STM8S eForth Programming
Forth is a very simple but highly extensible programming language. It's possible to define what a Forth implementation can do "in Forth": self-reference is the most powerful feature of the language.
STM8 eForth runs on a target µC, and the main use case is embedded control with integrated interactive development and debugging. It has features like interactive programming and testing, multitasking, interrupt handlers, character I/O redirection, and more.
TG9541/STM8EF board support packages focus on ease of use. For getting started, a supported board (or just a bare µC), an inexpensive ST-LINK adapter, and a serial interface adapter are needed (please refer to STM8S Programming for more information).
This page provides a Forth walk-through. Recommendations for further reading are Starting Forth, which provides a friendly introduction to the programming language (most of the examples work with STM8EF), and Thinking Forth by Leo Brodie as a introduction to the Forth programming method.
The following pages provide in-depth and technical information on specific topics:
- STM8S eForth Compile to Flash: non-volatile Forth programs, and auto-start
- STM8S eForth Background Task: Forth tasks that run in the background
- STM8S eForth Interrupts: interrupt handlers in Forth
- STM8S eForth Alias Words: temporary dictionary entries for headerless words
STM8 eForth uses a terminal emulation program, and a standard serial interface for accessing the console. Please refer to the hardware section for details.
The Forth console can be used for interpreting and compiling code interactively. If you've familiar with using HP RPN calculators you already know how to write mathematical expressions: 3 7 + 5 * is equivalent to ( 3 + 7 ) * 5 = (no equals).
The Forth console (the interpreter) is written in Forth. The compiler is based on the interpreter, and, even on an STM8 with 8K Flash and 1K RAM, both can be extended interactively.
Forth is a stack based language: most of the data flow between sub-routines ("words") doesn't require variables or registers. The advantage that is that words be simply chained, and form a phrase.
Interactive code execution in Forth follows a simple pattern: put data on the stack, write the name of one or more Forth words (e.g. + and . for printing), and press enter:
10 -2 * .<enter> -20 ok
After typing 10 -2 * . pressing <enter> starts the evaluation. 10 and -2 are pushed to the stack, + pops both numbers, adds them and pushes the result, and . pops the result and prints it. After printing ok, the interpreter waits for new input (Read Evaluate Print Loop). A simple Forth like STM8EF is typeless, and all information on the stack is represented as 16bit numbers.
On the lowest level of Forth there are words for manipulating the data stack, e.g. DUP (duplicate), SWAP (swap the two elements), DROP (remove), ROT (rotate the top 3 elements). On a higher level there are words that manipulate data, text, or code. Please refer to Starting Forth for further reading.
6 7 -1 2 ok
* DUP . -2 ok
.S
6 7 -2 <sp ok
SWAP
.S
6 -2 7 <sp ok
The word .S is a debugging word: it prints (.) the contents of the Stack ("S").
It's important how many items a Forth interpreter loop takes from the data stack, and how much it pushes back. When there is an error (e.g. a word is unknown), the interpreter resets the stack. It will also tell you when there is a stack "underflow" after execution, which means that more items were consumed than what was initially on the stack (note: running DROP DROP DROP 0 0 0 on an empty stack will cause an underflow but it won't trigger an error).
STM8EF is a 16bit STC Forth, which means that data stack, return stack, a memory cell, and addresses are all 16 bit wide (some words use 8 or 32 bit data). In STC, compiled code is executable machine code.
Code units in Forth are called words. To list all Forth words available in a session (core, and user-defined) type WORDS on the Forth console. Also note that in the globalconf.inc of most boards the option CASEINSENSITIVE is set (i.e. words and WORDS means the same).
The STM8EF glossary docs/words.md (a list of Forth words in forth.asm) describes what words using a n extended data-flow notation:
; @ ( a -- n ) ( TOS STM8: -- Y,Z,N )
; Push memory location to stack
@ (read) gets address a from the stack, reads the 16bit cell at the 16bit address a and puts the value n on the stack (the Forth stack comment conventions are described here). The second part is meant for the assembly programmer: after execution of @ the register Y contains the TOS (top of stack) value . The Z (zero), and N (negative) flags correspond to n.
