[ Back to index ]
Click here to see the table of contents.
- Motivation
- Obtaining shared CM scripts
- Getting started with CM scripts
- Understanding CM scripts
- Assembling pipeline to compile and run image corner detection
- Using Python virtual environments
- Assembling pipelines with other artifacts included
- Unifying host OS and CPU detection
- Detecting, installing and caching system dependencies
- Using variations
- Running CM scripts inside containers
- Getting help about other script automation flags
- Further reading
We suggest you to check CM introduction and CM CLI/API to understand CM motivation and concepts. You can also try CM tutorials to run some applications and benchmarks on your platform using CM scripts.
While helping the community reproduce 150+ research papers, we have noticed that researchers always create their own ad-hoc scripts, environment variable and files to perform exactly the same steps (actions) across all papers to prepare, run and reproduce their experiments across different software, hardware, models and data.
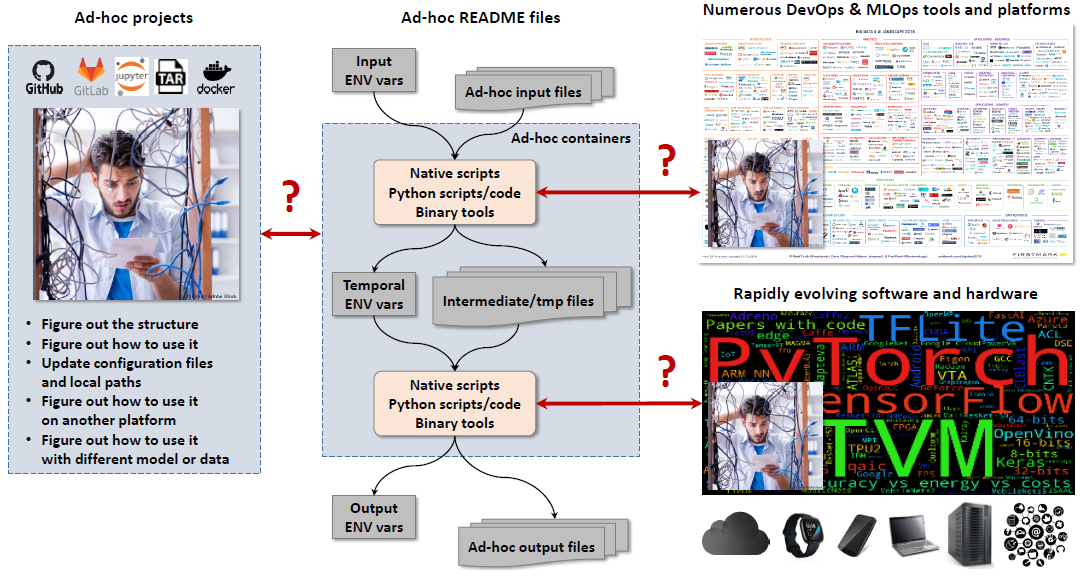
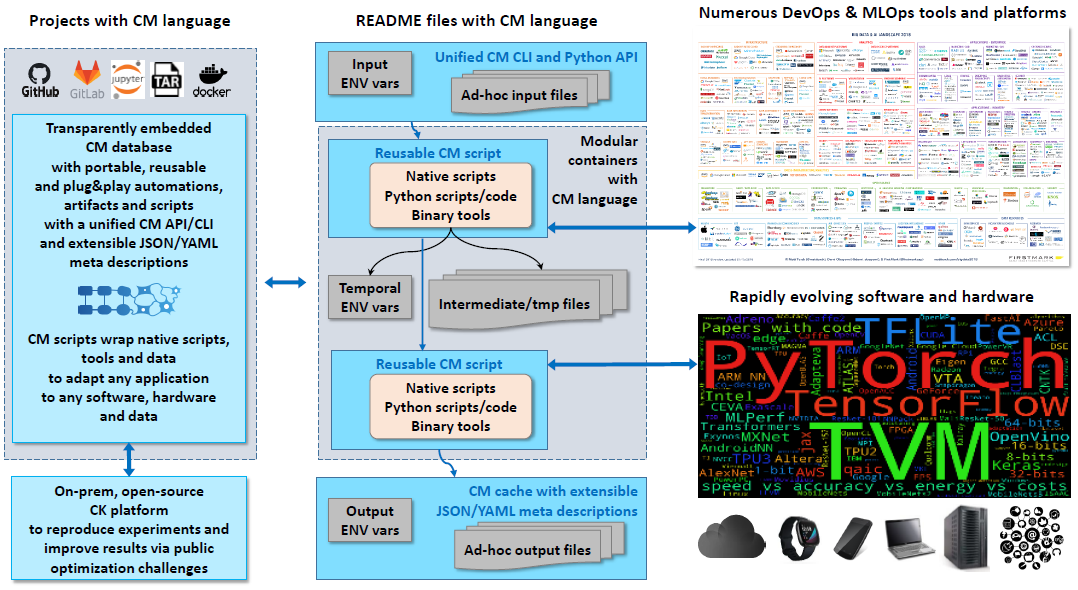
This experience motivated us to create a CM automation called "script" to warp native scripts from research and industrial projects with a common, simple and unified CM Command Line Interface and Python API.
