输入图像大小维度$(B,C,H,W)$,不重叠地划分为$(B,\frac{HW}{P^2},CP^2)$个patch,然后做patch embedding,改变patch的特征维度$(B,\frac{HW}{P^2},dim)$。concat用于分类的cls token,维度变为$(B,\frac{HW}{P^2}+1,dim)$,加入可学习的绝对位置编码,送入transformer的主体。
transformer的attention部分,先通过线性层变成$(B,\frac{HW}{P^2}+1,3*dim_{head}\cdot{heads})$,分成三份q,k,v,并变形为$(B,heads,\frac{HW}{P^2}+1,dim_{head})$,然后是经典的 $$ {Attention}(Q, K, V)={SoftMax}(Q K^{T}/ \sqrt{dim_{head}}) V $$ 注意$Q K^{T}$后得到的attention weights的维度是$(B,heads,\frac{HW}{P^2}+1,\frac{HW}{P^2}+1)$,attention前后张量维度不变,仍保持$(B,heads,\frac{HW}{P^2}+1,dim_{head})$。
- 如果要加入mask屏蔽,应该在未softmax前的attention weights进行屏蔽。
- 最终送入分类头时,可以选择对所有patch求均值或只送入cls token。
DeiT与ViT差异不大,多加入了一个distill token用于蒸馏学习
主要在于Reattention的加入,缓解深层ViT中注意力坍塌的问题。
定义了一个端到端可学习的变换矩阵,变换矩阵沿着头部维度乘以自注意力映射图,将多头注意力映射图混合到重新生成的新的注意力映射图中,并且Norm取得是BatchNorm而不是传统的LayerNorm,然后与Value相乘。实现时,变换矩阵是一个(heads,head,1,1)的二维卷积。
试图训练更深的ViT,主要贡献:
-
加入Large scale,帮助深度ViT更容易收敛

large scale是在self attention或FFN后乘一组可学习的参数$\lambda$,在$(B,\frac{HW}{P^2}+1,dim_{head}\cdot{heads})$的特征(最后)维乘。
- cls token只在最后两层transformer加入进行信息交互,且最后两层transformer只有cls token与其他token交互,其他token之间不相互交互。
关注点在transformer的位置编码,当输入图片大小改变时,可以通过对pos embedding插值适应图像。CPVT在第一个encoder之后灵活地引入位置信息,可以通过二维深度可分离卷积,且加入一圈zero padding(或其他更复杂的操作),就能引入位置信息。

卷积和transformer的深度结合,初始的patch embedding和每个stage开始都要做token embedding,以普通的二维卷积实现(注意没有用深度可分离,并且每个stage前都要再嵌入一次,这是ViT所没有的)。生成q, k, v的过程使用深度可分离卷积,且k, v的stride为2,可以减小特征图大小(转而加深了通道,计算量并没有改变)。属于金字塔型ViT。
每个stage都是:卷积嵌入→layernorm→transformer块,共三个stage,每个stage后特征图变小。最后一个stage加入了cls token,用于分类,或者像通常的CNN那样全局池化后分类。


同样试图在transformer中加入卷积操作,但没有CvT那样彻底。使用卷积做嵌入(先用卷积+最大池化把特征图变小,再用卷积嵌入),保持MSA模块不变,保留捕获token之间全局相似性的能力,原来的前馈网络层被Locally-enhanced Feed-Forward layer 取代:

Layer-wise Class token Attention模块则是把所有层的cls token输入做相关和前馈,注意仅最后一层的cls token和其他层cls token交互。

引入卷积的操作使ViT更快,属于金字塔型ViT。一开始先四个卷积提取底层特征且减小特征图大小,然后是stage1(若干个transformer块)→下采样attention块→stage2→下采样attention块→stage3,后接全局平均池化直接分类,也可加入蒸馏。