Depending on the board configuration in globalconf.inc only a subset of the words listed in words.md is linked (visible), or included in the binary release for a particular variant (board). The words declared in boardcore.inc are also missing from the list even if they're part of the dictionary.
Forth has a console which can be used for interpreting code, and for defining new words. A Forth programmer breaks the problem down into easily testable words (units of code), and then defines new words that contain "phrases" of already defined words.
Defining new words is simple: write : followed by the name of the new word, a sequence of already defined words, and ; at the end:
: by-2 ( w -- w ) \ multiply w by -2
-2 * ; ok
10 by-2 . -20 ok
The sequence :, identifier, code, and ; is called a "colon definition". The word : brings Forth into compilation state.
In Forth, there is next to no syntax checking (there isn't much syntax anyway). The there are few requirements for an identifier: it must consist of one or more printable characters (including numbers, punctuation marks, etc. Words can be redefined, but definitions based using the old word will continue to do so. There are words that can only be used during compilation (e.g. ; which ends a colon definition).
Of course there are structure words in Forth, e.g. IF and THEN. As Forth is a stack oriented language it does things a bit differently:
: test ( n -- ) \ demonstrate if else then
IF
." true"
ELSE
." false"
THEN ; ok
0 test false ok
5 test true ok
In Forth, code is also data, and the compiler simply transforms one stream of data (text) into another stream of data (code). Compiling "structure words" (IF, ELSE, THEN) relies on storing addresses for unresolved branch targets on the data stack, much like the data in-between arithmetics words in 2 3 4 + *.
In Forth there is no fundamental difference between compiler and interpreter. In fact, the role of the interpreter is similar to a C preprocessor:
: param ( -- n ) \ use the interpreter for calculating a parameter
[ -622 37 100 */ ] LITERAL ; \ store the result of the calculation
param . 230 ok
[ switches from the compilation to the interpreter state. The code until ] is executed, and the result is then pushed to the data stack. The immediate word LITERAL puts the result into the word param as a constant. Note that immediate words like [ and LITERAL can be defined by labeling a new word as IMMEDIATE after compilation (likewise a word can be labeled as "compile only" which means that they won't be executed in interpreter state, e.g. IF or THEN).
STM8EF starts in mode RAM, and new words are compiled to volatile memory. After switching to NVM mode, words are stored in (non volatile) Flash memory. Please refer to STM8S eForth Compile to Flash for more information.
STM8EF stores compiled code on the target but the µC doesn't contain enough memory for storage of source code. Hence it makes little sense to have a editor for Forth screens in it: the only source code storage in STM8EF is a 80 bytes line buffer, and backspace (^h) is the only editing feature.
Instead, source code should be stored on a host computer, and transferred to the µC line-by-line. This can be done using any of the following tools:
-
e4thcom using the STM8EF plugin (
#includeand#require, synchronization) -
codeload.py (
#includeand#require, synchronization) -
simload.sh using uCsim (
#includeand#require, synchronization, simulated STM8S) - ascii-xfr (flat files, no synchronization, last resort)
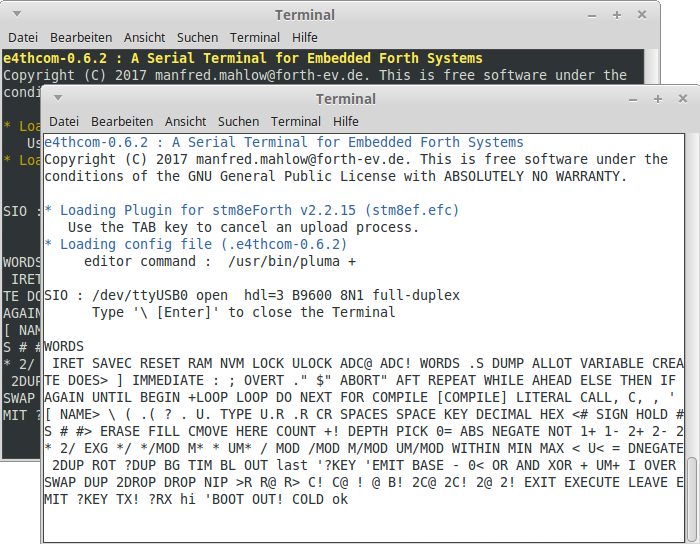
e4thcom is a terminal program for embedded Forth systems, e.g. noForth, AmForth, and Mecrisp with a line editor, a line history, and conditional/direct source upload. X86 Linux, and Raspberry Pi binaries are provided. The transfer method used in e4thcom is recommended as of release v2.2.15.