Such non-intrusive wrapping helps to make numerous native scripts and tools more reusable, interoperable, portable, findable and deterministic across different projects with different artifacts based on FAIR principles.
CM scripts can be embedded into existing projects with minimal or no modifications at all, and they can be connected into powerful and portable pipelines and workflows using simple JSON or YAML files to prepare, run and reproduce experiments across continuously changing technology.
Importantly, CM scripts can be executed in the same way in a native user environment, Python virtual environments (to avoid messing up native environment) and containers while automatically adapting to a given environment!
In order to reuse some CM scripts embedded into shared projects, you need to install these projects via the CM interface.
For example, to use automation scripts developed by the MLCommons task force on automation and reproducibility and shared via GitHub, you just need to pull this repository via CM:
cm pull repo --url=https://github.com/mlcommons/ckor
cm pull repo mlcommons@ckYou can now see all available CM scripts in your system as follows:
cm find script
cm find script install* | sort
You can run any of the above CM script on any platform as follows:
cm run script "tags separated by space" --keys=values --env.KEY=VALUE
cm run script --tags="tags separated by comma" --keys=values --env.KEY=VALUEor using a shortcut cmr available in CM V1.4.0+:
cmr "tags separated by space" --keys=values --env.KEY=VALUEYou can also use -j flag to print JSON output at the end of the script execution
and -v flag to show extra debug information during script execution.
For example, you can download a RESNET-50 model in ONNX format from Zenodo using the following script:
cmr "download file" --url=https://zenodo.org/record/4735647/files/resnet50_v1.onnxYou can also obtain info about your OS (Linux, Windows, MacOS) in a unified way and print JSON output as well as CM debug info as follows:
cmr "detect os" -j -vCM scripts are treated as standard CM artifacts with the associated CM automation "script", CM action "run", and JSON and/or YAML meta descriptions.
CM scripts can be invoked by using their alias, unique ID and human-readable tags (preferred method).
For example, the CM "Print Hello World" script
simply wraps 2 native run.sh and run.bat scripts to print "Hello World" on Linux, MacOs or Windows
together with a few environment variables:
ls `cm find script print-hello-world`
README.md _cm.json run.bat run.shIt is described by this _cm.json meta description file with the following alias, UID and tags:
{
"automation_alias": "script",
"automation_uid": "5b4e0237da074764",
"alias": "print-hello-world",
"uid": "b9f0acba4aca4baa",
"default_env": {
"CM_ENV_TEST1": "TEST1"
},
"env": {
"CM_ENV_TEST2": "TEST2"
},
"input_mapping": {
"test1": "CM_ENV_TEST1"
},
"new_env_keys": [
"CM_ENV_TEST*"
],
"new_state_keys": [
"hello_test*"
],
"tags": [
"print",
"hello-world",
"hello world",
"hello",
"world",
"native-script",
"native",
"script"
]
}The automation_alias and automation_uid tells CM that this artifact can be used with the CM "script" automation.
