- 有些註解的資訊應該放在別的地方而不是程式碼裡 比如說作者 最後修改日期等等
- 當註解變成過時或是不正確 就是個廢棄的註解 當你發現廢棄註解就趕快移除它
-
如果原本的程式碼已經夠清楚了 就不要再寫多餘的註解 比如說
i++;// increment i
或是
*/** * @param sellRequest * @return * @throws ManagedComponentException */*public SellResponse beginSellItem(SellRequest sellRequest) throws ManagedComponentException
-
註解就是要寫程式本身無法表達的資訊
- 不要說廢話 不要說些顯而易見的事 去確保這是你所能寫出的最好註解
- 當你看到你的程式碼裡面有段被註解掉的Code 你會真的不知道該怎麼處理 能刪嗎? 要留嗎? 因為沒人敢動 所以日復一日就讓你的程式越來越難維護
- 所以下次當你看到被註解掉的程式碼 把它刪掉就對了 你真的需要的話 version control會幫你找回來的
- 當你看到註解時 你可以先想想是不是可以Refactor,常常在你重構完之後你會發現註解完全不必要,因為程式碼簡潔到不需要註解
- 建立一個專案應該要是一個步驟的自動化行為 你不應該東找西找jar檔或是XML檔拼拼湊湊
- 你應該只需要一個步驟就可以跑完所有的測試,在最好的情況下只需要按IDE上的一個按鈕,在最糟的情況下只需要下一行簡單的指令,就可以跑完所有測試。
- 函式的參數不能太多 最好是不要有參數 要是有超過三個參數 那必要性是非常值得懷疑的
-
讀者通常預期參數是用來輸入的 而不是用來輸出結果的
比如說如果你看到
appendFooter(s);
ㄜ… 這是什麼意思 是把東西接在s之後 還是s會被接在某個東西之後呢 你必須被逼著看函式的宣告
public void appendFooter(StringBuffer report)
你就知道 ok 有東西要接在s後面 這種就是屬於輸出型參數 因為一般人都會直觀地認為 函式的參數就是一些input 直覺的不會再把input參數拿來繼續用
-
如果你想要改變物件的狀態 那就改成這樣
report.appendFooter();
-
Bool參數就是在說"該函式作了超過一件的任務",他們會造成困惑,應該被移除
-
例如
doSomething(boolean flag)
這種宣告就是很不好的習慣 你應該分成兩個函式 然後取個更好的函式名稱
- 那些不再被呼叫的函式就大膽的把它刪除 version control會幫你記得他們的
- 一個Source File就是一個語言 有超過一個語言就會讓人困惑
- 如果不得不使用多個語言,也應該要盡力將使用的語言數量減到最少
-
遵循"最少驚奇法則"(The Principle of Least Surprice),任何函式或類別應該要實現使用者預期該有的行為
-
比如一個將星期幾轉成enum的函式
Day day = DayDate.StringToDay(String dayName);
使用者可能會預期輸入 “Monday” 會回傳
Day.MONDAY,並且預期 “monday”, “MON”, “mon”, “MONDAY”等等都要回傳正確的值 如果你沒有全部實作的話 會失去大家對這個函式的信賴
- 為你的演算法在所有情況都寫好測試 不要依賴直覺
- 比如手動控管
[serialVersionUID](https://www.jyt0532.com/2017/10/12/decrypting-serialized-java-object/)或是把Compiler的警告關掉 都是很危險的事
- 本書最重要的規範之一 要非常認真看待
- 如果你看到相同的程式碼 代表在過去發生了該進行抽象而未進行抽象的情形
- 常見的情況如下
- 如果兩個函式有一樣的程式碼 就提取這些一樣的程式碼到新的函式 讓人家呼叫
- 如果兩個subclass有一樣的程式碼 那可以提取這些程式碼到parent class
- 那如果兩個subclass只是有類似的程式碼 比如說演算法有一點點差異呢? 使用 Template Method 或 Strategy Pattern
-
要建立能劃分 高層次的一般概念 和 低層次細節概念的抽象模型 我們想把高層次的概念都放在base class 低層次的概念都放在derived class
-
來看一個可愛的Stack抽象
public interface Stack { Object pop(); void push(Object o); double percentFull(); }
有沒有哪個函式看起來怪怪?
