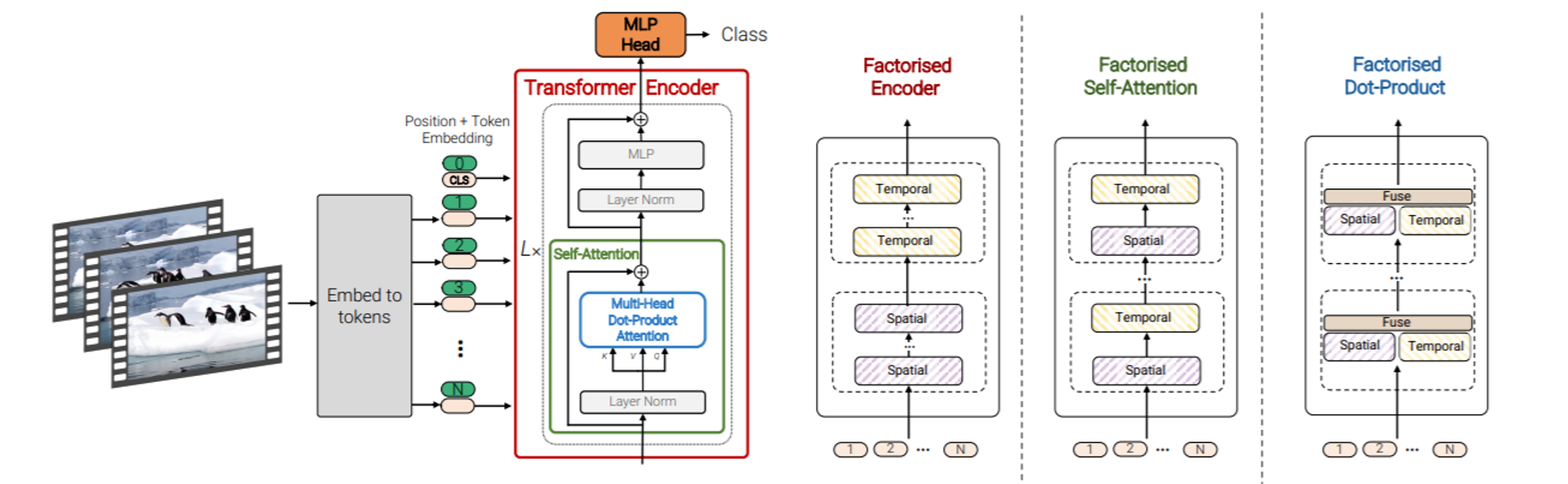
@@ -131,6 +138,7 @@ In model 3, instead of computing multi-headed self-attention across all pairs of
In model 4, half of the attention heads are designed to operate with keys and values from spatial indices, the other half operate with keys and values from same temporal indices.
**complexity : same as model 2, 3**
+
### Experiments and Discussion
From c0c6617fd26abcb1b1975a2a902a997164ebebad Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:35:03 +0900
Subject: [PATCH 27/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index ff6f43ef1..bfb258bf2 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -18,7 +18,7 @@ The abstract from the paper is as follows;
*Inspired by the Transformer scaling successes in NLP, we experiment with applying a standard Transformer directly to images, with the fewest possible modifications. To do so, we split an image into patches and provide the sequence of linear embeddings of these patches as an input to a Transformer. Image patches are treated the same way as tokens (words) in an NLP application. We train the model on image classification in supervised fashion.*
-

+
From fff1703677f99c50737e056c32aef7f7a0a20af6 Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:35:13 +0900
Subject: [PATCH 28/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index bfb258bf2..08d568e0f 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -33,7 +33,7 @@ The key techniques proposed in the ViT paper are as follows:
### Performance & Limitation
-

