/test_datasets/test_animal_datasets/test_fly_dataset.py
index 71984377e4..9765e318db 100644
--- a/tests/test_datasets/test_datasets/test_animal_datasets/test_fly_dataset.py
+++ b/tests/test_datasets/test_datasets/test_animal_datasets/test_fly_dataset.py
@@ -89,7 +89,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_fly_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -104,7 +104,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_fly_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_animal_datasets/test_horse10_dataset.py b/tests/test_datasets/test_datasets/test_animal_datasets/test_horse10_dataset.py
index 38a8b985ee..39e32c1a7b 100644
--- a/tests/test_datasets/test_datasets/test_animal_datasets/test_horse10_dataset.py
+++ b/tests/test_datasets/test_datasets/test_animal_datasets/test_horse10_dataset.py
@@ -89,7 +89,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_horse10_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -105,7 +105,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 3)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_horse10_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 3)
diff --git a/tests/test_datasets/test_datasets/test_animal_datasets/test_locust_dataset.py b/tests/test_datasets/test_datasets/test_animal_datasets/test_locust_dataset.py
index a3224c5959..3f48696a4b 100644
--- a/tests/test_datasets/test_datasets/test_animal_datasets/test_locust_dataset.py
+++ b/tests/test_datasets/test_datasets/test_animal_datasets/test_locust_dataset.py
@@ -89,7 +89,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_locust_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -105,7 +105,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_locust_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_animal_datasets/test_macaque_dataset.py b/tests/test_datasets/test_datasets/test_animal_datasets/test_macaque_dataset.py
index 92e54e8e00..1dee242812 100644
--- a/tests/test_datasets/test_datasets/test_animal_datasets/test_macaque_dataset.py
+++ b/tests/test_datasets/test_datasets/test_animal_datasets/test_macaque_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_macaque_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -107,7 +107,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_macaque_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_animal_datasets/test_zebra_dataset.py b/tests/test_datasets/test_datasets/test_animal_datasets/test_zebra_dataset.py
index 7abe7d53a5..c0a2db9a2a 100644
--- a/tests/test_datasets/test_datasets/test_animal_datasets/test_zebra_dataset.py
+++ b/tests/test_datasets/test_datasets/test_animal_datasets/test_zebra_dataset.py
@@ -89,7 +89,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_zebra_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -104,7 +104,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_zebra_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py
index 1eaaa7cbf2..ae00a64393 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_aic_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_aic_dataset(data_mode='topdown')
self.assertEqual(dataset.bbox_file, None)
@@ -104,7 +104,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 9)
self.check_data_info_keys(dataset[0], data_mode='topdown')
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_aic_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 3)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py
index bd1b575735..de78264dae 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_coco_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_coco_dataset(data_mode='topdown')
self.assertEqual(len(dataset), 12)
@@ -118,7 +118,7 @@ def test_top_down(self):
filter_cfg=dict(bbox_score_thr=0.3))
self.assertEqual(len(dataset), 33)
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_coco_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 4)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py
index b9543df1f1..8d63925257 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_crowdpose_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_crowdpose_dataset(data_mode='topdown')
# filter an invalid instance due to num_keypoints = 0
@@ -121,7 +121,7 @@ def test_top_down(self):
filter_cfg=dict(bbox_score_thr=0.97))
self.assertEqual(len(dataset), 5)
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_crowdpose_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py
index 280f3c3172..d7aa46b067 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_jhmdb_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_jhmdb_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -104,7 +104,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 3)
self.check_data_info_keys(dataset[0], data_mode='topdown')
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_jhmdb_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 3)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py
index e32b9af1f3..e93a524611 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_mhp_dataset.py
@@ -94,7 +94,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_mhp_dataset(data_mode='topdown')
self.assertEqual(dataset.bbox_file, None)
@@ -107,7 +107,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 4)
self.check_data_info_keys(dataset[0], data_mode='topdown')
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_mhp_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py
index b46d816694..f6431af429 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_dataset.py
@@ -104,7 +104,7 @@ def test_topdown(self):
self.assertEqual(len(dataset), 5)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_mpii_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 5)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_trb_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_trb_dataset.py
index 57a829bf94..bd64662ce3 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_trb_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_mpii_trb_dataset.py
@@ -103,7 +103,7 @@ def test_topdown(self):
self.assertEqual(len(dataset), 5)
self.check_data_info_keys(dataset[0], data_mode='topdown')
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_mpii_trb_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 5)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_ochuman_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_ochuman_dataset.py
index 2712c74352..8e9f3ad532 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_ochuman_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_ochuman_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_ochuman_dataset(data_mode='topdown')
self.assertEqual(len(dataset), 5)
@@ -103,7 +103,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 5)
self.check_data_info_keys(dataset[0], data_mode='topdown')
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_ochuman_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 3)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py
index 438856ef03..ef3cd82dfb 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_posetrack18_dataset(data_mode='topdown')
self.assertEqual(len(dataset), 14)
@@ -119,7 +119,7 @@ def test_top_down(self):
filter_cfg=dict(bbox_score_thr=0.3))
self.assertEqual(len(dataset), 119)
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_posetrack18_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 3)
diff --git a/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_video_dataset.py b/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_video_dataset.py
index b51a4df755..88b58e486d 100644
--- a/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_video_dataset.py
+++ b/tests/test_datasets/test_datasets/test_body_datasets/test_posetrack18_video_dataset.py
@@ -101,7 +101,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training, frame_sampler_mode = 'random'
dataset = self.build_posetrack18_video_dataset(
data_mode='topdown', frame_sampler_mode='random')
@@ -164,7 +164,7 @@ def test_top_down(self):
filter_cfg=dict(bbox_score_thr=0.3))
self.assertEqual(len(dataset), 119)
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_posetrack18_video_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 3)
diff --git a/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py b/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py
new file mode 100644
index 0000000000..698f1f060d
--- /dev/null
+++ b/tests/test_datasets/test_datasets/test_dataset_wrappers/test_combined_dataset.py
@@ -0,0 +1,89 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import numpy as np
+
+from mmpose.datasets.dataset_wrappers import CombinedDataset
+
+
+class TestCombinedDataset(TestCase):
+
+ def build_combined_dataset(self, **kwargs):
+
+ coco_cfg = dict(
+ type='CocoDataset',
+ ann_file='test_coco.json',
+ bbox_file=None,
+ data_mode='topdown',
+ data_root='tests/data/coco',
+ pipeline=[],
+ test_mode=False)
+
+ aic_cfg = dict(
+ type='AicDataset',
+ ann_file='test_aic.json',
+ bbox_file=None,
+ data_mode='topdown',
+ data_root='tests/data/aic',
+ pipeline=[],
+ test_mode=False)
+
+ cfg = dict(
+ metainfo=dict(from_file='configs/_base_/datasets/coco.py'),
+ datasets=[coco_cfg, aic_cfg],
+ pipeline=[])
+ cfg.update(kwargs)
+ return CombinedDataset(**cfg)
+
+ def check_data_info_keys(self,
+ data_info: dict,
+ data_mode: str = 'topdown'):
+ if data_mode == 'topdown':
+ expected_keys = dict(
+ img_id=int,
+ img_path=str,
+ bbox=np.ndarray,
+ bbox_score=np.ndarray,
+ keypoints=np.ndarray,
+ keypoints_visible=np.ndarray,
+ id=int)
+ elif data_mode == 'bottomup':
+ expected_keys = dict(
+ img_id=int,
+ img_path=str,
+ bbox=np.ndarray,
+ bbox_score=np.ndarray,
+ keypoints=np.ndarray,
+ keypoints_visible=np.ndarray,
+ invalid_segs=list,
+ id=list)
+ else:
+ raise ValueError(f'Invalid data_mode {data_mode}')
+
+ for key, type_ in expected_keys.items():
+ self.assertIn(key, data_info)
+ self.assertIsInstance(data_info[key], type_, key)
+
+ def test_get_subset_index(self):
+ dataset = self.build_combined_dataset()
+ lens = dataset._lens
+
+ with self.assertRaises(ValueError):
+ subset_idx, sample_idx = dataset._get_subset_index(sum(lens))
+
+ index = lens[0]
+ subset_idx, sample_idx = dataset._get_subset_index(index)
+ self.assertEqual(subset_idx, 1)
+ self.assertEqual(sample_idx, 0)
+
+ index = -lens[1] - 1
+ subset_idx, sample_idx = dataset._get_subset_index(index)
+ self.assertEqual(subset_idx, 0)
+ self.assertEqual(sample_idx, lens[0] - 1)
+
+ def test_prepare_data(self):
+ dataset = self.build_combined_dataset()
+ lens = dataset._lens
+
+ data_info = dataset[lens[0]]
+ self.check_data_info_keys(data_info)
diff --git a/tests/test_datasets/test_datasets/test_face_datasets/test_aflw_dataset.py b/tests/test_datasets/test_datasets/test_face_datasets/test_aflw_dataset.py
index 795a1812c7..dfc3a5ccce 100644
--- a/tests/test_datasets/test_datasets/test_face_datasets/test_aflw_dataset.py
+++ b/tests/test_datasets/test_datasets/test_face_datasets/test_aflw_dataset.py
@@ -86,7 +86,7 @@ def test_metainfo(self):
self.assertEqual(
len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints)
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_aflw_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -101,7 +101,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_aflw_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_face_datasets/test_coco_wholebody_face_dataset.py b/tests/test_datasets/test_datasets/test_face_datasets/test_coco_wholebody_face_dataset.py
index d5943dc04d..7c296c64ad 100644
--- a/tests/test_datasets/test_datasets/test_face_datasets/test_coco_wholebody_face_dataset.py
+++ b/tests/test_datasets/test_datasets/test_face_datasets/test_coco_wholebody_face_dataset.py
@@ -87,7 +87,7 @@ def test_metainfo(self):
# note that len(sigmas) may be zero if dataset.metainfo['sigmas'] = []
self.assertEqual(len(dataset.metainfo['sigmas']), num_keypoints)
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_coco_wholebody_face_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -104,18 +104,18 @@ def test_top_down(self):
self.assertEqual(len(dataset), 4)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_coco_wholebody_face_dataset(data_mode='bottomup')
- # filter one invalid insances due to face_valid = false
+ # filter one invalid instance due to face_valid = false
self.assertEqual(len(dataset), 3)
self.check_data_info_keys(dataset[0], data_mode='bottomup')
# test bottomup testing
dataset = self.build_coco_wholebody_face_dataset(
data_mode='bottomup', test_mode=True)
- # filter invalid insances due to face_valid = false
- self.assertEqual(len(dataset), 3)
+ # all images are used for evaluation
+ self.assertEqual(len(dataset), 4)
self.check_data_info_keys(dataset[0], data_mode='bottomup')
def test_exceptions_and_warnings(self):
diff --git a/tests/test_datasets/test_datasets/test_face_datasets/test_cofw_dataset.py b/tests/test_datasets/test_datasets/test_face_datasets/test_cofw_dataset.py
index a6ace1f07d..c8801a677a 100644
--- a/tests/test_datasets/test_datasets/test_face_datasets/test_cofw_dataset.py
+++ b/tests/test_datasets/test_datasets/test_face_datasets/test_cofw_dataset.py
@@ -84,7 +84,7 @@ def test_metainfo(self):
self.assertEqual(
len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints)
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_cofw_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -99,7 +99,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_cofw_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_face_datasets/test_face_300w_dataset.py b/tests/test_datasets/test_datasets/test_face_datasets/test_face_300w_dataset.py
index 5cb8ff0d05..c45330536f 100644
--- a/tests/test_datasets/test_datasets/test_face_datasets/test_face_300w_dataset.py
+++ b/tests/test_datasets/test_datasets/test_face_datasets/test_face_300w_dataset.py
@@ -86,7 +86,7 @@ def test_metainfo(self):
self.assertEqual(
len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints)
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_face_300w_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -102,7 +102,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_face_300w_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_face_datasets/test_wflw_dataset.py b/tests/test_datasets/test_datasets/test_face_datasets/test_wflw_dataset.py
index 5970de1f73..aab0fd1813 100644
--- a/tests/test_datasets/test_datasets/test_face_datasets/test_wflw_dataset.py
+++ b/tests/test_datasets/test_datasets/test_face_datasets/test_wflw_dataset.py
@@ -86,7 +86,7 @@ def test_metainfo(self):
self.assertEqual(
len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints)
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_wflw_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -101,7 +101,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 4)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_wflw_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_fashion_datasets/test_deepfashion_dataset.py b/tests/test_datasets/test_datasets/test_fashion_datasets/test_deepfashion_dataset.py
index 102e2c2480..2140a23467 100644
--- a/tests/test_datasets/test_datasets/test_fashion_datasets/test_deepfashion_dataset.py
+++ b/tests/test_datasets/test_datasets/test_fashion_datasets/test_deepfashion_dataset.py
@@ -111,7 +111,7 @@ def test_metainfo(self):
self.assertEqual(
len(dataset.metainfo['dataset_keypoint_weights']), num_keypoints)
- def test_top_down(self):
+ def test_topdown(self):
# test subset = 'full' topdown training
dataset = self.build_deepfashion_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -127,7 +127,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 2)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test subset = 'full' bottomup training
dataset = self.build_deepfashion_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 2)
diff --git a/tests/test_datasets/test_datasets/test_hand_datasets/test_coco_wholebody_hand_dataset.py b/tests/test_datasets/test_datasets/test_hand_datasets/test_coco_wholebody_hand_dataset.py
index 0cccef320b..6bb425bf81 100644
--- a/tests/test_datasets/test_datasets/test_hand_datasets/test_coco_wholebody_hand_dataset.py
+++ b/tests/test_datasets/test_datasets/test_hand_datasets/test_coco_wholebody_hand_dataset.py
@@ -92,7 +92,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_coco_wholebody_hand_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -110,7 +110,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 10)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_coco_wholebody_hand_dataset(data_mode='bottomup')
# filter repeated images
diff --git a/tests/test_datasets/test_datasets/test_hand_datasets/test_freihand_dataset.py b/tests/test_datasets/test_datasets/test_hand_datasets/test_freihand_dataset.py
index 974f130f9c..046a2dd602 100644
--- a/tests/test_datasets/test_datasets/test_hand_datasets/test_freihand_dataset.py
+++ b/tests/test_datasets/test_datasets/test_hand_datasets/test_freihand_dataset.py
@@ -89,7 +89,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_freihand_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -105,7 +105,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 8)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_freihand_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 8)
diff --git a/tests/test_datasets/test_datasets/test_hand_datasets/test_onehand10k_dataset.py b/tests/test_datasets/test_datasets/test_hand_datasets/test_onehand10k_dataset.py
index b1e5526229..38ff6c4083 100644
--- a/tests/test_datasets/test_datasets/test_hand_datasets/test_onehand10k_dataset.py
+++ b/tests/test_datasets/test_datasets/test_hand_datasets/test_onehand10k_dataset.py
@@ -89,7 +89,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_onehand10k_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -105,7 +105,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 4)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_onehand10k_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 4)
diff --git a/tests/test_datasets/test_datasets/test_hand_datasets/test_panoptic_hand2d_dataset.py b/tests/test_datasets/test_datasets/test_hand_datasets/test_panoptic_hand2d_dataset.py
index c8496cab8f..665795c985 100644
--- a/tests/test_datasets/test_datasets/test_hand_datasets/test_panoptic_hand2d_dataset.py
+++ b/tests/test_datasets/test_datasets/test_hand_datasets/test_panoptic_hand2d_dataset.py
@@ -94,7 +94,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_panoptic_hand2d_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -110,7 +110,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 4)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_panoptic_hand2d_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 4)
diff --git a/tests/test_datasets/test_datasets/test_hand_datasets/test_rhd2d_dataset.py b/tests/test_datasets/test_datasets/test_hand_datasets/test_rhd2d_dataset.py
index 62cb435add..852966c8fd 100644
--- a/tests/test_datasets/test_datasets/test_hand_datasets/test_rhd2d_dataset.py
+++ b/tests/test_datasets/test_datasets/test_hand_datasets/test_rhd2d_dataset.py
@@ -88,7 +88,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_rhd2d_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -103,7 +103,7 @@ def test_top_down(self):
self.assertEqual(len(dataset), 3)
self.check_data_info_keys(dataset[0])
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_rhd2d_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 3)
diff --git a/tests/test_datasets/test_datasets/test_wholebody_datasets/test_coco_wholebody_dataset.py b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_coco_wholebody_dataset.py
index 5f527ca027..a6ae20e534 100644
--- a/tests/test_datasets/test_datasets/test_wholebody_datasets/test_coco_wholebody_dataset.py
+++ b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_coco_wholebody_dataset.py
@@ -91,7 +91,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_coco_wholebody_dataset(data_mode='topdown')
# filter two invalid instances due to num_keypoints = 0
@@ -120,7 +120,7 @@ def test_top_down(self):
filter_cfg=dict(bbox_score_thr=0.3))
self.assertEqual(len(dataset), 33)
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_coco_wholebody_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 4)
diff --git a/tests/test_datasets/test_datasets/test_wholebody_datasets/test_halpe_dataset.py b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_halpe_dataset.py
index 482624400a..9ea79fc2cc 100644
--- a/tests/test_datasets/test_datasets/test_wholebody_datasets/test_halpe_dataset.py
+++ b/tests/test_datasets/test_datasets/test_wholebody_datasets/test_halpe_dataset.py
@@ -90,7 +90,7 @@ def test_metainfo(self):
len(dataset.metainfo['skeleton_links']),
len(dataset.metainfo['skeleton_link_colors']))
- def test_top_down(self):
+ def test_topdown(self):
# test topdown training
dataset = self.build_halpe_dataset(data_mode='topdown')
self.assertEqual(dataset.data_mode, 'topdown')
@@ -121,7 +121,7 @@ def test_top_down(self):
self.assertEqual(dataset.data_mode, 'topdown')
self.assertEqual(len(dataset), 33)
- def test_bottom_up(self):
+ def test_bottomup(self):
# test bottomup training
dataset = self.build_halpe_dataset(data_mode='bottomup')
self.assertEqual(len(dataset), 4)
diff --git a/tests/test_datasets/test_transforms/test_bottomup_transforms.py b/tests/test_datasets/test_transforms/test_bottomup_transforms.py
index 988b1863ec..cded7a6efb 100644
--- a/tests/test_datasets/test_transforms/test_bottomup_transforms.py
+++ b/tests/test_datasets/test_transforms/test_bottomup_transforms.py
@@ -110,20 +110,20 @@ def test_transform(self):
# single-scale, fit
transform = BottomupResize(input_size=(256, 256), resize_mode='fit')
results = transform(deepcopy(self.data_info))
- scale = 256 / 480
- expected_warp_mat = np.array([[scale, 0, 0], [0, scale, 0]])
- # the upper-half is the resized image content, and the lower-half is
- # the padded zeros
+ # the middle section of the image is the resized content, while the
+ # top and bottom are padded with zeros
self.assertEqual(results['img'].shape, (256, 256, 3))
- self.assertTrue(np.allclose(results['warp_mat'], expected_warp_mat))
- self.assertTrue(np.all(results['img'][:128] > 0))
- self.assertTrue(np.all(results['img'][128:] == 0))
+ self.assertTrue(
+ np.allclose(results['input_scale'], np.array([480., 480.])))
+ self.assertTrue(
+ np.allclose(results['input_center'], np.array([240., 120.])))
