This portfolio showcases a diverse collection of projects that demonstrate advanced proficiency in mathematics, programming, data science, data visualization, and communication. Each project employs a variety of programming languages and mathematical concepts to solve a real-world problem, demonstrating the ability to apply quantitative skills to various domains, ranging from marketing to astrophysics, and from finance to entomology. Moreover, each project highlights the importance of making insights accessible and engaging to a non-technical audience using clear and concise visualizations.
- LLMs, Web Scraping, and AWS Deployment
- Exoplanets and Image Processing
- Numerical Hydrodynamics in C++
- Agent Based Modeling with Javascript and HTML
- Network Theory and Information Theory
- Discount-Lift Tradeoffs
- A/B Testing
- Quantitative Finance
- Adobe Analytics

This project uses Large Language Models (LLMs) and web-scraping tools to create targeted contact directories connecting buyers and sellers. We demonstrate this with a Florida-based apiary looking to partner with gourmet grocery stores interested in local artisan products. The resulting contact directory includes store names, descriptions and compatibility scores generated by the LLM, as well as websites, addresses, phone numbers, and emails.
The algorithm crawls through Google Maps search results using the query "Gourmet Grocery Stores". The results from this search are then used to query the Google Place API, which provides verification of local businesses and additional information including websites, ratings, reviews, and addresses. This detailed information from the Place API is then processed and cleaned before being fed into an LLM (GPT-4) for compatability analysis using a prompt designed to match the places under consideration with the artisan apiary .The prompt is benchmarked against human-evaluated data in order to ensure its effectiveness before being implemented across the entire dataset. The flowchart below illustrates this process.


The algorithm is devoloped in Python, rendered in HTML using Flask, and deployed in a cloud environment using AWS Elastic Beanstalk.

In this project, I use the Karhunen-Loève Transform (KLT) to directly detect new exoplanets. This algorithm is a generalization of principal component analysis that diagonalizes the covariance matrix of a set of reference images. The result is a set of uncorrelated variables called Karhunen-Loève basis functions that can be ordered based on their importance.
In Astronomy, these basis functions capture systematic defects in the telescope optics that result in a speckle pattern that is the same order of magnitude as astrophysical sources. By subtracting the basis functions, you can remove the systematic defects while retaining the astrophysical signal - enabling the discovery of faint exoplanets in bright environments.
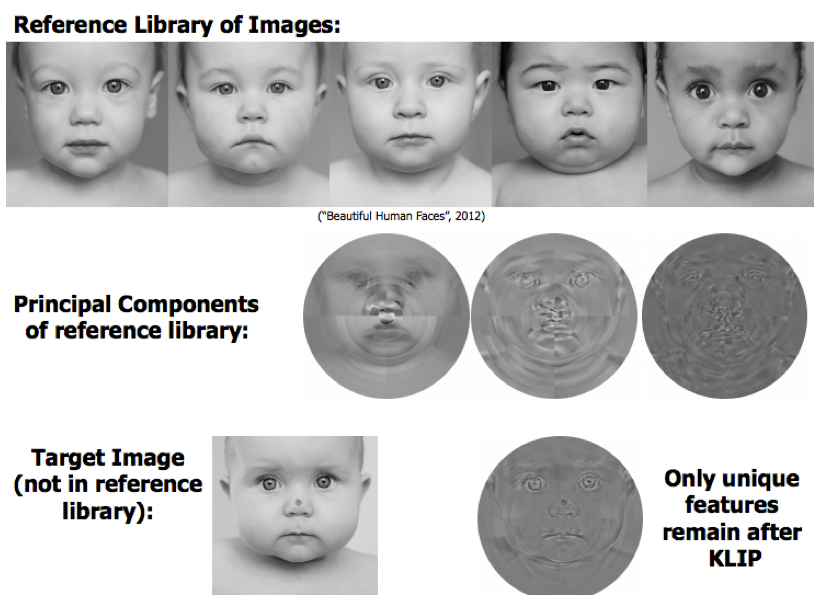 Overview of Karhunen-Loève Image Processing. Notice that the birthmark and eyes, being unique features of the target image, are not removed by subtraction of the basis functions. Image by author.
Overview of Karhunen-Loève Image Processing. Notice that the birthmark and eyes, being unique features of the target image, are not removed by subtraction of the basis functions. Image by author.
