- Writer: DongYeon Woo
- Title: (cs231n) Lecture 5: convolutional Neural Networks
- Link: http://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture5.pdf
- Keywords: ConvNets, Fully Connected Layer, Convolution Layer, Pooling Layer
-
ConvNets are used everywhere such as
- Classification
- Image Retrieval
- Detection
- Segmentation
- Pose recognition
- etc
-
ConvNet is a sequence of Convolution Layers and each filter produces an activation map.
-
Each layer features an image in hierarchal way.
i.e.
- First layer extracts low-level features such as color and intensity.
- Second layer extracts mid-level features such as shape of objects.
- Third layer extracts high-level features such as parts of objects.
- Object classes generated after go through all layers.
-
Input: Stretch a 32 x 32 x 3 image to 3072 x 1 vector.
-
Weight: Size of number of classes which will be 10 x 3072 matrix.
-
Output: Output will be dot product of input and weight matrix which is 1 x 10.
10 neuron outputs will be generated.
-
Parameters
- W: width, H: height, D: depth
- K: Number of filter
- F: Size of filter
- S: Stride
- P: Amount of padding
-
The size of the input preserved as original spatial structure W x H x D.
-
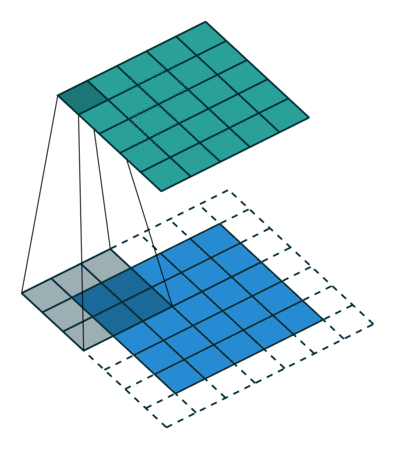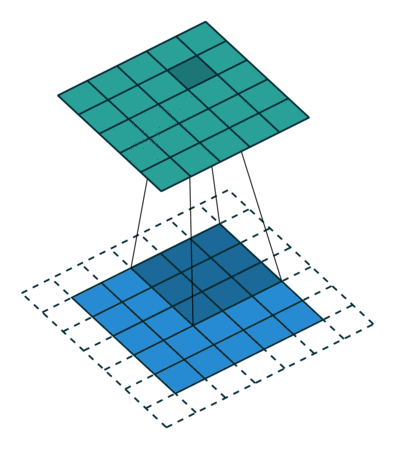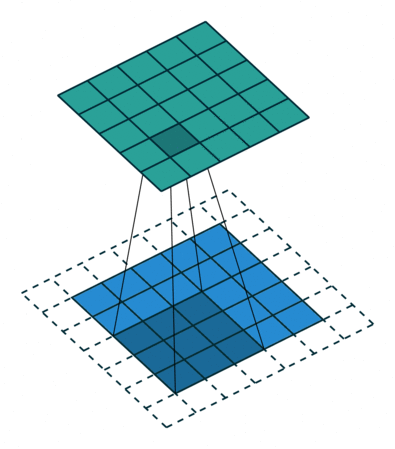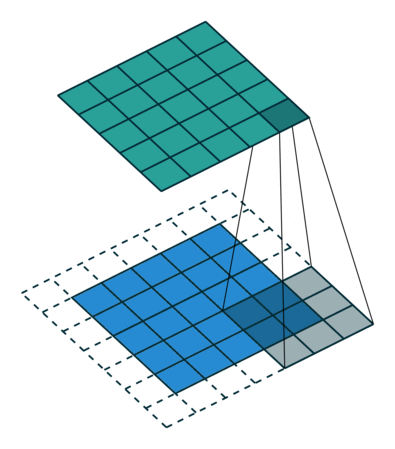
The filter slides over the original size of W x H x D image by computing dot products.
- Output size: (N - F)/S + 1 where N is size of input image.
※ The depth of the filter must be same as input depth.
i.e. 2D convolution) 5 x 5 input with 3 x 3 filter with stride = 1 -> 3 x 3 output
-
Padding makes the output to be same as input size by padding dummy on the border such as zeros.
- Output size: [(W - F + 2P)/S + 1] x [(H - F + 2P)/S + 1] x D
- Number of parameters: (F x F x D + 1) x K where 1 is bias
-
Purposes of padding
- To preserve spatial structure.
- To use data at corners.
i.e. Padding) 5 x 5 input with 3 x 3 filter with stride = 1 and Pad = 1 -> 5 x 5 output
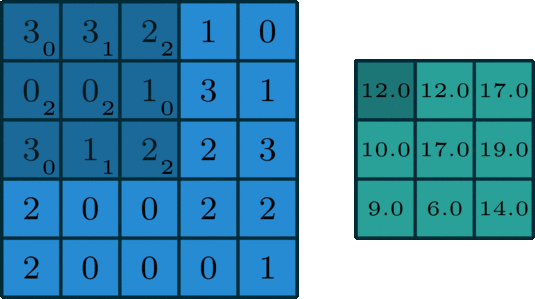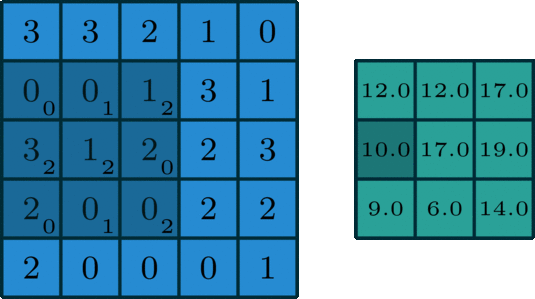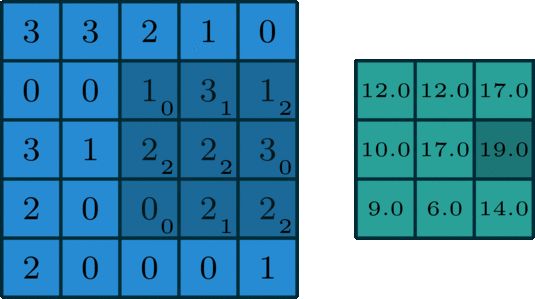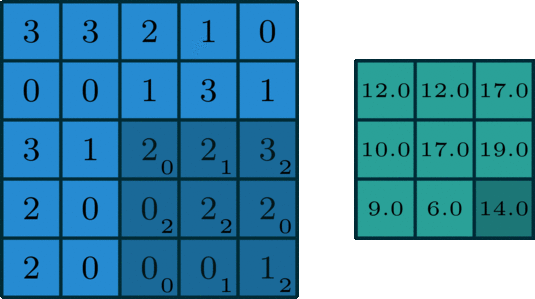
- Spatial structure
- FC Layer ignores spatial structure by flattening all pixels in 1 dimension while Convolution Layer preserve the spatial structure with depth, stride, and padding.