+ self.assertTrue(np.all(results['img'][64:192] > 0))
+ self.assertTrue(np.all(results['img'][:64] == 0))
+ self.assertTrue(np.all(results['img'][192:] == 0))
# single-scale, expand
transform = BottomupResize(input_size=(256, 256), resize_mode='expand')
results = transform(deepcopy(self.data_info))
- scale = 256 / 240
- expected_warp_mat = np.array([[scale, 0, 0], [0, scale, 0]])
# the actual input size is expanded to (512, 256) according to the
# original image shape
self.assertEqual(results['img'].shape, (256, 512, 3))
@@ -138,9 +138,10 @@ def test_transform(self):
# multi-scale
transform = BottomupResize(
- input_size=(256, 256), aux_scales=[1.5], resize_mode='fit')
+ input_size=(256, 256), aug_scales=[1.5], resize_mode='fit')
results = transform(deepcopy(self.data_info))
self.assertIsInstance(results['img'], list)
- self.assertIsInstance(results['warp_mat'], np.ndarray)
+ self.assertIsInstance(results['input_center'], np.ndarray)
+ self.assertIsInstance(results['input_scale'], np.ndarray)
self.assertEqual(results['img'][0].shape, (256, 256, 3))
self.assertEqual(results['img'][1].shape, (384, 384, 3))
diff --git a/tests/test_datasets/test_transforms/test_common_transforms.py b/tests/test_datasets/test_transforms/test_common_transforms.py
index 3412393678..2818081dca 100644
--- a/tests/test_datasets/test_transforms/test_common_transforms.py
+++ b/tests/test_datasets/test_transforms/test_common_transforms.py
@@ -465,7 +465,7 @@ def setUp(self):
with_bbox_cs=True,
with_img_mask=True)
- def test_generate_heatmap(self):
+ def test_generate_single_target(self):
encoder = dict(
type='MSRAHeatmap',
input_size=(192, 256),
@@ -475,7 +475,7 @@ def test_generate_heatmap(self):
# generate heatmap
pipeline = Compose([
TopdownAffine(input_size=(192, 256)),
- GenerateTarget(target_type='heatmap', encoder=encoder)
+ GenerateTarget(encoder=encoder)
])
results = pipeline(deepcopy(self.data_info))
@@ -487,7 +487,6 @@ def test_generate_heatmap(self):
pipeline = Compose([
TopdownAffine(input_size=(192, 256)),
GenerateTarget(
- target_type='heatmap',
encoder=encoder,
use_dataset_keypoint_weights=True,
)
@@ -500,7 +499,7 @@ def test_generate_heatmap(self):
np.allclose(results['keypoint_weights'],
self.data_info['dataset_keypoint_weights'][None]))
- def test_generate_multilevel_heatmap(self):
+ def test_generate_multilevel_target(self):
encoder_0 = dict(
type='MSRAHeatmap',
input_size=(192, 256),
@@ -512,61 +511,92 @@ def test_generate_multilevel_heatmap(self):
pipeline = Compose([
TopdownAffine(input_size=(192, 256)),
GenerateTarget(
- target_type='multilevel_heatmap',
- encoder=[encoder_0, encoder_1])
+ encoder=[encoder_0, encoder_1],
+ multilevel=True,
+ use_dataset_keypoint_weights=True)
])
results = pipeline(deepcopy(self.data_info))
self.assertTrue(is_list_of(results['heatmaps'], np.ndarray))
+ self.assertTrue(is_list_of(results['keypoint_weights'], np.ndarray))
self.assertEqual(results['heatmaps'][0].shape, (17, 64, 48))
self.assertEqual(results['heatmaps'][1].shape, (17, 32, 24))
- self.assertEqual(results['keypoint_weights'].shape, (1, 2, 17))
-
- def test_generate_keypoint_label(self):
- encoder = dict(type='RegressionLabel', input_size=(192, 256))
+ self.assertEqual(results['keypoint_weights'][0].shape, (1, 17))
- # generate keypoint label
+ def test_generate_combined_target(self):
+ encoder_0 = dict(
+ type='MSRAHeatmap',
+ input_size=(192, 256),
+ heatmap_size=(48, 64),
+ sigma=2.0)
+ encoder_1 = dict(type='RegressionLabel', input_size=(192, 256))
+ # generate multilevel heatmap
pipeline = Compose([
TopdownAffine(input_size=(192, 256)),
- GenerateTarget(target_type='keypoint_label', encoder=encoder)
+ GenerateTarget(
+ encoder=[encoder_0, encoder_1],
+ multilevel=False,
+ use_dataset_keypoint_weights=True)
])
results = pipeline(deepcopy(self.data_info))
+
+ self.assertEqual(results['heatmaps'].shape, (17, 64, 48))
self.assertEqual(results['keypoint_labels'].shape, (1, 17, 2))
- self.assertTrue(
- np.allclose(results['keypoint_weights'], np.ones((1, 17))))
+ self.assertIsInstance(results['keypoint_weights'], list)
+ self.assertEqual(results['keypoint_weights'][0].shape, (1, 17))
+
+ def test_errors(self):
- # generate keypoint label and use meta keypoint weights
+ # single encoder with `multilevel=True`
+ encoder = dict(
+ type='MSRAHeatmap',
+ input_size=(192, 256),
+ heatmap_size=(48, 64),
+ sigma=2.0)
+
+ with self.assertRaisesRegex(AssertionError,
+ 'Need multiple encoder configs'):
+ _ = GenerateTarget(encoder=encoder, multilevel=True)
+
+ # diverse keys in multilevel encoding
+ encoder_0 = dict(
+ type='MSRAHeatmap',
+ input_size=(192, 256),
+ heatmap_size=(48, 64),
+ sigma=2.0)
+
+ encoder_1 = dict(type='RegressionLabel', input_size=(192, 256))
pipeline = Compose([
TopdownAffine(input_size=(192, 256)),
- GenerateTarget(
- target_type='keypoint_label',
- encoder=encoder,
- use_dataset_keypoint_weights=True)
+ GenerateTarget(encoder=[encoder_0, encoder_1], multilevel=True)
])
- results = pipeline(deepcopy(self.data_info))
- self.assertEqual(results['keypoint_labels'].shape, (1, 17, 2))
- self.assertEqual(results['keypoint_weights'].shape, (1, 17))
- self.assertTrue(
- np.allclose(results['keypoint_weights'],
- self.data_info['dataset_keypoint_weights'][None]))
+ with self.assertRaisesRegex(ValueError, 'have the same keys'):
+ _ = pipeline(deepcopy(self.data_info))
- def test_generate_keypoint_xy_label(self):
+ # overlapping keys in combined encoding
encoder = dict(
- type='SimCCLabel',
+ type='MSRAHeatmap',
input_size=(192, 256),
- smoothing_type='gaussian',
- simcc_split_ratio=2.0)
+ heatmap_size=(48, 64),
+ sigma=2.0)
- # generate keypoint label
pipeline = Compose([
TopdownAffine(input_size=(192, 256)),
- GenerateTarget(target_type='keypoint_xy_label', encoder=encoder)
+ GenerateTarget(encoder=[encoder, encoder], multilevel=False)
])
- results = pipeline(deepcopy(self.data_info))
- self.assertEqual(results['keypoint_x_labels'].shape, (1, 17, 192 * 2))
- self.assertEqual(results['keypoint_y_labels'].shape, (1, 17, 256 * 2))
- self.assertTrue(
- np.allclose(results['keypoint_weights'], np.ones((1, 17))))
+ with self.assertRaisesRegex(ValueError, 'Overlapping item'):
+ _ = pipeline(deepcopy(self.data_info))
+
+ # deprecated argument `target_type` is given
+ encoder = dict(
+ type='MSRAHeatmap',
+ input_size=(192, 256),
+ heatmap_size=(48, 64),
+ sigma=2.0)
+
+ with self.assertWarnsRegex(DeprecationWarning,
+ '`target_type` is deprecated'):
+ _ = GenerateTarget(encoder=encoder, target_type='heatmap')
diff --git a/tests/test_datasets/test_transforms/test_converting.py b/tests/test_datasets/test_transforms/test_converting.py
new file mode 100644
index 0000000000..f345a44063
--- /dev/null
+++ b/tests/test_datasets/test_transforms/test_converting.py
@@ -0,0 +1,36 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+from mmpose.datasets.transforms import KeypointConverter
+from mmpose.testing import get_coco_sample
+
+
+class TestKeypointConverter(TestCase):
+
+ def setUp(self):
+ # prepare dummy bottom-up data sample with COCO metainfo
+ self.data_info = get_coco_sample(
+ img_shape=(240, 320), num_instances=4, with_bbox_cs=True)
+
+ def test_transform(self):
+ mapping = [(3, 0), (6, 1), (16, 2), (5, 3)]
+ transform = KeypointConverter(num_keypoints=5, mapping=mapping)
+ results = transform(self.data_info.copy())
+
+ # check shape
+ self.assertEqual(results['keypoints'].shape[0],
+ self.data_info['keypoints'].shape[0])
+ self.assertEqual(results['keypoints'].shape[1], 5)
+ self.assertEqual(results['keypoints'].shape[2], 2)
+ self.assertEqual(results['keypoints_visible'].shape[0],
+ self.data_info['keypoints_visible'].shape[0])
+ self.assertEqual(results['keypoints_visible'].shape[1], 5)
+
+ # check value
+ for source_index, target_index in mapping:
+ self.assertTrue((results['keypoints'][:, target_index] ==
+ self.data_info['keypoints'][:,
+ source_index]).all())
+ self.assertTrue(
+ (results['keypoints_visible'][:, target_index] ==
+ self.data_info['keypoints_visible'][:, source_index]).all())
diff --git a/tests/test_datasets/test_transforms/test_loading.py b/tests/test_datasets/test_transforms/test_loading.py
new file mode 100644
index 0000000000..0a63003c75
--- /dev/null
+++ b/tests/test_datasets/test_transforms/test_loading.py
@@ -0,0 +1,31 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import numpy as np
+from mmcv import imread
+
+from mmpose.datasets.transforms.loading import LoadImage
+
+
+class TestLoadImage(TestCase):
+
+ def test_load_image(self):
+
+ transform = LoadImage()
+ results = dict(img_path='tests/data/coco/000000000785.jpg')
+
+ results = transform(results)
+
+ self.assertIsInstance(results['img'], np.ndarray)
+
+ def test_with_input_image(self):
+ transform = LoadImage(to_float32=True)
+
+ img_path = 'tests/data/coco/000000000785.jpg'
+ results = dict(
+ img_path=img_path, img=imread(img_path).astype(np.uint8))
+
+ results = transform(results)
+
+ self.assertIsInstance(results['img'], np.ndarray)
+ self.assertTrue(results['img'].dtype, np.float32)
diff --git a/tests/test_engine/test_hooks/test_visualization_hook.py b/tests/test_engine/test_hooks/test_visualization_hook.py
index 0081e53791..3e4a202198 100644
--- a/tests/test_engine/test_hooks/test_visualization_hook.py
+++ b/tests/test_engine/test_hooks/test_visualization_hook.py
@@ -27,7 +27,7 @@ def _rand_poses(num_boxes, h, w):
class TestVisualizationHook(TestCase):
def setUp(self) -> None:
- PoseLocalVisualizer.get_instance('visualizer')
+ PoseLocalVisualizer.get_instance('test_visualization_hook')
data_sample = PoseDataSample()
data_sample.set_metainfo({
@@ -35,7 +35,7 @@ def setUp(self) -> None:
osp.join(
osp.dirname(__file__), '../../data/coco/000000000785.jpg')
})
- self.data_batch = [{'data_sample': data_sample}] * 2
+ self.data_batch = {'data_samples': [data_sample] * 2}
pred_instances = InstanceData()
pred_instances.keypoints = _rand_poses(5, 10, 12)
@@ -48,7 +48,7 @@ def test_after_val_iter(self):
runner = MagicMock()
runner.iter = 1
runner.val_evaluator.dataset_meta = dict()
- hook = PoseVisualizationHook(interval=1)
+ hook = PoseVisualizationHook(interval=1, enable=True)
hook.after_val_iter(runner, 1, self.data_batch, self.outputs)
def test_after_test_iter(self):
diff --git a/tests/test_evaluation/test_functional/test_nms.py b/tests/test_evaluation/test_functional/test_nms.py
new file mode 100644
index 0000000000..b29ed86ccb
--- /dev/null
+++ b/tests/test_evaluation/test_functional/test_nms.py
@@ -0,0 +1,40 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import numpy as np
+
+from mmpose.evaluation.functional.nms import nearby_joints_nms
+
+
+class TestNearbyJointsNMS(TestCase):
+
+ def test_nearby_joints_nms(self):
+
+ kpts_db = []
+ keep_pose_inds = nearby_joints_nms(
+ kpts_db, 0.05, score_per_joint=True, max_dets=1)
+ self.assertEqual(len(keep_pose_inds), 0)
+
+ kpts_db = []
+ for _ in range(5):
+ kpts_db.append(
+ dict(keypoints=np.random.rand(3, 2), score=np.random.rand(3)))
+ keep_pose_inds = nearby_joints_nms(
+ kpts_db, 0.05, score_per_joint=True, max_dets=1)
+ self.assertEqual(len(keep_pose_inds), 1)
+ self.assertLess(keep_pose_inds[0], 5)
+
+ kpts_db = []
+ for _ in range(5):
+ kpts_db.append(
+ dict(keypoints=np.random.rand(3, 2), score=np.random.rand()))
+ keep_pose_inds = nearby_joints_nms(
+ kpts_db, 0.05, num_nearby_joints_thr=2)
+ self.assertLessEqual(len(keep_pose_inds), 5)
+ self.assertGreater(len(keep_pose_inds), 0)
+
+ with self.assertRaises(AssertionError):
+ _ = nearby_joints_nms(kpts_db, 0, num_nearby_joints_thr=2)
+
+ with self.assertRaises(AssertionError):
+ _ = nearby_joints_nms(kpts_db, 0.05, num_nearby_joints_thr=3)
diff --git a/tests/test_evaluation/test_metrics/test_coco_metric.py b/tests/test_evaluation/test_metrics/test_coco_metric.py
index bdffc9c760..82bf0bc572 100644
--- a/tests/test_evaluation/test_metrics/test_coco_metric.py
+++ b/tests/test_evaluation/test_metrics/test_coco_metric.py
@@ -1,4 +1,5 @@
# Copyright (c) OpenMMLab. All rights reserved.
+import copy
import os.path as osp
import tempfile
from collections import defaultdict
@@ -6,6 +7,7 @@
import numpy as np
from mmengine.fileio import dump, load
+from xtcocotools.coco import COCO
from mmpose.datasets.datasets.utils import parse_pose_metainfo
from mmpose.evaluation.metrics import CocoMetric
@@ -20,17 +22,21 @@ def setUp(self):
tearDown() -> cleanUp()
"""
self.tmp_dir = tempfile.TemporaryDirectory()
- self.ann_file = 'tests/data/coco/test_coco.json'
- coco_meta_info = dict(from_file='configs/_base_/datasets/coco.py')
- self.coco_dataset_meta = parse_pose_metainfo(coco_meta_info)
- self.db = load(self.ann_file)
-
- self.topdown_data = self._convert_ann_to_topdown_batch_data()
- assert len(self.topdown_data) == 14
- self.bottomup_data = self._convert_ann_to_bottomup_batch_data()
- assert len(self.bottomup_data) == 4
- self.target = {
+ self.ann_file_coco = 'tests/data/coco/test_coco.json'
+ meta_info_coco = dict(from_file='configs/_base_/datasets/coco.py')
+ self.dataset_meta_coco = parse_pose_metainfo(meta_info_coco)
+ self.coco = COCO(self.ann_file_coco)
+ self.dataset_meta_coco['CLASSES'] = self.coco.loadCats(
+ self.coco.getCatIds())
+
+ self.topdown_data_coco = self._convert_ann_to_topdown_batch_data(
+ self.ann_file_coco)
+ assert len(self.topdown_data_coco) == 14
+ self.bottomup_data_coco = self._convert_ann_to_bottomup_batch_data(
+ self.ann_file_coco)
+ assert len(self.bottomup_data_coco) == 4
+ self.target_coco = {
'coco/AP': 1.0,
'coco/AP .5': 1.0,
'coco/AP .75': 1.0,
@@ -43,10 +49,68 @@ def setUp(self):
'coco/AR (L)': 1.0,
}
- def _convert_ann_to_topdown_batch_data(self):
+ self.ann_file_crowdpose = 'tests/data/crowdpose/test_crowdpose.json'
+ self.coco_crowdpose = COCO(self.ann_file_crowdpose)
+ meta_info_crowdpose = dict(
+ from_file='configs/_base_/datasets/crowdpose.py')
+ self.dataset_meta_crowdpose = parse_pose_metainfo(meta_info_crowdpose)
+ self.dataset_meta_crowdpose['CLASSES'] = self.coco_crowdpose.loadCats(
+ self.coco_crowdpose.getCatIds())
+
+ self.topdown_data_crowdpose = self._convert_ann_to_topdown_batch_data(
+ self.ann_file_crowdpose)
+ assert len(self.topdown_data_crowdpose) == 5
+ self.bottomup_data_crowdpose = \
+ self._convert_ann_to_bottomup_batch_data(self.ann_file_crowdpose)
+ assert len(self.bottomup_data_crowdpose) == 2
+
+ self.target_crowdpose = {
+ 'crowdpose/AP': 1.0,
+ 'crowdpose/AP .5': 1.0,
+ 'crowdpose/AP .75': 1.0,
+ 'crowdpose/AR': 1.0,
+ 'crowdpose/AR .5': 1.0,
+ 'crowdpose/AR .75': 1.0,
+ 'crowdpose/AP(E)': -1.0,
+ 'crowdpose/AP(M)': 1.0,
+ 'crowdpose/AP(H)': -1.0,
+ }
+
+ self.ann_file_ap10k = 'tests/data/ap10k/test_ap10k.json'
+ self.coco_ap10k = COCO(self.ann_file_ap10k)
+ meta_info_ap10k = dict(from_file='configs/_base_/datasets/ap10k.py')
+ self.dataset_meta_ap10k = parse_pose_metainfo(meta_info_ap10k)
+ self.dataset_meta_ap10k['CLASSES'] = self.coco_ap10k.loadCats(
+ self.coco_ap10k.getCatIds())
+
+ self.topdown_data_ap10k = self._convert_ann_to_topdown_batch_data(
+ self.ann_file_ap10k)
+ assert len(self.topdown_data_ap10k) == 2
+ self.bottomup_data_ap10k = self._convert_ann_to_bottomup_batch_data(
+ self.ann_file_ap10k)
+ assert len(self.bottomup_data_ap10k) == 2
+
+ self.target_ap10k = {
+ 'coco/AP': 1.0,
+ 'coco/AP .5': 1.0,
+ 'coco/AP .75': 1.0,
+ 'coco/AP (M)': -1.0,
+ 'coco/AP (L)': 1.0,
+ 'coco/AR': 1.0,
+ 'coco/AR .5': 1.0,
+ 'coco/AR .75': 1.0,
+ 'coco/AR (M)': -1.0,
+ 'coco/AR (L)': 1.0,
+ }
+
+ def _convert_ann_to_topdown_batch_data(self, ann_file):
"""Convert annotations to topdown-style batch data."""
topdown_data = []
- for ann in self.db['annotations']:
+ db = load(ann_file)
+ imgid2info = dict()
+ for img in db['images']:
+ imgid2info[img['id']] = img
+ for ann in db['annotations']:
w, h = ann['bbox'][2], ann['bbox'][3]
bboxes = np.array(ann['bbox'], dtype=np.float32).reshape(-1, 4)
bbox_scales = np.array([w * 1.25, h * 1.25]).reshape(-1, 2)
@@ -66,9 +130,19 @@ def _convert_ann_to_topdown_batch_data(self):
data_sample = {
'id': ann['id'],
'img_id': ann['image_id'],
+ 'category_id': ann.get('category_id', 1),
'gt_instances': gt_instances,
- 'pred_instances': pred_instances
+ 'pred_instances': pred_instances,
+ # dummy image_shape for testing
+ 'ori_shape': [640, 480],
+ # store the raw annotation info to test without ann_file
+ 'raw_ann_info': copy.deepcopy(ann),
}
+
+ # add crowd_index to data_sample if it is present in the image_info
+ if 'crowdIndex' in imgid2info[ann['image_id']]:
+ data_sample['crowd_index'] = imgid2info[
+ ann['image_id']]['crowdIndex']
# batch size = 1
data_batch = [data]
data_samples = [data_sample]
@@ -76,10 +150,11 @@ def _convert_ann_to_topdown_batch_data(self):
return topdown_data
- def _convert_ann_to_bottomup_batch_data(self):
+ def _convert_ann_to_bottomup_batch_data(self, ann_file):
"""Convert annotations to bottomup-style batch data."""
img2ann = defaultdict(list)
- for ann in self.db['annotations']:
+ db = load(ann_file)
+ for ann in db['annotations']:
img2ann[ann['image_id']].append(ann)
bottomup_data = []
@@ -118,129 +193,57 @@ def test_init(self):
# test score_mode option
with self.assertRaisesRegex(ValueError,
'`score_mode` should be one of'):
- _ = CocoMetric(ann_file=self.ann_file, score_mode='keypoint')
+ _ = CocoMetric(ann_file=self.ann_file_coco, score_mode='invalid')
# test nms_mode option
with self.assertRaisesRegex(ValueError, '`nms_mode` should be one of'):
- _ = CocoMetric(ann_file=self.ann_file, nms_mode='invalid')
+ _ = CocoMetric(ann_file=self.ann_file_coco, nms_mode='invalid')
# test format_only option
with self.assertRaisesRegex(
AssertionError,
'`outfile_prefix` can not be None when `format_only` is True'):
_ = CocoMetric(
- ann_file=self.ann_file, format_only=True, outfile_prefix=None)
-
- def test_topdown_evaluate(self):
- """test topdown-style COCO metric evaluation."""
- # case 1: score_mode='bbox', nms_mode='none'
- coco_metric = CocoMetric(
- ann_file=self.ann_file,
- outfile_prefix=f'{self.tmp_dir.name}/test',
- score_mode='bbox',
- nms_mode='none')
- coco_metric.dataset_meta = self.coco_dataset_meta
-
- # process samples
- for data_batch, data_samples in self.topdown_data:
- coco_metric.process(data_batch, data_samples)
-
- eval_results = coco_metric.evaluate(size=len(self.topdown_data))
-
- self.assertDictEqual(eval_results, self.target)
- self.assertTrue(
- osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
-
- # case 2: score_mode='bbox_keypoint', nms_mode='oks_nms'
- coco_metric = CocoMetric(
- ann_file=self.ann_file,
- outfile_prefix=f'{self.tmp_dir.name}/test',
- score_mode='bbox_keypoint',
- nms_mode='oks_nms')
- coco_metric.dataset_meta = self.coco_dataset_meta
-
- # process samples
- for data_batch, data_samples in self.topdown_data:
- coco_metric.process(data_batch, data_samples)
-
- eval_results = coco_metric.evaluate(size=len(self.topdown_data))
-
- self.assertDictEqual(eval_results, self.target)
- self.assertTrue(
- osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
-
- # case 3: score_mode='bbox_rle', nms_mode='soft_oks_nms'
- coco_metric = CocoMetric(
- ann_file=self.ann_file,
- outfile_prefix=f'{self.tmp_dir.name}/test',
- score_mode='bbox_rle',
- nms_mode='soft_oks_nms')
- coco_metric.dataset_meta = self.coco_dataset_meta
-
- # process samples
- for data_batch, data_samples in self.topdown_data:
- coco_metric.process(data_batch, data_samples)
-
- eval_results = coco_metric.evaluate(size=len(self.topdown_data))
-
- self.assertDictEqual(eval_results, self.target)
- self.assertTrue(
- osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
-
- def test_bottomup_evaluate(self):
- """test bottomup-style COCO metric evaluation."""
- # case1: score_mode='bbox', nms_mode='none'
- coco_metric = CocoMetric(
- ann_file=self.ann_file,
- outfile_prefix=f'{self.tmp_dir.name}/test',
- score_mode='bbox',
- nms_mode='none')
- coco_metric.dataset_meta = self.coco_dataset_meta
-
- # process samples
- for data_batch, data_samples in self.bottomup_data:
- coco_metric.process(data_batch, data_samples)
-
- eval_results = coco_metric.evaluate(size=len(self.bottomup_data))
- self.assertDictEqual(eval_results, self.target)
- self.assertTrue(
- osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
+ ann_file=self.ann_file_coco,
+ format_only=True,
+ outfile_prefix=None)
def test_other_methods(self):
"""test other useful methods."""
# test `_sort_and_unique_bboxes` method
- coco_metric = CocoMetric(
- ann_file=self.ann_file, score_mode='bbox', nms_mode='none')
- coco_metric.dataset_meta = self.coco_dataset_meta
+ metric_coco = CocoMetric(
+ ann_file=self.ann_file_coco, score_mode='bbox', nms_mode='none')
+ metric_coco.dataset_meta = self.dataset_meta_coco
# process samples
- for data_batch, data_samples in self.topdown_data:
- coco_metric.process(data_batch, data_samples)
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
# process one extra sample
- data_batch, data_samples = self.topdown_data[0]
- coco_metric.process(data_batch, data_samples)
+ data_batch, data_samples = self.topdown_data_coco[0]
+ metric_coco.process(data_batch, data_samples)
# an extra sample
- eval_results = coco_metric.evaluate(size=len(self.topdown_data) + 1)
- self.assertDictEqual(eval_results, self.target)
+ eval_results = metric_coco.evaluate(
+ size=len(self.topdown_data_coco) + 1)
+ self.assertDictEqual(eval_results, self.target_coco)
def test_format_only(self):
"""test `format_only` option."""