 Very Large Telescope (VLT) images of the HR8799 stellar system processed using my implementation of the KLT algorithm. Multiple directly imaged exoplanets can clearly be seen in white.
Very Large Telescope (VLT) images of the HR8799 stellar system processed using my implementation of the KLT algorithm. Multiple directly imaged exoplanets can clearly be seen in white.
Haumea is a dwarf planet located beyond Neptune's orbit. It is one of several dwarf planets that would have to be added to the nine recognized planets in our solar system if Pluto were to remain. Unlike other planets, Haumea is so small and distant that its angular width is less than a single pixel when imaged with a telescope. This means that its shape and density cannot be directly measured.
Instead, we must rely on self-consistent gravitational/hydrodynamic simulations to infer a shape and composition consistent with the planet's known mass and photometric observations. Here, we provide such a simulation, assuming a stable, 3D self-gravitating body in hydrostatic equilibrium with a differentiated ice crust. We find that Haumea's formation history likely included liquid water and the potential for habitability for a period of approximately 100 million years.

Self-consistent 3D gravitational simulation of the dwarf planet Haumea.

Nest site selection in ant colonies is a fascinating example of collective decision-making without centralized control. To better understand this process, we modeled the ant species Temnothorax Rugatulus as particles undergoing Brownian motion within the nest. By fine-tuning the parameters of the Brownian random walk, we were able to show that this simple model can be optimized for specific nest geometries based on the quorum density within the nest. When a quorum threshold is met, ants transition from slow nest exploration to rapid brood carrying, indicating the successful selection of a new nest site. Our study provides insight into the underlying mechanisms of ant collective decision-making and underscores the ability of natural selection to delegate critical aspects of a collective decision to the physical environment.
 Ant colony on the left with a screenshot of the agent-based simulation on the right.
Ant colony on the left with a screenshot of the agent-based simulation on the right.
The goal of this project was to quantify how information sharing affects the fitness of group-living animals, focusing specifically on the ant species Temnothorax rugatulus during colony emigrations. Using clustering methods and network analysis, we quantify the degree of behavioral heterogeneity among ants and identify four behavioral castes: primary, secondary, passive, and wandering. We then characterize the distinct roles played by each caste in the spread of information during emigration. We find that understanding the contribution of each worker can improve models of collective decision-making in this species and provide a deeper understanding of behavioral variation at the colony level. Ultimately, the study highlights the importance of behavioral heterogeneity in the spread of information among group-living animals and advantages of addressing this problem quantitatively.
 This ethogram shows the behavior of every ant in the colony as a function of time. This is actual data derived from videos of nest site selection. See publication for more details.
This ethogram shows the behavior of every ant in the colony as a function of time. This is actual data derived from videos of nest site selection. See publication for more details.
In marketing, one is often faced with the challenge of determining the discount threshold beyond which a discount is no longer be profitable. To evaluate this, it is crucial to have knowledge of the lifetime revenue (LTR) of your customers. Once the LTR is established, you can calculate the necessary lift required to make a specific discount profitable. Here, I use LTR data for five different products to generate segmented discount-lift curves that inform us of the required lift levels to achieve profitable discounts for each product offer.
 The lift required (y-axis) for any given discount amount (x-axis). The different colors show that different products require different lifts in order to be profitable due to differences in LTR.
The lift required (y-axis) for any given discount amount (x-axis). The different colors show that different products require different lifts in order to be profitable due to differences in LTR.
Bayesian confidence intervals are crucial in A/B testing as they allow us to estimate the uncertainty around the mean conversion rate of each experience. Without such estimates, we cannot draw conclusions about the effectiveness of our marketing strategies with any degree of confidence. Here, I use Bayes Theorem to constrain the uncertainty about the mean, which enables the calculation of reliable confidence intervals that give us a better understanding of the true conversion rate for each experience. This information is essential for making data-driven decisions and improving the success of marketing campaigns.
 Example of Bayesian inference in practice. Rather than reporting a single conversion rate, I report the conversion rate with an uncertainty estimate calculated using the Bayesian posterior. This allows one to easily visualize whether or not differences in conversion are significant.
Example of Bayesian inference in practice. Rather than reporting a single conversion rate, I report the conversion rate with an uncertainty estimate calculated using the Bayesian posterior. This allows one to easily visualize whether or not differences in conversion are significant.
