。更多信息,参考 [mydumper 文档](https://github.com/mydumper/mydumper)。
+
+## DataX
+
+**基本特性:**
+
+- 高效传输
+- 支持多种数据源
+- 配置灵活
+
+**适用场景:**
+
+* DataX 适用于从几十 GB 到几 TB 甚至更大规模的数据迁移任务。
+
+**使用参考:**
+
+* 更多信息,参考 [DataX 文档](https://github.com/alibaba/DataX/blob/master/README.md)。
+
+## 导出方案选择
+
+|**对比项**|**OBDUMPER**|**OUTFILE**|**mysqldump**|**mydumper**|**DataX**|
+|---|---|---|---|---|---|
+| 场景推荐 | 数据逻辑备份数据处理数据高压缩|简单数据导出| 全量和增量备份| 全量和增量备份| 提供强大的数据源支持。数据源可以是运行中的数据库,消息队列等。可用于数据库离线迁移。 |
+| 数据源 | 静态文件 | 静态文件 | 静态文件 | 静态文件 | 结构化和非结构化数据源 |
+| 格式 | 文本格式:CSV(RFC-4180),INSERT SQL,Delimited Text, Fixed Length。
二进制格式:Apache ORC,Apaceh Parquet,Apache Avro。 | 文本文件| SQL 文件、Delimited Text | SQL 文件、文本文件 | 各关系型数据库,文本,Hbase,Kafka 等。 |
+| 性能 | 高 | 一般 | 低 | 高 | 高 |
+| 是否支持压缩 | 是 | 否 | 是 | 是 | 是 |
+| 是否支持带条件导出 | 是 | 否 | 是 | 是 | 是 |
+| DDL | 是 | 否 | 是 | 是 | 否 |
+| 数据预处理 | 是 | 是 | 是 | 否 | 否 |
+| 实时监控 | 是 | 否 | 否 | 否 | 否 |
+| 文件编码 | 可指定,只要系统支持的都可以 | 系统默认编码 | UTF-8 | 支持的文件编码格式与文本文件编码的支持情况相关 | UTF-8 |
\ No newline at end of file
diff --git a/zh-CN/620.obap/600.obap-query/10.obap-statistic-info.md b/zh-CN/620.obap/600.obap-query/10.obap-statistic-info.md
new file mode 100644
index 0000000000..4adcb1a3ec
--- /dev/null
+++ b/zh-CN/620.obap/600.obap-query/10.obap-statistic-info.md
@@ -0,0 +1,119 @@
+# 统计信息
+
+统计信息是优化器生成执行计划必不可少的信息,准确、及时的统计信息可以帮助优化器生成性能更优的计划。在大多数的系统中,用户无需关心统计信息的问题,优化器每天会执行一个定时任务去收集统计信息需要更新的表的统计信息。而在 AP 系统中,往往存在一些超大表,使用默认的统计信息收集策略可能会导致统计信息无法正常收集完成,影响计划生成。因此我们需要按需对统计信息做一些配置。
+
+## 调整统计信息收集窗口
+
+默认情况下,OceanBase 优化器通过维护窗口来进行每日自动统计信息收集,从而保证统计信息能够迭代更新。其中周一到周五的任务默认开始时间为 22:00,最大收集时长 4 小时,周六周日的默认开始时间为 6:00,最大收集时长为 20 小时,如下表所示。
+
+|**维护窗口名称**|**开始时间/频率**|**最大收集时长**|
+|---|---|---|
+| MONDAY_WINDOW | 22:00/per week | 4 hours |
+| TUESDAY_WINDOW | 22:00/per week | 4 hours |
+| WEDNESDAY_WINDOW | 22:00/per week | 4 hours |
+| THURSDAY_WINDOW | 22:00/per week | 4 hours |
+| FRIDAY_WINDOW | 22:00/per week | 4 hours |
+| SATURDAY_WINDOW | 6:00/per week | 20 hours |
+| SUNDAY_WINDOW | 6:00/per week | 20 hours |
+
+我们需要根据业务的实际情况合理的配置维护窗口。例如当维护窗口刚好与业务高峰重合,可以调整维护窗口的开始时间,或者在特定日期不做统计信息收集。当业务环境中表的数量很多,或存在很多超大表的时候,可以调整维护窗口的收集时长。
+
+下面是一些配置示例。
+
+```sql
+-- 禁用周一自动收集统计信息
+call dbms_scheduler.disable('MONDAY_WINDOW');
+
+-- 启用周一自动收集统计信息
+call dbms_scheduler.enable('MONDAY_WINDOW');
+
+-- 设置周一自动收集统计信息开始的时间在晚上8点
+call dbms_scheduler.set_attribute('MONDAY_WINDOW', 'NEXT_DATE', '2022-09-12 20:00:00');
+
+-- 设置周一自动收集统计信息的持续时长为6小时
+-- 6小时 <=> 6 * 60 * 60 * 1000 * 1000 <=> 21600000000 us
+call dbms_scheduler.set_attribute('WEDNESDAY_WINDOW', 'JOB_ACTION', 'DBMS_STATS.GATHER_DATABASE_STATS_JOB_PROC(21600000000)');
+```
+
+## 超大表统计信息收集策略
+
+存在超大表的场景下,优化器的默认统计信息收集策略可能会导致表的统计信息在一次维护窗口中收集不完。因此需要针对超大表设置合理的收集策略。在收集超大表的统计信息时,耗时的地方主要有三个:
+
+* 表数据量大,收集需要全表扫,耗时高。
+* 直方图收集涉及复杂的计算,带来额外成本的耗时。
+* 大分区表默认收集二级分区、一级分区、全表的统计信息和直方图,3 * (cost(全表扫)+cost(直方图))代价
+
+根据上述耗时点,可以根据表的实际情况及相关查询情况进行优化。建议如下:
+
+* 设置合适的默认收集并行度,需要注意的是设置并行度之后,需要调整相关的自动收集任务在业务低峰期进行,避免影响业务,建议并行度控制 8 个以内,可使用如下方式设置。
+
+ ```plsql
+ -- Oracle或者MySQL业务租户相同:
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'degree', '8');
+ ```
+
+* 设置默认列的直方图收集方式,考虑给数据分布均匀的列设置不收集直方图。
+
+ ```plsql
+ -- Oracle或者MySQL业务租户相同
+ -- 1.如果该表所有列的数据分布都是均匀的,可以使用如下方式设置所有列都不收集直方图:
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'method_opt', 'for all columns size 1');
+
+ -- 2.如果该表仅极少数列数据分布不均匀,需要收集直方图,其他列都不需要,则可以使用如下方式设置(c1,c2收集直方图,c3,c4,c5不收集直方图)
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'method_opt', 'for columns c1 size 254, c2 size 254, c3 size 1, c4 size 1, c5 size 1');
+ ```
+
+* 设置默认分区表的收集粒度,针对一些分区表,形如 hash 分区/key 分区之类的,可以考虑只收集全局的统计信息,或者也可以设置分区推导全局的收集方式。
+
+ ```plsql
+ -- Oracle或者MySQL业务租户相同
+ -- 1.设置只收集全局的统计信息
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'granularity', 'GLOBAL');
+
+ -- 2.设置分区推导全局的收集方式
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'granularity', 'APPROX_GLOBAL AND PARTITION');
+ ```
+
+* 慎用设置大表采样的方式收集统计信息,设置大表采样收集时,直方图的样本数量也会变得很大,存在适得其反的效果,设置采样的方式收集仅仅适合只收集基础统计信息,不收集直方图的场景。
+
+ ```plsql
+ -- Oracle或者MySQL业务租户相同,如删除granularity
+ -- 1.设置所有列都不收集直方图:
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'method_opt', 'for all columns size 1');
+
+ -- 2.设置采样比例为10%
+ call dbms_stats.set_table_prefs('database_name', 'table_name', 'estimate_percent', '10');
+ ```
+
+除此之外,如果需要清空/删除已设置的默认收集策略,只需要指定清除的属性即可 {attribute},使用如下方式。
+
+ ```plsql
+ -- Oracle或者MySQL业务租户相同,如删除granularity
+ call dbms_stats.delete_table_prefs('database_name', 'table_name', 'granularity');
+ ```
+
+如果设置好了相关收集策略,需要查询是否设置成功,可以使用如下方式查询。
+
+ ```plsql
+ -- Oracle或者MySQL业务租户相同,如获取指定的并行度degree
+ select dbms_stats.get_prefs('degree', 'database_name','table_name') from dual;
+ ```
+
+除了上述方式以外,也可以考虑能否手动收集完大表统计信息之后,锁定相关的统计信息。需要注意的是当表的统计信息锁定之后,自动收集将不会更新,适用于一些对数据特征变化不太大、数据值不敏感的场景,如果需要重新收集锁定的统计信息,需要先将其解锁。
+
+ ```plsql
+ -- Oracle或者MySQL业务租户相同, 锁定表的统计信息
+ call dbms_stats.lock_table_stats('database_name', 'table_name');
+
+ -- Oracle或者MySQL业务租户相同, 解锁表的统计信息
+ call dbms_stats.unlock_table_stats('database_name', 'table_name');
+ ```
+
+## 相关文档
+
+有关统计信息的详细介绍和使用指导,可以查看以下文档:
+
+* 统计信息包含表统计信息(Table Level Statistics)和列统计信息(Column Level Statistics)两种类型,更多关于统计信息类型的介绍,参见 [统计信息概述](../../700.reference/1000.performance-tuning-guide/500.sql-optimization/400.sql-optimization/400.optimizer-statistics/100.statistics-overview.md)。
+* OceanBase 数据库优化器支持手动收集统计信息和自动收集统计信息,有关统计信息收集的详细介绍和操作指导,参见 [统计信息收集方式概述](../../700.reference/1000.performance-tuning-guide/500.sql-optimization/400.sql-optimization/400.optimizer-statistics/200.statistics-collection-methods/100.overview-of-statistics-collection-methods.md)。
+* 关于统计信息管理的详细操作指导,参见 [统计信息管理](../../700.reference/1000.performance-tuning-guide/500.sql-optimization/400.sql-optimization/400.optimizer-statistics/100.statistics-overview.md) 章节。
+* 通过一个简单的示例了解统计信息的使用,[查看示例](../../700.reference/1000.performance-tuning-guide/500.sql-optimization/400.sql-optimization/400.optimizer-statistics/500.comprehensive-example.md)。
\ No newline at end of file
diff --git a/zh-CN/620.obap/600.obap-query/100.obap-materialized-view.md b/zh-CN/620.obap/600.obap-query/100.obap-materialized-view.md
new file mode 100644
index 0000000000..d66763234c
--- /dev/null
+++ b/zh-CN/620.obap/600.obap-query/100.obap-materialized-view.md
@@ -0,0 +1,658 @@
+# 物化视图
+
+物化视图存储了视图定义查询的结果。可以加速该视图查询,减少查询的系统资源消耗(cpu, 网络,磁盘等)。利用存储物化视图结果的空间换取的查询时候的时间。
+
+## 常见用例
+
+- 数据汇总:汇总每天、每周或每月的销售数据、统计用户行为数据等
+- 统计信息报表数据生成:报表系统需要定期生成固定格式的数据报告
+- 复杂查询优化:对于特别消耗资源的查询,可以将结果物化避免查询重复计算
+- 分发数据:冗余多份数据放到不同的区域中,便于各个区域的人就近访问数据
+- 监控数据的预聚合:监控数据会按照不同的时间间隔进行展示
+
+## 使用示例
+
+基于给定的表和物化视图创建情况,以下是如何生成一个物化视图来加速查询的具体示例。首先,让我们确保我们有一个适当的表结构和物化视图定义。
+
+### 表结构定义
+
+```plsql
+CREATE TABLE orders (
+ order_id INT primary key,
+ user_id INT,
+ item_id INT,
+ item_count INT,
+ item_price DECIMAL(10, 2) NOT NULL,
+ region VARCHAR(100)
+);
+
+CREATE TABLE order_items (
+ order_id INT,
+ product_id INT,
+ quantity INT,
+ price_per_item DECIMAL(10, 2) NOT NULL,
+ primary key (order_id, product_id)
+);
+```
+
+### 创建物化视图
+
+以下是基于提供的信息创建物化视图的示例。
+
+**汇总物化视图**:计算每个地区的总销售额
+
+```plsql
+CREATE MATERIALIZED VIEW m1
+REFRESH FAST ON DEMAND
+AS
+SELECT
+ SUM(item_count * item_price) AS total_sales,
+ region
+FROM
+ orders
+GROUP BY
+ region;
+```
+
+**宽表物化视图**:将订单与商品详情关联,形成一个宽表
+
+```plsql
+CREATE MATERIALIZED VIEW wide_orders
+REFRESH FAST ON DEMAND
+AS
+SELECT
+ o.order_id,
+ o.user_id AS customer_id,
+ o.item_id,
+ o.item_count AS quantity,
+ o.item_price AS price_per_item,
+ o.region
+FROM
+ orders o
+JOIN
+ order_items oi ON o.order_id = oi.order_id;
+```
+
+### 加速查询示例
+
+假设我们有一个查询,需要快速获取某个地区的订单详情和销售总额,可以使用上述物化视图来加速查询。以下是一个具体的示例查询。
+
+```plsql
+-- 查询某个地区的所有订单详情和总销售额
+SELECT
+ wo.order_id,
+ wo.customer_id,
+ wo.product_id,
+ wo.quantity,
+ wo.price_per_item,
+ m1.total_sales
+FROM
+ wide_orders wo
+JOIN
+ m1 ON wo.region = m1.region
+WHERE
+ wo.region = 'North America';
+```
+
+在这个查询中,**wide_orders** 物化视图提供了订单与商品详情的宽表数据,**m1** 物化视图提供了每个地区的总销售额。通过将这两个物化视图结合起来,我们可以快速查询特定地区的订单详情和总销售额。
+
+### 刷新策略
+
+为了保持物化视图的数据最新,我们可以根据需求设置合适的刷新策略。上述示例中,我们使用了 **REFRESH FAST ON DEMAND**,表示需要手动触发刷新。如果需要定期自动刷新,可以修改刷新策略,例如:
+
+```plsql
+-- 每小时自动刷新一次
+CREATE MATERIALIZED VIEW m1
+REFRESH FAST
+START WITH SYSDATE
+NEXT SYSDATE + 1/24
+AS
+SELECT
+ SUM(item_count * item_price) AS total_sales,
+ region
+FROM
+ orders
+GROUP BY
+ region;
+
+-- 每天自动刷新一次
+CREATE MATERIALIZED VIEW wide_orders
+REFRESH FAST
+START WITH SYSDATE
+NEXT SYSDATE + 1
+AS
+SELECT
+ o.order_id,
+ o.user_id AS customer_id,
+ o.item_id,
+ o.item_count AS quantity,
+ o.item_price AS price_per_item,
+ o.region
+FROM
+ orders o
+JOIN
+ order_items oi ON o.order_id = oi.order_id;
+```
+
+通过这种方式,物化视图可以在指定的时间间隔内自动刷新,以确保数据的及时性和准确性,从而加速查询性能。
+
+## 创建物化视图
+
+```sql
+create_mv_stmt :=
+CREATE MATERIALIZED VIEW view_name opt_column_list opt_table_option_list opt_partition_option [refresh_clause] AS view_select_stmt
+
+refresh_clause :=
+REFRESH [FAST/COMPLETE/FORCE] [mv_refresh_on_clause]
+/
+NEVER REFRESH
+
+
+mv_refresh_on_clause :=
+[ON DEMAND] [[START WITH expr] [NEXT expr]]
+```
+
+语法如上图所示,和创建普通视图类似。最主要的是增加了 refresh 子句来描述刷新的信息。在刷新章节会详细介绍。
+
+在创建物化视图时,可以通过指定刷新子句(refresh_clause)来定义物化视图的定时刷新策略。这包括选择增量刷新(FAST)、全量刷新(COMPLETE)或根据情况自动选择的强制刷新(FORCE)。此外,还可以设置刷新触发条件,如按需(ON DEMAND)、指定开始时间(START WITH expr)和下一次刷新时间(NEXT expr)。以下是定义物化视图定时刷新的语法和示例。
+
+### 语法
+
+```sql
+CREATE MATERIALIZED VIEW view_name
+REFRESH [FAST | COMPLETE | FORCE]
+[ON DEMAND | START WITH expr NEXT expr | NEVER REFRESH]
+AS
+SELECT ...
+```
+
+- FAST:进行增量刷新。
+- COMPLETE:进行全量刷新。
+- FORCE:根据当前情况自动选择增量或全量刷新。
+- ON DEMAND:按需刷新,即手动触发刷新。
+- START WITH expr:定义首次刷新的时间。
+- NEXT expr:定义下一次刷新的时间。
+- NEVER REFRESH:不自动刷新,只能手动刷新。
+
+### 示例
+
+按需增量刷新
+
+```plsql
+CREATE MATERIALIZED VIEW sales_mv
+REFRESH FAST ON DEMAND
+AS
+SELECT product_id, SUM(amount) AS total_sales
+FROM sales
+GROUP BY product_id;
+```
+
+每日全量刷新
+
+```plsql
+CREATE MATERIALIZED VIEW daily_sales_mv
+REFRESH COMPLETE
+START WITH SYSDATE
+NEXT SYSDATE + 1
+AS
+SELECT product_id, SUM(amount) AS total_sales
+FROM sales
+GROUP BY product_id;
+```
+
+每小时自动选择刷新类型
+
+```plsql
+CREATE MATERIALIZED VIEW hourly_sales_mv
+REFRESH FORCE
+START WITH SYSDATE
+NEXT SYSDATE + 1/24
+AS
+SELECT product_id, SUM(amount) AS total_sales
+FROM sales
+GROUP BY product_id;
+```
+
+从不自动刷新
+
+```plsql
+CREATE MATERIALIZED VIEW static_sales_mv
+REFRESH NEVER
+AS
+SELECT product_id, SUM(amount) AS total_sales
+FROM sales
+GROUP BY product_id;
+```
+
+**解释:**
+
+- 按需增量刷新:物化视图 sales_mv 将使用增量刷新,但仅在手动触发时刷新。
+- 每日全量刷新:物化视图 daily_sales_mv 每天刷新一次,每次执行全量刷新,刷新时间从创建时开始,每隔一天刷新一次。
+- 每小时自动选择刷新类型:物化视图 hourly_sales_mv 每小时刷新一次,数据库会自动选择使用增量刷新还是全量刷新。
+- 从不自动刷新:物化视图 static_sales_mv 不会自动刷新,只能通过手动操作进行刷新。
+
+通过合理设置这些刷新策略,可以根据具体需求和系统性能要求,确保物化视图的数据既及时又高效地保持最新。
+
+## 删除物化视图
+
+```sql
+DROP MATERIALIZED VIEW opt_if_exists table_list opt_drop_behavior
+```
+
+物化视图不能单独进回收站。删除 database 的时候,物化视图能进回收站。
+
+## 刷新
+
+物化视图刷新(Materialized View Refresh)是确保物化视图中的数据保持最新状态的重要操作。物化视图是一种存储查询结果的数据库对象,可以显著提高查询性能。然而,随着源数据的变化,物化视图的数据也需要更新以反映最新的状态。物化视图的刷新可以分为全量刷新和增量刷新两种方式。
+
+全量刷新(Complete Refresh)指的是重新计算并替换物化视图中的所有数据。这种方式确保了物化视图数据的完整性和准确性,但由于涉及大量数据的重算和写入操作,全量刷新通常会消耗较多的系统资源和时间。
+
+增量刷新(Incremental Refresh),也称为快速刷新(Fast Refresh),则是只更新自上次刷新以来发生变化的数据。这种方式可以显著减少刷新所需的资源和时间,但需要在数据库中维护额外的日志或触发器,以跟踪数据的变化。
+
+由于刷新操作会消耗系统资源,因此需要根据实际需求和系统负载,合理安排物化视图的刷新频率。常见的做法是定期刷新,可以是每天、每小时甚至更频繁地执行,以确保物化视图数据的及时性和准确性。
+
+### 全量刷新
+
+物化视图全量刷新(Complete Refresh)是一种确保物化视图数据与源数据完全一致的刷新方式。在全量刷新过程中,物化视图会重新执行定义它的查询语句,并完全替换其内部数据。这意味着,不论查询的复杂度和涉及的数据量多大,全量刷新都会执行整个查询并将结果集全部重新存储到物化视图中。因此,全量刷新能够支持任何类型的查询语句,包括复杂的联接、聚合和嵌套查询。
+
+全量刷新的主要优势在于其简单和可靠性。因为它每次都会重建整个数据集,所以能够确保物化视图中的数据绝对准确,与源数据保持完全一致。尤其在源数据变化频繁或数据更新模式复杂的场景下,全量刷新提供了一种无视这些复杂变化、直接获取最新数据的方法。
+
+然而,由于全量刷新涉及对全部数据的重新计算和写入,因此相对来说,它会消耗更多的系统资源和时间,特别是在处理大规模数据集时。这种资源消耗不仅包括计算能力,还包括 I/O 操作的开销。因此,虽然全量刷新能够提供数据准确性和完整性,但在实际应用中需要慎重考虑其执行频率,以平衡系统性能和数据及时性之间的关系。
+
+刷新语法
+
+```sql
+DBMS_MVIEW.REFRESH (
+ IN mv_name VARCHAR(65535), -- 物化视图名称
+ IN method VARCHAR(65535) DEFAULT NULL, -- 刷新选项
+ -- f 快速刷新
+ -- ? 强制刷新
+ -- C|c 完全刷新
+ -- A|a 始终刷新,等价于C
+ IN refresh_parallel INT DEFAULT 1); -- 刷新并行度
+```
+
+### 增量刷新
+
+物化视图增量刷新(Incremental Refresh),也称为快速刷新(Fast Refresh),是一种仅更新自上次刷新以来发生变化的数据的刷新方式。与全量刷新不同,增量刷新只对源数据中发生变更的部分进行处理和更新,从而提高刷新效率,减少系统资源消耗和刷新时间。然而,增量刷新仅支持部分 SELECT 语句,通常需要满足特定的语法和结构要求,如简单的联接和聚合操作。
+
+增量刷新依赖于物化日志(Materialized View Log, 简称 MLOG)的支持。MLOG 是一个特殊的数据库对象,用于记录基表中发生的增量变化。每当基表中的数据被插入、更新或删除时,这些变化都会记录在 MLOG 中。增量刷新时,系统读取 MLOG 中的记录,识别并处理这些变化,从而只更新物化视图中的相关部分数据。
+虽然增量刷新显著提高了刷新效率,但 MLOG 的使用会额外占用数据库空间,因为它需要存储基表的变更日志。随着时间推移和数据变更的积累,MLOG 的大小可能不断增长,需定期管理和维护,以避免占用过多存储资源。
+
+## 物化视图查询改写
+
+通过使用物化视图来加速查询,当输入一个不使用物化视图的查询时,系统会自动将查询重写为使用现有物化视图的查询。该方法的原理是将查询语句与物化视图的定义进行匹配,如果发现匹配的物化视图,则自动将查询重写为使用物化视图的查询,这样可以大大提高查询性能和效率。
+
+### 物化视图查询改写使用限制
+
+* 物化视图满足以下要求:
+
+ * 创建物化视图时,指定 `ENABLE QUERY REWRITE` 开启当前物化视图的自动改写。
+ * 需要物化视图仅包含 `SELECT JOIN` 与 `WHERE` 子句,即 SPJ 查询。对于不满足条件的物化视图,不会报错,但不会被用于改写。
+
+* 当前查询满足以下要求:
+
+ * 查询为 `SELECT` 查询,不是集合查询或层次查询,并且不包含窗口函数。
+ * `FROM` 子句与物化视图完全匹配。
+ * `WHERE` 条件物化视图是当前查询的子集,当前查询有聚合的情况下需要完全匹配。例如,物化视图的 `WHERE` 是 `c1 > 10`,当前查询的 `WHERE` 是 `c1 > 10 AND c2 >20`。这样物化视图的条件 {c1 > 10} 是当前查询 {c1>10, c2>20} 的子集。
+ * 当前查询所涉及的 `SELECT` 项、`WHERE`、`HAVING` 和 `GROUP BY` 等条件中的列,都需要包含在物化视图的 `SELECT` 语句中的列中。
+
+### 规则/代价检查
+
+查询改写时,OceanBase 数据库当前版本不进行代价检查,但规则检查要求改写后的 `WHERE` 条件能够使用至少一个物化视图上的索引。此外,当有超过 10 个的物化视图存在时,物化视图查询改写将仅尝试使用前 10 个物化视图。
+
+### 物化视图改写
+
+控制物化视图查询改写的系统变量如下:
+
+* `query_rewrite_enabled`:用于是否开启物化视图改写功能。该变量的详细介绍信息,参见 [query_rewrite_enabled](../../700.reference/800.configuration-items-and-system-variables/200.system-variable/300.global-system-variable/11050.query_rewrite_enabled-global.md)。
+
+ **示例如下:**
+
+ ```sql
+ SET query_rewrite_enabled = 'force';
+ ```
+
+* `query_rewrite_integrity`:用于指定物化视图改写的数据一致性检查级别。该变量的详细介绍信息,参见 [query_rewrite_integrity](../../700.reference/800.configuration-items-and-system-variables/200.system-variable/300.global-system-variable/11060.query_rewrite_integrity-global.md)。
+
+ **示例如下:**
+
+ ```sql
+ SET query_rewrite_integrity = 'stale_tolerated';
+ ```
+
+**通过以下示例展示物化视图改写:**
+
+1. 创建表 `test_tbl1`。
+
+ ```sql
+ CREATE TABLE test_tbl1 (col1 INT, col2 INT, col3 INT);
+ ```
+
+2. 创建表 `test_tbl2`。
+
+ ```sql
+ CREATE TABLE test_tbl2 (col1 INT, col2 INT, col3 INT);
+ ```
+
+3. 创建名为 `mv_test_tbl1_tbl2` 的物化视图,并开启当前物化视图的自动改写。
+
+ ```sql
+ CREATE MATERIALIZED VIEW mv_test_tbl1_tbl2
+ ENABLE QUERY REWRITE
+ AS SELECT t1.col1 col1, t1.col2 t1col2, t1.col3 t1col3, t2.col2 t2col2, t2.col3 t2col3
+ FROM test_tbl1 t1, test_tbl2 t2
+ WHERE t1.col1 = t2.col1;
+ ```
+
+4. 当输入查询 `SELECT count(*), test_tbl1.col1 col1 FROM test_tbl1, test_tbl2 WHERE test_tbl1.col1 = test_tbl2.col1 AND test_tbl2.col2 > 10 GROUP BY col1;` 时,发生物化视图查询改写。
+
+ ```sql
+ SELECT count(*), test_tbl1.col1 col1 FROM test_tbl1, test_tbl2 WHERE test_tbl1.col1 = test_tbl2.col1 AND test_tbl2.col2 > 10 GROUP BY col1;
+
+ MV REWRITE ==>
+
+ SELECT count(*), mv_test_tbl1_tbl2.col1 col1 FROM mv_test_tbl1_tbl2 WHERE mv_test_tbl1_tbl2.t2col2 > 10 GROUP BY mv_test_tbl1_tbl2.col1;
+ ```
+
+ 物化视图查询改写要求输入的查询与物化视图的 `FROM` 完全匹配,`WHERE` 条件包含物化视图中的所有 `WHERE` 条件。
+
+### 物化视图查询改写控制
+
+物化视图查询改写控制包括 `MV_REWRITE`、`NO_MV_REWRITE` 两个 Hint,并且这两个 Hint 的优先级高于系统变量 `query_rewrite_enabled`。
+
+#### MV_REWRITE
+
+`MV_REWRITE` 语法如下:
+
+```sql
+/*+ MV_REWRITE (@ queryblock [mv_name_list]) */
+
+mv_name_list:
+ mv_name [, mv_name ...]
+```
+
+单独使用 `MV_REWRITE` Hint 时可以跳过物化视图查询改写的规则/代价检查,直接使用可以使用的改写。Hint 后指定一个或多个物化视图的情况,除了跳过规则/代价检查外,物化视图查询改写将只使用指定的物化视图尝试改写,忽略所有没被指定的物化视图。
+
+使用 `MV_REWRITE` Hint 指定物化视图时,无法强制使用没有 `ENABLE QUERY REWRITE`(开启当前物化视图的自动改写) 子句的物化视图,无法在系统变量 `query_rewrite_integrity` 设置为 `enforced` 的情况下强制使用非实时物化视图。
+
+#### NO_MV_REWRITE
+
+`NO_MV_REWRITE` 语法如下:
+
+```sql
+/*+ NO_MV_REWRITE (@ queryblock) */
+```
+
+禁止物化视图查询改写,可以指定 query block。
+
+#### 物化视图查询改写控制 Hint 使用示例
+
+1. 创建基表 `tbl2`。
+
+ ```sql
+ CREATE TABLE tbl2 (col1 INT, col2 INT);
+ ```
+
+2. 向基表 `tbl2` 中插入两条数据。
+
+ ```sql
+ INSERT INTO tbl2 VALUES (1,2),(3,4);
+ ```
+
+ 返回结果如下:
+
+ ```shell
+ Query OK, 2 rows affected
+ Records: 2 Duplicates: 0 Warnings: 0
+ ```
+
+3. 创建物化视图 `mv1_tbl2`,并开启当前物化视图的自动改写。
+
+ ```sql
+ CREATE MATERIALIZED VIEW mv1_tbl2 NEVER REFRESH ENABLE QUERY REWRITE AS SELECT * FROM tbl2;
+ ```
+
+4. 创建物化视图 `mv2_tbl2`,并开启当前物化视图的自动改写。
+
+ ```sql
+ CREATE MATERIALIZED VIEW mv2_tbl2 NEVER REFRESH ENABLE QUERY REWRITE AS SELECT * FROM tbl2 WHERE tbl2.col1 > 1;
+ ```
+
+5. 设置系统变量 `query_rewrite_integrity` 为 `stale_tolerated`。
+
+
+ 说明
+ MV_REWRITE 和 NO_MV_REWRITE Hint 的优先级高于系统变量 query_rewrite_enabled,因此不需要设置 query_rewrite_enabled。但是需要设置 query_rewrite_integrity 为 stale_tolerated 才可以使用非实时物化视图进行改写。
+
+
+ ```sql
+ SET query_rewrite_integrity = 'stale_tolerated';
+ ```
+
+6. 使用 `MV_REWRITE` Hint 用物化视图尝试进行改写,并跳过改写代价/规则检查。下面两条查询都将使用物化视图 `mv1_tbl2` 进行改写。
+
+ * `/*+mv_rewrite*/` 将尝试使用符合改写条件的物化视图进行改写,一旦找到了符合改写要求的物化视图,后续的物化视图将不再被考虑,并跳过改写代价/规则检查。
+
+ ```sql
+ EXPLAIN SELECT /*+mv_rewrite*/ count(*), col1 FROM tbl2 WHERE tbl2.col1 > 1 GROUP BY col1;
+ ```
+
+ 返回结果如下:
+
+ ```shell
+ +------------------------------------------------------------------------------------+
+ | Query Plan |
+ +------------------------------------------------------------------------------------+
+ | ===================================================== |
+ | |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
+ | ----------------------------------------------------- |
+ | |0 |HASH GROUP BY | |1 |3 | |
+ | |1 |└─TABLE FULL SCAN|mv1_tbl2|1 |3 | |
+ | ===================================================== |
+ | Outputs & filters: |
+ | ------------------------------------- |
+ | 0 - output([T_FUN_COUNT(*)], [mv1_tbl2.col1]), filter(nil), rowset=16 |
+ | group([mv1_tbl2.col1]), agg_func([T_FUN_COUNT(*)]) |
+ | 1 - output([mv1_tbl2.col1]), filter([mv1_tbl2.col1 > 1]), rowset=16 |
+ | access([mv1_tbl2.col1]), partitions(p0) |
+ | is_index_back=false, is_global_index=false, filter_before_indexback[false], |
+ | range_key([mv1_tbl2.__pk_increment]), range(MIN ; MAX)always true |
+ +------------------------------------------------------------------------------------+
+ 14 rows in set
+ ```
+
+ * `/*+mv_rewrite(mv2_tbl2)*/` 将尝试使用 `mv2_tbl2` 进行改写,并跳过改写代价/规则检查。
+
+ ```sql
+ EXPLAIN SELECT /*+mv_rewrite(mv2_tbl2)*/ count(*), col1 FROM tbl2 WHERE tbl2.col1 > 1 GROUP BY col1;
+ ```
+
+ 返回结果如下:
+
+ ```shell
+ +-------------------------------------------------------------------------+
+ | Query Plan |
+ +-------------------------------------------------------------------------+
+ | ===================================================== |
+ | |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
+ | ----------------------------------------------------- |
+ | |0 |HASH GROUP BY | |1 |3 | |
+ | |1 |└─TABLE FULL SCAN|mv2_tbl2|1 |3 | |
+ | ===================================================== |
+ | Outputs & filters: |
+ | ------------------------------------- |
+ | 0 - output([T_FUN_COUNT(*)], [mv2_tbl2.col1]), filter(nil), rowset=16 |
+ | group([mv2_tbl2.col1]), agg_func([T_FUN_COUNT(*)]) |
+ | 1 - output([mv2_tbl2.col1]), filter(nil), rowset=16 |
+ | access([mv2_tbl2.col1]), partitions(p0) |
+ | is_index_back=false, is_global_index=false, |
+ | range_key([mv2_tbl2.__pk_increment]), range(MIN ; MAX)always true |
+ +-------------------------------------------------------------------------+
+ 14 rows in set
+ ```
+
+7. 虽然查询指定使用 `mv2_tbl2` 来查询改写,由于查询语句的 `WHERE` 条件不满足要求,`mv2_tbl2` 无法用于查询改写,所以此查询不会进行物化视图查询改写。
+
+ ```sql
+ EXPLAIN SELECT /*+mv_rewrite(mv2_tbl2)*/ count(*), col1 FROM tbl2 WHERE tbl2.col1 < 1 GROUP BY col1;
+ ```
+
+ 返回结果如下:
+
+ ```shell
+ +------------------------------------------------------------------------------------+
+ | Query Plan |
+ +------------------------------------------------------------------------------------+
+ | ================================================= |
+ | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
+ | ------------------------------------------------- |
+ | |0 |HASH GROUP BY | |1 |3 | |
+ | |1 |└─TABLE FULL SCAN|tbl2|1 |3 | |
+ | ================================================= |
+ | Outputs & filters: |
+ | ------------------------------------- |
+ | 0 - output([T_FUN_COUNT(*)], [tbl2.col1]), filter(nil), rowset=16 |
+ | group([tbl2.col1]), agg_func([T_FUN_COUNT(*)]) |
+ | 1 - output([tbl2.col1]), filter([tbl2.col1 < 1]), rowset=16 |
+ | access([tbl2.col1]), partitions(p0) |
+ | is_index_back=false, is_global_index=false, filter_before_indexback[false], |
+ | range_key([tbl2.__pk_increment]), range(MIN ; MAX)always true |
+ +------------------------------------------------------------------------------------+
+ 14 rows in set
+ ```
+
+8. 使用 `/*+ no_mv_rewrite*/` Hint,不会进行物化视图查询改写。
+
+ ```sql
+ EXPLAIN SELECT /*+no_mv_rewrite*/ count(*), col1 FROM tbl2 WHERE tbl2.col1 > 1 GROUP BY col1;
+ ```
+
+ 返回结果如下:
+
+ ```shell
+ +------------------------------------------------------------------------------------+
+ | Query Plan |
+ +------------------------------------------------------------------------------------+
+ | ================================================= |
+ | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
+ | ------------------------------------------------- |
+ | |0 |HASH GROUP BY | |1 |3 | |
+ | |1 |└─TABLE FULL SCAN|tbl2|1 |3 | |
+ | ================================================= |
+ | Outputs & filters: |
+ | ------------------------------------- |
+ | 0 - output([T_FUN_COUNT(*)], [tbl2.col1]), filter(nil), rowset=16 |
+ | group([tbl2.col1]), agg_func([T_FUN_COUNT(*)]) |
+ | 1 - output([tbl2.col1]), filter([tbl2.col1 > 1]), rowset=16 |
+ | access([tbl2.col1]), partitions(p0) |
+ | is_index_back=false, is_global_index=false, filter_before_indexback[false], |
+ | range_key([tbl2.__pk_increment]), range(MIN ; MAX)always true |
+ +------------------------------------------------------------------------------------+
+ 14 rows in set
+ ```
+
+## 物化视图日志
+
+### 定义
+
+物化视图日志(Materialized View Log)是一种特殊的数据库对象,用于记录在基表(base table)上发生的数据更改。它是实现物化视图(Materialized View)增量刷新机制的关键组件。物化视图日志是关联到基表,用于捕获和存储基表上每次数据修改(插入、更新、删除)的详细信息。这些日志使得物化视图在刷新时无需重新扫描整个基表,而是只需应用自上次刷新以来记录在日志中的更改,从而提高刷新效率。
+
+### 创建物化视图日志
+
+以下为创建物化视图日志的语法。
+
+```
+CREATE MATERIALIZED VIEW LOG ON [ schema. ] table
+ [ parallel_clause ]
+ [ WITH [ { PRIMARY KEY
+ | ROWID
+ | SEQUENCE
+ }
+ [ { , PRIMARY KEY
+ | , ROWID
+ | , SEQUENCE
+ }
+ ]... ]
+ (column [, column ]...)
