Sources: Kaggle, Github blog, Anaconda blog, Open Data Science, DataCamp, Shopdev, Simplilearn, Knowledgehut, Data Science Society, AI Business, DrivenData.
Python’s ecosystem and communities offer the most accessible and broad open source data science entry point. It makes up for lack of performance (which is debatable but a common complaint) with powerful packages that leverage C. It is widely used in science and enterprise. With syntax that is very close to written English, it is popular for its readability and simplicity and is very often used in IT books about Data Science and arguably has the largest and most active open source community and support system, despite the enduring popularity of R, Go, Scala, Julia or Matlab in niche application or specialized fields. Over the last 15 years or so, the quantitative finance community has largely moved from C++ to Python for these reasons, especially among smaller players, academic publication or open source use.
Some Python packages are so well established that they are de facto part of the “batteries included” scientific Python stack in most distributions. It is somewhat subjective to draw the line what is included in this definition. From our experience, NumPy, Pandas, Matplotlib, and Jupyter Notebooks are beyond doubt default data science packages and cannot be replaced wholesale by any other packages. Let’s take a quick look at their open source status, community and licenses.
-
NumPy is the package for numerical python in general and works much faster than pure Python because it has compiled C and C++ code under the hood, allowing large, multi-dimensional arrays, data vectorization and matrix algebra. Used by 2.2m on Github with 9.3k forks and 26.4k stars. Distributed under “a liberal BSD license”, NumPy is developed and maintained publicly on GitHub by a vibrant, responsive, and diverse community. In the context of Project Catalyst, larger datasets like Community Advisor / Reviewer scores across different funding amounts and categories could be presented as multidimensional and fit into machine learning or AI tools that take vectors or matrixes but not spreadsheets as inputs.
-
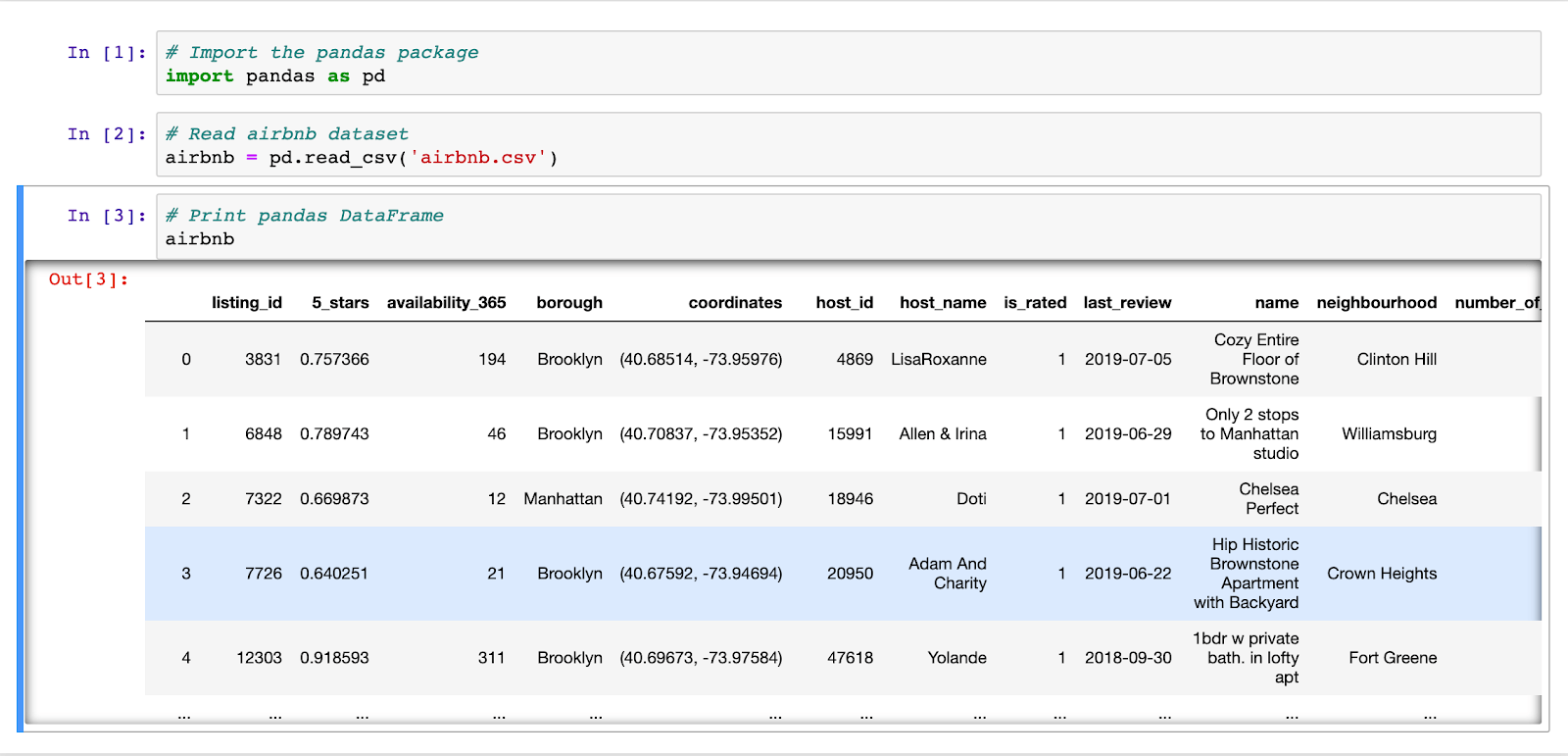
Pandas provides labeled data structures similar to R and spreadsheet - like data manipulation and statistical functions. This makes it ideal to import and export Excel-like tables. It began in 2008 inside quant hedge fund AQR Capital Management, by the end of 2009 it had been open sourced. Used by 1.6m on Github with 17.3k forks and 42k stars. Distributed under BSD-3-Clause license. Since 2015, pandas is a NumFOCUS sponsored project. This will help ensure the success of development of pandas as a “world-class open-source project”. For Catalyst, DataFrames would be an elegant alternative to Excel spreadsheets as the C-powered vectorization allows much faster data analysis, inbuilt plotting and direct access from other data science packages.