- coco_metric = CocoMetric(
- ann_file=self.ann_file,
+ metric_coco = CocoMetric(
+ ann_file=self.ann_file_coco,
format_only=True,
outfile_prefix=f'{self.tmp_dir.name}/test',
score_mode='bbox_keypoint',
nms_mode='oks_nms')
- coco_metric.dataset_meta = self.coco_dataset_meta
+ metric_coco.dataset_meta = self.dataset_meta_coco
# process one sample
- data_batch, data_samples = self.topdown_data[0]
- coco_metric.process(data_batch, data_samples)
- eval_results = coco_metric.evaluate(size=1)
+ data_batch, data_samples = self.topdown_data_coco[0]
+ metric_coco.process(data_batch, data_samples)
+ eval_results = metric_coco.evaluate(size=1)
self.assertDictEqual(eval_results, {})
self.assertTrue(
osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
# test when gt annotations are absent
- db_ = load(self.ann_file)
+ db_ = load(self.ann_file_coco)
del db_['annotations']
tmp_ann_file = osp.join(self.tmp_dir.name, 'temp_ann.json')
dump(db_, tmp_ann_file, sort_keys=True, indent=4)
@@ -249,11 +252,32 @@ def test_format_only(self):
'Ground truth annotations are required for evaluation'):
_ = CocoMetric(ann_file=tmp_ann_file, format_only=False)
+ def test_bottomup_evaluate(self):
+ """test bottomup-style COCO metric evaluation."""
+ # case1: score_mode='bbox', nms_mode='none'
+ metric_coco = CocoMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test',
+ score_mode='bbox',
+ nms_mode='none')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.bottomup_data_coco:
+ metric_coco.process(data_batch, data_samples)
+
+ eval_results = metric_coco.evaluate(size=len(self.bottomup_data_coco))
+ self.assertDictEqual(eval_results, self.target_coco)
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
+
def test_topdown_alignment(self):
"""Test whether the output of CocoMetric and the original
TopDownCocoDataset are the same."""
topdown_data = []
- for ann in self.db['annotations']:
+ db = load(self.ann_file_coco)
+
+ for ann in db['annotations']:
w, h = ann['bbox'][2], ann['bbox'][3]
bboxes = np.array(ann['bbox'], dtype=np.float32).reshape(-1, 4)
bbox_scales = np.array([w * 1.25, h * 1.25]).reshape(-1, 2)
@@ -288,18 +312,18 @@ def test_topdown_alignment(self):
# case 1:
# typical setting: score_mode='bbox_keypoint', nms_mode='oks_nms'
- coco_metric = CocoMetric(
- ann_file=self.ann_file,
- outfile_prefix=f'{self.tmp_dir.name}/test',
+ metric_coco = CocoMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test_align1',
score_mode='bbox_keypoint',
nms_mode='oks_nms')
- coco_metric.dataset_meta = self.coco_dataset_meta
+ metric_coco.dataset_meta = self.dataset_meta_coco
# process samples
for data_batch, data_samples in topdown_data:
- coco_metric.process(data_batch, data_samples)
+ metric_coco.process(data_batch, data_samples)
- eval_results = coco_metric.evaluate(size=len(topdown_data))
+ eval_results = metric_coco.evaluate(size=len(topdown_data))
target = {
'coco/AP': 0.5287458745874587,
@@ -318,21 +342,22 @@ def test_topdown_alignment(self):
self.assertAlmostEqual(eval_results[key], target[key])
self.assertTrue(
- osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
+ osp.isfile(
+ osp.join(self.tmp_dir.name, 'test_align1.keypoints.json')))
# case 2: score_mode='bbox_rle', nms_mode='oks_nms'
- coco_metric = CocoMetric(
- ann_file=self.ann_file,
- outfile_prefix=f'{self.tmp_dir.name}/test',
+ metric_coco = CocoMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test_align2',
score_mode='bbox_rle',
nms_mode='oks_nms')
- coco_metric.dataset_meta = self.coco_dataset_meta
+ metric_coco.dataset_meta = self.dataset_meta_coco
# process samples
for data_batch, data_samples in topdown_data:
- coco_metric.process(data_batch, data_samples)
+ metric_coco.process(data_batch, data_samples)
- eval_results = coco_metric.evaluate(size=len(topdown_data))
+ eval_results = metric_coco.evaluate(size=len(topdown_data))
target = {
'coco/AP': 0.5004950495049505,
@@ -351,10 +376,12 @@ def test_topdown_alignment(self):
self.assertAlmostEqual(eval_results[key], target[key])
self.assertTrue(
- osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
+ osp.isfile(
+ osp.join(self.tmp_dir.name, 'test_align2.keypoints.json')))
+ # case 3: score_mode='bbox_keypoint', nms_mode='soft_oks_nms'
topdown_data = []
- anns = self.db['annotations']
+ anns = db['annotations']
for i, ann in enumerate(anns):
w, h = ann['bbox'][2], ann['bbox'][3]
bboxes = np.array(ann['bbox'], dtype=np.float32).reshape(-1, 4)
@@ -414,21 +441,20 @@ def test_topdown_alignment(self):
data_samples = [data_sample0, data_sample1]
topdown_data.append((data_batch, data_samples))
- # case 3: score_mode='bbox_keypoint', nms_mode='soft_oks_nms'
- coco_metric = CocoMetric(
- ann_file=self.ann_file,
- outfile_prefix=f'{self.tmp_dir.name}/test',
+ metric_coco = CocoMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test_align3',
score_mode='bbox_keypoint',
keypoint_score_thr=0.2,
nms_thr=0.9,
nms_mode='soft_oks_nms')
- coco_metric.dataset_meta = self.coco_dataset_meta
+ metric_coco.dataset_meta = self.dataset_meta_coco
# process samples
for data_batch, data_samples in topdown_data:
- coco_metric.process(data_batch, data_samples)
+ metric_coco.process(data_batch, data_samples)
- eval_results = coco_metric.evaluate(size=len(topdown_data) * 2)
+ eval_results = metric_coco.evaluate(size=len(topdown_data) * 2)
target = {
'coco/AP': 0.17073707370737073,
@@ -447,4 +473,140 @@ def test_topdown_alignment(self):
self.assertAlmostEqual(eval_results[key], target[key])
self.assertTrue(
- osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
+ osp.isfile(
+ osp.join(self.tmp_dir.name, 'test_align3.keypoints.json')))
+
+ def test_topdown_evaluate(self):
+ """test topdown-style COCO metric evaluation."""
+ # case 1: score_mode='bbox', nms_mode='none'
+ metric_coco = CocoMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test1',
+ score_mode='bbox',
+ nms_mode='none')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
+
+ eval_results = metric_coco.evaluate(size=len(self.topdown_data_coco))
+
+ self.assertDictEqual(eval_results, self.target_coco)
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test1.keypoints.json')))
+
+ # case 2: score_mode='bbox_keypoint', nms_mode='oks_nms'
+ metric_coco = CocoMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test2',
+ score_mode='bbox_keypoint',
+ nms_mode='oks_nms')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
+
+ eval_results = metric_coco.evaluate(size=len(self.topdown_data_coco))
+
+ self.assertDictEqual(eval_results, self.target_coco)
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test2.keypoints.json')))
+
+ # case 3: score_mode='bbox_rle', nms_mode='soft_oks_nms'
+ metric_coco = CocoMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test3',
+ score_mode='bbox_rle',
+ nms_mode='soft_oks_nms')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
+
+ eval_results = metric_coco.evaluate(size=len(self.topdown_data_coco))
+
+ self.assertDictEqual(eval_results, self.target_coco)
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test3.keypoints.json')))
+
+ # case 4: test without providing ann_file
+ metric_coco = CocoMetric(outfile_prefix=f'{self.tmp_dir.name}/test4')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
+ eval_results = metric_coco.evaluate(size=len(self.topdown_data_coco))
+ self.assertDictEqual(eval_results, self.target_coco)
+ # test whether convert the annotation to COCO format
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test4.gt.json')))
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test4.keypoints.json')))
+
+ # case 5: test Crowdpose dataset
+ metric_crowdpose = CocoMetric(
+ ann_file=self.ann_file_crowdpose,
+ outfile_prefix=f'{self.tmp_dir.name}/test5',
+ use_area=False,
+ iou_type='keypoints_crowd',
+ prefix='crowdpose')
+ metric_crowdpose.dataset_meta = self.dataset_meta_crowdpose
+ # process samples
+ for data_batch, data_samples in self.topdown_data_crowdpose:
+ metric_crowdpose.process(data_batch, data_samples)
+ eval_results = metric_crowdpose.evaluate(
+ size=len(self.topdown_data_crowdpose))
+ self.assertDictEqual(eval_results, self.target_crowdpose)
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test5.keypoints.json')))
+
+ # case 6: test Crowdpose dataset + without ann_file
+ metric_crowdpose = CocoMetric(
+ outfile_prefix=f'{self.tmp_dir.name}/test6',
+ use_area=False,
+ iou_type='keypoints_crowd',
+ prefix='crowdpose')
+ metric_crowdpose.dataset_meta = self.dataset_meta_crowdpose
+ # process samples
+ for data_batch, data_samples in self.topdown_data_crowdpose:
+ metric_crowdpose.process(data_batch, data_samples)
+ eval_results = metric_crowdpose.evaluate(
+ size=len(self.topdown_data_crowdpose))
+ self.assertDictEqual(eval_results, self.target_crowdpose)
+ # test whether convert the annotation to COCO format
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test6.gt.json')))
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test6.keypoints.json')))
+
+ # case 7: test AP10k dataset
+ metric_ap10k = CocoMetric(
+ ann_file=self.ann_file_ap10k,
+ outfile_prefix=f'{self.tmp_dir.name}/test7')
+ metric_ap10k.dataset_meta = self.dataset_meta_ap10k
+ # process samples
+ for data_batch, data_samples in self.topdown_data_ap10k:
+ metric_ap10k.process(data_batch, data_samples)
+ eval_results = metric_ap10k.evaluate(size=len(self.topdown_data_ap10k))
+ for key in self.target_ap10k:
+ self.assertAlmostEqual(eval_results[key], self.target_ap10k[key])
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test7.keypoints.json')))
+
+ # case 8: test Crowdpose dataset + without ann_file
+ metric_ap10k = CocoMetric(outfile_prefix=f'{self.tmp_dir.name}/test8')
+ metric_ap10k.dataset_meta = self.dataset_meta_ap10k
+ # process samples
+ for data_batch, data_samples in self.topdown_data_ap10k:
+ metric_ap10k.process(data_batch, data_samples)
+ eval_results = metric_ap10k.evaluate(size=len(self.topdown_data_ap10k))
+ for key in self.target_ap10k:
+ self.assertAlmostEqual(eval_results[key], self.target_ap10k[key])
+ # test whether convert the annotation to COCO format
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test8.gt.json')))
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test8.keypoints.json')))
diff --git a/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py b/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py
new file mode 100644
index 0000000000..46e8498851
--- /dev/null
+++ b/tests/test_evaluation/test_metrics/test_coco_wholebody_metric.py
@@ -0,0 +1,294 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+import tempfile
+from collections import defaultdict
+from unittest import TestCase
+
+import numpy as np
+from mmengine.fileio import dump, load
+from xtcocotools.coco import COCO
+
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
+from mmpose.evaluation.metrics import CocoWholeBodyMetric
+
+
+class TestCocoWholeBodyMetric(TestCase):
+
+ def setUp(self):
+ """Setup some variables which are used in every test method.
+
+ TestCase calls functions in this order: setUp() -> testMethod() ->
+ tearDown() -> cleanUp()
+ """
+ self.tmp_dir = tempfile.TemporaryDirectory()
+
+ self.ann_file_coco = 'tests/data/coco/test_coco_wholebody.json'
+ meta_info_coco = dict(
+ from_file='configs/_base_/datasets/coco_wholebody.py')
+ self.dataset_meta_coco = parse_pose_metainfo(meta_info_coco)
+ self.coco = COCO(self.ann_file_coco)
+ self.dataset_meta_coco['CLASSES'] = self.coco.loadCats(
+ self.coco.getCatIds())
+
+ self.topdown_data_coco = self._convert_ann_to_topdown_batch_data(
+ self.ann_file_coco)
+ assert len(self.topdown_data_coco) == 14
+ self.bottomup_data_coco = self._convert_ann_to_bottomup_batch_data(
+ self.ann_file_coco)
+ assert len(self.bottomup_data_coco) == 4
+ self.target_coco = {
+ 'coco-wholebody/AP': 1.0,
+ 'coco-wholebody/AP .5': 1.0,
+ 'coco-wholebody/AP .75': 1.0,
+ 'coco-wholebody/AP (M)': 1.0,
+ 'coco-wholebody/AP (L)': 1.0,
+ 'coco-wholebody/AR': 1.0,
+ 'coco-wholebody/AR .5': 1.0,
+ 'coco-wholebody/AR .75': 1.0,
+ 'coco-wholebody/AR (M)': 1.0,
+ 'coco-wholebody/AR (L)': 1.0,
+ }
+
+ def _convert_ann_to_topdown_batch_data(self, ann_file):
+ """Convert annotations to topdown-style batch data."""
+ topdown_data = []
+ db = load(ann_file)
+ imgid2info = dict()
+ for img in db['images']:
+ imgid2info[img['id']] = img
+ for ann in db['annotations']:
+ w, h = ann['bbox'][2], ann['bbox'][3]
+ bboxes = np.array(ann['bbox'], dtype=np.float32).reshape(-1, 4)
+ bbox_scales = np.array([w * 1.25, h * 1.25]).reshape(-1, 2)
+ _keypoints = np.array(ann['keypoints'] + ann['foot_kpts'] +
+ ann['face_kpts'] + ann['lefthand_kpts'] +
+ ann['righthand_kpts']).reshape(1, -1, 3)
+
+ gt_instances = {
+ 'bbox_scales': bbox_scales,
+ 'bbox_scores': np.ones((1, ), dtype=np.float32),
+ 'bboxes': bboxes,
+ }
+ pred_instances = {
+ 'keypoints': _keypoints[..., :2],
+ 'keypoint_scores': _keypoints[..., -1],
+ }
+
+ data = {'inputs': None}
+ data_sample = {
+ 'id': ann['id'],
+ 'img_id': ann['image_id'],
+ 'category_id': ann.get('category_id', 1),
+ 'gt_instances': gt_instances,
+ 'pred_instances': pred_instances,
+ # dummy image_shape for testing
+ 'ori_shape': [640, 480],
+ # store the raw annotation info to test without ann_file
+ 'raw_ann_info': copy.deepcopy(ann),
+ }
+
+ # batch size = 1
+ data_batch = [data]
+ data_samples = [data_sample]
+ topdown_data.append((data_batch, data_samples))
+
+ return topdown_data
+
+ def _convert_ann_to_bottomup_batch_data(self, ann_file):
+ """Convert annotations to bottomup-style batch data."""
+ img2ann = defaultdict(list)
+ db = load(ann_file)
+ for ann in db['annotations']:
+ img2ann[ann['image_id']].append(ann)
+
+ bottomup_data = []
+ for img_id, anns in img2ann.items():
+ _keypoints = []
+ for ann in anns:
+ _keypoints.append(ann['keypoints'] + ann['foot_kpts'] +
+ ann['face_kpts'] + ann['lefthand_kpts'] +
+ ann['righthand_kpts'])
+ keypoints = np.array(_keypoints).reshape((len(anns), -1, 3))
+
+ gt_instances = {
+ 'bbox_scores': np.ones((len(anns)), dtype=np.float32)
+ }
+
+ pred_instances = {
+ 'keypoints': keypoints[..., :2],
+ 'keypoint_scores': keypoints[..., -1],
+ }
+
+ data = {'inputs': None}
+ data_sample = {
+ 'id': [ann['id'] for ann in anns],
+ 'img_id': img_id,
+ 'gt_instances': gt_instances,
+ 'pred_instances': pred_instances
+ }
+
+ # batch size = 1
+ data_batch = [data]
+ data_samples = [data_sample]
+ bottomup_data.append((data_batch, data_samples))
+ return bottomup_data
+
+ def tearDown(self):
+ self.tmp_dir.cleanup()
+
+ def test_init(self):
+ """test metric init method."""
+ # test score_mode option
+ with self.assertRaisesRegex(ValueError,
+ '`score_mode` should be one of'):
+ _ = CocoWholeBodyMetric(
+ ann_file=self.ann_file_coco, score_mode='invalid')
+
+ # test nms_mode option
+ with self.assertRaisesRegex(ValueError, '`nms_mode` should be one of'):
+ _ = CocoWholeBodyMetric(
+ ann_file=self.ann_file_coco, nms_mode='invalid')
+
+ # test format_only option
+ with self.assertRaisesRegex(
+ AssertionError,
+ '`outfile_prefix` can not be None when `format_only` is True'):
+ _ = CocoWholeBodyMetric(
+ ann_file=self.ann_file_coco,
+ format_only=True,
+ outfile_prefix=None)
+
+ def test_other_methods(self):
+ """test other useful methods."""
+ # test `_sort_and_unique_bboxes` method
+ metric_coco = CocoWholeBodyMetric(
+ ann_file=self.ann_file_coco, score_mode='bbox', nms_mode='none')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
+ # process one extra sample
+ data_batch, data_samples = self.topdown_data_coco[0]
+ metric_coco.process(data_batch, data_samples)
+ # an extra sample
+ eval_results = metric_coco.evaluate(
+ size=len(self.topdown_data_coco) + 1)
+ self.assertDictEqual(eval_results, self.target_coco)
+
+ def test_format_only(self):
+ """test `format_only` option."""
+ metric_coco = CocoWholeBodyMetric(
+ ann_file=self.ann_file_coco,
+ format_only=True,
+ outfile_prefix=f'{self.tmp_dir.name}/test',
+ score_mode='bbox_keypoint',
+ nms_mode='oks_nms')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+ # process one sample
+ data_batch, data_samples = self.topdown_data_coco[0]
+ metric_coco.process(data_batch, data_samples)
+ eval_results = metric_coco.evaluate(size=1)
+ self.assertDictEqual(eval_results, {})
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
+
+ # test when gt annotations are absent
+ db_ = load(self.ann_file_coco)
+ del db_['annotations']
+ tmp_ann_file = osp.join(self.tmp_dir.name, 'temp_ann.json')
+ dump(db_, tmp_ann_file, sort_keys=True, indent=4)
+ with self.assertRaisesRegex(
+ AssertionError,
+ 'Ground truth annotations are required for evaluation'):
+ _ = CocoWholeBodyMetric(ann_file=tmp_ann_file, format_only=False)
+
+ def test_bottomup_evaluate(self):
+ """test bottomup-style COCO metric evaluation."""
+ # case1: score_mode='bbox', nms_mode='none'
+ metric_coco = CocoWholeBodyMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test',
+ score_mode='bbox',
+ nms_mode='none')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.bottomup_data_coco:
+ metric_coco.process(data_batch, data_samples)
+
+ eval_results = metric_coco.evaluate(size=len(self.bottomup_data_coco))
+ self.assertDictEqual(eval_results, self.target_coco)
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test.keypoints.json')))
+
+ def test_topdown_evaluate(self):
+ """test topdown-style COCO metric evaluation."""
+ # case 1: score_mode='bbox', nms_mode='none'
+ metric_coco = CocoWholeBodyMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test1',
+ score_mode='bbox',
+ nms_mode='none')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
+
+ eval_results = metric_coco.evaluate(size=len(self.topdown_data_coco))
+
+ self.assertDictEqual(eval_results, self.target_coco)
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test1.keypoints.json')))
+
+ # case 2: score_mode='bbox_keypoint', nms_mode='oks_nms'
+ metric_coco = CocoWholeBodyMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test2',
+ score_mode='bbox_keypoint',
+ nms_mode='oks_nms')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
+
+ eval_results = metric_coco.evaluate(size=len(self.topdown_data_coco))
+
+ self.assertDictEqual(eval_results, self.target_coco)
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test2.keypoints.json')))
+
+ # case 3: score_mode='bbox_rle', nms_mode='soft_oks_nms'
+ metric_coco = CocoWholeBodyMetric(
+ ann_file=self.ann_file_coco,
+ outfile_prefix=f'{self.tmp_dir.name}/test3',
+ score_mode='bbox_rle',
+ nms_mode='soft_oks_nms')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
+
+ eval_results = metric_coco.evaluate(size=len(self.topdown_data_coco))
+
+ self.assertDictEqual(eval_results, self.target_coco)
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test3.keypoints.json')))
+
+ # case 4: test without providing ann_file
+ metric_coco = CocoWholeBodyMetric(
+ outfile_prefix=f'{self.tmp_dir.name}/test4')
+ metric_coco.dataset_meta = self.dataset_meta_coco
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric_coco.process(data_batch, data_samples)
+ eval_results = metric_coco.evaluate(size=len(self.topdown_data_coco))
+ self.assertDictEqual(eval_results, self.target_coco)
+ # test whether convert the annotation to COCO format
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test4.gt.json')))
+ self.assertTrue(
+ osp.isfile(osp.join(self.tmp_dir.name, 'test4.keypoints.json')))
diff --git a/tests/test_evaluation/test_metrics/test_keypoint_2d_metrics.py b/tests/test_evaluation/test_metrics/test_keypoint_2d_metrics.py
index ab2be5ed54..fdb029c40d 100644
--- a/tests/test_evaluation/test_metrics/test_keypoint_2d_metrics.py
+++ b/tests/test_evaluation/test_metrics/test_keypoint_2d_metrics.py
@@ -2,11 +2,11 @@
from unittest import TestCase
import numpy as np
-import torch
from mmengine.structures import InstanceData
from mmpose.datasets.datasets.utils import parse_pose_metainfo
-from mmpose.evaluation.metrics import AUC, EPE, NME, PCKAccuracy
+from mmpose.evaluation.metrics import (AUC, EPE, NME, JhmdbPCKAccuracy,
+ MpiiPCKAccuracy, PCKAccuracy)
class TestPCKAccuracy(TestCase):
@@ -34,7 +34,7 @@ def setUp(self):
gt_instances.head_size = np.random.random((1, 1)) * 10 * i
pred_instances = InstanceData()
- pred_instances.keypoints = torch.from_numpy(keypoints)
+ pred_instances.keypoints = keypoints
data = {'inputs': None}
data_sample = {
@@ -58,14 +58,14 @@ def test_evaluate(self):
pck_metric = PCKAccuracy(thr=0.5, norm_item='bbox')
pck_metric.process(self.data_batch, self.data_samples)
pck = pck_metric.evaluate(self.batch_size)
- target = {'pck/PCK@0.5': 1.0}
+ target = {'PCK': 1.0}
self.assertDictEqual(pck, target)
# test normalized by 'head_size'
pckh_metric = PCKAccuracy(thr=0.3, norm_item='head')
pckh_metric.process(self.data_batch, self.data_samples)
pckh = pckh_metric.evaluate(self.batch_size)
- target = {'pck/PCKh@0.3': 1.0}
+ target = {'PCKh': 1.0}
self.assertDictEqual(pckh, target)
# test normalized by 'torso_size'
@@ -74,12 +74,153 @@ def test_evaluate(self):
tpck = tpck_metric.evaluate(self.batch_size)
self.assertIsInstance(tpck, dict)
target = {
- 'pck/PCK@0.05': 1.0,
- 'pck/tPCK@0.05': 1.0,
+ 'PCK': 1.0,
+ 'tPCK': 1.0,
}
self.assertDictEqual(tpck, target)
+class TestMpiiPCKAccuracy(TestCase):
+
+ def setUp(self):
+ """Setup some variables which are used in every test method.