沒錯
percentFull因為不是所有的Stack都有 多滿 的概念 這種東西就應該放在比如
BoundedStack之類的衍生類別裡
- 限制類別和模組中曝露的介面數量 當一個類別擁有的方法數量越少就越好 當一個函式知道的變數越少就越好 當一個類別擁有的實體變數越少就越好
- 專心的在讓你的介面緊實簡短,限制公開資訊,保持低耦合
- 也就是不會被執行的程式碼
- 比如永遠不會跑到的if區 或是永遠不會拋出例外的catch區 這些區塊永遠不會跑到 但若一直放著 久了就會有臭味,因為他們不會隨著設計的變動而同步更動
- 將被遺棄的程式碼刪掉
- 變數和函式應該要定義在靠近使用的地方 比如說
- 區域變數應該要在第一次被使用的位置的正上方 垂直距離越短越好
- 私有函式應該要被定義在第一次被呼叫的地方的下面,而且距離不遠,讓人可以馬上找到
- 不論是命名還是其他事項 都應該遵從一樣的慣例
- 用不到的東西 不需要的東西 都全部拿掉
- 比如default constructor就可以直接拿掉
- 比如說把enum或是某個static變數宣告在某個類別裡 這樣會迫使enum的使用者必須了解整個類別
- 這種沒有直接目的將兩個模組之間加上了耦合,是一種懶惰且草率的作法,這是將變數, 常數, 函式放置在一個臨時方便但不恰當的地方所導致的結果
-
一個類別的方法 應該只對同一個類別的變數和函式感興趣 而不是對其他類別的感興趣
-
來看個例子
public class HourlyPayCalculator { public Money calculateWeeklyPay(HourlyEmployee e) { int tenthRate = e.getTenthRate().getPennies(); int tenthsWorked = e.getTenthsWorked(); int straightTime = Math.min(400, tenthsWorked); int overTime = Math.max(0, tenthsWorked - straightTime); int straightPay = straightTime * tenthRate; int overtimePay = (int)Math.round(overTime*tenthRate*1.5); return new Money(straightPay + overtimePay); } }
這明明就是在
HourlyPayCalculator裡面的函式 但卻一直去跟HourLyEmployee要資料 這可能就代表calculateWeeklyPay這個函式本身就該存在HourlyEmployee裡
- 如同F3(旗標參數),不過選擇性參數不一定bool,可以是enum, int, 或任何可以用來選擇函式行為的參數
- 這是避免將一個大函式拆解成許多小函式的偷懶作法,擁有較多小函式會比透過參數傳給大函式要好
- 我們需要程式可以盡可能地具有表達力,跨行的表達、匈牙利命名或魔術數字都會讓人困惑
public int m_otCalc() {
return iThsWkd * iThsRte +
(int) Math.round(0.5 * iThsRte *
Math.max(0, iThsWkd - 400)
);
}這什麼鬼 原本2秒可以看懂的程式變成要花10秒
- 軟體工程師能夠做的最重要決定之一 就是應該把程式碼放在哪
- 比如說
PI這個常數應該放在Math裡 還是Trigonometry裡 還是Circle裡?
