

An NLP workflow system building upon sciluigi (https://github.com/pharmbio/sciluigi), which is in turn based on luigi (https://github.com/spotify/luigi).
This started out as a proof of concept intended to be used for the PICCL and Quoll NLP pipelines developed at Radboud University Nijmegen.
This is a solution for either a single computing node or a cluster of nodes (Hadoop, SLURM, not tested yet). The individual components are not webservices, nor is data passed around. This ensures minimal overhead and higher performance.
- Abstraction of workflow/pipeline logic: a generic, scalable and adaptable solution
- Modularisation; clear separation of all components from the workflow system itself
- Automatic dependency resolution (similar to GNU Make, top-down)
- Robust failure recovery: when failures occur, fix the problem and run the workflow again, tasks that have completed will not be rerun.
- Easy to extend with new modules (i.e. workflow components & tasks).
- Traceability of all intermediate steps, retain intermediate results until explicitly discarded
- Explicit workflow definitions
- Automatic parallellisation of tasks where possible
- Keep it simple, minimize overhead for the developer of the workflow, use Pythonic principles,
- Python-based, all workflow and component specifications are in Python rather than external.
- Protection against shell injection attacks for tasks that invoke external tools
- Runnable standalone from command-line
LuigiNLP follows a goal-oriented paradigm. The user invokes the workflow system by specifying a target workflow component along with an initial input file. Given the target and an initial input file, a sequence of workflow components will be automatically found that leads from initial input to the desired goal, processing the data each step of the way. Workflow components are defined in a backwards manner, as is also common in tools such as GNU Make. Each component expresses which other components it accepts as input, or which input files it accepts directly. This enables you to run the component either directly on an input file, or have the input go through other components first for necessary preprocessing. The dependency resolution mechanism will automatically chose a path based on the specified input and selected parameters.
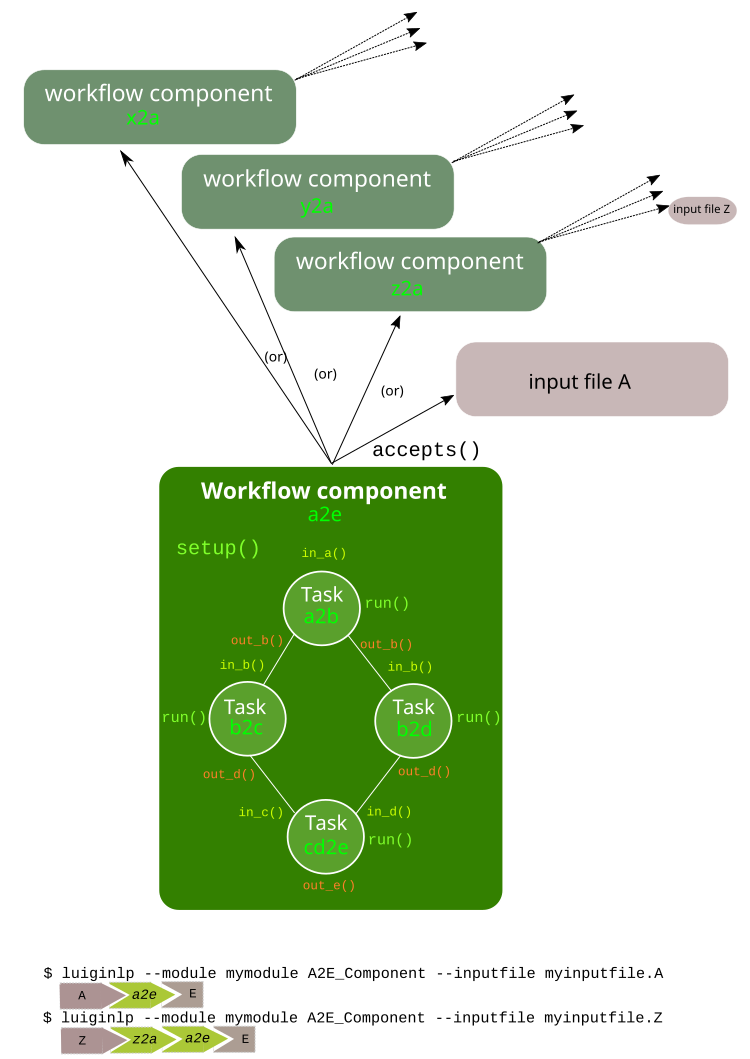
A workflow component consists of a specification that chains together tasks. Whereas a workflow component represents a more comprehensive piece of work that is defined in a context of other components, a task represents the smallest unit of work and is defined independently of any other tasks or components, making it a highly reusable part. A task consists of one or more input slots, corresponding to input files of a particular type, one or more output slots corresponding to output files of a particular type, and parameters. A workflow component only glues together different tasks, the task performs an actual job, either by invoking an external tool, or by running Python code directly. Chaining together tasks in the definition of the workflow component is done by connecting output slots of one task, to input slots of the other.