-
Matplotlib: NumPy and Pandas both have data visualization functionality built in, but do not come near the capabilities of this essential library for any type of table, chart or diagram ranging from pretty to scientific. Used by 1.1m on Github with 7.4k forks and 19.3k stars. Matplotlib only uses BSD compatible code, and its license is based on the PSF license. As this covers graphs the most basic line charts ("number of proposals from Fund-7 to Fund-11") to complex 3-dimensional scatterplots (showing relationships between Reviewer Scores, funds requested and funds awarded for example) it is highly relevant to Catalyst.
-
Jupyter Notebooks Transcending the Python ecosystem, IPython notebooks have become a favorite for interactive code and contained showcases or tutorials. Code areas can be changed and executed by the user and allow inline plotting, charting or import of other packages. According to it's website "its flexible interface allows users to configure and arrange workflows in data science, scientific computing, computational journalism, and machine learning. A modular design invites extensions to expand and enrich functionality. Free software, open standards, and web services for interactive computing across all programming languages " Used by 279k on Github with 4.6k forks and 11.2k stars. It is licensed under the terms of the 3-Clause BSD License also known as New or Revised or Modified BSD License, or the BSD-3-Clause license. Jupyter Notebooks have been used by IOG from its Haskell Course to Atala Prism Pioneer program and are a great way for anyone to present code-based application interactively and simply.
Chosen from the most used and most popular, but excluding complex Deep Learning, LLM and Machine Learning Optimization as our Catalyst datasets are likely small and we want to avoid black boxes when communicating data-driven insights to the wider community. Some packages that used to enjoy considerable popularity have been deprecated or neglected for others that are maintained by more active communities or seen are more suitable for the boom in generative AI. Theano and Chainer for deep learning are good examples.
Not all of these packages come pre-installed with all scientific Python distributions (such as Anaconda) but can normally be installed quite easily through package management. As the main Anaconda repository can be slow to add new releases, it can be preferable to use conda-forge such as:
conda install seaborn -c conda-forge
For those who prefer to install using the command line, we have provided the pip command in the listings below such as:
pip install seaborn
or pip3 for Linux and WSL if working with Python 3 (as we do).