+
From 59ed64d07c3016e8fa211228d363c8afa10dc591 Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:35:21 +0900
Subject: [PATCH 29/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index 08d568e0f..42f0fe6c6 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -48,7 +48,7 @@ The abstract from the [paper](https://arxiv.org/abs/2103.15691) is as follows:
*We present pure-transformer based models for video classification, drawing upon the recent success of such models in image classification. Our model extracts spatiotemporal tokens from the input video, which are then encoded by a series of transformer layers. In order to handle the long sequences of tokens encountered in video, we propose several, efficient variants of our model which factorise the spatial- and temporal-dimensions of the input. Although transformer-based models are known to only be effective when large training datasets are available, we show how we can effectively regularise the model during training and leverage pretrained image models to be able to train on comparatively small datasets. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple video classification benchmarks including Kinetics 400 and 600, Epic Kitchens, Something-Something v2 and Moments in Time, outperforming prior methods based on deep 3D convolutional networks. To facilitate further research, we release code at https://github.com/google-research/scenic.*
-
+
From bcb5e8f35533631d18116bf9db6a8633885d22cb Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:35:30 +0900
Subject: [PATCH 30/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index 42f0fe6c6..7b98cc333 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -74,7 +74,7 @@ These two techniques represent fundamental approaches in video processing that h
#### Uniform Frame Sampling
-

+
From 38e2da25ff0f6e53e69c335501122d357f54a4bb Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:35:39 +0900
Subject: [PATCH 31/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index 7b98cc333..54cd9fe95 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -109,7 +109,7 @@ However, using attention on all spatio-temporal tokens can lead to heavy computa
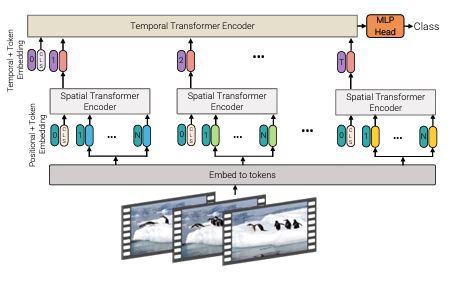
The approach in Model 1 was somewhat inefficient, as it contextualized all patches simultaneously. To improve upon this, Model 2 separates the spatial and temporal encoders sequentially.
-
+
From 8bc4722f8a7ebea206799cab614a9e7487e6c4db Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:35:46 +0900
Subject: [PATCH 32/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index 54cd9fe95..383668b36 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -120,7 +120,7 @@ First, only spatial interactions are contextualized through a Spatial Transforme
#### Model 3 : Factorised Self-Attention
-

+
From 2fbe7f97ffcb45beed6891eb3da932b6fa39c5a9 Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:35:52 +0900
Subject: [PATCH 33/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index 383668b36..459ae5d44 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -131,7 +131,7 @@ In model 3, instead of computing multi-headed self-attention across all pairs of
#### Model 4 : Factorized dot-product attention
-

+
From c6d8a3e5c2df85bdfb60e72b6b03081ed951fa95 Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:35:59 +0900
Subject: [PATCH 34/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index 459ae5d44..fc138991a 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -142,7 +142,7 @@ In model 4, half of the attention heads are designed to operate with keys and va
### Experiments and Discussion
-

+
From dab2328d46b6af973da1083549150f2b1473a644 Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:36:05 +0900
Subject: [PATCH 35/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index fc138991a..bae5ae26b 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -155,7 +155,7 @@ After comparing Models 1, 2, 3, and 4, it is evident that Model 1 achieved the b
TimeSFormer is a concurrent work with ViViT, applying Transformer on video classification. The following sections are explanations of each type of attention.
-

+
From 487a44211f415c24320e23ad2b438d0666fcc52b Mon Sep 17 00:00:00 2001
From: Jiwook Han <33192762+mreraser@users.noreply.github.com>
Date: Thu, 14 Nov 2024 17:36:13 +0900
Subject: [PATCH 36/36] Update
chapters/en/unit7/video-processing/transformers-based-models.mdx
---
.../en/unit7/video-processing/transformers-based-models.mdx | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/chapters/en/unit7/video-processing/transformers-based-models.mdx b/chapters/en/unit7/video-processing/transformers-based-models.mdx
index bae5ae26b..a5c9e7d6f 100644
--- a/chapters/en/unit7/video-processing/transformers-based-models.mdx
+++ b/chapters/en/unit7/video-processing/transformers-based-models.mdx
@@ -84,7 +84,7 @@ e. g. one frame per every 2 frames.
#### Tubelet Embedding
-

+