Therefore, this script can be executed from the command line in any of the following ways:
cm run script print-hello-world
cm run script b9f0acba4aca4baa
cm run script --tags=print,native-script,hello-world
cm run script "print native-script hello-world"The same script can be also executed using CM Python API as follows:
import cmind
output = cmind.access({'action':'run', 'automation':'script', 'tags':'print,native-script,hello-world'})
if output['return']>0:
cmind.error(output)
import json
print (json.dumps(output, indent=2))Normally you should see the following output along with some debug information (that will be removed soon):
...
CM_ENV_TEST1 = TEST1
CM_ENV_TEST2 = TEST2
HELLO WORLD!
...run.bat and run.sh are native scripts that will be executed by this CM script in a unified way on Linux, MacOS and Windows:
echo ""
echo "CM_ENV_TEST1 = ${CM_ENV_TEST1}"
echo "CM_ENV_TEST2 = ${CM_ENV_TEST2}"
echo ""
echo "HELLO WORLD!"The idea to use native scripts is to make it easier for researchers and engineers to reuse their existing automation scripts while providing a common CM wrapper with a unified CLI, Python API and extensible meta descriptions.
CM script automation CLI uses a flag --env.VAR=VALUE to set some environment variable and pass it to a native script
as shown in this example:
cm run script "print native-script hello-world" \
--env.CM_ENV_TEST1=ABC1 --env.CM_ENV_TEST2=ABC2
...
CM_ENV_TEST1 = ABC1
CM_ENV_TEST2 = TEST2
HELLO WORLD!Note, that CM_ENV_TEST2 did not change. This happened because dictionary env in the _cm.json forces CM_ENV_TEST2 to TEST2,
while default_env dictionary allows environment variables to be updated externally.
You can still force an environment variable to a given value externally using a --const flag as follows:
cm run script "print native-script hello-world" \
--env.CM_ENV_TEST1=ABC1 --const.CM_ENV_TEST2=ABC2
...
CM_ENV_TEST1 = ABC1
CM_ENV_TEST2 = ABC2
HELLO WORLD!
You can also use a JSON file instead of flags. Create input.json (or any other filename):
{
"tags":"print,native-script,hello-world",
"env":{
"CM_ENV_TEST1":"ABC1"
}
}and run the CM script with this input file as follows:
cm run script @input.json
You can use YAML file instead of CLI. Create input.yaml (or any other filename):
tags: "print,hello-world,script"
env:
CM_ENV_TEST1: "ABC1"and run the CM script with this input file as follows:
cm run script @input.yaml
Finally, you can map any other flag from the script CLI to an environment variable
using the key input_mapping in the _cm.json meta description of this script:
cm run script "print native-script hello-world" --test1=ABC1
...
CM_ENV_TEST1 = ABC1
CM_ENV_TEST2 = TEST2
HELLO WORLD!
You can see the output of a given CM script in the JSON format by adding --out=json flag as follows:
cm run script --tags=print,hello-world,script --env.CM_ENV_TEST1=ABC1 --out=json
...
CM_ENV_TEST1 = ABC1
CM_ENV_TEST2 = ABC2
HELLO WORLD!
{
"deps": [],
"env": {
"CM_ENV_TEST1": "ABC1",
"CM_ENV_TEST2": "TEST2"
},
"new_env": {
"CM_ENV_TEST1": "ABC1",
"CM_ENV_TEST2": "TEST2"
},
"new_state": {},
"return": 0,
"state": {}
}Note that new_envshows new environment variables produced and explicitly exposed by this script
via a new_env_keys key in the _cm.json meta description of this script.
This is needed to assemble automation pipelines and workflows while avoiding their contamination with temporal environments. CM script must explicitly expose environment variables that will go to the next stage of a pipeline.
In the following example, CM_ENV_TEST3 will be added to the new_env while CM_XYZ will not
since it is not included in "new_env_keys":["CM_ENV_TEST*"]:
cm run script --tags=print,hello-world,script --env.CM_ENV_TEST1=ABC1 --out=json --env.CM_ENV_TEST3=ABC3 --env.CM_XYZ=XYZSometimes, it is needed to use more complex structures than environment variables in scripts and workflows.
We use a dictionary state that can be updated and exposed by a given script via new_state_keys key
in the _cm.json meta description of this script.