- So, it has advantage of training objects like image data accurately.
- Parameter sharing

- Thus, the number of parameters in a conv layer reduced through parameter sharing from 105,415,600 to 34,944 in this example.
- The number of weight updates during backpropagation reduced by parameter sharing and therefore, the training time reduced.
-
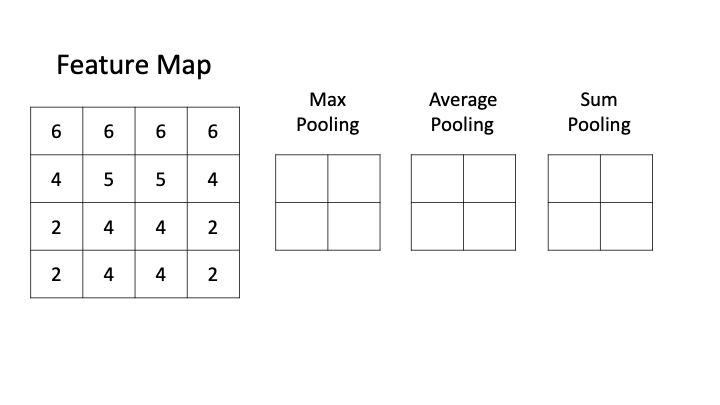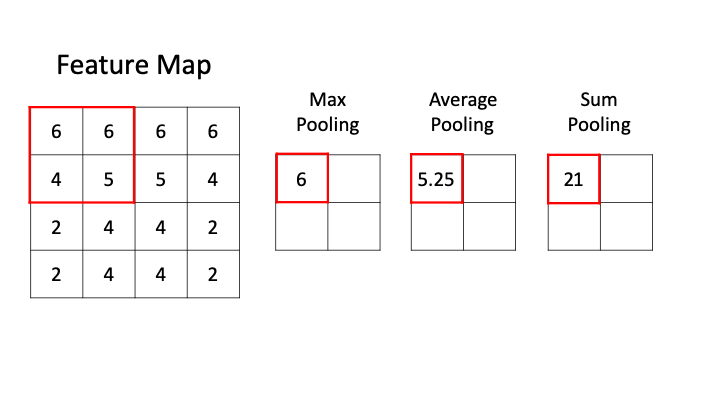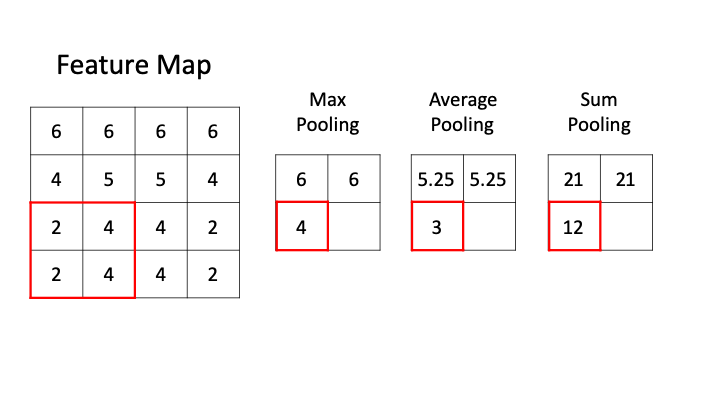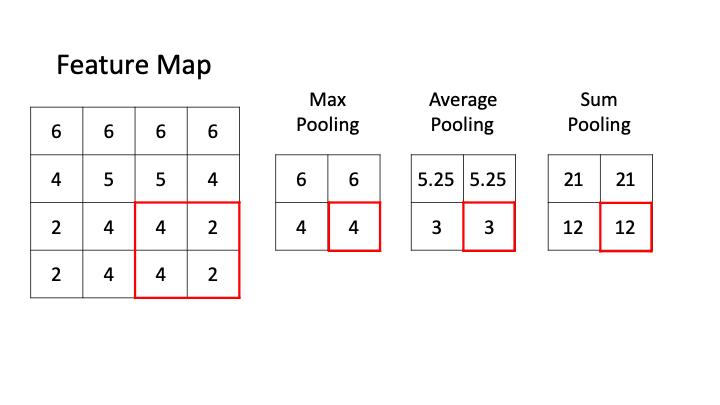
Pooling layer downsamples the activation map.
-
Filter convolve the feature map and pooling representative value.
i.e) 2 x 2 Filter with stirde =2
-
Therefore, spatial structure preserved and computational complexity reduced.