+
+ TestCase calls functions in this order: setUp() -> testMethod() ->
+ tearDown() -> cleanUp()
+ """
+ self.batch_size = 8
+ num_keypoints = 16
+ self.data_batch = []
+ self.data_samples = []
+
+ for i in range(self.batch_size):
+ gt_instances = InstanceData()
+ keypoints = np.zeros((1, num_keypoints, 2))
+ keypoints[0, i] = [0.5 * i, 0.5 * i]
+ gt_instances.keypoints = keypoints + 1.0
+ gt_instances.keypoints_visible = np.ones(
+ (1, num_keypoints, 1)).astype(bool)
+ gt_instances.keypoints_visible[0, (2 * i) % 8, 0] = False
+ gt_instances.bboxes = np.random.random((1, 4)) * 20 * i
+ gt_instances.head_size = np.random.random((1, 1)) * 10 * i
+
+ pred_instances = InstanceData()
+ pred_instances.keypoints = keypoints
+
+ data = {'inputs': None}
+ data_sample = {
+ 'gt_instances': gt_instances.to_dict(),
+ 'pred_instances': pred_instances.to_dict(),
+ }
+
+ self.data_batch.append(data)
+ self.data_samples.append(data_sample)
+
+ def test_init(self):
+ """test metric init method."""
+ # test invalid normalized_items
+ with self.assertRaisesRegex(
+ KeyError, "Should be one of 'bbox', 'head', 'torso'"):
+ MpiiPCKAccuracy(norm_item='invalid')
+
+ def test_evaluate(self):
+ """test PCK accuracy evaluation metric."""
+ # test normalized by 'head_size'
+ mpii_pck_metric = MpiiPCKAccuracy(thr=0.3, norm_item='head')
+ mpii_pck_metric.process(self.data_batch, self.data_samples)
+ pck_results = mpii_pck_metric.evaluate(self.batch_size)
+ target = {
+ 'Head PCK': 100.0,
+ 'Shoulder PCK': 100.0,
+ 'Elbow PCK': 100.0,
+ 'Wrist PCK': 100.0,
+ 'Hip PCK': 100.0,
+ 'Knee PCK': 100.0,
+ 'Ankle PCK': 100.0,
+ 'PCK': 100.0,
+ 'PCK@0.1': 100.0,
+ }
+ self.assertDictEqual(pck_results, target)
+
+
+class TestJhmdbPCKAccuracy(TestCase):
+
+ def setUp(self):
+ """Setup some variables which are used in every test method.
+
+ TestCase calls functions in this order: setUp() -> testMethod() ->
+ tearDown() -> cleanUp()
+ """
+ self.batch_size = 8
+ num_keypoints = 15
+ self.data_batch = []
+ self.data_samples = []
+
+ for i in range(self.batch_size):
+ gt_instances = InstanceData()
+ keypoints = np.zeros((1, num_keypoints, 2))
+ keypoints[0, i] = [0.5 * i, 0.5 * i]
+ gt_instances.keypoints = keypoints
+ gt_instances.keypoints_visible = np.ones(
+ (1, num_keypoints, 1)).astype(bool)
+ gt_instances.keypoints_visible[0, (2 * i) % 8, 0] = False
+ gt_instances.bboxes = np.random.random((1, 4)) * 20 * i
+ gt_instances.head_size = np.random.random((1, 1)) * 10 * i
+
+ pred_instances = InstanceData()
+ pred_instances.keypoints = keypoints
+
+ data = {'inputs': None}
+ data_sample = {
+ 'gt_instances': gt_instances.to_dict(),
+ 'pred_instances': pred_instances.to_dict(),
+ }
+
+ self.data_batch.append(data)
+ self.data_samples.append(data_sample)
+
+ def test_init(self):
+ """test metric init method."""
+ # test invalid normalized_items
+ with self.assertRaisesRegex(
+ KeyError, "Should be one of 'bbox', 'head', 'torso'"):
+ JhmdbPCKAccuracy(norm_item='invalid')
+
+ def test_evaluate(self):
+ """test PCK accuracy evaluation metric."""
+ # test normalized by 'bbox_size'
+ jhmdb_pck_metric = JhmdbPCKAccuracy(thr=0.5, norm_item='bbox')
+ jhmdb_pck_metric.process(self.data_batch, self.data_samples)
+ pck_results = jhmdb_pck_metric.evaluate(self.batch_size)
+ target = {
+ 'Head PCK': 1.0,
+ 'Sho PCK': 1.0,
+ 'Elb PCK': 1.0,
+ 'Wri PCK': 1.0,
+ 'Hip PCK': 1.0,
+ 'Knee PCK': 1.0,
+ 'Ank PCK': 1.0,
+ 'PCK': 1.0,
+ }
+ self.assertDictEqual(pck_results, target)
+
+ # test normalized by 'torso_size'
+ jhmdb_tpck_metric = JhmdbPCKAccuracy(thr=0.2, norm_item='torso')
+ jhmdb_tpck_metric.process(self.data_batch, self.data_samples)
+ tpck_results = jhmdb_tpck_metric.evaluate(self.batch_size)
+ target = {
+ 'Head tPCK': 1.0,
+ 'Sho tPCK': 1.0,
+ 'Elb tPCK': 1.0,
+ 'Wri tPCK': 1.0,
+ 'Hip tPCK': 1.0,
+ 'Knee tPCK': 1.0,
+ 'Ank tPCK': 1.0,
+ 'tPCK': 1.0,
+ }
+ self.assertDictEqual(tpck_results, target)
+
+
class TestAUCandEPE(TestCase):
def setUp(self):
@@ -112,7 +253,7 @@ def setUp(self):
[[True, True, False, True, True]])
pred_instances = InstanceData()
- pred_instances.keypoints = torch.from_numpy(output)
+ pred_instances.keypoints = output
data = {'inputs': None}
data_sample = {
@@ -128,7 +269,7 @@ def test_auc_evaluate(self):
auc_metric = AUC(norm_factor=20, num_thrs=4)
auc_metric.process(self.data_batch, self.data_samples)
auc = auc_metric.evaluate(1)
- target = {'auc/@4thrs': 0.375}
+ target = {'AUC': 0.375}
self.assertDictEqual(auc, target)
def test_epe_evaluate(self):
@@ -136,7 +277,7 @@ def test_epe_evaluate(self):
epe_metric = EPE()
epe_metric.process(self.data_batch, self.data_samples)
epe = epe_metric.evaluate(1)
- self.assertAlmostEqual(epe['epe/epe'], 11.5355339)
+ self.assertAlmostEqual(epe['EPE'], 11.5355339)
class TestNME(TestCase):
@@ -161,7 +302,7 @@ def _generate_data(self,
gt_instances[norm_item] = np.random.random((1, 1)) * 20 * i
pred_instances = InstanceData()
- pred_instances.keypoints = torch.from_numpy(keypoints)
+ pred_instances.keypoints = keypoints
data = {'inputs': None}
data_sample = {
@@ -187,7 +328,7 @@ def test_nme_evaluate(self):
batch_size=4, num_keypoints=19, norm_item=norm_item)
nme_metric.process(data_batch, data_samples)
nme = nme_metric.evaluate(4)
- target = {'nme/@box_size': 0.0}
+ target = {'NME': 0.0}
self.assertDictEqual(nme, target)
# test when norm_mode = 'keypoint_distance'
@@ -204,7 +345,7 @@ def test_nme_evaluate(self):
nme_metric.process(data_batch, data_samples)
nme = nme_metric.evaluate(4)
- target = {'nme/@[0, 1]': 0.0}
+ target = {'NME': 0.0}
self.assertDictEqual(nme, target)
# test when norm_mode = 'keypoint_distance'
@@ -221,7 +362,7 @@ def test_nme_evaluate(self):
nme_metric.process(data_batch, data_samples)
nme = nme_metric.evaluate(2)
- target = {f'nme/@{keypoint_indices}': 0.0}
+ target = {'NME': 0.0}
self.assertDictEqual(nme, target)
def test_exceptions_and_warnings(self):
diff --git a/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py b/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py
new file mode 100644
index 0000000000..2b1a60c113
--- /dev/null
+++ b/tests/test_evaluation/test_metrics/test_keypoint_partition_metric.py
@@ -0,0 +1,525 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import copy
+import os.path as osp
+import tempfile
+from collections import defaultdict
+from unittest import TestCase
+
+import numpy as np
+from mmengine.fileio import load
+from mmengine.structures import InstanceData
+from xtcocotools.coco import COCO
+
+from mmpose.datasets.datasets.utils import parse_pose_metainfo
+from mmpose.evaluation.metrics import KeypointPartitionMetric
+
+
+class TestKeypointPartitionMetricWrappingCocoMetric(TestCase):
+
+ def setUp(self):
+ """Setup some variables which are used in every test method.
+
+ TestCase calls functions in this order: setUp() -> testMethod() ->
+ tearDown() -> cleanUp()
+ """
+ self.tmp_dir = tempfile.TemporaryDirectory()
+
+ self.ann_file_coco = \
+ 'tests/data/coco/test_keypoint_partition_metric.json'
+ meta_info_coco = dict(
+ from_file='configs/_base_/datasets/coco_wholebody.py')
+ self.dataset_meta_coco = parse_pose_metainfo(meta_info_coco)
+ self.coco = COCO(self.ann_file_coco)
+ self.dataset_meta_coco['CLASSES'] = self.coco.loadCats(
+ self.coco.getCatIds())
+
+ self.topdown_data_coco = self._convert_ann_to_topdown_batch_data(
+ self.ann_file_coco)
+ assert len(self.topdown_data_coco) == 14
+ self.bottomup_data_coco = self._convert_ann_to_bottomup_batch_data(
+ self.ann_file_coco)
+ assert len(self.bottomup_data_coco) == 4
+ """
+ The target results were obtained from CocoWholebodyMetric with
+ score_mode='bbox' and nms_mode='none'. We cannot compare other
+ combinations of score_mode and nms_mode because CocoWholebodyMetric
+ calculates scores and nms using all keypoints while
+ KeypointPartitionMetric calculates scores and nms part by part.
+ As long as this case is tested correct, the other cases should be
+ correct.
+ """
+ self.target_bbox_none = {
+ 'body/coco/AP': 0.749,
+ 'body/coco/AR': 0.800,
+ 'foot/coco/AP': 0.840,
+ 'foot/coco/AR': 0.850,
+ 'face/coco/AP': 0.051,
+ 'face/coco/AR': 0.050,
+ 'left_hand/coco/AP': 0.283,
+ 'left_hand/coco/AR': 0.300,
+ 'right_hand/coco/AP': 0.383,
+ 'right_hand/coco/AR': 0.380,
+ 'all/coco/AP': 0.284,
+ 'all/coco/AR': 0.450,
+ }
+
+ def _convert_ann_to_topdown_batch_data(self, ann_file):
+ """Convert annotations to topdown-style batch data."""
+ topdown_data = []
+ db = load(ann_file)
+ imgid2info = dict()
+ for img in db['images']:
+ imgid2info[img['id']] = img
+ for ann in db['annotations']:
+ w, h = ann['bbox'][2], ann['bbox'][3]
+ bboxes = np.array(ann['bbox'], dtype=np.float32).reshape(-1, 4)
+ bbox_scales = np.array([w * 1.25, h * 1.25]).reshape(-1, 2)
+ _keypoints = np.array(ann['keypoints']).reshape((1, -1, 3))
+
+ gt_instances = {
+ 'bbox_scales': bbox_scales,
+ 'bbox_scores': np.ones((1, ), dtype=np.float32),
+ 'bboxes': bboxes,
+ 'keypoints': _keypoints[..., :2],
+ 'keypoints_visible': _keypoints[..., 2:3]
+ }
+
+ # fake predictions
+ keypoints = np.zeros_like(_keypoints)
+ keypoints[..., 0] = _keypoints[..., 0] * 0.99
+ keypoints[..., 1] = _keypoints[..., 1] * 1.02
+ keypoints[..., 2] = _keypoints[..., 2] * 0.8
+
+ pred_instances = {
+ 'keypoints': keypoints[..., :2],
+ 'keypoint_scores': keypoints[..., -1],
+ }
+
+ data = {'inputs': None}
+ data_sample = {
+ 'id': ann['id'],
+ 'img_id': ann['image_id'],
+ 'category_id': ann.get('category_id', 1),
+ 'gt_instances': gt_instances,
+ 'pred_instances': pred_instances,
+ # dummy image_shape for testing
+ 'ori_shape': [640, 480],
+ # store the raw annotation info to test without ann_file
+ 'raw_ann_info': copy.deepcopy(ann),
+ }
+
+ # add crowd_index to data_sample if it is present in the image_info
+ if 'crowdIndex' in imgid2info[ann['image_id']]:
+ data_sample['crowd_index'] = imgid2info[
+ ann['image_id']]['crowdIndex']
+ # batch size = 1
+ data_batch = [data]
+ data_samples = [data_sample]
+ topdown_data.append((data_batch, data_samples))
+
+ return topdown_data
+
+ def _convert_ann_to_bottomup_batch_data(self, ann_file):
+ """Convert annotations to bottomup-style batch data."""
+ img2ann = defaultdict(list)
+ db = load(ann_file)
+ for ann in db['annotations']:
+ img2ann[ann['image_id']].append(ann)
+
+ bottomup_data = []
+ for img_id, anns in img2ann.items():
+ _keypoints = np.array([ann['keypoints'] for ann in anns]).reshape(
+ (len(anns), -1, 3))
+
+ gt_instances = {
+ 'bbox_scores': np.ones((len(anns)), dtype=np.float32),
+ 'keypoints': _keypoints[..., :2],
+ 'keypoints_visible': _keypoints[..., 2:3]
+ }
+
+ # fake predictions
+ keypoints = np.zeros_like(_keypoints)
+ keypoints[..., 0] = _keypoints[..., 0] * 0.99
+ keypoints[..., 1] = _keypoints[..., 1] * 1.02
+ keypoints[..., 2] = _keypoints[..., 2] * 0.8
+
+ pred_instances = {
+ 'keypoints': keypoints[..., :2],
+ 'keypoint_scores': keypoints[..., -1],
+ }
+
+ data = {'inputs': None}
+ data_sample = {
+ 'id': [ann['id'] for ann in anns],
+ 'img_id': img_id,
+ 'gt_instances': gt_instances,
+ 'pred_instances': pred_instances,
+ # dummy image_shape for testing
+ 'ori_shape': [640, 480],
+ 'raw_ann_info': copy.deepcopy(anns),
+ }
+
+ # batch size = 1
+ data_batch = [data]
+ data_samples = [data_sample]
+ bottomup_data.append((data_batch, data_samples))
+ return bottomup_data
+
+ def _assert_outfiles(self, prefix):
+ for part in ['body', 'foot', 'face', 'left_hand', 'right_hand', 'all']:
+ self.assertTrue(
+ osp.isfile(
+ osp.join(self.tmp_dir.name,
+ f'{prefix}.{part}.keypoints.json')))
+
+ def tearDown(self):
+ self.tmp_dir.cleanup()
+
+ def test_init(self):
+ """test metric init method."""
+ # test wrong metric type
+ with self.assertRaisesRegex(
+ ValueError, 'Metrics supported by KeypointPartitionMetric'):
+ _ = KeypointPartitionMetric(
+ metric=dict(type='Metric'), partitions=dict(all=range(133)))
+
+ # test ann_file arg warning
+ with self.assertWarnsRegex(UserWarning,
+ 'does not support the ann_file argument'):
+ _ = KeypointPartitionMetric(
+ metric=dict(type='CocoMetric', ann_file=''),
+ partitions=dict(all=range(133)))
+
+ # test score_mode arg warning
+ with self.assertWarnsRegex(UserWarning, "if score_mode is not 'bbox'"):
+ _ = KeypointPartitionMetric(
+ metric=dict(type='CocoMetric'),
+ partitions=dict(all=range(133)))
+
+ # test nms arg warning
+ with self.assertWarnsRegex(UserWarning, 'oks_nms and soft_oks_nms'):
+ _ = KeypointPartitionMetric(
+ metric=dict(type='CocoMetric'),
+ partitions=dict(all=range(133)))
+
+ # test partitions
+ with self.assertRaisesRegex(AssertionError, 'at least one partition'):
+ _ = KeypointPartitionMetric(
+ metric=dict(type='CocoMetric'), partitions=dict())
+
+ with self.assertRaisesRegex(AssertionError, 'should be a sequence'):
+ _ = KeypointPartitionMetric(
+ metric=dict(type='CocoMetric'), partitions=dict(all={}))
+
+ with self.assertRaisesRegex(AssertionError, 'at least one element'):
+ _ = KeypointPartitionMetric(
+ metric=dict(type='CocoMetric'), partitions=dict(all=[]))
+
+ def test_bottomup_evaluate(self):
+ """test bottomup-style COCO metric evaluation."""
+ # case1: score_mode='bbox', nms_mode='none'
+ metric = KeypointPartitionMetric(
+ metric=dict(
+ type='CocoMetric',
+ outfile_prefix=f'{self.tmp_dir.name}/test_bottomup',
+ score_mode='bbox',
+ nms_mode='none'),
+ partitions=dict(
+ body=range(17),
+ foot=range(17, 23),
+ face=range(23, 91),
+ left_hand=range(91, 112),
+ right_hand=range(112, 133),
+ all=range(133)))
+ metric.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.bottomup_data_coco:
+ metric.process(data_batch, data_samples)
+
+ eval_results = metric.evaluate(size=len(self.bottomup_data_coco))
+ for key in self.target_bbox_none.keys():
+ self.assertAlmostEqual(
+ eval_results[key], self.target_bbox_none[key], places=3)
+ self._assert_outfiles('test_bottomup')
+
+ def test_topdown_evaluate(self):
+ """test topdown-style COCO metric evaluation."""
+ # case 1: score_mode='bbox', nms_mode='none'
+ metric = KeypointPartitionMetric(
+ metric=dict(
+ type='CocoMetric',
+ outfile_prefix=f'{self.tmp_dir.name}/test_topdown1',
+ score_mode='bbox',
+ nms_mode='none'),
+ partitions=dict(
+ body=range(17),
+ foot=range(17, 23),
+ face=range(23, 91),
+ left_hand=range(91, 112),
+ right_hand=range(112, 133),
+ all=range(133)))
+ metric.dataset_meta = self.dataset_meta_coco
+
+ # process samples
+ for data_batch, data_samples in self.topdown_data_coco:
+ metric.process(data_batch, data_samples)
+
+ eval_results = metric.evaluate(size=len(self.topdown_data_coco))
+ for key in self.target_bbox_none.keys():
+ self.assertAlmostEqual(
+ eval_results[key], self.target_bbox_none[key], places=3)
+ self._assert_outfiles('test_topdown1')
+
+
+class TestKeypointPartitionMetricWrappingPCKAccuracy(TestCase):
+
+ def setUp(self):
+ """Setup some variables which are used in every test method.
+
+ TestCase calls functions in this order: setUp() -> testMethod() ->
+ tearDown() -> cleanUp()
+ """
+ self.batch_size = 8
+ num_keypoints = 24
+ self.data_batch = []
+ self.data_samples = []
+
+ for i in range(self.batch_size):
+ gt_instances = InstanceData()
+ keypoints = np.zeros((1, num_keypoints, 2))
+ for j in range(num_keypoints):
+ keypoints[0, j] = [0.5 * i * j, 0.5 * i * j]
+ gt_instances.keypoints = keypoints
+ gt_instances.keypoints_visible = np.ones(
+ (1, num_keypoints, 1)).astype(bool)
+ gt_instances.keypoints_visible[0, (2 * i) % 8, 0] = False
+ gt_instances.bboxes = np.array([[0.1, 0.2, 0.3, 0.4]]) * 20 * i
+ gt_instances.head_size = np.array([[0.1]]) * 10 * i
+
+ pred_instances = InstanceData()
+ # fake predictions
+ _keypoints = np.zeros_like(keypoints)
+ _keypoints[0, :, 0] = keypoints[0, :, 0] * 0.95
+ _keypoints[0, :, 1] = keypoints[0, :, 1] * 1.05
+ pred_instances.keypoints = _keypoints
+
+ data = {'inputs': None}
+ data_sample = {
+ 'gt_instances': gt_instances.to_dict(),
+ 'pred_instances': pred_instances.to_dict(),
+ }
+
+ self.data_batch.append(data)
+ self.data_samples.append(data_sample)
+
+ def test_init(self):
+ # test norm_item arg warning
+ with self.assertWarnsRegex(UserWarning,
+ 'norm_item torso is used in JhmdbDataset'):
+ _ = KeypointPartitionMetric(
+ metric=dict(
+ type='PCKAccuracy', thr=0.05, norm_item=['bbox', 'torso']),
+ partitions=dict(all=range(133)))
+
+ def test_evaluate(self):
+ """test PCK accuracy evaluation metric."""