The architecture is visualised in the following scheme:
Tasks and workflow components may take parameters. These are available
within a task's run() method to either be propagated to an external tool
or to be handled within Python directly. At the component level, parameters may also be used to influence
task composition, though often they are just passed on to the tasks.
The simplest instance of a workflow component is just one that accepts one particular type of input file and sets up just a single task.
Both tasks and workflow components are defined in a module (in the Python sense of the word), which simply groups several tasks and workflow components together.
LuigiNLP relies heavily on filename extensions. Input formats are matched on the basis of an extension, and generally each task reads a file and outputs a file with a new extension. Re-use of the same filename (i.e. writing output to the input file), is strictly forbidden!
It is important to understand that the actual input files are only open for
inspection when a Task is executed (its run() method is invoked). During
workflow composition in a component (in its setup()/autosetup() method), files can not
be inspected as the composition by definition preceeds the existence of any
files, and the whole process has to proceed deterministically.
- No circular dependencies allowed in workflow components
- Intermediate files are not open for inspection in workflow specifications, only within
Task.run()
luiginlp/luiginlp.py- Main toolluiginlp/modules/- Modules, each addressing a specific tool/goal. A module consists of workflow components and tasks.luiginlp/util.py- Auxiliary functionssetup.py- Installation script for LuigiNLP (only covers LuigiNLP and its direct python dependencies)
Install as follows:
$ python setup.py install
(If this fails due to a python-daemon error, just run it again. There is a
problem in that package)
Many of the implemented modules rely on software distributed as part of LaMachine (https://proycon.github.io/LaMachine), so LuigiNLP is best used from within a LaMachine installation. LuigiNLP itself is included in LaMachine as well.
Example, specify a workflow corresponding to your intended goal and an input file. Workflows may take extra parameters (--skip for Frog in this case):
$ luiginlp Frog --module luiginlp.modules.frog --inputfile test.rst --skip p
A workflow can be run parallelised for multiple input files as well, the number of workers should be explicitly set:
$ luiginlp Parallel --module luiginlp.modules.frog --component Frog --inputfiles test.rst,test2.rst --workers 2 --skip p
You can always pass workflow-component-specific parameters by using the workflow component name as a prefix. For
instance, the Frog component takes an option skip, you can use --Frog-skip to explicitly set it.