- 比如說
- 有時候我們會用一點小聰明來把程式碼放在我們覺得方便使用的地方 但這並不是對讀者來說最直觀的地方
- 可透過函式的名稱決定函式要放在哪裡
-
我們喜歡把一些常用的函式當作靜態函式來用 比如
Math.max(double a, double b); -
這是很合理的 畢竟我們不想要每次需要比較的時候需要new一個物件
new Math().max(a, b)或是
a.max(b)這些都不太實用
-
但也不是所有東西都該宣告能靜態函數 比如說
HourlyPayCalculator.calculatePay(employee, overtimeRate)乍看之下合理,但是仔細想一下,我們應該很有可能會需要support這個函式的polymorphism(多型)
- 例如希望時薪實做不同的演算法,例如OvertimeHourlyPayCalculator和StraightTimeHourlyPayCalculator
-
總而言之,應該偏向使用非靜態函式,當你真的需要把它變成靜態的時候,先考慮你需不需要在未來支持多型
- 讓程式可讀性提昇最有效的方式之一,就是將計算過程拆解成許多富有意義名稱的暫存變數

- 如果你必須仔細看這個函式的實作 才知道它到底做了什麼 那你應該取個好點的名稱
- 你必須先瞭解你要實作的算法,再去寫實作的函式,只是通過你所想到的所有測試是不夠的
- 瞭解演算法最好的方法,就是重構,使之變得足夠簡潔且具說明性
- 模組相依在另一個模組上,就是實體相依
- 相依的模組不應該對被相依的模組有任何預先的假設(也就是邏輯相依),他應該要向被相依的模組清楚地詢問所需的所有訊息
- 當你在物件導向的語言看到switch可能可以用多型來取代
class Employee {
int payAmount() {
switch (getType()) {
case EmployeeType.ENGINEER:
return _monthlySalary;
case EmployeeType.SALESMAN:
return _monthlySalary + _commission;
case EmployeeType.MANAGER:
return _monthlySalary + _bonus;
default:
throw new RuntimeException("Incorrect Employee");
}
}
}- 當你看到這個,就可以用可愛的Strategy來替換
class Salesman{
int payAmount(Employee emp) {
return emp.getMonthlySalary() + emp.getCommission();
}
}
class Manager{
int payAmount(Employee emp) {
return emp.getMonthlySalary() + emp.getBonus();
}
}- 別忘了把base class的函式改成抽象函式
class EmployeeType{
abstract int payAmount(Employee emp)
}- 使用多型會比switch/case好,其中一個原因是多型會強迫工程師實做基底類別的所有抽象方法,然而沒有人會被強迫用相同的方式實作switch/case
- 比如用
SECOND_PER_DAY而不是86400
- 模稜兩可和不精確的程式碼,是由懶惰以及不一致所造成的,比如
- 單純用浮點數來代表貨幣利率(幾乎是犯罪行為)
- 因為不想處理同步問題所以不用lock或是transaction management
- 明明宣告List就夠了你卻硬要宣告為ArrayList來過度限制
- 讓所有變數都沒有access modifier(直接變成package protected)
- 當你在程式碼中下任何決定時 都要有充足的理由 不要得過且過
-
將條件判斷的意圖擷取出來
-
比如這個判斷
if (shouldBeDeleted(timer))就比這個清楚很多
if (timer.hasExpired() && !timer.isRecurrent())
-
否定的判斷比肯定的難了解
-
你自己來看看這兩個哪個需要讀懂的時間少一點
if (buffer.shouldCompact())if (!buffer.shouldNotCompact())
-
我們來看看付錢給員工的函式
