Goal - Writing a Proper Job Script for Slurm#
-Le principal objectif de ce chapitre est de vous permettre d’analyser -vos besoins dans le but de déterminer les ressources nécessaires -pour vos tâches de calcul. -Chaque tâche de calcul est définie par un script de tâche destiné à -l’ordonnanceur Slurm. -Typiquement écrit en commandes Bash, on y retrouve :
+The main goal of this chapter is to teach you how to +analyze your compute tasks in order to determine the +required resources to run tasks on compute clusters. +Each compute task will eventually be defined +in a job script to be submitted to the +Slurm scheduler. +Typically written in Bash commands, job scripts have:
-
-
Le shebang en toute -première ligne. Par exemple :
#!/bin/bash
-Les options
#SBATCHen entête pour les besoins de la tâche. Les -options en entête seront lues par la commande de soumission de tâche -sbatch
-Chargement des modules requis
-Les commandes Bash qui seront exécutées automatiquement sur des -processeurs réservés pour la tâche
+A shebang +at the first line. For example:
#!/bin/bash
+A header of
#SBATCHoptions for the job’s requirements. +These options will be parsed at submission time by the +sbatchcommand
+Modules +loaded before running the compute task
+The Bash commands that will be executed +automatically on the reserved resources for the job
For example : scripts/mpi-hello.sh
cat scripts/mpi-hello.sh
@@ -448,70 +450,73 @@ Goal - Writing a Proper Job Script for Slurm
Analysing Compute Jobs on Your Computer#
-Lorsqu’une tâche est en cours d’exécution sur votre ordinateur,
-vous pouvez surveiller différentes métriques :
+While a compute task is running on your computer,
+you can monitor different metrics:
-Utilisation CPU (et GPU, s’il y a lieu)
Mémoire-vive utilisée
Accès au stockage
CPU usage (and GPU usage, if applicable)
Memory usage
Storage access (IOPS, bandwidth)
In Windows#
-Pour le faire afficher, on le trouve de deux manières :
+You can find it in two ways:
-Chercher Gestionnaire des tâches dans le menu Démarrer
Raccourcis clavier Ctrl+Alt+Suppr
Look for Task Manager in the Start menu, or
With the keyboard shortcut Ctrl+Alt+Delete
-
+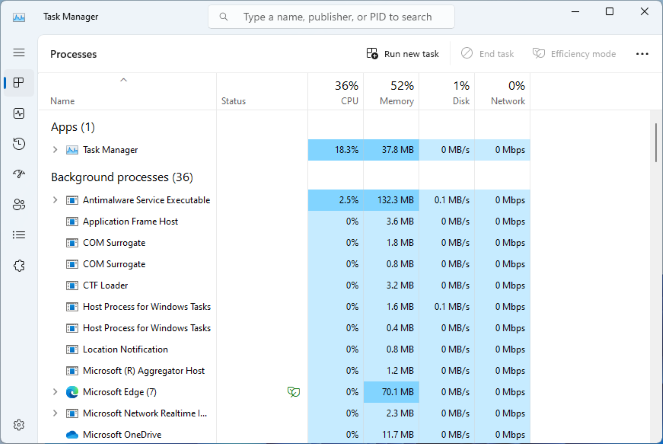 +Image from Wikimedia
+Image from Wikimedia
-
-In Mac OS#
+
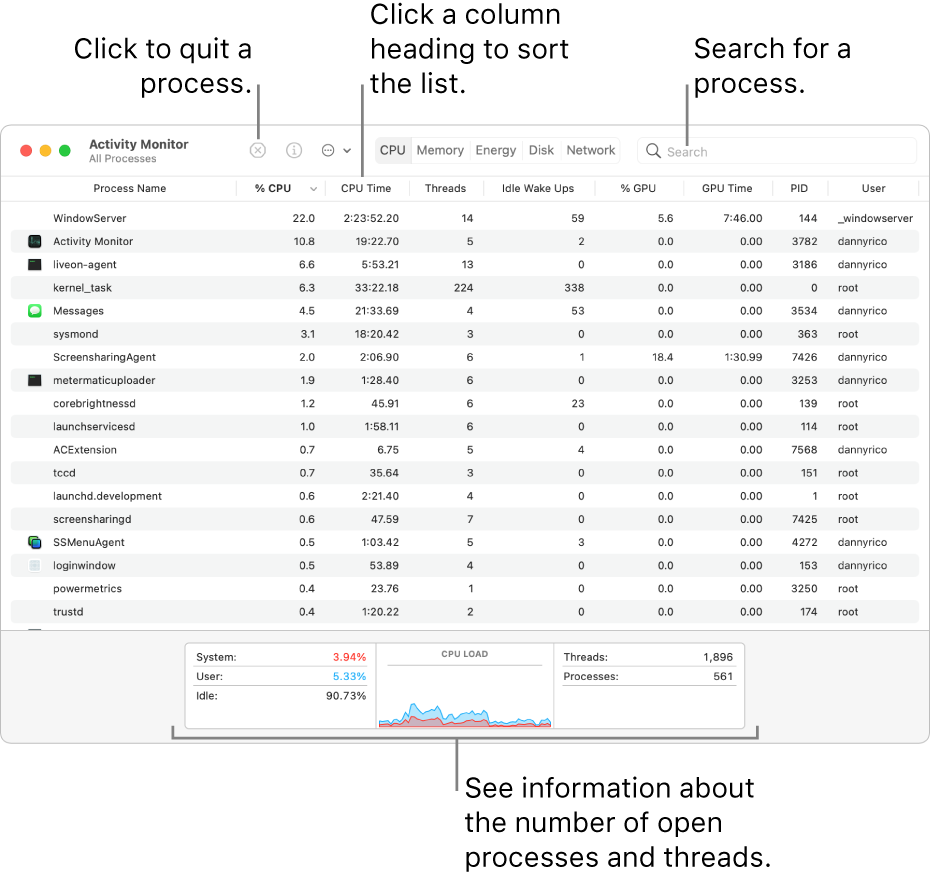
+In macOS#
-Pour le faire afficher :
+To open the Activity Monitor:
-Démarrer l’application à partir des Applications et Utilitaires de Mac OS
Sinon, utiliser le raccourcis clavier Commande+Espace et taper les
-premières lettres de “Moniteur d’activité” pour pouvoir sélectionner
-cette application
Start it from the Applications and Utilities directory in macOS
Otherwise, use the Command+Space shortcut and start typing
+the first letters of “Activity Monitor” to find and select it
-
+
+Image from Apple Support
In Linux#
-Dans un terminal Unix, on peut utiliser :
+In a Linux terminal, you can use:
-La commande top (q pour quitter)
The top command
+(Press Q to quit)
-
+
-La commande htop (q pour quitter)
The htop command
+(Press Q to quit)
-
+
Analysing Compute Jobs on Clusters#
-On commence par se connecter au noeud frontal de la grappe :
+As a first step, we need to connect to the cluster:
ssh login1
...
Notes :
-Pour accéder aux grappes de calcul en production, il vaut mieux
-utiliser une paire de clés SSH.
L’authentification multifacteur
-est maintenant offerte sur les grappes nationales.
-Vidéo d’introduction ici.
Avec votre accès par défaut, vous avez un compte de calcul
-def-* de base qui vous permet de lancer des tâches.
To connect to the national systems in production, you better use a
+pair of SSH keys
Multifactor authentication
+is now available on national clusters. See the
+introductory video here
With your default access, you can use at least one
+def-* account, which allows you to submit compute jobs
To submit a job script, we use the
sbatch command :
@@ -611,7 +616,7 @@ (Demo) Checking Resources Used by a Running GPU Job
-
-
For Windows and Mac OS, you can install proprietary software +
For Windows and macOS, you can install proprietary software that allows real time visualization of the GPU utilization. Please check the documentation of the GPU manufacturer for details
In Linux, with an NVIDIA GPU, we first have the @@ -654,26 +659,29 @@
Exercise - Testing
Comparing the Speed of CPU Cores and a GPU#
-Avant d’utiliser massivement les GPUs d’une grappe de calcul, il faut -tout d’abord que l’application ou l’algorithme puisse démontrer une -“bonne performance” en utilisant plusieurs processeurs en parallèle.
-Quelques définitions :
+Before using GPUs on compute clusters, your application +and its main algorithm must at first demonstrate a “good +performance” while using regular CPU cores in parallel.
+A few definitions:
-
-
Temps écoulé = temps d’exécution total que l’on perçoit et non le temps CPU
-Accélération = (temps avec un processeur) / (temps avec parallélisme)
-Efficacité = (Accélération) / (nombre de processeurs)
+Elapsed time = total perceived execution time, not the CPU time
+Acceleration = (Elapsed time with
1CPU core) / +(Elapsed time withNCPU cores)
+Efficiency = (Acceleration) /
N
Le coût d’un noeud GPU étant cinq fois supérieur à celui d’un noeud -régulier, l’utilisation d’un seul GPU doit permettre une accélération -d’au moins cinq fois (5x) la vitesse de huit (8) à douze (12) processeurs.
+The acquisition cost of a GPU node being about five times +the cost of a regular CPU node, the use of a single GPU +must accelerate an application at least five times (5x) +the speed of 8 to 16 cores in parallel to be worth it.
-
-
Accélération = (temps avec 8 à 12 processeurs) / (temps avec un accélérateur)
+GPU Acceleration = (time with 8 to 16 CPU cores) / +(time with a single GPU) >= 5
Jobs Analysis via Cluster Portals#
-Béluga et Narval ont chacun un portail pour l’analyse des tâches :
+Béluga and Narval each have a great portal for job monitoring:
- @@ -684,34 +692,34 @@
Le calcul est une efficacité d’au moins 90%
+The compute efficiency is at least 90%
-
-
Tâches séquentielles : il faut optimiser les accès aux données
+Serial tasks: may need to optimize the access to the data
-
-
Utiliser adéquatement les différents types de stockage
+Use each type of storage spaces adequately (see chapter 4)
-Tâches parallèles : il existe un nombre maximal de processeurs -à utiliser pour respecter ce seuil :
+Parallel tasks: there is a maximum number +of CPU cores that can reach this target:
-
-
Principe de scalabilité -et Loi d’Amdahl
+Scalability +principle and the +Amdahl’s law
-La mémoire-vive est une consommation de l’ordre de 80% -de ce qui est demandé à l’ordonnanceur Slurm
+The memory usage should be around 80% +of what was requested to the Slurm scheduler
CPU UtilizedetCPU Efficiency
-Memory UtilizedetMemory Efficiency
+CPU UtilizedandCPU Efficiency
+Memory UtilizedandMemory EfficiencyVous pouvez mesurer le temps d’exécution (avec la -commande
time) en fonction de la taille du problème. -En extrapolant les résultats, il serait possible de prévoir -le comportement du programme sur une grappe de calcul.
+You can measure the execution time (with the +
timecommand) in function of the size of the problem. +By extrapolating the results, you should be able to +predict the program behavior on the compute cluster.Vous pouvez considérer le format des données en entrées pour -deviner l’ordre du calcul principal.
+You can also considerate the shape of the input data +in order to guess the order of the main calculation.
La quantité en octets (ou Go)
+The quantity in bytes (or GB)
-
-
Peut servir à estimer l’utilisation de la mémoire-vive
-Tenir compte de la taille du stockage local rapide pour -optimiser les accès aux fichiers
+Can be used to estimate the memory usage
+Take into account the size limit of the +local storage for optimized file access
-Le nombre de fichiers à traiter
+The number of files to process
-
-
Considérer le parallélisme de données
-Multiplier la durée moyenne du traitement d’un fichier par -le nombre de fichiers pour estimer la durée d’une tâche
-Multiplier la taille moyenne des fichiers par leur nombre -pour estimer l’espace en mémoire-vive (par exemple : des images)
-Utiliser le stockage rapide pour optimiser les accès -aléatoires et nombreux
+Data parallelism could be a solution
+Multiply the average run time needed to process a file by +the total number of files to get an approximate job time limit
+Multiply the average size of files by their number to +estimate the space needed in memory (example: loading images)
+Use the local storage to optimize +repetitive and random accesses
Sous Windows : dans l’explorateur Windows (raccourcis clavier : Windows + E)
+In Windows: in Windows Explorer (keyboard shorcut: Windows + E)
-
-
Sélectionner un dossier ou plusieurs fichiers
-Bouton droit de la souris -> Propriétés
+Select one directory or multiple files
+Right-click -> Select Properties
Sous Mac OS : dans Finder
+In macOS: with Finder
-
-
Sélectionner un dossier ou plusieurs fichiers
-Bouton droit de la souris -> Get Info
-Autrement : avec l’affichage Par liste
- -
+Select one directory or multiple files
+Right-click -> Select Get Info
In Linux and on compute clusters :
+In Linux and on compute clusters:
The graphical environment can provide similar tools, but it depends on the Linux distribution and the chosen desktop
The command
du -sb DIRECTORY(sfor total sum,bfor apparent size in bytes) recursively computes and displays the total size of used space in bytes. The apparent size is -important to consider while transferring or backuping the data
+important to considerate while transferring or backuping the data
The command
find DIRECTORY | wc -lrecursively counts and displays the number of files and subdirectoriesPrévoir les paramètres d’une tâche Slurm
+Estimate Slurm job parameters
-
-
Nombre de processeurs (CPU) et de noeuds de calcul
-Nombre d’accélérateurs (GPU)
-Quantité de mémoire-vive (RAM)
-Temps du calcul (
JJ-H:MouH:M:S)
+Number of CPU cores and compute nodes
+Number of accelerators (GPU)
+Memory (RAM)
+Compute time (
DD-H:MorH:M:S)
-Différents outils pour surveiller les ressources utilisées
+Different tools to monitor used resources
-
-
timeet autres bibliothèques de mesure du temps écoulé
+timeand other libraries to measure elapsed timetop,htop,nvtop,nvidia-smisacct,seff
-du -sb,find | wc -let autres outils du système d’exploitation
+du -sb,find | wc -land other operating system tools
-On vise une efficacité de 90% et plus pour les tâches CPU
+Target efficiency of at least 90% for CPU jobs
-
-
L’accélération avec un accélérateur (GPU) doit être significative (>5x)
+The acceleration with a GPU should be significant (>5x)
-Le choix de la grappe dépend des besoins de chaque type de calcul
+The choice of a cluster depends on +the needs of each type of compute tasks
- Analysing Compute Jobs on Your Computer diff --git a/_images/win-task-manager.png b/_images/win-task-manager.png deleted file mode 100644 index 35e39f3..0000000 Binary files a/_images/win-task-manager.png and /dev/null differ diff --git a/_sources/2-resources.ipynb b/_sources/2-resources.ipynb index 036a56c..2579895 100644 --- a/_sources/2-resources.ipynb +++ b/_sources/2-resources.ipynb @@ -22,20 +22,22 @@ "metadata": {}, "source": [ "## Goal - Writing a Proper Job Script for Slurm\n", - "Le principal objectif de ce chapitre est de vous permettre d'analyser\n", - "vos besoins dans le but de **déterminer les ressources nécessaires**\n", - "pour vos tâches de calcul.\n", - "Chaque tâche de calcul est définie par un **script de tâche** destiné à\n", - "[l'ordonnanceur Slurm](https://slurm.schedmd.com/documentation.html).\n", - "Typiquement écrit en commandes Bash, on y retrouve :\n", - "* Le [shebang](https://fr.wikipedia.org/wiki/Shebang) en toute\n", - " première ligne. Par exemple : `#!/bin/bash`\n", - "* Les options `#SBATCH` en entête pour les besoins de la tâche. Les\n", - " options en entête seront lues par la commande de soumission de tâche\n", - " [`sbatch`](https://slurm.schedmd.com/sbatch.html)\n", - "* [Chargement des modules](https://docs.alliancecan.ca/wiki/Utiliser_des_modules) requis\n", - "* Les commandes Bash qui seront exécutées automatiquement sur des\n", - " processeurs réservés pour la tâche" + "The main goal of this chapter is to teach you how to\n", + "analyze your compute tasks in order to **determine the\n", + "required resources** to run tasks on compute clusters.\n", + "Each compute task will eventually be defined\n", + "in a **job script** to be submitted to the\n", + "[Slurm scheduler](https://slurm.schedmd.com/documentation.html).\n", + "Typically written in Bash commands, job scripts have:\n", + "* A [shebang](https://en.wikipedia.org/wiki/Shebang_(Unix))\n", + " at the first line. For example: `#!/bin/bash`\n", + "* A header of `#SBATCH` options for the job's requirements.