Learn the basics and become familiar with training transformers on HPUs with 🤗 Optimum. Start here if you are using 🤗 Optimum Habana for the first time!
- -Practical guides to help you achieve a specific goal. Take a look at these guides to learn how to use 🤗 Optimum Habana to solve real-world problems.
- -High-level explanations for building a better understanding of important topics such as HPUs.
- -Technical descriptions of how the Habana classes and methods of 🤗 Optimum Habana work.
- -
- 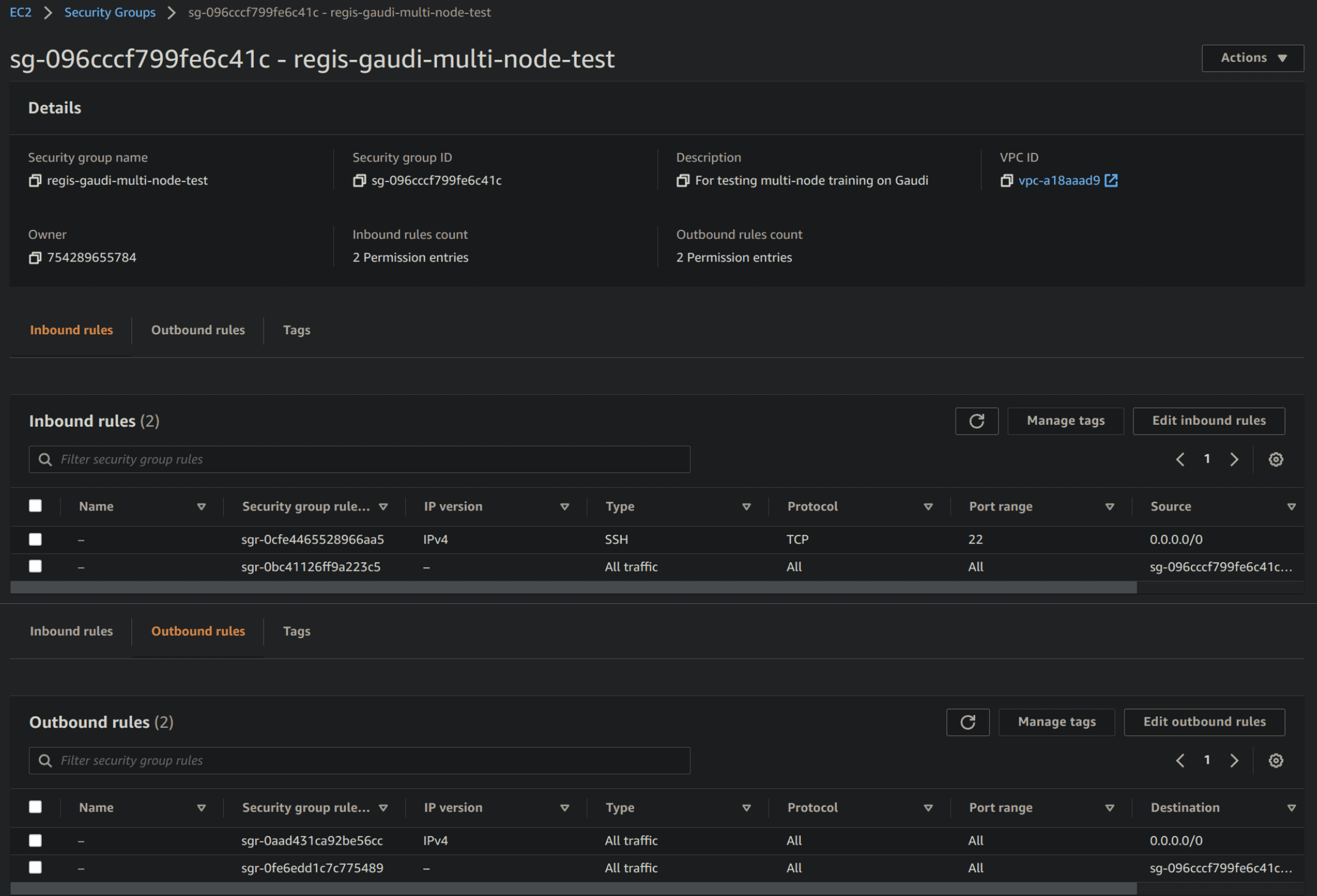 - Security group for multi-node training on AWS DL1 instances
-
- Security group for multi-node training on AWS DL1 instances
-
- 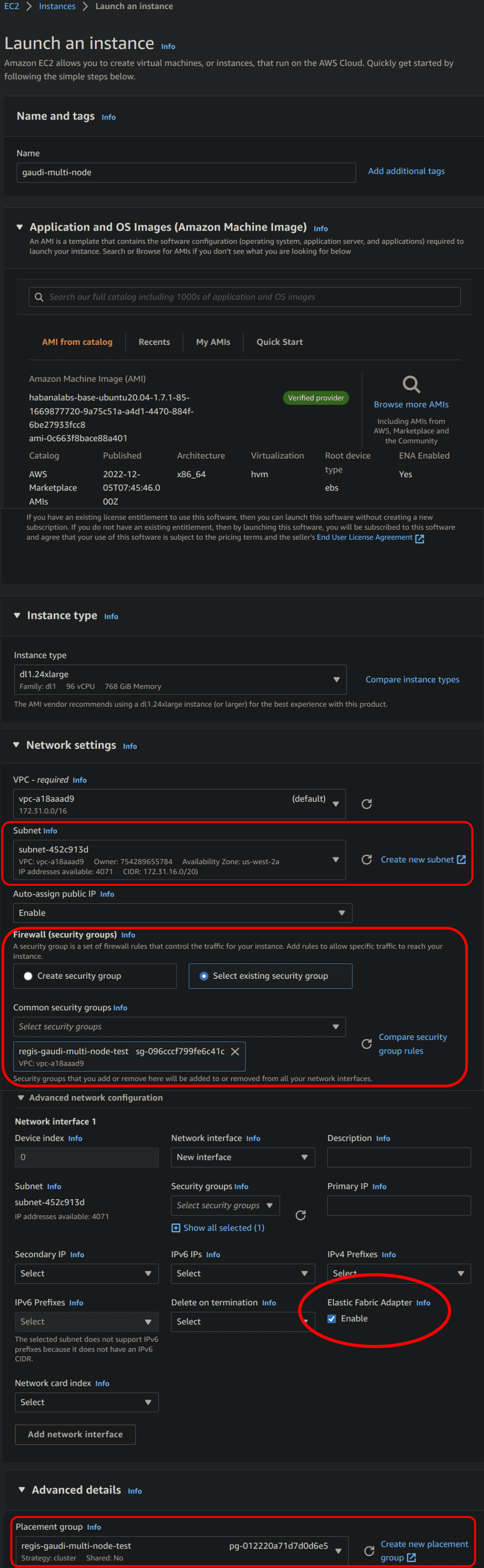 - Parameters for launching EFA-enabled AWS instances. The important parameters to set are circled in red. For the sake of clarity, not all parameters are represented.
-
- Parameters for launching EFA-enabled AWS instances. The important parameters to set are circled in red. For the sake of clarity, not all parameters are represented.
-
def remove_non_ascii(s: str) -> str:\n """\n return result\n ', - ' \n ```\nThis downloads the LLaMA inference code and installs the repository as a local pip package.\n ', - ' \ndef main():\n factory = InterfaceManagerFactory(start=datetime.now())\n managers = []\n for i in range(10):\n managers.append(factory.build(id=i))\n ', - ' = 0 :=\nbegin\nsplit,\n{ intros h f,\n rw pi_1_etalisation at h,\n simp [h],\n refl\n},\n{ intro h,\n have := @quasi_adjoint C D P,\n simp [←pi_1_etalisation, this, h],\n refl\n}\nend\n ' - ] - # fmt: on - self.assertEqual(processed_text, EXPECTED_TEXT) - processed_text_suffix_first = tokenizer.batch_decode( - tokenizer(self.PROMPTS, suffix_first=True, add_special_tokens=False)["input_ids"] - ) - - # fmt: off - EXPECTED_TEXT = [ - ' \n return result\n def remove_non_ascii(s: str) -> str:\n """ ', - ' \n ```\nThis downloads the LLaMA inference code and installs the repository as a local pip package.\n # Installation instructions:\n ```bash\n', - ' \ndef main():\n factory = InterfaceManagerFactory(start=datetime.now())\n managers = []\n for i in range(10):\n managers.append(factory.build(id=i))\n class InterfaceManagerFactory(AbstractManagerFactory):\n def __init__(', - ' = 0 :=\nbegin\nsplit,\n{ intros h f,\n rw pi_1_etalisation at h,\n simp [h],\n refl\n},\n{ intro h,\n have := @quasi_adjoint C D P,\n simp [←pi_1_etalisation, this, h],\n refl\n}\nend\n /-- A quasi-prefunctoid is 1-connected iff all its etalisations are 1-connected. -/\ntheorem connected_iff_etalisation [C D : precategoroid] (P : quasi_prefunctoid C D) :\nπ₁ P = 0 ↔ ' - ] - EXPECTED_IDS = torch.tensor([[ 1, 32007, 822, 3349, 29918, 5464, 29918, 294, 18869, 29898,29879, 29901, 851, 29897, 1599, 851, 29901, 13, 1678, 9995, 29871, 32008, 13, 1678, 736, 1121, 13, 32009, 15941, 1661, 29899, 28599, 2687, 4890, 515, 263, 1347, 29889, 13, 13, 1678, 826, 3174, 29901, 13, 4706, 269, 29901, 450, 1347, 304, 3349, 1661, 29899, 28599, 2687, 4890, 515, 29889, 13, 13, 1678, 16969, 29901, 13, 4706, 450, 1347, 411, 1661, 29899, 28599, 2687, 4890, 6206, 29889, 13, 1678, 9995, 13, 1678, 1121, 353, 5124, 13, 1678, 363, 274, 297, 269, 29901, 13, 4706, 565, 4356, 29898, 29883, 29897, 529, 29871, 29896, 29906, 29947, 29901, 13, 9651, 1121, 4619, 274, 32010, 2]]) - # fmt: on - self.assertEqual(processed_text_suffix_first, EXPECTED_TEXT) - input_ids = tokenizer(self.PROMPTS[0], return_tensors="pt")["input_ids"] - generated_ids = model.generate(input_ids.to(torch_device), max_new_tokens=128) - torch.testing.assert_close(generated_ids, EXPECTED_IDS) - - EXPECTED_INFILLING = [ - ' ' - ] - infilling = tokenizer.batch_decode(generated_ids) - self.assertEqual(infilling, EXPECTED_INFILLING) diff --git a/tests/transformers/tests/models/mistral/__init__.py b/tests/transformers/tests/models/mistral/__init__.py deleted file mode 100644 index e69de29bb2..0000000000 diff --git a/tests/transformers/tests/models/mistral/test_modeling_mistral.py b/tests/transformers/tests/models/mistral/test_modeling_mistral.py deleted file mode 100644 index 6014175668..0000000000 --- a/tests/transformers/tests/models/mistral/test_modeling_mistral.py +++ /dev/null @@ -1,634 +0,0 @@ - -# coding=utf-8 -# Copyright 2023 Mistral AI and The HuggingFace Inc. team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -""" Testing suite for the PyTorch Mistral model. """ - - -import gc -import tempfile -import unittest - -import pytest - -from transformers import AutoTokenizer, MistralConfig, is_torch_available, set_seed -from transformers.testing_utils import ( - backend_empty_cache, - is_flaky, - require_bitsandbytes, - require_flash_attn, - require_torch, - require_torch_gpu, - require_torch_sdpa, - slow, - torch_device, -) - -from optimum.habana.transformers.modeling_utils import adapt_transformers_to_gaudi - -from ...generation.test_utils import GenerationTesterMixin -from ...test_configuration_common import ConfigTester -from ...test_modeling_common import ModelTesterMixin, ids_tensor - - -torch_device = "hpu" -adapt_transformers_to_gaudi() - -if is_torch_available(): - import torch - - from transformers import ( - MistralForCausalLM, - MistralForSequenceClassification, - MistralModel, - ) - - -class MistralModelTester: - def __init__( - self, - parent, - batch_size=13, - seq_length=7, - is_training=True, - use_input_mask=True, - use_token_type_ids=False, - use_labels=True, - vocab_size=99, - hidden_size=32, - num_hidden_layers=2, - num_attention_heads=4, - num_key_value_heads=2, - intermediate_size=37, - hidden_act="gelu", - hidden_dropout_prob=0.1, - attention_probs_dropout_prob=0.1, - max_position_embeddings=512, - type_vocab_size=16, - type_sequence_label_size=2, - initializer_range=0.02, - num_labels=3, - num_choices=4, - pad_token_id=0, - scope=None, - ): - self.parent = parent - self.batch_size = batch_size - self.seq_length = seq_length - self.is_training = is_training - self.use_input_mask = use_input_mask - self.use_token_type_ids = use_token_type_ids - self.use_labels = use_labels - self.vocab_size = vocab_size - self.hidden_size = hidden_size - self.num_hidden_layers = num_hidden_layers - self.num_attention_heads = num_attention_heads - self.num_key_value_heads = num_key_value_heads - self.intermediate_size = intermediate_size - self.hidden_act = hidden_act - self.hidden_dropout_prob = hidden_dropout_prob - self.attention_probs_dropout_prob = attention_probs_dropout_prob - self.max_position_embeddings = max_position_embeddings - self.type_vocab_size = type_vocab_size - self.type_sequence_label_size = type_sequence_label_size - self.initializer_range = initializer_range - self.num_labels = num_labels - self.num_choices = num_choices - self.pad_token_id = pad_token_id - self.scope = scope - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs - def prepare_config_and_inputs(self): - input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size) - - input_mask = None - if self.use_input_mask: - input_mask = torch.tril(torch.ones(self.batch_size, self.seq_length)).to(torch_device) - - token_type_ids = None - if self.use_token_type_ids: - token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size) - - sequence_labels = None - token_labels = None - choice_labels = None - if self.use_labels: - sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size) - token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels) - choice_labels = ids_tensor([self.batch_size], self.num_choices) - - config = self.get_config() - - return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - - def get_config(self): - return MistralConfig( - vocab_size=self.vocab_size, - hidden_size=self.hidden_size, - num_hidden_layers=self.num_hidden_layers, - num_attention_heads=self.num_attention_heads, - num_key_value_heads=self.num_key_value_heads, - intermediate_size=self.intermediate_size, - hidden_act=self.hidden_act, - hidden_dropout_prob=self.hidden_dropout_prob, - attention_probs_dropout_prob=self.attention_probs_dropout_prob, - max_position_embeddings=self.max_position_embeddings, - type_vocab_size=self.type_vocab_size, - is_decoder=False, - initializer_range=self.initializer_range, - pad_token_id=self.pad_token_id, - ) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model with Llama->Mistral - def create_and_check_model( - self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - ): - model = MistralModel(config=config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=input_mask) - result = model(input_ids) - self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size)) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model_as_decoder with Llama->Mistral - def create_and_check_model_as_decoder( - self, - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ): - config.add_cross_attention = True - model = MistralModel(config) - model.to(torch_device) - model.eval() - result = model( - input_ids, - attention_mask=input_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - ) - result = model( - input_ids, - attention_mask=input_mask, - encoder_hidden_states=encoder_hidden_states, - ) - result = model(input_ids, attention_mask=input_mask) - self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size)) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_for_causal_lm with Llama->Mistral - def create_and_check_for_causal_lm( - self, - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ): - model = MistralForCausalLM(config=config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=input_mask, labels=token_labels) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size)) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_decoder_model_past_large_inputs with Llama->Mistral - def create_and_check_decoder_model_past_large_inputs( - self, - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ): - config.is_decoder = True - config.add_cross_attention = True - model = MistralForCausalLM(config=config) - model.to(torch_device) - model.eval() - - # first forward pass - outputs = model( - input_ids, - attention_mask=input_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - use_cache=True, - ) - past_key_values = outputs.past_key_values - - # create hypothetical multiple next token and extent to next_input_ids - next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size) - next_mask = ids_tensor((self.batch_size, 3), vocab_size=2) - - # append to next input_ids and - next_input_ids = torch.cat([input_ids, next_tokens], dim=-1) - next_attention_mask = torch.cat([input_mask, next_mask], dim=-1) - - output_from_no_past = model( - next_input_ids, - attention_mask=next_attention_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - output_hidden_states=True, - )["hidden_states"][0] - output_from_past = model( - next_tokens, - attention_mask=next_attention_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - past_key_values=past_key_values, - output_hidden_states=True, - )["hidden_states"][0] - - # select random slice - random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item() - output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach() - output_from_past_slice = output_from_past[:, :, random_slice_idx].detach() - - self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1]) - - # test that outputs are equal for slice - self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs_for_common - def prepare_config_and_inputs_for_common(self): - config_and_inputs = self.prepare_config_and_inputs() - ( - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - ) = config_and_inputs - inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask} - return config, inputs_dict - - -@require_torch -class MistralModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase): - all_model_classes = ( - (MistralModel, MistralForCausalLM, MistralForSequenceClassification) if is_torch_available() else () - ) - all_generative_model_classes = (MistralForCausalLM,) if is_torch_available() else () - pipeline_model_mapping = ( - { - "feature-extraction": MistralModel, - "text-classification": MistralForSequenceClassification, - "text-generation": MistralForCausalLM, - "zero-shot": MistralForSequenceClassification, - } - if is_torch_available() - else {} - ) - test_headmasking = False - test_pruning = False - - # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79245/workflows/9490ef58-79c2-410d-8f51-e3495156cf9c/jobs/1012146 - def is_pipeline_test_to_skip( - self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name - ): - return True - - # TODO: @Fxmarty - @is_flaky(max_attempts=3, description="flaky on some models.") - @require_torch_sdpa - @slow - def test_eager_matches_sdpa_generate(self): - super().test_eager_matches_sdpa_generate() - - def setUp(self): - self.model_tester = MistralModelTester(self) - self.config_tester = ConfigTester(self, config_class=MistralConfig, hidden_size=37) - - def test_config(self): - self.config_tester.run_common_tests() - - def test_model(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_model_various_embeddings(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - for type in ["absolute", "relative_key", "relative_key_query"]: - config_and_inputs[0].position_embedding_type = type - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_Mistral_sequence_classification_model(self): - config, input_dict = self.model_tester.prepare_config_and_inputs_for_common() - print(config) - config.num_labels = 3 - input_ids = input_dict["input_ids"] - attention_mask = input_ids.ne(1).to(torch_device) - sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size) - model = MistralForSequenceClassification(config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels) - self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels)) - - def test_Mistral_sequence_classification_model_for_single_label(self): - config, input_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.num_labels = 3 - config.problem_type = "single_label_classification" - input_ids = input_dict["input_ids"] - attention_mask = input_ids.ne(1).to(torch_device) - sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size) - model = MistralForSequenceClassification(config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels) - self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels)) - - def test_Mistral_sequence_classification_model_for_multi_label(self): - config, input_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.num_labels = 3 - config.problem_type = "multi_label_classification" - input_ids = input_dict["input_ids"] - attention_mask = input_ids.ne(1).to(torch_device) - sequence_labels = ids_tensor( - [self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size - ).to(torch.float) - model = MistralForSequenceClassification(config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels) - self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels)) - - @unittest.skip("Mistral buffers include complex numbers, which breaks this test") - def test_save_load_fast_init_from_base(self): - pass - - @unittest.skip("Mistral uses GQA on all models so the KV cache is a non standard format") - def test_past_key_values_format(self): - pass - - @require_flash_attn - @require_torch_gpu - @pytest.mark.flash_attn_test - @slow - def test_flash_attn_2_generate_padding_right(self): - import torch - - for model_class in self.all_generative_model_classes: - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - model = model_class(config) - - with tempfile.TemporaryDirectory() as tmpdirname: - model.save_pretrained(tmpdirname) - model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to( - torch_device - ) - - dummy_input = torch.LongTensor([[0, 2, 3, 4], [0, 2, 3, 4]]).to(torch_device) - dummy_attention_mask = torch.LongTensor([[1, 1, 1, 1], [1, 1, 1, 0]]).to(torch_device) - - model.generate(dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False) - - model = model_class.from_pretrained( - tmpdirname, - torch_dtype=torch.float16, - attn_implementation="flash_attention_2", - low_cpu_mem_usage=True, - ).to(torch_device) - - with self.assertRaises(ValueError): - _ = model.generate( - dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False - ) - - @require_flash_attn - @require_torch_gpu - @pytest.mark.flash_attn_test - @slow - def test_flash_attn_2_generate_use_cache(self): - import torch - - max_new_tokens = 30 - - for model_class in self.all_generative_model_classes: - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - dummy_input = inputs_dict[model_class.main_input_name] - if dummy_input.dtype in [torch.float32, torch.bfloat16]: - dummy_input = dummy_input.to(torch.float16) - - # make sure that all models have enough positions for generation - if hasattr(config, "max_position_embeddings"): - config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1 - - model = model_class(config) - - with tempfile.TemporaryDirectory() as tmpdirname: - model.save_pretrained(tmpdirname) - - dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input)) - # NOTE: Mistral apparently does not support right padding + use_cache with FA2. - dummy_attention_mask[:, -1] = 1 - - model = model_class.from_pretrained( - tmpdirname, - torch_dtype=torch.float16, - attn_implementation="flash_attention_2", - low_cpu_mem_usage=True, - ).to(torch_device) - - # Just test that a large cache works as expected - _ = model.generate( - dummy_input, - attention_mask=dummy_attention_mask, - max_new_tokens=max_new_tokens, - do_sample=False, - use_cache=True, - ) - - @require_flash_attn - @require_torch_gpu - @pytest.mark.flash_attn_test - @slow - def test_flash_attn_2_inference_equivalence_right_padding(self): - self.skipTest("Mistral flash attention does not support right padding") - - -@require_torch_gpu -class MistralIntegrationTest(unittest.TestCase): - # This variable is used to determine which CUDA device are we using for our runners (A10 or T4) - # Depending on the hardware we get different logits / generations - cuda_compute_capability_major_version = None - - @classmethod - def setUpClass(cls): - if is_torch_available() and torch.cuda.is_available(): - # 8 is for A100 / A10 and 7 for T4 - cls.cuda_compute_capability_major_version = torch.cuda.get_device_capability()[0] - - def tearDown(self): - torch.cuda.empty_cache() - gc.collect() - - @slow - def test_model_7b_logits(self): - input_ids = [1, 306, 4658, 278, 6593, 310, 2834, 338] - model = MistralForCausalLM.from_pretrained( - "mistralai/Mistral-7B-v0.1", device_map="auto", torch_dtype=torch.float16 - ) - input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device) - with torch.no_grad(): - out = model(input_ids).logits.cpu() - # Expected mean on dim = -1 - EXPECTED_MEAN = torch.tensor([[-2.5548, -2.5737, -3.0600, -2.5906, -2.8478, -2.8118, -2.9325, -2.7694]]) - torch.testing.assert_close(out.mean(-1), EXPECTED_MEAN, atol=1e-2, rtol=1e-2) - - EXPECTED_SLICE = { - 7: torch.tensor([-5.8781, -5.8616, -0.1052, -4.7200, -5.8781, -5.8774, -5.8773, -5.8777, -5.8781, -5.8780, -5.8781, -5.8779, -1.0787, 1.7583, -5.8779, -5.8780, -5.8783, -5.8778, -5.8776, -5.8781, -5.8784, -5.8778, -5.8778, -5.8777, -5.8779, -5.8778, -5.8776, -5.8780, -5.8779, -5.8781]), - 8: torch.tensor([-5.8711, -5.8555, -0.1050, -4.7148, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -1.0781, 1.7568, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711, -5.8711]), - } # fmt: skip - - print(out[0, 0, :30]) - torch.testing.assert_close( - out[0, 0, :30], EXPECTED_SLICE[self.cuda_compute_capability_major_version], atol=1e-4, rtol=1e-4 - ) - - del model - backend_empty_cache(torch_device) - gc.collect() - - @slow - @require_bitsandbytes - def test_model_7b_generation(self): - EXPECTED_TEXT_COMPLETION = { - 7: "My favourite condiment is 100% ketchup. I love it on everything. I'm not a big", - 8: "My favourite condiment is 100% ketchup. I’m not a fan of mustard, mayo,", - } - - prompt = "My favourite condiment is " - tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", use_fast=False) - model = MistralForCausalLM.from_pretrained( - "mistralai/Mistral-7B-v0.1", device_map={"": torch_device}, load_in_4bit=True - ) - input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device) - - # greedy generation outputs - generated_ids = model.generate(input_ids, max_new_tokens=20, temperature=0) - text = tokenizer.decode(generated_ids[0], skip_special_tokens=True) - self.assertEqual(EXPECTED_TEXT_COMPLETION[self.cuda_compute_capability_major_version], text) - - del model - backend_empty_cache(torch_device) - gc.collect() - - @require_bitsandbytes - @slow - @require_flash_attn - def test_model_7b_long_prompt(self): - EXPECTED_OUTPUT_TOKEN_IDS = [306, 338] - # An input with 4097 tokens that is above the size of the sliding window - input_ids = [1] + [306, 338] * 2048 - model = MistralForCausalLM.from_pretrained( - "mistralai/Mistral-7B-v0.1", - device_map={"": torch_device}, - load_in_4bit=True, - attn_implementation="flash_attention_2", - ) - input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device) - generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0) - self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist()) - - # Assisted generation - assistant_model = model - assistant_model.generation_config.num_assistant_tokens = 2 - assistant_model.generation_config.num_assistant_tokens_schedule = "constant" - generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0) - self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist()) - - del assistant_model - del model - backend_empty_cache(torch_device) - gc.collect() - - @slow - @require_torch_sdpa - def test_model_7b_long_prompt_sdpa(self): - EXPECTED_OUTPUT_TOKEN_IDS = [306, 338] - # An input with 4097 tokens that is above the size of the sliding window - input_ids = [1] + [306, 338] * 2048 - model = MistralForCausalLM.from_pretrained( - "mistralai/Mistral-7B-v0.1", device_map="auto", attn_implementation="sdpa", torch_dtype=torch.float16 - ) - input_ids = torch.tensor([input_ids]).to(model.model.embed_tokens.weight.device) - generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0) - self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist()) - - # Assisted generation - assistant_model = model - assistant_model.generation_config.num_assistant_tokens = 2 - assistant_model.generation_config.num_assistant_tokens_schedule = "constant" - generated_ids = model.generate(input_ids, max_new_tokens=4, temperature=0) - self.assertEqual(EXPECTED_OUTPUT_TOKEN_IDS, generated_ids[0][-2:].tolist()) - - del assistant_model - - backend_empty_cache(torch_device) - gc.collect() - - EXPECTED_TEXT_COMPLETION = """My favourite condiment is 100% ketchup. I love it on everything. I’m not a big""" - prompt = "My favourite condiment is " - tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", use_fast=False) - - input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device) - - # greedy generation outputs - generated_ids = model.generate(input_ids, max_new_tokens=20, temperature=0) - text = tokenizer.decode(generated_ids[0], skip_special_tokens=True) - self.assertEqual(EXPECTED_TEXT_COMPLETION, text) - - @slow - def test_speculative_generation(self): - EXPECTED_TEXT_COMPLETION = { - 7: "My favourite condiment is 100% Sriracha. I love the heat, the tang and the fact costs", - 8: "My favourite condiment is 100% Sriracha. I love the heat, the sweetness, the tang", - } - prompt = "My favourite condiment is " - tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", use_fast=False) - model = MistralForCausalLM.from_pretrained( - "mistralai/Mistral-7B-v0.1", device_map="auto", torch_dtype=torch.float16 - ) - input_ids = tokenizer.encode(prompt, return_tensors="pt").to(model.model.embed_tokens.weight.device) - - # greedy generation outputs - set_seed(0) - generated_ids = model.generate( - input_ids, max_new_tokens=20, do_sample=True, temperature=0.3, assistant_model=model - ) - text = tokenizer.decode(generated_ids[0], skip_special_tokens=True) - self.assertEqual(EXPECTED_TEXT_COMPLETION[self.cuda_compute_capability_major_version], text) - - del model - backend_empty_cache(torch_device) - gc.collect() - diff --git a/tests/transformers/tests/models/mixtral/__init__.py b/tests/transformers/tests/models/mixtral/__init__.py deleted file mode 100644 index e69de29bb2..0000000000 diff --git a/tests/transformers/tests/models/mixtral/test_modeling_mixtral.py b/tests/transformers/tests/models/mixtral/test_modeling_mixtral.py deleted file mode 100644 index 857a254a5d..0000000000 --- a/tests/transformers/tests/models/mixtral/test_modeling_mixtral.py +++ /dev/null @@ -1,611 +0,0 @@ - -# coding=utf-8 -# Copyright 2023 The HuggingFace Inc. team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -""" Testing suite for the PyTorch Mixtral model. """ - - -import tempfile -import unittest - -import pytest - -from transformers import MixtralConfig, is_torch_available -from transformers.testing_utils import ( - is_flaky, - require_flash_attn, - require_torch, - require_torch_gpu, - require_torch_sdpa, - slow, - torch_device, -) - -from optimum.habana.transformers.modeling_utils import adapt_transformers_to_gaudi - -from ...generation.test_utils import GenerationTesterMixin -from ...test_configuration_common import ConfigTester -from ...test_modeling_common import ModelTesterMixin, ids_tensor - - -torch_device = "hpu" -adapt_transformers_to_gaudi() - -if is_torch_available(): - import torch - - from transformers import MixtralForCausalLM, MixtralForSequenceClassification, MixtralModel - - -class MixtralModelTester: - def __init__( - self, - parent, - batch_size=13, - seq_length=7, - is_training=True, - use_input_mask=True, - use_token_type_ids=False, - use_labels=True, - vocab_size=99, - hidden_size=32, - num_hidden_layers=2, - num_attention_heads=4, - num_key_value_heads=2, - intermediate_size=37, - hidden_act="gelu", - hidden_dropout_prob=0.1, - attention_probs_dropout_prob=0.1, - max_position_embeddings=512, - type_vocab_size=16, - type_sequence_label_size=2, - initializer_range=0.02, - num_labels=3, - num_choices=4, - pad_token_id=0, - scope=None, - router_jitter_noise=0.1, - ): - self.parent = parent - self.batch_size = batch_size - self.seq_length = seq_length - self.is_training = is_training - self.use_input_mask = use_input_mask - self.use_token_type_ids = use_token_type_ids - self.use_labels = use_labels - self.vocab_size = vocab_size - self.hidden_size = hidden_size - self.num_hidden_layers = num_hidden_layers - self.num_attention_heads = num_attention_heads - self.num_key_value_heads = num_key_value_heads - self.intermediate_size = intermediate_size - self.hidden_act = hidden_act - self.hidden_dropout_prob = hidden_dropout_prob - self.attention_probs_dropout_prob = attention_probs_dropout_prob - self.max_position_embeddings = max_position_embeddings - self.type_vocab_size = type_vocab_size - self.type_sequence_label_size = type_sequence_label_size - self.initializer_range = initializer_range - self.num_labels = num_labels - self.num_choices = num_choices - self.pad_token_id = pad_token_id - self.scope = scope - self.router_jitter_noise = router_jitter_noise - - # Copied from tests.models.mistral.test_modeling_mistral.MistralModelTester.prepare_config_and_inputs - def prepare_config_and_inputs(self): - input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size) - - input_mask = None - if self.use_input_mask: - input_mask = torch.tril(torch.ones(self.batch_size, self.seq_length)).to(torch_device) - - token_type_ids = None - if self.use_token_type_ids: - token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size) - - sequence_labels = None - token_labels = None - choice_labels = None - if self.use_labels: - sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size) - token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels) - choice_labels = ids_tensor([self.batch_size], self.num_choices) - - config = self.get_config() - - return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - - def get_config(self): - return MixtralConfig( - vocab_size=self.vocab_size, - hidden_size=self.hidden_size, - num_hidden_layers=self.num_hidden_layers, - num_attention_heads=self.num_attention_heads, - num_key_value_heads=self.num_key_value_heads, - intermediate_size=self.intermediate_size, - hidden_act=self.hidden_act, - hidden_dropout_prob=self.hidden_dropout_prob, - attention_probs_dropout_prob=self.attention_probs_dropout_prob, - max_position_embeddings=self.max_position_embeddings, - type_vocab_size=self.type_vocab_size, - is_decoder=False, - initializer_range=self.initializer_range, - pad_token_id=self.pad_token_id, - num_experts_per_tok=2, - num_local_experts=2, - router_jitter_noise=self.router_jitter_noise, - ) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model with Llama->Mixtral - def create_and_check_model( - self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - ): - model = MixtralModel(config=config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=input_mask) - result = model(input_ids) - self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size)) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_model_as_decoder with Llama->Mixtral - def create_and_check_model_as_decoder( - self, - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ): - config.add_cross_attention = True - model = MixtralModel(config) - model.to(torch_device) - model.eval() - result = model( - input_ids, - attention_mask=input_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - ) - result = model( - input_ids, - attention_mask=input_mask, - encoder_hidden_states=encoder_hidden_states, - ) - result = model(input_ids, attention_mask=input_mask) - self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size)) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_for_causal_lm with Llama->Mixtral - def create_and_check_for_causal_lm( - self, - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ): - model = MixtralForCausalLM(config=config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=input_mask, labels=token_labels) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size)) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.create_and_check_decoder_model_past_large_inputs with Llama->Mixtral - def create_and_check_decoder_model_past_large_inputs( - self, - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ): - config.is_decoder = True - config.add_cross_attention = True - model = MixtralForCausalLM(config=config) - model.to(torch_device) - model.eval() - - # first forward pass - outputs = model( - input_ids, - attention_mask=input_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - use_cache=True, - ) - past_key_values = outputs.past_key_values - - # create hypothetical multiple next token and extent to next_input_ids - next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size) - next_mask = ids_tensor((self.batch_size, 3), vocab_size=2) - - # append to next input_ids and - next_input_ids = torch.cat([input_ids, next_tokens], dim=-1) - next_attention_mask = torch.cat([input_mask, next_mask], dim=-1) - - output_from_no_past = model( - next_input_ids, - attention_mask=next_attention_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - output_hidden_states=True, - )["hidden_states"][0] - output_from_past = model( - next_tokens, - attention_mask=next_attention_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - past_key_values=past_key_values, - output_hidden_states=True, - )["hidden_states"][0] - - # select random slice - random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item() - output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach() - output_from_past_slice = output_from_past[:, :, random_slice_idx].detach() - - self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1]) - - # test that outputs are equal for slice - self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)) - - # Copied from tests.models.llama.test_modeling_llama.LlamaModelTester.prepare_config_and_inputs_for_common with Llama->Mixtral - def prepare_config_and_inputs_for_common(self): - config_and_inputs = self.prepare_config_and_inputs() - ( - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - ) = config_and_inputs - inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask} - return config, inputs_dict - - -@require_torch -# Copied from tests.models.mistral.test_modeling_mistral.MistralModelTest with Mistral->Mixtral -class MixtralModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase): - all_model_classes = ( - (MixtralModel, MixtralForCausalLM, MixtralForSequenceClassification) if is_torch_available() else () - ) - all_generative_model_classes = (MixtralForCausalLM,) if is_torch_available() else () - pipeline_model_mapping = ( - { - "feature-extraction": MixtralModel, - "text-classification": MixtralForSequenceClassification, - "text-generation": MixtralForCausalLM, - "zero-shot": MixtralForSequenceClassification, - } - if is_torch_available() - else {} - ) - test_headmasking = False - test_pruning = False - - # TODO (ydshieh): Check this. See https://app.circleci.com/pipelines/github/huggingface/transformers/79245/workflows/9490ef58-79c2-410d-8f51-e3495156cf9c/jobs/1012146 - def is_pipeline_test_to_skip( - self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name - ): - return True - - # TODO: @Fxmarty - @is_flaky(max_attempts=3, description="flaky on some models.") - @require_torch_sdpa - @slow - def test_eager_matches_sdpa_generate(self): - super().test_eager_matches_sdpa_generate() - - def setUp(self): - self.model_tester = MixtralModelTester(self) - self.config_tester = ConfigTester(self, config_class=MixtralConfig, hidden_size=37) - - def test_config(self): - self.config_tester.run_common_tests() - - def test_model(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_model_various_embeddings(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - for type in ["absolute", "relative_key", "relative_key_query"]: - config_and_inputs[0].position_embedding_type = type - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_Mixtral_sequence_classification_model(self): - config, input_dict = self.model_tester.prepare_config_and_inputs_for_common() - print(config) - config.num_labels = 3 - input_ids = input_dict["input_ids"] - attention_mask = input_ids.ne(1).to(torch_device) - sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size) - model = MixtralForSequenceClassification(config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels) - self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels)) - - def test_Mixtral_sequence_classification_model_for_single_label(self): - config, input_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.num_labels = 3 - config.problem_type = "single_label_classification" - input_ids = input_dict["input_ids"] - attention_mask = input_ids.ne(1).to(torch_device) - sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size) - model = MixtralForSequenceClassification(config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels) - self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels)) - - def test_Mixtral_sequence_classification_model_for_multi_label(self): - config, input_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.num_labels = 3 - config.problem_type = "multi_label_classification" - input_ids = input_dict["input_ids"] - attention_mask = input_ids.ne(1).to(torch_device) - sequence_labels = ids_tensor( - [self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size - ).to(torch.float) - model = MixtralForSequenceClassification(config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels) - self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels)) - - @unittest.skip("Mixtral buffers include complex numbers, which breaks this test") - def test_save_load_fast_init_from_base(self): - pass - - @unittest.skip("Mixtral uses GQA on all models so the KV cache is a non standard format") - def test_past_key_values_format(self): - pass - - @require_flash_attn - @require_torch_gpu - @pytest.mark.flash_attn_test - @slow - def test_flash_attn_2_generate_padding_right(self): - import torch - - for model_class in self.all_generative_model_classes: - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - model = model_class(config) - - with tempfile.TemporaryDirectory() as tmpdirname: - model.save_pretrained(tmpdirname) - model = model_class.from_pretrained(tmpdirname, torch_dtype=torch.float16, low_cpu_mem_usage=True).to( - torch_device - ) - - dummy_input = torch.LongTensor([[0, 2, 3, 4], [0, 2, 3, 4]]).to(torch_device) - dummy_attention_mask = torch.LongTensor([[1, 1, 1, 1], [1, 1, 1, 0]]).to(torch_device) - - model.generate(dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False) - - model = model_class.from_pretrained( - tmpdirname, - torch_dtype=torch.float16, - attn_implementation="flash_attention_2", - low_cpu_mem_usage=True, - ).to(torch_device) - - with self.assertRaises(ValueError): - _ = model.generate( - dummy_input, attention_mask=dummy_attention_mask, max_new_tokens=1, do_sample=False - ) - - @require_flash_attn - @require_torch_gpu - @pytest.mark.flash_attn_test - @slow - def test_flash_attn_2_generate_use_cache(self): - import torch - - max_new_tokens = 30 - - for model_class in self.all_generative_model_classes: - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - dummy_input = inputs_dict[model_class.main_input_name] - if dummy_input.dtype in [torch.float32, torch.bfloat16]: - dummy_input = dummy_input.to(torch.float16) - - # make sure that all models have enough positions for generation - if hasattr(config, "max_position_embeddings"): - config.max_position_embeddings = max_new_tokens + dummy_input.shape[1] + 1 - - model = model_class(config) - - with tempfile.TemporaryDirectory() as tmpdirname: - model.save_pretrained(tmpdirname) - - dummy_attention_mask = inputs_dict.get("attention_mask", torch.ones_like(dummy_input)) - # NOTE: Mixtral apparently does not support right padding + use_cache with FA2. - dummy_attention_mask[:, -1] = 1 - - model = model_class.from_pretrained( - tmpdirname, - torch_dtype=torch.float16, - attn_implementation="flash_attention_2", - low_cpu_mem_usage=True, - ).to(torch_device) - - # Just test that a large cache works as expected - _ = model.generate( - dummy_input, - attention_mask=dummy_attention_mask, - max_new_tokens=max_new_tokens, - do_sample=False, - use_cache=True, - ) - - @require_flash_attn - @require_torch_gpu - @pytest.mark.flash_attn_test - @slow - def test_flash_attn_2_inference_equivalence_right_padding(self): - self.skipTest("Mixtral flash attention does not support right padding") - - # Ignore copy - def test_load_balancing_loss(self): - r""" - Let's make sure we can actually compute the loss and do a backward on it. - """ - config, input_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.num_labels = 3 - config.num_local_experts = 8 - config.output_router_logits = True - input_ids = input_dict["input_ids"] - attention_mask = input_ids.ne(1).to(torch_device) - model = MixtralForCausalLM(config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=attention_mask) - self.assertEqual(result.router_logits[0].shape, (91, config.num_local_experts)) - torch.testing.assert_close(result.aux_loss.cpu(), torch.tensor(2, dtype=torch.float32), rtol=1e-2, atol=1e-2) - - # First, we make sure that adding padding tokens doesn't change the loss - # loss(input_ids, attention_mask=None) == loss(input_ids + padding, attention_mask=attention_mask_with_padding) - pad_length = 1000 - # Add padding tokens (assume that pad_token_id=1) to input_ids - padding_block = torch.ones(input_ids.shape[0], pad_length, dtype=torch.int32).to(torch_device) - padded_input_ids = torch.cat((padding_block, input_ids), dim=1) # this is to simulate padding to the left - padded_attention_mask = padded_input_ids.ne(1).to(torch_device) - - padded_result = model(padded_input_ids, attention_mask=padded_attention_mask) - torch.testing.assert_close(result.aux_loss.cpu(), padded_result.aux_loss.cpu(), rtol=1e-4, atol=1e-4) - - # We make sure that the loss of includding padding tokens != the loss without padding tokens - # if attention_mask=None --> we don't exclude padding tokens - include_padding_result = model(padded_input_ids, attention_mask=None) - - # This is to mimic torch.testing.assert_not_close - self.assertNotAlmostEqual(include_padding_result.aux_loss.item(), result.aux_loss.item()) - - -@require_torch -class MixtralIntegrationTest(unittest.TestCase): - # This variable is used to determine which CUDA device are we using for our runners (A10 or T4) - # Depending on the hardware we get different logits / generations - cuda_compute_capability_major_version = None - - @classmethod - def setUpClass(cls): - if is_torch_available() and torch.cuda.is_available(): - # 8 is for A100 / A10 and 7 for T4 - cls.cuda_compute_capability_major_version = torch.cuda.get_device_capability()[0] - - @slow - @require_torch_gpu - def test_small_model_logits(self): - model_id = "hf-internal-testing/Mixtral-tiny" - dummy_input = torch.LongTensor([[0, 1, 0], [0, 1, 0]]).to(torch_device) - - model = MixtralForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True).to( - torch_device - ) - # TODO: might need to tweak it in case the logits do not match on our daily runners - # these logits have been obtained with the original megablocks impelmentation. - EXPECTED_LOGITS = { - 7: torch.Tensor([[0.1670, 0.1620, 0.6094], [-0.8906, -0.1588, -0.6060], [0.1572, 0.1290, 0.7246]]).to( - torch_device - ), - 8: torch.Tensor([[0.1631, 0.1621, 0.6094], [-0.8906, -0.1621, -0.6094], [0.1572, 0.1270, 0.7227]]).to( - torch_device - ), - } - with torch.no_grad(): - logits = model(dummy_input).logits - - torch.testing.assert_close( - logits[0, :3, :3], EXPECTED_LOGITS[self.cuda_compute_capability_major_version], atol=1e-3, rtol=1e-3 - ) - torch.testing.assert_close( - logits[1, :3, :3], EXPECTED_LOGITS[self.cuda_compute_capability_major_version], atol=1e-3, rtol=1e-3 - ) - - @slow - @require_torch_gpu - def test_small_model_logits_batched(self): - model_id = "hf-internal-testing/Mixtral-tiny" - dummy_input = torch.LongTensor([[0, 0, 0, 0, 0, 0, 1, 2, 3], [1, 1, 2, 3, 4, 5, 6, 7, 8]]).to(torch_device) - attention_mask = dummy_input.ne(0).to(torch.long) - - model = MixtralForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, low_cpu_mem_usage=True).to( - torch_device - ) - - # TODO: might need to tweak it in case the logits do not match on our daily runners - EXPECTED_LOGITS_LEFT = { - 7: torch.Tensor( - [[0.1750, 0.0537, 0.7007], [0.1750, 0.0537, 0.7007], [0.1750, 0.0537, 0.7007]], - ).to(torch_device), - 8: torch.Tensor([[0.1914, 0.0508, 0.7188], [0.1953, 0.0510, 0.7227], [0.1973, 0.0562, 0.7148]]).to( - torch_device - ), - } - - EXPECTED_LOGITS_LEFT_UNPADDED = { - 7: torch.Tensor( - [[0.2212, 0.5200, -0.3816], [0.8213, -0.2313, 0.6069], [0.2664, -0.7090, 0.2468]], - ).to(torch_device), - 8: torch.Tensor([[0.2217, 0.5195, -0.3828], [0.8203, -0.2295, 0.6055], [0.2676, -0.7109, 0.2461]]).to( - torch_device - ), - } - - EXPECTED_LOGITS_RIGHT_UNPADDED = { - 7: torch.Tensor([[0.2205, 0.1232, -0.1611], [-0.3484, 0.3030, -1.0312], [0.0742, 0.7930, 0.7969]]).to( - torch_device - ), - 8: torch.Tensor([[0.2178, 0.1260, -0.1621], [-0.3496, 0.2988, -1.0312], [0.0693, 0.7930, 0.8008]]).to( - torch_device - ), - } - - with torch.no_grad(): - logits = model(dummy_input, attention_mask=attention_mask).logits - - torch.testing.assert_close( - logits[0, :3, :3], EXPECTED_LOGITS_LEFT[self.cuda_compute_capability_major_version], atol=1e-3, rtol=1e-3 - ) - torch.testing.assert_close( - logits[0, -3:, -3:], - EXPECTED_LOGITS_LEFT_UNPADDED[self.cuda_compute_capability_major_version], - atol=1e-3, - rtol=1e-3, - ) - torch.testing.assert_close( - logits[1, -3:, -3:], - EXPECTED_LOGITS_RIGHT_UNPADDED[self.cuda_compute_capability_major_version], - atol=1e-3, - rtol=1e-3, - ) - diff --git a/tests/transformers/tests/models/roberta/__init__.py b/tests/transformers/tests/models/roberta/__init__.py deleted file mode 100644 index e69de29bb2..0000000000 diff --git a/tests/transformers/tests/models/roberta/test_modeling_roberta.py b/tests/transformers/tests/models/roberta/test_modeling_roberta.py deleted file mode 100644 index eaa7aa7564..0000000000 --- a/tests/transformers/tests/models/roberta/test_modeling_roberta.py +++ /dev/null @@ -1,587 +0,0 @@ - -# coding=utf-8 -# Copyright 2020 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - - -import unittest - -from transformers import RobertaConfig, is_torch_available -from transformers.testing_utils import TestCasePlus, require_torch, slow, torch_device - -from optimum.habana.transformers.modeling_utils import adapt_transformers_to_gaudi - -from ...generation.test_utils import GenerationTesterMixin -from ...test_configuration_common import ConfigTester -from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask - - -torch_device = "hpu" -adapt_transformers_to_gaudi() - -if is_torch_available(): - import torch - - from transformers import ( - RobertaForCausalLM, - RobertaForMaskedLM, - RobertaForMultipleChoice, - RobertaForQuestionAnswering, - RobertaForSequenceClassification, - RobertaForTokenClassification, - RobertaModel, - ) - from transformers.models.roberta.modeling_roberta import ( - ROBERTA_PRETRAINED_MODEL_ARCHIVE_LIST, - RobertaEmbeddings, - create_position_ids_from_input_ids, - ) - -ROBERTA_TINY = "sshleifer/tiny-distilroberta-base" - - -class RobertaModelTester: - def __init__( - self, - parent, - batch_size=13, - seq_length=7, - is_training=True, - use_input_mask=True, - use_token_type_ids=True, - use_labels=True, - vocab_size=99, - hidden_size=32, - num_hidden_layers=2, - num_attention_heads=4, - intermediate_size=37, - hidden_act="gelu", - hidden_dropout_prob=0.1, - attention_probs_dropout_prob=0.1, - max_position_embeddings=512, - type_vocab_size=16, - type_sequence_label_size=2, - initializer_range=0.02, - num_labels=3, - num_choices=4, - scope=None, - ): - self.parent = parent - self.batch_size = batch_size - self.seq_length = seq_length - self.is_training = is_training - self.use_input_mask = use_input_mask - self.use_token_type_ids = use_token_type_ids - self.use_labels = use_labels - self.vocab_size = vocab_size - self.hidden_size = hidden_size - self.num_hidden_layers = num_hidden_layers - self.num_attention_heads = num_attention_heads - self.intermediate_size = intermediate_size - self.hidden_act = hidden_act - self.hidden_dropout_prob = hidden_dropout_prob - self.attention_probs_dropout_prob = attention_probs_dropout_prob - self.max_position_embeddings = max_position_embeddings - self.type_vocab_size = type_vocab_size - self.type_sequence_label_size = type_sequence_label_size - self.initializer_range = initializer_range - self.num_labels = num_labels - self.num_choices = num_choices - self.scope = scope - - def prepare_config_and_inputs(self): - input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size) - - input_mask = None - if self.use_input_mask: - input_mask = random_attention_mask([self.batch_size, self.seq_length]) - - token_type_ids = None - if self.use_token_type_ids: - token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size) - - sequence_labels = None - token_labels = None - choice_labels = None - if self.use_labels: - sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size) - token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels) - choice_labels = ids_tensor([self.batch_size], self.num_choices) - - config = self.get_config() - - return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - - def get_config(self): - return RobertaConfig( - vocab_size=self.vocab_size, - hidden_size=self.hidden_size, - num_hidden_layers=self.num_hidden_layers, - num_attention_heads=self.num_attention_heads, - intermediate_size=self.intermediate_size, - hidden_act=self.hidden_act, - hidden_dropout_prob=self.hidden_dropout_prob, - attention_probs_dropout_prob=self.attention_probs_dropout_prob, - max_position_embeddings=self.max_position_embeddings, - type_vocab_size=self.type_vocab_size, - initializer_range=self.initializer_range, - ) - - def get_pipeline_config(self): - config = self.get_config() - config.vocab_size = 300 - return config - - def prepare_config_and_inputs_for_decoder(self): - ( - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - ) = self.prepare_config_and_inputs() - - config.is_decoder = True - encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size]) - encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2) - - return ( - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ) - - def create_and_check_model( - self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - ): - model = RobertaModel(config=config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids) - result = model(input_ids, token_type_ids=token_type_ids) - result = model(input_ids) - - self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size)) - self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size)) - - def create_and_check_model_as_decoder( - self, - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ): - config.add_cross_attention = True - model = RobertaModel(config) - model.to(torch_device) - model.eval() - result = model( - input_ids, - attention_mask=input_mask, - token_type_ids=token_type_ids, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - ) - result = model( - input_ids, - attention_mask=input_mask, - token_type_ids=token_type_ids, - encoder_hidden_states=encoder_hidden_states, - ) - result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids) - self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size)) - self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size)) - - def create_and_check_for_causal_lm( - self, - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ): - model = RobertaForCausalLM(config=config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size)) - - def create_and_check_decoder_model_past_large_inputs( - self, - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ): - config.is_decoder = True - config.add_cross_attention = True - model = RobertaForCausalLM(config=config).to(torch_device).eval() - - # make sure that ids don't start with pad token - mask = input_ids.ne(config.pad_token_id).long() - input_ids = input_ids * mask - - # first forward pass - outputs = model( - input_ids, - attention_mask=input_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - use_cache=True, - ) - past_key_values = outputs.past_key_values - - # create hypothetical multiple next token and extent to next_input_ids - next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size) - - # make sure that ids don't start with pad token - mask = next_tokens.ne(config.pad_token_id).long() - next_tokens = next_tokens * mask - next_mask = ids_tensor((self.batch_size, 3), vocab_size=2) - - # append to next input_ids and - next_input_ids = torch.cat([input_ids, next_tokens], dim=-1) - next_attention_mask = torch.cat([input_mask, next_mask], dim=-1) - - output_from_no_past = model( - next_input_ids, - attention_mask=next_attention_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - output_hidden_states=True, - )["hidden_states"][0] - output_from_past = model( - next_tokens, - attention_mask=next_attention_mask, - encoder_hidden_states=encoder_hidden_states, - encoder_attention_mask=encoder_attention_mask, - past_key_values=past_key_values, - output_hidden_states=True, - )["hidden_states"][0] - - # select random slice - random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item() - output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach() - output_from_past_slice = output_from_past[:, :, random_slice_idx].detach() - - self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1]) - - # test that outputs are equal for slice - self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)) - - def create_and_check_for_masked_lm( - self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - ): - model = RobertaForMaskedLM(config=config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size)) - - def create_and_check_for_token_classification( - self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - ): - config.num_labels = self.num_labels - model = RobertaForTokenClassification(config=config) - model.to(torch_device) - model.eval() - result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels)) - - def create_and_check_for_multiple_choice( - self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - ): - config.num_choices = self.num_choices - model = RobertaForMultipleChoice(config=config) - model.to(torch_device) - model.eval() - multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous() - multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous() - multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous() - result = model( - multiple_choice_inputs_ids, - attention_mask=multiple_choice_input_mask, - token_type_ids=multiple_choice_token_type_ids, - labels=choice_labels, - ) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices)) - - def create_and_check_for_question_answering( - self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels - ): - model = RobertaForQuestionAnswering(config=config) - model.to(torch_device) - model.eval() - result = model( - input_ids, - attention_mask=input_mask, - token_type_ids=token_type_ids, - start_positions=sequence_labels, - end_positions=sequence_labels, - ) - self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length)) - self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length)) - - def prepare_config_and_inputs_for_common(self): - config_and_inputs = self.prepare_config_and_inputs() - ( - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - ) = config_and_inputs - inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask} - return config, inputs_dict - - -@require_torch -class RobertaModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase): - all_model_classes = ( - ( - RobertaForCausalLM, - RobertaForMaskedLM, - RobertaModel, - RobertaForSequenceClassification, - RobertaForTokenClassification, - RobertaForMultipleChoice, - RobertaForQuestionAnswering, - ) - if is_torch_available() - else () - ) - all_generative_model_classes = (RobertaForCausalLM,) if is_torch_available() else () - pipeline_model_mapping = ( - { - "feature-extraction": RobertaModel, - "fill-mask": RobertaForMaskedLM, - "question-answering": RobertaForQuestionAnswering, - "text-classification": RobertaForSequenceClassification, - "text-generation": RobertaForCausalLM, - "token-classification": RobertaForTokenClassification, - "zero-shot": RobertaForSequenceClassification, - } - if is_torch_available() - else {} - ) - fx_compatible = True - model_split_percents = [0.5, 0.8, 0.9] - - def setUp(self): - self.model_tester = RobertaModelTester(self) - self.config_tester = ConfigTester(self, config_class=RobertaConfig, hidden_size=37) - - def test_config(self): - self.config_tester.run_common_tests() - - def test_model(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_model_various_embeddings(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - for type in ["absolute", "relative_key", "relative_key_query"]: - config_and_inputs[0].position_embedding_type = type - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_model_as_decoder(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder() - self.model_tester.create_and_check_model_as_decoder(*config_and_inputs) - - def test_model_as_decoder_with_default_input_mask(self): - # This regression test was failing with PyTorch < 1.3 - ( - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ) = self.model_tester.prepare_config_and_inputs_for_decoder() - - input_mask = None - - self.model_tester.create_and_check_model_as_decoder( - config, - input_ids, - token_type_ids, - input_mask, - sequence_labels, - token_labels, - choice_labels, - encoder_hidden_states, - encoder_attention_mask, - ) - - def test_for_causal_lm(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder() - self.model_tester.create_and_check_for_causal_lm(*config_and_inputs) - - def test_decoder_model_past_with_large_inputs(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder() - self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs) - - def test_decoder_model_past_with_large_inputs_relative_pos_emb(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder() - config_and_inputs[0].position_embedding_type = "relative_key" - self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs) - - def test_for_masked_lm(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_for_masked_lm(*config_and_inputs) - - def test_for_token_classification(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_for_token_classification(*config_and_inputs) - - def test_for_multiple_choice(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs) - - def test_for_question_answering(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_for_question_answering(*config_and_inputs) - - @slow - def test_model_from_pretrained(self): - model_name = "FacebookAI/roberta-base" - model = RobertaModel.from_pretrained(model_name) - self.assertIsNotNone(model) - - def test_create_position_ids_respects_padding_index(self): - """Ensure that the default position ids only assign a sequential . This is a regression - test for https://github.com/huggingface/transformers/issues/1761 - - The position ids should be masked with the embedding object's padding index. Therefore, the - first available non-padding position index is RobertaEmbeddings.padding_idx + 1 - """ - config = self.model_tester.prepare_config_and_inputs()[0] - model = RobertaEmbeddings(config=config) - - input_ids = torch.as_tensor([[12, 31, 13, model.padding_idx]]) - expected_positions = torch.as_tensor( - [[0 + model.padding_idx + 1, 1 + model.padding_idx + 1, 2 + model.padding_idx + 1, model.padding_idx]] - ) - - position_ids = create_position_ids_from_input_ids(input_ids, model.padding_idx) - self.assertEqual(position_ids.shape, expected_positions.shape) - self.assertTrue(torch.all(torch.eq(position_ids, expected_positions))) - - def test_create_position_ids_from_inputs_embeds(self): - """Ensure that the default position ids only assign a sequential . This is a regression - test for https://github.com/huggingface/transformers/issues/1761 - - The position ids should be masked with the embedding object's padding index. Therefore, the - first available non-padding position index is RobertaEmbeddings.padding_idx + 1 - """ - config = self.model_tester.prepare_config_and_inputs()[0] - embeddings = RobertaEmbeddings(config=config) - - inputs_embeds = torch.empty(2, 4, 30) - expected_single_positions = [ - 0 + embeddings.padding_idx + 1, - 1 + embeddings.padding_idx + 1, - 2 + embeddings.padding_idx + 1, - 3 + embeddings.padding_idx + 1, - ] - expected_positions = torch.as_tensor([expected_single_positions, expected_single_positions]) - position_ids = embeddings.create_position_ids_from_inputs_embeds(inputs_embeds) - self.assertEqual(position_ids.shape, expected_positions.shape) - self.assertTrue(torch.all(torch.eq(position_ids, expected_positions))) - - -@require_torch -class RobertaModelIntegrationTest(TestCasePlus): - @slow - def test_inference_masked_lm(self): - model = RobertaForMaskedLM.from_pretrained("FacebookAI/roberta-base") - - input_ids = torch.tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]]) - with torch.no_grad(): - output = model(input_ids)[0] - expected_shape = torch.Size((1, 11, 50265)) - self.assertEqual(output.shape, expected_shape) - # compare the actual values for a slice. - expected_slice = torch.tensor( - [[[33.8802, -4.3103, 22.7761], [4.6539, -2.8098, 13.6253], [1.8228, -3.6898, 8.8600]]] - ) - - # roberta = torch.hub.load('pytorch/fairseq', 'roberta.base') - # roberta.eval() - # expected_slice = roberta.model.forward(input_ids)[0][:, :3, :3].detach() - - self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4)) - - @slow - def test_inference_no_head(self): - model = RobertaModel.from_pretrained("FacebookAI/roberta-base") - - input_ids = torch.tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]]) - with torch.no_grad(): - output = model(input_ids)[0] - # compare the actual values for a slice. - expected_slice = torch.tensor( - [[[-0.0231, 0.0782, 0.0074], [-0.1854, 0.0540, -0.0175], [0.0548, 0.0799, 0.1687]]] - ) - - # roberta = torch.hub.load('pytorch/fairseq', 'roberta.base') - # roberta.eval() - # expected_slice = roberta.extract_features(input_ids)[:, :3, :3].detach() - - self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4)) - - @slow - def test_inference_classification_head(self): - model = RobertaForSequenceClassification.from_pretrained("FacebookAI/roberta-large-mnli") - - input_ids = torch.tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]]) - with torch.no_grad(): - output = model(input_ids)[0] - expected_shape = torch.Size((1, 3)) - self.assertEqual(output.shape, expected_shape) - expected_tensor = torch.tensor([[-0.9469, 0.3913, 0.5118]]) - - # roberta = torch.hub.load('pytorch/fairseq', 'roberta.large.mnli') - # roberta.eval() - # expected_tensor = roberta.predict("mnli", input_ids, return_logits=True).detach() - - self.assertTrue(torch.allclose(output, expected_tensor, atol=1e-4)) - diff --git a/tests/transformers/tests/models/swin/__init__.py b/tests/transformers/tests/models/swin/__init__.py deleted file mode 100644 index e69de29bb2..0000000000 diff --git a/tests/transformers/tests/models/swin/test_modeling_swin.py b/tests/transformers/tests/models/swin/test_modeling_swin.py deleted file mode 100644 index 41b26c11ee..0000000000 --- a/tests/transformers/tests/models/swin/test_modeling_swin.py +++ /dev/null @@ -1,507 +0,0 @@ -# coding=utf-8 -# Copyright 2022 The HuggingFace Inc. team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -""" Testing suite for the PyTorch Swin model. """ - -import collections -import unittest - -from transformers import SwinConfig -from transformers.testing_utils import require_torch, require_vision, slow, torch_device -from transformers.utils import cached_property, is_torch_available, is_vision_available - -from optimum.habana.transformers.modeling_utils import adapt_transformers_to_gaudi - -from ...test_configuration_common import ConfigTester -from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor - - -torch_device = "hpu" -adapt_transformers_to_gaudi() - -if is_torch_available(): - import torch - from torch import nn - - from transformers import SwinBackbone, SwinForImageClassification, SwinForMaskedImageModeling, SwinModel - from transformers.models.swin.modeling_swin import SWIN_PRETRAINED_MODEL_ARCHIVE_LIST - - -if is_vision_available(): - from PIL import Image - - from transformers import AutoImageProcessor - - -class SwinModelTester: - def __init__( - self, - parent, - batch_size=13, - image_size=32, - patch_size=2, - num_channels=3, - embed_dim=16, - depths=[1, 2, 1], - num_heads=[2, 2, 4], - window_size=2, - mlp_ratio=2.0, - qkv_bias=True, - hidden_dropout_prob=0.0, - attention_probs_dropout_prob=0.0, - drop_path_rate=0.1, - hidden_act="gelu", - use_absolute_embeddings=False, - patch_norm=True, - initializer_range=0.02, - layer_norm_eps=1e-5, - is_training=True, - scope=None, - use_labels=True, - type_sequence_label_size=10, - encoder_stride=8, - out_features=["stage1", "stage2"], - out_indices=[1, 2], - ): - self.parent = parent - self.batch_size = batch_size - self.image_size = image_size - self.patch_size = patch_size - self.num_channels = num_channels - self.embed_dim = embed_dim - self.depths = depths - self.num_heads = num_heads - self.window_size = window_size - self.mlp_ratio = mlp_ratio - self.qkv_bias = qkv_bias - self.hidden_dropout_prob = hidden_dropout_prob - self.attention_probs_dropout_prob = attention_probs_dropout_prob - self.drop_path_rate = drop_path_rate - self.hidden_act = hidden_act - self.use_absolute_embeddings = use_absolute_embeddings - self.patch_norm = patch_norm - self.layer_norm_eps = layer_norm_eps - self.initializer_range = initializer_range - self.is_training = is_training - self.scope = scope - self.use_labels = use_labels - self.type_sequence_label_size = type_sequence_label_size - self.encoder_stride = encoder_stride - self.out_features = out_features - self.out_indices = out_indices - - def prepare_config_and_inputs(self): - pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size]) - - labels = None - if self.use_labels: - labels = ids_tensor([self.batch_size], self.type_sequence_label_size) - - config = self.get_config() - - return config, pixel_values, labels - - def get_config(self): - return SwinConfig( - image_size=self.image_size, - patch_size=self.patch_size, - num_channels=self.num_channels, - embed_dim=self.embed_dim, - depths=self.depths, - num_heads=self.num_heads, - window_size=self.window_size, - mlp_ratio=self.mlp_ratio, - qkv_bias=self.qkv_bias, - hidden_dropout_prob=self.hidden_dropout_prob, - attention_probs_dropout_prob=self.attention_probs_dropout_prob, - drop_path_rate=self.drop_path_rate, - hidden_act=self.hidden_act, - use_absolute_embeddings=self.use_absolute_embeddings, - path_norm=self.patch_norm, - layer_norm_eps=self.layer_norm_eps, - initializer_range=self.initializer_range, - encoder_stride=self.encoder_stride, - out_features=self.out_features, - out_indices=self.out_indices, - ) - - def create_and_check_model(self, config, pixel_values, labels): - model = SwinModel(config=config) - model.to(torch_device) - model.eval() - result = model(pixel_values) - - expected_seq_len = ((config.image_size // config.patch_size) ** 2) // (4 ** (len(config.depths) - 1)) - expected_dim = int(config.embed_dim * 2 ** (len(config.depths) - 1)) - - self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, expected_seq_len, expected_dim)) - - def create_and_check_backbone(self, config, pixel_values, labels): - model = SwinBackbone(config=config) - model.to(torch_device) - model.eval() - result = model(pixel_values) - - # verify hidden states - self.parent.assertEqual(len(result.feature_maps), len(config.out_features)) - self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, model.channels[0], 16, 16]) - - # verify channels - self.parent.assertEqual(len(model.channels), len(config.out_features)) - - # verify backbone works with out_features=None - config.out_features = None - model = SwinBackbone(config=config) - model.to(torch_device) - model.eval() - result = model(pixel_values) - - # verify feature maps - self.parent.assertEqual(len(result.feature_maps), 1) - self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, model.channels[-1], 4, 4]) - - # verify channels - self.parent.assertEqual(len(model.channels), 1) - - def create_and_check_for_masked_image_modeling(self, config, pixel_values, labels): - model = SwinForMaskedImageModeling(config=config) - model.to(torch_device) - model.eval() - result = model(pixel_values) - self.parent.assertEqual( - result.logits.shape, (self.batch_size, self.num_channels, self.image_size, self.image_size) - ) - - # test greyscale images - config.num_channels = 1 - model = SwinForMaskedImageModeling(config) - model.to(torch_device) - model.eval() - - pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size]) - result = model(pixel_values) - self.parent.assertEqual(result.logits.shape, (self.batch_size, 1, self.image_size, self.image_size)) - - def create_and_check_for_image_classification(self, config, pixel_values, labels): - config.num_labels = self.type_sequence_label_size - model = SwinForImageClassification(config) - model.to(torch_device) - model.eval() - result = model(pixel_values, labels=labels) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size)) - - # test greyscale images - config.num_channels = 1 - model = SwinForImageClassification(config) - model.to(torch_device) - model.eval() - - pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size]) - result = model(pixel_values) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size)) - - def prepare_config_and_inputs_for_common(self): - config_and_inputs = self.prepare_config_and_inputs() - ( - config, - pixel_values, - labels, - ) = config_and_inputs - inputs_dict = {"pixel_values": pixel_values} - return config, inputs_dict - - -@require_torch -class SwinModelTest(ModelTesterMixin, unittest.TestCase): - all_model_classes = ( - ( - SwinModel, - SwinBackbone, - SwinForImageClassification, - SwinForMaskedImageModeling, - ) - if is_torch_available() - else () - ) - pipeline_model_mapping = ( - {"image-feature-extraction": SwinModel, "image-classification": SwinForImageClassification} - if is_torch_available() - else {} - ) - fx_compatible = True - - test_pruning = False - test_resize_embeddings = False - test_head_masking = False - - def setUp(self): - self.model_tester = SwinModelTester(self) - self.config_tester = ConfigTester(self, config_class=SwinConfig, embed_dim=37) - - def test_config(self): - self.create_and_test_config_common_properties() - self.config_tester.create_and_test_config_to_json_string() - self.config_tester.create_and_test_config_to_json_file() - self.config_tester.create_and_test_config_from_and_save_pretrained() - self.config_tester.create_and_test_config_with_num_labels() - self.config_tester.check_config_can_be_init_without_params() - self.config_tester.check_config_arguments_init() - - def create_and_test_config_common_properties(self): - return - - def test_model(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model(*config_and_inputs) - - # TODO: check if this works again for PyTorch 2.x.y - @unittest.skip(reason="Got `CUDA error: misaligned address` with PyTorch 2.0.0.") - def test_multi_gpu_data_parallel_forward(self): - pass - - def test_training_gradient_checkpointing(self): - super().test_training_gradient_checkpointing() - - def test_backbone(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_backbone(*config_and_inputs) - - def test_for_masked_image_modeling(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_for_masked_image_modeling(*config_and_inputs) - - def test_for_image_classification(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_for_image_classification(*config_and_inputs) - - @unittest.skip(reason="Swin does not use inputs_embeds") - def test_inputs_embeds(self): - pass - - @unittest.skip(reason="Swin Transformer does not use feedforward chunking") - def test_feed_forward_chunking(self): - pass - - def test_model_common_attributes(self): - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - model = model_class(config) - self.assertIsInstance(model.get_input_embeddings(), (nn.Module)) - x = model.get_output_embeddings() - self.assertTrue(x is None or isinstance(x, nn.Linear)) - - def test_attention_outputs(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.return_dict = True - - for model_class in self.all_model_classes: - inputs_dict["output_attentions"] = True - inputs_dict["output_hidden_states"] = False - config.return_dict = True - model = model_class(config) - model.to(torch_device) - model.eval() - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - attentions = outputs.attentions - expected_num_attentions = len(self.model_tester.depths) - self.assertEqual(len(attentions), expected_num_attentions) - - # check that output_attentions also work using config - del inputs_dict["output_attentions"] - config.output_attentions = True - window_size_squared = config.window_size**2 - model = model_class(config) - model.to(torch_device) - model.eval() - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - attentions = outputs.attentions - self.assertEqual(len(attentions), expected_num_attentions) - - self.assertListEqual( - list(attentions[0].shape[-3:]), - [self.model_tester.num_heads[0], window_size_squared, window_size_squared], - ) - out_len = len(outputs) - - # Check attention is always last and order is fine - inputs_dict["output_attentions"] = True - inputs_dict["output_hidden_states"] = True - model = model_class(config) - model.to(torch_device) - model.eval() - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - - # also another +1 for reshaped_hidden_states - added_hidden_states = 1 if model_class.__name__ == "SwinBackbone" else 2 - self.assertEqual(out_len + added_hidden_states, len(outputs)) - - self_attentions = outputs.attentions - - self.assertEqual(len(self_attentions), expected_num_attentions) - - self.assertListEqual( - list(self_attentions[0].shape[-3:]), - [self.model_tester.num_heads[0], window_size_squared, window_size_squared], - ) - - def check_hidden_states_output(self, inputs_dict, config, model_class, image_size): - model = model_class(config) - model.to(torch_device) - model.eval() - - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - - hidden_states = outputs.hidden_states - - expected_num_layers = getattr( - self.model_tester, "expected_num_hidden_layers", len(self.model_tester.depths) + 1 - ) - self.assertEqual(len(hidden_states), expected_num_layers) - - # Swin has a different seq_length - patch_size = ( - config.patch_size - if isinstance(config.patch_size, collections.abc.Iterable) - else (config.patch_size, config.patch_size) - ) - - num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0]) - - self.assertListEqual( - list(hidden_states[0].shape[-2:]), - [num_patches, self.model_tester.embed_dim], - ) - - if not model_class.__name__ == "SwinBackbone": - reshaped_hidden_states = outputs.reshaped_hidden_states - self.assertEqual(len(reshaped_hidden_states), expected_num_layers) - - batch_size, num_channels, height, width = reshaped_hidden_states[0].shape - reshaped_hidden_states = ( - reshaped_hidden_states[0].view(batch_size, num_channels, height * width).permute(0, 2, 1) - ) - self.assertListEqual( - list(reshaped_hidden_states.shape[-2:]), - [num_patches, self.model_tester.embed_dim], - ) - - def test_hidden_states_output(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - image_size = ( - self.model_tester.image_size - if isinstance(self.model_tester.image_size, collections.abc.Iterable) - else (self.model_tester.image_size, self.model_tester.image_size) - ) - - for model_class in self.all_model_classes: - inputs_dict["output_hidden_states"] = True - self.check_hidden_states_output(inputs_dict, config, model_class, image_size) - - # check that output_hidden_states also work using config - del inputs_dict["output_hidden_states"] - config.output_hidden_states = True - - self.check_hidden_states_output(inputs_dict, config, model_class, image_size) - - def test_hidden_states_output_with_padding(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.patch_size = 3 - - image_size = ( - self.model_tester.image_size - if isinstance(self.model_tester.image_size, collections.abc.Iterable) - else (self.model_tester.image_size, self.model_tester.image_size) - ) - patch_size = ( - config.patch_size - if isinstance(config.patch_size, collections.abc.Iterable) - else (config.patch_size, config.patch_size) - ) - - padded_height = image_size[0] + patch_size[0] - (image_size[0] % patch_size[0]) - padded_width = image_size[1] + patch_size[1] - (image_size[1] % patch_size[1]) - - for model_class in self.all_model_classes: - inputs_dict["output_hidden_states"] = True - self.check_hidden_states_output(inputs_dict, config, model_class, (padded_height, padded_width)) - - # check that output_hidden_states also work using config - del inputs_dict["output_hidden_states"] - config.output_hidden_states = True - self.check_hidden_states_output(inputs_dict, config, model_class, (padded_height, padded_width)) - - @slow - def test_model_from_pretrained(self): - model_name = "microsoft/swin-tiny-patch4-window7-224" - model = SwinModel.from_pretrained(model_name) - self.assertIsNotNone(model) - - def test_initialization(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - configs_no_init = _config_zero_init(config) - for model_class in self.all_model_classes: - model = model_class(config=configs_no_init) - for name, param in model.named_parameters(): - if "embeddings" not in name and param.requires_grad: - self.assertIn( - ((param.data.mean() * 1e9).round() / 1e9).item(), - [0.0, 1.0], - msg=f"Parameter {name} of model {model_class} seems not properly initialized", - ) - - -@require_vision -@require_torch -class SwinModelIntegrationTest(unittest.TestCase): - @cached_property - def default_image_processor(self): - return ( - AutoImageProcessor.from_pretrained("microsoft/swin-tiny-patch4-window7-224") - if is_vision_available() - else None - ) - - @slow - def test_inference_image_classification_head(self): - model = SwinForImageClassification.from_pretrained("microsoft/swin-tiny-patch4-window7-224").to(torch_device) - image_processor = self.default_image_processor - - image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png") - inputs = image_processor(images=image, return_tensors="pt").to(torch_device) - - # forward pass - with torch.no_grad(): - outputs = model(**inputs) - - # verify the logits - expected_shape = torch.Size((1, 1000)) - self.assertEqual(outputs.logits.shape, expected_shape) - expected_slice = torch.tensor([-0.0948, -0.6454, -0.0921]).to(torch_device) - self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4)) - - -@require_torch -class SwinBackboneTest(unittest.TestCase): - all_model_classes = (SwinBackbone,) if is_torch_available() else () - config_class = SwinConfig - - def setUp(self): - self.model_tester = SwinModelTester(self) diff --git a/tests/transformers/tests/models/t5/__init__.py b/tests/transformers/tests/models/t5/__init__.py deleted file mode 100644 index e69de29bb2..0000000000 diff --git a/tests/transformers/tests/models/t5/test_modeling_t5.py b/tests/transformers/tests/models/t5/test_modeling_t5.py deleted file mode 100644 index a24cd608de..0000000000 --- a/tests/transformers/tests/models/t5/test_modeling_t5.py +++ /dev/null @@ -1,1639 +0,0 @@ -# coding=utf-8 -# Copyright 2018 Google T5 Authors and HuggingFace Inc. team. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - - -import copy -import os -import pickle -import tempfile -import unittest - -from transformers import T5Config, is_torch_available -from transformers.models.auto.modeling_auto import MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES -from transformers.testing_utils import ( - require_accelerate, - require_sentencepiece, - require_tokenizers, - require_torch, - slow, - torch_device, -) -from transformers.utils import cached_property, is_torch_fx_available - -from optimum.habana.transformers.modeling_utils import adapt_transformers_to_gaudi - -from ...generation.test_utils import GenerationTesterMixin -from ...test_configuration_common import ConfigTester -from ...test_modeling_common import ModelTesterMixin, _config_zero_init, ids_tensor - - -if is_torch_fx_available(): - from transformers.utils.fx import symbolic_trace - - -if is_torch_available(): - import torch - - from transformers import ( - AutoTokenizer, - ByT5Tokenizer, - T5EncoderModel, - T5ForConditionalGeneration, - T5ForQuestionAnswering, - T5ForSequenceClassification, - T5ForTokenClassification, - T5Model, - T5Tokenizer, - ) - from transformers.models.t5.modeling_t5 import T5_PRETRAINED_MODEL_ARCHIVE_LIST - - -torch_device = "hpu" -adapt_transformers_to_gaudi() - - -class T5ModelTester: - def __init__( - self, - parent, - vocab_size=99, - batch_size=13, - encoder_seq_length=7, - decoder_seq_length=7, - # For common tests - is_training=True, - use_attention_mask=True, - use_labels=True, - hidden_size=32, - num_hidden_layers=2, - num_attention_heads=4, - d_ff=37, - relative_attention_num_buckets=8, - dropout_rate=0.1, - initializer_factor=0.002, - eos_token_id=1, - pad_token_id=0, - decoder_start_token_id=0, - scope=None, - decoder_layers=None, - ): - self.parent = parent - self.batch_size = batch_size - self.encoder_seq_length = encoder_seq_length - self.decoder_seq_length = decoder_seq_length - # For common tests - self.seq_length = self.decoder_seq_length - self.is_training = is_training - self.use_attention_mask = use_attention_mask - self.use_labels = use_labels - self.vocab_size = vocab_size - self.hidden_size = hidden_size - self.num_hidden_layers = num_hidden_layers - self.num_attention_heads = num_attention_heads - self.d_ff = d_ff - self.relative_attention_num_buckets = relative_attention_num_buckets - self.dropout_rate = dropout_rate - self.initializer_factor = initializer_factor - self.eos_token_id = eos_token_id - self.pad_token_id = pad_token_id - self.decoder_start_token_id = decoder_start_token_id - self.scope = None - self.decoder_layers = decoder_layers - - def get_large_model_config(self): - return T5Config.from_pretrained("google-t5/t5-base") - - def prepare_config_and_inputs(self): - input_ids = ids_tensor([self.batch_size, self.encoder_seq_length], self.vocab_size).clamp(2) - input_ids[:, -1] = self.eos_token_id # Eos Token - decoder_input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size) - - attention_mask = None - decoder_attention_mask = None - if self.use_attention_mask: - attention_mask = ids_tensor([self.batch_size, self.encoder_seq_length], vocab_size=2) - decoder_attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2) - - lm_labels = None - if self.use_labels: - lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size) - - config = self.get_config() - - return ( - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ) - - def get_pipeline_config(self): - return T5Config( - vocab_size=166, # t5 forces 100 extra tokens - d_model=self.hidden_size, - d_ff=self.d_ff, - d_kv=self.hidden_size // self.num_attention_heads, - num_layers=self.num_hidden_layers, - num_decoder_layers=self.decoder_layers, - num_heads=self.num_attention_heads, - relative_attention_num_buckets=self.relative_attention_num_buckets, - dropout_rate=self.dropout_rate, - initializer_factor=self.initializer_factor, - eos_token_id=self.eos_token_id, - bos_token_id=self.pad_token_id, - pad_token_id=self.pad_token_id, - decoder_start_token_id=self.decoder_start_token_id, - ) - - def get_config(self): - return T5Config( - vocab_size=self.vocab_size, - d_model=self.hidden_size, - d_ff=self.d_ff, - d_kv=self.hidden_size // self.num_attention_heads, - num_layers=self.num_hidden_layers, - num_decoder_layers=self.decoder_layers, - num_heads=self.num_attention_heads, - relative_attention_num_buckets=self.relative_attention_num_buckets, - dropout_rate=self.dropout_rate, - initializer_factor=self.initializer_factor, - eos_token_id=self.eos_token_id, - bos_token_id=self.pad_token_id, - pad_token_id=self.pad_token_id, - decoder_start_token_id=self.decoder_start_token_id, - ) - - def check_prepare_lm_labels_via_shift_left( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - model = T5Model(config=config) - model.to(torch_device) - model.eval() - - # make sure that lm_labels are correctly padded from the right - lm_labels.masked_fill_((lm_labels == self.decoder_start_token_id), self.eos_token_id) - - # add casaul pad token mask - triangular_mask = torch.tril(lm_labels.new_ones(lm_labels.shape)).logical_not() - lm_labels.masked_fill_(triangular_mask, self.pad_token_id) - decoder_input_ids = model._shift_right(lm_labels) - - for i, (decoder_input_ids_slice, lm_labels_slice) in enumerate(zip(decoder_input_ids, lm_labels)): - # first item - self.parent.assertEqual(decoder_input_ids_slice[0].item(), self.decoder_start_token_id) - if i < decoder_input_ids_slice.shape[-1]: - if i < decoder_input_ids.shape[-1] - 1: - # items before diagonal - self.parent.assertListEqual( - decoder_input_ids_slice[1 : i + 1].tolist(), lm_labels_slice[:i].tolist() - ) - # pad items after diagonal - if i < decoder_input_ids.shape[-1] - 2: - self.parent.assertListEqual( - decoder_input_ids_slice[i + 2 :].tolist(), lm_labels_slice[i + 1 : -1].tolist() - ) - else: - # all items after square - self.parent.assertListEqual(decoder_input_ids_slice[1:].tolist(), lm_labels_slice[:-1].tolist()) - - def create_and_check_model( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - model = T5Model(config=config) - model.to(torch_device) - model.eval() - result = model( - input_ids=input_ids, - decoder_input_ids=decoder_input_ids, - attention_mask=attention_mask, - decoder_attention_mask=decoder_attention_mask, - ) - result = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids) - decoder_output = result.last_hidden_state - decoder_past = result.past_key_values - encoder_output = result.encoder_last_hidden_state - - self.parent.assertEqual(encoder_output.size(), (self.batch_size, self.encoder_seq_length, self.hidden_size)) - self.parent.assertEqual(decoder_output.size(), (self.batch_size, self.decoder_seq_length, self.hidden_size)) - # There should be `num_layers` key value embeddings stored in decoder_past - self.parent.assertEqual(len(decoder_past), config.num_layers) - # There should be a self attn key, a self attn value, a cross attn key and a cross attn value stored in each decoder_past tuple - self.parent.assertEqual(len(decoder_past[0]), 4) - - def create_and_check_with_lm_head( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - model = T5ForConditionalGeneration(config=config).to(torch_device).eval() - outputs = model( - input_ids=input_ids, - decoder_input_ids=decoder_input_ids, - decoder_attention_mask=decoder_attention_mask, - labels=lm_labels, - ) - self.parent.assertEqual(len(outputs), 4) - self.parent.assertEqual(outputs["logits"].size(), (self.batch_size, self.decoder_seq_length, self.vocab_size)) - self.parent.assertEqual(outputs["loss"].size(), ()) - - def create_and_check_with_sequence_classification_head( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - labels = torch.tensor([1] * self.batch_size, dtype=torch.long, device=torch_device) - model = T5ForSequenceClassification(config=config).to(torch_device).eval() - outputs = model( - input_ids=input_ids, - decoder_input_ids=input_ids, - labels=labels, - ) - # self.parent.assertEqual(len(outputs), 4) - self.parent.assertEqual(outputs["logits"].size(), (self.batch_size, config.num_labels)) - self.parent.assertEqual(outputs["loss"].size(), ()) - - def create_and_check_decoder_model_past( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - model = T5Model(config=config).get_decoder().to(torch_device).eval() - # first forward pass - outputs = model(input_ids, use_cache=True) - outputs_use_cache_conf = model(input_ids) - outputs_no_past = model(input_ids, use_cache=False) - - self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf)) - self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1) - - output, past_key_values = outputs.to_tuple() - - # create hypothetical next token and extent to next_input_ids - next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size) - - # append to next input_ids and - next_input_ids = torch.cat([input_ids, next_tokens], dim=-1) - - output_from_no_past = model(next_input_ids)["last_hidden_state"] - output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"] - - # select random slice - random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item() - output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach() - output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach() - - # test that outputs are equal for slice - self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)) - - def create_and_check_decoder_model_attention_mask_past( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - model = T5Model(config=config).get_decoder() - model.to(torch_device) - model.eval() - - # create attention mask - attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device) - - half_seq_length = input_ids.shape[-1] // 2 - attn_mask[:, half_seq_length:] = 0 - - # first forward pass - output, past_key_values = model(input_ids, attention_mask=attn_mask, use_cache=True).to_tuple() - - # create hypothetical next token and extent to next_input_ids - next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size) - - # change a random masked slice from input_ids - random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1 - random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1) - input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens - - # append to next input_ids and attn_mask - next_input_ids = torch.cat([input_ids, next_tokens], dim=-1) - attn_mask = torch.cat( - [attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)], - dim=1, - ) - - # get two different outputs - output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"] - output_from_past = model(next_tokens, past_key_values=past_key_values, attention_mask=attn_mask)[ - "last_hidden_state" - ] - - # select random slice - random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item() - output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach() - output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach() - - # test that outputs are equal for slice - self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)) - - def create_and_check_decoder_model_past_large_inputs( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - model = T5Model(config=config).get_decoder().to(torch_device).eval() - # first forward pass - outputs = model(input_ids, attention_mask=attention_mask, use_cache=True) - - output, past_key_values = outputs.to_tuple() - - # create hypothetical multiple next token and extent to next_input_ids - next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size) - next_mask = ids_tensor((self.batch_size, 3), vocab_size=2) - - # append to next input_ids and - next_input_ids = torch.cat([input_ids, next_tokens], dim=-1) - next_attention_mask = torch.cat([attention_mask, next_mask], dim=-1) - - output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"] - output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[ - "last_hidden_state" - ] - - # select random slice - random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item() - output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach() - output_from_past_slice = output_from_past[:, :, random_slice_idx].detach() - - self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1]) - - # test that outputs are equal for slice - self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)) - - def create_and_check_generate_with_past_key_values( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - model = T5ForConditionalGeneration(config=config).to(torch_device).eval() - torch.manual_seed(0) - output_without_past_cache = model.generate( - input_ids[:1], num_beams=2, max_length=5, do_sample=True, use_cache=False - ) - torch.manual_seed(0) - output_with_past_cache = model.generate(input_ids[:1], num_beams=2, max_length=5, do_sample=True) - self.parent.assertTrue(torch.all(output_with_past_cache == output_without_past_cache)) - - def create_and_check_model_fp16_forward( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - model = T5Model(config=config).to(torch_device).half().eval() - output = model(input_ids, decoder_input_ids=input_ids, attention_mask=attention_mask)["last_hidden_state"] - self.parent.assertFalse(torch.isnan(output).any().item()) - - def create_and_check_encoder_decoder_shared_weights( - self, - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ): - for model_class in [T5Model, T5ForConditionalGeneration]: - torch.manual_seed(0) - model = model_class(config=config).to(torch_device).eval() - # load state dict copies weights but does not tie them - model.encoder.load_state_dict(model.decoder.state_dict(), strict=False) - - torch.manual_seed(0) - tied_config = copy.deepcopy(config) - tied_config.tie_encoder_decoder = True - tied_model = model_class(config=tied_config).to(torch_device).eval() - - model_result = model( - input_ids=input_ids, - decoder_input_ids=decoder_input_ids, - attention_mask=attention_mask, - decoder_attention_mask=decoder_attention_mask, - ) - - tied_model_result = tied_model( - input_ids=input_ids, - decoder_input_ids=decoder_input_ids, - attention_mask=attention_mask, - decoder_attention_mask=decoder_attention_mask, - ) - - # check that models has less parameters - self.parent.assertLess( - sum(p.numel() for p in tied_model.parameters()), sum(p.numel() for p in model.parameters()) - ) - random_slice_idx = ids_tensor((1,), model_result[0].shape[-1]).item() - - # check that outputs are equal - self.parent.assertTrue( - torch.allclose( - model_result[0][0, :, random_slice_idx], tied_model_result[0][0, :, random_slice_idx], atol=1e-4 - ) - ) - - # check that outputs after saving and loading are equal - with tempfile.TemporaryDirectory() as tmpdirname: - tied_model.save_pretrained(tmpdirname) - tied_model = model_class.from_pretrained(tmpdirname) - tied_model.to(torch_device) - tied_model.eval() - - # check that models has less parameters - self.parent.assertLess( - sum(p.numel() for p in tied_model.parameters()), sum(p.numel() for p in model.parameters()) - ) - random_slice_idx = ids_tensor((1,), model_result[0].shape[-1]).item() - - tied_model_result = tied_model( - input_ids=input_ids, - decoder_input_ids=decoder_input_ids, - attention_mask=attention_mask, - decoder_attention_mask=decoder_attention_mask, - ) - - # check that outputs are equal - self.parent.assertTrue( - torch.allclose( - model_result[0][0, :, random_slice_idx], - tied_model_result[0][0, :, random_slice_idx], - atol=1e-4, - ) - ) - - def check_resize_embeddings_t5_v1_1( - self, - config, - ): - prev_vocab_size = config.vocab_size - - config.tie_word_embeddings = False - model = T5ForConditionalGeneration(config=config).to(torch_device).eval() - model.resize_token_embeddings(prev_vocab_size - 10) - - self.parent.assertEqual(model.get_input_embeddings().weight.shape[0], prev_vocab_size - 10) - self.parent.assertEqual(model.get_output_embeddings().weight.shape[0], prev_vocab_size - 10) - self.parent.assertEqual(model.config.vocab_size, prev_vocab_size - 10) - - def prepare_config_and_inputs_for_common(self): - config_and_inputs = self.prepare_config_and_inputs() - ( - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ) = config_and_inputs - - inputs_dict = { - "input_ids": input_ids, - "attention_mask": attention_mask, - "decoder_input_ids": decoder_input_ids, - "decoder_attention_mask": decoder_attention_mask, - "use_cache": False, - } - return config, inputs_dict - - -@require_torch -class T5ModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase): - all_model_classes = ( - (T5Model, T5ForConditionalGeneration, T5ForSequenceClassification, T5ForQuestionAnswering) - if is_torch_available() - else () - ) - all_generative_model_classes = (T5ForConditionalGeneration,) if is_torch_available() else () - pipeline_model_mapping = ( - { - "conversational": T5ForConditionalGeneration, - "feature-extraction": T5Model, - "question-answering": T5ForQuestionAnswering, - "summarization": T5ForConditionalGeneration, - "text-classification": T5ForSequenceClassification, - "text2text-generation": T5ForConditionalGeneration, - "translation": T5ForConditionalGeneration, - "zero-shot": T5ForSequenceClassification, - } - if is_torch_available() - else {} - ) - all_parallelizable_model_classes = (T5Model, T5ForConditionalGeneration) if is_torch_available() else () - fx_compatible = True - test_pruning = False - test_resize_embeddings = True - test_model_parallel = True - is_encoder_decoder = True - # The small T5 model needs higher percentages for CPU/MP tests - model_split_percents = [0.8, 0.9] - - def setUp(self): - self.model_tester = T5ModelTester(self) - self.config_tester = ConfigTester(self, config_class=T5Config, d_model=37) - - # `QAPipelineTests` is not working well with slow tokenizers (for some models) and we don't want to touch the file - # `src/transformers/data/processors/squad.py` (where this test fails for this model) - def is_pipeline_test_to_skip( - self, pipeline_test_case_name, config_class, model_architecture, tokenizer_name, processor_name - ): - if tokenizer_name is None: - return True - if pipeline_test_case_name == "QAPipelineTests" and not tokenizer_name.endswith("Fast"): - return True - - return False - - def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=False): - if not is_torch_fx_available() or not self.fx_compatible: - return - - configs_no_init = _config_zero_init(config) # To be sure we have no Nan - configs_no_init.return_dict = False - - for model_class in self.all_model_classes: - if model_class.__name__ == "T5ForSequenceClassification": - continue - model = model_class(config=configs_no_init) - model.to(torch_device) - model.eval() - inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=output_loss) - - try: - if model.config.is_encoder_decoder: - model.config.use_cache = False # FSTM still requires this hack -> FSTM should probably be refactored similar to BART afterward - labels = inputs.get("labels", None) - input_names = [ - "attention_mask", - "decoder_attention_mask", - "decoder_input_ids", - "input_features", - "input_ids", - "input_values", - ] - if labels is not None: - input_names.append("labels") - - filtered_inputs = {k: v for (k, v) in inputs.items() if k in input_names} - input_names = list(filtered_inputs.keys()) - - model_output = model(**filtered_inputs) - - traced_model = symbolic_trace(model, input_names) - traced_output = traced_model(**filtered_inputs) - else: - input_names = [ - "attention_mask", - "bbox", - "input_features", - "input_ids", - "input_values", - "pixel_values", - "token_type_ids", - "visual_feats", - "visual_pos", - ] - - labels = inputs.get("labels", None) - start_positions = inputs.get("start_positions", None) - end_positions = inputs.get("end_positions", None) - if labels is not None: - input_names.append("labels") - if start_positions is not None: - input_names.append("start_positions") - if end_positions is not None: - input_names.append("end_positions") - - filtered_inputs = {k: v for (k, v) in inputs.items() if k in input_names} - input_names = list(filtered_inputs.keys()) - - if model.__class__.__name__ in set(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES.values()) and ( - not hasattr(model.config, "problem_type") or model.config.problem_type is None - ): - model.config.problem_type = "single_label_classification" - - traced_model = symbolic_trace(model, input_names) - traced_output = traced_model(**filtered_inputs) - model_output = model(**filtered_inputs) - - except Exception as e: - self.fail(f"Couldn't trace module: {e}") - - def flatten_output(output): - flatten = [] - for x in output: - if isinstance(x, (tuple, list)): - flatten += flatten_output(x) - elif not isinstance(x, torch.Tensor): - continue - else: - flatten.append(x) - return flatten - - model_output = flatten_output(model_output) - traced_output = flatten_output(traced_output) - num_outputs = len(model_output) - - for i in range(num_outputs): - self.assertTrue( - torch.allclose(model_output[i], traced_output[i]), - f"traced {i}th output doesn't match model {i}th output for {model_class}", - ) - - # Test that the model can be serialized and restored properly - with tempfile.TemporaryDirectory() as tmp_dir_name: - pkl_file_name = os.path.join(tmp_dir_name, "model.pkl") - try: - with open(pkl_file_name, "wb") as f: - pickle.dump(traced_model, f) - with open(pkl_file_name, "rb") as f: - loaded = pickle.load(f) - except Exception as e: - self.fail(f"Couldn't serialize / deserialize the traced model: {e}") - - loaded_output = loaded(**filtered_inputs) - loaded_output = flatten_output(loaded_output) - - for i in range(num_outputs): - self.assertTrue( - torch.allclose(model_output[i], loaded_output[i]), - f"serialized model {i}th output doesn't match model {i}th output for {model_class}", - ) - - # Avoid memory leak. Without this, each call increase RAM usage by ~20MB. - # (Even with this call, there are still memory leak by ~0.04MB) - self.clear_torch_jit_class_registry() - - def test_config(self): - self.config_tester.run_common_tests() - - def test_shift_right(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_prepare_lm_labels_via_shift_left(*config_and_inputs) - - def test_model(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_model_v1_1(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - # check that gated gelu feed forward and different word embeddings work - config = config_and_inputs[0] - config.tie_word_embeddings = False - config.feed_forward_proj = "gated-gelu" - self.model_tester.create_and_check_model(config, *config_and_inputs[1:]) - - # T5ForSequenceClassification does not support inputs_embeds - def test_inputs_embeds(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in (T5Model, T5ForConditionalGeneration, T5ForQuestionAnswering): - model = model_class(config) - model.to(torch_device) - model.eval() - - inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class)) - - if not self.is_encoder_decoder: - input_ids = inputs["input_ids"] - del inputs["input_ids"] - else: - encoder_input_ids = inputs["input_ids"] - decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids) - del inputs["input_ids"] - inputs.pop("decoder_input_ids", None) - - wte = model.get_input_embeddings() - if not self.is_encoder_decoder: - inputs["inputs_embeds"] = wte(input_ids) - else: - inputs["inputs_embeds"] = wte(encoder_input_ids) - inputs["decoder_inputs_embeds"] = wte(decoder_input_ids) - - with torch.no_grad(): - model(**inputs)[0] - - def test_config_and_model_silu_gated(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - config = config_and_inputs[0] - config.feed_forward_proj = "gated-silu" - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_with_lm_head(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_with_lm_head(*config_and_inputs) - - def test_with_sequence_classification_head(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_with_sequence_classification_head(*config_and_inputs) - - def test_decoder_model_past(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_decoder_model_past(*config_and_inputs) - - def test_decoder_model_past_with_attn_mask(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_decoder_model_attention_mask_past(*config_and_inputs) - - def test_decoder_model_past_with_3d_attn_mask(self): - ( - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ) = self.model_tester.prepare_config_and_inputs() - - attention_mask = ids_tensor( - [self.model_tester.batch_size, self.model_tester.encoder_seq_length, self.model_tester.encoder_seq_length], - vocab_size=2, - ) - decoder_attention_mask = ids_tensor( - [self.model_tester.batch_size, self.model_tester.decoder_seq_length, self.model_tester.decoder_seq_length], - vocab_size=2, - ) - - self.model_tester.create_and_check_decoder_model_attention_mask_past( - config, - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ) - - def test_decoder_model_past_with_large_inputs(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs) - - @unittest.skip("Does not support on gaudi.") - def test_generate_with_past_key_values(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_generate_with_past_key_values(*config_and_inputs) - - def test_encoder_decoder_shared_weights(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_encoder_decoder_shared_weights(*config_and_inputs) - - @unittest.skipIf(torch_device == "cpu", "Cant do half precision") - def test_model_fp16_forward(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model_fp16_forward(*config_and_inputs) - - def test_v1_1_resize_embeddings(self): - config = self.model_tester.prepare_config_and_inputs()[0] - self.model_tester.check_resize_embeddings_t5_v1_1(config) - - @slow - def test_model_from_pretrained(self): - model_name = "google-t5/t5-small" - model = T5Model.from_pretrained(model_name) - self.assertIsNotNone(model) - - @unittest.skip("Test has a segmentation fault on torch 1.8.0") - def test_export_to_onnx(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - model = T5Model(config_and_inputs[0]).to(torch_device) - with tempfile.TemporaryDirectory() as tmpdirname: - torch.onnx.export( - model, - (config_and_inputs[1], config_and_inputs[3], config_and_inputs[2]), - f"{tmpdirname}/t5_test.onnx", - export_params=True, - opset_version=9, - input_names=["input_ids", "decoder_input_ids"], - ) - - def test_generate_with_head_masking(self): - attention_names = ["encoder_attentions", "decoder_attentions", "cross_attentions"] - config_and_inputs = self.model_tester.prepare_config_and_inputs() - config = config_and_inputs[0] - max_length = config_and_inputs[1].shape[-1] + 3 - model = T5ForConditionalGeneration(config).eval() - model.to(torch_device) - - head_masking = { - "head_mask": torch.zeros(config.num_layers, config.num_heads, device=torch_device), - "decoder_head_mask": torch.zeros(config.num_decoder_layers, config.num_heads, device=torch_device), - "cross_attn_head_mask": torch.zeros(config.num_decoder_layers, config.num_heads, device=torch_device), - } - - for attn_name, (name, mask) in zip(attention_names, head_masking.items()): - head_masks = {name: mask} - # Explicitly pass decoder_head_mask as it is required from T5 model when head_mask specified - if name == "head_mask": - head_masks["decoder_head_mask"] = torch.ones( - config.num_decoder_layers, config.num_heads, device=torch_device - ) - - out = model.generate( - config_and_inputs[1], - num_beams=1, - max_length=max_length, - output_attentions=True, - return_dict_in_generate=True, - **head_masks, - ) - # We check the state of decoder_attentions and cross_attentions just from the last step - attn_weights = out[attn_name] if attn_name == attention_names[0] else out[attn_name][-1] - self.assertEqual(sum([w.sum().item() for w in attn_weights]), 0.0) - - @unittest.skip("Does not work on the tiny model as we keep hitting edge cases.") - def test_disk_offload(self): - pass - - @unittest.skip("Does not support conversations.") - def test_pipeline_conversational(self): - pass - - -class T5EncoderOnlyModelTester: - def __init__( - self, - parent, - vocab_size=99, - batch_size=13, - encoder_seq_length=7, - # For common tests - use_attention_mask=True, - hidden_size=32, - num_hidden_layers=2, - num_attention_heads=4, - d_ff=37, - relative_attention_num_buckets=8, - is_training=False, - dropout_rate=0.1, - initializer_factor=0.002, - is_encoder_decoder=False, - eos_token_id=1, - pad_token_id=0, - scope=None, - ): - self.parent = parent - self.batch_size = batch_size - self.encoder_seq_length = encoder_seq_length - # For common tests - self.seq_length = self.encoder_seq_length - self.use_attention_mask = use_attention_mask - self.vocab_size = vocab_size - self.hidden_size = hidden_size - self.num_hidden_layers = num_hidden_layers - self.num_attention_heads = num_attention_heads - self.d_ff = d_ff - self.relative_attention_num_buckets = relative_attention_num_buckets - self.dropout_rate = dropout_rate - self.initializer_factor = initializer_factor - self.eos_token_id = eos_token_id - self.pad_token_id = pad_token_id - self.is_encoder_decoder = is_encoder_decoder - self.scope = None - self.is_training = is_training - - def get_large_model_config(self): - return T5Config.from_pretrained("google-t5/t5-base") - - def prepare_config_and_inputs(self): - input_ids = ids_tensor([self.batch_size, self.encoder_seq_length], self.vocab_size) - - attention_mask = None - if self.use_attention_mask: - attention_mask = ids_tensor([self.batch_size, self.encoder_seq_length], vocab_size=2) - - config = T5Config( - vocab_size=self.vocab_size, - d_model=self.hidden_size, - d_ff=self.d_ff, - d_kv=self.hidden_size // self.num_attention_heads, - num_layers=self.num_hidden_layers, - num_heads=self.num_attention_heads, - relative_attention_num_buckets=self.relative_attention_num_buckets, - dropout_rate=self.dropout_rate, - initializer_factor=self.initializer_factor, - eos_token_id=self.eos_token_id, - bos_token_id=self.pad_token_id, - pad_token_id=self.pad_token_id, - is_encoder_decoder=self.is_encoder_decoder, - ) - - return ( - config, - input_ids, - attention_mask, - ) - - def create_and_check_model( - self, - config, - input_ids, - attention_mask, - ): - model = T5EncoderModel(config=config) - model.to(torch_device) - model.eval() - result = model( - input_ids=input_ids, - attention_mask=attention_mask, - ) - result = model(input_ids=input_ids) - encoder_output = result.last_hidden_state - - self.parent.assertEqual(encoder_output.size(), (self.batch_size, self.encoder_seq_length, self.hidden_size)) - - def create_and_check_model_fp16_forward( - self, - config, - input_ids, - attention_mask, - ): - model = T5EncoderModel(config=config).to(torch_device).half().eval() - output = model(input_ids, attention_mask=attention_mask)["last_hidden_state"] - self.parent.assertFalse(torch.isnan(output).any().item()) - - def create_and_check_with_token_classification_head( - self, - config, - input_ids, - attention_mask, - ): - labels = torch.tensor([1] * self.seq_length * self.batch_size, dtype=torch.long, device=torch_device) - model = T5ForTokenClassification(config=config).to(torch_device).eval() - outputs = model( - input_ids=input_ids, - labels=labels, - attention_mask=attention_mask, - ) - self.parent.assertEqual(outputs["logits"].size(), (self.batch_size, self.seq_length, config.num_labels)) - self.parent.assertEqual(outputs["loss"].size(), ()) - - def prepare_config_and_inputs_for_common(self): - config_and_inputs = self.prepare_config_and_inputs() - ( - config, - input_ids, - attention_mask, - ) = config_and_inputs - - inputs_dict = { - "input_ids": input_ids, - "attention_mask": attention_mask, - } - return config, inputs_dict - - -class T5EncoderOnlyModelTest(ModelTesterMixin, unittest.TestCase): - all_model_classes = (T5EncoderModel, T5ForTokenClassification) if is_torch_available() else () - test_pruning = False - test_resize_embeddings = False - test_model_parallel = True - pipeline_model_mapping = ( - { - "token-classification": T5ForTokenClassification, - } - if is_torch_available() - else {} - ) - all_parallelizable_model_classes = (T5EncoderModel,) if is_torch_available() else () - - def setUp(self): - self.model_tester = T5EncoderOnlyModelTester(self) - self.config_tester = ConfigTester(self, config_class=T5Config, d_model=37) - - def test_config(self): - self.config_tester.run_common_tests() - - def test_model(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model(*config_and_inputs) - - @unittest.skipIf(torch_device == "cpu", "Cant do half precision") - def test_model_fp16_forward(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model_fp16_forward(*config_and_inputs) - - def test_with_token_classification_head(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_with_token_classification_head(*config_and_inputs) - - -def use_task_specific_params(model, task): - model.config.update(model.config.task_specific_params[task]) - - -@require_torch -@require_accelerate -@require_tokenizers -@slow -class T5ModelFp16Tests(unittest.TestCase): - def test_fp16_fp32_conversion(self): - r""" - A test to check whether the argument `keep_in_fp32_modules` correctly does its job - """ - orig_import = __import__ - accelerate_mock = unittest.mock.Mock() - - # mock import of accelerate - def import_accelerate_mock(name, *args, **kwargs): - if name == "accelerate": - if accelerate_available: - return accelerate_mock - else: - raise ImportError - return orig_import(name, *args, **kwargs) - - # Load without using `accelerate` - with unittest.mock.patch("builtins.__import__", side_effect=import_accelerate_mock): - accelerate_available = False - - model = T5ForConditionalGeneration.from_pretrained("google-t5/t5-small", torch_dtype=torch.float16) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wo.weight.dtype == torch.float32) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wi.weight.dtype == torch.float16) - - # Load without in bf16 - model = T5ForConditionalGeneration.from_pretrained("google-t5/t5-small", torch_dtype=torch.bfloat16) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wo.weight.dtype == torch.bfloat16) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wi.weight.dtype == torch.bfloat16) - - # Load using `accelerate` in bf16 - model = T5ForConditionalGeneration.from_pretrained( - "google-t5/t5-small", torch_dtype=torch.bfloat16, device_map="auto" - ) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wo.weight.dtype == torch.bfloat16) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wi.weight.dtype == torch.bfloat16) - - # Load using `accelerate` in bf16 - model = T5ForConditionalGeneration.from_pretrained( - "google-t5/t5-small", torch_dtype=torch.bfloat16, low_cpu_mem_usage=True - ) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wo.weight.dtype == torch.bfloat16) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wi.weight.dtype == torch.bfloat16) - - # Load without using `accelerate` - model = T5ForConditionalGeneration.from_pretrained( - "google-t5/t5-small", torch_dtype=torch.float16, low_cpu_mem_usage=True - ) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wo.weight.dtype == torch.float32) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wi.weight.dtype == torch.float16) - - # Load using `accelerate` - model = T5ForConditionalGeneration.from_pretrained( - "google-t5/t5-small", torch_dtype=torch.float16, device_map="auto" - ) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wo.weight.dtype == torch.float32) - self.assertTrue(model.decoder.block[0].layer[2].DenseReluDense.wi.weight.dtype == torch.float16) - - -@require_torch -@require_sentencepiece -@require_tokenizers -class T5ModelIntegrationTests(unittest.TestCase): - @cached_property - def model(self): - return T5ForConditionalGeneration.from_pretrained("google-t5/t5-base").to(torch_device) - - @cached_property - def tokenizer(self): - return T5Tokenizer.from_pretrained("google-t5/t5-base") - - @slow - def test_torch_quant(self): - r""" - Test that a simple `torch.quantization.quantize_dynamic` call works on a T5 model. - """ - model_name = "google/flan-t5-small" - tokenizer = T5Tokenizer.from_pretrained(model_name) - model = T5ForConditionalGeneration.from_pretrained(model_name) - model = torch.quantization.quantize_dynamic(model, {torch.nn.Linear}, dtype=torch.qint8) - input_text = "Answer the following yes/no question by reasoning step-by-step. Can you write a whole Haiku in a single tweet?" - input_ids = tokenizer(input_text, return_tensors="pt").input_ids - _ = model.generate(input_ids) - - @slow - def test_small_generation(self): - model = T5ForConditionalGeneration.from_pretrained("google-t5/t5-small").to(torch_device) - model.config.max_length = 8 - model.config.num_beams = 1 - model.config.do_sample = False - tokenizer = T5Tokenizer.from_pretrained("google-t5/t5-small") - - input_ids = tokenizer("summarize: Hello there", return_tensors="pt").input_ids.to(torch_device) - - sequences = model.generate(input_ids) - - output_str = tokenizer.batch_decode(sequences, skip_special_tokens=True)[0] - self.assertTrue(output_str == "Hello there!") - - @slow - def test_small_integration_test(self): - """ - For comparision run: - >>> import t5 # pip install t5==0.7.1 - >>> from t5.data.sentencepiece_vocabulary import SentencePieceVocabulary - - >>> path_to_mtf_small_t5_checkpoint = 'def remove_non_ascii(s: str) -> str:\n """\n return result\n Remove non-ASCII characters from a string.\n\n Args:\n s: The string to remove non-ASCII characters from.\n\n Returns:\n The string with non-ASCII characters removed.\n """\n result = ""\n for c in s:\n if ord(c) < 128:\n result += c ' - >>> path_to_mtf_small_spm_model_path = ' ' - >>> t5_model = t5.models.MtfModel(model_dir=path_to_mtf_small_t5_checkpoint, batch_size=1, tpu=None) - >>> vocab = SentencePieceVocabulary(path_to_mtf_small_spm_model_path, extra_ids=100) - >>> score = t5_model.score(inputs=["Hello there"], targets=["Hi I am"], vocabulary=vocab) - """ - - model = T5ForConditionalGeneration.from_pretrained("google-t5/t5-small").to(torch_device) - tokenizer = T5Tokenizer.from_pretrained("google-t5/t5-small") - - input_ids = tokenizer("Hello there", return_tensors="pt").input_ids - labels = tokenizer("Hi I am", return_tensors="pt").input_ids - - loss = model(input_ids.to(torch_device), labels=labels.to(torch_device)).loss - mtf_score = -(labels.shape[-1] * loss.item()) - - EXPECTED_SCORE = -19.0845 - self.assertTrue(abs(mtf_score - EXPECTED_SCORE) < 1e-4) - - @slow - def test_small_v1_1_integration_test(self): - """ - For comparision run: - >>> import t5 # pip install t5==0.7.1 - >>> from t5.data.sentencepiece_vocabulary import SentencePieceVocabulary - - >>> path_to_mtf_small_t5_v1_1_checkpoint = ' ' - >>> path_to_mtf_small_spm_model_path = ' ' - >>> t5_model = t5.models.MtfModel(model_dir=path_to_mtf_small_t5_v1_1_checkpoint, batch_size=1, tpu=None) - >>> vocab = SentencePieceVocabulary(path_to_mtf_small_spm_model_path, extra_ids=100) - >>> score = t5_model.score(inputs=["Hello there"], targets=["Hi I am"], vocabulary=vocab) - """ - - model = T5ForConditionalGeneration.from_pretrained("google/t5-v1_1-small").to(torch_device) - tokenizer = T5Tokenizer.from_pretrained("google/t5-v1_1-small") - - input_ids = tokenizer("Hello there", return_tensors="pt").input_ids - labels = tokenizer("Hi I am", return_tensors="pt").input_ids - - loss = model(input_ids.to(torch_device), labels=labels.to(torch_device)).loss - mtf_score = -(labels.shape[-1] * loss.item()) - - EXPECTED_SCORE = -59.0293 - self.assertTrue(abs(mtf_score - EXPECTED_SCORE) < 1e-4) - - @slow - def test_small_byt5_integration_test(self): - """ - For comparision run: - >>> import t5 # pip install t5==0.9.1 - - >>> path_to_byt5_small_checkpoint = ' ' - >>> t5_model = t5.models.MtfModel(model_dir=path_to_tf_checkpoint, batch_size=1, tpu=None) - >>> vocab = t5.data.ByteVocabulary() - >>> score = t5_model.score(inputs=["Hello there"], targets=["Hi I am"], vocabulary=vocab) - """ - - model = T5ForConditionalGeneration.from_pretrained("google/byt5-small").to(torch_device) - tokenizer = ByT5Tokenizer.from_pretrained("google/byt5-small") - - input_ids = tokenizer("Hello there", return_tensors="pt").input_ids - labels = tokenizer("Hi I am", return_tensors="pt").input_ids - - loss = model(input_ids.to(torch_device), labels=labels.to(torch_device)).loss - mtf_score = -(labels.shape[-1] * loss.item()) - - EXPECTED_SCORE = -60.7397 - self.assertTrue(abs(mtf_score - EXPECTED_SCORE) < 1e-4) - - @slow - def test_summarization(self): - model = self.model - tok = self.tokenizer - - FRANCE_ARTICLE = ( # @noqa - "Marseille, France (CNN)The French prosecutor leading an investigation into the crash of Germanwings" - " Flight 9525 insisted Wednesday that he was not aware of any video footage from on board the plane." - ' Marseille prosecutor Brice Robin told CNN that "so far no videos were used in the crash investigation."' - ' He added, "A person who has such a video needs to immediately give it to the investigators." Robin\'s' - " comments follow claims by two magazines, German daily Bild and French Paris Match, of a cell phone video" - " showing the harrowing final seconds from on board Germanwings Flight 9525 as it crashed into the French" - " Alps. All 150 on board were killed. Paris Match and Bild reported that the video was recovered from a" - " phone at the wreckage site. The two publications described the supposed video, but did not post it on" - " their websites. The publications said that they watched the video, which was found by a source close to" - " the investigation. \"One can hear cries of 'My God' in several languages,\" Paris Match reported." - ' "Metallic banging can also be heard more than three times, perhaps of the pilot trying to open the' - " cockpit door with a heavy object. Towards the end, after a heavy shake, stronger than the others, the" - ' screaming intensifies. Then nothing." "It is a very disturbing scene," said Julian Reichelt,' - " editor-in-chief of Bild online. An official with France's accident investigation agency, the BEA, said" - " the agency is not aware of any such video. Lt. Col. Jean-Marc Menichini, a French Gendarmerie spokesman" - " in charge of communications on rescue efforts around the Germanwings crash site, told CNN that the" - ' reports were "completely wrong" and "unwarranted." Cell phones have been collected at the site, he said,' - ' but that they "hadn\'t been exploited yet." Menichini said he believed the cell phones would need to be' - " sent to the Criminal Research Institute in Rosny sous-Bois, near Paris, in order to be analyzed by" - " specialized technicians working hand-in-hand with investigators. But none of the cell phones found so" - " far have been sent to the institute, Menichini said. Asked whether staff involved in the search could" - ' have leaked a memory card to the media, Menichini answered with a categorical "no." Reichelt told "Erin' - ' Burnett: Outfront" that he had watched the video and stood by the report, saying Bild and Paris Match' - ' are "very confident" that the clip is real. He noted that investigators only revealed they\'d recovered' - ' cell phones from the crash site after Bild and Paris Match published their reports. "That is something' - " we did not know before. ... Overall we can say many things of the investigation weren't revealed by the" - ' investigation at the beginning," he said. What was mental state of Germanwings co-pilot? German airline' - " Lufthansa confirmed Tuesday that co-pilot Andreas Lubitz had battled depression years before he took the" - " controls of Germanwings Flight 9525, which he's accused of deliberately crashing last week in the" - ' French Alps. Lubitz told his Lufthansa flight training school in 2009 that he had a "previous episode of' - ' severe depression," the airline said Tuesday. Email correspondence between Lubitz and the school' - " discovered in an internal investigation, Lufthansa said, included medical documents he submitted in" - " connection with resuming his flight training. The announcement indicates that Lufthansa, the parent" - " company of Germanwings, knew of Lubitz's battle with depression, allowed him to continue training and" - " ultimately put him in the cockpit. Lufthansa, whose CEO Carsten Spohr previously said Lubitz was 100%" - ' fit to fly, described its statement Tuesday as a "swift and seamless clarification" and said it was' - " sharing the information and documents -- including training and medical records -- with public" - " prosecutors. Spohr traveled to the crash site Wednesday, where recovery teams have been working for the" - " past week to recover human remains and plane debris scattered across a steep mountainside. He saw the" - " crisis center set up in Seyne-les-Alpes, laid a wreath in the village of Le Vernet, closer to the crash" - " site, where grieving families have left flowers at a simple stone memorial. Menichini told CNN late" - " Tuesday that no visible human remains were left at the site but recovery teams would keep searching." - " French President Francois Hollande, speaking Tuesday, said that it should be possible to identify all" - " the victims using DNA analysis by the end of the week, sooner than authorities had previously suggested." - " In the meantime, the recovery of the victims' personal belongings will start Wednesday, Menichini said." - " Among those personal belongings could be more cell phones belonging to the 144 passengers and six crew" - " on board. Check out the latest from our correspondents . The details about Lubitz's correspondence with" - " the flight school during his training were among several developments as investigators continued to" - " delve into what caused the crash and Lubitz's possible motive for downing the jet. A Lufthansa" - " spokesperson told CNN on Tuesday that Lubitz had a valid medical certificate, had passed all his" - ' examinations and "held all the licenses required." Earlier, a spokesman for the prosecutor\'s office in' - " Dusseldorf, Christoph Kumpa, said medical records reveal Lubitz suffered from suicidal tendencies at" - " some point before his aviation career and underwent psychotherapy before he got his pilot's license." - " Kumpa emphasized there's no evidence suggesting Lubitz was suicidal or acting aggressively before the" - " crash. Investigators are looking into whether Lubitz feared his medical condition would cause him to" - " lose his pilot's license, a European government official briefed on the investigation told CNN on" - ' Tuesday. While flying was "a big part of his life," the source said, it\'s only one theory being' - " considered. Another source, a law enforcement official briefed on the investigation, also told CNN that" - " authorities believe the primary motive for Lubitz to bring down the plane was that he feared he would" - " not be allowed to fly because of his medical problems. Lubitz's girlfriend told investigators he had" - " seen an eye doctor and a neuropsychologist, both of whom deemed him unfit to work recently and concluded" - " he had psychological issues, the European government official said. But no matter what details emerge" - " about his previous mental health struggles, there's more to the story, said Brian Russell, a forensic" - ' psychologist. "Psychology can explain why somebody would turn rage inward on themselves about the fact' - " that maybe they weren't going to keep doing their job and they're upset about that and so they're" - ' suicidal," he said. "But there is no mental illness that explains why somebody then feels entitled to' - " also take that rage and turn it outward on 149 other people who had nothing to do with the person's" - ' problems." Germanwings crash compensation: What we know . Who was the captain of Germanwings Flight' - " 9525? CNN's Margot Haddad reported from Marseille and Pamela Brown from Dusseldorf, while Laura" - " Smith-Spark wrote from London. CNN's Frederik Pleitgen, Pamela Boykoff, Antonia Mortensen, Sandrine" - " Amiel and Anna-Maja Rappard contributed to this report." - ) - SHORTER_ARTICLE = ( - "(CNN)The Palestinian Authority officially became the 123rd member of the International Criminal Court on" - " Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories. The" - " formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is based." - " The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted its" - ' jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including East' - ' Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination into the' - " situation in Palestinian territories, paving the way for possible war crimes investigations against" - " Israelis. As members of the court, Palestinians may be subject to counter-charges as well. Israel and" - " the United States, neither of which is an ICC member, opposed the Palestinians' efforts to join the" - " body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony, said it was a" - ' move toward greater justice. "As Palestine formally becomes a State Party to the Rome Statute today, the' - ' world is also a step closer to ending a long era of impunity and injustice," he said, according to an' - ' ICC news release. "Indeed, today brings us closer to our shared goals of justice and peace." Judge' - " Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was just the first step for the" - ' Palestinians. "As the Rome Statute today enters into force for the State of Palestine, Palestine' - " acquires all the rights as well as responsibilities that come with being a State Party to the Statute." - ' These are substantive commitments, which cannot be taken lightly," she said. Rights group Human Rights' - ' Watch welcomed the development. "Governments seeking to penalize Palestine for joining the ICC should' - " immediately end their pressure, and countries that support universal acceptance of the court's treaty" - ' should speak out to welcome its membership," said Balkees Jarrah, international justice counsel for the' - " group. \"What's objectionable is the attempts to undermine international justice, not Palestine's" - ' decision to join a treaty to which over 100 countries around the world are members." In January, when' - " the preliminary ICC examination was opened, Israeli Prime Minister Benjamin Netanyahu described it as an" - ' outrage, saying the court was overstepping its boundaries. The United States also said it "strongly"' - " disagreed with the court's decision. \"As we have said repeatedly, we do not believe that Palestine is a" - ' state and therefore we do not believe that it is eligible to join the ICC," the State Department said in' - ' a statement. It urged the warring sides to resolve their differences through direct negotiations. "We' - ' will continue to oppose actions against Israel at the ICC as counterproductive to the cause of peace,"' - " it said. But the ICC begs to differ with the definition of a state for its purposes and refers to the" - ' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows the' - " court to review evidence and determine whether to investigate suspects on both sides. Prosecutor Fatou" - ' Bensouda said her office would "conduct its analysis in full independence and impartiality." The war' - " between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The inquiry" - " will include alleged war crimes committed since June. The International Criminal Court was set up in" - " 2002 to prosecute genocide, crimes against humanity and war crimes. CNN's Vasco Cotovio, Kareem Khadder" - " and Faith Karimi contributed to this report." - ) - IRAN_ARTICLE = ( - "(CNN)The United States and its negotiating partners reached a very strong framework agreement with Iran" - " in Lausanne, Switzerland, on Thursday that limits Iran's nuclear program in such a way as to effectively" - " block it from building a nuclear weapon. Expect pushback anyway, if the recent past is any harbinger." - " Just last month, in an attempt to head off such an agreement, House Speaker John Boehner invited Israeli" - " Prime Minister Benjamin Netanyahu to preemptively blast it before Congress, and 47 senators sent a" - " letter to the Iranian leadership warning them away from a deal. The debate that has already begun since" - " the announcement of the new framework will likely result in more heat than light. It will not be helped" - " by the gathering swirl of dubious assumptions and doubtful assertions. Let us address some of these: ." - " The most misleading assertion, despite universal rejection by experts, is that the negotiations'" - " objective at the outset was the total elimination of any nuclear program in Iran. That is the position" - " of Netanyahu and his acolytes in the U.S. Congress. But that is not and never was the objective. If it" - " had been, there would have been no Iranian team at the negotiating table. Rather, the objective has" - " always been to structure an agreement or series of agreements so that Iran could not covertly develop a" - " nuclear arsenal before the United States and its allies could respond. The new framework has exceeded" - " expectations in achieving that goal. It would reduce Iran's low-enriched uranium stockpile, cut by" - " two-thirds its number of installed centrifuges and implement a rigorous inspection regime. Another" - " dubious assumption of opponents is that the Iranian nuclear program is a covert weapons program. Despite" - " sharp accusations by some in the United States and its allies, Iran denies having such a program, and" - " U.S. intelligence contends that Iran has not yet made the decision to build a nuclear weapon. Iran's" - " continued cooperation with International Atomic Energy Agency inspections is further evidence on this" - " point, and we'll know even more about Iran's program in the coming months and years because of the deal." - " In fact, the inspections provisions that are part of this agreement are designed to protect against any" - " covert action by the Iranians. What's more, the rhetoric of some members of Congress has implied that" - " the negotiations have been between only the United States and Iran (i.e., the 47 senators' letter" - " warning that a deal might be killed by Congress or a future president). This of course is not the case." - " The talks were between Iran and the five permanent members of the U.N. Security Council (United States," - " United Kingdom, France, China and Russia) plus Germany, dubbed the P5+1. While the United States has" - " played a leading role in the effort, it negotiated the terms alongside its partners. If the agreement" - " reached by the P5+1 is rejected by Congress, it could result in an unraveling of the sanctions on Iran" - " and threaten NATO cohesion in other areas. Another questionable assertion is that this agreement" - " contains a sunset clause, after which Iran will be free to do as it pleases. Again, this is not the" - " case. Some of the restrictions on Iran's nuclear activities, such as uranium enrichment, will be eased" - " or eliminated over time, as long as 15 years. But most importantly, the framework agreement includes" - " Iran's ratification of the Additional Protocol, which allows IAEA inspectors expanded access to nuclear" - " sites both declared and nondeclared. This provision will be permanent. It does not sunset. Thus, going" - " forward, if Iran decides to enrich uranium to weapons-grade levels, monitors will be able to detect such" - " a move in a matter of days and alert the U.N. Security Council. Many in Congress have said that the" - ' agreement should be a formal treaty requiring the Senate to "advise and consent." But the issue is not' - " suited for a treaty. Treaties impose equivalent obligations on all signatories. For example, the New" - " START treaty limits Russia and the United States to 1,550 deployed strategic warheads. But any agreement" - " with Iran will not be so balanced. The restrictions and obligations in the final framework agreement" - " will be imposed almost exclusively on Iran. The P5+1 are obligated only to ease and eventually remove" - " most but not all economic sanctions, which were imposed as leverage to gain this final deal. Finally" - " some insist that any agreement must address Iranian missile programs, human rights violations or support" - " for Hamas or Hezbollah. As important as these issues are, and they must indeed be addressed, they are" - " unrelated to the most important aim of a nuclear deal: preventing a nuclear Iran. To include them in" - " the negotiations would be a poison pill. This agreement should be judged on its merits and on how it" - " affects the security of our negotiating partners and allies, including Israel. Those judgments should be" - " fact-based, not based on questionable assertions or dubious assumptions." - ) - ARTICLE_SUBWAY = ( - "New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A" - " year later, she got married again in Westchester County, but to a different man and without divorcing" - " her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos" - ' declared "I do" five more times, sometimes only within two weeks of each other. In 2010, she married' - " once more, this time in the Bronx. In an application for a marriage license, she stated it was her" - ' "first and only" marriage. Barrientos, now 39, is facing two criminal counts of "offering a false' - ' instrument for filing in the first degree," referring to her false statements on the 2010 marriage' - " license application, according to court documents. Prosecutors said the marriages were part of an" - " immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to" - " her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was" - " arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New" - " York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total," - " Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All" - " occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be" - " married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors" - " said the immigration scam involved some of her husbands, who filed for permanent residence status" - " shortly after the marriages. Any divorces happened only after such filings were approved. It was" - " unclear whether any of the men will be prosecuted. The case was referred to the Bronx District" - " Attorney's Office by Immigration and Customs Enforcement and the Department of Homeland Security's" - ' Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt,' - " Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his" - " native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces" - " up to four years in prison. Her next court appearance is scheduled for May 18." - ) - - expected_summaries = [ - 'prosecutor: "so far no videos were used in the crash investigation" two magazines claim to have found a' - " cell phone video of the final seconds . \"one can hear cries of 'My God' in several languages,\" one" - " magazine says .", - "the formal accession was marked by a ceremony at The Hague, in the Netherlands . the ICC opened a" - " preliminary examination into the situation in the occupied Palestinian territory . as members of the" - " court, Palestinians may be subject to counter-charges as well .", - "the u.s. and its negotiating partners reached a very strong framework agreement with Iran . aaron miller:" - " the debate that has already begun since the announcement of the new framework will likely result in more" - " heat than light . the deal would reduce Iran's low-enriched uranium stockpile, cut centrifuges and" - " implement a rigorous inspection regime .", - "prosecutors say the marriages were part of an immigration scam . if convicted, barrientos faces two" - ' criminal counts of "offering a false instrument for filing in the first degree" she has been married 10' - " times, with nine of her marriages occurring between 1999 and 2002 .", - ] - - use_task_specific_params(model, "summarization") - - dct = tok( - [model.config.prefix + x for x in [FRANCE_ARTICLE, SHORTER_ARTICLE, IRAN_ARTICLE, ARTICLE_SUBWAY]], - padding="max_length", - truncation=True, - return_tensors="pt", - ).to(torch_device) - self.assertEqual(512, dct["input_ids"].shape[1]) - - hypotheses_batch = model.generate( - **dct, - num_beams=4, - length_penalty=2.0, - max_length=142, - min_length=56, - no_repeat_ngram_size=3, - do_sample=False, - early_stopping=True, - ) - - decoded = tok.batch_decode(hypotheses_batch, skip_special_tokens=True, clean_up_tokenization_spaces=False) - self.assertListEqual( - expected_summaries, - decoded, - ) - - @slow - def test_translation_en_to_de(self): - model = self.model - tok = self.tokenizer - use_task_specific_params(model, "translation_en_to_de") - - en_text = '"Luigi often said to me that he never wanted the brothers to end up in court", she wrote.' - expected_translation = ( - '"Luigi sagte mir oft, dass er nie wollte, dass die Brüder am Gericht sitzen", schrieb sie.' - ) - - input_ids = tok.encode(model.config.prefix + en_text, return_tensors="pt") - input_ids = input_ids.to(torch_device) - output = model.generate(input_ids) - translation = tok.decode(output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False) - self.assertEqual(translation, expected_translation) - - @slow - def test_translation_en_to_fr(self): - model = self.model # google-t5/t5-base - tok = self.tokenizer - use_task_specific_params(model, "translation_en_to_fr") - - en_text = ( - ' This image section from an infrared recording by the Spitzer telescope shows a "family portrait" of' - " countless generations of stars: the oldest stars are seen as blue dots. " - ) - - input_ids = tok.encode(model.config.prefix + en_text, return_tensors="pt") - input_ids = input_ids.to(torch_device) - - output = model.generate( - input_ids=input_ids, - num_beams=4, - length_penalty=2.0, - max_length=100, - no_repeat_ngram_size=3, - do_sample=False, - early_stopping=True, - ) - translation = tok.decode(output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False) - new_truncated_translation = ( - "Cette section d'images provenant de l'enregistrement infrarouge effectué par le télescope Spitzer montre " - "un " - "« portrait familial » de générations innombrables d’étoiles : les plus anciennes sont observées " - "sous forme " - "de points bleus." - ) - - self.assertEqual(translation, new_truncated_translation) - - @slow - def test_translation_en_to_ro(self): - model = self.model - tok = self.tokenizer - use_task_specific_params(model, "translation_en_to_ro") - en_text = "Taco Bell said it plans to add 2,000 locations in the US by 2022." - expected_translation = "Taco Bell a declarat că intenţionează să adauge 2 000 de locaţii în SUA până în 2022." - - inputs = tok(model.config.prefix + en_text, return_tensors="pt").to(torch_device) - output = model.generate(**inputs) - translation = tok.decode(output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False) - self.assertEqual(translation, expected_translation) - - @slow - def test_contrastive_search_t5(self): - article = ( - " New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A" - " year later, she got married again in Westchester County, but to a different man and without divorcing" - " her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos" - ' declared "I do" five more times, sometimes only within two weeks of each other. In 2010, she married' - " once more, this time in the Bronx. In an application for a marriage license, she stated it was her" - ' "first and only" marriage. Barrientos, now 39, is facing two criminal counts of "offering a false' - ' instrument for filing in the first degree," referring to her false statements on the 2010 marriage' - " license application, according to court documents. Prosecutors said the marriages were part of an" - " immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to" - " her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was" - " arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New" - " York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total," - " Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All" - " occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be" - " married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors" - " said the immigration scam involved some of her husbands, who filed for permanent residence status" - " shortly after the marriages. Any divorces happened only after such filings were approved. It was" - " unclear whether any of the men will be prosecuted. The case was referred to the Bronx District" - " Attorney's Office by Immigration and Customs Enforcement and the Department of Homeland Security's" - ' Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt,' - " Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his" - " native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces" - " up to four years in prison. Her next court appearance is scheduled for May 18." - ) - article = "summarize: " + article.strip() - t5_tokenizer = AutoTokenizer.from_pretrained("flax-community/t5-base-cnn-dm") - t5_model = T5ForConditionalGeneration.from_pretrained("flax-community/t5-base-cnn-dm").to(torch_device) - input_ids = t5_tokenizer( - article, add_special_tokens=False, truncation=True, max_length=512, return_tensors="pt" - ).input_ids.to(torch_device) - - outputs = t5_model.generate(input_ids, penalty_alpha=0.5, top_k=5, max_length=64) - generated_text = t5_tokenizer.batch_decode(outputs, skip_special_tokens=True) - - self.assertListEqual( - generated_text, - [ - "Liana Barrientos has been married 10 times, nine of them in the Bronx. Her husbands filed for " - "permanent residence after the marriages, prosecutors say." - ], - ) - - -@require_torch -class TestAsymmetricT5(unittest.TestCase): - def build_model_and_check_forward_pass(self, **kwargs): - tester = T5ModelTester(self, **kwargs) - config, *inputs = tester.prepare_config_and_inputs() - ( - input_ids, - decoder_input_ids, - attention_mask, - decoder_attention_mask, - lm_labels, - ) = inputs - model = T5ForConditionalGeneration(config=config).to(torch_device).eval() - outputs = model( - input_ids=input_ids, - decoder_input_ids=decoder_input_ids, - decoder_attention_mask=decoder_attention_mask, - labels=lm_labels, - ) - # outputs = model(*inputs) - assert len(outputs) == 4 - assert outputs["logits"].size() == (tester.batch_size, tester.decoder_seq_length, tester.vocab_size) - assert outputs["loss"].size() == () - return model - - def test_small_decoder(self): - # num_hidden_layers is passed to T5Config as num_layers - model = self.build_model_and_check_forward_pass(decoder_layers=1, num_hidden_layers=2) - assert len(model.encoder.block) == 2 - assert len(model.decoder.block) == 1 - - def test_defaulting_to_symmetry(self): - # num_hidden_layers is passed to T5Config as num_layers - model = self.build_model_and_check_forward_pass(num_hidden_layers=2) - assert len(model.decoder.block) == len(model.encoder.block) == 2 diff --git a/tests/transformers/tests/models/vit/__init__.py b/tests/transformers/tests/models/vit/__init__.py deleted file mode 100644 index e69de29bb2..0000000000 diff --git a/tests/transformers/tests/models/vit/test_modeling_vit.py b/tests/transformers/tests/models/vit/test_modeling_vit.py deleted file mode 100644 index 3b86395362..0000000000 --- a/tests/transformers/tests/models/vit/test_modeling_vit.py +++ /dev/null @@ -1,328 +0,0 @@ - -# coding=utf-8 -# Copyright 2021 The HuggingFace Inc. team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -""" Testing suite for the PyTorch ViT model. """ - - -import unittest - -from transformers import ViTConfig -from transformers.testing_utils import ( - require_accelerate, - require_torch, - require_torch_accelerator, - require_torch_fp16, - require_vision, - slow, - torch_device, -) -from transformers.utils import cached_property, is_torch_available, is_vision_available - -from optimum.habana.transformers.modeling_utils import adapt_transformers_to_gaudi - -from ...test_configuration_common import ConfigTester -from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor - - -if is_torch_available(): - import torch - from torch import nn - - from transformers import ViTForImageClassification, ViTForMaskedImageModeling, ViTModel - from transformers.models.vit.modeling_vit import VIT_PRETRAINED_MODEL_ARCHIVE_LIST - - -if is_vision_available(): - from PIL import Image - - from transformers import ViTImageProcessor - -torch_device = "hpu" -adapt_transformers_to_gaudi() - - -class ViTModelTester: - def __init__( - self, - parent, - batch_size=13, - image_size=30, - patch_size=2, - num_channels=3, - is_training=True, - use_labels=True, - hidden_size=32, - num_hidden_layers=2, - num_attention_heads=4, - intermediate_size=37, - hidden_act="gelu", - hidden_dropout_prob=0.1, - attention_probs_dropout_prob=0.1, - type_sequence_label_size=10, - initializer_range=0.02, - scope=None, - encoder_stride=2, - ): - self.parent = parent - self.batch_size = batch_size - self.image_size = image_size - self.patch_size = patch_size - self.num_channels = num_channels - self.is_training = is_training - self.use_labels = use_labels - self.hidden_size = hidden_size - self.num_hidden_layers = num_hidden_layers - self.num_attention_heads = num_attention_heads - self.intermediate_size = intermediate_size - self.hidden_act = hidden_act - self.hidden_dropout_prob = hidden_dropout_prob - self.attention_probs_dropout_prob = attention_probs_dropout_prob - self.type_sequence_label_size = type_sequence_label_size - self.initializer_range = initializer_range - self.scope = scope - self.encoder_stride = encoder_stride - - # in ViT, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token) - num_patches = (image_size // patch_size) ** 2 - self.seq_length = num_patches + 1 - - def prepare_config_and_inputs(self): - pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size]) - - labels = None - if self.use_labels: - labels = ids_tensor([self.batch_size], self.type_sequence_label_size) - - config = self.get_config() - - return config, pixel_values, labels - - def get_config(self): - return ViTConfig( - image_size=self.image_size, - patch_size=self.patch_size, - num_channels=self.num_channels, - hidden_size=self.hidden_size, - num_hidden_layers=self.num_hidden_layers, - num_attention_heads=self.num_attention_heads, - intermediate_size=self.intermediate_size, - hidden_act=self.hidden_act, - hidden_dropout_prob=self.hidden_dropout_prob, - attention_probs_dropout_prob=self.attention_probs_dropout_prob, - is_decoder=False, - initializer_range=self.initializer_range, - encoder_stride=self.encoder_stride, - ) - - def create_and_check_model(self, config, pixel_values, labels): - model = ViTModel(config=config) - model.to(torch_device) - model.eval() - result = model(pixel_values) - self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size)) - - def create_and_check_for_masked_image_modeling(self, config, pixel_values, labels): - model = ViTForMaskedImageModeling(config=config) - model.to(torch_device) - model.eval() - result = model(pixel_values) - self.parent.assertEqual( - result.reconstruction.shape, (self.batch_size, self.num_channels, self.image_size, self.image_size) - ) - - # test greyscale images - config.num_channels = 1 - model = ViTForMaskedImageModeling(config) - model.to(torch_device) - model.eval() - - pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size]) - result = model(pixel_values) - self.parent.assertEqual(result.reconstruction.shape, (self.batch_size, 1, self.image_size, self.image_size)) - - def create_and_check_for_image_classification(self, config, pixel_values, labels): - config.num_labels = self.type_sequence_label_size - model = ViTForImageClassification(config) - model.to(torch_device) - model.eval() - result = model(pixel_values, labels=labels) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size)) - - # test greyscale images - config.num_channels = 1 - model = ViTForImageClassification(config) - model.to(torch_device) - model.eval() - - pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size]) - result = model(pixel_values) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size)) - - def prepare_config_and_inputs_for_common(self): - config_and_inputs = self.prepare_config_and_inputs() - ( - config, - pixel_values, - labels, - ) = config_and_inputs - inputs_dict = {"pixel_values": pixel_values} - return config, inputs_dict - - -@require_torch -class ViTModelTest(ModelTesterMixin, unittest.TestCase): - """ - Here we also overwrite some of the tests of test_modeling_common.py, as ViT does not use input_ids, inputs_embeds, - attention_mask and seq_length. - """ - - all_model_classes = ( - ( - ViTModel, - ViTForImageClassification, - ViTForMaskedImageModeling, - ) - if is_torch_available() - else () - ) - pipeline_model_mapping = ( - {"image-feature-extraction": ViTModel, "image-classification": ViTForImageClassification} - if is_torch_available() - else {} - ) - fx_compatible = True - - test_pruning = False - test_resize_embeddings = False - test_head_masking = False - - def setUp(self): - self.model_tester = ViTModelTester(self) - self.config_tester = ConfigTester(self, config_class=ViTConfig, has_text_modality=False, hidden_size=37) - - def test_config(self): - self.config_tester.run_common_tests() - - @unittest.skip(reason="ViT does not use inputs_embeds") - def test_inputs_embeds(self): - pass - - def test_model_common_attributes(self): - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - model = model_class(config) - self.assertIsInstance(model.get_input_embeddings(), (nn.Module)) - x = model.get_output_embeddings() - self.assertTrue(x is None or isinstance(x, nn.Linear)) - - def test_model(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_for_masked_image_modeling(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_for_masked_image_modeling(*config_and_inputs) - - def test_for_image_classification(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_for_image_classification(*config_and_inputs) - - @slow - def test_model_from_pretrained(self): - model_name = "google/vit-base-patch16-224" - model = ViTModel.from_pretrained(model_name) - self.assertIsNotNone(model) - - -# We will verify our results on an image of cute cats -def prepare_img(): - image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png") - return image - - -@require_torch -@require_vision -class ViTModelIntegrationTest(unittest.TestCase): - @cached_property - def default_image_processor(self): - return ViTImageProcessor.from_pretrained("google/vit-base-patch16-224") if is_vision_available() else None - - @slow - def test_inference_image_classification_head(self): - model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224").to(torch_device) - - image_processor = self.default_image_processor - image = prepare_img() - inputs = image_processor(images=image, return_tensors="pt").to(torch_device) - - # forward pass - with torch.no_grad(): - outputs = model(**inputs) - - # verify the logits - expected_shape = torch.Size((1, 1000)) - self.assertEqual(outputs.logits.shape, expected_shape) - - expected_slice = torch.tensor([-0.2744, 0.8215, -0.0836]).to(torch_device) - - self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4)) - - @slow - def test_inference_interpolate_pos_encoding(self): - # ViT models have an `interpolate_pos_encoding` argument in their forward method, - # allowing to interpolate the pre-trained position embeddings in order to use - # the model on higher resolutions. The DINO model by Facebook AI leverages this - # to visualize self-attention on higher resolution images. - model = ViTModel.from_pretrained("facebook/dino-vits8").to(torch_device) - - image_processor = ViTImageProcessor.from_pretrained("facebook/dino-vits8", size=480) - image = prepare_img() - inputs = image_processor(images=image, return_tensors="pt") - pixel_values = inputs.pixel_values.to(torch_device) - - # forward pass - with torch.no_grad(): - outputs = model(pixel_values, interpolate_pos_encoding=True) - - # verify the logits - expected_shape = torch.Size((1, 3601, 384)) - self.assertEqual(outputs.last_hidden_state.shape, expected_shape) - - expected_slice = torch.tensor( - [[4.2340, 4.3906, -6.6692], [4.5463, 1.8928, -6.7257], [4.4429, 0.8496, -5.8585]] - ).to(torch_device) - - self.assertTrue(torch.allclose(outputs.last_hidden_state[0, :3, :3], expected_slice, atol=1e-4)) - - @slow - @require_accelerate - @require_torch_accelerator - @require_torch_fp16 - def test_inference_fp16(self): - r""" - A small test to make sure that inference work in half precision without any problem. - """ - model = ViTModel.from_pretrained("facebook/dino-vits8", torch_dtype=torch.float16, device_map="auto") - image_processor = self.default_image_processor - - image = prepare_img() - inputs = image_processor(images=image, return_tensors="pt") - pixel_values = inputs.pixel_values.to(torch_device) - - # forward pass to make sure inference works in fp16 - with torch.no_grad(): - _ = model(pixel_values) - diff --git a/tests/transformers/tests/models/wav2vec2/__init__.py b/tests/transformers/tests/models/wav2vec2/__init__.py deleted file mode 100644 index e69de29bb2..0000000000 diff --git a/tests/transformers/tests/models/wav2vec2/test_modeling_wav2vec2.py b/tests/transformers/tests/models/wav2vec2/test_modeling_wav2vec2.py deleted file mode 100644 index 00a44f2129..0000000000 --- a/tests/transformers/tests/models/wav2vec2/test_modeling_wav2vec2.py +++ /dev/null @@ -1,2000 +0,0 @@ -# coding=utf-8 -# Copyright 2021 The HuggingFace Inc. team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -""" Testing suite for the PyTorch Wav2Vec2 model. """ - -import gc -import math -import multiprocessing -import os -import pickle -import tempfile -import traceback -import unittest - -import numpy as np -from datasets import load_dataset - -from transformers import Wav2Vec2Config, is_torch_available -from transformers.testing_utils import ( - CaptureLogger, - backend_empty_cache, - is_pt_flax_cross_test, - is_pyctcdecode_available, - is_torchaudio_available, - require_pyctcdecode, - require_soundfile, - require_torch, - require_torchaudio, - run_test_in_subprocess, - slow, - torch_device, -) -from transformers.utils import is_torch_fx_available - -from optimum.habana.transformers.modeling_utils import adapt_transformers_to_gaudi - -from ...test_configuration_common import ConfigTester -from ...test_modeling_common import ( - ModelTesterMixin, - _config_zero_init, - floats_tensor, - ids_tensor, - random_attention_mask, -) - - -if is_torch_available(): - import torch - from safetensors.torch import save_file as safe_save_file - - from transformers import ( - Wav2Vec2FeatureExtractor, - Wav2Vec2ForAudioFrameClassification, - Wav2Vec2ForCTC, - Wav2Vec2ForMaskedLM, - Wav2Vec2ForPreTraining, - Wav2Vec2ForSequenceClassification, - Wav2Vec2ForXVector, - Wav2Vec2Model, - Wav2Vec2Processor, - ) - from transformers.models.wav2vec2.modeling_wav2vec2 import ( - WAV2VEC2_ADAPTER_PT_FILE, - WAV2VEC2_ADAPTER_SAFE_FILE, - Wav2Vec2GumbelVectorQuantizer, - _compute_mask_indices, - _sample_negative_indices, - ) - - -if is_torchaudio_available(): - import torchaudio - - -if is_pyctcdecode_available(): - import pyctcdecode.decoder - - from transformers import Wav2Vec2ProcessorWithLM - from transformers.models.wav2vec2_with_lm import processing_wav2vec2_with_lm - - -if is_torch_fx_available(): - from transformers.utils.fx import symbolic_trace - -torch_device = "hpu" -adapt_transformers_to_gaudi() - -def _test_wav2vec2_with_lm_invalid_pool(in_queue, out_queue, timeout): - error = None - try: - _ = in_queue.get(timeout=timeout) - - ds = load_dataset("mozilla-foundation/common_voice_11_0", "es", split="test", streaming=True) - sample = next(iter(ds)) - - resampled_audio = torchaudio.functional.resample( - torch.tensor(sample["audio"]["array"]), 48_000, 16_000 - ).numpy() - - model = Wav2Vec2ForCTC.from_pretrained("patrickvonplaten/wav2vec2-large-xlsr-53-spanish-with-lm").to( - torch_device - ) - processor = Wav2Vec2ProcessorWithLM.from_pretrained("patrickvonplaten/wav2vec2-large-xlsr-53-spanish-with-lm") - - input_values = processor(resampled_audio, return_tensors="pt").input_values - - with torch.no_grad(): - logits = model(input_values.to(torch_device)).logits - - # use a spawn pool, which should trigger a warning if different than fork - with CaptureLogger(pyctcdecode.decoder.logger) as cl, multiprocessing.get_context("spawn").Pool(1) as pool: - transcription = processor.batch_decode(logits.cpu().numpy(), pool).text - - unittest.TestCase().assertIn("Falling back to sequential decoding.", cl.out) - unittest.TestCase().assertEqual(transcription[0], "habitan aguas poco profundas y rocosas") - - # force batch_decode to internally create a spawn pool, which should trigger a warning if different than fork - multiprocessing.set_start_method("spawn", force=True) - with CaptureLogger(processing_wav2vec2_with_lm.logger) as cl: - transcription = processor.batch_decode(logits.cpu().numpy()).text - - unittest.TestCase().assertIn("Falling back to sequential decoding.", cl.out) - unittest.TestCase().assertEqual(transcription[0], "habitan aguas poco profundas y rocosas") - except Exception: - error = f"{traceback.format_exc()}" - - results = {"error": error} - out_queue.put(results, timeout=timeout) - out_queue.join() - - -class Wav2Vec2ModelTester: - def __init__( - self, - parent, - batch_size=13, - seq_length=1024, # speech is longer - is_training=False, - hidden_size=16, - feat_extract_norm="group", - feat_extract_dropout=0.0, - feat_extract_activation="gelu", - conv_dim=(32, 32, 32), - conv_stride=(4, 4, 4), - conv_kernel=(8, 8, 8), - conv_bias=False, - num_conv_pos_embeddings=16, - num_conv_pos_embedding_groups=2, - num_hidden_layers=2, - num_attention_heads=2, - hidden_dropout_prob=0.1, # this is most likely not correctly set yet - intermediate_size=20, - layer_norm_eps=1e-5, - hidden_act="gelu", - initializer_range=0.02, - mask_time_prob=0.5, - mask_time_length=2, - vocab_size=32, - do_stable_layer_norm=False, - num_adapter_layers=1, - adapter_stride=2, - tdnn_dim=(32, 32), - tdnn_kernel=(5, 3), - tdnn_dilation=(1, 2), - xvector_output_dim=32, - scope=None, - ): - self.parent = parent - self.batch_size = batch_size - self.seq_length = seq_length - self.is_training = is_training - self.hidden_size = hidden_size - self.feat_extract_norm = feat_extract_norm - self.feat_extract_dropout = feat_extract_dropout - self.feat_extract_activation = feat_extract_activation - self.conv_dim = conv_dim - self.conv_stride = conv_stride - self.conv_kernel = conv_kernel - self.conv_bias = conv_bias - self.num_conv_pos_embeddings = num_conv_pos_embeddings - self.num_conv_pos_embedding_groups = num_conv_pos_embedding_groups - self.num_hidden_layers = num_hidden_layers - self.num_attention_heads = num_attention_heads - self.hidden_dropout_prob = hidden_dropout_prob - self.intermediate_size = intermediate_size - self.layer_norm_eps = layer_norm_eps - self.hidden_act = hidden_act - self.initializer_range = initializer_range - self.vocab_size = vocab_size - self.do_stable_layer_norm = do_stable_layer_norm - self.num_adapter_layers = num_adapter_layers - self.adapter_stride = adapter_stride - self.mask_time_prob = mask_time_prob - self.mask_time_length = mask_time_length - self.scope = scope - self.tdnn_dim = tdnn_dim - self.tdnn_kernel = tdnn_kernel - self.tdnn_dilation = tdnn_dilation - self.xvector_output_dim = xvector_output_dim - - output_seq_length = self.seq_length - for kernel, stride in zip(self.conv_kernel, self.conv_stride): - output_seq_length = (output_seq_length - (kernel - 1)) / stride - self.output_seq_length = int(math.ceil(output_seq_length)) - self.encoder_seq_length = self.output_seq_length - - self.adapter_output_seq_length = (self.output_seq_length - 1) // adapter_stride + 1 - - def prepare_config_and_inputs(self): - input_values = floats_tensor([self.batch_size, self.seq_length], scale=1.0) - attention_mask = random_attention_mask([self.batch_size, self.seq_length]) - - config = self.get_config() - - return config, input_values, attention_mask - - def get_config(self): - return Wav2Vec2Config( - hidden_size=self.hidden_size, - feat_extract_norm=self.feat_extract_norm, - feat_extract_dropout=self.feat_extract_dropout, - feat_extract_activation=self.feat_extract_activation, - conv_dim=self.conv_dim, - conv_stride=self.conv_stride, - conv_kernel=self.conv_kernel, - conv_bias=self.conv_bias, - mask_time_prob=self.mask_time_prob, - mask_time_length=self.mask_time_length, - num_conv_pos_embeddings=self.num_conv_pos_embeddings, - num_conv_pos_embedding_groups=self.num_conv_pos_embedding_groups, - num_hidden_layers=self.num_hidden_layers, - num_attention_heads=self.num_attention_heads, - hidden_dropout_prob=self.hidden_dropout_prob, - intermediate_size=self.intermediate_size, - layer_norm_eps=self.layer_norm_eps, - do_stable_layer_norm=self.do_stable_layer_norm, - hidden_act=self.hidden_act, - initializer_range=self.initializer_range, - vocab_size=self.vocab_size, - num_adapter_layers=self.num_adapter_layers, - adapter_stride=self.adapter_stride, - tdnn_dim=self.tdnn_dim, - tdnn_kernel=self.tdnn_kernel, - tdnn_dilation=self.tdnn_dilation, - xvector_output_dim=self.xvector_output_dim, - ) - - def create_and_check_model(self, config, input_values, attention_mask): - model = Wav2Vec2Model(config=config) - model.to(torch_device) - model.eval() - result = model(input_values, attention_mask=attention_mask) - self.parent.assertEqual( - result.last_hidden_state.shape, (self.batch_size, self.output_seq_length, self.hidden_size) - ) - - def create_and_check_model_with_adapter(self, config, input_values, attention_mask): - config.add_adapter = True - model = Wav2Vec2Model(config=config) - model.to(torch_device) - model.eval() - result = model(input_values, attention_mask=attention_mask) - self.parent.assertEqual( - result.last_hidden_state.shape, (self.batch_size, self.adapter_output_seq_length, self.hidden_size) - ) - - def create_and_check_model_with_adapter_for_ctc(self, config, input_values, attention_mask): - config.add_adapter = True - config.output_hidden_size = 2 * config.hidden_size - model = Wav2Vec2ForCTC(config=config) - model.to(torch_device) - model.eval() - result = model(input_values, attention_mask=attention_mask) - self.parent.assertEqual( - result.logits.shape, (self.batch_size, self.adapter_output_seq_length, self.vocab_size) - ) - - def create_and_check_model_with_adapter_proj_dim(self, config, input_values, attention_mask): - config.add_adapter = True - config.output_hidden_size = 8 - model = Wav2Vec2Model(config=config) - model.to(torch_device) - model.eval() - result = model(input_values, attention_mask=attention_mask) - self.parent.assertEqual( - result.last_hidden_state.shape, - (self.batch_size, self.adapter_output_seq_length, config.output_hidden_size), - ) - - def create_and_check_model_with_attn_adapter(self, config, input_values, attention_mask): - config.adapter_attn_dim = 16 - model = Wav2Vec2ForCTC(config=config) - - self.parent.assertIsNotNone(model._get_adapters()) - - model.to(torch_device) - model.eval() - result = model(input_values, attention_mask=attention_mask) - self.parent.assertEqual(result.logits.shape, (self.batch_size, self.output_seq_length, self.vocab_size)) - - def create_and_check_batch_inference(self, config, input_values, *args): - # test does not pass for models making use of `group_norm` - # check: https://github.com/pytorch/fairseq/issues/3227 - model = Wav2Vec2Model(config=config) - model.to(torch_device) - model.eval() - - input_values = input_values[:3] - attention_mask = torch.ones(input_values.shape, device=torch_device, dtype=torch.bool) - - input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]] - - # pad input - for i in range(len(input_lengths)): - input_values[i, input_lengths[i] :] = 0.0 - attention_mask[i, input_lengths[i] :] = 0.0 - - batch_outputs = model(input_values, attention_mask=attention_mask).last_hidden_state - - for i in range(input_values.shape[0]): - input_slice = input_values[i : i + 1, : input_lengths[i]] - output = model(input_slice).last_hidden_state - - batch_output = batch_outputs[i : i + 1, : output.shape[1]] - self.parent.assertTrue(torch.allclose(output, batch_output, atol=1e-3)) - - def check_ctc_loss(self, config, input_values, *args): - model = Wav2Vec2ForCTC(config=config) - model.to(torch_device) - - # make sure that dropout is disabled - model.eval() - - input_values = input_values[:3] - attention_mask = torch.ones(input_values.shape, device=torch_device, dtype=torch.long) - - input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]] - max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths)) - labels = ids_tensor((input_values.shape[0], min(max_length_labels) - 1), model.config.vocab_size) - - # pad input - for i in range(len(input_lengths)): - input_values[i, input_lengths[i] :] = 0.0 - attention_mask[i, input_lengths[i] :] = 0 - - model.config.ctc_loss_reduction = "sum" - sum_loss = model(input_values, attention_mask=attention_mask, labels=labels).loss.item() - - model.config.ctc_loss_reduction = "mean" - mean_loss = model(input_values, attention_mask=attention_mask, labels=labels).loss.item() - - self.parent.assertTrue(isinstance(sum_loss, float)) - self.parent.assertTrue(isinstance(mean_loss, float)) - - def check_seq_classifier_loss(self, config, input_values, *args): - model = Wav2Vec2ForSequenceClassification(config=config) - model.to(torch_device) - - # make sure that dropout is disabled - model.eval() - - input_values = input_values[:3] - attention_mask = torch.ones(input_values.shape, device=torch_device, dtype=torch.long) - - input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]] - labels = ids_tensor((input_values.shape[0], 1), len(model.config.id2label)) - - # pad input - for i in range(len(input_lengths)): - input_values[i, input_lengths[i] :] = 0.0 - attention_mask[i, input_lengths[i] :] = 0 - - masked_loss = model(input_values, attention_mask=attention_mask, labels=labels).loss.item() - unmasked_loss = model(input_values, labels=labels).loss.item() - - self.parent.assertTrue(isinstance(masked_loss, float)) - self.parent.assertTrue(isinstance(unmasked_loss, float)) - self.parent.assertTrue(masked_loss != unmasked_loss) - - def check_ctc_training(self, config, input_values, *args): - config.ctc_zero_infinity = True - model = Wav2Vec2ForCTC(config=config) - model.to(torch_device) - model.train() - - # freeze feature encoder - model.freeze_feature_encoder() - - input_values = input_values[:3] - - input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]] - max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths)) - labels = ids_tensor((input_values.shape[0], max(max_length_labels) - 2), model.config.vocab_size) - - # pad input - for i in range(len(input_lengths)): - input_values[i, input_lengths[i] :] = 0.0 - - if max_length_labels[i] < labels.shape[-1]: - # it's important that we make sure that target lengths are at least - # one shorter than logit lengths to prevent -inf - labels[i, max_length_labels[i] - 1 :] = -100 - - loss = model(input_values, labels=labels).loss - self.parent.assertFalse(torch.isinf(loss).item()) - - loss.backward() - - def check_seq_classifier_training(self, config, input_values, *args): - config.ctc_zero_infinity = True - model = Wav2Vec2ForSequenceClassification(config=config) - model.to(torch_device) - model.train() - - # freeze everything but the classification head - model.freeze_base_model() - - input_values = input_values[:3] - - input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]] - labels = ids_tensor((input_values.shape[0], 1), len(model.config.id2label)) - - # pad input - for i in range(len(input_lengths)): - input_values[i, input_lengths[i] :] = 0.0 - - loss = model(input_values, labels=labels).loss - self.parent.assertFalse(torch.isinf(loss).item()) - - loss.backward() - - def check_xvector_training(self, config, input_values, *args): - config.ctc_zero_infinity = True - model = Wav2Vec2ForXVector(config=config) - model.to(torch_device) - model.train() - - # freeze everything but the classification head - model.freeze_base_model() - - input_values = input_values[:3] - - input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]] - labels = ids_tensor((input_values.shape[0], 1), len(model.config.id2label)) - - # pad input - for i in range(len(input_lengths)): - input_values[i, input_lengths[i] :] = 0.0 - - loss = model(input_values, labels=labels).loss - self.parent.assertFalse(torch.isinf(loss).item()) - - loss.backward() - - def check_labels_out_of_vocab(self, config, input_values, *args): - model = Wav2Vec2ForCTC(config) - model.to(torch_device) - model.train() - - input_values = input_values[:3] - - input_lengths = [input_values.shape[-1] // i for i in [4, 2, 1]] - max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths)) - labels = ids_tensor((input_values.shape[0], max(max_length_labels) - 2), model.config.vocab_size + 100) - - with self.parent.assertRaises(ValueError): - model(input_values, labels=labels) - - def prepare_config_and_inputs_for_common(self): - config, input_values, attention_mask = self.prepare_config_and_inputs() - inputs_dict = {"input_values": input_values, "attention_mask": attention_mask} - return config, inputs_dict - - -@require_torch -class Wav2Vec2ModelTest(ModelTesterMixin, unittest.TestCase): - all_model_classes = ( - (Wav2Vec2ForCTC, Wav2Vec2Model, Wav2Vec2ForMaskedLM, Wav2Vec2ForSequenceClassification, Wav2Vec2ForPreTraining) - if is_torch_available() - else () - ) - pipeline_model_mapping = ( - { - "audio-classification": Wav2Vec2ForSequenceClassification, - "automatic-speech-recognition": Wav2Vec2ForCTC, - "feature-extraction": Wav2Vec2Model, - "fill-mask": Wav2Vec2ForMaskedLM, - } - if is_torch_available() - else {} - ) - fx_compatible = True - test_pruning = False - test_headmasking = False - - def setUp(self): - self.model_tester = Wav2Vec2ModelTester(self) - self.config_tester = ConfigTester(self, config_class=Wav2Vec2Config, hidden_size=37) - - def test_config(self): - self.config_tester.run_common_tests() - - def test_model(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_model_with_adapter(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model_with_adapter(*config_and_inputs) - - def test_model_with_adapter_for_ctc(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model_with_adapter_for_ctc(*config_and_inputs) - - def test_model_with_adapter_proj_dim(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model_with_adapter_proj_dim(*config_and_inputs) - - def test_ctc_loss_inference(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_ctc_loss(*config_and_inputs) - - def test_seq_classifier_loss_inference(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_seq_classifier_loss(*config_and_inputs) - - def test_ctc_train(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_ctc_training(*config_and_inputs) - - def test_seq_classifier_train(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_seq_classifier_training(*config_and_inputs) - - def test_xvector_train(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_xvector_training(*config_and_inputs) - - def test_labels_out_of_vocab(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_labels_out_of_vocab(*config_and_inputs) - - # Wav2Vec2 has no inputs_embeds - def test_inputs_embeds(self): - pass - - # `input_ids` is renamed to `input_values` - def test_forward_signature(self): - pass - - # Wav2Vec2 cannot resize token embeddings - # since it has no tokens embeddings - def test_resize_tokens_embeddings(self): - pass - - # Wav2Vec2 has no inputs_embeds - # and thus the `get_input_embeddings` fn - # is not implemented - def test_model_common_attributes(self): - pass - - @is_pt_flax_cross_test - # non-robust architecture does not exist in Flax - def test_equivalence_flax_to_pt(self): - pass - - @is_pt_flax_cross_test - # non-robust architecture does not exist in Flax - def test_equivalence_pt_to_flax(self): - pass - - def test_retain_grad_hidden_states_attentions(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.output_hidden_states = True - config.output_attentions = True - - # no need to test all models as different heads yield the same functionality - model_class = self.all_model_classes[0] - model = model_class(config) - model.to(torch_device) - - # set layer drop to 0 - model.config.layerdrop = 0.0 - - input_values = inputs_dict["input_values"] - - input_lengths = torch.tensor( - [input_values.shape[1] for _ in range(input_values.shape[0])], dtype=torch.long, device=torch_device - ) - output_lengths = model._get_feat_extract_output_lengths(input_lengths) - - labels = ids_tensor((input_values.shape[0], output_lengths[0] - 2), self.model_tester.vocab_size) - inputs_dict["attention_mask"] = torch.ones_like(inputs_dict["attention_mask"]) - inputs_dict["labels"] = labels - - outputs = model(**inputs_dict) - - output = outputs[0] - - # Encoder-/Decoder-only models - hidden_states = outputs.hidden_states[0] - attentions = outputs.attentions[0] - - hidden_states.retain_grad() - attentions.retain_grad() - - output.flatten()[0].backward(retain_graph=True) - - self.assertIsNotNone(hidden_states.grad) - self.assertIsNotNone(attentions.grad) - - def test_initialization(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - configs_no_init = _config_zero_init(config) - for model_class in self.all_model_classes: - model = model_class(config=configs_no_init) - for name, param in model.named_parameters(): - uniform_init_parms = [ - "conv.weight", - "conv.parametrizations.weight", - "masked_spec_embed", - "codevectors", - "quantizer.weight_proj.weight", - "project_hid.weight", - "project_hid.bias", - "project_q.weight", - "project_q.bias", - "feature_projection.projection.weight", - "feature_projection.projection.bias", - "objective.weight", - ] - if param.requires_grad: - if any(x in name for x in uniform_init_parms): - self.assertTrue( - -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0, - msg=f"Parameter {name} of model {model_class} seems not properly initialized", - ) - else: - self.assertIn( - ((param.data.mean() * 1e9).round() / 1e9).item(), - [0.0, 1.0], - msg=f"Parameter {name} of model {model_class} seems not properly initialized", - ) - - # overwrite from test_modeling_common - def _mock_init_weights(self, module): - if hasattr(module, "weight") and module.weight is not None: - module.weight.data.fill_(3) - if hasattr(module, "weight_g") and module.weight_g is not None: - module.weight_g.data.fill_(3) - if hasattr(module, "weight_v") and module.weight_v is not None: - module.weight_v.data.fill_(3) - if hasattr(module, "bias") and module.bias is not None: - module.bias.data.fill_(3) - if hasattr(module, "codevectors") and module.codevectors is not None: - module.codevectors.data.fill_(3) - if hasattr(module, "masked_spec_embed") and module.masked_spec_embed is not None: - module.masked_spec_embed.data.fill_(3) - - def test_mask_feature_prob_ctc(self): - model = Wav2Vec2ForCTC.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", mask_feature_prob=0.2, mask_feature_length=2 - ) - model.to(torch_device).train() - processor = Wav2Vec2Processor.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", return_attention_mask=True - ) - - batch_duration_in_seconds = [1, 3, 2, 6] - input_features = [np.random.random(16_000 * s) for s in batch_duration_in_seconds] - - batch = processor( - input_features, padding=True, sampling_rate=processor.feature_extractor.sampling_rate, return_tensors="pt" - ) - - logits = model( - input_values=batch["input_values"].to(torch_device), - attention_mask=batch["attention_mask"].to(torch_device), - ).logits - - self.assertEqual(logits.shape, (4, 1498, 32)) - - def test_mask_time_prob_ctc(self): - model = Wav2Vec2ForCTC.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", mask_time_prob=0.2, mask_time_length=2 - ) - model.to(torch_device).train() - processor = Wav2Vec2Processor.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", return_attention_mask=True - ) - - batch_duration_in_seconds = [1, 3, 2, 6] - input_features = [np.random.random(16_000 * s) for s in batch_duration_in_seconds] - - batch = processor( - input_features, padding=True, sampling_rate=processor.feature_extractor.sampling_rate, return_tensors="pt" - ) - - logits = model( - input_values=batch["input_values"].to(torch_device), - attention_mask=batch["attention_mask"].to(torch_device), - ).logits - - self.assertEqual(logits.shape, (4, 1498, 32)) - - @unittest.skip(reason="Feed forward chunking is not implemented") - def test_feed_forward_chunking(self): - pass - - @slow - def test_model_from_pretrained(self): - model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-base-960h") - self.assertIsNotNone(model) - - # Wav2Vec2 cannot be torchscripted because of group norm. - def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=False): - # TODO: fix it - self.skipTest("torch 2.1 breaks torch fx tests for wav2vec2/hubert.") - - if not is_torch_fx_available() or not self.fx_compatible: - return - - configs_no_init = _config_zero_init(config) # To be sure we have no Nan - configs_no_init.return_dict = False - - for model_class in self.all_model_classes: - model = model_class(config=configs_no_init) - model.to(torch_device) - model.eval() - inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=output_loss) - - try: - input_names = [ - "attention_mask", - "bbox", - "input_features", - "input_ids", - "input_values", - "pixel_values", - "token_type_ids", - "visual_feats", - "visual_pos", - ] - - labels = inputs.get("labels", None) - start_positions = inputs.get("start_positions", None) - end_positions = inputs.get("end_positions", None) - if labels is not None: - input_names.append("labels") - if start_positions is not None: - input_names.append("start_positions") - if end_positions is not None: - input_names.append("end_positions") - - filtered_inputs = {k: v for (k, v) in inputs.items() if k in input_names} - input_names = list(filtered_inputs.keys()) - - model_output = model(**filtered_inputs) - - if ( - isinstance(model, Wav2Vec2ForSequenceClassification) - and not hasattr(model.config, "problem_type") - or model.config.problem_type is None - ): - model.config.problem_type = "single_label_classification" - - traced_model = symbolic_trace(model, input_names) - traced_output = traced_model(**filtered_inputs) - - except Exception as e: - self.fail(f"Couldn't trace module: {e}") - - def flatten_output(output): - flatten = [] - for x in output: - if isinstance(x, (tuple, list)): - flatten += flatten_output(x) - elif not isinstance(x, torch.Tensor): - continue - else: - flatten.append(x) - return flatten - - model_output = flatten_output(model_output) - traced_output = flatten_output(traced_output) - num_outputs = len(model_output) - - for i in range(num_outputs): - self.assertTrue( - torch.allclose(model_output[i], traced_output[i]), - f"traced {i}th output doesn't match model {i}th output for {model_class}", - ) - - # Test that the model can be serialized and restored properly - with tempfile.TemporaryDirectory() as tmp_dir_name: - pkl_file_name = os.path.join(tmp_dir_name, "model.pkl") - try: - with open(pkl_file_name, "wb") as f: - pickle.dump(traced_model, f) - with open(pkl_file_name, "rb") as f: - loaded = pickle.load(f) - except Exception as e: - self.fail(f"Couldn't serialize / deserialize the traced model: {e}") - - loaded_output = loaded(**filtered_inputs) - loaded_output = flatten_output(loaded_output) - - for i in range(num_outputs): - self.assertTrue( - torch.allclose(model_output[i], loaded_output[i]), - f"serialized model {i}th output doesn't match model {i}th output for {model_class}", - ) - - # Avoid memory leak. Without this, each call increase RAM usage by ~20MB. - # (Even with this call, there are still memory leak by ~0.04MB) - self.clear_torch_jit_class_registry() - - @unittest.skip( - "Need to investigate why config.do_stable_layer_norm is set to False here when it doesn't seem to be supported" - ) - def test_flax_from_pt_safetensors(self): - return - - -@require_torch -class Wav2Vec2RobustModelTest(ModelTesterMixin, unittest.TestCase): - all_model_classes = ( - ( - Wav2Vec2ForCTC, - Wav2Vec2Model, - Wav2Vec2ForMaskedLM, - Wav2Vec2ForSequenceClassification, - Wav2Vec2ForPreTraining, - Wav2Vec2ForAudioFrameClassification, - Wav2Vec2ForXVector, - ) - if is_torch_available() - else () - ) - test_pruning = False - test_headmasking = False - - def setUp(self): - self.model_tester = Wav2Vec2ModelTester( - self, conv_stride=(3, 3, 3), feat_extract_norm="layer", do_stable_layer_norm=True - ) - self.config_tester = ConfigTester(self, config_class=Wav2Vec2Config, hidden_size=37) - - def test_config(self): - self.config_tester.run_common_tests() - - def test_model(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model(*config_and_inputs) - - def test_model_with_adapter(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model_with_adapter(*config_and_inputs) - - def test_model_with_adapter_proj_dim(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model_with_adapter_proj_dim(*config_and_inputs) - - def test_model_with_attn_adapter(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_model_with_attn_adapter(*config_and_inputs) - - def test_batched_inference(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.create_and_check_batch_inference(*config_and_inputs) - - def test_ctc_loss_inference(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_ctc_loss(*config_and_inputs) - - def test_seq_classifier_loss_inference(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_seq_classifier_loss(*config_and_inputs) - - def test_ctc_train(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_ctc_training(*config_and_inputs) - - def test_seq_classifier_train(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_seq_classifier_training(*config_and_inputs) - - def test_xvector_train(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_xvector_training(*config_and_inputs) - - def test_labels_out_of_vocab(self): - config_and_inputs = self.model_tester.prepare_config_and_inputs() - self.model_tester.check_labels_out_of_vocab(*config_and_inputs) - - # Wav2Vec2 has no inputs_embeds - def test_inputs_embeds(self): - pass - - # `input_ids` is renamed to `input_values` - def test_forward_signature(self): - pass - - # Wav2Vec2 cannot resize token embeddings - # since it has no tokens embeddings - def test_resize_tokens_embeddings(self): - pass - - # Wav2Vec2 has no inputs_embeds - # and thus the `get_input_embeddings` fn - # is not implemented - def test_model_common_attributes(self): - pass - - def test_retain_grad_hidden_states_attentions(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.output_hidden_states = True - config.output_attentions = True - - # no need to test all models as different heads yield the same functionality - model_class = self.all_model_classes[0] - model = model_class(config) - model.to(torch_device) - - # set layer drop to 0 - model.config.layerdrop = 0.0 - - input_values = inputs_dict["input_values"] - - input_lengths = torch.tensor( - [input_values.shape[1] for _ in range(input_values.shape[0])], dtype=torch.long, device=torch_device - ) - output_lengths = model._get_feat_extract_output_lengths(input_lengths) - - labels = ids_tensor((input_values.shape[0], output_lengths[0] - 2), self.model_tester.vocab_size) - inputs_dict["attention_mask"] = torch.ones_like(inputs_dict["attention_mask"]) - inputs_dict["labels"] = labels - - outputs = model(**inputs_dict) - - output = outputs[0] - - # Encoder-/Decoder-only models - hidden_states = outputs.hidden_states[0] - attentions = outputs.attentions[0] - - hidden_states.retain_grad() - attentions.retain_grad() - - output.flatten()[0].backward(retain_graph=True) - - self.assertIsNotNone(hidden_states.grad) - self.assertIsNotNone(attentions.grad) - - def test_initialization(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - configs_no_init = _config_zero_init(config) - for model_class in self.all_model_classes: - model = model_class(config=configs_no_init) - for name, param in model.named_parameters(): - uniform_init_parms = [ - "conv.weight", - "conv.parametrizations.weight", - "masked_spec_embed", - "codevectors", - "quantizer.weight_proj.weight", - "project_hid.weight", - "project_hid.bias", - "project_q.weight", - "project_q.bias", - "feature_projection.projection.weight", - "feature_projection.projection.bias", - "objective.weight", - ] - if param.requires_grad: - if any(x in name for x in uniform_init_parms): - self.assertTrue( - -1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0, - msg=f"Parameter {name} of model {model_class} seems not properly initialized", - ) - else: - self.assertIn( - ((param.data.mean() * 1e9).round() / 1e9).item(), - [0.0, 1.0], - msg=f"Parameter {name} of model {model_class} seems not properly initialized", - ) - - # overwrite from test_modeling_common - def _mock_init_weights(self, module): - if hasattr(module, "weight") and module.weight is not None: - module.weight.data.fill_(3) - if hasattr(module, "weight_g") and module.weight_g is not None: - module.weight_g.data.fill_(3) - if hasattr(module, "weight_v") and module.weight_v is not None: - module.weight_v.data.fill_(3) - if hasattr(module, "bias") and module.bias is not None: - module.bias.data.fill_(3) - if hasattr(module, "codevectors") and module.codevectors is not None: - module.codevectors.data.fill_(3) - if hasattr(module, "masked_spec_embed") and module.masked_spec_embed is not None: - module.masked_spec_embed.data.fill_(3) - - def test_model_for_pretraining(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - model = Wav2Vec2ForPreTraining(config).to(torch_device) - - batch_size = inputs_dict["input_values"].shape[0] - feature_seq_length = int(model._get_feat_extract_output_lengths(inputs_dict["input_values"].shape[1])) - - features_shape = (batch_size, feature_seq_length) - - mask_time_indices = _compute_mask_indices( - features_shape, - model.config.mask_time_prob, - model.config.mask_time_length, - min_masks=2, - ) - sampled_negative_indices = _sample_negative_indices(features_shape, 10, mask_time_indices) - - mask_time_indices = torch.from_numpy(mask_time_indices).to(torch_device) - sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device) - - loss = model( - inputs_dict["input_values"], - attention_mask=inputs_dict["attention_mask"], - mask_time_indices=mask_time_indices, - sampled_negative_indices=sampled_negative_indices, - ).loss - - # more losses - mask_time_indices[:, : mask_time_indices.shape[-1] // 2] = True - - sampled_negative_indices = _sample_negative_indices(features_shape, 10, mask_time_indices.cpu().numpy()) - sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device) - loss_more_masked = model( - inputs_dict["input_values"], - attention_mask=inputs_dict["attention_mask"], - mask_time_indices=mask_time_indices, - sampled_negative_indices=sampled_negative_indices, - ).loss - - # loss_more_masked has to be bigger or equal loss since more masked inputs have to be predicted - self.assertTrue(loss.detach().item() <= loss_more_masked.detach().item()) - - def test_mask_feature_prob_ctc(self): - model = Wav2Vec2ForCTC.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", mask_feature_prob=0.2, mask_feature_length=2 - ) - model.to(torch_device).train() - processor = Wav2Vec2Processor.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", return_attention_mask=True - ) - - batch_duration_in_seconds = [1, 3, 2, 6] - input_features = [np.random.random(16_000 * s) for s in batch_duration_in_seconds] - - batch = processor( - input_features, padding=True, sampling_rate=processor.feature_extractor.sampling_rate, return_tensors="pt" - ) - - logits = model( - input_values=batch["input_values"].to(torch_device), - attention_mask=batch["attention_mask"].to(torch_device), - ).logits - - self.assertEqual(logits.shape, (4, 1498, 32)) - - def test_mask_time_prob_ctc(self): - model = Wav2Vec2ForCTC.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", mask_time_prob=0.2, mask_time_length=2 - ) - model.to(torch_device).train() - processor = Wav2Vec2Processor.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", return_attention_mask=True - ) - - batch_duration_in_seconds = [1, 3, 2, 6] - input_features = [np.random.random(16_000 * s) for s in batch_duration_in_seconds] - - batch = processor( - input_features, padding=True, sampling_rate=processor.feature_extractor.sampling_rate, return_tensors="pt" - ) - - logits = model( - input_values=batch["input_values"].to(torch_device), - attention_mask=batch["attention_mask"].to(torch_device), - ).logits - - self.assertEqual(logits.shape, (4, 1498, 32)) - - def test_mask_time_feature_prob_ctc_single_batch(self): - model = Wav2Vec2ForCTC.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", - mask_time_prob=0.2, - mask_feature_prob=0.2, - mask_time_length=2, - mask_feature_length=2, - ) - model.to(torch_device).train() - processor = Wav2Vec2Processor.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", return_attention_mask=True - ) - - batch_duration_in_seconds = [6] - input_features = [np.random.random(16_000 * s) for s in batch_duration_in_seconds] - - batch = processor( - input_features, padding=True, sampling_rate=processor.feature_extractor.sampling_rate, return_tensors="pt" - ) - - logits = model( - input_values=batch["input_values"].to(torch_device), - attention_mask=batch["attention_mask"].to(torch_device), - ).logits - - self.assertEqual(logits.shape, (1, 1498, 32)) - - @unittest.skip(reason="Feed forward chunking is not implemented") - def test_feed_forward_chunking(self): - pass - - def test_load_and_set_attn_adapter(self): - processor = Wav2Vec2Processor.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", return_attention_mask=True - ) - - def get_logits(model, input_features): - model = model.to(torch_device) - batch = processor( - input_features, - padding=True, - sampling_rate=processor.feature_extractor.sampling_rate, - return_tensors="pt", - ) - - with torch.no_grad(): - logits = model( - input_values=batch["input_values"].to(torch_device), - attention_mask=batch["attention_mask"].to(torch_device), - ).logits - return logits - - input_features = [np.random.random(16_000 * s) for s in [1, 3, 2, 6]] - - model = Wav2Vec2ForCTC.from_pretrained("hf-internal-testing/tiny-random-wav2vec2-adapter", target_lang="it") - - logits = get_logits(model, input_features) - - model_2 = Wav2Vec2ForCTC.from_pretrained("hf-internal-testing/tiny-random-wav2vec2-adapter") - model_2.load_adapter("it") - - logits_2 = get_logits(model_2, input_features) - - self.assertTrue(torch.allclose(logits, logits_2, atol=1e-3)) - - # test that loading adapter weights with mismatched vocab sizes can be loaded - def test_load_target_lang_with_mismatched_size(self): - processor = Wav2Vec2Processor.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", return_attention_mask=True - ) - - def get_logits(model, input_features): - model = model.to(torch_device) - batch = processor( - input_features, - padding=True, - sampling_rate=processor.feature_extractor.sampling_rate, - return_tensors="pt", - ) - - with torch.no_grad(): - logits = model( - input_values=batch["input_values"].to(torch_device), - attention_mask=batch["attention_mask"].to(torch_device), - ).logits - return logits - - input_features = [np.random.random(16_000 * s) for s in [1, 3, 2, 6]] - - model = Wav2Vec2ForCTC.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2-adapter", target_lang="fr", ignore_mismatched_sizes=True - ) - - logits = get_logits(model, input_features) - - model_2 = Wav2Vec2ForCTC.from_pretrained("hf-internal-testing/tiny-random-wav2vec2-adapter") - model_2.load_adapter("fr") - - logits_2 = get_logits(model_2, input_features) - - self.assertTrue(torch.allclose(logits, logits_2, atol=1e-3)) - - def test_load_attn_adapter(self): - processor = Wav2Vec2Processor.from_pretrained( - "hf-internal-testing/tiny-random-wav2vec2", return_attention_mask=True - ) - - def get_logits(model, input_features): - model = model.to(torch_device) - batch = processor( - input_features, - padding=True, - sampling_rate=processor.feature_extractor.sampling_rate, - return_tensors="pt", - ) - - with torch.no_grad(): - logits = model( - input_values=batch["input_values"].to(torch_device), - attention_mask=batch["attention_mask"].to(torch_device), - ).logits - return logits - - input_features = [np.random.random(16_000 * s) for s in [1, 3, 2, 6]] - - model = Wav2Vec2ForCTC.from_pretrained("hf-internal-testing/tiny-random-wav2vec2", adapter_attn_dim=16) - - with tempfile.TemporaryDirectory() as tempdir: - model.save_pretrained(tempdir) - model = Wav2Vec2ForCTC.from_pretrained(tempdir) - - logits = get_logits(model, input_features) - adapter_weights = model._get_adapters() - - # save safe weights - safe_filepath = os.path.join(tempdir, WAV2VEC2_ADAPTER_SAFE_FILE.format("eng")) - safe_save_file(adapter_weights, safe_filepath, metadata={"format": "pt"}) - - model.load_adapter("eng") - model.load_adapter("eng", use_safetensors=True) - - with self.assertRaises(OSError): - model.load_adapter("eng", use_safetensors=False) - with self.assertRaises(Exception): - model.load_adapter("ita", use_safetensors=True) - logits_2 = get_logits(model, input_features) - - self.assertTrue(torch.allclose(logits, logits_2, atol=1e-3)) - - with tempfile.TemporaryDirectory() as tempdir: - model.save_pretrained(tempdir) - model = Wav2Vec2ForCTC.from_pretrained(tempdir) - - logits = get_logits(model, input_features) - adapter_weights = model._get_adapters() - - # save pt weights - pt_filepath = os.path.join(tempdir, WAV2VEC2_ADAPTER_PT_FILE.format("eng")) - torch.save(adapter_weights, pt_filepath) - - model.load_adapter("eng") - model.load_adapter("eng", use_safetensors=False) - - with self.assertRaises(OSError): - model.load_adapter("eng", use_safetensors=True) - - logits_2 = get_logits(model, input_features) - - self.assertTrue(torch.allclose(logits, logits_2, atol=1e-3)) - - model = Wav2Vec2ForCTC.from_pretrained("hf-internal-testing/tiny-random-wav2vec2-adapter") - logits = get_logits(model, input_features) - - model.load_adapter("eng") - model.load_adapter("eng", use_safetensors=False) - model.load_adapter("eng", use_safetensors=True) - - logits_2 = get_logits(model, input_features) - - self.assertTrue(torch.allclose(logits, logits_2, atol=1e-3)) - - @slow - def test_model_from_pretrained(self): - model = Wav2Vec2Model.from_pretrained("facebook/wav2vec2-base-960h") - self.assertIsNotNone(model) - - -@require_torch -class Wav2Vec2UtilsTest(unittest.TestCase): - def test_compute_mask_indices(self): - batch_size = 4 - sequence_length = 60 - mask_prob = 0.5 - mask_length = 1 - - mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length) - mask = torch.from_numpy(mask).to(torch_device) - - self.assertListEqual(mask.sum(axis=-1).tolist(), [mask_prob * sequence_length for _ in range(batch_size)]) - - def test_compute_mask_indices_low_prob(self): - # with these settings num_masked_spans=0.5, which means probabilistic rounding - # ensures that in 5 out of 10 method calls, num_masked_spans=0, and in - # the other 5 out of 10, cases num_masked_spans=1 - n_trials = 100 - batch_size = 4 - sequence_length = 100 - mask_prob = 0.05 - mask_length = 10 - - count_dimensions_masked = 0 - count_dimensions_not_masked = 0 - - for _ in range(n_trials): - mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length) - mask = torch.from_numpy(mask).to(torch_device) - - num_masks = torch.sum(mask).item() - - if num_masks > 0: - count_dimensions_masked += 1 - else: - count_dimensions_not_masked += 1 - - # as we test for at least 10 masked dimension and at least - # 10 non-masked dimension, this test could fail with probability: - # P(100 coin flips, at most 9 heads) = 1.66e-18 - self.assertGreater(count_dimensions_masked, int(n_trials * 0.1)) - self.assertGreater(count_dimensions_not_masked, int(n_trials * 0.1)) - - def test_compute_mask_indices_overlap(self): - batch_size = 4 - sequence_length = 80 - mask_prob = 0.5 - mask_length = 4 - - mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length) - mask = torch.from_numpy(mask).to(torch_device) - - # because of overlap mask don't have to add up exactly to `mask_prob * sequence_length`, but have to be smaller or equal - for batch_sum in mask.sum(axis=-1): - self.assertTrue(int(batch_sum) <= mask_prob * sequence_length) - - def test_compute_mask_indices_attn_mask_overlap(self): - batch_size = 4 - sequence_length = 80 - mask_prob = 0.5 - mask_length = 4 - - attention_mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device) - attention_mask[:2, sequence_length // 2 :] = 0 - - mask = _compute_mask_indices( - (batch_size, sequence_length), mask_prob, mask_length, attention_mask=attention_mask - ) - mask = torch.from_numpy(mask).to(torch_device) - - for batch_sum in mask.sum(axis=-1): - self.assertTrue(int(batch_sum) <= mask_prob * sequence_length) - - self.assertTrue(mask[:2, sequence_length // 2 :].sum() == 0) - - def test_compute_mask_indices_short_audio(self): - batch_size = 4 - sequence_length = 100 - mask_prob = 0.05 - mask_length = 10 - - attention_mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device) - # force one example to be heavily padded - attention_mask[0, 5:] = 0 - - mask = _compute_mask_indices( - (batch_size, sequence_length), mask_prob, mask_length, attention_mask=attention_mask, min_masks=2 - ) - - # make sure that non-padded examples cannot be padded - self.assertFalse(mask[0][attention_mask[0].to(torch.bool).cpu()].any()) - - def test_compute_perplexity(self): - probs = torch.arange(100, device=torch_device).reshape(2, 5, 10) / 100 - - ppl = Wav2Vec2GumbelVectorQuantizer._compute_perplexity(probs) - self.assertTrue(abs(ppl.item() - 141.4291) < 1e-3) - - # mask half of the input - mask = torch.ones((2,), device=torch_device, dtype=torch.bool) - mask[0] = 0 - - ppl = Wav2Vec2GumbelVectorQuantizer._compute_perplexity(probs, mask) - self.assertTrue(abs(ppl.item() - 58.6757) < 1e-3) - - def test_sample_negatives(self): - batch_size = 2 - sequence_length = 10 - hidden_size = 4 - num_negatives = 3 - sequence = torch.div( - torch.arange(sequence_length * hidden_size, device=torch_device), hidden_size, rounding_mode="floor" - ) - features = sequence.view(sequence_length, hidden_size) # each value in vector consits of same value - features = features[None, :].expand(batch_size, sequence_length, hidden_size).contiguous() - - # sample negative indices - sampled_negative_indices = _sample_negative_indices((batch_size, sequence_length), num_negatives, None) - sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device) - negatives = features.view(-1, hidden_size)[sampled_negative_indices.long().view(-1)] - negatives = negatives.view(batch_size, sequence_length, -1, hidden_size).permute(2, 0, 1, 3) - self.assertTrue(negatives.shape == (num_negatives, batch_size, sequence_length, hidden_size)) - - # make sure no negatively sampled vector is actually a positive one - for negative in negatives: - self.assertTrue(((negative - features) == 0).sum() == 0.0) - - # make sure that full vectors are sampled and not values of vectors => this means that `unique()` yields a single value for `hidden_size` dim - self.assertEqual(negatives.unique(dim=-1).shape, (num_negatives, batch_size, sequence_length, 1)) - - def test_sample_negatives_with_mask(self): - batch_size = 2 - sequence_length = 10 - hidden_size = 4 - num_negatives = 3 - - # second half of last input tensor is padded - mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device) - mask[-1, sequence_length // 2 :] = 0 - - sequence = torch.div( - torch.arange(sequence_length * hidden_size, device=torch_device), hidden_size, rounding_mode="floor" - ) - features = sequence.view(sequence_length, hidden_size) # each value in vector consits of same value - features = features[None, :].expand(batch_size, sequence_length, hidden_size).contiguous() - - # replace masked feature vectors with -100 to test that those are not sampled - features = torch.where(mask[:, :, None].expand(features.shape).bool(), features, -100) - - # sample negative indices - sampled_negative_indices = _sample_negative_indices( - (batch_size, sequence_length), num_negatives, mask.cpu().numpy() - ) - sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device) - negatives = features.view(-1, hidden_size)[sampled_negative_indices.long().view(-1)] - negatives = negatives.view(batch_size, sequence_length, -1, hidden_size).permute(2, 0, 1, 3) - - self.assertTrue((negatives >= 0).all().item()) - - self.assertTrue(negatives.shape == (num_negatives, batch_size, sequence_length, hidden_size)) - - # make sure no negatively sampled vector is actually a positive one - for negative in negatives: - self.assertTrue(((negative - features) == 0).sum() == 0.0) - - # make sure that full vectors are sampled and not values of vectors => this means that `unique()` yields a single value for `hidden_size` dim - self.assertEqual(negatives.unique(dim=-1).shape, (num_negatives, batch_size, sequence_length, 1)) - - -@require_torch -@require_soundfile -@slow -class Wav2Vec2ModelIntegrationTest(unittest.TestCase): - def tearDown(self): - super().tearDown() - # clean-up as much as possible GPU memory occupied by PyTorch - gc.collect() - backend_empty_cache(torch_device) - - def _load_datasamples(self, num_samples): - ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation") - # automatic decoding with librispeech - speech_samples = ds.sort("id").filter( - lambda x: x["id"] in [f"1272-141231-000{i}" for i in range(num_samples)] - )[:num_samples]["audio"] - - return [x["array"] for x in speech_samples] - - def _load_superb(self, task, num_samples): - ds = load_dataset("anton-l/superb_dummy", task, split="test") - - return ds[:num_samples] - - def test_inference_ctc_normal(self): - model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h") - model.to(torch_device) - processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h", do_lower_case=True) - input_speech = self._load_datasamples(1) - - input_values = processor(input_speech, return_tensors="pt").input_values.to(torch_device) - - with torch.no_grad(): - logits = model(input_values).logits - - predicted_ids = torch.argmax(logits, dim=-1) - predicted_trans = processor.batch_decode(predicted_ids) - - EXPECTED_TRANSCRIPTIONS = ["a man said to the universe sir i exist"] - self.assertListEqual(predicted_trans, EXPECTED_TRANSCRIPTIONS) - - def test_inference_ctc_normal_batched(self): - model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h") - model.to(torch_device) - processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h", do_lower_case=True) - - input_speech = self._load_datasamples(2) - - inputs = processor(input_speech, return_tensors="pt", padding=True) - - input_values = inputs.input_values.to(torch_device) - - with torch.no_grad(): - logits = model(input_values).logits - - predicted_ids = torch.argmax(logits, dim=-1) - predicted_trans = processor.batch_decode(predicted_ids) - - EXPECTED_TRANSCRIPTIONS = [ - "a man said to the universe sir i exist", - "sweat covered brion's body trickling into the tight lowing cloth that was the only garment he wore", - ] - self.assertListEqual(predicted_trans, EXPECTED_TRANSCRIPTIONS) - - def test_inference_ctc_robust_batched(self): - model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60-self").to(torch_device) - processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60-self", do_lower_case=True) - - input_speech = self._load_datasamples(4) - - inputs = processor(input_speech, return_tensors="pt", padding=True) - - input_values = inputs.input_values.to(torch_device) - attention_mask = inputs.attention_mask.to(torch_device) - - with torch.no_grad(): - logits = model(input_values, attention_mask=attention_mask).logits - - predicted_ids = torch.argmax(logits, dim=-1) - predicted_trans = processor.batch_decode(predicted_ids) - - EXPECTED_TRANSCRIPTIONS = [ - "a man said to the universe sir i exist", - "sweat covered brion's body trickling into the tight loin cloth that was the only garment he wore", - "the cut on his chest still dripping blood the ache of his overstrained eyes even the soaring arena around" - " him with the thousands of spectators were trivialities not worth thinking about", - "his instant panic was followed by a small sharp blow high on his chest", - ] - self.assertListEqual(predicted_trans, EXPECTED_TRANSCRIPTIONS) - - @unittest.skipIf(torch_device != "cpu", "cannot make deterministic on GPU") - def test_inference_integration(self): - model = Wav2Vec2ForPreTraining.from_pretrained("facebook/wav2vec2-base") - model.to(torch_device) - feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("facebook/wav2vec2-base") - input_speech = self._load_datasamples(2) - - inputs_dict = feature_extractor(input_speech, return_tensors="pt", padding=True) - - batch_size = inputs_dict["input_values"].shape[0] - feature_seq_length = int(model._get_feat_extract_output_lengths(inputs_dict["input_values"].shape[1])) - - features_shape = (batch_size, feature_seq_length) - - np.random.seed(4) - mask_time_indices = _compute_mask_indices( - features_shape, - model.config.mask_time_prob, - model.config.mask_time_length, - min_masks=2, - ) - mask_time_indices = torch.from_numpy(mask_time_indices).to(torch_device) - - with torch.no_grad(): - outputs = model( - inputs_dict.input_values.to(torch_device), - mask_time_indices=mask_time_indices, - ) - - # compute cosine similarity - cosine_sim = torch.cosine_similarity(outputs.projected_states, outputs.projected_quantized_states, dim=-1) - - # retrieve cosine sim of masked features - cosine_sim_masked = cosine_sim[mask_time_indices] - - # cosine similarity of model is all > 0.5 as model is - # pre-trained on contrastive loss - # fmt: off - expected_cosine_sim_masked = torch.tensor([ - 0.8523, 0.5860, 0.6905, 0.5557, 0.7456, 0.5249, 0.6639, 0.7654, 0.7565, - 0.8167, 0.8222, 0.7960, 0.8034, 0.8166, 0.8310, 0.8263, 0.8274, 0.8258, - 0.8179, 0.8412, 0.8536, 0.5098, 0.4728, 0.6461, 0.4498, 0.6002, 0.5774, - 0.6457, 0.7123, 0.5668, 0.6866, 0.4960, 0.6293, 0.7423, 0.7419, 0.7526, - 0.7768, 0.4898, 0.5393, 0.8183 - ], device=torch_device) - # fmt: on - - self.assertTrue(torch.allclose(cosine_sim_masked, expected_cosine_sim_masked, atol=1e-3)) - - def test_inference_pretrained(self): - model = Wav2Vec2ForPreTraining.from_pretrained("facebook/wav2vec2-base") - model.to(torch_device) - feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained( - "facebook/wav2vec2-base", return_attention_mask=True - ) - input_speech = self._load_datasamples(2) - - inputs_dict = feature_extractor(input_speech, return_tensors="pt", padding=True) - - batch_size = inputs_dict["input_values"].shape[0] - feature_seq_length = int(model._get_feat_extract_output_lengths(inputs_dict["input_values"].shape[1])) - - features_shape = (batch_size, feature_seq_length) - - torch.manual_seed(0) - mask_time_indices = _compute_mask_indices( - features_shape, - model.config.mask_time_prob, - model.config.mask_time_length, - min_masks=2, - ) - mask_time_indices = torch.from_numpy(mask_time_indices).to(torch_device) - - with torch.no_grad(): - outputs = model( - inputs_dict.input_values.to(torch_device), - attention_mask=inputs_dict.attention_mask.to(torch_device), - mask_time_indices=mask_time_indices, - ) - - # compute cosine similarity - cosine_sim = torch.cosine_similarity(outputs.projected_states, outputs.projected_quantized_states, dim=-1) - - # retrieve cosine sim of masked features - cosine_sim_masked = cosine_sim[mask_time_indices] - - # ... now compare to randomly initialized model - - config = Wav2Vec2Config.from_pretrained("facebook/wav2vec2-base") - model_rand = Wav2Vec2ForPreTraining(config).to(torch_device).eval() - - with torch.no_grad(): - outputs_rand = model_rand( - inputs_dict.input_values.to(torch_device), - attention_mask=inputs_dict.attention_mask.to(torch_device), - mask_time_indices=mask_time_indices, - ) - - # compute cosine similarity - cosine_sim_rand = torch.cosine_similarity( - outputs_rand.projected_states, outputs_rand.projected_quantized_states, dim=-1 - ) - - # retrieve cosine sim of masked features - cosine_sim_masked_rand = cosine_sim_rand[mask_time_indices] - - # a pretrained wav2vec2 model has learned to predict the quantized latent states - # => the cosine similarity between quantized states and predicted states > 0.5 - # a random wav2vec2 model has not learned to predict the quantized latent states - # => the cosine similarity between quantized states and predicted states is very likely < 0.1 - self.assertTrue(cosine_sim_masked.mean().item() - 5 * cosine_sim_masked_rand.mean().item() > 0) - - @unittest.skipIf(torch_device != "cpu", "cannot make deterministic on GPU") - def test_loss_pretraining(self): - model = Wav2Vec2ForPreTraining.from_pretrained( - "facebook/wav2vec2-base", - attention_dropout=0.0, - feat_proj_dropout=0.0, - hidden_dropout=0.0, - layerdrop=0.0, - ) - model.to(torch_device).train() - - feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained( - "facebook/wav2vec2-base", return_attention_mask=True - ) - input_speech = self._load_datasamples(2) - - inputs_dict = feature_extractor(input_speech, return_tensors="pt", padding=True) - - batch_size = inputs_dict["input_values"].shape[0] - feature_seq_length = int(model._get_feat_extract_output_lengths(inputs_dict["input_values"].shape[1])) - - features_shape = (batch_size, feature_seq_length) - - torch.manual_seed(0) - np.random.seed(0) - - mask_time_indices = _compute_mask_indices( - features_shape, - model.config.mask_time_prob, - model.config.mask_time_length, - min_masks=2, - ) - sampled_negative_indices = _sample_negative_indices( - mask_time_indices.shape, model.config.num_negatives, mask_time_indices - ) - - mask_time_indices = torch.from_numpy(mask_time_indices).to(torch_device) - sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device) - - with torch.no_grad(): - outputs = model( - inputs_dict.input_values.to(torch_device), - attention_mask=inputs_dict.attention_mask.to(torch_device), - mask_time_indices=mask_time_indices, - sampled_negative_indices=sampled_negative_indices, - ) - - # check diversity loss - num_codevectors = model.config.num_codevectors_per_group * model.config.num_codevector_groups - diversity_loss = (num_codevectors - outputs.codevector_perplexity) / num_codevectors - self.assertTrue(abs(diversity_loss.item() - 0.9538) < 1e-3) - - # check overall loss (contrastive loss + diversity loss) - expected_loss = 116.7094 - - self.assertTrue(abs(outputs.loss.item() - expected_loss) < 1e-3) - - def test_inference_keyword_spotting(self): - model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-ks").to(torch_device) - processor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-ks") - input_data = self._load_superb("ks", 4) - inputs = processor(input_data["speech"], return_tensors="pt", padding=True) - - input_values = inputs.input_values.to(torch_device) - attention_mask = inputs.attention_mask.to(torch_device) - with torch.no_grad(): - outputs = model(input_values, attention_mask=attention_mask) - predicted_logits, predicted_ids = torch.max(outputs.logits, dim=-1) - - expected_labels = [7, 6, 10, 9] - # s3prl logits for the same batch - expected_logits = torch.tensor([6.1186, 11.8961, 10.2931, 6.0898], device=torch_device) - - self.assertListEqual(predicted_ids.tolist(), expected_labels) - self.assertTrue(torch.allclose(predicted_logits, expected_logits, atol=1e-2)) - - def test_inference_intent_classification(self): - model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-ic").to(torch_device) - processor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-ic") - input_data = self._load_superb("ic", 4) - inputs = processor(input_data["speech"], return_tensors="pt", padding=True) - - input_values = inputs.input_values.to(torch_device) - attention_mask = inputs.attention_mask.to(torch_device) - with torch.no_grad(): - outputs = model(input_values, attention_mask=attention_mask) - - predicted_logits_action, predicted_ids_action = torch.max(outputs.logits[:, :6], dim=-1) - predicted_logits_object, predicted_ids_object = torch.max(outputs.logits[:, 6:20], dim=-1) - predicted_logits_location, predicted_ids_location = torch.max(outputs.logits[:, 20:24], dim=-1) - - expected_labels_action = [0, 0, 2, 3] - expected_logits_action = torch.tensor([0.4568, 11.0848, 1.6621, 9.3841], device=torch_device) - expected_labels_object = [3, 10, 3, 4] - expected_logits_object = torch.tensor([1.5322, 10.7094, 5.2469, 22.1318], device=torch_device) - expected_labels_location = [0, 0, 0, 1] - expected_logits_location = torch.tensor([1.5335, 6.5096, 10.5704, 11.0569], device=torch_device) - - self.assertListEqual(predicted_ids_action.tolist(), expected_labels_action) - self.assertListEqual(predicted_ids_object.tolist(), expected_labels_object) - self.assertListEqual(predicted_ids_location.tolist(), expected_labels_location) - - self.assertTrue(torch.allclose(predicted_logits_action, expected_logits_action, atol=1e-2)) - self.assertTrue(torch.allclose(predicted_logits_object, expected_logits_object, atol=1e-2)) - self.assertTrue(torch.allclose(predicted_logits_location, expected_logits_location, atol=1e-2)) - - def test_inference_speaker_identification(self): - model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-sid").to(torch_device) - processor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-sid") - input_data = self._load_superb("si", 4) - - output_logits = [] - with torch.no_grad(): - for example in input_data["speech"]: - input = processor(example, return_tensors="pt", padding=True) - output = model(input.input_values.to(torch_device), attention_mask=None) - output_logits.append(output.logits[0]) - output_logits = torch.stack(output_logits) - predicted_logits, predicted_ids = torch.max(output_logits, dim=-1) - - expected_labels = [251, 1, 1, 3] - # s3prl logits for the same batch - expected_logits = torch.tensor([37.5627, 71.6362, 64.2419, 31.7778], device=torch_device) - - self.assertListEqual(predicted_ids.tolist(), expected_labels) - self.assertTrue(torch.allclose(predicted_logits, expected_logits, atol=1e-2)) - - def test_inference_emotion_recognition(self): - model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-er").to(torch_device) - processor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-er") - input_data = self._load_superb("er", 4) - inputs = processor(input_data["speech"], return_tensors="pt", padding=True) - - input_values = inputs.input_values.to(torch_device) - attention_mask = inputs.attention_mask.to(torch_device) - with torch.no_grad(): - outputs = model(input_values, attention_mask=attention_mask) - predicted_logits, predicted_ids = torch.max(outputs.logits, dim=-1) - - expected_labels = [1, 1, 2, 2] - # s3prl logits for the same batch - expected_logits = torch.tensor([2.1722, 3.0779, 8.0287, 6.6797], device=torch_device) - - self.assertListEqual(predicted_ids.tolist(), expected_labels) - self.assertTrue(torch.allclose(predicted_logits, expected_logits, atol=1e-2)) - - def test_phoneme_recognition(self): - model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-lv-60-espeak-cv-ft").to(torch_device) - processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-lv-60-espeak-cv-ft") - - input_speech = self._load_datasamples(4) - - inputs = processor(input_speech, return_tensors="pt", padding=True) - - input_values = inputs.input_values.to(torch_device) - attention_mask = inputs.attention_mask.to(torch_device) - - with torch.no_grad(): - logits = model(input_values, attention_mask=attention_mask).logits - - predicted_ids = torch.argmax(logits, dim=-1) - predicted_trans = processor.batch_decode(predicted_ids) - - EXPECTED_TRANSCRIPTIONS = [ - "ɐ m æ n s ɛ d t ə ð ə j uː n ɪ v ɚ s s ɚ aɪ ɛ ɡ z ɪ s t", - "s w ɛ t k ʌ v ɚ d b ɹ iː ɔ n z b ɑː d i t ɹ ɪ k l ɪ ŋ ɪ n t ə ð ə t aɪ t l oɪ n k l ɑː θ ð æ w ʌ z ð ɪ oʊ" - " n l i ɡ ɑːɹ m ə n t h iː w ɔːɹ", - "ð ə k aɪ t ɔ n h ɪ z tʃ ɛ s t s t ɪ l d ɹ ɪ p ɪ ŋ b l ʌ d ð ɪ eɪ k ʌ v h ɪ z oʊ v ɚ s t ɹ eɪ n d aɪ z iː" - " v ə n ð ə s ɔːɹ ɹ ɪ ŋ ɐ ɹ iː n ɐ ɚ ɹ aʊ n d h ɪ m w ɪ ð ə θ aʊ z ə n d z ʌ v s p ɛ k t eɪ ɾ ɚ z w ɜː t ɹ" - " ɪ v ɪ æ l ᵻ ɾ i z n ɑː t w ɜː θ θ ɪ ŋ k ɪ ŋ ɐ b aʊ t", - "h ɪ z ɪ n s t ə n t v p æ n ɪ k w ʌ z f ɑː l oʊ d b aɪ ɐ s m ɔː l ʃ ɑːɹ p b l oʊ h aɪ ɔ n h ɪ z tʃ ɛ s t", - ] - # should correspond to =>: - # [ - # "a man said to the universe sir i exist", - # "sweat covered brion's body trickling into the tight loin cloth that was the only garment he wore", - # "the cut on his chest still dripping blood the ache of his overstrained eyes even the soaring arena around him with the thousands of spectators were trivialities not worth thinking about", - # "his instant panic was followed by a small sharp blow high on his chest", - # ] - self.assertListEqual(predicted_trans, EXPECTED_TRANSCRIPTIONS) - - @require_pyctcdecode - @require_torchaudio - def test_wav2vec2_with_lm(self): - ds = load_dataset("mozilla-foundation/common_voice_11_0", "es", split="test", streaming=True) - sample = next(iter(ds)) - - resampled_audio = torchaudio.functional.resample( - torch.tensor(sample["audio"]["array"]), 48_000, 16_000 - ).numpy() - - model = Wav2Vec2ForCTC.from_pretrained("patrickvonplaten/wav2vec2-large-xlsr-53-spanish-with-lm").to( - torch_device - ) - processor = Wav2Vec2ProcessorWithLM.from_pretrained("patrickvonplaten/wav2vec2-large-xlsr-53-spanish-with-lm") - - input_values = processor(resampled_audio, return_tensors="pt").input_values - - with torch.no_grad(): - logits = model(input_values.to(torch_device)).logits - - transcription = processor.batch_decode(logits.cpu().numpy()).text - - self.assertEqual(transcription[0], "habitan aguas poco profundas y rocosas") - - @require_pyctcdecode - @require_torchaudio - def test_wav2vec2_with_lm_pool(self): - ds = load_dataset("mozilla-foundation/common_voice_11_0", "es", split="test", streaming=True) - sample = next(iter(ds)) - - resampled_audio = torchaudio.functional.resample( - torch.tensor(sample["audio"]["array"]), 48_000, 16_000 - ).numpy() - - model = Wav2Vec2ForCTC.from_pretrained("patrickvonplaten/wav2vec2-large-xlsr-53-spanish-with-lm").to( - torch_device - ) - processor = Wav2Vec2ProcessorWithLM.from_pretrained("patrickvonplaten/wav2vec2-large-xlsr-53-spanish-with-lm") - - input_values = processor(resampled__audio, return_tensors="pt").input_values - - with torch.no_grad(): - logits = model(input_values.to(torch_device)).logits - - # test user-managed pool - with multiprocessing.get_context("fork").Pool(2) as pool: - transcription = processor.batch_decode(logits.cpu().numpy(), pool).text - - self.assertEqual(transcription[0], "habitan aguas poco profundas y rocosas") - - # user-managed pool + num_processes should trigger a warning - with CaptureLogger(processing_wav2vec2_with_lm.logger) as cl, multiprocessing.get_context("fork").Pool( - 2 - ) as pool: - transcription = processor.batch_decode(logits.cpu().numpy(), pool, num_processes=2).text - - self.assertIn("num_process", cl.out) - self.assertIn("it will be ignored", cl.out) - - self.assertEqual(transcription[0], "habitan aguas poco profundas y rocosas") - - @require_pyctcdecode - @require_torchaudio - def test_wav2vec2_with_lm_invalid_pool(self): - run_test_in_subprocess(test_case=self, target_func=_test_wav2vec2_with_lm_invalid_pool, inputs=None) - - def test_inference_diarization(self): - model = Wav2Vec2ForAudioFrameClassification.from_pretrained("anton-l/wav2vec2-base-superb-sd").to(torch_device) - processor = Wav2Vec2FeatureExtractor.from_pretrained("anton-l/wav2vec2-base-superb-sd") - input_data = self._load_superb("sd", 4) - inputs = processor(input_data["speech"], return_tensors="pt", padding=True, sampling_rate=16_000) - - input_values = inputs.input_values.to(torch_device) - attention_mask = inputs.attention_mask.to(torch_device) - with torch.no_grad(): - outputs = model(input_values, attention_mask=attention_mask) - # labels is a one-hot array of shape (num_frames, num_speakers) - labels = (outputs.logits > 0).long() - - # s3prl logits for the same batch - expected_logits = torch.tensor( - [ - [[-5.2807, -5.1272], [-5.4059, -4.7757], [-5.2764, -4.9621], [-5.0117, -4.5851]], - [[-1.7643, -0.5462], [-1.7369, -0.2649], [-1.5066, -0.6200], [-4.5703, -2.4863]], - [[-0.8656, -0.4783], [-0.8899, -0.3289], [-0.9267, -0.5781], [-0.7817, -0.4619]], - [[-4.8625, -2.5316], [-5.2339, -2.2155], [-4.9835, -2.0344], [-4.4727, -1.8421]], - ], - device=torch_device, - ) - self.assertEqual(labels[0, :, 0].sum(), 555) - self.assertEqual(labels[0, :, 1].sum(), 299) - self.assertTrue(torch.allclose(outputs.logits[:, :4], expected_logits, atol=1e-2)) - - def test_inference_speaker_verification(self): - model = Wav2Vec2ForXVector.from_pretrained("anton-l/wav2vec2-base-superb-sv").to(torch_device) - processor = Wav2Vec2FeatureExtractor.from_pretrained("anton-l/wav2vec2-base-superb-sv") - input_data = self._load_superb("si", 4) - - inputs = processor(input_data["speech"], return_tensors="pt", padding=True, sampling_rate=16_000) - labels = torch.tensor([5, 1, 1, 3], device=torch_device).T - - with torch.no_grad(): - input_values = inputs.input_values.to(torch_device) - attention_mask = inputs.attention_mask.to(torch_device) - outputs = model(input_values, attention_mask=attention_mask, labels=labels) - embeddings = torch.nn.functional.normalize(outputs.embeddings, dim=-1).cpu() - - cosine_sim = torch.nn.CosineSimilarity(dim=-1) - # id10002 vs id10002 - self.assertAlmostEqual(cosine_sim(embeddings[1], embeddings[2]).numpy(), 0.9758, 3) - # id10006 vs id10002 - self.assertAlmostEqual(cosine_sim(embeddings[0], embeddings[1]).numpy(), 0.7579, 3) - # id10002 vs id10004 - self.assertAlmostEqual(cosine_sim(embeddings[2], embeddings[3]).numpy(), 0.7594, 3) - - self.assertAlmostEqual(outputs.loss.item(), 17.7963, 2) - - @require_torchaudio - def test_inference_mms_1b_all(self): - model = Wav2Vec2ForCTC.from_pretrained("facebook/mms-1b-all").to(torch_device) - processor = Wav2Vec2Processor.from_pretrained("facebook/mms-1b-all") - - LANG_MAP = {"it": "ita", "es": "spa", "fr": "fra", "en": "eng"} - - def run_model(lang): - ds = load_dataset("mozilla-foundation/common_voice_11_0", lang, split="test", streaming=True) - sample = next(iter(ds)) - - wav2vec2_lang = LANG_MAP[lang] - - model.load_adapter(wav2vec2_lang) - processor.tokenizer.set_target_lang(wav2vec2_lang) - - resampled_audio = torchaudio.functional.resample( - torch.tensor(sample["audio"]["array"]), 48_000, 16_000 - ).numpy() - - inputs = processor(resampled_audio, sampling_rate=16_000, return_tensors="pt") - input_values = inputs.input_values.to(torch_device) - attention_mask = inputs.attention_mask.to(torch_device) - - with torch.no_grad(): - outputs = model(input_values, attention_mask=attention_mask).logits - - ids = torch.argmax(outputs, dim=-1)[0] - - transcription = processor.decode(ids) - return transcription - - TRANSCRIPTIONS = { - "it": "il libro ha suscitato molte polemiche a causa dei suoi contenuti", - "es": "habitan aguas poco profundas y rocosas", - "fr": "ce dernier est volé tout au long de l'histoire romaine", - "en": "joe keton disapproved of films and buster also had reservations about the media", - } - - for lang in LANG_MAP.keys(): - assert run_model(lang) == TRANSCRIPTIONS[lang] diff --git a/tests/transformers/tests/test_configuration_common.py b/tests/transformers/tests/test_configuration_common.py deleted file mode 100644 index 5fb93f71eb..0000000000 --- a/tests/transformers/tests/test_configuration_common.py +++ /dev/null @@ -1,155 +0,0 @@ -# coding=utf-8 -# Copyright 2019 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import copy -import json -import os -import tempfile - -from transformers import is_torch_available - -from .test_configuration_utils import config_common_kwargs - - -class ConfigTester(object): - def __init__(self, parent, config_class=None, has_text_modality=True, common_properties=None, **kwargs): - self.parent = parent - self.config_class = config_class - self.has_text_modality = has_text_modality - self.inputs_dict = kwargs - self.common_properties = common_properties - - def create_and_test_config_common_properties(self): - config = self.config_class(**self.inputs_dict) - common_properties = ( - ["hidden_size", "num_attention_heads", "num_hidden_layers"] - if self.common_properties is None - else self.common_properties - ) - - # Add common fields for text models - if self.has_text_modality: - common_properties.extend(["vocab_size"]) - - # Test that config has the common properties as getters - for prop in common_properties: - self.parent.assertTrue(hasattr(config, prop), msg=f"`{prop}` does not exist") - - # Test that config has the common properties as setter - for idx, name in enumerate(common_properties): - try: - setattr(config, name, idx) - self.parent.assertEqual( - getattr(config, name), idx, msg=f"`{name} value {idx} expected, but was {getattr(config, name)}" - ) - except NotImplementedError: - # Some models might not be able to implement setters for common_properties - # In that case, a NotImplementedError is raised - pass - - # Test if config class can be called with Config(prop_name=..) - for idx, name in enumerate(common_properties): - try: - config = self.config_class(**{name: idx}) - self.parent.assertEqual( - getattr(config, name), idx, msg=f"`{name} value {idx} expected, but was {getattr(config, name)}" - ) - except NotImplementedError: - # Some models might not be able to implement setters for common_properties - # In that case, a NotImplementedError is raised - pass - - def create_and_test_config_to_json_string(self): - config = self.config_class(**self.inputs_dict) - obj = json.loads(config.to_json_string()) - for key, value in self.inputs_dict.items(): - self.parent.assertEqual(obj[key], value) - - def create_and_test_config_to_json_file(self): - config_first = self.config_class(**self.inputs_dict) - - with tempfile.TemporaryDirectory() as tmpdirname: - json_file_path = os.path.join(tmpdirname, "config.json") - config_first.to_json_file(json_file_path) - config_second = self.config_class.from_json_file(json_file_path) - - self.parent.assertEqual(config_second.to_dict(), config_first.to_dict()) - - def create_and_test_config_from_and_save_pretrained(self): - config_first = self.config_class(**self.inputs_dict) - - with tempfile.TemporaryDirectory() as tmpdirname: - config_first.save_pretrained(tmpdirname) - config_second = self.config_class.from_pretrained(tmpdirname) - - self.parent.assertEqual(config_second.to_dict(), config_first.to_dict()) - - def create_and_test_config_from_and_save_pretrained_subfolder(self): - config_first = self.config_class(**self.inputs_dict) - - subfolder = "test" - with tempfile.TemporaryDirectory() as tmpdirname: - sub_tmpdirname = os.path.join(tmpdirname, subfolder) - config_first.save_pretrained(sub_tmpdirname) - config_second = self.config_class.from_pretrained(tmpdirname, subfolder=subfolder) - - self.parent.assertEqual(config_second.to_dict(), config_first.to_dict()) - - def create_and_test_config_with_num_labels(self): - config = self.config_class(**self.inputs_dict, num_labels=5) - self.parent.assertEqual(len(config.id2label), 5) - self.parent.assertEqual(len(config.label2id), 5) - - config.num_labels = 3 - self.parent.assertEqual(len(config.id2label), 3) - self.parent.assertEqual(len(config.label2id), 3) - - def check_config_can_be_init_without_params(self): - if self.config_class.is_composition: - with self.parent.assertRaises(ValueError): - config = self.config_class() - else: - config = self.config_class() - self.parent.assertIsNotNone(config) - - def check_config_arguments_init(self): - kwargs = copy.deepcopy(config_common_kwargs) - config = self.config_class(**kwargs) - wrong_values = [] - for key, value in config_common_kwargs.items(): - if key == "torch_dtype": - if not is_torch_available(): - continue - else: - import torch - - if config.torch_dtype != torch.float16: - wrong_values.append(("torch_dtype", config.torch_dtype, torch.float16)) - elif getattr(config, key) != value: - wrong_values.append((key, getattr(config, key), value)) - - if len(wrong_values) > 0: - errors = "\n".join([f"- {v[0]}: got {v[1]} instead of {v[2]}" for v in wrong_values]) - raise ValueError(f"The following keys were not properly set in the config:\n{errors}") - - def run_common_tests(self): - self.create_and_test_config_common_properties() - self.create_and_test_config_to_json_string() - self.create_and_test_config_to_json_file() - self.create_and_test_config_from_and_save_pretrained() - self.create_and_test_config_from_and_save_pretrained_subfolder() - self.create_and_test_config_with_num_labels() - self.check_config_can_be_init_without_params() - self.check_config_arguments_init() diff --git a/tests/transformers/tests/test_configuration_utils.py b/tests/transformers/tests/test_configuration_utils.py deleted file mode 100644 index b7323c5905..0000000000 --- a/tests/transformers/tests/test_configuration_utils.py +++ /dev/null @@ -1,292 +0,0 @@ -# coding=utf-8 -# Copyright 2019 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import json -import os -import shutil -import sys -import tempfile -import unittest -import unittest.mock as mock -from pathlib import Path - -from huggingface_hub import HfFolder, delete_repo -from requests.exceptions import HTTPError -from transformers import AutoConfig, BertConfig, GPT2Config -from transformers.configuration_utils import PretrainedConfig -from transformers.testing_utils import TOKEN, USER, is_staging_test - - -sys.path.append(str(Path(__file__).parent.parent / "utils")) - -from test_module.custom_configuration import CustomConfig # noqa E402 - - -config_common_kwargs = { - "return_dict": False, - "output_hidden_states": True, - "output_attentions": True, - "torchscript": True, - "torch_dtype": "float16", - "use_bfloat16": True, - "tf_legacy_loss": True, - "pruned_heads": {"a": 1}, - "tie_word_embeddings": False, - "is_decoder": True, - "cross_attention_hidden_size": 128, - "add_cross_attention": True, - "tie_encoder_decoder": True, - "max_length": 50, - "min_length": 3, - "do_sample": True, - "early_stopping": True, - "num_beams": 3, - "num_beam_groups": 3, - "diversity_penalty": 0.5, - "temperature": 2.0, - "top_k": 10, - "top_p": 0.7, - "typical_p": 0.2, - "repetition_penalty": 0.8, - "length_penalty": 0.8, - "no_repeat_ngram_size": 5, - "encoder_no_repeat_ngram_size": 5, - "bad_words_ids": [1, 2, 3], - "num_return_sequences": 3, - "chunk_size_feed_forward": 5, - "output_scores": True, - "return_dict_in_generate": True, - "forced_bos_token_id": 2, - "forced_eos_token_id": 3, - "remove_invalid_values": True, - "architectures": ["BertModel"], - "finetuning_task": "translation", - "id2label": {0: "label"}, - "label2id": {"label": "0"}, - "tokenizer_class": "BertTokenizerFast", - "prefix": "prefix", - "bos_token_id": 6, - "pad_token_id": 7, - "eos_token_id": 8, - "sep_token_id": 9, - "decoder_start_token_id": 10, - "exponential_decay_length_penalty": (5, 1.01), - "suppress_tokens": [0, 1], - "begin_suppress_tokens": 2, - "task_specific_params": {"translation": "some_params"}, - "problem_type": "regression", -} - - -@is_staging_test -class ConfigPushToHubTester(unittest.TestCase): - @classmethod - def setUpClass(cls): - cls._token = TOKEN - HfFolder.save_token(TOKEN) - - @classmethod - def tearDownClass(cls): - try: - delete_repo(token=cls._token, repo_id="test-config") - except HTTPError: - pass - - try: - delete_repo(token=cls._token, repo_id="valid_org/test-config-org") - except HTTPError: - pass - - try: - delete_repo(token=cls._token, repo_id="test-dynamic-config") - except HTTPError: - pass - - def test_push_to_hub(self): - config = BertConfig( - vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37 - ) - config.push_to_hub("test-config", token=self._token) - - new_config = BertConfig.from_pretrained(f"{USER}/test-config") - for k, v in config.to_dict().items(): - if k != "transformers_version": - self.assertEqual(v, getattr(new_config, k)) - - # Reset repo - delete_repo(token=self._token, repo_id="test-config") - - # Push to hub via save_pretrained - with tempfile.TemporaryDirectory() as tmp_dir: - config.save_pretrained(tmp_dir, repo_id="test-config", push_to_hub=True, token=self._token) - - new_config = BertConfig.from_pretrained(f"{USER}/test-config") - for k, v in config.to_dict().items(): - if k != "transformers_version": - self.assertEqual(v, getattr(new_config, k)) - - def test_push_to_hub_in_organization(self): - config = BertConfig( - vocab_size=99, hidden_size=32, num_hidden_layers=5, num_attention_heads=4, intermediate_size=37 - ) - config.push_to_hub("valid_org/test-config-org", use_auth_token=self._token) - - new_config = BertConfig.from_pretrained("valid_org/test-config-org") - for k, v in config.to_dict().items(): - if k != "transformers_version": - self.assertEqual(v, getattr(new_config, k)) - - # Reset repo - delete_repo(token=self._token, repo_id="valid_org/test-config-org") - - # Push to hub via save_pretrained - with tempfile.TemporaryDirectory() as tmp_dir: - config.save_pretrained( - tmp_dir, repo_id="valid_org/test-config-org", push_to_hub=True, use_auth_token=self._token - ) - - new_config = BertConfig.from_pretrained("valid_org/test-config-org") - for k, v in config.to_dict().items(): - if k != "transformers_version": - self.assertEqual(v, getattr(new_config, k)) - - def test_push_to_hub_dynamic_config(self): - CustomConfig.register_for_auto_class() - config = CustomConfig(attribute=42) - - config.push_to_hub("test-dynamic-config", use_auth_token=self._token) - - # This has added the proper auto_map field to the config - self.assertDictEqual(config.auto_map, {"AutoConfig": "custom_configuration.CustomConfig"}) - - new_config = AutoConfig.from_pretrained(f"{USER}/test-dynamic-config", trust_remote_code=True) - # Can't make an isinstance check because the new_config is from the FakeConfig class of a dynamic module - self.assertEqual(new_config.__class__.__name__, "CustomConfig") - self.assertEqual(new_config.attribute, 42) - - -class ConfigTestUtils(unittest.TestCase): - def test_config_from_string(self): - c = GPT2Config() - - # attempt to modify each of int/float/bool/str config records and verify they were updated - n_embd = c.n_embd + 1 # int - resid_pdrop = c.resid_pdrop + 1.0 # float - scale_attn_weights = not c.scale_attn_weights # bool - summary_type = c.summary_type + "foo" # str - c.update_from_string( - f"n_embd={n_embd},resid_pdrop={resid_pdrop},scale_attn_weights={scale_attn_weights},summary_type={summary_type}" - ) - self.assertEqual(n_embd, c.n_embd, "mismatch for key: n_embd") - self.assertEqual(resid_pdrop, c.resid_pdrop, "mismatch for key: resid_pdrop") - self.assertEqual(scale_attn_weights, c.scale_attn_weights, "mismatch for key: scale_attn_weights") - self.assertEqual(summary_type, c.summary_type, "mismatch for key: summary_type") - - def test_config_common_kwargs_is_complete(self): - base_config = PretrainedConfig() - missing_keys = [key for key in base_config.__dict__ if key not in config_common_kwargs] - # If this part of the test fails, you have arguments to addin config_common_kwargs above. - self.assertListEqual( - missing_keys, ["is_encoder_decoder", "_name_or_path", "_commit_hash", "transformers_version"] - ) - keys_with_defaults = [key for key, value in config_common_kwargs.items() if value == getattr(base_config, key)] - if len(keys_with_defaults) > 0: - raise ValueError( - "The following keys are set with the default values in" - " `test_configuration_common.config_common_kwargs` pick another value for them:" - f" {', '.join(keys_with_defaults)}." - ) - - def test_nested_config_load_from_dict(self): - config = AutoConfig.from_pretrained( - "hf-internal-testing/tiny-random-CLIPModel", text_config={"num_hidden_layers": 2} - ) - self.assertNotIsInstance(config.text_config, dict) - self.assertEqual(config.text_config.__class__.__name__, "CLIPTextConfig") - - def test_from_pretrained_subfolder(self): - with self.assertRaises(OSError): - # config is in subfolder, the following should not work without specifying the subfolder - _ = BertConfig.from_pretrained("hf-internal-testing/tiny-random-bert-subfolder") - - config = BertConfig.from_pretrained("hf-internal-testing/tiny-random-bert-subfolder", subfolder="bert") - - self.assertIsNotNone(config) - - def test_cached_files_are_used_when_internet_is_down(self): - # A mock response for an HTTP head request to emulate server down - response_mock = mock.Mock() - response_mock.status_code = 500 - response_mock.headers = {} - response_mock.raise_for_status.side_effect = HTTPError - response_mock.json.return_value = {} - - # Download this model to make sure it's in the cache. - _ = BertConfig.from_pretrained("hf-internal-testing/tiny-random-bert") - - # Under the mock environment we get a 500 error when trying to reach the model. - with mock.patch("requests.Session.request", return_value=response_mock) as mock_head: - _ = BertConfig.from_pretrained("hf-internal-testing/tiny-random-bert") - # This check we did call the fake head request - mock_head.assert_called() - - def test_legacy_load_from_url(self): - # This test is for deprecated behavior and can be removed in v5 - _ = BertConfig.from_pretrained( - "https://huggingface.co/hf-internal-testing/tiny-random-bert/resolve/main/config.json" - ) - - def test_local_versioning(self): - configuration = AutoConfig.from_pretrained("bert-base-cased") - configuration.configuration_files = ["config.4.0.0.json"] - - with tempfile.TemporaryDirectory() as tmp_dir: - configuration.save_pretrained(tmp_dir) - configuration.hidden_size = 2 - json.dump(configuration.to_dict(), open(os.path.join(tmp_dir, "config.4.0.0.json"), "w")) - - # This should pick the new configuration file as the version of Transformers is > 4.0.0 - new_configuration = AutoConfig.from_pretrained(tmp_dir) - self.assertEqual(new_configuration.hidden_size, 2) - - # Will need to be adjusted if we reach v42 and this test is still here. - # Should pick the old configuration file as the version of Transformers is < 4.42.0 - configuration.configuration_files = ["config.42.0.0.json"] - configuration.hidden_size = 768 - configuration.save_pretrained(tmp_dir) - shutil.move(os.path.join(tmp_dir, "config.4.0.0.json"), os.path.join(tmp_dir, "config.42.0.0.json")) - new_configuration = AutoConfig.from_pretrained(tmp_dir) - self.assertEqual(new_configuration.hidden_size, 768) - - def test_repo_versioning_before(self): - # This repo has two configuration files, one for v4.0.0 and above with a different hidden size. - repo = "hf-internal-testing/test-two-configs" - - import transformers as new_transformers - - new_transformers.configuration_utils.__version__ = "v4.0.0" - new_configuration, kwargs = new_transformers.models.auto.AutoConfig.from_pretrained( - repo, return_unused_kwargs=True - ) - self.assertEqual(new_configuration.hidden_size, 2) - # This checks `_configuration_file` ia not kept in the kwargs by mistake. - self.assertDictEqual(kwargs, {}) - - # Testing an older version by monkey-patching the version in the module it's used. - import transformers as old_transformers - - old_transformers.configuration_utils.