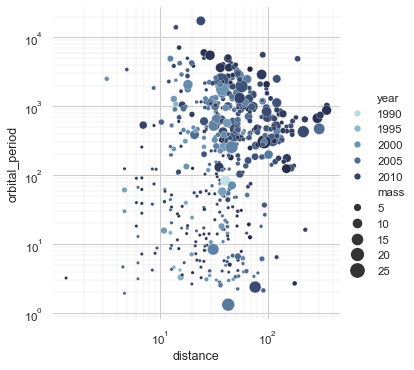
1. Seaborn Seaborn is a Python data visualization library based on matplotlib. It provides a high-level interface for drawing attractive and informative statistical graphics. It is particularly useful for making complex visualizations from data in pandas DataFrames. Seaborn arguably looks better and requires less code than Matplotlib, but lacks some cutomization features of its older sibling. When DataFrames are used instead of spreadsheets for Fund data, plotting with Seaborn would be particularly easy and attractive.
Installation:
pip install seaborn
Open Source Status: BSD-3-Clause license.
Example of a scatterplot:
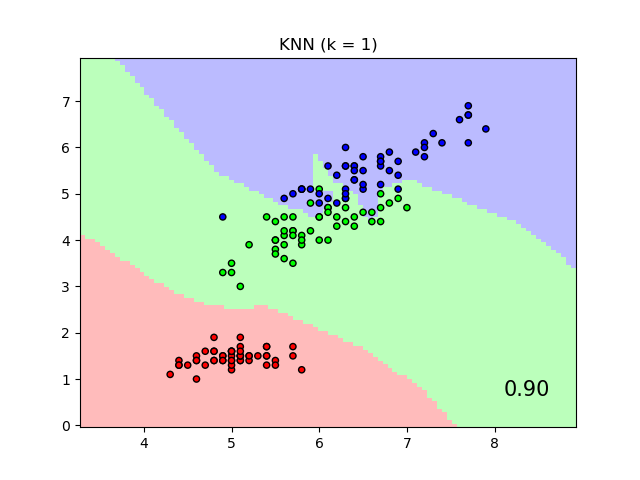
2. SciKit Learn (SKL) Scikit-learn is a machine learning library for Python. It features various classification, regression, and clustering algorithms, and is designed to interoperate with the Python numerical and scientific libraries NumPy and SciPy. For pure machine learning, this is the go-to workhorse that can easily benefit Catalyst by looking for clusters in data or understand relationships that go beyond spreadsheet (linear) regression but do not need or benefit from "emergent" AI treatment. k-nearest neighbors algorithm is a perfect example of where SKL shines.
Installation:
pip install scikit-learn
Open Source Status: BSD license.
Example of KNN visualization from SciKit Learn:
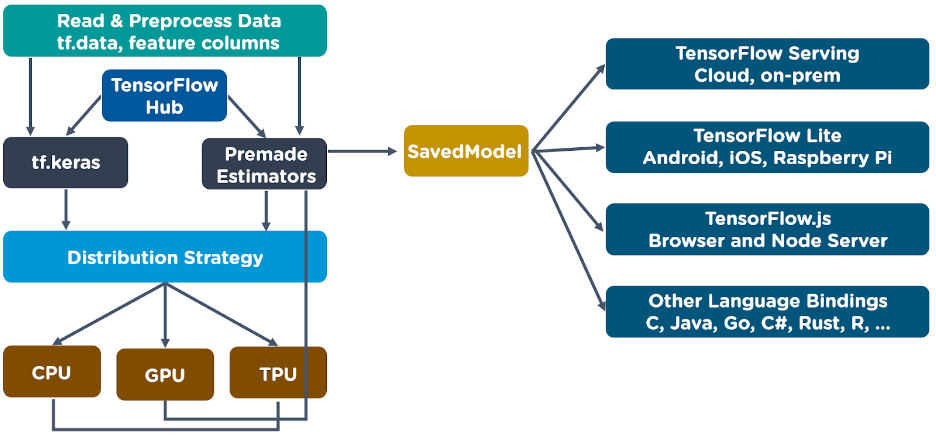
3. TensorFlow TensorFlow is an end-to-end open source platform for machine learning that works across platforms and programming languages. It has a comprehensive, flexible ecosystem of tools, libraries, and community resources that lets researchers push the state-of-the-art in ML, and developers easily build and deploy ML-powered applications. For the multi-faceted Catalyst ecosystem with decentralized, community-powered apps and analytics, it can be used integrating various different sources and endpoints. It is somewhat more cutting-edge and heavyweight than "oldie-but-goldie" SKL. It was developed by the Google Brain team for Google's internal use in research and production. For Catalyst, if you have the right idea, TF is likely to be able to help. It can be used to develop models for various tasks including natural language processing, image recognition, similarity recognition, and different computational-based simulations covering unsupervised, supervised and black-box modelss.