\n", + " These options will be parsed at submission time by the\n", + " [`sbatch` command](https://slurm.schedmd.com/sbatch.html)\n", + "* [Modules](https://docs.alliancecan.ca/wiki/Utiliser_des_modules/en)\n", + " loaded before running the compute task\n", + "* The Bash commands that will be executed\n", + " automatically on the reserved resources for the job" ] }, { @@ -67,11 +69,11 @@ "metadata": {}, "source": [ "## Analysing Compute Jobs on Your Computer\n", - "Lorsqu'une tâche est en cours d'exécution sur votre ordinateur,\n", - "vous pouvez surveiller différentes métriques :\n", - "* Utilisation CPU (et GPU, s'il y a lieu)\n", - "* Mémoire-vive utilisée\n", - "* Accès au stockage" + "While a compute task is running on your computer,\n", + "you can monitor different metrics:\n", + "* CPU usage (and GPU usage, if applicable)\n", + "* Memory usage\n", + "* Storage access (IOPS, bandwidth)" ] }, { @@ -79,27 +81,28 @@ "metadata": {}, "source": [ "### In Windows\n", - "* [Gestionnaire des tâches Windows](https://fr.wikipedia.org/wiki/Gestionnaire_des_t%C3%A2ches_Windows)\n", - "* Pour le faire afficher, on le trouve de deux manières :\n", - " * Chercher *Gestionnaire des tâches* dans le menu Démarrer\n", - " * Raccourcis clavier Ctrl+Alt+Suppr\n", + "* [Windows Tasks Manager](https://en.wikipedia.org/wiki/Task_Manager_(Windows))\n", + "* You can find it in two ways:\n", + " * Look for *Task Manager* in the Start menu, or\n", + " * With the keyboard shortcut Ctrl+Alt+Delete\n", "\n", - "" + "\n", + "_Image from Wikimedia_" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ - "### In Mac OS\n", - "* [Moniteur d’activité](https://support.apple.com/fr-ca/guide/activity-monitor/actmntr1001/mac)\n", - "* Pour le faire afficher :\n", - " * Démarrer l'application à partir des *Applications et Utilitaires* de Mac OS\n", - " * Sinon, utiliser le raccourcis clavier Commande+Espace et taper les\n", - " premières lettres de \"Moniteur d'activité\" pour pouvoir sélectionner\n", - " cette application\n", + "### In macOS\n", + "* [Activity Monitor](https://support.apple.com/en-ca/guide/activity-monitor/actmntr1001/mac)\n", + "* To open the Activity Monitor:\n", + " * Start it from the *Applications and Utilities* directory in macOS\n", + " * Otherwise, use the Command+Space shortcut and start typing\n", + " the first letters of \"Activity Monitor\" to find and select it\n", "\n", - "" + "\n", + "_Image from Apple Support_" ] }, { @@ -107,19 +110,21 @@ "metadata": {}, "source": [ "### In Linux\n", - "Dans un terminal Unix, on peut utiliser :\n", - "* La [commande `top`](https://man7.org/linux/man-pages/man1/top.1.html) (`q` pour quitter)\n", + "In a Linux terminal, you can use:\n", + "* The [`top` command](https://man7.org/linux/man-pages/man1/top.1.html)\n", + " (Press Q to quit)\n", "\n", - "" + "" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ - "* La [commande `htop`](https://man7.org/linux/man-pages/man1/htop.1.html) (`q` pour quitter)\n", + "* The [`htop` command](https://man7.org/linux/man-pages/man1/htop.1.html)\n", + " (Press Q to quit)\n", "\n", - "" + "" ] }, { @@ -127,19 +132,19 @@ "metadata": {}, "source": [ "## Analysing Compute Jobs on Clusters\n", - "On commence par **se connecter au noeud frontal** de la grappe :\n", + "As a first step, we need to **connect to the cluster**:\n", "```Bash\n", "ssh login1\n", "...\n", "```\n", "**Notes** :\n", - "* Pour accéder aux grappes de calcul en production, il vaut mieux\n", - " utiliser [une paire de clés SSH](https://docs.alliancecan.ca/wiki/Using_SSH_keys_in_Linux/fr).\n", - "* [L'authentification multifacteur](https://docs.alliancecan.ca/wiki/Multifactor_authentication/fr)\n", - " est maintenant offerte sur les grappes nationales.\n", - " [Vidéo d'introduction ici](https://www.youtube.com/watch?v=ciycOUbchl8).\n", - "* Avec votre accès par défaut, vous avez un compte de calcul\n", - " `def-*` de base qui vous permet de lancer des tâches." + "* To connect to the national systems in production, you better use a\n", + " [pair of SSH keys](https://docs.alliancecan.ca/wiki/Using_SSH_keys_in_Linux)\n", + "* [Multifactor authentication](https://docs.alliancecan.ca/wiki/Multifactor_authentication)\n", + " is now available on national clusters. See the\n", + " [introductory video here](https://www.youtube.com/watch?v=qNsUsZ73HP0)\n", + "* With your default access, you can use at least one\n", + " `def-*` account, which allows you to submit compute jobs" ] }, { @@ -271,7 +276,7 @@ "salloc --cpus-per-task=4 --mem=8000M --time=0:15:0 --gres=gpu:1\n", "```\n", "\n", - "* For Windows and Mac OS, you can install proprietary software\n", + "* For Windows and macOS, you can install proprietary software\n", " that allows real time visualization of the GPU utilization.\n", " Please check the documentation of the GPU manufacturer for details\n", "* In Linux, with an NVIDIA GPU, we first have the\n", @@ -337,19 +342,22 @@ "metadata": {}, "source": [ "#### Comparing the Speed of CPU Cores and a GPU\n", - "Avant d'utiliser massivement les GPUs d'une grappe de calcul, il faut\n", - "tout d'abord que l'application ou l'algorithme puisse démontrer une\n", - "\"bonne performance\" en utilisant plusieurs processeurs en parallèle.\n", + "Before using GPUs on compute clusters, your application\n", + "and its main algorithm must at first demonstrate a \"good\n", + "performance\" while using regular CPU cores in parallel.\n", "\n", - "Quelques définitions :\n", - "* **Temps écoulé** = temps d'exécution total que l'on perçoit et non le temps CPU\n", - "* **Accélération** = (temps avec un processeur) / (temps avec parallélisme)\n", - "* **Efficacité** = (Accélération) / (nombre de processeurs)\n", + "A few definitions:\n", + "* **Elapsed time** = total perceived execution time, not the CPU time\n", + "* **Acceleration** = (Elapsed time with `1` CPU core) /\n", + " (Elapsed time with `N` CPU cores)\n", + "* **Efficiency** = (Acceleration) / `N`\n", "\n", - "Le coût d'un noeud GPU étant cinq fois supérieur à celui d'un noeud\n", - "régulier, l'utilisation d'un seul GPU doit permettre une accélération\n", - "d'au moins cinq fois (5x) la vitesse de huit (8) à douze (12) processeurs.\n", - "* **Accélération** = (temps avec 8 à 12 processeurs) / (temps avec un accélérateur)" + "The acquisition cost of a GPU node being about five times\n", + "the cost of a regular CPU node, the use of a single GPU\n", + "must accelerate an application at least five times (5x)\n", + "the speed of 8 to 16 cores in parallel to be worth it.\n", + "* **GPU Acceleration** = (time with 8 to 16 CPU cores) /\n", + " (time with a single GPU) >= 5" ] }, { @@ -357,7 +365,7 @@ "metadata": {}, "source": [ "### Jobs Analysis via Cluster Portals\n", - "Béluga et Narval ont chacun un portail pour l'analyse des tâches :\n", + "Béluga and Narval each have a great portal for job monitoring:\n", "* [https://portail.beluga.calculquebec.ca/](https://portail.beluga.calculquebec.ca/)\n", "* [https://portail.narval.calculquebec.ca/](https://portail.narval.calculquebec.ca/)" ] @@ -368,23 +376,23 @@ "source": [ "## Estimating Required Compute Resources\n", "### Target Efficiency of a Job\n", - "À coût d'essais et erreurs avec une **tâche de petite taille**,\n", - "la cible pour :\n", - "* **Le calcul** est une **efficacité d'au moins 90%**\n", - " * Tâches séquentielles : il faut **optimiser les accès aux données**\n", - " * Utiliser adéquatement les différents types de stockage\n", - " * Tâches parallèles : il existe un **nombre maximal de processeurs**\n", - " à utiliser pour respecter ce seuil :\n", - " * Principe de [scalabilité](https://docs.alliancecan.ca/wiki/Scalability/fr)\n", - " et [Loi d'Amdahl](https://fr.wikipedia.org/wiki/Loi_d%27Amdahl)\n", - "* **La mémoire-vive** est une consommation **de l'ordre de 80%**\n", - " de ce qui est demandé à l'ordonnanceur Slurm\n", + "When testing with a **short and small job**, the target for:\n", + "* The **compute efficiency** is **at least 90%**\n", + " * Serial tasks: may need to **optimize the access to the data**\n", + " * Use each type of storage spaces adequately (see chapter 4)\n", + " * Parallel tasks: there is a **maximum number\n", + " of CPU cores** that can reach this target:\n", + " * [Scalability](https://docs.alliancecan.ca/wiki/Scalability)\n", + " principle and the\n", + " [Amdahl's law](https://en.wikipedia.org/wiki/Amdahl%27s_law)\n", + "* The **memory usage** should be around **80%**\n", + " of what was requested to the Slurm scheduler\n", "\n", - "**Rappel** - vous pouvez obtenir ces pourcentages via les commandes\n", - "`sacct -X` (surtout pour obtenir les numéros de tâches) et `seff`.\n", - "Les valeurs à considérer sont :\n", - "* `CPU Utilized` et `CPU Efficiency`\n", - "* `Memory Utilized` et `Memory Efficiency`" + "**Reminder** - you can get these percentages with the commands\n", + "`sacct -X` (mainly to get job IDs) and `seff`.\n", + "The important values are:\n", + "* `CPU Utilized` and `CPU Efficiency`\n", + "* `Memory Utilized` and `Memory Efficiency`" ] }, { @@ -407,23 +415,22 @@ "metadata": {}, "source": [ "### Extrapolating Required Compute Resources\n", - "La question qui se pose :\n", - "**en augmentant la ou les dimensions du problème**, quelles devraient\n", - " être la durée du calcul et la consommation en mémoire-vive?\n", - "[Une analyse détaillée du code](https://fr.wikipedia.org/wiki/Analyse_de_la_complexit%C3%A9_des_algorithmes)\n", - "n'est pas nécessaire pour déterminer le type de calcul qui est fait :\n", + "**If you increase the size of the problem**, what\n", + "should be the expected compute time and memory usage?\n", + "[A detailed code analysis](https://en.wikipedia.org/wiki/Analysis_of_algorithms)\n", + "is not necessary to make that approximation:\n", "\n", - "* Vous pouvez **mesurer le temps d'exécution** (avec la\n", - " commande `time`) en fonction de la taille du problème.\n", - " En extrapolant les résultats, il serait possible de prévoir\n", - " le comportement du programme sur une grappe de calcul.\n", + "* You can **measure the execution time** (with the\n", + " `time` command) in function of the size of the problem.\n", + " By extrapolating the results, you should be able to\n", + " predict the program behavior on the compute cluster.\n", "\n", "```Bash\n", "time -p sleep 2\n", "```\n", "\n", - "* Vous pouvez considérer le **format des données en entrées** pour\n", - " deviner l'ordre du calcul principal. " + "* You can also considerate the **shape of the input data**\n", + " in order to guess the order of the main calculation." ] }, { @@ -431,30 +438,30 @@ "metadata": {}, "source": [ "### Data Size and Number of Files to Process\n", - "En plus du temps de calcul et de l'espace mémoire, il faut aussi\n", - "considérer **l'utilisation du stockage**. Les valeurs à tenir compte :\n", - "1. La **quantité** en octets (ou Go)\n", - " * Peut servir à **estimer** l'utilisation de la mémoire-vive\n", - " * Tenir compte de la taille du **stockage local rapide** pour\n", - " optimiser les accès aux fichiers\n", - "1. Le **nombre** de fichiers à traiter\n", - " * Considérer le **parallélisme de données**\n", - " * **Multiplier la durée moyenne** du traitement d'un fichier par\n", - " le nombre de fichiers pour estimer la durée d'une tâche\n", - " * **Multiplier la taille moyenne** des fichiers par leur nombre\n", - " pour estimer l'espace en mémoire-vive (par exemple : des images)\n", - " * Utiliser le stockage rapide pour **optimiser les accès**\n", - " aléatoires et nombreux" + "On top of the compute time and memory usage, you must also considerate\n", + "the **storage space usage**. Values to take into account are:\n", + "1. The **quantity** in bytes (or GB)\n", + " * Can be used to **estimate** the memory usage\n", + " * Take into account the size limit of the\n", + " **local storage** for optimized file access\n", + "1. The **number** of files to process\n", + " * **Data parallelism** could be a solution\n", + " * **Multiply the average run time** needed to process a file by\n", + " the total number of files to get an approximate job time limit\n", + " * **Multiply the average size of files** by their number to\n", + " estimate the space needed in memory (example: loading images)\n", + " * Use the local storage to **optimize\n", + " repetitive and random accesses**" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ - "Pour obtenir le nombre de fichiers et la taille totale :\n", - "* **Sous Windows** : dans l'explorateur Windows (raccourcis clavier : Windows + E)\n", - " * Sélectionner un dossier ou plusieurs fichiers\n", - " * Bouton droit de la souris -> *Propriétés*\n", + "To get the number of files and the total size:\n", + "* **In Windows**: in Windows Explorer (keyboard shorcut: Windows + E)\n", + " * Select one directory or multiple files\n", + " * Right-click -> Select *Properties*\n", "\n", "" ] @@ -463,24 +470,22 @@ "cell_type": "markdown", "metadata": {}, "source": [ - "* **Sous Mac OS** : dans *Finder*\n", - " * Sélectionner un dossier ou plusieurs fichiers\n", - " * Bouton droit de la souris -> *Get Info*\n", - " * Autrement : avec l'affichage *Par liste*\n", - " * [Activer *Calculer toutes les tailles*](https://www.solutionenligne.org/comment-afficher-taille-dossiers-fichiers-dans-finder-mac-os/)" + "* **In macOS**: with *Finder*\n", + " * Select one directory or multiple files\n", + " * Right-click -> Select *Get Info*" ] }, { "cell_type": "markdown", "metadata": {}, "source": [ - "* **In Linux** and on **compute clusters** :\n", + "* **In Linux** and on **compute clusters**:\n", " * The graphical environment can provide similar tools, but\n", " it depends on the Linux distribution and the chosen desktop\n", " * The command `du -sb DIRECTORY` (`s` for total sum, `b` for\n", " apparent size in bytes) recursively computes and displays\n", " the total size of used space in bytes. The apparent size is\n", - " important to consider while transferring or backuping the data\n", + " important to considerate while transferring or backuping the data\n", " * The command `find DIRECTORY | wc -l` recursively counts\n", " and displays the number of files and subdirectories\n", "\n", @@ -577,19 +582,20 @@ "metadata": {}, "source": [ "## Key Points\n", - "* Prévoir les **paramètres d'une tâche Slurm**\n", - " * Nombre de processeurs (CPU) et de noeuds de calcul\n", - " * Nombre d'accélérateurs (GPU)\n", - " * Quantité de mémoire-vive (RAM)\n", - " * Temps du calcul (`JJ-H:M` ou `H:M:S`)\n", - "* Différents **outils pour surveiller** les ressources utilisées\n", - " * `time` et autres bibliothèques de mesure du temps écoulé\n", + "* Estimate **Slurm job parameters**\n", + " * Number of CPU cores and compute nodes\n", + " * Number of accelerators (GPU)\n", + " * Memory (RAM)\n", + " * Compute time (`DD-H:M` or `H:M:S`)\n", + "* Different **tools to monitor** used resources\n", + " * `time` and other libraries to measure elapsed time\n", " * `top`, `htop`, `nvtop`, `nvidia-smi`\n", " * `sacct`, `seff`\n", - " * `du -sb`, `find | wc -l` et autres outils du système d'exploitation\n", - "* On vise une **efficacité de 90%** et plus pour les tâches CPU\n", - " * L'accélération avec un accélérateur (GPU) doit être significative (>5x)\n", - "* Le choix de la grappe dépend des besoins de chaque type de calcul" + " * `du -sb`, `find | wc -l` and other operating system tools\n", + "* Target **efficiency of at least 90%** for CPU jobs\n", + " * The acceleration with a GPU should be significant (>5x)\n", + "* The choice of a cluster depends on\n", + " the needs of each type of compute tasks" ] }, { diff --git a/searchindex.js b/searchindex.js index 9d3bab7..494547b 100644 --- a/searchindex.js +++ b/searchindex.js @@ -1 +1 @@ -Search.setIndex({"docnames": ["0-about", "1-introduction", "2-resources", "3-task-arrays", "4-storage", "90-exercises", "99-references", "data/README", "extra/acceleration", "extra/estimer-mem", "extra/glost-meta-farm", "extra/maitriser-slurm", "extra/stockage-avance"], "filenames": ["0-about.ipynb", "1-introduction.ipynb", "2-resources.ipynb", "3-task-arrays.ipynb", "4-storage.ipynb", "90-exercises.ipynb", "99-references.ipynb", "data/README.md", "extra/acceleration.ipynb", "extra/estimer-mem.ipynb", "extra/glost-meta-farm.ipynb", "extra/maitriser-slurm.ipynb", "extra/stockage-avance.ipynb"], "titles": ["Mastering the Alliance\u2019s Compute Systems", "Introduction", "Use Resources Wisely", "Task Arrays for Data Parallelism", "Storage Spaces", "Additional Exercises", "References", "Generating the data", "Analyse d\u2019acc\u00e9l\u00e9ration", "Estimation des besoins en m\u00e9moire-vive", "Le Greedy Launcher Of Small Tasks, ou GLOST", "Ma\u00eetriser l\u2019ordonnanceur Slurm", "Notions avanc\u00e9es du stockage"], "terms": {"intermedi": 0, "level": 0, "i": [0, 1, 2, 3, 4, 10, 11], "follow": [0, 2, 3, 4], "up": 0, "first": [0, 2], "step": [0, 2], "cluster": [0, 1, 6], "The": [0, 2, 3, 4], "main": [0, 3], "goal": 0, "explor": [0, 5, 8], "more": 0, "depth": 0, "some": [0, 1, 2], "kei": [0, 6], "concept": 0, "advanc": [0, 1], "research": [0, 2, 6], "note": [0, 2, 8, 12], "notebook": [0, 6], "script": [0, 3, 4, 5, 6, 8, 10, 11], "ar": [0, 1, 2, 3, 4], "publish": 0, "github": 0, "introduct": [0, 2], "remind": 0, "high": [0, 2], "perform": [0, 2, 3, 4, 5, 8], "differ": 0, "kind": 0, "task": [0, 2, 6], "question": [0, 2, 5, 6, 12], "think": 0, "us": [0, 1, 4, 6], "resourc": [0, 1, 3, 6], "wise": 0, "analys": [0, 11], "job": [0, 1, 4, 6, 11], "your": [0, 1, 6], "estim": [0, 1, 11], "requir": [0, 1, 3], "comparison": 0, "arrai": [0, 1, 6], "data": [0, 6], "parallel": [0, 2, 6, 12], "gnu": [0, 6], "storag": [0, 1, 2, 6], "space": [0, 1, 2, 6], "type": [0, 1, 2, 6, 10, 12], "manag": [0, 1, 6], "see": [0, 3], "page": [0, 2, 3, 8], "initi": 1, "problem": [1, 2], "when": [1, 3], "we": [1, 2, 3], "need": 1, "run": [1, 3, 6, 10, 11], "veri": 1, "larg": [1, 2, 3, 6, 12], "number": [1, 4], "calcul": [1, 2, 3, 4, 5, 6, 9, 10, 11, 12], "process": [1, 4], "dataset": 1, "becom": [1, 4], "necessari": [1, 4], "becaus": 1, "share": [1, 6], "demand": [1, 4], "each": [1, 3, 4], "submit": [1, 2, 3, 6, 10], "schedul": [1, 6], "It": [1, 4], "execut": [1, 2, 3], "two": [1, 2], "categori": 1, "work": [1, 3], "same": [1, 3], "within": 1, "set": [1, 6], "serial": 1, "have": [1, 2, 3, 4, 6], "vector": 1, "descript": [1, 4, 12], "oper": [1, 2], "appli": 1, "modern": 1, "processor": 1, "an": [1, 2], "acceler": 1, "gpu": [1, 4, 5, 6, 11], "A": [1, 3, 8, 9, 11], "lot": [1, 3], "independ": 1, "multipl": [1, 5], "simultan": 1, "probabl": [1, 4], "Or": [1, 4, 8, 12], "split": 1, "chunk": [1, 7], "what": 1, "do": 1, "you": [1, 2, 3, 4, 6], "perhap": 1, "small": 1, "file": [1, 3, 4, 6, 7], "few": 1, "which": [1, 2, 3, 4], "should": [1, 2, 3], "chosen": [1, 2], "quantiti": 1, "request": [1, 2], "how": 1, "plan": [1, 4], "usag": [1, 2, 3, 4], "activ": [1, 2, 6], "who": 1, "abl": 1, "access": [1, 2, 4, 6, 12], "archiv": [1, 4, 6], "final": [1, 8], "optim": 1, "monitor": [1, 2, 3, 4, 6], "profil": [1, 2, 6], "those": 1, "With": [2, 6], "digit": [2, 6], "allianc": [2, 6], "canada": [2, 6], "account": [2, 6], "mani": [2, 3], "b\u00e9luga": [2, 4, 6], "cedar": [2, 4, 6], "graham": [2, 4, 6], "narval": [2, 4, 6], "niagara": [2, 4, 6], "temporari": 2, "project": [2, 6], "nearlin": [2, 6], "while": 2, "being": 2, "still": 2, "limit": [2, 10, 11], "carefulli": 2, "everyon": 2, "order": [2, 3], "maximis": 2, "amount": 2, "produc": 2, "scientif": 2, "result": [2, 3], "themselv": 2, "other": [2, 6], "le": [2, 3, 4, 5, 11, 12], "princip": 2, "objectif": 2, "de": [2, 3, 4, 8, 11], "ce": [2, 3, 4, 5, 8, 11, 12], "chapitr": [2, 3, 4, 11, 12], "est": [2, 3, 4, 5, 8, 10, 11, 12], "vou": [2, 3, 5, 8, 11, 12], "permettr": [2, 8], "d": [2, 3, 4, 5, 9, 10], "vo": [2, 4, 5, 11], "besoin": [2, 4, 11], "dan": [2, 3, 4, 5, 8, 9, 10, 11], "d\u00e9termin": [2, 11], "ressourc": [2, 3, 11], "n\u00e9cessair": [2, 3, 4, 12], "pour": [2, 3, 4, 5, 8, 10, 11, 12], "t\u00e2che": [2, 3, 4, 5, 10, 12], "chaqu": [2, 3, 4, 9, 10, 11, 12], "d\u00e9fini": 2, "par": [2, 3, 4, 5, 8, 9, 10, 11, 12], "un": [2, 3, 4, 5, 9, 10], "destin\u00e9": 2, "\u00e0": [2, 3, 4, 5, 8, 12], "l": [2, 3, 4, 8, 9, 10, 12], "ordonnanceur": [2, 3, 5, 8], "typiqu": [2, 4, 9, 12], "\u00e9crit": [2, 12], "en": [2, 3, 4, 5, 8, 10, 12], "command": [2, 4, 5, 6, 8, 10, 11, 12], "bash": [2, 3, 4, 5, 8, 10, 11], "y": [2, 3, 4, 10, 12], "retrouv": [2, 3], "shebang": [2, 6], "tout": [2, 3, 4, 5, 8, 9, 10, 11, 12], "premi\u00e8r": 2, "lign": [2, 3, 10], "exempl": [2, 3, 8, 9, 10], "bin": 2, "option": [2, 3], "sbatch": [2, 3, 5, 6, 10, 11], "ent\u00eat": [2, 3], "la": [2, 3, 4, 5, 9, 10, 11, 12], "seront": [2, 3, 4, 5], "lue": 2, "soumiss": [2, 10], "chargement": 2, "modul": [2, 5, 6, 9, 10], "requi": [2, 5, 8], "qui": [2, 3, 4, 8, 10, 11, 12], "ex\u00e9cut\u00e9": [2, 3], "automatiqu": [2, 3, 12], "sur": [2, 4, 8, 10, 11, 12], "processeur": [2, 3, 5, 8, 10, 11], "r\u00e9serv\u00e9": 2, "For": [2, 3], "exampl": [2, 3], "mpi": [2, 10], "hello": 2, "sh": [2, 3, 4, 5, 8, 10, 11], "cat": [2, 3, 5, 8, 10, 11, 12], "ntask": 2, "10": [2, 3, 4, 7, 9, 10, 12], "mem": 2, "per": [2, 3, 4], "1000m": 2, "time": [2, 4, 5, 7], "0": [2, 3, 5, 7, 8, 9, 10, 11], "00": 2, "load": [2, 5, 7, 9, 10], "gcc": [2, 5, 7], "9": [2, 7, 8], "3": [2, 3, 5, 7, 9], "dev": 2, "null": 2, "mpirun": 2, "printenv": 2, "hostnam": [2, 6], "ompi_comm_world_rank": 2, "ompi_comm_world_s": 2, "our": 2, "document": [2, 3, 6], "about": [2, 4, 6], "start": 2, "thi": [2, 3], "lorsqu": [2, 3, 5, 8, 10, 11, 12], "cour": [2, 3, 10, 11], "ex\u00e9cut": [2, 3, 4, 5, 8, 10], "votr": [2, 11, 12], "ordinateur": [2, 5], "pouvez": [2, 5, 8, 11, 12], "surveil": 2, "diff\u00e9rent": [2, 3, 4, 5, 9, 11, 12], "m\u00e9triqu": 2, "utilis": [2, 3, 4, 8, 9, 10, 11, 12], "et": [2, 3, 4, 5, 9, 12], "": [2, 3, 4, 5, 6, 8, 10, 12], "il": [2, 3, 4, 5, 8, 9, 10, 11, 12], "lieu": [2, 3, 12], "m\u00e9moir": [2, 5, 8, 11], "vive": [2, 5, 8], "utilis\u00e9": [2, 3, 4, 11, 12], "acc\u00e8": [2, 4], "au": [2, 3, 8, 10, 11, 12], "stockag": [2, 4], "gestionnair": [2, 4, 10], "fair": [2, 12], "affich": [2, 11], "trouv": 2, "deux": [2, 9, 12], "mani\u00e8r": 2, "chercher": 2, "menu": 2, "d\u00e9marrer": 2, "raccourci": 2, "clavier": 2, "ctrl": [2, 8, 9], "alt": 2, "suppr": 2, "moniteur": 2, "activit\u00e9": 2, "applic": [2, 8, 9], "partir": [2, 12], "utilitair": 2, "sinon": 2, "espac": [2, 4, 9, 12], "taper": 2, "lettr": 2, "pouvoir": [2, 5], "s\u00e9lectionn": 2, "cett": [2, 5, 11, 12], "termin": [2, 8, 10, 12], "unix": 2, "peut": [2, 3, 4, 8, 9, 10, 12], "top": [2, 6, 10], "q": [2, 3, 10], "quitter": [2, 10], "htop": [2, 6], "On": [2, 4, 5, 8, 10], "commenc": 2, "se": [2, 4, 5, 9, 10, 11, 12], "connect": [2, 6], "noeud": [2, 3, 4, 5, 8, 10, 11, 12], "frontal": 2, "grapp": [2, 4, 8, 11, 12], "ssh": [2, 6, 10], "login1": [2, 4], "acc\u00e9der": 2, "aux": [2, 4, 5, 12], "product": 2, "vaut": [2, 3, 4, 11, 12], "mieux": [2, 3, 4, 11, 12], "pair": 2, "cl\u00e9": 2, "authentif": 2, "multifacteur": 2, "mainten": 2, "offert": 2, "national": [2, 4, 11], "vid\u00e9o": 2, "ici": [2, 3], "avec": [2, 3, 4, 5, 8, 9, 11, 12], "d\u00e9faut": [2, 4], "avez": 2, "compt": [2, 11], "def": [2, 4, 11, 12], "base": 2, "permet": [2, 3, 5, 10, 11], "lancer": 2, "To": [2, 3, 4, 12], "blastn": [2, 3, 4], "gen": [2, 3, 5], "seq": [2, 3], "And": 2, "statu": [2, 3, 6], "squeue": [2, 3, 4, 5, 6, 10, 11], "u": [2, 3, 4, 5, 10, 11], "user": [2, 3, 4, 5, 10, 11], "sq": 2, "sacct": [2, 5, 6, 8, 11], "can": [2, 3], "get": [2, 6], "detail": [2, 4], "tabl": [2, 4, 10], "sinc": 2, "midnight": 2, "seff": [2, 3, 5, 6, 8, 11], "short": [2, 4], "report": [2, 4], "singl": 2, "includ": 2, "elaps": [2, 11], "total": [2, 3, 8, 11, 12], "maximum": [2, 3, 4], "memori": [2, 6, 8], "valu": 2, "given": 2, "percentag": [2, 6], "job_id": [2, 3], "3d": 2, "matrix": 2, "python": [2, 4, 5, 6, 7, 9], "interact": 2, "salloc": [2, 4], "4": [2, 3, 5, 8, 9, 10], "8000m": 2, "15": [2, 7], "one": [2, 3, 6], "1": [2, 3, 5, 8, 9, 10, 11, 12], "press": [2, 3], "quit": [2, 3, 9], "four": [2, 3, 7], "grep": 2, "sec": 2, "log": [2, 7], "exit": [2, 4, 10], "go": [2, 12], "back": 2, "If": [2, 3], "jupyterhub": [2, 6], "code": [2, 4, 5, 6], "visual": [2, 6], "real": 2, "machin": [2, 9, 12], "tab": 2, "dashboard": 2, "allow": [2, 3, 4], "correspond": [2, 8], "node": [2, 3, 4, 6], "inv": [2, 5], "mat": [2, 5], "here": 2, "gener": [2, 4], "valid": [2, 3, 5], "identifi": [2, 3, 5, 11], "node_nam": 2, "100": [2, 8, 9, 12], "n": [2, 3, 5, 8, 10, 11, 12], "where": [2, 3], "reserv": [2, 6], "doe": 2, "seem": 2, "fulli": 2, "util": [2, 8], "inspect": [2, 3, 11], "time_inv": 2, "csv": [2, 5], "ani": 2, "find": [2, 3, 4], "caus": [2, 11], "correct": [2, 5], "compil": [2, 4], "paramet": 2, "resubmit": 2, "redo": 2, "abov": [2, 3], "gre": 2, "instal": [2, 4, 6], "proprietari": 2, "softwar": [2, 6], "pleas": 2, "manufactur": 2, "nvidia": [2, 6], "smi": [2, 6], "There": 2, "also": 2, "nvtop": [2, 6], "tg": 2, "1gpu": 2, "tail": [2, 3], "24": [2, 5], "avant": [2, 4, 8, 12], "massiv": [2, 8], "faut": [2, 4, 8, 10, 11, 12], "abord": [2, 8, 10], "que": [2, 3, 4, 5, 8, 9, 10, 12], "ou": [2, 3, 4, 8, 9, 11, 12], "algorithm": [2, 6, 8], "puiss": [2, 8], "d\u00e9montrer": [2, 8], "bonn": [2, 8], "plusieur": [2, 3, 4, 8, 10, 12], "parall\u00e8l": [2, 3, 4, 10], "quelqu": [2, 3, 4, 8, 10, 12], "d\u00e9finit": [2, 8], "temp": [2, 3, 4, 5, 8, 10, 11, 12], "\u00e9coul\u00e9": [2, 8, 11], "per\u00e7oit": [2, 8], "non": [2, 3, 4, 8, 12], "acc\u00e9l\u00e9rat": 2, "parall\u00e9lism": [2, 3, 8], "efficacit\u00e9": [2, 3, 5], "nombr": [2, 3, 4, 5, 8, 10, 11], "co\u00fbt": [2, 8, 12], "\u00e9tant": [2, 8, 12], "cinq": [2, 8], "foi": [2, 5, 8, 11, 12], "sup\u00e9rieur": [2, 8], "celui": [2, 8], "r\u00e9gulier": [2, 8], "seul": [2, 3, 5, 8, 10, 12], "doit": [2, 3, 8, 10], "moin": [2, 3, 8], "5x": [2, 8], "vitess": [2, 5], "huit": [2, 8], "8": [2, 3, 5, 7, 8, 9, 10], "douz": [2, 8], "12": [2, 3, 5, 7, 8], "acc\u00e9l\u00e9rateur": [2, 8], "ont": [2, 4, 10], "chacun": [2, 5, 9], "portail": 2, "http": [2, 11], "beluga": 2, "calculquebec": 2, "ca": [2, 3, 4, 5, 8, 11, 12], "essai": 2, "erreur": [2, 5], "petit": [2, 3, 4, 12], "taill": [2, 3, 4, 5, 9], "cibl": 2, "90": [2, 8], "s\u00e9quentiel": [2, 3, 8, 10], "optimis": [2, 4, 12], "donn\u00e9": [2, 3, 4, 5, 8, 9, 11], "ad\u00e9quat": 2, "exist": [2, 8, 12], "maxim": [2, 8], "respect": [2, 8], "seuil": [2, 8], "scalabilit\u00e9": 2, "loi": 2, "amdahl": [2, 6], "consomm": [2, 5, 8], "ordr": [2, 5, 8], "80": [2, 8], "demand\u00e9": [2, 8, 11], "rappel": [2, 5, 8], "obtenir": [2, 4, 5, 8, 11, 12], "pourcentag": [2, 3, 5, 8], "x": [2, 3, 8, 12], "surtout": [2, 8, 12], "num\u00e9ro": [2, 5, 8], "valeur": [2, 3, 5, 8, 9], "consid\u00e9r": [2, 3, 4, 5, 8, 9], "sont": [2, 3, 4, 5, 8, 10, 11, 12], "list": [2, 3, 5, 6, 11], "pose": 2, "augment": [2, 4, 11], "dimens": [2, 5], "du": [2, 3, 4, 5, 11], "probl\u00e8m": [2, 12], "quell": [2, 5, 12], "devraient": 2, "\u00eatre": [2, 3, 5, 8, 10, 12], "dur\u00e9": [2, 4, 12], "d\u00e9taill\u00e9": 2, "pa": [2, 3, 4, 5, 11, 12], "fait": [2, 5, 8, 10, 11, 12], "mesur": [2, 5, 12], "fonction": [2, 3, 4, 8, 12], "r\u00e9sultat": [2, 3, 4, 5, 8, 10, 12], "serait": 2, "possibl": [2, 3, 8, 9, 10, 11, 12], "pr\u00e9voir": 2, "comport": 2, "programm": [2, 3, 8], "p": [2, 3, 5, 7, 8, 10, 11, 12], "sleep": [2, 3, 11], "2": [2, 3, 5, 7, 9, 10], "format": [2, 6, 11, 12], "entr\u00e9": [2, 4], "devin": 2, "plu": [2, 3, 4, 9, 10, 11, 12], "aussi": [2, 3, 8, 11], "tenir": 2, "quantit\u00e9": [2, 5, 12], "octet": [2, 9, 12], "servir": 2, "local": [2, 3, 6, 12], "rapid": [2, 4], "fichier": [2, 4, 5, 8, 9, 10], "traiter": [2, 4, 9, 11], "multipli": [2, 9], "moyenn": [2, 9], "traitement": [2, 4], "leur": [2, 3, 11, 12], "imag": [2, 12], "al\u00e9atoir": [2, 5], "nombreux": [2, 4, 12], "sou": [2, 10, 12], "explorateur": 2, "e": [2, 8], "dossier": [2, 4, 5, 10], "bouton": 2, "droit": 2, "souri": 2, "propri\u00e9t\u00e9": 2, "finder": 2, "info": 2, "autrement": [2, 11], "affichag": [2, 11], "graphic": 2, "environ": [2, 5], "provid": [2, 3], "similar": [2, 3], "tool": [2, 6], "depend": 2, "distribut": 2, "desktop": 2, "sb": 2, "directori": [2, 3, 4, 6], "sum": 2, "b": [2, 3, 5, 9], "appar": [2, 12], "byte": 2, "recurs": 2, "displai": 2, "import": [2, 4, 8, 9, 11, 12], "consid": 2, "transfer": [2, 6], "backup": [2, 12], "wc": [2, 4, 10], "count": 2, "subdirectori": 2, "avail": [2, 4, 6], "march": 2, "2019": 2, "june": 2, "2017": 2, "octob": 2, "2021": 2, "april": 