__version__ = "v3.0.0" - old_configuration = old_transformers.models.auto.AutoConfig.from_pretrained(repo) - self.assertEqual(old_configuration.hidden_size, 768) diff --git a/tests/transformers/tests/test_modeling_common.py b/tests/transformers/tests/test_modeling_common.py deleted file mode 100755 index 900466aaa2..0000000000 --- a/tests/transformers/tests/test_modeling_common.py +++ /dev/null @@ -1,2294 +0,0 @@ -# coding=utf-8 -# Copyright 2019 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import collections -import copy -import gc -import inspect -import os -import os.path -import pickle -import random -import re -import tempfile -import warnings -from collections import defaultdict -from typing import Dict, List, Tuple - -import numpy as np -from pytest import mark -from transformers import ( - AutoModel, - AutoModelForSequenceClassification, - PretrainedConfig, - is_torch_available, - logging, -) -from transformers.models.auto import get_values -from transformers.models.auto.modeling_auto import ( - MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES, - MODEL_FOR_AUDIO_XVECTOR_MAPPING_NAMES, - MODEL_FOR_BACKBONE_MAPPING_NAMES, - MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING_NAMES, - MODEL_FOR_CAUSAL_LM_MAPPING_NAMES, - MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING_NAMES, - MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES, - MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES, - MODEL_FOR_MASKED_LM_MAPPING_NAMES, - MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES, - MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES, - MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES, - MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES, - MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES, - MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES, - MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES, - MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES, - MODEL_MAPPING_NAMES, -) -from transformers.testing_utils import ( - CaptureLogger, - require_accelerate, - require_safetensors, - require_torch, - require_torch_gpu, - require_torch_multi_gpu, -) -from transformers.utils import ( - CONFIG_NAME, - GENERATION_CONFIG_NAME, - WEIGHTS_NAME, - is_accelerate_available, - is_torch_fx_available, -) - -from optimum.habana.transformers.modeling_utils import adapt_transformers_to_gaudi - - -if is_accelerate_available(): - from accelerate.utils import compute_module_sizes - - -if is_torch_available(): - import torch - from safetensors.torch import save_file as safe_save_file - from torch import nn - from transformers import MODEL_MAPPING, AdaptiveEmbedding - from transformers.pytorch_utils import id_tensor_storage - - -if is_torch_fx_available(): - from transformers.utils.fx import symbolic_trace - -torch_device = "hpu" -adapt_transformers_to_gaudi() - - -def _config_zero_init(config): - configs_no_init = copy.deepcopy(config) - for key in configs_no_init.__dict__.keys(): - if "_range" in key or "_std" in key or "initializer_factor" in key or "layer_scale" in key: - setattr(configs_no_init, key, 1e-10) - if isinstance(getattr(configs_no_init, key, None), PretrainedConfig): - no_init_subconfig = _config_zero_init(getattr(configs_no_init, key)) - setattr(configs_no_init, key, no_init_subconfig) - return configs_no_init - - -def _mock_init_weights(self, module): - for name, param in module.named_parameters(recurse=False): - # Use the first letter of the name to get a value and go from a <> -13 to z <> 12 - value = ord(name[0].lower()) - 110 - param.data.fill_(value) - - -def _mock_all_init_weights(self): - # Prune heads if needed - if self.config.pruned_heads: - self.prune_heads(self.config.pruned_heads) - - import transformers.modeling_utils - - if transformers.modeling_utils._init_weights: - for module in self.modules(): - module._is_hf_initialized = False - # Initialize weights - self.apply(self._initialize_weights) - - # Tie weights should be skipped when not initializing all weights - # since from_pretrained(...) calls tie weights anyways - self.tie_weights() - - -@require_torch -class ModelTesterMixin: - model_tester = None - all_model_classes = () - all_generative_model_classes = () - fx_compatible = False - test_torchscript = True - test_pruning = True - test_resize_embeddings = True - test_resize_position_embeddings = False - test_head_masking = True - test_mismatched_shapes = True - test_missing_keys = True - test_model_parallel = False - is_encoder_decoder = False - has_attentions = True - model_split_percents = [0.5, 0.7, 0.9] - - def _prepare_for_class(self, inputs_dict, model_class, return_labels=False): - inputs_dict = copy.deepcopy(inputs_dict) - if model_class.__name__ in get_values(MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES): - inputs_dict = { - k: v.unsqueeze(1).expand(-1, self.model_tester.num_choices, -1).contiguous() - if isinstance(v, torch.Tensor) and v.ndim > 1 - else v - for k, v in inputs_dict.items() - } - elif model_class.__name__ in get_values(MODEL_FOR_AUDIO_XVECTOR_MAPPING_NAMES): - inputs_dict.pop("attention_mask") - - if return_labels: - if model_class.__name__ in get_values(MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES): - inputs_dict["labels"] = torch.ones(self.model_tester.batch_size, dtype=torch.long, device=torch_device) - elif model_class.__name__ in [ - *get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES), - *get_values(MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING_NAMES), - ]: - inputs_dict["start_positions"] = torch.zeros( - self.model_tester.batch_size, dtype=torch.long, device=torch_device - ) - inputs_dict["end_positions"] = torch.zeros( - self.model_tester.batch_size, dtype=torch.long, device=torch_device - ) - elif model_class.__name__ in [ - *get_values(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES), - *get_values(MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES), - *get_values(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES), - *get_values(MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING_NAMES), - *get_values(MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES), - ]: - inputs_dict["labels"] = torch.zeros( - self.model_tester.batch_size, dtype=torch.long, device=torch_device - ) - elif model_class.__name__ in [ - *get_values(MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES), - *get_values(MODEL_FOR_CAUSAL_LM_MAPPING_NAMES), - *get_values(MODEL_FOR_CAUSAL_IMAGE_MODELING_MAPPING_NAMES), - *get_values(MODEL_FOR_MASKED_LM_MAPPING_NAMES), - *get_values(MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES), - ]: - inputs_dict["labels"] = torch.zeros( - (self.model_tester.batch_size, self.model_tester.seq_length), dtype=torch.long, device=torch_device - ) - elif model_class.__name__ in get_values(MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING_NAMES): - num_patches = self.model_tester.image_size // self.model_tester.patch_size - inputs_dict["bool_masked_pos"] = torch.zeros( - (self.model_tester.batch_size, num_patches**2), dtype=torch.long, device=torch_device - ) - elif model_class.__name__ in get_values(MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING_NAMES): - batch_size, num_channels, height, width = inputs_dict["pixel_values"].shape - inputs_dict["labels"] = torch.zeros( - [self.model_tester.batch_size, height, width], device=torch_device - ).long() - - return inputs_dict - - def test_save_load(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - def check_save_load(out1, out2): - # make sure we don't have nans - out_2 = out2.cpu().numpy() - out_2[np.isnan(out_2)] = 0 - - out_1 = out1.cpu().numpy() - out_1[np.isnan(out_1)] = 0 - max_diff = np.amax(np.abs(out_1 - out_2)) - self.assertLessEqual(max_diff, 1e-5) - - for model_class in self.all_model_classes: - model = model_class(config) - model.to(torch_device) - model.eval() - with torch.no_grad(): - first = model(**self._prepare_for_class(inputs_dict, model_class))[0] - - with tempfile.TemporaryDirectory() as tmpdirname: - model.save_pretrained(tmpdirname) - - # the config file (and the generation config file, if it can generate) should be saved - self.assertTrue(os.path.exists(os.path.join(tmpdirname, CONFIG_NAME))) - self.assertEqual( - model.can_generate(), os.path.exists(os.path.join(tmpdirname, GENERATION_CONFIG_NAME)) - ) - - model = model_class.from_pretrained(tmpdirname) - model.to(torch_device) - with torch.no_grad(): - second = model(**self._prepare_for_class(inputs_dict, model_class))[0] - - if isinstance(first, tuple) and isinstance(second, tuple): - for tensor1, tensor2 in zip(first, second): - check_save_load(tensor1, tensor2) - else: - check_save_load(first, second) - - def test_from_pretrained_no_checkpoint(self): - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - for model_class in self.all_model_classes: - model = model_class(config) - state_dict = model.state_dict() - - new_model = model_class.from_pretrained( - pretrained_model_name_or_path=None, config=config, state_dict=state_dict - ) - for p1, p2 in zip(model.parameters(), new_model.parameters()): - self.assertTrue(torch.equal(p1, p2)) - - def test_save_load_keys_to_ignore_on_save(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - model = model_class(config) - _keys_to_ignore_on_save = getattr(model, "_keys_to_ignore_on_save", None) - if _keys_to_ignore_on_save is None: - continue - - # check the keys are in the original state_dict - for k in _keys_to_ignore_on_save: - self.assertIn(k, model.state_dict().keys(), "\n".join(model.state_dict().keys())) - - # check that certain keys didn't get saved with the model - with tempfile.TemporaryDirectory() as tmpdirname: - model.save_pretrained(tmpdirname) - output_model_file = os.path.join(tmpdirname, WEIGHTS_NAME) - state_dict_saved = torch.load(output_model_file) - for k in _keys_to_ignore_on_save: - self.assertNotIn(k, state_dict_saved.keys(), "\n".join(state_dict_saved.keys())) - - # Test we can load the state dict in the model, necessary for the checkpointing API in Trainer. - load_result = model.load_state_dict(state_dict_saved, strict=False) - self.assertTrue( - len(load_result.missing_keys) == 0 - or set(load_result.missing_keys) == set(model._keys_to_ignore_on_save) - ) - self.assertTrue(len(load_result.unexpected_keys) == 0) - - def test_gradient_checkpointing_backward_compatibility(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - if not model_class.supports_gradient_checkpointing: - continue - - config.gradient_checkpointing = True - model = model_class(config) - self.assertTrue(model.is_gradient_checkpointing) - - def test_gradient_checkpointing_enable_disable(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - if not model_class.supports_gradient_checkpointing: - continue - - # at init model should have gradient checkpointing disabled - model = model_class(config) - self.assertFalse(model.is_gradient_checkpointing) - - # check enable works - model.gradient_checkpointing_enable() - self.assertTrue(model.is_gradient_checkpointing) - - # check disable works - model.gradient_checkpointing_disable() - self.assertFalse(model.is_gradient_checkpointing) - - def test_save_load_fast_init_from_base(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - if config.__class__ not in MODEL_MAPPING: - return - base_class = MODEL_MAPPING[config.__class__] - - if isinstance(base_class, tuple): - base_class = base_class[0] - - for model_class in self.all_model_classes: - if model_class == base_class: - continue - - # make a copy of model class to not break future tests - # from https://stackoverflow.com/questions/9541025/how-to-copy-a-python-class - class CopyClass(model_class): - pass - - model_class_copy = CopyClass - - # make sure that all keys are expected for test - model_class_copy._keys_to_ignore_on_load_missing = [] - - # make init deterministic, but make sure that - # non-initialized weights throw errors nevertheless - model_class_copy._init_weights = _mock_init_weights - model_class_copy.init_weights = _mock_all_init_weights - - model = base_class(config) - state_dict = model.state_dict() - - # this will often delete a single weight of a multi-weight module - # to test an edge case - random_key_to_del = random.choice(list(state_dict.keys())) - del state_dict[random_key_to_del] - - # check that certain keys didn't get saved with the model - with tempfile.TemporaryDirectory() as tmpdirname: - model.save_pretrained(tmpdirname) - torch.save(state_dict, os.path.join(tmpdirname, "pytorch_model.bin")) - - model_fast_init = model_class_copy.from_pretrained(tmpdirname) - model_slow_init = model_class_copy.from_pretrained(tmpdirname, _fast_init=False) - # Before we test anything - - for key in model_fast_init.state_dict().keys(): - if isinstance(model_slow_init.state_dict()[key], torch.BoolTensor): - max_diff = (model_slow_init.state_dict()[key] ^ model_fast_init.state_dict()[key]).sum().item() - else: - max_diff = (model_slow_init.state_dict()[key] - model_fast_init.state_dict()[key]).sum().item() - self.assertLessEqual(max_diff, 1e-3, msg=f"{key} not identical") - - def test_save_load_fast_init_to_base(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - if config.__class__ not in MODEL_MAPPING: - return - base_class = MODEL_MAPPING[config.__class__] - - if isinstance(base_class, tuple): - base_class = base_class[0] - - for model_class in self.all_model_classes: - if model_class == base_class: - continue - - # make a copy of model class to not break future tests - # from https://stackoverflow.com/questions/9541025/how-to-copy-a-python-class - class CopyClass(base_class): - pass - - base_class_copy = CopyClass - - # make sure that all keys are expected for test - base_class_copy._keys_to_ignore_on_load_missing = [] - - # make init deterministic, but make sure that - # non-initialized weights throw errors nevertheless - base_class_copy._init_weights = _mock_init_weights - base_class_copy.init_weights = _mock_all_init_weights - - model = model_class(config) - state_dict = model.state_dict() - - # this will often delete a single weight of a multi-weight module - # to test an edge case - random_key_to_del = random.choice(list(state_dict.keys())) - del state_dict[random_key_to_del] - - # check that certain keys didn't get saved with the model - with tempfile.TemporaryDirectory() as tmpdirname: - model.save_pretrained(tmpdirname) - torch.save(state_dict, os.path.join(tmpdirname, "pytorch_model.bin")) - - model_fast_init = base_class_copy.from_pretrained(tmpdirname) - model_slow_init = base_class_copy.from_pretrained(tmpdirname, _fast_init=False) - - for key in model_fast_init.state_dict().keys(): - if isinstance(model_slow_init.state_dict()[key], torch.BoolTensor): - max_diff = torch.max( - model_slow_init.state_dict()[key] ^ model_fast_init.state_dict()[key] - ).item() - else: - max_diff = torch.max( - torch.abs(model_slow_init.state_dict()[key] - model_fast_init.state_dict()[key]) - ).item() - self.assertLessEqual(max_diff, 1e-3, msg=f"{key} not identical") - - def test_initialization(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - configs_no_init = _config_zero_init(config) - for model_class in self.all_model_classes: - model = model_class(config=configs_no_init) - for name, param in model.named_parameters(): - if param.requires_grad: - self.assertIn( - ((param.data.mean() * 1e9).round() / 1e9).item(), - [0.0, 1.0], - msg=f"Parameter {name} of model {model_class} seems not properly initialized", - ) - - def test_determinism(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - def check_determinism(first, second): - out_1 = first.cpu().numpy() - out_2 = second.cpu().numpy() - out_1 = out_1[~np.isnan(out_1)] - out_2 = out_2[~np.isnan(out_2)] - max_diff = np.amax(np.abs(out_1 - out_2)) - self.assertLessEqual(max_diff, 1e-5) - - for model_class in self.all_model_classes: - model = model_class(config) - model.to(torch_device) - model.eval() - with torch.no_grad(): - first = model(**self._prepare_for_class(inputs_dict, model_class))[0] - second = model(**self._prepare_for_class(inputs_dict, model_class))[0] - - if isinstance(first, tuple) and isinstance(second, tuple): - for tensor1, tensor2 in zip(first, second): - check_determinism(tensor1, tensor2) - else: - check_determinism(first, second) - - def test_forward_signature(self): - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - model = model_class(config) - signature = inspect.signature(model.forward) - # signature.parameters is an OrderedDict => so arg_names order is deterministic - arg_names = [*signature.parameters.keys()] - - if model.config.is_encoder_decoder: - expected_arg_names = [ - "input_ids", - "attention_mask", - "decoder_input_ids", - "decoder_attention_mask", - ] - expected_arg_names.extend( - ["head_mask", "decoder_head_mask", "cross_attn_head_mask", "encoder_outputs"] - if "head_mask" and "decoder_head_mask" and "cross_attn_head_mask" in arg_names - else ["encoder_outputs"] - ) - self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names) - else: - expected_arg_names = ["input_ids"] - self.assertListEqual(arg_names[:1], expected_arg_names) - - @mark.skip("Skipped for Gaudi : TODO") - def test_training(self): - if not self.model_tester.is_training: - return - - for model_class in self.all_model_classes: - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.return_dict = True - - if model_class.__name__ in [ - *get_values(MODEL_MAPPING_NAMES), - *get_values(MODEL_FOR_BACKBONE_MAPPING_NAMES), - ]: - continue - - model = model_class(config) - model.to(torch_device) - model.train() - inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - loss = model(**inputs).loss - loss.backward() - - @mark.skip("Skipped for Gaudi : TODO") - def test_training_gradient_checkpointing(self): - if not self.model_tester.is_training: - return - - for model_class in self.all_model_classes: - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.use_cache = False - config.return_dict = True - - if ( - model_class.__name__ - in [*get_values(MODEL_MAPPING_NAMES), *get_values(MODEL_FOR_BACKBONE_MAPPING_NAMES)] - or not model_class.supports_gradient_checkpointing - ): - continue - model = model_class(config) - model.to(torch_device) - model.gradient_checkpointing_enable() - model.train() - inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - loss = model(**inputs).loss - loss.backward() - - def test_attention_outputs(self): - if not self.has_attentions: - self.skipTest(reason="Model does not output attentions") - - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.return_dict = True - - seq_len = getattr(self.model_tester, "seq_length", None) - decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len) - encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len) - decoder_key_length = getattr(self.model_tester, "decoder_key_length", decoder_seq_length) - encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length) - chunk_length = getattr(self.model_tester, "chunk_length", None) - if chunk_length is not None and hasattr(self.model_tester, "num_hashes"): - encoder_seq_length = encoder_seq_length * self.model_tester.num_hashes - - for model_class in self.all_model_classes: - inputs_dict["output_attentions"] = True - inputs_dict["output_hidden_states"] = False - config.return_dict = True - model = model_class(config) - model.to(torch_device) - model.eval() - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions - self.assertEqual(len(attentions), self.model_tester.num_hidden_layers) - - # check that output_attentions also work using config - del inputs_dict["output_attentions"] - config.output_attentions = True - model = model_class(config) - model.to(torch_device) - model.eval() - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions - self.assertEqual(len(attentions), self.model_tester.num_hidden_layers) - - if chunk_length is not None: - self.assertListEqual( - list(attentions[0].shape[-4:]), - [self.model_tester.num_attention_heads, encoder_seq_length, chunk_length, encoder_key_length], - ) - else: - self.assertListEqual( - list(attentions[0].shape[-3:]), - [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length], - ) - out_len = len(outputs) - - if self.is_encoder_decoder: - correct_outlen = 5 - - # loss is at first position - if "labels" in inputs_dict: - correct_outlen += 1 # loss is added to beginning - # Question Answering model returns start_logits and end_logits - if model_class.__name__ in [ - *get_values(MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES), - *get_values(MODEL_FOR_DOCUMENT_QUESTION_ANSWERING_MAPPING_NAMES), - ]: - correct_outlen += 1 # start_logits and end_logits instead of only 1 output - if "past_key_values" in outputs: - correct_outlen += 1 # past_key_values have been returned - - self.assertEqual(out_len, correct_outlen) - - # decoder attentions - decoder_attentions = outputs.decoder_attentions - self.assertIsInstance(decoder_attentions, (list, tuple)) - self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers) - self.assertListEqual( - list(decoder_attentions[0].shape[-3:]), - [self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length], - ) - - # cross attentions - cross_attentions = outputs.cross_attentions - self.assertIsInstance(cross_attentions, (list, tuple)) - self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers) - self.assertListEqual( - list(cross_attentions[0].shape[-3:]), - [ - self.model_tester.num_attention_heads, - decoder_seq_length, - encoder_key_length, - ], - ) - - # Check attention is always last and order is fine - inputs_dict["output_attentions"] = True - inputs_dict["output_hidden_states"] = True - model = model_class(config) - model.to(torch_device) - model.eval() - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - - if hasattr(self.model_tester, "num_hidden_states_types"): - added_hidden_states = self.model_tester.num_hidden_states_types - elif self.is_encoder_decoder: - added_hidden_states = 2 - else: - added_hidden_states = 1 - self.assertEqual(out_len + added_hidden_states, len(outputs)) - - self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions - - self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers) - if chunk_length is not None: - self.assertListEqual( - list(self_attentions[0].shape[-4:]), - [self.model_tester.num_attention_heads, encoder_seq_length, chunk_length, encoder_key_length], - ) - else: - self.assertListEqual( - list(self_attentions[0].shape[-3:]), - [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length], - ) - - @mark.skip("Segmentation fault is observed") - def test_torchscript_simple(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - self._create_and_check_torchscript(config, inputs_dict) - - @mark.skip("Segmentation fault is observed") - def test_torchscript_output_attentions(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.output_attentions = True - self._create_and_check_torchscript(config, inputs_dict) - - @mark.skip("Segmentation fault is observed") - def test_torchscript_output_hidden_state(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.output_hidden_states = True - self._create_and_check_torchscript(config, inputs_dict) - - # This is copied from `torch/testing/_internal/jit_utils.py::clear_class_registry` - def clear_torch_jit_class_registry(self): - torch._C._jit_clear_class_registry() - torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore() - # torch 1.8 has no `_clear_class_state` in `torch.jit._state` - if hasattr(torch.jit._state, "_clear_class_state"): - torch.jit._state._clear_class_state() - - def _create_and_check_torchscript(self, config, inputs_dict): - if not self.test_torchscript: - return - - configs_no_init = _config_zero_init(config) # To be sure we have no Nan - configs_no_init.torchscript = True - for model_class in self.all_model_classes: - model = model_class(config=configs_no_init) - model.to(torch_device) - model.eval() - inputs = self._prepare_for_class(inputs_dict, model_class) - - main_input_name = model_class.main_input_name - - try: - if model.config.is_encoder_decoder: - model.config.use_cache = False # FSTM still requires this hack -> FSTM should probably be refactored similar to BART afterward - main_input = inputs[main_input_name] - attention_mask = inputs["attention_mask"] - decoder_input_ids = inputs["decoder_input_ids"] - decoder_attention_mask = inputs["decoder_attention_mask"] - model(main_input, attention_mask, decoder_input_ids, decoder_attention_mask) - traced_model = torch.jit.trace( - model, (main_input, attention_mask, decoder_input_ids, decoder_attention_mask) - ) - elif "bbox" in inputs and "image" in inputs: # LayoutLMv2 requires additional inputs - input_ids = inputs["input_ids"] - bbox = inputs["bbox"] - image = inputs["image"].tensor - model(input_ids, bbox, image) - traced_model = torch.jit.trace( - model, (input_ids, bbox, image), check_trace=False - ) # when traced model is checked, an error is produced due to name mangling - else: - main_input = inputs[main_input_name] - model(main_input) - traced_model = torch.jit.trace(model, main_input) - except RuntimeError: - self.fail("Couldn't trace module.") - - with tempfile.TemporaryDirectory() as tmp_dir_name: - pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt") - - try: - torch.jit.save(traced_model, pt_file_name) - except Exception: - self.fail("Couldn't save module.") - - try: - loaded_model = torch.jit.load(pt_file_name) - except Exception: - self.fail("Couldn't load module.") - - model.to(torch_device) - model.eval() - - loaded_model.to(torch_device) - loaded_model.eval() - - model_state_dict = model.state_dict() - loaded_model_state_dict = loaded_model.state_dict() - - non_persistent_buffers = {} - for key in loaded_model_state_dict.keys(): - if key not in model_state_dict.keys(): - non_persistent_buffers[key] = loaded_model_state_dict[key] - - loaded_model_state_dict = { - key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers - } - - self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys())) - - model_buffers = list(model.buffers()) - for non_persistent_buffer in non_persistent_buffers.values(): - found_buffer = False - for i, model_buffer in enumerate(model_buffers): - if torch.equal(non_persistent_buffer, model_buffer): - found_buffer = True - break - - self.assertTrue(found_buffer) - model_buffers.pop(i) - - models_equal = True - for layer_name, p1 in model_state_dict.items(): - if layer_name in loaded_model_state_dict: - p2 = loaded_model_state_dict[layer_name] - if p1.data.ne(p2.data).sum() > 0: - models_equal = False - - self.assertTrue(models_equal) - - # Avoid memory leak. Without this, each call increase RAM usage by ~20MB. - # (Even with this call, there are still memory leak by ~0.04MB) - self.clear_torch_jit_class_registry() - - def test_torch_fx(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - self._create_and_check_torch_fx_tracing(config, inputs_dict) - - def test_torch_fx_output_loss(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - self._create_and_check_torch_fx_tracing(config, inputs_dict, output_loss=True) - - def _create_and_check_torch_fx_tracing(self, config, inputs_dict, output_loss=False): - if not is_torch_fx_available() or not self.fx_compatible: - return - - configs_no_init = _config_zero_init(config) # To be sure we have no Nan - configs_no_init.return_dict = False - - for model_class in self.all_model_classes: - model = model_class(config=configs_no_init) - model.to(torch_device) - model.eval() - inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=output_loss) - - try: - if model.config.is_encoder_decoder: - model.config.use_cache = False # FSTM still requires this hack -> FSTM should probably be refactored similar to BART afterward - labels = inputs.get("labels", None) - input_names = [ - "attention_mask", - "decoder_attention_mask", - "decoder_input_ids", - "input_features", - "input_ids", - "input_values", - ] - if labels is not None: - input_names.append("labels") - - filtered_inputs = {k: v for (k, v) in inputs.items() if k in input_names} - input_names = list(filtered_inputs.keys()) - - model_output = model(**filtered_inputs) - - traced_model = symbolic_trace(model, input_names) - traced_output = traced_model(**filtered_inputs) - else: - input_names = [ - "attention_mask", - "bbox", - "input_features", - "input_ids", - "input_values", - "pixel_values", - "token_type_ids", - "visual_feats", - "visual_pos", - ] - - labels = inputs.get("labels", None) - start_positions = inputs.get("start_positions", None) - end_positions = inputs.get("end_positions", None) - if labels is not None: - input_names.append("labels") - if start_positions is not None: - input_names.append("start_positions") - if end_positions is not None: - input_names.append("end_positions") - - filtered_inputs = {k: v for (k, v) in inputs.items() if k in input_names} - input_names = list(filtered_inputs.keys()) - - if model.__class__.__name__ in set(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES.values()) and ( - not hasattr(model.config, "problem_type") or model.config.problem_type is None - ): - model.config.problem_type = "single_label_classification" - - traced_model = symbolic_trace(model, input_names) - traced_output = traced_model(**filtered_inputs) - model_output = model(**filtered_inputs) - - except Exception as e: - self.fail(f"Couldn't trace module: {e}") - - def flatten_output(output): - flatten = [] - for x in output: - if isinstance(x, (tuple, list)): - flatten += flatten_output(x) - elif not isinstance(x, torch.Tensor): - continue - else: - flatten.append(x) - return flatten - - model_output = flatten_output(model_output) - traced_output = flatten_output(traced_output) - num_outputs = len(model_output) - - for i in range(num_outputs): - self.assertTrue( - torch.allclose(model_output[i], traced_output[i]), - f"traced {i}th output doesn't match model {i}th output for {model_class}", - ) - - # Test that the model can be serialized and restored properly - with tempfile.TemporaryDirectory() as tmp_dir_name: - pkl_file_name = os.path.join(tmp_dir_name, "model.pkl") - try: - with open(pkl_file_name, "wb") as f: - pickle.dump(traced_model, f) - with open(pkl_file_name, "rb") as f: - loaded = pickle.load(f) - except Exception as e: - self.fail(f"Couldn't serialize / deserialize the traced model: {e}") - - loaded_output = loaded(**filtered_inputs) - loaded_output = flatten_output(loaded_output) - - for i in range(num_outputs): - self.assertTrue( - torch.allclose(model_output[i], loaded_output[i]), - f"serialized model {i}th output doesn't match model {i}th output for {model_class}", - ) - - # Avoid memory leak. Without this, each call increase RAM usage by ~20MB. - # (Even with this call, there are still memory leak by ~0.04MB) - self.clear_torch_jit_class_registry() - - def test_headmasking(self): - if not self.test_head_masking: - return - - global_rng.seed(42) - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - global_rng.seed() - - inputs_dict["output_attentions"] = True - config.output_hidden_states = True - configs_no_init = _config_zero_init(config) # To be sure we have no Nan - for model_class in self.all_model_classes: - model = model_class(config=configs_no_init) - model.to(torch_device) - model.eval() - - # Prepare head_mask - # Set require_grad after having prepared the tensor to avoid error (leaf variable has been moved into the graph interior) - head_mask = torch.ones( - self.model_tester.num_hidden_layers, - self.model_tester.num_attention_heads, - device=torch_device, - ) - head_mask[0, 0] = 0 - head_mask[-1, :-1] = 0 - head_mask.requires_grad_(requires_grad=True) - inputs = self._prepare_for_class(inputs_dict, model_class).copy() - inputs["head_mask"] = head_mask - if model.config.is_encoder_decoder: - signature = inspect.signature(model.forward) - arg_names = [*signature.parameters.keys()] - if "decoder_head_mask" in arg_names: # necessary diferentiation because of T5 model - inputs["decoder_head_mask"] = head_mask - if "cross_attn_head_mask" in arg_names: - inputs["cross_attn_head_mask"] = head_mask - outputs = model(**inputs, return_dict=True) - - # Test that we can get a gradient back for importance score computation - output = sum(t.sum() for t in outputs[0]) - output = output.sum() - output.backward() - multihead_outputs = head_mask.grad - - self.assertIsNotNone(multihead_outputs) - self.assertEqual(len(multihead_outputs), self.model_tester.num_hidden_layers) - - def check_attentions_validity(attentions): - # Remove Nan - for t in attentions: - self.assertLess( - torch.sum(torch.isnan(t)), t.numel() / 4 - ) # Check we don't have more than 25% nans (arbitrary) - attentions = [ - t.masked_fill(torch.isnan(t), 0.0) for t in attentions - ] # remove them (the test is less complete) - - self.assertAlmostEqual(attentions[0][..., 0, :, :].flatten().sum().item(), 0.0) - self.assertNotEqual(attentions[0][..., -1, :, :].flatten().sum().item(), 0.0) - if len(attentions) > 2: # encoder-decoder models have only 2 layers in each module - self.assertNotEqual(attentions[1][..., 0, :, :].flatten().sum().item(), 0.0) - self.assertAlmostEqual(attentions[-1][..., -2, :, :].flatten().sum().item(), 0.0) - self.assertNotEqual(attentions[-1][..., -1, :, :].flatten().sum().item(), 0.0) - - if model.config.is_encoder_decoder: - check_attentions_validity(outputs.encoder_attentions) - check_attentions_validity(outputs.decoder_attentions) - check_attentions_validity(outputs.cross_attentions) - else: - check_attentions_validity(outputs.attentions) - - def test_head_pruning(self): - if not self.test_pruning: - return - - for model_class in self.all_model_classes: - ( - config, - inputs_dict, - ) = self.model_tester.prepare_config_and_inputs_for_common() - - if "head_mask" in inputs_dict: - del inputs_dict["head_mask"] - - inputs_dict["output_attentions"] = True - config.output_hidden_states = False - model = model_class(config=config) - model.to(torch_device) - model.eval() - heads_to_prune = { - 0: list(range(1, self.model_tester.num_attention_heads)), - -1: [0], - } - model.prune_heads(heads_to_prune) - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - - attentions = outputs[-1] - - self.assertEqual(attentions[0].shape[-3], 1) - # TODO: To have this check, we will need at least 3 layers. Do we really need it? - # self.assertEqual(attentions[1].shape[-3], self.model_tester.num_attention_heads) - self.assertEqual(attentions[-1].shape[-3], self.model_tester.num_attention_heads - 1) - - def test_head_pruning_save_load_from_pretrained(self): - if not self.test_pruning: - return - - for model_class in self.all_model_classes: - ( - config, - inputs_dict, - ) = self.model_tester.prepare_config_and_inputs_for_common() - - if "head_mask" in inputs_dict: - del inputs_dict["head_mask"] - - inputs_dict["output_attentions"] = True - config.output_hidden_states = False - model = model_class(config=config) - model.to(torch_device) - model.eval() - heads_to_prune = { - 0: list(range(1, self.model_tester.num_attention_heads)), - -1: [0], - } - model.prune_heads(heads_to_prune) - - with tempfile.TemporaryDirectory() as temp_dir_name: - model.save_pretrained(temp_dir_name) - model = model_class.from_pretrained(temp_dir_name) - model.to(torch_device) - - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - attentions = outputs[-1] - self.assertEqual(attentions[0].shape[-3], 1) - # TODO: To have this check, we will need at least 3 layers. Do we really need it? - # self.assertEqual(attentions[1].shape[-3], self.model_tester.num_attention_heads) - self.assertEqual(attentions[-1].shape[-3], self.model_tester.num_attention_heads - 1) - - def test_head_pruning_save_load_from_config_init(self): - if not self.test_pruning: - return - - for model_class in self.all_model_classes: - ( - config, - inputs_dict, - ) = self.model_tester.prepare_config_and_inputs_for_common() - - if "head_mask" in inputs_dict: - del inputs_dict["head_mask"] - - inputs_dict["output_attentions"] = True - config.output_hidden_states = False - - heads_to_prune = { - 0: list(range(1, self.model_tester.num_attention_heads)), - -1: [0], - } - config.pruned_heads = heads_to_prune - - model = model_class(config=config) - model.to(torch_device) - model.eval() - - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - attentions = outputs[-1] - - self.assertEqual(attentions[0].shape[-3], 1) - # TODO: To have this check, we will need at least 3 layers. Do we really need it? - # self.assertEqual(attentions[1].shape[-3], self.model_tester.num_attention_heads) - self.assertEqual(attentions[-1].shape[-3], self.model_tester.num_attention_heads - 1) - - def test_head_pruning_integration(self): - if not self.test_pruning: - return - - for model_class in self.all_model_classes: - ( - config, - inputs_dict, - ) = self.model_tester.prepare_config_and_inputs_for_common() - - if "head_mask" in inputs_dict: - del inputs_dict["head_mask"] - - inputs_dict["output_attentions"] = True - config.output_hidden_states = False - - heads_to_prune = {1: [1, 2]} - config.pruned_heads = heads_to_prune - - model = model_class(config=config) - model.to(torch_device) - model.eval() - - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - attentions = outputs[-1] - - self.assertEqual(attentions[0].shape[-3], self.model_tester.num_attention_heads - 0) - self.assertEqual(attentions[1].shape[-3], self.model_tester.num_attention_heads - 2) - - with tempfile.TemporaryDirectory() as temp_dir_name: - model.save_pretrained(temp_dir_name) - model = model_class.from_pretrained(temp_dir_name) - model.to(torch_device) - - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - attentions = outputs[-1] - - self.assertEqual(attentions[0].shape[-3], self.model_tester.num_attention_heads - 0) - self.assertEqual(attentions[1].shape[-3], self.model_tester.num_attention_heads - 2) - - heads_to_prune = {0: [0], 1: [1, 2]} - model.prune_heads(heads_to_prune) - - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - attentions = outputs[-1] - - self.assertEqual(attentions[0].shape[-3], self.model_tester.num_attention_heads - 1) - self.assertEqual(attentions[1].shape[-3], self.model_tester.num_attention_heads - 2) - - self.assertDictEqual(model.config.pruned_heads, {0: [0], 1: [1, 2]}) - - def test_hidden_states_output(self): - def check_hidden_states_output(inputs_dict, config, model_class): - model = model_class(config) - model.to(torch_device) - model.eval() - - with torch.no_grad(): - outputs = model(**self._prepare_for_class(inputs_dict, model_class)) - - hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states - - expected_num_layers = getattr( - self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1 - ) - self.assertEqual(len(hidden_states), expected_num_layers) - - if hasattr(self.model_tester, "encoder_seq_length"): - seq_length = self.model_tester.encoder_seq_length - if hasattr(self.model_tester, "chunk_length") and self.model_tester.chunk_length > 1: - seq_length = seq_length * self.model_tester.chunk_length - else: - seq_length = self.model_tester.seq_length - - self.assertListEqual( - list(hidden_states[0].shape[-2:]), - [seq_length, self.model_tester.hidden_size], - ) - - if config.is_encoder_decoder: - hidden_states = outputs.decoder_hidden_states - - self.assertIsInstance(hidden_states, (list, tuple)) - self.assertEqual(len(hidden_states), expected_num_layers) - seq_len = getattr(self.model_tester, "seq_length", None) - decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len) - - self.assertListEqual( - list(hidden_states[0].shape[-2:]), - [decoder_seq_length, self.model_tester.hidden_size], - ) - - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - inputs_dict["output_hidden_states"] = True - check_hidden_states_output(inputs_dict, config, model_class) - - # check that output_hidden_states also work using config - del inputs_dict["output_hidden_states"] - config.output_hidden_states = True - - check_hidden_states_output(inputs_dict, config, model_class) - - def test_retain_grad_hidden_states_attentions(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.output_hidden_states = True - config.output_attentions = self.has_attentions - - # no need to test all models as different heads yield the same functionality - model_class = self.all_model_classes[0] - model = model_class(config) - model.to(torch_device) - - inputs = self._prepare_for_class(inputs_dict, model_class) - - outputs = model(**inputs) - - output = outputs[0] - - if config.is_encoder_decoder: - # Seq2Seq models - encoder_hidden_states = outputs.encoder_hidden_states[0] - encoder_hidden_states.retain_grad() - - decoder_hidden_states = outputs.decoder_hidden_states[0] - decoder_hidden_states.retain_grad() - - if self.has_attentions: - encoder_attentions = outputs.encoder_attentions[0] - encoder_attentions.retain_grad() - - decoder_attentions = outputs.decoder_attentions[0] - decoder_attentions.retain_grad() - - cross_attentions = outputs.cross_attentions[0] - cross_attentions.retain_grad() - - output.flatten()[0].backward(retain_graph=True) - - self.assertIsNotNone(encoder_hidden_states.grad) - self.assertIsNotNone(decoder_hidden_states.grad) - - if self.has_attentions: - self.assertIsNotNone(encoder_attentions.grad) - self.assertIsNotNone(decoder_attentions.grad) - self.assertIsNotNone(cross_attentions.grad) - else: - # Encoder-/Decoder-only models - hidden_states = outputs.hidden_states[0] - hidden_states.retain_grad() - - if self.has_attentions: - attentions = outputs.attentions[0] - attentions.retain_grad() - - output.flatten()[0].backward(retain_graph=True) - - self.assertIsNotNone(hidden_states.grad) - - if self.has_attentions: - self.assertIsNotNone(attentions.grad) - - def test_feed_forward_chunking(self): - ( - original_config, - inputs_dict, - ) = self.model_tester.prepare_config_and_inputs_for_common() - for model_class in self.all_model_classes: - torch.manual_seed(0) - config = copy.deepcopy(original_config) - model = model_class(config) - model.to(torch_device) - model.eval() - - hidden_states_no_chunk = model(**self._prepare_for_class(inputs_dict, model_class))[0] - - torch.manual_seed(0) - config.chunk_size_feed_forward = 1 - model = model_class(config) - model.to(torch_device) - model.eval() - - hidden_states_with_chunk = model(**self._prepare_for_class(inputs_dict, model_class))[0] - self.assertTrue(torch.allclose(hidden_states_no_chunk, hidden_states_with_chunk, atol=1e-3)) - - def test_resize_position_vector_embeddings(self): - if not self.test_resize_position_embeddings: - return - - ( - original_config, - inputs_dict, - ) = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - config = copy.deepcopy(original_config) - model = model_class(config) - model.to(torch_device) - - if self.model_tester.is_training is False: - model.eval() - - max_position_embeddings = config.max_position_embeddings - - # Retrieve the embeddings and clone theme - if model.config.is_encoder_decoder: - encoder_model_embed, decoder_model_embed = model.get_position_embeddings() - encoder_cloned_embeddings = encoder_model_embed.weight.clone() - decoder_cloned_embeddings = decoder_model_embed.weight.clone() - else: - model_embed = model.get_position_embeddings() - cloned_embeddings = model_embed.weight.clone() - - # Check that resizing the position embeddings with a larger max_position_embeddings increases - # the model's postion embeddings size - model.resize_position_embeddings(max_position_embeddings + 10) - self.assertEqual(model.config.max_position_embeddings, max_position_embeddings + 10) - - # Check that it actually resizes the embeddings matrix - if model.config.is_encoder_decoder: - encoder_model_embed, decoder_model_embed = model.get_position_embeddings() - self.assertEqual(encoder_model_embed.weight.shape[0], encoder_cloned_embeddings.shape[0] + 10) - self.assertEqual(decoder_model_embed.weight.shape[0], decoder_cloned_embeddings.shape[0] + 10) - else: - model_embed = model.get_position_embeddings() - self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] + 10) - - # Check that the model can still do a forward pass successfully (every parameter should be resized) - model(**self._prepare_for_class(inputs_dict, model_class)) - - # Check that resizing the position embeddings with a smaller max_position_embeddings decreases - # the model's max_position_embeddings - model.resize_position_embeddings(max_position_embeddings - 5) - self.assertEqual(model.config.max_position_embeddings, max_position_embeddings - 5) - - # Check that it actually resizes the embeddings matrix - if model.config.is_encoder_decoder: - encoder_model_embed, decoder_model_embed = model.get_position_embeddings() - self.assertEqual(encoder_model_embed.weight.shape[0], encoder_cloned_embeddings.shape[0] - 5) - self.assertEqual(decoder_model_embed.weight.shape[0], decoder_cloned_embeddings.shape[0] - 5) - else: - model_embed = model.get_position_embeddings() - self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] - 5) - - # Check that the model can still do a forward pass successfully (every parameter should be resized) - model(**self._prepare_for_class(inputs_dict, model_class)) - - # Check that adding and removing tokens has not modified the first part of the embedding matrix. - models_equal = True - - if model.config.is_encoder_decoder: - for p1, p2 in zip(encoder_cloned_embeddings, encoder_model_embed.weight): - if p1.data.ne(p2.data).sum() > 0: - models_equal = False - for p1, p2 in zip(decoder_cloned_embeddings, decoder_model_embed.weight): - if p1.data.ne(p2.data).sum() > 0: - models_equal = False - else: - for p1, p2 in zip(cloned_embeddings, model_embed.weight): - if p1.data.ne(p2.data).sum() > 0: - models_equal = False - - self.assertTrue(models_equal) - - @mark.skip("Skipped for Gaudi") - def test_resize_tokens_embeddings(self): - ( - original_config, - inputs_dict, - ) = self.model_tester.prepare_config_and_inputs_for_common() - if not self.test_resize_embeddings: - return - - for model_class in self.all_model_classes: - config = copy.deepcopy(original_config) - model = model_class(config) - model.to(torch_device) - - if self.model_tester.is_training is False: - model.eval() - - model_vocab_size = config.vocab_size - # Retrieve the embeddings and clone theme - model_embed = model.resize_token_embeddings(model_vocab_size) - cloned_embeddings = model_embed.weight.clone() - - # Check that resizing the token embeddings with a larger vocab size increases the model's vocab size - model_embed = model.resize_token_embeddings(model_vocab_size + 10) - self.assertEqual(model.config.vocab_size, model_vocab_size + 10) - # Check that it actually resizes the embeddings matrix - self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] + 10) - # Check that the model can still do a forward pass successfully (every parameter should be resized) - model(**self._prepare_for_class(inputs_dict, model_class)) - - # Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size - model_embed = model.resize_token_embeddings(model_vocab_size - 15) - self.assertEqual(model.config.vocab_size, model_vocab_size - 15) - # Check that it actually resizes the embeddings matrix - self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] - 15) - - # Check that the model can still do a forward pass successfully (every parameter should be resized) - # Input ids should be clamped to the maximum size of the vocabulary - inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 1) - - # make sure that decoder_input_ids are resized as well - if "decoder_input_ids" in inputs_dict: - inputs_dict["decoder_input_ids"].clamp_(max=model_vocab_size - 15 - 1) - model(**self._prepare_for_class(inputs_dict, model_class)) - - # Check that adding and removing tokens has not modified the first part of the embedding matrix. - models_equal = True - for p1, p2 in zip(cloned_embeddings, model_embed.weight): - if p1.data.ne(p2.data).sum() > 0: - models_equal = False - - self.assertTrue(models_equal) - - config = copy.deepcopy(original_config) - model = model_class(config) - model.to(torch_device) - - model_vocab_size = config.vocab_size - model.resize_token_embeddings(model_vocab_size + 10, pad_to_multiple_of=1) - self.assertTrue(model.config.vocab_size + 10, model_vocab_size) - - model_embed = model.resize_token_embeddings(model_vocab_size, pad_to_multiple_of=64) - self.assertTrue(model_embed.weight.shape[0] // 64, 0) - - model_embed = model.resize_token_embeddings(model_vocab_size + 13, pad_to_multiple_of=64) - self.assertTrue(model_embed.weight.shape[0] // 64, 0) - - with self.assertRaisesRegex( - ValueError, - "Asking to pad the embedding matrix to a multiple of `1.3`, which is not and integer. Please make sure to pass an integer", - ): - model.resize_token_embeddings(model_vocab_size, pad_to_multiple_of=1.3) - - def test_resize_embeddings_untied(self): - ( - original_config, - inputs_dict, - ) = self.model_tester.prepare_config_and_inputs_for_common() - if not self.test_resize_embeddings: - return - - original_config.tie_word_embeddings = False - - # if model cannot untied embeddings -> leave test - if original_config.tie_word_embeddings: - return - - for model_class in self.all_model_classes: - config = copy.deepcopy(original_config) - model = model_class(config).to(torch_device) - - # if no output embeddings -> leave test - if model.get_output_embeddings() is None: - continue - - # Check that resizing the token embeddings with a larger vocab size increases the model's vocab size - model_vocab_size = config.vocab_size - model.resize_token_embeddings(model_vocab_size + 10) - self.assertEqual(model.config.vocab_size, model_vocab_size + 10) - output_embeds = model.get_output_embeddings() - self.assertEqual(output_embeds.weight.shape[0], model_vocab_size + 10) - # Check bias if present - if output_embeds.bias is not None: - self.assertEqual(output_embeds.bias.shape[0], model_vocab_size + 10) - # Check that the model can still do a forward pass successfully (every parameter should be resized) - model(**self._prepare_for_class(inputs_dict, model_class)) - - # Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size - model.resize_token_embeddings(model_vocab_size - 15) - self.assertEqual(model.config.vocab_size, model_vocab_size - 15) - # Check that it actually resizes the embeddings matrix - output_embeds = model.get_output_embeddings() - self.assertEqual(output_embeds.weight.shape[0], model_vocab_size - 15) - # Check bias if present - if output_embeds.bias is not None: - self.assertEqual(output_embeds.bias.shape[0], model_vocab_size - 15) - # Check that the model can still do a forward pass successfully (every parameter should be resized) - # Input ids should be clamped to the maximum size of the vocabulary - inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 1) - if "decoder_input_ids" in inputs_dict: - inputs_dict["decoder_input_ids"].clamp_(max=model_vocab_size - 15 - 1) - # Check that the model can still do a forward pass successfully (every parameter should be resized) - model(**self._prepare_for_class(inputs_dict, model_class)) - - def test_model_common_attributes(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - model = model_class(config) - self.assertIsInstance(model.get_input_embeddings(), (nn.Embedding, AdaptiveEmbedding)) - model.set_input_embeddings(nn.Embedding(10, 10)) - x = model.get_output_embeddings() - self.assertTrue(x is None or isinstance(x, nn.Linear)) - - def test_model_main_input_name(self): - for model_class in self.all_model_classes: - model_signature = inspect.signature(getattr(model_class, "forward")) - # The main input is the name of the argument after `self` - observed_main_input_name = list(model_signature.parameters.keys())[1] - self.assertEqual(model_class.main_input_name, observed_main_input_name) - - def test_correct_missing_keys(self): - if not self.test_missing_keys: - return - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - model = model_class(config) - base_model_prefix = model.base_model_prefix - - if hasattr(model, base_model_prefix): - extra_params = {k: v for k, v in model.named_parameters() if not k.startswith(base_model_prefix)} - extra_params.update({k: v for k, v in model.named_buffers() if not k.startswith(base_model_prefix)}) - # Some models define this as None - if model._keys_to_ignore_on_load_missing: - for key in model._keys_to_ignore_on_load_missing: - extra_params.pop(key, None) - - if not extra_params: - # In that case, we *are* on a head model, but every - # single key is not actual parameters and this is - # tested in `test_tied_model_weights_key_ignore` test. - continue - - with tempfile.TemporaryDirectory() as temp_dir_name: - model.base_model.save_pretrained(temp_dir_name) - model, loading_info = model_class.from_pretrained(temp_dir_name, output_loading_info=True) - self.assertGreater(len(loading_info["missing_keys"]), 0, model.__class__.__name__) - - def test_tie_model_weights(self): - if not self.test_torchscript: - return - - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - def check_same_values(layer_1, layer_2): - equal = True - for p1, p2 in zip(layer_1.weight, layer_2.weight): - if p1.data.ne(p2.data).sum() > 0: - equal = False - return equal - - for model_class in self.all_model_classes: - config.torchscript = True - model_not_tied = model_class(config) - if model_not_tied.get_output_embeddings() is None: - continue - - config_tied = copy.deepcopy(config) - config_tied.torchscript = False - model_tied = model_class(config_tied) - params_tied = list(model_tied.parameters()) - # Check that the embedding layer and decoding layer are the same in size and in value - # self.assertTrue(check_same_values(embeddings, decoding)) - - # # Check that after modification, they remain the same. - # embeddings.weight.data.div_(2) - # # Check that the embedding layer and decoding layer are the same in size and in value - # self.assertTrue(embeddings.weight.shape, decoding.weight.shape) - # self.assertTrue(check_same_values(embeddings, decoding)) - - # # Check that after modification, they remain the same. - # decoding.weight.data.div_(4) - # # Check that the embedding layer and decoding layer are the same in size and in value - # self.assertTrue(embeddings.weight.shape, decoding.weight.shape) - # self.assertTrue(check_same_values(embeddings, decoding)) - - # Check that after resize they remain tied. - model_tied.resize_token_embeddings(config.vocab_size + 10) - params_tied_2 = list(model_tied.parameters()) - self.assertEqual(len(params_tied_2), len(params_tied)) - - # decoding.weight.data.mul_(20) - # # Check that the embedding layer and decoding layer are the same in size and in value - # self.assertTrue(model.transformer.wte.weight.shape, model.lm_head.weight.shape) - # self.assertTrue(check_same_values(model.transformer.wte, model.lm_head)) - - @require_safetensors - def test_can_use_safetensors(self): - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - for model_class in self.all_model_classes: - model_tied = model_class(config) - with tempfile.TemporaryDirectory() as d: - try: - model_tied.save_pretrained(d, safe_serialization=True) - except Exception as e: - raise Exception(f"Class {model_class.__name__} cannot be saved using safetensors: {e}") - - model_reloaded, infos = model_class.from_pretrained(d, output_loading_info=True) - # Checking the state dicts are correct - reloaded_state = model_reloaded.state_dict() - for k, v in model_tied.state_dict().items(): - self.assertIn(k, reloaded_state, f"Key {k} is missing from reloaded") - torch.testing.assert_close( - v, reloaded_state[k], msg=lambda x: f"{model_class.__name__}: Tensor {k}: {x}" - ) - # Checking there was no complain of missing weights - self.assertEqual(infos["missing_keys"], []) - - # Checking the tensor sharing are correct - ptrs = defaultdict(list) - for k, v in model_tied.state_dict().items(): - ptrs[v.data_ptr()].append(k) - - shared_ptrs = {k: v for k, v in ptrs.items() if len(v) > 1} - - for _, shared_names in shared_ptrs.items(): - reloaded_ptrs = {reloaded_state[k].data_ptr() for k in shared_names} - self.assertEqual( - len(reloaded_ptrs), - 1, - f"The shared pointers are incorrect, found different pointers for keys {shared_names}", - ) - - def test_load_save_without_tied_weights(self): - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - config.tie_word_embeddings = False - for model_class in self.all_model_classes: - model = model_class(config) - with tempfile.TemporaryDirectory() as d: - model.save_pretrained(d) - - model_reloaded, infos = model_class.from_pretrained(d, output_loading_info=True) - # Checking the state dicts are correct - reloaded_state = model_reloaded.state_dict() - for k, v in model.state_dict().items(): - self.assertIn(k, reloaded_state, f"Key {k} is missing from reloaded") - torch.testing.assert_close( - v, reloaded_state[k], msg=lambda x: f"{model_class.__name__}: Tensor {k}: {x}" - ) - # Checking there was no complain of missing weights - self.assertEqual(infos["missing_keys"], []) - - def test_tied_weights_keys(self): - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - config.tie_word_embeddings = True - for model_class in self.all_model_classes: - model_tied = model_class(config) - - ptrs = collections.defaultdict(list) - for name, tensor in model_tied.state_dict().items(): - ptrs[id_tensor_storage(tensor)].append(name) - - # These are all the pointers of shared tensors. - tied_params = [names for _, names in ptrs.items() if len(names) > 1] - - tied_weight_keys = model_tied._tied_weights_keys if model_tied._tied_weights_keys is not None else [] - # Detect we get a hit for each key - for key in tied_weight_keys: - if not any(re.search(key, p) for group in tied_params for p in group): - raise ValueError(f"{key} is not a tied weight key for {model_class}.") - - # Removed tied weights found from tied params -> there should only be one left after - for key in tied_weight_keys: - for i in range(len(tied_params)): - tied_params[i] = [p for p in tied_params[i] if re.search(key, p) is None] - - tied_params = [group for group in tied_params if len(group) > 1] - self.assertListEqual( - tied_params, - [], - f"Missing `_tied_weights_keys` for {model_class}: add all of {tied_params} except one.", - ) - - def test_model_weights_reload_no_missing_tied_weights(self): - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - for model_class in self.all_model_classes: - model = model_class(config) - with tempfile.TemporaryDirectory() as tmp_dir: - model.save_pretrained(tmp_dir) - - # We are nuking ALL weights on file, so every parameter should - # yell on load. We're going to detect if we yell too much, or too little. - placeholder_dict = {"tensor": torch.tensor([1, 2])} - safe_save_file(placeholder_dict, os.path.join(tmp_dir, "model.safetensors"), metadata={"format": "pt"}) - model_reloaded, infos = model_class.from_pretrained(tmp_dir, output_loading_info=True) - - prefix = f"{model_reloaded.base_model_prefix}." - params = dict(model_reloaded.named_parameters()) - params.update(dict(model_reloaded.named_buffers())) - param_names = {k[len(prefix) :] if k.startswith(prefix) else k for k in params.keys()} - - missing_keys = set(infos["missing_keys"]) - - extra_missing = missing_keys - param_names - # Remove tied weights from extra missing: they are normally not warned as missing if their tied - # counterpart is present but here there are no weights at all so we do get the warning. - ptrs = collections.defaultdict(list) - for name, tensor in model_reloaded.state_dict().items(): - ptrs[id_tensor_storage(tensor)].append(name) - tied_params = [names for _, names in ptrs.items() if len(names) > 1] - for group in tied_params: - group = {k[len(prefix) :] if k.startswith(prefix) else k for k in group} - # We remove the group from extra_missing if not all weights from group are in it - if len(group - extra_missing) > 0: - extra_missing = extra_missing - set(group) - - self.assertEqual( - extra_missing, - set(), - f"This model {model_class.__name__} might be missing some `keys_to_ignore`: {extra_missing}. " - f"For debugging, tied parameters are {tied_params}", - ) - - missed_missing = param_names - missing_keys - # Remove nonpersistent buffers from missed_missing - buffers = [n for n, _ in model_reloaded.named_buffers()] - nonpersistent_buffers = {n for n in buffers if n not in model_reloaded.state_dict()} - nonpersistent_buffers = { - k[len(prefix) :] if k.startswith(prefix) else k for k in nonpersistent_buffers - } - missed_missing = missed_missing - nonpersistent_buffers - - if model_reloaded._keys_to_ignore_on_load_missing is None: - expected_missing = set() - else: - expected_missing = set(model_reloaded._keys_to_ignore_on_load_missing) - self.assertEqual( - missed_missing, - expected_missing, - f"This model {model_class.__name__} ignores keys {missed_missing} but they look like real" - " parameters. If they are non persistent buffers make sure to instantiate them with" - " `persistent=False`", - ) - - @mark.skip("skip - test is slow") - def test_model_outputs_equivalence(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - def set_nan_tensor_to_zero(t): - t[t != t] = 0 - return t - - def check_equivalence(model, tuple_inputs, dict_inputs, additional_kwargs={}): - with torch.no_grad(): - tuple_output = model(**tuple_inputs, return_dict=False, **additional_kwargs) - dict_output = model(**dict_inputs, return_dict=True, **additional_kwargs).to_tuple() - - def recursive_check(tuple_object, dict_object): - if isinstance(tuple_object, (List, Tuple)): - for tuple_iterable_value, dict_iterable_value in zip(tuple_object, dict_object): - recursive_check(tuple_iterable_value, dict_iterable_value) - elif isinstance(tuple_object, Dict): - for tuple_iterable_value, dict_iterable_value in zip( - tuple_object.values(), dict_object.values() - ): - recursive_check(tuple_iterable_value, dict_iterable_value) - elif tuple_object is None: - return - else: - self.assertTrue( - torch.allclose( - set_nan_tensor_to_zero(tuple_object), set_nan_tensor_to_zero(dict_object), atol=1e-5 - ), - msg=( - "Tuple and dict output are not equal. Difference:" - f" {torch.max(torch.abs(tuple_object - dict_object))}. Tuple has `nan`:" - f" {torch.isnan(tuple_object).any()} and `inf`: {torch.isinf(tuple_object)}. Dict has" - f" `nan`: {torch.isnan(dict_object).any()} and `inf`: {torch.isinf(dict_object)}." - ), - ) - - recursive_check(tuple_output, dict_output) - - for model_class in self.all_model_classes: - model = model_class(config) - model.to(torch_device) - model.eval() - - tuple_inputs = self._prepare_for_class(inputs_dict, model_class) - dict_inputs = self._prepare_for_class(inputs_dict, model_class) - check_equivalence(model, tuple_inputs, dict_inputs) - - tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - check_equivalence(model, tuple_inputs, dict_inputs) - - tuple_inputs = self._prepare_for_class(inputs_dict, model_class) - dict_inputs = self._prepare_for_class(inputs_dict, model_class) - check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True}) - - tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - check_equivalence(model, tuple_inputs, dict_inputs, {"output_hidden_states": True}) - - if self.has_attentions: - tuple_inputs = self._prepare_for_class(inputs_dict, model_class) - dict_inputs = self._prepare_for_class(inputs_dict, model_class) - check_equivalence(model, tuple_inputs, dict_inputs, {"output_attentions": True}) - - tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - check_equivalence(model, tuple_inputs, dict_inputs, {"output_attentions": True}) - - tuple_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - dict_inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - check_equivalence( - model, tuple_inputs, dict_inputs, {"output_hidden_states": True, "output_attentions": True} - ) - - # Don't copy this method to model specific test file! - # TODO: remove this method once the issues are all fixed! - def _make_attention_mask_non_null(self, inputs_dict): - """Make sure no sequence has all zeros as attention mask""" - - for k in ["attention_mask", "encoder_attention_mask", "decoder_attention_mask"]: - if k in inputs_dict: - attention_mask = inputs_dict[k] - - # Make sure no all 0s attention masks - to avoid failure at this moment. - # Put `1` at the beginning of sequences to make it still work when combining causal attention masks. - # TODO: remove this line once a fix regarding large negative values for attention mask is done. - attention_mask = torch.cat( - [torch.ones_like(attention_mask[:, :1], dtype=attention_mask.dtype), attention_mask[:, 1:]], dim=-1 - ) - - # Here we make the first sequence with all 0s as attention mask. - # Currently, this will fail for `TFWav2Vec2Model`. This is caused by the different large negative - # values, like `1e-4`, `1e-9`, `1e-30` and `-inf` for attention mask across models/frameworks. - # TODO: enable this block once the large negative values thing is cleaned up. - # (see https://github.com/huggingface/transformers/issues/14859) - # attention_mask = torch.cat( - # [torch.zeros_like(attention_mask[:1], dtype=attention_mask.dtype), attention_mask[1:]], - # dim=0 - # ) - - inputs_dict[k] = attention_mask - - # Don't copy this method to model specific test file! - # TODO: remove this method once the issues are all fixed! - def _postprocessing_to_ignore_test_cases(self, tf_outputs, pt_outputs, model_class): - """For temporarily ignoring some failed test cases (issues to be fixed)""" - - tf_keys = {k for k, v in tf_outputs.items() if v is not None} - pt_keys = {k for k, v in pt_outputs.items() if v is not None} - - key_differences = tf_keys.symmetric_difference(pt_keys) - - if model_class.__name__ in [ - "FlaubertWithLMHeadModel", - "FunnelForPreTraining", - "ElectraForPreTraining", - "XLMWithLMHeadModel", - "TransfoXLLMHeadModel", - ]: - for k in key_differences: - if k in ["loss", "losses"]: - tf_keys.discard(k) - pt_keys.discard(k) - elif model_class.__name__.startswith("GPT2"): - # `TFGPT2` has `past_key_values` as a tensor while `GPT2` has it as a tuple. - tf_keys.discard("past_key_values") - pt_keys.discard("past_key_values") - - # create new outputs from the remaining fields - new_tf_outputs = type(tf_outputs)(**{k: tf_outputs[k] for k in tf_keys}) - new_pt_outputs = type(pt_outputs)(**{k: pt_outputs[k] for k in pt_keys}) - - return new_tf_outputs, new_pt_outputs - - def test_inputs_embeds(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - model = model_class(config) - model.to(torch_device) - model.eval() - - inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class)) - - if not self.is_encoder_decoder: - input_ids = inputs["input_ids"] - del inputs["input_ids"] - else: - encoder_input_ids = inputs["input_ids"] - decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids) - del inputs["input_ids"] - inputs.pop("decoder_input_ids", None) - - wte = model.get_input_embeddings() - if not self.is_encoder_decoder: - inputs["inputs_embeds"] = wte(input_ids) - else: - inputs["inputs_embeds"] = wte(encoder_input_ids) - inputs["decoder_inputs_embeds"] = wte(decoder_input_ids) - - with torch.no_grad(): - model(**inputs)[0] - - @require_torch_multi_gpu - def test_multi_gpu_data_parallel_forward(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - # some params shouldn't be scattered by nn.DataParallel - # so just remove them if they are present. - blacklist_non_batched_params = ["head_mask", "decoder_head_mask", "cross_attn_head_mask"] - for k in blacklist_non_batched_params: - inputs_dict.pop(k, None) - - # move input tensors to cuda:O - for k, v in inputs_dict.items(): - if torch.is_tensor(v): - inputs_dict[k] = v.to(0) - - for model_class in self.all_model_classes: - model = model_class(config=config) - model.to(0) - model.eval() - - # Wrap model in nn.DataParallel - model = nn.DataParallel(model) - with torch.no_grad(): - _ = model(**self._prepare_for_class(inputs_dict, model_class)) - - @require_torch_multi_gpu - def test_model_parallelization(self): - if not self.test_model_parallel: - return - - # a candidate for testing_utils - def get_current_gpu_memory_use(): - """returns a list of cuda memory allocations per GPU in MBs""" - - per_device_memory = [] - for id in range(torch.cuda.device_count()): - with torch.cuda.device(id): - per_device_memory.append(torch.cuda.memory_allocated() >> 20) - - return per_device_memory - - # Needs a large model to see the difference. - config = self.model_tester.get_large_model_config() - - for model_class in self.all_parallelizable_model_classes: - torch.cuda.empty_cache() - - # 1. single gpu memory load + unload + memory measurements - # Retrieve initial memory usage (can easily be ~0.6-1.5GB if cuda-kernels have been preloaded by previous tests) - memory_at_start = get_current_gpu_memory_use() - - # Put model on device 0 and take a memory snapshot - model = model_class(config) - model.to("cuda:0") - memory_after_model_load = get_current_gpu_memory_use() - - # The memory use on device 0 should be higher than it was initially. - self.assertGreater(memory_after_model_load[0], memory_at_start[0]) - - del model - gc.collect() - torch.cuda.empty_cache() - - # 2. MP test - # it's essential to re-calibrate the usage before the next stage - memory_at_start = get_current_gpu_memory_use() - - # Spread model layers over multiple devices - model = model_class(config) - model.parallelize() - memory_after_parallelization = get_current_gpu_memory_use() - - # Assert that the memory use on all devices is higher than it was when loaded only on CPU - for n in range(len(model.device_map.keys())): - self.assertGreater(memory_after_parallelization[n], memory_at_start[n]) - - # Assert that the memory use of device 0 is lower than it was when the entire model was loaded on it - self.assertLess(memory_after_parallelization[0], memory_after_model_load[0]) - - # Assert that the memory use of device 1 is higher than it was when the entire model was loaded - # on device 0 and device 1 wasn't used at all - self.assertGreater(memory_after_parallelization[1], memory_after_model_load[1]) - - del model - gc.collect() - torch.cuda.empty_cache() - - @require_torch_multi_gpu - def test_model_parallel_equal_results(self): - if not self.test_model_parallel: - return - - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_parallelizable_model_classes: - inputs_dict = self._prepare_for_class(inputs_dict, model_class) - - def cast_to_device(dictionary, device): - output = {} - for k, v in dictionary.items(): - if isinstance(v, torch.Tensor): - output[k] = v.to(device) - else: - output[k] = v - - return output - - model = model_class(config) - output = model(**cast_to_device(inputs_dict, "cpu")) - - model.parallelize() - - parallel_output = model(**cast_to_device(inputs_dict, "cuda:0")) - - for value, parallel_value in zip(output, parallel_output): - if isinstance(value, torch.Tensor): - self.assertTrue(torch.allclose(value, parallel_value.to("cpu"), atol=1e-7)) - elif isinstance(value, (Tuple, List)): - for value_, parallel_value_ in zip(value, parallel_value): - self.assertTrue(torch.allclose(value_, parallel_value_.to("cpu"), atol=1e-7)) - - @require_torch_multi_gpu - def test_model_parallel_beam_search(self): - if not self.test_model_parallel: - return - - all_generative_and_parallelizable_model_classes = tuple( - set(self.all_generative_model_classes).intersection(self.all_parallelizable_model_classes) - ) - - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in all_generative_and_parallelizable_model_classes: - inputs_dict = self._prepare_for_class(inputs_dict, model_class) - model = model_class(config) - - def cast_to_device(dictionary, device): - output = {} - for k, v in dictionary.items(): - if isinstance(v, torch.Tensor): - output[k] = v.to(device) - else: - output[k] = v - - return output - - model.parallelize() - model.generate(**cast_to_device(inputs_dict, "cuda:0"), num_beams=2) - - def check_device_map_is_respected(self, model, device_map): - for param_name, param in model.named_parameters(): - # Find device in device_map - while len(param_name) > 0 and param_name not in device_map: - param_name = ".".join(param_name.split(".")[:-1]) - if param_name not in device_map: - raise ValueError("device map is incomplete, it does not contain any device for `param_name`.") - - param_device = device_map[param_name] - if param_device in ["cpu", "disk"]: - self.assertEqual(param.device, torch.device("meta")) - else: - self.assertEqual(param.device, torch.device(param_device)) - - @require_accelerate - @mark.accelerate_tests - @require_torch_gpu - def test_disk_offload(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - if model_class._no_split_modules is None: - continue - - inputs_dict_class = self._prepare_for_class(inputs_dict, model_class) - model = model_class(config).eval() - model = model.to(torch_device) - torch.manual_seed(0) - base_output = model(**inputs_dict_class) - - model_size = compute_module_sizes(model)[""] - with tempfile.TemporaryDirectory() as tmp_dir: - model.cpu().save_pretrained(tmp_dir) - - with self.assertRaises(ValueError): - max_size = int(self.model_split_percents[0] * model_size) - max_memory = {0: max_size, "cpu": max_size} - # This errors out cause it's missing an offload folder - new_model = model_class.from_pretrained(tmp_dir, device_map="auto", max_memory=max_memory) - - max_size = int(self.model_split_percents[1] * model_size) - max_memory = {0: max_size, "cpu": max_size} - new_model = model_class.from_pretrained( - tmp_dir, device_map="auto", max_memory=max_memory, offload_folder=tmp_dir - ) - - self.check_device_map_is_respected(new_model, new_model.hf_device_map) - torch.manual_seed(0) - new_output = new_model(**inputs_dict_class) - - self.assertTrue(torch.allclose(base_output[0], new_output[0], atol=1e-5)) - - @require_accelerate - @mark.accelerate_tests - @require_torch_gpu - def test_cpu_offload(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - if model_class._no_split_modules is None: - continue - - inputs_dict_class = self._prepare_for_class(inputs_dict, model_class) - model = model_class(config).eval() - model = model.to(torch_device) - - torch.manual_seed(0) - base_output = model(**inputs_dict_class) - - model_size = compute_module_sizes(model)[""] - # We test several splits of sizes to make sure it works. - max_gpu_sizes = [int(p * model_size) for p in self.model_split_percents[1:]] - with tempfile.TemporaryDirectory() as tmp_dir: - model.cpu().save_pretrained(tmp_dir) - - for max_size in max_gpu_sizes: - max_memory = {0: max_size, "cpu": model_size * 2} - new_model = model_class.from_pretrained(tmp_dir, device_map="auto", max_memory=max_memory) - # Making sure part of the model will actually end up offloaded - self.assertSetEqual(set(new_model.hf_device_map.values()), {0, "cpu"}) - - self.check_device_map_is_respected(new_model, new_model.hf_device_map) - - torch.manual_seed(0) - new_output = new_model(**inputs_dict_class) - - self.assertTrue(torch.allclose(base_output[0], new_output[0], atol=1e-5)) - - @require_accelerate - @mark.accelerate_tests - @require_torch_multi_gpu - def test_model_parallelism(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - if model_class._no_split_modules is None: - continue - - inputs_dict_class = self._prepare_for_class(inputs_dict, model_class) - model = model_class(config).eval() - model = model.to(torch_device) - - torch.manual_seed(0) - base_output = model(**inputs_dict_class) - - model_size = compute_module_sizes(model)[""] - # We test several splits of sizes to make sure it works. - max_gpu_sizes = [int(p * model_size) for p in self.model_split_percents[1:]] - with tempfile.TemporaryDirectory() as tmp_dir: - model.cpu().save_pretrained(tmp_dir) - - for max_size in max_gpu_sizes: - max_memory = {0: max_size, 1: model_size * 2, "cpu": model_size * 2} - new_model = model_class.from_pretrained(tmp_dir, device_map="auto", max_memory=max_memory) - # Making sure part of the model will actually end up offloaded - self.assertSetEqual(set(new_model.hf_device_map.values()), {0, 1}) - - self.check_device_map_is_respected(new_model, new_model.hf_device_map) - - torch.manual_seed(0) - new_output = new_model(**inputs_dict_class) - - self.assertTrue(torch.allclose(base_output[0], new_output[0], atol=1e-5)) - - def test_problem_types(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - problem_types = [ - {"title": "multi_label_classification", "num_labels": 2, "dtype": torch.float}, - {"title": "single_label_classification", "num_labels": 1, "dtype": torch.long}, - {"title": "regression", "num_labels": 1, "dtype": torch.float}, - ] - - for model_class in self.all_model_classes: - if model_class.__name__ not in [ - *get_values(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES), - *get_values(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES), - ]: - continue - - for problem_type in problem_types: - with self.subTest(msg=f"Testing {model_class} with {problem_type['title']}"): - config.problem_type = problem_type["title"] - config.num_labels = problem_type["num_labels"] - - model = model_class(config) - model.to(torch_device) - model.train() - - inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True) - - if problem_type["num_labels"] > 1: - inputs["labels"] = inputs["labels"].unsqueeze(1).repeat(1, problem_type["num_labels"]) - - inputs["labels"] = inputs["labels"].to(problem_type["dtype"]) - - # This tests that we do not trigger the warning form PyTorch "Using a target size that is different - # to the input size. This will likely lead to incorrect results due to broadcasting. Please ensure - # they have the same size." which is a symptom something in wrong for the regression problem. - # See https://github.com/huggingface/transformers/issues/11780 - with warnings.catch_warnings(record=True) as warning_list: - loss = model(**inputs).loss - for w in warning_list: - if "Using a target size that is different to the input size" in str(w.message): - raise ValueError( - f"Something is going wrong in the regression problem: intercepted {w.message}" - ) - - loss.backward() - - def test_load_with_mismatched_shapes(self): - if not self.test_mismatched_shapes: - return - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - if model_class.