+ # test normalized by 'bbox'
+ pck_metric = KeypointPartitionMetric(
+ metric=dict(type='PCKAccuracy', thr=0.5, norm_item='bbox'),
+ partitions=dict(
+ p1=range(10),
+ p2=range(10, 24),
+ all=range(24),
+ ))
+ pck_metric.process(self.data_batch, self.data_samples)
+ pck = pck_metric.evaluate(self.batch_size)
+ target = {'p1/PCK': 1.0, 'p2/PCK': 1.0, 'all/PCK': 1.0}
+ self.assertDictEqual(pck, target)
+
+ # test normalized by 'head_size'
+ pckh_metric = KeypointPartitionMetric(
+ metric=dict(type='PCKAccuracy', thr=0.3, norm_item='head'),
+ partitions=dict(
+ p1=range(10),
+ p2=range(10, 24),
+ all=range(24),
+ ))
+ pckh_metric.process(self.data_batch, self.data_samples)
+ pckh = pckh_metric.evaluate(self.batch_size)
+ target = {'p1/PCKh': 0.9, 'p2/PCKh': 0.0, 'all/PCKh': 0.375}
+ self.assertDictEqual(pckh, target)
+
+ # test normalized by 'torso_size'
+ tpck_metric = KeypointPartitionMetric(
+ metric=dict(
+ type='PCKAccuracy', thr=0.05, norm_item=['bbox', 'torso']),
+ partitions=dict(
+ p1=range(10),
+ p2=range(10, 24),
+ all=range(24),
+ ))
+ tpck_metric.process(self.data_batch, self.data_samples)
+ tpck = tpck_metric.evaluate(self.batch_size)
+ self.assertIsInstance(tpck, dict)
+ target = {
+ 'p1/PCK': 0.6,
+ 'p1/tPCK': 0.11428571428571428,
+ 'p2/PCK': 0.0,
+ 'p2/tPCK': 0.0,
+ 'all/PCK': 0.25,
+ 'all/tPCK': 0.047619047619047616
+ }
+ self.assertDictEqual(tpck, target)
+
+
+class TestKeypointPartitionMetricWrappingAUCandEPE(TestCase):
+
+ def setUp(self):
+ """Setup some variables which are used in every test method.
+
+ TestCase calls functions in this order: setUp() -> testMethod() ->
+ tearDown() -> cleanUp()
+ """
+ output = np.zeros((1, 5, 2))
+ target = np.zeros((1, 5, 2))
+ # first channel
+ output[0, 0] = [10, 4]
+ target[0, 0] = [10, 0]
+ # second channel
+ output[0, 1] = [10, 18]
+ target[0, 1] = [10, 10]
+ # third channel
+ output[0, 2] = [0, 0]
+ target[0, 2] = [0, -1]
+ # fourth channel
+ output[0, 3] = [40, 40]
+ target[0, 3] = [30, 30]
+ # fifth channel
+ output[0, 4] = [20, 10]
+ target[0, 4] = [0, 10]
+
+ gt_instances = InstanceData()
+ gt_instances.keypoints = target
+ gt_instances.keypoints_visible = np.array(
+ [[True, True, False, True, True]])
+
+ pred_instances = InstanceData()
+ pred_instances.keypoints = output
+
+ data = {'inputs': None}
+ data_sample = {
+ 'gt_instances': gt_instances.to_dict(),
+ 'pred_instances': pred_instances.to_dict()
+ }
+
+ self.data_batch = [data]
+ self.data_samples = [data_sample]
+
+ def test_auc_evaluate(self):
+ """test AUC evaluation metric."""
+ auc_metric = KeypointPartitionMetric(
+ metric=dict(type='AUC', norm_factor=20, num_thrs=4),
+ partitions=dict(
+ p1=range(3),
+ p2=range(3, 5),
+ all=range(5),
+ ))
+ auc_metric.process(self.data_batch, self.data_samples)
+ auc = auc_metric.evaluate(1)
+ target = {'p1/AUC': 0.625, 'p2/AUC': 0.125, 'all/AUC': 0.375}
+ self.assertDictEqual(auc, target)
+
+ def test_epe_evaluate(self):
+ """test EPE evaluation metric."""
+ epe_metric = KeypointPartitionMetric(
+ metric=dict(type='EPE', ),
+ partitions=dict(
+ p1=range(3),
+ p2=range(3, 5),
+ all=range(5),
+ ))
+ epe_metric.process(self.data_batch, self.data_samples)
+ epe = epe_metric.evaluate(1)
+ target = {
+ 'p1/EPE': 6.0,
+ 'p2/EPE': 17.071067810058594,
+ 'all/EPE': 11.535533905029297
+ }
+ self.assertDictEqual(epe, target)
+
+
+class TestKeypointPartitionMetricWrappingNME(TestCase):
+
+ def setUp(self):
+ """Setup some variables which are used in every test method.
+
+ TestCase calls functions in this order: setUp() -> testMethod() ->
+ tearDown() -> cleanUp()
+ """
+ self.batch_size = 4
+ num_keypoints = 19
+ self.data_batch = []
+ self.data_samples = []
+
+ for i in range(self.batch_size):
+ gt_instances = InstanceData()
+ keypoints = np.zeros((1, num_keypoints, 2))
+ for j in range(num_keypoints):
+ keypoints[0, j] = [0.5 * i * j, 0.5 * i * j]
+ gt_instances.keypoints = keypoints
+ gt_instances.keypoints_visible = np.ones(
+ (1, num_keypoints, 1)).astype(bool)
+ gt_instances.keypoints_visible[0, (2 * i) % self.batch_size,
+ 0] = False
+ gt_instances['box_size'] = np.array([[0.1]]) * 10 * i
+
+ pred_instances = InstanceData()
+ # fake predictions
+ _keypoints = np.zeros_like(keypoints)
+ _keypoints[0, :, 0] = keypoints[0, :, 0] * 0.95
+ _keypoints[0, :, 1] = keypoints[0, :, 1] * 1.05
+ pred_instances.keypoints = _keypoints
+
+ data = {'inputs': None}
+ data_sample = {
+ 'gt_instances': gt_instances.to_dict(),
+ 'pred_instances': pred_instances.to_dict(),
+ }
+
+ self.data_batch.append(data)
+ self.data_samples.append(data_sample)
+
+ def test_init(self):
+ # test norm_mode arg missing
+ with self.assertRaisesRegex(AssertionError, 'Missing norm_mode'):
+ _ = KeypointPartitionMetric(
+ metric=dict(type='NME', ), partitions=dict(all=range(133)))
+
+ # test norm_mode = keypoint_distance
+ with self.assertRaisesRegex(ValueError,
+ "NME norm_mode 'keypoint_distance'"):
+ _ = KeypointPartitionMetric(
+ metric=dict(type='NME', norm_mode='keypoint_distance'),
+ partitions=dict(all=range(133)))
+
+ def test_nme_evaluate(self):
+ """test NME evaluation metric."""
+ # test when norm_mode = 'use_norm_item'
+ # test norm_item = 'box_size' like in `AFLWDataset`
+ nme_metric = KeypointPartitionMetric(
+ metric=dict(
+ type='NME', norm_mode='use_norm_item', norm_item='box_size'),
+ partitions=dict(
+ p1=range(10),
+ p2=range(10, 19),
+ all=range(19),
+ ))
+ nme_metric.process(self.data_batch, self.data_samples)
+ nme = nme_metric.evaluate(4)
+ target = {
+ 'p1/NME': 0.1715388651247378,
+ 'p2/NME': 0.4949747721354167,
+ 'all/NME': 0.333256827460395
+ }
+ self.assertDictEqual(nme, target)
diff --git a/tests/test_evaluation/test_metrics/test_posetrack18_metric.py b/tests/test_evaluation/test_metrics/test_posetrack18_metric.py
index e7c0c829d4..fe44047e31 100644
--- a/tests/test_evaluation/test_metrics/test_posetrack18_metric.py
+++ b/tests/test_evaluation/test_metrics/test_posetrack18_metric.py
@@ -41,7 +41,7 @@ def setUp(self):
'posetrack18/Hip AP': 100.0,
'posetrack18/Knee AP': 100.0,
'posetrack18/Ankl AP': 100.0,
- 'posetrack18/Total AP': 100.0,
+ 'posetrack18/AP': 100.0,
}
def _convert_ann_to_topdown_batch_data(self):
@@ -118,8 +118,7 @@ def test_init(self):
# test score_mode option
with self.assertRaisesRegex(ValueError,
'`score_mode` should be one of'):
- _ = PoseTrack18Metric(
- ann_file=self.ann_file, score_mode='keypoint')
+ _ = PoseTrack18Metric(ann_file=self.ann_file, score_mode='invalid')
# test nms_mode option
with self.assertRaisesRegex(ValueError, '`nms_mode` should be one of'):
diff --git a/tests/test_models/test_heads/test_heatmap_heads/test_ae_head.py b/tests/test_models/test_heads/test_heatmap_heads/test_ae_head.py
new file mode 100644
index 0000000000..c59c48f8bf
--- /dev/null
+++ b/tests/test_models/test_heads/test_heatmap_heads/test_ae_head.py
@@ -0,0 +1,148 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import unittest
+from itertools import product
+from unittest import TestCase
+
+import numpy as np
+import torch
+from mmengine.structures import InstanceData, PixelData
+from mmengine.utils import is_tuple_of
+
+from mmpose.codecs import AssociativeEmbedding # noqa
+from mmpose.models.heads import AssociativeEmbeddingHead
+from mmpose.registry import KEYPOINT_CODECS
+from mmpose.testing._utils import get_packed_inputs
+
+
+class TestAssociativeEmbeddingHead(TestCase):
+
+ def _get_tags(self, heatmaps, keypoint_indices, tag_per_keypoint: bool):
+
+ K, H, W = heatmaps.shape
+ N = keypoint_indices.shape[0]
+
+ if tag_per_keypoint:
+ tags = np.zeros((K, H, W), dtype=np.float32)
+ else:
+ tags = np.zeros((1, H, W), dtype=np.float32)
+
+ for n, k in product(range(N), range(K)):
+ y, x = np.unravel_index(keypoint_indices[n, k, 0], (H, W))
+ if tag_per_keypoint:
+ tags[k, y, x] = n
+ else:
+ tags[0, y, x] = n
+
+ return tags
+
+ def test_forward(self):
+
+ head = AssociativeEmbeddingHead(
+ in_channels=32,
+ num_keypoints=17,
+ tag_dim=1,
+ tag_per_keypoint=True,
+ deconv_out_channels=None)
+
+ feats = [torch.rand(1, 32, 64, 64)]
+ output = head.forward(feats) # should be (heatmaps, tags)
+ self.assertTrue(is_tuple_of(output, torch.Tensor))
+ self.assertEqual(output[0].shape, (1, 17, 64, 64))
+ self.assertEqual(output[1].shape, (1, 17, 64, 64))
+
+ def test_predict(self):
+
+ codec_cfg = dict(
+ type='AssociativeEmbedding',
+ input_size=(256, 256),
+ heatmap_size=(64, 64),
+ use_udp=False,
+ decode_keypoint_order=[
+ 0, 1, 2, 3, 4, 5, 6, 11, 12, 7, 8, 9, 10, 13, 14, 15, 16
+ ])
+
+ # get test data
+ codec = KEYPOINT_CODECS.build(codec_cfg)
+ batch_data_samples = get_packed_inputs(
+ 1,
+ input_size=(256, 256),
+ heatmap_size=(64, 64),
+ img_shape=(256, 256))['data_samples']
+
+ keypoints = batch_data_samples[0].gt_instances['keypoints']
+ keypoints_visible = batch_data_samples[0].gt_instances[
+ 'keypoints_visible']
+
+ encoded = codec.encode(keypoints, keypoints_visible)
+ heatmaps = encoded['heatmaps']
+ keypoint_indices = encoded['keypoint_indices']
+
+ tags = self._get_tags(
+ heatmaps, keypoint_indices, tag_per_keypoint=True)
+
+ dummy_feat = np.concatenate((heatmaps, tags), axis=0)
+ feats = [torch.from_numpy(dummy_feat)[None]]
+
+ head = AssociativeEmbeddingHead(
+ in_channels=34,
+ num_keypoints=17,
+ tag_dim=1,
+ tag_per_keypoint=True,
+ deconv_out_channels=None,
+ has_final_layer=False,
+ decoder=codec_cfg)
+
+ preds = head.predict(feats, batch_data_samples)
+ self.assertTrue(np.allclose(preds[0].keypoints, keypoints, atol=4.0))
+
+ def test_loss(self):
+
+ codec_cfg = dict(
+ type='AssociativeEmbedding',
+ input_size=(256, 256),
+ heatmap_size=(64, 64),
+ use_udp=False,
+ decode_keypoint_order=[
+ 0, 1, 2, 3, 4, 5, 6, 11, 12, 7, 8, 9, 10, 13, 14, 15, 16
+ ])
+
+ # get test data
+ codec = KEYPOINT_CODECS.build(codec_cfg)
+
+ batch_data_samples = get_packed_inputs(
+ 1,
+ input_size=(256, 256),
+ heatmap_size=(64, 64),
+ img_shape=(256, 256))['data_samples']
+
+ keypoints = batch_data_samples[0].gt_instances['keypoints']
+ keypoints_visible = batch_data_samples[0].gt_instances[
+ 'keypoints_visible']
+ encoded = codec.encode(keypoints, keypoints_visible)
+ heatmaps = encoded['heatmaps']
+ keypoint_indices = encoded['keypoint_indices']
+ keypoint_weights = encoded['keypoint_weights']
+
+ heatmap_mask = np.ones((1, ) + heatmaps.shape[1:], dtype=np.float32)
+ batch_data_samples[0].gt_fields = PixelData(
+ heatmaps=heatmaps, heatmap_mask=heatmap_mask).to_tensor()
+ batch_data_samples[0].gt_instance_labels = InstanceData(
+ keypoint_indices=keypoint_indices,
+ keypoint_weights=keypoint_weights).to_tensor()
+
+ feats = [torch.rand(1, 32, 64, 64)]
+ head = AssociativeEmbeddingHead(
+ in_channels=32,
+ num_keypoints=17,
+ tag_dim=1,
+ tag_per_keypoint=True,
+ deconv_out_channels=None)
+
+ losses = head.loss(feats, batch_data_samples)
+ for name in ['loss_kpt', 'loss_pull', 'loss_push']:
+ self.assertIn(name, losses)
+ self.assertIsInstance(losses[name], torch.Tensor)
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/test_models/test_heads/test_heatmap_heads/test_cid_head.py b/tests/test_models/test_heads/test_heatmap_heads/test_cid_head.py
new file mode 100644
index 0000000000..29fd9e57eb
--- /dev/null
+++ b/tests/test_models/test_heads/test_heatmap_heads/test_cid_head.py
@@ -0,0 +1,128 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+from unittest import TestCase
+
+import numpy as np
+import torch
+
+from mmpose.models.heads import CIDHead
+from mmpose.testing import get_coco_sample, get_packed_inputs
+from mmpose.utils.tensor_utils import to_tensor
+
+
+class TestCIDHead(TestCase):
+
+ def _get_feats(
+ self,
+ batch_size: int = 1,
+ feat_shapes: List[Tuple[int, int, int]] = [(32, 128, 128)],
+ ):
+
+ feats = [
+ torch.rand((batch_size, ) + shape, dtype=torch.float32)
+ for shape in feat_shapes
+ ]
+
+ if len(feats) > 1:
+ feats = [[x] for x in feats]
+
+ return feats
+
+ def _get_data_samples(self):
+ data_samples = get_packed_inputs(
+ 1,
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ img_shape=(512, 512))['data_samples']
+ return data_samples
+
+ def test_forward(self):
+
+ head = CIDHead(in_channels=32, num_keypoints=17, gfd_channels=32)
+
+ feats = [torch.rand(1, 32, 128, 128)]
+ with torch.no_grad():
+ output = head.forward(feats)
+ self.assertIsInstance(output, torch.Tensor)
+ self.assertEqual(output.shape[1:], (17, 128, 128))
+
+ def test_predict(self):
+
+ codec = dict(
+ type='DecoupledHeatmap',
+ input_size=(512, 512),
+ heatmap_size=(128, 128))
+
+ head = CIDHead(
+ in_channels=32, num_keypoints=17, gfd_channels=32, decoder=codec)
+
+ feats = self._get_feats()
+ data_samples = self._get_data_samples()
+ with torch.no_grad():
+ preds = head.predict(feats, data_samples)
+ self.assertEqual(len(preds), 1)
+ self.assertEqual(preds[0].keypoints.shape[1:], (17, 2))
+ self.assertEqual(preds[0].keypoint_scores.shape[1:], (17, ))
+
+ # tta
+ with torch.no_grad():
+ feats_flip = self._get_feats(feat_shapes=[(32, 128,
+ 128), (32, 128, 128)])
+ preds = head.predict(feats_flip, data_samples,
+ dict(flip_test=True))
+ self.assertEqual(len(preds), 1)
+ self.assertEqual(preds[0].keypoints.shape[1:], (17, 2))
+ self.assertEqual(preds[0].keypoint_scores.shape[1:], (17, ))
+
+ # output heatmaps
+ with torch.no_grad():
+ _, pred_fields = head.predict(feats, data_samples,
+ dict(output_heatmaps=True))
+ self.assertEqual(len(pred_fields), 1)
+ self.assertEqual(pred_fields[0].heatmaps.shape[1:], (128, 128))
+ self.assertEqual(pred_fields[0].heatmaps.shape[0] % 17, 0)
+
+ def test_loss(self):
+ data = get_coco_sample(img_shape=(512, 512), num_instances=1)
+ data['bbox'] = np.tile(data['bbox'], 2).reshape(-1, 4, 2)
+ data['bbox'][:, 1:3, 0] = data['bbox'][:, 0:2, 0]
+
+ codec_cfg = dict(
+ type='DecoupledHeatmap',
+ input_size=(512, 512),
+ heatmap_size=(128, 128))
+
+ head = CIDHead(
+ in_channels=32,
+ num_keypoints=17,
+ gfd_channels=32,
+ decoder=codec_cfg,
+ coupled_heatmap_loss=dict(
+ type='FocalHeatmapLoss', loss_weight=1.0),
+ decoupled_heatmap_loss=dict(
+ type='FocalHeatmapLoss', loss_weight=4.0),
+ contrastive_loss=dict(type='InfoNCELoss', loss_weight=1.0))
+
+ encoded = head.decoder.encode(data['keypoints'],
+ data['keypoints_visible'], data['bbox'])
+ feats = self._get_feats()
+ data_samples = self._get_data_samples()
+ for data_sample in data_samples:
+ data_sample.gt_fields.set_data({
+ 'heatmaps':
+ to_tensor(encoded['heatmaps']),
+ 'instance_heatmaps':
+ to_tensor(encoded['instance_heatmaps'])
+ })
+ data_sample.gt_instance_labels.set_data(
+ {'instance_coords': to_tensor(encoded['instance_coords'])})
+ data_sample.gt_instance_labels.set_data(
+ {'keypoint_weights': to_tensor(encoded['keypoint_weights'])})
+
+ losses = head.loss(feats, data_samples)
+ self.assertIn('loss/heatmap_coupled', losses)
+ self.assertEqual(losses['loss/heatmap_coupled'].ndim, 0)
+ self.assertIn('loss/heatmap_decoupled', losses)
+ self.assertEqual(losses['loss/heatmap_decoupled'].ndim, 0)
+ self.assertIn('loss/contrastive', losses)
+ self.assertEqual(losses['loss/contrastive'].ndim, 0)
diff --git a/tests/test_models/test_heads/test_heatmap_heads/test_cpm_head.py b/tests/test_models/test_heads/test_heatmap_heads/test_cpm_head.py
index 02802d0c53..7b0c958b64 100644
--- a/tests/test_models/test_heads/test_heatmap_heads/test_cpm_head.py
+++ b/tests/test_models/test_heads/test_heatmap_heads/test_cpm_head.py
@@ -23,17 +23,15 @@ def _get_feats(self,
return feats
def _get_data_samples(self, batch_size: int = 2):
- batch_data_samples = [
- inputs['data_sample'] for inputs in get_packed_inputs(
- batch_size=batch_size,
- num_instances=1,
- num_keypoints=17,
- img_shape=(128, 128),
- input_size=(192, 256),
- heatmap_size=(24, 32),
- with_heatmap=True,
- with_reg_label=False)
- ]
+ batch_data_samples = get_packed_inputs(
+ batch_size=batch_size,
+ num_instances=1,
+ num_keypoints=17,
+ img_shape=(128, 128),
+ input_size=(192, 256),
+ heatmap_size=(24, 32),
+ with_heatmap=True,
+ with_reg_label=False)['data_samples']
return batch_data_samples
def test_init(self):
@@ -223,7 +221,7 @@ def test_loss(self):
def test_errors(self):
# Invalid arguments
- with self.assertRaisesRegex(ValueError, 'Got unmatched values'):
+ with self.assertRaisesRegex(ValueError, 'Got mismatched lengths'):
_ = CPMHead(
num_stages=1,
in_channels=17,
diff --git a/tests/test_models/test_heads/test_heatmap_heads/test_heatmap_head.py b/tests/test_models/test_heads/test_heatmap_heads/test_heatmap_head.py
index 93bcecf944..e9848dd16a 100644
--- a/tests/test_models/test_heads/test_heatmap_heads/test_heatmap_head.py
+++ b/tests/test_models/test_heads/test_heatmap_heads/test_heatmap_head.py
@@ -23,12 +23,6 @@ def _get_feats(self,
]
return feats
- def _get_data_samples(self, batch_size: int = 2):
- batch_data_samples = [
- inputs['data_sample'] for inputs in get_packed_inputs(batch_size)
- ]
- return batch_data_samples
-
def test_init(self):
# w/o deconv
head = HeatmapHead(
@@ -87,7 +81,7 @@ def test_predict(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -108,7 +102,7 @@ def test_predict(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -116,7 +110,31 @@ def test_predict(self):
self.assertEqual(preds[0].keypoints.shape,
batch_data_samples[0].gt_instances.keypoints.shape)
- # input transform: output heatmap
+ # input transform: none
+ head = HeatmapHead(
+ in_channels=[16, 32],
+ out_channels=17,
+ input_transform='resize_concat',
+ input_index=[0, 1],
+ deconv_out_channels=(256, 256),
+ deconv_kernel_sizes=(4, 4),
+ conv_out_channels=(256, ),
+ conv_kernel_sizes=(1, ),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(48, 16, 12)])[0]
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
+ with self.assertWarnsRegex(
+ Warning,
+ 'the input of HeatmapHead is a tensor instead of a tuple '
+ 'or list. The argument `input_transform` will be ignored.'):
+ preds = head.predict(feats, batch_data_samples)
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ # output heatmap
head = HeatmapHead(
in_channels=[16, 32],
out_channels=17,
@@ -125,7 +143,7 @@ def test_predict(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
_, pred_heatmaps = head.predict(
feats, batch_data_samples, test_cfg=dict(output_heatmaps=True))
@@ -149,7 +167,7 @@ def test_tta(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict([feats, feats],
batch_data_samples,
test_cfg=dict(
@@ -177,7 +195,7 @@ def test_tta(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict([feats, feats],
batch_data_samples,
test_cfg=dict(
@@ -200,7 +218,7 @@ def test_loss(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
losses = head.loss(feats, batch_data_samples)
self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
self.assertEqual(losses['loss_kpt'].shape, torch.Size(()))
@@ -208,14 +226,14 @@ def test_loss(self):
def test_errors(self):
# Invalid arguments
- with self.assertRaisesRegex(ValueError, 'Got unmatched values'):
+ with self.assertRaisesRegex(ValueError, 'Got mismatched lengths'):
_ = HeatmapHead(
in_channels=[16, 32],
out_channels=17,
deconv_out_channels=(256, ),
deconv_kernel_sizes=(4, 4))
- with self.assertRaisesRegex(ValueError, 'Got unmatched values'):
+ with self.assertRaisesRegex(ValueError, 'Got mismatched lengths'):
_ = HeatmapHead(
in_channels=[16, 32],
out_channels=17,
diff --git a/tests/test_models/test_heads/test_heatmap_heads/test_mspn_head.py b/tests/test_models/test_heads/test_heatmap_heads/test_mspn_head.py
index cff61b842b..ce3d19b688 100644
--- a/tests/test_models/test_heads/test_heatmap_heads/test_mspn_head.py
+++ b/tests/test_models/test_heads/test_heatmap_heads/test_mspn_head.py
@@ -34,18 +34,16 @@ def _get_data_samples(self,
batch_size: int = 2,
heatmap_size=(48, 64),
num_levels=1):
- batch_data_samples = [
- inputs['data_sample'] for inputs in get_packed_inputs(