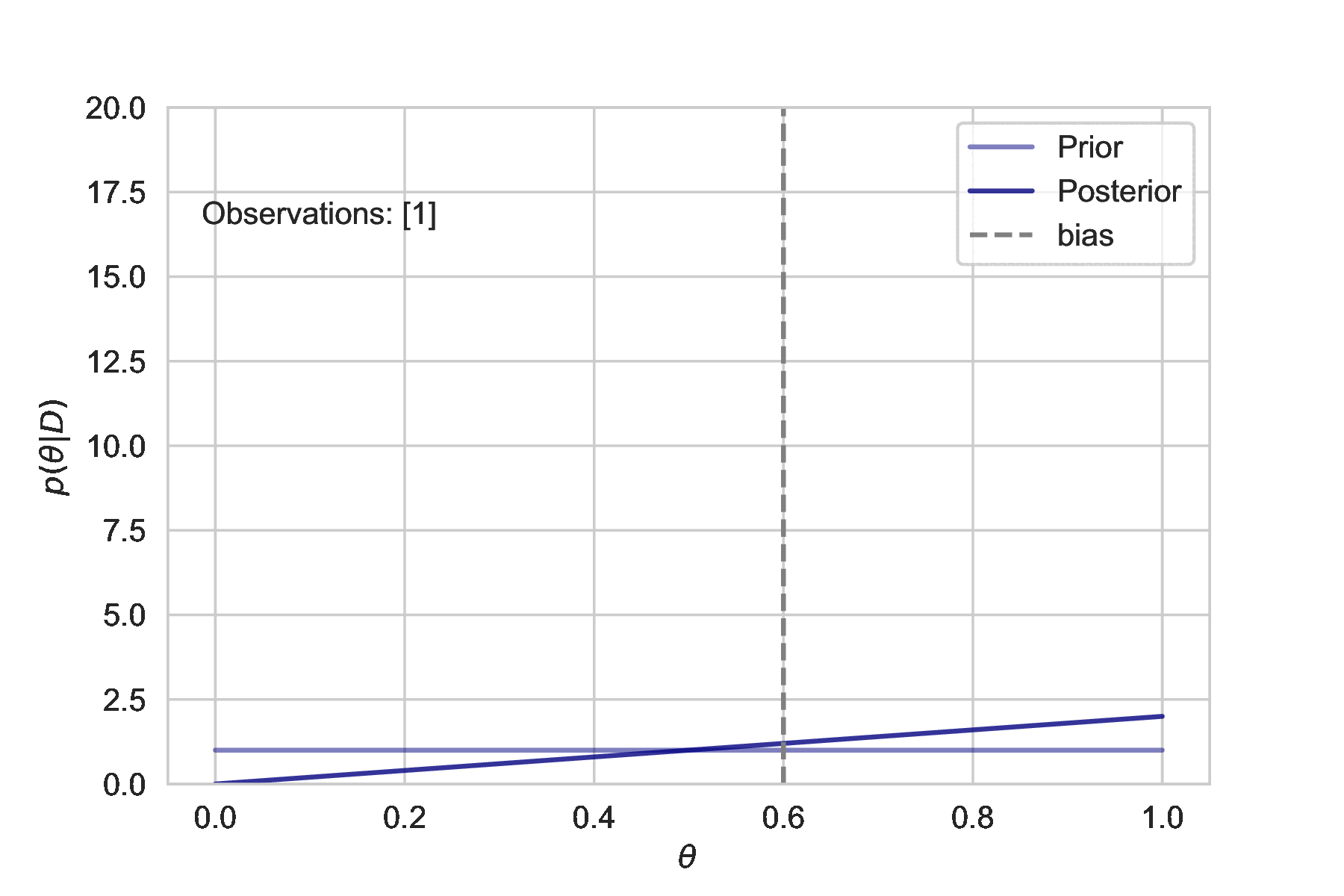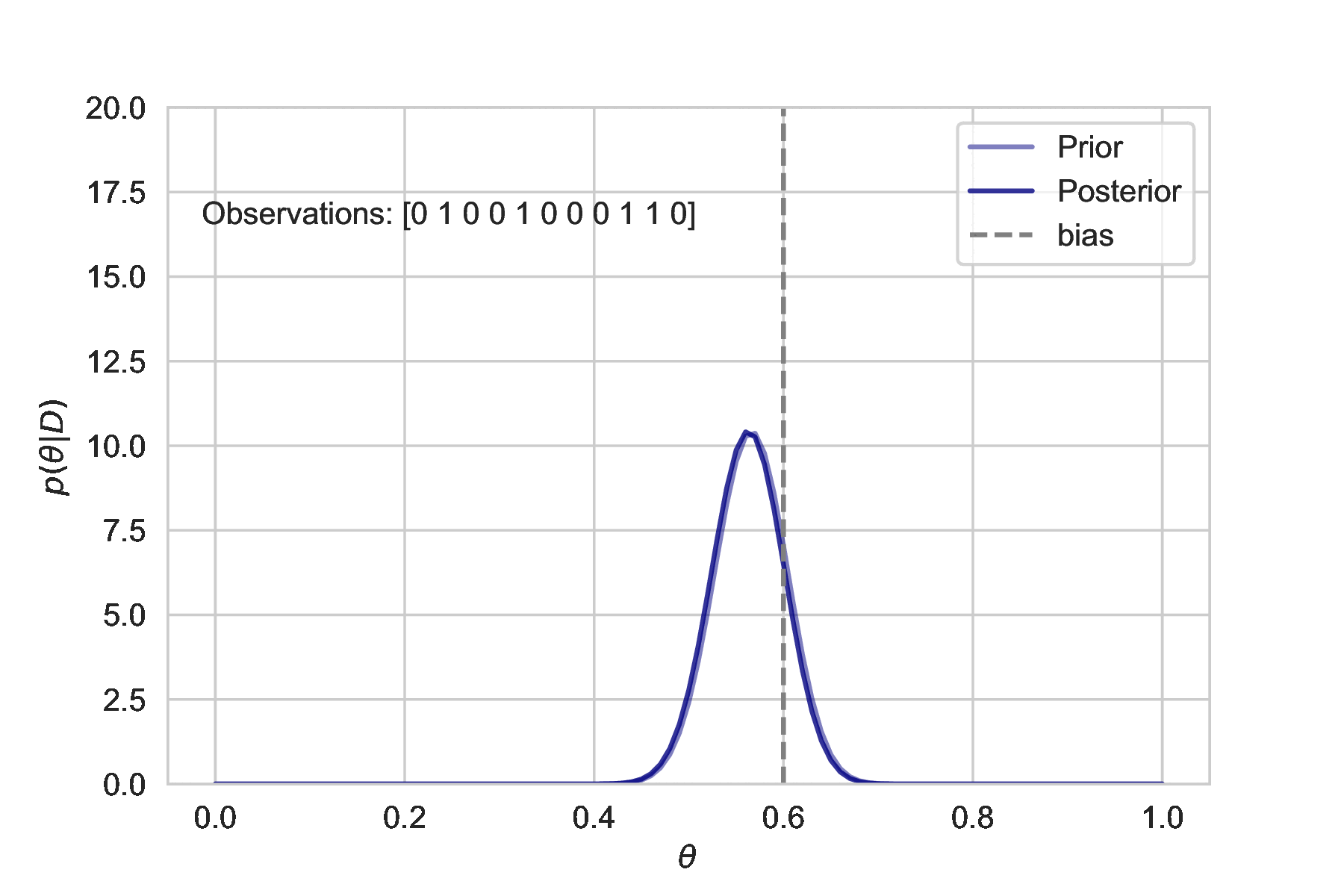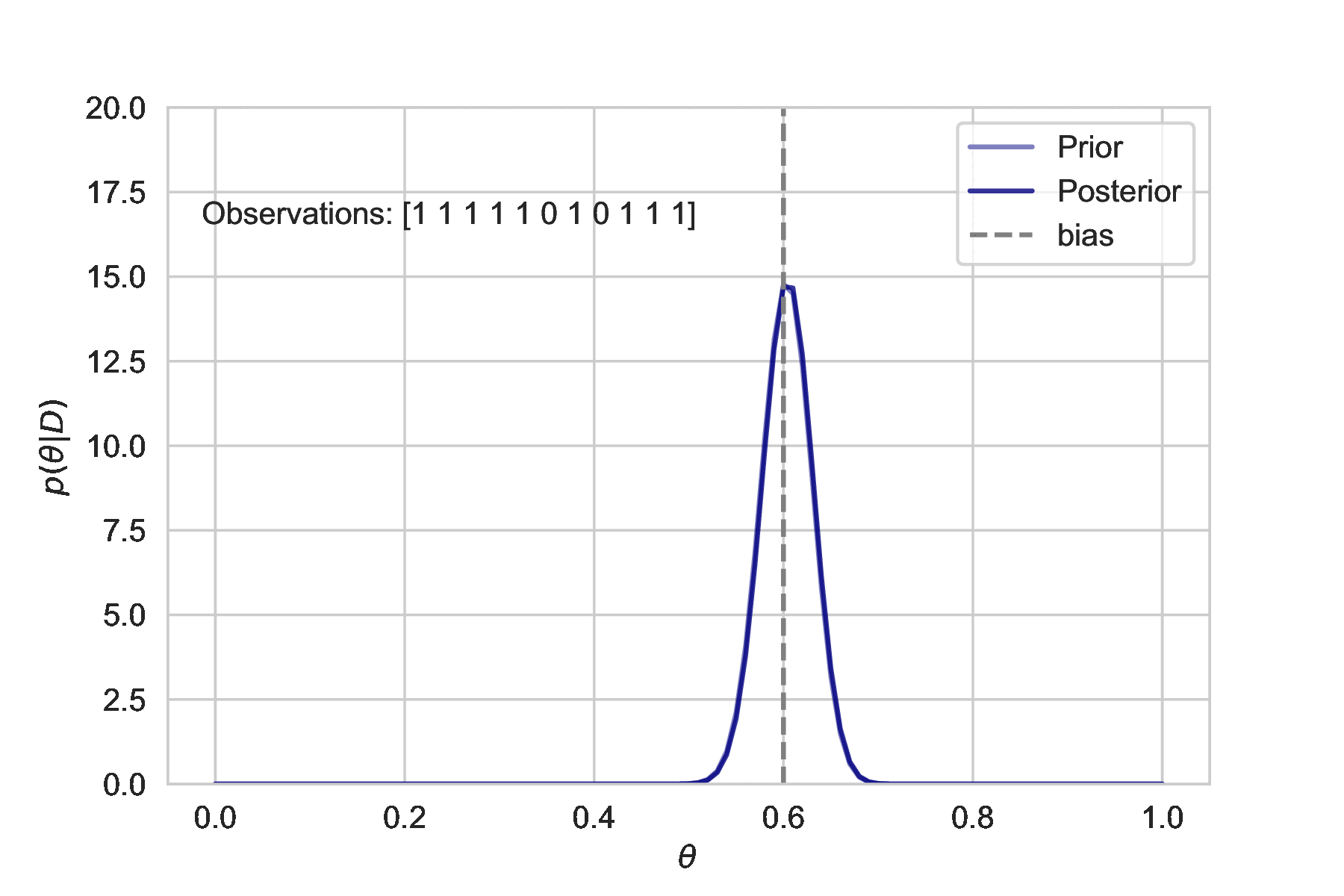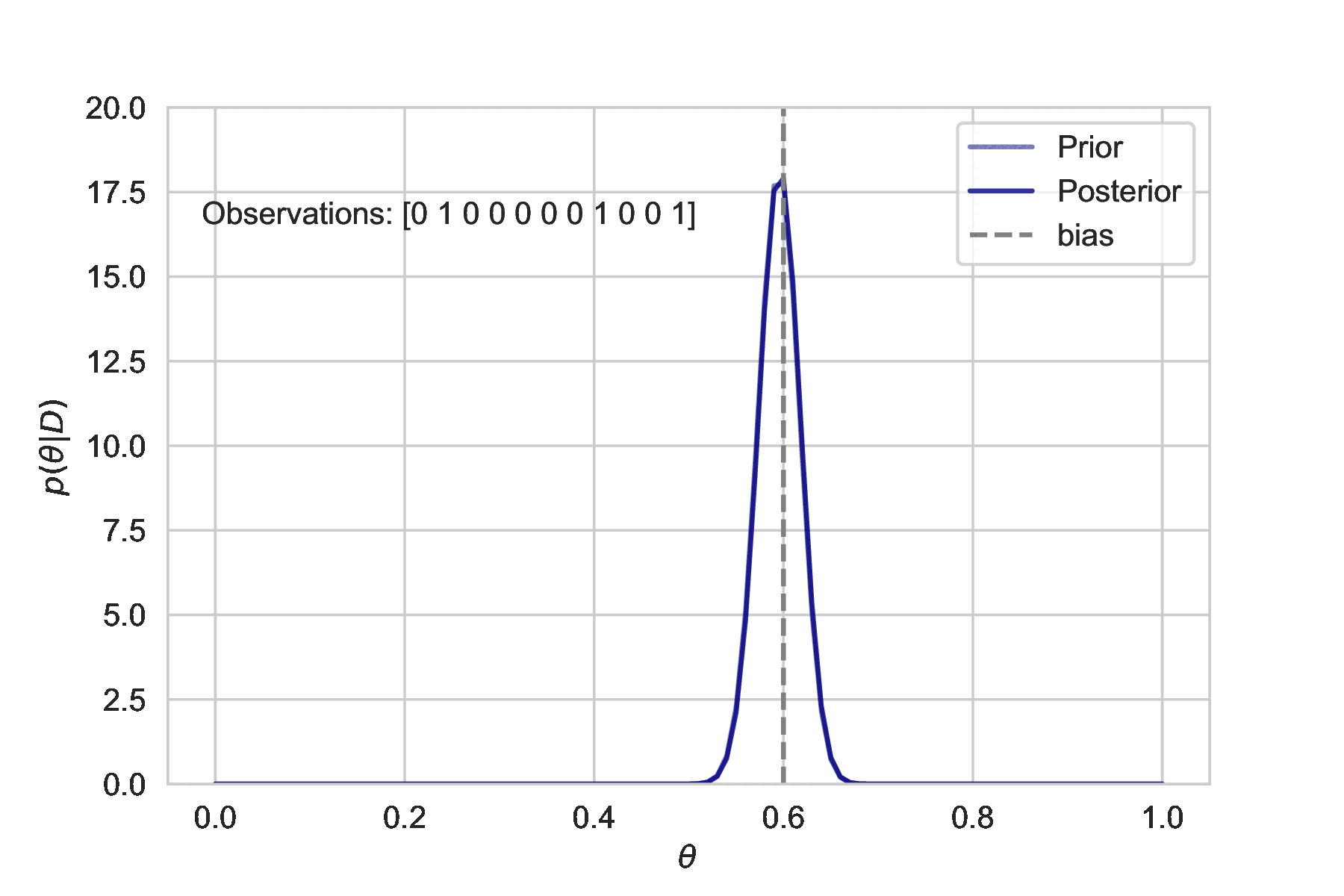 This simulation shows how additional observations affect the uncertainty estimate. The more we observe, the tighter the posterior distribution is centered about the true bias.
This simulation shows how additional observations affect the uncertainty estimate. The more we observe, the tighter the posterior distribution is centered about the true bias.
Using Python, I backtested pre-earnings straddles over six years, analyzing options trading data to assess profitability. The findings indicate that pre-earnings