The article is not yet finished
Using a GPU instead of a CPU can really speed things up. An NVidia 1080Ti is in some of my benchmarks more than 60 times(!) faster than an AMD 1950X. Several articles, from Illia Karmanov, Marek Kolodziej and Bohumir Zamecnik hint at extra speedups when using multiple GPU's. How much faster a multi GPU setup performs depends on the deep learning net that is being trained. The articles discuss Convolutional networks while I am interested in Recurrent networks, especially fitting a lot of sequences with a Recurrent Neural Network (RNN).
Models do not always profit from more than one GPU. Sometimes they get even slower. The main reason for this is that there is too much data exchange between the GPU and main memory (RAM) via the CPU. This exchange is relatively slow compared to the speed of the GPU. When using one GPU the computations between batches take place on this GPU. When using more GPU's data and weights must be exchanged between the GPU's. Only when your batch is large enough or the model complex enough, the slowdown of the exchange is overcome by the speed of the GPU's. I tried to figure out how batch size and complexity impacted my model on multiple GPU's. I also discuss some issues I was confronted with.
Tensorflow has the function list_devices to list which computing devices are present in the system. It lists all CPU's, GPU's and TPU's, so one has to filter out the relevant devices.
from keras import backend as K
import tensorflow as tf
print('Tensorflow version: ' + tf.__version__)
print('Keras version: ' + keras.__version__)
# Get all computing devices
devices_s = K.get_session().list_devices()
print('Computing devices\n', devices_s)
# Filter GPU's
gpu_s = [x for x in devices_s if 'GPU' in str(x)]
print('\nof which GPU\'s\n', gpu_s)
G = len(gpu_s)
print("\n# of GPU's: " + str(G))
You can do more things as testing the GPU capabilities and the path of the CuDNN library. I gathered some examples from the web (I forgot from whom, sorry) into gpu_test.py which you can find in the repository.
If you want to use the GPU's then the typical way to proceed is as follows:
if gpu > 1: # Create a model to run on all GPU's
with tf.device("/cpu:0"):
model = create_model(X, Y, layers, dropout)
model = multi_gpu_model(model, gpus=gpu)
print('Running a multi GPU model')
else: # Create a model to run on GPU:0
with tf.device("/gpu:0"):
model = create_model(X, Y, layers, dropout)
print('Running a single GPU model')
model.compile(...)
As you can see keras makes it very easy to create multi GPU models. Trouble is that in my case multiple GPU's seem to slow down instead of speed up the training of an LSTM or GRU network.
I usually prefer GRU over LSTM. It tends to be faster and has better performance in terms of (validation) accuracy. My standard environment is tensorflow 1.9 and Keras 2.2.2. When I tried to use Tensorflow/Keras 1.10/2.2.2 and 1.12/2.2.4 the system crashed without warning when I used 2 GPU's (it worked for 1 GPU). The same happened to LSTM.
In Keras there are RNN layers specific for the CuDNN library: CuDNNGRU and CuDNNLSTM. They only work with the CuDNN library. They have two pleasant properties:
- they speed up the models, sometimes by even a factor 2, though by about 1.25 is more usual.
- they can be parallised in the newest versions of Tensorflow and Keras.
I wanted to know if they were more compatible with newer version of Tensorflow and Keras. I tested several combinations of layers and installed packages, see below.
Tabel 1. Version and working layer types on 2 GPU's.
| Package/Layer | Combi 1 | Combi 2 | Combi 3 |
|---|---|---|---|
| Tensorflow | 1.9 | 1.1 | 1.12 |
| Keras | 2.2.2 | 2.2.2 | 2.2.4 |
| Pyton | 3.5.6 | 3.6.8 | 3.6.7 |
| GRU | O | X | X |
| LSTM | X | X | X |
| CuDNNGRU | O | ? | O |
| CuDNNLSTM | O | ? | O |
O = Ok, X = system hangs, ? = not tested
For benchmarking I decided to use CuDNNGRU.