You can also invoke LuigiNLP from within Python of course:
import luiginlp
from luiginlp.modules.frog import Frog
luiginlp.run(Frog(inputfile="test.rst",skip='p'))To parallelize multiple tasks you can just do:
import luiginlp
from luiginlp.modules.frog import Frog
luiginlp.run(
Frog(inputfile="test.rst",skip='p'),
Frog(inputfile="test2.rst",skip='p'))Or use the Parallel interface:
import luiginlp
from luiginlp.modules.frog import Frog
from luiginlp.engine import Parallel, PassParameters
luiginlp.run(
Parallel(component="Frog",inputfiles="test.rst,test2.rst",
passparameters=PassParameters(skip='p')
)
)Here's an example of running an OCR workflow for a scanned PDF file (requires the tools pdfimages,
Tesseract, FoLiA-hocr and foliacat, the latter two are a part of LaMachine):
$ luiginlp --module luiginlp.modules.ocr OCR_folia --inputfile OllevierGeets.pdf --language eng
LuigiNLP automatically finds a sequence of components leading from your input
file (provided it's name matches whatever convention you use) to the target
component. You may, however, force an inputfile by setting the --inputslot
parameter to some input format ID. This can be useful if you want to feed an
input file that does not comply to your naming convention.
You may also specify a --startcomponent to explicitly state which component
should be the first one, this may be useful in cases of ambiguity where
multiple paths are possible (the first possibility would be otherwise be chosen).
In order to plug in your own tools into LuigiNLP, you will need to do several things:
- Create a new module that groups your code (inside LuigiNLP these reside in
luiginlp/modules/*.py, but you may just as well have a module in an external Python project) - Write one or more tasks, tasks are classes derived from
luiginlp.engine.Task - Write one or more workflow components that chain tasks together, workflow components are classes derived from
luiginlp.engine.WorkflowComponent, you usually want to derive fromluiginlp.engine.StandardWorkflowComponentwhich is a standard component that takes one inputfile as parameter.
Always take in mind the following guidelines when writing tasks and components for LuigiNLP:
- Tasks should cover the smallest unit of work, do not do too much in one task, but chain tasks instead.
- Be very specific in your file extensions. If two tasks output a file with the
same extension, they are considered identical for all intents and purposes! Multiple stacking extensions are fine and
recommend (
*.x.y.z). Generally, each task strips input extensions (optional) and adds a a new extension. - Input and output filenames may never be the same! It is forbidden to change a file in-place.
- Consider whether you want to chain multiple workflow components and to use the automatic resolution mechanism, or whether you have larger components that chain multiple tasks. Components are needed whenever you want to have multiple entry points.
Let's begin by writing a simple task that invokes the tokeniser
ucto (https://languagemachines.github.io/ucto) to convert plain text to
tokenised plain text. We prescribe that the plain text document has the
extension txt and tokenised text has the extension tok. The tokeniser
takes one mandatory parameter: the language the text is in.
We can now turn this task into a simple component that we can invoke:
Assuming you wrote all this in a mymodule.py file, you now can invoke this
workflow component on a text document as follows:
$ luiginlp Ucto --module mymodule --inputfile test.txt --language en
Ucto does not just support plain text input, it can also handle input in the
FoLiA format (https://proycon.github.io/folia), an XML-based format for linguistic
annotation. We could write a task Ucto_folia2tok that runs ucto in this
manner. Suppose we did that, we could extend our workflow component as
follows:
def accepts(self):
return InputFormat(self, format_id='txt',extension='txt'), InputFormat(self, format_id='folia', extension='folia.xml')
def autosetup(self):
return Ucto_txt2tok, Ucto_folia2tokNow the workflow component will be able automatically figure out which of the tasks to run based on the supplied input, allowing us to do:
$ luiginlp Ucto --module mymodule --inputfile test.folia.xml --language en
What about any other file format? Ucto itself can only handle plain text or
FoLiA. What if our input text is in PDF format, MarkDown format, or God forbid,
in MS Word format? We could solve this problem by writing a
ConvertToPlaintext component that handles a multitude of formats and simply
instructs ucto to accept the plaintext output from that component. We need some extra imports
and would then modify the accepts() to tie in the component:
from luiginlp.engine import InputComponent
from some.other.module import ConvertToPlaintextdef accepts(self):
return (
InputFormat(self, format_id='txt',extension='txt'),
InputFormat(self, format_id='folia', extension='folia.xml'),
InputComponent(self, ConvertToPlaintext) #you can pass parameters using keyword arguments here
)Our ucto component thus-far has been fairly simple, we first used autosetup() to
wrap a single task, and later to choose amongst two tasks. Let's look at a more
explicit example with actual task chaining.