+ [ new_values_clause ]
+ ] [ mv_log_purge_clause ]
+;
+```
+
+以下为具体的语义解释。
+
+- schema:物化视图日志基表所在的 schema(数据库),不指定就在当前的 schema 中。
+- table:物化视图日志对应的基表名称。
+- parallel_clause:创建物化视图表的 dop
+- with_clause:指定物化视图日志中包含的辅助列,primary key 表示基表的所有主键列,rowid 表示基表为无主键表时的隐藏主键列,sequence 表示一个事务内的多行更新序号号(seq_no)。规则如下:
+ - with primary key 只能用在有主键表中,在无主键表中使用不会有任何效果,如果不指定,则系统会自动带上。
+ - with rowid 只能用在无主键表中,在有主键表中使用不会有任何效果,如果不指定,则系统会自动带上。
+ - with sequence 会自动加上。
+- new_values_clause:是否在物化视图日志中同时记录 update 操作中的旧值和新值。
+
+如果希望 MV 支持快速刷新,则必须指定 INCLUDING NEW VALUES。
+
+```
+{ INCLUDING | EXCLUDING } NEW VALUES
+```
+
+规则:
+
+ - including new values 会自动加上
+ - excluding new values 会报错
+ - mv_log_purge_clause:指定物化视图日志中数据的清除时间。
+
+```
+PURGE { IMMEDIATE [ SYNCHRONOUS | ASYNCHRONOUS ]
+ | START WITH datetime_expr [ NEXT datetime_expr ]
+ | [ START WITH datetime_expr ] NEXT datetime_expr
+ }
+```
+
+子选项说明:
+
+ - IMMEDIATE 表示在每次刷新完物化视图后就立即清除相应的物化视图日志,其中 SYNCHRONOUS 表示同步地执行清除,而 ASYNCHRONOUS 则表示异步地执行清除,但是目前不支持异步清除,用户设置该异步选项会报错。
+ - START WITH datetime_expr 表示第一次清除物化视图日志的时间,NEXT datetime_expr 则是下一次清除的时间,这两个时间必须是在未来,否则会报错。
+ - 如果 START WITH datetime_expr 参数没有指定,而只指定了 NEXT datetime_expr,那么第一次清除物化视图日志的时间将被设置为 NEXT datetime_expr 参数值。
+
+示例:“在表 t1 上面创建一个物化视图日志,从创建的时刻开始,每天清除一次”的语句如下。
+
+```plsql
+--mysql模式
+create materialized view log on t1 purge start with sysdate() next sysdate() + interval 1 day;
+
+--oracle模式(oracle模式中建议使用current_date表示当前时区时间,因为sysdate不受时区影响)
+create materialized view log on t1 purge start with current_date next current_date + 1;
+```
+
+
+ 说明
+ mlog 暂时不支持指定 partition,现在是类似 local index 的实现,mlog 的 partition 和基表的 partition 是绑定关系。
+
+
+### 删除物化视图日志
+
+以下为删除物化视图日志的语法。
+
+表示删除某个基表对应的物化视图日志。
+
+```
+DROP MATERIALIZED VIEW LOG ON [ schema. ] table;
+```
+
+删除物化视图日志时,如果基表正处于某个运行的事务中,则直到该事务结束前,删除操作都会阻塞。
+
+### 物化视图日志的局限性
+
+虽然物化视图日志在数据库系统中具有重要的作用,特别是在实现增量刷新方面,但它们也存在一些局限性和缺点:
+
+- **占用额外空间**: 物化视图日志需要在数据库中存储基表的更改记录,这会占用额外的磁盘空间。特别是在数据更新频繁的场景下,日志表可能会迅速增长,导致大量的磁盘空间被占用。
+- **性能影响**: 每次对基表的插入、更新或删除操作,都会在物化视图日志中记录相应的更改。这意味着每次写操作都需要额外的开销,可能会影响基表的写入性能。
+- **长期不刷新带来的空间占用**: 如果物化视图长时间不刷新,物化视图日志中的未处理记录会不断积累,占用大量磁盘空间。这样的累积不仅会影响存储资源,还可能影响数据库的整体性能。
+- **管理复杂性**: 物化视图日志需要定期维护和管理,例如确定适当的刷新间隔、监控日志大小以及清理过期日志记录等。这增加了数据库管理员的工作负担和管理复杂性。
+- **恢复和备份挑战**:目前物化视图日志不支持备份恢复。
+
+## 相关文档
+
+* 有关物化视图的详细介绍和使用指导,参见 [物化视图概述(MySQL 模式)](../../700.reference/300.database-object-management/100.manage-object-of-mysql-mode/600.manage-views-of-mysql-mode/200.manage-materialized-views-of-mysql-mode/100.materialized-views-of-mysql-mode/100.materialized-views-overview-of-mysql-mode.md) 和 [物化视图概述(Oracle 模式)](../../700.reference/300.database-object-management/200.manage-object-of-oracle-mode/500.manage-views-of-oracle-mode/200.manage-materialized-views-of-oracle-mode/100.materialized-views-of-oracle-mode/100.materialized-views-overview-of-oracle-mode.md)。
\ No newline at end of file
diff --git a/zh-CN/620.obap/600.obap-query/200.obap-hint.md b/zh-CN/620.obap/600.obap-query/200.obap-hint.md
new file mode 100644
index 0000000000..93eebc90d1
--- /dev/null
+++ b/zh-CN/620.obap/600.obap-query/200.obap-hint.md
@@ -0,0 +1,140 @@
+# Hint
+
+Hint 是 SQL 语句中一种特殊的注释,用于向数据库传达一些信息。OceanBase 数据库中可以使用 Hint 干预优化器行为,使优化器按照 Hint 指定方式生成特定形态的执行计划。
+
+一般情况下,优化器会自动为用户查询选择最优执行计划,不需要用户使用 Hint 进行干预。但某些场景下,优化器自动生成的执行计划可能无法满足用户需求,这时需要用户使用 Hint 来主动指定并生成特殊的执行计划。
+
+查询优化过程中,应该尽量避免使用 Hint。只有在收集完相关表的统计信息,并通过 EXPLAIN PLAN 语句在无 Hint 状态下评估了优化器的计划后,才建议用户谨慎考虑使用 Hint。需要注意,使用 Hint 仅会强制干预优化器的正常优化逻辑,Hint 生效后的查询性能需要用户进行评估,不当的 Hint 使用会对性能产生重大影响。
+
+## 常用 Hint
+
+### USE_PLAN_CACHE
+
+**说明**
+
+* 指定 plan cache 的使用策略。
+
+**常见用法**
+
+* 在 AP 系统中部分 SQL 的参数存在大小账号的区别,并且大小账号参数无法共享一个最优计划。此时可以通过 USE_PLAN_CACHE 来指定这一类 SQL 不使用 plan cache 共享执行计划,而是每次根据具体的参数生成执行计划。
+
+**示例**
+
+如下示例中的 hint 指定了当前 SQL 不使用 plan cache 中的计划,生成的计划也不保存到 plan cache 中。
+
+```sql
+SELECT /*+USE_PLAN_CACHE(NONE)*/ *
+FROM T1
+WHERE user_id = 123456
+ and create_time > date(date_sub(now(), interval 1 day)));
+```
+
+### PARALLEL
+
+**说明**
+
+* 设置查询级别并行度。
+
+**常见用法**
+
+* 指定 SQL 执行的并行度,让查询执行期间使用更多的线程并行执行,提升查询性能。
+
+**示例**
+
+如下示例中的 hint 指定了当前 SQL 开启并行执行,并且并行度为 8。
+
+```sql
+SELECT /*+PARALLEL(8)*/ *
+FROM T1
+WHERE user_id = 123456
+ and create_time > date(date_sub(now(), interval 1 day)));
+```
+
+### INDEX
+
+**说明**
+
+* 指定表使用特定索引。
+
+**常见用法**
+
+* 当用户明确知道查询中某个表使用特定的索引过滤性极好,并且默认情况下优化器没有选到这个索引;或者明确知道查询中某个索引的过滤性不好,并且默认情况下优化器选到了这个索引时,可以通过这个 hint 指定查询中的这个表使用特定的索引。
+
+**示例**
+
+如下示例中的 hint 指定了当前 SQL 中读取 T1 表时使用索引 IDX_USER_ID。
+
+```sql
+SELECT /*+INDEX(T1 IDX_USER_ID)*/ *
+FROM T1
+WHERE user_id = 123456
+ and create_time > date(date_sub(now(), interval 1 day)));
+```
+
+### LEADING
+
+**说明**
+
+* 指定连接顺序。
+
+**常见用法**
+
+* 受统计信息过期、连接谓词存在关联性、数据非均匀分布等因素影响,优化器可能会生成不优的连接顺序。例如两表连接后的行数很少,但是优化器没有先连接这两个表;两个表连接行数非常多,但是优化器选择了先连接这两个表。此时可以通过此HINT指定表的连接顺序,让过滤性更强的连接先执行。
+
+**示例**
+
+如下示例中的 hint 指定了当前 SQL 中 T1 先于 T4 和 T2 的连接结果连接,然后再与 T3 连接。使用该 hint 生成的连接树如下所示。
+
+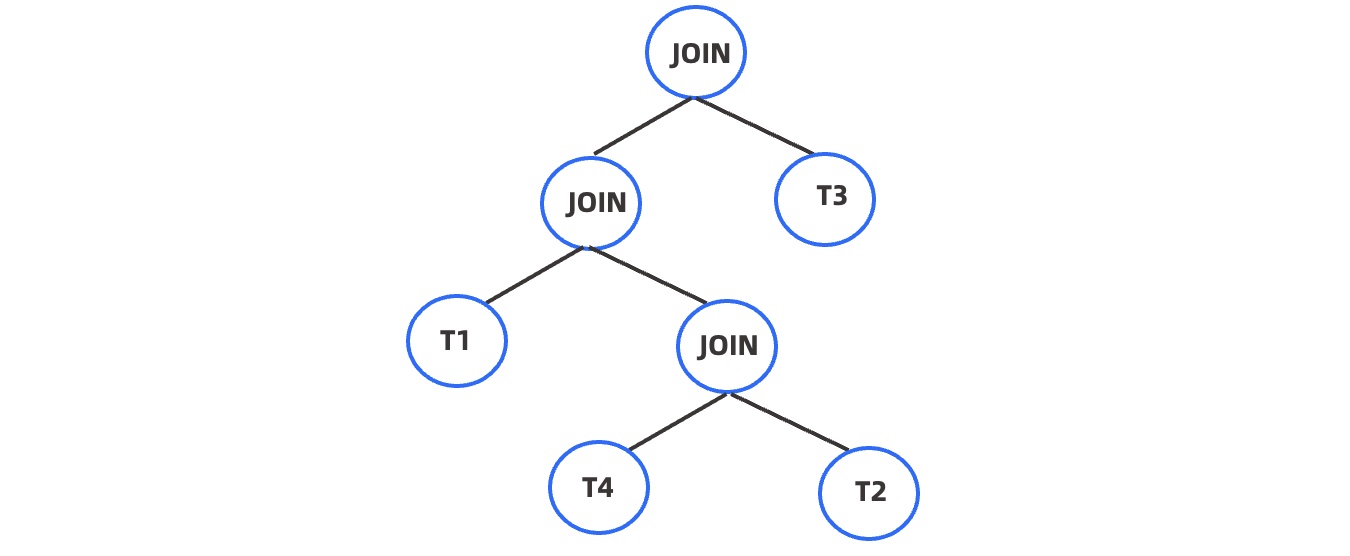
+
+```sql
+SELECT /*+leading(T1 (T4 T2) T3)*/ *
+FROM T1, T2, T3, T4
+WHERE T1.id = T2.id
+ and T2.id = T3.id
+ and T3.id = T4.id;
+```
+
+### USE_MERGE / USE_HASH / USE_NL
+
+**说明**
+
+* 指定特定表出现在连接右侧时使用 merge(USE_MERGE)、hash(USE_HASH)、nest loop(USE_NL)连接算法。
+
+**常见用法**
+
+* 当优化器错误的估计了连接驱动表的行数时,可能会选择错误的连接算法,严重影响连接的性能。此时可以通过这个 hint 指定连接的算法。需要注意的是这个 HINT 的含义是指定的表出现在连接右侧时使用指定的连接方式,因此通常需要结合 LEADING 一起使用。
+
+**示例**
+
+如下示例中的 hint 指定了两表连接时 T1 作为驱动表,T2 作为右表,并且指定 T2 作为连接右表时使用 HASH 连接算法。
+
+```sql
+SELECT /*+leading(T1 T2) USE_HASH(T2)*/ *
+FROM T1, T2
+WHERE T1.id = T2.id;
+```
+
+### PX_JOIN_FILTER
+
+**说明**
+
+* 控制 hash join 使用 join filter。
+
+**常见用法**
+
+* join filter 是 AP 类查询中减少连接表数据传输量,提升执行性能的一种有效手段。使用此 HINT 可以指定特定表作为 hash join 的右表时使用 join filter 做执行期的过滤。
+
+**示例**
+
+如下示例中的 hint 指定了两表连接时使用 HASH 连接算法,并且在 T2 表上分配出 join filter。
+
+```sql
+SELECT /*+leading(T1 T2) USE_HASH(T2) PX_JOIN_FILTER(T2)*/ *
+FROM T1, T2
+WHERE T1.id = T2.id;
+```
+## 相关文档
+
+- 有关 Hint 的详细介绍和使用方式,参见 [Hint 概述](../../700.reference/500.sql-reference/100.sql-syntax/300.common-tenant-of-oracle-mode/300.basic-elements-of-oracle-mode/600.annotation-of-oracle-mode/400.hint-of-oracle-mode/100.hint-overview-of-oracle-mode.md)。
+- 有关全量 Hint 列表和每个 Hint 的详细介绍,参见 [Hint 列表](../../700.reference/500.sql-reference/100.sql-syntax/300.common-tenant-of-oracle-mode/300.basic-elements-of-oracle-mode/600.annotation-of-oracle-mode/400.hint-of-oracle-mode/200.hint-list-of-oracle-mode/100.the-hint-related-to-the-access-path-of-oracle-mode.md)。
diff --git a/zh-CN/620.obap/600.obap-query/300.obap-auto-dop.md b/zh-CN/620.obap/600.obap-query/300.obap-auto-dop.md
new file mode 100644
index 0000000000..2ec1f74bec
--- /dev/null
+++ b/zh-CN/620.obap/600.obap-query/300.obap-auto-dop.md
@@ -0,0 +1,143 @@
+# Auto DOP
+
+为了加速查询并满足业务需求,通常以并行执行来优化查询时间。那么,并行资源为多少才合适呢?在优化器中,并行资源量可以使用并行度(DOP:Degree of Parallel)来描述,在实际业务场景中,并行是否开启及并行度大小,根据查询的执行实际情况和业务需求以经验为基础来决定。
+
+在人为指定并行度时,可以通过系统变量对当前会话中的所有执行查询开启并行,并指定并行度。然而,这对会话中本不需要并行加速或无需使用较高 DOP 的查询带来额外的并行执行开销,从而导致性能下降。另一方面,可以通过 hint 的方式来指定特定查询的并行度,但这需要对每一条业务查询进行单独考量,对于存在大量业务查询的情况,是不可行的。
+
+为了解决手动指定并行度的不便和限制,查询优化器可以通过 Auto DOP 功能在生成查询计划时评估查询需要执行的时间,自动确定是否开启并行和开启适量的并行度。这样可以避免由于手动指定并行度而导致的性能下降。
+
+
+ 注意
+
+ - 开启 Auto DOP 后,需要关注调整 parallel_min_scan_time_threshold 和 parallel_degree_limit 两个相关参数的设置,否则 Auto DOP 可能对 AP 系统有不良影响。
+ - Auto DOP 仅根据评估的查询执行开销,以减小 RT 为目标决策开启并行并计算 DOP,如果业务负载中存在用户不关注的慢查询,需要使用资源隔离手段进行处理,否则开启 Auto DOP 后,对所有查询使用 Auto DOP 给定并行度,将对系统造成不良影响。
+
+
+
+## 开启 Auto DOP
+
+优化器的 DOP 选择策略目前分为 AUTO 模式和 MANUAL 模式。AUTO 模式下优化器可以根据查询实际情况,自动选择开启并行,并确定并行度。MANUAL 模式仅能通过人为干预开启并行。
+
+优化器的 DOP 选择策略有两种控制方式,可以通过系统变量 parallel_degree_policy 进行全局或 session 级别的 DOP 选择策略配置,也通过更高优先级的 hint 进行查询级别的 DOP 选择策略配置。
+
+### 使用系统变量开启 Auto DOP
+
+
+ 注意
+ 参数类型为系统变量,全局级别修改变量后,只有新建连接可以生效,已有连接需要断连。
+
+
+```sql
+-- 在全局级别启用 Auto DOP
+set global parallel_degree_policy = AUTO;
+-- 在 session 级别启用 Auto DOP
+set session parallel_degree_policy = AUTO;
+set parallel_degree_policy = AUTO;
+
+-- 在全局级别关闭 Auto DOP
+set global parallel_degree_policy = MANUAL;
+-- 在 session 级别关闭 Auto DOP
+set session parallel_degree_policy = MANUAL;
+set parallel_degree_policy = MANUAL;
+```
+
+### 使用 Hint 开启 Auto DOP
+
+Hint 相比系统变量有更高的优先级,可以在查询级别控制开启/关闭 Auto DOP。
+
+```cpp
+-- 使用 hint 在查询级别启用 Auto DOP
+select /*+parallel(auto)*/ * from t1;
+-- 使用 hint 在查询级别关闭 Auto DOP
+select /*+parallel(manual)*/ * from t1;
+select /*+parallel(8)*/ * from t1;
+```
+
+## 相关参数设置
+
+Auto DOP 计算查询 DOP 时,最终给定的 DOP 大小受下面两个系统变量影响。在不同部署资源和业务负载条件下,也可以通过调整这两个参数干预 Auto DOP 行为。
+
+
+ 注意
+ 参数类型为系统变量,全局级别修改变量后,只有新建连接可以生效,已有连接需要断连。
+
+
+### parallel_min_scan_time_threshold
+
+parallel_min_scan_time_threshold 用于设置对基表扫描开启并行的门限值,影响是否对查询开启并行和使用 DOP 的大小。参数单位为 ms,默认值为 1000,最小值为 10。
+
+**使用场景:**
+
+调整参数大小,控制 AP 系统中开启并行查询的数量与使用的并行度。开启 Auto DOP 后,如果部分关注的查询没有开启并行,或使用并行度较小且没有达到并行度的上限,可以调小 parallel_min_scan_time_threshold 的设定值,调整后会有更多查询开启并行,已开启并行的查询也可能使用更大并行度。相反情况,可以调大参数设定值。
+
+为避免开启 Auto DOP 后大量查询以较高并行度开启并行、占用系统过多资源,参数默认值较为保守,开启 Auto DOP 一般需要评估系统负载情况,将参数调小到合适值。
+
+**示例:**
+
+```sql
+-- 设置当前 session 开启 Auto DOP 给定的最大并行度为 8
+set parallel_min_scan_time_threshold = 10;
+
+-- 设置全局使用 Auto DOP 给定的最大并行度为 8
+set global parallel_min_scan_time_threshold = 10;
+```
+
+```sql
+explain select /*+parallel(auto)*/ * from t1;
+
+-- 设置参数为 20, 最终使用 DOP 为 4, 开启并行后基表扫描评估代价为 12 ms
+set parallel_min_scan_time_threshold = 20;
+=========================================================
+|ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)|
+---------------------------------------------------------
+|0 |PX COORDINATOR | |512000 |619089 |
+|1 |└─EXCHANGE OUT DISTR |:EX10000|512000 |230501 |
+|2 | └─PX BLOCK ITERATOR| |512000 |12189 |
+|3 | └─TABLE FULL SCAN|t1 |512000 |12189 |
+=========================================================
+Outputs & filters:
+-------------------------------------
+ 0 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3, t1.c4)]), filter(nil), rowset=256
+ 1 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3, t1.c4)]), filter(nil), rowset=256
+ dop=4
+
+-- 设置参数为 10, 最终使用 DOP 为 6, 开启并行后基表扫描评估代价为 8 ms
+set parallel_min_scan_time_threshold = 10;
+=========================================================
+|ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)|
+---------------------------------------------------------
+|0 |PX COORDINATOR | |512000 |542256 |
+|1 |└─EXCHANGE OUT DISTR |:EX10000|512000 |153667 |
+|2 | └─PX BLOCK ITERATOR| |512000 |8126 |
+|3 | └─TABLE FULL SCAN|t1 |512000 |8126 |
+=========================================================
+Outputs & filters:
+-------------------------------------
+ 0 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3, t1.c4)]), filter(nil), rowset=256
+ 1 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3, t1.c4)]), filter(nil), rowset=256
+ dop=6
+```
+
+### parallel_degree_limit
+
+parallel_degree_limit 用于限制使用 Auto DOP 后能够使用的最大 DOP。默认值为 0,此时优化器会根据租户CPU 和系统变量 parallel_servers_target 限制最大 DOP。
+
+**使用场景:**
+
+AP 系统中开启 Auto DOP 后,如果出现大量需要使用较大并行度的查询,导致系统负载过高,可以通过设置 parallel_degree_limit 进一步限制允许的最大 DOP,此时根据需要将 parallel_degree_limit 设置为小于 CPU 的某个值。
+
+系统中只有单条 AP 查询执行时,parallel_degree_limit 为默认值,查询最大只能使用 CPU 数的并行度。如果有需要在 Auto DOP 下使用更大并行度,可以将 parallel_degree_limit 设为大于 CPU 数的值,解除 CPU 数对 DOP 的限制。这种调整仅限在单条 AP 查询极致性能优化时使用,生产环境禁止使用。
+
+**示例:**
+
+```sql
+-- 设置当前 session 使用 Auto DOP 给定的最大并行度为 8
+set parallel_degree_limit = 8;
+
+-- 设置全局使用 Auto DOP 给定的最大并行度为 8
+set global parallel_degree_limit = 8;
+```
+
+## 相关文档
+
+* 有关 Auto DOP 的更多信息,参见 [Auto DOP](../../700.reference/1000.performance-tuning-guide/500.sql-optimization/300.distributed-execution-plan/600.auto-dop.md)。
diff --git a/zh-CN/620.obap/600.obap-query/500.obap-bypass-import.md b/zh-CN/620.obap/600.obap-query/500.obap-bypass-import.md
new file mode 100644
index 0000000000..a1d23d8f6f
--- /dev/null
+++ b/zh-CN/620.obap/600.obap-query/500.obap-bypass-import.md
@@ -0,0 +1,115 @@
+# 全量旁路导入
+
+通过普通方式向 OceanBase 数据库导入数据之后,需要执行一次合并才能使查询性能达到较高程度。但是通过全量旁路导入向 OceanBase 数据库导入数据后无需执行合并即可达到较高的查询性能。
+
+OceanBase 数据库的旁路导入分为全量导入和增量导入两种模式。其中,全量导入模式会直接生成 major sstable,对于列存表而言,生成的 major sstable 会直接采用列存格式,从而快速响应 AP 查询。另一种模式是增量导入模式,数据会写入转储,而转储采用行存格式。为了提高 AP 查询性能,需要进行一次合并以生成列存格式。
+
+## 使用示例
+
+1. 创建表。
+
+ ```cpp
+ OceanBase(root@test)>create table lineitem(
+ l_orderkey bigint(20) NOT NULL ,
+ l_partkey bigint(20) NOT NULL ,
+ l_suppkey bigint(20) NOT NULL ,
+ l_linenumber bigint(20) NOT NULL ,
+ l_quantity bigint(20) NOT NULL ,
+ l_extendedprice decimal(10,2) NOT NULL ,
+ l_discount decimal(10,2) NOT NULL ,
+ l_tax decimal(10,2) NOT NULL ,
+ l_returnflag char(1) ,
+ l_linestatus char(1) ,
+ l_shipdate date ,
+ l_commitdate date ,
+ l_receiptdate date ,
+ l_shipinstruct char(25) ,
+ l_shipmode char(10) ,
+ l_comment varchar(44),
+ primary key(l_orderkey, l_linenumber)
+ ) with column group (each column);
+ ```
+
+ 返回结果。
+
+ ```cpp
+ Query OK, 0 row affected (0.08 sec)
+ ```
+
+2. 通过增量旁路导入方式导入数据。
+
+ ```cpp
+ OceanBase(root@test)>load data /*+ query_timeout(10000000000) parallel(64) direct(true,0,'inc_replace') */ infile '/path/to/lineitem.tbl' into table lineitem FIELDS TERMINATED BY '|' enclosed BY '' ESCAPED BY '';
+ ```
+
+ 返回结果。
+
+ ```cpp
+ Query OK, 59986052 rows affected (45.66 sec)
+ Records: 59986052 Delected: 0 Skipped: 0 Warnings: 0
+ ```
+
+3. 查询数据。
+
+ ```cpp
+ OceanBase(root@test)>select /*+ query_timeout(10000000000) */ count(*) from lineitem;
+ ```
+
+ 查询结果如下。
+
+ ```cpp
+ +----------+
+ | count(*)|
+ +----------+
+ | 59986052 |
+ +----------+
+ 1 row in set (45.42 sec)
+ ```
+
+4. 清理数据。
+
+ ```cpp
+ OceanBase(root@test)>truncate lineitem;
+ ```
+
+ 返回结果。
+
+ ```cpp
+ Query OK, 0 rows affected (0.05 sec)
+ ```
+
+5. 通过全量旁路导入方式导入数据。
+
+ ```cpp
+ OceanBase(root@test)>load data /*+ query_timeout(10000000000) parallel(64) direct(true,0) */ infile '/path/to/lineitem.tbl' into table lineitem FIELDS TERMINATED BY '|' enclosed BY '' ESCAPED BY '';
+ ```
+
+ 返回结果。
+
+ ```cpp
+ Query OK, 59986052 rows affected (1 min 3.83 sec)
+ Records: 50086052 Deleted: 0 Skipped: 0 Warnings: 0
+ ```
+
+6. 查询数据。
+
+ ```cpp
+ OceanBase(root@test)>select /*+ query_timeout(10000000000) */ count(*) from lineitem;
+ ```
+
+ 查询结果。
+
+ ```cpp
+ +----------+
+ | count(*)|
+ +----------+
+ | 59986052 |
+ +----------+
+ 1 row in set (0.01 sec)
+ ```
+
+增量旁路导入以后,查询速度暂时不是列存的速度。全量旁路导入之后,速度能达到列存的性能。
+
+## 相关文档
+
+* 有关旁路导入的详细介绍,参见 [旁路导入](../../500.data-migration/1100.bypass-import/100.overview-of-bypass-import.md)。
\ No newline at end of file
diff --git a/zh-CN/620.obap/600.obap-query/600.obap-table-group.md b/zh-CN/620.obap/600.obap-query/600.obap-table-group.md
new file mode 100644
index 0000000000..4819dd5403
--- /dev/null
+++ b/zh-CN/620.obap/600.obap-query/600.obap-table-group.md
@@ -0,0 +1,161 @@
+# 表组
+
+在分布式 AP 系统中,表的数据量通常比较多。不同表的数据随机分布的情况下,表连接时的数据传输的开销往往不可忽视。合理的使用表组可以让分区方式相同的分区表数据按照特定的规则对齐,让具有关联关系的数据聚集在同一台机器上,使得这些表连接时能够使用 Partition Wise Join 的方式执行,能够有效降低连接场景下的数据传输的开销,提升性能。
+
+## 表组介绍
+
+对于分布式数据库, 多个表中的数据可能会分布在不同的机器上, 这样在执行 Join 查询或跨表事务等复杂操作时就需要涉及跨机器的通信,而表组功能可以避免这种跨机器操作,从而提高数据库性能。
+
+作为分布式数据库,为了满足扩展性和多点写入等需求,OceanBase 数据库支持分区功能,即将一个表的数据分成多个分区来存储。表中用来参与具体数据分区的列称为分区键,通过一行数据的分区键值,对其进行 Hash 计算(数据分区的方式有多种,这里以 Hash 分区为例),能够锁定其所属的分区。
+
+让用户将分区方式相同的表聚集到一起就形成了表组(以 Hash 分区为例,分区方式相同等价于分区个数相同,当然计算分区的 Hash 算法也是一样的),表组内每个表的同号分区称为一个分区组,如下图所示。
+
+
+
+OceanBase 数据库在分区创建以及之后可能发生的负载均衡时, 会将一个分区组的分区放到一个机器,这样即便存在跨表操作,只要操作数据所在的分区是属于同一个分区组,那么就不存在跨机器的操作。那么如何保障操作的数据在同一个分区组呢?OceanBase 数据库无法干涉用户的操作,但是可以根据业务特点大概率地保障某些操作涉及的跨表数据在同一分区组中。
+
+## 使用示例一
+
+创建一个 sharding 属性为 ADAPTIVE 的表组 tg1,和两个一级分区表 tbl1、tbl2。当两个分区表连接且连接条件中包含分区键的连接条件时,可以使用 Partition Wise Join 的方式提升性能。
+
+```sql
+CREATE TABLEGROUP tg1 SHARDING = 'ADAPTIVE';
+
+CREATE TABLE tbl1 (id BIGINT PRIMARY KEY, VARCHAR(50)) TABLEGROUP = tg1
+PARTITION BY HASH(id) partitions 128;
+
+CREATE TABLE tbl2 (id BIGINT, col1 VARCHAR(50)) TABLEGROUP = tg1
+PARTITION BY HASH(id) partitions 128;
+
+SELECT count(*)
+FROM tbl1, tbl2
+where tbl1.id = tbl2.id;
+```
+
+## 使用示例二
+
+创建一个 sharding 属性为 ADAPTIVE 的表组 tg2,和两个二级分区表 tbl3、tbl4。当两个分区表连接且连接条件中包含分区键的连接条件时,可以使用 Partition Wise Join 的方式提升性能。
+
+```sql
+CREATE TABLEGROUP tg2 SHARDING = 'ADAPTIVE';
+
+CREATE TABLE tbl3 (id BIGINT PRIMARY KEY, gmt_date datetime) TABLEGROUP = tg2
+PARTITION BY RANGE(gmt_date)
+SUBPARTITION BY HASH(id) subpartitions 128
+(partition P202401 values less than(timestamp '2024-02-01 00:00:00'),
+ partition P202402 values less than(timestamp '2024-03-01 00:00:00'),
+ partition P202403 values less than(timestamp '2024-04-01 00:00:00'),
+ partition P202401 values less than(timestamp '2024-05-01 00:00:00'),
+ partition P202405 values less than(timestamp '2024-06-01 00:00:00'),
+ partition P202406 values less than(timestamp '2024-07-01 00:00:00')
+);
+
+
+CREATE TABLE tbl4 (id BIGINT, gmt_date datetime) TABLEGROUP = tg2
+PARTITION BY RANGE(gmt_date)
+SUBPARTITION BY HASH(id) subpartitions 128
+(partition P202401 values less than(timestamp '2024-02-01 00:00:00'),
+ partition P202402 values less than(timestamp '2024-03-01 00:00:00'),
+ partition P202403 values less than(timestamp '2024-04-01 00:00:00'),
+ partition P202401 values less than(timestamp '2024-05-01 00:00:00'),
+ partition P202405 values less than(timestamp '2024-06-01 00:00:00'),
+ partition P202406 values less than(timestamp '2024-07-01 00:00:00')
+);
+
+SELECT count(*)
+FROM tbl3, tbl4
+where tbl3.id = tbl4.id
+ and tbl3.gmt_date = tble4.gmt_date;
+```
+
+## 使用示例三
+
+下面是 TPCH Q9 开启 AUTO DOP 后的执行计划,其中 PART、SUPPLIER、LINEITEM、PARTSUPP、ORDERS 是分区表并且在同一个表组中,NATION 不是分区表。由于表的定义比较长,这里就不展示表定义的具体写法了。
+
+从执行计划中可以看到,PART(23 号算子)与 PARTSUPP(25 号算子)的连接(21号算子)及 ORDERS(29 号算子)与 LINEITEM(27 号算子)的连接(7 号算子)均采用了 Partition Wise Join 的方式。计划中可以很明显的看到这两个连接的左右支上不需要通过 EXCHANGE 算子进行数据传输,能够节省掉大量数据传输的开销。而 PARTSUPP(25 号算子)与 LINEITEM(27 号算子)的连接(17 号算子)没有采用 Partition Wise Join 的方式,虽然这两个表是在同一个表组内,但是由于两表的连接键不包含分区键,因此无法使用 Partition Wise Join 的方式节省数据传输的开销。
+
+```
+explain
+SELECT /*+parallel(auto)*/ NATION,
+ O_YEAR,
+ SUM(AMOUNT) AS SUM_PROFIT
+FROM
+ (SELECT N_NAME AS NATION,
+ DATE_FORMAT(O_ORDERDATE, '%Y') AS O_YEAR,
+ L_EXTENDEDPRICE*(1-L_DISCOUNT)-PS_SUPPLYCOST*L_QUANTITY AS AMOUNT
+ FROM PART,
+ SUPPLIER,
+ LINEITEM,
+ PARTSUPP,
+ ORDERS,
+ NATION
+ WHERE S_SUPPKEY = L_SUPPKEY
+ AND PS_SUPPKEY= L_SUPPKEY
+ AND PS_PARTKEY = L_PARTKEY
+ AND P_PARTKEY= L_PARTKEY
+ AND O_ORDERKEY = L_ORDERKEY
+ AND S_NATIONKEY = N_NATIONKEY
+ AND P_NAME LIKE '%%green%%') AS PROFIT
+GROUP BY NATION,
+ O_YEAR
+ORDER BY NATION,
+ O_YEAR DESC;
+
+===========================================================================================
+|ID|OPERATOR |NAME |EST.ROWS |EST.TIME(us)|
+-------------------------------------------------------------------------------------------
+|0 |PX COORDINATOR MERGE SORT | |42833 |9793228 |
+|1 |└─EXCHANGE OUT DISTR |:EX10004|42833 |9761934 |
+|2 | └─SORT | |42833 |9758876 |
+|3 | └─HASH GROUP BY | |42833 |9757694 |
+|4 | └─EXCHANGE IN DISTR | |985159 |9752609 |
+|5 | └─EXCHANGE OUT DISTR (HASH) |:EX10003|985159 |9721315 |
+|6 | └─HASH GROUP BY | |985159 |9650996 |
+|7 | └─HASH JOIN | |42590286 |9438413 |
+|8 | ├─SHARED HASH JOIN | |40579279 |8156738 |
+|9 | │ ├─EXCHANGE IN DISTR | |25 |26 |
+|10| │ │ └─EXCHANGE OUT DISTR (BC2HOST) |:EX10000|25 |26 |
+|11| │ │ └─COLUMN TABLE FULL SCAN |nation |25 |5 |
+|12| │ └─SHARED HASH JOIN | |40579279 |8006668 |
+|13| │ ├─EXCHANGE IN DISTR | |1000000 |880987 |
+|14| │ │ └─EXCHANGE OUT DISTR (BC2HOST) |:EX10001|1000000 |864431 |
+|15| │ │ └─PX PARTITION ITERATOR | |1000000 |10326 |
+|16| │ │ └─COLUMN TABLE FULL SCAN |supplier|1000000 |10326 |
+|17| │ └─SHARED HASH JOIN | |40579279 |6966307 |
+|18| │ ├─EXCHANGE IN DISTR | |5410229 |3596101 |
+|19| │ │ └─EXCHANGE OUT DISTR (BC2HOST) |:EX10002|5410229 |3426468 |
+|20| │ │ └─PX PARTITION ITERATOR | |5410229 |504193 |
+|21| │ │ └─HASH JOIN | |5410229 |504193 |
+|22| │ │ ├─JOIN FILTER CREATE |:RF0000 |1355668 |326112 |
+|23| │ │ │ └─COLUMN TABLE FULL SCAN|part |1355668 |326112 |
+|24| │ │ └─JOIN FILTER USE |:RF0000 |5410660 |30374 |
+|25| │ │ └─COLUMN TABLE FULL SCAN|partsupp|5410660 |30374 |
+|26| │ └─PX PARTITION ITERATOR | |600037902|921105 |
+|27| │ └─COLUMN TABLE FULL SCAN |lineitem|600037902|921105 |
+|28| └─PX PARTITION ITERATOR | |150000000|76768 |
+|29| └─COLUMN TABLE FULL SCAN |orders |150000000|76768 |
+===========================================================================================
+```
+
+## 相关文档
+
+有关表组的详细介绍和使用,参见以下文档:
+
+:::tab
+tab MySQL 模式
+ - [关于表组](../../700.reference/300.database-object-management/100.manage-object-of-mysql-mode/400.manage-table-groups-of-mysql-mode/100.about-table-groups-of-mysql-mode.md)
+ - [创建表组](../../700.reference/300.database-object-management/100.manage-object-of-mysql-mode/400.manage-table-groups-of-mysql-mode/200.create-a-table-group-of-mysql-mode.md)
+ - [查看表组信息](../../700.reference/300.database-object-management/100.manage-object-of-mysql-mode/400.manage-table-groups-of-mysql-mode/300.view-the-information-of-a-table-group-of-mysql-mode.md)
+ - [将表添加到表组](../../700.reference/300.database-object-management/100.manage-object-of-mysql-mode/400.manage-table-groups-of-mysql-mode/400.add-tables-to-a-table-group-of-mysql-mode.md)
+ - [修改表组的 SHARDING 属性](../../700.reference/300.database-object-management/100.manage-object-of-mysql-mode/400.manage-table-groups-of-mysql-mode/500.modify-the-sharding-attribute-ot-a-table-group-of-mysql-mode.md)