I had a serious memory leakage problem when running the demo model. That turned out to be a version problem. In the versions 1.12/2.2.4 this problem has been solved.
The big question for me of course was whether my model should be faster by the use of 2 GPU's. I noticed no differences between Tensorflow/Keras 1.9/2.2.2 and 1.12/2.2.4: the results were identical within the first two decimals (that was before I was confronted with the memory leakage).
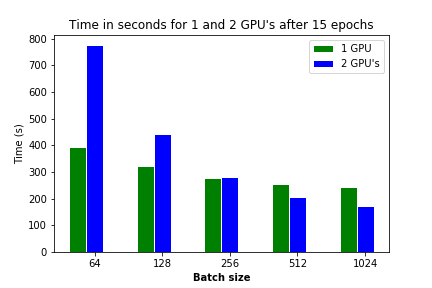
Tabel 2. Running an RNN model for 15 epochs, different batch sizes and 1 or 2 GPU's.
| Epochs | Model type | Dropouts | Batch size | GPU's | Acc | Val. Acc | Time | Speed up |
|---|---|---|---|---|---|---|---|---|
| 15 | 2 | 0 | 64 | 1 | 0.84 | 0.43 | 392 | |
| 15 | 2 | 0 | 64 | 2 | 0.87 | 0.43 | 776 | 0.51 |
| 15 | 2 | 0 | 128 | 1 | 0.88 | 0.42 | 324 | |
| 15 | 2 | 0 | 128 | 2 | 0.90 | 0.39 | 444 | 0.73 |
| 15 | 2 | 0 | 256 | 1 | 0.90 | 0.40 | 276 | |
| 15 | 2 | 0 | 256 | 2 | 0.91 | 0.39 | 282 | 0.98 |
| 15 | 2 | 0 | 512 | 1 | 0.76 | 0.41 | 256 | |
| 15 | 2 | 0 | 512 | 2 | 0.81 | 0.42 | 206 | 1.24 |
| 15 | 2 | 0 | 1024 | 1 | 0.59 | 0.47 | 245 | |
| 15 | 2 | 0 | 1024 | 2 | 0.58 | 0.49 | 171 | 1.43 |
As you can see the larger the batch size, the faster the multiple GPU solution is. There is break even for accuracy at a batch size of 256 and after that it is faster. This change in relative speed was already demonstrated in the articles.
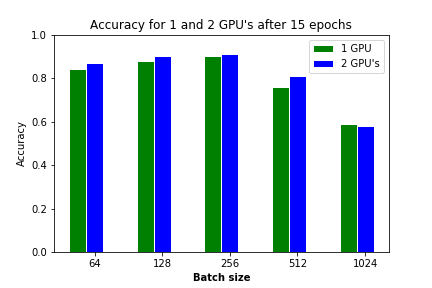
There is a decreasing accuracy when using larger batch sizes as is to be expected. But there is hardly any difference between 1 and 2 GPU's.
Picture is a bit different for the validation accuracy. With increasing batch size the validation accuracy increases. Actually the mode overfits less.
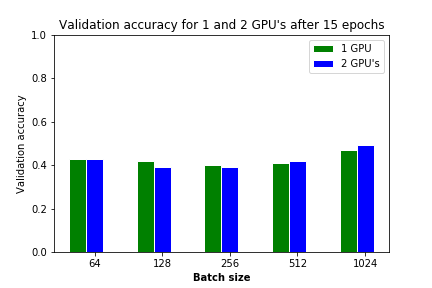
Maybe this is an example of the law of preservation of misery. What you win in one indicator (time when batch size is large) you lose in another indicator (validation accuracy).
TODO Keras has an early stop callback. I should rerun the examples with this callback to see at what level of validation accuracy the model stops.
Work in progress
Hardware:
- AMD 1950X
- 96GB RAM
- 2 x 1080Ti
Software:
- Ubuntu 18.04
- Anaconda Spyder 3.3.1
- Python 3.5.6
- Tensorflow 1.9/1.12
- Keras 2.2.2/2.2.4
- NVidia driversversion 415