Suppose we want the Ucto component to lowercase our text before passing it on
to the actual task that invokes ucto. We can write a simple lowercase task as
follows, for this one we just use Python and call no external tools (i.e. we
set no executable and do not call ex()):
Now we go back to our Ucto component, we forget about the FoLiA part for a
bit, and we set up explicit chaining using setup() instead of
autosetup(), which is a bit more work but gives us complete control over
everything.
We have seen that the ex() method on a task can be invoked from it's
run() method to call external tools. The executable to execute is defined
in the task's executable property.
The ex() method allows you to define your calls to external tools in a
python way, and ensures that all parameter values are properly escaped to prevent any
shell injection attacks. Its offers cleaner and more secure code.
When you call ex(), all keyword arguments will be passed as parameters. The
keyword argument x (one letter) to ex() , will result in the flag -x,
whereas keyword argument foo (multiple letters), will result in the flag
--foo. If you want to force single hyphens for multiletter options, set __singlehyphen=True.
Keyword arguments starting with a double underscore are special directives to
ex(). A double underscore inside a parameter will be translated to a
hyphen, as Python does not allow variables with hyphens. So keyword argument
foo__bar will result in the option --foo-bar.
Keyword arguments with a boolean value are passed as flags without
value, i.e. passing foo=True results just in --foo, whereas foo=5
yields --foo 5. If you want to force the use of an assignment operator, as
in --foo=5, pass __assignop=True.
Shell redirects (<,``>``,``2>``) are supported through the special keyword
arguments __stin_from, __stdout_to and __stderr_to, each expecting
a path to a file. Further piping is not supported through the ex() command.
Keyword arguments starting with a single underscore will have that underscore
removed, this is useful in cases where parameters clash with reserved keywords
in Python, such as from or import.
Processes are expected to return proper exit codes (0 for success, non-zero for
failure), LuigiNLP will interpret it as such and consider the task failed if a
non-zero exit code is obtained. If you want to ignore failures,
set __ignorefailure=True.
Workflows are static in the sense that based on the format of the input file
and all given parameters, all workflow components and tasks are assembled
deterministically. This means that, within a components setup() method, it
is not possible to inspect input/intermediate files nor adjust the flow based
on file contents.
At times, however, more dynamic workflows are needed. In such cases, the common
theme is that input data has to be inspected and decisions made accordingly.
The only stage at which input files can be inspected is in a task's
run() method. Fortunately, there are facilities here to implement more
dynamic dependencies, a task's run() method is allowed to yield (in the
Python sense of the word) a list of other tasks that it depends on.
A good example would be if we create a new tokenisation component that does not
just take an input file, but takes a directory containing input files and
produces a directory of output files. The proper way to implement this is to
reuse the component that performs on the individual files (i.e. our Ucto
component). Consider the following task and component:
import glob
from luiginlp.engine import Task, StandardWorkflowComponent, InputSlot, Parameter
class Ucto_txtdir2tokdir(Task):
language = Parameter()
in_txtdir = InputSlot()
def out_tokdir(self):
return self.outputfrominput(inputformat='txtdir',stripextension='.txtdir',addextension='.tokdir')
def run(self):
#setup the output directory
# this creates the directory and also moves it out of the way again when failures occur in this task
self.setup_output_dir(self.out_tokdir().path)
#gather input files
inputfiles = [ filename for filename in glob.glob(self.in_txtdir().path + '/*.txt' ]
#inception aka dynamic dependencies: we yield a list of components which could not have been predicted statically
#in this case we run the Ucto component for each input file in the directory
yield [ Ucto(inputfile=inputfile,outputdir=self.out_tokdir().path,language=self.language) for inputfile in inputfiles ]
class Ucto_collection(StandardWorkflowComponent):
def accepts(self):
return (
InputFormat(self, format_id='txtdir',extension='txtdir', directory=True),
)
def autosetup(self):
return Ucto_txtdir2tokdirThe magic happens in the task's run() method, as that it the only stage
where we can examine the contents of any input files, in this case: the contents
of the input directory. First we set up the output directory with a call to
self.setup_output_dir(). This creates the directory if it doesn't exist
yet, but also makes sure the directory is stashed away when the task fails,
ensuring you can always rerun the pipeline if happens to break off. (in
technical terms, this preserves idempotency).