+ - [管理表组内的表](../../700.reference/300.database-object-management/100.manage-object-of-mysql-mode/400.manage-table-groups-of-mysql-mode/600.manage-tables-within-a-table-group-of-mysql-mode.md)
+ - [删除表组](../../700.reference/300.database-object-management/100.manage-object-of-mysql-mode/400.manage-table-groups-of-mysql-mode/700.delete-a-table-group-of-mysql-mode.md)
+tab Oracle 模式
+ - [关于表组](../../700.reference/300.database-object-management/200.manage-object-of-oracle-mode/300.manage-table-groups-of-oracle-mode/100.about-table-groups-of-oracle-mode.md)
+ - [创建表组](../../700.reference/300.database-object-management/200.manage-object-of-oracle-mode/300.manage-table-groups-of-oracle-mode/200.create-a-table-group-of-oracle-mode.md)
+ - [查看表组信息](../../700.reference/300.database-object-management/200.manage-object-of-oracle-mode/300.manage-table-groups-of-oracle-mode/300.view-the-information-of-a-table-group-of-oracle-mode.md)
+ - [将表添加到表组](../../700.reference/300.database-object-management/200.manage-object-of-oracle-mode/300.manage-table-groups-of-oracle-mode/400.add-tables-to-a-table-group-of-oracle-mode.md)
+ - [修改表组的 SHARDING 属性](../../700.reference/300.database-object-management/200.manage-object-of-oracle-mode/300.manage-table-groups-of-oracle-mode/500.modify-the-sharding-attribute-ot-a-table-group-of-oracle-mode.md)
+ - [管理表组内的表](../../700.reference/300.database-object-management/200.manage-object-of-oracle-mode/300.manage-table-groups-of-oracle-mode/600.manage-tables-within-a-table-group-of-oracle-mode.md)
+ - [删除表组](../../700.reference/300.database-object-management/200.manage-object-of-oracle-mode/300.manage-table-groups-of-oracle-mode/700.delete-a-table-group-of-oracle-mode.md)
+:::
diff --git a/zh-CN/620.obap/600.obap-query/700.obap-row-column-hybrid-storage.md b/zh-CN/620.obap/600.obap-query/700.obap-row-column-hybrid-storage.md
new file mode 100644
index 0000000000..8f897fb4be
--- /dev/null
+++ b/zh-CN/620.obap/600.obap-query/700.obap-row-column-hybrid-storage.md
@@ -0,0 +1,26 @@
+# 行列混存
+
+通常,我们在数据库中选择行存来满足 OLTP 业务中高频次短查询需求,选择列存满足 OLAP 业务中大量数据扫描分析。当业务即有高频次短查询,又有大量涉及大量数据的复杂分析查询时,通常选择两套数据库系统,通过 ETL、CDC、流计算等方式在两套系统间进行数据同步。并在两套系统上分别选择行存,列存以分别满足 TP 和 AP 的查询需求。业务不仅要维护多套系统的复杂度,忍受两者间的数据延迟,还要手动为每个查询选择用哪套系统支持。
+
+OcenaBase 数据库支持行列冗余表,在一套系统中同时满足 TP,AP 查询需求,没有数据延迟,也能通过优化器自动选择行存或列存。行列冗余表语法如:
+
+```sql
+CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 INT, c3 INT, c4 VARCHAR(100)) WITH COLUMN GROUP (ALL COLUMNS, EACH COLUMN)
+```
+
+这样我们建了一个 t1 表,即有行存也有列存。
+
+典型的 TP SQL,如:
+
+```sql
+UPDATE t1 SET c2 = 3, c4 = 'abc' WHERE c1 = 20445883;
+```
+
+�SQL 优化器会选择读行存。
+
+典型的 AP SQL,如:
+
+```sql
+SELECT SUM(c3) GROUP BY c2;
+```
+SQL 优化器会选择使用列存。
diff --git a/zh-CN/620.obap/70.obap-features.md b/zh-CN/620.obap/70.obap-features.md
new file mode 100644
index 0000000000..ad60b96e9b
--- /dev/null
+++ b/zh-CN/620.obap/70.obap-features.md
@@ -0,0 +1,202 @@
+# OceanBase AP 核心特性
+
+## 列存引擎
+
+在大规模数据复杂分析或海量数据即席查询场景中,列式存储是 AP 数据库的关键能力之一。列式存储是一种数据文件组织方式,区别于行式存储,它将表中的数据按照列进行物理排列。数据进行列式存储时,分析场景可仅扫描用于查询计算的列数据,避免整行扫描,减少 IO 和内存等资源使用,提升计算速度。另外按列存储也天然具备更好的数据压缩条件,更易获得较高的压缩比,减少存储空间和网络传输带宽。
+
+OceanBase 数据库从诞生起就一直坚持 LSM-Tree 架构,不断打磨功能支持了各类典型的 TP 类型业务,持续优化性能满足各种极限负载压力,积累了大量工程实践经验,打造出一套纯自主研发且有充分特色的业界领先 LSM-tree 存储引擎。常见的 OLAP 场景往往是批量写入,不会有大量随机更新,尽量保证列存组织数据是静态的,这种场景天然适合 LSM-Tree 架构。
+
+在 V4.3 版本,基于原有技术积累,OceanBase 存储引擎继续扩展,实现对列存的支持,实现存储一体化,一套代码一个架构一个 OBServer,列存数据和行存数据完美共存,这样真正实现了对 TP 类和 AP 类查询的性能的兼顾。
+
+### 整体架构
+
+OceanBase 数据库作为原生分布式数据库,用户数据默认会多副本存储,为了利用多副本的优势,为用户提供数据强校验以及迁移数据重用等进一步的增强体验,自研的 LSM-Tree 存储引擎也做了较多的针对性设计,首先每个用户数据整体可以分成两个大部分基线数据和增量数据。
+
+- **基线数据。**
+
+ 不同于其它主流 LSM-Tree 数据库,OceanBase 数据库利用分布式多副本的基础,提出'每日合并'的概念,租户会定期或者根据用户操作选择一个全局版本号,租户数据的所有副本均以这个版本完成一轮Major Compaction,最后生成这个版本的**基线数据,**所有副本同一个版本的基线数据物理完全一致。
+
+- **增量数据。**
+
+ 相对基线数据而言,用户数据在最新版本的基线数据之后所有写入数据均属于增量数据,具体来说,增量数据可以是用户刚写入 Memtable 的内存数据,也可以是已经转储为 SSTable 的磁盘数据。 对于用户数据的所有副本来说,增量数据各个副本独立维护,不保证一致,并且不同于基线数据基于指定版本生成,增量数据包含所有多版本数据。
+
+基于列存应用场景随机更新量可控的背景,**OceanBase 数据库结合自身基线数据和增量数据的特质,提出了一套对上层透明的列存实现方式**:
+
+- 基线数据存储为列存模式,增量数据保持行存,用户所有 DML 操作不受影响,上下游同步无缝接入,列存表数据仍然可以像行存表一样进行所有事务操作。
+- 列存模式下每列数据存储为一个独立 SSTable,所有列的 SSTable 组合成为一个虚拟 SSTable 作为用户的列存基线数据,如下图所示。
+- 根据用户建表指定设置,基线数据可以有行存,列存,行存列存冗余三种模式。
+
+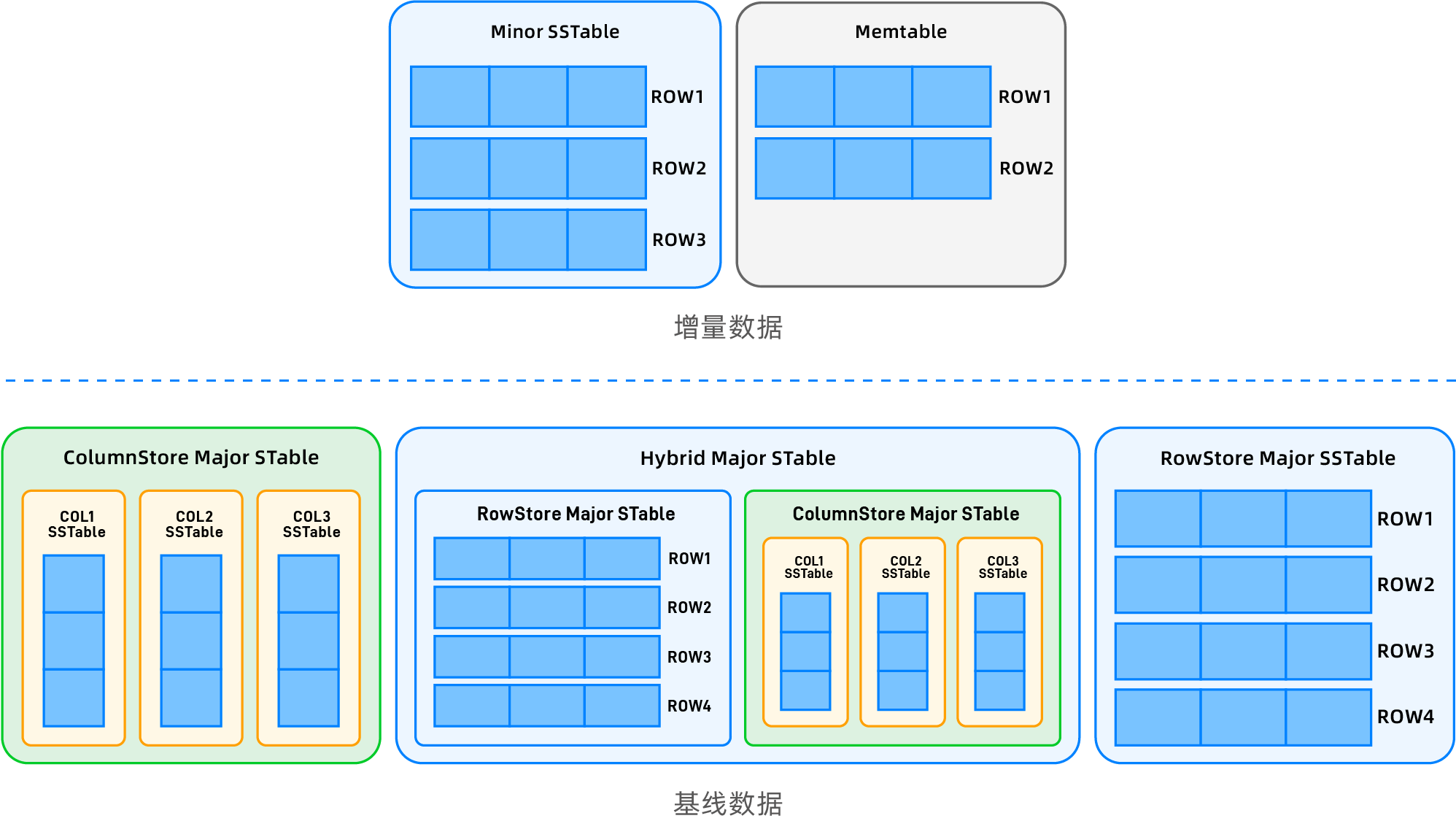
+
+我们不仅在存储引擎中实现了列存模式,为了让用户能够更容易从其它 OLAP 数据库迁移过来,以及帮助之前有 OLAP 需求的 OceanBase 客户升级到列存,从优化器到执行器以及存储其它相关模块,都针对列存进行了适配以及优化,让用户迁移到列存后基本对业务无感,能够像使用行存一样享受到列存带来的性能优势。 也让OceanBase 数据库真正实现了 TP/AP 一体化,实现一套引擎一套代码支持不同类型业务的目标,打造完善的 HTAP 引擎。
+
+
+
+- SQL一体化
+ - 为列存设计实现了新的代价模型,并增加列存相关统计信息,优化器根据数据表存储模式根据代价自动选择计划。
+ - 实现新的向量化引擎,完成关键算子的新引擎重构,不同类型计划根据代价自适应选择向量化以及批大小。
+- 存储一体化
+ - 用户数据根据表模式指定,可以根据业务负载类型灵活设置为列存行存或者行列冗余模式,用户查询/备份恢复等操作完全透明。
+ - 列存表完整支持所有在线及离线 DDL 操作,完整支持所有数据类型及二级索引创建,保证用户使用方法和行存别无二致。
+- 事务一体化
+ - 增量数据全部为行存,事务内修改、日志内容以及多版本控制等和行存完全共享逻辑。
+
+### 核心特性
+
+- **特性 1:自适应 Compaction**
+
+ 引入新的列存存储模式之后,数据合并行为和原有行存数据有较大变化,由于增量数据全部是行存,需要和基线数据合并后拆分到每个列的独立 SSTable 中,合并时间和资源占用相对行存会有较大增长。
+
+ 为了加速列存表合并速度,Compaction 流程进行大幅增强,对于列存表,除了能够像行存表一样进行水平拆分并行合并加速之外,还增加了垂直拆分加速,列存表会降多个列的合并动作放在一个合并任务内进行,并且一个任务内的列数能够根据系统资源自主选择升降,保证整体在合并速度以及内存开销达到更好的平衡。
+
+- **特性 2:列式编码算法**
+
+ OceanBase 数据库一直以来存储数据会经过两级压缩,第一级是 OceanBase 自研的行列混合编码压缩,第二级是通用压缩,其中行列混合编码由于是数据库内置算法,因此可以支持不解压直接查询,同时可以利用编码信息进行查询过滤加速,尤其对 AP 类查询会有极大的加速。
+
+ 但是原有行列混合编码算法仍然偏向行组织,因此针对列存表实现了全新的列式编码算法,相比原有编码算法,新算法支持查询的全面向量化执行,支持兼容不同指令集的 SIMD 优化,同时针对数值类型大幅提高压缩比,实现对原有算法在性能和压缩比上的全面提升。
+
+- **特性 3:Skip Index**
+
+ 常见列存数据库一般均会对每列数据按照一定的粒度进行预聚合计算,聚合的结果随数据一起持久化,当用户查询请求访问列数据时,数据库能够通过预聚合数据过滤数据,大幅减少数据访问开销,减少不必要的 IO 消耗。
+
+ 在列存引擎中,我们同样增加了 skip index 的支持,针对每列数据会按照微块粒度进行最大值、最小值、和以及 null 总量等多个维度的聚合计算,并逐层向上聚合累加获得宏块、SSTable 等更大粒度的聚合值,用户查询能够根据扫描范围不断下钻选取合适粒度聚合值进行过滤以及聚合输出。
+
+- **特性 4:查询下压**
+
+ OceanBase 数据库在 V3.2 版本开始初步支持简单的查询下压,从 V4.x 版本开始存储全面支持了向量化以及更多的下压支持,在列存引擎中,下压功能进一步得到增强和扩展,具体包括:
+
+ - 所有查询 filter 下压,同时根据 filter 类型,能够进一步利用 skip index 以及编码信息加速。
+ - 常用聚合函数的下压,非 group by 场景下,目前 count/max/min/sum/avg 等聚合函数已能下压到存储引擎。
+ - group by 下压,在 NDV 较少的列上,支持 group by 下压存储计算,利用微块内字典信息进行大幅加速。
+
+ 有关列存的详细介绍和使用指导,参见[列存](../700.reference/100.oceanbase-database-concepts/900.storage-architecture/200.data-storage/320.columnstore-engine.md)。
+
+## 全新向量引擎
+
+向量化执行是一种高效的按批处理数据的技术,在分析型查询中,向量化执行可以大大提升执行性能。OceanBase 数据库在 V3.2 版本引入了向量化执行引擎,但默认关闭。从 OceanBase 数据库 V4.0 版本开始,默认开启了向量化执行引擎,并在 OceanBase 数据库 V4.3 版本中实现了向量化引擎 2.0,通过对数据格式,算子实现优化及存储向量化优化等大幅提升了向量化引擎执行性能。
+
+### 数据格式优化
+
+向量化数据格式优化是向量化引擎 2.0 核心改进点,向量化引擎 1.0 实现中,存储层数据投影后,某列表达式一批数据在内存中的组织格式,是由多个连续数据描述单元及实际数据组成,每个数据描述单元中,均包含 null 描述,数据长度 len 及数据指针 ptr,实际数据值并不在数据单元描述中,而是存在 ptr 指向的地址,对于定长数据,存在以下几个问题:
+
+- **读写访问不够高效**
+
+ 每次访问(读/写)都需要先获取数据描述单元,然后通过数据描述单元中 ptr 访问数据,不能直接访问数据。
+
+- **内存使用更多**
+
+ 比如存放 N 行 int32_t 数据,数据描述单元结构占 12 个字节,从而总共需要 N * (12+4) 字节,而实际数据只有 N * 4 个字节,空间会放大 4 倍,导致内存访问、数据物化和数据 shuffle 时开销均更高。
+
+- **SIMD计算不够友好**
+
+ 一批数据对应的实际数据不一定连续存放,对 SIMD 的使用不够友好。
+
+- **序列化/物化开销更多**
+
+ 在进行数据序列化和数据物化时,需要进行指针的 swizzling,即将指针转换为相对偏移。
+
+
+
+为优化向量化 1.0 数据格式带来的以上不足,向量化引擎 2.0 中,实现了新的按列的数据格式。将数据描述信息 null、len、ptr 信息,分别按列的方式,分开连续存放,避免数据信息冗余存储,针对不同数据类型和使用场景,实现了 3 种数据格式:定长数据格式、 变长离散格式、变长连续格式。
+
+- **定长数据格式**
+
+ 只需要 null bitmap 和连续的数据信息、length 信息,只需要存放一份 length 值,不需要一批数据中每个数据冗余存放相同值,也不再需要间接访问的指针信息。相比以前向量化 1.0 数据格式,数据信息没有冗余存放,更加节省空间;可以直接访问,并且访问数据局部性更好;数据能确保连续存放,对于 SIMD 使用也更友好;此外在进行物化及序列化时,不需要对数据进行指针的 swizzling 操作,效率更高。
+
+- **变长离散格式**
+
+ 是指一批数据中,每个数据在内存中存放可能是不连续的,每个数据使用数据地址指针和长度描述,长度信息和指针信息,分别按列的方式连续存放;使用这种格式,存储层如果是编码数据,投影时不需要深拷贝数据,只需要投影 len 和 ptr 信息,并且对于短路计算场景,一批数据可能仅计算其中几行,这时也可以使用该格式描述并且不需要重整数据。
+
+- **变长连续格式**
+
+ 是指数据是连续存放在内存中的,每个数据的长度信息和偏移地址,使用 offset 数组描述,该描述格式,相比离散格式,在数据组织时,需要确保数据连续,对数据访问和数据按批 copy 效率更高,不过对于短路计算场景及列存编码数据投影不是很友好,需要对数据进行数据重整及深拷贝,当前该格式主要用于按列物化场景。
+
+### 算子及表达式性能优化
+
+向量化引擎 2.0,对算子及表达式实现进行了全面优化,主要优化思路是基于新的格式,使用 batch 数据属性信息、算法数据结构优化及特化实现,从而减少 CPU 数据 Cache Miss,降低 CPU 分支预测错误及 CPU 指令开销,提升整体执行性能;向量化 2.0 将 Sort、Hash Join、Hash Group By、数据 Shuffle、聚合计算等算子和表达式按新格式进行了重新设计与实现,整体计算性能全面提升。
+
+- **利用 batch 数据属性信息**
+
+ 向量化引擎 2.0,维护了执行过程中过程中,batch 数据的特征信息,包括是否不存在 null,是否 batch 中行均不需要被过滤等信息,利用这些信息,可大大加速表达式计算,比如 NULL 如果不存在,则表达式计算过程中不需要考虑对 NULL 的特殊处理,如果数据行均没有被过滤,则不需要计算时每行去判断是否已经被过滤,并且数据是连续的,没有被过滤,对使用 SIMD 计算也更友好。
+
+- **算法及数据结构优化**
+
+ 在算法及数据结构优化方面,实现了更加紧凑的中间结果物化结构,支持按行/列物化数据,空间更省,访问也更更加高效;Sort 算子实现了 sort key 与非 sort key 分离物化,结合对 sort key 保序编码(将多列数据编码为 1 列,可直接使用 memcpy 进行比较),Sort 在比较过程中访问数据 Cache Miss 更低,比较计算本身更快,整体排序效率更高;HashGroupBy 对 Hash 表结构均进行了优化,HashBucket 中数据存放更加紧凑,并对低基数 Group Key 使用 ARRAY 优化,分组及聚合结果内存连续存放等优化等。
+
+- **特化实现优化**
+
+ 特化实现优化,主要是利用模版针对不同场景进行更加高效的实现,比如 Hash Join 特化实现了将多列定长 join key 编码为一个定长列,并且将 join key 数据放入到 bucket 中,对数据预期也进行了优化,减少了多列数据访问时数据 Cache Miss;支持聚合计算特化实现,不同的聚合计算进行特化分开实现,从而减少每次计算聚合函数指令及分支判断,执行效率大幅提升。
+
+### 存储向量化优化
+
+存储层全面支持新的向量化格式,对于投影、谓词下压、聚合下压和 groupby下压更多地使用 SIMD。投影定长和变长数据时,按列类型、列长度,以及是否包含 null 等信息定制化模板,按批浅拷投影。计算下压谓词时,对于简单的谓词计算,直接在列编码上进行;复杂的谓词,投影成新向量化格式在表达式上按批计算。聚合下压充分利用了中间层的预聚合信息,如 count、sum、max、min 等。groupby 下压则利用充分利用编码数据信息,对于字典类型的编码,加速效果非常明显。
+
+## 物化视图
+
+物化视图是支撑 AP 业务的一个关键特性,它通过预计算和存储视图的查询结果,减少实时计算来提升查询性能,简化复杂查询逻辑,常用于快速报表生成和数据分析场景。因为物化视图需要存储查询结果集来优化查询性能,而物化视图与基础表之间存在数据依赖关系,每当基础表数据发生变动时,物化视图中的数据必须进行相应更新以保持同步,所以新版本也引入了物化视图刷新机制,包括全量刷新和增量刷新两种策略。全量刷新是一种较为直接的方式,每次执行刷新操作时,系统会重新执行物化视图对应的查询语句,完整地计算并覆盖原有的视图结果数据,这种方式适用于数据量相对较小的场景。相对来讲,增量刷新仅需处理自上次刷新以来发生变更的部分。为了实现精确的增量刷新,OceanBase 实现了类似 Oracle MLOG(Materialized View Log)的物化视图日志功能,通过日志详细跟踪记录基础表的增量更新数据,从而确保物化视图能够进行快速增量刷新。增量刷新方式尤其适用于数据量庞大且变更频繁的业务场景。
+
+物化视图场景使用示例:
+
+- 数据汇总:汇总每天、每周或每月的销售数据、统计用户行为数据等
+- 统计信息报表数据生成:报表系统需要定期生成固定格式的数据报告
+- 复杂查询优化:对于特别消耗资源查询,如:JOIN操作,可以将结果物化避免查询重复计算
+- 分发数据
+- 监控数据的预聚合
+
+有关物化视图的详细介绍和使用指导,参见 [物化视图概述(MySQL 模式)](../700.reference/300.database-object-management/100.manage-object-of-mysql-mode/600.manage-views-of-mysql-mode/200.manage-materialized-views-of-mysql-mode/100.materialized-views-of-mysql-mode/100.materialized-views-overview-of-mysql-mode.md) 和 [物化视图概述(Oracle 模式)](../700.reference/300.database-object-management/200.manage-object-of-oracle-mode/500.manage-views-of-oracle-mode/200.manage-materialized-views-of-oracle-mode/100.materialized-views-of-oracle-mode/100.materialized-views-overview-of-oracle-mode.md)。
+
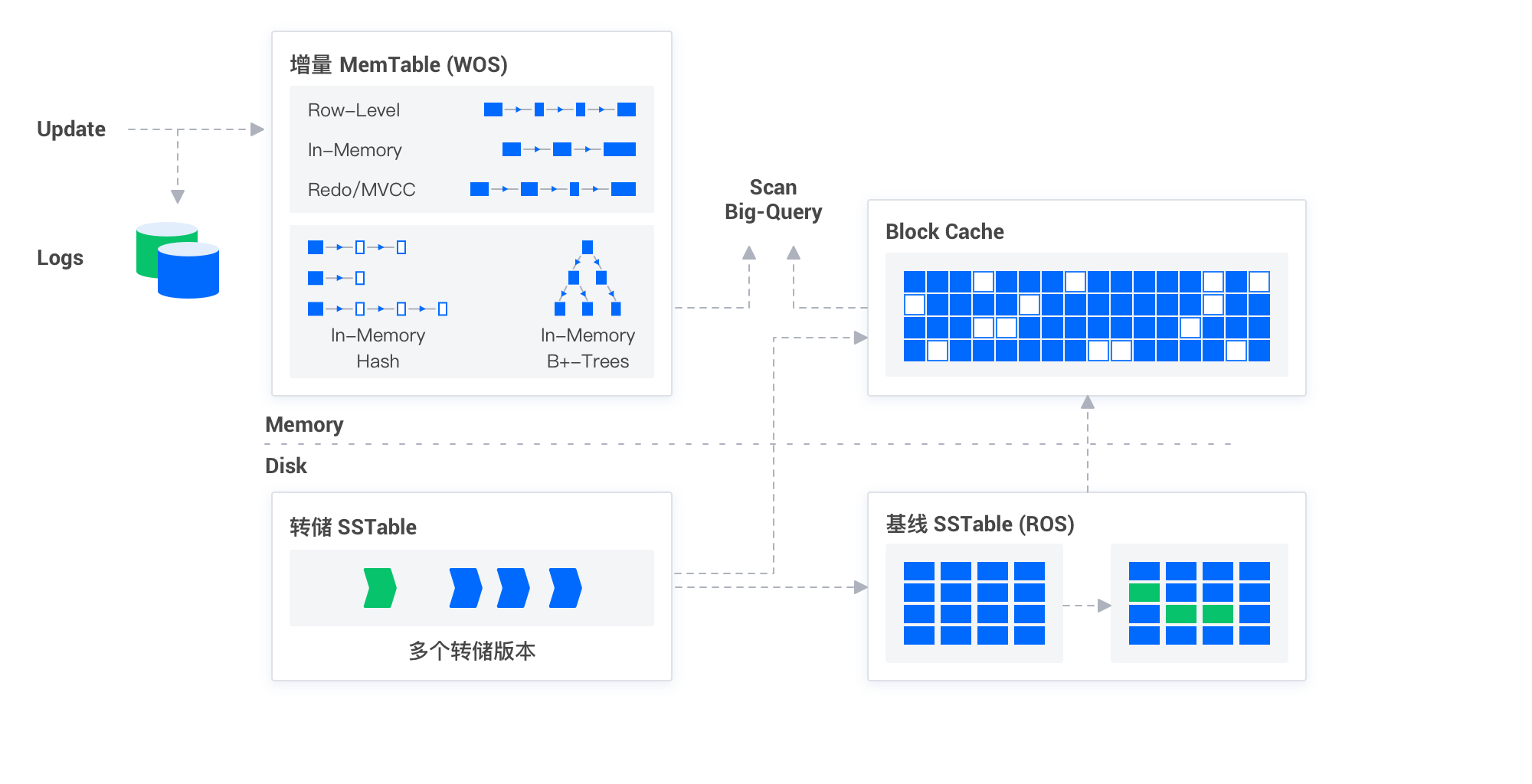
+## 实时写入
+
+OceanBase 是一个高性能、高可用的分布式关系数据库系统,采用了独特的存储架构设计来满足现代应用的需求。为应对大规模数据的写入和分析处理,OceanBase 引入了列式存储与 LSM-Tree (Log-Structured Merge-tree) 结构相结合的技术。这一设计不仅保证了数据库的实时写入能力,同时也优化了分析查询的性能。下面将对 OceanBase 的实时写入能力进行详细介绍。
+
+### 核心存储机制
+
+#### 列式存储
+
+OceanBase 数据库通过引入列式存储机制,优化了数据库的分析处理能力。在列式存储中,数据以列的形式独立存储,这使得在进行数据分析查询时,系统可以高效地读取相关列的数据,大幅降低了不必要的I/O操作,提高了查询效率。同时,列式存储还有利于数据的压缩和编码,进一步优化了数据存储空间的使用效率。
+
+#### LSM-Tree
+
+为了支持高效的实时写入,OceanBase 采用了 LSM-Tree 结构来存储增量数据。LSM-Tree 是一种特殊的树结构,专为优化写入操作而设计。其核心思想是先将写入操作记录在内存中的结构里,待到一定量后再异步批量写入磁盘,这样大大减少了磁盘I/O的次数,提高了写入性能。OceanBase 将这些增量数据定期通过转储、合并过程与基线数据合并,确保数据的一致性和完整性。
+
+### 实时写入能力
+
+OceanBase 数据库的这种结合列式存储和 LSM-Tree 架构的设计,使得它在处理实时数据写入时表现出卓越的性能。无论是小量的数据更新还是大量的数据导入,OceanBase 数据库都能快速响应,保证数据的实时写入。其主要体现在以下几个方面:
+
+1. **高效的写入处理**:通过 LSM-Tree,OceanBase 将写入操作集中处理,减少了磁盘操作,提升了写入效率。
+2. **数据的即时可查性**:数据一旦被写入 LSM-Tree 的内存结构,即可对外提供查询,保证了数据的实时性。
+3. **优化的数据合并过程**:通过智能的转储和合并策略,OceanBase 保证了底层存储的数据总是最新、最优的状态,支持高效查询。
+4. **强大的并发处理能力**:利用分布式架构,OceanBase 可以在多节点上并行处理写入操作,极大提升了实时数据处理的能力。
+
+
+
+## MySQL 生态兼容
+
+在追求极致性能与扩展性的同时,OceanBase 数据库还致力于提供与 MySQL 生态系统的高度兼容性,从而让广大 MySQL 用户能够无缝迁移至 OceanBase 数据库,并充分利用现有的 OLAP 生态工具与技术栈,实现数据分析与业务洞察的快速迭代与创新。
+
+语法兼容性:OceanBase 数据库全面支持 MySQL 的 SQL 标准语法,包括但不限于数据定义语言(DDL)、数据操作语言(DML)以及数据控制语言(DCL)。这意味着,如果您之前使用MySQL编写的数据查询、表结构定义、索引创建、权限管理等语句,几乎可以直接在 OceanBase 数据库上运行,无需进行大量语法调整,大大降低了迁移成本和学习曲线。
+
+- **无缝迁移**:现有 MySQL 应用可以快速迁移到 OceanBase 数据库,减少迁移过程中的代码修改工作量。
+- **技能复用**:MySQL 开发人员和 DBA 无需额外学习新的数据库语法,缩短适应周期。
+- **生态融合**:与 MySQL 生态兼容的语法基础,使得 OceanBase 数据库能更好地融入现有的 BI、ETL、数据可视化等工具链中。
+
+视图兼容性:OceanBase 兼容了 MySQL 的 information_schema 视图,例如:
+
+- **表信息查询**:支持如 TABLES、COLUMNS 视图,用户可以查询数据库中所有表的结构、列信息,这对于数据字典管理和第三方工具的集成至关重要。
+- **权限管理**:支持 SCHEMATA、SCHEMA_PRIVILEGES 等视图,帮助管理员便捷地查看和管理数据库、表的权限设置。
+
+许多数据库管理、监控和分析工具依赖 INFORMATION_SCHEMA 来获取数据库状态和架构信息。OceanBase 数据库的这一兼容特性,使得这些工具可以直接在 OceanBase 数据库上运行,无需定制适配。OceanBase 数据库支持各类 OLAP 生态工具,例如:
+
+**BI 工具**
+
+- **Tableau**:作为业界领先的商业智能工具,Tableau 广泛用于数据可视化分析。OceanBase 数据库的 MySQL 兼容性使得 Tableau 可以直接连接数据库,利用 SQL 查询快速构建仪表盘和报告。
+- **Quick BI**:阿里云 Quick BI 是一款高效的企业级大数据分析和展现工具,助力用户快速搭建数据门户、制作交互式报表,灵活分析数据,驱动业务智能化决策。OceanBase 数据库的 MySQL 兼容性使得 Quick BI 可以直接连接数据库。
+- **Fine BI**:帆软 FineBI 是自助式数据分析平台,提供强大的数据处理、可视化分析能力,支持多种数据源接入,帮助企业轻松实现数据到价值的快速转化。OceanBase 数据库已完成了对其验证和适配。
+
+**ETL 工具**
+
+- **Apache Flink**:Apache Flink 是开源流处理和批处理统一框架,擅长高吞吐、低延迟的数据流处理,支持事件时间处理和状态管理。与 OceanBase 数据库兼容,Flink 用户可无缝对接,实现实时数据分析与存储,加强 OLAP 能力。
+
+OceanBase 数据库与 MySQL OLAP 生态的深度兼容,不仅为用户提供了平滑迁移的路径,还保障了在不牺牲原有技术投资的基础上,能够充分利用丰富的 OLAP 生态工具,加速数据分析与业务决策过程。
+
+关于目前 OceanBase 的 OLAP 生态集成情况,参见 [生态集成](../620.obap/900.obap-integrations.md)。
diff --git a/zh-CN/620.obap/700.performance-tuning/100.dbms-xplan.md b/zh-CN/620.obap/700.performance-tuning/100.dbms-xplan.md
new file mode 100644
index 0000000000..f7045f4bff
--- /dev/null
+++ b/zh-CN/620.obap/700.performance-tuning/100.dbms-xplan.md
@@ -0,0 +1,544 @@
+# 诊断实践:使用 DBMS_XPLAN 系统包进行性能诊断
+
+DBMS_XPLAN 系统包提供了逻辑计划管理相关的功能,包括逻辑计划优化追踪等。
+
+## 系统包介绍
+
+### display_cursor
+
+#### 功能介绍
+
+OceanBase 数据库会保存用户执行过的所有查询的计划,包括物理计划以及逻辑计划,用户后续排查问题使用。为了方便用户解读历史查询计划,OceanBase 数据库提供了相关了 DBMS 包格式化计划。不同于 explain 的计划,用户执行过的计划会一直保存在数据库中,即使用户断开连接。只有当用户重启集群时,数据库才会清理保存的查询计划。
+
+#### 相关包函数说明
+
+```sql
+-- display sql plan table`s plan
+function display_cursor(plan_id integer default 0, -- default value: last plan
+ format varchar2 default 'TYPICAL',
+ svr_ip varchar2 default null, -- default value: server connected by client
+ svr_port integer default 0, -- default value: server connected by client
+ tenant_id integer default 0 -- default value: current tenant
+ )
+return dbms_xplan_type_table;
+```
+
+参数说明:
+
+- plan_id:计划 ID,如果不指定,表示上一次执行的计划。
+- format:计划的格式,同上。
+- svr_ip、svr_port:计划所在的节点 IP,默认是 session 连接的节点 IP。
+- tenant_id:计划所属租户 ID,默认是 session 当前连接的租户。
+
+#### 相关数据字典说明
+
+计划信息存放所在的数据字典为 __all_virtual_sql_plan,每个租户下也有对应的系统视图 gv$ob_sql_plan(当前租户所有机器的计划)、v$ob_sql_plan(当前租户在当前机器的计划)。
+
+```sql
++--------------------+---------------------+------+-----+---------+-------+
+| Field | Type | Null | Key | Default | Extra |
++--------------------+---------------------+------+-----+---------+-------+
+| tenant_id | bigint(20) | NO | PRI | NULL | |
+| plan_id | bigint(20) | NO | PRI | NULL | |
+| svr_ip | varchar(46) | NO | PRI | NULL | |
+| svr_port | bigint(20) | NO | PRI | NULL | |
+| sql_id | varchar(32) | NO | | NULL | |
+| db_id | bigint(20) | NO | | NULL | |
+| plan_hash | bigint(20) unsigned | NO | | NULL | |
+| gmt_create | timestamp(6) | NO | | NULL | |
+| operator | varchar(255) | NO | | NULL | |
+| options | varchar(255) | NO | | NULL | |
+| object_node | varchar(40) | NO | | NULL | |
+| object_id | bigint(20) | NO | | NULL | |
+| object_owner | varchar(128) | NO | | NULL | |
+| object_name | varchar(128) | NO | | NULL | |
+| object_alias | varchar(261) | NO | | NULL | |
+| object_type | varchar(20) | NO | | NULL | |
+| optimizer | varchar(4000) | NO | | NULL | |
+| id | bigint(20) | NO | | NULL | |
+| parent_id | bigint(20) | NO | | NULL | |
+| depth | bigint(20) | NO | | NULL | |
+| position | bigint(20) | NO | | NULL | |
+| search_columns | bigint(20) | NO | | NULL | |
+| is_last_child | bigint(20) | NO | | NULL | |
+| cost | bigint(20) | NO | | NULL | |
+| real_cost | bigint(20) | NO | | NULL | |
+| cardinality | bigint(20) | NO | | NULL | |
+| real_cardinality | bigint(20) | NO | | NULL | |
+| bytes | bigint(20) | NO | | NULL | |
+| rowset | bigint(20) | NO | | NULL | |
+| other_tag | varchar(4000) | NO | | NULL | |
+| partition_start | varchar(4000) | NO | | NULL | |
+| partition_stop | varchar(4000) | NO | | NULL | |
+| partition_id | bigint(20) | NO | | NULL | |
+| other | varchar(4000) | NO | | NULL | |
+| distribution | varchar(64) | NO | | NULL | |
+| cpu_cost | bigint(20) | NO | | NULL | |
+| io_cost | bigint(20) | NO | | NULL | |
+| temp_space | bigint(20) | NO | | NULL | |
+| access_predicates | varchar(4000) | NO | | NULL | |
+| filter_predicates | varchar(4000) | NO | | NULL | |
+| startup_predicates | varchar(4000) | NO | | NULL | |
+| projection | varchar(4000) | NO | | NULL | |
+| special_predicates | varchar(4000) | NO | | NULL | |
+| time | bigint(20) | NO | | NULL | |
+| qblock_name | varchar(128) | NO | | NULL | |
+| remarks | varchar(4000) | NO | | NULL | |
+| other_xml | varchar(4000) | NO | | NULL | |
++--------------------+---------------------+------+-----+---------+-------+
+```
+
+### display_active_session_plan
+
+#### 功能介绍
+
+典型的应用场景:当用户在执行一条大 SQL 时,当前连接执行了很久,用户想要了解查询执行的情况,例如执行计划、执行进程。在这种情况下,由于当前 session 被大 SQL 占用,需要开启一条新连接,通过 show full processlist 命令找到该大 SQL 所在的 session,使用 session_id 以及 display_active_session_plan 展示大 SQL 的执行详情。
+
+#### 相关包函数说明
+
+```sql
+-- disable real time plan
+function display_active_session_plan(
+ session_id integer default 0,
+ format varchar2 default 'TYPICAL',
+ svr_ip varchar2 default null, -- default value: server connected by client
+ svr_port integer default 0 -- default value: server connected by client
+ )
+return dbms_xplan_type_table;
+```
+
+- session_id:用户连接的 session id,注意不是 proxy session id,是 server 的 session id。
+- format:计划格式,同上。
+- svr_ip、svr_port:session 所在的节点 IP,默认是当前 session 连接的节点 IP。
+
+### enable_opt_trace
+
+#### 功能介绍
+
+优化器生成计划的过程非常复杂,排查次优计划问题需要花费大量时间收集相关信息。本功能设计了一套优化器全链路追踪机制,能够一次收集优化器生成计划所需的完整信息,方便分析生成次优计划的问题。该功能包含以下追踪信息:
+
+- **env:**
+ - 系统信息、session 信息
+ - 用户 SQL
+ - 优化器相关变量信息
+- **transformer:**
+ - 每个改写规则报告改写前后的 SQL
+ - 每个改写规则发生改写或不发生改写的详细原因(hint 控制还是什么条件不满足)
+- **optimizer:**
+ - 使用的统计信息
+ - 基表路径生成日志(包括过程条件、行数、代价估计信息,skyline 剪枝规则过程)
+ - join order 枚举的详细过程
+ - top 算子的分配、优化过程
+
+#### 相关包函数说明
+
+**DBMS_XPLAN.ENABLE_OPT_TRACE**
+
+```sql
+DEFAULT_INENTIFIER constant VARCHAR2(20) := '';
+DEFAULT_LEVEL constant INT := 1;
+PROCEDURE enable_opt_trace(
+ sql_id IN VARCHAR2 DEFAULT '',
+ identifier IN VARCHAR2 DEFAULT DEFAULT_INENTIFIER,
+ level IN INT DEFAULT DEFAULT_LEVEL
+);
+```
+
+DBMS_XPLAN.ENABLE_OPT_TRACE 函数用于开启优化器全链路追踪,开启之后,当前 session 的每个计划生成过程都会追踪。
+
+参数介绍:
+
+- sql_id 用于标记需要追踪的 SQL,例如当前测试需要跑pl程序,同时希望只追踪 PL 函数内特定的 SQL,可以通过设置 sql_id 标记。一旦设置了 sql_id,只会追踪特定的 SQL,否则追踪所有的 SQL。
+- level 用于设置追踪的级别。
+ - 0: 默认行为。
+ - 1: 额外打印每个模块的使用的内存、时间。
+ - 2: 额外打印每个改写 query block 对应的 SQL,无论发不发生改写。
+
+
+ 注意
+ level 是数据库关键字,使用时 Oracle 租户需要使用双引号包裹,MySQL 租户需要使用 ` 包裹。
+
+- identifier 用于标记 trace 文件后缀,方便用户查找自己的 trace 文件。
+
+**DBMS_XPLAN.DISABLE_OPT_TRACE**
+
+```sql
+PROCEDURE disable_opt_trace;
+```
+
+DBMS_XPLAN.DISABLE_OPT_TRACE 用于关闭当前 session 的优化器全链路追踪功能。
+
+**DBMS_XPLAN.SET_OPT_TRACE_PARAMETER**
+
+```sql
+PROCEDURE set_opt_trace_parameter(
+ sql_id IN VARCHAR2 DEFAULT '',
+ identifier IN VARCHAR2 DEFAULT DEFAULT_INENTIFIER,
+ level IN INT DEFAULT DEFAULT_LEVEL
+);
+```
+
+DBMS_XPLAN.SET_OPT_TRACE_PARAMETER 用于修改当前 session 的优化器全链路追踪的参数。
+
+## 典型场景诊断
+
+### 查询可以执行结束,但是执行很慢
+
+**收集查询执行详情信息:**
+
+:::tab
+tab Oracle 租户使用示例
+ 1. Proxy“保持”会话。
+
+ ```sql
+ SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
+ ```
+
+ 2. 执行查询。
+
+ ```sql
+ select * from t1;
+ ```
+
+ 3. 使用 DBMS_XPLAN 包查看上一个计划。
+
+ ```sql
+ select * from table(dbms_xplan.display_cursor(format=>'all'));
+
+ +--------------------------------------------------------------------------------------------------+
+ | COLUMN_VALUE |
+ +--------------------------------------------------------------------------------------------------+
+ | ================================================================================================ |
+ | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)|REAL.ROWS|REAL.TIME(us)|IO TIME(us)|CPU TIME(us)| |
+ | ------------------------------------------------------------------------------------------------ |
+ | |0 |TABLE FULL SCAN|T1 |1 |2 |0 |0 |0 |0 | |
+ | ================================================================================================ |
+ | Outputs & filters: |
+ | ------------------------------------- |
+ | 0 - output([T1.C1]), filter(nil), rowset=256 |
+ | access([T1.C1]), partitions(p0) |
+ | is_index_back=false, is_global_index=false, |
+ | range_key([T1.__pk_increment]), range(MIN ; MAX)always true |
+ +--------------------------------------------------------------------------------------------------+
+ ```
+tab MySQL 租户使用示例
+ 1. Proxy“保持”会话。
+
+ ```sql
+ SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
+ ```
+
+ 2. 执行查询。
+
+ ```sql
+ select * from t1;
+ ```
+
+ 3. 使用 DBMS_XPLAN 包配合 sql_audit 查看上一个计划。
+
+ ```sql
+ select dbms_xplan.display_cursor(0, 'all');
+
+ +--------------------------------------------------------------------------------------------------+
+ | COLUMN_VALUE |
+ +--------------------------------------------------------------------------------------------------+
+ | ================================================================================================ |
+ | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)|REAL.ROWS|REAL.TIME(us)|IO TIME(us)|CPU TIME(us)| |
+ | ------------------------------------------------------------------------------------------------ |
+ | |0 |TABLE FULL SCAN|T1 |1 |2 |0 |0 |0 |0 | |
+ | ================================================================================================ |
+ | Outputs & filters: |
+ | ------------------------------------- |
+ | 0 - output([T1.C1]), filter(nil), rowset=256 |
+ | access([T1.C1]), partitions(p0) |
+ | is_index_back=false, is_global_index=false, |
+ | range_key([T1.__pk_increment]), range(MIN ; MAX)always true |