Installation:
pip install tensorflow
Open Source Status: Apache 2.0 license.
Example of TF flow from Simplilearn:
4. BeautifulSoup BeautifulSoup is the classic webscraping package for Python data applications. This lets users define and run scraping "bots" to collect data anywhere accessible on the web, either static data as part of a larger scale (re)search operation, or the same data as it is updated periodically to keep track of change. In a decentralized ecosystem like Catalyst, this is extremely usesful as it can bypass APIs requirements or simply access data that is in their own silo or community while being highly relevant to the overall truth discovery (such as community governance projects and DAOs). It works by allowing parsing HTML and XML documents. It creates a parse tree for parsed web pages based on specific criteria that can be used to extract, navigate, search, and modify data from HTML.
Installation:
pip install beautifulsoup4
Open Source Status: MIT license.
Uses Libraries.io instead of Github.

5. Scrapy Scrapy is a comprehensive web scraping framework, perfect for large-scale data extraction projects and offers built-in support for crawling, whereas Beautiful Soup is a parsing library best suited for smaller, more straightforward scraping tasks without the built-in crawling capabilities. Scrapy allows defining "Items", a data structure that holds the user's data. Instead of yielding scraped data in the form of a dictionary for example, it allows defining an Item schema beforehand in an items.py file and use this schema when scraping data. This enables quickly and easily checking what structured data are being collected in the project, and will raise exceptions if incorrect data is used with the Item.
Installation:
pip install Scrapy
Or ideally using Conda:
conda install -c conda-forge scrapy
Open Source Status: BSD-3-Clause license.
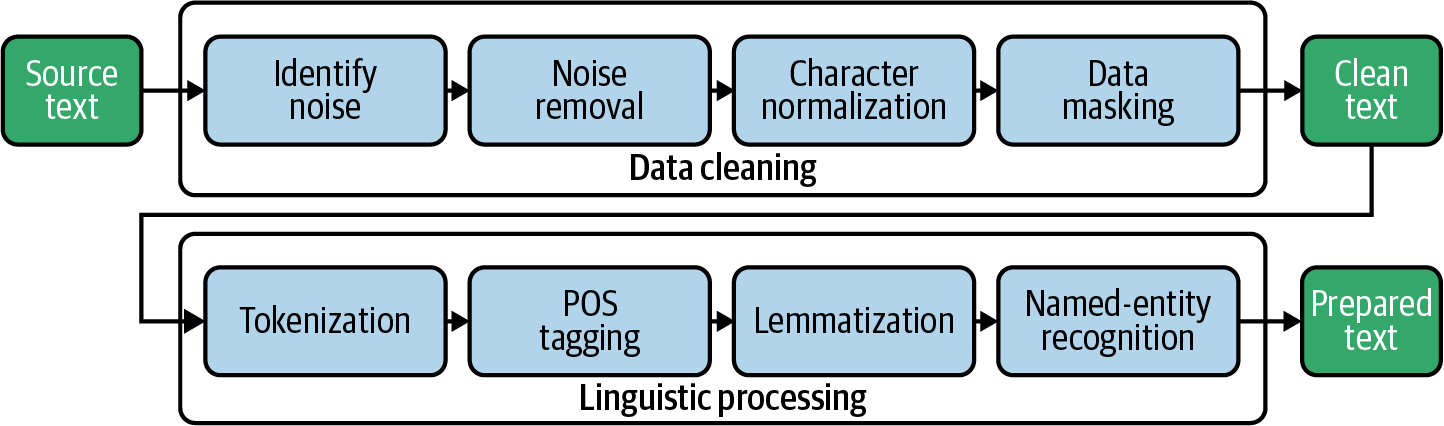
6. NLTK Natural Language Toolkit (NLTK) is a suite of libraries and programs for symbolic and statistical natural language processing (NLP) for English written in Python. It is the best known natural language processing tool and various books and tutorials exists how to use it. Needless to say, a lot of Project Catalyst data is text like CA/CR reviews, proposal bodies, Github readmes and so on so this package is crucial to convert text into numbers, which Machine Learning models can then easily work with. It is also powerful for sentiment analysis parsing Twitter/X posts. If text suddenly becomes numbers, a whole new universe of possibilities for analysis opens up. This makes NLTK one of the most useful packages - but this isn't trivial. Careful production planning from ideation over signal processing to dimensionality reduction need to be considered, making this a science onto itself. We will try to open up as much Catalyst text to analysis as possible, but expect the first steps to be quite basic before deeper insights can be gained from large datasets of free-form text such as the entirety of proposal reviews in one Fund.