{kind=link}
From the Linux command line, e4thcom can be started in the following way:
e4thcom-0.6.2/e4thcom-0.6.2 -t stm8ef -d ttyUSB0
e4thcom starts in interactive mode, \ at the beginning of a line initiates the terminal control mode (\ alone closes e4thcom). #i and #r are short forms for #include and #require). These commands, followed by the name of a source file, bring the terminal into the non-interactive transfer mode.
In transfer mode, e4thcom looks in the source code for the following pseudo-words:
#include <filename> \ unconditional uploading
#require <filename> \ conditional uploading if there is no word like <filename> in the dictionary
\res MCU: STM8S103 \ load the STM8S103.efr symbol/address file
\res export PA_ODR \ get address for symbol PA_ODR, create `hex 5000 CONSTANT PA_ODR`
\\ ignore the rest of the file
Conditional uploading checks for a marker word equal to <filename> (e.g. math/double.fs), and uploads the file if the marker is not there. After successful upload it creates the marker as a dummy word. Source files can include other source files.
e4thcom has a build in search path for include files: the search is done in the order cwd:cwd/mcu:cwd/target:cwd/lib (cwd is the directory from which e4thcom was started).
The author suggests the following organization for source code:
- project-specific source code in
cwd - hardware-specific in
cwd/mcu - symlink to (or copy of) target specific words or aliases in
cwd/target - target-independent code in
cwd/lib.
TG9541/STM8EF the directories lib and mcu which are also included in the binary release. Please refer to the documentation provided on the e4thcom page.
The code transfer command line tool codeload.py written in Python 2.7 emulates the features of e4thcom. It can be used with the same source files, search directories, and \res MCU: ... \res export directives.
thomas@w500:~/source/stm8s/stm8ef$ tools/codeload.py -h
usage: codeload.py [-h] [-p port] [-t tracefile] [-q]
{serial,telnet,dryrun} [files [files ...]]
positional arguments:
{serial,telnet,dryrun}
transfer method
files name of one or more files to transfer
optional arguments:
-h, --help show this help message and exit
-p port, --port port PORT for transfer, default: /dev/ttyUSB0,
localhost:10000
-t tracefile, --trace tracefile
write source code (with includes) to tracefile
-q, --quiet don't print status messages to stdout
codeload.py is intended to be platform independent. However, up to bbf69e1 it has only be tested on Linux x86-64. Please file an issue if you have new test results, e.g. on MAC or Windows (positive or negative).
STM8EF can be configured to support a FILE mode, which basically replaces the OK prompt by a "pace character" (ASCII VT - a serial ASCII transfer program can use this to synchronize with the compilation progress). After the transfer, the word HAND can be used to switch back to interactive mode.
The general pattern is this:
FILE
( lines
with instructions
here )
HAND
@RigTig wrote a nifty little STM8EF Forth transfer tool in Python, which uses the pace character for synchronization.
The following picocom wrapper works for full-duplex and wired-or half-duplex with implicit echo (e.g. W1209). It also sets a suitable line delay for programming Forth to NVM without handshake:
#!/bin/sh
# "$@" --imap lfcrlf --emap crcrlf --omap delbs \
exec picocom \
--send-cmd="ascii-xfr -s -c10 -l500" \
"$@" --imap igncr,lfcrlf --omap delbs \
/dev/ttyUSB0
The following section contains some simple idioms, patterns, and example programs. Board-W1209 contains some more examples for startup code with an interactive background task that uses W1209 I/O.
The following example defines a simple greeting word. It's also possible to initialize background tasks, or to run complex embedded control applications.
NVM
: mystart CR 3 FOR I . NEXT CR ." Hi!" CR ;
' mystart 'BOOT !