__name__ not in get_values(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES): - continue - - with self.subTest(msg=f"Testing {model_class}"): - with tempfile.TemporaryDirectory() as tmp_dir: - model = model_class(config) - model.save_pretrained(tmp_dir) - - # Fails when we don't set ignore_mismatched_sizes=True - with self.assertRaises(RuntimeError): - new_model = AutoModelForSequenceClassification.from_pretrained(tmp_dir, num_labels=42) - with self.assertRaises(RuntimeError): - new_model_without_prefix = AutoModel.from_pretrained(tmp_dir, vocab_size=10) - - logger = logging.get_logger("transformers.modeling_utils") - - with CaptureLogger(logger) as cl: - new_model = AutoModelForSequenceClassification.from_pretrained( - tmp_dir, num_labels=42, ignore_mismatched_sizes=True - ) - self.assertIn("the shapes did not match", cl.out) - new_model.to(torch_device) - inputs = self._prepare_for_class(inputs_dict, model_class) - logits = new_model(**inputs).logits - self.assertEqual(logits.shape[1], 42) - - with CaptureLogger(logger) as cl: - new_model_without_prefix = AutoModel.from_pretrained( - tmp_dir, vocab_size=10, ignore_mismatched_sizes=True - ) - self.assertIn("the shapes did not match", cl.out) - input_ids = ids_tensor((2, 8), 10) - new_model_without_prefix.to(torch_device) - if self.is_encoder_decoder: - new_model_without_prefix(input_ids, decoder_input_ids=input_ids) - else: - new_model_without_prefix(input_ids) - - def test_model_is_small(self): - # Just a consistency check to make sure we are not running tests on 80M parameter models. - config, _ = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes: - model = model_class(config) - num_params = model.num_parameters() - assert ( - num_params < 1000000 - ), f"{model_class} is too big for the common tests ({num_params})! It should have 1M max." - - -global_rng = random.Random() - - -def ids_tensor(shape, vocab_size, rng=None, name=None): - # Creates a random int32 tensor of the shape within the vocab size - if rng is None: - rng = global_rng - - total_dims = 1 - for dim in shape: - total_dims *= dim - - values = [] - for _ in range(total_dims): - values.append(rng.randint(0, vocab_size - 1)) - - return torch.tensor(data=values, dtype=torch.long, device=torch_device).view(shape).contiguous() - - -def random_attention_mask(shape, rng=None, name=None): - attn_mask = ids_tensor(shape, vocab_size=2, rng=None, name=None) - # make sure that at least one token is attended to for each batch - attn_mask[:, -1] = 1 - return attn_mask - - -def floats_tensor(shape, scale=1.0, rng=None, name=None): - """Creates a random float32 tensor""" - if rng is None: - rng = global_rng - - total_dims = 1 - for dim in shape: - total_dims *= dim - - values = [] - for _ in range(total_dims): - values.append(rng.random() * scale) - - return torch.tensor(data=values, dtype=torch.float, device=torch_device).view(shape).contiguous() diff --git a/tests/transformers/tests/utils/__init__.py b/tests/transformers/tests/utils/__init__.py deleted file mode 100644 index e69de29bb2..0000000000 diff --git a/tests/transformers/tests/utils/test_activations.py b/tests/transformers/tests/utils/test_activations.py deleted file mode 100644 index 5e58205d09..0000000000 --- a/tests/transformers/tests/utils/test_activations.py +++ /dev/null @@ -1,73 +0,0 @@ -# Copyright 2020 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import unittest - -from transformers import is_torch_available -from transformers.testing_utils import require_torch - - -if is_torch_available(): - import torch - from transformers.activations import gelu_new, gelu_python, get_activation - - -@require_torch -class TestActivations(unittest.TestCase): - def test_gelu_versions(self): - x = torch.tensor([-100, -1, -0.1, 0, 0.1, 1.0, 100]) - torch_builtin = get_activation("gelu") - self.assertTrue(torch.allclose(gelu_python(x), torch_builtin(x))) - self.assertFalse(torch.allclose(gelu_python(x), gelu_new(x))) - - def test_gelu_10(self): - x = torch.tensor([-100, -1, -0.1, 0, 0.1, 1.0, 100]) - torch_builtin = get_activation("gelu") - gelu10 = get_activation("gelu_10") - - y_gelu = torch_builtin(x) - y_gelu_10 = gelu10(x) - - clipped_mask = torch.where(y_gelu_10 < 10.0, 1, 0) - - self.assertTrue(torch.max(y_gelu_10).item() == 10.0) - self.assertTrue(torch.allclose(y_gelu * clipped_mask, y_gelu_10 * clipped_mask)) - - def test_get_activation(self): - get_activation("gelu") - get_activation("gelu_10") - get_activation("gelu_fast") - get_activation("gelu_new") - get_activation("gelu_python") - get_activation("gelu_pytorch_tanh") - get_activation("linear") - get_activation("mish") - get_activation("quick_gelu") - get_activation("relu") - get_activation("sigmoid") - get_activation("silu") - get_activation("swish") - get_activation("tanh") - with self.assertRaises(KeyError): - get_activation("bogus") - with self.assertRaises(KeyError): - get_activation(None) - - def test_activations_are_distinct_objects(self): - act1 = get_activation("gelu") - act1.a = 1 - act2 = get_activation("gelu") - self.assertEqual(act1.a, 1) - with self.assertRaises(AttributeError): - _ = act2.a diff --git a/tests/transformers/tests/utils/test_activations_tf.py b/tests/transformers/tests/utils/test_activations_tf.py deleted file mode 100644 index a8533ae362..0000000000 --- a/tests/transformers/tests/utils/test_activations_tf.py +++ /dev/null @@ -1,58 +0,0 @@ -# Copyright 2020 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import unittest - -import numpy as np -from transformers import is_tf_available -from transformers.testing_utils import require_tf - - -if is_tf_available(): - import tensorflow as tf - from transformers.activations_tf import get_tf_activation - - -@require_tf -class TestTFActivations(unittest.TestCase): - def test_gelu_10(self): - x = tf.constant([-100, -1.0, -0.1, 0, 0.1, 1.0, 100.0]) - gelu = get_tf_activation("gelu") - gelu10 = get_tf_activation("gelu_10") - - y_gelu = gelu(x) - y_gelu_10 = gelu10(x) - - clipped_mask = tf.where(y_gelu_10 < 10.0, 1.0, 0.0) - - self.assertEqual(tf.math.reduce_max(y_gelu_10).numpy().item(), 10.0) - self.assertTrue(np.allclose(y_gelu * clipped_mask, y_gelu_10 * clipped_mask)) - - def test_get_activation(self): - get_tf_activation("gelu") - get_tf_activation("gelu_10") - get_tf_activation("gelu_fast") - get_tf_activation("gelu_new") - get_tf_activation("glu") - get_tf_activation("mish") - get_tf_activation("quick_gelu") - get_tf_activation("relu") - get_tf_activation("sigmoid") - get_tf_activation("silu") - get_tf_activation("swish") - get_tf_activation("tanh") - with self.assertRaises(KeyError): - get_tf_activation("bogus") - with self.assertRaises(KeyError): - get_tf_activation(None) diff --git a/tests/transformers/tests/utils/test_add_new_model_like.py b/tests/transformers/tests/utils/test_add_new_model_like.py deleted file mode 100644 index 61ccc184f5..0000000000 --- a/tests/transformers/tests/utils/test_add_new_model_like.py +++ /dev/null @@ -1,1548 +0,0 @@ -# Copyright 2022 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -import os -import re -import tempfile -import unittest -from pathlib import Path - -import transformers -from transformers.commands.add_new_model_like import ( - ModelPatterns, - _re_class_func, - add_content_to_file, - add_content_to_text, - clean_frameworks_in_init, - duplicate_doc_file, - duplicate_module, - filter_framework_files, - find_base_model_checkpoint, - get_model_files, - get_module_from_file, - parse_module_content, - replace_model_patterns, - retrieve_info_for_model, - retrieve_model_classes, - simplify_replacements, -) -from transformers.testing_utils import require_flax, require_tf, require_torch - - -BERT_MODEL_FILES = { - "src/transformers/models/bert/__init__.py", - "src/transformers/models/bert/configuration_bert.py", - "src/transformers/models/bert/tokenization_bert.py", - "src/transformers/models/bert/tokenization_bert_fast.py", - "src/transformers/models/bert/tokenization_bert_tf.py", - "src/transformers/models/bert/modeling_bert.py", - "src/transformers/models/bert/modeling_flax_bert.py", - "src/transformers/models/bert/modeling_tf_bert.py", - "src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py", - "src/transformers/models/bert/convert_bert_original_tf2_checkpoint_to_pytorch.py", - "src/transformers/models/bert/convert_bert_pytorch_checkpoint_to_original_tf.py", - "src/transformers/models/bert/convert_bert_token_dropping_original_tf2_checkpoint_to_pytorch.py", -} - -VIT_MODEL_FILES = { - "src/transformers/models/vit/__init__.py", - "src/transformers/models/vit/configuration_vit.py", - "src/transformers/models/vit/convert_dino_to_pytorch.py", - "src/transformers/models/vit/convert_vit_timm_to_pytorch.py", - "src/transformers/models/vit/feature_extraction_vit.py", - "src/transformers/models/vit/image_processing_vit.py", - "src/transformers/models/vit/modeling_vit.py", - "src/transformers/models/vit/modeling_tf_vit.py", - "src/transformers/models/vit/modeling_flax_vit.py", -} - -WAV2VEC2_MODEL_FILES = { - "src/transformers/models/wav2vec2/__init__.py", - "src/transformers/models/wav2vec2/configuration_wav2vec2.py", - "src/transformers/models/wav2vec2/convert_wav2vec2_original_pytorch_checkpoint_to_pytorch.py", - "src/transformers/models/wav2vec2/convert_wav2vec2_original_s3prl_checkpoint_to_pytorch.py", - "src/transformers/models/wav2vec2/feature_extraction_wav2vec2.py", - "src/transformers/models/wav2vec2/modeling_wav2vec2.py", - "src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py", - "src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py", - "src/transformers/models/wav2vec2/processing_wav2vec2.py", - "src/transformers/models/wav2vec2/tokenization_wav2vec2.py", -} - -REPO_PATH = Path(transformers.__path__[0]).parent.parent - - -@require_torch -@require_tf -@require_flax -class TestAddNewModelLike(unittest.TestCase): - def init_file(self, file_name, content): - with open(file_name, "w", encoding="utf-8") as f: - f.write(content) - - def check_result(self, file_name, expected_result): - with open(file_name, "r", encoding="utf-8") as f: - result = f.read() - self.assertEqual(result, expected_result) - - def test_re_class_func(self): - self.assertEqual(_re_class_func.search("def my_function(x, y):").groups()[0], "my_function") - self.assertEqual(_re_class_func.search("class MyClass:").groups()[0], "MyClass") - self.assertEqual(_re_class_func.search("class MyClass(SuperClass):").groups()[0], "MyClass") - - def test_model_patterns_defaults(self): - model_patterns = ModelPatterns("GPT-New new", "huggingface/gpt-new-base") - - self.assertEqual(model_patterns.model_type, "gpt-new-new") - self.assertEqual(model_patterns.model_lower_cased, "gpt_new_new") - self.assertEqual(model_patterns.model_camel_cased, "GPTNewNew") - self.assertEqual(model_patterns.model_upper_cased, "GPT_NEW_NEW") - self.assertEqual(model_patterns.config_class, "GPTNewNewConfig") - self.assertIsNone(model_patterns.tokenizer_class) - self.assertIsNone(model_patterns.feature_extractor_class) - self.assertIsNone(model_patterns.processor_class) - - def test_parse_module_content(self): - test_code = """SOME_CONSTANT = a constant - -CONSTANT_DEFINED_ON_SEVERAL_LINES = [ - first_item, - second_item -] - -def function(args): - some code - -# Copied from transformers.some_module -class SomeClass: - some code -""" - - expected_parts = [ - "SOME_CONSTANT = a constant\n", - "CONSTANT_DEFINED_ON_SEVERAL_LINES = [\n first_item,\n second_item\n]", - "", - "def function(args):\n some code\n", - "# Copied from transformers.some_module\nclass SomeClass:\n some code\n", - ] - self.assertEqual(parse_module_content(test_code), expected_parts) - - def test_add_content_to_text(self): - test_text = """all_configs = { - "gpt": "GPTConfig", - "bert": "BertConfig", - "t5": "T5Config", -}""" - - expected = """all_configs = { - "gpt": "GPTConfig", - "gpt2": "GPT2Config", - "bert": "BertConfig", - "t5": "T5Config", -}""" - line = ' "gpt2": "GPT2Config",' - - self.assertEqual(add_content_to_text(test_text, line, add_before="bert"), expected) - self.assertEqual(add_content_to_text(test_text, line, add_before="bert", exact_match=True), test_text) - self.assertEqual( - add_content_to_text(test_text, line, add_before=' "bert": "BertConfig",', exact_match=True), expected - ) - self.assertEqual(add_content_to_text(test_text, line, add_before=re.compile(r'^\s*"bert":')), expected) - - self.assertEqual(add_content_to_text(test_text, line, add_after="gpt"), expected) - self.assertEqual(add_content_to_text(test_text, line, add_after="gpt", exact_match=True), test_text) - self.assertEqual( - add_content_to_text(test_text, line, add_after=' "gpt": "GPTConfig",', exact_match=True), expected - ) - self.assertEqual(add_content_to_text(test_text, line, add_after=re.compile(r'^\s*"gpt":')), expected) - - def test_add_content_to_file(self): - test_text = """all_configs = { - "gpt": "GPTConfig", - "bert": "BertConfig", - "t5": "T5Config", -}""" - - expected = """all_configs = { - "gpt": "GPTConfig", - "gpt2": "GPT2Config", - "bert": "BertConfig", - "t5": "T5Config", -}""" - line = ' "gpt2": "GPT2Config",' - - with tempfile.TemporaryDirectory() as tmp_dir: - file_name = os.path.join(tmp_dir, "code.py") - - self.init_file(file_name, test_text) - add_content_to_file(file_name, line, add_before="bert") - self.check_result(file_name, expected) - - self.init_file(file_name, test_text) - add_content_to_file(file_name, line, add_before="bert", exact_match=True) - self.check_result(file_name, test_text) - - self.init_file(file_name, test_text) - add_content_to_file(file_name, line, add_before=' "bert": "BertConfig",', exact_match=True) - self.check_result(file_name, expected) - - self.init_file(file_name, test_text) - add_content_to_file(file_name, line, add_before=re.compile(r'^\s*"bert":')) - self.check_result(file_name, expected) - - self.init_file(file_name, test_text) - add_content_to_file(file_name, line, add_after="gpt") - self.check_result(file_name, expected) - - self.init_file(file_name, test_text) - add_content_to_file(file_name, line, add_after="gpt", exact_match=True) - self.check_result(file_name, test_text) - - self.init_file(file_name, test_text) - add_content_to_file(file_name, line, add_after=' "gpt": "GPTConfig",', exact_match=True) - self.check_result(file_name, expected) - - self.init_file(file_name, test_text) - add_content_to_file(file_name, line, add_after=re.compile(r'^\s*"gpt":')) - self.check_result(file_name, expected) - - def test_simplify_replacements(self): - self.assertEqual(simplify_replacements([("Bert", "NewBert")]), [("Bert", "NewBert")]) - self.assertEqual( - simplify_replacements([("Bert", "NewBert"), ("bert", "new-bert")]), - [("Bert", "NewBert"), ("bert", "new-bert")], - ) - self.assertEqual( - simplify_replacements([("BertConfig", "NewBertConfig"), ("Bert", "NewBert"), ("bert", "new-bert")]), - [("Bert", "NewBert"), ("bert", "new-bert")], - ) - - def test_replace_model_patterns(self): - bert_model_patterns = ModelPatterns("Bert", "bert-base-cased") - new_bert_model_patterns = ModelPatterns("New Bert", "huggingface/bert-new-base") - bert_test = '''class TFBertPreTrainedModel(PreTrainedModel): - """ - An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained - models. - """ - - config_class = BertConfig - load_tf_weights = load_tf_weights_in_bert - base_model_prefix = "bert" - is_parallelizable = True - supports_gradient_checkpointing = True - model_type = "bert" - -BERT_CONSTANT = "value" -''' - bert_expected = '''class TFNewBertPreTrainedModel(PreTrainedModel): - """ - An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained - models. - """ - - config_class = NewBertConfig - load_tf_weights = load_tf_weights_in_new_bert - base_model_prefix = "new_bert" - is_parallelizable = True - supports_gradient_checkpointing = True - model_type = "new-bert" - -NEW_BERT_CONSTANT = "value" -''' - - bert_converted, replacements = replace_model_patterns(bert_test, bert_model_patterns, new_bert_model_patterns) - self.assertEqual(bert_converted, bert_expected) - # Replacements are empty here since bert as been replaced by bert_new in some instances and bert-new - # in others. - self.assertEqual(replacements, "") - - # If we remove the model type, we will get replacements - bert_test = bert_test.replace(' model_type = "bert"\n', "") - bert_expected = bert_expected.replace(' model_type = "new-bert"\n', "") - bert_converted, replacements = replace_model_patterns(bert_test, bert_model_patterns, new_bert_model_patterns) - self.assertEqual(bert_converted, bert_expected) - self.assertEqual(replacements, "BERT->NEW_BERT,Bert->NewBert,bert->new_bert") - - gpt_model_patterns = ModelPatterns("GPT2", "gpt2") - new_gpt_model_patterns = ModelPatterns("GPT-New new", "huggingface/gpt-new-base") - gpt_test = '''class GPT2PreTrainedModel(PreTrainedModel): - """ - An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained - models. - """ - - config_class = GPT2Config - load_tf_weights = load_tf_weights_in_gpt2 - base_model_prefix = "transformer" - is_parallelizable = True - supports_gradient_checkpointing = True - -GPT2_CONSTANT = "value" -''' - - gpt_expected = '''class GPTNewNewPreTrainedModel(PreTrainedModel): - """ - An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained - models. - """ - - config_class = GPTNewNewConfig - load_tf_weights = load_tf_weights_in_gpt_new_new - base_model_prefix = "transformer" - is_parallelizable = True - supports_gradient_checkpointing = True - -GPT_NEW_NEW_CONSTANT = "value" -''' - - gpt_converted, replacements = replace_model_patterns(gpt_test, gpt_model_patterns, new_gpt_model_patterns) - self.assertEqual(gpt_converted, gpt_expected) - # Replacements are empty here since GPT2 as been replaced by GPTNewNew in some instances and GPT_NEW_NEW - # in others. - self.assertEqual(replacements, "") - - roberta_model_patterns = ModelPatterns("RoBERTa", "roberta-base", model_camel_cased="Roberta") - new_roberta_model_patterns = ModelPatterns( - "RoBERTa-New", "huggingface/roberta-new-base", model_camel_cased="RobertaNew" - ) - roberta_test = '''# Copied from transformers.models.bert.BertModel with Bert->Roberta -class RobertaModel(RobertaPreTrainedModel): - """ The base RoBERTa model. """ - checkpoint = roberta-base - base_model_prefix = "roberta" - ''' - roberta_expected = '''# Copied from transformers.models.bert.BertModel with Bert->RobertaNew -class RobertaNewModel(RobertaNewPreTrainedModel): - """ The base RoBERTa-New model. """ - checkpoint = huggingface/roberta-new-base - base_model_prefix = "roberta_new" - ''' - roberta_converted, replacements = replace_model_patterns( - roberta_test, roberta_model_patterns, new_roberta_model_patterns - ) - self.assertEqual(roberta_converted, roberta_expected) - - def test_get_module_from_file(self): - self.assertEqual( - get_module_from_file("/git/transformers/src/transformers/models/bert/modeling_tf_bert.py"), - "transformers.models.bert.modeling_tf_bert", - ) - self.assertEqual( - get_module_from_file("/transformers/models/gpt2/modeling_gpt2.py"), - "transformers.models.gpt2.modeling_gpt2", - ) - with self.assertRaises(ValueError): - get_module_from_file("/models/gpt2/modeling_gpt2.py") - - def test_duplicate_module(self): - bert_model_patterns = ModelPatterns("Bert", "bert-base-cased") - new_bert_model_patterns = ModelPatterns("New Bert", "huggingface/bert-new-base") - bert_test = '''class TFBertPreTrainedModel(PreTrainedModel): - """ - An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained - models. - """ - - config_class = BertConfig - load_tf_weights = load_tf_weights_in_bert - base_model_prefix = "bert" - is_parallelizable = True - supports_gradient_checkpointing = True - -BERT_CONSTANT = "value" -''' - bert_expected = '''class TFNewBertPreTrainedModel(PreTrainedModel): - """ - An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained - models. - """ - - config_class = NewBertConfig - load_tf_weights = load_tf_weights_in_new_bert - base_model_prefix = "new_bert" - is_parallelizable = True - supports_gradient_checkpointing = True - -NEW_BERT_CONSTANT = "value" -''' - bert_expected_with_copied_from = ( - "# Copied from transformers.bert_module.TFBertPreTrainedModel with Bert->NewBert,bert->new_bert\n" - + bert_expected - ) - with tempfile.TemporaryDirectory() as tmp_dir: - work_dir = os.path.join(tmp_dir, "transformers") - os.makedirs(work_dir) - file_name = os.path.join(work_dir, "bert_module.py") - dest_file_name = os.path.join(work_dir, "new_bert_module.py") - - self.init_file(file_name, bert_test) - duplicate_module(file_name, bert_model_patterns, new_bert_model_patterns) - self.check_result(dest_file_name, bert_expected_with_copied_from) - - self.init_file(file_name, bert_test) - duplicate_module(file_name, bert_model_patterns, new_bert_model_patterns, add_copied_from=False) - self.check_result(dest_file_name, bert_expected) - - def test_duplicate_module_with_copied_from(self): - bert_model_patterns = ModelPatterns("Bert", "bert-base-cased") - new_bert_model_patterns = ModelPatterns("New Bert", "huggingface/bert-new-base") - bert_test = '''# Copied from transformers.models.xxx.XxxModel with Xxx->Bert -class TFBertPreTrainedModel(PreTrainedModel): - """ - An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained - models. - """ - - config_class = BertConfig - load_tf_weights = load_tf_weights_in_bert - base_model_prefix = "bert" - is_parallelizable = True - supports_gradient_checkpointing = True - -BERT_CONSTANT = "value" -''' - bert_expected = '''# Copied from transformers.models.xxx.XxxModel with Xxx->NewBert -class TFNewBertPreTrainedModel(PreTrainedModel): - """ - An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained - models. - """ - - config_class = NewBertConfig - load_tf_weights = load_tf_weights_in_new_bert - base_model_prefix = "new_bert" - is_parallelizable = True - supports_gradient_checkpointing = True - -NEW_BERT_CONSTANT = "value" -''' - with tempfile.TemporaryDirectory() as tmp_dir: - work_dir = os.path.join(tmp_dir, "transformers") - os.makedirs(work_dir) - file_name = os.path.join(work_dir, "bert_module.py") - dest_file_name = os.path.join(work_dir, "new_bert_module.py") - - self.init_file(file_name, bert_test) - duplicate_module(file_name, bert_model_patterns, new_bert_model_patterns) - # There should not be a new Copied from statement, the old one should be adapated. - self.check_result(dest_file_name, bert_expected) - - self.init_file(file_name, bert_test) - duplicate_module(file_name, bert_model_patterns, new_bert_model_patterns, add_copied_from=False) - self.check_result(dest_file_name, bert_expected) - - def test_filter_framework_files(self): - files = ["modeling_bert.py", "modeling_tf_bert.py", "modeling_flax_bert.py", "configuration_bert.py"] - self.assertEqual(filter_framework_files(files), files) - self.assertEqual(set(filter_framework_files(files, ["pt", "tf", "flax"])), set(files)) - - self.assertEqual(set(filter_framework_files(files, ["pt"])), {"modeling_bert.py", "configuration_bert.py"}) - self.assertEqual(set(filter_framework_files(files, ["tf"])), {"modeling_tf_bert.py", "configuration_bert.py"}) - self.assertEqual( - set(filter_framework_files(files, ["flax"])), {"modeling_flax_bert.py", "configuration_bert.py"} - ) - - self.assertEqual( - set(filter_framework_files(files, ["pt", "tf"])), - {"modeling_tf_bert.py", "modeling_bert.py", "configuration_bert.py"}, - ) - self.assertEqual( - set(filter_framework_files(files, ["tf", "flax"])), - {"modeling_tf_bert.py", "modeling_flax_bert.py", "configuration_bert.py"}, - ) - self.assertEqual( - set(filter_framework_files(files, ["pt", "flax"])), - {"modeling_bert.py", "modeling_flax_bert.py", "configuration_bert.py"}, - ) - - def test_get_model_files(self): - # BERT - bert_files = get_model_files("bert") - - doc_file = str(Path(bert_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/bert.md") - - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in bert_files["model_files"]} - self.assertEqual(model_files, BERT_MODEL_FILES) - - self.assertEqual(bert_files["module_name"], "bert") - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in bert_files["test_files"]} - bert_test_files = { - "tests/models/bert/test_tokenization_bert.py", - "tests/models/bert/test_modeling_bert.py", - "tests/models/bert/test_modeling_tf_bert.py", - "tests/models/bert/test_modeling_flax_bert.py", - } - self.assertEqual(test_files, bert_test_files) - - # VIT - vit_files = get_model_files("vit") - doc_file = str(Path(vit_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/vit.md") - - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in vit_files["model_files"]} - self.assertEqual(model_files, VIT_MODEL_FILES) - - self.assertEqual(vit_files["module_name"], "vit") - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in vit_files["test_files"]} - vit_test_files = { - "tests/models/vit/test_image_processing_vit.py", - "tests/models/vit/test_modeling_vit.py", - "tests/models/vit/test_modeling_tf_vit.py", - "tests/models/vit/test_modeling_flax_vit.py", - } - self.assertEqual(test_files, vit_test_files) - - # Wav2Vec2 - wav2vec2_files = get_model_files("wav2vec2") - doc_file = str(Path(wav2vec2_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/wav2vec2.md") - - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in wav2vec2_files["model_files"]} - self.assertEqual(model_files, WAV2VEC2_MODEL_FILES) - - self.assertEqual(wav2vec2_files["module_name"], "wav2vec2") - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in wav2vec2_files["test_files"]} - wav2vec2_test_files = { - "tests/models/wav2vec2/test_feature_extraction_wav2vec2.py", - "tests/models/wav2vec2/test_modeling_wav2vec2.py", - "tests/models/wav2vec2/test_modeling_tf_wav2vec2.py", - "tests/models/wav2vec2/test_modeling_flax_wav2vec2.py", - "tests/models/wav2vec2/test_processor_wav2vec2.py", - "tests/models/wav2vec2/test_tokenization_wav2vec2.py", - } - self.assertEqual(test_files, wav2vec2_test_files) - - def test_get_model_files_only_pt(self): - # BERT - bert_files = get_model_files("bert", frameworks=["pt"]) - - doc_file = str(Path(bert_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/bert.md") - - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in bert_files["model_files"]} - bert_model_files = BERT_MODEL_FILES - { - "src/transformers/models/bert/modeling_tf_bert.py", - "src/transformers/models/bert/modeling_flax_bert.py", - } - self.assertEqual(model_files, bert_model_files) - - self.assertEqual(bert_files["module_name"], "bert") - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in bert_files["test_files"]} - bert_test_files = { - "tests/models/bert/test_tokenization_bert.py", - "tests/models/bert/test_modeling_bert.py", - } - self.assertEqual(test_files, bert_test_files) - - # VIT - vit_files = get_model_files("vit", frameworks=["pt"]) - doc_file = str(Path(vit_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/vit.md") - - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in vit_files["model_files"]} - vit_model_files = VIT_MODEL_FILES - { - "src/transformers/models/vit/modeling_tf_vit.py", - "src/transformers/models/vit/modeling_flax_vit.py", - } - self.assertEqual(model_files, vit_model_files) - - self.assertEqual(vit_files["module_name"], "vit") - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in vit_files["test_files"]} - vit_test_files = { - "tests/models/vit/test_image_processing_vit.py", - "tests/models/vit/test_modeling_vit.py", - } - self.assertEqual(test_files, vit_test_files) - - # Wav2Vec2 - wav2vec2_files = get_model_files("wav2vec2", frameworks=["pt"]) - doc_file = str(Path(wav2vec2_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/wav2vec2.md") - - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in wav2vec2_files["model_files"]} - wav2vec2_model_files = WAV2VEC2_MODEL_FILES - { - "src/transformers/models/wav2vec2/modeling_tf_wav2vec2.py", - "src/transformers/models/wav2vec2/modeling_flax_wav2vec2.py", - } - self.assertEqual(model_files, wav2vec2_model_files) - - self.assertEqual(wav2vec2_files["module_name"], "wav2vec2") - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in wav2vec2_files["test_files"]} - wav2vec2_test_files = { - "tests/models/wav2vec2/test_feature_extraction_wav2vec2.py", - "tests/models/wav2vec2/test_modeling_wav2vec2.py", - "tests/models/wav2vec2/test_processor_wav2vec2.py", - "tests/models/wav2vec2/test_tokenization_wav2vec2.py", - } - self.assertEqual(test_files, wav2vec2_test_files) - - def test_get_model_files_tf_and_flax(self): - # BERT - bert_files = get_model_files("bert", frameworks=["tf", "flax"]) - - doc_file = str(Path(bert_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/bert.md") - - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in bert_files["model_files"]} - bert_model_files = BERT_MODEL_FILES - {"src/transformers/models/bert/modeling_bert.py"} - self.assertEqual(model_files, bert_model_files) - - self.assertEqual(bert_files["module_name"], "bert") - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in bert_files["test_files"]} - bert_test_files = { - "tests/models/bert/test_tokenization_bert.py", - "tests/models/bert/test_modeling_tf_bert.py", - "tests/models/bert/test_modeling_flax_bert.py", - } - self.assertEqual(test_files, bert_test_files) - - # VIT - vit_files = get_model_files("vit", frameworks=["tf", "flax"]) - doc_file = str(Path(vit_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/vit.md") - - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in vit_files["model_files"]} - vit_model_files = VIT_MODEL_FILES - {"src/transformers/models/vit/modeling_vit.py"} - self.assertEqual(model_files, vit_model_files) - - self.assertEqual(vit_files["module_name"], "vit") - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in vit_files["test_files"]} - vit_test_files = { - "tests/models/vit/test_image_processing_vit.py", - "tests/models/vit/test_modeling_tf_vit.py", - "tests/models/vit/test_modeling_flax_vit.py", - } - self.assertEqual(test_files, vit_test_files) - - # Wav2Vec2 - wav2vec2_files = get_model_files("wav2vec2", frameworks=["tf", "flax"]) - doc_file = str(Path(wav2vec2_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/wav2vec2.md") - - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in wav2vec2_files["model_files"]} - wav2vec2_model_files = WAV2VEC2_MODEL_FILES - {"src/transformers/models/wav2vec2/modeling_wav2vec2.py"} - self.assertEqual(model_files, wav2vec2_model_files) - - self.assertEqual(wav2vec2_files["module_name"], "wav2vec2") - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in wav2vec2_files["test_files"]} - wav2vec2_test_files = { - "tests/models/wav2vec2/test_feature_extraction_wav2vec2.py", - "tests/models/wav2vec2/test_modeling_tf_wav2vec2.py", - "tests/models/wav2vec2/test_modeling_flax_wav2vec2.py", - "tests/models/wav2vec2/test_processor_wav2vec2.py", - "tests/models/wav2vec2/test_tokenization_wav2vec2.py", - } - self.assertEqual(test_files, wav2vec2_test_files) - - def test_find_base_model_checkpoint(self): - self.assertEqual(find_base_model_checkpoint("bert"), "bert-base-uncased") - self.assertEqual(find_base_model_checkpoint("gpt2"), "gpt2") - - def test_retrieve_model_classes(self): - gpt_classes = {k: set(v) for k, v in retrieve_model_classes("gpt2").items()} - expected_gpt_classes = { - "pt": {"GPT2ForTokenClassification", "GPT2Model", "GPT2LMHeadModel", "GPT2ForSequenceClassification"}, - "tf": {"TFGPT2Model", "TFGPT2ForSequenceClassification", "TFGPT2LMHeadModel"}, - "flax": {"FlaxGPT2Model", "FlaxGPT2LMHeadModel"}, - } - self.assertEqual(gpt_classes, expected_gpt_classes) - - del expected_gpt_classes["flax"] - gpt_classes = {k: set(v) for k, v in retrieve_model_classes("gpt2", frameworks=["pt", "tf"]).items()} - self.assertEqual(gpt_classes, expected_gpt_classes) - - del expected_gpt_classes["pt"] - gpt_classes = {k: set(v) for k, v in retrieve_model_classes("gpt2", frameworks=["tf"]).items()} - self.assertEqual(gpt_classes, expected_gpt_classes) - - def test_retrieve_info_for_model_with_bert(self): - bert_info = retrieve_info_for_model("bert") - bert_classes = [ - "BertForTokenClassification", - "BertForQuestionAnswering", - "BertForNextSentencePrediction", - "BertForSequenceClassification", - "BertForMaskedLM", - "BertForMultipleChoice", - "BertModel", - "BertForPreTraining", - "BertLMHeadModel", - ] - expected_model_classes = { - "pt": set(bert_classes), - "tf": {f"TF{m}" for m in bert_classes}, - "flax": {f"Flax{m}" for m in bert_classes[:-1] + ["BertForCausalLM"]}, - } - - self.assertEqual(set(bert_info["frameworks"]), {"pt", "tf", "flax"}) - model_classes = {k: set(v) for k, v in bert_info["model_classes"].items()} - self.assertEqual(model_classes, expected_model_classes) - - all_bert_files = bert_info["model_files"] - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in all_bert_files["model_files"]} - self.assertEqual(model_files, BERT_MODEL_FILES) - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in all_bert_files["test_files"]} - bert_test_files = { - "tests/models/bert/test_tokenization_bert.py", - "tests/models/bert/test_modeling_bert.py", - "tests/models/bert/test_modeling_tf_bert.py", - "tests/models/bert/test_modeling_flax_bert.py", - } - self.assertEqual(test_files, bert_test_files) - - doc_file = str(Path(all_bert_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/bert.md") - - self.assertEqual(all_bert_files["module_name"], "bert") - - bert_model_patterns = bert_info["model_patterns"] - self.assertEqual(bert_model_patterns.model_name, "BERT") - self.assertEqual(bert_model_patterns.checkpoint, "bert-base-uncased") - self.assertEqual(bert_model_patterns.model_type, "bert") - self.assertEqual(bert_model_patterns.model_lower_cased, "bert") - self.assertEqual(bert_model_patterns.model_camel_cased, "Bert") - self.assertEqual(bert_model_patterns.model_upper_cased, "BERT") - self.assertEqual(bert_model_patterns.config_class, "BertConfig") - self.assertEqual(bert_model_patterns.tokenizer_class, "BertTokenizer") - self.assertIsNone(bert_model_patterns.feature_extractor_class) - self.assertIsNone(bert_model_patterns.processor_class) - - def test_retrieve_info_for_model_pt_tf_with_bert(self): - bert_info = retrieve_info_for_model("bert", frameworks=["pt", "tf"]) - bert_classes = [ - "BertForTokenClassification", - "BertForQuestionAnswering", - "BertForNextSentencePrediction", - "BertForSequenceClassification", - "BertForMaskedLM", - "BertForMultipleChoice", - "BertModel", - "BertForPreTraining", - "BertLMHeadModel", - ] - expected_model_classes = {"pt": set(bert_classes), "tf": {f"TF{m}" for m in bert_classes}} - - self.assertEqual(set(bert_info["frameworks"]), {"pt", "tf"}) - model_classes = {k: set(v) for k, v in bert_info["model_classes"].items()} - self.assertEqual(model_classes, expected_model_classes) - - all_bert_files = bert_info["model_files"] - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in all_bert_files["model_files"]} - bert_model_files = BERT_MODEL_FILES - {"src/transformers/models/bert/modeling_flax_bert.py"} - self.assertEqual(model_files, bert_model_files) - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in all_bert_files["test_files"]} - bert_test_files = { - "tests/models/bert/test_tokenization_bert.py", - "tests/models/bert/test_modeling_bert.py", - "tests/models/bert/test_modeling_tf_bert.py", - } - self.assertEqual(test_files, bert_test_files) - - doc_file = str(Path(all_bert_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/bert.md") - - self.assertEqual(all_bert_files["module_name"], "bert") - - bert_model_patterns = bert_info["model_patterns"] - self.assertEqual(bert_model_patterns.model_name, "BERT") - self.assertEqual(bert_model_patterns.checkpoint, "bert-base-uncased") - self.assertEqual(bert_model_patterns.model_type, "bert") - self.assertEqual(bert_model_patterns.model_lower_cased, "bert") - self.assertEqual(bert_model_patterns.model_camel_cased, "Bert") - self.assertEqual(bert_model_patterns.model_upper_cased, "BERT") - self.assertEqual(bert_model_patterns.config_class, "BertConfig") - self.assertEqual(bert_model_patterns.tokenizer_class, "BertTokenizer") - self.assertIsNone(bert_model_patterns.feature_extractor_class) - self.assertIsNone(bert_model_patterns.processor_class) - - def test_retrieve_info_for_model_with_vit(self): - vit_info = retrieve_info_for_model("vit") - vit_classes = ["ViTForImageClassification", "ViTModel"] - pt_only_classes = ["ViTForMaskedImageModeling"] - expected_model_classes = { - "pt": set(vit_classes + pt_only_classes), - "tf": {f"TF{m}" for m in vit_classes}, - "flax": {f"Flax{m}" for m in vit_classes}, - } - - self.assertEqual(set(vit_info["frameworks"]), {"pt", "tf", "flax"}) - model_classes = {k: set(v) for k, v in vit_info["model_classes"].items()} - self.assertEqual(model_classes, expected_model_classes) - - all_vit_files = vit_info["model_files"] - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in all_vit_files["model_files"]} - self.assertEqual(model_files, VIT_MODEL_FILES) - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in all_vit_files["test_files"]} - vit_test_files = { - "tests/models/vit/test_image_processing_vit.py", - "tests/models/vit/test_modeling_vit.py", - "tests/models/vit/test_modeling_tf_vit.py", - "tests/models/vit/test_modeling_flax_vit.py", - } - self.assertEqual(test_files, vit_test_files) - - doc_file = str(Path(all_vit_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/vit.md") - - self.assertEqual(all_vit_files["module_name"], "vit") - - vit_model_patterns = vit_info["model_patterns"] - self.assertEqual(vit_model_patterns.model_name, "ViT") - self.assertEqual(vit_model_patterns.checkpoint, "google/vit-base-patch16-224-in21k") - self.assertEqual(vit_model_patterns.model_type, "vit") - self.assertEqual(vit_model_patterns.model_lower_cased, "vit") - self.assertEqual(vit_model_patterns.model_camel_cased, "ViT") - self.assertEqual(vit_model_patterns.model_upper_cased, "VIT") - self.assertEqual(vit_model_patterns.config_class, "ViTConfig") - self.assertEqual(vit_model_patterns.feature_extractor_class, "ViTFeatureExtractor") - self.assertEqual(vit_model_patterns.image_processor_class, "ViTImageProcessor") - self.assertIsNone(vit_model_patterns.tokenizer_class) - self.assertIsNone(vit_model_patterns.processor_class) - - def test_retrieve_info_for_model_with_wav2vec2(self): - wav2vec2_info = retrieve_info_for_model("wav2vec2") - wav2vec2_classes = [ - "Wav2Vec2Model", - "Wav2Vec2ForPreTraining", - "Wav2Vec2ForAudioFrameClassification", - "Wav2Vec2ForCTC", - "Wav2Vec2ForMaskedLM", - "Wav2Vec2ForSequenceClassification", - "Wav2Vec2ForXVector", - ] - expected_model_classes = { - "pt": set(wav2vec2_classes), - "tf": {f"TF{m}" for m in wav2vec2_classes[:1]}, - "flax": {f"Flax{m}" for m in wav2vec2_classes[:2]}, - } - - self.assertEqual(set(wav2vec2_info["frameworks"]), {"pt", "tf", "flax"}) - model_classes = {k: set(v) for k, v in wav2vec2_info["model_classes"].items()} - self.assertEqual(model_classes, expected_model_classes) - - all_wav2vec2_files = wav2vec2_info["model_files"] - model_files = {str(Path(f).relative_to(REPO_PATH)) for f in all_wav2vec2_files["model_files"]} - self.assertEqual(model_files, WAV2VEC2_MODEL_FILES) - - test_files = {str(Path(f).relative_to(REPO_PATH)) for f in all_wav2vec2_files["test_files"]} - wav2vec2_test_files = { - "tests/models/wav2vec2/test_feature_extraction_wav2vec2.py", - "tests/models/wav2vec2/test_modeling_wav2vec2.py", - "tests/models/wav2vec2/test_modeling_tf_wav2vec2.py", - "tests/models/wav2vec2/test_modeling_flax_wav2vec2.py", - "tests/models/wav2vec2/test_processor_wav2vec2.py", - "tests/models/wav2vec2/test_tokenization_wav2vec2.py", - } - self.assertEqual(test_files, wav2vec2_test_files) - - doc_file = str(Path(all_wav2vec2_files["doc_file"]).relative_to(REPO_PATH)) - self.assertEqual(doc_file, "docs/source/en/model_doc/wav2vec2.md") - - self.assertEqual(all_wav2vec2_files["module_name"], "wav2vec2") - - wav2vec2_model_patterns = wav2vec2_info["model_patterns"] - self.assertEqual(wav2vec2_model_patterns.model_name, "Wav2Vec2") - self.assertEqual(wav2vec2_model_patterns.checkpoint, "facebook/wav2vec2-base-960h") - self.assertEqual(wav2vec2_model_patterns.model_type, "wav2vec2") - self.assertEqual(wav2vec2_model_patterns.model_lower_cased, "wav2vec2") - self.assertEqual(wav2vec2_model_patterns.model_camel_cased, "Wav2Vec2") - self.assertEqual(wav2vec2_model_patterns.model_upper_cased, "WAV_2_VEC_2") - self.assertEqual(wav2vec2_model_patterns.config_class, "Wav2Vec2Config") - self.assertEqual(wav2vec2_model_patterns.feature_extractor_class, "Wav2Vec2FeatureExtractor") - self.assertEqual(wav2vec2_model_patterns.processor_class, "Wav2Vec2Processor") - self.assertEqual(wav2vec2_model_patterns.tokenizer_class, "Wav2Vec2CTCTokenizer") - - def test_clean_frameworks_in_init_with_gpt(self): - test_init = """ -from typing import TYPE_CHECKING - -from ...utils import _LazyModule, is_flax_available, is_tf_available, is_tokenizers_available, is_torch_available - -_import_structure = { - "configuration_gpt2": ["GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP", "GPT2Config", "GPT2OnnxConfig"], - "tokenization_gpt2": ["GPT2Tokenizer"], -} - -try: - if not is_tokenizers_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["tokenization_gpt2_fast"] = ["GPT2TokenizerFast"] - -try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_gpt2"] = ["GPT2Model"] - -try: - if not is_tf_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_tf_gpt2"] = ["TFGPT2Model"] - -try: - if not is_flax_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_flax_gpt2"] = ["FlaxGPT2Model"] - -if TYPE_CHECKING: - from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config, GPT2OnnxConfig - from .tokenization_gpt2 import GPT2Tokenizer - - try: - if not is_tokenizers_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .tokenization_gpt2_fast import GPT2TokenizerFast - - try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_gpt2 import GPT2Model - - try: - if not is_tf_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_tf_gpt2 import TFGPT2Model - - try: - if not is_flax_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_flax_gpt2 import FlaxGPT2Model - -else: - import sys - - sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure) -""" - - init_no_tokenizer = """ -from typing import TYPE_CHECKING - -from ...utils import _LazyModule, is_flax_available, is_tf_available, is_torch_available - -_import_structure = { - "configuration_gpt2": ["GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP", "GPT2Config", "GPT2OnnxConfig"], -} - -try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_gpt2"] = ["GPT2Model"] - -try: - if not is_tf_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_tf_gpt2"] = ["TFGPT2Model"] - -try: - if not is_flax_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_flax_gpt2"] = ["FlaxGPT2Model"] - -if TYPE_CHECKING: - from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config, GPT2OnnxConfig - - try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_gpt2 import GPT2Model - - try: - if not is_tf_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_tf_gpt2 import TFGPT2Model - - try: - if not is_flax_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_flax_gpt2 import FlaxGPT2Model - -else: - import sys - - sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure) -""" - - init_pt_only = """ -from typing import TYPE_CHECKING - -from ...utils import _LazyModule, is_tokenizers_available, is_torch_available - -_import_structure = { - "configuration_gpt2": ["GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP", "GPT2Config", "GPT2OnnxConfig"], - "tokenization_gpt2": ["GPT2Tokenizer"], -} - -try: - if not is_tokenizers_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["tokenization_gpt2_fast"] = ["GPT2TokenizerFast"] - -try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_gpt2"] = ["GPT2Model"] - -if TYPE_CHECKING: - from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config, GPT2OnnxConfig - from .tokenization_gpt2 import GPT2Tokenizer - - try: - if not is_tokenizers_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .tokenization_gpt2_fast import GPT2TokenizerFast - - try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_gpt2 import GPT2Model - -else: - import sys - - sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure) -""" - - init_pt_only_no_tokenizer = """ -from typing import TYPE_CHECKING - -from ...utils import _LazyModule, is_torch_available - -_import_structure = { - "configuration_gpt2": ["GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP", "GPT2Config", "GPT2OnnxConfig"], -} - -try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_gpt2"] = ["GPT2Model"] - -if TYPE_CHECKING: - from .configuration_gpt2 import GPT2_PRETRAINED_CONFIG_ARCHIVE_MAP, GPT2Config, GPT2OnnxConfig - - try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_gpt2 import GPT2Model - -else: - import sys - - sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure) -""" - - with tempfile.TemporaryDirectory() as tmp_dir: - file_name = os.path.join(tmp_dir, "../__init__.py") - - self.init_file(file_name, test_init) - clean_frameworks_in_init(file_name, keep_processing=False) - self.check_result(file_name, init_no_tokenizer) - - self.init_file(file_name, test_init) - clean_frameworks_in_init(file_name, frameworks=["pt"]) - self.check_result(file_name, init_pt_only) - - self.init_file(file_name, test_init) - clean_frameworks_in_init(file_name, frameworks=["pt"], keep_processing=False) - self.check_result(file_name, init_pt_only_no_tokenizer) - - def test_clean_frameworks_in_init_with_vit(self): - test_init = """ -from typing import TYPE_CHECKING - -from ...utils import _LazyModule, is_flax_available, is_tf_available, is_torch_available, is_vision_available - -_import_structure = { - "configuration_vit": ["VIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViTConfig"], -} - -try: - if not is_vision_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["image_processing_vit"] = ["ViTImageProcessor"] - -try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_vit"] = ["ViTModel"] - -try: - if not is_tf_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_tf_vit"] = ["TFViTModel"] - -try: - if not is_flax_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_flax_vit"] = ["FlaxViTModel"] - -if TYPE_CHECKING: - from .configuration_vit import VIT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViTConfig - - try: - if not is_vision_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .image_processing_vit import ViTImageProcessor - - try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_vit import ViTModel - - try: - if not is_tf_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_tf_vit import TFViTModel - - try: - if not is_flax_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_flax_vit import FlaxViTModel - -else: - import sys - - sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure) -""" - - init_no_feature_extractor = """ -from typing import TYPE_CHECKING - -from ...utils import _LazyModule, is_flax_available, is_tf_available, is_torch_available - -_import_structure = { - "configuration_vit": ["VIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViTConfig"], -} - -try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_vit"] = ["ViTModel"] - -try: - if not is_tf_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_tf_vit"] = ["TFViTModel"] - -try: - if not is_flax_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_flax_vit"] = ["FlaxViTModel"] - -if TYPE_CHECKING: - from .configuration_vit import VIT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViTConfig - - try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_vit import ViTModel - - try: - if not is_tf_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_tf_vit import TFViTModel - - try: - if not is_flax_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_flax_vit import FlaxViTModel - -else: - import sys - - sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure) -""" - - init_pt_only = """ -from typing import TYPE_CHECKING - -from ...utils import _LazyModule, is_torch_available, is_vision_available - -_import_structure = { - "configuration_vit": ["VIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViTConfig"], -} - -try: - if not is_vision_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["image_processing_vit"] = ["ViTImageProcessor"] - -try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_vit"] = ["ViTModel"] - -if TYPE_CHECKING: - from .configuration_vit import VIT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViTConfig - - try: - if not is_vision_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .image_processing_vit import ViTImageProcessor - - try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_vit import ViTModel - -else: - import sys - - sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure) -""" - - init_pt_only_no_feature_extractor = """ -from typing import TYPE_CHECKING - -from ...utils import _LazyModule, is_torch_available - -_import_structure = { - "configuration_vit": ["VIT_PRETRAINED_CONFIG_ARCHIVE_MAP", "ViTConfig"], -} - -try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() -except OptionalDependencyNotAvailable: - pass -else: - _import_structure["modeling_vit"] = ["ViTModel"] - -if TYPE_CHECKING: - from .configuration_vit import VIT_PRETRAINED_CONFIG_ARCHIVE_MAP, ViTConfig - - try: - if not is_torch_available(): - raise OptionalDependencyNotAvailable() - except OptionalDependencyNotAvailable: - pass - else: - from .modeling_vit import ViTModel - -else: - import sys - - sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure) -""" - - with tempfile.TemporaryDirectory() as tmp_dir: - file_name = os.path.join(tmp_dir, "../__init__.py") - - self.init_file(file_name, test_init) - clean_frameworks_in_init(file_name, keep_processing=False) - self.check_result(file_name, init_no_feature_extractor) - - self.init_file(file_name, test_init) - clean_frameworks_in_init(file_name, frameworks=["pt"]) - self.check_result(file_name, init_pt_only) - - self.init_file(file_name, test_init) - clean_frameworks_in_init(file_name, frameworks=["pt"], keep_processing=False) - self.check_result(file_name, init_pt_only_no_feature_extractor) - - def test_duplicate_doc_file(self): - test_doc = """ -# GPT2 - -## Overview - -Overview of the model. - -## GPT2Config - -[[autodoc]] GPT2Config - -## GPT2Tokenizer - -[[autodoc]] GPT2Tokenizer - - save_vocabulary - -## GPT2TokenizerFast - -[[autodoc]] GPT2TokenizerFast - -## GPT2 specific outputs - -[[autodoc]] models.gpt2.modeling_gpt2.GPT2DoubleHeadsModelOutput - -[[autodoc]] models.gpt2.modeling_tf_gpt2.TFGPT2DoubleHeadsModelOutput - -## GPT2Model - -[[autodoc]] GPT2Model - - forward - -## TFGPT2Model - -[[autodoc]] TFGPT2Model - - call - -## FlaxGPT2Model - -[[autodoc]] FlaxGPT2Model - - __call__ - -""" - test_new_doc = """ -# GPT-New New - -## Overview - -The GPT-New New model was proposed in [ ]( ) by . - - -The abstract from the paper is the following: - -* * - -Tips: - - - -This model was contributed by [INSERT YOUR HF USERNAME HERE](https://huggingface.co/ ). -The original code can be found [here]( ). - - -## GPTNewNewConfig - -[[autodoc]] GPTNewNewConfig - -## GPTNewNewTokenizer - -[[autodoc]] GPTNewNewTokenizer - - save_vocabulary - -## GPTNewNewTokenizerFast - -[[autodoc]] GPTNewNewTokenizerFast - -## GPTNewNew specific outputs - -[[autodoc]] models.gpt_new_new.modeling_gpt_new_new.GPTNewNewDoubleHeadsModelOutput - -[[autodoc]] models.gpt_new_new.modeling_tf_gpt_new_new.TFGPTNewNewDoubleHeadsModelOutput - -## GPTNewNewModel - -[[autodoc]] GPTNewNewModel - - forward - -## TFGPTNewNewModel - -[[autodoc]] TFGPTNewNewModel - - call - -## FlaxGPTNewNewModel - -[[autodoc]] FlaxGPTNewNewModel - - __call__ - -""" - - with tempfile.TemporaryDirectory() as tmp_dir: - doc_file = os.path.join(tmp_dir, "gpt2.md") - new_doc_file = os.path.join(tmp_dir, "gpt-new-new.md") - - gpt2_model_patterns = ModelPatterns("GPT2", "gpt2", tokenizer_class="GPT2Tokenizer") - new_model_patterns = ModelPatterns( - "GPT-New New", "huggingface/gpt-new-new", tokenizer_class="GPTNewNewTokenizer" - ) - - self.init_file(doc_file, test_doc) - duplicate_doc_file(doc_file, gpt2_model_patterns, new_model_patterns) - self.check_result(new_doc_file, test_new_doc) - - test_new_doc_pt_only = test_new_doc.replace( - """ -## TFGPTNewNewModel - -[[autodoc]] TFGPTNewNewModel - - call - -## FlaxGPTNewNewModel - -[[autodoc]] FlaxGPTNewNewModel - - __call__ - -""", - "", - ) - self.init_file(doc_file, test_doc) - duplicate_doc_file(doc_file, gpt2_model_patterns, new_model_patterns, frameworks=["pt"]) - self.check_result(new_doc_file, test_new_doc_pt_only) - - test_new_doc_no_tok = test_new_doc.replace( - """ -## GPTNewNewTokenizer - -[[autodoc]] GPTNewNewTokenizer - - save_vocabulary - -## GPTNewNewTokenizerFast - -[[autodoc]] GPTNewNewTokenizerFast -""", - "", - ) - new_model_patterns = ModelPatterns( - "GPT-New New", "huggingface/gpt-new-new", tokenizer_class="GPT2Tokenizer" - ) - self.init_file(doc_file, test_doc) - duplicate_doc_file(doc_file, gpt2_model_patterns, new_model_patterns) - print(test_new_doc_no_tok) - self.check_result(new_doc_file, test_new_doc_no_tok) - - test_new_doc_pt_only_no_tok = test_new_doc_no_tok.replace( - """ -## TFGPTNewNewModel - -[[autodoc]] TFGPTNewNewModel - - call - -## FlaxGPTNewNewModel - -[[autodoc]] FlaxGPTNewNewModel - - __call__ - -""", - "", - ) - self.init_file(doc_file, test_doc) - duplicate_doc_file(doc_file, gpt2_model_patterns, new_model_patterns, frameworks=["pt"]) - self.check_result(new_doc_file, test_new_doc_pt_only_no_tok) diff --git a/tests/transformers/tests/utils/test_audio_utils.py b/tests/transformers/tests/utils/test_audio_utils.py deleted file mode 100644 index f81a0dffd5..0000000000 --- a/tests/transformers/tests/utils/test_audio_utils.py +++ /dev/null @@ -1,651 +0,0 @@ -# coding=utf-8 -# Copyright 2023 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import unittest - -import numpy as np -import pytest -from transformers.audio_utils import ( - amplitude_to_db, - hertz_to_mel, - mel_filter_bank, - mel_to_hertz, - power_to_db, - spectrogram, - window_function, -) - - -class AudioUtilsFunctionTester(unittest.TestCase): - def test_hertz_to_mel(self): - self.assertEqual(hertz_to_mel(0.0), 0.0) - self.assertAlmostEqual(hertz_to_mel(100), 150.48910241) - - inputs = np.array([100, 200]) - expected = np.array([150.48910241, 283.22989816]) - self.assertTrue(np.allclose(hertz_to_mel(inputs), expected)) - - self.assertEqual(hertz_to_mel(0.0, "slaney"), 0.0) - self.assertEqual(hertz_to_mel(100, "slaney"), 1.5) - - inputs = np.array([60, 100, 200, 1000, 1001, 2000]) - expected = np.array([0.9, 1.5, 3.0, 15.0, 15.01453781, 25.08188016]) - self.assertTrue(np.allclose(hertz_to_mel(inputs, "slaney"), expected)) - - with pytest.raises(ValueError): - hertz_to_mel(100, mel_scale=None) - - def test_mel_to_hertz(self): - self.assertEqual(mel_to_hertz(0.0), 0.0) - self.assertAlmostEqual(mel_to_hertz(150.48910241), 100) - - inputs = np.array([150.48910241, 283.22989816]) - expected = np.array([100, 200]) - self.assertTrue(np.allclose(mel_to_hertz(inputs), expected)) - - self.assertEqual(mel_to_hertz(0.0, "slaney"), 0.0) - self.assertEqual(mel_to_hertz(1.5, "slaney"), 100) - - inputs = np.array([0.9, 1.5, 3.0, 15.0, 15.01453781, 25.08188016]) - expected = np.array([60, 100, 200, 1000, 1001, 2000]) - self.assertTrue(np.allclose(mel_to_hertz(inputs, "slaney"), expected)) - - with pytest.raises(ValueError): - mel_to_hertz(100, mel_scale=None) - - def test_mel_filter_bank_shape(self): - mel_filters = mel_filter_bank( - num_frequency_bins=513, - num_mel_filters=13, - min_frequency=100, - max_frequency=4000, - sampling_rate=16000, - norm=None, - mel_scale="htk", - ) - self.assertEqual(mel_filters.shape, (513, 13)) - - mel_filters = mel_filter_bank( - num_frequency_bins=513, - num_mel_filters=13, - min_frequency=100, - max_frequency=4000, - sampling_rate=16000, - norm="slaney", - mel_scale="slaney", - ) - self.assertEqual(mel_filters.shape, (513, 13)) - - def test_mel_filter_bank_htk(self): - mel_filters = mel_filter_bank( - num_frequency_bins=16, - num_mel_filters=4, - min_frequency=0, - max_frequency=2000, - sampling_rate=4000, - norm=None, - mel_scale="htk", - ) - # fmt: off - expected = np.array([ - [0.0 , 0.0 , 0.0 , 0.0 ], - [0.61454786, 0.0 , 0.0 , 0.0 ], - [0.82511046, 0.17488954, 0.0 , 0.0 ], - [0.35597035, 0.64402965, 0.0 , 0.0 ], - [0.0 , 0.91360726, 0.08639274, 0.0 ], - [0.0 , 0.55547007, 0.44452993, 0.0 ], - [0.0 , 0.19733289, 0.80266711, 0.0 ], - [0.0 , 0.0 , 0.87724349, 0.12275651], - [0.0 , 0.0 , 0.6038449 , 0.3961551 ], - [0.0 , 0.0 , 0.33044631, 0.66955369], - [0.0 , 0.0 , 0.05704771, 0.94295229], - [0.0 , 0.0 , 0.0 , 0.83483975], - [0.0 , 0.0 , 0.0 , 0.62612982], - [0.0 , 0.0 , 0.0 , 0.41741988], - [0.0 , 0.0 , 0.0 , 0.20870994], - [0.0 , 0.0 , 0.0 , 0.0 ] - ]) - # fmt: on - self.assertTrue(np.allclose(mel_filters, expected)) - - def test_mel_filter_bank_slaney(self): - mel_filters = mel_filter_bank( - num_frequency_bins=16, - num_mel_filters=4, - min_frequency=0, - max_frequency=2000, - sampling_rate=4000, - norm=None, - mel_scale="slaney", - ) - # fmt: off - expected = np.array([ - [0.0 , 0.0 , 0.0 , 0.0 ], - [0.39869419, 0.0 , 0.0 , 0.0 ], - [0.79738839, 0.0 , 0.0 , 0.0 ], - [0.80391742, 0.19608258, 0.0 , 0.0 ], - [0.40522322, 0.59477678, 0.0 , 0.0 ], - [0.00652903, 0.99347097, 0.0 , 0.0 ], - [0.0 , 0.60796161, 0.39203839, 0.0 ], - [0.0 , 0.20939631, 0.79060369, 0.0 ], - [0.0 , 0.0 , 0.84685344, 0.15314656], - [0.0 , 0.0 , 0.52418477, 0.47581523], - [0.0 , 0.0 , 0.2015161 , 0.7984839 ], - [0.0 , 0.0 , 0.0 , 0.9141874 ], - [0.0 , 0.0 , 0.0 , 0.68564055], - [0.0 , 0.0 , 0.0 , 0.4570937 ], - [0.0 , 0.0 , 0.0 , 0.22854685], - [0.0 , 0.0 , 0.0 , 0.0 ] - ]) - # fmt: on - self.assertTrue(np.allclose(mel_filters, expected)) - - def test_mel_filter_bank_slaney_norm(self): - mel_filters = mel_filter_bank( - num_frequency_bins=16, - num_mel_filters=4, - min_frequency=0, - max_frequency=2000, - sampling_rate=4000, - norm="slaney", - mel_scale="slaney", - ) - # fmt: off - expected = np.array([ - [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], - [1.19217795e-03, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], - [2.38435591e-03, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00], - [2.40387905e-03, 5.86232616e-04, 0.00000000e+00, 0.00000000e+00], - [1.21170110e-03, 1.77821783e-03, 0.00000000e+00, 0.00000000e+00], - [1.95231437e-05, 2.97020305e-03, 0.00000000e+00, 0.00000000e+00], - [0.00000000e+00, 1.81763684e-03, 1.04857612e-03, 0.00000000e+00], - [0.00000000e+00, 6.26036972e-04, 2.11460963e-03, 0.00000000e+00], - [0.00000000e+00, 0.00000000e+00, 2.26505954e-03, 3.07332945e-04], - [0.00000000e+00, 0.00000000e+00, 1.40202503e-03, 9.54861093e-04], - [0.00000000e+00, 0.00000000e+00, 5.38990521e-04, 1.60238924e-03], - [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 1.83458185e-03], - [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 1.37593638e-03], - [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 9.17290923e-04], - [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 4.58645462e-04], - [0.00000000e+00, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00] - ]) - # fmt: on - self.assertTrue(np.allclose(mel_filters, expected)) - - def test_window_function(self): - window = window_function(16, "hann") - self.assertEqual(len(window), 16) - - # fmt: off - expected = np.array([ - 0.0, 0.03806023, 0.14644661, 0.30865828, 0.5, 0.69134172, 0.85355339, 0.96193977, - 1.0, 0.96193977, 0.85355339, 0.69134172, 0.5, 0.30865828, 0.14644661, 0.03806023, - ]) - # fmt: on - self.assertTrue(np.allclose(window, expected)) - - def _load_datasamples(self, num_samples): - from datasets import load_dataset - - ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation") - speech_samples = ds.sort("id").select(range(num_samples))[:num_samples]["audio"] - return [x["array"] for x in speech_samples] - - def test_spectrogram_impulse(self): - waveform = np.zeros(40) - waveform[9] = 1.0 # impulse shifted in time - - spec = spectrogram( - waveform, - window_function(12, "hann", frame_length=16), - frame_length=16, - hop_length=4, - power=1.0, - center=True, - pad_mode="reflect", - onesided=True, - ) - self.assertEqual(spec.shape, (9, 11)) - - expected = np.array([[0.0, 0.0669873, 0.9330127, 0.5, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0]]) - self.assertTrue(np.allclose(spec, expected)) - - def test_spectrogram_integration_test(self): - waveform = self._load_datasamples(1)[0] - - spec = spectrogram( - waveform, - window_function(400, "hann", frame_length=512), - frame_length=512, - hop_length=128, - power=1.0, - center=True, - pad_mode="reflect", - onesided=True, - ) - self.assertEqual(spec.shape, (257, 732)) - - # fmt: off - expected = np.array([ - 0.02464888, 0.04648664, 0.05872392, 0.02311783, 0.0327175 , - 0.02433643, 0.01198814, 0.02055709, 0.01559287, 0.01394357, - 0.01299037, 0.01728045, 0.0254554 , 0.02486533, 0.02011792, - 0.01755333, 0.02100457, 0.02337024, 0.01436963, 0.01464558, - 0.0211017 , 0.0193489 , 0.01272165, 0.01858462, 0.03722598, - 0.0456542 , 0.03281558, 0.00620586, 0.02226466, 0.03618042, - 0.03508182, 0.02271432, 0.01051649, 0.01225771, 0.02315293, - 0.02331886, 0.01417785, 0.0106844 , 0.01791214, 0.017177 , - 0.02125114, 0.05028201, 0.06830665, 0.05216664, 0.01963666, - 0.06941418, 0.11513043, 0.12257859, 0.10948435, 0.08568069, - 0.05509328, 0.05047818, 0.047112 , 0.05060737, 0.02982424, - 0.02803827, 0.02933729, 0.01760491, 0.00587815, 0.02117637, - 0.0293578 , 0.03452379, 0.02194803, 0.01676056, - ]) - # fmt: on - self.assertTrue(np.allclose(spec[:64, 400], expected)) - - spec = spectrogram( - waveform, - window_function(400, "hann"), - frame_length=400, - hop_length=128, - fft_length=512, - power=1.0, - center=True, - pad_mode="reflect", - onesided=True, - ) - self.assertEqual(spec.shape, (257, 732)) - self.assertTrue(np.allclose(spec[:64, 400], expected)) - - def test_spectrogram_center_padding(self): - waveform = self._load_datasamples(1)[0] - - spec = spectrogram( - waveform, - window_function(512, "hann"), - frame_length=512, - hop_length=128, - center=True, - pad_mode="reflect", - ) - self.assertEqual(spec.shape, (257, 732)) - - # fmt: off - expected = np.array([ - 0.1287945 , 0.12792738, 0.08311573, 0.03155122, 0.02470202, - 0.00727857, 0.00910694, 0.00686163, 0.01238981, 0.01473668, - 0.00336144, 0.00370314, 0.00600871, 0.01120164, 0.01942998, - 0.03132008, 0.0232842 , 0.01124642, 0.02754783, 0.02423725, - 0.00147893, 0.00038027, 0.00112299, 0.00596233, 0.00571529, - 0.02084235, 0.0231855 , 0.00810006, 0.01837943, 0.00651339, - 0.00093931, 0.00067426, 0.01058399, 0.01270507, 0.00151734, - 0.00331913, 0.00302416, 0.01081792, 0.00754549, 0.00148963, - 0.00111943, 0.00152573, 0.00608017, 0.01749986, 0.01205949, - 0.0143082 , 0.01910573, 0.00413786, 0.03916619, 0.09873404, - 0.08302026, 0.02673891, 0.00401255, 0.01397392, 0.00751862, - 0.01024884, 0.01544606, 0.00638907, 0.00623633, 0.0085103 , - 0.00217659, 0.00276204, 0.00260835, 0.00299299, - ]) - # fmt: on - self.assertTrue(np.allclose(spec[:64, 0], expected)) - - spec = spectrogram( - waveform, - window_function(512, "hann"), - frame_length=512, - hop_length=128, - center=True, - pad_mode="constant", - ) - self.assertEqual(spec.shape, (257, 732)) - - # fmt: off - expected = np.array([ - 0.06558744, 0.06889656, 0.06263352, 0.04264418, 0.03404115, - 0.03244197, 0.02279134, 0.01646339, 0.01452216, 0.00826055, - 0.00062093, 0.0031821 , 0.00419456, 0.00689327, 0.01106367, - 0.01712119, 0.01721762, 0.00977533, 0.01606626, 0.02275621, - 0.01727687, 0.00992739, 0.01217688, 0.01049927, 0.01022947, - 0.01302475, 0.01166873, 0.01081812, 0.01057327, 0.00767912, - 0.00429567, 0.00089625, 0.00654583, 0.00912084, 0.00700984, - 0.00225026, 0.00290545, 0.00667712, 0.00730663, 0.00410813, - 0.00073102, 0.00219296, 0.00527618, 0.00996585, 0.01123781, - 0.00872816, 0.01165121, 0.02047945, 0.03681747, 0.0514379 , - 0.05137928, 0.03960042, 0.02821562, 0.01813349, 0.01201322, - 0.01260964, 0.00900654, 0.00207905, 0.00456714, 0.00850599, - 0.00788239, 0.00664407, 0.00824227, 0.00628301, - ]) - # fmt: on - self.assertTrue(np.allclose(spec[:64, 0], expected)) - - spec = spectrogram( - waveform, - window_function(512, "hann"), - frame_length=512, - hop_length=128, - center=False, - ) - self.assertEqual(spec.shape, (257, 728)) - - # fmt: off - expected = np.array([ - 0.00250445, 0.02161521, 0.06232229, 0.04339567, 0.00937727, - 0.01080616, 0.00248685, 0.0095264 , 0.00727476, 0.0079152 , - 0.00839946, 0.00254932, 0.00716622, 0.005559 , 0.00272623, - 0.00581774, 0.01896395, 0.01829788, 0.01020514, 0.01632692, - 0.00870888, 0.02065827, 0.0136022 , 0.0132382 , 0.011827 , - 0.00194505, 0.0189979 , 0.026874 , 0.02194014, 0.01923883, - 0.01621437, 0.00661967, 0.00289517, 0.00470257, 0.00957801, - 0.00191455, 0.00431664, 0.00544359, 0.01126213, 0.00785778, - 0.00423469, 0.01322504, 0.02226548, 0.02318576, 0.03428908, - 0.03648811, 0.0202938 , 0.011902 , 0.03226198, 0.06347476, - 0.01306318, 0.05308729, 0.05474771, 0.03127991, 0.00998512, - 0.01449977, 0.01272741, 0.00868176, 0.00850386, 0.00313876, - 0.00811857, 0.00538216, 0.00685749, 0.00535275, - ]) - # fmt: on - self.assertTrue(np.allclose(spec[:64, 0], expected)) - - def test_spectrogram_shapes(self): - waveform = self._load_datasamples(1)[0] - - spec = spectrogram( - waveform, - window_function(400, "hann"), - frame_length=400, - hop_length=128, - power=1.0, - center=True, - pad_mode="reflect", - onesided=True, - ) - self.assertEqual(spec.shape, (201, 732)) - - spec = spectrogram( - waveform, - window_function(400, "hann"), - frame_length=400, - hop_length=128, - power=1.0, - center=False, - pad_mode="reflect", - onesided=True, - ) - self.assertEqual(spec.shape, (201, 729)) - - spec = spectrogram( - waveform, - window_function(400, "hann"), - frame_length=400, - hop_length=128, - fft_length=512, - power=1.0, - center=True, - pad_mode="reflect", - onesided=True, - ) - self.assertEqual(spec.shape, (257, 732)) - - spec = spectrogram( - waveform, - window_function(400, "hann", frame_length=512), - frame_length=512, - hop_length=64, - power=1.0, - center=True, - pad_mode="reflect", - onesided=False, - ) - self.assertEqual(spec.shape, (512, 1464)) - - spec = spectrogram( - waveform, - window_function(512, "hann"), - frame_length=512, - hop_length=64, - power=1.0, - center=True, - pad_mode="reflect", - onesided=False, - ) - self.assertEqual(spec.shape, (512, 1464)) - - spec = spectrogram( - waveform, - window_function(512, "hann"), - frame_length=512, - hop_length=512, - power=1.0, - center=True, - pad_mode="reflect", - onesided=False, - ) - self.assertEqual(spec.shape, (512, 183)) - - def test_mel_spectrogram(self): - waveform = self._load_datasamples(1)[0] - - mel_filters = mel_filter_bank( - num_frequency_bins=513, - num_mel_filters=13, - min_frequency=100, - max_frequency=4000, - sampling_rate=16000, - norm=None, - mel_scale="htk", - ) - self.assertEqual(mel_filters.shape, (513, 13)) - - spec = spectrogram( - waveform, - window_function(800, "hann", frame_length=1024), - frame_length=1024, - hop_length=128, - power=2.0, - ) - self.assertEqual(spec.shape, (513, 732)) - - spec = spectrogram( - waveform, - window_function(800, "hann", frame_length=1024), - frame_length=1024, - hop_length=128, - power=2.0, - mel_filters=mel_filters, - ) - self.assertEqual(spec.shape, (13, 732)) - - # fmt: off - expected = np.array([ - 1.08027889e+02, 1.48080673e+01, 7.70758213e+00, 9.57676639e-01, - 8.81639061e-02, 5.26073833e-02, 1.52736155e-02, 9.95350117e-03, - 7.95364356e-03, 1.01148004e-02, 4.29241020e-03, 9.90708797e-03, - 9.44153646e-04 - ]) - # fmt: on - self.assertTrue(np.allclose(spec[:, 300], expected)) - - def test_spectrogram_power(self): - waveform = self._load_datasamples(1)[0] - - spec = spectrogram( - waveform, - window_function(400, "hann", frame_length=512), - frame_length=512, - hop_length=128, - power=None, - ) - self.assertEqual(spec.shape, (257, 732)) - self.assertEqual(spec.dtype, np.complex64) - - # fmt: off - expected = np.array([ - 0.01452305+0.01820039j, -0.01737362-0.01641946j, - 0.0121028 +0.01565081j, -0.02794554-0.03021514j, - 0.04719803+0.04086519j, -0.04391563-0.02779365j, - 0.05682834+0.01571325j, -0.08604821-0.02023657j, - 0.07497991+0.0186641j , -0.06366091-0.00922475j, - 0.11003416+0.0114788j , -0.13677941-0.01523552j, - 0.10934535-0.00117226j, -0.11635598+0.02551187j, - 0.14708674-0.03469823j, -0.1328196 +0.06034218j, - 0.12667368-0.13973421j, -0.14764774+0.18912019j, - 0.10235471-0.12181523j, -0.00773012+0.04730498j, - -0.01487191-0.07312611j, -0.02739162+0.09619419j, - 0.02895459-0.05398273j, 0.01198589+0.05276592j, - -0.02117299-0.10123465j, 0.00666388+0.09526499j, - -0.01672773-0.05649684j, 0.02723125+0.05939891j, - -0.01879361-0.062954j , 0.03686557+0.04568823j, - -0.07394181-0.07949649j, 0.06238583+0.13905765j, - ]) - # fmt: on - self.assertTrue(np.allclose(spec[64:96, 321], expected)) - - spec = spectrogram( - waveform, - window_function(400, "hann", frame_length=512), - frame_length=512, - hop_length=128, - power=1.0, - ) - self.assertEqual(spec.shape, (257, 732)) - self.assertEqual(spec.dtype, np.float64) - - # fmt: off - expected = np.array([ - 0.02328461, 0.02390484, 0.01978448, 0.04115711, 0.0624309 , - 0.05197181, 0.05896072, 0.08839577, 0.07726794, 0.06432579, - 0.11063128, 0.13762532, 0.10935163, 0.11911998, 0.15112405, - 0.14588428, 0.18860507, 0.23992978, 0.15910825, 0.04793241, - 0.07462307, 0.10001811, 0.06125769, 0.05411011, 0.10342509, - 0.09549777, 0.05892122, 0.06534349, 0.06569936, 0.05870678, - 0.10856833, 0.1524107 , 0.11463385, 0.05766969, 0.12385171, - 0.14472842, 0.11978184, 0.10353675, 0.07244056, 0.03461861, - 0.02624896, 0.02227475, 0.01238363, 0.00885281, 0.0110049 , - 0.00807005, 0.01033663, 0.01703181, 0.01445856, 0.00585615, - 0.0132431 , 0.02754132, 0.01524478, 0.0204908 , 0.07453328, - 0.10716327, 0.07195779, 0.08816078, 0.18340898, 0.16449876, - 0.12322842, 0.1621659 , 0.12334293, 0.06033659, - ]) - # fmt: on - self.assertTrue(np.allclose(spec[64:128, 321], expected)) - - spec = spectrogram( - waveform, - window_function(400, "hann", frame_length=512), - frame_length=512, - hop_length=128, - power=2.0, - ) - self.assertEqual(spec.shape, (257, 732)) - self.assertEqual(spec.dtype, np.float64) - - # fmt: off - expected = np.array([ - 5.42173162e-04, 5.71441371e-04, 3.91425507e-04, 1.69390778e-03, - 3.89761780e-03, 2.70106923e-03, 3.47636663e-03, 7.81381316e-03, - 5.97033510e-03, 4.13780799e-03, 1.22392802e-02, 1.89407300e-02, - 1.19577805e-02, 1.41895693e-02, 2.28384770e-02, 2.12822221e-02, - 3.55718732e-02, 5.75663000e-02, 2.53154356e-02, 2.29751552e-03, - 5.56860259e-03, 1.00036217e-02, 3.75250424e-03, 2.92790355e-03, - 1.06967501e-02, 9.11982451e-03, 3.47171025e-03, 4.26977174e-03, - 4.31640586e-03, 3.44648538e-03, 1.17870830e-02, 2.32290216e-02, - 1.31409196e-02, 3.32579296e-03, 1.53392460e-02, 2.09463164e-02, - 1.43476883e-02, 1.07198600e-02, 5.24763530e-03, 1.19844836e-03, - 6.89007982e-04, 4.96164430e-04, 1.53354369e-04, 7.83722571e-05, - 1.21107812e-04, 6.51257360e-05, 1.06845939e-04, 2.90082477e-04, - 2.09049831e-04, 3.42945241e-05, 1.75379610e-04, 7.58524227e-04, - 2.32403356e-04, 4.19872697e-04, 5.55520924e-03, 1.14839673e-02, - 5.17792348e-03, 7.77232368e-03, 3.36388536e-02, 2.70598419e-02, - 1.51852425e-02, 2.62977779e-02, 1.52134784e-02, 3.64050455e-03, - ]) - # fmt: on - self.assertTrue(np.allclose(spec[64:128, 321], expected)) - - def test_power_to_db(self): - spectrogram = np.zeros((2, 3)) - spectrogram[0, 0] = 2.0 - spectrogram[0, 1] = 0.5 - spectrogram[0, 2] = 0.707 - spectrogram[1, 1] = 1.0 - - output = power_to_db(spectrogram, reference=1.0) - expected = np.array([[3.01029996, -3.01029996, -1.50580586], [-100.0, 0.0, -100.0]]) - self.assertTrue(np.allclose(output, expected)) - - output = power_to_db(spectrogram, reference=2.0) - expected = np.array([[0.0, -6.02059991, -4.51610582], [-103.01029996, -3.01029996, -103.01029996]]) - self.assertTrue(np.allclose(output, expected)) - - output = power_to_db(spectrogram, min_value=1e-6) - expected = np.array([[3.01029996, -3.01029996, -1.50580586], [-60.0, 0.0, -60.0]]) - self.assertTrue(np.allclose(output, expected)) - - output = power_to_db(spectrogram, db_range=80) - expected = np.array([[3.01029996, -3.01029996, -1.50580586], [-76.98970004, 0.0, -76.98970004]]) - self.assertTrue(np.allclose(output, expected)) - - output = power_to_db(spectrogram, reference=2.0, db_range=80) - expected = np.array([[0.0, -6.02059991, -4.51610582], [-80.0, -3.01029996, -80.0]]) - self.assertTrue(np.allclose(output, expected)) - - output = power_to_db(spectrogram, reference=2.0, min_value=1e-6, db_range=80) - expected = np.array([[0.0, -6.02059991, -4.51610582], [-63.01029996, -3.01029996, -63.01029996]]) - self.assertTrue(np.allclose(output, expected)) - - with pytest.raises(ValueError): - power_to_db(spectrogram, reference=0.0) - with pytest.raises(ValueError): - power_to_db(spectrogram, min_value=0.0) - with pytest.raises(ValueError): - power_to_db(spectrogram, db_range=-80) - - def test_amplitude_to_db(self): - spectrogram = np.zeros((2, 3)) - spectrogram[0, 0] = 2.0 - spectrogram[0, 1] = 0.5 - spectrogram[0, 2] = 0.707 - spectrogram[1, 1] = 1.0 - - output = amplitude_to_db(spectrogram, reference=1.0) - expected = np.array([[6.02059991, -6.02059991, -3.01161172], [-100.0, 0.0, -100.0]]) - self.assertTrue(np.allclose(output, expected)) - - output = amplitude_to_db(spectrogram, reference=2.0) - expected = np.array([[0.0, -12.04119983, -9.03221164], [-106.02059991, -6.02059991, -106.02059991]]) - self.assertTrue(np.allclose(output, expected)) - - output = amplitude_to_db(spectrogram, min_value=1e-3) - expected = np.array([[6.02059991, -6.02059991, -3.01161172], [-60.0, 0.0, -60.0]]) - self.assertTrue(np.allclose(output, expected)) - - output = amplitude_to_db(spectrogram, db_range=80) - expected = np.array([[6.02059991, -6.02059991, -3.01161172], [-73.97940009, 0.0, -73.97940009]]) - self.assertTrue(np.allclose(output, expected)) - - output = amplitude_to_db(spectrogram, reference=2.0, db_range=80) - expected = np.array([[0.0, -12.04119983, -9.03221164], [-80.0, -6.02059991, -80.0]]) - self.assertTrue(np.allclose(output, expected)) - - output = amplitude_to_db(spectrogram, reference=2.0, min_value=1e-3, db_range=80) - expected = np.array([[0.0, -12.04119983, -9.03221164], [-66.02059991, -6.02059991, -66.02059991]]) - self.assertTrue(np.allclose(output, expected)) - - with pytest.raises(ValueError): - amplitude_to_db(spectrogram, reference=0.0) - with pytest.raises(ValueError): - amplitude_to_db(spectrogram, min_value=0.0) - with pytest.raises(ValueError): - amplitude_to_db(spectrogram, db_range=-80) diff --git a/tests/transformers/tests/utils/test_backbone_utils.py b/tests/transformers/tests/utils/test_backbone_utils.py deleted file mode 100644 index 66b7087da2..0000000000 --- a/tests/transformers/tests/utils/test_backbone_utils.py +++ /dev/null @@ -1,102 +0,0 @@ -# Copyright 2023 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import unittest - -from transformers.utils.backbone_utils import ( - BackboneMixin, - get_aligned_output_features_output_indices, - verify_out_features_out_indices, -) - - -class BackboneUtilsTester(unittest.TestCase): - def test_get_aligned_output_features_output_indices(self): - stage_names = ["a", "b", "c"] - - # Defaults to last layer if both are None - out_features, out_indices = get_aligned_output_features_output_indices(None, None, stage_names) - self.assertEqual(out_features, ["c"]) - self.assertEqual(out_indices, [2]) - - # Out indices set to match out features - out_features, out_indices = get_aligned_output_features_output_indices(["a", "c"], None, stage_names) - self.assertEqual(out_features, ["a", "c"]) - self.assertEqual(out_indices, [0, 2]) - - # Out features set to match out indices - out_features, out_indices = get_aligned_output_features_output_indices(None, [0, 2], stage_names) - self.assertEqual(out_features, ["a", "c"]) - self.assertEqual(out_indices, [0, 2]) - - # Out features selected from negative indices - out_features, out_indices = get_aligned_output_features_output_indices(None, [-3, -1], stage_names) - self.assertEqual(out_features, ["a", "c"]) - self.assertEqual(out_indices, [-3, -1]) - - def test_verify_out_features_out_indices(self): - # Stage names must be set - with self.assertRaises(ValueError): - verify_out_features_out_indices(["a", "b"], (0, 1), None) - - # Out features must be a list - with self.assertRaises(ValueError): - verify_out_features_out_indices(("a", "b"), (0, 1), ["a", "b"]) - - # Out features must be a subset of stage names - with self.assertRaises(ValueError): - verify_out_features_out_indices(["a", "b"], (0, 1), ["a"]) - - # Out indices must be a list or tuple - with self.assertRaises(ValueError): - verify_out_features_out_indices(None, 0, ["a", "b"]) - - # Out indices must be a subset of stage names - with self.assertRaises(ValueError): - verify_out_features_out_indices(None, (0, 1), ["a"]) - - # Out features and out indices must be the same length - with self.assertRaises(ValueError): - verify_out_features_out_indices(["a", "b"], (0,), ["a", "b", "c"]) - - # Out features should match out indices - with self.assertRaises(ValueError): - verify_out_features_out_indices(["a", "b"], (0, 2), ["a", "b", "c"]) - - # Out features and out indices should be in order - with self.assertRaises(ValueError): - verify_out_features_out_indices(["b", "a"], (0, 1), ["a", "b"]) - - # Check passes with valid inputs - verify_out_features_out_indices(["a", "b", "d"], (0, 1, -1), ["a", "b", "c", "d"]) - - def test_backbone_mixin(self): - backbone = BackboneMixin() - - backbone.stage_names = ["a", "b", "c"] - backbone._out_features = ["a", "c"] - backbone._out_indices = [0, 2] - - # Check that the output features and indices are set correctly - self.assertEqual(backbone.out_features, ["a", "c"]) - self.assertEqual(backbone.out_indices, [0, 2]) - - # Check out features and indices are updated correctly - backbone.out_features = ["a", "b"] - self.assertEqual(backbone.out_features, ["a", "b"]) - self.assertEqual(backbone.out_indices, [0, 1]) - - backbone.out_indices = [-3, -1] - self.assertEqual(backbone.out_features, ["a", "c"]) - self.assertEqual(backbone.out_indices, [-3, -1]) diff --git a/tests/transformers/tests/utils/test_cli.py b/tests/transformers/tests/utils/test_cli.py deleted file mode 100644 index fc7b8ebb5e..0000000000 --- a/tests/transformers/tests/utils/test_cli.py +++ /dev/null @@ -1,91 +0,0 @@ -# coding=utf-8 -# Copyright 2019-present, the HuggingFace Inc. team. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import os -import shutil -import unittest -from unittest.mock import patch - -from transformers.testing_utils import CaptureStd, is_pt_tf_cross_test, require_torch - - -class CLITest(unittest.TestCase): - @patch("sys.argv", ["fakeprogrampath", "env"]) - def test_cli_env(self): - # test transformers-cli env - import transformers.commands.transformers_cli - - with CaptureStd() as cs: - transformers.commands.transformers_cli.main() - self.assertIn("Python version", cs.out) - self.assertIn("Platform", cs.out) - self.assertIn("Using distributed or parallel set-up in script?", cs.out) - - @is_pt_tf_cross_test - @patch( - "sys.argv", ["fakeprogrampath", "pt-to-tf", "--model-name", "hf-internal-testing/tiny-random-gptj", "--no-pr"] - ) - def test_cli_pt_to_tf(self): - import transformers.commands.transformers_cli - - shutil.rmtree("/tmp/hf-internal-testing/tiny-random-gptj", ignore_errors=True) # cleans potential past runs - transformers.commands.transformers_cli.main() - - # The original repo has no TF weights -- if they exist, they were created by the CLI - self.assertTrue(os.path.exists("/tmp/hf-internal-testing/tiny-random-gptj/tf_model.h5")) - - @require_torch - @patch("sys.argv", ["fakeprogrampath", "download", "hf-internal-testing/tiny-random-gptj", "--cache-dir", "/tmp"]) - def test_cli_download(self): - import transformers.commands.transformers_cli - - # # remove any previously downloaded model to start clean - shutil.rmtree("/tmp/models--hf-internal-testing--tiny-random-gptj", ignore_errors=True) - - # run the command - transformers.commands.transformers_cli.main() - - # check if the model files are downloaded correctly on /tmp/models--hf-internal-testing--tiny-random-gptj - self.assertTrue(os.path.exists("/tmp/models--hf-internal-testing--tiny-random-gptj/blobs")) - self.assertTrue(os.path.exists("/tmp/models--hf-internal-testing--tiny-random-gptj/refs")) - self.assertTrue(os.path.exists("/tmp/models--hf-internal-testing--tiny-random-gptj/snapshots")) - - @require_torch - @patch( - "sys.argv", - [ - "fakeprogrampath", - "download", - "hf-internal-testing/test_dynamic_model_with_tokenizer", - "--trust-remote-code", - "--cache-dir", - "/tmp", - ], - ) - def test_cli_download_trust_remote(self): - import transformers.commands.transformers_cli - - # # remove any previously downloaded model to start clean - shutil.rmtree("/tmp/models--hf-internal-testing--test_dynamic_model_with_tokenizer", ignore_errors=True) - - # run the command - transformers.commands.transformers_cli.main() - - # check if the model files are downloaded correctly on /tmp/models--hf-internal-testing--test_dynamic_model_with_tokenizer - self.assertTrue(os.path.exists("/tmp/models--hf-internal-testing--test_dynamic_model_with_tokenizer/blobs")) - self.assertTrue(os.path.exists("/tmp/models--hf-internal-testing--test_dynamic_model_with_tokenizer/refs")) - self.assertTrue( - os.path.exists("/tmp/models--hf-internal-testing--test_dynamic_model_with_tokenizer/snapshots") - ) diff --git a/tests/transformers/tests/utils/test_convert_slow_tokenizer.py b/tests/transformers/tests/utils/test_convert_slow_tokenizer.py deleted file mode 100644 index edeb06c390..0000000000 --- a/tests/transformers/tests/utils/test_convert_slow_tokenizer.py +++ /dev/null @@ -1,35 +0,0 @@ -import unittest -import warnings -from dataclasses import dataclass - -from transformers.convert_slow_tokenizer import SpmConverter -from transformers.testing_utils import get_tests_dir - - -@dataclass -class FakeOriginalTokenizer: - vocab_file: str - - -class ConvertSlowTokenizerTest(unittest.TestCase): - def test_spm_converter_bytefallback_warning(self): - spm_model_file_without_bytefallback = get_tests_dir("fixtures/test_sentencepiece.model") - spm_model_file_with_bytefallback = get_tests_dir("fixtures/test_sentencepiece_with_bytefallback.model") - - original_tokenizer_without_bytefallback = FakeOriginalTokenizer(vocab_file=spm_model_file_without_bytefallback) - - with warnings.catch_warnings(record=True) as w: - _ = SpmConverter(original_tokenizer_without_bytefallback) - self.assertEqual(len(w), 0) - - original_tokenizer_with_bytefallback = FakeOriginalTokenizer(vocab_file=spm_model_file_with_bytefallback) - - with warnings.catch_warnings(record=True) as w: - _ = SpmConverter(original_tokenizer_with_bytefallback) - self.assertEqual(len(w), 1) - - self.assertIn( - "The sentencepiece tokenizer that you are converting to a fast tokenizer uses the byte fallback option" - " which is not implemented in the fast tokenizers.", - str(w[0].message), - ) diff --git a/tests/transformers/tests/utils/test_doc_samples.py b/tests/transformers/tests/utils/test_doc_samples.py deleted file mode 100644 index 84c5a4d2bf..0000000000 --- a/tests/transformers/tests/utils/test_doc_samples.py +++ /dev/null @@ -1,114 +0,0 @@ -# coding=utf-8 -# Copyright 2019-present, the HuggingFace Inc. team. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import doctest -import logging -import os -import unittest -from pathlib import Path -from typing import List, Union - -import transformers -from transformers.testing_utils import require_tf, require_torch, slow - - -logger = logging.getLogger() - - -@unittest.skip("Temporarily disable the doc tests.") -@require_torch -@require_tf -@slow -class TestCodeExamples(unittest.TestCase): - def analyze_directory( - self, - directory: Path, - identifier: Union[str, None] = None, - ignore_files: Union[List[str], None] = None, - n_identifier: Union[str, List[str], None] = None, - only_modules: bool = True, - ): - """ - Runs through the specific directory, looking for the files identified with `identifier`. Executes - the doctests in those files - - Args: - directory (`Path`): Directory containing the files - identifier (`str`): Will parse files containing this - ignore_files (`List[str]`): List of files to skip - n_identifier (`str` or `List[str]`): Will not parse files containing this/these identifiers. - only_modules (`bool`): Whether to only analyze modules - """ - files = [file for file in os.listdir(directory) if os.path.isfile(os.path.join(directory, file))] - - if identifier is not None: - files = [file for file in files if identifier in file] - - if n_identifier is not None: - if isinstance(n_identifier, List): - for n_ in n_identifier: - files = [file for file in files if n_ not in file] - else: - files = [file for file in files if n_identifier not in file] - - ignore_files = ignore_files or [] - ignore_files.append("__init__.py") - files = [file for file in files if file not in ignore_files] - - for file in files: - # Open all files - print("Testing", file) - - if only_modules: - module_identifier = file.split(".")[0] - try: - module_identifier = getattr(transformers, module_identifier) - suite = doctest.DocTestSuite(module_identifier) - result = unittest.TextTestRunner().run(suite) - self.assertIs(len(result.failures), 0) - except AttributeError: - logger.info(f"{module_identifier} is not a module.") - else: - result = doctest.testfile(str(".." / directory / file), optionflags=doctest.ELLIPSIS) - self.assertIs(result.failed, 0) - - def test_modeling_examples(self): - transformers_directory = Path("src/transformers") - files = "modeling" - ignore_files = [ - "modeling_ctrl.py", - "modeling_tf_ctrl.py", - ] - self.analyze_directory(transformers_directory, identifier=files, ignore_files=ignore_files) - - def test_tokenization_examples(self): - transformers_directory = Path("src/transformers") - files = "tokenization" - self.analyze_directory(transformers_directory, identifier=files) - - def test_configuration_examples(self): - transformers_directory = Path("src/transformers") - files = "configuration" - self.analyze_directory(transformers_directory, identifier=files) - - def test_remaining_examples(self): - transformers_directory = Path("src/transformers") - n_identifiers = ["configuration", "modeling", "tokenization"] - self.analyze_directory(transformers_directory, n_identifier=n_identifiers) - - def test_doc_sources(self): - doc_source_directory = Path("docs/source") - ignore_files = ["favicon.ico"] - self.analyze_directory(doc_source_directory, ignore_files=ignore_files, only_modules=False) diff --git a/tests/transformers/tests/utils/test_dynamic_module_utils.py b/tests/transformers/tests/utils/test_dynamic_module_utils.py deleted file mode 100644 index c9b2694937..0000000000 --- a/tests/transformers/tests/utils/test_dynamic_module_utils.py +++ /dev/null @@ -1,128 +0,0 @@ -# Copyright 2023 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import os - -import pytest -from transformers.dynamic_module_utils import get_imports - - -TOP_LEVEL_IMPORT = """ -import os -""" - -IMPORT_IN_FUNCTION = """ -def foo(): - import os - return False -""" - -DEEPLY_NESTED_IMPORT = """ -def foo(): - def bar(): - if True: - import os - return False - return bar() -""" - -TOP_LEVEL_TRY_IMPORT = """ -import os - -try: - import bar -except ImportError: - raise ValueError() -""" - -TRY_IMPORT_IN_FUNCTION = """ -import os - -def foo(): - try: - import bar - except ImportError: - raise ValueError() -""" - -MULTIPLE_EXCEPTS_IMPORT = """ -import os - -try: - import bar -except (ImportError, AttributeError): - raise ValueError() -""" - -EXCEPT_AS_IMPORT = """ -import os - -try: - import bar -except ImportError as e: - raise ValueError() -""" - -GENERIC_EXCEPT_IMPORT = """ -import os - -try: - import bar -except: - raise ValueError() -""" - -MULTILINE_TRY_IMPORT = """ -import os - -try: - import bar - import baz -except ImportError: - raise ValueError() -""" - -MULTILINE_BOTH_IMPORT = """ -import os - -try: - import bar - import baz -except ImportError: - x = 1 - raise ValueError() -""" - -CASES = [ - TOP_LEVEL_IMPORT, - IMPORT_IN_FUNCTION, - DEEPLY_NESTED_IMPORT, - TOP_LEVEL_TRY_IMPORT, - GENERIC_EXCEPT_IMPORT, - MULTILINE_TRY_IMPORT, - MULTILINE_BOTH_IMPORT, - MULTIPLE_EXCEPTS_IMPORT, - EXCEPT_AS_IMPORT, - TRY_IMPORT_IN_FUNCTION, -] - - -@pytest.mark.parametrize("case", CASES) -def test_import_parsing(tmp_path, case): - tmp_file_path = os.path.join(tmp_path, "test_file.py") - with open(tmp_file_path, "w") as _tmp_file: - _tmp_file.write(case) - - parsed_imports = get_imports(tmp_file_path) - assert parsed_imports == ["os"] diff --git a/tests/transformers/tests/utils/test_file_utils.py b/tests/transformers/tests/utils/test_file_utils.py deleted file mode 100644 index 1cbde0fb18..0000000000 --- a/tests/transformers/tests/utils/test_file_utils.py +++ /dev/null @@ -1,133 +0,0 @@ -# Copyright 2020 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import contextlib -import importlib -import io -import unittest - -import transformers - -# Try to import everything from transformers to ensure every object can be loaded. -from transformers import * # noqa F406 -from transformers.testing_utils import DUMMY_UNKNOWN_IDENTIFIER, require_flax, require_tf, require_torch -from transformers.utils import ContextManagers, find_labels, is_flax_available, is_tf_available, is_torch_available - - -if is_torch_available(): - from transformers import BertForPreTraining, BertForQuestionAnswering, BertForSequenceClassification - -if is_tf_available(): - from transformers import TFBertForPreTraining, TFBertForQuestionAnswering, TFBertForSequenceClassification - -if is_flax_available(): - from transformers import FlaxBertForPreTraining, FlaxBertForQuestionAnswering, FlaxBertForSequenceClassification - - -MODEL_ID = DUMMY_UNKNOWN_IDENTIFIER -# An actual model hosted on huggingface.co - -REVISION_ID_DEFAULT = "main" -# Default branch name -REVISION_ID_ONE_SPECIFIC_COMMIT = "f2c752cfc5c0ab6f4bdec59acea69eefbee381c2" -# One particular commit (not the top of `main`) -REVISION_ID_INVALID = "aaaaaaa" -# This commit does not exist, so we should 404. - -PINNED_SHA1 = "d9e9f15bc825e4b2c9249e9578f884bbcb5e3684" -# Sha-1 of config.json on the top of `main`, for checking purposes -PINNED_SHA256 = "4b243c475af8d0a7754e87d7d096c92e5199ec2fe168a2ee7998e3b8e9bcb1d3" -# Sha-256 of pytorch_model.bin on the top of `main`, for checking purposes - - -# Dummy contexts to test `ContextManagers` -@contextlib.contextmanager -def context_en(): - print("Welcome!") - yield - print("Bye!") - - -@contextlib.contextmanager -def context_fr(): - print("Bonjour!") - yield - print("Au revoir!") - - -class TestImportMechanisms(unittest.TestCase): - def test_module_spec_available(self): - # If the spec is missing, importlib would not be able to import the module dynamically. - assert transformers.__spec__ is not None - assert importlib.util.find_spec("transformers") is not None - - -class GenericUtilTests(unittest.TestCase): - @unittest.mock.patch("sys.stdout", new_callable=io.StringIO) - def test_context_managers_no_context(self, mock_stdout): - with ContextManagers([]): - print("Transformers are awesome!") - # The print statement adds a new line at the end of the output - self.assertEqual(mock_stdout.getvalue(), "Transformers are awesome!\n") - - @unittest.mock.patch("sys.stdout", new_callable=io.StringIO) - def test_context_managers_one_context(self, mock_stdout): - with ContextManagers([context_en()]): - print("Transformers are awesome!") - # The output should be wrapped with an English welcome and goodbye - self.assertEqual(mock_stdout.getvalue(), "Welcome!\nTransformers are awesome!\nBye!\n") - - @unittest.mock.patch("sys.stdout", new_callable=io.StringIO) - def test_context_managers_two_context(self, mock_stdout): - with ContextManagers([context_fr(), context_en()]): - print("Transformers are awesome!") - # The output should be wrapped with an English and French welcome and goodbye - self.assertEqual(mock_stdout.getvalue(), "Bonjour!\nWelcome!\nTransformers are awesome!\nBye!\nAu revoir!\n") - - @require_torch - def test_find_labels_pt(self): - self.assertEqual(find_labels(BertForSequenceClassification), ["labels"]) - self.assertEqual(find_labels(BertForPreTraining), ["labels", "next_sentence_label"]) - self.assertEqual(find_labels(BertForQuestionAnswering), ["start_positions", "end_positions"]) - - # find_labels works regardless of the class name (it detects the framework through inheritance) - class DummyModel(BertForSequenceClassification): - pass - - self.assertEqual(find_labels(DummyModel), ["labels"]) - - @require_tf - def test_find_labels_tf(self): - self.assertEqual(find_labels(TFBertForSequenceClassification), ["labels"]) - self.assertEqual(find_labels(TFBertForPreTraining), ["labels", "next_sentence_label"]) - self.assertEqual(find_labels(TFBertForQuestionAnswering), ["start_positions", "end_positions"]) - - # find_labels works regardless of the class name (it detects the framework through inheritance) - class DummyModel(TFBertForSequenceClassification): - pass - - self.assertEqual(find_labels(DummyModel), ["labels"]) - - @require_flax - def test_find_labels_flax(self): - # Flax models don't have labels - self.assertEqual(find_labels(FlaxBertForSequenceClassification), []) - self.assertEqual(find_labels(FlaxBertForPreTraining), []) - self.assertEqual(find_labels(FlaxBertForQuestionAnswering), []) - - # find_labels works regardless of the class name (it detects the framework through inheritance) - class DummyModel(FlaxBertForSequenceClassification): - pass - - self.assertEqual(find_labels(DummyModel), []) diff --git a/tests/transformers/tests/utils/test_generic.py b/tests/transformers/tests/utils/test_generic.py deleted file mode 100644 index e9001289d4..0000000000 --- a/tests/transformers/tests/utils/test_generic.py +++ /dev/null @@ -1,199 +0,0 @@ -# coding=utf-8 -# Copyright 2019-present, the HuggingFace Inc. team. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import unittest - -import numpy as np -from transformers.testing_utils import require_flax, require_tf, require_torch -from transformers.utils import ( - expand_dims, - flatten_dict, - is_flax_available, - is_tf_available, - is_torch_available, - reshape, - squeeze, - transpose, -) - - -if is_flax_available(): - import jax.numpy as jnp - -if is_tf_available(): - import tensorflow as tf - -if is_torch_available(): - import torch - - -class GenericTester(unittest.TestCase): - def test_flatten_dict(self): - input_dict = { - "task_specific_params": { - "summarization": {"length_penalty": 1.0, "max_length": 128, "min_length": 12, "num_beams": 4}, - "summarization_cnn": {"length_penalty": 2.0, "max_length": 142, "min_length": 56, "num_beams": 4}, - "summarization_xsum": {"length_penalty": 1.0, "max_length": 62, "min_length": 11, "num_beams": 6}, - } - } - expected_dict = { - "task_specific_params.summarization.length_penalty": 1.0, - "task_specific_params.summarization.max_length": 128, - "task_specific_params.summarization.min_length": 12, - "task_specific_params.summarization.num_beams": 4, - "task_specific_params.summarization_cnn.length_penalty": 2.0, - "task_specific_params.summarization_cnn.max_length": 142, - "task_specific_params.summarization_cnn.min_length": 56, - "task_specific_params.summarization_cnn.num_beams": 4, - "task_specific_params.summarization_xsum.length_penalty": 1.0, - "task_specific_params.summarization_xsum.max_length": 62, - "task_specific_params.summarization_xsum.min_length": 11, - "task_specific_params.summarization_xsum.num_beams": 6, - } - - self.assertEqual(flatten_dict(input_dict), expected_dict) - - def test_transpose_numpy(self): - x = np.random.randn(3, 4) - self.assertTrue(np.allclose(transpose(x), x.transpose())) - - x = np.random.randn(3, 4, 5) - self.assertTrue(np.allclose(transpose(x, axes=(1, 2, 0)), x.transpose((1, 2, 0)))) - - @require_torch - def test_transpose_torch(self): - x = np.random.randn(3, 4) - t = torch.tensor(x) - self.assertTrue(np.allclose(transpose(x), transpose(t).numpy())) - - x = np.random.randn(3, 4, 5) - t = torch.tensor(x) - self.assertTrue(np.allclose(transpose(x, axes=(1, 2, 0)), transpose(t, axes=(1, 2, 0)).numpy())) - - @require_tf - def test_transpose_tf(self): - x = np.random.randn(3, 4) - t = tf.constant(x) - self.assertTrue(np.allclose(transpose(x), transpose(t).numpy())) - - x = np.random.randn(3, 4, 5) - t = tf.constant(x) - self.assertTrue(np.allclose(transpose(x, axes=(1, 2, 0)), transpose(t, axes=(1, 2, 0)).numpy())) - - @require_flax - def test_transpose_flax(self): - x = np.random.randn(3, 4) - t = jnp.array(x) - self.assertTrue(np.allclose(transpose(x), np.asarray(transpose(t)))) - - x = np.random.randn(3, 4, 5) - t = jnp.array(x) - self.assertTrue(np.allclose(transpose(x, axes=(1, 2, 0)), np.asarray(transpose(t, axes=(1, 2, 0))))) - - def test_reshape_numpy(self): - x = np.random.randn(3, 4) - self.assertTrue(np.allclose(reshape(x, (4, 3)), np.reshape(x, (4, 3)))) - - x = np.random.randn(3, 4, 5) - self.assertTrue(np.allclose(reshape(x, (12, 5)), np.reshape(x, (12, 5)))) - - @require_torch - def test_reshape_torch(self): - x = np.random.randn(3, 4) - t = torch.tensor(x) - self.assertTrue(np.allclose(reshape(x, (4, 3)), reshape(t, (4, 3)).numpy())) - - x = np.random.randn(3, 4, 5) - t = torch.tensor(x) - self.assertTrue(np.allclose(reshape(x, (12, 5)), reshape(t, (12, 5)).numpy())) - - @require_tf - def test_reshape_tf(self): - x = np.random.randn(3, 4) - t = tf.constant(x) - self.assertTrue(np.allclose(reshape(x, (4, 3)), reshape(t, (4, 3)).numpy())) - - x = np.random.randn(3, 4, 5) - t = tf.constant(x) - self.assertTrue(np.allclose(reshape(x, (12, 5)), reshape(t, (12, 5)).numpy())) - - @require_flax - def test_reshape_flax(self): - x = np.random.randn(3, 4) - t = jnp.array(x) - self.assertTrue(np.allclose(reshape(x, (4, 3)), np.asarray(reshape(t, (4, 3))))) - - x = np.random.randn(3, 4, 5) - t = jnp.array(x) - self.assertTrue(np.allclose(reshape(x, (12, 5)), np.asarray(reshape(t, (12, 5))))) - - def test_squeeze_numpy(self): - x = np.random.randn(1, 3, 4) - self.assertTrue(np.allclose(squeeze(x), np.squeeze(x))) - - x = np.random.randn(1, 4, 1, 5) - self.assertTrue(np.allclose(squeeze(x, axis=2), np.squeeze(x, axis=2))) - - @require_torch - def test_squeeze_torch(self): - x = np.random.randn(1, 3, 4) - t = torch.tensor(x) - self.assertTrue(np.allclose(squeeze(x), squeeze(t).numpy())) - - x = np.random.randn(1, 4, 1, 5) - t = torch.tensor(x) - self.assertTrue(np.allclose(squeeze(x, axis=2), squeeze(t, axis=2).numpy())) - - @require_tf - def test_squeeze_tf(self): - x = np.random.randn(1, 3, 4) - t = tf.constant(x) - self.assertTrue(np.allclose(squeeze(x), squeeze(t).numpy())) - - x = np.random.randn(1, 4, 1, 5) - t = tf.constant(x) - self.assertTrue(np.allclose(squeeze(x, axis=2), squeeze(t, axis=2).numpy())) - - @require_flax - def test_squeeze_flax(self): - x = np.random.randn(1, 3, 4) - t = jnp.array(x) - self.assertTrue(np.allclose(squeeze(x), np.asarray(squeeze(t)))) - - x = np.random.randn(1, 4, 1, 5) - t = jnp.array(x) - self.assertTrue(np.allclose(squeeze(x, axis=2), np.asarray(squeeze(t, axis=2)))) - - def test_expand_dims_numpy(self): - x = np.random.randn(3, 4) - self.assertTrue(np.allclose(expand_dims(x, axis=1), np.expand_dims(x, axis=1))) - - @require_torch - def test_expand_dims_torch(self): - x = np.random.randn(3, 4) - t = torch.tensor(x) - self.assertTrue(np.allclose(expand_dims(x, axis=1), expand_dims(t, axis=1).numpy())) - - @require_tf - def test_expand_dims_tf(self): - x = np.random.randn(3, 4) - t = tf.constant(x) - self.assertTrue(np.allclose(expand_dims(x, axis=1), expand_dims(t, axis=1).numpy())) - - @require_flax - def test_expand_dims_flax(self): - x = np.random.randn(3, 4) - t = jnp.array(x) - self.assertTrue(np.allclose(expand_dims(x, axis=1), np.asarray(expand_dims(t, axis=1)))) diff --git a/tests/transformers/tests/utils/test_hf_argparser.py b/tests/transformers/tests/utils/test_hf_argparser.py deleted file mode 100644 index 4d0997861d..0000000000 --- a/tests/transformers/tests/utils/test_hf_argparser.py +++ /dev/null @@ -1,406 +0,0 @@ -# Copyright 2020 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import argparse -import json -import os -import sys -import tempfile -import unittest -from argparse import Namespace -from dataclasses import dataclass, field -from enum import Enum -from pathlib import Path -from typing import List, Literal, Optional - -import yaml -from transformers import HfArgumentParser, TrainingArguments -from transformers.hf_argparser import make_choice_type_function, string_to_bool - - -# Since Python 3.10, we can use the builtin `|` operator for Union types -# See PEP 604: https://peps.python.org/pep-0604 -is_python_no_less_than_3_10 = sys.version_info >= (3, 10) - - -def list_field(default=None, metadata=None): - return field(default_factory=lambda: default, metadata=metadata) - - -@dataclass -class BasicExample: - foo: int - bar: float - baz: str - flag: bool - - -@dataclass -class WithDefaultExample: - foo: int = 42 - baz: str = field(default="toto", metadata={"help": "help message"}) - - -@dataclass -class WithDefaultBoolExample: - foo: bool = False - baz: bool = True - opt: Optional[bool] = None - - -class BasicEnum(Enum): - titi = "titi" - toto = "toto" - - -class MixedTypeEnum(Enum): - titi = "titi" - toto = "toto" - fourtytwo = 42 - - -@dataclass -class EnumExample: - foo: BasicEnum = "toto" - - def __post_init__(self): - self.foo = BasicEnum(self.foo) - - -@dataclass -class MixedTypeEnumExample: - foo: MixedTypeEnum = "toto" - - def __post_init__(self): - self.foo = MixedTypeEnum(self.foo) - - -@dataclass -class OptionalExample: - foo: Optional[int] = None - bar: Optional[float] = field(default=None, metadata={"help": "help message"}) - baz: Optional[str] = None - ces: Optional[List[str]] = list_field(default=[]) - des: Optional[List[int]] = list_field(default=[]) - - -@dataclass -class ListExample: - foo_int: List[int] = list_field(default=[]) - bar_int: List[int] = list_field(default=[1, 2, 3]) - foo_str: List[str] = list_field(default=["Hallo", "Bonjour", "Hello"]) - foo_float: List[float] = list_field(default=[0.1, 0.2, 0.3]) - - -@dataclass -class RequiredExample: - required_list: List[int] = field() - required_str: str = field() - required_enum: BasicEnum = field() - - def __post_init__(self): - self.required_enum = BasicEnum(self.required_enum) - - -@dataclass -class StringLiteralAnnotationExample: - foo: int - required_enum: "BasicEnum" = field() - opt: "Optional[bool]" = None - baz: "str" = field(default="toto", metadata={"help": "help message"}) - foo_str: "List[str]" = list_field(default=["Hallo", "Bonjour", "Hello"]) - - -if is_python_no_less_than_3_10: - - @dataclass - class WithDefaultBoolExamplePep604: - foo: bool = False - baz: bool = True - opt: bool | None = None - - @dataclass - class OptionalExamplePep604: - foo: int | None = None - bar: float | None = field(default=None, metadata={"help": "help message"}) - baz: str | None = None - ces: list[str] | None = list_field(default=[]) - des: list[int] | None = list_field(default=[]) - - -class HfArgumentParserTest(unittest.TestCase): - def argparsersEqual(self, a: argparse.ArgumentParser, b: argparse.ArgumentParser): - """ - Small helper to check pseudo-equality of parsed arguments on `ArgumentParser` instances. - """ - self.assertEqual(len(a._actions), len(b._actions)) - for x, y in zip(a._actions, b._actions): - xx = {k: v for k, v in vars(x).items() if k != "container"} - yy = {k: v for k, v in vars(y).items() if k != "container"} - - # Choices with mixed type have custom function as "type" - # So we need to compare results directly for equality - if xx.get("choices", None) and yy.get("choices", None): - for expected_choice in yy["choices"] + xx["choices"]: - self.assertEqual(xx["type"](expected_choice), yy["type"](expected_choice)) - del xx["type"], yy["type"] - - self.assertEqual(xx, yy) - - def test_basic(self): - parser = HfArgumentParser(BasicExample) - - expected = argparse.ArgumentParser() - expected.add_argument("--foo", type=int, required=True) - expected.add_argument("--bar", type=float, required=True) - expected.add_argument("--baz", type=str, required=True) - expected.add_argument("--flag", type=string_to_bool, default=False, const=True, nargs="?") - self.argparsersEqual(parser, expected) - - args = ["--foo", "1", "--baz", "quux", "--bar", "0.5"] - (example,) = parser.parse_args_into_dataclasses(args, look_for_args_file=False) - self.assertFalse(example.flag) - - def test_with_default(self): - parser = HfArgumentParser(WithDefaultExample) - - expected = argparse.ArgumentParser() - expected.add_argument("--foo", default=42, type=int) - expected.add_argument("--baz", default="toto", type=str, help="help message") - self.argparsersEqual(parser, expected) - - def test_with_default_bool(self): - expected = argparse.ArgumentParser() - expected.add_argument("--foo", type=string_to_bool, default=False, const=True, nargs="?") - expected.add_argument("--baz", type=string_to_bool, default=True, const=True, nargs="?") - # A boolean no_* argument always has to come after its "default: True" regular counter-part - # and its default must be set to False - expected.add_argument("--no_baz", action="store_false", default=False, dest="baz") - expected.add_argument("--opt", type=string_to_bool, default=None) - - dataclass_types = [WithDefaultBoolExample] - if is_python_no_less_than_3_10: - dataclass_types.append(WithDefaultBoolExamplePep604) - - for dataclass_type in dataclass_types: - parser = HfArgumentParser(dataclass_type) - self.argparsersEqual(parser, expected) - - args = parser.parse_args([]) - self.assertEqual(args, Namespace(foo=False, baz=True, opt=None)) - - args = parser.parse_args(["--foo", "--no_baz"]) - self.assertEqual(args, Namespace(foo=True, baz=False, opt=None)) - - args = parser.parse_args(["--foo", "--baz"]) - self.assertEqual(args, Namespace(foo=True, baz=True, opt=None)) - - args = parser.parse_args(["--foo", "True", "--baz", "True", "--opt", "True"]) - self.assertEqual(args, Namespace(foo=True, baz=True, opt=True)) - - args = parser.parse_args(["--foo", "False", "--baz", "False", "--opt", "False"]) - self.assertEqual(args, Namespace(foo=False, baz=False, opt=False)) - - def test_with_enum(self): - parser = HfArgumentParser(MixedTypeEnumExample) - - expected = argparse.ArgumentParser() - expected.add_argument( - "--foo", - default="toto", - choices=["titi", "toto", 42], - type=make_choice_type_function(["titi", "toto", 42]), - ) - self.argparsersEqual(parser, expected) - - args = parser.parse_args([]) - self.assertEqual(args.foo, "toto") - enum_ex = parser.parse_args_into_dataclasses([])[0] - self.assertEqual(enum_ex.foo, MixedTypeEnum.toto) - - args = parser.parse_args(["--foo", "titi"]) - self.assertEqual(args.foo, "titi") - enum_ex = parser.parse_args_into_dataclasses(["--foo", "titi"])[0] - self.assertEqual(enum_ex.foo, MixedTypeEnum.titi) - - args = parser.parse_args(["--foo", "42"]) - self.assertEqual(args.foo, 42) - enum_ex = parser.parse_args_into_dataclasses(["--foo", "42"])[0] - self.assertEqual(enum_ex.foo, MixedTypeEnum.fourtytwo) - - def test_with_literal(self): - @dataclass - class LiteralExample: - foo: Literal["titi", "toto", 42] = "toto" - - parser = HfArgumentParser(LiteralExample) - - expected = argparse.ArgumentParser() - expected.add_argument( - "--foo", - default="toto", - choices=("titi", "toto", 42), - type=make_choice_type_function(["titi", "toto", 42]), - ) - self.argparsersEqual(parser, expected) - - args = parser.parse_args([]) - self.assertEqual(args.foo, "toto") - - args = parser.parse_args(["--foo", "titi"]) - self.assertEqual(args.foo, "titi") - - args = parser.parse_args(["--foo", "42"]) - self.assertEqual(args.foo, 42) - - def test_with_list(self): - parser = HfArgumentParser(ListExample) - - expected = argparse.ArgumentParser() - expected.add_argument("--foo_int", nargs="+", default=[], type=int) - expected.add_argument("--bar_int", nargs="+", default=[1, 2, 3], type=int) - expected.add_argument("--foo_str", nargs="+", default=["Hallo", "Bonjour", "Hello"], type=str) - expected.add_argument("--foo_float", nargs="+", default=[0.1, 0.2, 0.3], type=float) - - self.argparsersEqual(parser, expected) - - args = parser.parse_args([]) - self.assertEqual( - args, - Namespace(foo_int=[], bar_int=[1, 2, 3], foo_str=["Hallo", "Bonjour", "Hello"], foo_float=[0.1, 0.2, 0.3]), - ) - - args = parser.parse_args("--foo_int 1 --bar_int 2 3 --foo_str a b c --foo_float 0.1 0.7".split()) - self.assertEqual(args, Namespace(foo_int=[1], bar_int=[2, 3], foo_str=["a", "b", "c"], foo_float=[0.1, 0.7])) - - def test_with_optional(self): - expected = argparse.ArgumentParser() - expected.add_argument("--foo", default=None, type=int) - expected.add_argument("--bar", default=None, type=float, help="help message") - expected.add_argument("--baz", default=None, type=str) - expected.add_argument("--ces", nargs="+", default=[], type=str) - expected.add_argument("--des", nargs="+", default=[], type=int) - - dataclass_types = [OptionalExample] - if is_python_no_less_than_3_10: - dataclass_types.append(OptionalExamplePep604) - - for dataclass_type in dataclass_types: - parser = HfArgumentParser(dataclass_type) - - self.argparsersEqual(parser, expected) - - args = parser.parse_args([]) - self.assertEqual(args, Namespace(foo=None, bar=None, baz=None, ces=[], des=[])) - - args = parser.parse_args("--foo 12 --bar 3.14 --baz 42 --ces a b c --des 1 2 3".split()) - self.assertEqual(args, Namespace(foo=12, bar=3.14, baz="42", ces=["a", "b", "c"], des=[1, 2, 3])) - - def test_with_required(self): - parser = HfArgumentParser(RequiredExample) - - expected = argparse.ArgumentParser() - expected.add_argument("--required_list", nargs="+", type=int, required=True) - expected.add_argument("--required_str", type=str, required=True) - expected.add_argument( - "--required_enum", - type=make_choice_type_function(["titi", "toto"]), - choices=["titi", "toto"], - required=True, - ) - self.argparsersEqual(parser, expected) - - def test_with_string_literal_annotation(self): - parser = HfArgumentParser(StringLiteralAnnotationExample) - - expected = argparse.ArgumentParser() - expected.add_argument("--foo", type=int, required=True) - expected.add_argument( - "--required_enum", - type=make_choice_type_function(["titi", "toto"]), - choices=["titi", "toto"], - required=True, - ) - expected.add_argument("--opt", type=string_to_bool, default=None) - expected.add_argument("--baz", default="toto", type=str, help="help message") - expected.add_argument("--foo_str", nargs="+", default=["Hallo", "Bonjour", "Hello"], type=str) - self.argparsersEqual(parser, expected) - - def test_parse_dict(self): - parser = HfArgumentParser(BasicExample) - - args_dict = { - "foo": 12, - "bar": 3.14, - "baz": "42", - "flag": True, - } - - parsed_args = parser.parse_dict(args_dict)[0] - args = BasicExample(**args_dict) - self.assertEqual(parsed_args, args) - - def test_parse_dict_extra_key(self): - parser = HfArgumentParser(BasicExample) - - args_dict = { - "foo": 12, - "bar": 3.14, - "baz": "42", - "flag": True, - "extra": 42, - } - - self.assertRaises(ValueError, parser.parse_dict, args_dict, allow_extra_keys=False) - - def test_parse_json(self): - parser = HfArgumentParser(BasicExample) - - args_dict_for_json = { - "foo": 12, - "bar": 3.14, - "baz": "42", - "flag": True, - } - with tempfile.TemporaryDirectory() as tmp_dir: - temp_local_path = os.path.join(tmp_dir, "temp_json") - os.mkdir(temp_local_path) - with open(temp_local_path + ".json", "w+") as f: - json.dump(args_dict_for_json, f) - parsed_args = parser.parse_yaml_file(Path(temp_local_path + ".json"))[0] - - args = BasicExample(**args_dict_for_json) - self.assertEqual(parsed_args, args) - - def test_parse_yaml(self): - parser = HfArgumentParser(BasicExample) - - args_dict_for_yaml = { - "foo": 12, - "bar": 3.14, - "baz": "42", - "flag": True, - } - with tempfile.TemporaryDirectory() as tmp_dir: - temp_local_path = os.path.join(tmp_dir, "temp_yaml") - os.mkdir(temp_local_path) - with open(temp_local_path + ".yaml", "w+") as f: - yaml.dump(args_dict_for_yaml, f) - parsed_args = parser.parse_yaml_file(Path(temp_local_path + ".yaml"))[0] - args = BasicExample(**args_dict_for_yaml) - self.assertEqual(parsed_args, args) - - def test_integration_training_args(self): - parser = HfArgumentParser(TrainingArguments) - self.assertIsNotNone(parser) diff --git a/tests/transformers/tests/utils/test_hub_utils.py b/tests/transformers/tests/utils/test_hub_utils.py deleted file mode 100644 index 836f4f5fa7..0000000000 --- a/tests/transformers/tests/utils/test_hub_utils.py +++ /dev/null @@ -1,140 +0,0 @@ -# Copyright 2020 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -import json -import os -import tempfile -import unittest -import unittest.mock as mock -from pathlib import Path - -from requests.exceptions import HTTPError -from transformers.utils import ( - CONFIG_NAME, - FLAX_WEIGHTS_NAME, - TF2_WEIGHTS_NAME, - TRANSFORMERS_CACHE, - WEIGHTS_NAME, - cached_file, - get_file_from_repo, - has_file, -) - - -RANDOM_BERT = "hf-internal-testing/tiny-random-bert" -CACHE_DIR = os.path.join(TRANSFORMERS_CACHE, "models--hf-internal-testing--tiny-random-bert") -FULL_COMMIT_HASH = "9b8c223d42b2188cb49d29af482996f9d0f3e5a6" - -GATED_REPO = "hf-internal-testing/dummy-gated-model" -README_FILE = "README.md" - - -class GetFromCacheTests(unittest.TestCase): - def test_cached_file(self): - archive_file = cached_file(RANDOM_BERT, CONFIG_NAME) - # Should have downloaded the file in here - self.assertTrue(os.path.isdir(CACHE_DIR)) - # Cache should contain at least those three subfolders: - for subfolder in ["blobs", "refs", "snapshots"]: - self.assertTrue(os.path.isdir(os.path.join(CACHE_DIR, subfolder))) - with open(os.path.join(CACHE_DIR, "refs", "main")) as f: - main_commit = f.read() - self.assertEqual(archive_file, os.path.join(CACHE_DIR, "snapshots", main_commit, CONFIG_NAME)) - self.assertTrue(os.path.isfile(archive_file)) - - # File is cached at the same place the second time. - new_archive_file = cached_file(RANDOM_BERT, CONFIG_NAME) - self.assertEqual(archive_file, new_archive_file) - - # Using a specific revision to test the full commit hash. - archive_file = cached_file(RANDOM_BERT, CONFIG_NAME, revision="9b8c223") - self.assertEqual(archive_file, os.path.join(CACHE_DIR, "snapshots", FULL_COMMIT_HASH, CONFIG_NAME)) - - def test_cached_file_errors(self): - with self.assertRaisesRegex(EnvironmentError, "is not a valid model identifier"): - _ = cached_file("tiny-random-bert", CONFIG_NAME) - - with self.assertRaisesRegex(EnvironmentError, "is not a valid git identifier"): - _ = cached_file(RANDOM_BERT, CONFIG_NAME, revision="aaaa") - - with self.assertRaisesRegex(EnvironmentError, "does not appear to have a file named"): - _ = cached_file(RANDOM_BERT, "conf") - - def test_non_existence_is_cached(self): - with self.assertRaisesRegex(EnvironmentError, "does not appear to have a file named"): - _ = cached_file(RANDOM_BERT, "conf") - - with open(os.path.join(CACHE_DIR, "refs", "main")) as f: - main_commit = f.read() - self.assertTrue(os.path.isfile(os.path.join(CACHE_DIR, ".no_exist", main_commit, "conf"))) - - path = cached_file(RANDOM_BERT, "conf", _raise_exceptions_for_missing_entries=False) - self.assertIsNone(path) - - path = cached_file(RANDOM_BERT, "conf", local_files_only=True, _raise_exceptions_for_missing_entries=False) - self.assertIsNone(path) - - response_mock = mock.Mock() - response_mock.status_code = 500 - response_mock.headers = {} - response_mock.raise_for_status.side_effect = HTTPError - response_mock.json.return_value = {} - - # Under the mock environment we get a 500 error when trying to reach the tokenizer. - with mock.patch("requests.Session.request", return_value=response_mock) as mock_head: - path = cached_file(RANDOM_BERT, "conf", _raise_exceptions_for_connection_errors=False) - self.assertIsNone(path) - # This check we did call the fake head request - mock_head.assert_called() - - def test_has_file(self): - self.assertTrue(has_file("hf-internal-testing/tiny-bert-pt-only", WEIGHTS_NAME)) - self.assertFalse(has_file("hf-internal-testing/tiny-bert-pt-only", TF2_WEIGHTS_NAME)) - self.assertFalse(has_file("hf-internal-testing/tiny-bert-pt-only", FLAX_WEIGHTS_NAME)) - - def test_get_file_from_repo_distant(self): - # `get_file_from_repo` returns None if the file does not exist - self.assertIsNone(get_file_from_repo("bert-base-cased", "ahah.txt")) - - # The function raises if the repository does not exist. - with self.assertRaisesRegex(EnvironmentError, "is not a valid model identifier"): - get_file_from_repo("bert-base-case", CONFIG_NAME) - - # The function raises if the revision does not exist. - with self.assertRaisesRegex(EnvironmentError, "is not a valid git identifier"): - get_file_from_repo("bert-base-cased", CONFIG_NAME, revision="ahaha") - - resolved_file = get_file_from_repo("bert-base-cased", CONFIG_NAME) - # The name is the cached name which is not very easy to test, so instead we load the content. - config = json.loads(open(resolved_file, "r").read()) - self.assertEqual(config["hidden_size"], 768) - - def test_get_file_from_repo_local(self): - with tempfile.TemporaryDirectory() as tmp_dir: - filename = Path(tmp_dir) / "a.txt" - filename.touch() - self.assertEqual(get_file_from_repo(tmp_dir, "a.txt"), str(filename)) - - self.assertIsNone(get_file_from_repo(tmp_dir, "b.txt")) - - @unittest.skip("Test is broken, fix me Wauplain!") - def test_get_file_gated_repo(self): - """Test download file from a gated repo fails with correct message when not authenticated.""" - with self.assertRaisesRegex(EnvironmentError, "You are trying to access a gated repo."): - cached_file(GATED_REPO, README_FILE, use_auth_token=False) - - @unittest.skip("Test is broken, fix me Wauplain!") - def test_has_file_gated_repo(self): - """Test check file existence from a gated repo fails with correct message when not authenticated.""" - with self.assertRaisesRegex(EnvironmentError, "is a gated repository"): - has_file(GATED_REPO, README_FILE, use_auth_token=False) diff --git a/tests/transformers/tests/utils/test_image_processing_utils.py b/tests/transformers/tests/utils/test_image_processing_utils.py deleted file mode 100644 index afb6283e6e..0000000000 --- a/tests/transformers/tests/utils/test_image_processing_utils.py +++ /dev/null @@ -1,71 +0,0 @@ -# coding=utf-8 -# Copyright 2022 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import unittest - -from transformers.image_processing_utils import get_size_dict - - -class ImageProcessingUtilsTester(unittest.TestCase): - def test_get_size_dict(self): - # Test a dict with the wrong keys raises an error - inputs = {"wrong_key": 224} - with self.assertRaises(ValueError): - get_size_dict(inputs) - - inputs = {"height": 224} - with self.assertRaises(ValueError): - get_size_dict(inputs) - - inputs = {"width": 224, "shortest_edge": 224} - with self.assertRaises(ValueError): - get_size_dict(inputs) - - # Test a dict with the correct keys is returned as is - inputs = {"height": 224, "width": 224} - outputs = get_size_dict(inputs) - self.assertEqual(outputs, inputs) - - inputs = {"shortest_edge": 224} - outputs = get_size_dict(inputs) - self.assertEqual(outputs, {"shortest_edge": 224}) - - inputs = {"longest_edge": 224, "shortest_edge": 224} - outputs = get_size_dict(inputs) - self.assertEqual(outputs, {"longest_edge": 224, "shortest_edge": 224}) - - # Test a single int value which represents (size, size) - outputs = get_size_dict(224) - self.assertEqual(outputs, {"height": 224, "width": 224}) - - # Test a single int value which represents the shortest edge - outputs = get_size_dict(224, default_to_square=False) - self.assertEqual(outputs, {"shortest_edge": 224}) - - # Test a tuple of ints which represents (height, width) - outputs = get_size_dict((150, 200)) - self.assertEqual(outputs, {"height": 150, "width": 200}) - - # Test a tuple of ints which represents (width, height) - outputs = get_size_dict((150, 200), height_width_order=False) - self.assertEqual(outputs, {"height": 200, "width": 150}) - - # Test an int representing the shortest edge and max_size which represents the longest edge - outputs = get_size_dict(224, max_size=256, default_to_square=False) - self.assertEqual(outputs, {"shortest_edge": 224, "longest_edge": 256}) - - # Test int with default_to_square=True and max_size fails - with self.assertRaises(ValueError): - get_size_dict(224, max_size=256, default_to_square=True) diff --git a/tests/transformers/tests/utils/test_image_utils.py b/tests/transformers/tests/utils/test_image_utils.py deleted file mode 100644 index a5efb87c03..0000000000 --- a/tests/transformers/tests/utils/test_image_utils.py +++ /dev/null @@ -1,628 +0,0 @@ -# coding=utf-8 -# Copyright 2021 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import unittest - -import datasets -import numpy as np -import pytest -from requests import ReadTimeout -from transformers import is_torch_available, is_vision_available -from transformers.image_utils import ChannelDimension, get_channel_dimension_axis, make_list_of_images -from transformers.testing_utils import is_flaky, require_torch, require_vision - -from tests.pipelines.test_pipelines_document_question_answering import INVOICE_URL - - -if is_torch_available(): - import torch - -if is_vision_available(): - import PIL.Image - from transformers import ImageFeatureExtractionMixin - from transformers.image_utils import get_image_size, infer_channel_dimension_format, load_image - - -def get_random_image(height, width): - random_array = np.random.randint(0, 256, (height, width, 3), dtype=np.uint8) - return PIL.Image.fromarray(random_array) - - -@require_vision -class ImageFeatureExtractionTester(unittest.TestCase): - def test_conversion_image_to_array(self): - feature_extractor = ImageFeatureExtractionMixin() - image = get_random_image(16, 32) - - # Conversion with defaults (rescale + channel first) - array1 = feature_extractor.to_numpy_array(image) - self.assertTrue(array1.dtype, np.float32) - self.assertEqual(array1.shape, (3, 16, 32)) - - # Conversion with rescale and not channel first - array2 = feature_extractor.to_numpy_array(image, channel_first=False) - self.assertTrue(array2.dtype, np.float32) - self.assertEqual(array2.shape, (16, 32, 3)) - self.assertTrue(np.array_equal(array1, array2.transpose(2, 0, 1))) - - # Conversion with no rescale and channel first - array3 = feature_extractor.to_numpy_array(image, rescale=False) - self.assertTrue(array3.dtype, np.uint8) - self.assertEqual(array3.shape, (3, 16, 32)) - self.assertTrue(np.array_equal(array1, array3.astype(np.float32) * (1 / 255.0))) - - # Conversion with no rescale and not channel first - array4 = feature_extractor.to_numpy_array(image, rescale=False, channel_first=False) - self.assertTrue(array4.dtype, np.uint8) - self.assertEqual(array4.shape, (16, 32, 3)) - self.assertTrue(np.array_equal(array2, array4.astype(np.float32) * (1 / 255.0))) - - def test_conversion_array_to_array(self): - feature_extractor = ImageFeatureExtractionMixin() - array = np.random.randint(0, 256, (16, 32, 3), dtype=np.uint8) - - # By default, rescale (for an array of ints) and channel permute - array1 = feature_extractor.to_numpy_array(array) - self.assertTrue(array1.dtype, np.float32) - self.assertEqual(array1.shape, (3, 16, 32)) - self.assertTrue(np.array_equal(array1, array.transpose(2, 0, 1).astype(np.float32) * (1 / 255.0))) - - # Same with no permute - array2 = feature_extractor.to_numpy_array(array, channel_first=False) - self.assertTrue(array2.dtype, np.float32) - self.assertEqual(array2.shape, (16, 32, 3)) - self.assertTrue(np.array_equal(array2, array.astype(np.float32) * (1 / 255.0))) - - # Force rescale to False - array3 = feature_extractor.to_numpy_array(array, rescale=False) - self.assertTrue(array3.dtype, np.uint8) - self.assertEqual(array3.shape, (3, 16, 32)) - self.assertTrue(np.array_equal(array3, array.transpose(2, 0, 1))) - - # Force rescale to False and no channel permute - array4 = feature_extractor.to_numpy_array(array, rescale=False, channel_first=False) - self.assertTrue(array4.dtype, np.uint8) - self.assertEqual(array4.shape, (16, 32, 3)) - self.assertTrue(np.array_equal(array4, array)) - - # Now test the default rescale for a float array (defaults to False) - array5 = feature_extractor.to_numpy_array(array2) - self.assertTrue(array5.dtype, np.float32) - self.assertEqual(array5.shape, (3, 16, 32)) - self.assertTrue(np.array_equal(array5, array1)) - - def test_make_list_of_images_numpy(self): - # Test a single image is converted to a list of 1 image - images = np.random.randint(0, 256, (16, 32, 3)) - images_list = make_list_of_images(images) - self.assertEqual(len(images_list), 1) - self.assertTrue(np.array_equal(images_list[0], images)) - self.assertIsInstance(images_list, list) - - # Test a batch of images is converted to a list of images - images = np.random.randint(0, 256, (4, 16, 32, 3)) - images_list = make_list_of_images(images) - self.assertEqual(len(images_list), 4) - self.assertTrue(np.array_equal(images_list[0], images[0])) - self.assertIsInstance(images_list, list) - - # Test a list of images is not modified - images = [np.random.randint(0, 256, (16, 32, 3)) for _ in range(4)] - images_list = make_list_of_images(images) - self.assertEqual(len(images_list), 4) - self.assertTrue(np.array_equal(images_list[0], images[0])) - self.assertIsInstance(images_list, list) - - # Test batched masks with no channel dimension are converted to a list of masks - masks = np.random.randint(0, 2, (4, 16, 32)) - masks_list = make_list_of_images(masks, expected_ndims=2) - self.assertEqual(len(masks_list), 4) - self.assertTrue(np.array_equal(masks_list[0], masks[0])) - self.assertIsInstance(masks_list, list) - - @require_torch - def test_make_list_of_images_torch(self): - # Test a single image is converted to a list of 1 image - images = torch.randint(0, 256, (16, 32, 3)) - images_list = make_list_of_images(images) - self.assertEqual(len(images_list), 1) - self.assertTrue(np.array_equal(images_list[0], images)) - self.assertIsInstance(images_list, list) - - # Test a batch of images is converted to a list of images - images = torch.randint(0, 256, (4, 16, 32, 3)) - images_list = make_list_of_images(images) - self.assertEqual(len(images_list), 4) - self.assertTrue(np.array_equal(images_list[0], images[0])) - self.assertIsInstance(images_list, list) - - # Test a list of images is left unchanged - images = [torch.randint(0, 256, (16, 32, 3)) for _ in range(4)] - images_list = make_list_of_images(images) - self.assertEqual(len(images_list), 4) - self.assertTrue(np.array_equal(images_list[0], images[0])) - self.assertIsInstance(images_list, list) - - @require_torch - def test_conversion_torch_to_array(self): - feature_extractor = ImageFeatureExtractionMixin() - tensor = torch.randint(0, 256, (16, 32, 3)) - array = tensor.numpy() - - # By default, rescale (for a tensor of ints) and channel permute - array1 = feature_extractor.to_numpy_array(array) - self.assertTrue(array1.dtype, np.float32) - self.assertEqual(array1.shape, (3, 16, 32)) - self.assertTrue(np.array_equal(array1, array.transpose(2, 0, 1).astype(np.float32) * (1 / 255.0))) - - # Same with no permute - array2 = feature_extractor.to_numpy_array(array, channel_first=False) - self.assertTrue(array2.dtype, np.float32) - self.assertEqual(array2.shape, (16, 32, 3)) - self.assertTrue(np.array_equal(array2, array.astype(np.float32) * (1 / 255.0))) - - # Force rescale to False - array3 = feature_extractor.to_numpy_array(array, rescale=False) - self.assertTrue(array3.dtype, np.uint8) - self.assertEqual(array3.shape, (3, 16, 32)) - self.assertTrue(np.array_equal(array3, array.transpose(2, 0, 1))) - - # Force rescale to False and no channel permute - array4 = feature_extractor.to_numpy_array(array, rescale=False, channel_first=False) - self.assertTrue(array4.dtype, np.uint8) - self.assertEqual(array4.shape, (16, 32, 3)) - self.assertTrue(np.array_equal(array4, array)) - - # Now test the default rescale for a float tensor (defaults to False) - array5 = feature_extractor.to_numpy_array(array2) - self.assertTrue(array5.dtype, np.float32) - self.assertEqual(array5.shape, (3, 16, 32)) - self.assertTrue(np.array_equal(array5, array1)) - - def test_conversion_image_to_image(self): - feature_extractor = ImageFeatureExtractionMixin() - image = get_random_image(16, 32) - - # On an image, `to_pil_image1` is a noop. - image1 = feature_extractor.to_pil_image(image) - self.assertTrue(isinstance(image, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image), np.array(image1))) - - def test_conversion_array_to_image(self): - feature_extractor = ImageFeatureExtractionMixin() - array = np.random.randint(0, 256, (16, 32, 3), dtype=np.uint8) - - # By default, no rescale (for an array of ints) - image1 = feature_extractor.to_pil_image(array) - self.assertTrue(isinstance(image1, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image1), array)) - - # If the array is channel-first, proper reordering of the channels is done. - image2 = feature_extractor.to_pil_image(array.transpose(2, 0, 1)) - self.assertTrue(isinstance(image2, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image2), array)) - - # If the array has floating type, it's rescaled by default. - image3 = feature_extractor.to_pil_image(array.astype(np.float32) * (1 / 255.0)) - self.assertTrue(isinstance(image3, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image3), array)) - - # You can override the default to rescale. - image4 = feature_extractor.to_pil_image(array.astype(np.float32), rescale=False) - self.assertTrue(isinstance(image4, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image4), array)) - - # And with floats + channel first. - image5 = feature_extractor.to_pil_image(array.transpose(2, 0, 1).astype(np.float32) * (1 / 255.0)) - self.assertTrue(isinstance(image5, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image5), array)) - - @require_torch - def test_conversion_tensor_to_image(self): - feature_extractor = ImageFeatureExtractionMixin() - tensor = torch.randint(0, 256, (16, 32, 3)) - array = tensor.numpy() - - # By default, no rescale (for a tensor of ints) - image1 = feature_extractor.to_pil_image(tensor) - self.assertTrue(isinstance(image1, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image1), array)) - - # If the tensor is channel-first, proper reordering of the channels is done. - image2 = feature_extractor.to_pil_image(tensor.permute(2, 0, 1)) - self.assertTrue(isinstance(image2, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image2), array)) - - # If the tensor has floating type, it's rescaled by default. - image3 = feature_extractor.to_pil_image(tensor.float() / 255.0) - self.assertTrue(isinstance(image3, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image3), array)) - - # You can override the default to rescale. - image4 = feature_extractor.to_pil_image(tensor.float(), rescale=False) - self.assertTrue(isinstance(image4, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image4), array)) - - # And with floats + channel first. - image5 = feature_extractor.to_pil_image(tensor.permute(2, 0, 1).float() * (1 / 255.0)) - self.assertTrue(isinstance(image5, PIL.Image.Image)) - self.assertTrue(np.array_equal(np.array(image5), array)) - - def test_resize_image_and_array(self): - feature_extractor = ImageFeatureExtractionMixin() - image = get_random_image(16, 32) - array = np.array(image) - - # Size can be an int or a tuple of ints. - resized_image = feature_extractor.resize(image, 8) - self.assertTrue(isinstance(resized_image, PIL.Image.Image)) - self.assertEqual(resized_image.size, (8, 8)) - - resized_image1 = feature_extractor.resize(image, (8, 16)) - self.assertTrue(isinstance(resized_image1, PIL.Image.Image)) - self.assertEqual(resized_image1.size, (8, 16)) - - # Passing an array converts it to a PIL Image. - resized_image2 = feature_extractor.resize(array, 8) - self.assertTrue(isinstance(resized_image2, PIL.Image.Image)) - self.assertEqual(resized_image2.size, (8, 8)) - self.assertTrue(np.array_equal(np.array(resized_image), np.array(resized_image2))) - - resized_image3 = feature_extractor.resize(image, (8, 16)) - self.assertTrue(isinstance(resized_image3, PIL.Image.Image)) - self.assertEqual(resized_image3.size, (8, 16)) - self.assertTrue(np.array_equal(np.array(resized_image1), np.array(resized_image3))) - - def test_resize_image_and_array_non_default_to_square(self): - feature_extractor = ImageFeatureExtractionMixin() - - heights_widths = [ - # height, width - # square image - (28, 28), - (27, 27), - # rectangular image: h < w - (28, 34), - (29, 35), - # rectangular image: h > w - (34, 28), - (35, 29), - ] - - # single integer or single integer in tuple/list - sizes = [22, 27, 28, 36, [22], (27,)] - - for (height, width), size in zip(heights_widths, sizes): - for max_size in (None, 37, 1000): - image = get_random_image(height, width) - array = np.array(image) - - size = size[0] if isinstance(size, (list, tuple)) else size - # Size can be an int or a tuple of ints. - # If size is an int, smaller edge of the image will be matched to this number. - # i.e, if height > width, then image will be rescaled to (size * height / width, size). - if height < width: - exp_w, exp_h = (int(size * width / height), size) - if max_size is not None and max_size < exp_w: - exp_w, exp_h = max_size, int(max_size * exp_h / exp_w) - elif width < height: - exp_w, exp_h = (size, int(size * height / width)) - if max_size is not None and max_size < exp_h: - exp_w, exp_h = int(max_size * exp_w / exp_h), max_size - else: - exp_w, exp_h = (size, size) - if max_size is not None and max_size < size: - exp_w, exp_h = max_size, max_size - - resized_image = feature_extractor.resize(image, size=size, default_to_square=False, max_size=max_size) - self.assertTrue(isinstance(resized_image, PIL.Image.Image)) - self.assertEqual(resized_image.size, (exp_w, exp_h)) - - # Passing an array converts it to a PIL Image. - resized_image2 = feature_extractor.resize(array, size=size, default_to_square=False, max_size=max_size) - self.assertTrue(isinstance(resized_image2, PIL.Image.Image)) - self.assertEqual(resized_image2.size, (exp_w, exp_h)) - self.assertTrue(np.array_equal(np.array(resized_image), np.array(resized_image2))) - - @require_torch - def test_resize_tensor(self): - feature_extractor = ImageFeatureExtractionMixin() - tensor = torch.randint(0, 256, (16, 32, 3)) - array = tensor.numpy() - - # Size can be an int or a tuple of ints. - resized_image = feature_extractor.resize(tensor, 8) - self.assertTrue(isinstance(resized_image, PIL.Image.Image)) - self.assertEqual(resized_image.size, (8, 8)) - - resized_image1 = feature_extractor.resize(tensor, (8, 16)) - self.assertTrue(isinstance(resized_image1, PIL.Image.Image)) - self.assertEqual(resized_image1.size, (8, 16)) - - # Check we get the same results as with NumPy arrays. - resized_image2 = feature_extractor.resize(array, 8) - self.assertTrue(np.array_equal(np.array(resized_image), np.array(resized_image2))) - - resized_image3 = feature_extractor.resize(array, (8, 16)) - self.assertTrue(np.array_equal(np.array(resized_image1), np.array(resized_image3))) - - def test_normalize_image(self): - feature_extractor = ImageFeatureExtractionMixin() - image = get_random_image(16, 32) - array = np.array(image) - mean = [0.1, 0.5, 0.9] - std = [0.2, 0.4, 0.6] - - # PIL Image are converted to NumPy arrays for the normalization - normalized_image = feature_extractor.normalize(image, mean, std) - self.assertTrue(isinstance(normalized_image, np.ndarray)) - self.assertEqual(normalized_image.shape, (3, 16, 32)) - - # During the conversion rescale and channel first will be applied. - expected = array.transpose(2, 0, 1).astype(np.float32) * (1 / 255.0) - np_mean = np.array(mean).astype(np.float32)[:, None, None] - np_std = np.array(std).astype(np.float32)[:, None, None] - expected = (expected - np_mean) / np_std - self.assertTrue(np.array_equal(normalized_image, expected)) - - def test_normalize_array(self): - feature_extractor = ImageFeatureExtractionMixin() - array = np.random.random((16, 32, 3)) - mean = [0.1, 0.5, 0.9] - std = [0.2, 0.4, 0.6] - - # mean and std can be passed as lists or NumPy arrays. - expected = (array - np.array(mean)) / np.array(std) - normalized_array = feature_extractor.normalize(array, mean, std) - self.assertTrue(np.array_equal(normalized_array, expected)) - - normalized_array = feature_extractor.normalize(array, np.array(mean), np.array(std)) - self.assertTrue(np.array_equal(normalized_array, expected)) - - # Normalize will detect automatically if channel first or channel last is used. - array = np.random.random((3, 16, 32)) - expected = (array - np.array(mean)[:, None, None]) / np.array(std)[:, None, None] - normalized_array = feature_extractor.normalize(array, mean, std) - self.assertTrue(np.array_equal(normalized_array, expected)) - - normalized_array = feature_extractor.normalize(array, np.array(mean), np.array(std)) - self.assertTrue(np.array_equal(normalized_array, expected)) - - @require_torch - def test_normalize_tensor(self): - feature_extractor = ImageFeatureExtractionMixin() - tensor = torch.rand(16, 32, 3) - mean = [0.1, 0.5, 0.9] - std = [0.2, 0.4, 0.6] - - # mean and std can be passed as lists or tensors. - expected = (tensor - torch.tensor(mean)) / torch.tensor(std) - normalized_tensor = feature_extractor.normalize(tensor, mean, std) - self.assertTrue(torch.equal(normalized_tensor, expected)) - - normalized_tensor = feature_extractor.normalize(tensor, torch.tensor(mean), torch.tensor(std)) - self.assertTrue(torch.equal(normalized_tensor, expected)) - - # Normalize will detect automatically if channel first or channel last is used. - tensor = torch.rand(3, 16, 32) - expected = (tensor - torch.tensor(mean)[:, None, None]) / torch.tensor(std)[:, None, None] - normalized_tensor = feature_extractor.normalize(tensor, mean, std) - self.assertTrue(torch.equal(normalized_tensor, expected)) - - normalized_tensor = feature_extractor.normalize(tensor, torch.tensor(mean), torch.tensor(std)) - self.assertTrue(torch.equal(normalized_tensor, expected)) - - def test_center_crop_image(self): - feature_extractor = ImageFeatureExtractionMixin() - image = get_random_image(16, 32) - - # Test various crop sizes: bigger on all dimensions, on one of the dimensions only and on both dimensions. - crop_sizes = [8, (8, 64), 20, (32, 64)] - for size in crop_sizes: - cropped_image = feature_extractor.center_crop(image, size) - self.assertTrue(isinstance(cropped_image, PIL.Image.Image)) - - # PIL Image.size is transposed compared to NumPy or PyTorch (width first instead of height first). - expected_size = (size, size) if isinstance(size, int) else (size[1], size[0]) - self.assertEqual(cropped_image.size, expected_size) - - def test_center_crop_array(self): - feature_extractor = ImageFeatureExtractionMixin() - image = get_random_image(16, 32) - array = feature_extractor.to_numpy_array(image) - - # Test various crop sizes: bigger on all dimensions, on one of the dimensions only and on both dimensions. - crop_sizes = [8, (8, 64), 20, (32, 64)] - for size in crop_sizes: - cropped_array = feature_extractor.center_crop(array, size) - self.assertTrue(isinstance(cropped_array, np.ndarray)) - - expected_size = (size, size) if isinstance(size, int) else size - self.assertEqual(cropped_array.shape[-2:], expected_size) - - # Check result is consistent with PIL.Image.crop - cropped_image = feature_extractor.center_crop(image, size) - self.assertTrue(np.array_equal(cropped_array, feature_extractor.to_numpy_array(cropped_image))) - - @require_torch - def test_center_crop_tensor(self): - feature_extractor = ImageFeatureExtractionMixin() - image = get_random_image(16, 32) - array = feature_extractor.to_numpy_array(image) - tensor = torch.tensor(array) - - # Test various crop sizes: bigger on all dimensions, on one of the dimensions only and on both dimensions. - crop_sizes = [8, (8, 64), 20, (32, 64)] - for size in crop_sizes: - cropped_tensor = feature_extractor.center_crop(tensor, size) - self.assertTrue(isinstance(cropped_tensor, torch.Tensor)) - - expected_size = (size, size) if isinstance(size, int) else size - self.assertEqual(cropped_tensor.shape[-2:], expected_size) - - # Check result is consistent with PIL.Image.crop - cropped_image = feature_extractor.center_crop(image, size) - self.assertTrue(torch.equal(cropped_tensor, torch.tensor(feature_extractor.to_numpy_array(cropped_image)))) - - -@require_vision -class LoadImageTester(unittest.TestCase): - def test_load_img_url(self): - img = load_image(INVOICE_URL) - img_arr = np.array(img) - - self.assertEqual(img_arr.shape, (1061, 750, 3)) - - @is_flaky() - def test_load_img_url_timeout(self): - with self.assertRaises(ReadTimeout): - load_image(INVOICE_URL, timeout=0.001) - - def test_load_img_local(self): - img = load_image("./tests/fixtures/tests_samples/COCO/000000039769.png") - img_arr = np.array(img) - - self.assertEqual( - img_arr.shape, - (480, 640, 3), - ) - - def test_load_img_rgba(self): - dataset = datasets.load_dataset("hf-internal-testing/fixtures_image_utils", "image", split="test") - - img = load_image(dataset[0]["file"]) # img with mode RGBA - img_arr = np.array(img) - - self.assertEqual( - img_arr.shape, - (512, 512, 3), - ) - - def test_load_img_la(self): - dataset = datasets.load_dataset("hf-internal-testing/fixtures_image_utils", "image", split="test") - - img = load_image(dataset[1]["file"]) # img with mode LA - img_arr = np.array(img) - - self.assertEqual( - img_arr.shape, - (512, 768, 3), - ) - - def test_load_img_l(self): - dataset = datasets.load_dataset("hf-internal-testing/fixtures_image_utils", "image", split="test") - - img = load_image(dataset[2]["file"]) # img with mode L - img_arr = np.array(img) - - self.assertEqual( - img_arr.shape, - (381, 225, 3), - ) - - def test_load_img_exif_transpose(self): - dataset = datasets.load_dataset("hf-internal-testing/fixtures_image_utils", "image", split="test") - img_file = dataset[3]["file"] - - img_without_exif_transpose = PIL.Image.open(img_file) - img_arr_without_exif_transpose = np.array(img_without_exif_transpose) - - self.assertEqual( - img_arr_without_exif_transpose.shape, - (333, 500, 3), - ) - - img_with_exif_transpose = load_image(img_file) - img_arr_with_exif_transpose = np.array(img_with_exif_transpose) - - self.assertEqual( - img_arr_with_exif_transpose.shape, - (500, 333, 3), - ) - - -class UtilFunctionTester(unittest.TestCase): - def test_get_image_size(self): - # Test we can infer the size and channel dimension of an image. - image = np.random.randint(0, 256, (32, 64, 3)) - self.assertEqual(get_image_size(image), (32, 64)) - - image = np.random.randint(0, 256, (3, 32, 64)) - self.assertEqual(get_image_size(image), (32, 64)) - - # Test the channel dimension can be overriden - image = np.random.randint(0, 256, (3, 32, 64)) - self.assertEqual(get_image_size(image, channel_dim=ChannelDimension.LAST), (3, 32)) - - def test_infer_channel_dimension(self): - # Test we fail with invalid input - with pytest.raises(ValueError): - infer_channel_dimension_format(np.random.randint(0, 256, (10, 10))) - - with pytest.raises(ValueError): - infer_channel_dimension_format(np.random.randint(0, 256, (10, 10, 10, 10, 10))) - - # Test we fail if neither first not last dimension is of size 3 or 1 - with pytest.raises(ValueError): - infer_channel_dimension_format(np.random.randint(0, 256, (10, 1, 50))) - - # But if we explicitly set one of the number of channels to 50 it works - inferred_dim = infer_channel_dimension_format(np.random.randint(0, 256, (10, 1, 50)), num_channels=50) - self.assertEqual(inferred_dim, ChannelDimension.LAST) - - # Test we correctly identify the channel dimension - image = np.random.randint(0, 256, (3, 4, 5)) - inferred_dim = infer_channel_dimension_format(image) - self.assertEqual(inferred_dim, ChannelDimension.FIRST) - - image = np.random.randint(0, 256, (1, 4, 5)) - inferred_dim = infer_channel_dimension_format(image) - self.assertEqual(inferred_dim, ChannelDimension.FIRST) - - image = np.random.randint(0, 256, (4, 5, 3)) - inferred_dim = infer_channel_dimension_format(image) - self.assertEqual(inferred_dim, ChannelDimension.LAST) - - image = np.random.randint(0, 256, (4, 5, 1)) - inferred_dim = infer_channel_dimension_format(image) - self.assertEqual(inferred_dim, ChannelDimension.LAST) - - # We can take a batched array of images and find the dimension - image = np.random.randint(0, 256, (1, 3, 4, 5)) - inferred_dim = infer_channel_dimension_format(image) - self.assertEqual(inferred_dim, ChannelDimension.FIRST) - - def test_get_channel_dimension_axis(self): - # Test we correctly identify the channel dimension - image = np.random.randint(0, 256, (3, 4, 5)) - inferred_axis = get_channel_dimension_axis(image) - self.assertEqual(inferred_axis, 0) - - image = np.random.randint(0, 256, (1, 4, 5)) - inferred_axis = get_channel_dimension_axis(image) - self.assertEqual(inferred_axis, 0) - - image = np.random.randint(0, 256, (4, 5, 3)) - inferred_axis = get_channel_dimension_axis(image) - self.assertEqual(inferred_axis, 2) - - image = np.random.randint(0, 256, (4, 5, 1)) - inferred_axis = get_channel_dimension_axis(image) - self.assertEqual(inferred_axis, 2) - - # We can take a batched array of images and find the dimension - image = np.random.randint(0, 256, (1, 3, 4, 5)) - inferred_axis = get_channel_dimension_axis(image) - self.assertEqual(inferred_axis, 1) diff --git a/tests/transformers/tests/utils/test_logging.py b/tests/transformers/tests/utils/test_logging.py deleted file mode 100644 index 50b3ad78cf..0000000000 --- a/tests/transformers/tests/utils/test_logging.py +++ /dev/null @@ -1,134 +0,0 @@ -# Copyright 2020 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import os -import unittest - -import transformers.models.bart.tokenization_bart -from huggingface_hub.utils import are_progress_bars_disabled -from transformers import logging -from transformers.testing_utils import CaptureLogger, mockenv, mockenv_context -from transformers.utils.logging import disable_progress_bar, enable_progress_bar - - -class HfArgumentParserTest(unittest.TestCase): - def test_set_level(self): - logger = logging.get_logger() - - # the current default level is logging.WARNING - level_origin = logging.get_verbosity() - - logging.set_verbosity_error() - self.assertEqual(logger.getEffectiveLevel(), logging.get_verbosity()) - - logging.set_verbosity_warning() - self.assertEqual(logger.getEffectiveLevel(), logging.get_verbosity()) - - logging.set_verbosity_info() - self.assertEqual(logger.getEffectiveLevel(), logging.get_verbosity()) - - logging.set_verbosity_debug() - self.assertEqual(logger.getEffectiveLevel(), logging.get_verbosity()) - - # restore to the original level - logging.set_verbosity(level_origin) - - def test_integration(self): - level_origin = logging.get_verbosity() - - logger = logging.get_logger("transformers.models.bart.tokenization_bart") - msg = "Testing 1, 2, 3" - - # should be able to log warnings (if default settings weren't overridden by `pytest --log-level-all`) - if level_origin <= logging.WARNING: - with CaptureLogger(logger) as cl: - logger.warning(msg) - self.assertEqual(cl.out, msg + "\n") - - # this is setting the level for all of `transformers.*` loggers - logging.set_verbosity_error() - - # should not be able to log warnings - with CaptureLogger(logger) as cl: - logger.warning(msg) - self.assertEqual(cl.out, "") - - # should be able to log warnings again - logging.set_verbosity_warning() - with CaptureLogger(logger) as cl: - logger.warning(msg) - self.assertEqual(cl.out, msg + "\n") - - # restore to the original level - logging.set_verbosity(level_origin) - - @mockenv(TRANSFORMERS_VERBOSITY="error") - def test_env_override(self): - # reset for the env var to take effect, next time some logger call is made - transformers.utils.logging._reset_library_root_logger() - # this action activates the env var - _ = logging.get_logger("transformers.models.bart.tokenization_bart") - - env_level_str = os.getenv("TRANSFORMERS_VERBOSITY", None) - env_level = logging.log_levels[env_level_str] - - current_level = logging.get_verbosity() - self.assertEqual( - env_level, - current_level, - f"TRANSFORMERS_VERBOSITY={env_level_str}/{env_level}, but internal verbosity is {current_level}", - ) - - # restore to the original level - os.environ["TRANSFORMERS_VERBOSITY"] = "" - transformers.utils.logging._reset_library_root_logger() - - @mockenv(TRANSFORMERS_VERBOSITY="super-error") - def test_env_invalid_override(self): - # reset for the env var to take effect, next time some logger call is made - transformers.utils.logging._reset_library_root_logger() - logger = logging.logging.getLogger() - with CaptureLogger(logger) as cl: - # this action activates the env var - logging.get_logger("transformers.models.bart.tokenization_bart") - self.assertIn("Unknown option TRANSFORMERS_VERBOSITY=super-error", cl.out) - - # no need to restore as nothing was changed - - def test_advisory_warnings(self): - # testing `logger.warning_advice()` - transformers.utils.logging._reset_library_root_logger() - - logger = logging.get_logger("transformers.models.bart.tokenization_bart") - msg = "Testing 1, 2, 3" - - with mockenv_context(TRANSFORMERS_NO_ADVISORY_WARNINGS="1"): - # nothing should be logged as env var disables this method - with CaptureLogger(logger) as cl: - logger.warning_advice(msg) - self.assertEqual(cl.out, "") - - with mockenv_context(TRANSFORMERS_NO_ADVISORY_WARNINGS=""): - # should log normally as TRANSFORMERS_NO_ADVISORY_WARNINGS is unset - with CaptureLogger(logger) as cl: - logger.warning_advice(msg) - self.assertEqual(cl.out, msg + "\n") - - -def test_set_progress_bar_enabled(): - disable_progress_bar() - assert are_progress_bars_disabled() - - enable_progress_bar() - assert not are_progress_bars_disabled() diff --git a/tests/transformers/tests/utils/test_model_card.py b/tests/transformers/tests/utils/test_model_card.py deleted file mode 100644 index 7d0e8795e0..0000000000 --- a/tests/transformers/tests/utils/test_model_card.py +++ /dev/null @@ -1,84 +0,0 @@ -# coding=utf-8 -# Copyright 2019 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - - -import json -import os -import tempfile -import unittest - -from transformers.modelcard import ModelCard - - -class ModelCardTester(unittest.TestCase): - def setUp(self): - self.inputs_dict = { - "model_details": { - "Organization": "testing", - "Model date": "today", - "Model version": "v2.1, Developed by Test Corp in 2019.", - "Architecture": "Convolutional Neural Network.", - }, - "metrics": "BLEU and ROUGE-1", - "evaluation_data": { - "Datasets": {"BLEU": "My-great-dataset-v1", "ROUGE-1": "My-short-dataset-v2.1"}, - "Preprocessing": "See details on https://arxiv.org/pdf/1810.03993.pdf", - }, - "training_data": { - "Dataset": "English Wikipedia dump dated 2018-12-01", - "Preprocessing": ( - "Using SentencePiece vocabulary of size 52k tokens. See details on" - " https://arxiv.org/pdf/1810.03993.pdf" - ), - }, - "quantitative_analyses": {"BLEU": 55.1, "ROUGE-1": 76}, - } - - def test_model_card_common_properties(self): - modelcard = ModelCard.from_dict(self.inputs_dict) - self.assertTrue(hasattr(modelcard, "model_details")) - self.assertTrue(hasattr(modelcard, "intended_use")) - self.assertTrue(hasattr(modelcard, "factors")) - self.assertTrue(hasattr(modelcard, "metrics")) - self.assertTrue(hasattr(modelcard, "evaluation_data")) - self.assertTrue(hasattr(modelcard, "training_data")) - self.assertTrue(hasattr(modelcard, "quantitative_analyses")) - self.assertTrue(hasattr(modelcard, "ethical_considerations")) - self.assertTrue(hasattr(modelcard, "caveats_and_recommendations")) - - def test_model_card_to_json_string(self): - modelcard = ModelCard.from_dict(self.inputs_dict) - obj = json.loads(modelcard.to_json_string()) - for key, value in self.inputs_dict.items(): - self.assertEqual(obj[key], value) - - def test_model_card_to_json_file(self): - model_card_first = ModelCard.from_dict(self.inputs_dict) - - with tempfile.TemporaryDirectory() as tmpdirname: - filename = os.path.join(tmpdirname, "modelcard.json") - model_card_first.to_json_file(filename) - model_card_second = ModelCard.from_json_file(filename) - - self.assertEqual(model_card_second.to_dict(), model_card_first.to_dict()) - - def test_model_card_from_and_save_pretrained(self): - model_card_first = ModelCard.from_dict(self.inputs_dict) - - with tempfile.TemporaryDirectory() as tmpdirname: - model_card_first.save_pretrained(tmpdirname) - model_card_second = ModelCard.from_pretrained(tmpdirname) - - self.assertEqual(model_card_second.to_dict(), model_card_first.to_dict()) diff --git a/tests/transformers/tests/utils/test_model_output.py b/tests/transformers/tests/utils/test_model_output.py deleted file mode 100644 index b415b6c2ef..0000000000 --- a/tests/transformers/tests/utils/test_model_output.py +++ /dev/null @@ -1,145 +0,0 @@ -# coding=utf-8 -# Copyright 2020 The Hugging Face Team. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import unittest -from dataclasses import dataclass -from typing import Optional - -from transformers.testing_utils import require_torch -from transformers.utils import ModelOutput - - -@dataclass -class ModelOutputTest(ModelOutput): - a: float - b: Optional[float] = None - c: Optional[float] = None - - -class ModelOutputTester(unittest.TestCase): - def test_get_attributes(self): - x = ModelOutputTest(a=30) - self.assertEqual(x.a, 30) - self.assertIsNone(x.b) - self.assertIsNone(x.c) - with self.assertRaises(AttributeError): - _ = x.d - - def test_index_with_ints_and_slices(self): - x = ModelOutputTest(a=30, b=10) - self.assertEqual(x[0], 30) - self.assertEqual(x[1], 10) - self.assertEqual(x[:2], (30, 10)) - self.assertEqual(x[:], (30, 10)) - - x = ModelOutputTest(a=30, c=10) - self.assertEqual(x[0], 30) - self.assertEqual(x[1], 10) - self.assertEqual(x[:2], (30, 10)) - self.assertEqual(x[:], (30, 10)) - - def test_index_with_strings(self): - x = ModelOutputTest(a=30, b=10) - self.assertEqual(x["a"], 30) - self.assertEqual(x["b"], 10) - with self.assertRaises(KeyError): - _ = x["c"] - - x = ModelOutputTest(a=30, c=10) - self.assertEqual(x["a"], 30) - self.assertEqual(x["c"], 10) - with self.assertRaises(KeyError): - _ = x["b"] - - def test_dict_like_properties(self): - x = ModelOutputTest(a=30) - self.assertEqual(list(x.keys()), ["a"]) - self.assertEqual(list(x.values()), [30]) - self.assertEqual(list(x.items()), [("a", 30)]) - self.assertEqual(list(x), ["a"]) - - x = ModelOutputTest(a=30, b=10) - self.assertEqual(list(x.keys()), ["a", "b"]) - self.assertEqual(list(x.values()), [30, 10]) - self.assertEqual(list(x.items()), [("a", 30), ("b", 10)]) - self.assertEqual(list(x), ["a", "b"]) - - x = ModelOutputTest(a=30, c=10) - self.assertEqual(list(x.keys()), ["a", "c"]) - self.assertEqual(list(x.values()), [30, 10]) - self.assertEqual(list(x.items()), [("a", 30), ("c", 10)]) - self.assertEqual(list(x), ["a", "c"]) - - with self.assertRaises(Exception): - x = x.update({"d": 20}) - with self.assertRaises(Exception): - del x["a"] - with self.assertRaises(Exception): - _ = x.pop("a") - with self.assertRaises(Exception): - _ = x.setdefault("d", 32) - - def test_set_attributes(self): - x = ModelOutputTest(a=30) - x.a = 10 - self.assertEqual(x.a, 10) - self.assertEqual(x["a"], 10) - - def test_set_keys(self): - x = ModelOutputTest(a=30) - x["a"] = 10 - self.assertEqual(x.a, 10) - self.assertEqual(x["a"], 10) - - def test_instantiate_from_dict(self): - x = ModelOutputTest({"a": 30, "b": 10}) - self.assertEqual(list(x.keys()), ["a", "b"]) - self.assertEqual(x.a, 30) - self.assertEqual(x.b, 10) - - def test_instantiate_from_iterator(self): - x = ModelOutputTest([("a", 30), ("b", 10)]) - self.assertEqual(list(x.keys()), ["a", "b"]) - self.assertEqual(x.a, 30) - self.assertEqual(x.b, 10) - - with self.assertRaises(ValueError): - _ = ModelOutputTest([("a", 30), (10, 10)]) - - x = ModelOutputTest(a=(30, 30)) - self.assertEqual(list(x.keys()), ["a"]) - self.assertEqual(x.a, (30, 30)) - - @require_torch - def test_torch_pytree(self): - # ensure torch.utils._pytree treats ModelOutput subclasses as nodes (and not leaves) - # this is important for DistributedDataParallel gradient synchronization with static_graph=True - import torch - import torch.utils._pytree - - x = ModelOutputTest(a=1.0, c=2.0) - self.assertFalse(torch.utils._pytree._is_leaf(x)) - - expected_flat_outs = [1.0, 2.0] - expected_tree_spec = torch.utils._pytree.TreeSpec( - ModelOutputTest, ["a", "c"], [torch.utils._pytree.LeafSpec(), torch.utils._pytree.LeafSpec()] - ) - - actual_flat_outs, actual_tree_spec = torch.utils._pytree.tree_flatten(x) - self.assertEqual(expected_flat_outs, actual_flat_outs) - self.assertEqual(expected_tree_spec, actual_tree_spec) - - unflattened_x = torch.utils._pytree.tree_unflatten(actual_flat_outs, actual_tree_spec) - self.assertEqual(x, unflattened_x) diff --git a/tests/transformers/tests/utils/test_modeling_tf_core.py b/tests/transformers/tests/utils/test_modeling_tf_core.py deleted file mode 100644 index d170dba3ad..0000000000 --- a/tests/transformers/tests/utils/test_modeling_tf_core.py +++ /dev/null @@ -1,416 +0,0 @@ -# coding=utf-8 -# Copyright 2019 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - - -from __future__ import annotations - -import copy -import os -import tempfile -from importlib import import_module -from math import isnan - -from transformers import is_tf_available -from transformers.models.auto import get_values -from transformers.testing_utils import _tf_gpu_memory_limit, require_tf, slow - -from ..test_modeling_tf_common import ids_tensor - - -if is_tf_available(): - import numpy as np - import tensorflow as tf - from transformers import ( - TF_MODEL_FOR_CAUSAL_LM_MAPPING, - TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING, - TF_MODEL_FOR_MASKED_LM_MAPPING, - TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING, - TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING, - TF_MODEL_FOR_PRETRAINING_MAPPING, - TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING, - TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING, - TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING, - TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING, - TFSharedEmbeddings, - ) - - if _tf_gpu_memory_limit is not None: - gpus = tf.config.list_physical_devices("GPU") - for gpu in gpus: - # Restrict TensorFlow to only allocate x GB of memory on the GPUs - try: - tf.config.set_logical_device_configuration( - gpu, [tf.config.LogicalDeviceConfiguration(memory_limit=_tf_gpu_memory_limit)] - ) - logical_gpus = tf.config.list_logical_devices("GPU") - print("Logical GPUs", logical_gpus) - except RuntimeError as e: - # Virtual devices must be set before GPUs have been initialized - print(e) - - -@require_tf -class TFCoreModelTesterMixin: - model_tester = None - all_model_classes = () - all_generative_model_classes = () - test_mismatched_shapes = True - test_resize_embeddings = True - test_head_masking = True - is_encoder_decoder = False - - def _prepare_for_class(self, inputs_dict, model_class, return_labels=False) -> dict: - inputs_dict = copy.deepcopy(inputs_dict) - - if model_class in get_values(TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING): - inputs_dict = { - k: tf.tile(tf.expand_dims(v, 1), (1, self.model_tester.num_choices) + (1,) * (v.ndim - 1)) - if isinstance(v, tf.Tensor) and v.ndim > 0 - else v - for k, v in inputs_dict.items() - } - - if return_labels: - if model_class in get_values(TF_MODEL_FOR_MULTIPLE_CHOICE_MAPPING): - inputs_dict["labels"] = tf.ones(self.model_tester.batch_size, dtype=tf.int32) - elif model_class in get_values(TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING): - inputs_dict["start_positions"] = tf.zeros(self.model_tester.batch_size, dtype=tf.int32) - inputs_dict["end_positions"] = tf.zeros(self.model_tester.batch_size, dtype=tf.int32) - elif model_class in [ - *get_values(TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING), - *get_values(TF_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING), - ]: - inputs_dict["labels"] = tf.zeros(self.model_tester.batch_size, dtype=tf.int32) - elif model_class in get_values(TF_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING): - inputs_dict["next_sentence_label"] = tf.zeros(self.model_tester.batch_size, dtype=tf.int32) - elif model_class in [ - *get_values(TF_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING), - *get_values(TF_MODEL_FOR_CAUSAL_LM_MAPPING), - *get_values(TF_MODEL_FOR_MASKED_LM_MAPPING), - *get_values(TF_MODEL_FOR_PRETRAINING_MAPPING), - *get_values(TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING), - ]: - inputs_dict["labels"] = tf.zeros( - (self.model_tester.batch_size, self.model_tester.seq_length), dtype=tf.int32 - ) - return inputs_dict - - @slow - def test_graph_mode(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - for model_class in self.all_model_classes[:2]: - inputs = self._prepare_for_class(inputs_dict, model_class) - model = model_class(config) - - @tf.function - def run_in_graph_mode(): - return model(inputs) - - outputs = run_in_graph_mode() - self.assertIsNotNone(outputs) - - @slow - def test_xla_mode(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - for model_class in self.all_model_classes[:2]: - inputs = self._prepare_for_class(inputs_dict, model_class) - model = model_class(config) - - @tf.function(experimental_compile=True) - def run_in_graph_mode(): - return model(inputs) - - outputs = run_in_graph_mode() - self.assertIsNotNone(outputs) - - @slow - def test_xla_fit(self): - # This is a copy of the test_keras_fit method, but we use XLA compilation instead of eager - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - for model_class in self.all_model_classes[:2]: - model = model_class(config) - if getattr(model, "hf_compute_loss", None): - # Test that model correctly compute the loss with kwargs - prepared_for_class = self._prepare_for_class(inputs_dict.copy(), model_class, return_labels=True) - # Is there a better way to remove these decoder inputs? - prepared_for_class = { - key: val - for key, val in prepared_for_class.items() - if key not in ("head_mask", "decoder_head_mask", "cross_attn_head_mask", "decoder_input_ids") - } - - possible_label_cols = { - "labels", - "label", - "label_ids", - "start_positions", - "start_position", - "end_positions", - "end_position", - "next_sentence_label", - } - label_names = possible_label_cols.intersection(set(prepared_for_class)) - self.assertGreater(len(label_names), 0, msg="No matching label names found!") - labels = {key: val for key, val in prepared_for_class.items() if key in label_names} - inputs_minus_labels = {key: val for key, val in prepared_for_class.items() if key not in label_names} - self.assertGreater(len(inputs_minus_labels), 0) - - # Make sure it works with XLA! - model.compile(optimizer=tf.keras.optimizers.SGD(0.0), jit_compile=True) - # Make sure the model fits without crashing regardless of where we pass the labels - history = model.fit( - prepared_for_class, - validation_data=prepared_for_class, - steps_per_epoch=1, - validation_steps=1, - shuffle=False, - verbose=0, - ) - loss = history.history["loss"][0] - self.assertTrue(not isnan(loss)) - val_loss = history.history["val_loss"][0] - self.assertTrue(not isnan(val_loss)) - - # Now test it with separate labels, to make sure that path works in XLA too. - model = model_class(config) - model.compile(optimizer=tf.keras.optimizers.SGD(0.0), jit_compile=True) - history = model.fit( - inputs_minus_labels, - labels, - validation_data=(inputs_minus_labels, labels), - steps_per_epoch=1, - validation_steps=1, - shuffle=False, - verbose=0, - ) - - loss = history.history["loss"][0] - self.assertTrue(not isnan(loss)) - val_loss = history.history["val_loss"][0] - self.assertTrue(not isnan(val_loss)) - - @slow - def test_saved_model_creation_extended(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - config.output_hidden_states = True - config.output_attentions = True - - if hasattr(config, "use_cache"): - config.use_cache = True - - encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", self.model_tester.seq_length) - encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length) - - for model_class in self.all_model_classes[:2]: - class_inputs_dict = self._prepare_for_class(inputs_dict, model_class) - model = model_class(config) - model.build() - num_out = len(model(class_inputs_dict)) - - for key in list(class_inputs_dict.keys()): - # Remove keys not in the serving signature, as the SavedModel will not be compiled to deal with them - if key not in model.input_signature: - del class_inputs_dict[key] - # Check it's a tensor, in case the inputs dict has some bools in it too - elif isinstance(class_inputs_dict[key], tf.Tensor) and class_inputs_dict[key].dtype.is_integer: - class_inputs_dict[key] = tf.cast(class_inputs_dict[key], tf.int32) - - if set(class_inputs_dict.keys()) != set(model.input_signature.keys()): - continue # Some models have inputs that the preparation functions don't create, we skip those - - with tempfile.TemporaryDirectory() as tmpdirname: - model.save_pretrained(tmpdirname, saved_model=True) - saved_model_dir = os.path.join(tmpdirname, "saved_model", "1") - model = tf.keras.models.load_model(saved_model_dir) - outputs = model(class_inputs_dict) - - if self.is_encoder_decoder: - output_hidden_states = outputs["encoder_hidden_states"] - output_attentions = outputs["encoder_attentions"] - else: - output_hidden_states = outputs["hidden_states"] - output_attentions = outputs["attentions"] - - self.assertEqual(len(outputs), num_out) - - expected_num_layers = getattr( - self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1 - ) - - self.assertEqual(len(output_hidden_states), expected_num_layers) - self.assertListEqual( - list(output_hidden_states[0].shape[-2:]), - [self.model_tester.seq_length, self.model_tester.hidden_size], - ) - - self.assertEqual(len(output_attentions), self.model_tester.num_hidden_layers) - self.assertListEqual( - list(output_attentions[0].shape[-3:]), - [self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length], - ) - - @slow - def test_mixed_precision(self): - tf.keras.mixed_precision.set_global_policy("mixed_float16") - - # try/finally block to ensure subsequent tests run in float32 - try: - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - for model_class in self.all_model_classes[:2]: - class_inputs_dict = self._prepare_for_class(inputs_dict, model_class) - model = model_class(config) - outputs = model(class_inputs_dict) - - self.assertIsNotNone(outputs) - finally: - tf.keras.mixed_precision.set_global_policy("float32") - - @slow - def test_train_pipeline_custom_model(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - # head_mask and decoder_head_mask has different shapes than other input args - if "head_mask" in inputs_dict: - del inputs_dict["head_mask"] - if "decoder_head_mask" in inputs_dict: - del inputs_dict["decoder_head_mask"] - if "cross_attn_head_mask" in inputs_dict: - del inputs_dict["cross_attn_head_mask"] - tf_main_layer_classes = { - module_member - for model_class in self.all_model_classes - for module in (import_module(model_class.