In the following example, hello_world key will be updated in the new_state dictionary,
while hello key will not be updated because it is not included in the wild card "new_state_key":["hello_world*"]:
cm run script --tags=print,hello-world,script --out=json \
--state.hello=xyz1 --state.hello_world=xyz2
...
{
"deps": [],
"env": {
"CM_ENV_TEST1": "TEST1",
"CM_ENV_TEST2": "TEST2"
},
"new_env": {
"CM_ENV_TEST1": "TEST1",
"CM_ENV_TEST2": "TEST2"
},
"new_state": {
"hello_world": "xyz2"
},
"return": 0,
"state": {
"hello": "xyz1",
"hello_world": "xyz2"
}
}You can run a given CM script from python or Jupyter notebooks as follows:
import cmind
r = cmind.access({'action':'run',
'automation':'script',
'tags':'print,hello-world,script',
'const':{
'CM_ENV_TEST1':'ABC1',
},
'env':{
'CM_ENV_TEST2':'ABC2'
},
'state': {
'hello':'xyz1',
'hello_world':'xyz2'
}
})
print (r)...
CM_ENV_TEST1 = ABC1
CM_ENV_TEST2 = ABC2
HELLO WORLD!
{'return': 0,
'env': {'CM_ENV_TEST2': 'TEST2', 'CM_ENV_TEST1': 'ABC1'},
'new_env': {'CM_ENV_TEST2': 'TEST2', 'CM_ENV_TEST1': 'ABC1'},
'state': {'hello': 'xyz1', 'hello_world': 'xyz2'},
'new_state': {'hello_world': 'xyz2'},
'deps': []}
We've added a simple mechanism to chain reusable CM scripts into complex pipelines without the need for specialized workflow frameworks.
Simply add the following dictionary "deps" to the _cm.json or _cm.yaml of your script as follows:
{
"deps": [
{
"tags": "a string of tags separated by comma to find and execute the 1st CM script"
},
{
"tags": "a string of tags separated by comma to find and execute the 1st CM script"
},
...
]
}
This CM script will run all dependent scripts in above sequence, aggregate environment variable and state dictionary,
and will then run native scripts.
You can also turn on specific dependencies based on some values in specific environment variables or min/max version (if supported) in this pipeline as follows:
{
"deps": [
{
"tags": "a string of tags separated by comma to find and execute the 1st CM script",
"enable_if_env": { "USE_CUDA" : ["yes", "YES", "true"] }
},
{
"tags": "a string of tags separated by comma to find and execute the 1st CM script"
"enable_if_env": { "USE_CPU" : ["yes", "YES", "true"] },
"version_min": "3.10"
},
...
]
}
You can also specify dependencies to be invoked after executing native scripts
using a dictionary "post_deps" with the same format "deps".
You can see an example of such dependencies in the _cm.json
of the "print-hello-world-py" CM script
that detects and unifies OS parameters using the "detect-os" CM script,
detects or builds Python using the "get-python3" CM script
and then runs code.py with "Hello World" from run.sh or run.bat:
cm run script "print python hello-world"If a developer adds customize.py file inside a given CM script,
it can be used to programmatically update environment variables, prepare input scripts
and even invoke other scripts programmatically using Python.
If a function preprocess exists in this file, CM script will call it before
invoking a native script.
If this function returns {"skip":True} in the output,
further execution of this script will be skipped.
After executing the preprocess function, the CM script automation will record the global state dictionary into tmp-state.json and the local state dictionary from this CM script into tmp-state-new.json.
The CM script automation will then run a native script (run.sh on Linux/MacOS or run.bat on Windows) with all merged environment variables from previous scripts.
Note that native scripts can also create 2 files that will be automatically picked up and processed by the CM script automation:
- tmp-run-env.out - list of environment variables to update the "new_env" of a given CM script
- tmp-run-state.json - the state dictionary to update the "new_state" of a given CM script
If postprocess function exists in the customize.py file, the CM script will call it
to finalize the postprocessing of files, environment variables, and the state dictionary.
You can see an example of such customize.py module in the CM script
to detect or install/build Python interpreter in a unified way on any machine.