+ +--------------------------------------------------------------------------------------------------+
+ ```
+:::
+
+### 查询执行很慢,执行很久不结束
+
+**收集计划执行详情信息:**
+
+:::tab
+tab Oracle 租户使用示例
+ 1. 连接 A 执行慢 SQL。
+
+ ```sql
+ select count(*) from table(generator(100000)) A, table(generator(10000))B;
+ ```
+
+ 2. 系统租户登录,查询 `__all_virtual_processlist`,找到正在执行慢 SQL 的 session 信息(seesion_id, svr_ip, svr_port)。
+
+ ```sql
+ select id, svr_ip, svr_ip, svr_port, info from __all_virtual_processlist where info like "%select%"\G
+
+ id: 3221489189
+ svr_ip: 11.162.218.196
+ svr_port: 50000
+ info: select count(*) from table(generator(100000)) A, table(generator(10000))B
+ ```
+
+ 3. 展示 session 计划详情。
+
+ ```sql
+ select dbms_xplan.display_active_session_plan(3221668463, 'all', '11.162.218.196', 50000);
+ +--------------------------------------------------------------------------------------------------------------------+
+ | COLUMN_VALUE |
+ +--------------------------------------------------------------------------------------------------------------------+
+ | ============================================================================================================== |
+ | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)|REAL.ROWS|REAL.TIME(us)|IO TIME(us)|CPU TIME(us)| |
+ | -------------------------------------------------------------------------------------------------------------- |
+ | |0 |SCALAR GROUP BY | |1 |1794 |0 |0 |0 |0 | |
+ | |1 |└─NESTED-LOOP JOIN CARTESIAN | |39601 |1076 |0 |0 |0 |0 | |
+ | |2 | ├─FUNCTION_TABLE |A |199 |1 |0 |0 |0 |0 | |
+ | |3 | └─MATERIAL | |199 |80 |0 |0 |0 |0 | |
+ | |4 | └─FUNCTION_TABLE |B |199 |1 |0 |0 |0 |0 | |
+ | ============================================================================================================== |
+ | Outputs & filters: |
+ | ------------------------------------- |
+ | 0 - output([T_FUN_COUNT(*)]), filter(nil), rowset=256 |
+ | group(nil), agg_func([T_FUN_COUNT(*)]) |
+ | 1 - output(nil), filter(nil), rowset=256 |
+ | conds(nil), nl_params_(nil), use_batch=false |
+ | 2 - output(nil), filter(nil) |
+ | value(GENERATOR(cast(:0, BIGINT(-1, 0)))) |
+ | 3 - output(nil), filter(nil), rowset=256 |
+ | 4 - output(nil), filter(nil) |
+ | value(GENERATOR(cast(:1, BIGINT(-1, 0)))) |
+ +--------------------------------------------------------------------------------------------------------------------+
+ ```
+tab MySQL 租户使用示例
+ 1. 连接 A 执行慢SQL。
+
+ ```sql
+ select count(*) from table(generator(100000)) A, table(generator(10000))B;
+ ```
+
+ 2. 系统租户登录,查询 `__all_virtual_processlist`,找到正在执行慢 SQL 的 session 信息(seesion_id, svr_ip, svr_port)。
+
+ ```sql
+ select id, svr_ip, svr_ip, svr_port, info from __all_virtual_processlist where info like "%select%"\G
+
+ id: 3221489189
+ svr_ip: 11.162.218.196
+ svr_port: 50000
+ info: select count(*) from table(generator(100000)) A, table(generator(10000))B
+ ```
+
+ 3. 展示 session 计划详情。
+
+ ```sql
+ select dbms_xplan.display_active_session_plan(3221668463, 'all', '11.162.218.196', 50000);
+ +--------------------------------------------------------------------------------------------------------------------+
+ | COLUMN_VALUE |
+ +--------------------------------------------------------------------------------------------------------------------+
+ | ============================================================================================================== |
+ | |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)|REAL.ROWS|REAL.TIME(us)|IO TIME(us)|CPU TIME(us)| |
+ | -------------------------------------------------------------------------------------------------------------- |
+ | |0 |SCALAR GROUP BY | |1 |1794 |0 |0 |0 |0 | |
+ | |1 |└─NESTED-LOOP JOIN CARTESIAN | |39601 |1076 |0 |0 |0 |0 | |
+ | |2 | ├─FUNCTION_TABLE |A |199 |1 |0 |0 |0 |0 | |
+ | |3 | └─MATERIAL | |199 |80 |0 |0 |0 |0 | |
+ | |4 | └─FUNCTION_TABLE |B |199 |1 |0 |0 |0 |0 | |
+ | ============================================================================================================== |
+ | Outputs & filters: |
+ | ------------------------------------- |
+ | 0 - output([T_FUN_COUNT(*)]), filter(nil), rowset=256 |
+ | group(nil), agg_func([T_FUN_COUNT(*)]) |
+ | 1 - output(nil), filter(nil), rowset=256 |
+ | conds(nil), nl_params_(nil), use_batch=false |
+ | 2 - output(nil), filter(nil) |
+ | value(GENERATOR(cast(:0, BIGINT(-1, 0)))) |
+ | 3 - output(nil), filter(nil), rowset=256 |
+ | 4 - output(nil), filter(nil) |
+ | value(GENERATOR(cast(:1, BIGINT(-1, 0)))) |
+ +--------------------------------------------------------------------------------------------------------------------+
+ ```
+:::
+
+### 计划生成时间很长,或者计划生成过程中爆内存不足,生成了非预期的计划
+
+**收集查询优化信息:**
+
+:::tab
+tab Oracle 租户使用示例
+ 1. Proxy“保持”会话。
+
+ ```sql
+ SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
+ ```
+
+ 2. 开启当前 session 的优化器追踪功能。
+
+ ```sql
+ call dbms_xplan.enable_opt_trace();
+ ```
+
+ 3. 设置追踪日志的 level 和日志文件后缀。
+
+ ```sql
+ call dbms_xplan.set_opt_trace_parameter(identifier=>'trace_test', "level"=>3);
+ ```
+
+ 4. 查询计划。
+
+ ```sql
+ explain select * from t1;
+ ```
+
+ 5. 在 `observer` 日志目录下查看 `trace_test` 为后缀的追踪日志。
+
+ ```shell
+ vi /home/admin/oceanbase/log/optimizer_trace_BkkGn1_trace_test.trac
+ ```
+
+ 6. 关闭优当前 session 的化器追踪功能。
+
+ ```shell
+ call dbms_xplan.disable_opt_trace();
+ ```
+tab MySQL 租户使用示例
+ 1. Proxy “保持”会话。
+
+ ```sql
+ SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
+ ```
+
+ 2. 开启当前 session 的优化器追踪功能。
+
+ ```sql
+ call dbms_xplan.enable_opt_trace();
+ ```
+
+ 3. 设置追踪日志的 level 和日志文件后缀。
+
+ ```
+ call dbms_xplan.set_opt_trace_parameter(identifier=>'trace_test', `level`=>3);
+ ```
+
+ 4. 查询计划。
+
+ ```
+ explain select * from t1;
+ ```
+
+ 5. 在 `observer` 日志目录下查看 `trace_test` 为后缀的追踪日志。
+
+ ```
+ vi /home/admin/oceanbase/log/optimizer_trace_BkkGn1_trace_test.trac
+ ```
+
+ 6. 关闭优当前 session 的化器追踪功能。
+
+ ```
+ call dbms_xplan.disable_opt_trace();
+ ```
+:::
+
+## 信息解读
+
+### plan table 的字段介绍
+
+|**字段**|**描述**|
+|---|---|
+| **OPERATOR** | 算子名称 |
+| **NAME** | 扫描的表名 |
+| **EST.ROWS** | 优化器估算的输出行数 |
+| **EST.TIME(us)** | 优化器估算的算子结束计算时间 |
+| **REAL.ROWS** | 当前算子真实的输出行数 |
+| **REAL.TIME(us)** | 当前算子真实的结束计算时间 |
+| **IO TIME(us)** | 当前算子的等待时间(单位微秒),对于 EXCHANGE IN、EXCHANGE OUT、PX COORD 算子,这个时间描述的是网络等待时间。 |
+| **CPU TIME(us)** | 当前算子的 CPU 时间(单位微秒),对于EXCHANGE IN、EXCHANGE OUT、PX COORD 算子,这个时间并不是真正的网络开销,不需要关注。 |
+
+### optimizer info 介绍
+
+```sql
+Optimization Info:
+-------------------------------------
+ t1:
+ table_rows:3
+ physical_range_rows:1
+ logical_range_rows:1
+ index_back_rows:0
+ output_rows:1
+ table_dop:1
+ dop_method:Table DOP
+ avaiable_index_name:[idx_ct, idx_pc, t1]
+ pruned_index_name:[idx_ct, idx_pc]
+ stats version:0
+ dynamic sampling level:0
+ estimation method:[DEFAULT]
+ Plan Type:
+ DISTRIBUTED
+ Note:
+ Degree of Parallelisim is 1 because of table property
+```
+
+|属性名称|说明|
+|---|---|
+| **table_rows** | t1 表的原始行数 |
+| **physical_range_rows** | t1 表在索引上需要扫描的物理行数 |
+| **logical_range_rows** | t1 表在索引上需要扫描的逻辑行数 |
+| **index_back_rows** | t1 表需要回表的行数 |
+| **output_rows** | t1 表经过过滤之后的行数 |
+| **table_dop** | t1 表扫描的并行度 |
+| **dop_method** | 决定表扫描并行度的原因,可以是TableDOP(表定义的并行度)、AutoDop(优化器基于代价选择的并行度,需要打开auto dop功能)、global parallel(parallel hint或系统变量设置的并行度)|
+| **available_index_name** | t1 表可用的索引列表 |
+| **pruned_index_name** | 当前查询基于规则删除的索引列表 |
+| **stats_version** | t1 表统计信息版本号,如果值为 0,表示该表没有收集统计信息,为了保证计划生成正确,请手动收集该表统计信息 |
+| **dynamic_sampling_level** | 动态采样(一种优化器优化工具,详细介绍请见官网文档)等级,如果值为0,表示该表没有使用动态采样 |
+| **estimation_method** | t1 表行数估计方式,可以是 DEFAULT(使用的默认统计信息,这种情况行数估计非常不准,需要 DBA 介入优化)、STORAGE(使用存储层实时估行)、STATS(使用统计信息估行) |
+| **Plan Type** | 当前计划类型,可以为 LOCAL、REMOTE、DISTRIBUTED |
+| **Note** | 生成该计划的一些备注信息,例如:“Degree of Parallelisim is 1 because of table property”表示由于当前表的并行度设置为 1,所以当前查询的并行度被设置为 1。|
+
+### 快速定位计划性能差的原因
+
+1. 找到 CPU TIME 高的 topN 个算子,除去 EXCHANGE IN、EXCHANGE OUT、PX COORD 几个算子,如果有以下算子:
+
+ - TABLE SCAN:查看 Output & filter 信息里面是否有回表 is_index_back=true。如果有,关注一下 optimizer info 里面的 index_back_rows,行数比较多的情况下就需要优化下索引。如果 REAL.ROWS 远高于 EST.ROWS,需要关注一下是否收集过统计信息,或者统计信息过期(通过 optimizer info 的 stats version 字段查看)。都有的话就关注一下是否有复杂的过滤条件,例如 case when、like 等等。这种情况下可以通过手动开启动态采样 /*+dynamic_sampling(1)*/ 来提高估行的准确度。如果这个算子在 Nested Loop Join、SubPlan Filter 算子的右侧,说明是 rescan 太多导致的开销大。
+ - Nested Loop Join:首先看看左侧算子的行数估计是否正确,如果行数偏差较大,则关注下统计信息问题,或者开启动态采样 /*+dynamic_sampling(1)*/ 来提高估行的准确度,如果这些都没用就使用 /*+use_hash(xxx)*/ 来绑定其他计划。如果行数估计正常,性能还是差,需要关注一下 Output & filter 信息,是否使用了 batch_join。
+ - SubPlan Filter:首先看看左侧算子的行数估计是否正确,如果行数偏差较大,则关注下统计信息问题,或者开启动态采样 /*+dynamic_sampling(1)*/ 来提高估行的准确度。如果行数估计正常,性能还是差,需要关注一下 Output & filter 信息,是否使用了 batch。如果以上方式都对,需要在 SQL 里面找到对应的子查询,看看能不能改写优化 /*+unnest*/。
+
+ 对于其他比较慢的算子,关注一下估行及统计信息的状态,收集统计信息或开启动态采样之后依然没有改善,说明就是数据量比较大,需要开启并行执行 /*+parallel(xxx)*/,对于 INSERT、UPDATE、DELETE、MERGE 类型算子,需要额外开启 PDML 来优化 /*+parallel(xxx) enable_parallel_dml*/。
+
+2. 如果注意到 HASH DISTINCT、SORT、HASH GROUP BY、HASH JOIN 等算子有 IO TIME,说明这些算子有落盘的情况,可以适当调整 sql_work_area_size 参数。
+
+### opt_trace 日志解读
+
+理解这部分内容需要具备一定的优化器基础知识,了解 OceanBase 优化器的基础工作原理,包含迭代式的查询改写流程、索引优化、连接枚举、分布式计划优化等。
+
+opt_trace 日志会记录以下信息:
+
+**transformer:**
+
+- 每个改写规则报告改写前后的 SQL
+- 每个改写规则发生改写或不发生改写的详细原因(hint 控制还是什么条件不满足)
+
+**optimizer:**
+
+- 使用的统计信息
+- 基表路径生成日志(包括过程条件、行数、代价估计信息,skyline 剪枝规则过程)
+- join order 枚举的详细过程
+- top 算子的分配、优化过程
+
+同时日志会在每个模块结束后记录时间和内存开销:
+
+```
+SECTION TIME USAGE: 233135 us
+TOTAL TIME USAGE: 233135 us
+SECTION MEM USAGE: 48744 KB
+TOTAL MEM USAGE: 62961 KB
+```
+
+- SECTION TIME USAGE 表示从上个优化步骤结束到当前优化步骤结束所使用的时间。
+- TOTAL TIME USAGE 表示从查询优化开始到当前优化步骤结束所使用的时间。
+- SECTION MEM USAGE 表示从上个优化步骤结束到当前优化步骤结束所使用的租户内存。
+- TOTAL MEM USAGE 表示从查询优化开始到当前优化步骤结束所使用的租户内存。
+
+通过这个信息可以快速定位计划生成耗时、耗内存的优化步骤,并且通过使用 hint 关闭对应优化功能,能够快速解决问题,不再需要粗暴的使用 no_rewrite 关闭整个改写来降低计划生成开销。
+
+## 相关文档
+
+* 有关 DBMS_XPLAN 系统包的详细介绍,参见 [DBMS_XPLAN(MySQL 模式)](../../700.reference/500.sql-reference/300.pl-reference/200.pl-mysql/1000.pl-system-package-mysql/20700.dbms-xplan-mysql/100.dbms-xplan-overview-mysql.md) 和 [DBMS_XPLAN(Oracle 模式)](../../700.reference/500.sql-reference/300.pl-reference/300.pl-oracle/1400.pl-system-package-oracle/20700.dbms-xplan-oracle/100.dbms-xplan-overview-oracle.md)
\ No newline at end of file
diff --git a/zh-CN/620.obap/700.performance-tuning/200.obap-sql-plan-monitor.md b/zh-CN/620.obap/700.performance-tuning/200.obap-sql-plan-monitor.md
new file mode 100644
index 0000000000..c8608ddd30
--- /dev/null
+++ b/zh-CN/620.obap/700.performance-tuning/200.obap-sql-plan-monitor.md
@@ -0,0 +1,155 @@
+# 诊断实践:使用 SQL_PLAN_MONITOR 分析性能问题
+
+SQL 在 AP 场景下缺乏算子级别的执行监控,例如并行执行任务划分了多少个,是否有倾斜,HASH 冲突是否严重,执行 hang 住时卡在了哪个算子上等等问题,诊断问题依赖于日志。为了解决这些问题,OceanBase 数据库引入了 Oracle 兼容视图 GV$SQL_PLAN_MONITOR,通过该视图可以精确了解每个算子的执行关键细节。
+
+## 视图介绍
+
+支持 SQL 算子级监控,每一行对应一个算子实例运行时的监控数据,包含一般性监控数据和算子特有监控数据,一般性监控数据如算子处理的数据行数、open 和 close 的时间、占用内存多少等,特有监控数据如 HASH 冲突率、GI 切分 block 数、table scan 扫描行数等。
+
+视图中重点字段的详细介绍如下。
+
+|**列名**|**类型**|**描述**|
+|---|---|---|
+| CON_ID | NUMBER | 租户 ID |
+| SVR_IP | VARCHAR2(32) | 算子所在机器 IP |
+| SVR_PORT | NUMBER | 算子所在机器端口 |
+| TRACE_ID | VARCHAR2(128) | TRACE_ID |
+| FIRST_REFRESH_TIME | DATE | 算子开始监控时间 |
+| LAST_REFRESH_TIME | DATE | 算子结束监控时间 |
+| FIRST_CHANGE_TIME | DATE | 算子吐出首行数据时间 |
+| LAST_CHANGE_TIME| DATE | 算子吐出最后一行数据时间 |
+| PROCESS_NAME | VARCHAR2(6) | 执行线程 ID |
+| SQL_ID | VARCHAR2(13) | SQL ID |
+| PLAN_PARENT_ID | NUMBER | 父算子 ID |
+| PLAN_LINE_ID | NUMBER | 算子行号 |
+| PLAN_OPERATION | VARCHAR2(30) | 算子名称 |
+| PLAN_DEPTH | NUMBER | 算子在计划树中的深度 |
+| STARTS | NUMBER | 算子被 rescan 的次数 |
+| OUTPUT_ROWS | NUMBER | 算子输出的总行数(所有本算子的执行实例行数累加值) |
+| WORKAREA_MEM | NUMBER | 算子占用的 workarea 内存量 |
+| WORKAREA_MAX_MEM | NUMBER | 算子可占用的 workarea 内存上限 |
+| WORKAREA_TEMPSEG | NUMBER | 算子占用的磁盘 dump 空间 |
+| WORKAREA_MAX_TEMPSEG | NUMBER | 算子可占用的最大磁盘 dump 空间 |
+| OTHERSTAT_1_ID | NUMBER | 实现相关 |
+| OTHERSTAT_1_VALUE | NUMBER | 实现相关 |
+| OTHERSTAT_2_ID | NUMBER | 实现相关 |
+| OTHERSTAT_2_VALUE | NUMBER | 实现相关 |
+| OTHERSTAT_3_ID | NUMBER | 实现相关 |
+| OTHERSTAT_3_VALUE | NUMBER | 实现相关 |
+| OTHERSTAT_4_ID | NUMBER | 实现相关 |
+| OTHERSTAT_4_VALUE | NUMBER | 实现相关 |
+| OTHERSTAT_5_ID | NUMBER | 实现相关 |
+| OTHERSTAT_5_VALUE | NUMBER | 实现相关 |
+| OTHERSTAT_6_ID | NUMBER | 实现相关 |
+| OTHERSTAT_6_VALUE | NUMBER | 实现相关 |
+| OTHERSTAT_7_ID | NUMBER | 实现相关 |
+| OTHERSTAT_7_VALUE | NUMBER | 实现相关 |
+| OTHERSTAT_8_ID | NUMBER | 实现相关 |
+| OTHERSTAT_8_VALUE | NUMBER | 实现相关 |
+| OTHERSTAT_9_ID | NUMBER | 实现相关 |
+| OTHERSTAT_9_VALUE | NUMBER | 实现相关 |
+| OTHERSTAT_10_ID | NUMBER | 实现相关 |
+| OTHERSTAT_10_VALUE | NUMBER | 实现相关 |
+| OUTPUT_BATCHES | NUMBER | 向量化模式下,算子调用 get_next_batch 接口的次数。
OceanBase 数据库特有字段。 |
+| SKIPPED_ROWS_COUNT | NUMBER | 向量化模式下,算子计算过程中,不需要计算的总行数(被 filter 掉的总行数)。
OceanBase 数据库特有字段。|
+| DB_TIME | NUMBER | DB Time 是当前算子消耗的执行时间,包括消耗 CPU 的时间、等待必要 IO 的时间(如读写磁盘、网络包等)。单位:us。注:不包括 child 算子消耗的执行时间。 |
+| USER_IO_WAIT_TIME | NUMBER | 当前算子必要的 IO 等待时间,包括磁盘 IO 和网络等时间。单位:us。注:不包括 child 算子消耗的执行时间。 |
+
+不同算子可以赋予 OTHERSTAT_N_VALUE 不同的含义,填不同的值。
+
+具体可以利用 OTHERSTAT_N_ID 的值,查询 V$SQL_MONITOR_STATNAME 表对 ID 列进行过滤。
+
+## 性能问题分析示例
+
+SQL_PLAN_MONITOR 常用于分析性能问题。
+
+### 索引不优问题分析
+
+```cpp
+obclient [SYS]> select output_rows, plan_operation, OTHERSTAT_3_VALUE scans from gv$sql_plan_monitor where trace_id = 'xxx' and plan_operation like '%TABLE_SCAN';
++-------------+--------------------+--------+
+| OUTPUT_ROWS | PLAN_OPERATION | SCANS |
++-------------+--------------------+--------+
+| 5 | PHY_VEC_TABLE_SCAN | 500072 |
+```
+
+利用上面的 SQL 可以查询出 table scan 算子扫描的行数和输出的行数,当二者相差较大时,比如上面的例子扫描了 50 万行只输出了 5 行,说明该表上缺少合适的索引。
+
+### JOIN 方法选择不优问题分析
+
+常见的是应该走 hash join,实际生成了 nested-loop join, 左表行数较多时,会 rescan 右表非常多次,性能较差。可以使用下面的 SQL 查询算子最大 rescan 次数,如果这个值比较大,极有可能发生了 join 方法选错的问题。
+
+```cpp
+select max(starts) rescans from gv$sql_plan_monitor where trace_id = 'xxx';
+```
+
+### 通用分析方法
+
+逐个判断是否存在上面的问题可能有点麻烦,大多数情况下,可以直接使用通用方法判断是计划中哪个部分比较耗时。
+
+1. 首先使用下面的 SQL 查询出这条 query 对应的 SQL_PLAN_MONITOR 记录。查询结果包含了每个算子open、close、输出第一行和输出最后一行的时间。
+
+ ```sql
+ select plan_line_id, concat(lpad(' ', plan_depth, ' '), plan_operation) op, sum(output_rows) rowss, sum(STARTS) rescan, min(first_refresh_time) open_time, max(last_refresh_time) close_time, min(first_change_time) first_row_time, max(last_change_time) last_row_eof_time, count(1) threads from gv$sql_plan_monitor where trace_id = 'xxx' group by plan_line_id, plan_operation, plan_depth order by 1;
+ ```
+
+2. 从上向下观察查询结果。首先最顶层的 0 号算子,它的 LAST_ROW_EOF_TIME 应该约等于 CLOSE_TIME, 假设它是 hash join 算子,hash join 执行时是先从左侧收取全部数据构建 hash 表,再从右孩子取数据逐行 probe hash 表。那么我们可以观察 1 号算子即 hash join 左孩子的 LAST_ROW_EOF_TIME。
+
+ 1. 如果 1 号算子的 LAST_ROW_EOF_TIME 比较大,说明大部分时间在执行 hash join 的左支,那么可以继续观察 1 号算子下面的子计划。
+ 2. 如果 1 号算子的 LAST_ROW_EOF_TIME 比较小,说明大部分时间都在执行 hash join 的右支,以及进行 hash 表的探测,那么可以继续观察 0 号 hash join 右孩子的子计划。
+
+以下面的计划为例说明如何分析。
+
+首先观察到顶层是个 merge join 算子,该算子会先从左孩子拿一行,再从右孩子拿一行。可以看到算子的 open 时间是 25.792777 秒,merge join 左孩子输出第一行的时间是 25.793831,merge join 右孩子输出第一行的时间是 27.572661,由此可见,merge join 右支为了输出第一行数据耗费了一秒多的时间。
+
+继续观察 merge join 右孩子,发现是一个 sort 算子,该算子会接收下层所有数据,排序后再向上层输出,从 ROWSS 字段可以看到该算子收取了 160 万行数据,对其进行排序会耗费大量时间。可以通过在排序键上建立索引消除排序,提升性能。
+
+```sql
+| ========================================================== |
+| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
+| ---------------------------------------------------------- |
+| |0 |MERGE JOIN | |1 |5 | |
+| |1 |├─SORT | |1 |3 | |
+| |2 |│ └─COLUMN TABLE FULL SCAN|T1 |1 |3 | |
+| |3 |└─SORT | |1 |3 | |
+| |4 | └─TABLE FULL SCAN |T0 |1 |3 | |
+| ========================================================== |
+```
+
+```sql
+select plan_line_id, concat(lpad(' ', plan_depth, ' '), plan_operation) op, sum(output_rows) rowss, sum(STARTS) rescan, min(first_refresh_time) open_time, max(last_refresh_time) close_time, min(first_change_time) first_row_time, max(last_change_time) last_row_eof_time, count(1) threads from gv$sql_plan_monitor where trace_id = 'YC3500BA2DAC4-0006198CC947196A-0-0' group by plan_line_id, plan_operation, plan_depth order by 1;
+```
+
+```sql
++--------------+-----------------------+---------+--------+----------------------------+----------------------------+----------------------------+----------------------------+---------+
+| PLAN_LINE_ID | OP | ROWSS | RESCAN | OPEN_TIME | CLOSE_TIME | FIRST_ROW_TIME | LAST_ROW_EOF_TIME | THREADS |
++--------------+-----------------------+---------+--------+----------------------------+----------------------------+----------------------------+----------------------------+---------+
+| 0 | PHY_MERGE_JOIN | 0 | 0 | 2024-05-29 16:29:25.792777 | 2024-05-29 16:29:27.664014 | NULL | 2024-05-29 16:29:27.664014 | 1 |
+| 1 | PHY_SORT | 2 | 0 | 2024-05-29 16:29:25.792777 | 2024-05-29 16:29:27.664014 | 2024-05-29 16:29:25.793831 | NULL | 1 |
+| 2 | PHY_VEC_TABLE_SCAN | 2 | 0 | 2024-05-29 16:29:25.792777 | 2024-05-29 16:29:27.664014 | 2024-05-29 16:29:25.793831 | 2024-05-29 16:29:25.793831 | 1 |
+| 3 | PHY_SORT | 1599984 | 0 | 2024-05-29 16:29:25.792777 | 2024-05-29 16:29:27.664014 | 2024-05-29 16:29:27.572661 | 2024-05-29 16:29:27.664014 | 1 |
+| 4 | PHY_VEC_TABLE_SCAN | 1599984 | 0 | 2024-05-29 16:29:25.792777 | 2024-05-29 16:29:27.664014 | 2024-05-29 16:29:25.793831 | 2024-05-29 16:29:26.642023 | 1 |
++--------------+-----------------------+---------+--------+----------------------------+----------------------------+----------------------------+----------------------------+---------+
+```
+
+可以发现,要通过 SQL PLAN MONITOR 分析性能问题,需要对不同算子的执行方式有一定的了解。下面列出了一些常见算子的执行方式。
+
+1. 流式输出。一边从下层收数据,一边向上层输出数据。
+
+ limit, merge group by, merge distinct, subplan scan
+
+2. 阻塞式。从下层收取全部数据后再向上层输出数据。
+
+ sort, hash group by, hash distinct, material
+
+3. 其他
+
+ |**算子**|**执行方式**|
+ |---|---|
+ | merge join/union/intersect/except | 同时从两个孩子收取数据,先从左侧收起。 |
+ | nested-loop join, subplan filter | 逐行从第一个孩子收取数据,然后 rescan 其他孩子并收取数据。 |
+ | hash join/union/intersect/except | 先从左孩子收取全部数据,再从右孩子收取数据。 |
+
+## 相关文档
+
+* 关于 GV$SQL_PLAN_MONITOR 视图的详细介绍,参见 [GV$SQL_PLAN_MONITOR(MySQL 模式)](../../700.reference/700.system-views/400.system-view-of-mysql-mode/300.performance-view-of-mysql-mode/3700.gv-ob_sql_plan-of-mysql-mode.md) 和 [GV$SQL_PLAN_MONITOR(MySQL 模式)](../../700.reference/700.system-views/500.system-view-of-oracle-mode/300.performance-view-of-oracle-mode/3600.gv-ob_sql_plan-of-oracle-mode.md)。
\ No newline at end of file
diff --git a/zh-CN/620.obap/700.performance-tuning/500.obap-performance-related-views.md b/zh-CN/620.obap/700.performance-tuning/500.obap-performance-related-views.md
new file mode 100644
index 0000000000..87a77a41ef
--- /dev/null
+++ b/zh-CN/620.obap/700.performance-tuning/500.obap-performance-related-views.md
@@ -0,0 +1,197 @@
+# AP 性能分析相关视图
+
+本文介绍在诊断和分析 AP 性能问题时,可以使用的主要视图。
+
+## GV$SQL_WORKAREA
+
+**视图介绍:**
+
+展示已受 SQL 自动内存管理负责执行的所有 Operator 的 workarea 统计信息。
+
+通过查询该视图,我们可以知道执行计划的每个算子内存使用量,以及落盘的数据量,后续可以根据视图的数据来合理的调整租户的 sql_work_area 大小,使得计划能够完全在内存中执行计划,提高查询性能。
+
+**常用字段解析:**
+
+|**属性名称**|**说明**|
+|---|---|
+| `CHILD_NUMBER` | 该算子所属的计划 ID |
+| `OPERATION_TYPE` | 物理算子名称 |
+| `OPERATION_ID` | 物理算子编号 |
+| `LAST_MEMORY_USED` | 该算子上一次平均内存使用量 |
+| `LAST_DEGREE` | 该算子上一次执行的并行度 |
+| `LAST_TEMPSEG_SIZE` | 该算子上一次平均落盘的数据量 |
+| `MAX_TEMPSEG_SIZE` | 该算子在所有执行次数下,最大落盘数据量 |
+
+**使用示例:**
+
+```sql
+select CHILD_NUMBER,OPERATION_TYPE,OPERATION_ID,LAST_MEMORY_USED,LAST_DEGREE,MAX_TEMPSEG_SIZE,LAST_TEMPSEG_SIZE from oceanbase.gv$sql_workarea where sql_id='80FAF8DB736A82604D54DD82005238EC';
+```
+
+**相关文档:**
+
+可以查看以下文档了解关于该视图的更多详细信息。
+
+- [GV$SQL_WORKAREA(SYS 租户)](../../700.reference/700.system-views/300.system-view-of-sys-tenant/300.performance-view-of-sys-tenant/5400.gv-sql_workarea-of-sys-tenant.md)
+- [GV$SQL_WORKAREA(MySQL 租户)](../../700.reference/700.system-views/400.system-view-of-mysql-mode/300.performance-view-of-mysql-mode/5300.gv-sql_workarea-of-mysql-mode.md)
+- [GV$SQL_WORKAREA(Oracle 租户)](../../700.reference/700.system-views/500.system-view-of-oracle-mode/300.performance-view-of-oracle-mode/35700.v-sql_workarea-of-oracle-mode.md)
+
+## GV$SQL_PLAN_MONITOR
+
+**视图介绍:**
+
+该视图展示所有 OBServer 节点慢查询的 Plan 层面的统计,每个慢查询都会有一条统计信息,同时记录该 Plan 的 Trace 信息。
+
+**使用示例:**
+
+按照如下方式执行,获取慢 SQL 的执行信息,用于分析。
+
+1. 给要分析的慢 SQL 增加一个 HINT(/*+ monitor */)。
+2. 执行增加了 HIINT 后的慢 SQL,拿到 Trace_id,替换下面的 Yxxxxxxxxx。
+3. 执行下面的 SQL,保存返回结果用于分析。
+
+ ```cpp
+ --说明:open_dt 表示算子从 Open 到 Close 的时间间隔
+ --说明:row_dt 表示算子从吐出第一行,到吐出 OB_ITER_END 的时间间隔
+ --说明:如果值为 NULL,表示没有吐出过第一行或者没有吐出过 OB_ITER_END
+
+ MySQL 租户:
+
+ -- 汇总
+ select op_id, op, rows, rescan, threads, (close_time - open_time) open_dt, (last_row_eof_time-first_row_time) row_dt, open_time, close_time, first_row_time, last_row_eof_time FROM
+ (
+ select plan_line_id op_id, concat(lpad('', plan_depth, ' '), plan_operation) op, sum(output_rows) rows, sum(STARTS) rescan, min(first_refresh_time) open_time, max(last_refresh_time) close_time, min(first_change_time) first_row_time, max(last_change_time) last_row_eof_time, count(1) threads from oceanbase.gv$sql_plan_monitor where trace_id = 'Yxxxxxxxxx' group by plan_line_id, plan_operation order by plan_line_id
+ ) a;
+
+
+ -- 明细
+ select op_id, thread, op, rows, rescan, (close_time - open_time) open_dt, (last_row_eof_time-first_row_time) row_dt, open_time, close_time, first_row_time, last_row_eof_time FROM
+ (