2, "2018": 2, "citi": 2, "montr\u00e9al": 2, "burnabi": 2, "waterloo": 2, "toronto": 2, "provinc": 2, "qu\u00e9bec": [2, 6], "c": [2, 3, 4, 8, 9, 11, 12], "ontario": 2, "amd": 2, "intel": 2, "broadwel": 2, "avx2": 2, "724": 2, "32": [2, 5, 9], "983": 2, "skylak": 2, "avx512": 2, "802": 2, "40": 2, "640": 2, "48": [2, 5], "1548": 2, "cascad": 2, "lake": 2, "768": 2, "136": 2, "44": 2, "476": 2, "epyc": 2, "rome": 2, "1181": 2, "64": [2, 3, 9], "2400m": 2, "160": 2, "4000m": 2, "1408": 2, "903": 2, "1145": 2, "576": 2, "4400m": 2, "4800m": 2, "589": 2, "2024": 2, "96": [2, 5], "56": 2, "16000m": 2, "19200m": 2, "53": [2, 9], "32000m": 2, "36": 2, "48000m": 2, "96000m": 2, "model": 2, "mist": [2, 6], "power9": [2, 6], "p100": 2, "12g": 2, "456": 2, "320": 2, "16g": 2, "128": [2, 9], "t4": 2, "144": [2, 5], "v100": 2, "688": 2, "54": 2, "32g": 2, "16": [2, 3, 5, 7, 8, 9], "216": 2, "a100": 2, "40g": 2, "636": 2, "specif": [2, 4, 6], "fast": 2, "network": 2, "infiniband": 2, "omnipath": 2, "topologi": 2, "fat": 2, "tree": 2, "dragonfli": 2, "island": 2, "1200": 2, "1024": 2, "1536": 2, "3072": 2, "3584": 2, "17280": 2, "block": 2, "factor": 2, "max": [2, 8, 9], "5": [2, 3, 5, 8], "7": [2, 3, 9, 11, 12], "granular": 2, "dai": [2, 4], "28": 2, "all": [2, 3, 6], "describ": 2, "last": 2, "chapter": [2, 3], "param\u00e8tr": [2, 3, 5, 10], "ram": 2, "jj": 2, "h": [2, 4, 10], "m": [2, 3, 11], "outil": [2, 3, 10, 12], "autr": [2, 4, 10, 12], "biblioth\u00e8qu": [2, 9], "syst\u00e8m": [2, 4, 12], "exploit": 2, "vise": [2, 8], "signif": 2, "choix": 2, "d\u00e9pend": [2, 9, 11], "haut": 3, "consist": 3, "seulement": [3, 4, 10, 11, 12], "mai": [3, 4, 5, 9, 10, 11], "processu": [3, 10], "simultan\u00e9": 3, "donnera": 3, "g\u00e9rer": [3, 12], "grand": [3, 4, 11, 12], "projet": [3, 4, 12], "recherch": [3, 4, 11, 12], "requiert": 3, "centain": 3, "pleinement": 3, "g\u00e9rant": 3, "longu": [3, 4, 12], "peu": [3, 4, 10], "comm": [3, 4, 10], "\u00e9chell": [3, 9, 12], "officiel": 3, "tutoriel": 3, "ok": 3, "pourquoi": [3, 4], "ne": [3, 4, 10, 11, 12], "simplement": 3, "soumettr": [3, 4, 5], "moment": 3, "1000": [3, 4, 9], "pend": [3, 11], "certain": [3, 9, 11, 12], "tellement": 3, "court": [3, 10], "minut": [3, 4, 11], "d\u00e9marrag": [3, 5], "fin": [3, 4], "compterai": 3, "significatif": 3, "r\u00e9el": 3, "diminu": [3, 8], "avantag": 3, "nou": [3, 10, 12], "\u00e9vite": 3, "boucl": 3, "soumett": 3, "similair": 3, "bien": [3, 10, 11], "facilit": 3, "semblabl": 3, "dispon": [3, 4, 10, 11], "sp\u00e9cifier": [3, 11, 12], "reprendr": 3, "s\u00e9quenc": 3, "situat": 3, "h\u00e2tive": 3, "basic": 3, "element": 3, "command_templ": 3, "manual": 3, "man": 3, "default": [3, 4], "placehold": 3, "chang": 3, "echo": [3, 10], "txt": [3, 5, 10], "citat": 3, "commit": 3, "cite": 3, "develop": 3, "rewrit": 3, "expans": 3, "01": 3, "like": [3, 6], "In": 3, "text": 3, "param": 3, "specifi": 3, "separ": 3, "between": 3, "argument": [3, 5], "filenam": 3, "prll": 3, "exec": 3, "prefer": 3, "prior": 3, "comput": [3, 4, 6], "cmd": 3, "much": 3, "simplifi": [3, 5], "flag": 3, "done": 3, "alreadi": 3, "fasta": 3, "fa": [3, 7], "were": 3, "creat": [3, 4], "previou": 3, "fictiv": 3, "speci": [3, 7], "known": 3, "These": 3, "convert": [3, 7], "blast": [3, 7], "databas": [3, 7], "unknown": 3, "k": 3, "through": 3, "z": [3, 12], "want": 3, "o": [3, 5, 12], "r": [3, 11, 12], "t": [3, 11, 12], "v": 3, "w": [3, 12], "make": [3, 4, 7], "test": 3, "cpu": [3, 4, 5, 6, 11, 12], "core": 3, "res_prll": [3, 4], "At": 3, "end": 3, "check": [3, 4, 6], "glost": [3, 6], "meta": [3, 6], "farm": [3, 6], "meilleur": [3, 5], "alor": [3, 10, 11], "pr\u00e9c\u00e9dent": 3, "vraiment": [3, 12], "appropri\u00e9": 3, "long": [3, 6], "veut": 3, "\u00e9viter": [3, 4], "d\u00e9passent": 3, "troi": [3, 5, 9], "jour": [3, 4, 11, 12], "r\u00e9duir": [3, 10], "risqu": 3, "subir": 3, "d\u00e9faillanc": 3, "mat\u00e9riel": 3, "vecteur": 3, "o\u00f9": [3, 10, 12], "m\u00eame": [3, 4, 5, 10, 11, 12], "combinaison": [3, 5, 10], "moyen": 3, "coder": 3, "tell": 3, "sort": [3, 5, 6], "d\u00e9termin\u00e9": 3, "indic": 3, "uniqu": [3, 10], "soit": [3, 5], "ajout": [3, 12], "voir": [3, 4, 8, 10, 12], "contient": 3, "caract\u00e8r": [3, 9], "soulign": 3, "_": 3, "associ\u00e9": 3, "25249551_15": 3, "variabl": [3, 4, 10, 12], "environn": [3, 4], "slurm_array_task_id": 3, "actuel": 3, "agit": [3, 5], "entier": 3, "parmi": 3, "wai": 3, "below": 3, "export": [3, 4], "71": 3, "onli": 3, "param_r": 3, "integ": 3, "divis": [3, 8], "param_c": 3, "modulo": 3, "remaind": 3, "head": 3, "onc": 3, "out": 3, "res_arrai": 3, "modifi": [3, 12], "investig": [3, 6], "values1": 3, "values2": 3, "sep": 3, "param_pair": 3, "n_processes_per_nod": 3, "command_list": 3, "99": 3, "personnel": 4, "temporair": [4, 12], "r\u00e9seau": 4, "partag\u00e9": [4, 12], "aspect": 4, "gro": [4, 12], "tr\u00e8": [4, 10, 11, 12], "transf\u00e9rabilit\u00e9": 4, "regroup\u00e9": 4, "compress\u00e9": [4, 12], "vie": 4, "pendant": [4, 10, 12], "entr": [4, 11, 12], "niveau": [4, 12], "confidentiel": 4, "publi\u00e9": [4, 12], "principaux": 4, "gestion": 4, "show": [4, 6, 11], "from": [4, 6], "login": 4, "ye": 4, "No": 4, "cd": [4, 10, 12], "ld": [4, 12], "lor": [4, 12], "connexion": 4, "quota": [4, 6, 12], "relativ": 4, "accept": 4, "id\u00e9al": [4, 12], "logiciel": 4, "df": 4, "limit\u00e9": [4, 12], "faibl": [4, 11, 12], "latenc": 4, "compar\u00e9": 4, "lustr": [4, 6, 12], "band": [4, 12], "passant": [4, 12], "particuli": 4, "supprim\u00e9": 4, "si": [4, 11, 12], "travail": [4, 10], "son": [4, 8, 11], "propr": 4, "r\u00e9p\u00e9tition": [4, 12], "sauvegard": [4, 12], "constam": 4, "modifi\u00e9": 4, "ver": 4, "capacit\u00e9": 4, "sauvegard\u00e9": [4, 5], "purg": [4, 6], "mensuel": 4, "\u00e2g\u00e9e": 4, "60": 4, "selon": [4, 8, 10, 11], "ensembl": 4, "utilisateur": [4, 11], "stocker": 4, "interm\u00e9diair": 4, "trop": [4, 5], "sponsor00": [4, 12], "group": [4, 10, 11], "sauf": [4, 12], "simpl": [4, 9, 10, 11], "jusqu": [4, 9], "\u00e9lev\u00e9": [4, 11], "alloc": [4, 6, 11], "sp\u00e9cial": 4, "quotidienn": 4, "500k": [4, 12], "potentiel": [4, 12], "configur": [4, 12], "acl": 4, "important": [4, 12], "jeux": 4, "r\u00e9utilis\u00e9": 4, "moi": [4, 12], "personn": [4, 12], "finaux": 4, "co\u00fbteux": 4, "reproduir": [4, 12], "interfac": 4, "disqu": [4, 12], "ancienn": 4, "ruban": 4, "diagnostiqu": 4, "\u00e9tat": 4, "part": 4, "migrat": 4, "r\u00e9duit": [4, 11], "\u00e9conomi": 4, "argent": 4, "lectur": [4, 8, 12], "migr\u00e9": 4, "cr\u00e9era": 4, "requ\u00eat": 4, "bloquant": 4, "causant": 4, "r\u00e9pons": 4, "heur": 4, "archivag": 4, "surcharg\u00e9": 4, "voil\u00e0": 4, "imp\u00e9ratif": 4, "copier": 4, "regroup": 4, "proven": 4, "As": 4, "pass": [4, 11], "tend": 4, "accumul": [4, 12], "eventu": 4, "well": 4, "hi": 4, "diskusage_report": [4, 6], "insid": 4, "everi": 4, "stat": 4, "name": 4, "json": 4, "diskusage_explor": [4, 6], "summari": 4, "navig": 4, "sub": 4, "further": 4, "analysi": [4, 6], "inform": [4, 6, 10, 11], "good": 4, "easier": 4, "delet": 4, "\u00e9tape": 4, "t\u00e9l\u00e9chargement": 4, "semain": [4, 12], "nul": 4, "prot\u00e9ger": 4, "davantag": 4, "s\u00e9rie": 4, "partit": [4, 6], "fic": 4, "d\u00e9placer": 4, "pr\u00e9sent": [4, 12], "fournir": [4, 12], "nom": [4, 11, 12], "redirig": 4, "sorti": [4, 5], "rapatri": 4, "post": 4, "tou": [4, 5, 11, 12], "afin": [4, 5, 8], "garder": [4, 12], "essentiel": 4, "postprocess": 4, "both": 4, "tsv": 4, "professeur": 4, "soient": [4, 9], "contr": 4, "avoir": [4, 12], "consent": 4, "isol\u00e9": 4, "involontair": 4, "absenc": 4, "politiqu": [4, 12], "universit\u00e9": [4, 12], "permettra": 4, "planifi": 4, "d\u00e8": [4, 12], "optimis\u00e9": [4, 12], "mo": [4, 12], "mettr": 4, "r\u00e9pertoir": [4, 12], "item": 4, "transfert": [4, 12], "zip": [4, 12], "dar": [4, 6, 12], "etc": [4, 5, 8], "devrait": [4, 8, 12], "quoi": 4, "quand": [4, 10, 12], "aper\u00e7u": 4, "critiqu": [4, 12], "copi": [4, 12], "ailleur": 4, "version": 4, "cet": 5, "exercic": 5, "invers": 5, "matric": [5, 9], "py": 5, "suivr": 5, "\u00e9volut": 5, "30": 5, "second": [5, 10, 12], "temps_inv": 5, "panda": 5, "numpi": [5, 9], "pred": 5, "scipi": [5, 9], "stack": [5, 9], "\u00e9t\u00e9": 5, "maximal": 5, "effectu": [5, 10], "matriciel": 5, "home": [5, 6], "b5d": 5, "tirer": 5, "profit": 5, "niveaux": 5, "cach": 5, "d\u00e9couper": 5, "cube": [5, 9], "bloc": 5, "b1": 5, "b2": 5, "b3": 5, "prism": 5, "p1": 5, "p2": 5, "p3": 5, "donc": [5, 8, 9, 10, 12], "peuvent": [5, 9, 10], "fourni": 5, "omp": 5, "compil\u00e9": 5, "openmp": 5, "fonctionn": [5, 10], "ind\u00e9pendant": 5, "g\u00e9n\u00e9rer": 5, "extra": [5, 8], "scratch": [5, 6, 10, 12], "\u00e9ditez": 5, "demandez": 5, "slurm": [5, 6, 8, 10], "charger": 5, "apr\u00e8": 5, "construisez": 5, "srun": [5, 10], "compl\u00e9t\u00e9": [5, 10, 11], "devriez": 5, "optimal": 5, "2000m": 5, "appel\u00e9": 5, "auront": 5, "tester": [5, 10], "6": 5, "utilisez": 5, "d\u00e9tail": [5, 11], "derni\u00e8r": 5, "consomm\u00e9": 5, "sachant": 5, "nouveau": [5, 10, 11, 12], "lancement": 5, "successif": 5, "r\u00e9servez": 5, "suffisam": 5, "soumettez": 5, "v\u00e9rifiez": 5, "essayez": 5, "system": 6, "nation": 6, "compress": 6, "disk": [6, 12], "tape": [6, 12], "tar": [6, 12], "filesystem": 6, "polici": 6, "automat": 6, "frequent": 6, "ask": 6, "exceed": 6, "handl": 6, "collect": 6, "hierarch": 6, "hdf5": 6, "slurm_tmpdir": 6, "mid": 6, "term": 6, "rsync": 6, "host": 6, "linux": 6, "multifactor": 6, "authent": 6, "complet": 6, "debug": 6, "scalabl": 6, "restart": 6, "capabl": 6, "ccdb": [6, 11], "competit": 6, "feder": 6, "repositori": 6, "frdr": 6, "cloud": 6, "servic": 6, "sshare": [6, 11], "scontrol": [6, 11], "extern": 6, "link": 6, "window": 6, "maco": 6, "resid": 6, "size": [6, 12], "rss": 6, "law": 6, "apach": 6, "parquet": 6, "feather": 6, "offici": 6, "subsystem": 6, "wsl": 6, "editor": 6, "jupyterlab": 6, "jupyt": 6, "spyder": 6, "id": [6, 10, 12], "studio": 6, "train": 6, "workshop": 6, "tutori": 6, "webinar": 6, "upcom": 6, "carpentri": 6, "lesson": 6, "seqkit": 7, "know": 7, "species_": 7, "unknow": 7, "chr_": 7, "divid": 7, "db": 7, "species_a": 7, "queri": 7, "chr_m": 7, "out_a_m": 7, "suppos": 8, "suivant": [8, 11], "lanc\u00e9": 8, "proc": 8, "876": 8, "220": 8, "035": 8, "calc": 8, "acc": 8, "eff": 8, "minim": 8, "figur": 8, "section": 8, "via": [8, 10], "effici": 8, "voici": 8, "t_": 8, "fraction": 8, "op\u00e9rat": 8, "\u00e9critur": 8, "commun": 8, "synchronis": [8, 12], "mod\u00e8l": 8, "t_p": 8, "left": 8, "frac": 8, "right": 8, "l\u00e0": 8, "red\u00e9finir": 8, "isol": 8, "\u00e9ventuel": 8, "impli": 8, "impos": 8, "minimal": 8, "geq": 8, "leq": 8, "con\u00e7u": 8, "recevoir": 8, "redirig\u00e9": 8, "canal": 8, "stdin": 8, "blocag": 8, "n_max": 8, "61": 8, "donner": 8, "qu": [8, 10, 11, 12], "arrondir": 8, "baiss": 8, "car": [8, 12], "metriqu": 8, "970874": 8, "58333": 8, "n_max_enti": 8, "ayant": 9, "id\u00e9": [9, 11], "devient": [9, 11], "prendront": 9, "prend": [9, 10], "cepend": 9, "langu": 9, "encodag": 9, "utf": 9, "rendr": 9, "quatr": 9, "latin": 9, "germaniqu": 9, "session": 9, "sy": 9, "euro": 9, "getsizeof": 9, "49": 9, "76": 9, "78": 9, "sortir": 9, "prennent": [9, 12], "bit": 9, "plage": 9, "souhait\u00e9": 9, "65": 9, "mill": 9, "65535": 9, "32767": 9, "milliard": 9, "31": 9, "18": 9, "trillion": 9, "63": 9, "np": 9, "zero": 9, "dtype": 9, "int64": 9, "8000136": 9, "int32": 9, "4000136": 9, "iinfo": 9, "int16": 9, "min": 9, "32768": 9, "voit": 9, "apprentissag": 9, "n\u00e9anmoin": 9, "initial": 9, "doubl": 9, "pr\u00e9cision": 9, "r\u00e9solut": 9, "23": 9, "d\u00e9cimal": 9, "38": 9, "52": 9, "11": 9, "308": 9, "ndarrai": 9, "float32": 9, "pi": 9, "print": 9, "1415927": 9, "141592653589793": 9, "langag": 9, "syst\u00e9matiqu": 9, "compilateur": 9, "repr\u00e9sent\u00e9": 9, "complex": 9, "nb_matric": 9, "prod_mat": 9, "25000": 9, "carr\u00e9": 9, "octets_par_nombr": 9, "memoir": 9, "diff\u00e9renc": [10, 12], "ordonnanc": 10, "architectur": 10, "travailleur": 10, "envoi": 10, "signal": 10, "d\u00e9finir": 10, "list\u00e9": 10, "s\u00e9par\u00e9": 10, "op\u00e9rateur": 10, "bonjour": 10, "mond": 10, "g\u00e9n\u00e9rez": 10, "less": 10, "lancez": 10, "allez": 10, "nom_noeud": 10, "jobid": [10, 11], "no_tach": 10, "pty": 10, "listez": 10, "res_glost": 10, "puissant": 10, "reprend": 10, "z\u00e9ro": 10, "mode": 10, "impliqu": [10, 12], "restant": [10, 11], "consult": 10, "prochain": 10, "prendr": 10, "ell": [10, 11, 12], "atteint": 10, "sa": 10, "rest": [10, 11], "\u00e9chou\u00e9": 10, "relanc": 10, "cr\u00e9er": [10, 12], "farm_init": 10, "align": 10, "adxkr": 10, "dat": 10, "contenir": 10, "recycl\u00e9": 10, "cp": 10, "sed": 10, "_glost": 10, "_meta": 10, "g": [10, 12], "sera": [10, 11], "trait\u00e9": [10, 12], "individuel": 10, "single_cas": 10, "nano": 10, "mkdir": [10, 12], "donne": [10, 12], "aller": [10, 11], "bon": 10, "revenir": 10, "\u00e9tion": 10, "nos": [10, 11, 12], "dt_fail": 10, "config": 10, "appel": [10, 11], "job_script": 10, "commande1a": 10, "commande1b": 10, "fichier1": 10, "commande2a": 10, "commande2b": 10, "fichier2": 10, "glost_launch": 10, "liste_command": 10, "approfondir": 11, "remplisson": 11, "g\u00e9r\u00e9e": 11, "300": [11, 12], "r\u00e9p\u00e9ter": 11, "trier": 11, "priorit\u00e9": 11, "priorit": 11, "propo": [11, 12], "colonn": 11, "num\u00e9riqu": 11, "cr\u00e9e": 11, "charg": 11, "jamai": 11, "venait": 11, "watch": 11, "chose": 11, "savoir": 11, "g\u00e9n\u00e9ralement": [11, 12], "comp\u00e9tit": 11, "ainsi": [11, 12], "aucun": [11, 12], "impact": 11, "incluant": 11, "laquel": 11, "assign\u00e9": 11, "dd": 11, "comprendr": 11, "majoritair": 11, "r\u00e9cent": 11, "proport": 11, "concern": [11, 12], "prof1_cpu": 11, "prof1": 11, "grad2": 11, "postdoc3": 11, "levelf": 