Mext, we construct a list of all the txt files in the directory. We use this
list to yield a list of components to run, one component for each input file.
Now, when the task's run() method is called, a series of components will be
scheduled and run in parallel (up to the number of workers).
You may be tempted to yield the components individually one by one, but that won't result in parallisation, you must really yield an entire list (or tuple).
Note that we added an outputdir parameter to the Ucto component which we
hadn't implemented yet. This is necessary to ensure all individual output files
end up in the directory that groups our output. The Ucto component should
simply pass this parameter on to the Ucto_txt2tok task. The outputdir
parameter is implicitly present on all tasks as well as on
StandardWorkflowComponent, the outputfrominput() method automatically
supports this parameter.
Assuming you have a collecting of text files in a directory corpus.txtdir/,
you can now invoke LuigiNLP as follows and end up with a corpus.tokdir/
directory with tokenised output texts:
$ luiginlp Ucto_collection --module mymodule --inputfile corpus.txtdir --language en --workers 4
Note the --workers parameter, which is the generic way to tell LuigiNLP how
many workers may run in parallel. You will want to explicitly set this to a
value that approximates the number of free CPU cores as the default value is
one (no parallellisation).
Components often inherit parameters from the tasks they wrap. When you use
autosetup(), parameters with the matching names are automatically passed
from component to task. Similarly, if you use workflow.new_task() in your
setup method, you can set the keyword argument autopass=True to also
accomplish this.
Still, you actually need to which parameters on the component. This can be done in the usual way, but if a task already defines them, you may want to inherit the parameters automatically and prevent any code duplication. This is done as follows:
class MyComponent(WorkflowComponent):
...
MyComponent.inherit_parameters(MyTask1,MyTask2,MyTask3)Note that the inherit_parameters() call is not part of the class definition (not in class scope) but placed after it.
Tasks may defined multiple input slots (and multiple output slots). Components
may accept multiple inputs similtaneously as well. Consider for example a
classifier that takes a training file and a test file. Components can not use
autosetup() in this case, but you need to explicitly define a setup()
method.
To define multiple concurrent inputs, group them together in a tuple and return
this as part of a list or tuple from accepts(). The following example
components is for a classifier, it takes two inputs (trainfile and
testfile) rather than the standard inputfile pre-defined in
StandardWorkflowComponent (this class is therefore subclassed from
WorkflowComponent instead, which does not predefine inputfile).
Note furthermore that the InputFormat tuple contains the inputparameter
keyword argument that binds the proper inputformat to the proper parameter (the
default was inputparameter="inputfile" so we never needed it before).
@registercomponent
class TimblClassifier(WorkflowComponent):
"""A Timbl classifier that takes training data, test data, and outputs the test data with classification"""
trainfile = Parameter()
testfile = Parameter()
def accepts(self):
#Note: tuple in a list, the outer list corresponds to options (just one here), while the inner tuples are conjunctions
return [ ( InputFormat(self, format_id='train', extension='train',inputparameter='trainfile'), InputFormat(self, format_id='test', extension='test',inputparameter='testfile')) ]
def setup(self, workflow, input_feeds):
timbl_train = workflow.new_task('timbl_train',Timbl_train, autopass=True)
timbl_train.in_train = input_feeds['train']
timbl_test = workflow.new_task('timbl_test',Timbl_test, autopass=True)
timbl_test.in_test = input_feeds['test']
timbl_test.in_ibase = timbl_train.out_ibase
timbl_test.in_wgt = timbl_train.out_wgt
return timbl_testWe have not defined the tasks here, but you can infer that the Timbl_train
task has at least two output slots, and Timbl_test has two input slots.