__module__),) - for module_member_name in dir(module) - if module_member_name.endswith("MainLayer") - for module_member in (getattr(module, module_member_name),) - if isinstance(module_member, type) - and tf.keras.layers.Layer in module_member.__bases__ - and getattr(module_member, "_keras_serializable", False) - } - - for main_layer_class in tf_main_layer_classes: - # T5MainLayer needs an embed_tokens parameter when called without the inputs_embeds parameter - if "T5" in main_layer_class.__name__: - # Take the same values than in TFT5ModelTester for this shared layer - shared = TFSharedEmbeddings(self.model_tester.vocab_size, self.model_tester.hidden_size, name="shared") - config.use_cache = False - main_layer = main_layer_class(config, embed_tokens=shared) - else: - main_layer = main_layer_class(config) - - symbolic_inputs = { - name: tf.keras.Input(tensor.shape[1:], dtype=tensor.dtype) for name, tensor in inputs_dict.items() - } - - if hasattr(self.model_tester, "num_labels"): - num_labels = self.model_tester.num_labels - else: - num_labels = 2 - - X = tf.data.Dataset.from_tensor_slices( - (inputs_dict, np.ones((self.model_tester.batch_size, self.model_tester.seq_length, num_labels, 1))) - ).batch(1) - - hidden_states = main_layer(symbolic_inputs)[0] - outputs = tf.keras.layers.Dense(num_labels, activation="softmax", name="outputs")(hidden_states) - model = tf.keras.models.Model(inputs=symbolic_inputs, outputs=[outputs]) - - model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["binary_accuracy"]) - model.fit(X, epochs=1) - - with tempfile.TemporaryDirectory() as tmpdirname: - filepath = os.path.join(tmpdirname, "keras_model.h5") - model.save(filepath) - if "T5" in main_layer_class.__name__: - model = tf.keras.models.load_model( - filepath, - custom_objects={ - main_layer_class.__name__: main_layer_class, - "TFSharedEmbeddings": TFSharedEmbeddings, - }, - ) - else: - model = tf.keras.models.load_model( - filepath, custom_objects={main_layer_class.__name__: main_layer_class} - ) - assert isinstance(model, tf.keras.Model) - model(inputs_dict) - - @slow - def test_graph_mode_with_inputs_embeds(self): - config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common() - - for model_class in self.all_model_classes[:2]: - model = model_class(config) - - inputs = copy.deepcopy(inputs_dict) - - if not self.is_encoder_decoder: - input_ids = inputs["input_ids"] - del inputs["input_ids"] - else: - encoder_input_ids = inputs["input_ids"] - decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids) - del inputs["input_ids"] - inputs.pop("decoder_input_ids", None) - - if not self.is_encoder_decoder: - inputs["inputs_embeds"] = model.get_input_embeddings()(input_ids) - else: - inputs["inputs_embeds"] = model.get_input_embeddings()(encoder_input_ids) - inputs["decoder_inputs_embeds"] = model.get_input_embeddings()(decoder_input_ids) - - inputs = self._prepare_for_class(inputs, model_class) - - @tf.function - def run_in_graph_mode(): - return model(inputs) - - outputs = run_in_graph_mode() - self.assertIsNotNone(outputs) - - def _generate_random_bad_tokens(self, num_bad_tokens, model): - # special tokens cannot be bad tokens - special_tokens = [] - if model.config.bos_token_id is not None: - special_tokens.append(model.config.bos_token_id) - if model.config.pad_token_id is not None: - special_tokens.append(model.config.pad_token_id) - if model.config.eos_token_id is not None: - special_tokens.append(model.config.eos_token_id) - - # create random bad tokens that are not special tokens - bad_tokens = [] - while len(bad_tokens) < num_bad_tokens: - token = tf.squeeze(ids_tensor((1, 1), self.model_tester.vocab_size), 0).numpy()[0] - if token not in special_tokens: - bad_tokens.append(token) - return bad_tokens - - def _check_generated_ids(self, output_ids): - for token_id in output_ids[0].numpy().tolist(): - self.assertGreaterEqual(token_id, 0) - self.assertLess(token_id, self.model_tester.vocab_size) - - def _check_match_tokens(self, generated_ids, bad_words_ids): - # for all bad word tokens - for bad_word_ids in bad_words_ids: - # for all slices in batch - for generated_ids_slice in generated_ids: - # for all word idx - for i in range(len(bad_word_ids), len(generated_ids_slice)): - # if tokens match - if generated_ids_slice[i - len(bad_word_ids) : i] == bad_word_ids: - return True - return False diff --git a/tests/transformers/tests/utils/test_offline.py b/tests/transformers/tests/utils/test_offline.py deleted file mode 100644 index ecc7938bf3..0000000000 --- a/tests/transformers/tests/utils/test_offline.py +++ /dev/null @@ -1,206 +0,0 @@ -# Copyright 2020 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import subprocess -import sys - -from transformers import BertConfig, BertModel, BertTokenizer, pipeline -from transformers.testing_utils import TestCasePlus, require_torch - - -class OfflineTests(TestCasePlus): - @require_torch - def test_offline_mode(self): - # this test is a bit tricky since TRANSFORMERS_OFFLINE can only be changed before - # `transformers` is loaded, and it's too late for inside pytest - so we are changing it - # while running an external program - - # python one-liner segments - - # this must be loaded before socket.socket is monkey-patched - load = """ -from transformers import BertConfig, BertModel, BertTokenizer, pipeline - """ - - run = """ -mname = "hf-internal-testing/tiny-random-bert" -BertConfig.from_pretrained(mname) -BertModel.from_pretrained(mname) -BertTokenizer.from_pretrained(mname) -pipe = pipeline(task="fill-mask", model=mname) -print("success") - """ - - mock = """ -import socket -def offline_socket(*args, **kwargs): raise RuntimeError("Offline mode is enabled, we shouldn't access internet") -socket.socket = offline_socket - """ - - # Force fetching the files so that we can use the cache - mname = "hf-internal-testing/tiny-random-bert" - BertConfig.from_pretrained(mname) - BertModel.from_pretrained(mname) - BertTokenizer.from_pretrained(mname) - pipeline(task="fill-mask", model=mname) - - # baseline - just load from_pretrained with normal network - cmd = [sys.executable, "-c", "\n".join([load, run, mock])] - - # should succeed - env = self.get_env() - # should succeed as TRANSFORMERS_OFFLINE=1 tells it to use local files - env["TRANSFORMERS_OFFLINE"] = "1" - result = subprocess.run(cmd, env=env, check=False, capture_output=True) - self.assertEqual(result.returncode, 0, result.stderr) - self.assertIn("success", result.stdout.decode()) - - @require_torch - def test_offline_mode_no_internet(self): - # python one-liner segments - # this must be loaded before socket.socket is monkey-patched - load = """ -from transformers import BertConfig, BertModel, BertTokenizer, pipeline - """ - - run = """ -mname = "hf-internal-testing/tiny-random-bert" -BertConfig.from_pretrained(mname) -BertModel.from_pretrained(mname) -BertTokenizer.from_pretrained(mname) -pipe = pipeline(task="fill-mask", model=mname) -print("success") - """ - - mock = """ -import socket -def offline_socket(*args, **kwargs): raise socket.error("Faking flaky internet") -socket.socket = offline_socket - """ - - # Force fetching the files so that we can use the cache - mname = "hf-internal-testing/tiny-random-bert" - BertConfig.from_pretrained(mname) - BertModel.from_pretrained(mname) - BertTokenizer.from_pretrained(mname) - pipeline(task="fill-mask", model=mname) - - # baseline - just load from_pretrained with normal network - cmd = [sys.executable, "-c", "\n".join([load, run, mock])] - - # should succeed - env = self.get_env() - result = subprocess.run(cmd, env=env, check=False, capture_output=True) - self.assertEqual(result.returncode, 0, result.stderr) - self.assertIn("success", result.stdout.decode()) - - @require_torch - def test_offline_mode_sharded_checkpoint(self): - # this test is a bit tricky since TRANSFORMERS_OFFLINE can only be changed before - # `transformers` is loaded, and it's too late for inside pytest - so we are changing it - # while running an external program - - # python one-liner segments - - # this must be loaded before socket.socket is monkey-patched - load = """ -from transformers import BertConfig, BertModel, BertTokenizer - """ - - run = """ -mname = "hf-internal-testing/tiny-random-bert-sharded" -BertConfig.from_pretrained(mname) -BertModel.from_pretrained(mname) -print("success") - """ - - mock = """ -import socket -def offline_socket(*args, **kwargs): raise ValueError("Offline mode is enabled") -socket.socket = offline_socket - """ - - # baseline - just load from_pretrained with normal network - cmd = [sys.executable, "-c", "\n".join([load, run])] - - # should succeed - env = self.get_env() - result = subprocess.run(cmd, env=env, check=False, capture_output=True) - self.assertEqual(result.returncode, 0, result.stderr) - self.assertIn("success", result.stdout.decode()) - - # next emulate no network - cmd = [sys.executable, "-c", "\n".join([load, mock, run])] - - # Doesn't fail anymore since the model is in the cache due to other tests, so commenting this. - # env["TRANSFORMERS_OFFLINE"] = "0" - # result = subprocess.run(cmd, env=env, check=False, capture_output=True) - # self.assertEqual(result.returncode, 1, result.stderr) - - # should succeed as TRANSFORMERS_OFFLINE=1 tells it to use local files - env["TRANSFORMERS_OFFLINE"] = "1" - result = subprocess.run(cmd, env=env, check=False, capture_output=True) - self.assertEqual(result.returncode, 0, result.stderr) - self.assertIn("success", result.stdout.decode()) - - @require_torch - def test_offline_mode_pipeline_exception(self): - load = """ -from transformers import pipeline - """ - run = """ -mname = "hf-internal-testing/tiny-random-bert" -pipe = pipeline(model=mname) - """ - - mock = """ -import socket -def offline_socket(*args, **kwargs): raise socket.error("Offline mode is enabled") -socket.socket = offline_socket - """ - env = self.get_env() - env["TRANSFORMERS_OFFLINE"] = "1" - cmd = [sys.executable, "-c", "\n".join([load, mock, run])] - result = subprocess.run(cmd, env=env, check=False, capture_output=True) - self.assertEqual(result.returncode, 1, result.stderr) - self.assertIn( - "You cannot infer task automatically within `pipeline` when using offline mode", - result.stderr.decode().replace("\n", ""), - ) - - @require_torch - def test_offline_model_dynamic_model(self): - load = """ -from transformers import AutoModel - """ - run = """ -mname = "hf-internal-testing/test_dynamic_model" -AutoModel.from_pretrained(mname, trust_remote_code=True) -print("success") - """ - - # baseline - just load from_pretrained with normal network - cmd = [sys.executable, "-c", "\n".join([load, run])] - - # should succeed - env = self.get_env() - result = subprocess.run(cmd, env=env, check=False, capture_output=True) - self.assertEqual(result.returncode, 0, result.stderr) - self.assertIn("success", result.stdout.decode()) - - # should succeed as TRANSFORMERS_OFFLINE=1 tells it to use local files - env["TRANSFORMERS_OFFLINE"] = "1" - result = subprocess.run(cmd, env=env, check=False, capture_output=True) - self.assertEqual(result.returncode, 0, result.stderr) - self.assertIn("success", result.stdout.decode()) diff --git a/tests/transformers/tests/utils/test_skip_decorators.py b/tests/transformers/tests/utils/test_skip_decorators.py deleted file mode 100644 index 94a870e656..0000000000 --- a/tests/transformers/tests/utils/test_skip_decorators.py +++ /dev/null @@ -1,119 +0,0 @@ -# coding=utf-8 -# Copyright 2019-present, the HuggingFace Inc. team. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. -# -# -# -# this test validates that we can stack skip decorators in groups and whether -# they work correctly with other decorators -# -# since the decorators have already built their decision params (like checking -# env[], we can't mock the env and test each of the combinations), so ideally -# the following 4 should be run. But since we have different CI jobs running -# different configs, all combinations should get covered -# -# RUN_SLOW=1 pytest -rA tests/test_skip_decorators.py -# RUN_SLOW=1 CUDA_VISIBLE_DEVICES="" pytest -rA tests/test_skip_decorators.py -# RUN_SLOW=0 pytest -rA tests/test_skip_decorators.py -# RUN_SLOW=0 CUDA_VISIBLE_DEVICES="" pytest -rA tests/test_skip_decorators.py - -import os -import unittest - -import pytest -from parameterized import parameterized -from transformers.testing_utils import require_torch, require_torch_gpu, slow, torch_device - - -# skipping in unittest tests - -params = [(1,)] - - -# test that we can stack our skip decorators with 3rd party decorators -def check_slow(): - run_slow = bool(os.getenv("RUN_SLOW", 0)) - if run_slow: - assert True - else: - assert False, "should have been skipped" - - -# test that we can stack our skip decorators -def check_slow_torch_cuda(): - run_slow = bool(os.getenv("RUN_SLOW", 0)) - if run_slow and torch_device == "cuda": - assert True - else: - assert False, "should have been skipped" - - -@require_torch -class SkipTester(unittest.TestCase): - @slow - @require_torch_gpu - def test_2_skips_slow_first(self): - check_slow_torch_cuda() - - @require_torch_gpu - @slow - def test_2_skips_slow_last(self): - check_slow_torch_cuda() - - # The combination of any skip decorator, followed by parameterized fails to skip the tests - # 1. @slow manages to correctly skip `test_param_slow_first` - # 2. but then `parameterized` creates new tests, with a unique name for each parameter groups. - # It has no idea that they are to be skipped and so they all run, ignoring @slow - # Therefore skip decorators must come after `parameterized` - # - # @slow - # @parameterized.expand(params) - # def test_param_slow_first(self, param=None): - # check_slow() - - # This works as expected: - # 1. `parameterized` creates new tests with unique names - # 2. each of them gets an opportunity to be skipped - @parameterized.expand(params) - @slow - def test_param_slow_last(self, param=None): - check_slow() - - -# skipping in non-unittest tests -# no problem at all here - - -@slow -@require_torch_gpu -def test_pytest_2_skips_slow_first(): - check_slow_torch_cuda() - - -@require_torch_gpu -@slow -def test_pytest_2_skips_slow_last(): - check_slow_torch_cuda() - - -@slow -@pytest.mark.parametrize("param", [1]) -def test_pytest_param_slow_first(param): - check_slow() - - -@pytest.mark.parametrize("param", [1]) -@slow -def test_pytest_param_slow_last(param): - check_slow() diff --git a/tests/transformers/tests/utils/test_versions_utils.py b/tests/transformers/tests/utils/test_versions_utils.py deleted file mode 100644 index 14839400c2..0000000000 --- a/tests/transformers/tests/utils/test_versions_utils.py +++ /dev/null @@ -1,97 +0,0 @@ -# Copyright 2020 The HuggingFace Team. All rights reserved. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - -import importlib.metadata -import sys - -from transformers.testing_utils import TestCasePlus -from transformers.utils.versions import require_version, require_version_core - - -numpy_ver = importlib.metadata.version("numpy") -python_ver = ".".join([str(x) for x in sys.version_info[:3]]) - - -class DependencyVersionCheckTest(TestCasePlus): - def test_core(self): - # lt + different version strings - require_version_core("numpy<1000.4.5") - require_version_core("numpy<1000.4") - require_version_core("numpy<1000") - - # le - require_version_core("numpy<=1000.4.5") - require_version_core(f"numpy<={numpy_ver}") - - # eq - require_version_core(f"numpy=={numpy_ver}") - - # ne - require_version_core("numpy!=1000.4.5") - - # ge - require_version_core("numpy>=1.0") - require_version_core("numpy>=1.0.0") - require_version_core(f"numpy>={numpy_ver}") - - # gt - require_version_core("numpy>1.0.0") - - # mix - require_version_core("numpy>1.0.0,<1000") - - # requirement w/o version - require_version_core("numpy") - - # unmet requirements due to version conflict - for req in ["numpy==1.0.0", "numpy>=1000.0.0", f"numpy<{numpy_ver}"]: - try: - require_version_core(req) - except ImportError as e: - self.assertIn(f"{req} is required", str(e)) - self.assertIn("but found", str(e)) - - # unmet requirements due to missing module - for req in ["numpipypie>1", "numpipypie2"]: - try: - require_version_core(req) - except importlib.metadata.PackageNotFoundError as e: - self.assertIn(f"The '{req}' distribution was not found and is required by this application", str(e)) - self.assertIn("Try: pip install transformers -U", str(e)) - - # bogus requirements formats: - # 1. whole thing - for req in ["numpy??1.0.0", "numpy1.0.0"]: - try: - require_version_core(req) - except ValueError as e: - self.assertIn("requirement needs to be in the pip package format", str(e)) - # 2. only operators - for req in ["numpy=1.0.0", "numpy == 1.00", "numpy<>1.0.0", "numpy><1.00", "numpy>>1.0.0"]: - try: - require_version_core(req) - except ValueError as e: - self.assertIn("need one of ", str(e)) - - def test_python(self): - # matching requirement - require_version("python>=3.6.0") - - # not matching requirements - for req in ["python>9.9.9", "python<3.0.0"]: - try: - require_version_core(req) - except ImportError as e: - self.assertIn(f"{req} is required", str(e)) - self.assertIn(f"but found python=={python_ver}", str(e)) diff --git a/tests/transformers/tests/utils/tiny_model_summary.json b/tests/transformers/tests/utils/tiny_model_summary.json deleted file mode 100644 index b7fdf87bac..0000000000 --- a/tests/transformers/tests/utils/tiny_model_summary.json +++ /dev/null @@ -1,6924 +0,0 @@ -{ - "ASTForAudioClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ASTFeatureExtractor" - ], - "model_classes": [ - "ASTForAudioClassification" - ], - "sha": "83d6e076db7768a3645401bad3204624985e1d08" - }, - "ASTModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ASTFeatureExtractor" - ], - "model_classes": [ - "ASTModel" - ], - "sha": "75e68f956f6f2c0709b01e596e7a6aecb1b29dce" - }, - "AlbertForMaskedLM": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "AlbertForMaskedLM", - "TFAlbertForMaskedLM" - ], - "sha": "d29de71ac29e1019c3a7762f7357f750730cb037" - }, - "AlbertForMultipleChoice": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "AlbertForMultipleChoice", - "TFAlbertForMultipleChoice" - ], - "sha": "242aecce6a589a2964c0f695621fa22a83751579" - }, - "AlbertForPreTraining": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "AlbertForPreTraining", - "TFAlbertForPreTraining" - ], - "sha": "41330be4b271687f4d88ddc96346c12aa11de983" - }, - "AlbertForQuestionAnswering": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "AlbertForQuestionAnswering", - "TFAlbertForQuestionAnswering" - ], - "sha": "040b81c15f437f4722349dc5b41fccd17ebd7fdc" - }, - "AlbertForSequenceClassification": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "AlbertForSequenceClassification", - "TFAlbertForSequenceClassification" - ], - "sha": "39c1a0e2c1c2623106d3211d751e9b32f23a91a0" - }, - "AlbertForTokenClassification": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "AlbertForTokenClassification", - "TFAlbertForTokenClassification" - ], - "sha": "359c3f4a311a4053a6f6d6a880db5f82c8e3ff1f" - }, - "AlbertModel": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "AlbertModel", - "TFAlbertModel" - ], - "sha": "34a63314686b64aaeb595ddb95006f1ff2ffda17" - }, - "AlignModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "EfficientNetImageProcessor" - ], - "model_classes": [ - "AlignModel" - ], - "sha": "68a4f9d3f493f44efa7c1dde6fcca23350e2c92b" - }, - "AltCLIPModel": { - "tokenizer_classes": [ - "XLMRobertaTokenizerFast" - ], - "processor_classes": [ - "CLIPImageProcessor" - ], - "model_classes": [ - "AltCLIPModel" - ], - "sha": "3106af0fd503970717c05f27218e5cacf19ba872" - }, - "BartForCausalLM": { - "tokenizer_classes": [ - "BartTokenizer", - "BartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BartForCausalLM" - ], - "sha": "c25526ac67d2dbe79fe5462af4b7908ca2fbc3ff" - }, - "BartForConditionalGeneration": { - "tokenizer_classes": [ - "BartTokenizer", - "BartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BartForConditionalGeneration", - "TFBartForConditionalGeneration" - ], - "sha": "3a489a21e4b04705f4a6047924b7616a67be7e37" - }, - "BartForQuestionAnswering": { - "tokenizer_classes": [ - "BartTokenizer", - "BartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BartForQuestionAnswering" - ], - "sha": "3ebf9aab39a57ceab55128d5fc6f61e4db0dadd4" - }, - "BartForSequenceClassification": { - "tokenizer_classes": [ - "BartTokenizer", - "BartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BartForSequenceClassification", - "TFBartForSequenceClassification" - ], - "sha": "ea452fd9a928cfebd71723afa50feb20326917bc" - }, - "BartModel": { - "tokenizer_classes": [ - "BartTokenizer", - "BartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BartModel", - "TFBartModel" - ], - "sha": "e5df6d1aa75f03833b2df328b9c35463f73a421b" - }, - "BeitForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "BeitImageProcessor" - ], - "model_classes": [ - "BeitForImageClassification" - ], - "sha": "e997587bb890f82faad4bd25eb23d85ba21ecaaa" - }, - "BeitForSemanticSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "BeitImageProcessor" - ], - "model_classes": [ - "BeitForSemanticSegmentation" - ], - "sha": "d4afa9e21e3fe5b087578ed68974d9b3ffc1fb22" - }, - "BeitModel": { - "tokenizer_classes": [], - "processor_classes": [ - "BeitImageProcessor" - ], - "model_classes": [ - "BeitModel" - ], - "sha": "5c4a051f0cca6f64d02c6168deb88413cae10d2c" - }, - "BertForMaskedLM": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BertForMaskedLM", - "TFBertForMaskedLM" - ], - "sha": "3e32baa52ce044c75edfb5c28abd51ee8d051282" - }, - "BertForMultipleChoice": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BertForMultipleChoice", - "TFBertForMultipleChoice" - ], - "sha": "0b8c3a6d411d1e19e5fd98d4d8631ae7616eeeaa" - }, - "BertForNextSentencePrediction": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BertForNextSentencePrediction", - "TFBertForNextSentencePrediction" - ], - "sha": "628e70debf8864bd0b63aff7901d17d9c4f7612c" - }, - "BertForPreTraining": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BertForPreTraining", - "TFBertForPreTraining" - ], - "sha": "c748ad37e6a200a6f64b2764191bfe13f976032f" - }, - "BertForQuestionAnswering": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BertForQuestionAnswering", - "TFBertForQuestionAnswering" - ], - "sha": "4671ad0c21493b97c5eb2f0201192704c29876d5" - }, - "BertForSequenceClassification": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BertForSequenceClassification", - "TFBertForSequenceClassification" - ], - "sha": "37a9d44022264c12bdf3ec257778f953b63d4aaf" - }, - "BertForTokenClassification": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BertForTokenClassification", - "TFBertForTokenClassification" - ], - "sha": "d7dc3a0793ff6dfcb794b21130ee0f185d2c61a2" - }, - "BertLMHeadModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BertLMHeadModel", - "TFBertLMHeadModel" - ], - "sha": "b4e3acc1990f3e365ffddbd54b620a26d9fb4b09" - }, - "BertModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BertModel", - "TFBertModel" - ], - "sha": "3956d303d3cddf0708ff20660c1ea5f6ec30e434" - }, - "BigBirdForCausalLM": { - "tokenizer_classes": [ - "BigBirdTokenizer", - "BigBirdTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdForCausalLM" - ], - "sha": "5c7a487af5248d9c01b45d5481b7d7bb9b36e1b5" - }, - "BigBirdForMaskedLM": { - "tokenizer_classes": [ - "BigBirdTokenizer", - "BigBirdTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdForMaskedLM" - ], - "sha": "476ef8225c0f69270b577706ad4f1dda13e4dde5" - }, - "BigBirdForMultipleChoice": { - "tokenizer_classes": [ - "BigBirdTokenizer", - "BigBirdTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdForMultipleChoice" - ], - "sha": "cf93eaa1019987112c171a407745bc183a20513a" - }, - "BigBirdForPreTraining": { - "tokenizer_classes": [ - "BigBirdTokenizer", - "BigBirdTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdForPreTraining" - ], - "sha": "5fb9efa13334431e7c186a9fa314b89c4a1eee72" - }, - "BigBirdForQuestionAnswering": { - "tokenizer_classes": [ - "BigBirdTokenizer", - "BigBirdTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdForQuestionAnswering" - ], - "sha": "f82f88bd71fba819a8ffb0692915d3529e705417" - }, - "BigBirdForSequenceClassification": { - "tokenizer_classes": [ - "BigBirdTokenizer", - "BigBirdTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdForSequenceClassification" - ], - "sha": "ea398090858f9af93b54fc9a8d65cfed78ac27ff" - }, - "BigBirdForTokenClassification": { - "tokenizer_classes": [ - "BigBirdTokenizer", - "BigBirdTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdForTokenClassification" - ], - "sha": "2cdea118999fa58ba9fb0162d99e2ffa146c3df1" - }, - "BigBirdModel": { - "tokenizer_classes": [ - "BigBirdTokenizer", - "BigBirdTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdModel" - ], - "sha": "9c55989f31df156194e6997606fb14d9897e0300" - }, - "BigBirdPegasusForCausalLM": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdPegasusForCausalLM" - ], - "sha": "49bc8816c666dee32e27cd8e00136b604eb85243" - }, - "BigBirdPegasusForConditionalGeneration": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdPegasusForConditionalGeneration" - ], - "sha": "e791aa6d1af5a76ca0926d95b1f28bd2d8adf376" - }, - "BigBirdPegasusForQuestionAnswering": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdPegasusForQuestionAnswering" - ], - "sha": "7650e076713ca707a37062adc8c9c1cd60dad7c7" - }, - "BigBirdPegasusForSequenceClassification": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdPegasusForSequenceClassification" - ], - "sha": "02500e8ebd9c53528750013fb963fbdc2be34034" - }, - "BigBirdPegasusModel": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BigBirdPegasusModel" - ], - "sha": "b07c5304dfba673cf8b9cf5cd1aa45fbfea1c2f3" - }, - "BioGptForCausalLM": { - "tokenizer_classes": [ - "BioGptTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "BioGptForCausalLM" - ], - "sha": "07073b31da84054fd12226e3cae4cb3beb2547f9" - }, - "BioGptForSequenceClassification": { - "tokenizer_classes": [ - "BioGptTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "BioGptForSequenceClassification" - ], - "sha": "8e18ad6218abd795e050dec324a8c827ccedacb4" - }, - "BioGptForTokenClassification": { - "tokenizer_classes": [ - "BioGptTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "BioGptForTokenClassification" - ], - "sha": "67f8173c1a17273064d452a9031a51b67f327b6a" - }, - "BioGptModel": { - "tokenizer_classes": [ - "BioGptTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "BioGptModel" - ], - "sha": "fe18551d0743538a990520b75707294ec57b4ebe" - }, - "BitBackbone": { - "tokenizer_classes": [], - "processor_classes": [ - "BitImageProcessor" - ], - "model_classes": [ - "BitBackbone" - ], - "sha": "2f06f6b4395b6dce2b00ac839ff757410e743cd7" - }, - "BitForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "BitImageProcessor" - ], - "model_classes": [ - "BitForImageClassification" - ], - "sha": "d0d8476f2d285ddda7c42c0d4a8e4bf6f5d2bfdf" - }, - "BitModel": { - "tokenizer_classes": [], - "processor_classes": [ - "BitImageProcessor" - ], - "model_classes": [ - "BitModel" - ], - "sha": "30a8a9b1a6b253cc500c01cf41bc1fc9581ea5e5" - }, - "BlenderbotForCausalLM": { - "tokenizer_classes": [ - "BlenderbotTokenizer", - "BlenderbotTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BlenderbotForCausalLM" - ], - "sha": "8aad2e13e8920bca3cf988ba45f8a7b008b51a81" - }, - "BlenderbotForConditionalGeneration": { - "tokenizer_classes": [ - "BlenderbotTokenizer", - "BlenderbotTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BlenderbotForConditionalGeneration", - "TFBlenderbotForConditionalGeneration" - ], - "sha": "e8532878b9924fa02fb4b059b7f6e7fa372fff91" - }, - "BlenderbotModel": { - "tokenizer_classes": [ - "BlenderbotTokenizer", - "BlenderbotTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BlenderbotModel", - "TFBlenderbotModel" - ], - "sha": "ff848a40c30ca98eb7c6870bbb02677d5af9db55" - }, - "BlenderbotSmallForCausalLM": { - "tokenizer_classes": [ - "BlenderbotSmallTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "BlenderbotSmallForCausalLM" - ], - "sha": "4c57c106630932eb9de4d76210a540d04616304d" - }, - "BlenderbotSmallForConditionalGeneration": { - "tokenizer_classes": [ - "BlenderbotSmallTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "BlenderbotSmallForConditionalGeneration", - "TFBlenderbotSmallForConditionalGeneration" - ], - "sha": "b8db01fcf3e37a5b369cd50e169bf383b8e905d8" - }, - "BlenderbotSmallModel": { - "tokenizer_classes": [ - "BlenderbotSmallTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "BlenderbotSmallModel", - "TFBlenderbotSmallModel" - ], - "sha": "0a10c70e225ec63278faffa8fabf759f063f0e55" - }, - "Blip2ForConditionalGeneration": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [ - "BlipImageProcessor" - ], - "model_classes": [ - "Blip2ForConditionalGeneration" - ], - "sha": "35e1ef43da3554af62eb29a7b3dbbef3f3bef48e" - }, - "Blip2Model": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [ - "BlipImageProcessor" - ], - "model_classes": [ - "Blip2Model" - ], - "sha": "c23378f225be31872fff33c103cf0ebc2454ffcc" - }, - "BlipForConditionalGeneration": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "BlipImageProcessor" - ], - "model_classes": [ - "BlipForConditionalGeneration", - "TFBlipForConditionalGeneration" - ], - "sha": "eaf32bc0369349deef0c777442fc185119171d1f" - }, - "BlipModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "BlipImageProcessor" - ], - "model_classes": [ - "BlipModel", - "TFBlipModel" - ], - "sha": "3d1d1c15eff22d6b2664a2d15757fa6f5d93827d" - }, - "BloomForCausalLM": { - "tokenizer_classes": [ - "BloomTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BloomForCausalLM" - ], - "sha": "0f4f06f162cd67d34d03ee156484e4001d468500" - }, - "BloomForQuestionAnswering": { - "tokenizer_classes": [ - "BloomTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BloomForQuestionAnswering" - ], - "sha": "23f369f163eef8c9c9685900440b0cbb0f3439fd" - }, - "BloomForSequenceClassification": { - "tokenizer_classes": [ - "BloomTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BloomForSequenceClassification" - ], - "sha": "b2280eef7172835f39b265eb0c46623257f67bbe" - }, - "BloomForTokenClassification": { - "tokenizer_classes": [ - "BloomTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BloomForTokenClassification" - ], - "sha": "9796aa45f99adff987c978089e11c0bd9d7b997f" - }, - "BloomModel": { - "tokenizer_classes": [ - "BloomTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "BloomModel" - ], - "sha": "28b600fcfdc4f4938406fb518abf895620048cb2" - }, - "CLIPModel": { - "tokenizer_classes": [ - "CLIPTokenizer", - "CLIPTokenizerFast" - ], - "processor_classes": [ - "CLIPImageProcessor" - ], - "model_classes": [ - "CLIPModel", - "TFCLIPModel" - ], - "sha": "0452d344074485d0e7eb5d5c12447b7c9dbc9619" - }, - "CLIPSegModel": { - "tokenizer_classes": [ - "CLIPTokenizer", - "CLIPTokenizerFast" - ], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "CLIPSegModel" - ], - "sha": "7b1305214ccc85d29b776ffbee06748693852a04" - }, - "CTRLForSequenceClassification": { - "tokenizer_classes": [ - "CTRLTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "CTRLForSequenceClassification", - "TFCTRLForSequenceClassification" - ], - "sha": "280b5a3502d607c55c9f8d9f198fe9c2802d6f73" - }, - "CTRLLMHeadModel": { - "tokenizer_classes": [ - "CTRLTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "CTRLLMHeadModel", - "TFCTRLLMHeadModel" - ], - "sha": "662381663b216f1dd3c9cd30e2e83cb4c6fc9552" - }, - "CTRLModel": { - "tokenizer_classes": [ - "CTRLTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "CTRLModel", - "TFCTRLModel" - ], - "sha": "68b19b4f132d5a191a73acd78d983cbdcf068e9c" - }, - "CanineForMultipleChoice": { - "tokenizer_classes": [ - "CanineTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "CanineForMultipleChoice" - ], - "sha": "fa0451453ed202f903ff7dcf6071aab6630fb89f" - }, - "CanineForQuestionAnswering": { - "tokenizer_classes": [ - "CanineTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "CanineForQuestionAnswering" - ], - "sha": "5e1012bb086ac2e0b1497eeb7ed14eb2183d4ecb" - }, - "CanineForSequenceClassification": { - "tokenizer_classes": [ - "CanineTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "CanineForSequenceClassification" - ], - "sha": "75336dc9179153869c38a8047ce4b1e02677a260" - }, - "CanineForTokenClassification": { - "tokenizer_classes": [ - "CanineTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "CanineForTokenClassification" - ], - "sha": "65a622ea8e12597e12f45e59d46d8dbe8461fc10" - }, - "CanineModel": { - "tokenizer_classes": [ - "CanineTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "CanineModel" - ], - "sha": "531ef67ad4f0b3dc7a9e5d722c774096b7401b1b" - }, - "ChineseCLIPModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "ChineseCLIPImageProcessor" - ], - "model_classes": [ - "ChineseCLIPModel" - ], - "sha": "504271a3c5fd9c2e877f5b4c01848bc18778c7c3" - }, - "ClapModel": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [ - "ClapFeatureExtractor" - ], - "model_classes": [ - "ClapModel" - ], - "sha": "a7874595b900f9b2ddc79130dafc3ff48f4fbfb9" - }, - "CodeGenForCausalLM": { - "tokenizer_classes": [ - "CodeGenTokenizer", - "CodeGenTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "CodeGenForCausalLM" - ], - "sha": "a3fc69d757fd1f0aa01bcbc4337f586651c7cb10" - }, - "CodeGenModel": { - "tokenizer_classes": [ - "CodeGenTokenizer", - "CodeGenTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "CodeGenModel" - ], - "sha": "dad4941a2b7429fc6e8206fcc4a04fc40f4a0beb" - }, - "ConditionalDetrForObjectDetection": { - "tokenizer_classes": [], - "processor_classes": [ - "ConditionalDetrImageProcessor" - ], - "model_classes": [ - "ConditionalDetrForObjectDetection" - ], - "sha": "762c213a0285edc84eb813a2ed90063cf971ca43" - }, - "ConditionalDetrModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ConditionalDetrImageProcessor" - ], - "model_classes": [ - "ConditionalDetrModel" - ], - "sha": "18b75874158cac520c63605293b06e0b1327c263" - }, - "ConvBertForMaskedLM": { - "tokenizer_classes": [ - "ConvBertTokenizer", - "ConvBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ConvBertForMaskedLM", - "TFConvBertForMaskedLM" - ], - "sha": "307c70e32c3d3c18aeb45e0cbdc9fcd2957d9aba" - }, - "ConvBertForMultipleChoice": { - "tokenizer_classes": [ - "ConvBertTokenizer", - "ConvBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ConvBertForMultipleChoice", - "TFConvBertForMultipleChoice" - ], - "sha": "d6561a21ffdb82d03c1822af0510eb7482ce5026" - }, - "ConvBertForQuestionAnswering": { - "tokenizer_classes": [ - "ConvBertTokenizer", - "ConvBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ConvBertForQuestionAnswering", - "TFConvBertForQuestionAnswering" - ], - "sha": "8a056da5cc421415c2a24b9f644dd95ca279411d" - }, - "ConvBertForSequenceClassification": { - "tokenizer_classes": [ - "ConvBertTokenizer", - "ConvBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ConvBertForSequenceClassification", - "TFConvBertForSequenceClassification" - ], - "sha": "8bb8b20e51d282d777cc567cacadd97a35f0811e" - }, - "ConvBertForTokenClassification": { - "tokenizer_classes": [ - "ConvBertTokenizer", - "ConvBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ConvBertForTokenClassification", - "TFConvBertForTokenClassification" - ], - "sha": "8db0dd3c2b8ccc958fa9a84801f4f837b42fcf2c" - }, - "ConvBertModel": { - "tokenizer_classes": [ - "ConvBertTokenizer", - "ConvBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ConvBertModel", - "TFConvBertModel" - ], - "sha": "c9c5b1a74f0e468d8467473cabeaa67fcdbaddb7" - }, - "ConvNextBackbone": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "ConvNextBackbone" - ], - "sha": "499c7d6a97825b79e19663b70f3b60c4813b6bf2" - }, - "ConvNextForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "ConvNextForImageClassification", - "TFConvNextForImageClassification" - ], - "sha": "0b490fd6b19cdbf721025dbd6ee45dcc5828e6e3" - }, - "ConvNextModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "ConvNextModel", - "TFConvNextModel" - ], - "sha": "7b3b47a57b9a9120e022b91d6067daeac55b794f" - }, - "ConvNextV2Backbone": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "ConvNextV2Backbone" - ], - "sha": "c82fc526949dfd892a1fee3c34be6f8d80c4d3df" - }, - "ConvNextV2ForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "ConvNextV2ForImageClassification" - ], - "sha": "ee22bae1cbb87d66fc7f62f7e15a43d6ff80d3cc" - }, - "ConvNextV2Model": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "ConvNextV2Model" - ], - "sha": "c4dd68ee1102cba05bcc483da2a88e39427b7249" - }, - "CvtForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "CvtForImageClassification", - "TFCvtForImageClassification" - ], - "sha": "4b1938e252fdb26a06c1f5755e07fa8f6eed2d75" - }, - "CvtModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "CvtModel", - "TFCvtModel" - ], - "sha": "27fed12c174f4f4f1fe27075d1c29602fe0669f0" - }, - "DPRQuestionEncoder": { - "tokenizer_classes": [ - "DPRQuestionEncoderTokenizer", - "DPRQuestionEncoderTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DPRQuestionEncoder", - "TFDPRQuestionEncoder" - ], - "sha": "09ae0269780271e0a4916f7bab1dbc4f8a76070d" - }, - "DPTForDepthEstimation": { - "tokenizer_classes": [], - "processor_classes": [ - "DPTImageProcessor" - ], - "model_classes": [ - "DPTForDepthEstimation" - ], - "sha": "11b7735d64d95b6599811631b012d2dec6eaa2c1" - }, - "DPTForSemanticSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "DPTImageProcessor" - ], - "model_classes": [ - "DPTForSemanticSegmentation" - ], - "sha": "e140c3c716a4bf11dad875e5f5f0abd2bd4cbbcb" - }, - "DPTModel": { - "tokenizer_classes": [], - "processor_classes": [ - "DPTImageProcessor" - ], - "model_classes": [ - "DPTModel" - ], - "sha": "1d6ae6c0b60868dffbef0dddeda381c51c6dcba5" - }, - "Data2VecAudioForAudioFrameClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Data2VecAudioForAudioFrameClassification" - ], - "sha": "a64828b27e73fc8dd95aeb315108ca2f6a66b55f" - }, - "Data2VecAudioForCTC": { - "tokenizer_classes": [], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Data2VecAudioForCTC" - ], - "sha": "bb161b6a181bd2c22cf30222f46fa6ef42225744" - }, - "Data2VecAudioForSequenceClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Data2VecAudioForSequenceClassification" - ], - "sha": "8de17e0a959eca5f72b2ea59a11bc1fa744785d9" - }, - "Data2VecAudioForXVector": { - "tokenizer_classes": [], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Data2VecAudioForXVector" - ], - "sha": "dcb92484cf28fb4fe1dcf5d6e8d78e04382fdce9" - }, - "Data2VecAudioModel": { - "tokenizer_classes": [], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Data2VecAudioModel" - ], - "sha": "73f503fdff73b7616154f64dbe38a685cc48e8eb" - }, - "Data2VecTextForCausalLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "Data2VecTextForCausalLM" - ], - "sha": "1f3658ce623653338cd31516551e8181aa08bb38" - }, - "Data2VecTextForMaskedLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "Data2VecTextForMaskedLM" - ], - "sha": "fb41ac30d0faa0899bf5afaa0986df8993395ca6" - }, - "Data2VecTextForMultipleChoice": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "Data2VecTextForMultipleChoice" - ], - "sha": "e7556d520ad90ebae5ad88554d45a37488d00040" - }, - "Data2VecTextForQuestionAnswering": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "Data2VecTextForQuestionAnswering" - ], - "sha": "9630833d76a1fd7e96b904d87bb11b7c00ccd021" - }, - "Data2VecTextForSequenceClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "Data2VecTextForSequenceClassification" - ], - "sha": "156e4019c37d9592f193ba80553cd245cbccecb3" - }, - "Data2VecTextForTokenClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "Data2VecTextForTokenClassification" - ], - "sha": "55b3a49fdbf22479d6eb939261d4b884ea288270" - }, - "Data2VecTextModel": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "Data2VecTextModel" - ], - "sha": "c21be3e4f88e8357bf33bfba8f8e05ae2e735124" - }, - "Data2VecVisionForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "BeitImageProcessor" - ], - "model_classes": [ - "Data2VecVisionForImageClassification", - "TFData2VecVisionForImageClassification" - ], - "sha": "d640e7ced7a3fbbb8c8661a4f67b934e55406172" - }, - "Data2VecVisionForSemanticSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "BeitImageProcessor" - ], - "model_classes": [ - "Data2VecVisionForSemanticSegmentation", - "TFData2VecVisionForSemanticSegmentation" - ], - "sha": "3eba3cd694fab6530b7e5da8f49d3951301c816a" - }, - "Data2VecVisionModel": { - "tokenizer_classes": [], - "processor_classes": [ - "BeitImageProcessor" - ], - "model_classes": [ - "Data2VecVisionModel", - "TFData2VecVisionModel" - ], - "sha": "2a7ad25e4359970dc70494a2f3eb98e2a3c9806d" - }, - "DebertaForMaskedLM": { - "tokenizer_classes": [ - "DebertaTokenizer", - "DebertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaForMaskedLM", - "TFDebertaForMaskedLM" - ], - "sha": "e0f9ada9e0f6d4d7cc39d7cbd58369b0c84de33d" - }, - "DebertaForQuestionAnswering": { - "tokenizer_classes": [ - "DebertaTokenizer", - "DebertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaForQuestionAnswering", - "TFDebertaForQuestionAnswering" - ], - "sha": "a3eb69cdb0b52f7d0fb730e882f1a54b9a7442ea" - }, - "DebertaForSequenceClassification": { - "tokenizer_classes": [ - "DebertaTokenizer", - "DebertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaForSequenceClassification", - "TFDebertaForSequenceClassification" - ], - "sha": "32af91d12c4e9b6d62b420bee93311fd77d3c933" - }, - "DebertaForTokenClassification": { - "tokenizer_classes": [ - "DebertaTokenizer", - "DebertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaForTokenClassification", - "TFDebertaForTokenClassification" - ], - "sha": "ba62ba2726d813e60e512476fc1b178aa3858175" - }, - "DebertaModel": { - "tokenizer_classes": [ - "DebertaTokenizer", - "DebertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaModel", - "TFDebertaModel" - ], - "sha": "4273294e14cd04c0e2cd1dcff5cf7e5d4fe906ba" - }, - "DebertaV2ForMaskedLM": { - "tokenizer_classes": [ - "DebertaV2Tokenizer", - "DebertaV2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaV2ForMaskedLM", - "TFDebertaV2ForMaskedLM" - ], - "sha": "a053dedc2cdf32918a84277cb0c05186604496a5" - }, - "DebertaV2ForMultipleChoice": { - "tokenizer_classes": [ - "DebertaV2Tokenizer", - "DebertaV2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaV2ForMultipleChoice" - ], - "sha": "07e39f520ce239b39ef8cb24cd7874d06c791063" - }, - "DebertaV2ForQuestionAnswering": { - "tokenizer_classes": [ - "DebertaV2Tokenizer", - "DebertaV2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaV2ForQuestionAnswering", - "TFDebertaV2ForQuestionAnswering" - ], - "sha": "9cecb3a7fc6b95099122283644ea1f8ced287d1b" - }, - "DebertaV2ForSequenceClassification": { - "tokenizer_classes": [ - "DebertaV2Tokenizer", - "DebertaV2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaV2ForSequenceClassification", - "TFDebertaV2ForSequenceClassification" - ], - "sha": "df9ea1f5c0f2ccd139b21cfb3963a5a5ebfb5b81" - }, - "DebertaV2ForTokenClassification": { - "tokenizer_classes": [ - "DebertaV2Tokenizer", - "DebertaV2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaV2ForTokenClassification", - "TFDebertaV2ForTokenClassification" - ], - "sha": "51fe01989df38a540ac1abca5ee71a51365defd5" - }, - "DebertaV2Model": { - "tokenizer_classes": [ - "DebertaV2Tokenizer", - "DebertaV2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DebertaV2Model", - "TFDebertaV2Model" - ], - "sha": "211df4bd1a4a9b66c97af3f9231a5d2af8de7b9f" - }, - "DeformableDetrForObjectDetection": { - "tokenizer_classes": [], - "processor_classes": [ - "DeformableDetrImageProcessor" - ], - "model_classes": [ - "DeformableDetrForObjectDetection" - ], - "sha": "8fa0db215c458f60ae4d455d6fb067c1c5e39fdc" - }, - "DeformableDetrModel": { - "tokenizer_classes": [], - "processor_classes": [ - "DeformableDetrImageProcessor" - ], - "model_classes": [ - "DeformableDetrModel" - ], - "sha": "0faac5624696b03edd14694642f9804f2cd8f3da" - }, - "DeiTForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "DeiTImageProcessor" - ], - "model_classes": [ - "DeiTForImageClassification", - "TFDeiTForImageClassification" - ], - "sha": "21fc864199dafa0130f16a45769c6b6ca22c7784" - }, - "DeiTForImageClassificationWithTeacher": { - "tokenizer_classes": [], - "processor_classes": [ - "DeiTImageProcessor" - ], - "model_classes": [ - "DeiTForImageClassificationWithTeacher", - "TFDeiTForImageClassificationWithTeacher" - ], - "sha": "5a5738a109e27f3d4b78a0db4cb1d3331140c10e" - }, - "DeiTForMaskedImageModeling": { - "tokenizer_classes": [], - "processor_classes": [ - "DeiTImageProcessor" - ], - "model_classes": [ - "DeiTForMaskedImageModeling", - "TFDeiTForMaskedImageModeling" - ], - "sha": "d5df5c538fe1efb8d668a3893d1691d505a0de06" - }, - "DeiTModel": { - "tokenizer_classes": [], - "processor_classes": [ - "DeiTImageProcessor" - ], - "model_classes": [ - "DeiTModel", - "TFDeiTModel" - ], - "sha": "0fdbff6f44b7c6933c2027fec1d7f87bec06b590" - }, - "DetaForObjectDetection": { - "tokenizer_classes": [], - "processor_classes": [ - "DetaImageProcessor" - ], - "model_classes": [ - "DetaForObjectDetection" - ], - "sha": "a15ad6ce64fbcb5021b2b99e9587c4011ef3341d" - }, - "DetaModel": { - "tokenizer_classes": [], - "processor_classes": [ - "DetaImageProcessor" - ], - "model_classes": [ - "DetaModel" - ], - "sha": "8820f2297ec0dec8f1875054559c8b7a162098e3" - }, - "DetrForObjectDetection": { - "tokenizer_classes": [], - "processor_classes": [ - "DetrImageProcessor" - ], - "model_classes": [ - "DetrForObjectDetection" - ], - "sha": "7dc967c53f4b3f07904c42b255346b744d0ad84e" - }, - "DetrForSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "DetrImageProcessor" - ], - "model_classes": [ - "DetrForSegmentation" - ], - "sha": "e34330acdae359588ef853e961a78d419dc4e8eb" - }, - "DetrModel": { - "tokenizer_classes": [], - "processor_classes": [ - "DetrImageProcessor" - ], - "model_classes": [ - "DetrModel" - ], - "sha": "f15ce38a10c7447e8048b1681e4811322a005722" - }, - "DinatBackbone": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "DinatBackbone" - ], - "sha": "3ba13790a0796d90104c207f75bb3d5d79723d51" - }, - "DinatForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "DinatForImageClassification" - ], - "sha": "624cf2d864a7ea2f90e24014a213e34597e8bd76" - }, - "DinatModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "DinatModel" - ], - "sha": "d6c75bc51196f0a683afb12de6310fdda13efefd" - }, - "Dinov2ForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "BitImageProcessor" - ], - "model_classes": [ - "Dinov2ForImageClassification" - ], - "sha": "ae44840966456aae33641df2c8c8a4af5b457b24" - }, - "Dinov2Model": { - "tokenizer_classes": [], - "processor_classes": [ - "BitImageProcessor" - ], - "model_classes": [ - "Dinov2Model" - ], - "sha": "6f560b1cc9806bcf84fe0b0c60b5faf9c29be959" - }, - "DistilBertForMaskedLM": { - "tokenizer_classes": [ - "DistilBertTokenizer", - "DistilBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DistilBertForMaskedLM", - "TFDistilBertForMaskedLM" - ], - "sha": "b2dfda30b012821996e6e603729562d9c900bc0f" - }, - "DistilBertForMultipleChoice": { - "tokenizer_classes": [ - "DistilBertTokenizer", - "DistilBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DistilBertForMultipleChoice", - "TFDistilBertForMultipleChoice" - ], - "sha": "ec6b83129a7d1be2a6b8d58303abcca5541a5cb3" - }, - "DistilBertForQuestionAnswering": { - "tokenizer_classes": [ - "DistilBertTokenizer", - "DistilBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DistilBertForQuestionAnswering", - "TFDistilBertForQuestionAnswering" - ], - "sha": "812406b226415044469b0e0a84c4fe0ff338c5d3" - }, - "DistilBertForSequenceClassification": { - "tokenizer_classes": [ - "DistilBertTokenizer", - "DistilBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DistilBertForSequenceClassification", - "TFDistilBertForSequenceClassification" - ], - "sha": "6f427ce7b3e5aaa596938fbd98437d3875581b7b" - }, - "DistilBertForTokenClassification": { - "tokenizer_classes": [ - "DistilBertTokenizer", - "DistilBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DistilBertForTokenClassification", - "TFDistilBertForTokenClassification" - ], - "sha": "166dbe3f5d6ecd871762567069454d6ec65234b4" - }, - "DistilBertModel": { - "tokenizer_classes": [ - "DistilBertTokenizer", - "DistilBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "DistilBertModel", - "TFDistilBertModel" - ], - "sha": "cc4425ad0676f3ec00e8bffe485fe83cae61041a" - }, - "DonutSwinModel": { - "tokenizer_classes": [], - "processor_classes": [ - "DonutImageProcessor" - ], - "model_classes": [ - "DonutSwinModel" - ], - "sha": "1b10654fbfe2f2ea410a672ab605bd5c60d3f284" - }, - "EfficientFormerForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "EfficientFormerImageProcessor" - ], - "model_classes": [ - "EfficientFormerForImageClassification", - "TFEfficientFormerForImageClassification" - ], - "sha": "ebadb628e12f268e321fcc756fa4606f7b5b3178" - }, - "EfficientFormerForImageClassificationWithTeacher": { - "tokenizer_classes": [], - "processor_classes": [ - "EfficientFormerImageProcessor" - ], - "model_classes": [ - "EfficientFormerForImageClassificationWithTeacher", - "TFEfficientFormerForImageClassificationWithTeacher" - ], - "sha": "1beabce6da9cb4ebbeafcd1ef23fac36b4a269e2" - }, - "EfficientFormerModel": { - "tokenizer_classes": [], - "processor_classes": [ - "EfficientFormerImageProcessor" - ], - "model_classes": [ - "EfficientFormerModel", - "TFEfficientFormerModel" - ], - "sha": "200fae5b875844d09c8a91d1c155b72b06a517f6" - }, - "EfficientNetForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "EfficientNetImageProcessor" - ], - "model_classes": [ - "EfficientNetForImageClassification" - ], - "sha": "6ed195ee636d2c0b885139da8c7b45d57ebaeee0" - }, - "EfficientNetModel": { - "tokenizer_classes": [], - "processor_classes": [ - "EfficientNetImageProcessor" - ], - "model_classes": [ - "EfficientNetModel" - ], - "sha": "eb03c90d4aaad98af0f19e0dfbdc41106297ffff" - }, - "ElectraForCausalLM": { - "tokenizer_classes": [ - "ElectraTokenizer", - "ElectraTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ElectraForCausalLM" - ], - "sha": "c78396bc8cdd8db247892339de8da80d691d1d04" - }, - "ElectraForMaskedLM": { - "tokenizer_classes": [ - "ElectraTokenizer", - "ElectraTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ElectraForMaskedLM", - "TFElectraForMaskedLM" - ], - "sha": "631337703dbd8d41904c39891a41c6f1edd31813" - }, - "ElectraForMultipleChoice": { - "tokenizer_classes": [ - "ElectraTokenizer", - "ElectraTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ElectraForMultipleChoice", - "TFElectraForMultipleChoice" - ], - "sha": "66fdea6e22cfcbd3caa49ea82f31871c460612fa" - }, - "ElectraForPreTraining": { - "tokenizer_classes": [ - "ElectraTokenizer", - "ElectraTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ElectraForPreTraining", - "TFElectraForPreTraining" - ], - "sha": "7b2d0fa8726b1180c7d6cde4f4afc3800eba7e6f" - }, - "ElectraForQuestionAnswering": { - "tokenizer_classes": [ - "ElectraTokenizer", - "ElectraTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ElectraForQuestionAnswering", - "TFElectraForQuestionAnswering" - ], - "sha": "c6b127fd9f3019462e4ca2373762836207e39ce2" - }, - "ElectraForSequenceClassification": { - "tokenizer_classes": [ - "ElectraTokenizer", - "ElectraTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ElectraForSequenceClassification", - "TFElectraForSequenceClassification" - ], - "sha": "41f0089ab7876abe0e28dbbd565144acb31f8127" - }, - "ElectraForTokenClassification": { - "tokenizer_classes": [ - "ElectraTokenizer", - "ElectraTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ElectraForTokenClassification", - "TFElectraForTokenClassification" - ], - "sha": "1fdbbe70c1ddd16503820a1443d6a379a15ed777" - }, - "ElectraModel": { - "tokenizer_classes": [ - "ElectraTokenizer", - "ElectraTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ElectraModel", - "TFElectraModel" - ], - "sha": "312b532cbef26610d80f2bd008650160cae4f7a1" - }, - "EncodecModel": { - "tokenizer_classes": [], - "processor_classes": [ - "EncodecFeatureExtractor" - ], - "model_classes": [ - "EncodecModel" - ], - "sha": "e14c5a2fd6529c85cd4ac5a05ee9e550ced6a006" - }, - "EncoderDecoderModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "EncoderDecoderModel", - "TFEncoderDecoderModel" - ], - "sha": "1038be9fd1b87b2e0a8f33721ff8e4612d34b3b6" - }, - "ErnieForCausalLM": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ErnieForCausalLM" - ], - "sha": "b49e00112ff06c2f0a0e54499921dddcf8c3c6a8" - }, - "ErnieForMaskedLM": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ErnieForMaskedLM" - ], - "sha": "30429830d1997222d885dcfdbd36d5e02d0d34b1" - }, - "ErnieForMultipleChoice": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ErnieForMultipleChoice" - ], - "sha": "5a21144bf35dfb60560ff8249116ad4459c0069a" - }, - "ErnieForNextSentencePrediction": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ErnieForNextSentencePrediction" - ], - "sha": "ed5868efb39bf6afb29f0cf444deafcf1e50b5bc" - }, - "ErnieForPreTraining": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ErnieForPreTraining" - ], - "sha": "e4ad30d291c310fea25e6f91f91393f993513b42" - }, - "ErnieForQuestionAnswering": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ErnieForQuestionAnswering" - ], - "sha": "fe7c74b763f63a9fd864dad325385075df7c80c8" - }, - "ErnieForSequenceClassification": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ErnieForSequenceClassification" - ], - "sha": "84e0be05fcd52f54e96a69f67a2481323a58a9db" - }, - "ErnieForTokenClassification": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ErnieForTokenClassification" - ], - "sha": "91cf62c43a5a83332552ffa2d8e5e44d63a224ea" - }, - "ErnieMForMultipleChoice": { - "tokenizer_classes": [ - "ErnieMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "ErnieMForMultipleChoice" - ], - "sha": "c42ee7fcb132a323ace314c32e63c8a7d36ce18f" - }, - "ErnieMForQuestionAnswering": { - "tokenizer_classes": [ - "ErnieMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "ErnieMForQuestionAnswering" - ], - "sha": "2b90dee75ca87b214f96db00002aa18244ec8e84" - }, - "ErnieMForSequenceClassification": { - "tokenizer_classes": [ - "ErnieMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "ErnieMForSequenceClassification" - ], - "sha": "d8368646d8b1c67b1460af9c6ec13fd9d894cae6" - }, - "ErnieMForTokenClassification": { - "tokenizer_classes": [ - "ErnieMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "ErnieMForTokenClassification" - ], - "sha": "a9e29ba60fa0b7bedc2ed26a6b9911427df1ca6b" - }, - "ErnieMModel": { - "tokenizer_classes": [ - "ErnieMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "ErnieMModel" - ], - "sha": "7306eac3f38c3cf6211f0e741fdb81c6cc92bc09" - }, - "ErnieModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ErnieModel" - ], - "sha": "b51478a9f40e353c41be3a29ccef103dcfe22b4b" - }, - "EsmForMaskedLM": { - "tokenizer_classes": [ - "EsmTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "EsmForMaskedLM", - "TFEsmForMaskedLM" - ], - "sha": "b56297b6cd64b9ba7c613d0cd146f1ecbea8115e" - }, - "EsmForSequenceClassification": { - "tokenizer_classes": [ - "EsmTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "EsmForSequenceClassification", - "TFEsmForSequenceClassification" - ], - "sha": "cc6d7ef0a4763540d67b7a4fb31bede9a7d3f245" - }, - "EsmForTokenClassification": { - "tokenizer_classes": [ - "EsmTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "EsmForTokenClassification", - "TFEsmForTokenClassification" - ], - "sha": "498953f66e260b974c504abbc863ee266d6c84a9" - }, - "EsmModel": { - "tokenizer_classes": [ - "EsmTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "EsmModel", - "TFEsmModel" - ], - "sha": "183838263b70809310117a0761542501acf64c21" - }, - "FNetForMaskedLM": { - "tokenizer_classes": [ - "FNetTokenizer", - "FNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FNetForMaskedLM" - ], - "sha": "91eaae1eac894af5d96c0221ec9bcef7f1af41c8" - }, - "FNetForMultipleChoice": { - "tokenizer_classes": [ - "FNetTokenizer", - "FNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FNetForMultipleChoice" - ], - "sha": "c15d98d5f7a6f3ef3099b1257949bee208d5466e" - }, - "FNetForNextSentencePrediction": { - "tokenizer_classes": [ - "FNetTokenizer", - "FNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FNetForNextSentencePrediction" - ], - "sha": "c59440b44d07d61fc45a90ded7fc11d6f25b143d" - }, - "FNetForPreTraining": { - "tokenizer_classes": [ - "FNetTokenizer", - "FNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FNetForPreTraining" - ], - "sha": "c05f55ccfb2f2533babd3c6e99de7749bc8081da" - }, - "FNetForQuestionAnswering": { - "tokenizer_classes": [ - "FNetTokenizer", - "FNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FNetForQuestionAnswering" - ], - "sha": "47788e49dd435653fa2aa4b3ccae3572a870758e" - }, - "FNetForSequenceClassification": { - "tokenizer_classes": [ - "FNetTokenizer", - "FNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FNetForSequenceClassification" - ], - "sha": "a3049b896ea6c5a32c364989c3afe604ee58b9fc" - }, - "FNetForTokenClassification": { - "tokenizer_classes": [ - "FNetTokenizer", - "FNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FNetForTokenClassification" - ], - "sha": "3bcdafca57d544bb81e2f7eead1e512c168582fc" - }, - "FNetModel": { - "tokenizer_classes": [ - "FNetTokenizer", - "FNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FNetModel" - ], - "sha": "48fa66de37df126504db3b658806135eb877f505" - }, - "FSMTForConditionalGeneration": { - "tokenizer_classes": [ - "FSMTTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "FSMTForConditionalGeneration" - ], - "sha": "6a1a981b29c8a98c1fd31bd0ad809f5575ca6c7a" - }, - "FSMTModel": { - "tokenizer_classes": [ - "FSMTTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "FSMTModel" - ], - "sha": "683f6f73a2ab87801f1695a72d1af63cf173ab7c" - }, - "FlaubertForMultipleChoice": { - "tokenizer_classes": [ - "FlaubertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "FlaubertForMultipleChoice", - "TFFlaubertForMultipleChoice" - ], - "sha": "8b12bd87a63f2e86c3482431742f6d8abf6ec4fd" - }, - "FlaubertForQuestionAnsweringSimple": { - "tokenizer_classes": [ - "FlaubertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "FlaubertForQuestionAnsweringSimple", - "TFFlaubertForQuestionAnsweringSimple" - ], - "sha": "5c0e7ad1efae7e3497f5cd6d2d9519403df49d37" - }, - "FlaubertForSequenceClassification": { - "tokenizer_classes": [ - "FlaubertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "FlaubertForSequenceClassification", - "TFFlaubertForSequenceClassification" - ], - "sha": "762f12a8c99690be8ed2663b7af3011660174a7c" - }, - "FlaubertForTokenClassification": { - "tokenizer_classes": [ - "FlaubertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "FlaubertForTokenClassification", - "TFFlaubertForTokenClassification" - ], - "sha": "d2ab741c937bb69ef27c89e4c86a8c9d444874ca" - }, - "FlaubertModel": { - "tokenizer_classes": [ - "FlaubertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "FlaubertModel", - "TFFlaubertModel" - ], - "sha": "bdc2f8e17bb869393053429ec8c1c842bfeabb07" - }, - "FlaubertWithLMHeadModel": { - "tokenizer_classes": [ - "FlaubertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "FlaubertWithLMHeadModel", - "TFFlaubertWithLMHeadModel" - ], - "sha": "f20eb0932c90061003c9cc4e109c6ea22559c4f2" - }, - "FlavaForPreTraining": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "FlavaImageProcessor" - ], - "model_classes": [ - "FlavaForPreTraining" - ], - "sha": "6e9b2094060a5fa27984c7b49e5d0e820a88b487" - }, - "FlavaModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "FlavaImageProcessor" - ], - "model_classes": [ - "FlavaModel" - ], - "sha": "31ebf1b7a0ef1fd5059b98e28e5ab1c366d2c482" - }, - "FocalNetBackbone": { - "tokenizer_classes": [], - "processor_classes": [ - "BitImageProcessor" - ], - "model_classes": [ - "FocalNetBackbone" - ], - "sha": "eb8c580969443cb87de7dd9a256deaface03692f" - }, - "FocalNetForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "BitImageProcessor" - ], - "model_classes": [ - "FocalNetForImageClassification" - ], - "sha": "28d30ded26a3213e8fb7011a455afc3aa98b0a95" - }, - "FocalNetForMaskedImageModeling": { - "tokenizer_classes": [], - "processor_classes": [ - "BitImageProcessor" - ], - "model_classes": [ - "FocalNetForMaskedImageModeling" - ], - "sha": "0ea7626d19c9dd2f3113d977f643a1babc720bd3" - }, - "FocalNetModel": { - "tokenizer_classes": [], - "processor_classes": [ - "BitImageProcessor" - ], - "model_classes": [ - "FocalNetModel" - ], - "sha": "107b004e6aa14108a359b7d22bdb9aa141ec05d5" - }, - "FunnelBaseModel": { - "tokenizer_classes": [ - "FunnelTokenizer", - "FunnelTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FunnelBaseModel", - "TFFunnelBaseModel" - ], - "sha": "87fed4252812df23315a56531625333e315681c6" - }, - "FunnelForMaskedLM": { - "tokenizer_classes": [ - "FunnelTokenizer", - "FunnelTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FunnelForMaskedLM", - "TFFunnelForMaskedLM" - ], - "sha": "5543daf29f185cd45f2599bd6f38c96064c9c8de" - }, - "FunnelForMultipleChoice": { - "tokenizer_classes": [ - "FunnelTokenizer", - "FunnelTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FunnelForMultipleChoice", - "TFFunnelForMultipleChoice" - ], - "sha": "a8bf597e37dbefb1ac5c97c4cb162c3d522a33a1" - }, - "FunnelForPreTraining": { - "tokenizer_classes": [ - "FunnelTokenizer", - "FunnelTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FunnelForPreTraining", - "TFFunnelForPreTraining" - ], - "sha": "cbcb300d60aacd5950a45409b6e3f0f240c9082e" - }, - "FunnelForQuestionAnswering": { - "tokenizer_classes": [ - "FunnelTokenizer", - "FunnelTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FunnelForQuestionAnswering", - "TFFunnelForQuestionAnswering" - ], - "sha": "6a5675305e096434e818486a13892cb55daffd13" - }, - "FunnelForSequenceClassification": { - "tokenizer_classes": [ - "FunnelTokenizer", - "FunnelTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FunnelForSequenceClassification", - "TFFunnelForSequenceClassification" - ], - "sha": "1bc557a1e4314da21a44dee57b799e95a7025e5c" - }, - "FunnelForTokenClassification": { - "tokenizer_classes": [ - "FunnelTokenizer", - "FunnelTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FunnelForTokenClassification", - "TFFunnelForTokenClassification" - ], - "sha": "693bc1217a224efd558f410ddc8ffc63739bebc3" - }, - "FunnelModel": { - "tokenizer_classes": [ - "FunnelTokenizer", - "FunnelTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "FunnelModel", - "TFFunnelModel" - ], - "sha": "bfbaa8fa21c3abf80b94e7168b5ecff8ec5b5f76" - }, - "GLPNForDepthEstimation": { - "tokenizer_classes": [], - "processor_classes": [ - "GLPNImageProcessor" - ], - "model_classes": [ - "GLPNForDepthEstimation" - ], - "sha": "32ca1c1ef5d33242e5e7c0433bcd773c082f0260" - }, - "GLPNModel": { - "tokenizer_classes": [], - "processor_classes": [ - "GLPNImageProcessor" - ], - "model_classes": [ - "GLPNModel" - ], - "sha": "24a8dbb48b1aa0ba2eba44324fcd0c78cca64dd4" - }, - "GPT2ForQuestionAnswering": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPT2ForQuestionAnswering" - ], - "sha": "a5bdd6bd4d79feece85ea9a8bd4ee5fe54c1d45b" - }, - "GPT2ForSequenceClassification": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPT2ForSequenceClassification", - "TFGPT2ForSequenceClassification" - ], - "sha": "90a2d78e5c7f288152f8456c3d58a43b40a58449" - }, - "GPT2ForTokenClassification": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPT2ForTokenClassification" - ], - "sha": "da78bc95b45fab2da9d43f2ca27164996e31ade1" - }, - "GPT2LMHeadModel": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPT2LMHeadModel", - "TFGPT2LMHeadModel" - ], - "sha": "78f56535d4ce19e9d7c0992e390085c5a4196b37" - }, - "GPT2Model": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPT2Model", - "TFGPT2Model" - ], - "sha": "d6694b0d8fe17978761c9305dc151780506b192e" - }, - "GPTBigCodeForCausalLM": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTBigCodeForCausalLM" - ], - "sha": "99f7aaadf9c29669c63ef6c16f6bc5c07dbb9126" - }, - "GPTBigCodeForSequenceClassification": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTBigCodeForSequenceClassification" - ], - "sha": "64a7398d5763161037b818314c60dd83d93d03e9" - }, - "GPTBigCodeForTokenClassification": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTBigCodeForTokenClassification" - ], - "sha": "310537ecd22d45f71bf594b17922cf2abc338eaf" - }, - "GPTBigCodeModel": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTBigCodeModel" - ], - "sha": "3069419084a9dc36802d47de9df3d314ccfc2f28" - }, - "GPTJForCausalLM": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTJForCausalLM", - "TFGPTJForCausalLM" - ], - "sha": "1fff390baa45cb187903ebdd269c975bb9ed7386" - }, - "GPTJForQuestionAnswering": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTJForQuestionAnswering", - "TFGPTJForQuestionAnswering" - ], - "sha": "3d4ec61dbed01f844d4c309971eeb5ad722c6c84" - }, - "GPTJForSequenceClassification": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTJForSequenceClassification", - "TFGPTJForSequenceClassification" - ], - "sha": "4b5db259cd16ca84ae2cd79aa4851cdd14479128" - }, - "GPTJModel": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTJModel", - "TFGPTJModel" - ], - "sha": "d8e1db30d08fbf57da6fc139aea3ffd63ab6226e" - }, - "GPTNeoForCausalLM": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoForCausalLM" - ], - "sha": "e88934e402c15195dd99b2947632415dd7645268" - }, - "GPTNeoForQuestionAnswering": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoForQuestionAnswering" - ], - "sha": "623883e94bd08caf9b3f839b98debeea72d5bc2b" - }, - "GPTNeoForSequenceClassification": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoForSequenceClassification" - ], - "sha": "bf2090d5d91a70eb37ba51fbdcf23afc7031fea8" - }, - "GPTNeoForTokenClassification": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoForTokenClassification" - ], - "sha": "d5208e73e24a1671219776b50fe5f96e0e4cd218" - }, - "GPTNeoModel": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoModel" - ], - "sha": "72a7cd49da613c3125a90884df4763545c594e56" - }, - "GPTNeoXForCausalLM": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoXForCausalLM" - ], - "sha": "0229cfaaa843c6b492ac2abffabb00f1ff1936f8" - }, - "GPTNeoXForQuestionAnswering": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoXForQuestionAnswering" - ], - "sha": "7d2f08c959c211129952ee03b5562add09fe6864" - }, - "GPTNeoXForSequenceClassification": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoXForSequenceClassification" - ], - "sha": "17c4b845ee2e0bb780ca2dea2d59a3d9d5d3c651" - }, - "GPTNeoXForTokenClassification": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoXForTokenClassification" - ], - "sha": "3aa4fe8a562f32230041d6d3616aa5ecc3f30192" - }, - "GPTNeoXJapaneseForCausalLM": { - "tokenizer_classes": [ - "GPTNeoXJapaneseTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoXJapaneseForCausalLM" - ], - "sha": "5fca2479f1064fd22e17f944c8fcc14f7e73f1d5" - }, - "GPTNeoXJapaneseModel": { - "tokenizer_classes": [ - "GPTNeoXJapaneseTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoXJapaneseModel" - ], - "sha": "5c6ed124150df845cfc701d70b97fdcde687be52" - }, - "GPTNeoXModel": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "GPTNeoXModel" - ], - "sha": "33114ba2f72189d5a2bd63f0cdb78551189242ff" - }, - "GPTSanJapaneseForConditionalGeneration": { - "tokenizer_classes": [ - "GPTSanJapaneseTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "GPTSanJapaneseForConditionalGeneration" - ], - "sha": "ff6a41faaa713c7fbd5d9a1a50539745f9e1178e" - }, - "GitForCausalLM": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "CLIPImageProcessor" - ], - "model_classes": [ - "GitForCausalLM" - ], - "sha": "60f9c50466ae0beeb11776ca5bfeb6473f441554" - }, - "GitModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "CLIPImageProcessor" - ], - "model_classes": [ - "GitModel" - ], - "sha": "3d2eb6bddf95bb4a4e59b045d4e464c730c07f41" - }, - "GroupViTModel": { - "tokenizer_classes": [ - "CLIPTokenizer", - "CLIPTokenizerFast" - ], - "processor_classes": [ - "CLIPImageProcessor" - ], - "model_classes": [ - "GroupViTModel", - "TFGroupViTModel" - ], - "sha": "05a3a02dd46cb9eb078608dec98f633c0cf559ef" - }, - "HubertForCTC": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "HubertForCTC" - ], - "sha": "13431b76106f993eedcff48a75bae590a09b14f7" - }, - "HubertForSequenceClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "HubertForSequenceClassification" - ], - "sha": "d23f46607a900b1a55dfee4b7ed205a6823035b1" - }, - "HubertModel": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "HubertModel", - "TFHubertModel" - ], - "sha": "3224562c86c4669db65ae7defdc5fb555b113e95" - }, - "IBertForMaskedLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "IBertForMaskedLM" - ], - "sha": "e333a9c9d375f4d839b7e9e21d1a1c8dad58d7d1" - }, - "IBertForMultipleChoice": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "IBertForMultipleChoice" - ], - "sha": "a81f7d64cd7ce5fe6cd726b23d9d14ac5d17bf53" - }, - "IBertForQuestionAnswering": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "IBertForQuestionAnswering" - ], - "sha": "7b66d13d4d6801a82cbeb7f9fd853ca1630d1f8b" - }, - "IBertForSequenceClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "IBertForSequenceClassification" - ], - "sha": "309d57145c40f889222fe5df62f14dddf4496b38" - }, - "IBertForTokenClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "IBertForTokenClassification" - ], - "sha": "b032e9bff4b081b78c098b2d8bc610ac035c6ddf" - }, - "IBertModel": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "IBertModel" - ], - "sha": "6749164c678d4883d455f98b1dfc98c62da8f08b" - }, - "ImageGPTForCausalImageModeling": { - "tokenizer_classes": [], - "processor_classes": [ - "ImageGPTImageProcessor" - ], - "model_classes": [ - "ImageGPTForCausalImageModeling" - ], - "sha": "9a7d1fc04439ab1d9d690de9c3e7673f08568cdf" - }, - "ImageGPTForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ImageGPTImageProcessor" - ], - "model_classes": [ - "ImageGPTForImageClassification" - ], - "sha": "d92c7aed4ba5de74a1f542b736010090e4a58b42" - }, - "ImageGPTModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ImageGPTImageProcessor" - ], - "model_classes": [ - "ImageGPTModel" - ], - "sha": "5a7983e48d5841704733dd0756177680ed50c074" - }, - "LEDForConditionalGeneration": { - "tokenizer_classes": [ - "LEDTokenizer", - "LEDTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LEDForConditionalGeneration", - "TFLEDForConditionalGeneration" - ], - "sha": "a354b49a79351f3ea8ae7776d9f8352ae26cfc14" - }, - "LEDForQuestionAnswering": { - "tokenizer_classes": [ - "LEDTokenizer", - "LEDTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LEDForQuestionAnswering" - ], - "sha": "47c7a75a1e650dae60ff6e9bbab0f2386946670c" - }, - "LEDForSequenceClassification": { - "tokenizer_classes": [ - "LEDTokenizer", - "LEDTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LEDForSequenceClassification" - ], - "sha": "3571e2c9d9f2f2ec0b8fe47090330b128be05126" - }, - "LEDModel": { - "tokenizer_classes": [ - "LEDTokenizer", - "LEDTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LEDModel", - "TFLEDModel" - ], - "sha": "3c3f6eb142545afc570187bfdabfe65d43dafbe4" - }, - "LayoutLMForMaskedLM": { - "tokenizer_classes": [ - "LayoutLMTokenizer", - "LayoutLMTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LayoutLMForMaskedLM", - "TFLayoutLMForMaskedLM" - ], - "sha": "0368bd9bd8fd3eb43b8a3b38962b5345b8765514" - }, - "LayoutLMForQuestionAnswering": { - "tokenizer_classes": [ - "LayoutLMTokenizer", - "LayoutLMTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LayoutLMForQuestionAnswering", - "TFLayoutLMForQuestionAnswering" - ], - "sha": "0d6a4bc614fccfa313c1fb6d132a250929518f85" - }, - "LayoutLMForSequenceClassification": { - "tokenizer_classes": [ - "LayoutLMTokenizer", - "LayoutLMTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LayoutLMForSequenceClassification", - "TFLayoutLMForSequenceClassification" - ], - "sha": "1bd68c73dbf6c8c0526d24fbe2831be82998c440" - }, - "LayoutLMForTokenClassification": { - "tokenizer_classes": [ - "LayoutLMTokenizer", - "LayoutLMTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LayoutLMForTokenClassification", - "TFLayoutLMForTokenClassification" - ], - "sha": "155e7da3f1d786aa39d957b16080c52de4a7efd7" - }, - "LayoutLMModel": { - "tokenizer_classes": [ - "LayoutLMTokenizer", - "LayoutLMTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LayoutLMModel", - "TFLayoutLMModel" - ], - "sha": "14f77b30d267910f11f0fd532a91a6b85ab3a4de" - }, - "LayoutLMv2ForQuestionAnswering": { - "tokenizer_classes": [ - "LayoutLMv2Tokenizer", - "LayoutLMv2TokenizerFast" - ], - "processor_classes": [ - "LayoutLMv2ImageProcessor" - ], - "model_classes": [ - "LayoutLMv2ForQuestionAnswering" - ], - "sha": "f452e28dd34d3c38cce046b1cc7b0ada69f587b1" - }, - "LayoutLMv2ForSequenceClassification": { - "tokenizer_classes": [ - "LayoutLMv2Tokenizer", - "LayoutLMv2TokenizerFast" - ], - "processor_classes": [ - "LayoutLMv2ImageProcessor" - ], - "model_classes": [ - "LayoutLMv2ForSequenceClassification" - ], - "sha": "b483e08fd143113629ecda3dbfd57e69bfeb5f11" - }, - "LayoutLMv2ForTokenClassification": { - "tokenizer_classes": [ - "LayoutLMv2Tokenizer", - "LayoutLMv2TokenizerFast" - ], - "processor_classes": [ - "LayoutLMv2ImageProcessor" - ], - "model_classes": [ - "LayoutLMv2ForTokenClassification" - ], - "sha": "0721ae69bff00ecfff1b3d1521a475cde0253299" - }, - "LayoutLMv2Model": { - "tokenizer_classes": [ - "LayoutLMv2Tokenizer", - "LayoutLMv2TokenizerFast" - ], - "processor_classes": [ - "LayoutLMv2ImageProcessor" - ], - "model_classes": [ - "LayoutLMv2Model" - ], - "sha": "6a1b510769b344979a910a7d0bade613a9ec2dfc" - }, - "LayoutLMv3ForQuestionAnswering": { - "tokenizer_classes": [ - "LayoutLMv3Tokenizer", - "LayoutLMv3TokenizerFast" - ], - "processor_classes": [ - "LayoutLMv3ImageProcessor" - ], - "model_classes": [ - "LayoutLMv3ForQuestionAnswering", - "TFLayoutLMv3ForQuestionAnswering" - ], - "sha": "4640242388e69cf77ea2dd3ac36ec6f1b26628c8" - }, - "LayoutLMv3ForSequenceClassification": { - "tokenizer_classes": [ - "LayoutLMv3Tokenizer", - "LayoutLMv3TokenizerFast" - ], - "processor_classes": [ - "LayoutLMv3ImageProcessor" - ], - "model_classes": [ - "LayoutLMv3ForSequenceClassification", - "TFLayoutLMv3ForSequenceClassification" - ], - "sha": "96515f699874cfbfbec7a64c539ae92419e4c6dc" - }, - "LayoutLMv3ForTokenClassification": { - "tokenizer_classes": [ - "LayoutLMv3Tokenizer", - "LayoutLMv3TokenizerFast" - ], - "processor_classes": [ - "LayoutLMv3ImageProcessor" - ], - "model_classes": [ - "LayoutLMv3ForTokenClassification", - "TFLayoutLMv3ForTokenClassification" - ], - "sha": "ed4ffc464f2028fe50dfc6823f4eda78d34be7e6" - }, - "LayoutLMv3Model": { - "tokenizer_classes": [ - "LayoutLMv3Tokenizer", - "LayoutLMv3TokenizerFast" - ], - "processor_classes": [ - "LayoutLMv3ImageProcessor" - ], - "model_classes": [ - "LayoutLMv3Model", - "TFLayoutLMv3Model" - ], - "sha": "69725e5e2445e5c1c3aa8a2aa49cfd72e0a44565" - }, - "LevitForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "LevitImageProcessor" - ], - "model_classes": [ - "LevitForImageClassification" - ], - "sha": "5ae8ccaa1fe1c947cb8ae6499e4a150c668bb9f0" - }, - "LevitForImageClassificationWithTeacher": { - "tokenizer_classes": [], - "processor_classes": [ - "LevitImageProcessor" - ], - "model_classes": [ - "LevitForImageClassificationWithTeacher" - ], - "sha": "568cc0d965b9bd293f240e7724314db6d50f6722" - }, - "LevitModel": { - "tokenizer_classes": [], - "processor_classes": [ - "LevitImageProcessor" - ], - "model_classes": [ - "LevitModel" - ], - "sha": "172efa52b50c75c3b3e498fa638f55e65b2ebf87" - }, - "LiltForQuestionAnswering": { - "tokenizer_classes": [ - "LayoutLMv3Tokenizer", - "LayoutLMv3TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LiltForQuestionAnswering" - ], - "sha": "0a348441999e98ec003b29fc4d5a67ad22ee6ca2" - }, - "LiltForSequenceClassification": { - "tokenizer_classes": [ - "LayoutLMv3Tokenizer", - "LayoutLMv3TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LiltForSequenceClassification" - ], - "sha": "c53ab0ba33536fe564a4a1e4f1674d990c01b83a" - }, - "LiltForTokenClassification": { - "tokenizer_classes": [ - "LayoutLMv3Tokenizer", - "LayoutLMv3TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LiltForTokenClassification" - ], - "sha": "14f85076f9b3f7016917e324d51ebd22511a2ae5" - }, - "LiltModel": { - "tokenizer_classes": [ - "LayoutLMv3Tokenizer", - "LayoutLMv3TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LiltModel" - ], - "sha": "3f1166cc14c532388df7e82336a8e575a813bd3f" - }, - "LongT5ForConditionalGeneration": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LongT5ForConditionalGeneration" - ], - "sha": "c685cbbe706ad5c9a28689631765726a1874dcc7" - }, - "LongT5Model": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LongT5Model" - ], - "sha": "6b468e55e2490565e6155690201086ac00c72062" - }, - "LongformerForMaskedLM": { - "tokenizer_classes": [ - "LongformerTokenizer", - "LongformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LongformerForMaskedLM", - "TFLongformerForMaskedLM" - ], - "sha": "929d3bda9a1485d9bae41f9dbfc1d149c1c4e78e" - }, - "LongformerForMultipleChoice": { - "tokenizer_classes": [ - "LongformerTokenizer", - "LongformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LongformerForMultipleChoice", - "TFLongformerForMultipleChoice" - ], - "sha": "60b1ecac6b9385ce18c7e6978ab161cce8e7f9d4" - }, - "LongformerForQuestionAnswering": { - "tokenizer_classes": [ - "LongformerTokenizer", - "LongformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LongformerForQuestionAnswering", - "TFLongformerForQuestionAnswering" - ], - "sha": "be45ab1321b703f2200cbbcae560aaf2e2afef88" - }, - "LongformerForSequenceClassification": { - "tokenizer_classes": [ - "LongformerTokenizer", - "LongformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LongformerForSequenceClassification", - "TFLongformerForSequenceClassification" - ], - "sha": "8bc0de0b0f740bf397eb2770ec3ce3a24f3d7af9" - }, - "LongformerForTokenClassification": { - "tokenizer_classes": [ - "LongformerTokenizer", - "LongformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LongformerForTokenClassification", - "TFLongformerForTokenClassification" - ], - "sha": "efa33a9b6f47f0f7979af08ae8d04a5a7363a14b" - }, - "LongformerModel": { - "tokenizer_classes": [ - "LongformerTokenizer", - "LongformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LongformerModel", - "TFLongformerModel" - ], - "sha": "b023d531688e8655fc09300ac36742588efb3240" - }, - "LukeForMaskedLM": { - "tokenizer_classes": [ - "LukeTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "LukeForMaskedLM" - ], - "sha": "954cf6cd2bf1f298a3956b10c36656c57387506d" - }, - "LukeForMultipleChoice": { - "tokenizer_classes": [ - "LukeTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "LukeForMultipleChoice" - ], - "sha": "d1310a9174ad50d60b30ad6049e165deb2539034" - }, - "LukeForQuestionAnswering": { - "tokenizer_classes": [ - "LukeTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "LukeForQuestionAnswering" - ], - "sha": "3ea38da4e32cb4e45bea82b2e81a8639aeba2c35" - }, - "LukeForSequenceClassification": { - "tokenizer_classes": [ - "LukeTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "LukeForSequenceClassification" - ], - "sha": "b5b11248aeb4f5976379d15a977aeb2677e0c0f9" - }, - "LukeForTokenClassification": { - "tokenizer_classes": [ - "LukeTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "LukeForTokenClassification" - ], - "sha": "8aab1a33ad26a344a6f4dfd68630e9661e174471" - }, - "LukeModel": { - "tokenizer_classes": [ - "LukeTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "LukeModel" - ], - "sha": "ae23a674e7297d41f33c9af86e039757dfd2d531" - }, - "LxmertForPreTraining": { - "tokenizer_classes": [ - "LxmertTokenizer", - "LxmertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LxmertForPreTraining", - "TFLxmertForPreTraining" - ], - "sha": "7b0843403c187aef00f20d5087086468d9613d2c" - }, - "LxmertForQuestionAnswering": { - "tokenizer_classes": [ - "LxmertTokenizer", - "LxmertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LxmertForQuestionAnswering" - ], - "sha": "27a74bd2cd156e46656c43ceb432c4deda0df5c1" - }, - "LxmertModel": { - "tokenizer_classes": [ - "LxmertTokenizer", - "LxmertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "LxmertModel", - "TFLxmertModel" - ], - "sha": "97612a0d6b14406ea9bfd7672e6974e0961cbef1" - }, - "M2M100ForConditionalGeneration": { - "tokenizer_classes": [ - "M2M100Tokenizer" - ], - "processor_classes": [], - "model_classes": [ - "M2M100ForConditionalGeneration" - ], - "sha": "32ac347092d51f658b41ffc111b67d49acdeab46" - }, - "M2M100Model": { - "tokenizer_classes": [ - "M2M100Tokenizer" - ], - "processor_classes": [], - "model_classes": [ - "M2M100Model" - ], - "sha": "e95c2ae168c7ba19f8114def40e1b1edd953b2f5" - }, - "MBartForCausalLM": { - "tokenizer_classes": [ - "MBartTokenizer", - "MBartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MBartForCausalLM" - ], - "sha": "a45044f8056328d20a764356eca3d0746a7a195e" - }, - "MBartForConditionalGeneration": { - "tokenizer_classes": [ - "MBartTokenizer", - "MBartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MBartForConditionalGeneration", - "TFMBartForConditionalGeneration" - ], - "sha": "171e918962d6c0ee56c6b070858e19e16c8dd09f" - }, - "MBartForQuestionAnswering": { - "tokenizer_classes": [ - "MBartTokenizer", - "MBartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MBartForQuestionAnswering" - ], - "sha": "1ee08565d24777335595e0d2940e454abdcff731" - }, - "MBartForSequenceClassification": { - "tokenizer_classes": [ - "MBartTokenizer", - "MBartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MBartForSequenceClassification" - ], - "sha": "53e9c88ecfa2475d27afe099ffa7a8bcdb7ef7e4" - }, - "MBartModel": { - "tokenizer_classes": [ - "MBartTokenizer", - "MBartTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MBartModel", - "TFMBartModel" - ], - "sha": "2d492b34d69dd63b411990d5c8bb692fd637e91c" - }, - "MCTCTForCTC": { - "tokenizer_classes": [], - "processor_classes": [ - "MCTCTFeatureExtractor" - ], - "model_classes": [ - "MCTCTForCTC" - ], - "sha": "895a3d74f87b344b1f0a71eae4f085941d51b5cf" - }, - "MCTCTModel": { - "tokenizer_classes": [], - "processor_classes": [ - "MCTCTFeatureExtractor" - ], - "model_classes": [ - "MCTCTModel" - ], - "sha": "ce73d5c2b6fe163de778697d7b0543bf00d7ffa8" - }, - "MPNetForMaskedLM": { - "tokenizer_classes": [ - "MPNetTokenizer", - "MPNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MPNetForMaskedLM", - "TFMPNetForMaskedLM" - ], - "sha": "50af96e7d0202aef86e396c136e4c4fde8afe183" - }, - "MPNetForMultipleChoice": { - "tokenizer_classes": [ - "MPNetTokenizer", - "MPNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MPNetForMultipleChoice", - "TFMPNetForMultipleChoice" - ], - "sha": "af4ff8bf296a3a51f5ab6cd9f56741e4c732487c" - }, - "MPNetForQuestionAnswering": { - "tokenizer_classes": [ - "MPNetTokenizer", - "MPNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MPNetForQuestionAnswering", - "TFMPNetForQuestionAnswering" - ], - "sha": "3e1a25c0d3243f78f81580c312ada3b39c06b428" - }, - "MPNetForSequenceClassification": { - "tokenizer_classes": [ - "MPNetTokenizer", - "MPNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MPNetForSequenceClassification", - "TFMPNetForSequenceClassification" - ], - "sha": "43da45c0a0d73c5a5567b4c7ec512ec5023e52dd" - }, - "MPNetForTokenClassification": { - "tokenizer_classes": [ - "MPNetTokenizer", - "MPNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MPNetForTokenClassification", - "TFMPNetForTokenClassification" - ], - "sha": "4e825eff24df533321ebab823eb66ce67e4ab3d9" - }, - "MPNetModel": { - "tokenizer_classes": [ - "MPNetTokenizer", - "MPNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MPNetModel", - "TFMPNetModel" - ], - "sha": "847c68344c2922e9a71fa8835b87a0f6f72b9f47" - }, - "MarianForCausalLM": { - "tokenizer_classes": [ - "MarianTokenizer" - ], - "processor_classes": [], - "model_classes": [], - "sha": "5fb205e6db8e18e3c6cdd4e4709be292ba4599f3" - }, - "MarianMTModel": { - "tokenizer_classes": [ - "MarianTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "MarianMTModel", - "TFMarianMTModel" - ], - "sha": "0405f542b31561592231a86e3009d05256cbf49f" - }, - "MarianModel": { - "tokenizer_classes": [ - "MarianTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "MarianModel", - "TFMarianModel" - ], - "sha": "3649748c0286c6d5179a7013a716f7314db182a8" - }, - "MarkupLMForQuestionAnswering": { - "tokenizer_classes": [ - "MarkupLMTokenizer", - "MarkupLMTokenizerFast" - ], - "processor_classes": [ - "MarkupLMFeatureExtractor" - ], - "model_classes": [ - "MarkupLMForQuestionAnswering" - ], - "sha": "c8bb9f93591d980362547b0bdca9f23ace2f383e" - }, - "MarkupLMForSequenceClassification": { - "tokenizer_classes": [ - "MarkupLMTokenizer", - "MarkupLMTokenizerFast" - ], - "processor_classes": [ - "MarkupLMFeatureExtractor" - ], - "model_classes": [ - "MarkupLMForSequenceClassification" - ], - "sha": "c2cb7245d68d76e0a5f993fc8a3de099ecebc68b" - }, - "MarkupLMForTokenClassification": { - "tokenizer_classes": [ - "MarkupLMTokenizer", - "MarkupLMTokenizerFast" - ], - "processor_classes": [ - "MarkupLMFeatureExtractor" - ], - "model_classes": [ - "MarkupLMForTokenClassification" - ], - "sha": "b9f924e82f400de0b34b46ee4ba276d686bd4890" - }, - "MarkupLMModel": { - "tokenizer_classes": [ - "MarkupLMTokenizer", - "MarkupLMTokenizerFast" - ], - "processor_classes": [ - "MarkupLMFeatureExtractor" - ], - "model_classes": [ - "MarkupLMModel" - ], - "sha": "9687ba29f1c59d978e3d4b0fa702031f88eff53b" - }, - "Mask2FormerForUniversalSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "Mask2FormerImageProcessor" - ], - "model_classes": [ - "Mask2FormerForUniversalSegmentation" - ], - "sha": "6429a7349527c9ef140ae691b83c47702cce1bc0" - }, - "Mask2FormerModel": { - "tokenizer_classes": [], - "processor_classes": [ - "Mask2FormerImageProcessor" - ], - "model_classes": [ - "Mask2FormerModel" - ], - "sha": "9bee8709204024b3669d503cdfe8890182f2a075" - }, - "MaskFormerForInstanceSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "MaskFormerImageProcessor" - ], - "model_classes": [ - "MaskFormerForInstanceSegmentation" - ], - "sha": "f844aaa81f55cb199c115f1bf95c217a70685570" - }, - "MaskFormerModel": { - "tokenizer_classes": [], - "processor_classes": [ - "MaskFormerImageProcessor" - ], - "model_classes": [ - "MaskFormerModel" - ], - "sha": "473b54a464bc0ccee29bc23b4f6610f32eec05af" - }, - "MegaForCausalLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegaForCausalLM" - ], - "sha": "6642b9da860f8b62abcfb0660feabcebf6698418" - }, - "MegaForMaskedLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegaForMaskedLM" - ], - "sha": "6b2d47ba03bec9e6f7eefdd4a67351fa191aae6f" - }, - "MegaForMultipleChoice": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegaForMultipleChoice" - ], - "sha": "2b1e751da36a4410473eef07a62b09227a26d504" - }, - "MegaForQuestionAnswering": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegaForQuestionAnswering" - ], - "sha": "612acd9a53c351c42514adb3c04f2057d2870be7" - }, - "MegaForSequenceClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegaForSequenceClassification" - ], - "sha": "4871572da1613b7e9cfd3640c6d1129af004eefb" - }, - "MegaForTokenClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegaForTokenClassification" - ], - "sha": "450d3722c3b995215d06b9c12544c99f958581c7" - }, - "MegaModel": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegaModel" - ], - "sha": "ca0862db27428893fe22f9bb5d2eb0875c2156f3" - }, - "MegatronBertForCausalLM": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegatronBertForCausalLM" - ], - "sha": "ff08d05ef8f98fdccf1f01560ec6ec4adbc8a3e3" - }, - "MegatronBertForMaskedLM": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegatronBertForMaskedLM" - ], - "sha": "2ed25e2681d26b51b404ef1347a385c5f2c86a9a" - }, - "MegatronBertForMultipleChoice": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegatronBertForMultipleChoice" - ], - "sha": "1485af4b75f8f234d2b4b5aea50ab2ec55223a15" - }, - "MegatronBertForNextSentencePrediction": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegatronBertForNextSentencePrediction" - ], - "sha": "52bc9ee1d5145344f66b088ed278f07ed3d90584" - }, - "MegatronBertForPreTraining": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegatronBertForPreTraining" - ], - "sha": "e580d0efd54e1c92789e39b32929234e36ee427f" - }, - "MegatronBertForQuestionAnswering": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegatronBertForQuestionAnswering" - ], - "sha": "7342ba042a3c30c15382d00fcb0521533fc43841" - }, - "MegatronBertForSequenceClassification": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegatronBertForSequenceClassification" - ], - "sha": "6a7cd480511d817a1e221c8f7558c55a93baed1b" - }, - "MegatronBertForTokenClassification": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegatronBertForTokenClassification" - ], - "sha": "8b5334b6ec5f025293ca861de474b57ca84bc005" - }, - "MegatronBertModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MegatronBertModel" - ], - "sha": "f2457fbe535ba97ea13db049f53618b42e13f047" - }, - "MgpstrForSceneTextRecognition": { - "tokenizer_classes": [], - "processor_classes": [ - "MgpstrProcessor" - ], - "model_classes": [ - "MgpstrForSceneTextRecognition" - ], - "sha": "f197d5bfa1fe27b5f28a6e6d4e3ad229b753450a" - }, - "MobileBertForMaskedLM": { - "tokenizer_classes": [ - "MobileBertTokenizer", - "MobileBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MobileBertForMaskedLM", - "TFMobileBertForMaskedLM" - ], - "sha": "d689e737d73ad23aed3aabd3177591fc827d1c62" - }, - "MobileBertForMultipleChoice": { - "tokenizer_classes": [ - "MobileBertTokenizer", - "MobileBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MobileBertForMultipleChoice", - "TFMobileBertForMultipleChoice" - ], - "sha": "403d1f88be7eb0c769ff3a8e57eab21cc3e75afb" - }, - "MobileBertForNextSentencePrediction": { - "tokenizer_classes": [ - "MobileBertTokenizer", - "MobileBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MobileBertForNextSentencePrediction", - "TFMobileBertForNextSentencePrediction" - ], - "sha": "b4d8836a0f259ee3bca9f230093836c9117c5e4d" - }, - "MobileBertForPreTraining": { - "tokenizer_classes": [ - "MobileBertTokenizer", - "MobileBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MobileBertForPreTraining", - "TFMobileBertForPreTraining" - ], - "sha": "fbaa13ea6f9fcebb9fde620dd009d12510440d17" - }, - "MobileBertForQuestionAnswering": { - "tokenizer_classes": [ - "MobileBertTokenizer", - "MobileBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MobileBertForQuestionAnswering", - "TFMobileBertForQuestionAnswering" - ], - "sha": "ba6a55cf2daec55bfb220c9bab0bc4ad96510087" - }, - "MobileBertForSequenceClassification": { - "tokenizer_classes": [ - "MobileBertTokenizer", - "MobileBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MobileBertForSequenceClassification", - "TFMobileBertForSequenceClassification" - ], - "sha": "17ab35603bec351457e035eef2d0426538071f72" - }, - "MobileBertForTokenClassification": { - "tokenizer_classes": [ - "MobileBertTokenizer", - "MobileBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MobileBertForTokenClassification", - "TFMobileBertForTokenClassification" - ], - "sha": "dee83e820e6c4f069886a5d1875bf6775897313e" - }, - "MobileBertModel": { - "tokenizer_classes": [ - "MobileBertTokenizer", - "MobileBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MobileBertModel", - "TFMobileBertModel" - ], - "sha": "09b2db33ea798a762eeaf7e727e95f9ea8a6d14f" - }, - "MobileNetV1ForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileNetV1ImageProcessor" - ], - "model_classes": [ - "MobileNetV1ForImageClassification" - ], - "sha": "55023dbd0935f147bf1bccf960cea01ca07e0f0c" - }, - "MobileNetV1Model": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileNetV1ImageProcessor" - ], - "model_classes": [ - "MobileNetV1Model" - ], - "sha": "178bd24528147a028938d6ee5c7e65c969ea37b0" - }, - "MobileNetV2ForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileNetV2ImageProcessor" - ], - "model_classes": [ - "MobileNetV2ForImageClassification" - ], - "sha": "ff907f740cf9ea91bc3cdf403a94ae28fbb2548a" - }, - "MobileNetV2ForSemanticSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileNetV2ImageProcessor" - ], - "model_classes": [ - "MobileNetV2ForSemanticSegmentation" - ], - "sha": "48adbc340e42882f52b54d4f5dd045e16e9ef2d6" - }, - "MobileNetV2Model": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileNetV2ImageProcessor" - ], - "model_classes": [ - "MobileNetV2Model" - ], - "sha": "e876885828825472a80ef1796d89d60b901813ba" - }, - "MobileViTForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileViTImageProcessor" - ], - "model_classes": [ - "MobileViTForImageClassification", - "TFMobileViTForImageClassification" - ], - "sha": "7d0b31864f856e00f9e34e8c6781dcc7a8cdaf1e" - }, - "MobileViTForSemanticSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileViTImageProcessor" - ], - "model_classes": [ - "MobileViTForSemanticSegmentation", - "TFMobileViTForSemanticSegmentation" - ], - "sha": "215f727caa3c3fc94fa4df486aa706e5d99d4194" - }, - "MobileViTModel": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileViTImageProcessor" - ], - "model_classes": [ - "MobileViTModel", - "TFMobileViTModel" - ], - "sha": "b3a1452e7cb44b600b21ee14f3d5382366855a46" - }, - "MobileViTV2ForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileViTImageProcessor" - ], - "model_classes": [ - "MobileViTV2ForImageClassification" - ], - "sha": "25752b0967ad594341d1b685401450d7f698433c" - }, - "MobileViTV2ForSemanticSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileViTImageProcessor" - ], - "model_classes": [ - "MobileViTV2ForSemanticSegmentation" - ], - "sha": "13b953f50be33219d55a12f1098be38b88000897" - }, - "MobileViTV2Model": { - "tokenizer_classes": [], - "processor_classes": [ - "MobileViTImageProcessor" - ], - "model_classes": [ - "MobileViTV2Model" - ], - "sha": "2f46357659db2d6d54d870e28073deeea1c8cb64" - }, - "MptForCausalLM": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MptForCausalLM" - ], - "sha": "500c869b956c65f6b1a7b4867727f124c6f5728a" - }, - "MptForQuestionAnswering": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MptForQuestionAnswering" - ], - "sha": "6ee46572bf61eb5e7dbbdaf00b73c4d37efc42d9" - }, - "MptForSequenceClassification": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MptForSequenceClassification" - ], - "sha": "f0b9153413b5dfceeb96b67d4b0f22c94bbaf64a" - }, - "MptForTokenClassification": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MptForTokenClassification" - ], - "sha": "3f7c3ccd67cd0b2aae56d37613429a64ef813246" - }, - "MptModel": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MptModel" - ], - "sha": "ea747f234556661b0c8b84a626f267066ce586bf" - }, - "MraForMaskedLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MraForMaskedLM" - ], - "sha": "c00ee46cfd2b8fed29cc37f0a4ead40ad51a439c" - }, - "MraForMultipleChoice": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MraForMultipleChoice" - ], - "sha": "f397469ba8109f64dab2d75335ea7bf0c2dbeb74" - }, - "MraForQuestionAnswering": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MraForQuestionAnswering" - ], - "sha": "c2ed75acd20e5440a76d6504d9a3ebc2513011f0" - }, - "MraForSequenceClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MraForSequenceClassification" - ], - "sha": "f47672d3708508bda7774215bee44a92ec16ab2f" - }, - "MraForTokenClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MraForTokenClassification" - ], - "sha": "f0961ab5818bca473607fb94b391c186dc1d3492" - }, - "MraModel": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MraModel" - ], - "sha": "315f34f30bcc4b0b66b11987726df2a80c50e271" - }, - "MvpForCausalLM": { - "tokenizer_classes": [ - "MvpTokenizer", - "MvpTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MvpForCausalLM" - ], - "sha": "105e5f2c8a0f20d404cb71795539cda5dd49716d" - }, - "MvpForConditionalGeneration": { - "tokenizer_classes": [ - "MvpTokenizer", - "MvpTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MvpForConditionalGeneration" - ], - "sha": "b0b706f14b2f8aae288cba30ae0064e0be7e888b" - }, - "MvpForQuestionAnswering": { - "tokenizer_classes": [ - "MvpTokenizer", - "MvpTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MvpForQuestionAnswering" - ], - "sha": "82f152b36a40a4c22edcb146e6eaec636d84fa2d" - }, - "MvpForSequenceClassification": { - "tokenizer_classes": [ - "MvpTokenizer", - "MvpTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MvpForSequenceClassification" - ], - "sha": "506b68544d064001929ee9e6db3752e62972a6aa" - }, - "MvpModel": { - "tokenizer_classes": [ - "MvpTokenizer", - "MvpTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "MvpModel" - ], - "sha": "3f4653184721a2bc029b27706d335ef7ddd219d5" - }, - "NatBackbone": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "NatBackbone" - ], - "sha": "d5cc5eccba4da609c82e9f5c649301b9f9fee9fb" - }, - "NatForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "NatForImageClassification" - ], - "sha": "2ff4c9e73c49c392c02a467e87b5511fd924242a" - }, - "NatModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "NatModel" - ], - "sha": "75e9756bb94d0ccdce98a8e963eeecbc66f9d573" - }, - "NezhaForMaskedLM": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NezhaForMaskedLM" - ], - "sha": "5991cca4b78f0ed7299259a71f3eeed3f3452b72" - }, - "NezhaForMultipleChoice": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NezhaForMultipleChoice" - ], - "sha": "0f6e9ec791d85ad4503acdec50b3a120f984016b" - }, - "NezhaForNextSentencePrediction": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NezhaForNextSentencePrediction" - ], - "sha": "9a34316c14ec8ecc98ff08e46760915c80098a57" - }, - "NezhaForPreTraining": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NezhaForPreTraining" - ], - "sha": "6259db427a0073061de352ea819d38a74798edd7" - }, - "NezhaForQuestionAnswering": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NezhaForQuestionAnswering" - ], - "sha": "31c6a34e85ae8c41294e0f4ef25044e00e511c4d" - }, - "NezhaForSequenceClassification": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NezhaForSequenceClassification" - ], - "sha": "db057c308ba2e05f223404de11e1816ce4bd62a9" - }, - "NezhaForTokenClassification": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NezhaForTokenClassification" - ], - "sha": "235f4e10b4a59709650c2bece3e342ec153d9cfc" - }, - "NezhaModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NezhaModel" - ], - "sha": "80e05ba7c55bcdd7f4d1387ef9a09a7a8e95b5ac" - }, - "NllbMoeForConditionalGeneration": { - "tokenizer_classes": [ - "NllbTokenizer", - "NllbTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NllbMoeForConditionalGeneration" - ], - "sha": "2a7f87dffe826af3d52086888f3f3773246e5528" - }, - "NllbMoeModel": { - "tokenizer_classes": [ - "NllbTokenizer", - "NllbTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NllbMoeModel" - ], - "sha": "9f7a2261eed4658e1aa5623be4672ba64bee7da5" - }, - "NystromformerForMaskedLM": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NystromformerForMaskedLM" - ], - "sha": "37036847783f1e65e81ecd43803270a1ecb276f3" - }, - "NystromformerForMultipleChoice": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NystromformerForMultipleChoice" - ], - "sha": "42a077d5ab6830e20560466eaccc525eff10c3ae" - }, - "NystromformerForQuestionAnswering": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NystromformerForQuestionAnswering" - ], - "sha": "1cfaf79051731824db4f09989f093f87f4fceec5" - }, - "NystromformerForSequenceClassification": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NystromformerForSequenceClassification" - ], - "sha": "d75231203066df41e9b6b25dbee9ad40e8515c18" - }, - "NystromformerForTokenClassification": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NystromformerForTokenClassification" - ], - "sha": "5a499dc96e106bf41fc9166f2ad06527ec7ca14e" - }, - "NystromformerModel": { - "tokenizer_classes": [ - "AlbertTokenizer", - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "NystromformerModel" - ], - "sha": "2b6adb37ec473b15d71e2eb459acea08df6940ce" - }, - "OPTForCausalLM": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "OPTForCausalLM", - "TFOPTForCausalLM" - ], - "sha": "190d1f4fc0011d2eaeaa05282e0fbd2445e4b11f" - }, - "OPTForQuestionAnswering": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "OPTForQuestionAnswering" - ], - "sha": "0fa9277ce10dbc3d0922b354befb684a136af00b" - }, - "OPTForSequenceClassification": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "OPTForSequenceClassification" - ], - "sha": "784ab288ab7280b1853ee400ef10ee2a965df352" - }, - "OPTModel": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "OPTModel", - "TFOPTModel" - ], - "sha": "901d92b8f51edb0ec9614cb185fb66a8b5d364c3" - }, - "OneFormerForUniversalSegmentation": { - "tokenizer_classes": [ - "CLIPTokenizer", - "CLIPTokenizerFast" - ], - "processor_classes": [ - "OneFormerImageProcessor" - ], - "model_classes": [ - "OneFormerForUniversalSegmentation" - ], - "sha": "fee1cfd676acc40f09017702ddac6504f3090d14" - }, - "OneFormerModel": { - "tokenizer_classes": [ - "CLIPTokenizer", - "CLIPTokenizerFast" - ], - "processor_classes": [ - "OneFormerImageProcessor" - ], - "model_classes": [ - "OneFormerModel" - ], - "sha": "4163a79328c78f93ec57942598698a138c19a577" - }, - "OpenAIGPTForSequenceClassification": { - "tokenizer_classes": [ - "OpenAIGPTTokenizer", - "OpenAIGPTTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "OpenAIGPTForSequenceClassification", - "TFOpenAIGPTForSequenceClassification" - ], - "sha": "c513f7f952935085f7573bf70a1ac3ad8f33434c" - }, - "OpenAIGPTLMHeadModel": { - "tokenizer_classes": [ - "OpenAIGPTTokenizer", - "OpenAIGPTTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "OpenAIGPTLMHeadModel", - "TFOpenAIGPTLMHeadModel" - ], - "sha": "33f59ecd860f7a998483ec7631fe32d257235461" - }, - "OpenAIGPTModel": { - "tokenizer_classes": [ - "OpenAIGPTTokenizer", - "OpenAIGPTTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "OpenAIGPTModel", - "TFOpenAIGPTModel" - ], - "sha": "00f6ec0a3a5276af71d08a26199e0ccbf2556fc9" - }, - "OwlViTForObjectDetection": { - "tokenizer_classes": [ - "CLIPTokenizer", - "CLIPTokenizerFast" - ], - "processor_classes": [ - "OwlViTImageProcessor" - ], - "model_classes": [ - "OwlViTForObjectDetection" - ], - "sha": "af958c9164f23d0f12921a8edf687f9aaa6af90e" - }, - "OwlViTModel": { - "tokenizer_classes": [ - "CLIPTokenizer", - "CLIPTokenizerFast" - ], - "processor_classes": [ - "OwlViTImageProcessor" - ], - "model_classes": [ - "OwlViTModel" - ], - "sha": "f0e27b2b4e53ba70e05d13dcfea8e85272b292a5" - }, - "PLBartForCausalLM": { - "tokenizer_classes": [ - "PLBartTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "PLBartForCausalLM" - ], - "sha": "6ee51133246dbdb18fc3681ebd62d21e421b9bb4" - }, - "PLBartForConditionalGeneration": { - "tokenizer_classes": [ - "PLBartTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "PLBartForConditionalGeneration" - ], - "sha": "ba191d28f4678d20b4dfed5fca5944018282cf20" - }, - "PLBartForSequenceClassification": { - "tokenizer_classes": [ - "PLBartTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "PLBartForSequenceClassification" - ], - "sha": "02063b3d9707fcff619a4e37a0d6e58f76e39b18" - }, - "PLBartModel": { - "tokenizer_classes": [ - "PLBartTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "PLBartModel" - ], - "sha": "cfbba29169b3f40d800403fc1b53982e1f88c5f8" - }, - "PegasusForCausalLM": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "PegasusForCausalLM" - ], - "sha": "6e685a698302a3ba33e5379d3a37eb0bc1ae2f70" - }, - "PegasusForConditionalGeneration": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "PegasusForConditionalGeneration", - "TFPegasusForConditionalGeneration" - ], - "sha": "15e58ee2ebc14b6e80ef2891259057ee5f049be2" - }, - "PegasusModel": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "PegasusModel", - "TFPegasusModel" - ], - "sha": "fa36b24523db411ef77903453346b8be81ef73fe" - }, - "PegasusXForConditionalGeneration": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "PegasusXForConditionalGeneration" - ], - "sha": "7588a8120f26a36c1687c14bdf1e9f9656891c1a" - }, - "PegasusXModel": { - "tokenizer_classes": [ - "PegasusTokenizer", - "PegasusTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "PegasusXModel" - ], - "sha": "a0bdff627416ac3c39c22d081f5d88d8b8fd99cc" - }, - "PerceiverForImageClassificationConvProcessing": { - "tokenizer_classes": [ - "PerceiverTokenizer" - ], - "processor_classes": [ - "PerceiverImageProcessor" - ], - "model_classes": [ - "PerceiverForImageClassificationConvProcessing" - ], - "sha": "2c1e5e62ebc9d0c931adc8c665fb05bde6c1c1f1" - }, - "PerceiverForImageClassificationFourier": { - "tokenizer_classes": [ - "PerceiverTokenizer" - ], - "processor_classes": [ - "PerceiverImageProcessor" - ], - "model_classes": [ - "PerceiverForImageClassificationFourier" - ], - "sha": "88da41b8851b76b8be0dacdb3de023db02bb031a" - }, - "PerceiverForImageClassificationLearned": { - "tokenizer_classes": [ - "PerceiverTokenizer" - ], - "processor_classes": [ - "PerceiverImageProcessor" - ], - "model_classes": [ - "PerceiverForImageClassificationLearned" - ], - "sha": "879bd1fa38d3baddb027bb2cacba2d160a741375" - }, - "PerceiverForMaskedLM": { - "tokenizer_classes": [ - "PerceiverTokenizer" - ], - "processor_classes": [ - "PerceiverImageProcessor" - ], - "model_classes": [ - "PerceiverForMaskedLM" - ], - "sha": "1d2459cbd281ef72da5682e65102aaca96183045" - }, - "PerceiverForSequenceClassification": { - "tokenizer_classes": [ - "PerceiverTokenizer" - ], - "processor_classes": [ - "PerceiverImageProcessor" - ], - "model_classes": [ - "PerceiverForSequenceClassification" - ], - "sha": "576f1f96348f0343458499fbf53d4102b5c0f2ff" - }, - "PerceiverModel": { - "tokenizer_classes": [ - "PerceiverTokenizer" - ], - "processor_classes": [ - "PerceiverImageProcessor" - ], - "model_classes": [ - "PerceiverModel" - ], - "sha": "83ec4d2d61ed62525ee033e13d144817beb29d19" - }, - "Pix2StructForConditionalGeneration": { - "tokenizer_classes": [ - "T5TokenizerFast" - ], - "processor_classes": [ - "Pix2StructImageProcessor", - "Pix2StructProcessor" - ], - "model_classes": [], - "sha": "42b3de00ad535076c4893e4ac5ae2d2748cc4ccb" - }, - "PoolFormerForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "PoolFormerImageProcessor" - ], - "model_classes": [ - "PoolFormerForImageClassification" - ], - "sha": "ef04de5a6896100d457fb9553dd9789c09cca98e" - }, - "PoolFormerModel": { - "tokenizer_classes": [], - "processor_classes": [ - "PoolFormerImageProcessor" - ], - "model_classes": [ - "PoolFormerModel" - ], - "sha": "e8037215ebdbf795329ef6525cdc6aa547f04ace" - }, - "ProphetNetForCausalLM": { - "tokenizer_classes": [ - "ProphetNetTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "ProphetNetForCausalLM" - ], - "sha": "d40b1e75bbc5ea0839563457aff6eee5bc0bb03e" - }, - "ProphetNetForConditionalGeneration": { - "tokenizer_classes": [ - "ProphetNetTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "ProphetNetForConditionalGeneration" - ], - "sha": "d842875c41278032af39c03c66902786bb5ff2c7" - }, - "ProphetNetModel": { - "tokenizer_classes": [ - "ProphetNetTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "ProphetNetModel" - ], - "sha": "f1ddbbcc768c7ba54c4d75b319540c1635e65937" - }, - "PvtForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "PvtImageProcessor" - ], - "model_classes": [ - "PvtForImageClassification" - ], - "sha": "589b37bd6941aff6dd248259f9eee3c422a41fde" - }, - "PvtModel": { - "tokenizer_classes": [], - "processor_classes": [ - "PvtImageProcessor" - ], - "model_classes": [ - "PvtModel" - ], - "sha": "c40765c382515ae627652d60e9077b6478448d48" - }, - "ReformerForMaskedLM": { - "tokenizer_classes": [ - "ReformerTokenizer", - "ReformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ReformerForMaskedLM" - ], - "sha": "1e6431e42c676b525e3215e9e3cc8f1404f9f82b" - }, - "ReformerForQuestionAnswering": { - "tokenizer_classes": [ - "ReformerTokenizer", - "ReformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ReformerForQuestionAnswering" - ], - "sha": "62b43977f244474bd6982c6327d0c57310258fcd" - }, - "ReformerForSequenceClassification": { - "tokenizer_classes": [ - "ReformerTokenizer", - "ReformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ReformerForSequenceClassification" - ], - "sha": "67bd534a990a7dcfa02406987e7f066caa2a30e8" - }, - "ReformerModel": { - "tokenizer_classes": [ - "ReformerTokenizer", - "ReformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "ReformerModel" - ], - "sha": "a34ddb1389067448e9bc1323de674951cfb4cff1" - }, - "ReformerModelWithLMHead": { - "tokenizer_classes": [ - "ReformerTokenizer", - "ReformerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [], - "sha": "e7a8addaea8407d4c55e144e48aee04be6cca618" - }, - "RegNetForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "RegNetForImageClassification", - "TFRegNetForImageClassification" - ], - "sha": "5ec67c84fc7944c0c5b386bd26820bc4d1f3b32a" - }, - "RegNetModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "RegNetModel", - "TFRegNetModel" - ], - "sha": "72375e1401dc8271d4abb6295c9cee376f7b8f1a" - }, - "RemBertForCausalLM": { - "tokenizer_classes": [ - "RemBertTokenizer", - "RemBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RemBertForCausalLM", - "TFRemBertForCausalLM" - ], - "sha": "8d9ae3d74a0e0a8958b4ee8c9dca3632abf52ef9" - }, - "RemBertForMaskedLM": { - "tokenizer_classes": [ - "RemBertTokenizer", - "RemBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RemBertForMaskedLM", - "TFRemBertForMaskedLM" - ], - "sha": "b7c27d01e1cc3bef9ddd6a78627d700b3bffd759" - }, - "RemBertForMultipleChoice": { - "tokenizer_classes": [ - "RemBertTokenizer", - "RemBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RemBertForMultipleChoice", - "TFRemBertForMultipleChoice" - ], - "sha": "2fe192677b9740cf24dd559339d46925e8ac23d4" - }, - "RemBertForQuestionAnswering": { - "tokenizer_classes": [ - "RemBertTokenizer", - "RemBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RemBertForQuestionAnswering", - "TFRemBertForQuestionAnswering" - ], - "sha": "22b8ba44681b96292a1cf7f6df4ba6bb7937ec6e" - }, - "RemBertForSequenceClassification": { - "tokenizer_classes": [ - "RemBertTokenizer", - "RemBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RemBertForSequenceClassification", - "TFRemBertForSequenceClassification" - ], - "sha": "20f3e89341ea15266d2685a8798142fba03c3f98" - }, - "RemBertForTokenClassification": { - "tokenizer_classes": [ - "RemBertTokenizer", - "RemBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RemBertForTokenClassification", - "TFRemBertForTokenClassification" - ], - "sha": "15712ff753708da3cf0550e76e73a5d0bba7784e" - }, - "RemBertModel": { - "tokenizer_classes": [ - "RemBertTokenizer", - "RemBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RemBertModel", - "TFRemBertModel" - ], - "sha": "59cc6d099b1ded0aaead8684457415b129f79e86" - }, - "ResNetBackbone": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "ResNetBackbone" - ], - "sha": "c84a6bcf8af4b6a3403dea3cf4c55965ac39f239" - }, - "ResNetForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "ResNetForImageClassification", - "TFResNetForImageClassification" - ], - "sha": "34a180ad24d80811d420d7aa4fbec4a17751aaf8" - }, - "ResNetModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "ResNetModel", - "TFResNetModel" - ], - "sha": "fafa6cdf9986c6cfbae360596b3574162430bcd3" - }, - "RoCBertForCausalLM": { - "tokenizer_classes": [ - "RoCBertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "RoCBertForCausalLM" - ], - "sha": "194d8dafc4f4142f8d31e6b4be14b55d812f923b" - }, - "RoCBertForMaskedLM": { - "tokenizer_classes": [ - "RoCBertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "RoCBertForMaskedLM" - ], - "sha": "8bc285f32f3b932dbd56ddf91b1170734d638eeb" - }, - "RoCBertForMultipleChoice": { - "tokenizer_classes": [ - "RoCBertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "RoCBertForMultipleChoice" - ], - "sha": "bb54e5ae021d728022d34b12fee3f087d9486af9" - }, - "RoCBertForPreTraining": { - "tokenizer_classes": [ - "RoCBertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "RoCBertForPreTraining" - ], - "sha": "86ebbd5b0bc84660ad7f505082eff19b86c137c8" - }, - "RoCBertForQuestionAnswering": { - "tokenizer_classes": [ - "RoCBertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "RoCBertForQuestionAnswering" - ], - "sha": "1bfc2dc3d6e76170e6dca1ff32a54a0887ff28a3" - }, - "RoCBertForSequenceClassification": { - "tokenizer_classes": [ - "RoCBertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "RoCBertForSequenceClassification" - ], - "sha": "c329038802241f454273894128fea38b60f7c739" - }, - "RoCBertForTokenClassification": { - "tokenizer_classes": [ - "RoCBertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "RoCBertForTokenClassification" - ], - "sha": "afe5ec22c2ad1d9ff6e3e64c87eb7555faaa936d" - }, - "RoCBertModel": { - "tokenizer_classes": [ - "RoCBertTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "RoCBertModel" - ], - "sha": "29de5580d5f5d3461a88673e7b4c492a9d8a67a4" - }, - "RoFormerForCausalLM": { - "tokenizer_classes": [ - "RoFormerTokenizer", - "RoFormerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RoFormerForCausalLM", - "TFRoFormerForCausalLM" - ], - "sha": "6e074219c6dd8f8b221bbfda64fba100f729f88d" - }, - "RoFormerForMaskedLM": { - "tokenizer_classes": [ - "RoFormerTokenizer", - "RoFormerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RoFormerForMaskedLM", - "TFRoFormerForMaskedLM" - ], - "sha": "a3a4d05f9b29601553a77244f2adcf8194f9367c" - }, - "RoFormerForMultipleChoice": { - "tokenizer_classes": [ - "RoFormerTokenizer", - "RoFormerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RoFormerForMultipleChoice", - "TFRoFormerForMultipleChoice" - ], - "sha": "aca3999a1d14f09644faed44e2cdfb28ed68a3d3" - }, - "RoFormerForQuestionAnswering": { - "tokenizer_classes": [ - "RoFormerTokenizer", - "RoFormerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RoFormerForQuestionAnswering", - "TFRoFormerForQuestionAnswering" - ], - "sha": "b8a20b3a788f178b9ef64e2eb9587f693dca1b69" - }, - "RoFormerForSequenceClassification": { - "tokenizer_classes": [ - "RoFormerTokenizer", - "RoFormerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RoFormerForSequenceClassification", - "TFRoFormerForSequenceClassification" - ], - "sha": "d092e2d5e62012bf4ec921e763b37865d6189216" - }, - "RoFormerForTokenClassification": { - "tokenizer_classes": [ - "RoFormerTokenizer", - "RoFormerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RoFormerForTokenClassification", - "TFRoFormerForTokenClassification" - ], - "sha": "85d3a17062e1f3e0539abfe738a88203e25349b6" - }, - "RoFormerModel": { - "tokenizer_classes": [ - "RoFormerTokenizer", - "RoFormerTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RoFormerModel", - "TFRoFormerModel" - ], - "sha": "22e7df2f4cd66caf449f2342f63d176005afccc9" - }, - "RobertaForCausalLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaForCausalLM", - "TFRobertaForCausalLM" - ], - "sha": "5d1d24d56f9735402e50a2ea513ffde44487733e" - }, - "RobertaForMaskedLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaForMaskedLM", - "TFRobertaForMaskedLM" - ], - "sha": "b21c9daf0b3b66530bf5d45d67df5ec392b5059c" - }, - "RobertaForMultipleChoice": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaForMultipleChoice", - "TFRobertaForMultipleChoice" - ], - "sha": "10020d9546d4d7318f4d514fe13daaad07e6269f" - }, - "RobertaForQuestionAnswering": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaForQuestionAnswering", - "TFRobertaForQuestionAnswering" - ], - "sha": "eea4a81306891746bac9e7715f805a2d9dbf4be7" - }, - "RobertaForSequenceClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaForSequenceClassification", - "TFRobertaForSequenceClassification" - ], - "sha": "6a6f53fc6ab98e29ed539e76b1cb76d25a2cd720" - }, - "RobertaForTokenClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaForTokenClassification", - "TFRobertaForTokenClassification" - ], - "sha": "9190044c4091eb0d98ae7638c453e24846bca5d7" - }, - "RobertaModel": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaModel", - "TFRobertaModel" - ], - "sha": "181a0b8a7ad24500ec327ad07ddb225f0680ac0a" - }, - "RobertaPreLayerNormForCausalLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaPreLayerNormForCausalLM", - "TFRobertaPreLayerNormForCausalLM" - ], - "sha": "73b6d4531b41f295a5d310d7aa44736004a59865" - }, - "RobertaPreLayerNormForMaskedLM": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaPreLayerNormForMaskedLM", - "TFRobertaPreLayerNormForMaskedLM" - ], - "sha": "a61723c77e5ab7adc95285e7823a0a49b99af395" - }, - "RobertaPreLayerNormForMultipleChoice": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaPreLayerNormForMultipleChoice", - "TFRobertaPreLayerNormForMultipleChoice" - ], - "sha": "3dcfa62e0771358c60232a18135bfe7c7f6d715e" - }, - "RobertaPreLayerNormForQuestionAnswering": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaPreLayerNormForQuestionAnswering", - "TFRobertaPreLayerNormForQuestionAnswering" - ], - "sha": "a8e76a5a50f7df60055e5ed6a1c3af2e7d34cf01" - }, - "RobertaPreLayerNormForSequenceClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaPreLayerNormForSequenceClassification", - "TFRobertaPreLayerNormForSequenceClassification" - ], - "sha": "7509cb0286d146ef2fc6beb8867ae31b92fb1b16" - }, - "RobertaPreLayerNormForTokenClassification": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaPreLayerNormForTokenClassification", - "TFRobertaPreLayerNormForTokenClassification" - ], - "sha": "3ad5814ba126b41e18c1978c970e396fab6da9bf" - }, - "RobertaPreLayerNormModel": { - "tokenizer_classes": [ - "RobertaTokenizer", - "RobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RobertaPreLayerNormModel", - "TFRobertaPreLayerNormModel" - ], - "sha": "4830db38fd310404c5ab70bd00684eca0bc06ca8" - }, - "RwkvForCausalLM": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RwkvForCausalLM" - ], - "sha": "2f452fd46b39e39b1a6a95fa1d8232405bbb3e96" - }, - "RwkvModel": { - "tokenizer_classes": [ - "GPTNeoXTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "RwkvModel" - ], - "sha": "88a52c9437dc3c06f65a8252490be7eb91197804" - }, - "SEWDForCTC": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "SEWDForCTC" - ], - "sha": "5c7495c77ae9e0f12c0de05d3a5fb95bdcd91768" - }, - "SEWDForSequenceClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "SEWDForSequenceClassification" - ], - "sha": "d6cbf1164ce1999fdaf3deeb7a6eba19a3b1f873" - }, - "SEWDModel": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "SEWDModel" - ], - "sha": "dde4e02219449f149bb3403bbeae127cafaf9c79" - }, - "SEWForCTC": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "SEWForCTC" - ], - "sha": "4477c7a277059fba08772acf91cf3e3dd3cb073b" - }, - "SEWForSequenceClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "SEWForSequenceClassification" - ], - "sha": "3b90fbb1c0c3848fed18f91a0169bb297a3e6619" - }, - "SEWModel": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "SEWModel" - ], - "sha": "0a0fbb844eeefa0dce62bd05db30a2bb91e5dc88" - }, - "SamModel": { - "tokenizer_classes": [], - "processor_classes": [ - "SamImageProcessor" - ], - "model_classes": [ - "SamModel", - "TFSamModel" - ], - "sha": "eca8651bc84e5ac3b1b62e784b744a6bd1b82575" - }, - "SegformerForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "SegformerImageProcessor" - ], - "model_classes": [ - "SegformerForImageClassification", - "TFSegformerForImageClassification" - ], - "sha": "c566ae0ed382be4ed61ed6dacffa2ba663e9cc19" - }, - "SegformerForSemanticSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "SegformerImageProcessor" - ], - "model_classes": [ - "SegformerForSemanticSegmentation", - "TFSegformerForSemanticSegmentation" - ], - "sha": "b73798972cdf24daafa858994713aca60e2bf90d" - }, - "SegformerModel": { - "tokenizer_classes": [], - "processor_classes": [ - "SegformerImageProcessor" - ], - "model_classes": [ - "SegformerModel", - "TFSegformerModel" - ], - "sha": "3d4ba8ed2bdf801e6afa855b9d77893f2b7f9e10" - }, - "Speech2TextForConditionalGeneration": { - "tokenizer_classes": [ - "Speech2TextTokenizer" - ], - "processor_classes": [ - "Speech2TextFeatureExtractor" - ], - "model_classes": [ - "Speech2TextForConditionalGeneration", - "TFSpeech2TextForConditionalGeneration" - ], - "sha": "1da80293ec78762e136cf6dd64b652693f9ab364" - }, - "Speech2TextModel": { - "tokenizer_classes": [ - "Speech2TextTokenizer" - ], - "processor_classes": [ - "Speech2TextFeatureExtractor" - ], - "model_classes": [ - "Speech2TextModel", - "TFSpeech2TextModel" - ], - "sha": "7c6e63bd0c15dd99ef01573d4c43f90e4920cc91" - }, - "SpeechEncoderDecoderModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "SpeechEncoderDecoderModel" - ], - "sha": "78602ae0857728e95de4042bdca8a31ef818890a" - }, - "SpeechT5ForSpeechToText": { - "tokenizer_classes": [ - "SpeechT5Tokenizer" - ], - "processor_classes": [ - "SpeechT5FeatureExtractor" - ], - "model_classes": [ - "SpeechT5ForSpeechToText" - ], - "sha": "d46f0a83324e5865420a27a738ef203292de3479" - }, - "SpeechT5Model": { - "tokenizer_classes": [ - "SpeechT5Tokenizer" - ], - "processor_classes": [ - "SpeechT5FeatureExtractor" - ], - "model_classes": [ - "SpeechT5Model" - ], - "sha": "7b248f77ca88ffddcdb538e772f6de63a86a4f9b" - }, - "SplinterForPreTraining": { - "tokenizer_classes": [ - "SplinterTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "SplinterForPreTraining" - ], - "sha": "e8a94efa740f1d685fa553f49132c6f022de5389" - }, - "SplinterForQuestionAnswering": { - "tokenizer_classes": [ - "SplinterTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "SplinterForQuestionAnswering" - ], - "sha": "d038b7b683face4a361ab0f474d8a5b111c44c4d" - }, - "SplinterModel": { - "tokenizer_classes": [ - "SplinterTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "SplinterModel" - ], - "sha": "a35b13cbb7faba46dc265761bb839267eb53d248" - }, - "SqueezeBertForMaskedLM": { - "tokenizer_classes": [ - "SqueezeBertTokenizer", - "SqueezeBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "SqueezeBertForMaskedLM" - ], - "sha": "33ce239408c22d2c98be63c9ab4607ef9ceb6d49" - }, - "SqueezeBertForMultipleChoice": { - "tokenizer_classes": [ - "SqueezeBertTokenizer", - "SqueezeBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "SqueezeBertForMultipleChoice" - ], - "sha": "7e9e666896420c7839e27dcb280981d034ba4da5" - }, - "SqueezeBertForQuestionAnswering": { - "tokenizer_classes": [ - "SqueezeBertTokenizer", - "SqueezeBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "SqueezeBertForQuestionAnswering" - ], - "sha": "bceb045a9ac6eb2ded7d358ed577c6dc28ea487a" - }, - "SqueezeBertForSequenceClassification": { - "tokenizer_classes": [ - "SqueezeBertTokenizer", - "SqueezeBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "SqueezeBertForSequenceClassification" - ], - "sha": "c5aeb1f454a1d059d41a5f8dacaf784b9de0b899" - }, - "SqueezeBertForTokenClassification": { - "tokenizer_classes": [ - "SqueezeBertTokenizer", - "SqueezeBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "SqueezeBertForTokenClassification" - ], - "sha": "70ba60ca44a380e6aa983a37b163c57217219df7" - }, - "SqueezeBertModel": { - "tokenizer_classes": [ - "SqueezeBertTokenizer", - "SqueezeBertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "SqueezeBertModel" - ], - "sha": "e0a3ac56a4047da3f921638252ead5e44438bbdb" - }, - "SwiftFormerForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "SwiftFormerForImageClassification" - ], - "sha": "a249b14a525d29e675b6e4af4baacd9ba7df7598" - }, - "SwiftFormerModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "SwiftFormerModel" - ], - "sha": "25ba2d88c770533f8c69811d2a454a00c1d09f5d" - }, - "Swin2SRModel": { - "tokenizer_classes": [], - "processor_classes": [ - "Swin2SRImageProcessor" - ], - "model_classes": [ - "Swin2SRModel" - ], - "sha": "c67f6ecff9ef8675c3869c987277b0a1e040f4be" - }, - "SwinBackbone": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "SwinBackbone" - ], - "sha": "89b28b8ec05a7b3357be75a77eb7809e6fd5cfef" - }, - "SwinForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "SwinForImageClassification", - "TFSwinForImageClassification" - ], - "sha": "e3c2e80f380ef79781313981da1a993dd8b8d34d" - }, - "SwinForMaskedImageModeling": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "SwinForMaskedImageModeling", - "TFSwinForMaskedImageModeling" - ], - "sha": "d84b061fbace1bc6e697e3253e222de42053f978" - }, - "SwinModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "SwinModel", - "TFSwinModel" - ], - "sha": "23ff641295660ec4fea399be8aa1bc14565961f8" - }, - "Swinv2ForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "Swinv2ForImageClassification" - ], - "sha": "3fd755cdf4cf611db83f72f9c9b00eb9257a38ca" - }, - "Swinv2ForMaskedImageModeling": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "Swinv2ForMaskedImageModeling" - ], - "sha": "8375c31eb6231fde36ec6533a34ba5b28e296163" - }, - "Swinv2Model": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "Swinv2Model" - ], - "sha": "70aeb72e8a266f668c8b51a517ec01003b8d6804" - }, - "SwitchTransformersForConditionalGeneration": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "SwitchTransformersForConditionalGeneration" - ], - "sha": "c8fcd2bb735894c78db7f1e5b51afc78aced7adb" - }, - "SwitchTransformersModel": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "SwitchTransformersModel" - ], - "sha": "275bbf6d389bfd0540b9f824c609c6b22a577328" - }, - "T5EncoderModel": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "T5EncoderModel", - "TFT5EncoderModel" - ], - "sha": "1c75090036a2b3740dfe2d570b889332ad8e59e8" - }, - "T5ForConditionalGeneration": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "T5ForConditionalGeneration", - "TFT5ForConditionalGeneration" - ], - "sha": "593fd6072a4e265f5cc73b1973cd8af76b261f29" - }, - "T5ForQuestionAnswering": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "T5ForQuestionAnswering" - ], - "sha": "b9edf2de494244ff032f67d2d7bdf6c591000c94" - }, - "T5ForSequenceClassification": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "T5ForSequenceClassification" - ], - "sha": "105b5c4c8e1efe927444108f1388c4f102ebad15" - }, - "T5Model": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "T5Model", - "TFT5Model" - ], - "sha": "eb3d20dda0ba77c1de618d78116a1a0c784c515c" - }, - "TableTransformerForObjectDetection": { - "tokenizer_classes": [], - "processor_classes": [ - "DetrImageProcessor" - ], - "model_classes": [ - "TableTransformerForObjectDetection" - ], - "sha": "9cf1e3f5c3555a727672a32b49f8b96c5aa20be6" - }, - "TableTransformerModel": { - "tokenizer_classes": [], - "processor_classes": [ - "DetrImageProcessor" - ], - "model_classes": [ - "TableTransformerModel" - ], - "sha": "7b446244d8739b0c29d98f7d537b15ad578577d5" - }, - "TapasForMaskedLM": { - "tokenizer_classes": [ - "TapasTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFTapasForMaskedLM", - "TapasForMaskedLM" - ], - "sha": "2cedb92dd9a3dc37ffb7d35ad5190b110992577c" - }, - "TapasForQuestionAnswering": { - "tokenizer_classes": [ - "TapasTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFTapasForQuestionAnswering", - "TapasForQuestionAnswering" - ], - "sha": "4cc91b9e5db662e6e392d8052587ae419896d72b" - }, - "TapasForSequenceClassification": { - "tokenizer_classes": [ - "TapasTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFTapasForSequenceClassification", - "TapasForSequenceClassification" - ], - "sha": "7c37bfb87a6fce2f8604bb3cab2a14e09a285e14" - }, - "TapasModel": { - "tokenizer_classes": [ - "TapasTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFTapasModel", - "TapasModel" - ], - "sha": "bc004af0a415afe1f566c3afe8dd4d48d08c1ce0" - }, - "TimesformerForVideoClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "VideoMAEImageProcessor" - ], - "model_classes": [ - "TimesformerForVideoClassification" - ], - "sha": "0b3b8e314618d7af34fb44477745491b44bf556d" - }, - "TimesformerModel": { - "tokenizer_classes": [], - "processor_classes": [ - "VideoMAEImageProcessor" - ], - "model_classes": [ - "TimesformerModel" - ], - "sha": "ea51f7ebb6426ad2b1fa1396e83f8e8ad5bc3b44" - }, - "TransfoXLForSequenceClassification": { - "tokenizer_classes": [ - "TransfoXLTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFTransfoXLForSequenceClassification", - "TransfoXLForSequenceClassification" - ], - "sha": "f3d370184350667d74056b979081b0bf5b0083c1" - }, - "TransfoXLLMHeadModel": { - "tokenizer_classes": [ - "TransfoXLTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFTransfoXLLMHeadModel", - "TransfoXLLMHeadModel" - ], - "sha": "e0d4cebcdde52d8d4c81782a1edc606830bd6afd" - }, - "TransfoXLModel": { - "tokenizer_classes": [ - "TransfoXLTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFTransfoXLModel", - "TransfoXLModel" - ], - "sha": "6938eeae35662a862accb01412dfc486454bdc8f" - }, - "TvltForPreTraining": { - "tokenizer_classes": [], - "processor_classes": [ - "TvltProcessor" - ], - "model_classes": [ - "TvltForPreTraining" - ], - "sha": "f7bd2833764eb6d55a921aaed81d3f21119016ae" - }, - "TvltModel": { - "tokenizer_classes": [], - "processor_classes": [ - "TvltProcessor" - ], - "model_classes": [ - "TvltModel" - ], - "sha": "c3cbf7a6159c038f333ce7adda2480ea3396b2b3" - }, - "UMT5EncoderModel": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "UMT5EncoderModel" - ], - "sha": "2894e49c9fbd17ea4b3dab56ec388be354c1a5f0" - }, - "UMT5ForQuestionAnswering": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "UMT5ForQuestionAnswering" - ], - "sha": "b381aa068a44200db539f2f48f4e34a5ed1cb093" - }, - "UMT5ForSequenceClassification": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "UMT5ForSequenceClassification" - ], - "sha": "aa9f77b7b3cff21425b7512e7c0f478af7b5db14" - }, - "UMT5Model": { - "tokenizer_classes": [ - "T5Tokenizer", - "T5TokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "UMT5Model" - ], - "sha": "9180d850b24e5494442a4f7a8ca1a4c102f9babd" - }, - "UniSpeechForCTC": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechForCTC" - ], - "sha": "102b56d76f4d74cface309801c0ad80892583751" - }, - "UniSpeechForPreTraining": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechForPreTraining" - ], - "sha": "830be5b3e85aaae7bcc961218e417c29743d6042" - }, - "UniSpeechForSequenceClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechForSequenceClassification" - ], - "sha": "a30ac1516944757ccd8efcbcf94033a03f8708bf" - }, - "UniSpeechModel": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechModel" - ], - "sha": "18e170eb1091715b74ace28c8c380b6bf2b6202d" - }, - "UniSpeechSatForAudioFrameClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechSatForAudioFrameClassification" - ], - "sha": "7eba5a1c6cd610928b27ecb217bb17c729a07a57" - }, - "UniSpeechSatForCTC": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechSatForCTC" - ], - "sha": "a8617538d3a2ae990f022bb0c36b8428a4870822" - }, - "UniSpeechSatForPreTraining": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechSatForPreTraining" - ], - "sha": "a772f66db0ab49e1050e524d7fcbe5106ebdaf96" - }, - "UniSpeechSatForSequenceClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechSatForSequenceClassification" - ], - "sha": "f1c16567bd829a6d8a7a2d167d22e9653149e625" - }, - "UniSpeechSatForXVector": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechSatForXVector" - ], - "sha": "71cb3780cf3678f74fba00e19df82df76dca6133" - }, - "UniSpeechSatModel": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "UniSpeechSatModel" - ], - "sha": "ea755bbc7c6c6aa649c58b4b000f243acbbd6b5a" - }, - "UperNetForSemanticSegmentation": { - "tokenizer_classes": [], - "processor_classes": [ - "SegformerImageProcessor" - ], - "model_classes": [ - "UperNetForSemanticSegmentation" - ], - "sha": "f1871cb388bc0b203f5397bfc06a373736c2fb9c" - }, - "VanForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "VanForImageClassification" - ], - "sha": "694eb147bc4768aeabeffbfb97732281b71a621d" - }, - "VanModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ConvNextImageProcessor" - ], - "model_classes": [ - "VanModel" - ], - "sha": "d8ac60ce952020f2b0355fc566d634b2c5ba635d" - }, - "ViTForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "TFViTForImageClassification", - "ViTForImageClassification" - ], - "sha": "5b3b44a3ed492070c273e481e30ecf4deddc5ec3" - }, - "ViTForMaskedImageModeling": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "ViTForMaskedImageModeling" - ], - "sha": "d984e0b432fe195c2c26952d4f249031e7b1e2ea" - }, - "ViTHybridForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTHybridImageProcessor" - ], - "model_classes": [ - "ViTHybridForImageClassification" - ], - "sha": "69c7c396032ffe60d54953b584394899fb95ccc1" - }, - "ViTHybridModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTHybridImageProcessor" - ], - "model_classes": [ - "ViTHybridModel" - ], - "sha": "077443bfefe40d625314dbd274d2ff8089624797" - }, - "ViTMAEForPreTraining": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "TFViTMAEForPreTraining", - "ViTMAEForPreTraining" - ], - "sha": "2d98d80d9c45eef0d5b6f5426d7196bb546fe9fc" - }, - "ViTMAEModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "TFViTMAEModel", - "ViTMAEModel" - ], - "sha": "c7c2f12c19d2dbec08851a9dac7485909629a5fd" - }, - "ViTMSNForImageClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "ViTMSNForImageClassification" - ], - "sha": "feda819aa7dbb55d850130f4cf1d210858d7eb89" - }, - "ViTMSNModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "ViTMSNModel" - ], - "sha": "0733abf168cb47a149821fdd2113d546e15c47de" - }, - "ViTModel": { - "tokenizer_classes": [], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "TFViTModel", - "ViTModel" - ], - "sha": "31817b7a64ebc3333fcd4801dfbb356ab07b13dd" - }, - "VideoMAEForPreTraining": { - "tokenizer_classes": [], - "processor_classes": [ - "VideoMAEImageProcessor" - ], - "model_classes": [ - "VideoMAEForPreTraining" - ], - "sha": "9de66c4bb759dc7269a7af17bf70b3194550acaa" - }, - "VideoMAEForVideoClassification": { - "tokenizer_classes": [], - "processor_classes": [ - "VideoMAEImageProcessor" - ], - "model_classes": [ - "VideoMAEForVideoClassification" - ], - "sha": "d3f743408386bc0ffe2d979de35335e87bc34aec" - }, - "VideoMAEModel": { - "tokenizer_classes": [], - "processor_classes": [ - "VideoMAEImageProcessor" - ], - "model_classes": [ - "VideoMAEModel" - ], - "sha": "a2be96beba888817d92b67525601569d830342ff" - }, - "ViltForQuestionAnswering": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "ViltImageProcessor" - ], - "model_classes": [ - "ViltForQuestionAnswering" - ], - "sha": "faeffbf43da6621717d8b13e7ebe87d58d750cb2" - }, - "ViltModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "ViltImageProcessor" - ], - "model_classes": [ - "ViltModel" - ], - "sha": "3a89b7b5782947c4f4125162ffe1c9cc18c9c800" - }, - "VisionEncoderDecoderModel": { - "tokenizer_classes": [ - "GPT2Tokenizer", - "GPT2TokenizerFast" - ], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "TFVisionEncoderDecoderModel", - "VisionEncoderDecoderModel" - ], - "sha": "23917761070cf16b26a6d033b6bff9100bbc618b" - }, - "VisionTextDualEncoderModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [ - "ViTImageProcessor" - ], - "model_classes": [ - "TFVisionTextDualEncoderModel", - "VisionTextDualEncoderModel" - ], - "sha": "c3569ef17f66acbacb76f7ceb6f71e02d075dd6c" - }, - "VisualBertForPreTraining": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "VisualBertForPreTraining" - ], - "sha": "ce5a4d93ce762971cd216cda9aef8b9ce3f0450b" - }, - "VisualBertModel": { - "tokenizer_classes": [ - "BertTokenizer", - "BertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "VisualBertModel" - ], - "sha": "85020189fb7bf1217eb9370b09bca8ec5bcfdafa" - }, - "Wav2Vec2ConformerForAudioFrameClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ConformerForAudioFrameClassification" - ], - "sha": "e316a18a1d165b4cb51a7f28f8e8dab676da4b56" - }, - "Wav2Vec2ConformerForCTC": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ConformerForCTC" - ], - "sha": "a2ecb2985fcbb9f3ed000c12c1af6da36f5eaa3a" - }, - "Wav2Vec2ConformerForPreTraining": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ConformerForPreTraining" - ], - "sha": "099279b69e5da19efb05589804ccee210a0e57ae" - }, - "Wav2Vec2ConformerForSequenceClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ConformerForSequenceClassification" - ], - "sha": "e8c1bca543c54bf15a6c026cb3761993b52cf617" - }, - "Wav2Vec2ConformerForXVector": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ConformerForXVector" - ], - "sha": "ba206a55998f16e134960728bd02006eaf39114f" - }, - "Wav2Vec2ConformerModel": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ConformerModel" - ], - "sha": "ef2fe3aa8c23e6f8696e6612061aaddecae49994" - }, - "Wav2Vec2ForAudioFrameClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ForAudioFrameClassification" - ], - "sha": "ab219f119e10f56e1059966c66d23f0df3c2c343" - }, - "Wav2Vec2ForCTC": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ForCTC" - ], - "sha": "6245fbb1cb99cea5c4de1e73f81fba978fb275ac" - }, - "Wav2Vec2ForMaskedLM": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ForMaskedLM" - ], - "sha": "e083cf4fefec4df3c241dbbe5e17a84a794a89bd" - }, - "Wav2Vec2ForPreTraining": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ForPreTraining" - ], - "sha": "a8d71e216334260353ccbf5ce84cd6924f7457da" - }, - "Wav2Vec2ForSequenceClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "TFWav2Vec2ForSequenceClassification", - "Wav2Vec2ForSequenceClassification" - ], - "sha": "2000b2022abcc37100241485f5872126b70164c9" - }, - "Wav2Vec2ForXVector": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "Wav2Vec2ForXVector" - ], - "sha": "f4c422db53aae061ea609f4407af7cd5b33c8942" - }, - "Wav2Vec2Model": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "TFWav2Vec2Model", - "Wav2Vec2Model" - ], - "sha": "7a998ee3ee0619a52828a79c3eed6872fd053f37" - }, - "WavLMForAudioFrameClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "WavLMForAudioFrameClassification" - ], - "sha": "b135610f8d5de0b1a5bf5ed7212966135c63d6ec" - }, - "WavLMForCTC": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "WavLMForCTC" - ], - "sha": "f1139c5ddf34d2327ae1f6917edd7da180b06971" - }, - "WavLMForSequenceClassification": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "WavLMForSequenceClassification" - ], - "sha": "4ba5f2019b46866ce2011c993194ebda60afc028" - }, - "WavLMForXVector": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "WavLMForXVector" - ], - "sha": "faf9264eac56a56d5510a0984d7e1146e4c8cf62" - }, - "WavLMModel": { - "tokenizer_classes": [ - "Wav2Vec2CTCTokenizer" - ], - "processor_classes": [ - "Wav2Vec2FeatureExtractor" - ], - "model_classes": [ - "WavLMModel" - ], - "sha": "e932275e37cb643be271f655bd1d649f4f4b4bd5" - }, - "WhisperForAudioClassification": { - "tokenizer_classes": [ - "WhisperTokenizer" - ], - "processor_classes": [ - "WhisperFeatureExtractor" - ], - "model_classes": [ - "WhisperForAudioClassification" - ], - "sha": "d71b13674b1a67443cd19d0594a3b5b1e5968f0d" - }, - "WhisperForConditionalGeneration": { - "tokenizer_classes": [ - "WhisperTokenizer", - "WhisperTokenizerFast" - ], - "processor_classes": [ - "WhisperFeatureExtractor" - ], - "model_classes": [ - "TFWhisperForConditionalGeneration", - "WhisperForConditionalGeneration" - ], - "sha": "598101b885b24508042d9292e54aa04bff96318e" - }, - "WhisperModel": { - "tokenizer_classes": [ - "WhisperTokenizer", - "WhisperTokenizerFast" - ], - "processor_classes": [ - "WhisperFeatureExtractor" - ], - "model_classes": [ - "TFWhisperModel", - "WhisperModel" - ], - "sha": "c04c50216bb6b0a8f4d55f2fa9f9f4cf61c8a77c" - }, - "XCLIPModel": { - "tokenizer_classes": [ - "CLIPTokenizer", - "CLIPTokenizerFast" - ], - "processor_classes": [ - "VideoMAEImageProcessor" - ], - "model_classes": [ - "XCLIPModel" - ], - "sha": "299ffffc6b94c3558bf7dbc38e24074c99490046" - }, - "XGLMForCausalLM": { - "tokenizer_classes": [ - "XGLMTokenizer", - "XGLMTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "TFXGLMForCausalLM", - "XGLMForCausalLM" - ], - "sha": "d5381ce297c249d559937c6bb6316cf1fdad2613" - }, - "XGLMModel": { - "tokenizer_classes": [ - "XGLMTokenizer", - "XGLMTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "TFXGLMModel", - "XGLMModel" - ], - "sha": "2b5cef167822cfaa558d259af1722e2f785cd3d5" - }, - "XLMForMultipleChoice": { - "tokenizer_classes": [ - "XLMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFXLMForMultipleChoice", - "XLMForMultipleChoice" - ], - "sha": "f0c8cc6462449ac9eb9b4158e433bd3c923db3af" - }, - "XLMForQuestionAnsweringSimple": { - "tokenizer_classes": [ - "XLMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFXLMForQuestionAnsweringSimple", - "XLMForQuestionAnsweringSimple" - ], - "sha": "82e93a2653cf3646eaaf02d8cc5f8ff9a4551523" - }, - "XLMForSequenceClassification": { - "tokenizer_classes": [ - "XLMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFXLMForSequenceClassification", - "XLMForSequenceClassification" - ], - "sha": "2d6892f5f703be9b481bca91477032bd0e36dbe5" - }, - "XLMForTokenClassification": { - "tokenizer_classes": [ - "XLMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFXLMForTokenClassification", - "XLMForTokenClassification" - ], - "sha": "9a591395e7a0643a03f5d2debb98caa3966e021c" - }, - "XLMModel": { - "tokenizer_classes": [ - "XLMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFXLMModel", - "XLMModel" - ], - "sha": "022b86df246414ff712475d9ca55db690ff1d3bf" - }, - "XLMRobertaXLForCausalLM": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XLMRobertaXLForCausalLM" - ], - "sha": "fc05408e5b33a31638476ef337719dfbb7615ef3" - }, - "XLMRobertaXLForMaskedLM": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XLMRobertaXLForMaskedLM" - ], - "sha": "e96f198eede757e5ae2c87632fdcfb341073ef6e" - }, - "XLMRobertaXLForMultipleChoice": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XLMRobertaXLForMultipleChoice" - ], - "sha": "52732625f1bfbbb7cb4ba1cf0963de596d81822d" - }, - "XLMRobertaXLForQuestionAnswering": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XLMRobertaXLForQuestionAnswering" - ], - "sha": "da388fdd2d28e0757eb0c2b2c612a8ff03af2223" - }, - "XLMRobertaXLForSequenceClassification": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XLMRobertaXLForSequenceClassification" - ], - "sha": "980721187633bcf21ac0b8edbed933527f4611df" - }, - "XLMRobertaXLForTokenClassification": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XLMRobertaXLForTokenClassification" - ], - "sha": "37a97280faf6fef0bd946d3934d77a1b60fbf473" - }, - "XLMRobertaXLModel": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XLMRobertaXLModel" - ], - "sha": "8fbeb39a984912e47f5d24a31be61639031a0fc3" - }, - "XLMWithLMHeadModel": { - "tokenizer_classes": [ - "XLMTokenizer" - ], - "processor_classes": [], - "model_classes": [ - "TFXLMWithLMHeadModel", - "XLMWithLMHeadModel" - ], - "sha": "db70bdefbaf095e88b8097e4b601d9105a511afa" - }, - "XLNetForMultipleChoice": { - "tokenizer_classes": [ - "XLNetTokenizer", - "XLNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "TFXLNetForMultipleChoice", - "XLNetForMultipleChoice" - ], - "sha": "8bb7e28d0cd1e93154d3232baf5e9c79acaf9f1a" - }, - "XLNetForQuestionAnsweringSimple": { - "tokenizer_classes": [ - "XLNetTokenizer", - "XLNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "TFXLNetForQuestionAnsweringSimple", - "XLNetForQuestionAnsweringSimple" - ], - "sha": "fabd06a45d947f3d46f1b8dce2186cf3b27776dc" - }, - "XLNetForSequenceClassification": { - "tokenizer_classes": [ - "XLNetTokenizer", - "XLNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "TFXLNetForSequenceClassification", - "XLNetForSequenceClassification" - ], - "sha": "e3c194f24537ebf2c474ade60becb9397696edec" - }, - "XLNetForTokenClassification": { - "tokenizer_classes": [ - "XLNetTokenizer", - "XLNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "TFXLNetForTokenClassification", - "XLNetForTokenClassification" - ], - "sha": "16aa15029aa667046d504c4a88ceddfdd5b5fb40" - }, - "XLNetLMHeadModel": { - "tokenizer_classes": [ - "XLNetTokenizer", - "XLNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "TFXLNetLMHeadModel", - "XLNetLMHeadModel" - ], - "sha": "c9a98cc982a16ca162832a8cbea25116479bb938" - }, - "XLNetModel": { - "tokenizer_classes": [ - "XLNetTokenizer", - "XLNetTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "TFXLNetModel", - "XLNetModel" - ], - "sha": "1d6e231942135faf32b8d9a97773d8f6c85ca561" - }, - "XmodForCausalLM": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XmodForCausalLM" - ], - "sha": "c6b746071f2f067099a8fb4f57ce3c27a7e4b67d" - }, - "XmodForMaskedLM": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XmodForMaskedLM" - ], - "sha": "e1085818f4ed3c6073b2038635e5f3061208923d" - }, - "XmodForMultipleChoice": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XmodForMultipleChoice" - ], - "sha": "c63042cdf196be3fed846421b345d439b2483f69" - }, - "XmodForQuestionAnswering": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XmodForQuestionAnswering" - ], - "sha": "75acd3071fae9978c82618cd0f090c87aabc1f23" - }, - "XmodForSequenceClassification": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XmodForSequenceClassification" - ], - "sha": "523a16570be048618913ac17ccd00d343bcb5e99" - }, - "XmodForTokenClassification": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XmodForTokenClassification" - ], - "sha": "a0f0a02732b4579670dad11a69ae244ebd777b49" - }, - "XmodModel": { - "tokenizer_classes": [ - "XLMRobertaTokenizer", - "XLMRobertaTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "XmodModel" - ], - "sha": "bc286de0035450e7dcd6bcce78098a967b9c2b6c" - }, - "YolosForObjectDetection": { - "tokenizer_classes": [], - "processor_classes": [ - "YolosImageProcessor" - ], - "model_classes": [ - "YolosForObjectDetection" - ], - "sha": "0a4aae25bfbe8b5edd4815cb00d697a6ba7d2126" - }, - "YolosModel": { - "tokenizer_classes": [], - "processor_classes": [ - "YolosImageProcessor" - ], - "model_classes": [ - "YolosModel" - ], - "sha": "339bc51f1914f031a550e5f95095ed4a4c22a7de" - }, - "YosoForMaskedLM": { - "tokenizer_classes": [ - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "YosoForMaskedLM" - ], - "sha": "cb291bedcbec199ea195f086e3ebea6fab026bba" - }, - "YosoForMultipleChoice": { - "tokenizer_classes": [ - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "YosoForMultipleChoice" - ], - "sha": "cf2d3a3f0628bc9d0da68ea8de26b12016453fee" - }, - "YosoForQuestionAnswering": { - "tokenizer_classes": [ - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "YosoForQuestionAnswering" - ], - "sha": "e8c3091f674588adfa3371b3de0427a9b39dd03f" - }, - "YosoForSequenceClassification": { - "tokenizer_classes": [ - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "YosoForSequenceClassification" - ], - "sha": "88132cbaa1a9a87f65b6f9813c388011377f18cf" - }, - "YosoForTokenClassification": { - "tokenizer_classes": [ - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "YosoForTokenClassification" - ], - "sha": "fd2219856608d3dba70dc7b1a06af629903dec31" - }, - "YosoModel": { - "tokenizer_classes": [ - "AlbertTokenizerFast" - ], - "processor_classes": [], - "model_classes": [ - "YosoModel" - ], - "sha": "e144d9f1fe39c21eda1177702640e126892605ce" - } -} \ No newline at end of file diff --git a/tests/transformers/utils/test_module/__init__.py b/tests/transformers/utils/test_module/__init__.py deleted file mode 100644 index e69de29bb2..0000000000 diff --git a/tests/transformers/utils/test_module/custom_configuration.py b/tests/transformers/utils/test_module/custom_configuration.py deleted file mode 100644 index 676486fc51..0000000000 --- a/tests/transformers/utils/test_module/custom_configuration.py +++ /dev/null @@ -1,16 +0,0 @@ -from transformers import PretrainedConfig - - -class CustomConfig(PretrainedConfig): - model_type = "custom" - - def __init__(self, attribute=1, **kwargs): - self.attribute = attribute - super().__init__(**kwargs) - - -class NoSuperInitConfig(PretrainedConfig): - model_type = "custom" - - def __init__(self, attribute=1, **kwargs): - self.attribute = attribute diff --git a/tests/transformers/utils/test_module/custom_feature_extraction.py b/tests/transformers/utils/test_module/custom_feature_extraction.py deleted file mode 100644 index de367032d8..0000000000 --- a/tests/transformers/utils/test_module/custom_feature_extraction.py +++ /dev/null @@ -1,5 +0,0 @@ -from transformers import Wav2Vec2FeatureExtractor - - -class CustomFeatureExtractor(Wav2Vec2FeatureExtractor): - pass diff --git a/tests/transformers/utils/test_module/custom_image_processing.py b/tests/transformers/utils/test_module/custom_image_processing.py deleted file mode 100644 index e4984854ad..0000000000 --- a/tests/transformers/utils/test_module/custom_image_processing.py +++ /dev/null @@ -1,5 +0,0 @@ -from transformers import CLIPImageProcessor - - -class CustomImageProcessor(CLIPImageProcessor): - pass diff --git a/tests/transformers/utils/test_module/custom_modeling.py b/tests/transformers/utils/test_module/custom_modeling.py deleted file mode 100644 index 4c9e13d467..0000000000 --- a/tests/transformers/utils/test_module/custom_modeling.py +++ /dev/null @@ -1,32 +0,0 @@ -import torch -from transformers import PreTrainedModel - -from .custom_configuration import CustomConfig, NoSuperInitConfig - - -class CustomModel(PreTrainedModel): - config_class = CustomConfig - - def __init__(self, config): - super().__init__(config) - self.linear = torch.nn.Linear(config.hidden_size, config.hidden_size) - - def forward(self, x): - return self.linear(x) - - def _init_weights(self, module): - pass - - -class NoSuperInitModel(PreTrainedModel): - config_class = NoSuperInitConfig - - def __init__(self, config): - super().__init__(config) - self.linear = torch.nn.Linear(config.attribute, config.attribute) - - def forward(self, x): - return self.linear(x) - - def _init_weights(self, module): - pass diff --git a/tests/transformers/utils/test_module/custom_pipeline.py b/tests/transformers/utils/test_module/custom_pipeline.py deleted file mode 100644 index 4172bd0c66..0000000000 --- a/tests/transformers/utils/test_module/custom_pipeline.py +++ /dev/null @@ -1,32 +0,0 @@ -import numpy as np -from transformers import Pipeline - - -def softmax(outputs): - maxes = np.max(outputs, axis=-1, keepdims=True) - shifted_exp = np.exp(outputs - maxes) - return shifted_exp / shifted_exp.sum(axis=-1, keepdims=True) - - -class PairClassificationPipeline(Pipeline): - def _sanitize_parameters(self, **kwargs): - preprocess_kwargs = {} - if "second_text" in kwargs: - preprocess_kwargs["second_text"] = kwargs["second_text"] - return preprocess_kwargs, {}, {} - - def preprocess(self, text, second_text=None): - return self.tokenizer(text, text_pair=second_text, return_tensors=self.framework) - - def _forward(self, model_inputs): - return self.model(**model_inputs) - - def postprocess(self, model_outputs): - logits = model_outputs.logits[0].numpy() - probabilities = softmax(logits) - - best_class = np.argmax(probabilities) - label = self.model.config.id2label[best_class] - score = probabilities[best_class].item() - logits = logits.tolist() - return {"label": label, "score": score, "logits": logits} diff --git a/tests/transformers/utils/test_module/custom_processing.py b/tests/transformers/utils/test_module/custom_processing.py deleted file mode 100644 index 196fc511b6..0000000000 --- a/tests/transformers/utils/test_module/custom_processing.py +++ /dev/null @@ -1,6 +0,0 @@ -from transformers import ProcessorMixin - - -class CustomProcessor(ProcessorMixin): - feature_extractor_class = "AutoFeatureExtractor" - tokenizer_class = "AutoTokenizer" diff --git a/tests/transformers/utils/test_module/custom_tokenization.py b/tests/transformers/utils/test_module/custom_tokenization.py deleted file mode 100644 index d67b137304..0000000000 --- a/tests/transformers/utils/test_module/custom_tokenization.py +++ /dev/null @@ -1,5 +0,0 @@ -from transformers import BertTokenizer - - -class CustomTokenizer(BertTokenizer): - pass diff --git a/tests/transformers/utils/test_module/custom_tokenization_fast.py b/tests/transformers/utils/test_module/custom_tokenization_fast.py deleted file mode 100644 index ace94fdd1a..0000000000 --- a/tests/transformers/utils/test_module/custom_tokenization_fast.py +++ /dev/null @@ -1,8 +0,0 @@ -from transformers import BertTokenizerFast - -from .custom_tokenization import CustomTokenizer - - -class CustomTokenizerFast(BertTokenizerFast): - slow_tokenizer_class = CustomTokenizer - pass diff --git a/tests/utils.py b/tests/utils.py deleted file mode 100644 index cce23476e5..0000000000 --- a/tests/utils.py +++ /dev/null @@ -1,99 +0,0 @@ -# coding=utf-8 -# Copyright 2022 HuggingFace Inc. -# -# Licensed under the Apache License, Version 2.0 (the "License"); -# you may not use this file except in compliance with the License. -# You may obtain a copy of the License at -# -# http://www.apache.org/licenses/LICENSE-2.0 -# -# Unless required by applicable law or agreed to in writing, software -# distributed under the License is distributed on an "AS IS" BASIS, -# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. -# See the License for the specific language governing permissions and -# limitations under the License. - - -# Mapping between model families and specific model names with their configuration -MODELS_TO_TEST_MAPPING = { - "audio-spectrogram-transformer": [ - ("MIT/ast-finetuned-speech-commands-v2", "Habana/wav2vec2"), - ], - "bert": [ - # ("bert-base-uncased", "Habana/bert-base-uncased"), - ("bert-large-uncased-whole-word-masking", "Habana/bert-large-uncased-whole-word-masking"), - ], - "roberta": [ - ("roberta-base", "Habana/roberta-base"), - ("roberta-large", "Habana/roberta-large"), - ], - "albert": [ - ("albert-large-v2", "Habana/albert-large-v2"), - ("albert-xxlarge-v1", "Habana/albert-xxlarge-v1"), - ], - "distilbert": [ - ("distilbert-base-uncased", "Habana/distilbert-base-uncased"), - ], - "gpt2": [ - ("gpt2", "Habana/gpt2"), - ("gpt2-xl", "Habana/gpt2"), - ], - "t5": [ - ("t5-small", "Habana/t5"), - ("google/flan-t5-xxl", "Habana/t5"), - ], - "vit": [ - ("google/vit-base-patch16-224-in21k", "Habana/vit"), - ], - "wav2vec2": [ - ("facebook/wav2vec2-base", "Habana/wav2vec2"), - ("facebook/wav2vec2-large-lv60", "Habana/wav2vec2"), - ], - "swin": [("microsoft/swin-base-patch4-window7-224-in22k", "Habana/swin")], - "clip": [("./clip-roberta", "Habana/clip")], - "bridgetower": [("BridgeTower/bridgetower-large-itm-mlm-itc", "Habana/clip")], - "gpt_neox": [("EleutherAI/gpt-neox-20b", "Habana/gpt2")], - "llama": [("huggyllama/llama-7b", "Habana/llama")], - "falcon": [("tiiuae/falcon-40b", "Habana/falcon")], - "bloom": [("bigscience/bloom-7b1", "Habana/roberta-base")], - "whisper": [("openai/whisper-small", "Habana/whisper")], - "llama_guard": [("meta-llama/LlamaGuard-7b", "Habana/llama")], - "code_llama": [("codellama/CodeLlama-13b-Instruct-hf", "Habana/llama")], - "protst": [("mila-intel/protst-esm1b-for-sequential-classification", "Habana/gpt2")], -} - -MODELS_TO_TEST_FOR_QUESTION_ANSWERING = [ - "bert", - "roberta", - "albert", - "distilbert", -] - -# Only BERT has been officially validated for sequence classification -MODELS_TO_TEST_FOR_SEQUENCE_CLASSIFICATION = [ - "bert", - "llama_guard", - # "roberta", - # "albert", - # "distilbert", -] - -MODELS_TO_TEST_FOR_CAUSAL_LANGUAGE_MODELING = ["gpt2", "gpt_neox", "bloom", "code_llama"] - -MODELS_TO_TEST_FOR_SEQ2SEQ = ["t5"] - -MODELS_TO_TEST_FOR_IMAGE_CLASSIFICATION = ["vit", "swin"] - -# Only RoBERTa is tested in CI for MLM -MODELS_TO_TEST_FOR_MASKED_LANGUAGE_MODELING = [ - # "bert", - "roberta", - # "albert", - # "distilbert", -] - -MODELS_TO_TEST_FOR_AUDIO_CLASSIFICATION = ["wav2vec2", "audio-spectrogram-transformer"] - -MODELS_TO_TEST_FOR_SPEECH_RECOGNITION = ["wav2vec2", "whisper"] - -MODELS_TO_TEST_FOR_IMAGE_TEXT = ["clip"] diff --git a/text-generation-inference/README.md b/text-generation-inference/README.md deleted file mode 100644 index b7803fb3d6..0000000000 --- a/text-generation-inference/README.md +++ /dev/null @@ -1,19 +0,0 @@ - - -# Text Generation Inference on Intel® Gaudi® AI Accelerators - -Please refer to the following fork of TGI for deploying it on Habana Gaudi: https://github.com/huggingface/tgi-gaudi