11, "consid\u00e9r\u00e9": 11, "normal": [11, 12], "autour": 11, "proch": 11, "bass": 11, "perd": 11, "progressiv": 11, "ratio": 11, "r\u00e9duisant": 11, "50": 11, "cons\u00e9quent": 11, "allou\u00e9": [11, 12], "j": 11, "jobnam": 11, "maxrss": 11, "encor": 11, "permett": [11, 12], "ajust": 11, "ultim": 11, "computecanada": 11, "me": 11, "group_usag": 11, "tenant": 11, "pass\u00e9": 11, "concour": 11, "lister": [11, 12], "possibilit\u00e9": 11, "direct": 11, "pr\u00e9cise": 11, "avon": 12, "vu": 12, "comment": 12, "gpf": 12, "dire": 12, "ko": 12, "\u00e9gale": 12, "difficil": 12, "point": 12, "vue": 12, "raisonn": 12, "3k": 12, "lourdeur": 12, "sentir": 12, "10k": 12, "classer": 12, "facil": 12, "1m": 12, "5m": 12, "24h": 12, "10m": 12, "fr\u00e9quent": 12, "m\u00e9tadonn\u00e9": 12, "pr\u00e9f\u00e9rabl": 12, "jeu": 12, "d\u00e9codabl": 12, "winzip": 12, "7z": 12, "gzip": 12, "d\u00e9monstrat": 12, "cr\u00e9ation": 12, "arch": 12, "tair": 12, "avertiss": 12, "\u00e9crasement": 12, "existant": 12, "d\u00e9coup": 12, "extens": 12, "png": 12, "exclur": 12, "voulon": 12, "lire": 12, "\u00e9crire": 12, "avantageux": 12, "d\u00e9compress": 12, "plut\u00f4t": 12, "montr": 12, "r\u00e9ellement": 12, "noter": 12, "surcharg": 12, "survol": 12, "r\u00e9cursif": 12, "constitu": 12, "pratiqu": 12, "offrent": 12, "efficac": 12, "restez": 12, "aff\u00fbt": 12, "dont": 12, "repr\u00e9sent": 12, "volum": 12, "virtuel": 12, "\u00e9conomis": 12, "serveur": 12, "h\u00f4te": 12, "lu": 12, "catastrophiqu": 12, "solut": 12, "encapsul": 12, "attent": 12, "manipul\u00e9": 12, "planif": 12, "poser": 12, "affair": 12, "persistant": 12, "pert": 12, "recalcul": 12, "oui": 12, "quel": 12, "fr\u00e9quenc": 12, "combien": 12, "s\u00e9pare": 12, "courant": 12, "tard": 12, "publier": 12, "d\u00e9p\u00f4t": 12, "urgenc": 12, "doivent": 12, "place": 12, "mal": 12, "d\u00e9crite": 12, "identif": 12, "compr\u00e9hens": 12, "public": 12, "devienn": 12, "laborieus": 12, "h\u00e9ritent": 12, "gitignor": 12, "ignor": 12, "readm": 12, "md": 12, "confidentialit\u00e9": 12, "h\u00e9berger": 12, "d\u00e9part": 12, "r\u00e9f\u00e9rez": 12, "san": 12, "pr\u00e9caution": 12, "laissez": 12, "risquent": 12, "membr": 12, "laboratoir": 12, "poursuiv": 12, "mettez": 12, "enlev": 12, "chmod": 12, "gid": 12, "chgrp": 12, "resultat": 12, "lr": 12, "permiss": 12, "r\u00e9cursiv": 12, "rx": 12, "visit": 12, "userxi": 12, "pwd": 12}, "objects": {}, "objtypes": {}, "objnames": {}, "titleterms": {"master": 0, "allianc": 0, "": 0, "comput": [0, 1, 2], "system": 0, "about": [0, 1], "thi": 0, "workshop": 0, "tabl": 0, "content": 0, "refer": [0, 6], "introduct": 1, "remind": 1, "high": 1, "perform": 1, "differ": [1, 4], "kind": 1, "task": [1, 3, 10], "data": [1, 2, 3, 4, 7], "parallel": [1, 3, 5, 10], "question": 1, "think": 1, "us": [2, 3], "resourc": 2, "wise": 2, "goal": 2, "write": 2, "proper": 2, "job": [2, 3], "script": 2, "slurm": [2, 3, 11], "analys": [2, 5, 8], "your": [2, 4], "In": [2, 4], "window": 2, "mac": 2, "o": 2, "linux": 2, "cluster": 2, "complet": 2, "run": [2, 4], "exercis": [2, 3, 4, 5], "check": 2, "demo": 2, "gpu": [2, 8], "test": 2, "crunch": 2, "py": 2, "One": [2, 3], "compar": [2, 8], "speed": 2, "cpu": [2, 8], "core": 2, "analysi": 2, "via": 2, "portal": 2, "estim": [2, 9], "requir": [2, 7], "target": 2, "effici": 2, "extrapol": [2, 8], "size": 2, "number": [2, 3], "file": [2, 12], "process": [2, 3], "comparison": 2, "kei": [2, 3, 4], "point": [2, 3, 4, 10, 11], "arrai": 3, "gnu": [3, 5, 10], "why": 3, "Not": 3, "command": 3, "syntax": 3, "case": [3, 4], "sequenc": [3, 7], "paramet": 3, "valu": 3, "multipl": 3, "combin": 3, "limit": 3, "simultan": 3, "align": 3, "dna": 3, "other": 3, "tool": 3, "storag": 4, "space": 4, "type": [4, 9], "home": 4, "person": 4, "slurm_tmpdir": 4, "temporari": 4, "local": 4, "scratch": 4, "network": 4, "project": 4, "share": 4, "nearlin": 4, "long": 4, "term": 4, "manag": 4, "life": 4, "cycl": 4, "activ": [4, 11, 12], "exampl": [4, 7], "small": [4, 10], "pipelin": 4, "inaccess": 4, "addit": 5, "complexit\u00e9": 5, "de": [5, 9, 10, 12], "l": [5, 11], "algorithm": 5, "instal": 5, "benchmark": 5, "5d": 5, "utilis": 5, "glost": [5, 10], "ressourc": [5, 8], "utilis\u00e9": 5, "probl\u00e8m": 5, "plu": 5, "grand": 5, "gener": 7, "modul": 7, "random": 7, "blastn": [7, 10], "d": [8, 11, 12], "acc\u00e9l\u00e9rat": 8, "la": 8, "vitess": 8, "v": 8, "exercic": [8, 10], "calcul": 8, "et": [8, 10, 11], "efficacit\u00e9": 8, "le": [8, 9, 10], "n\u00e9cessair": 8, "cibl": 8, "du": [8, 12], "parall\u00e8l": 8, "loi": 8, "amdahl": 8, "taill": [8, 12], "maximal": 8, "un": [8, 11, 12], "t\u00e2che": [8, 11], "besoin": 9, "en": [9, 11], "m\u00e9moir": 9, "vive": 9, "stockag": [9, 12], "selon": 9, "base": 9, "pour": 9, "text": 9, "nombr": [9, 12], "entier": 9, "\u00e0": [9, 10, 11], "virgul": 9, "flottant": 9, "greedi": 10, "launcher": 10, "Of": 10, "ou": 10, "list": 10, "ca": 10, "avec": 10, "meta": 10, "farm": 10, "meilleur": 10, "retenir": [10, 11], "ma\u00eetris": 11, "ordonnanceur": 11, "attent": 11, "partit": 11, "autr": 11, "sp\u00e9cific": 11, "politiqu": 11, "ordonnanc": 11, "termin\u00e9": 11, "notion": 12, "avanc\u00e9": 12, "caract\u00e9ristiqu": 12, "vo": 12, "donn\u00e9": 12, "transf\u00e9rabilit\u00e9": 12, "regroup": 12, "dan": 12, "fichier": 12, "archiv": 12, "compress": 12, "\u00e9par": 12, "spars": 12, "plan": 12, "gestion": 12, "vie": 12, "niveaux": 12, "acc\u00e8": 12, "exempl": 12, "partag": 12, "dossier": 12}, "envversion": {"sphinx.domains.c": 3, "sphinx.domains.changeset": 1, "sphinx.domains.citation": 1, "sphinx.domains.cpp": 9, "sphinx.domains.index": 1, "sphinx.domains.javascript": 3, "sphinx.domains.math": 2, "sphinx.domains.python": 4, "sphinx.domains.rst": 2, "sphinx.domains.std": 2, "sphinx.ext.intersphinx": 1, "sphinx": 60}, "alltitles": {"Mastering the Alliance\u2019s Compute Systems": [[0, "mastering-the-alliance-s-compute-systems"]], "About this workshop": [[0, "about-this-workshop"]], "Table of Contents": [[0, "table-of-contents"]], "References": [[0, "references"], [6, "references"]], "Introduction": [[1, "introduction"]], "Reminder - High Performance Computing": [[1, "reminder-high-performance-computing"]], "Different Kinds of Compute Tasks": [[1, "different-kinds-of-compute-tasks"]], "Data Parallelism": [[1, "data-parallelism"]], "Questions to Think About": [[1, "questions-to-think-about"]], "Use Resources Wisely": [[2, "use-resources-wisely"]], "Goal - Writing a Proper Job Script for Slurm": [[2, "goal-writing-a-proper-job-script-for-slurm"]], "Analysing Compute Jobs on Your Computer": [[2, "analysing-compute-jobs-on-your-computer"]], "In Windows": [[2, "in-windows"]], "In Mac OS": [[2, "in-mac-os"]], "In Linux": [[2, "in-linux"]], "Analysing Compute Jobs on Clusters": [[2, "analysing-compute-jobs-on-clusters"]], "Resources Used by a Completed Job": [[2, "resources-used-by-a-completed-job"]], "Resources Used by a Running Job": [[2, "resources-used-by-a-running-job"]], "Exercise - Checking Resources Used by a Running Job": [[2, "exercise-checking-resources-used-by-a-running-job"]], "(Demo) Checking Resources Used by a Running GPU Job": [[2, "demo-checking-resources-used-by-a-running-gpu-job"]], "Exercise - Testing crunch.py with One GPU": [[2, "exercise-testing-crunch-py-with-one-gpu"]], "Comparing the Speed of CPU Cores and a GPU": [[2, "comparing-the-speed-of-cpu-cores-and-a-gpu"]], "Jobs Analysis via Cluster Portals": [[2, "jobs-analysis-via-cluster-portals"]], "Estimating Required Compute Resources": [[2, "estimating-required-compute-resources"]], "Target Efficiency of a Job": [[2, "target-efficiency-of-a-job"]], "Exercise - Job Efficiency": [[2, "exercise-job-efficiency"]], "Extrapolating Required Compute Resources": [[2, "extrapolating-required-compute-resources"]], "Data Size and Number of Files to Process": [[2, "data-size-and-number-of-files-to-process"]], "Comparison of Compute Clusters": [[2, "comparison-of-compute-clusters"]], "Key Points": [[2, "key-points"], [3, "key-points"], [4, "key-points"]], "Task Arrays for Data Parallelism": [[3, "task-arrays-for-data-parallelism"]], "GNU Parallel": [[3, "gnu-parallel"]], "Why Not Slurm?": [[3, "why-not-slurm"]], "GNU Parallel Command Syntax": [[3, "gnu-parallel-command-syntax"]], "Use Cases": [[3, "use-cases"]], "One Sequence of Parameter Values": [[3, "one-sequence-of-parameter-values"]], "Multiple Combinations of Parameter Values": [[3, "multiple-combinations-of-parameter-values"]], "Limiting the Number of Simultaneous Processes": [[3, "limiting-the-number-of-simultaneous-processes"]], "Exercise - Aligning DNA Sequences": [[3, "exercise-aligning-dna-sequences"]], "Other Tools": [[3, "other-tools"]], "Job Arrays": [[3, "job-arrays"]], "Exercise - Job Arrays": [[3, "exercise-job-arrays"]], "Storage Spaces": [[4, "storage-spaces"]], "Different Types of Storage": [[4, "different-types-of-storage"]], "$HOME - Your Personal Space": [[4, "home-your-personal-space"]], "$SLURM_TMPDIR - Temporary Local Space": [[4, "slurm-tmpdir-temporary-local-space"]], "$SCRATCH - Temporary Network Space": [[4, "scratch-temporary-network-space"]], "/project - Shared Project Space": [[4, "project-shared-project-space"]], "/nearline - Long Term Storage": [[4, "nearline-long-term-storage"]], "Storage Management": [[4, "storage-management"]], "Life Cycle of Active Data": [[4, "life-cycle-of-active-data"]], "Example of the Life Cycle of Active Data": [[4, "example-of-the-life-cycle-of-active-data"]], "Exercise - Running a Small Pipeline": [[4, "exercise-running-a-small-pipeline"]], "In Case of Inaccessible Data": [[4, "in-case-of-inaccessible-data"]], "Additional Exercises": [[5, "additional-exercises"]], "Complexit\u00e9 de l\u2019algorithme": [[5, "complexite-de-l-algorithme"]], "Installation de Benchmark 5D": [[5, "installation-de-benchmark-5d"]], "Utiliser GLOST": [[5, "utiliser-glost"]], "Utiliser GNU Parallel": [[5, "utiliser-gnu-parallel"]], "Analyse des ressources utilis\u00e9es": [[5, "analyse-des-ressources-utilisees"]], "Probl\u00e8me plus grand": [[5, "probleme-plus-grand"]], "Generating the data": [[7, "generating-the-data"]], "Required modules": [[7, "required-modules"]], "Generating random sequences": [[7, "generating-random-sequences"]], "Blastn example": [[7, "blastn-example"]], "Analyse d\u2019acc\u00e9l\u00e9ration": [[8, "analyse-d-acceleration"]], "Comparer la vitesse CPU vs GPU": [[8, "comparer-la-vitesse-cpu-vs-gpu"]], "Exercice - Calcul d\u2019acc\u00e9l\u00e9ration et d\u2019efficacit\u00e9": [[8, "exercice-calcul-d-acceleration-et-d-efficacite"]], "Extrapoler les ressources n\u00e9cessaires": [[8, "extrapoler-les-ressources-necessaires"]], "Efficacit\u00e9 cible du calcul parall\u00e8le": [[8, "efficacite-cible-du-calcul-parallele"]], "Loi d\u2019Amdahl": [[8, "loi-d-amdahl"]], "Exercice - Taille maximale d\u2019une t\u00e2che parall\u00e8le": [[8, "exercice-taille-maximale-d-une-tache-parallele"]], "Estimation des besoins en m\u00e9moire-vive": [[9, "estimation-des-besoins-en-memoire-vive"]], "Stockage en m\u00e9moire selon les types de base": [[9, "stockage-en-memoire-selon-les-types-de-base"]], "Pour des textes": [[9, "pour-des-textes"]], "Pour des nombres entiers": [[9, "pour-des-nombres-entiers"]], "Pour des nombres \u00e0 virgule flottante": [[9, "pour-des-nombres-a-virgule-flottante"]], "Le Greedy Launcher Of Small Tasks, ou GLOST": [[10, "le-greedy-launcher-of-small-tasks-ou-glost"]], "Exercice - Liste de cas Blastn avec GLOST": [[10, "exercice-liste-de-cas-blastn-avec-glost"]], "META-Farm - Le meilleur de GNU Parallel et GLOST": [[10, "meta-farm-le-meilleur-de-gnu-parallel-et-glost"]], "Points \u00e0 retenir": [[10, "points-a-retenir"], [11, "points-a-retenir"]], "Ma\u00eetriser l\u2019ordonnanceur Slurm": [[11, "maitriser-l-ordonnanceur-slurm"]], "T\u00e2ches en attente": [[11, "taches-en-attente"]], "Partition et autres sp\u00e9cifications d\u2019une t\u00e2che": [[11, "partition-et-autres-specifications-d-une-tache"]], "Politique d\u2019ordonnancement": [[11, "politique-d-ordonnancement"]], "T\u00e2ches actives": [[11, "taches-actives"]], "T\u00e2ches termin\u00e9es": [[11, "taches-terminees"]], "Notions avanc\u00e9es du stockage": [[12, "notions-avancees-du-stockage"]], "Caract\u00e9ristiques de vos donn\u00e9es": [[12, "caracteristiques-de-vos-donnees"]], "Taille": [[12, "taille"]], "Nombre": [[12, "nombre"]], "Transf\u00e9rabilit\u00e9": [[12, "transferabilite"]], "Regroupement dans un fichier archive": [[12, "regroupement-dans-un-fichier-archive"]], "Compression des fichiers": [[12, "compression-des-fichiers"]], "Fichiers \u00e9pars (sparse files)": [[12, "fichiers-epars-sparse-files"]], "Plan de gestion des donn\u00e9es actives": [[12, "plan-de-gestion-des-donnees-actives"]], "Vie des donn\u00e9es": [[12, "vie-des-donnees"]], "Niveaux d\u2019acc\u00e8s": [[12, "niveaux-d-acces"]], "Exemple de partage de dossier:": [[12, "exemple-de-partage-de-dossier"]]}, "indexentries": {}}) \ No newline at end of file +Search.setIndex({"docnames": ["0-about", "1-introduction", "2-resources", "3-task-arrays", "4-storage", "90-exercises", "99-references", "data/README", "extra/acceleration", "extra/estimer-mem", "extra/glost-meta-farm", "extra/maitriser-slurm", "extra/stockage-avance"], "filenames": ["0-about.ipynb", "1-introduction.ipynb", "2-resources.ipynb", "3-task-arrays.ipynb", "4-storage.ipynb", "90-exercises.ipynb", "99-references.ipynb", "data/README.md", "extra/acceleration.ipynb", "extra/estimer-mem.ipynb", "extra/glost-meta-farm.ipynb", "extra/maitriser-slurm.ipynb", "extra/stockage-avance.ipynb"], "titles": ["Mastering the Alliance\u2019s Compute Systems", "Introduction", "Use Resources Wisely", "Task Arrays for Data Parallelism", "Storage Spaces", "Additional Exercises", "References", "Generating the data", "Analyse