- Everything is run sequentially, nothing is parallelised? -- Did you explicitly supply a
workersparameter with the desired maximum number of threads? Otherwise just one worker will be used and everything is sequential. If you did supply multiple workers, it may just be the case that there is simply nothing to run in parallel in your invoked workflow. - I get no errors but nothing seems to run when I rerun my workflow? -- If all output files already exist, then the workflow has nothing to do. You will need to explicitly delete your output if you want to rerun things that have already been produced succesfully.
- error: unrecognized argument -- You are passing an argument that
is not known to the target component. Perhaps you forgot to inherit certain
parameters from tasks to components using
inherit_parameters()? - RuntimeError: Unfulfilled dependency at run time -- This error says that the specified task or component has not delivered the output files that were promised by the output slots. You should ensure all of the promised files are delivered and there are no typos in the filenames/extensions.
- InvalidInput: Unable to find an entry point for supplied input -- The
filename you specified can not be matched with one of the input formats. Are
you supplying the right file and that your target component has a possible
path to that input (through
accepts()). Either make sure it has the expected extension so it is automatically detected. You may also explicitly supply aninputslotparameter with the ID of the format, possibly in combination with astartcomponentparameter with the name of the component you want to start with. - ValueError: Workflow setup() did not return a valid last task (or sequence of
tasks) or TypeError: setup() did not return a Task or a sequence of Tasks -- At the end of your component's
setup()method you must return the last task instance, or a list of the last task instances. Is a return statement missing? - Exception: Input item is neither callable, TargetInfo, nor list: None. --
All
out_*()methods must return aTargetInfoinstance, which is usually achieved by returning whateveroutputfrominput()returns. Is a return statement missing in an output slot? - ValueError: Inputslot .... of ..... is not connected to any output slot! -- You forgot to connect the specified input slot of the specified
task to an output slot (in a components
setup()method). All input slots must be satisfied. - ValueError: Specified inputslot for ... does not exist in .... -- Your call
to
outputfrominput()has ainputformatargument that does not correspond to any of the input slots. If you have an input slotin_x, the inputformat should bex. - Exception: No executable defined for ..... -- You are invoking the
ex()method to execute through the shell but the Task's class does not specify an executable to run. Setexecutable = "yourexecutable"in the class. - TypeError: Invalid element in accepts(), must be InputFormat or InputComponent -- Your component's accepts() method returns something it shouldn't, you may return a list/tuple of InputFormat or InputComponent instances, you may also includes tuples grouping multiple InputFormats or InputComponents in case the component takes multiple input files.
- AutoSetupError: AutoSetup expected a Task class -- Your components
autosetup()method must return either a single Task class (not an instance) or a list/tuple of Task classes. - AutoSetupError: No outputslot found on .... -- The task you are returning in a component's
autosetup()method has no output slots (one or moreout_*()methods). - AutoSetupError: AutoSetup only works for single input/output tasks now -- You can not use
autosetup()for components that take multiple input files, usesetup()instead. - AutoSetupError: No matching input slots found for the specified task -- Autosetup was not able to automatically connect any of the supplied input formats or input components (those in
accept()) to one of the tasks defined inautosetup(), there is probably a mismatch between format names (outputslot using a different format id than the inputslot). Use thesetup()method instead ofautosetup()and connect everything explicitly there. - NotImplementedError: Override the setup() or autosetup() method for your workflow component -- Each component must define a
setup()orautosetup()method, it is missing here.
- Expand autosetup to build longer sequential chains of tasks (a2b b2c c2d)
- [tentative] Integration with CLAM to automatically create webservices of workflow components
- Further testing...