注意力里生成q,k,v也用了卷积,前馈操作也都变成了卷积(注意都没有用深度可分离)。shrink attention就是生成q时的stride变为2完成下采样,由于特征图的大小的变化,这个注意块没有残差连接。
LeViT在attention map中引入了bias,注意力偏置替代位置嵌入。参考https://zhuanlan.zhihu.com/p/385827894
略略略
Swin Transformer构建了像ResNet的层次结构,可以用于各种下游任务,且除了Patcg Embedding部分,是不含卷积的。

Patcg Embedding用步长为2的卷积实现,Patch Merging是yolov5的focus模块(了解nn.Unfold函数)+线性层降维,Window-based MSA和Shifted Window-based MSA交替进行。最大的特点就是W-MSA只在各个窗口内自己计算attention,然后SW-MSA重新划分窗口,加强不同窗口间的联系。
W-MSA:输入x的维度$(B,H,W,dim)$,$num_{window}_h=H/window_size_{h},num_{window}_w=W/window_size_{w}$,q k v的维度变化为$(B,heads,num_{window}_h*num_{window}_w,window_size_{h}window_size_{w},dim_{head})$,attention map维度$(B,heads,num_{window}_hnum_{window}_w,window_size_{h}*window_size_{w},window_size_{h}window_size_{w})$,注意点乘是发生在$num_{window}_hnum_{window}_w$维度上,也就是在窗口内计算自注意力。相对位置编码加在attention map后,这部分详细还是要参考zzk大佬:https://zhuanlan.zhihu.com/p/367111046,注意是不同head的所有窗口共享一个$( window_size_{h}*window_size_{w},window_size_{h}*window_size_{w})$的位置编码。乘完v后在变形回$(B,H,W,dim)$。
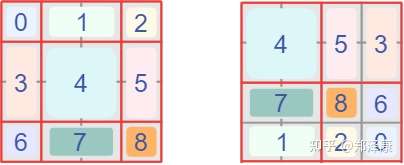
SW-MSA:通过torch.roll函数实现窗口的滑动,维度不变。像上面一样生成attention map,加相对位置编码,然后加mask屏蔽滑动得到的大窗口内其他小窗口的影响,最后再滑动回去。mask是盖在每个窗口上,故维度为$(window_size_{h}*window_size_{w},window_size_{h}*window_size_{w})$。参照上述教程生成下面图中计算1、7窗口的upper_lower_mask,计算5、3窗口的left_right_mask,巧妙的是,在这个实现中,upper_lower_mask+left_right_mask便可覆盖8 6 2 0窗口。
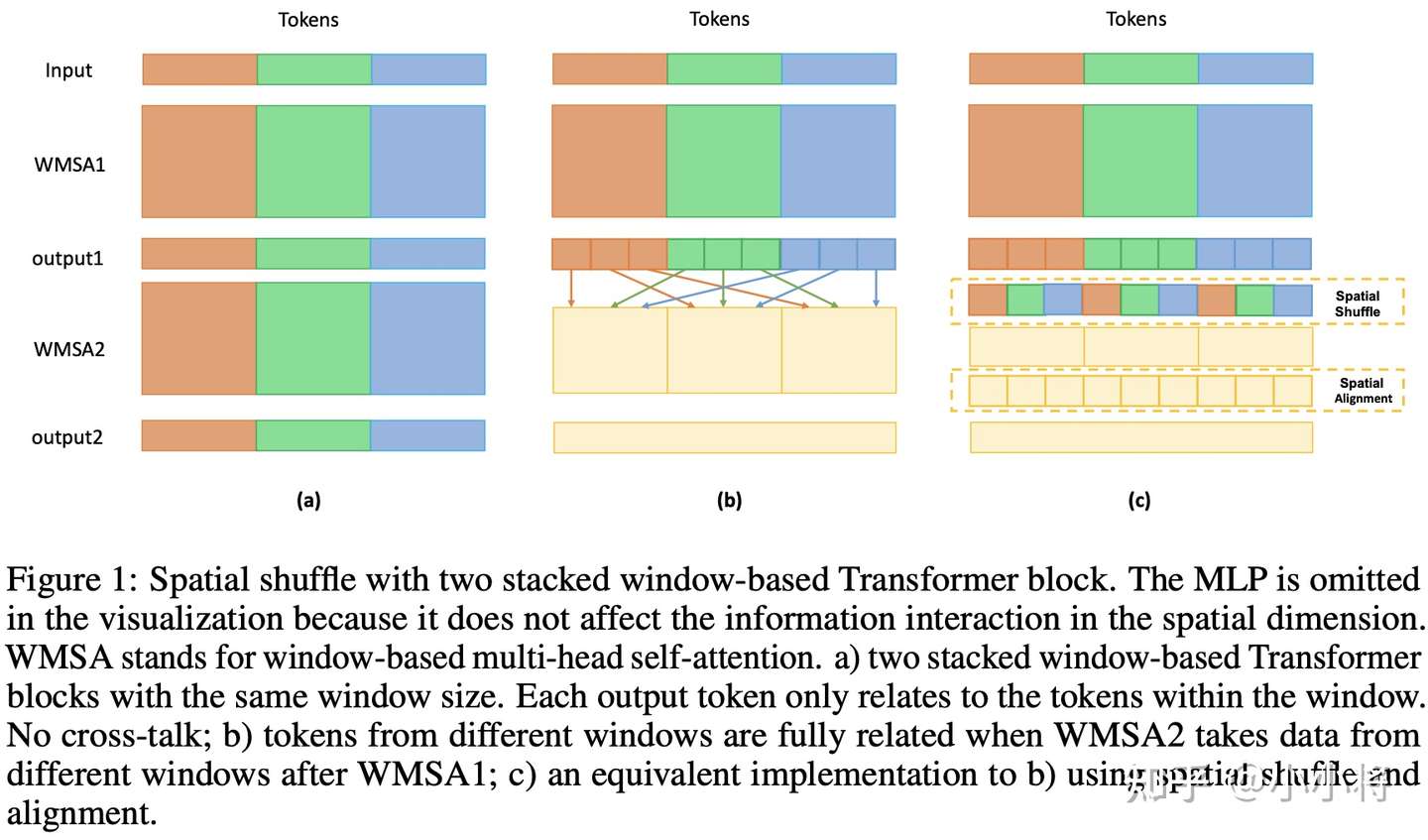
shuffle transformer的架构和swin一致,同样采用相对位置编码,把较复杂的滑动窗口注意力用shuffle机制代替。此外把layernorm都用batchnorm替换了。