There is also a useful discussion of NLP for beginners and the available toolkit on LinkedIN
Installation:
pip install nltk
Open Source Status: Apache 2.0 license.
GitHub Page: NLTK GitHub
How NLTK works (DataCamp):
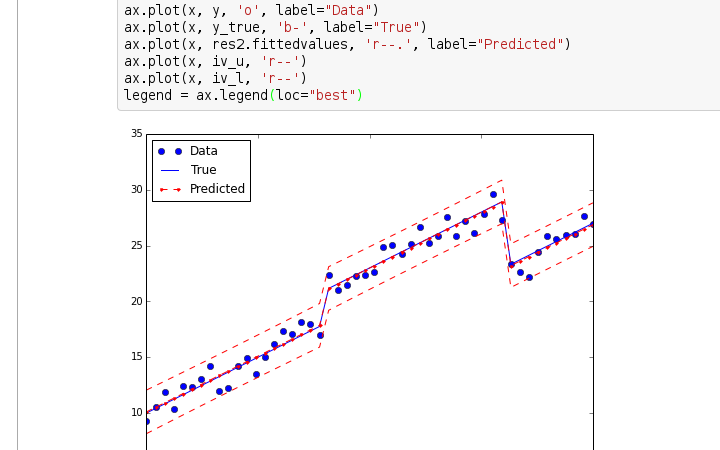
7. Statsmodels Statsmodels is a library for statistical and econometric analysis in Python. It supports many kinds of classic but also more advanced statistical models and tests, making it useful for regression, time series analysis, and hypothesis testing. Do not discount this as "old school statistics" though, as many intuitions about complex relationships require initial sanity checks and without basic foundation in correlation and hypothesis testing, spurious relationships and biases creep in. Together with Pandas and Numpy, this is one of the workhorses for working with data, developing and testing ideas. Open Source Status: Open source, BSD license.
Installation:
pip install statsmodels
Example of Statsmodels (from their website):
8. Keras Keras is a high-level neural networks API, written in Python and capable of running on top of TensorFlow, CNTK, or Theano. It enables fast experimentation with deep neural networks. It was developed by Google and is primarily used to make the implementation of neural networks easy(ier). It also supports multiple backend neural network computation. Keras is used for distributed training of deep learning models and especially popular by companies that require complex studies of customer behavior, for example Netflix or Uber. Some traders have successfully used it to develop crypto trading algorithms but for Catalyst it is probably a bit too "black box" to yield results that can inform governance. Most likely use cases are in spotting AI impersonation through learning models or other similar highly complex tasks.
Installation:
pip install keras
Open Source Status: MIT license. GitHub Page
9. PyTorch PyTorch is an open source machine learning library based on the Torch library, used for applications such as natural language processing. It is primarily developed by Facebook's AI Research lab. According to 6sense, the top alternatives for PyTorch data-science-machine-learning tool are TensorFlow with 38.39%, OpenCV with 19.45%, Keras with 18.28% market share - so it is used for similar jobs even though we would utilize it mainly for the support of NLP applications and use TensorFlow as the go-to solution for doing complex ML with numbers or vectors (other thank vectorized text tokens). This is based on Sapient's preferences and the Catalyst Team or community users may develop their own favorites.