RAM
NVM switches to Flash mode. mystart is the word that's to be run as start-up code. ' (tick) retrieves its address of mystart, 'BOOT retrieves the address of the startup word pointer, and ! stores the address of our word to it. RAM changes to RAM mode and stores pointers permanently.
On reset or through cold start STM8EF now shows the following behavior:
COLD
3 2 1 0
Hi!
The original start-up behavior can be restored by running ' HI 'BOOT !, or using RESET, which not only makes STM8EF forget any vocabulary in Flash, but also resets the start-up code to HI.
The STM8S003F3 and STM8S103F3 both have 5 usable multiplexed ADC channels (AIN2 to AIN6). The words ADC! and ADC@ provide access to the STM8 ADC.
The following example shows how to read AIN3, which is an alternative function of PD2:
: conv ADC! ADC@ ;
3 conv . 771 ok
ADC! selects a channel for conversion, ADC@ starts the conversion and gets the result. The example declares the word conv to combine both actions. Please note that the conversion time of ADC@ is longer after selecting a different channel with ADC!.
Also note that AIN5 and AIN6 are an alternative function of the ports PD5 and PD6 which are also used for RS232 TxD and RxD. The phrase 6 ADC! switches PD6 to analog mode (AIN6) while detaching the UART (RxD). The eForth system will appear to be hanging (the phrase 6 ADC! ADC@ 0 ADC! . will show a 10bit analog read-out of the RxD level).
The STM8SEF board support provides the word OUT! for setting the binary state of up to 8 relays, LEDs or other digital output devices (new board support packages should extend provide a new mapping).
The following example blinks Relay 1 of a C0135 STM8S103 Relay Control Board, the relay of a W1209 thermostat or the status LED of a STM8S103F3P6 Breakout Board with a frequency of about 0.75 Hz ( 1/(128 * 5 msec) ):
: task TIM 128 AND IF 1 ELSE 0 THEN OUT! ;
' task BG !
Data output to 7S-LED displays is supported by vectored I/O. In background tasks the EMIT vector points to E7S by default, and using it is simple (see example code on the W1209 page).
Numeric output to multiple groups of 7S-LED displays (e.g. boards W1219 2 x 3 digits, or W1401 3 x 2 digits) is also simple:
-
CRmoves the output to the first "tab" group without changing the display contents - a
spacecharacter moves the output to the next 7S-LED group if it was not preceded by a move, and clears the current 7S-LED group digits
The following code displays different data (all scaled to a range of 0..99) on the 3x2 digit 7S-LED groups of the board W1401:
: timer TIM 655 / ;
: ain 5 ADC! ADC@ 100 1023 */ ;
: show timer . ain . BKEY . CR ;
' show bg !
The word show displays the values scaled to 0..99 from the BG timer, the sensor analog input, and the board key bitmap BKEY followed by a CR (new line). When the word show runs in the background, it displays the ticker on the left yellow 7S-LED group, ain on the middle red LEDs, and the board key bitmap on the right yellow group.
STM8EF is based on eForth, a Forth dialect that builds all higher level words out of a small set of primitives.
Loop structures like DO ( condition ) IF LEAVE THEN +LOOP are useful for things like dictionary search. The FOR .. NEXT loop, provided by eForth, runs "from start down-to 0".
However, in eForth a similar loop structure can be implemented with an "idiomatic" combination of FOR .. NEXT, WHILE, and ELSE .. THEN:
: myLoop
FOR
DUP I = NOT WHILE
I . \ limit not reached
NEXT
." end"
ELSE
." limit"
R> DROP \ remove the FOR loop counter
THEN
DROP \ drop limit
;
In this example, 5 10 myloop prints 10 9 8 5 6 limit, and 5 4 myloop prints 4 3 2 1 0 end.
WHILE puts a the address of its conditional branch target on the stack above the start address of FOR the for loop (which is used when compiling NEXT). ELSE then uses this address to make WHILE exit to the code block delimited by THEN.
However, DO .. LEAVE .. +LOOP is available in TG9541/STM8EF as an extension of the original eForth vocabulary.