d\u2019acc\u00e9l\u00e9ration", "Estimation des besoins en m\u00e9moire-vive", "Le Greedy Launcher Of Small Tasks, ou GLOST", "Ma\u00eetriser l\u2019ordonnanceur Slurm", "Notions avanc\u00e9es du stockage"], "terms": {"intermedi": 0, "level": 0, "i": [0, 1, 2, 3, 4, 10, 11], "follow": [0, 2, 3, 4], "up": 0, "first": [0, 2], "step": [0, 2], "cluster": [0, 1, 6], "The": [0, 2, 3, 4], "main": [0, 2, 3], "goal": 0, "explor": [0, 2, 5, 8], "more": 0, "depth": 0, "some": [0, 1, 2], "kei": [0, 6], "concept": 0, "advanc": [0, 1], "research": [0, 2, 6], "note": [0, 2, 8, 12], "notebook": [0, 6], "script": [0, 3, 4, 5, 6, 8, 10, 11], "ar": [0, 1, 2, 3, 4], "publish": 0, "github": 0, "introduct": 0, "remind": [0, 2], "high": [0, 2], "perform": [0, 2, 3, 4, 5, 8], "differ": [0, 2], "kind": 0, "task": [0, 2, 6], "question": [0, 5, 6, 12], "think": 0, "us": [0, 1, 4, 6], "resourc": [0, 1, 3, 6], "wise": 0, "analys": [0, 11], "job": [0, 1, 4, 6, 11], "your": [0, 1, 6], "estim": [0, 1, 11], "requir": [0, 1, 3], "comparison": 0, "arrai": [0, 1, 6], "data": [0, 6], "parallel": [0, 2, 6, 12], "gnu": [0, 6], "storag": [0, 1, 2, 6], "space": [0, 1, 2, 6], "type": [0, 1, 2, 6, 10, 12], "manag": [0, 1, 2, 6], "see": [0, 2, 3], "page": [0, 2, 3, 8], "initi": 1, "problem": [1, 2], "when": [1, 2, 3], "we": [1, 2, 3], "need": [1, 2], "run": [1, 3, 6, 10, 11], "veri": 1, "larg": [1, 2, 3, 6, 12], "number": [1, 4], "calcul": [1, 2, 3, 4, 5, 6, 9, 10, 11, 12], "process": [1, 4], "dataset": 1, "becom": [1, 4], "necessari": [1, 2, 4], "becaus": 1, "share": [1, 6], "demand": [1, 4], "each": [1, 2, 3, 4], "submit": [1, 2, 3, 6, 10], "schedul": [1, 2, 6], "It": [1, 4], "execut": [1, 2, 3], "two": [1, 2], "categori": 1, "work": [1, 3], "same": [1, 3], "within": 1, "set": [1, 6], "serial": [1, 2], "have": [1, 2, 3, 4, 6], "vector": 1, "descript": [1, 4, 12], "oper": [1, 2], "appli": 1, "modern": 1, "processor": 1, "an": [1, 2], "acceler": [1, 2], "gpu": [1, 4, 5, 6, 11], "A": [1, 2, 3, 8, 9, 11], "lot": [1, 3], "independ": 1, "multipl": [1, 2, 5], "simultan": 1, "probabl": [1, 4], "Or": [1, 4, 8, 12], "split": 1, "chunk": [1, 7], "what": [1, 2], "do": 1, "you": [1, 2, 3, 4, 6], "perhap": 1, "small": [1, 2], "file": [1, 3, 4, 6, 7], "few": [1, 2], "which": [1, 2, 3, 4], "should": [1, 2, 3], "chosen": [1, 2], "quantiti": [1, 2], "request": [1, 2], "how": [1, 2], "plan": [1, 4], "usag": [1, 2, 3, 4], "activ": [1, 2, 6], "who": 1, "abl": [1, 2], "access": [1, 2, 4, 6, 12], "archiv": [1, 4, 6], "final": [1, 8], "optim": [1, 2], "monitor": [1, 2, 3, 4, 6], "profil": [1, 2, 6], "those": 1, "With": [2, 6], "digit": [2, 6], "allianc": [2, 6], "canada": [2, 6], "account": [2, 6], "mani": [2, 3], "b\u00e9luga": [2, 4, 6], "cedar": [2, 4, 6], "graham": [2, 4, 6], "narval": [2, 4, 6], "niagara": [2, 4, 6], "temporari": 2, "project": [2, 6], "nearlin": [2, 6], "while": 2, "being": 2, "still": 2, "limit": [2, 10, 11], "carefulli": 2, "everyon": 2, "order": [2, 3], "maximis": 2, "amount": 2, "produc": 2, "scientif": 2, "result": [2, 3], "themselv": 2, "other": [2, 6], "thi": [2, 3], "chapter": [2, 3], "teach": 2, "analyz": 2, "determin": 2, "eventu": [2, 4], "defin": 2, "typic": 2, "written": 2, "bash": [2, 3, 4, 5, 8, 10, 11], "command": [2, 4, 5, 6, 8, 10, 11, 12], "shebang": [2, 6], "line": 2, "For": [2, 3], "exampl": [2, 3], "bin": 2, "header": 2, "sbatch": [2, 3, 5, 6, 10, 11], "option": [2, 3], "": [2, 3, 4, 5, 6, 8, 10, 12], "These": [2, 3], "pars": 2, "submiss": 2, "time": [2, 4, 5, 7], "modul": [2, 5, 6, 9, 10], "load": [2, 5, 7, 9, 10], "befor": 2, "automat": [2, 6], "reserv": [2, 6], "mpi": [2, 10], "hello": 2, "sh": [2, 3, 4, 5, 8, 10, 11], "cat": [2, 3, 5, 8, 10, 11, 12], "ntask": 2, "10": [2, 3, 4, 7, 9, 10, 12], "mem": 2, "per": [2, 3, 4], "1000m": 2, "0": [2, 3, 5, 7, 8, 9, 10, 11], "00": 2, "gcc": [2, 5, 7], "9": [2, 7, 8], "3": [2, 3, 5, 7, 9], "dev": 2, "null": 2, "mpirun": 2, "printenv": 2, "hostnam": [2, 6], "ompi_comm_world_rank": 2, "ompi_comm_world_s": 2, "our": 2, "document": [2, 3, 6], "about": [2, 4, 6], "start": 2, "can": [2, 3], "metric": 2, "applic": [2, 8, 9], "memori": [2, 6, 8], "iop": 2, "bandwidth": 2, "find": [2, 3, 4], "wai": [2, 3], "look": 2, "menu": 2, "keyboard": 2, "shortcut": 2, "ctrl": [2, 8, 9], "alt": 2, "delet": [2, 4], "imag": [2, 12], "from": [2, 4, 6], "wikimedia": 2, "To": [2, 3, 4, 12], "open": 2, "util": [2, 8], "directori": [2, 3, 4, 6], "otherwis": 2, "letter": 2, "select": 2, "appl": 2, "support": 2, "termin": [2, 8, 10, 12], "top": [2, 6, 10], "press": [2, 3], "q": [2, 3, 10], "quit": [2, 3, 9], "htop": [2, 6], "As": [2, 4], "connect": [2, 6], "ssh": [2, 6, 10], "login1": [2, 4], "nation": [2, 6], "system": [2, 6], "product": 2, "better": 2, "pair": 2, "multifactor": [2, 6], "authent": [2, 6], "now": 2, "avail": [2, 4, 6], "introductori": 2, "video": 2, "here": 2, "default": [2, 3, 4], "least": 2, "one": [2, 3, 6], "def": [2, 4, 11, 12], "allow": [2, 3, 4], "blastn": [2, 3, 4], "gen": [2, 3, 5], "seq": [2, 3], "And": 2, "statu": [2, 3, 6], "squeue": [2, 3, 4, 5, 6, 10, 11], "u": [2, 3, 4, 5, 10, 11], "user": [2, 3, 4, 5, 10, 11], "sq": 2, "sacct": [2, 5, 6, 8, 11], "get": [2, 6], "detail": [2, 4], "tabl": [2, 4, 10], "sinc": 2, "midnight": 2, "seff": [2, 3, 5, 6, 8, 11], "short": [2, 4], "report": [2, 4], "singl": 2, "includ": 2, "elaps": [2, 11], "total": [2, 3, 8, 11, 12], "maximum": [2, 3, 4], "valu": 2, "given": 2, "percentag": [2, 6], "job_id": [2, 3], "3d": 2, "matrix": 2, "python": [2, 4, 5, 6, 7, 9], "interact": 2, "salloc": [2, 4], "4": [2, 3, 5, 8, 9, 10], "8000m": 2, "15": [2, 7], "1": [2, 3, 5, 8, 9, 10, 11, 12], "four": [2, 3, 7], "grep": 2, "sec": 2, "log": [2, 7], "exit": [2, 4, 10], "go": [2, 12], "back": 2, "If": [2, 3], "jupyterhub": [2, 6], "code": [2, 4, 5, 6], "visual": [2, 6], "real": 2, "machin": [2, 9, 12], "tab": 2, "dashboard": 2, "correspond": [2, 8], "node": [2, 3, 4, 6], "inv": [2, 5], "mat": [2, 5], "gener": [2, 4], "valid": [2, 3, 5], "identifi": [2, 3, 5, 11], "node_nam": 2, "100": [2, 8, 9, 12], "n": [2, 3, 5, 8, 10, 11, 12], "where": [2, 3], "doe": 2, "seem": 2, "fulli": 2, "inspect": [2, 3, 11], "time_inv": 2, "csv": [2, 5], "ani": 2, "caus": [2, 11], "correct": [2, 5], "compil": [2, 4], "paramet": 2, "resubmit": 2, "redo": 2, "abov": [2, 3], "gre": 2, "instal": [2, 4, 6], "proprietari": 2, "softwar": [2, 6], "pleas": 2, "manufactur": 2, "nvidia": [2, 6], "smi": [2, 6], "There": 2, "also": 2, "nvtop": [2, 6], "tg": 2, "1gpu": 2, "tail": [2, 3], "24": [2, 5], "l": [2, 3, 4, 8, 9, 10, 12], "its": 2, "algorithm": [2, 6, 8], "must": 2, "demonstr": 2, "good": [2, 4], "regular": 2, "definit": 2, "perceiv": 2, "acquisit": 2, "cost": 2, "five": 2, "5x": [2, 8], "8": [2, 3, 5, 7, 8, 9, 10], "16": [2, 3, 5, 7, 8, 9], "worth": 2, "5": [2, 3, 5, 8], "great": 2, "http": [2, 11], "portail": 2, "beluga": 2, "calculquebec": 2, "ca": [2, 3, 4, 5, 8, 11, 12], "90": [2, 8], "mai": [2, 3, 4, 5, 9, 10, 11], "adequ": 2, "reach": 2, "scalabl": [2, 6], "principl": 2, "amdahl": [2, 6], "law": [2, 6], "around": 2, "80": [2, 8], "wa": 2, "x": [2, 3, 8, 12], "mainli": 2, "id": [2, 6, 10, 12], "import": [2, 4, 8, 9, 11, 12], "list": [2, 3, 5, 6, 11], "increas": 2, "expect": 2, "make": [2, 3, 4, 7], "approxim": 2, "measur": 2, "function": 2, "By": 2, "predict": 2, "program": 2, "behavior": 2, "p": [2, 3, 5, 7, 8, 10, 11, 12], "sleep": [2, 3, 11], "2": [2, 3, 5, 7, 9, 10], "consider": 2, "shape": 2, "input": 2, "guess": 2, "On": [2, 4, 5, 8, 10], "take": 2, "byte": 2, "gb": 2, "local": [2, 3, 6, 12], "could": 2, "solut": [2, 12], "multipli": [2, 9], "averag": 2, "repetit": 2, "random": 2, "shorcut": 2, "e": [2, 8], "right": [2, 8], "click": 2, "properti": 2, "finder": 2, "info": 2, "graphic": 2, "environ": [2, 5], "provid": [2, 3], "similar": [2, 3], "tool": [2, 6], "depend": 2, "distribut": 2, "desktop": 2, "du": [2, 3, 4, 5, 11], "sb": 2, "sum": 2, "b": [2, 3, 5, 9], "appar": [2, 12], "recurs": 2, "displai": 2, "transfer": [2, 6], "backup": [2, 12], "wc": [2, 4, 10], "count": 2, "subdirectori": 2, "march": 2, "2019": 2, "june": 2, "2017": 2, "octob": 2, "2021": 2, "april": 2, "2018": 2, "citi": 2, "montr\u00e9al": 2, "burnabi": 2, "waterloo": 2, "toronto": 2, "provinc": 2, "qu\u00e9bec": [2, 6], "c": [2, 3, 4, 8, 9, 11, 12], "ontario": 2, "amd": 2, "intel": 2, "broadwel": 2, "avx2": 2, "724": 2, "32": [2, 5, 9], "983": 2, "skylak": 2, "avx512": 2, "802": 2, "40": 2, "640": 2, "48": [2, 5], "1548": 2, "cascad": 2, "lake": 2, "768": 2, "136": 2, "44": 2, "476": 2, "epyc": 2, "rome": 2, "1181": 2, "64": [2, 3, 9], "2400m": 2, "160": 2, "4000m": 2, "1408": 2, "903": 2, "1145": 2, "576": 2, "4400m": 2, "4800m": 2, "589": 2, "2024": 2, "96": [2, 5], "56": 2, "16000m": 2, "19200m": 2, "53": [2, 9], "32000m": 2, "36": 2, "48000m": 2, "96000m": 2, "model": 2, "mist": [2, 6], "power9": [2, 6], "p100": 2, "12g": 2, "456": 2, "320": 2, "16g": 2, "128": [2, 9], "t4": 2, "144": [2, 5], "v100": 2, "688": 2, "54": 2, "32g": 2, "216": 2, "a100": 2, "40g": 2, "636": 2, "specif": [2, 4, 6], "fast": 2, "network": 2, "infiniband": 2, "omnipath": 2, "topologi": 2, "fat": 2, "tree": 2, "dragonfli": 2, "island": 2, "1200": 2, "1024": 2, "1536": 2, "3072": 2, "3584": 2, "17280": 2, "block": 2, "factor": 2, "max": [2, 8, 9], "7": [2, 3, 9, 11, 12], "granular": 2, "dai": [2, 4], "28": 2, "all": [2, 3, 6], "describ": 2, "last": 2, "ram": 2, "dd": [2, 11], "h": [2, 4, 10], "m": [2, 3, 11], "librari": 2, "signific": 2, "choic": 2, "le": [3, 4, 5, 11, 12], "haut": 3, "consist": 3, "non": [3, 4, 8, 12], "seulement": [3, 4, 10, 11, 12], "au": [3, 8, 10, 11, 12], "parall\u00e8l": [3, 4, 10], "par": [3, 4, 5, 8, 9, 10, 11, 12], "t\u00e2che": [3, 4, 5, 10, 12], "parall\u00e9lism": [3, 8], "de": [3, 4, 8, 11], "aussi": [3, 8, 11], "donn\u00e9": [3, 4, 5, 8, 9, 11], "en": [3, 4, 5, 8, 10, 12], "dan": [3, 4, 5, 8, 9, 10, 11], "plusieur": [3, 4, 8, 10, 12], "et": [3, 4, 5, 9, 12], "ou": [3, 4, 8, 9, 11, 12], "processu": [3, 10], "simultan\u00e9": 3, "ce": [3, 4, 5, 8, 11, 12], "chapitr": [3, 4, 11, 12], "vou": [3, 5, 8, 11, 12], "donnera": 3, "outil": [3, 10, 12], "n\u00e9cessair": [3, 4, 12], "pour": [3, 4, 5, 8, 10, 11, 12], "g\u00e9rer": [3, 12], "un": [3, 4, 5, 9, 10], "grand": [3, 4, 11, 12], "nombr": [3, 4, 5, 8, 10, 11], "lorsqu": [3, 5, 8, 10, 11, 12], "projet": [3, 4, 12], "recherch": [3, 4, 11, 12], "requiert": 3, "centain": 3, "r\u00e9sultat": [3, 4, 5, 8, 10, 12], "la": [3, 4, 5, 9, 10, 11, 12], "permet": [3, 5, 10, 11], "d": [3, 4, 5, 9, 10], "utilis": [3, 4, 8, 9, 10, 11, 12], "pleinement": 3, "ressourc": [3, 11], "noeud": [3, 4, 5, 8, 10, 11, 12], "g\u00e9rant": 3, "ex\u00e9cut": [3, 4, 5, 8, 10], "longu": [3, 4, 12], "petit": [3, 4, 12], "taill": [3, 4, 5, 9], "est": [3, 4, 5, 8, 10, 11, 12], "peu": [3, 4, 10], "comm": [3, 4, 10], "ordonnanceur": [3, 5, 8], "\u00e0": [3, 4, 5, 8, 12], "plu": [3, 4, 9, 10, 11, 12], "\u00e9chell": [3, 9, 12], "lieu": [3, 12], "officiel": 3, "tutoriel": 3, "ok": 3, "pourquoi": [3, 4], "ne": [3, 4, 10, 11, 12], "pa": [3, 4, 5, 11, 12], "tout": [3, 4, 5, 8, 9, 10, 11, 12], "simplement": 3, "soumettr": [3, 4, 5], "moment": 3, "chaqu": [3, 4, 9, 10, 11, 12], "1000": [3, 4, 9], "pend": [3, 11], "certain": [3, 9, 11, 12], "sont": [3, 4, 5, 8, 10, 11, 12], "tellement": 3, "court": [3, 10], "minut": [3, 4, 11], "que": [3, 4, 5, 8, 9, 10, 12], "d\u00e9marrag": [3, 5], "fin": [3, 4], "compterai": 3, "pourcentag": [3, 5, 8], "significatif": 3, "temp": [3, 4, 5, 8, 10, 11, 12], "r\u00e9el": 3, "utilis\u00e9": [3, 4, 11, 12], "qui": [3, 4, 8, 10, 11, 12], "diminu": [3, 8], "leur": [3, 11, 12], "efficacit\u00e9": [3, 5], "avantag": 3, "consid\u00e9r": [3, 4, 5, 8, 9], "nou": [3, 10, 12], "\u00e9vite": 3, "boucl": 3, "soumett": 3, "similair": 3, "bien": [3, 10, 11], "facilit": 3, "semblabl": 3, "processeur": [3, 5, 8, 10, 11], "dispon": [3, 4, 10, 11], "automatiqu": [3, 12], "ex\u00e9cut\u00e9": 3, "possibl": [3, 8, 9, 10, 11, 12], "sp\u00e9cifier": [3, 11, 12], "peut": [3, 4, 8, 9, 10, 12], "reprendr": 3, "s\u00e9quenc": 3, "situat": 3, "h\u00e2tive": 3, "basic": 3, "element": 3, "command_templ": 3, "manual": 3, "man": 3, "placehold": 3, "chang": 3, "echo": [3, 10], "txt": [3, 5, 10], "citat": 3, "commit": 3, "cite": 3, "develop": 3, "rewrit": 3, "expans": 3, "01": 3, "like": [3, 6], "In": 3, "text": 3, "param": 3, "specifi": 3, "separ": 3, "between": 3, "argument": [3, 5], "filenam": 3, "prll": 3, "exec": 3, "prefer": 3, "prior": 3, "comput": [3, 4, 6], "cmd": 3, "much": 3, "simplifi": [3, 5], "flag": 3, "done": 3, "alreadi": 3, "fasta": 3, "fa": [3, 7], "were": 3, "creat": [3, 4], "previou": 3, "fictiv": 3, "speci": [3, 7], "known": 3, "convert": [3, 7], "blast": [3, 7], "databas": [3, 7], "unknown": 3, "k": 3, "through": 3, "z": [3, 12], "want": 3, "o": [3, 5, 12], "r": [3, 11, 12], "t": [3, 11, 12], "v": 3, "w": [3, 12], "y": [3, 4, 10, 12], "test": 3, "cpu": [3, 4, 5, 6, 11, 12], "core": 3, "res_prll": [3, 4], "At": 3, "end": 3, "check": [3, 4, 6], "glost": [3, 6], "s\u00e9quentiel": [3, 8, 10], "meta": [3, 6], "farm": [3, 6], "meilleur": [3, 5], "alor": [3, 10, 11], "pr\u00e9c\u00e9dent": 3, "avec": [3, 4, 5, 8, 9, 11, 12], "moin": [3, 8], "il": [3, 4, 5, 8, 9, 10, 11, 12], "vraiment": [3, 12], "appropri\u00e9": 3, "long": [3, 6], "veut": 3, "\u00e9viter": [3, 4], "d\u00e9passent": 3, "troi": [3, 5, 9], "jour": [3, 4, 11, 12], "r\u00e9duir": [3, 10], "risqu": 3, "subir": 3, "d\u00e9faillanc": 3, "mat\u00e9riel": 3, "vaut": [3, 4, 11, 12], "mieux": [3, 4, 11, 12], "vecteur": 3, "o\u00f9": [3, 10, 12], "m\u00eame": [3, 4, 5, 10, 11, 12], "programm": [3, 8], "doit": [3, 8, 10], "\u00eatre": [3, 5, 8, 10, 12], "diff\u00e9rent": [3, 4, 5, 9, 11, 12], "combinaison": [3, 5, 10], "param\u00e8tr": [3, 5, 10], "moyen": 3, "seul": [3, 5, 8, 10, 12], "coder": 3, "tell": 3, "sort": [3, 