- batch_size=batch_size,
- num_instances=1,
- num_keypoints=17,
- img_shape=(128, 128),
- input_size=(192, 256),
- heatmap_size=heatmap_size,
- with_heatmap=True,
- with_reg_label=False,
- num_levels=num_levels)
- ]
+ batch_data_samples = get_packed_inputs(
+ batch_size=batch_size,
+ num_instances=1,
+ num_keypoints=17,
+ img_shape=(128, 128),
+ input_size=(192, 256),
+ heatmap_size=heatmap_size,
+ with_heatmap=True,
+ with_reg_label=False,
+ num_levels=num_levels)['data_samples']
return batch_data_samples
def test_init(self):
diff --git a/tests/test_models/test_heads/test_heatmap_heads/test_rtmcc_head.py b/tests/test_models/test_heads/test_heatmap_heads/test_rtmcc_head.py
new file mode 100644
index 0000000000..b7f833d362
--- /dev/null
+++ b/tests/test_models/test_heads/test_heatmap_heads/test_rtmcc_head.py
@@ -0,0 +1,722 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import unittest
+from typing import List, Tuple
+from unittest import TestCase
+
+import torch
+import torch.nn as nn
+from mmengine.structures import InstanceData
+from mmengine.utils import digit_version
+from mmengine.utils.dl_utils import TORCH_VERSION
+
+from mmpose.models.heads import RTMCCHead
+from mmpose.models.utils import RTMCCBlock
+from mmpose.testing import get_packed_inputs
+
+
+class TestRTMCCHead(TestCase):
+
+ def _get_feats(self,
+ batch_size: int = 2,
+ feat_shapes: List[Tuple[int, int, int]] = [(32, 6, 8)]):
+
+ feats = [
+ torch.rand((batch_size, ) + shape, dtype=torch.float32)
+ for shape in feat_shapes
+ ]
+ return feats
+
+ def test_init(self):
+
+ if digit_version(TORCH_VERSION) < digit_version('1.7.0'):
+ return unittest.skip('RTMCCHead requires PyTorch >= 1.7')
+
+ # original version
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False))
+ self.assertIsNotNone(head.decoder)
+ self.assertTrue(isinstance(head.final_layer, nn.Conv2d))
+ self.assertTrue(isinstance(head.mlp, nn.Sequential))
+ self.assertTrue(isinstance(head.gau, RTMCCBlock))
+ self.assertTrue(isinstance(head.cls_x, nn.Linear))
+ self.assertTrue(isinstance(head.cls_y, nn.Linear))
+
+ # w/ 1x1 conv
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=1,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False))
+ self.assertIsNotNone(head.decoder)
+ self.assertTrue(isinstance(head.final_layer, nn.Conv2d))
+ self.assertTrue(isinstance(head.mlp, nn.Sequential))
+ self.assertTrue(isinstance(head.gau, RTMCCBlock))
+ self.assertTrue(isinstance(head.cls_x, nn.Linear))
+ self.assertTrue(isinstance(head.cls_y, nn.Linear))
+
+ # hidden_dims
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=512,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False))
+ self.assertIsNotNone(head.decoder)
+ self.assertTrue(isinstance(head.final_layer, nn.Conv2d))
+ self.assertTrue(isinstance(head.mlp, nn.Sequential))
+ self.assertTrue(isinstance(head.gau, RTMCCBlock))
+ self.assertTrue(isinstance(head.cls_x, nn.Linear))
+ self.assertTrue(isinstance(head.cls_y, nn.Linear))
+
+ # s = 256
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=256,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False))
+ self.assertIsNotNone(head.decoder)
+ self.assertTrue(isinstance(head.final_layer, nn.Conv2d))
+ self.assertTrue(isinstance(head.mlp, nn.Sequential))
+ self.assertTrue(isinstance(head.gau, RTMCCBlock))
+ self.assertTrue(isinstance(head.cls_x, nn.Linear))
+ self.assertTrue(isinstance(head.cls_y, nn.Linear))
+
+ def test_predict(self):
+
+ if digit_version(TORCH_VERSION) < digit_version('1.7.0'):
+ return unittest.skip('RTMCCHead requires PyTorch >= 1.7')
+
+ decoder_cfg_list = []
+ # original version
+ decoder_cfg = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False)
+ decoder_cfg_list.append(decoder_cfg)
+
+ # single sigma
+ decoder_cfg = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=6.,
+ simcc_split_ratio=2.0,
+ normalize=False)
+ decoder_cfg_list.append(decoder_cfg)
+
+ # normalize
+ decoder_cfg = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=6.,
+ simcc_split_ratio=2.0,
+ normalize=True)
+ decoder_cfg_list.append(decoder_cfg)
+
+ # dark
+ decoder_cfg = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=6.,
+ simcc_split_ratio=2.0,
+ use_dark=True)
+ decoder_cfg_list.append(decoder_cfg)
+
+ for decoder_cfg in decoder_cfg_list:
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, _ = head.predict(feats, batch_data_samples)
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(
+ preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ # 1x1 conv
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=1,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, _ = head.predict(feats, batch_data_samples)
+
+ # hidden dims
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=512,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, _ = head.predict(feats, batch_data_samples)
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(
+ preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ # s
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=64,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, _ = head.predict(feats, batch_data_samples)
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(
+ preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ # expansion factor
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=3,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, _ = head.predict(feats, batch_data_samples)
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(
+ preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ # drop path
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.1,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, _ = head.predict(feats, batch_data_samples)
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(
+ preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ # act fn
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='ReLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, _ = head.predict(feats, batch_data_samples)
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(
+ preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ # use_rel_bias
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=True,
+ pos_enc=False),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, _ = head.predict(feats, batch_data_samples)
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(
+ preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ # pos_enc
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=True),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, _ = head.predict(feats, batch_data_samples)
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(
+ preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ # output_heatmaps
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=decoder_cfg,
+ )
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, pred_heatmaps = head.predict(
+ feats, batch_data_samples, test_cfg=dict(output_heatmaps=True))
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(preds[0].keypoint_x_labels.shape, (1, 17, 384))
+ self.assertEqual(preds[0].keypoint_y_labels.shape, (1, 17, 512))
+ self.assertEqual(
+ preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+ self.assertEqual(pred_heatmaps[0].heatmaps.shape, (17, 512, 384))
+
+ def test_tta(self):
+ if digit_version(TORCH_VERSION) < digit_version('1.7.0'):
+ return unittest.skip('RTMCCHead requires PyTorch >= 1.7')
+
+ # flip test
+ decoder_cfg = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False)
+
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ decoder=decoder_cfg)
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, simcc_split_ratio=2.0,
+ with_simcc_label=True)['data_samples']
+ preds = head.predict([feats, feats],
+ batch_data_samples,
+ test_cfg=dict(flip_test=True))
+
+ self.assertTrue(len(preds), 2)
+ self.assertIsInstance(preds[0], InstanceData)
+ self.assertEqual(preds[0].keypoints.shape,
+ batch_data_samples[0].gt_instances.keypoints.shape)
+
+ def test_loss(self):
+ if digit_version(TORCH_VERSION) < digit_version('1.7.0'):
+ return unittest.skip('RTMCCHead requires PyTorch >= 1.7')
+
+ decoder_cfg_list = []
+ decoder_cfg = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False)
+ decoder_cfg_list.append(decoder_cfg)
+
+ decoder_cfg = dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=True)
+ decoder_cfg_list.append(decoder_cfg)
+
+ # decoder
+ for decoder_cfg in decoder_cfg_list:
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=1.,
+ label_softmax=False,
+ ),
+ decoder=decoder_cfg)
+
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, simcc_split_ratio=2.0,
+ with_simcc_label=True)['data_samples']
+ losses = head.loss(feats, batch_data_samples)
+ self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
+ self.assertEqual(losses['loss_kpt'].shape, torch.Size(()))
+ self.assertIsInstance(losses['acc_pose'], torch.Tensor)
+
+ # beta = 10
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=False,
+ ),
+ decoder=decoder_cfg)
+
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, simcc_split_ratio=2.0,
+ with_simcc_label=True)['data_samples']
+ losses = head.loss(feats, batch_data_samples)
+ self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
+ self.assertEqual(losses['loss_kpt'].shape, torch.Size(()))
+ self.assertIsInstance(losses['acc_pose'], torch.Tensor)
+
+ # label softmax
+ head = RTMCCHead(
+ in_channels=32,
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True,
+ ),
+ decoder=decoder_cfg)
+
+ feats = self._get_feats(batch_size=2, feat_shapes=[(32, 8, 6)])
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, simcc_split_ratio=2.0,
+ with_simcc_label=True)['data_samples']
+ losses = head.loss(feats, batch_data_samples)
+ self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
+ self.assertEqual(losses['loss_kpt'].shape, torch.Size(()))
+ self.assertIsInstance(losses['acc_pose'], torch.Tensor)
+
+ def test_errors(self):
+ if digit_version(TORCH_VERSION) < digit_version('1.7.0'):
+ return unittest.skip('RTMCCHead requires PyTorch >= 1.7')
+
+ # Invalid arguments
+ with self.assertRaisesRegex(ValueError, 'multiple input features'):
+ _ = RTMCCHead(
+ in_channels=(16, 32),
+ out_channels=17,
+ input_size=(192, 256),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
+ final_layer_kernel_size=7,
+ gau_cfg=dict(
+ hidden_dims=256,
+ s=128,
+ expansion_factor=2,
+ dropout_rate=0.,
+ drop_path=0.,
+ act_fn='SiLU',
+ use_rel_bias=False,
+ pos_enc=False),
+ input_transform='select',
+ input_index=[0, 1],
+ loss=dict(
+ type='KLDiscretLoss',
+ use_target_weight=True,
+ beta=10.,
+ label_softmax=True,
+ ),
+ decoder=dict(
+ type='SimCCLabel',
+ input_size=(192, 256),
+ smoothing_type='gaussian',
+ sigma=(4.9, 5.66),
+ simcc_split_ratio=2.0,
+ normalize=False))
+
+
+if __name__ == '__main__':
+ unittest.main()
diff --git a/tests/test_models/test_heads/test_heatmap_heads/test_simcc_head.py b/tests/test_models/test_heads/test_heatmap_heads/test_simcc_head.py
index 20af073e3f..4b332f4663 100644
--- a/tests/test_models/test_heads/test_heatmap_heads/test_simcc_head.py
+++ b/tests/test_models/test_heads/test_heatmap_heads/test_simcc_head.py
@@ -22,20 +22,6 @@ def _get_feats(self,
]
return feats
- def _get_data_samples(self,
- batch_size: int = 2,
- simcc_split_ratio: float = 2.0,
- with_simcc_label=False):
-
- batch_data_samples = [
- inputs['data_sample'] for inputs in get_packed_inputs(
- batch_size,
- simcc_split_ratio=simcc_split_ratio,
- with_simcc_label=with_simcc_label)
- ]
-
- return batch_data_samples
-
def test_init(self):
# w/ gaussian decoder
@@ -43,7 +29,8 @@ def test_init(self):
in_channels=32,
out_channels=17,
input_size=(192, 256),
- in_featuremap_size=(8, 6),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
decoder=dict(
type='SimCCLabel',
input_size=(192, 256),
@@ -57,7 +44,8 @@ def test_init(self):
in_channels=32,
out_channels=17,
input_size=(192, 256),
- in_featuremap_size=(8, 6),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=3.0,
decoder=dict(
type='SimCCLabel',
input_size=(192, 256),
@@ -72,7 +60,8 @@ def test_init(self):
in_channels=32,
out_channels=17,
input_size=(192, 256),
- in_featuremap_size=(8, 6),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=3.0,
decoder=dict(
type='SimCCLabel',
input_size=(192, 256),
@@ -110,14 +99,17 @@ def test_predict(self):
in_channels=[16, 32],
out_channels=17,
input_size=(192, 256),
- in_featuremap_size=(8, 6),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
input_transform='select',
input_index=-1,
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, simcc_split_ratio=2.0, with_simcc_label=True)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -141,8 +133,10 @@ def test_predict(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, simcc_split_ratio=2.0, with_simcc_label=True)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -156,21 +150,26 @@ def test_predict(self):
in_channels=[16, 32],
out_channels=17,
input_size=(192, 256),
- in_featuremap_size=(8, 6),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
input_transform='select',
input_index=-1,
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, simcc_split_ratio=2.0, with_simcc_label=True)
- preds = head.predict(
+ batch_data_samples = get_packed_inputs(
+ batch_size=2,
+ simcc_split_ratio=decoder_cfg['simcc_split_ratio'],
+ with_simcc_label=True)['data_samples']
+ preds, pred_heatmaps = head.predict(
feats, batch_data_samples, test_cfg=dict(output_heatmaps=True))
self.assertEqual(preds[0].keypoint_x_labels.shape,
(1, 17, 192 * 2))
self.assertEqual(preds[0].keypoint_y_labels.shape,
(1, 17, 256 * 2))
+ self.assertTrue(len(pred_heatmaps), 2)
+ self.assertEqual(pred_heatmaps[0].heatmaps.shape, (17, 512, 384))
def test_tta(self):
# flip test
@@ -185,14 +184,16 @@ def test_tta(self):
in_channels=[16, 32],
out_channels=17,
input_size=(192, 256),
- in_featuremap_size=(8, 6),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
input_transform='select',
input_index=-1,
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, simcc_split_ratio=2.0, with_simcc_label=True)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, simcc_split_ratio=2.0,
+ with_simcc_label=True)['data_samples']
preds = head.predict([feats, feats],
batch_data_samples,
test_cfg=dict(flip_test=True))
@@ -231,15 +232,17 @@ def test_loss(self):
in_channels=[16, 32],
out_channels=17,
input_size=(192, 256),
- in_featuremap_size=(8, 6),
+ in_featuremap_size=(6, 8),
+ simcc_split_ratio=2.0,
input_transform='select',
input_index=-1,
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, simcc_split_ratio=2.0, with_simcc_label=True)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, simcc_split_ratio=2.0,
+ with_simcc_label=True)['data_samples']
losses = head.loss(feats, batch_data_samples)
self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
self.assertEqual(losses['loss_kpt'].shape, torch.Size(()))
@@ -247,7 +250,7 @@ def test_loss(self):
def test_errors(self):
# Invalid arguments
- with self.assertRaisesRegex(ValueError, 'Got unmatched values'):
+ with self.assertRaisesRegex(ValueError, 'Got mismatched lengths'):
_ = SimCCHead(
in_channels=[16, 32],
out_channels=17,
@@ -256,7 +259,7 @@ def test_errors(self):
deconv_out_channels=(256, ),
deconv_kernel_sizes=(4, 4))
- with self.assertRaisesRegex(ValueError, 'Got unmatched values'):
+ with self.assertRaisesRegex(ValueError, 'Got mismatched lengths'):
_ = SimCCHead(
in_channels=[16, 32],
out_channels=17,
diff --git a/tests/test_models/test_heads/test_heatmap_heads/test_vipnas_head.py b/tests/test_models/test_heads/test_heatmap_heads/test_vipnas_head.py
index 8848b7983c..060fceced8 100644
--- a/tests/test_models/test_heads/test_heatmap_heads/test_vipnas_head.py
+++ b/tests/test_models/test_heads/test_heatmap_heads/test_vipnas_head.py
@@ -22,12 +22,6 @@ def _get_feats(self,
]
return feats
- def _get_data_samples(self, batch_size: int = 2):
- batch_data_samples = [
- inputs['data_sample'] for inputs in get_packed_inputs(batch_size)
- ]
- return batch_data_samples
-
def test_init(self):
# w/o deconv
head = ViPNASHead(
@@ -88,7 +82,7 @@ def test_predict(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -110,7 +104,7 @@ def test_predict(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -127,7 +121,7 @@ def test_predict(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
_, pred_heatmaps = head.predict(
feats, batch_data_samples, test_cfg=dict(output_heatmaps=True))
@@ -152,7 +146,7 @@ def test_tta(self):
decoder=decoder_cfg)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict([feats, feats],
batch_data_samples,
test_cfg=dict(
@@ -175,7 +169,7 @@ def test_loss(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
losses = head.loss(feats, batch_data_samples)
self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
self.assertEqual(losses['loss_kpt'].shape, torch.Size(()))
@@ -183,13 +177,13 @@ def test_loss(self):
def test_errors(self):
# Invalid arguments
- with self.assertRaisesRegex(ValueError, 'Got unmatched values'):
+ with self.assertRaisesRegex(ValueError, 'Got mismatched lengths'):
_ = ViPNASHead(
in_channels=[16, 32],
out_channels=17,
deconv_out_channels=(256, ),
deconv_kernel_sizes=(4, 4))
- with self.assertRaisesRegex(ValueError, 'Got unmatched values'):
+ with self.assertRaisesRegex(ValueError, 'Got mismatched lengths'):
_ = ViPNASHead(
in_channels=[16, 32],
out_channels=17,
@@ -197,7 +191,7 @@ def test_errors(self):
deconv_kernel_sizes=(4, 4),
deconv_num_groups=(1, ))
- with self.assertRaisesRegex(ValueError, 'Got unmatched values'):
+ with self.assertRaisesRegex(ValueError, 'Got mismatched lengths'):
_ = ViPNASHead(
in_channels=[16, 32],
out_channels=17,
diff --git a/tests/test_models/test_heads/test_hybrid_heads/test_dekr_head.py b/tests/test_models/test_heads/test_hybrid_heads/test_dekr_head.py
new file mode 100644
index 0000000000..957f3499d0
--- /dev/null
+++ b/tests/test_models/test_heads/test_hybrid_heads/test_dekr_head.py
@@ -0,0 +1,137 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from typing import List, Tuple
+from unittest import TestCase
+
+import torch
+from mmengine.utils import is_tuple_of
+
+from mmpose.models.heads import DEKRHead
+from mmpose.testing import get_coco_sample, get_packed_inputs
+from mmpose.utils.tensor_utils import to_tensor
+
+
+class TestDEKRHead(TestCase):
+
+ def _get_feats(
+ self,
+ batch_size: int = 1,
+ feat_shapes: List[Tuple[int, int, int]] = [(32, 128, 128)],
+ ):
+
+ feats = [
+ torch.rand((batch_size, ) + shape, dtype=torch.float32)
+ for shape in feat_shapes
+ ]
+
+ if len(feats) > 1:
+ feats = [[x] for x in feats]
+
+ return feats
+
+ def _get_data_samples(self):
+ data_samples = get_packed_inputs(
+ 1,
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ img_shape=(512, 512))['data_samples']
+ return data_samples
+
+ def test_forward(self):
+
+ head = DEKRHead(in_channels=32, num_keypoints=17)
+
+ feats = [torch.rand(1, 32, 128, 128)]
+ output = head.forward(feats) # should be (heatmaps, displacements)
+ self.assertTrue(is_tuple_of(output, torch.Tensor))
+ self.assertEqual(output[0].shape, (1, 18, 128, 128))
+ self.assertEqual(output[1].shape, (1, 34, 128, 128))
+
+ def test_predict(self):
+
+ codec_cfg = dict(
+ type='SPR',
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, 2),
+ generate_keypoint_heatmaps=True,
+ )
+
+ head = DEKRHead(in_channels=32, num_keypoints=17, decoder=codec_cfg)
+
+ feats = self._get_feats()
+ data_samples = self._get_data_samples()
+ with torch.no_grad():
+ preds = head.predict(feats, data_samples)
+ self.assertEqual(len(preds), 1)
+ self.assertEqual(preds[0].keypoints.shape[1:], (17, 2))
+ self.assertEqual(preds[0].keypoint_scores.shape[1:], (17, ))
+
+ # predict with rescore net
+ head = DEKRHead(
+ in_channels=32,
+ num_keypoints=17,
+ decoder=codec_cfg,