public void pay() { for (Employee e : employees) { if (e.isPayday()) { Money pay = e.calculatePay(); e.deliverPay(pay); } } }
-
這個函式做了三件事 檢查所有員工 檢查哪些員工應該拿錢 給錢 那我們就應該分成三個函式寫
public void pay() { for (Employee e : employees) payIfNecessary(e); } private void payIfNecessary(Employee e) { if (e.isPayday()) calculateAndDeliverPay(e); } private void calculateAndDeliverPay(Employee e) { Money pay = e.calculatePay(); e.deliverPay(pay); }
-
不要為了讓函式簡單 而隱藏了函式之間的依賴關係
-
例子
public class MoogDiver{ Gradient gradient; List<Spline> splines; public void dive(String reason){ saturateGradient(); reticulataSplines(); diveForMoog(reason); } }
- 當我們
dive的時候 一定需要按照這三個順序saturateGradient→reticulataSplines→diveForMoog - 你程式這樣寫很合理,但這可能讓任何其他的函式用任何他想用的順序呼叫,你身為這段程式碼的擁有者無法保證被呼叫的順序
- 當我們
-
當你函式有時間順序需求的時候,可以這樣寫
public class MoogDiver{ Gradient gradient; List<Spline> splines; public void dive(String reason){ Gradient gradient = saturateGradient(); List<Spline> splines = reticulataSplines(gradient); diveForMoog(splines,reason); } }
這樣就會逼著一定要按照順序了
- 你的程式碼的每個地方的結構都要清楚且一致,當你只要某個地方不一致,看的人或改的人就不會覺得保持一致很重要,就會越改越亂
-
當你要處理邊界條件的時候 可能會有這種情況
if(level + 1 < tags.length) { parts = new Parse(body, tags, level + 1, offset + endTag); body = null; }
-
+1出現了兩次,可以透過另一個變數nextLevel封裝起來int nextLevel = level + 1; if(nextLevel < tags.length) { parts = new Parse(body, tags, nextLevel, offset + endTag); body = null; }
好看多了
-
在一個函式裡的statement 都應該屬於同一個層次的抽象,也就是這個函式本身的低一層
-
比如說一個兩級抽象深的函式 裡面的內容就只能是三級抽象深的表達式 當你要使用四級抽象深的表達式 你需要再呼叫一個函式
-
例子:如果
size > 0就把hr(水平線)多一個size attributepublic String render() throws Exception { StringBuffer html = new StringBuffer("<hr"); if(size > 0) html.append(" size=\"").append(size + 1).append("\""); html.append(">"); return html.toString(); }
這個函式混雜了至少兩種以上的抽象層次
- 一種是水平線的粗細概念
- 一種是水平線的syntax概念
希望看到這裡的你,已經在心中有些sense這兩個概念不該是同一層的
-
重構例子