If an existing word in is re-defined in eForth the old definition can be used in the new definition, e.g.:
16 32 64 .S
16 32 64 <sp ok
: .S BASE @ >R HEX .S R> BASE ! ; reDef .S ok
10 20 40 <sp ok
The downside is that it's difficult to define recursive functions: in eForth, linking the new word to the dictionary is delayed until ; is executed.
The following example shows how to do recursion in eForth:
: RECURSE last @ NAME> CALL, ; IMMEDIATE
From the execution of : on, the word last provides the address of the code field of the new word.
The fibonacci function demonstrates a recursive reference with f(n-1) and f(n-2).
#require RECURSE
: fibonacci DUP 2 < IF DROP 1 ELSE DUP 2 - RECURSE SWAP 1 - RECURSE + THEN ;
: fibnums FOR I fibonacci U. NEXT ;
15 fibnums 987 610 377 233 144 89 55 34 21 13 8 5 3 2 1 1 ok
On a STM8S, the 27199 calls of 23 fibonacci (the maximum for 16bit arithmetics) execute in about 2.6s from RAM, or 2.3s from Flash. While that's no big problem for the stack this is a very long time for most embedded applications.
On a µC with limited RAM, recursion should be used with care. However, for some algorithms, e.g. tree traversal recursion can be very useful:
#require RECURSE
\ binary tree (dictionary)
\ https://rosettacode.org/wiki/Tree_traversal#Forth
\ minor modifications for eForth
: node ( l r data -- node ) here >r , , , r> ;
: leaf ( data -- node ) 0 0 rot node ;
: >data ( node -- ) @ ;
: >right ( node -- ) 2+ @ ;
: >left ( node -- ) 2+ 2+ @ ;
: preorder ( xt tree -- )
dup 0= if 2drop exit then
2dup >data swap execute
2dup >left recurse
>right recurse ;
: inorder ( xt tree -- )
dup 0= if 2drop exit then
2dup >left recurse
2dup >data swap execute
>right recurse ;
: postorder ( xt tree -- )
dup 0= if 2drop exit then
2dup >left recurse
2dup >right recurse
>data swap execute ;
: max-depth ( tree -- n )
dup 0= if exit then
dup >left recurse
swap >right recurse max 1+ ;
\ Define this binary tree
\ 1
\ / \
\ / \
\ / \
\ 2 3
\ / \ /
\ 4 5 6
\ / / \
\ 7 8 9
variable tree
7 leaf 0 4 node
5 leaf 2 node
8 leaf 9 leaf 6 node
0 3 node 1 node tree !
\ run some examples with "." (print) as the node action
cr ' . tree @ preorder \ 1 2 4 7 5 3 6 8 9
cr ' . tree @ inorder \ 7 4 2 5 1 8 6 9 3
cr ' . tree @ postorder \ 7 4 5 2 8 9 6 3 1
cr tree @ max-depth . \ 4
Note that the example traversal code (e.g. preorder) accepts the address of an action word. Of course, most practical applications (e.g. binary search) require some changes but Forth makes very lightweight and powerful solutions possible. It also gives you an idea of the code density: the 32 lines of code above compile to 385 bytes, that's about 200 bytes per screen.
As an extension of eForth TG9541/STM8EF supports defining defining words with CREATE..DOES>. Defining words, like CREATE, VARIABLE, or :, can be compared to classes in an OOP language, like Java, with a single method besides the constructor.
As an example, the definition of the defining word CONSTANT:
: CONSTANT CREATE , DOES> @ ;
New constants can now be defined with in the following way:
10000 CONSTANT ONE
31415 CONSTANT PI
: circumference ( n -- C )
2* PI ONE */ ;
\ test
500 circ . 3141 ok
Here is a more complex example from Forth.com:
: star ( -- )
42 EMIT
;
: .row ( c -- )
CR 1 7 FOR
2DUP AND IF STAR ELSE SPACE THEN 2*
NEXT 2DROP
;
: SHAPE ( 8 times n -- )
CREATE 7 FOR C, NEXT
DOES> DUP 7 FOR DUP R@ + C@ .row NEXT DROP CR
;
AA AA FE FE 38 38 38 FE SHAPE castle
7F 46 16 1E 16 06 0F 00 SHAPE F