+ select plan_line_id op_id, PROCESS_NAME thread, concat(lpad('', plan_depth, ' '), plan_operation) op, output_rows rows, STARTS rescan, first_refresh_time open_time, last_refresh_time close_time, first_change_time first_row_time, last_change_time last_row_eof_time from oceanbase.gv$sql_plan_monitor where trace_id = 'Yxxxxxxxxx' order by plan_line_id, PROCESS_NAME
+ ) a;
+
+
+ Oracle 租户:
+
+ --说明:open_dt 表示算子从 Open 到 Close 的时间间隔
+ --说明:row_dt 表示算子从吐出第一行,到吐出 OB_ITER_END 的时间间隔
+ --说明:如果值为 NULL,表示没有突出过第一行或者没有突出过 OB_ITER_END
+
+ -- 汇总
+ select op_id, op, output_rows, rescan,threads ,(close_time - open_time) open_dt, (last_row_eof_time-first_row_time) row_dt, open_time, close_time, first_row_time, last_row_eof_time FROM
+ (
+ select plan_line_id op_id, concat(lpad(' ', max(plan_depth), ' '), plan_operation) op, sum(output_rows) output_rows, sum(STARTS) rescan, min(first_refresh_time) open_time, max(last_refresh_time) close_time, min(first_change_time) first_row_time, max(last_change_time) last_row_eof_time, count(1) threads from sys.gv$sql_plan_monitor where trace_id = 'Yxxxxxxxxx' group by plan_line_id, plan_operation,plan_depth order by plan_line_id
+ ) a;
+
+
+ -- 明细
+ select op_id, thread, op, output_rows, rescan, (close_time - open_time) open_dt, (last_row_eof_time-first_row_time) row_dt, open_time, close_time, first_row_time, last_row_eof_time FROM
+ (
+ select plan_line_id op_id, PROCESS_NAME thread, concat(lpad(' ', plan_depth, ' '), plan_operation) op, output_rows, STARTS rescan, first_refresh_time open_time, last_refresh_time close_time, first_change_time first_row_time, last_change_time last_row_eof_time from sys.gv$sql_plan_monitor where trace_id = 'Yxxxxxxxxx' order by plan_line_id, process_name
+ ) a;
+ ```
+
+**相关文档:**
+
+可以查看以下文档了解关于该视图的更多详细信息。
+
+- [GV$SQL_PLAN_MONITOR(SYS 租户)](../../700.reference/700.system-views/300.system-view-of-sys-tenant/300.performance-view-of-sys-tenant/3800.gv-ob_sql_plan_monitor-of-sys-tenant.md)
+- [GV$SQL_PLAN_MONITOR(MySQL 租户)](../../700.reference/700.system-views/400.system-view-of-mysql-mode/300.performance-view-of-mysql-mode/3700.gv-ob_sql_plan-of-mysql-mode.md)
+- [GV$SQL_PLAN_MONITOR(Oracle 租户)](../../700.reference/700.system-views/500.system-view-of-oracle-mode/300.performance-view-of-oracle-mode/3600.gv-ob_sql_plan-of-oracle-mode.md)
+
+## GV$OB_SQL_AUDIT
+
+**视图介绍:**
+
+该视图用于展示所有 OBServer 节点上每一次 SQL 请求的来源、执行状态、资源消耗及等待时间等信息,除此之外还记录了 SQL 文本、执行计划等关键信息。该视图是按照租户拆分的,除了系统租户,其他租户不能跨租户查询。
+
+**使用示例:**
+
+通过 GV$OB_SQL_AUDIT 视图,我们可以方便的查询 SQL 执行的各种维度信息。
+
+查询执行耗时超过 100ms 的 SQL。
+
+```cpp
+select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql
+from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10;
++------------+----------------------------+--------------+------------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------+
+| request_id | usec_to_time(request_time) | ELAPSED_TIME | QUEUE_TIME | EXECUTE_TIME | query_sql |
++------------+----------------------------+--------------+------------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------+
+| 1538599798 | 2023-03-08 11:00:46.089711 | 335152 | 462 | 329196 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
+| 1538601580 | 2023-03-08 11:00:47.411316 | 276913 | 1420 | 275345 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
+| 1538603976 | 2023-03-08 11:00:49.258464 | 154873 | 461 | 154236 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
+| 1538613501 | 2023-03-08 11:00:56.123111 | 188973 | 688 | 188144 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
+| 1538712684 | 2023-03-08 11:02:07.504777 | 288516 | 1137 | 287180 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
+| 1538743161 | 2023-03-08 11:02:29.135127 | 289585 | 26 | 289380 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
+| 1538749786 | 2023-03-08 11:02:33.890317 | 294356 | 45 | 294180 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
+| 1538792259 | 2023-03-08 11:03:04.626596 | 192843 | 128 | 192569 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
+| 1538799117 | 2023-03-08 11:03:09.567622 | 201594 | 55 | 201388 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
+| 1538804299 | 2023-03-08 11:03:13.274090 | 235720 | 241 | 235302 | select request_id,usec_to_time(request_time),ELAPSED_TIME,QUEUE_TIME,EXECUTE_TIME,query_sql from v$OB_SQL_AUDIT where ELAPSED_TIME > 100000 limit 10 |
++------------+----------------------------+--------------+------------+--------------+------------------------------------------------------------------------------------------------------------------------------------------------------+
+10 rows in set (0.28 sec)
+
+```
+
+查询最近 1000 条 SQL 的平均排队时间。
+
+```cpp
+select /*+ query_timeout(30000000) */ avg(queue_time) from v$OB_SQL_AUDIT
+where request_id > (select max(request_id) from v$OB_SQL_AUDIT) - 1000 ;
++-----------------+
+| avg(queue_time) |
++-----------------+
+| 350.8740 |
++-----------------+
+1 row in set (0.26 sec)
+```
+
+查询占用租户资源最多的 SQL,按照 执行时间 * 执行次数 倒序排序,如果该租户当前存在容量不足(租户 CPU 使用率被打爆),可以通过该语句判断是否为 SQL 问题,及疑点 SQL。
+
+```cpp
+obclient>
+select SQL_ID,
+avg(ELAPSED_TIME),
+avg(QUEUE_TIME),
+avg(ROW_CACHE_HIT + BLOOM_FILTER_CACHE_HIT + BLOCK_CACHE_HIT + DISK_READS) avg_logical_read,
+avg(execute_time) avg_exec_time,
+count(*) cnt,
+avg(execute_time - TOTAL_WAIT_TIME_MICRO ) avg_cpu_time,
+avg( TOTAL_WAIT_TIME_MICRO ) avg_wait_time,
+WAIT_CLASS,
+avg(retry_cnt)
+from v$OB_SQL_AUDIT
+group by 1
+order by avg_exec_time * cnt desc limit 10;
++----------------------------------+-------------------+-----------------+------------------+---------------+--------+--------------+---------------+------------+----------------+
+| SQL_ID | avg(ELAPSED_TIME) | avg(QUEUE_TIME) | avg_logical_read | avg_exec_time | cnt | avg_cpu_time | avg_wait_time | WAIT_CLASS | avg(retry_cnt) |
++----------------------------------+-------------------+-----------------+------------------+---------------+--------+--------------+---------------+------------+----------------+
+| 2705182A6EAB699CEC8E59DA80710B64 | 54976.9269 | 43.8605 | 17664.2727 | 54821.5828 | 11759 | 54821.5828 | 0.0000 | OTHER | 0.0000 |
+| 32AB97A0126F566064F84DDDF4936F82 | 1520.9832 | 380.7903 | 63.7847 | 789.6781 | 63632 | 789.6781 | 0.0000 | OTHER | 0.0000 |
+| A5F514E873BE9D1F9A339D0DA7481D69 | 44032.5553 | 44.5149 | 8943.7834 | 43878.1405 | 1039 | 43878.1405 | 0.0000 | OTHER | 0.0000 |
+| 31FD78420DB07C11C8E3154F1658D237 | 7769857.0000 | 35.7500 | 399020.7500 | 7769682.7500 | 4 | 7769682.7500 | 0.0000 | NETWORK | 1.0000 |
+| C48AEE941D985D8DEB66892228D5E845 | 8528.6227 | 0.0000 | 0.0000 | 8450.4047 | 1601 | 8450.4047 | 0.0000 | OTHER | 0.0000 |
+| 101B7B79DFA9AE801BEE4F1A234AD294 | 158.2296 | 41.7211 | 0.0000 | 46.0345 | 286758 | 46.0345 | 0.0000 | OTHER | 0.0000 |
+| 1D0BA376E273B9D622641124D8C59264 | 1774.5924 | 0.0049 | 0.0000 | 1737.4885 | 5081 | 1737.4885 | 0.0000 | OTHER | 0.0000 |
+| 64CF75576816DB5614F3D5B1F35B1472 | 1801.8767 | 747.0343 | 0.0000 | 827.1674 | 10340 | 827.1674 | 0.0000 | OTHER | 0.0000 |
+| 23D1C653347BA469396896AD9B20DCA1 | 5564.9419 | 0.0000 | 0.0000 | 5478.2228 | 1257 | 5478.2228 | 0.0000 | OTHER | 0.0000 |
+| FA4F493FA5CE2DCC64F51CF3754F96C6 | 2478.3956 | 378.7557 | 3.1040 | 1731.1802 | 3357 | 1731.1802 | 0.0000 | OTHER | 0.0000 |
++----------------------------------+-------------------+-----------------+------------------+---------------+--------+--------------+---------------+------------+----------------+
+10 rows in set (1.34 sec)
+```
+
+
+ 说明
+
+ - 租户抖动时,表现一般是 “租户 CPU 被打满” 和 “所有 SQL RT 飙升”,此时首要判断 SQL RT 飙升是否是第一案发现场(是 SQL 自己的问题导致 RT 飙升,还是其他问题导致 SQL RT 飙升)。
+ - 上面介绍的这条 SQL 是一大利器,基于 SQL_ID 做聚合,按照资源占用量倒序排序(资源占用量可以认为是 avg_exec_time * cnt),观察 top 几条 SQL 是否存在明显异常,从而判断是否是第一案发现场。
+
+
+
+**相关文档:**
+
+可以查看以下文档了解关于该视图的更多详细信息。
+
+- [GV$OB_SQL_AUDIT(SYS 租户)](../../700.reference/700.system-views/300.system-view-of-sys-tenant/300.performance-view-of-sys-tenant/3500.gv-ob_sql_audit-of-sys-tenant.md)
+- [GV$OB_SQL_AUDIT(MySQL 租户)](../../700.reference/700.system-views/400.system-view-of-mysql-mode/300.performance-view-of-mysql-mode/3500.gv-ob_sql_audit-of-mysql-mode.md)
+- [GV$OB_SQL_AUDIT(Oracle 租户)](../../700.reference/700.system-views/500.system-view-of-oracle-mode/300.performance-view-of-oracle-mode/3400.gv-ob_sql_audit-of-oracle-mode.md)
+- [SQL Audit](../../600.manage/700.monitor/200.monitor-items-introduction/300.sql-monitor/200.sql-audit.md),了解该视图的具体使用方法
diff --git a/zh-CN/620.obap/750.obap-performance-test/10.obap-tpc-h-test.md b/zh-CN/620.obap/750.obap-performance-test/10.obap-tpc-h-test.md
new file mode 100644
index 0000000000..b0dfbc98f6
--- /dev/null
+++ b/zh-CN/620.obap/750.obap-performance-test/10.obap-tpc-h-test.md
@@ -0,0 +1,527 @@
+# OceanBase 数据库 TPC-H 测试
+
+本文介绍在 AP 场景下,如何基于 OceanBase 数据库进行 TPC-H 测试,提供了以下两种方式进行 TPC-H 性能测试。
+
+- 基于 OBDeployer 一键进行 TPC-H 测试。
+- 基于 TPC 官方 tpc-h 工具手动 step by step 进行 TPC-H 测试。
+
+
+ 说明
+ 为了提升用户体验和易用性,让每一个开发者在使用数据库时都能获得较好的性能,OceanBase 数据库在 V4.0.0 版本之后,做了大量的优化工作。本性能测试方法仅基于基础参数进行调优,让开发者获得较好的数据库性能体验。
+
+
+## 什么是 TPC-H
+
+TPC-H(商业智能计算测试)是美国交易处理效能委员会(TPC,Transaction Processing Performance Council)组织制定的用来模拟决策支持类应用的一个测试集。目前,学术界和工业界普遍采用 TPC-H 来评价决策支持技术方面应用的性能。这种商业测试可以全方位评测系统的整体商业计算综合能力,对厂商的要求更高,同时也具有普遍的商业实用意义,目前在银行信贷分析和信用卡分析、电信运营分析、税收分析、烟草行业决策分析中都有广泛的应用。
+
+TPC-H 基准测试由 TPC-D(由 TPC 于 1994 年制定的标准,用于决策支持系统方面的测试基准)发展而来的。TPC-H 用 3NF 实现了一个数据仓库,共包含 8 个基本关系,其主要评价指标是各个查询的响应时间,即从提交查询到结果返回所需时间。TPC-H 基准测试的度量单位是每小时执行的查询数(QphH@size),其中 H 表示每小时系统执行复杂查询的平均次数,size 表示数据库规模的大小,它能够反映出系统在处理查询时的能力。TPC-H 是根据真实的生产运行环境来建模的,这使得它可以评估一些其他测试所不能评估的关键性能参数。总而言之,TPC 组织颁布的 TPC-H 标准满足了数据仓库领域的测试需求,并且促使各个厂商以及研究机构将该项技术推向极限。
+
+## 环境准备
+
+测试前请按照如下要求准备您的测试环境:
+
+- JDK:建议使用 1.8u131 及以上版本。
+- make:yum install make。
+- gcc:yum install gcc。
+- mysql-devel:yum install mysql-devel。
+- Python 连接数据库的驱动:sudo yum install MySQL-python。
+- prettytable:pip install prettytable。
+- JDBC:建议使用 mysql-connector-java-5.1.47 版本。
+- tpch tool:点击 [下载地址](https://www.tpc.org/tpc_documents_current_versions/download_programs/tools-download-request5.asp?bm_type=TPC-H&bm_vers=3.0.0&mode=CURRENT-ONLY) 获取,如果使用 OBD 一键测试,可以跳过该工具。
+- OBClient:详细信息,请参考 [OBClient 文档](https://github.com/oceanbase/obclient/blob/master/README.md)。
+- OceanBase 数据库:详细信息,请参考 [快速体验 OceanBase 数据库](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000507531)。
+- iops:建议磁盘 iops 在 10000 以上。
+- 租户规格:
+
+ ```
+ CREATE RESOURCE UNIT tpch_unit max_cpu 30, memory_size '180g';
+ CREATE RESOURCE POOL tpch_pool unit = 'tpch_unit', unit_num = 1, zone_list=('zone1','zone2','zone3');
+ CREATE TENANT tpch_mysql resource_pool_list=('tpch_pool'), zone_list('zone1', 'zone2', 'zone3'), primary_zone=RANDOM, locality='F@zone1,F@zone2,F@zone3' set variables ob_compatibility_mode='mysql', ob_tcp_invited_nodes='%',secure_file_priv = '';
+ ```
+
+
+ 说明
+
+ - 上文中的租户规格是基于 OceanBase TPC-H 性能测试报告 中的硬件配置进行配置的,您需根据自身数据库的硬件配置进行动态调整。
+ - 部署集群时,建议不要使用 obd cluster autodeploy 命令,该命令为了保证稳定性,不会最大化资源利用率(例如不会使用所有内存),建议单独对配置文件进行调优,最大化资源利用率。
+
+
+
+## 部署集群
+
+1. 本次测试需要用到 4 台机器,TPC-H 和 OBD 单独部署在一台机器上,作为客户端的压力机器。通过 OBD 部署 OceanBase 集群需要使用 3 台机器,OceanBase 集群规模为 1:1:1。
+
+
+ 注意
+ 在 TPC-H 测试中,部署 TPC-H 和 OBD 的机器只需 4 核 16G 即可。
+
+
+2. 部署成功后,新建执行 TPC-H 测试的租户及用户(sys 租户是管理集群的内置系统租户,请勿直接使用 sys 租户进行测试)。将租户的 primary_zone 设置为 RANDOM。RANDOM 表示新建表分区的 Leader 随机到这 3 台机器。
+
+## 使用 OBD 一键进行 TPC-H 测试
+
+```shell
+sudo yum install -y yum-utils
+sudo yum-config-manager --add-repo https://mirrors.aliyun.com/oceanbase/OceanBase.repo
+sudo yum install obtpch
+sudo ln -s /usr/tpc-h-tools/tpc-h-tools/ /usr/local/
+obd test tpch obperf --tenant=tpch_mysql -s 100 --remote-tbl-dir=/tmp/tpch100
+```
+
+注意:
+
+- OBD 运行 tpch 的详细参数介绍请参考 [obd test tpch](https://www.oceanbase.com/docs/community-obd-cn-10000000001031935)。
+- 在本例中,大幅参数使用的是默认参数,在用户场景下,可以根据自己的具体情况做一些参数上的调整。例如,在本例中使用的集群名为 obperf,租户名是 tpch_mysql。
+- 使用 OBD 进行一键测试时,集群的部署必须是由 OBD 进行安装和部署,否则无法获取集群的信息,将导致无法根据集群的配置进行性能调优。
+- 如果系统租户的密码通过终端登陆并修改,非默认空值,则需要您先在终端中将密码修改为默认值,之后通过 [obd cluster edit-config](https://www.oceanbase.com/docs/community-obd-cn-10000000001031935) 命令在配置文件中为系统租户设置密码,配置项是 # root_password: # root user password。在 obd cluster edit-config 命令执行结束后,您还需执行 obd cluster reload 命令使修改生效。
+- 运行 obd test tpch 后,系统会详细列出运行步骤和输出,数据量越大耗时越久。
+- remote-tbl-dir 远程目录具备足够的容量能存储 tpch 的数据,建议单独一块盘存储加载测试数据。
+- obd test tpch 命令会自动完成所有操作,无需其他额外任何操作,包含测试数据的生成、传送、OceanBase 参数优化、加载和测试。当中间环节出错时,您可参考 [obd test tpch](https://www.oceanbase.com/docs/community-obd-cn-10000000001031935) 进行重试。例如:跳过数据的生成和传送,直接进行加载和测试。
+
+## 手动进行 TPC-H 测试
+
+### 进行环境调优
+
+1. OceanBase 数据库调优。
+
+ 在系统租户下执行 `obclient -h$host_ip -P$host_port -uroot@sys -A` 命令。
+
+ ```
+ ALTER SYSTEM flush plan cache GLOBAL;
+ ALTER system SET enable_sql_audit=false;
+ select sleep(5);
+ ALTER system SET enable_perf_event=false;
+ ALTER system SET syslog_level='PERF';
+ alter system set enable_record_trace_log=false;
+ ```
+
+2. 测试租户调优。
+
+ 在测试用户下执行 `obclient -h$host_ip -P$host_port -u$user@$tenant -p$password -A` 命令。
+
+ ```
+ SET GLOBAL ob_sql_work_area_percentage = 80;
+ SET GLOBAL ob_query_timeout = 36000000000;
+ SET GLOBAL ob_trx_timeout = 36000000000;
+ SET GLOBAL max_allowed_packet = 67108864;
+ # parallel_servers_target = max_cpu * server_num * 8
+ SET GLOBAL parallel_servers_target = 624;
+
+ set global ob_query_timeout=14400000000;
+ set global ob_trx_timeout=10000000000;
+ set global autocommit=1;
+ set global optimizer_use_sql_plan_baselines = true;
+ set global optimizer_capture_sql_plan_baselines = true;
+
+ alter system set ob_enable_batched_multi_statement='true';
+ ```
+
+### 指定用户租户默认创建表为列存
+
+在测试用户下执行 `obclient -h$host_ip -P$host_port -u$user@$tenant -p$password -A` 命令。
+
+```
+alter system set default_table_store_format = 'column';
+```
+
+### 安装 TPC-H Tool
+
+1. 下载 TPC-H Tool。
+
+ 详细信息请参考 [TPC-H Tool 下载页面](https://www.tpc.org/tpc_documents_current_versions/download_programs/tools-download-request5.asp?bm_type=TPC-H&bm_vers=3.0.0&mode=CURRENT-ONLYY)。
+
+2. 下载完成后解压文件,进入 TPC-H 解压后的目录。
+
+ ```
+ [wieck@localhost ~] $ unzip tpc-h-tool.zip
+ [wieck@localhost ~] $ cd TPC-H_Tools_v3.0.0
+ ```
+
+3. 复制 makefile.suite。
+
+ ```
+ [wieck@localhost TPC-H_Tools_v3.0.0] $ cd dbgen/
+ [wieck@localhost dbgen] $ cp makefile.suite Makefile
+ ```
+
+4. 修改 Makefile 文件中的 CC、DATABASE、MACHINE、WORKLOAD 等参数定义。
+
+ ```
+ [wieck@localhost dbgen] $ vim Makefile
+ CC = gcc
+ # Current values for DATABASE are: INFORMIX, DB2, TDAT (Teradata)
+ # SQLSERVER, SYBASE, ORACLE, VECTORWISE
+ # Current values for MACHINE are: ATT, DOS, HP, IBM, ICL, MVS,
+ # SGI, SUN, U2200, VMS, LINUX, WIN32
+ # Current values for WORKLOAD are: TPCH
+ DATABASE= MYSQL
+ MACHINE = LINUX
+ WORKLOAD = TPCH
+ ```
+
+5. 修改 tpcd.h 文件,并添加新的宏定义。
+
+ ```
+ [wieck@localhost dbgen] $ vim tpcd.h
+
+ #ifdef MYSQL
+ #define GEN_QUERY_PLAN ""
+ #define START_TRAN "START TRANSACTION"
+ #define END_TRAN "COMMIT"
+ #define SET_OUTPUT ""
+ #define SET_ROWCOUNT "limit %d;\n"
+ #define SET_DBASE "use %s;\n"
+ #endif
+ ```
+
+6. 编译文件。
+
+ ```
+ make
+ ```
+
+### 生成数据
+
+可以根据实际环境生成 TCP-H 10G、100G 或者 1T 数据。本文以生成 100G 数据为例。
+
+```
+./dbgen -s 100
+mkdir tpch100
+mv *.tbl tpch100
+```
+
+### 生成查询 SQL
+
+
+ 注意
+ 可参考本节中的下述步骤生成查询 SQL 后进行调整,也可直接使用 GitHub)中给出的查询 SQL。若选择使用 GitHub 中的查询 SQL,需将 SQL 语句中的 cpu_num 修改为实际并发数。
+
+
+1. 复制 qgen 和 dists.dss文件至 queries 目录。
+
+ ```
+ [wieck@localhost dbgen] $ cp qgen queries
+ [wieck@localhost dbgen] $ cp dists.dss queries
+ ```
+
+2. 在 queries 目录下创建 gen.sh 脚本生成查询 SQL。
+
+ ```
+ [wieck@localhost dbgen] $ cd queries
+ [wieck@localhost queries] $ vim gen.sh
+ #!/usr/bin/bash
+ for i in {1..22}
+ do
+ ./qgen -d $i -s 100 > db"$i".sql
+ done
+ ```
+
+3. 执行 gen.sh 脚本。
+
+ ```
+ [wieck@localhost queries] $ chmod +x gen.sh
+ [wieck@localhost queries] $ ./gen.sh
+ ```
+
+4. 查询 SQL 进行调整。
+
+ ```
+ [wieck@localhost queries] $ dos2unix *
+ ```
+
+调整后的查询 SQL 请参考 [GitHub](https://github.com/oceanbase/obdeploy/tree/master/plugins/tpch/3.1.0/queries)。您需将 GitHub 给出的 SQL 语句中的 cpu_num 修改为实际并发数。建议并发数的数值与可用 CPU 总数相同,两者相等时性能最好。
+
+在 SYS 租户下使用如下命令查看租户的可用 CPU 总数。
+
+ ```
+ obclient> SELECT sum(cpu_capacity_max) FROM oceanbase.__all_virtual_server;
+ ```
+
+以 q1 为例,修改后的 SQL 如下:
+
+```
+SELECT /*+ parallel(96) */ ---增加 parallel 并发执行
+ l_returnflag,
+ l_linestatus,
+ sum(l_quantity) as sum_qty,
+ sum(l_extendedprice) as sum_base_price,
+ sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
+ sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
+ avg(l_quantity) as avg_qty,
+ avg(l_extendedprice) as avg_price,
+ avg(l_discount) as avg_disc,
+ count(*) as count_order
+FROM
+ lineitem
+WHERE
+ l_shipdate <= date '1998-12-01' - interval '90' day
+GROUP BY
+ l_returnflag,
+ l_linestatus
+ORDER BY
+ l_returnflag,
+ l_linestatus;
+```
+
+### 新建表
+
+创建表结构文件 create_tpch_mysql_table_part.ddl。
+
+```
+create tablegroup if not exists tpch_tg_SF_TPC_USER_lineitem_order_group binding true partition by key 1 partitions 96;
+create tablegroup if not exists tpch_tg_SF_TPC_USER_partsupp_part binding true partition by key 1 partitions 96;
+
+drop table if exists LINEITEM;
+CREATE TABLE lineitem (
+ l_orderkey BIGINT NOT NULL,
+ l_partkey BIGINT NOT NULL,
+ l_suppkey INTEGER NOT NULL,
+ l_linenumber INTEGER NOT NULL,
+ l_quantity NUMBER(12,2) NOT NULL,
+ l_extendedprice NUMBER(12,2) NOT NULL,
+ l_discount NUMBER(12,2) NOT NULL,
+ l_tax NUMBER(12,2) NOT NULL,
+ l_returnflag char(1) DEFAULT NULL,
+ l_linestatus char(1) DEFAULT NULL,
+ l_shipdate date NOT NULL,
+ l_commitdate date DEFAULT NULL,
+ l_receiptdate date DEFAULT NULL,
+ l_shipinstruct char(25) DEFAULT NULL,
+ l_shipmode char(10) DEFAULT NULL,
+ l_comment varchar(44) DEFAULT NULL,
+primary key(l_orderkey, l_linenumber)
+)row_format = condensed
+tablegroup = tpch_tg_SF_TPC_USER_lineitem_order_group
+partition by key (l_orderkey) partitions 96;
+
+drop table if exists orders;
+CREATE TABLE orders (
+ o_orderkey BIGINT NOT NULL,
+ o_custkey BIGINT NOT NULL,
+ o_orderstatus char(1) DEFAULT NULL,
+ o_totalprice NUMBER(12,2) DEFAULT NULL,
+ o_orderdate date NOT NULL,
+ o_orderpriority char(15) DEFAULT NULL,
+ o_clerk char(15) DEFAULT NULL,
+ o_shippriority INTEGER DEFAULT NULL,
+ o_comment varchar(79) DEFAULT NULL,
+PRIMARY KEY (o_orderkey)
+)row_format = condensed
+tablegroup = tpch_tg_SF_TPC_USER_lineitem_order_group
+partition by key(o_orderkey) partitions 96;
+
+drop table if exists partsupp;
+CREATE TABLE partsupp (
+ ps_partkey BIGINT NOT NULL,
+ ps_suppkey INTEGER NOT NULL,
+ ps_availqty INTEGER DEFAULT NULL,
+ ps_supplycost NUMBER(12,2) DEFAULT NULL,
+ ps_comment varchar(199) DEFAULT NULL,
+ PRIMARY KEY (ps_partkey, ps_suppkey)) row_format = condensed
+tablegroup tpch_tg_SF_TPC_USER_partsupp_part
+partition by key(ps_partkey) partitions 96;
+
+drop table if exists PART;
+CREATE TABLE part (
+ p_partkey BIGINT NOT NULL,
+ p_name varchar(55) DEFAULT NULL,
+ p_mfgr char(25) DEFAULT NULL,
+ p_brand char(10) DEFAULT NULL,
+ p_type varchar(25) DEFAULT NULL,
+ p_size INTEGER DEFAULT NULL,
+ p_container char(10) DEFAULT NULL,
+ p_retailprice NUMBER(12,2) DEFAULT NULL,
+ p_comment varchar(23) DEFAULT NULL,
+ PRIMARY KEY (p_partkey)) row_format = condensed
+tablegroup tpch_tg_SF_TPC_USER_partsupp_part
+partition by key(p_partkey) partitions 96;
+
+drop table if exists CUSTOMER;
+CREATE TABLE customer (
+ c_custkey BIGINT NOT NULL,
+ c_name varchar(25) DEFAULT NULL,
+ c_address varchar(40) DEFAULT NULL,
+ c_nationkey INTEGER DEFAULT NULL,
+ c_phone char(15) DEFAULT NULL,
+ c_acctbal NUMBER(12,2) DEFAULT NULL,
+ c_mktsegment char(10) DEFAULT NULL,
+ c_comment varchar(117) DEFAULT NULL,
+ PRIMARY KEY (c_custkey)) row_format = condensed
+partition by key(c_custkey) partitions 96;
+
+drop table if exists SUPPLIER;
+CREATE TABLE supplier (
+ s_suppkey INTEGER NOT NULL,
+ s_name char(25) DEFAULT NULL,
+ s_address varchar(40) DEFAULT NULL,
+ s_nationkey INTEGER DEFAULT NULL,
+ s_phone char(15) DEFAULT NULL,
+ s_acctbal NUMBER(12,2) DEFAULT NULL,
+ s_comment varchar(101) DEFAULT NULL,
+ PRIMARY KEY (s_suppkey)
+) row_format = condensed partition by key(s_suppkey) partitions 96;
+
+drop table if exists NATION;
+CREATE TABLE nation (
+ n_nationkey INTEGER NOT NULL,
+ n_name char(25) DEFAULT NULL,
+ n_regionkey INTEGER DEFAULT NULL,
+ n_comment varchar(152) DEFAULT NULL,
+ PRIMARY KEY (n_nationkey)
+) row_format = condensed;
+
+drop table if exists REGION;
+CREATE TABLE region (
+ r_regionkey INTEGER NOT NULL,
+ r_name char(25) DEFAULT NULL,
+ r_comment varchar(152) DEFAULT NULL,
+ PRIMARY KEY (r_regionkey)
+) row_format = condensed;
+```
+
+### 加载数据
+
+根据上述步骤生成的数据和 SQL 自行编写脚本。加载数据示例操作如下:
+
+1. 创建加载脚本目录。
+
+ ```
+ [wieck@localhost dbgen] $ mkdir load
+ [wieck@localhost dbgen] $ cd load
+ [wieck@localhost load] $ cp xx/create_tpch_mysql_table_part.ddl ./
+ ```
+
+2. 创建 load.py 脚本。
+
+ ```
+ [wieck@localhost load] $ vim load.py
+
+ #!/usr/bin/env python
+ #-*- encoding:utf-8 -*-
+ import os
+ import sys
+ import time
+ import commands
+ hostname='$host_ip' # 注意!!请填写某个 observer,如 observer A 所在服务器的 IP 地址
+ port='$host_port' # observer A 的端口号
+ tenant='$tenant_name' # 租户名
+ user='$user' # 用户名
+ password='$password' # 密码
+ data_path='$path' # 注意!!请填写 observer A 所在服务器下 tbl 所在目录
+ db_name='$db_name' # 数据库名
+ # 创建表