public String render() throws Exception { HtmlTag hr = new HtmlTag("hr"); if (size > 0) hr.addAttribute("size", hrSize(size)); return hr.html(); } private String hrSize(int height) { int hrSize = height + 1; return String.format("%d", hrSize); }
這個重構把水平線應該要多粗和如何畫粗水平線的概念分開,如果所有
render()裡面的表達式都是第n層深的抽象的話,那hrSize()裡面的表達式都是第n+1層抽象 -
劃分抽象程式概念,是進行函式重構時最重要的行為之一
如果你有一個常數,比如說有預設值或是設定值,是已知應該存在於高階抽象層次上,那就要擺在高階的抽象層次上,不要藏到低層次的函式裡
-
如果模組A跟模組B合作,且模組B跟模組C合作,我們不希望模組A了解模組C的資訊
-
比如說
a.getB().getC().doSomething()我們稱為Message Chain 這意味著物件之間的緊密耦合
-
這樣的話 如果你未來想在B跟C之間插入一個Q,你會難以進行架構上的變動,你必須找到所有的
a.getB().getC()改成a.getB().getQ().getC() -
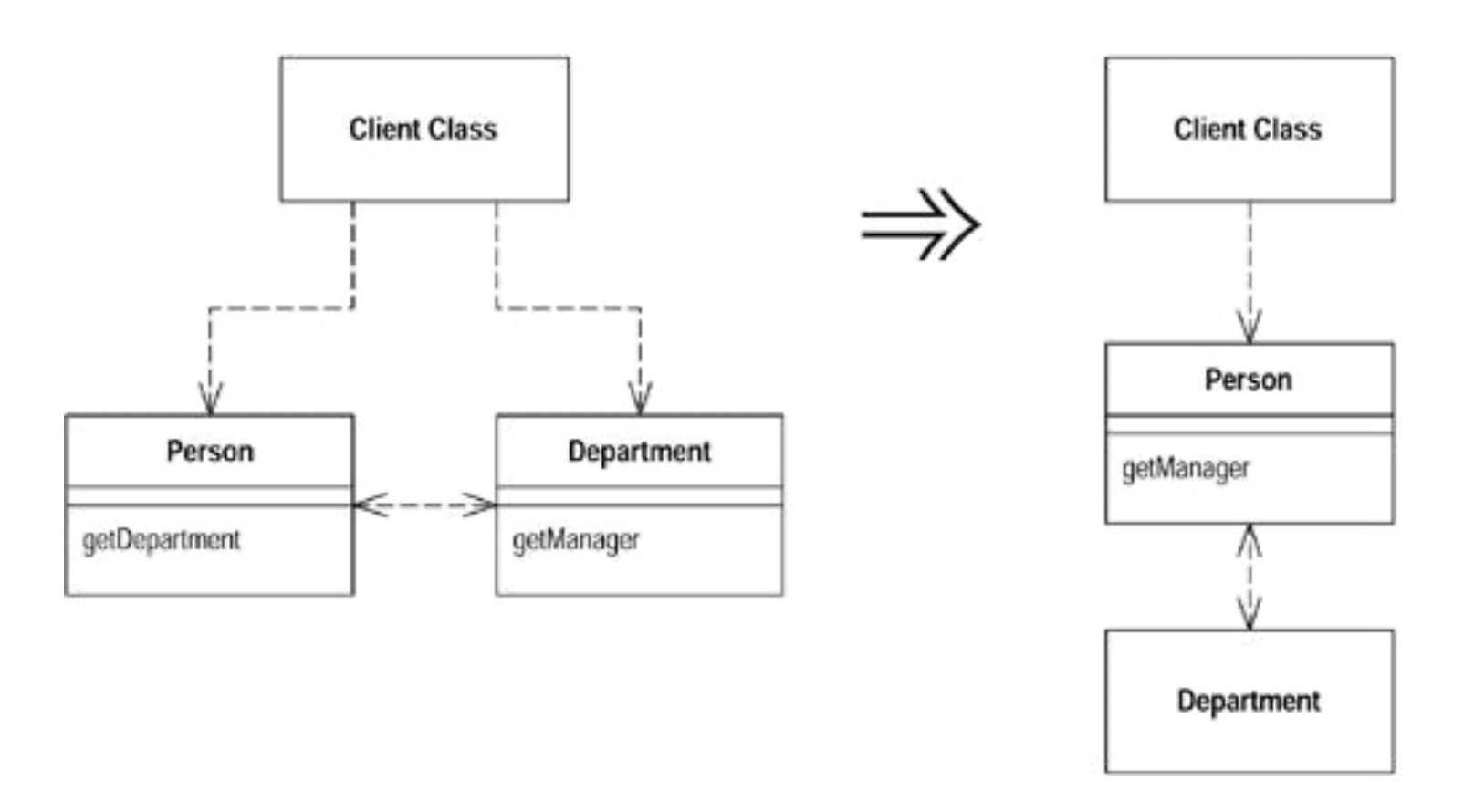
Hide Delegate
假設我們有個
Person和Departmentclass Person { Department _department; public Department getDepartment() { return _department; } public void setDepartment(Department arg) { _department = arg; } } class Department { private String _chargeCode; private Person _manager; public Department (Person manager) { _manager = manager; } public Person getManager() { return _manager; } }
這種情況下 你想知道一個人的老闆 只能
john.getDepartment().getManager()但這樣增加了
Person跟Department的耦合 畢竟Person根本就不CareDepartment那怎麼辦 就在Person裡面加一個Delegate method:
getManager()class Person { Department _department; public void setDepartment(Department arg) { _department = arg; } public Person getManager() { return _department.getManager(); } }
注意這時候我就可以拿掉
Person裡面的getDepartment()了
-
任何命名都不應該急著確定,要確保這個選定的名稱有足夠的描述性
-
命名因素在程式可讀性的比重有90%之高,需要花時間、有智慧地選擇名稱
-
例子:下面的程式碼簡直就是天書
public int x() { int q = 0; int z = 0; for (int kk = 0; kk < 10; kk++) { if (l[z] == 10) { q += 10 + (l[z + 1] + l[z + 2]); z += 1; } else if (l[z] + l[z + 1] == 10) { q += 10 + l[z + 2]; z += 2; } else { q += l[z] + l[z + 1]; z += 2; } } } return q; }
-
但要是稍微命名的好一點就很好理解
public int score() {
int score = 0;
int frame = 0;
for (int frameNumber = 0; frameNumber < 10; frameNumber++) {
if (isStrike(frame)) {
score += 10 + nextTwoBallsForStrike(frame); frame += 1;