Installation:
pip install torch
Open Source Status: BSD license.
Illustration by NVIDIA about the advantages of PyTorch.
10. Gensim Gensim is an open-source library for unsupervised topic modeling and natural language processing, using modern statistical machine learning. By representing text as semantic vectors, it enables the extraction of semantic topics from a large collection of documents using algorithms. A typical use case would be extracting the underlying topics from large volumes of text, for example to categorize a proposal as "DeFi" or "RWA" based on its content. It is a somewhat specialized alternative to NLTK if the text is known to be structured, as would often be the case in likely Catalyst data-analysis. Open Source Status: Open source, LGPL license.
Installation:
pip install gensim
Comparison of NLP packages and their capabilities.

11. SpaCy SpaCy is another open-source software library for advanced natural language processing, designed specifically for production use and helps you build applications that process and "understand" large volumes of text. You can refer to the image under Gensim for differences and strengths or likely use cases. We will delve deeper into NLP package comparison when dealing with text analysis of Catalyst fund data.
Installation:
pip install spacy
Open Source Status: MIT license. GitHub Page
12. Plotly Plotly is a graphing library that makes interactive, publication-quality graphs online. Examples of plots are line charts, scatter plots, area charts, bar charts, error bars, box plots, histograms, heatmaps, subplots, multiple-axes, polar charts, and bubble charts. So what's the difference to other charting tools like Matplotlib and Seaborn? It has a somewhat smaller community but according to some of its users, Plotly is "far ahead of the other options - easier to use, just as customizable, and offers interactivity if you want to show it on a website". This of course depends a lot on what you are trying to do - charting for trading and visualization of changes from fund to fund in CR score impact require very different chart types and some packages may excel at one type and look weird for others - it is literally down to who developed it for which main purpose initially.
Installation:
pip install plotly
Open Source Status: MIT license. GitHub Page
A few more to experiment with “next level” applications. We have a separate section for AI, but for high level, statistical and prediction machine learning, there is a rich sophisticated, niche package ecosystem for any need and any task. Some areas however increasingly rely on expensive non-open source APIs like OpenAI's. If there is a need for a deeper dive as we come across more use cases and community requests, we may expand on this section.
-
LightGBM LightGBM (Light Gradient Boosting Machine) is a highly efficient, distributed, and fast implementation of gradient boosting framework based on decision tree algorithms. It provides feature importance metrics which can help in understanding which factors are most influential in the scoring and voting outcomes. While not primarily designed for interpretability, various tools and methods (like SHAP values) can be used alongside LightGBM to understand model predictions, which is useful in understanding the comparative outcomes of different funding rounds. For Catalyst fund use, it is initially quite certainly overkill, but will prove invaluable for model optimization to the experienced user or later stage refinement.
-
cadCAD cadCAD (Complex Adaptive Dynamics Computer-Aided Design) is a Python-based modeling framework for research, validation, and Computer Aided Design of complex systems. It supports discrete-time simulations, enabling the study of system dynamics. cadCAD is particularly useful for understanding the dynamics and interdependencies within the funding process. It can model how different variables and their interactions affect outcomes over time. Ideal for systems with feedback loops and complex interactions, which are often present in voting and scoring systems involving multiple reviewers and proposals.
-
NetworkX NetworkX is a Python package for the creation, manipulation, and study of complex networks of nodes and edges. It is used for the analysis of the structure and dynamics of networks. Useful for identifying clusters or communities within the network, such as groups of reviewers who tend to score similarly.
-
Gephi Gephi is an open-source network analysis and visualization software package written in Java on the NetBeans platform. It is primarily used for graph and network visualization. Provides an interactive interface for exploring the network, which can help in understanding the distribution of scores and votes across different proposals.
-
LangChain More information about LangChain and using LLMs in general can also be found in our section about AI. This is an entire science to itself and has boomed after chatGPT made LLMs famous, although results are still somewhat experimental and can be "weird" or "moody" due to the emergent character of the AI.