+ cmd_str='obclient -h%s -P%s -u%s@%s -p%s -D%s < create_tpch_mysql_table_part.ddl'%(hostname,port,user,tenant,password,db_name)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str='obclient -h%s -P%s -u%s@%s -p%s -D%s -e "show tables;" '%(hostname,port,user,tenant,password,db_name)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/customer.tbl' into table customer fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/lineitem.tbl' into table lineitem fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/nation.tbl' into table nation fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/orders.tbl' into table orders fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -D%s -e "load data /*+ parallel(80) */ infile '%s/partsupp.tbl' into table partsupp fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/part.tbl' into table part fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/region.tbl' into table region fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/supplier.tbl' into table supplier fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ ```
+
+3. 加载数据。
+
+
+ 说明
+ 加载数据需要安装 OBClient 客户端。
+
+
+ ```
+ [wieck@localhost load] $ python load.py
+ ```
+
+4. 执行合并。
+
+ 登录测试租户,执行合并。
+
+ ```
+ obclient > ALTER SYSTEM MAJOR FREEZE;
+ ```
+
+5. 查看合并是否完成。
+
+ ```
+ SELECT * FROM oceanbase.DBA_OB_ZONE_MAJOR_COMPACTION\G
+ ```
+
+ 返回结果如下:
+
+ ```
+ *************************** 1. row ***************************
+ ZONE: zone1
+ BROADCAST_SCN: 1716172011046213913
+ LAST_SCN: 1716172011046213913
+ LAST_FINISH_TIME: 2024-05-20 10:35:07.829496
+ START_TIME: 2024-05-20 10:26:51.579881
+ STATUS: IDLE
+ 1 row in set
+ ```
+
+ 当 `STATUS` 状态为 `IDLE`,`BROADCAST_SCN` 和 `LAST_SCN` 的值相等时,表示合并完成。
+
+6. 手动收集统计信息。
+
+ 在测试用户下执行 obclient -h$host_ip -P$host_port -u$user@$tenant -p$password -A -D$database 命令。
+
+ ```
+ call dbms_stats.gather_schema_stats('$db_name',degree=>96);
+ ```
+
+### 执行测试
+
+根据上述步骤生成的数据和 SQL 自行编写脚本。执行测试示例操作如下:
+
+1. 在 queries 目录下编写测试脚本 tpch.sh。
+
+ ```
+ [wieck@localhost queries] $ vim tpch.sh
+
+ #!/bin/bash
+ TPCH_TEST="obclient -h $host_ip -P $host_port -utpch_100g_part@tpch_mysql -D tpch_100g_part -ptest -c"
+ # warmup预热
+ for i in {1..22}
+ do
+ sql1="source db${i}.sql"
+ echo $sql1| $TPCH_TEST >db${i}.log || ret=1
+ done
+ # 正式执行
+ for i in {1..22}
+ do
+ starttime=`date +%s%N`
+ echo `date '+[%Y-%m-%d %H:%M:%S]'` "BEGIN Q${i}"
+ sql1="source db${i}.sql"
+ echo $sql1| $TPCH_TEST >db${i}.log || ret=1
+ stoptime=`date +%s%N`
+ costtime=`echo $stoptime $starttime | awk '{printf "%0.2f\n", ($1 - $2) / 1000000000}'`
+ echo `date '+[%Y-%m-%d %H:%M:%S]'` "END,COST ${costtime}s"
+ done
+ ```
+
+2. 执行测试脚本。
+
+ ```
+ sh tpch.sh
+ ```
diff --git a/zh-CN/620.obap/750.obap-performance-test/20.obap-tpc-h-test-report.md b/zh-CN/620.obap/750.obap-performance-test/20.obap-tpc-h-test-report.md
new file mode 100644
index 0000000000..0185d618a0
--- /dev/null
+++ b/zh-CN/620.obap/750.obap-performance-test/20.obap-tpc-h-test-report.md
@@ -0,0 +1,62 @@
+# OceanBase 数据库 TPC-H 性能测试报告
+
+## 测试环境 (阿里云 ECS)
+
+- 3 节点硬件配置
+
+ |服务类型|ECS 类型|实列数|机器核心数|内存|
+ |---|---|---|---|---|
+ | OceanBase 数据库 | ecs.r6.8xlarge | 3 | 32c | 256G
+ 每台机器系统盘 300G、日志盘 400G、数据盘 2T,磁盘性能级别为 PL1 |
+ | TPC-H | ecs.r6.8xlarge | 1 | 32c | 256G |
+
+- 3 节点租户规格
+
+ ```
+ CREATE RESOURCE UNIT tpch_unit max_cpu 30, memory_size '180g'
+ CREATE RESOURCE POOL tpch_pool unit = 'tpch_unit', unit_num = 1, zone_list=('zone1','zone2','zone3');
+ CREATE TENANT tpch_mysql resource_pool_list=('tpch_pool'), zone_list('zone1', 'zone2', 'zone3'), primary_zone=RANDOM, locality='F@zone1,F@zone2,F@zone3' set variables ob_compatibility_mode='mysql', ob_tcp_invited_nodes='%';
+ ```
+
+- 软件版本
+
+ |服务类型|软件版本|
+ |---|---|
+ | OceanBase 数据库 | - 企业版:OceanBase 4.3.0.1
- 社区版:OceanBase_CE 4.3.0.1
|
+ | TPC-H | V3.0.0 |
+ | OS | CentOS Linux release 7.9.2009 (Core) |
+
+## 测试方案
+
+- 使用 OBD 部署 OceanBase 数据库集群。TPC-H 客户端需要部署在一台机器上, 作为客户端的压力机器。您无需部署 ODP,测试时直连任意一台机器即可。
+- 3 节点的 OceanBase 集群部署规模为 1:1:1。部署成功后先新建跑 TPCH 测试的租户及用户(sys 租户是管理集群的内置系统租户,请勿直接使用 sys 租户进行测试),设置租户的 primary_zone 为 RANDOM。
+- 测试数据量:100G。
+- 测试步骤详见 [OceanBase 数据库 TPC-H 测试](../750.obap-performance-test/10.obap-tpc-h-test.md)。
+
+## 测试结果
+
+|**Query ID**|**3 节点 OBServer V4.3.0 查询响应时间(单位:秒)**|
+|---|---|
+| Q1 | 1.97 |
+| Q2 | 0.30 |
+| Q3 | 0.58 |
+| Q4 | 0.42 |
+| Q5 | 0.80 |
+| Q6 | 0.06 |
+| Q7 | 1.33 |
+| Q8 | 0.86 |
+| Q9 | 2.26 |
+| Q10 | 0.72 |
+| Q11 | 0.19 |
+| Q12 | 0.38 |
+| Q13 | 1.89 |
+| Q14 | 0.24 |
+| Q15 | 0.44 |
+| Q16 | 0.62 |
+| Q17 | 1.48 |
+| Q18 | 1.45 |
+| Q19 | 0.27 |
+| Q20 | 0.66 |
+| Q21 | 3.09 |
+| Q22 | 1.18 |
+| Total | 21.33 |
\ No newline at end of file
diff --git a/zh-CN/620.obap/750.obap-performance-test/50.obap-tpc-ds-test.md b/zh-CN/620.obap/750.obap-performance-test/50.obap-tpc-ds-test.md
new file mode 100644
index 0000000000..a2a7a65d36
--- /dev/null
+++ b/zh-CN/620.obap/750.obap-performance-test/50.obap-tpc-ds-test.md
@@ -0,0 +1,1531 @@
+# OceanBase 数据库 TPC-DS 测试
+
+本文介绍在 AP 场景下,如何基于 OceanBase 数据库手动进行 TPC-DS 测试。
+
+
+ 说明
+ 为了提升用户体验和易用性,让每一个开发者在使用数据库时都能获得较好的性能,OceanBase 数据库在 V4.0.0 版本之后,做了大量的优化工作。本性能测试方法仅基于基础参数进行调优,让开发者获得较好的数据库性能体验。
+
+
+## 什么是 TPC-DS
+
+TPC-DS 是一个面向决策支持系统(decision support system)的包含多维度常规应用模型的决策支持基准,包括查询(queries)与数据维护。此基准对被测系统(System Under Test’s, SUT)在决策支持系统层面上的表现进行的评估具有代表性。
+
+**此基准体现决策支持系统以下特性:**
+
+- 测试大规模数据
+- 对实际商业问题进行解答
+- 执行需求多样或复杂的查询(如临时查询、报告、迭代 OLAP、数据挖掘)
+- 以高 CPU 和 IO 负载为特征
+- 通过数据库维护对 OLTP 数据库资源进行周期同步
+- 解决大数据问题,如关系型数据库(RDBMS),或基于 Hadoop/Spark 的系统
+
+基准结果用来测量,较为复杂的多用户决策中,单一用户模型下的查询响应时间,多用户模型下的查询吞吐量,以及数据维护表现。
+
+TPC-DS 采用星型、雪花型等多维数据模式。它包含 7 张事实表,17 张纬度表平均每张表含有 18 列。其工作负载包含 99 个 SQL 查询,覆盖 SQL99 和 2003 的核心部分以及 OLAP。这个测试集包含对大数据集的统计、报表生成、联机查询、数据挖掘等复杂应用,测试用的数据和值是有倾斜的,与真实数据一致。可以说 TPC-DS 是与真实场景非常接近的一个测试集,也是难度较大的一个测试集。
+
+## 环境准备
+
+测试前请按照如下要求准备您的测试环境:
+
+- JDK:建议使用 1.8u131 及以上版本。
+- make:yum install make。
+- gcc:yum install gcc。
+- mysql-devel:yum install mysql-devel。
+- Python 连接数据库的驱动:sudo yum install MySQL-python。
+- prettytable:pip install prettytable。
+- JDBC:建议使用 mysql-connector-java-5.1.47 版本。
+- tpcds tool:点击 [下载地址](https://www.tpc.org/tpc_documents_current_versions/download_programs/tools-download-request5.asp?bm_type=TPC-H&bm_vers=3.0.0&mode=CURRENT-ONLY) 获取。
+- OBClient:详细信息,请参考 [OBClient 文档](https://github.com/oceanbase/obclient/blob/master/README.md)。
+- OceanBase 数据库:详细信息,请参考 [快速体验 OceanBase 数据库](../../200.quickstart/100.quickly-experience-oceanbase-for-community.md)。
+- iops:建议磁盘 iops 在 10000 以上。
+- 租户规格:
+
+ ```
+ CREATE RESOURCE UNIT tpch_unit max_cpu 30, memory_size '180g';
+ CREATE RESOURCE POOL tpch_pool unit = 'tpch_unit', unit_num = 1, zone_list=('zone1','zone2','zone3');
+ CREATE TENANT tpch_mysql resource_pool_list=('tpch_pool'), zone_list('zone1', 'zone2', 'zone3'), primary_zone=RANDOM, locality='F@zone1,F@zone2,F@zone3' set variables ob_compatibility_mode='mysql', ob_tcp_invited_nodes='%',secure_file_priv = '';
+ ```
+
+
+ 注意
+
+ - 上文中的租户规格是基于 [OceanBase TPC-DS 性能测试报告](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000507724) 中的硬件配置进行配置的,您需根据自身数据库的硬件配置进行动态调整。
+ - 部署集群时,建议不要使用 obd cluster autodeploy 命令,该命令为了保证稳定性,不会最大化资源利用率(例如不会使用所有内存),建议单独对配置文件进行调优,最大化资源利用率。
+
+
+
+## 部署集群
+
+1. 本次测试需要用到 4 台机器,TPC-DS 单独部署在一台机器上,作为客户端的压力机器。部署 OceanBase 集群需要使用 3 台机器,OceanBase 集群规模为 1:1:1。
+
+
+ 说明
+ 在 TPC-DS 测试中,部署 TPC-DS 的机器只需 4 核 16G 即可。
+
+
+2. 部署成功后,新建执行 TPC-DS 测试的租户及用户(sys 租户是管理集群的内置系统租户,请勿直接使用 sys 租户进行测试)。将租户的 primary_zone 设置为 RANDOM。RANDOM 表示新建表分区的 Leader 随机到这 3 台机器。
+
+## 手动进行 TPC-DS 测试
+
+### 进行环境调优
+
+1. OceanBase 数据库调优。
+
+ 在系统租户下执行 `obclient -h$host_ip -P$host_port -uroot@sys -A` 命令。
+
+ ```
+ ALTER SYSTEM flush plan cache GLOBAL;
+ ALTER system SET enable_sql_audit=false;
+ select sleep(5);
+ ALTER system SET enable_perf_event=false;
+ ALTER system SET syslog_level='PERF';
+ alter system set enable_record_trace_log=false;
+ ```
+
+2. 测试租户调优。
+
+ 在测试用户下执行 `obclient -h$host_ip -P$host_port -u$user@$tenant -p$password -A` 命令。
+
+ ```
+ SET GLOBAL ob_sql_work_area_percentage = 80;
+ SET GLOBAL ob_query_timeout = 36000000000;
+ SET GLOBAL ob_trx_timeout = 36000000000;
+ SET GLOBAL max_allowed_packet = 67108864;
+ # parallel_servers_target = max_cpu * server_num * 8
+ SET GLOBAL parallel_servers_target = 624;
+ ```
+
+### 指定用户租户默认创建表为列存
+
+在测试用户下执行 `obclient -h$host_ip -P$host_port -u$user@$tenant -p$password -A` 命令。
+
+```
+alter system set default_table_store_format = 'column';
+```
+
+### 安装 TPC-DS Tool
+
+1. 下载 TPC-DS Tool。详细信息请参考 [TPC-DS Tool 下载页面](https://www.tpc.org/TPC_Documents_Current_Versions/download_programs/tools-download-request5.asp?bm_type=TPC-DS&bm_vers=3.2.0&mode=CURRENT-ONLY)。
+
+2. 下载完成后解压文件,进入 TPC-DS 解压后的目录。
+
+ ```
+ [wieck@localhost ~] $ unzip tpc-h-tool.zip
+ [wieck@localhost ~] $ cd TPC-H_Tools_v3.0.0
+ ```
+
+3. 复制 makefile.suite。
+
+ ```
+ [wieck@localhost TPC-H_Tools_v3.0.0] $ cd dbgen/
+ [wieck@localhost dbgen] $ cp makefile.suite Makefile
+ ```
+
+4. 修改 Makefile 文件中的 CC、DATABASE、MACHINE、WORKLOAD 等参数定义。
+
+ ```
+ [wieck@localhost dbgen] $ vim Makefile
+ CC = gcc
+ # Current values for DATABASE are: INFORMIX, DB2, TDAT (Teradata)
+ # SQLSERVER, SYBASE, ORACLE, VECTORWISE
+ # Current values for MACHINE are: ATT, DOS, HP, IBM, ICL, MVS,
+ # SGI, SUN, U2200, VMS, LINUX, WIN32
+ # Current values for WORKLOAD are: TPCH
+ DATABASE= MYSQL
+ MACHINE = LINUX
+ WORKLOAD = TPCH
+ ```
+
+5. 修改 tpcd.h 文件,并添加新的宏定义。
+
+ ```
+ [wieck@localhost dbgen] $ vim tpcd.h
+
+ #ifdef MYSQL
+ #define GEN_QUERY_PLAN ""
+ #define START_TRAN "START TRANSACTION"
+ #define END_TRAN "COMMIT"
+ #define SET_OUTPUT ""
+ #define SET_ROWCOUNT "limit %d;\n"
+ #define SET_DBASE "use %s;\n"
+ #endif
+ ```
+
+6. 编译文件。
+
+ ```
+ make
+ ```
+
+### 生成数据
+
+可以根据实际环境生成 TCP-H 10G、100G 或者 1T 数据。本文以生成 100G 数据为例。
+
+```
+./dbgen -s 100
+mkdir tpch100
+mv *.tbl tpch100
+```
+### 生成查询 SQL
+
+
+ 注意
+ 可参考本节中的下述步骤生成查询 SQL 后进行调整,也可直接使用 GitHub)中给出的查询 SQL。若选择使用 GitHub 中的查询 SQL,需将 SQL 语句中的 cpu_num 修改为实际并发数。
+
+
+1. 复制 qgen 和 dists.dss文件至 queries 目录。
+
+ ```
+ [wieck@localhost dbgen] $ cp qgen queries
+ [wieck@localhost dbgen] $ cp dists.dss queries
+ ```
+
+2. 在 queries 目录下创建 gen.sh 脚本生成查询 SQL。
+
+ ```
+ [wieck@localhost dbgen] $ cd queries
+ [wieck@localhost queries] $ vim gen.sh
+ #!/usr/bin/bash
+ for i in {1..100}
+ do
+ ./qgen -d $i -s 100 > db"$i".sql
+ done
+ ```
+
+3. 执行 gen.sh 脚本。
+
+ ```
+ [wieck@localhost queries] $ chmod +x gen.sh
+ [wieck@localhost queries] $ ./gen.sh
+ ```
+
+4. 查询 SQL 进行调整。
+
+ ```
+ [wieck@localhost queries] $ dos2unix *
+ ```
+
+ 调整后的查询 SQL 请参考 [GitHub](https://github.com/oceanbase/obdeploy/tree/master/plugins/tpch/3.1.0/queries)。您需将 GitHub 给出的 SQL 语句中的 cpu_num 修改为实际并发数。建议并发数的数值与可用 CPU 总数相同,两者相等时性能最好。
+
+ 在 SYS 租户下使用如下命令查看租户的可用 CPU 总数。
+
+ ```
+ obclient> SELECT sum(cpu_capacity_max) FROM oceanbase.__all_virtual_server;
+ ```
+
+ 以 q1 为例,修改后的 SQL 如下:
+
+ ```
+ SELECT /*+ parallel(96) */ ---增加 parallel 并发执行
+ count(*)
+ from store_sales
+ ,household_demographics
+ ,time_dim, store
+ where ss_sold_time_sk = time_dim.t_time_sk
+ and ss_hdemo_sk = household_demographics.hd_demo_sk
+ and ss_store_sk = s_store_sk
+ and time_dim.t_hour = 8 and time_dim.t_minute >= 30 and household_demographics.hd_dep_count = 5 and store.s_store_name = 'ese'order by count(*)
+ limit 100;
+ ```
+
+### 新建表
+
+创建表结构文件 create_tpch_mysql_table_part.ddl。
+
+```
+SET global NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS';
+SET global NLS_TIMESTAMP_FORMAT='YYYY-MM-DD HH24:MI:SS.FF';
+SET global NLS_TIMESTAMP_TZ_FORMAT='YYYY-MM-DD HH24:MI:SS.FF TZR TZD';
+
+set global ob_query_timeout=10800000000;
+set global ob_trx_timeout=10000000000;
+
+set global ob_sql_work_area_percentage=80;
+
+set global optimizer_use_sql_plan_baselines = true;
+set global optimizer_capture_sql_plan_baselines = true;
+
+alter system set ob_enable_batched_multi_statement='true';
+
+set global parallel_servers_target=10000;
+
+create tablegroup if not exists tpcds_tg_catalog_group_range binding true partition by hash partitions 128;
+create tablegroup if not exists tpcds_tg_store_group_range_72_hash binding true
+partition by range columns 1 subpartition BY hash subpartitions 64
+(partition part_1 values less than (2450846),
+partition part_2 values less than (2450874),
+partition part_3 values less than (2450905),
+partition part_4 values less than (2450935),
+partition part_5 values less than (2450966),
+partition part_6 values less than (2450996),
+partition part_7 values less than (2451027),
+partition part_8 values less than (2451058),
+partition part_9 values less than (2451088),
+partition part_10 values less than (2451119),
+partition part_11 values less than (2451149),
+partition part_12 values less than (2451180),
+partition part_13 values less than (2451211),
+partition part_14 values less than (2451239),
+partition part_15 values less than (2451270),
+partition part_16 values less than (2451300),
+partition part_17 values less than (2451331),
+partition part_18 values less than (2451361),
+partition part_19 values less than (2451392),
+partition part_20 values less than (2451423),
+partition part_21 values less than (2451453),
+partition part_22 values less than (2451484),
+partition part_23 values less than (2451514),
+partition part_24 values less than (2451545),
+partition part_25 values less than (2451576),
+partition part_26 values less than (2451605),
+partition part_27 values less than (2451636),
+partition part_28 values less than (2451666),
+partition part_29 values less than (2451697),
+partition part_30 values less than (2451727),
+partition part_31 values less than (2451758),
+partition part_32 values less than (2451789),
+partition part_33 values less than (2451819),
+partition part_34 values less than (2451850),
+partition part_35 values less than (2451880),
+partition part_36 values less than (2451911),
+partition part_37 values less than (2451942),
+partition part_38 values less than (2451970),
+partition part_39 values less than (2452001),
+partition part_40 values less than (2452031),
+partition part_41 values less than (2452062),
+partition part_42 values less than (2452092),
+partition part_43 values less than (2452123),
+partition part_44 values less than (2452154),
+partition part_45 values less than (2452184),
+partition part_46 values less than (2452215),
+partition part_47 values less than (2452245),
+partition part_48 values less than (2452276),
+partition part_49 values less than (2452307),
+partition part_50 values less than (2452335),
+partition part_51 values less than (2452366),
+partition part_52 values less than (2452396),
+partition part_53 values less than (2452427),
+partition part_54 values less than (2452457),
+partition part_55 values less than (2452488),
+partition part_56 values less than (2452519),
+partition part_57 values less than (2452549),
+partition part_58 values less than (2452580),
+partition part_59 values less than (2452610),
+partition part_60 values less than (2452641),
+partition part_61 values less than (2452672),
+partition part_62 values less than (2452700),
+partition part_63 values less than (2452731),
+partition part_64 values less than (2452761),
+partition part_65 values less than (2452792),
+partition part_66 values less than (2452822),
+partition part_67 values less than (2452853),
+partition part_68 values less than (2452884),
+partition part_69 values less than (2452914),
+partition part_70 values less than (2452945),
+partition part_71 values less than (2452975),
+partition part_72 values less than (2453006),
+partition part_73 values less than (maxvalue));
+
+create table dbgen_version
+(
+ dv_version varchar(16) ,
+ dv_create_date date ,
+ dv_create_time varchar(20) ,
+ dv_cmdline_args varchar(200)
+);
+
+create table customer_address
+(
+ ca_address_sk integer not null,
+ ca_address_id char(16) not null,
+ ca_street_number char(10) ,
+ ca_street_name varchar(60) ,
+ ca_street_type char(15) ,
+ ca_suite_number char(10) ,
+ ca_city varchar(60) ,
+ ca_county varchar(30) ,
+ ca_state char(2) ,
+ ca_zip char(10) ,
+ ca_country varchar(20) ,
+ ca_gmt_offset number(5,2) ,
+ ca_location_type char(20) ,
+ primary key (ca_address_sk)
+)partition by hash (ca_address_sk) partitions 128;
+
+create table customer_demographics
+(
+ cd_demo_sk integer not null,
+ cd_gender char(1) ,
+ cd_marital_status char(1) ,
+ cd_education_status char(20) ,
+ cd_purchase_estimate integer ,
+ cd_credit_rating char(10) ,
+ cd_dep_count integer ,
+ cd_dep_employed_count integer ,
+ cd_dep_college_count integer ,
+ primary key (cd_demo_sk)
+)partition by hash (cd_demo_sk) partitions 128;
+
+create table date_dim
+(
+ d_date_sk integer not null,
+ d_date_id char(16) not null,
+ d_date date ,
+ d_month_seq integer ,
+ d_week_seq integer ,
+ d_quarter_seq integer ,
+ d_year integer ,
+ d_dow integer ,
+ d_moy integer ,
+ d_dom integer ,
+ d_qoy integer ,
+ d_fy_year integer ,
+ d_fy_quarter_seq integer ,
+ d_fy_week_seq integer ,
+ d_day_name char(9) ,
+ d_quarter_name char(6) ,
+ d_holiday char(1) ,
+ d_weekend char(1) ,
+ d_following_holiday char(1) ,
+ d_first_dom integer ,
+ d_last_dom integer ,
+ d_same_day_ly integer ,
+ d_same_day_lq integer ,
+ d_current_day char(1) ,
+ d_current_week char(1) ,
+ d_current_month char(1) ,
+ d_current_quarter char(1) ,
+ d_current_year char(1) ,
+ primary key (d_date_sk)
+);
+
+create table warehouse
+(
+ w_warehouse_sk integer not null,
+ w_warehouse_id char(16) not null,
+ w_warehouse_name varchar(20) ,
+ w_warehouse_sq_ft integer ,
+ w_street_number char(10) ,
+ w_street_name varchar(60) ,
+ w_street_type char(15) ,
+ w_suite_number char(10) ,
+ w_city varchar(60) ,
+ w_county varchar(30) ,
+ w_state char(2) ,
+ w_zip char(10) ,
+ w_country varchar(20) ,
+ w_gmt_offset number(5,2) ,
+ primary key (w_warehouse_sk)
+);
+
+create table ship_mode
+(
+ sm_ship_mode_sk integer not null,
+ sm_ship_mode_id char(16) not null,
+ sm_type char(30) ,
+ sm_code char(10) ,
+ sm_carrier char(20) ,
+ sm_contract char(20) ,
+ primary key (sm_ship_mode_sk)
+);
+
+create table time_dim
+(
+ t_time_sk integer not null,
+ t_time_id char(16) not null,
+ t_time integer ,
+ t_hour integer ,
+ t_minute integer ,
+ t_second integer ,
+ t_am_pm char(2) ,
+ t_shift char(20) ,
+ t_sub_shift char(20) ,
+ t_meal_time char(20) ,
+ primary key (t_time_sk)
+);
+
+create table reason
+(
+ r_reason_sk integer not null,
+ r_reason_id char(16) not null,
+ r_reason_desc char(100) ,
+ primary key (r_reason_sk)
+);
+
+create table income_band
+(
+ ib_income_band_sk integer not null,
+ ib_lower_bound integer ,
+ ib_upper_bound integer ,
+ primary key (ib_income_band_sk)
+);
+
+create table item
+(
+ i_item_sk integer not null,
+ i_item_id char(16) not null,
+ i_rec_start_date date ,
+ i_rec_end_date date ,
+ i_item_desc varchar(200) ,
+ i_current_price number(7,2) ,
+ i_wholesale_cost number(7,2) ,
+ i_brand_id integer ,
+ i_brand char(50) ,
+ i_class_id integer ,
+ i_class char(50) ,
+ i_category_id integer ,
+ i_category char(50) ,
+ i_manufact_id integer ,
+ i_manufact char(50) ,
+ i_size char(20) ,
+ i_formulation char(20) ,
+ i_color char(20) ,
+ i_units char(10) ,
+ i_container char(10) ,
+ i_manager_id integer ,
+ i_product_name char(50) ,
+ primary key (i_item_sk)
+);
+
+create table store
+(
+ s_store_sk integer not null,
+ s_store_id char(16) not null,
+ s_rec_start_date date ,
+ s_rec_end_date date ,
+ s_closed_date_sk integer ,
+ s_store_name varchar(50) ,
+ s_number_employees integer ,
+ s_floor_space integer ,
+ s_hours char(20) ,
+ s_manager varchar(40) ,
+ s_market_id integer ,
+ s_geography_class varchar(100) ,
+ s_market_desc varchar(100) ,
+ s_market_manager varchar(40) ,
+ s_division_id integer ,
+ s_division_name varchar(50) ,
+ s_company_id integer ,
+ s_company_name varchar(50) ,
+ s_street_number varchar(10) ,
+ s_street_name varchar(60) ,
+ s_street_type char(15) ,
+ s_suite_number char(10) ,
+ s_city varchar(60) ,
+ s_county varchar(30) ,
+ s_state char(2) ,
+ s_zip char(10) ,
+ s_country varchar(20) ,
+ s_gmt_offset number(5,2) ,
+ s_tax_precentage number(5,2) ,
+ primary key (s_store_sk)
+);
+
+create table call_center
+(
+ cc_call_center_sk integer not null,
+ cc_call_center_id char(16) not null,
+ cc_rec_start_date date ,
+ cc_rec_end_date date ,
+ cc_closed_date_sk integer ,
+ cc_open_date_sk integer ,
+ cc_name varchar(50) ,
+ cc_class varchar(50) ,
+ cc_employees integer ,
+ cc_sq_ft integer ,
+ cc_hours char(20) ,
+ cc_manager varchar(40) ,
+ cc_mkt_id integer ,
+ cc_mkt_class char(50) ,
+ cc_mkt_desc varchar(100) ,
+ cc_market_manager varchar(40) ,
+ cc_division integer ,
+ cc_division_name varchar(50) ,
+ cc_company integer ,
+ cc_company_name char(50) ,
+ cc_street_number char(10) ,
+ cc_street_name varchar(60) ,
+ cc_street_type char(15) ,
+ cc_suite_number char(10) ,
+ cc_city varchar(60) ,
+ cc_county varchar(30) ,
+ cc_state char(2) ,
+ cc_zip char(10) ,
+ cc_country varchar(20) ,
+ cc_gmt_offset number(5,2) ,
+ cc_tax_percentage number(5,2) ,
+ primary key (cc_call_center_sk)
+);
+
+create table customer
+(
+ c_customer_sk integer not null,
+ c_customer_id char(16) not null,
+ c_current_cdemo_sk integer ,
+ c_current_hdemo_sk integer ,
+ c_current_addr_sk integer ,
+ c_first_shipto_date_sk integer ,
+ c_first_sales_date_sk integer ,
+ c_salutation char(10) ,
+ c_first_name char(20) ,
+ c_last_name char(30) ,
+ c_preferred_cust_flag char(1) ,
+ c_birth_day integer ,
+ c_birth_month integer ,
+ c_birth_year integer ,
+ c_birth_country varchar(20) ,
+ c_login char(13) ,
+ c_email_address char(50) ,
+ c_last_review_date char(10) ,
+ primary key (c_customer_sk)
+)partition by hash (c_customer_sk) partitions 128;
+
+create table web_site
+(