This script exposes a number of environment variables for a detected Python
in the postprocess function:
CM_PYTHON_BIN- python3.10 or python.exe or any other name of a Python interpreter on a given systemCM_PYTHON_BIN_PATH- path to a detected or installed pythonCM_PYTHON_BIN_WITH_PATH- full path to a detected or installed pythonLD_LIBRARY_PATH- updated LD_LIBRARY_PATH to pythonPATH- updated PATH to python
These environment variables can be reused by other CM scripts or external tools while decoupling them from specific python versions and paths, and even allowing multiple versions of tools and artifacts to co-exist on the same system and plugged into CM scripts:
cm run script "get python3" --out=jsonBy default, CM scripts run wrapped scripts and tools, update environment variables and produce new files in the current directory.
In many cases, we want to cache the output and environment variables when we run the same CM script with the same input again to avoid potentially lengthy detections, downloads, builds and data pre/post processing.
That's why we have developed another CM automation called "cache" to cache the output of scripts in the "cache" artifacts in the "local" CM repository that can be found by tags or unique IDs like any other CM artifact.
Our convention is to use names get-{tool or artifact} for CM scripts that detect already installed artifacts, prepare their environment and cache them in the local CM repository using the "cache" automation.
If installed artifact doesn't exist, we either enhance above scripts to include download, installation and even building for a given artifact (if it's a tool) or we create extra CM scripts install-{tool or artifact} that download and prepare tools and artifacts (install, build, preprocess, etc).
For example, the CM script get-python3 has customize.py with preprocess function that implements the search for python3 on Linux or python.exe on Windows, 2 native scripts run.sh and run.bat to obtain the version of the detected python installation, and postprocess function to prepare environment variables CM_PYTHON_BIN and CM_PYTHON_BIN_WITH_PATH that can be used by other CM scripts:
cm run script "get python" --out=jsonIf you run it for the first time and CM script detects multiple versions of python co-existing on your system, it will ask you to select one. CM will then cache the output in the cache artifact of the CM repository. You can see all cache CM entries for other tools and artifacts as follows:
cm show cacheor
cm show cache --tags=get,pythonYou can see the cached files as follows:
ls `cm find cache --tags=get,python`- _cm.json - CM meta description of this "cache" artifact with its unique ID, tags and other meta information
- cm-cached-state.json - dictionary with the new environment variables and the new state dictionary
- tmp-env-all.sh - all environment variables used during CM script execution
- tmp-env.sh - only new environment variables produced after CM script execution (it can be used directly by external tools)
- tmp-run.sh - all environment variables and a call to the native script (useful for reproducibility)
- tmp-state.json - the state before running native script - it can be loaded and used by native scripts and tools instead of using environment variables
- tmp-ver.out - the output of the --version command parsed by
postprocessanddetect_versionfunctions incustomize.py
If you (or other CM script) run this CM script to get the python tool for the second time, CM script will reuse the cached output:
cm run script "get python" --out=jsonThis also allows us to install multiple tool versions into different CM cache entries (python virtual environments, LLVM compiler, etc) and use them separately without the need to change higher-level CM scripts - these tools will be automatically plugged in:
cm run script "install prebuilt llvm" --version=14.0.0
cm run script "install prebuilt llvm" --version=16.0.0
cm run script "install src llvm"Such approach allows us to "probe" the user environment, detect different tools and artifacts, unify them and adapt complex applications to a user environment in an automatic, transparent and non-intrusive way as shown in the next example.
We can use automatically detected compiler from CM script to create simple and technology-neutral compilation and execution pipelines in CM scripts.
For example, we have implemented a simple image corner detection CM script with this meta description.
It uses two other reusable CM scripts to compile a given program using a detected/installed and cached compiler via CM (such as LLVM), and then run it with some input image.
First, let's detect installed LLVM it via CM:
cm run script "get llvm"or install a prebuilt version on Linux, MacOs or Windows:
cm run script "install prebuilt llvm" --version=14.0.0We can then run this CM script to compile and run image corner detection as follows:
cm run script "app image corner-detection" --input=`cm find script --tags=app,image,corner-detection`/computer_mouse.pgmThis CM script will preset environment variables for a detected/installed compiler,
compile our C program, run it via run.sh (Linux/MacOS) or run.bat (Windows)
and generate an output image output_image_with_corners.pgm in the output directory of this script:
ls `cm find script --tags=app,image,corner-detection`/output
image-corner output_image_with_corners.pgm
Note that this directory also contains the compiled tool "image-corner" that can now be used independently from CM if necessary.