Shuffle:swin中为了不同窗口间的交互,进行了滑窗。shuffle trans把每一个窗口的第1个patch,第2个......重新组合,最后再reshape到相同维度。(复习shufflenet的实现https://zhuanlan.zhihu.com/p/32304419)注意qk乘v之后要shuffle回去,这是确保**特征与图像内容在空间上对齐**。
NWC:当图像尺寸远大于窗口尺寸时会产生网格问题,shuffle trans引入了深度可分离卷积缓解这一问题,我认为这步也在不同窗口间进行了信息交互。
Pyramid Vision Transformer应该是第一个金字塔型的视觉transformer,方便迁移到下游任务。
共四个stage,每个stage起始处都有patch embed模块,用于下采样降低分辨率,第一个stage的patch_size为4,其余是2。下采样的方式采用普通卷积。
为了降低self attention的复杂度,引入了SRA。SRA会降低K和V的空间尺度,也是通过普通卷积降采样,attention前后与q的维度保持不变。
patch embed之后,加入绝对位置编码(如果输入分辨率变化,双线性插值位置编码)。最后一个stage加入cls token帮助分类。
相比v1有较小改动:
patch embed模块改用重叠的块嵌入,采用步幅为S、核大小2S−1、填充大小S−1的卷积,主要考虑图像的局部连续性。
去除了固定的位置编码,在前馈层中加入带一圈zero padding的深度可分离卷积引入位置信息(patch embed其实也能引入)。

Linear SRA对k和v的输入做自适应平均池化(对于任何大小的输入,可以将输出尺寸指定为参数值),再卷积和激活来计算k v。