+ web_site_sk integer not null,
+ web_site_id char(16) not null,
+ web_rec_start_date date ,
+ web_rec_end_date date ,
+ web_name varchar(50) ,
+ web_open_date_sk integer ,
+ web_close_date_sk integer ,
+ web_class varchar(50) ,
+ web_manager varchar(40) ,
+ web_mkt_id integer ,
+ web_mkt_class varchar(50) ,
+ web_mkt_desc varchar(100) ,
+ web_market_manager varchar(40) ,
+ web_company_id integer ,
+ web_company_name char(50) ,
+ web_street_number char(10) ,
+ web_street_name varchar(60) ,
+ web_street_type char(15) ,
+ web_suite_number char(10) ,
+ web_city varchar(60) ,
+ web_county varchar(30) ,
+ web_state char(2) ,
+ web_zip char(10) ,
+ web_country varchar(20) ,
+ web_gmt_offset number(5,2) ,
+ web_tax_percentage number(5,2) ,
+ primary key (web_site_sk)
+);
+
+create table store_returns
+(
+ sr_returned_date_sk integer ,
+ sr_return_time_sk integer ,
+ sr_item_sk integer not null,
+ sr_customer_sk integer ,
+ sr_cdemo_sk integer ,
+ sr_hdemo_sk integer ,
+ sr_addr_sk integer ,
+ sr_store_sk integer ,
+ sr_reason_sk integer ,
+ sr_ticket_number integer not null,
+ sr_return_quantity integer ,
+ sr_return_amt number(7,2) ,
+ sr_return_tax number(7,2) ,
+ sr_return_amt_inc_tax number(7,2) ,
+ sr_fee number(7,2) ,
+ sr_return_ship_cost number(7,2) ,
+ sr_refunded_cash number(7,2) ,
+ sr_reversed_charge number(7,2) ,
+ sr_store_credit number(7,2) ,
+ sr_net_loss number(7,2)
+)
+partition by range (sr_returned_date_sk)
+subpartition BY hash(sr_item_sk) subpartitions 64
+(partition part_1 values less than (2450846),
+partition part_2 values less than (2450874),
+partition part_3 values less than (2450905),
+partition part_4 values less than (2450935),
+partition part_5 values less than (2450966),
+partition part_6 values less than (2450996),
+partition part_7 values less than (2451027),
+partition part_8 values less than (2451058),
+partition part_9 values less than (2451088),
+partition part_10 values less than (2451119),
+partition part_11 values less than (2451149),
+partition part_12 values less than (2451180),
+partition part_13 values less than (2451211),
+partition part_14 values less than (2451239),
+partition part_15 values less than (2451270),
+partition part_16 values less than (2451300),
+partition part_17 values less than (2451331),
+partition part_18 values less than (2451361),
+partition part_19 values less than (2451392),
+partition part_20 values less than (2451423),
+partition part_21 values less than (2451453),
+partition part_22 values less than (2451484),
+partition part_23 values less than (2451514),
+partition part_24 values less than (2451545),
+partition part_25 values less than (2451576),
+partition part_26 values less than (2451605),
+partition part_27 values less than (2451636),
+partition part_28 values less than (2451666),
+partition part_29 values less than (2451697),
+partition part_30 values less than (2451727),
+partition part_31 values less than (2451758),
+partition part_32 values less than (2451789),
+partition part_33 values less than (2451819),
+partition part_34 values less than (2451850),
+partition part_35 values less than (2451880),
+partition part_36 values less than (2451911),
+partition part_37 values less than (2451942),
+partition part_38 values less than (2451970),
+partition part_39 values less than (2452001),
+partition part_40 values less than (2452031),
+partition part_41 values less than (2452062),
+partition part_42 values less than (2452092),
+partition part_43 values less than (2452123),
+partition part_44 values less than (2452154),
+partition part_45 values less than (2452184),
+partition part_46 values less than (2452215),
+partition part_47 values less than (2452245),
+partition part_48 values less than (2452276),
+partition part_49 values less than (2452307),
+partition part_50 values less than (2452335),
+partition part_51 values less than (2452366),
+partition part_52 values less than (2452396),
+partition part_53 values less than (2452427),
+partition part_54 values less than (2452457),
+partition part_55 values less than (2452488),
+partition part_56 values less than (2452519),
+partition part_57 values less than (2452549),
+partition part_58 values less than (2452580),
+partition part_59 values less than (2452610),
+partition part_60 values less than (2452641),
+partition part_61 values less than (2452672),
+partition part_62 values less than (2452700),
+partition part_63 values less than (2452731),
+partition part_64 values less than (2452761),
+partition part_65 values less than (2452792),
+partition part_66 values less than (2452822),
+partition part_67 values less than (2452853),
+partition part_68 values less than (2452884),
+partition part_69 values less than (2452914),
+partition part_70 values less than (2452945),
+partition part_71 values less than (2452975),
+partition part_72 values less than (2453006),
+partition part_73 values less than (maxvalue))
+;
+
+create table household_demographics
+(
+ hd_demo_sk integer not null,
+ hd_income_band_sk integer ,
+ hd_buy_potential char(15) ,
+ hd_dep_count integer ,
+ hd_vehicle_count integer ,
+ primary key (hd_demo_sk)
+);
+
+create table web_page
+(
+ wp_web_page_sk integer not null,
+ wp_web_page_id char(16) not null,
+ wp_rec_start_date date ,
+ wp_rec_end_date date ,
+ wp_creation_date_sk integer ,
+ wp_access_date_sk integer ,
+ wp_autogen_flag char(1) ,
+ wp_customer_sk integer ,
+ wp_url varchar(100) ,
+ wp_type char(50) ,
+ wp_char_count integer ,
+ wp_link_count integer ,
+ wp_image_count integer ,
+ wp_max_ad_count integer ,
+ primary key (wp_web_page_sk)
+);
+
+create table promotion
+(
+ p_promo_sk integer not null,
+ p_promo_id char(16) not null,
+ p_start_date_sk integer ,
+ p_end_date_sk integer ,
+ p_item_sk integer ,
+ p_cost number(15,2) ,
+ p_response_target integer ,
+ p_promo_name char(50) ,
+ p_channel_dmail char(1) ,
+ p_channel_email char(1) ,
+ p_channel_catalog char(1) ,
+ p_channel_tv char(1) ,
+ p_channel_radio char(1) ,
+ p_channel_press char(1) ,
+ p_channel_event char(1) ,
+ p_channel_demo char(1) ,
+ p_channel_details varchar(100) ,
+ p_purpose char(15) ,
+ p_discount_active char(1) ,
+ primary key (p_promo_sk)
+);
+
+create table catalog_page
+(
+ cp_catalog_page_sk integer not null,
+ cp_catalog_page_id char(16) not null,
+ cp_start_date_sk integer ,
+ cp_end_date_sk integer ,
+ cp_department varchar(50) ,
+ cp_catalog_number integer ,
+ cp_catalog_page_number integer ,
+ cp_description varchar(100) ,
+ cp_type varchar(100) ,
+ primary key (cp_catalog_page_sk)
+);
+
+create table inventory
+(
+ inv_date_sk integer not null,
+ inv_item_sk integer not null,
+ inv_warehouse_sk integer not null,
+ inv_quantity_on_hand integer
+)
+partition by range (inv_date_sk)
+subpartition BY hash(inv_item_sk) subpartitions 64
+(partition part_1 values less than (2450846),
+partition part_2 values less than (2450874),
+partition part_3 values less than (2450905),
+partition part_4 values less than (2450935),
+partition part_5 values less than (2450966),
+partition part_6 values less than (2450996),
+partition part_7 values less than (2451027),
+partition part_8 values less than (2451058),
+partition part_9 values less than (2451088),
+partition part_10 values less than (2451119),
+partition part_11 values less than (2451149),
+partition part_12 values less than (2451180),
+partition part_13 values less than (2451211),
+partition part_14 values less than (2451239),
+partition part_15 values less than (2451270),
+partition part_16 values less than (2451300),
+partition part_17 values less than (2451331),
+partition part_18 values less than (2451361),
+partition part_19 values less than (2451392),
+partition part_20 values less than (2451423),
+partition part_21 values less than (2451453),
+partition part_22 values less than (2451484),
+partition part_23 values less than (2451514),
+partition part_24 values less than (2451545),
+partition part_25 values less than (2451576),
+partition part_26 values less than (2451605),
+partition part_27 values less than (2451636),
+partition part_28 values less than (2451666),
+partition part_29 values less than (2451697),
+partition part_30 values less than (2451727),
+partition part_31 values less than (2451758),
+partition part_32 values less than (2451789),
+partition part_33 values less than (2451819),
+partition part_34 values less than (2451850),
+partition part_35 values less than (2451880),
+partition part_36 values less than (2451911),
+partition part_37 values less than (2451942),
+partition part_38 values less than (2451970),
+partition part_39 values less than (2452001),
+partition part_40 values less than (2452031),
+partition part_41 values less than (2452062),
+partition part_42 values less than (2452092),
+partition part_43 values less than (2452123),
+partition part_44 values less than (2452154),
+partition part_45 values less than (2452184),
+partition part_46 values less than (2452215),
+partition part_47 values less than (2452245),
+partition part_48 values less than (2452276),
+partition part_49 values less than (2452307),
+partition part_50 values less than (2452335),
+partition part_51 values less than (2452366),
+partition part_52 values less than (2452396),
+partition part_53 values less than (2452427),
+partition part_54 values less than (2452457),
+partition part_55 values less than (2452488),
+partition part_56 values less than (2452519),
+partition part_57 values less than (2452549),
+partition part_58 values less than (2452580),
+partition part_59 values less than (2452610),
+partition part_60 values less than (2452641),
+partition part_61 values less than (2452672),
+partition part_62 values less than (2452700),
+partition part_63 values less than (2452731),
+partition part_64 values less than (2452761),
+partition part_65 values less than (2452792),
+partition part_66 values less than (2452822),
+partition part_67 values less than (2452853),
+partition part_68 values less than (2452884),
+partition part_69 values less than (2452914),
+partition part_70 values less than (2452945),
+partition part_71 values less than (2452975),
+partition part_72 values less than (2453006),
+partition part_73 values less than (maxvalue));
+
+create table catalog_returns
+(
+ cr_returned_date_sk integer ,
+ cr_returned_time_sk integer ,
+ cr_item_sk integer not null,
+ cr_refunded_customer_sk integer ,
+ cr_refunded_cdemo_sk integer ,
+ cr_refunded_hdemo_sk integer ,
+ cr_refunded_addr_sk integer ,
+ cr_returning_customer_sk integer ,
+ cr_returning_cdemo_sk integer ,
+ cr_returning_hdemo_sk integer ,
+ cr_returning_addr_sk integer ,
+ cr_call_center_sk integer ,
+ cr_catalog_page_sk integer ,
+ cr_ship_mode_sk integer ,
+ cr_warehouse_sk integer ,
+ cr_reason_sk integer ,
+ cr_order_number integer not null,
+ cr_return_quantity integer ,
+ cr_return_amount number(7,2) ,
+ cr_return_tax number(7,2) ,
+ cr_return_amt_inc_tax number(7,2) ,
+ cr_fee number(7,2) ,
+ cr_return_ship_cost number(7,2) ,
+ cr_refunded_cash number(7,2) ,
+ cr_reversed_charge number(7,2) ,
+ cr_store_credit number(7,2) ,
+ cr_net_loss number(7,2) ,
+ primary key (cr_item_sk, cr_order_number)
+)
+tablegroup = tpcds_tg_catalog_group_range
+partition by hash(cr_item_sk) partitions 128
+;
+
+create table web_returns
+(
+ wr_returned_date_sk integer ,
+ wr_returned_time_sk integer ,
+ wr_item_sk integer not null,
+ wr_refunded_customer_sk integer ,
+ wr_refunded_cdemo_sk integer ,
+ wr_refunded_hdemo_sk integer ,
+ wr_refunded_addr_sk integer ,
+ wr_returning_customer_sk integer ,
+ wr_returning_cdemo_sk integer ,
+ wr_returning_hdemo_sk integer ,
+ wr_returning_addr_sk integer ,
+ wr_web_page_sk integer ,
+ wr_reason_sk integer ,
+ wr_order_number integer not null,
+ wr_return_quantity integer ,
+ wr_return_amt number(7,2) ,
+ wr_return_tax number(7,2) ,
+ wr_return_amt_inc_tax number(7,2) ,
+ wr_fee number(7,2) ,
+ wr_return_ship_cost number(7,2) ,
+ wr_refunded_cash number(7,2) ,
+ wr_reversed_charge number(7,2) ,
+ wr_account_credit number(7,2) ,
+ wr_net_loss number(7,2)
+)
+partition by range(wr_returned_date_sk)
+subpartition BY hash(wr_item_sk) subpartitions 64
+(partition part_1 values less than (2450846),
+partition part_2 values less than (2450874),
+partition part_3 values less than (2450905),
+partition part_4 values less than (2450935),
+partition part_5 values less than (2450966),
+partition part_6 values less than (2450996),
+partition part_7 values less than (2451027),
+partition part_8 values less than (2451058),
+partition part_9 values less than (2451088),
+partition part_10 values less than (2451119),
+partition part_11 values less than (2451149),
+partition part_12 values less than (2451180),
+partition part_13 values less than (2451211),
+partition part_14 values less than (2451239),
+partition part_15 values less than (2451270),
+partition part_16 values less than (2451300),
+partition part_17 values less than (2451331),
+partition part_18 values less than (2451361),
+partition part_19 values less than (2451392),
+partition part_20 values less than (2451423),
+partition part_21 values less than (2451453),
+partition part_22 values less than (2451484),
+partition part_23 values less than (2451514),
+partition part_24 values less than (2451545),
+partition part_25 values less than (2451576),
+partition part_26 values less than (2451605),
+partition part_27 values less than (2451636),
+partition part_28 values less than (2451666),
+partition part_29 values less than (2451697),
+partition part_30 values less than (2451727),
+partition part_31 values less than (2451758),
+partition part_32 values less than (2451789),
+partition part_33 values less than (2451819),
+partition part_34 values less than (2451850),
+partition part_35 values less than (2451880),
+partition part_36 values less than (2451911),
+partition part_37 values less than (2451942),
+partition part_38 values less than (2451970),
+partition part_39 values less than (2452001),
+partition part_40 values less than (2452031),
+partition part_41 values less than (2452062),
+partition part_42 values less than (2452092),
+partition part_43 values less than (2452123),
+partition part_44 values less than (2452154),
+partition part_45 values less than (2452184),
+partition part_46 values less than (2452215),
+partition part_47 values less than (2452245),
+partition part_48 values less than (2452276),
+partition part_49 values less than (2452307),
+partition part_50 values less than (2452335),
+partition part_51 values less than (2452366),
+partition part_52 values less than (2452396),
+partition part_53 values less than (2452427),
+partition part_54 values less than (2452457),
+partition part_55 values less than (2452488),
+partition part_56 values less than (2452519),
+partition part_57 values less than (2452549),
+partition part_58 values less than (2452580),
+partition part_59 values less than (2452610),
+partition part_60 values less than (2452641),
+partition part_61 values less than (2452672),
+partition part_62 values less than (2452700),
+partition part_63 values less than (2452731),
+partition part_64 values less than (2452761),
+partition part_65 values less than (2452792),
+partition part_66 values less than (2452822),
+partition part_67 values less than (2452853),
+partition part_68 values less than (2452884),
+partition part_69 values less than (2452914),
+partition part_70 values less than (2452945),
+partition part_71 values less than (2452975),
+partition part_72 values less than (2453006),
+partition part_73 values less than (maxvalue))
+;
+
+create table web_sales
+(
+ ws_sold_date_sk integer ,
+ ws_sold_time_sk integer ,
+ ws_ship_date_sk integer ,
+ ws_item_sk integer not null,
+ ws_bill_customer_sk integer ,
+ ws_bill_cdemo_sk integer ,
+ ws_bill_hdemo_sk integer ,
+ ws_bill_addr_sk integer ,
+ ws_ship_customer_sk integer ,
+ ws_ship_cdemo_sk integer ,
+ ws_ship_hdemo_sk integer ,
+ ws_ship_addr_sk integer ,
+ ws_web_page_sk integer ,
+ ws_web_site_sk integer ,
+ ws_ship_mode_sk integer ,
+ ws_warehouse_sk integer ,
+ ws_promo_sk integer ,
+ ws_order_number integer not null,
+ ws_quantity integer ,
+ ws_wholesale_cost number(7,2) ,
+ ws_list_price number(7,2) ,
+ ws_sales_price number(7,2) ,
+ ws_ext_discount_amt number(7,2) ,
+ ws_ext_sales_price number(7,2) ,
+ ws_ext_wholesale_cost number(7,2) ,
+ ws_ext_list_price number(7,2) ,
+ ws_ext_tax number(7,2) ,
+ ws_coupon_amt number(7,2) ,
+ ws_ext_ship_cost number(7,2) ,
+ ws_net_paid number(7,2) ,
+ ws_net_paid_inc_tax number(7,2) ,
+ ws_net_paid_inc_ship number(7,2) ,
+ ws_net_paid_inc_ship_tax number(7,2) ,
+ ws_net_profit number(7,2)
+)
+partition by range (ws_sold_date_sk)
+subpartition BY hash(ws_item_sk) subpartitions 64
+(partition part_1 values less than (2450846),
+partition part_2 values less than (2450874),
+partition part_3 values less than (2450905),
+partition part_4 values less than (2450935),
+partition part_5 values less than (2450966),
+partition part_6 values less than (2450996),
+partition part_7 values less than (2451027),
+partition part_8 values less than (2451058),
+partition part_9 values less than (2451088),
+partition part_10 values less than (2451119),
+partition part_11 values less than (2451149),
+partition part_12 values less than (2451180),
+partition part_13 values less than (2451211),
+partition part_14 values less than (2451239),
+partition part_15 values less than (2451270),
+partition part_16 values less than (2451300),
+partition part_17 values less than (2451331),
+partition part_18 values less than (2451361),
+partition part_19 values less than (2451392),
+partition part_20 values less than (2451423),
+partition part_21 values less than (2451453),
+partition part_22 values less than (2451484),
+partition part_23 values less than (2451514),
+partition part_24 values less than (2451545),
+partition part_25 values less than (2451576),
+partition part_26 values less than (2451605),
+partition part_27 values less than (2451636),
+partition part_28 values less than (2451666),
+partition part_29 values less than (2451697),
+partition part_30 values less than (2451727),
+partition part_31 values less than (2451758),
+partition part_32 values less than (2451789),
+partition part_33 values less than (2451819),
+partition part_34 values less than (2451850),
+partition part_35 values less than (2451880),
+partition part_36 values less than (2451911),
+partition part_37 values less than (2451942),
+partition part_38 values less than (2451970),
+partition part_39 values less than (2452001),
+partition part_40 values less than (2452031),
+partition part_41 values less than (2452062),
+partition part_42 values less than (2452092),
+partition part_43 values less than (2452123),
+partition part_44 values less than (2452154),
+partition part_45 values less than (2452184),
+partition part_46 values less than (2452215),
+partition part_47 values less than (2452245),
+partition part_48 values less than (2452276),
+partition part_49 values less than (2452307),
+partition part_50 values less than (2452335),
+partition part_51 values less than (2452366),
+partition part_52 values less than (2452396),
+partition part_53 values less than (2452427),
+partition part_54 values less than (2452457),
+partition part_55 values less than (2452488),
+partition part_56 values less than (2452519),
+partition part_57 values less than (2452549),
+partition part_58 values less than (2452580),
+partition part_59 values less than (2452610),
+partition part_60 values less than (2452641),
+partition part_61 values less than (2452672),
+partition part_62 values less than (2452700),
+partition part_63 values less than (2452731),
+partition part_64 values less than (2452761),
+partition part_65 values less than (2452792),
+partition part_66 values less than (2452822),
+partition part_67 values less than (2452853),
+partition part_68 values less than (2452884),
+partition part_69 values less than (2452914),
+partition part_70 values less than (2452945),
+partition part_71 values less than (2452975),
+partition part_72 values less than (2453006),
+partition part_73 values less than (maxvalue))
+;
+
+create table catalog_sales
+(
+ cs_sold_date_sk integer ,
+ cs_sold_time_sk integer ,
+ cs_ship_date_sk integer ,
+ cs_bill_customer_sk integer ,
+ cs_bill_cdemo_sk integer ,
+ cs_bill_hdemo_sk integer ,
+ cs_bill_addr_sk integer ,
+ cs_ship_customer_sk integer ,
+ cs_ship_cdemo_sk integer ,
+ cs_ship_hdemo_sk integer ,
+ cs_ship_addr_sk integer ,
+ cs_call_center_sk integer ,
+ cs_catalog_page_sk integer ,
+ cs_ship_mode_sk integer ,
+ cs_warehouse_sk integer ,
+ cs_item_sk integer not null,
+ cs_promo_sk integer ,
+ cs_order_number integer not null,
+ cs_quantity integer ,
+ cs_wholesale_cost number(7,2) ,
+ cs_list_price number(7,2) ,
+ cs_sales_price number(7,2) ,
+ cs_ext_discount_amt number(7,2) ,
+ cs_ext_sales_price number(7,2) ,
+ cs_ext_wholesale_cost number(7,2) ,
+ cs_ext_list_price number(7,2) ,
+ cs_ext_tax number(7,2) ,
+ cs_coupon_amt number(7,2) ,
+ cs_ext_ship_cost number(7,2) ,
+ cs_net_paid number(7,2) ,
+ cs_net_paid_inc_tax number(7,2) ,
+ cs_net_paid_inc_ship number(7,2) ,
+ cs_net_paid_inc_ship_tax number(7,2) ,
+ cs_net_profit number(7,2)
+)
+partition by range (cs_sold_date_sk)
+subpartition BY hash(cs_item_sk) subpartitions 64