When running a CM script with many sub-dependencies similar to above example, we may want to specify some version constraints on sub-dependencies such as LLVM.
One can use the key "names" in the "deps" list of any CM script meta description
to specify multiple names for a given dependency.
For example, a dependency to "get compiler" in CM script "compile-program"
has "names":["compiler"] as shown here.
We can now use a CM script flag --add_deps_recursive.{some name}.{some key}={some value} or
--adr.{above name}.{some key}={some value} to update a dictionary of all sub-dependencies
that has some name.
For example, we can now specify to use LLVM 16.0.0 for image corner detection as follows:
cm run script "app image corner-detection" --adr.compiler.tags=llvm --adr.compiler.version=16.0.0If this compiler was not yet detected or installed by CM, it will find related scripts to install either a prebuilt version of LLVM or build it from sources.
By default, CM scripts will install python dependencies into user space. This can influence other existing projects and may not be desirable. CM can be used inside virtual Python environments without any changes, but a user still need to do some manual steps to set up such environment. That's why we've developed a CM script to automate creation of multiple Python virtual environments with different names:
cm run script "install python-venv" --name={some name}CM will create a virtual environment using default Python and save it in CM cache. It is possible to create a python virtual environment with a minimal required version or a specific one on Linux and MacOS as follows:
cm run script "install python-venv" --version_min=3.8 --name=mlperf
cm run script "install python-venv" --version=3.10.8 --name=mlperf2In this case, CM will attempt to detect Python 3.10.8 on a system. If CM can't detect it, CM will then automatically download and build it using this script.
Now, when user runs pipelines that install Python dependencies, CM will detect virtual environment in the CM cache as well as native Python and will ask a user which one to use.
It is possible to avoid such questions by using the flag --adr.python.name=mlperf.
In such case, CM will propagate the name of a virtual environment to all sub-dependencies
as shown in the next example.
Instead of adding this flag to all scripts, you can specify it
using CM_SCRIPT_EXTRA_CMD environment variable as follows:
export CM_SCRIPT_EXTRA_CMD="--adr.python.name=mlperf"You can even specify min Python version required as follows:
export CM_SCRIPT_EXTRA_CMD="--adr.python.name=mlperf --adr.python.version_min=3.9"We can now use existing CM scripts as "LEGO" blocks to assemble more complex automation pipelines and workflows while automatically downloading and plugging in and pre-/post-processing all necessary artifacts (models, data sets, frameworks, compilers, etc) on any supported platform (Linux, MacOS, Windows).
For example, we have implemented a simple image classification application automated by the following CM script: app-image-classification-onnx-py.
It is described by the following _cm.yaml meta description:
alias: app-image-classification-onnx-py
uid: 3d5e908e472b417e
automation_alias: script
automation_uid: 5b4e0237da074764
category: "Modular ML/AI applications"
tags:
- app
- image-classification
- onnx
- python
default_env:
CM_BATCH_COUNT: '1'
CM_BATCH_SIZE: '1'
deps:
- tags: detect,os
- tags: get,sys-utils-cm
- names:
- python
- python3
tags: get,python3
- tags: get,cuda
names:
- cuda
enable_if_env:
USE_CUDA:
- yes
- tags: get,dataset,imagenet,image-classification,original
- tags: get,dataset-aux,imagenet-aux,image-classification
- tags: get,ml-model,resnet50,_onnx,image-classification
- tags: get,generic-python-lib,_onnxruntime
skip_if_env:
USE_CUDA:
- yes
- tags: get,generic-python-lib,_onnxruntime_gpu
enable_if_env:
USE_CUDA:
- yes
variations:
cuda:
env:
USE_CUDA: yesIts deps pipeline runs other CM scripts to detect OS parameters, detect or install Python,
install the latest ONNX run-time, download ResNet-50 model and the minimal ImageNet dataset (500).