+ rescore_cfg=dict(in_channels=74, norm_indexes=(5, 6)))
+
+ with torch.no_grad():
+ preds = head.predict(feats, data_samples)
+ self.assertEqual(len(preds), 1)
+ self.assertEqual(preds[0].keypoints.shape[1:], (17, 2))
+ self.assertEqual(preds[0].keypoint_scores.shape[1:], (17, ))
+
+ # tta
+ with torch.no_grad():
+ feats_flip = self._get_feats(feat_shapes=[(32, 128,
+ 128), (32, 128, 128)])
+ preds = head.predict(feats_flip, data_samples,
+ dict(flip_test=True))
+ self.assertEqual(len(preds), 1)
+ self.assertEqual(preds[0].keypoints.shape[1:], (17, 2))
+ self.assertEqual(preds[0].keypoint_scores.shape[1:], (17, ))
+
+ # output heatmaps
+ with torch.no_grad():
+ _, pred_fields = head.predict(feats, data_samples,
+ dict(output_heatmaps=True))
+ self.assertEqual(len(pred_fields), 1)
+ self.assertEqual(pred_fields[0].heatmaps.shape, (18, 128, 128))
+ self.assertEqual(pred_fields[0].displacements.shape,
+ (34, 128, 128))
+
+ def test_loss(self):
+ data = get_coco_sample(img_shape=(512, 512), num_instances=1)
+
+ codec_cfg = dict(
+ type='SPR',
+ input_size=(512, 512),
+ heatmap_size=(128, 128),
+ sigma=(4, 2),
+ generate_keypoint_heatmaps=True,
+ )
+
+ head = DEKRHead(
+ in_channels=32,
+ num_keypoints=17,
+ decoder=codec_cfg,
+ heatmap_loss=dict(type='KeypointMSELoss', use_target_weight=True),
+ displacement_loss=dict(
+ type='SoftWeightSmoothL1Loss',
+ use_target_weight=True,
+ supervise_empty=False,
+ beta=1 / 9,
+ ))
+
+ encoded = head.decoder.encode(data['keypoints'],
+ data['keypoints_visible'])
+ feats = self._get_feats()
+ data_samples = self._get_data_samples()
+ for data_sample in data_samples:
+ data_sample.gt_fields.set_data(
+ {k: to_tensor(v)
+ for k, v in encoded.items()})
+
+ losses = head.loss(feats, data_samples)
+ self.assertIn('loss/heatmap', losses)
+ self.assertEqual(losses['loss/heatmap'].ndim, 0)
+ self.assertIn('loss/displacement', losses)
+ self.assertEqual(losses['loss/displacement'].ndim, 0)
diff --git a/tests/test_models/test_heads/test_regression_heads/test_dsnt_head.py b/tests/test_models/test_heads/test_regression_heads/test_dsnt_head.py
index 84f86c39f3..0ccdb52e42 100644
--- a/tests/test_models/test_heads/test_regression_heads/test_dsnt_head.py
+++ b/tests/test_models/test_heads/test_regression_heads/test_dsnt_head.py
@@ -25,16 +25,6 @@ def _get_feats(
return feats
- def _get_data_samples(self,
- batch_size: int = 2,
- with_reg_label: bool = False):
- batch_data_samples = [
- inputs['data_sample'] for inputs in get_packed_inputs(
- batch_size, with_reg_label=with_reg_label)
- ]
-
- return batch_data_samples
-
def test_init(self):
# square heatmap
head = DSNTHead(
@@ -137,8 +127,8 @@ def test_predict(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_reg_label=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_reg_label=False)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -157,7 +147,7 @@ def test_predict(self):
)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -177,8 +167,8 @@ def test_predict(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_reg_label=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_reg_label=False)['data_samples']
_, pred_heatmaps = head.predict(
feats, batch_data_samples, test_cfg=dict(output_heatmaps=True))
@@ -205,8 +195,8 @@ def test_tta(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_reg_label=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_reg_label=False)['data_samples']
preds = head.predict([feats, feats],
batch_data_samples,
test_cfg=dict(flip_test=True))
@@ -233,8 +223,8 @@ def test_loss(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_reg_label=True)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_reg_label=True)['data_samples']
losses = head.loss(feats, batch_data_samples)
self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
diff --git a/tests/test_models/test_heads/test_regression_heads/test_integral_regression_head.py b/tests/test_models/test_heads/test_regression_heads/test_integral_regression_head.py
index 5357e0c2c3..5e93ae91cc 100644
--- a/tests/test_models/test_heads/test_regression_heads/test_integral_regression_head.py
+++ b/tests/test_models/test_heads/test_regression_heads/test_integral_regression_head.py
@@ -25,16 +25,6 @@ def _get_feats(
return feats
- def _get_data_samples(self,
- batch_size: int = 2,
- with_heatmap: bool = False):
- batch_data_samples = [
- inputs['data_sample'] for inputs in get_packed_inputs(
- batch_size, with_heatmap=with_heatmap)
- ]
-
- return batch_data_samples
-
def test_init(self):
# square heatmap
head = IntegralRegressionHead(
@@ -129,8 +119,8 @@ def test_predict(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_heatmap=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_heatmap=False)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -149,7 +139,7 @@ def test_predict(self):
)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -169,8 +159,8 @@ def test_predict(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_heatmap=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_heatmap=False)['data_samples']
_, pred_heatmaps = head.predict(
feats, batch_data_samples, test_cfg=dict(output_heatmaps=True))
@@ -193,8 +183,8 @@ def test_tta(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_heatmap=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_heatmap=False)['data_samples']
preds = head.predict([feats, feats],
batch_data_samples,
test_cfg=dict(
@@ -218,7 +208,7 @@ def test_loss(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 16, 12), (32, 8, 6)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
losses = head.loss(feats, batch_data_samples)
self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
diff --git a/tests/test_models/test_heads/test_regression_heads/test_regression_head.py b/tests/test_models/test_heads/test_regression_heads/test_regression_head.py
index 89c8d8c1ff..d0d8782ef0 100644
--- a/tests/test_models/test_heads/test_regression_heads/test_regression_head.py
+++ b/tests/test_models/test_heads/test_regression_heads/test_regression_head.py
@@ -25,17 +25,6 @@ def _get_feats(
return feats
- def _get_data_samples(self,
- batch_size: int = 2,
- with_heatmap: bool = False):
-
- batch_data_samples = [
- inputs['data_sample'] for inputs in get_packed_inputs(
- batch_size, with_heatmap=with_heatmap)
- ]
-
- return batch_data_samples
-
def test_init(self):
head = RegressionHead(in_channels=1024, num_joints=17)
@@ -64,8 +53,8 @@ def test_predict(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 1, 1), (32, 1, 1)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_heatmap=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_heatmap=False)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -83,7 +72,7 @@ def test_predict(self):
)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 1, 1), (32, 1, 1)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -105,8 +94,8 @@ def test_tta(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 1, 1), (32, 1, 1)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_heatmap=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_heatmap=False)['data_samples']
preds = head.predict([feats, feats],
batch_data_samples,
test_cfg=dict(flip_test=True, shift_coords=True))
@@ -126,8 +115,8 @@ def test_loss(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 1, 1), (32, 1, 1)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_heatmap=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_heatmap=False)['data_samples']
losses = head.loss(feats, batch_data_samples)
self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
diff --git a/tests/test_models/test_heads/test_regression_heads/test_rle_head.py b/tests/test_models/test_heads/test_regression_heads/test_rle_head.py
index c717bbf9c3..b4be688bfb 100644
--- a/tests/test_models/test_heads/test_regression_heads/test_rle_head.py
+++ b/tests/test_models/test_heads/test_regression_heads/test_rle_head.py
@@ -25,17 +25,6 @@ def _get_feats(
return feats
- def _get_data_samples(self,
- batch_size: int = 2,
- with_heatmap: bool = False):
-
- batch_data_samples = [
- inputs['data_sample'] for inputs in get_packed_inputs(
- batch_size, with_heatmap=with_heatmap)
- ]
-
- return batch_data_samples
-
def test_init(self):
# w/ sigma
@@ -65,8 +54,8 @@ def test_predict(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 1, 1), (32, 1, 1)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_heatmap=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_heatmap=False)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -84,7 +73,7 @@ def test_predict(self):
)
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 1, 1), (32, 1, 1)])
- batch_data_samples = self._get_data_samples(batch_size=2)
+ batch_data_samples = get_packed_inputs(batch_size=2)['data_samples']
preds = head.predict(feats, batch_data_samples)
self.assertTrue(len(preds), 2)
@@ -106,8 +95,8 @@ def test_tta(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 1, 1), (32, 1, 1)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_heatmap=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_heatmap=False)['data_samples']
preds = head.predict([feats, feats],
batch_data_samples,
test_cfg=dict(flip_test=True))
@@ -127,8 +116,8 @@ def test_loss(self):
feats = self._get_feats(
batch_size=2, feat_shapes=[(16, 1, 1), (32, 1, 1)])
- batch_data_samples = self._get_data_samples(
- batch_size=2, with_heatmap=False)
+ batch_data_samples = get_packed_inputs(
+ batch_size=2, with_heatmap=False)['data_samples']
losses = head.loss(feats, batch_data_samples)
self.assertIsInstance(losses['loss_kpt'], torch.Tensor)
diff --git a/tests/test_models/test_losses/test_ae_loss.py b/tests/test_models/test_losses/test_ae_loss.py
new file mode 100644
index 0000000000..406c075532
--- /dev/null
+++ b/tests/test_models/test_losses/test_ae_loss.py
@@ -0,0 +1,186 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from itertools import product
+from typing import Tuple
+from unittest import TestCase
+
+import numpy as np
+import torch
+import torch.nn as nn
+from torch import Tensor
+
+from mmpose.codecs.associative_embedding import AssociativeEmbedding
+from mmpose.models.losses.ae_loss import AssociativeEmbeddingLoss
+from mmpose.testing._utils import get_coco_sample
+
+
+class AELoss(nn.Module):
+ """Associative Embedding loss in MMPose v0.x."""
+
+ def __init__(self, loss_type):
+ super().__init__()
+ self.loss_type = loss_type
+
+ @staticmethod
+ def _make_input(t, requires_grad=False, device=torch.device('cpu')):
+ """Make zero inputs for AE loss.
+
+ Args:
+ t (torch.Tensor): input
+ requires_grad (bool): Option to use requires_grad.
+ device: torch device
+
+ Returns:
+ torch.Tensor: zero input.
+ """
+ inp = torch.autograd.Variable(t, requires_grad=requires_grad)
+ inp = inp.sum()
+ inp = inp.to(device)
+ return inp
+
+ def singleTagLoss(self, pred_tag, joints):
+ """Associative embedding loss for one image.
+
+ Note:
+ - heatmaps weight: W
+ - heatmaps height: H
+ - max_num_people: M
+ - num_keypoints: K
+
+ Args:
+ pred_tag (torch.Tensor[KxHxW,1]): tag of output for one image.
+ joints (torch.Tensor[M,K,2]): joints information for one image.
+ """
+ tags = []
+ pull = 0
+ pred_tag = pred_tag.view(17, -1, 1)
+ for joints_per_person in joints:
+ tmp = []
+ for k, joint in enumerate(joints_per_person):
+ if joint[1] > 0:
+ tmp.append(pred_tag[k, joint[0]])
+ if len(tmp) == 0:
+ continue
+ tmp = torch.stack(tmp)
+ tags.append(torch.mean(tmp, dim=0))
+ pull = pull + torch.mean((tmp - tags[-1].expand_as(tmp))**2)
+
+ num_tags = len(tags)
+ if num_tags == 0:
+ return (self._make_input(
+ torch.zeros(1).float(), device=pred_tag.device),
+ self._make_input(
+ torch.zeros(1).float(), device=pred_tag.device))
+ elif num_tags == 1:
+ return (self._make_input(
+ torch.zeros(1).float(), device=pred_tag.device), pull)
+
+ tags = torch.stack(tags)
+
+ size = (num_tags, num_tags)
+ A = tags.expand(*size)
+ B = A.permute(1, 0)
+
+ diff = A - B
+
+ if self.loss_type == 'exp':
+ diff = torch.pow(diff, 2)
+ push = torch.exp(-diff)
+ push = torch.sum(push)
+ elif self.loss_type == 'max':
+ diff = 1 - torch.abs(diff)
+ push = torch.clamp(diff, min=0).sum() - num_tags
+ else:
+ raise ValueError('Unknown ae loss type')
+
+ push_loss = push / ((num_tags - 1) * num_tags) * 0.5
+ pull_loss = pull / (num_tags)
+
+ return push_loss, pull_loss
+
+ def forward(self, tags, keypoint_indices):
+ assert tags.shape[0] == len(keypoint_indices)
+
+ pull_loss = 0.
+ push_loss = 0.
+
+ for i in range(tags.shape[0]):
+ _push, _pull = self.singleTagLoss(tags[i].view(-1, 1),
+ keypoint_indices[i])
+ pull_loss += _pull
+ push_loss += _push
+
+ return pull_loss, push_loss
+
+
+class TestAssociativeEmbeddingLoss(TestCase):
+
+ def _make_input(self, num_instance: int) -> Tuple[Tensor, Tensor]:
+
+ encoder = AssociativeEmbedding(
+ input_size=(256, 256), heatmap_size=(64, 64))
+
+ data = get_coco_sample(
+ img_shape=(256, 256), num_instances=num_instance)
+ encoded = encoder.encode(data['keypoints'], data['keypoints_visible'])
+ heatmaps = encoded['heatmaps']
+ keypoint_indices = encoded['keypoint_indices']
+
+ tags = self._get_tags(
+ heatmaps, keypoint_indices, tag_per_keypoint=True)
+
+ batch_tags = torch.from_numpy(tags[None])
+ batch_keypoint_indices = [torch.from_numpy(keypoint_indices)]
+
+ return batch_tags, batch_keypoint_indices
+
+ def _get_tags(self,
+ heatmaps,
+ keypoint_indices,
+ tag_per_keypoint: bool,
+ with_randomness: bool = True):
+
+ K, H, W = heatmaps.shape
+ N = keypoint_indices.shape[0]
+
+ if tag_per_keypoint:
+ tags = np.zeros((K, H, W), dtype=np.float32)
+ else:
+ tags = np.zeros((1, H, W), dtype=np.float32)
+
+ for n, k in product(range(N), range(K)):
+ y, x = np.unravel_index(keypoint_indices[n, k, 0], (H, W))
+
+ randomness = np.random.rand() if with_randomness else 0
+
+ if tag_per_keypoint:
+ tags[k, y, x] = n + randomness
+ else:
+ tags[0, y, x] = n + randomness
+
+ return tags
+
+ def test_loss(self):
+
+ tags, keypoint_indices = self._make_input(num_instance=2)
+
+ # test loss calculation
+ loss_module = AssociativeEmbeddingLoss()
+ pull_loss, push_loss = loss_module(tags, keypoint_indices)
+ _pull_loss, _push_loss = AELoss('exp')(tags, keypoint_indices)
+
+ self.assertTrue(torch.allclose(pull_loss, _pull_loss))
+ self.assertTrue(torch.allclose(push_loss, _push_loss))
+
+ # test loss weight
+ loss_module = AssociativeEmbeddingLoss(loss_weight=0.)
+ pull_loss, push_loss = loss_module(tags, keypoint_indices)
+
+ self.assertTrue(torch.allclose(pull_loss, torch.zeros(1)))
+ self.assertTrue(torch.allclose(push_loss, torch.zeros(1)))
+
+ # test push loss factor
+ loss_module = AssociativeEmbeddingLoss(push_loss_factor=0.)
+ pull_loss, push_loss = loss_module(tags, keypoint_indices)
+
+ self.assertFalse(torch.allclose(pull_loss, torch.zeros(1)))
+ self.assertTrue(torch.allclose(push_loss, torch.zeros(1)))
diff --git a/tests/test_models/test_losses/test_classification_losses.py b/tests/test_models/test_losses/test_classification_losses.py
new file mode 100644
index 0000000000..fd7d3fd898
--- /dev/null
+++ b/tests/test_models/test_losses/test_classification_losses.py
@@ -0,0 +1,22 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import torch
+
+from mmpose.models.losses.classification_loss import InfoNCELoss
+
+
+class TestInfoNCELoss(TestCase):
+
+ def test_loss(self):
+
+ # test loss w/o target_weight
+ loss = InfoNCELoss(temperature=0.05)
+
+ fake_pred = torch.arange(5 * 2).reshape(5, 2).float()
+ self.assertTrue(
+ torch.allclose(loss(fake_pred), torch.tensor(5.4026), atol=1e-4))
+
+ # check if the value of temperature is positive
+ with self.assertRaises(AssertionError):
+ loss = InfoNCELoss(temperature=0.)
diff --git a/tests/test_models/test_losses/test_heatmap_losses.py b/tests/test_models/test_losses/test_heatmap_losses.py
new file mode 100644
index 0000000000..bfabc84749
--- /dev/null
+++ b/tests/test_models/test_losses/test_heatmap_losses.py
@@ -0,0 +1,65 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import torch
+
+from mmpose.models.losses.heatmap_loss import (AdaptiveWingLoss,
+ FocalHeatmapLoss)
+
+
+class TestAdaptiveWingLoss(TestCase):
+
+ def test_loss(self):
+
+ # test loss w/o target_weight
+ loss = AdaptiveWingLoss(use_target_weight=False)
+
+ fake_pred = torch.zeros((1, 3, 2, 2))
+ fake_label = torch.zeros((1, 3, 2, 2))
+ self.assertTrue(
+ torch.allclose(loss(fake_pred, fake_label), torch.tensor(0.)))
+
+ fake_pred = torch.ones((1, 3, 2, 2))
+ fake_label = torch.zeros((1, 3, 2, 2))
+ self.assertTrue(
+ torch.allclose(
+ loss(fake_pred, fake_label), torch.tensor(8.4959), atol=1e-4))
+
+ # test loss w/ target_weight
+ loss = AdaptiveWingLoss(use_target_weight=True)
+
+ fake_pred = torch.zeros((1, 3, 2, 2))
+ fake_label = torch.zeros((1, 3, 2, 2))
+ fake_weight = torch.tensor([1, 0, 1]).reshape(1, 3).float()
+ self.assertTrue(
+ torch.allclose(
+ loss(fake_pred, fake_label, fake_weight), torch.tensor(0.)))
+
+
+class TestFocalHeatmapLoss(TestCase):
+
+ def test_loss(self):
+
+ loss = FocalHeatmapLoss(use_target_weight=False)
+
+ fake_pred = torch.zeros((1, 3, 5, 5))
+ fake_label = torch.zeros((1, 3, 5, 5))
+
+ self.assertTrue(
+ torch.allclose(loss(fake_pred, fake_label), torch.tensor(0.)))
+
+ fake_pred = torch.ones((1, 3, 5, 5)) * 0.4
+ fake_label = torch.ones((1, 3, 5, 5)) * 0.6
+ self.assertTrue(
+ torch.allclose(
+ loss(fake_pred, fake_label), torch.tensor(0.1569), atol=1e-4))
+
+ # test loss w/ target_weight
+ loss = FocalHeatmapLoss(use_target_weight=True)
+
+ fake_weight = torch.arange(3 * 5 * 5).reshape(1, 3, 5, 5).float()
+ self.assertTrue(
+ torch.allclose(
+ loss(fake_pred, fake_label, fake_weight),
+ torch.tensor(5.8062),
+ atol=1e-4))
diff --git a/tests/test_models/test_losses/test_regression_losses.py b/tests/test_models/test_losses/test_regression_losses.py
new file mode 100644
index 0000000000..0975ac6b55
--- /dev/null
+++ b/tests/test_models/test_losses/test_regression_losses.py
@@ -0,0 +1,48 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+from unittest import TestCase
+
+import torch
+
+from mmpose.models.losses.regression_loss import SoftWeightSmoothL1Loss
+
+
+class TestSoftWeightSmoothL1Loss(TestCase):
+
+ def test_loss(self):
+
+ # test loss w/o target_weight
+ loss = SoftWeightSmoothL1Loss(use_target_weight=False, beta=0.5)
+
+ fake_pred = torch.zeros((1, 3, 2))
+ fake_label = torch.zeros((1, 3, 2))
+ self.assertTrue(
+ torch.allclose(loss(fake_pred, fake_label), torch.tensor(0.)))
+
+ fake_pred = torch.ones((1, 3, 2))
+ fake_label = torch.zeros((1, 3, 2))
+ self.assertTrue(
+ torch.allclose(loss(fake_pred, fake_label), torch.tensor(.75)))
+
+ # test loss w/ target_weight
+ loss = SoftWeightSmoothL1Loss(
+ use_target_weight=True, supervise_empty=True)
+
+ fake_pred = torch.ones((1, 3, 2))
+ fake_label = torch.zeros((1, 3, 2))
+ fake_weight = torch.arange(6).reshape(1, 3, 2).float()
+ self.assertTrue(
+ torch.allclose(
+ loss(fake_pred, fake_label, fake_weight), torch.tensor(1.25)))
+
+ # test loss that does not take empty channels into account
+ loss = SoftWeightSmoothL1Loss(
+ use_target_weight=True, supervise_empty=False)
+ self.assertTrue(
+ torch.allclose(
+ loss(fake_pred, fake_label, fake_weight), torch.tensor(1.5)))
+
+ with self.assertRaises(ValueError):
+ _ = loss.smooth_l1_loss(fake_pred, fake_label, reduction='fake')
+
+ output = loss.smooth_l1_loss(fake_pred, fake_label, reduction='sum')
+ self.assertTrue(torch.allclose(output, torch.tensor(3.0)))
diff --git a/tests/test_models/test_pose_estimators/test_bottomup.py b/tests/test_models/test_pose_estimators/test_bottomup.py
new file mode 100644
index 0000000000..16258dacaf
--- /dev/null
+++ b/tests/test_models/test_pose_estimators/test_bottomup.py
@@ -0,0 +1,54 @@
+# Copyright (c) OpenMMLab. All rights reserved.