+(partition part_1 values less than (2450846),
+partition part_2 values less than (2450874),
+partition part_3 values less than (2450905),
+partition part_4 values less than (2450935),
+partition part_5 values less than (2450966),
+partition part_6 values less than (2450996),
+partition part_7 values less than (2451027),
+partition part_8 values less than (2451058),
+partition part_9 values less than (2451088),
+partition part_10 values less than (2451119),
+partition part_11 values less than (2451149),
+partition part_12 values less than (2451180),
+partition part_13 values less than (2451211),
+partition part_14 values less than (2451239),
+partition part_15 values less than (2451270),
+partition part_16 values less than (2451300),
+partition part_17 values less than (2451331),
+partition part_18 values less than (2451361),
+partition part_19 values less than (2451392),
+partition part_20 values less than (2451423),
+partition part_21 values less than (2451453),
+partition part_22 values less than (2451484),
+partition part_23 values less than (2451514),
+partition part_24 values less than (2451545),
+partition part_25 values less than (2451576),
+partition part_26 values less than (2451605),
+partition part_27 values less than (2451636),
+partition part_28 values less than (2451666),
+partition part_29 values less than (2451697),
+partition part_30 values less than (2451727),
+partition part_31 values less than (2451758),
+partition part_32 values less than (2451789),
+partition part_33 values less than (2451819),
+partition part_34 values less than (2451850),
+partition part_35 values less than (2451880),
+partition part_36 values less than (2451911),
+partition part_37 values less than (2451942),
+partition part_38 values less than (2451970),
+partition part_39 values less than (2452001),
+partition part_40 values less than (2452031),
+partition part_41 values less than (2452062),
+partition part_42 values less than (2452092),
+partition part_43 values less than (2452123),
+partition part_44 values less than (2452154),
+partition part_45 values less than (2452184),
+partition part_46 values less than (2452215),
+partition part_47 values less than (2452245),
+partition part_48 values less than (2452276),
+partition part_49 values less than (2452307),
+partition part_50 values less than (2452335),
+partition part_51 values less than (2452366),
+partition part_52 values less than (2452396),
+partition part_53 values less than (2452427),
+partition part_54 values less than (2452457),
+partition part_55 values less than (2452488),
+partition part_56 values less than (2452519),
+partition part_57 values less than (2452549),
+partition part_58 values less than (2452580),
+partition part_59 values less than (2452610),
+partition part_60 values less than (2452641),
+partition part_61 values less than (2452672),
+partition part_62 values less than (2452700),
+partition part_63 values less than (2452731),
+partition part_64 values less than (2452761),
+partition part_65 values less than (2452792),
+partition part_66 values less than (2452822),
+partition part_67 values less than (2452853),
+partition part_68 values less than (2452884),
+partition part_69 values less than (2452914),
+partition part_70 values less than (2452945),
+partition part_71 values less than (2452975),
+partition part_72 values less than (2453006),
+partition part_73 values less than (maxvalue));
+
+create table store_sales
+(
+ ss_sold_date_sk integer ,
+ ss_sold_time_sk integer ,
+ ss_item_sk integer not null,
+ ss_customer_sk integer ,
+ ss_cdemo_sk integer ,
+ ss_hdemo_sk integer ,
+ ss_addr_sk integer ,
+ ss_store_sk integer ,
+ ss_promo_sk integer ,
+ ss_ticket_number integer not null,
+ ss_quantity integer ,
+ ss_wholesale_cost number(7,2) ,
+ ss_list_price number(7,2) ,
+ ss_sales_price number(7,2) ,
+ ss_ext_discount_amt number(7,2) ,
+ ss_ext_sales_price number(7,2) ,
+ ss_ext_wholesale_cost number(7,2) ,
+ ss_ext_list_price number(7,2) ,
+ ss_ext_tax number(7,2) ,
+ ss_coupon_amt number(7,2) ,
+ ss_net_paid number(7,2) ,
+ ss_net_paid_inc_tax number(7,2) ,
+ ss_net_profit number(7,2)
+)
+partition by range(ss_sold_date_sk)
+subpartition BY hash(ss_item_sk) subpartitions 64
+(partition part_1 values less than (2450846),
+partition part_2 values less than (2450874),
+partition part_3 values less than (2450905),
+partition part_4 values less than (2450935),
+partition part_5 values less than (2450966),
+partition part_6 values less than (2450996),
+partition part_7 values less than (2451027),
+partition part_8 values less than (2451058),
+partition part_9 values less than (2451088),
+partition part_10 values less than (2451119),
+partition part_11 values less than (2451149),
+partition part_12 values less than (2451180),
+partition part_13 values less than (2451211),
+partition part_14 values less than (2451239),
+partition part_15 values less than (2451270),
+partition part_16 values less than (2451300),
+partition part_17 values less than (2451331),
+partition part_18 values less than (2451361),
+partition part_19 values less than (2451392),
+partition part_20 values less than (2451423),
+partition part_21 values less than (2451453),
+partition part_22 values less than (2451484),
+partition part_23 values less than (2451514),
+partition part_24 values less than (2451545),
+partition part_25 values less than (2451576),
+partition part_26 values less than (2451605),
+partition part_27 values less than (2451636),
+partition part_28 values less than (2451666),
+partition part_29 values less than (2451697),
+partition part_30 values less than (2451727),
+partition part_31 values less than (2451758),
+partition part_32 values less than (2451789),
+partition part_33 values less than (2451819),
+partition part_34 values less than (2451850),
+partition part_35 values less than (2451880),
+partition part_36 values less than (2451911),
+partition part_37 values less than (2451942),
+partition part_38 values less than (2451970),
+partition part_39 values less than (2452001),
+partition part_40 values less than (2452031),
+partition part_41 values less than (2452062),
+partition part_42 values less than (2452092),
+partition part_43 values less than (2452123),
+partition part_44 values less than (2452154),
+partition part_45 values less than (2452184),
+partition part_46 values less than (2452215),
+partition part_47 values less than (2452245),
+partition part_48 values less than (2452276),
+partition part_49 values less than (2452307),
+partition part_50 values less than (2452335),
+partition part_51 values less than (2452366),
+partition part_52 values less than (2452396),
+partition part_53 values less than (2452427),
+partition part_54 values less than (2452457),
+partition part_55 values less than (2452488),
+partition part_56 values less than (2452519),
+partition part_57 values less than (2452549),
+partition part_58 values less than (2452580),
+partition part_59 values less than (2452610),
+partition part_60 values less than (2452641),
+partition part_61 values less than (2452672),
+partition part_62 values less than (2452700),
+partition part_63 values less than (2452731),
+partition part_64 values less than (2452761),
+partition part_65 values less than (2452792),
+partition part_66 values less than (2452822),
+partition part_67 values less than (2452853),
+partition part_68 values less than (2452884),
+partition part_69 values less than (2452914),
+partition part_70 values less than (2452945),
+partition part_71 values less than (2452975),
+partition part_72 values less than (2453006),
+partition part_73 values less than (maxvalue));
+```
+
+### 加载数据
+
+根据上述步骤生成的数据和 SQL 自行编写脚本。加载数据示例操作如下:
+
+1. 创建加载脚本目录。
+
+ ```
+ [wieck@localhost dbgen] $ mkdir load
+ [wieck@localhost dbgen] $ cd load
+ [wieck@localhost load] $ cp xx/create_tpch_mysql_table_part.ddl ./
+ ```
+
+2. 创建 load.py 脚本。
+
+ ```
+ [wieck@localhost load] $ vim load.py
+
+ #!/usr/bin/env python
+ #-*- encoding:utf-8 -*-
+ import os
+ import sys
+ import time
+ import commands
+ hostname='$host_ip' # 注意!!请填写某个 observer,如 observer A 所在服务器的 IP 地址
+ port='$host_port' # observer A 的端口号
+ tenant='$tenant_name' # 租户名
+ user='$user' # 用户名
+ password='$password' # 密码
+ data_path='$path' # 注意!!请填写 observer A 所在服务器下 tbl 所在目录
+ db_name='$db_name' # 数据库名
+ # 创建表
+ cmd_str='obclient -h%s -P%s -u%s@%s -p%s -D%s < create_tpch_mysql_table_part.ddl'%(hostname,port,user,tenant,password,db_name)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str='obclient -h%s -P%s -u%s@%s -p%s -D%s -e "show tables;" '%(hostname,port,user,tenant,password,db_name)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/dbgen_version.dat' into table customer fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/customer_address.dat' into table lineitem fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/customer_demographics.dat' into table nation fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/date_dim.dat' into table orders fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -D%s -e "load data /*+ parallel(80) */ infile '%s/warehouse.dat' into table partsupp fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/ship_mode.dat' into table part fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/time_dim.dat' into table region fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/reason.dat' into table supplier fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/income_band.dat' into table customer fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/item.dat' into table lineitem fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/store.dat' into table nation fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/call_center.dat' into table orders fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -D%s -e "load data /*+ parallel(80) */ infile '%s/customer.dat' into table partsupp fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/web_site.dat' into table part fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/store_returns.dat' into table region fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/household_demographics.dat' into table supplier fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/web_page.dat' into table customer fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/promotion.dat' into table lineitem fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/catalog_page.dat' into table nation fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/inventory.dat' into table orders fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -D%s -e "load data /*+ parallel(80) */ infile '%s/catalog_returns.dat' into table partsupp fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/web_returns.dat' into table part fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/web_sales.dat' into table region fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/catalog_sales.dat' into table supplier fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ cmd_str=""" obclient -h%s -P%s -u%s@%s -p%s -c -D%s -e "load data /*+ parallel(80) */ infile '%s/store_sales.dat' into table supplier fields terminated by '|';" """ %(hostname,port,user,tenant,password,db_name,data_path)
+ result = commands.getstatusoutput(cmd_str)
+ print result
+ ```
+
+3. 加载数据。
+
+
+ 注意
+ 加载数据需要安装 OBClient 客户端。
+
+
+ ```
+ [wieck@localhost load] $ python load.py
+ ```
+
+4. 执行合并。
+
+ 登录测试租户,执行合并。
+
+ ```
+ obclient > ALTER SYSTEM SET undo_retention = 100;
+ obclient > ALTER SYSTEM MAJOR FREEZE;
+ ```
+
+5. 查看合并是否完成。
+
+ ```
+ SELECT * FROM oceanbase.DBA_OB_ZONE_MAJOR_COMPACTION\G
+ ```
+
+ 返回结果如下:
+
+ ```
+ *************************** 1. row ***************************
+ ZONE: zone1
+ BROADCAST_SCN: 1716172011046213913
+ LAST_SCN: 1716172011046213913
+ LAST_FINISH_TIME: 2024-05-20 10:35:07.829496
+ START_TIME: 2024-05-20 10:26:51.579881
+ STATUS: IDLE
+ 1 row in set
+ ```
+
+ 当 `STATUS` 状态为 `IDLE`,`BROADCAST_SCN` 和 `LAST_SCN` 的值相等时,表示合并完成。
+
+6. 手动收集统计信息。
+
+ 在测试用户下执行 `obclient -h$host_ip -P$host_port -u$user@$tenant -p$password -A -D$database` 命令。
+
+ ```
+ call dbms_stats.gather_schema_stats('$db_name',degree=>64);
+ ```
+
+### 执行测试
+
+根据上述步骤生成的数据和 SQL 自行编写脚本。执行测试示例操作如下:
+
+1. 在 queries 目录下编写测试脚本 tpch.sh。
+
+ ```
+ [wieck@localhost queries] $ vim tpch.sh
+
+ #!/bin/bash
+ TPCH_TEST="obclient -h $host_ip -P $host_port -utpch_100g_part@tpch_mysql -D tpch_100g_part -ptest -c"
+ # warmup预热
+ for i in {1..22}
+ do
+ sql1="source db${i}.sql"
+ echo $sql1| $TPCH_TEST >db${i}.log || ret=1
+ done
+ # 正式执行
+ for i in {1..22}
+ do
+ starttime=`date +%s%N`
+ echo `date '+[%Y-%m-%d %H:%M:%S]'` "BEGIN Q${i}"
+ sql1="source db${i}.sql"
+ echo $sql1| $TPCH_TEST >db${i}.log || ret=1
+ stoptime=`date +%s%N`
+ costtime=`echo $stoptime $starttime | awk '{printf "%0.2f\n", ($1 - $2) / 1000000000}'`
+ echo `date '+[%Y-%m-%d %H:%M:%S]'` "END,COST ${costtime}s"
+ done
+ ```
+
+2. 执行测试脚本。
+
+ ```
+ sh tpch.sh
+ ```
diff --git a/zh-CN/620.obap/750.obap-performance-test/60.obap-tpc-ds-test-report.md b/zh-CN/620.obap/750.obap-performance-test/60.obap-tpc-ds-test-report.md
new file mode 100644
index 0000000000..d32b89be81
--- /dev/null
+++ b/zh-CN/620.obap/750.obap-performance-test/60.obap-tpc-ds-test-report.md
@@ -0,0 +1,139 @@
+# OceanBase 数据库 TPC-DS 性能测试报告
+
+## 测试环境 (阿里云 ECS)
+
+- 3 节点硬件配置
+
+ |服务类型|ECS 类型|实列数|机器核心数|内存|
+ |---|---|---|---|---|
+ | OceanBase 数据库 | ecs.r6.8xlarge | 3 | 32c | 256G
+ 每台机器系统盘 300G、日志盘 400G、数据盘 2T,磁盘性能级别为 PL1 |
+ | TPC-H | ecs.r6.8xlarge | 1 | 32c | 256G |
+
+- 3 节点租户规格
+
+ ```
+ CREATE RESOURCE UNIT tpch_unit max_cpu 30, memory_size '180g'
+ CREATE RESOURCE POOL tpch_pool unit = 'tpch_unit', unit_num = 1, zone_list=('zone1','zone2','zone3');
+ CREATE TENANT tpch_mysql resource_pool_list=('tpch_pool'), zone_list('zone1', 'zone2', 'zone3'), primary_zone=RANDOM, locality='F@zone1,F@zone2,F@zone3' set variables ob_compatibility_mode='mysql', ob_tcp_invited_nodes='%';
+ ```
+
+- 软件版本
+
+|服务类型|软件版本|
+|---|---|
+| OceanBase 数据库 | - 企业版:OceanBase 4.3.0.1
- 社区版:OceanBase_CE 4.3.0.1
|
+| TPC-H | V3.0.0 |
+| OS | CentOS Linux release 7.9.2009 (Core) |
+
+## 测试方案
+
+- 使用 OBD 部署 OceanBase 数据库集群。TPC-H 客户端需要部署在一台机器上, 作为客户端的压力机器。您无需部署 ODP,测试时直连任意一台机器即可。
+- 3 节点的 OceanBase 集群部署规模为 1:1:1。部署成功后先新建跑 TPCH 测试的租户及用户(sys 租户是管理集群的内置系统租户,请勿直接使用 sys 租户进行测试),设置租户的 primary_zone 为 RANDOM。
+- 测试数据量:100G。
+- 测试步骤详见 [OceanBase 数据库 TPC-DS 测试](../750.obap-performance-test/50.obap-tpc-ds-test.md)。
+
+## 测试结果
+
+|**Query ID**|**3节点 OBServer V4.3.0 查询响应时间(单位:秒)**|
+|---|---|
+| Q1 | 0.23 |
+| Q2 | 1.18 |
+| Q3 | 0.14 |
+| Q4 | 11.64 |
+| Q5 | 1.22 |
+| Q6 | 0.24 |
+| Q7 | 0.27 |
+| Q8 | 0.26 |
+| Q9 | 0.53 |
+| Q10 | 0.56 |
+| Q11 | 6.99 |
+| Q12 | 0.29 |
+| Q13 | 0.21 |
+| Q14 | 9.31 |
+| Q15 | 0.43 |
+| Q16 | 0.7 |
+| Q17 | 0.45 |
+| Q18 | 0.35 |
+| Q19 | 0.18 |
+| Q20 | 0.24 |
+| Q21 | 0.18 |
+| Q22 | 1.32 |
+| Q23 | 13.09 |
+| Q24 | 0.99 |
+| Q25 | 0.68 |
+| Q26 | 0.21 |
+| Q27 | 0.34 |
+| Q28 | 0.92 |
+| Q29 | 0.53 |
+| Q30 | 0.25 |
+| Q31 | 0.71 |
+| Q32 | 0.11 |
+| Q33 | 0.57 |
+| Q34 | 0.34 |
+| Q35 | 0.86 |
+| Q36 | 0.31 |
+| Q37 | 0.33 |
+| Q38 | 1.97 |
+| Q39 | 0.84 |
+| Q40 | 0.16 |
+| Q41 | 0.03 |
+| Q42 | 0.11 |
+| Q43 | 0.59 |
+| Q44 | 0.47 |
+| Q45 | 0.38 |
+| Q46 | 0.41 |
+| Q47 | 1.19 |
+| Q48 | 0.24 |
+| Q49 | 0.93 |
+| Q50 | 0.51 |
+| Q51 | 2.94 |
+| Q52 | 0.11 |
+| Q53 | 0.18 |
+| Q54 | 0.7 |
+| Q55 | 0.11 |
+| Q56 | 0.63 |
+| Q57 | 0.78 |
+| Q58 | 0.74 |
+| Q59 | 2.67 |
+| Q60 | 0.66 |
+| Q61 | 0.37 |
+| Q62 | 0.42 |
+| Q63 | 0.19 |
+| Q64 | 1.02 |
+| Q65 | 0.85 |
+| Q66 | 0.45 |
+| Q67 | 10.62 |
+| Q68 | 0.33 |
+| Q69 | 0.53 |
+| Q70 | 1.19 |
+| Q71 | 0.5 |
+| Q72 | 10.83 |
+| Q73 | 0.2 |
+| Q74 | 4.43 |
+| Q75 | 2.09 |
+| Q76 | 0.49 |
+| Q77 | 0.81 |
+| Q78 | 3.05 |
+| Q79 | 0.61 |
+| Q80 | 1.27 |
+| Q81 | 0.19 |
+| Q82 | 0.52 |
+| Q83 | 0.62 |
+| Q84 | 0.19 |
+| Q85 | 0.57 |
+| Q86 | 0.4 |
+| Q87 | 2.12 |
+| Q88 | 3.37 |
+| Q89 | 0.28 |
+| Q90 | 0.18 |
+| Q91 | 0.12 |
+| Q92 | 0.11 |
+| Q93 | 0.56 |
+| Q94 | 0.57 |
+| Q95 | 7.13 |
+| Q96 | 0.28 |
+| Q97 | 1.09 |
+| Q98 | 0.37 |
+| Q99 | 0.73 |
+| Total | 134.76 |
diff --git a/zh-CN/620.obap/900.obap-integrations.md b/zh-CN/620.obap/900.obap-integrations.md
new file mode 100644
index 0000000000..ac4f881924
--- /dev/null
+++ b/zh-CN/620.obap/900.obap-integrations.md
@@ -0,0 +1,57 @@
+# 生态集成
+
+OceanBase 作为一款高性能分布式关系型数据库,已逐步构建起一个集诸多工具于一体的生态系统,简化数据库管理、提升运营效率,并实现与多样化的 IT 环境无缝对接。本文使用部分产品举例介绍 AP 场景下可能涉及到的一些工具,包含数据集成、编排、可视化等领域。
+
+
+ 说明
+ 关于 OceanBase 数据库完整的生态集成列表,参见 [生态集成概述](https://www.oceanbase.com/docs/common-oceanbase-database-cn-1000000000903440)。
+
+
+## 数据集成
+
+数据集成(Data Integration)是一个 IT 过程,旨在将数据从不同来源集中到一个统一的视图中,以支持分析、报告和业务决策。数据可能分散在多个系统中,例如关系数据库、文件、应用程序、NoSQL 数据库和云存储服务。
+
+在数据集成领域中,CDC (Change Data Capture,即变更数据捕获)是一项重要技术,能够帮助您识别从上次提取之后发生变化的数据。您可用 CDC 提供的数据做历史库、近实时缓存、提供给消息队列(MQ),做分析和审计等。
+
+OceanBase 数据库的 Binlog 服务与 MySQL 原生 Binlog 兼容,支持用户复用现有的 MySQL Binlog 增量解析系统来同步 OceanBase MySQL 租户的增量数据,无需更改现有的数据链路。关于 Binlog 服务,更多内容参见 [Binlog 日志服务](../700.reference/1500.Components-and-Tools/300.data-integrate/100.oblogproxy-overview.md)。
+
+OceanBase 数据库可以和各个主流的数据集成产品保持良好的兼容性,包括且不限于以下产品:
+
+|**名称**|**描述**|**相关文档**|
+|---|---|---|
+| Flink | 一个用于大规模数据处理和分析的开源框架 | 更多内容参见 [使用 Flink CDC 从 MySQL 数据库同步数据到 OceanBase 数据库](../500.data-migration/200.migrate-data-from-mysql-database-to-oceanbase-database/600.use-flink-cdc-to-migrate-data-from-mysql-database-to-oceanbase-database.md)。 |
+| Canal | 一个用于数据库同步和集成的变更数据捕获(CDC)框架 | 更多内容参见 [使用 Canal 从 MySQL 数据库同步数据到 OceanBase 数据库](../500.data-migration/200.migrate-data-from-mysql-database-to-oceanbase-database/500.use-canal-to-migrate-data-from-mysql-database-to-oceanbase-database.md)。 |
+| Maxwell | 一个用于 MySQL 数据库的变更数据捕获(CDC)工具 | 更多内容参见 [使用 Maxwell 读取 OceanBase 数据](../700.reference/1600.ecological-integration/1500.maxwell.md)。 |
+| SeaTunnel | 一个分布式、高性能的数据集成平台,用于数据迁移和实时流处理任务 | 更多内容参见 [使用 SeaTunnel 读取和同步 OceanBase 数据](../700.reference/1600.ecological-integration/1300.seatunnel.md)。注意
当前处于 Beta 状态,已完成初步测试,待进行深入全面的适配。
|
+| Debezium | 开源的企业级通用计算框架,支持多计算引擎的任务调度和管理 | 更多内容参见 [使用 Debezium 读取和同步 OceanBase 数据](../700.reference/1600.ecological-integration/1600.debezium.md)。 |
+| DataX | 离线数据同步工具/平台 | 更多内容参见 [使用 DataX 迁移 CSV 文件到 OceanBase 数据库](../500.data-migration/700.migrate-data-from-csv-file-to-oceanbase-database/100.use-datax-to-load-csv-data-files-to-oceanbase-database.md)。 |
+
+## 编排调度
+
+在数据集成(Data Integration)领域里,编排(Orchestration)工具是指那些能够管理、调度和协调不同数据处理任务和数据流程的软件工具。这些工具往往提供了一种高级的方式来组织和执行多个数据集成活动,比如数据提取(Extract)、转换(Transform)和加载(Load,即ETL过程),以及数据清洗、校验和发布等任务。
+
+|**名称**|**描述*** |**相关文档**|
+|---|---|---|
+| DolphinScheduler | 开源的分布式工作流任务调度系统,支持多种任务类型 | 更多内容参见 [为 DolphinScheduler 配置 OceanBase 数据源](../700.reference/1600.ecological-integration/1200.dolphinscheduler.md)。注意
当前处于 Beta 状态,已完成初步测试,待进行深入全面的适配。
|
+| Linkis | 开源的企业级通用计算框架,支持多计算引擎的任务调度和管理 | 更多内容参见 [Linkis 集成 OceanBase 数据库](../700.reference/1600.ecological-integration/1400.linkis.md)。 |
+
+## 可观测
+
+可观测性 (Observability) 通常是指能够监控、追踪、诊断和理解数据处理流程及系统状态的能力。在复杂的数据管道和数据系统中,保持高度的可观测性是非常重要的,这确保了运维团队能够及时发现和响应任何出现的问题,并维持系统的健康和性能。
+
+同时,数据质量是数据集成过程中的一个关键组成部分,并且同样需要很高的可观测性。数据质量可观测性工具允许团队验证数据准确性、一致性和完整性,监测数据是否符合预期的标准,从而确保业务决策能够依托于信任的数据。
+
+|**名称**|**描述**|**相关文档**|
+|---|---|---|
+| Prometheus | 强大的开源系统监控和警报工具包,专为可靠性和多维度数据收集而设计,广泛用于监控服务和应用程序的健康状况 | 更多内容参见 [通过 Prometheus 监控 OceanBase 数据](https://www.oceanbase.com/docs/common-ocp-1000000000826572)。 |
+
+## 可视化
+
+数据集成领域中的可视化工具是指那些可以帮助用户通过图形和图表形式来呈现、理解和沟通数据的软件工具。这些工具通常提供了从数据集成流程中获取数据,并将其转换为直观视图的功能,从而使得非技术用户也能够洞察数据背后的趋势和模式。
+
+|**名称**|**描述**|**相关文档**|
+|---|---|---|
+| Superset | 用于数据探索和可视化的开源业务智能工具 | 更多内容参见 [使用 Superset 和 OB Cloud 云数据库进行数据分析](../700.reference/1600.ecological-integration/100.superset-mysql-connection-oceanbase-sample-program.md)。 |
+| QuickBI | 一款易用的数据可视化和分析工具,支持快速数据报表生成 | 更多内容参见 [在 Quick BI 中连接 OB Cloud 云数据库](../700.reference/1600.ecological-integration/400.quick-bi.md)。 |
+| Tableau | 直观的数据可视化工具,用于制作交互式和可分享的报表 | 更多内容参见 [在 Tableau 中连接 OB Cloud 云数据库](../700.reference/1600.ecological-integration/500.tableau.md)。 |
+| PowerBI | 使用 Power BI,可以轻松连接到数据源,可视化并发现重要内容,并根据需要与任何人共享。 | 更多内容参见 [在 Power BI 中连接 OceanBase 并获取数据](../700.reference/1600.ecological-integration/300.power-bi.md)。 |
diff --git a/zh-CN/700.reference/500.sql-reference/100.sql-syntax/200.common-tenant-of-mysql-mode/600.sql-statement-of-mysql-mode/1750.alter-tablespace-of-mysql-mode.md b/zh-CN/700.reference/500.sql-reference/100.sql-syntax/200.common-tenant-of-mysql-mode/600.sql-statement-of-mysql-mode/1750.alter-tablespace-of-mysql-mode.md
index 18849d01a3..e704506876 100644
--- a/zh-CN/700.reference/500.sql-reference/100.sql-syntax/200.common-tenant-of-mysql-mode/600.sql-statement-of-mysql-mode/1750.alter-tablespace-of-mysql-mode.md
+++ b/zh-CN/700.reference/500.sql-reference/100.sql-syntax/200.common-tenant-of-mysql-mode/600.sql-statement-of-mysql-mode/1750.alter-tablespace-of-mysql-mode.md
@@ -1,4 +1,4 @@
-| Description | |
+| Description | |
|---------------|-----------------|
| keywords | |
| dir-name | |
@@ -12,9 +12,9 @@
该语句用来修改 TableSpace(表空间)加密方式。
## 语法
-
-```sql
-ALTER TABLESPACE tablespace_name ENCRYPTION [=] 'tablespace_encryption_option';
+
+```sql
+ALTER TABLESPACE tablespace_name ENCRYPTION [=] 'tablespace_encryption_option';
tablespace_encryption_option:
N