It also contains run.sh
and run.bat
to install extra Python requirements (not yet unified by CM scripts)
and run a Python script that classifies an image from ImageNet
or an image provided by user.
Before running it, let us install Python virtual environment via CM to avoid altering native Python installation:
cm run script "install python-venv" --name=my-test
cm show cache --tags=pythonYou can run it on any system as follows:
cm run script "python app image-classification onnx"
To avoid CM asking which python to use, you can force the use of Python virtual environment as follows:
cm run script "python app image-classification onnx" --adr.python.name=my-testIf you run this CM script for the first time, it may take some minutes because it will detect, download, build and cache all dependencies.
When you run it again, it will plug in all cached dependencies:
cm run script "python app image-classification onnx" --adr.python.name.my-test
You can then run it with your own image as follows:
cm run script --tags=app,image-classification,onnx,python \
--adr.python.name.my-test --input={path to my JPEG image}In order to make experiments more portable and interoperable, we need to unify the information about host OS and CPU across different systems. We are gradually improving the following two CM scripts:
These two CM script have customize.py with preprocess and postprocess functions and a native run script to detect OS info and update environment variables and the state dictionary needed by all other CM scripts.
You can run them on your platform as follows:
cm run script "detect os" --out=json
...
cm run script "detect cpu" --out=jsonIf some information is missing or not consistent across different platforms, you can improve it in a backwards compatible way. You can then submit a PR here to let the community reuse your knowledge and collaboratively enhance common automation scripts, pipelines and workflows - that's why we called our project "Collective Knowledge".
Many projects require installation of some system dependencies. Unfortunately, the procedure is different across different systems.
That's why we have developed two other CM script to unify and automate this process on any system.
They will install (minimal) system dependencies based on the OS and CPU info detected by CM scripts mentioned above.
The last script is particularly useful to make applications compatible with Windows where many typical tools like "wget", "patch", etc are missing - they will be automatically download by that script.
You can use them as follows:
cm run script "get sys-utils-min" --out=json
cm run script "get sys-utils-cm"In some cases, we want the same CM script to download some artifact in a different format.
For example, we may want to download and cache ResNet50 model in ONNX or PyTorch or TensorFlow or TFLite format.
In such case, we use so-called variations in the meta description of a given CM script.
For example, the CM script [get-ml-model-resnet50] has many variations and combinations separated by comma
to download this model in multiple formats:
onnxonnx,opset-11onnx,opset-8pytorchpytorch,fp32pytorch,int8tflitetflite,argmaxtflite,no-argmaxtensorflowbatch_size.1batch_size.#
These variations simply update environment variables and add more dependencies on other CM scripts
before running customize.py and native scripts as described in _cm.json.
It is possible to specify a required variation or multiple variations when running a given CM script by adding extra tags with "_" prefix.
For example, you can install quantized ResNet-50 model in PyTorch int8 format as follows:
cm run script "get ml-model resnet50 _pytorch _int8" --out=jsonYou can install another FP32 variation of this model at the same time:
cm run script "get ml-model resnet50 _pytorch _fp32" --out=jsonYou can now find them in cache by tags and variations as follows:
cm show cache --tags=get,ml-model,resnet50
cm show cache --tags=get,ml-model,resnet50,_pytorch
cm show cache --tags=get,ml-model,resnet50,_pytorch,_fp32One of the important ideas behind using a common automation language is to use it inside and outside containers thus avoiding the need to create ad-hoc manual containers and README files.
We can just use base containers and let the CM automation language detect installed tools and connect external data with the automation pipelines and workflows.
See examples of modular containers with CM language to automate the MLPerf inference benchmark from MLCommons here.
Note that we continue working on a CM functionality to automatically generate Docker containers and README files when executing CM scripts (a prototype was successfully validated in the MLPerf inference v3.0 submission):
- https://github.com/mlcommons/ck/tree/master/cm-mlops/script/build-dockerfile
- https://github.com/mlcommons/ck/tree/master/cm-mlops/script/build-docker-image
You can get help about all flags used to customize execution of a given CM script from the command line as follows:
cm run script --helpSome flags are useful to make it easier to debug scripts and save output in files.
You can find more info about CM script execution flow in this document.