5, 6], "seront": [3, 4, 5], "d\u00e9termin\u00e9": 3, "fonction": [3, 4, 8, 12], "indic": 3, "uniqu": [3, 10], "soit": [3, 5], "lign": [3, 10], "ent\u00eat": 3, "ajout": [3, 12], "voir": [3, 4, 8, 10, 12], "ici": 3, "quelqu": [3, 4, 8, 10, 12], "exempl": [3, 8, 9, 10], "contient": 3, "caract\u00e8r": [3, 9], "soulign": 3, "_": 3, "associ\u00e9": 3, "25249551_15": 3, "variabl": [3, 4, 10, 12], "environn": [3, 4], "slurm_array_task_id": 3, "retrouv": 3, "valeur": [3, 5, 8, 9], "actuel": 3, "cour": [3, 10, 11], "agit": [3, 5], "entier": 3, "parmi": 3, "below": 3, "export": [3, 4], "71": 3, "onli": 3, "param_r": 3, "12": [3, 5, 7, 8], "integ": 3, "divis": [3, 8], "param_c": 3, "modulo": 3, "remaind": 3, "head": 3, "onc": 3, "out": 3, "res_arrai": 3, "modifi": [3, 12], "investig": [3, 6], "values1": 3, "values2": 3, "sep": 3, "param_pair": 3, "n_processes_per_nod": 3, "command_list": 3, "99": 3, "stockag": 4, "sur": [4, 8, 10, 11, 12], "grapp": [4, 8, 11, 12], "national": [4, 11], "personnel": 4, "temporair": [4, 12], "r\u00e9seau": 4, "partag\u00e9": [4, 12], "dur\u00e9": [4, 12], "vo": [4, 5, 11], "ont": [4, 10], "aspect": 4, "gro": [4, 12], "tr\u00e8": [4, 10, 11, 12], "fichier": [4, 5, 8, 9, 10], "nombreux": [4, 12], "transf\u00e9rabilit\u00e9": 4, "regroup\u00e9": 4, "compress\u00e9": [4, 12], "vie": 4, "pendant": [4, 10, 12], "entr": [4, 11, 12], "autr": [4, 10, 12], "niveau": [4, 12], "acc\u00e8": 4, "confidentiel": 4, "publi\u00e9": [4, 12], "principaux": 4, "gestion": 4, "espac": [4, 9, 12], "show": [4, 6, 11], "login": 4, "ye": 4, "No": 4, "cd": [4, 10, 12], "ld": [4, 12], "entr\u00e9": 4, "d\u00e9faut": 4, "lor": [4, 12], "connexion": 4, "quota": [4, 6, 12], "relativ": 4, "accept": 4, "id\u00e9al": [4, 12], "logiciel": 4, "df": 4, "rapid": 4, "limit\u00e9": [4, 12], "faibl": [4, 11, 12], "latenc": 4, "compar\u00e9": 4, "lustr": [4, 6, 12], "band": [4, 12], "passant": [4, 12], "particuli": 4, "supprim\u00e9": 4, "si": [4, 11, 12], "travail": [4, 10], "son": [4, 8, 11], "propr": 4, "dossier": [4, 5, 10], "r\u00e9p\u00e9tition": [4, 12], "sauvegard": [4, 12], "constam": 4, "modifi\u00e9": 4, "ver": 4, "capacit\u00e9": 4, "sauvegard\u00e9": [4, 5], "purg": [4, 6], "mensuel": 4, "\u00e2g\u00e9e": 4, "60": 4, "selon": [4, 8, 10, 11], "ensembl": 4, "utilisateur": [4, 11], "stocker": 4, "interm\u00e9diair": 4, "trop": [4, 5], "sponsor00": [4, 12], "group": [4, 10, 11], "sauf": [4, 12], "augment": [4, 11], "simpl": [4, 9, 10, 11], "jusqu": [4, 9], "\u00e9lev\u00e9": [4, 11], "alloc": [4, 6, 11], "sp\u00e9cial": 4, "quotidienn": 4, "500k": [4, 12], "potentiel": [4, 12], "configur": [4, 12], "acl": 4, "typiqu": [4, 9, 12], "important": [4, 12], "jeux": 4, "r\u00e9utilis\u00e9": 4, "moi": [4, 12], "personn": [4, 12], "finaux": 4, "co\u00fbteux": 4, "reproduir": [4, 12], "interfac": 4, "disqu": [4, 12], "ancienn": 4, "ruban": 4, "diagnostiqu": 4, "\u00e9tat": 4, "part": 4, "migrat": 4, "r\u00e9duit": [4, 11], "\u00e9conomi": 4, "argent": 4, "lectur": [4, 8, 12], "migr\u00e9": 4, "cr\u00e9era": 4, "requ\u00eat": 4, "bloquant": 4, "causant": 4, "r\u00e9pons": 4, "heur": 4, "syst\u00e8m": [4, 12], "archivag": 4, "surcharg\u00e9": 4, "voil\u00e0": 4, "imp\u00e9ratif": 4, "copier": 4, "avant": [4, 8, 12], "regroup": 4, "proven": 4, "pass": [4, 11], "tend": 4, "accumul": [4, 12], "well": 4, "hi": 4, "diskusage_report": [4, 6], "insid": 4, "everi": 4, "stat": 4, "name": 4, "json": 4, "diskusage_explor": [4, 6], "summari": 4, "navig": 4, "sub": 4, "further": 4, "analysi": [4, 6], "inform": [4, 6, 10, 11], "easier": 4, "\u00e9tape": 4, "t\u00e9l\u00e9chargement": 4, "semain": [4, 12], "nul": 4, "besoin": [4, 11], "prot\u00e9ger": 4, "davantag": 4, "s\u00e9rie": 4, "partit": [4, 6], "fic": 4, "traiter": [4, 9, 11], "se": [4, 5, 9, 10, 11, 12], "d\u00e9placer": 4, "pr\u00e9sent": [4, 12], "fournir": [4, 12], "nom": [4, 11, 12], "redirig": 4, "sorti": [4, 5], "rapatri": 4, "post": 4, "traitement": 4, "tou": [4, 5, 11, 12], "afin": [4, 5, 8], "garder": [4, 12], "essentiel": 4, "postprocess": 4, "both": 4, "tsv": 4, "professeur": 4, "soient": [4, 9], "contr": 4, "obtenir": [4, 5, 8, 11, 12], "aux": [4, 5, 12], "faut": [4, 8, 10, 11, 12], "avoir": [4, 12], "consent": 4, "isol\u00e9": 4, "involontair": 4, "absenc": 4, "politiqu": [4, 12], "universit\u00e9": [4, 12], "permettra": 4, "planifi": 4, "d\u00e8": [4, 12], "optimis\u00e9": [4, 12], "mo": [4, 12], "mettr": 4, "r\u00e9pertoir": [4, 12], "item": 4, "transfert": [4, 12], "zip": [4, 12], "dar": [4, 6, 12], "etc": [4, 5, 8], "devrait": [4, 8, 12], "quoi": 4, "quand": [4, 10, 12], "optimis": [4, 12], "aper\u00e7u": 4, "critiqu": [4, 12], "copi": [4, 12], "ailleur": 4, "gestionnair": [4, 10], "version": 4, "cet": 5, "exercic": 5, "invers": 5, "matric": [5, 9], "al\u00e9atoir": 5, "py": 5, "suivr": 5, "\u00e9volut": 5, "30": 5, "second": [5, 10, 12], "mesur": [5, 12], "temps_inv": 5, "panda": 5, "numpi": [5, 9], "pred": 5, "scipi": [5, 9], "stack": [5, 9], "quell": [5, 12], "\u00e9t\u00e9": 5, "consomm": [5, 8], "maximal": 5, "m\u00e9moir": [5, 8, 11], "vive": [5, 8], "effectu": [5, 10], "matriciel": 5, "quantit\u00e9": [5, 12], "ordr": [5, 8], "home": [5, 6], "b5d": 5, "tirer": 5, "profit": 5, "niveaux": 5, "cach": 5, "ordinateur": 5, "d\u00e9couper": 5, "cube": [5, 9], "bloc": 5, "b1": 5, "b2": 5, "b3": 5, "prism": 5, "p1": 5, "p2": 5, "p3": 5, "donc": [5, 8, 9, 10, 12], "requi": [5, 8], "dimens": 5, "peuvent": [5, 9, 10], "fourni": 5, "omp": 5, "compil\u00e9": 5, "openmp": 5, "rappel": [5, 8], "fonctionn": [5, 10], "ind\u00e9pendant": 5, "g\u00e9n\u00e9rer": 5, "cett": [5, 11, 12], "extra": [5, 8], "scratch": [5, 6, 10, 12], "\u00e9ditez": 5, "demandez": 5, "slurm": [5, 6, 8, 10], "fait": [5, 8, 10, 11, 12], "charger": 5, "apr\u00e8": 5, "construisez": 5, "srun": [5, 10], "foi": [5, 8, 11, 12], "compl\u00e9t\u00e9": [5, 10, 11], "pouvez": [5, 8, 11, 12], "devriez": 5, "pouvoir": 5, "optimal": 5, "vitess": 5, "2000m": 5, "appel\u00e9": 5, "auront": 5, "tester": [5, 10], "6": 5, "utilisez": 5, "d\u00e9tail": [5, 11], "derni\u00e8r": 5, "num\u00e9ro": [5, 8], "consomm\u00e9": 5, "sachant": 5, "nouveau": [5, 10, 11, 12], "lancement": 5, "successif": 5, "r\u00e9servez": 5, "suffisam": 5, "chacun": [5, 9], "soumettez": 5, "v\u00e9rifiez": 5, "erreur": 5, "essayez": 5, "compress": 6, "disk": [6, 12], "tape": [6, 12], "tar": [6, 12], "filesystem": 6, "polici": 6, "frequent": 6, "ask": 6, "exceed": 6, "handl": 6, "collect": 6, "hierarch": 6, "format": [6, 11, 12], "hdf5": 6, "slurm_tmpdir": 6, "mid": 6, "term": 6, "rsync": 6, "host": 6, "linux": 6, "complet": 6, "debug": 6, "restart": 6, "capabl": 6, "ccdb": [6, 11], "competit": 6, "feder": 6, "repositori": 6, "frdr": 6, "cloud": 6, "servic": 6, "sshare": [6, 11], "scontrol": [6, 11], "extern": 6, "link": 6, "window": 6, "maco": 6, "resid": 6, "size": [6, 12], "rss": 6, "apach": 6, "parquet": 6, "feather": 6, "offici": 6, "subsystem": 6, "wsl": 6, "editor": 6, "jupyterlab": 6, "jupyt": 6, "spyder": 6, "studio": 6, "train": 6, "workshop": 6, "tutori": 6, "webinar": 6, "upcom": 6, "carpentri": 6, "lesson": 6, "seqkit": 7, "know": 7, "species_": 7, "unknow": 7, "chr_": 7, "divid": 7, "db": 7, "species_a": 7, "queri": 7, "chr_m": 7, "out_a_m": 7, "massiv": 8, "abord": [8, 10], "puiss": 8, "d\u00e9montrer": 8, "bonn": 8, "d\u00e9finit": 8, "\u00e9coul\u00e9": [8, 11], "per\u00e7oit": 8, "co\u00fbt": [8, 12], "\u00e9tant": [8, 12], "cinq": 8, "sup\u00e9rieur": 8, "celui": 8, "r\u00e9gulier": 8, "permettr": 8, "huit": 8, "douz": 8, "acc\u00e9l\u00e9rateur": 8, "suppos": 8, "suivant": [8, 11], "lanc\u00e9": 8, "proc": 8, "876": 8, "220": 8, "035": 8, "calc": 8, "acc": 8, "eff": 8, "seuil": 8, "minim": 8, "exist": [8, 12], "maxim": 8, "respect": 8, "figur": 8, "section": 8, "vise": 8, "demand\u00e9": [8, 11], "via": [8, 10], "surtout": [8, 12], "effici": 8, "voici": 8, "t_": 8, "fraction": 8, "op\u00e9rat": 8, "\u00e9critur": 8, "commun": 8, "synchronis": [8, 12], "mod\u00e8l": 8, "t_p": 8, "left": 8, "frac": 8, "l\u00e0": 8, "red\u00e9finir": 8, "isol": 8, "\u00e9ventuel": 8, "impli": 8, "impos": 8, "minimal": 8, "geq": 8, "leq": 8, "con\u00e7u": 8, "recevoir": 8, "redirig\u00e9": 8, "canal": 8, "stdin": 8, "blocag": 8, "n_max": 8, "61": 8, "donner": 8, "qu": [8, 10, 11, 12], "arrondir": 8, "baiss": 8, "car": [8, 12], "metriqu": 8, "970874": 8, "58333": 8, "n_max_enti": 8, "ayant": 9, "id\u00e9": [9, 11], "devient": [9, 11], "prendront": 9, "prend": [9, 10], "deux": [9, 12], "octet": [9, 12], "moyenn": 9, "cepend": 9, "langu": 9, "encodag": 9, "utf": 9, "rendr": 9, "quatr": 9, "latin": 9, "germaniqu": 9, "session": 9, "sy": 9, "euro": 9, "getsizeof": 9, "49": 9, "76": 9, "78": 9, "sortir": 9, "prennent": [9, 12], "bit": 9, "d\u00e9pend": [9, 11], "plage": 9, "souhait\u00e9": 9, "65": 9, "mill": 9, "65535": 9, "32767": 9, "milliard": 9, "31": 9, "18": 9, "trillion": 9, "63": 9, "np": 9, "zero": 9, "dtype": 9, "int64": 9, "8000136": 9, "int32": 9, "4000136": 9, "iinfo": 9, "int16": 9, "min": 9, "32768": 9, "voit": 9, "apprentissag": 9, "n\u00e9anmoin": 9, "initial": 9, "doubl": 9, "pr\u00e9cision": 9, "r\u00e9solut": 9, "23": 9, "d\u00e9cimal": 9, "38": 9, "52": 9, "11": 9, "308": 9, "ndarrai": 9, "float32": 9, "pi": 9, "print": 9, "1415927": 9, "141592653589793": 9, "langag": 9, "syst\u00e9matiqu": 9, "compilateur": 9, "biblioth\u00e8qu": 9, "repr\u00e9sent\u00e9": 9, "complex": 9, "nb_matric": 9, "prod_mat": 9, "25000": 9, "carr\u00e9": 9, "octets_par_nombr": 9, "memoir": 9, "diff\u00e9renc": [10, 12], "ordonnanc": 10, "architectur": 10, "travailleur": 10, "envoi": 10, "signal": 10, "quitter": 10, "d\u00e9finir": 10, "list\u00e9": 10, "sou": [10, 12], "s\u00e9par\u00e9": 10, "op\u00e9rateur": 10, "bonjour": 10, "mond": 10, "g\u00e9n\u00e9rez": 10, "less": 10, "lancez": 10, "allez": 10, "nom_noeud": 10, "jobid": [10, 11], "no_tach": 10, "pty": 10, "listez": 10, "res_glost": 10, "puissant": 10, "reprend": 10, "z\u00e9ro": 10, "mode": 10, "impliqu": [10, 12], "restant": [10, 11], "consult": 10, "prochain": 10, "prendr": 10, "ell": [10, 11, 12], "atteint": 10, "sa": 10, "rest": [10, 11], "\u00e9chou\u00e9": 10, "relanc": 10, "cr\u00e9er": [10, 12], "farm_init": 10, "align": 10, "adxkr": 10, "dat": 10, "contenir": 10, "recycl\u00e9": 10, "cp": 10, "sed": 10, "_glost": 10, "_meta": 10, "g": [10, 12], "sera": [10, 11], "trait\u00e9": [10, 12], "individuel": 10, "single_cas": 10, "nano": 10, "mkdir": [10, 12], "donne": [10, 12], "aller": [10, 11], "bon": 10, "revenir": 10, "\u00e9tion": 10, "nos": [10, 11, 12], "dt_fail": 10, "config": 10, "appel": [10, 11], "job_script": 10, "soumiss": 10, "commande1a": 10, "commande1b": 10, "fichier1": 10, "commande2a": 10, "commande2b": 10, "fichier2": 10, "glost_launch": 10, "liste_command": 10, "approfondir": 11, "remplisson": 11, "g\u00e9r\u00e9e": 11, "300": [11, 12], "r\u00e9p\u00e9ter": 11, "affich": 11, "trier": 11, "priorit\u00e9": 11, "affichag": 11, "priorit": 11, "propo": [11, 12], "colonn": 11, "num\u00e9riqu": 11, "compt": 11, "cr\u00e9e": 11, "charg": 11, "jamai": 11, "venait": 11, "watch": 11, "chose": 11, "savoir": 11, "g\u00e9n\u00e9ralement": [11, 12], "comp\u00e9tit": 11, "ainsi": [11, 12], "aucun": [11, 12], "impact": 11, "votr": [11, 12], "incluant": 11, "laquel": 11, "assign\u00e9": 11, "comprendr": 11, "majoritair": 11, "r\u00e9cent": 11, "proport": 11, "concern": [11, 12], "prof1_cpu": 11, "prof1": 11, "grad2": 11, "postdoc3": 11, "levelf": 11, "consid\u00e9r\u00e9": 11, "normal": [11, 12], "autour": 11, "proch": 11, "bass": 11, "perd": 11, "progressiv": 11, "ratio": 11, "r\u00e9duisant": 11, "50": 11, "cons\u00e9quent": 11, "allou\u00e9": [11, 12], "autrement": 11, "j": 11, "jobnam": 11, "maxrss": 11, "encor": 11, "permett": [11, 12], "ajust": 11, "d\u00e9termin": 11, "ultim": 11, "computecanada": 11, "me": 11, "group_usag": 11, "tenant": 11, "pass\u00e9": 11, "concour": 11, "lister": [11, 12], "possibilit\u00e9": 11, "direct": 11, "pr\u00e9cise": 11, "avon": 12, "vu": 12, "comment": 12, "gpf": 12, "dire": 12, "ko": 12, "\u00e9gale": 12, "difficil": 12, "point": 12, "vue": 12, "raisonn": 12, "3k": 12, "lourdeur": 12, "sentir": 12, "10k": 12, "classer": 12, "facil": 12, "1m": 12, "5m": 12, "24h": 12, "10m": 12, "fr\u00e9quent": 12, "m\u00e9tadonn\u00e9": 12, "pr\u00e9f\u00e9rabl": 12, "jeu": 12, "fair": 12, "d\u00e9codabl": 12, "winzip": 12, "7z": 12, "gzip": 12, "d\u00e9monstrat": 12, "cr\u00e9ation": 12, "arch": 12, "tair": 12, "avertiss": 12, "\u00e9crasement": 12, "existant": 12, "d\u00e9coup": 12, "extens": 12, "png": 12, "exclur": 12, "voulon": 12, "lire": 12, "\u00e9crire": 12, "avantageux": 12, "d\u00e9compress": 12, "plut\u00f4t": 12, "montr": 12, "r\u00e9ellement": 12, "noter": 12, "surcharg": 12, "survol": 12, "r\u00e9cursif": 12, "constitu": 12, "pratiqu": 12, "offrent": 12, "efficac": 12, "restez": 12, "aff\u00fbt": 12, "dont": 12, "repr\u00e9sent": 12, "\u00e9crit": 12, "volum": 12, "virtuel": 12, "\u00e9conomis": 12, "serveur": 12, "h\u00f4te": 12, "probl\u00e8m": 12, "lu": 12, "catastrophiqu": 12, "encapsul": 12, "attent": 12, "manipul\u00e9": 12, "planif": 12, "poser": 12, "affair": 12, "persistant": 12, "pert": 12, "recalcul": 12, "oui": 12, "quel": 12, "fr\u00e9quenc": 12, "combien": 12, "s\u00e9pare": 12, "courant": 12, "tard": 12, "publier": 12, "d\u00e9p\u00f4t": 12, "urgenc": 12, "doivent": 12, "place": 12, "mal": 12, "d\u00e9crite": 12, "identif": 12, "compr\u00e9hens": 12, "public": 12, "devienn": 12, "laborieus": 12, "h\u00e9ritent": 12, "gitignor": 12, "ignor": 12, "readm": 12, "md": 12, "confidentialit\u00e9": 12, "h\u00e9berger": 12, "d\u00e9part": 12, "partir": 12, "r\u00e9f\u00e9rez": 12, "san": 12, "pr\u00e9caution": 12, "laissez": 12, "risquent": 12, "membr": 12, "laboratoir": 12, "poursuiv": 12, "mettez": 12, "enlev": 12, "chmod": 