📃 [Paper] 🚀 [Demo] 💾 [Checkpoints]
This repository contains the official PyTorch implementation of the paper "VISION DIFFMASK: Faithful Interpretation of Vision Transformers with Differentiable Patch Masking" by Angelos Nalmpantis*, Apostolos Panagiotopoulos*, John Gkountouras*, Konstantinos Papakostas* and Wilker Aziz (CVPRW XAI4CV 2023)
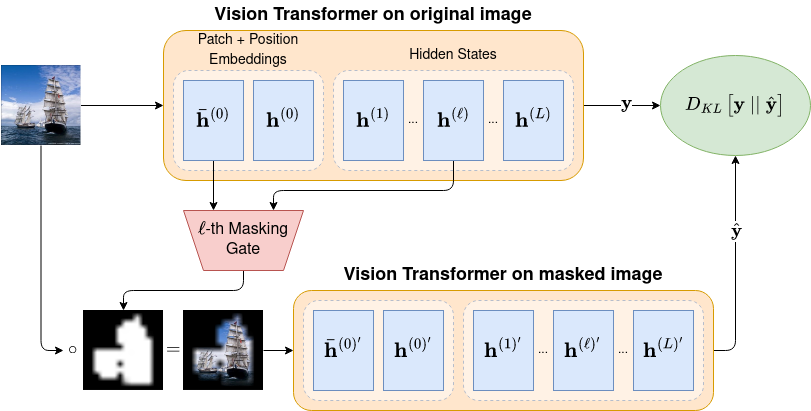
Vision DiffMask is a post-hoc interpretation method for vision tasks. Given a pre-trained model, it predicts the minimal subset of the input required to maintain the original output distribution. Currently, only Vision Transformer (ViT) for image classification is supported.
We provide a conda environment for the installation of the required packages.
conda env create -f environment.ymlThe project is organized in the following way:
.
├── code
│ ├── attributions/
│ ├── datamodules
│ │ ├── base.py
│ │ ├── image_classification.py
│ │ ├── transformations.py
│ │ ├── utils.py
│ │ └── visual_qa.py
│ ├── eval_base.py
│ ├── main.py
│ ├── models
│ │ ├── classification.py
│ │ ├── gates.py
│ │ ├── interpretation.py
│ │ └── utils.py
│ ├── train_base.py
│ └── utils
│ ├── distributions.py
│ ├── getters_setters.py
│ ├── metrics.py
│ ├── optimizer.py
│ └── plot.py
├── experiments/
To train a Vision DiffMask model on CIFAR-10 based on the Vision Transformer, use the following command:
python code/main.py --enable_progress_bar --num_epochs 20 --base_model ViT --dataset CIFAR10 \
--from_pretrained tanlq/vit-base-patch16-224-in21k-finetuned-cifar10You can refer to the next section for a full list of launch options.
Vision DiffMask
When training Vision DiffMask, the following launch options can be used:
Arguments:
--enable_progress_bar
Whether to enable the progress bar (NOT recommended when logging to file).
--num_epochs NUM_EPOCHS
Number of epochs to train.
--seed SEED Random seed for reproducibility.
--sample_images SAMPLE_IMAGES
Number of images to sample for the mask callback.
--log_every_n_steps LOG_EVERY_N_STEPS
Number of steps between logging media & checkpoints.
--base_model {ViT} Base model architecture to train.
--from_pretrained FROM_PRETRAINED
The name of the pretrained HF model to load.
--dataset {MNIST,CIFAR10,CIFAR10_QA,toy}
The dataset to use.
Vision DiffMask:
--alpha ALPHA Initial value for the Lagrangian
--lr LR Learning rate for DiffMask.
--eps EPS KL divergence tolerance.
--no_placeholder Whether to not use placeholder
--lr_placeholder LR_PLACEHOLDER
Learning for mask vectors.
--lr_alpha LR_ALPHA Learning rate for lagrangian optimizer.
--mul_activation MUL_ACTIVATION
Value to multiply gate activations.
--add_activation ADD_ACTIVATION
Value to add to gate activations.
--weighted_layer_distribution
Whether to use a weighted distribution when picking a layer in DiffMask forward.
Data Modules:
--data_dir DATA_DIR The directory where the data is stored.
--batch_size BATCH_SIZE
The batch size to use.
--add_noise Use gaussian noise augmentation.
--add_rotation Use rotation augmentation.
--add_blur Use blur augmentation.
--num_workers NUM_WORKERS
Number of workers to use for data loading.
Visual QA:
--class_idx CLASS_IDX
The class (index) to count.
--grid_size GRID_SIZE
The number of images per row in the grid.
Training the base model
When training the base model (usually not needed as we support pretrained models from HuggingFace), the following launch options can be used:
Arguments:
--checkpoint CHECKPOINT
Checkpoint to resume the training from.
--enable_progress_bar
Whether to show progress bar during training. NOT recommended when logging to files.
--num_epochs NUM_EPOCHS
Number of epochs to train.
--seed SEED Random seed for reproducibility.
--base_model {ViT,ConvNeXt}
Base model architecture to train.
--from_pretrained FROM_PRETRAINED
The name of the pretrained HF model to fine-tune from.
--dataset {MNIST,CIFAR10,CIFAR10_QA,toy}
The dataset to use.
Classification Model:
--optimizer {AdamW,RAdam}
The optimizer to use to train the model.
--weight_decay WEIGHT_DECAY
The optimizer's weight decay.
--lr LR The initial learning rate for the model.
Data Modules:
--data_dir DATA_DIR The directory where the data is stored.
--batch_size BATCH_SIZE
The batch size to use.
--add_noise Use gaussian noise augmentation.
--add_rotation Use rotation augmentation.
--add_blur Use blur augmentation.
--num_workers NUM_WORKERS
Number of workers to use for data loading.
Visual QA:
--class_idx CLASS_IDX
The class (index) to count.
--grid_size GRID_SIZE
The number of images per row in the grid.
Evaluating the base model
When evaluating the base model, the following launch options can be used:
Arguments:
--checkpoint CHECKPOINT
Checkpoint to resume the training from.
--enable_progress_bar
Whether to show progress bar during training. NOT recommended when logging to files.
--seed SEED Random seed for reproducibility.
--base_model {ViT,ConvNeXt}
Base model architecture to train.
--from_pretrained FROM_PRETRAINED
The name of the pretrained HF model to fine-tune from.
--dataset {MNIST,CIFAR10,CIFAR10_QA,toy}
The dataset to use.
Data Modules:
--data_dir DATA_DIR The directory where the data is stored.
--batch_size BATCH_SIZE
The batch size to use.
--add_noise Use gaussian noise augmentation.
--add_rotation Use rotation augmentation.
--add_blur Use blur augmentation.
--num_workers NUM_WORKERS
Number of workers to use for data loading.
Visual QA:
--class_idx CLASS_IDX
The class (index) to count.
--grid_size GRID_SIZE
The number of images per row in the grid.
This project is licensed under the MIT license.
Vision DiffMask is an adaptation of DiffMask in the vision domain. Parts of the code are heavilty inspired from its original PyTorch implementation.
If you use this code or find our work otherwise useful, please consider citing our paper:
@inproceedings{nalmpantis2023vision,
title={VISION DIFFMASK: Faithful Interpretation of Vision Transformers with Differentiable Patch Masking},
author={Nalmpantis, Angelos and Panagiotopoulos, Apostolos and Gkountouras, John and Papakostas, Konstantinos and Aziz, Wilker},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={3755--3762},
year={2023}
}