+import unittest
+from unittest import TestCase
+
+import torch
+from parameterized import parameterized
+
+from mmpose.testing import get_packed_inputs, get_pose_estimator_cfg
+from mmpose.utils import register_all_modules
+
+configs = [
+ 'body_2d_keypoint/associative_embedding/coco/'
+ 'ae_hrnet-w32_8xb24-300e_coco-512x512.py'
+]
+
+configs_with_devices = [(config, ('cpu', 'cuda')) for config in configs]
+
+
+class TestTopdownPoseEstimator(TestCase):
+
+ def setUp(self) -> None:
+ register_all_modules()
+
+ @parameterized.expand(configs)
+ def test_init(self, config):
+ model_cfg = get_pose_estimator_cfg(config)
+ model_cfg.backbone.init_cfg = None
+
+ from mmpose.models import build_pose_estimator
+ model = build_pose_estimator(model_cfg)
+ self.assertTrue(model.backbone)
+ self.assertTrue(model.head)
+ if model_cfg.get('neck', None):
+ self.assertTrue(model.neck)
+
+ @parameterized.expand(configs_with_devices)
+ def test_forward_tensor(self, config, devices):
+ model_cfg = get_pose_estimator_cfg(config)
+ model_cfg.backbone.init_cfg = None
+
+ from mmpose.models import build_pose_estimator
+
+ for device in devices:
+ model = build_pose_estimator(model_cfg)
+
+ if device == 'cuda':
+ if not torch.cuda.is_available():
+ return unittest.skip('test requires GPU and torch+cuda')
+ model = model.cuda()
+
+ packed_inputs = get_packed_inputs(2)
+ data = model.data_preprocessor(packed_inputs, training=True)
+ batch_results = model.forward(**data, mode='tensor')
+ self.assertIsInstance(batch_results, (tuple, torch.Tensor))
diff --git a/tests/test_models/test_pose_estimators/test_topdown.py b/tests/test_models/test_pose_estimators/test_topdown.py
index 62f52f5b54..bc65cecd3e 100644
--- a/tests/test_models/test_pose_estimators/test_topdown.py
+++ b/tests/test_models/test_pose_estimators/test_topdown.py
@@ -1,10 +1,102 @@
# Copyright (c) OpenMMLab. All rights reserved.
+import unittest
from unittest import TestCase
+import torch
+from parameterized import parameterized
+
+from mmpose.structures import PoseDataSample
+from mmpose.testing import get_packed_inputs, get_pose_estimator_cfg
from mmpose.utils import register_all_modules
+configs = [
+ 'body_2d_keypoint/topdown_heatmap/coco/'
+ 'td-hm_hrnet-w32_8xb64-210e_coco-256x192.py',
+ 'configs/body_2d_keypoint/topdown_regression/coco/'
+ 'td-reg_res50_8xb64-210e_coco-256x192.py',
+ 'configs/body_2d_keypoint/simcc/coco/'
+ 'simcc_mobilenetv2_wo-deconv-8xb64-210e_coco-256x192.py',
+]
+
+configs_with_devices = [(config, ('cpu', 'cuda')) for config in configs]
+
class TestTopdownPoseEstimator(TestCase):
def setUp(self) -> None:
register_all_modules()
+
+ @parameterized.expand(configs)
+ def test_init(self, config):
+ model_cfg = get_pose_estimator_cfg(config)
+ model_cfg.backbone.init_cfg = None
+
+ from mmpose.models import build_pose_estimator
+ model = build_pose_estimator(model_cfg)
+ self.assertTrue(model.backbone)
+ self.assertTrue(model.head)
+ if model_cfg.get('neck', None):
+ self.assertTrue(model.neck)
+
+ @parameterized.expand(configs_with_devices)
+ def test_forward_loss(self, config, devices):
+ model_cfg = get_pose_estimator_cfg(config)
+ model_cfg.backbone.init_cfg = None
+
+ from mmpose.models import build_pose_estimator
+
+ for device in devices:
+ model = build_pose_estimator(model_cfg)
+
+ if device == 'cuda':
+ if not torch.cuda.is_available():
+ return unittest.skip('test requires GPU and torch+cuda')
+ model = model.cuda()
+
+ packed_inputs = get_packed_inputs(2)
+ data = model.data_preprocessor(packed_inputs, training=True)
+ losses = model.forward(**data, mode='loss')
+ self.assertIsInstance(losses, dict)
+
+ @parameterized.expand(configs_with_devices)
+ def test_forward_predict(self, config, devices):
+ model_cfg = get_pose_estimator_cfg(config)
+ model_cfg.backbone.init_cfg = None
+
+ from mmpose.models import build_pose_estimator
+
+ for device in devices:
+ model = build_pose_estimator(model_cfg)
+
+ if device == 'cuda':
+ if not torch.cuda.is_available():
+ return unittest.skip('test requires GPU and torch+cuda')
+ model = model.cuda()
+
+ packed_inputs = get_packed_inputs(2)
+ model.eval()
+ with torch.no_grad():
+ data = model.data_preprocessor(packed_inputs, training=True)
+ batch_results = model.forward(**data, mode='predict')
+ self.assertEqual(len(batch_results), 2)
+ self.assertIsInstance(batch_results[0], PoseDataSample)
+
+ @parameterized.expand(configs_with_devices)
+ def test_forward_tensor(self, config, devices):
+ model_cfg = get_pose_estimator_cfg(config)
+ model_cfg.backbone.init_cfg = None
+
+ from mmpose.models import build_pose_estimator
+
+ for device in devices:
+ model = build_pose_estimator(model_cfg)
+
+ if device == 'cuda':
+ if not torch.cuda.is_available():
+ return unittest.skip('test requires GPU and torch+cuda')
+ model = model.cuda()
+
+ packed_inputs = get_packed_inputs(2)
+ data = model.data_preprocessor(packed_inputs, training=True)
+ batch_results = model.forward(**data, mode='tensor')
+ self.assertIsInstance(batch_results, (tuple, torch.Tensor))
diff --git a/tests/test_visualization/test_pose_visualizer.py b/tests/test_visualization/test_pose_visualizer.py
index 8de33fc1ed..d9eb502c30 100644
--- a/tests/test_visualization/test_pose_visualizer.py
+++ b/tests/test_visualization/test_pose_visualizer.py
@@ -97,6 +97,13 @@ def test_add_datasample(self):
out_file=out_file)
self._assert_image_and_shape(out_file, ((h * 2), (w * 2), 3))
+ def test_simcc_visualization(self):
+ img = np.zeros((512, 512, 3), dtype=np.uint8)
+ heatmap = torch.randn([17, 512, 512])
+ pixelData = PixelData()
+ pixelData.heatmaps = heatmap
+ self.visualizer._draw_instance_xy_heatmap(pixelData, img, 10)
+
def _assert_image_and_shape(self, out_file, out_shape):
self.assertTrue(os.path.exists(out_file))
drawn_img = cv2.imread(out_file)
diff --git a/tools/analysis_tools/get_flops.py b/tools/analysis_tools/get_flops.py
index 1445acfd92..9325037699 100644
--- a/tools/analysis_tools/get_flops.py
+++ b/tools/analysis_tools/get_flops.py
@@ -6,7 +6,6 @@
from mmengine.config import DictAction
from mmpose.apis.inference import init_model
-from mmpose.utils import register_all_modules as register_mmpose_modules
try:
from mmcv.cnn import get_model_complexity_info
@@ -70,7 +69,6 @@ def batch_constructor(flops_model, batch_size, input_shape):
def main():
- register_mmpose_modules()
args = parse_args()
diff --git a/tools/deployment/pytorch2onnx.py b/tools/deployment/pytorch2onnx.py
deleted file mode 100644
index 5caff6e070..0000000000
--- a/tools/deployment/pytorch2onnx.py
+++ /dev/null
@@ -1,165 +0,0 @@
-# Copyright (c) OpenMMLab. All rights reserved.
-import argparse
-import warnings
-
-import numpy as np
-import torch
-
-from mmpose.apis import init_pose_model
-
-try:
- import onnx
- import onnxruntime as rt
-except ImportError as e:
- raise ImportError(f'Please install onnx and onnxruntime first. {e}')
-
-try:
- from mmcv.onnx.symbolic import register_extra_symbolics
-except ModuleNotFoundError:
- raise NotImplementedError('please update mmcv to version>=1.0.4')
-
-
-def _convert_batchnorm(module):
- """Convert the syncBNs into normal BN3ds."""
- module_output = module
- if isinstance(module, torch.nn.SyncBatchNorm):
- module_output = torch.nn.BatchNorm3d(module.num_features, module.eps,
- module.momentum, module.affine,
- module.track_running_stats)
- if module.affine:
- module_output.weight.data = module.weight.data.clone().detach()
- module_output.bias.data = module.bias.data.clone().detach()
- # keep requires_grad unchanged
- module_output.weight.requires_grad = module.weight.requires_grad
- module_output.bias.requires_grad = module.bias.requires_grad
- module_output.running_mean = module.running_mean
- module_output.running_var = module.running_var
- module_output.num_batches_tracked = module.num_batches_tracked
- for name, child in module.named_children():
- module_output.add_module(name, _convert_batchnorm(child))
- del module
- return module_output
-
-
-def pytorch2onnx(model,
- input_shape,
- opset_version=11,
- show=False,
- output_file='tmp.onnx',
- verify=False):
- """Convert pytorch model to onnx model.
-
- Args:
- model (:obj:`nn.Module`): The pytorch model to be exported.
- input_shape (tuple[int]): The input tensor shape of the model.
- opset_version (int): Opset version of onnx used. Default: 11.
- show (bool): Determines whether to print the onnx model architecture.
- Default: False.
- output_file (str): Output onnx model name. Default: 'tmp.onnx'.
- verify (bool): Determines whether to verify the onnx model.
- Default: False.
- """
- model.cpu().eval()
-
- one_img = torch.randn(input_shape)
-
- register_extra_symbolics(opset_version)
- torch.onnx.export(
- model,
- one_img,
- output_file,
- export_params=True,
- keep_initializers_as_inputs=True,
- verbose=show,
- opset_version=opset_version)
-
- print(f'Successfully exported ONNX model: {output_file}')
- if verify:
- # check by onnx
- onnx_model = onnx.load(output_file)
- onnx.checker.check_model(onnx_model)
-
- # check the numerical value
- # get pytorch output
- pytorch_results = model(one_img)
- if not isinstance(pytorch_results, (list, tuple)):
- assert isinstance(pytorch_results, torch.Tensor)
- pytorch_results = [pytorch_results]
-
- # get onnx output
- input_all = [node.name for node in onnx_model.graph.input]
- input_initializer = [
- node.name for node in onnx_model.graph.initializer
- ]
- net_feed_input = list(set(input_all) - set(input_initializer))
- assert len(net_feed_input) == 1
- sess = rt.InferenceSession(output_file)
- onnx_results = sess.run(None,
- {net_feed_input[0]: one_img.detach().numpy()})
-
- # compare results
- assert len(pytorch_results) == len(onnx_results)
- for pt_result, onnx_result in zip(pytorch_results, onnx_results):
- assert np.allclose(
- pt_result.detach().cpu(), onnx_result, atol=1.e-5
- ), 'The outputs are different between Pytorch and ONNX'
- print('The numerical values are same between Pytorch and ONNX')
-
-
-def parse_args():
- parser = argparse.ArgumentParser(
- description='Convert MMPose models to ONNX')
- parser.add_argument('config', help='test config file path')
- parser.add_argument('checkpoint', help='checkpoint file')
- parser.add_argument('--show', action='store_true', help='show onnx graph')
- parser.add_argument('--output-file', type=str, default='tmp.onnx')
- parser.add_argument('--opset-version', type=int, default=11)
- parser.add_argument(
- '--verify',
- action='store_true',
- help='verify the onnx model output against pytorch output')
- parser.add_argument(
- '--shape',
- type=int,
- nargs='+',
- default=[1, 3, 256, 192],
- help='input size')
- args = parser.parse_args()
- return args
-
-
-if __name__ == '__main__':
- args = parse_args()
-
- assert args.opset_version == 11, 'MMPose only supports opset 11 now'
-
- # Following strings of text style are from colorama package
- bright_style, reset_style = '\x1b[1m', '\x1b[0m'
- red_text, blue_text = '\x1b[31m', '\x1b[34m'
- white_background = '\x1b[107m'
-
- msg = white_background + bright_style + red_text
- msg += 'DeprecationWarning: This tool will be deprecated in future. '
- msg += blue_text + 'Welcome to use the unified model deployment toolbox '
- msg += 'MMDeploy: https://github.com/open-mmlab/mmdeploy'
- msg += reset_style
- warnings.warn(msg)
-
- model = init_pose_model(args.config, args.checkpoint, device='cpu')
- model = _convert_batchnorm(model)
-
- # onnx.export does not support kwargs
- if hasattr(model, 'forward_dummy'):
- model.forward = model.forward_dummy
- else:
- raise NotImplementedError(
- 'Please implement the forward method for exporting.')
-
- # convert model to onnx file
- pytorch2onnx(
- model,
- args.shape,
- opset_version=args.opset_version,
- show=args.show,
- output_file=args.output_file,
- verify=args.verify)
diff --git a/tools/misc/browse_dataset.py b/tools/misc/browse_dataset.py
index b744b0a3c2..74dfa39d6b 100644
--- a/tools/misc/browse_dataset.py
+++ b/tools/misc/browse_dataset.py
@@ -7,12 +7,11 @@
import mmengine
import numpy as np
from mmengine import Config, DictAction
-from mmengine.registry import build_from_cfg
+from mmengine.registry import build_from_cfg, init_default_scope
from mmengine.structures import InstanceData
from mmpose.registry import DATASETS, VISUALIZERS
from mmpose.structures import PoseDataSample
-from mmpose.utils import register_all_modules
def parse_args():
@@ -84,7 +83,7 @@ def main():
file_client = mmengine.FileClient(**file_client_args)
# register all modules in mmpose into the registries
- register_all_modules()
+ init_default_scope(cfg.get('default_scope', 'mmpose'))
if args.mode == 'original':
cfg[f'{args.phase}_dataloader'].dataset.pipeline = []
diff --git a/tools/misc/publish_model.py b/tools/misc/publish_model.py
index 393721ab06..4a8338fdbd 100644
--- a/tools/misc/publish_model.py
+++ b/tools/misc/publish_model.py
@@ -4,6 +4,9 @@
from datetime import date
import torch
+from mmengine.logging import print_log
+from mmengine.utils import digit_version
+from mmengine.utils.dl_utils import TORCH_VERSION
def parse_args():
@@ -11,18 +14,37 @@ def parse_args():
description='Process a checkpoint to be published')
parser.add_argument('in_file', help='input checkpoint filename')
parser.add_argument('out_file', help='output checkpoint filename')
+ parser.add_argument(
+ '--save-keys',
+ nargs='+',
+ type=str,
+ default=['meta', 'state_dict'],
+ help='keys to save in published checkpoint (default: meta state_dict)')
args = parser.parse_args()
return args
-def process_checkpoint(in_file, out_file):
+def process_checkpoint(in_file, out_file, save_keys=['meta', 'state_dict']):
checkpoint = torch.load(in_file, map_location='cpu')
- # remove optimizer for smaller file size
- if 'optimizer' in checkpoint:
- del checkpoint['optimizer']
+
+ # only keep `meta` and `state_dict` for smaller file size
+ ckpt_keys = list(checkpoint.keys())
+ for k in ckpt_keys:
+ if k not in save_keys:
+ print_log(
+ f'Key `{k}` will be removed because it is not in '
+ f'save_keys. If you want to keep it, '
+ f'please set --save-keys.',
+ logger='current')
+ checkpoint.pop(k, None)
+
# if it is necessary to remove some sensitive data in checkpoint['meta'],
# add the code here.
- torch.save(checkpoint, out_file)
+
+ if digit_version(TORCH_VERSION) >= digit_version('1.6.0'):
+ torch.save(checkpoint, out_file, _use_new_zipfile_serialization=False)
+ else:
+ torch.save(checkpoint, out_file)
sha = subprocess.check_output(['sha256sum', out_file]).decode()
if out_file.endswith('.pth'):
out_file_name = out_file[:-4]
@@ -36,7 +58,7 @@ def process_checkpoint(in_file, out_file):
def main():
args = parse_args()
- process_checkpoint(args.in_file, args.out_file)
+ process_checkpoint(args.in_file, args.out_file, args.save_keys)
if __name__ == '__main__':
diff --git a/tools/test.py b/tools/test.py
index 673d64365f..3a22ae78c5 100644
--- a/tools/test.py
+++ b/tools/test.py
@@ -8,8 +8,6 @@
from mmengine.hooks import Hook
from mmengine.runner import Runner
-from mmpose.utils import register_all_modules
-
def parse_args():
parser = argparse.ArgumentParser(
@@ -92,10 +90,6 @@ def merge_args(cfg, args):
def main():
args = parse_args()
- # register all modules in mmpose into the registries
- # do not init the default scope here because it will be init in the runner
- register_all_modules(init_default_scope=False)
-
# load config
cfg = Config.fromfile(args.config)
cfg = merge_args(cfg, args)
diff --git a/tools/deployment/mmpose2torchserve.py b/tools/torchserve/mmpose2torchserve.py
similarity index 100%
rename from tools/deployment/mmpose2torchserve.py
rename to tools/torchserve/mmpose2torchserve.py
diff --git a/tools/deployment/mmpose_handler.py b/tools/torchserve/mmpose_handler.py
similarity index 100%
rename from tools/deployment/mmpose_handler.py
rename to tools/torchserve/mmpose_handler.py
diff --git a/tools/deployment/test_torchserver.py b/tools/torchserve/test_torchserver.py
similarity index 100%
rename from tools/deployment/test_torchserver.py
rename to tools/torchserve/test_torchserver.py
diff --git a/tools/train.py b/tools/train.py
index 374e6e4dd3..a29051d9e0 100644
--- a/tools/train.py
+++ b/tools/train.py
@@ -6,8 +6,6 @@
from mmengine.config import Config, DictAction
from mmengine.runner import Runner
-from mmpose.utils import register_all_modules
-
def parse_args():
parser = argparse.ArgumentParser(description='Train a pose model')
@@ -137,10 +135,6 @@ def merge_args(cfg, args):
def main():
args = parse_args()
- # register all modules in mmpose into the registries
- # do not init the default scope here because it will be init in the runner
- register_all_modules(init_default_scope=False)
-
# load config
cfg = Config.fromfile(args.config)
@@ -148,7 +142,9 @@ def main():
cfg = merge_args(cfg, args)
# set preprocess configs to model
- cfg.model.setdefault('data_preprocessor', cfg.get('preprocess_cfg', {}))
+ if 'preprocess_cfg' in cfg:
+ cfg.model.setdefault('data_preprocessor',
+ cfg.get('preprocess_cfg', {}))
# build the runner from config
runner = Runner.from_cfg(cfg)
 +
+  +
+
+
+  +
+  +
+  +
+

 +
+


 +
+









 +
+ +
+ +
+ +
+ +
+ +
+
 +
+ +
+ +
+
 +
+ +
+ +
+ +
+ +
+ +
+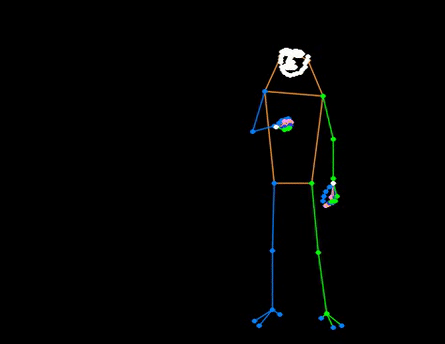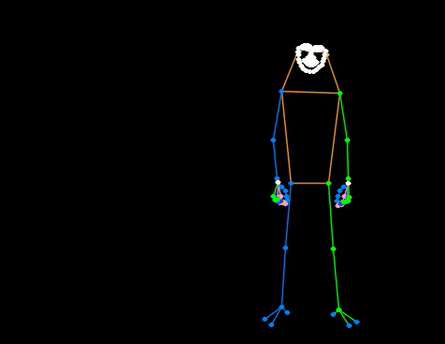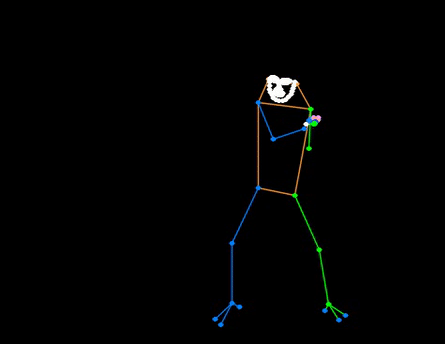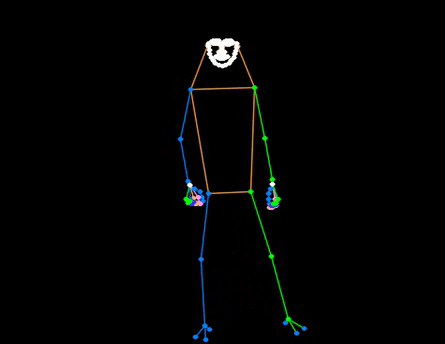
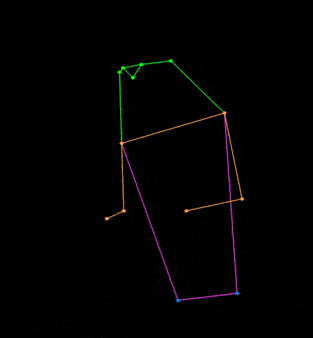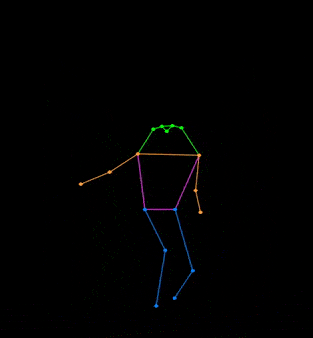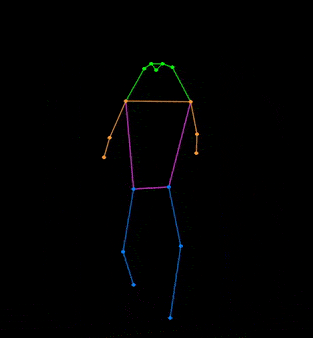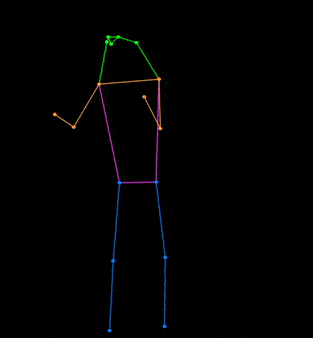
 +
+
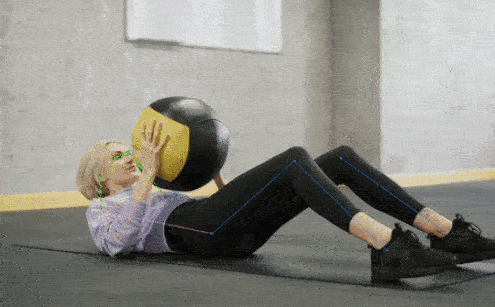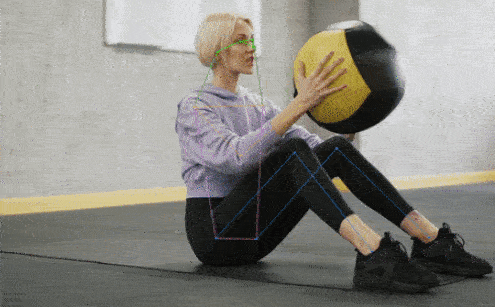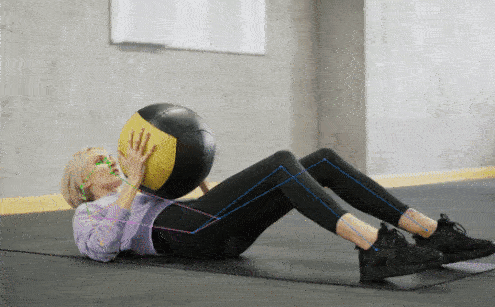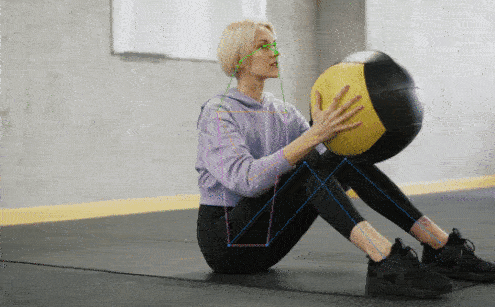 +
+
 +
+