12, "gid": 12, "chgrp": 12, "resultat": 12, "lr": 12, "permiss": 12, "r\u00e9cursiv": 12, "rx": 12, "visit": 12, "userxi": 12, "pwd": 12}, "objects": {}, "objtypes": {}, "objnames": {}, "titleterms": {"master": 0, "allianc": 0, "": 0, "comput": [0, 1, 2], "system": 0, "about": [0, 1], "thi": 0, "workshop": 0, "tabl": 0, "content": 0, "refer": [0, 6], "introduct": 1, "remind": 1, "high": 1, "perform": 1, "differ": [1, 4], "kind": 1, "task": [1, 3, 10], "data": [1, 2, 3, 4, 7], "parallel": [1, 3, 5, 10], "question": 1, "think": 1, "us": [2, 3], "resourc": 2, "wise": 2, "goal": 2, "write": 2, "proper": 2, "job": [2, 3], "script": 2, "slurm": [2, 3, 11], "analys": [2, 5, 8], "your": [2, 4], "In": [2, 4], "window": 2, "maco": 2, "linux": 2, "cluster": 2, "complet": 2, "run": [2, 4], "exercis": [2, 3, 4, 5], "check": 2, "demo": 2, "gpu": [2, 8], "test": 2, "crunch": 2, "py": 2, "One": [2, 3], "compar": [2, 8], "speed": 2, "cpu": [2, 8], "core": 2, "analysi": 2, "via": 2, "portal": 2, "estim": [2, 9], "requir": [2, 7], "target": 2, "effici": 2, "extrapol": [2, 8], "size": 2, "number": [2, 3], "file": [2, 12], "process": [2, 3], "comparison": 2, "kei": [2, 3, 4], "point": [2, 3, 4, 10, 11], "arrai": 3, "gnu": [3, 5, 10], "why": 3, "Not": 3, "command": 3, "syntax": 3, "case": [3, 4], "sequenc": [3, 7], "paramet": 3, "valu": 3, "multipl": 3, "combin": 3, "limit": 3, "simultan": 3, "align": 3, "dna": 3, "other": 3, "tool": 3, "storag": 4, "space": 4, "type": [4, 9], "home": 4, "person": 4, "slurm_tmpdir": 4, "temporari": 4, "local": 4, "scratch": 4, "network": 4, "project": 4, "share": 4, "nearlin": 4, "long": 4, "term": 4, "manag": 4, "life": 4, "cycl": 4, "activ": [4, 11, 12], "exampl": [4, 7], "small": [4, 10], "pipelin": 4, "inaccess": 4, "addit": 5, "complexit\u00e9": 5, "de": [5, 9, 10, 12], "l": [5, 11], "algorithm": 5, "instal": 5, "benchmark": 5, "5d": 5, "utilis": 5, "glost": [5, 10], "ressourc": [5, 8], "utilis\u00e9": 5, "probl\u00e8m": 5, "plu": 5, "grand": 5, "gener": 7, "modul": 7, "random": 7, "blastn": [7, 10], "d": [8, 11, 12], "acc\u00e9l\u00e9rat": 8, "la": 8, "vitess": 8, "v": 8, "exercic": [8, 10], "calcul": 8, "et": [8, 10, 11], "efficacit\u00e9": 8, "le": [8, 9, 10], "n\u00e9cessair": 8, "cibl": 8, "du": [8, 12], "parall\u00e8l": 8, "loi": 8, "amdahl": 8, "taill": [8, 12], "maximal": 8, "un": [8, 11, 12], "t\u00e2che": [8, 11], "besoin": 9, "en": [9, 11], "m\u00e9moir": 9, "vive": 9, "stockag": [9, 12], "selon": 9, "base": 9, "pour": 9, "text": 9, "nombr": [9, 12], "entier": 9, "\u00e0": [9, 10, 11], "virgul": 9, "flottant": 9, "greedi": 10, "launcher": 10, "Of": 10, "ou": 10, "list": 10, "ca": 10, "avec": 10, "meta": 10, "farm": 10, "meilleur": 10, "retenir": [10, 11], "ma\u00eetris": 11, "ordonnanceur": 11, "attent": 11, "partit": 11, "autr": 11, "sp\u00e9cific": 11, "politiqu": 11, "ordonnanc": 11, "termin\u00e9": 11, "notion": 12, "avanc\u00e9": 12, "caract\u00e9ristiqu": 12, "vo": 12, "donn\u00e9": 12, "transf\u00e9rabilit\u00e9": 12, "regroup": 12, "dan": 12, "fichier": 12, "archiv": 12, "compress": 12, "\u00e9par": 12, "spars": 12, "plan": 12, "gestion": 12, "vie": 12, "niveaux": 12, "acc\u00e8": 12, "exempl": 12, "partag": 12, "dossier": 12}, "envversion": {"sphinx.domains.c": 3, "sphinx.domains.changeset": 1, "sphinx.domains.citation": 1, "sphinx.domains.cpp": 9, "sphinx.domains.index": 1, "sphinx.domains.javascript": 3, "sphinx.domains.math": 2, "sphinx.domains.python": 4, "sphinx.domains.rst": 2, "sphinx.domains.std": 2, "sphinx.ext.intersphinx": 1, "sphinx": 60}, "alltitles": {"Mastering the Alliance\u2019s Compute Systems": [[0, "mastering-the-alliance-s-compute-systems"]], "About this workshop": [[0, "about-this-workshop"]], "Table of Contents": [[0, "table-of-contents"]], "References": [[0, "references"], [6, "references"]], "Introduction": [[1, "introduction"]], "Reminder - High Performance Computing": [[1, "reminder-high-performance-computing"]], "Different Kinds of Compute Tasks": [[1, "different-kinds-of-compute-tasks"]], "Data Parallelism": [[1, "data-parallelism"]], "Questions to Think About": [[1, "questions-to-think-about"]], "Use Resources Wisely": [[2, "use-resources-wisely"]], "Goal - Writing a Proper Job Script for Slurm": [[2, "goal-writing-a-proper-job-script-for-slurm"]], "Analysing Compute Jobs on Your Computer": [[2, "analysing-compute-jobs-on-your-computer"]], "In Windows": [[2, "in-windows"]], "In macOS": [[2, "in-macos"]], "In Linux": [[2, "in-linux"]], "Analysing Compute Jobs on Clusters": [[2, "analysing-compute-jobs-on-clusters"]], "Resources Used by a Completed Job": [[2, "resources-used-by-a-completed-job"]], "Resources Used by a Running Job": [[2, "resources-used-by-a-running-job"]], "Exercise - Checking Resources Used by a Running Job": [[2, "exercise-checking-resources-used-by-a-running-job"]], "(Demo) Checking Resources Used by a Running GPU Job": [[2, "demo-checking-resources-used-by-a-running-gpu-job"]], "Exercise - Testing crunch.py with One GPU": [[2, "exercise-testing-crunch-py-with-one-gpu"]], "Comparing the Speed of CPU Cores and a GPU": [[2, "comparing-the-speed-of-cpu-cores-and-a-gpu"]], "Jobs Analysis via Cluster Portals": [[2, "jobs-analysis-via-cluster-portals"]], "Estimating Required Compute Resources": [[2, "estimating-required-compute-resources"]], "Target Efficiency of a Job": [[2, "target-efficiency-of-a-job"]], "Exercise - Job Efficiency": [[2, "exercise-job-efficiency"]], "Extrapolating Required Compute Resources": [[2, "extrapolating-required-compute-resources"]], "Data Size and Number of Files to Process": [[2, "data-size-and-number-of-files-to-process"]], "Comparison of Compute Clusters": [[2, "comparison-of-compute-clusters"]], "Key Points": [[2, "key-points"], [3, "key-points"], [4, "key-points"]], "Task Arrays for Data Parallelism": [[3, "task-arrays-for-data-parallelism"]], "GNU Parallel": [[3, "gnu-parallel"]], "Why Not Slurm?": [[3, "why-not-slurm"]], "GNU Parallel Command Syntax": [[3, "gnu-parallel-command-syntax"]], "Use Cases": [[3, "use-cases"]], "One Sequence of Parameter Values": [[3, "one-sequence-of-parameter-values"]], "Multiple Combinations of Parameter Values": [[3, "multiple-combinations-of-parameter-values"]], "Limiting the Number of Simultaneous Processes": [[3, "limiting-the-number-of-simultaneous-processes"]], "Exercise - Aligning DNA Sequences": [[3, "exercise-aligning-dna-sequences"]], "Other Tools": [[3, "other-tools"]], "Job Arrays": [[3, "job-arrays"]], "Exercise - Job Arrays": [[3, "exercise-job-arrays"]], "Storage Spaces": [[4, "storage-spaces"]], "Different Types of Storage": [[4, "different-types-of-storage"]], "$HOME - Your Personal Space": [[4, "home-your-personal-space"]], "$SLURM_TMPDIR - Temporary Local Space": [[4, "slurm-tmpdir-temporary-local-space"]], "$SCRATCH - Temporary Network Space": [[4, "scratch-temporary-network-space"]], "/project - Shared Project Space": [[4, "project-shared-project-space"]], "/nearline - Long Term Storage": [[4, "nearline-long-term-storage"]], "Storage Management": [[4, "storage-management"]], "Life Cycle of Active Data": [[4, "life-cycle-of-active-data"]], "Example of the Life Cycle of Active Data": [[4, "example-of-the-life-cycle-of-active-data"]], "Exercise - Running a Small Pipeline": [[4, "exercise-running-a-small-pipeline"]], "In Case of Inaccessible Data": [[4, "in-case-of-inaccessible-data"]], "Additional Exercises": [[5, "additional-exercises"]], "Complexit\u00e9 de l\u2019algorithme": [[5, "complexite-de-l-algorithme"]], "Installation de Benchmark 5D": [[5, "installation-de-benchmark-5d"]], "Utiliser GLOST": [[5, "utiliser-glost"]], "Utiliser GNU Parallel": [[5, "utiliser-gnu-parallel"]], "Analyse des ressources utilis\u00e9es": [[5, "analyse-des-ressources-utilisees"]], "Probl\u00e8me plus grand": [[5, "probleme-plus-grand"]], "Generating the data": [[7, "generating-the-data"]], "Required modules": [[7, "required-modules"]], "Generating random sequences": [[7, "generating-random-sequences"]], "Blastn example": [[7, "blastn-example"]], "Analyse d\u2019acc\u00e9l\u00e9ration": [[8, "analyse-d-acceleration"]], "Comparer la vitesse CPU vs GPU": [[8, "comparer-la-vitesse-cpu-vs-gpu"]], "Exercice - Calcul d\u2019acc\u00e9l\u00e9ration et d\u2019efficacit\u00e9": [[8, "exercice-calcul-d-acceleration-et-d-efficacite"]], "Extrapoler les ressources n\u00e9cessaires": [[8, "extrapoler-les-ressources-necessaires"]], "Efficacit\u00e9 cible du calcul parall\u00e8le": [[8, "efficacite-cible-du-calcul-parallele"]], "Loi d\u2019Amdahl": [[8, "loi-d-amdahl"]], "Exercice - Taille maximale d\u2019une t\u00e2che parall\u00e8le": [[8, "exercice-taille-maximale-d-une-tache-parallele"]], "Estimation des besoins en m\u00e9moire-vive": [[9, "estimation-des-besoins-en-memoire-vive"]], "Stockage en m\u00e9moire selon les types de base": [[9, "stockage-en-memoire-selon-les-types-de-base"]], "Pour des textes": [[9, "pour-des-textes"]], "Pour des nombres entiers": [[9, "pour-des-nombres-entiers"]], "Pour des nombres \u00e0 virgule flottante": [[9, "pour-des-nombres-a-virgule-flottante"]], "Le Greedy Launcher Of Small Tasks, ou GLOST": [[10, "le-greedy-launcher-of-small-tasks-ou-glost"]], "Exercice - Liste de cas Blastn avec GLOST": [[10, "exercice-liste-de-cas-blastn-avec-glost"]], "META-Farm - Le meilleur de GNU Parallel et GLOST": [[10, "meta-farm-le-meilleur-de-gnu-parallel-et-glost"]], "Points \u00e0 retenir": [[10, "points-a-retenir"], [11, "points-a-retenir"]], "Ma\u00eetriser l\u2019ordonnanceur Slurm": [[11, "maitriser-l-ordonnanceur-slurm"]], "T\u00e2ches en attente": [[11, "taches-en-attente"]], "Partition et autres sp\u00e9cifications d\u2019une t\u00e2che": [[11, "partition-et-autres-specifications-d-une-tache"]], "Politique d\u2019ordonnancement": [[11, "politique-d-ordonnancement"]], "T\u00e2ches actives": [[11, "taches-actives"]], "T\u00e2ches termin\u00e9es": [[11, "taches-terminees"]], "Notions avanc\u00e9es du stockage": [[12, "notions-avancees-du-stockage"]], "Caract\u00e9ristiques de vos donn\u00e9es": [[12, "caracteristiques-de-vos-donnees"]], "Taille": [[12, "taille"]], "Nombre": [[12, "nombre"]], "Transf\u00e9rabilit\u00e9": [[12, "transferabilite"]], "Regroupement dans un fichier archive": [[12, "regroupement-dans-un-fichier-archive"]], "Compression des fichiers": [[12, "compression-des-fichiers"]], "Fichiers \u00e9pars (sparse files)": [[12, "fichiers-epars-sparse-files"]], "Plan de gestion des donn\u00e9es actives": [[12, "plan-de-gestion-des-donnees-actives"]], "Vie des donn\u00e9es": [[12, "vie-des-donnees"]], "Niveaux d\u2019acc\u00e8s": [[12, "niveaux-d-acces"]], "Exemple de partage de dossier:": [[12, "exemple-de-partage-de-dossier"]]}, "indexentries": {}}) \ No newline at end of file
Jobs Analysis via Cluster Portals#
Target Efficiency of a Job#
-À coût d’essais et erreurs avec une tâche de petite taille,
-la cible pour :
+When testing with a short and small job, the target for:
-
-Rappel - vous pouvez obtenir ces pourcentages via les commandes
-sacct -X (surtout pour obtenir les numéros de tâches) et seff.
-Les valeurs à considérer sont :
+Reminder - you can get these percentages with the commands
+sacct -X (mainly to get job IDs) and seff.
+The important values are:
-
Exercise - Job Efficiency#
@@ -727,81 +735,75 @@ Exercise - Job Efficiency
Extrapolating Required Compute Resources#
-La question qui se pose :
-en augmentant la ou les dimensions du problème, quelles devraient
-être la durée du calcul et la consommation en mémoire-vive?
-Une analyse détaillée du code
-n’est pas nécessaire pour déterminer le type de calcul qui est fait :
+If you increase the size of the problem, what
+should be the expected compute time and memory usage?
+A detailed code analysis
+is not necessary to make that approximation:
-
time -p sleep 2
-
Data Size and Number of Files to Process#
-En plus du temps de calcul et de l’espace mémoire, il faut aussi
-considérer l’utilisation du stockage. Les valeurs à tenir compte :
+On top of the compute time and memory usage, you must also considerate
+the storage space usage. Values to take into account are:
-
-Pour obtenir le nombre de fichiers et la taille totale :
+To get the number of files and the total size:
-

-
-
@@ -1110,28 +1112,29 @@ Comparison of Compute Clusters
Key Points#
-
@@ -1203,7 +1206,7 @@ Key PointsGoal - Writing a Proper Job Script for Slurm
Target Efficiency of a Job#
-À coût d’essais et erreurs avec une tâche de petite taille, -la cible pour :
+When testing with a short and small job, the target for:
-
-
Rappel - vous pouvez obtenir ces pourcentages via les commandes
-sacct -X (surtout pour obtenir les numéros de tâches) et seff.
-Les valeurs à considérer sont :
Reminder - you can get these percentages with the commands
+sacct -X (mainly to get job IDs) and seff.
+The important values are:
-
-
Exercise - Job Efficiency#
@@ -727,81 +735,75 @@Exercise - Job Efficiency
Extrapolating Required Compute Resources#
-La question qui se pose :
-en augmentant la ou les dimensions du problème, quelles devraient
-être la durée du calcul et la consommation en mémoire-vive?
-Une analyse détaillée du code
-n’est pas nécessaire pour déterminer le type de calcul qui est fait :
+If you increase the size of the problem, what
+should be the expected compute time and memory usage?
+A detailed code analysis
+is not necessary to make that approximation:
-
time -p sleep 2
-
time -p sleep 2
Data Size and Number of Files to Process#
-En plus du temps de calcul et de l’espace mémoire, il faut aussi -considérer l’utilisation du stockage. Les valeurs à tenir compte :
+On top of the compute time and memory usage, you must also considerate +the storage space usage. Values to take into account are:
-
-
Pour obtenir le nombre de fichiers et la taille totale :
+To get the number of files and the total size:
-
-
-
-
-
-