} else if (isSpare(frame)) {
score += 10 + nextBallForSpare(frame); frame += 2;
} else {
score += twoBallsInFrame(frame); frame += 2;
}
}
return score;
}-
不要選擇透露實現訊息的名稱,而是反映類別或函式抽象層次的名稱
-
例子:數據機
public interface Modem { boolean dial(String phoneNumber);//撥接 boolean disconnect(); boolean send(char c); char recv(); String getConnectedPhoneNumber(); }
乍看之下合理,但仔細看並不是所有數據機都是用
dial,因為可能有些是用USB,有些是用cable,這個命名把實現的細節給透露出來了 -
改成connect比較符合這一層抽象的名稱
public interface Modem { boolean connect(String connectionLocator); boolean disconnect(); boolean send(char c); char recv(); String getConnectedLocator(); }
- 比如你寫的是一個裝飾器 就應該取Decorator 比如
AutoHangupModemDecorator - 如果要把物件變成字串,就用
toString這些都是大家一看就懂的,可以省很多時間去閱讀你的程式
-
例子
private String doRename() throws Exception { if(refactorReferences) renameReferences(); renamePage(); pathToRename.removeNameFromEnd(); pathToRename.addNameToEnd(newName); return PathParser.render(pathToRename); }
doRename是什麼意思?這個裡面的renamePage又是什麼意思?沒有人看得懂,但如果你取名為renamePageAndOptionallyAllReferences雖然比較長但一看就懂
-
名稱的長度和視野的範圍有關,比如說一段程式只有五行,那你用i或j就沒什麼問題,大家都知道這個馬上就不會再用了
-
比如以下的迴圈
private void rollMany(int n, int pins) { for (int i=0; i<n; i++) g.roll(pins); }
這程式就夠清楚了 不用取太有意義的名稱
- 型態的資訊或是scope的資訊不要拿來命名,比如
m_或是f_等等,或是針對專案的命名比如vis_(針對視覺化影像系統) 在當今的開發環境這些都多餘了,不要被匈牙利命名法污染
- 這段程式來自TestNG
public ObjectOutputStream getOos() throws IOException {
if (m_oos == null) {
m_oos = new ObjectOutputStream(m_socket.getOutputStream());
}
return m_oos;
}- 這個函式做的事比獲取一個m_oos還要多,因為要是m_oos是null,那就會生一個,所以應該取名為
createOrReturnOos因為getOos看起來就是個沒有副作用的函式
- 只要有任何的條件沒有被測試到 那就算測試不夠完整
- 更快更輕易的找到沒被測試到的 if 或是 catch
- 這些簡單測試文件的說明價值高於撰寫的成本
- 有時因為需求不明確使得我們無法確定某個行為細節,我們可以利用被註解掉的測試或是@Ignore 來表達我們的疑問
- 邊界條件要特別測試,我們很常遇到一般情況正常但是邊界情況異常的程式碼
- Bug都是喜歡擠在一起的,當你在某個函式發現了Bug,你就應該對這個函式寫詳盡的測試,你很可能會發現Bug不只你發現的那個
- 一個厲害的測試,你只要看到測試失敗的Pattern,你就知道哪裡寫錯了
- 比如說對於所有字串長度超過五的測試都錯,或是這個函式第二個參數是負數的測試都錯,你的測試寫得好的話,你可以藉由失敗的Pattern找出bug而不是仔細去看每一個單獨的錯誤