straddles are generally not profitable, but may yield positive returns for specific indices over certain timeframes. For instance, I demonstrate that a composite index of the DOW 30 + NASDAQ 100 has an average return of +2.12% per straddle from 2012-2018. However, I also show that the underlying distribution lacks stationarity and small changes in the index can lead to losing outcomes, leading to the conclusion that this is not a reliable trading strategy.
 Pre-earnings straddle results for FANG stocks from 2013-2018. These four stocks show large gains using a pre-earnings straddle but they suffer from post-selection bias and are not representative of the strategy as a whole.
Pre-earnings straddle results for FANG stocks from 2013-2018. These four stocks show large gains using a pre-earnings straddle but they suffer from post-selection bias and are not representative of the strategy as a whole.

I find average returns of +2.12% over a six-year time frame for the composite DOW 30 + Nasdaq 100. However, these results do not generalize.

Observed win percentage (blue) compared to a binomial distribution (orange) with the same aggregate statistics. A Kolmogorov-Smirnov (KS) test shows the probability that the two distributions are drawn from the same underlying distribution to be 0.0023.
The goal of this project is to assign metadata to marketing campaigns within Adobe Analytics. Previously, campaign information was stored locally in our data warehouses but was unavailable in Adobe Analytics. This project synchronizes these two data sources, enabling us to easily build reports on the fly in Adobe Analytics using our internal campaign data.

An example of a breakdown in Adobe Analytics that utilizes the metadata implemented in this project. Notice that we are able to view each step in our signup flow using user-defined metrics, such as Marketing Manager and Name. This ability to assign marketing campaigns metadata based on user-defined properties is crucial for achieving alignment between Marketing and Finance.